Разыменовывание нулевого указателя приводит к неопределённому поведению
- Напомню историю обсуждений
- О языке Си
- О языке Си++
- Итого
- Разное в дополнение
- Благодарности
- Дополнительные ссылки
Ненароком я породил большую дискуссию, касающуюся того, допустимо ли использовать в Си/Си++ выражение &P->m_foo, если P является нулевым указателем. Программисты разделились на два лагеря. Одни уверенно доказывали, что так писать нельзя, другие столь же уверенно утверждали, что можно. Приводились различные аргументы и ссылки. И я понял, что нужно внести окончательную ясность в этот вопрос. Для этого я обратился к экспертам Microsoft MVP и разработчикам Visual C++, общающимся через закрытый список рассылки. Они помогли подготовить эту статью, и я представляю её всем желающим. Для нетерпеливых: этот код не корректен.
Напомню историю обсуждений
Все началось со статьи о проверке ядра Linux с помощью анализатора PVS-Studio. Но сама проверка ядра тут ни причём. Дело в том, что в статье я привёл следующий фрагмент из кода Linux:
Но сама проверка ядра тут ни причём. Дело в том, что в статье я привёл следующий фрагмент из кода Linux:
static int podhd_try_init(struct usb_interface *interface,
struct usb_line6_podhd *podhd)
{
int err;
struct usb_line6 *line6 = &podhd->line6;
if ((interface == NULL) || (podhd == NULL))
return -ENODEV;
....
}Я назвал этот код опасным, так как посчитал, что здесь имеет место неопределённое поведение.
По этому поводу я получил много возражений от читателей и даже одно время был готов поддаться на их убедительные речи в письмах и комментариях. Например, в качестве доказательства корректности кода приводили устройство макроса offsetof, который часто реализован так:
#define offsetof(st, m) ((size_t)(&((st *)0)->m))
Здесь имеет место разыменование нулевого указателя, но код успешно работает. Были и другие письма с рассуждениями того, что раз нет доступа по нулевому указателю, то нет и проблемы.
Хотя я и доверчивый, но стараюсь проверять информацию.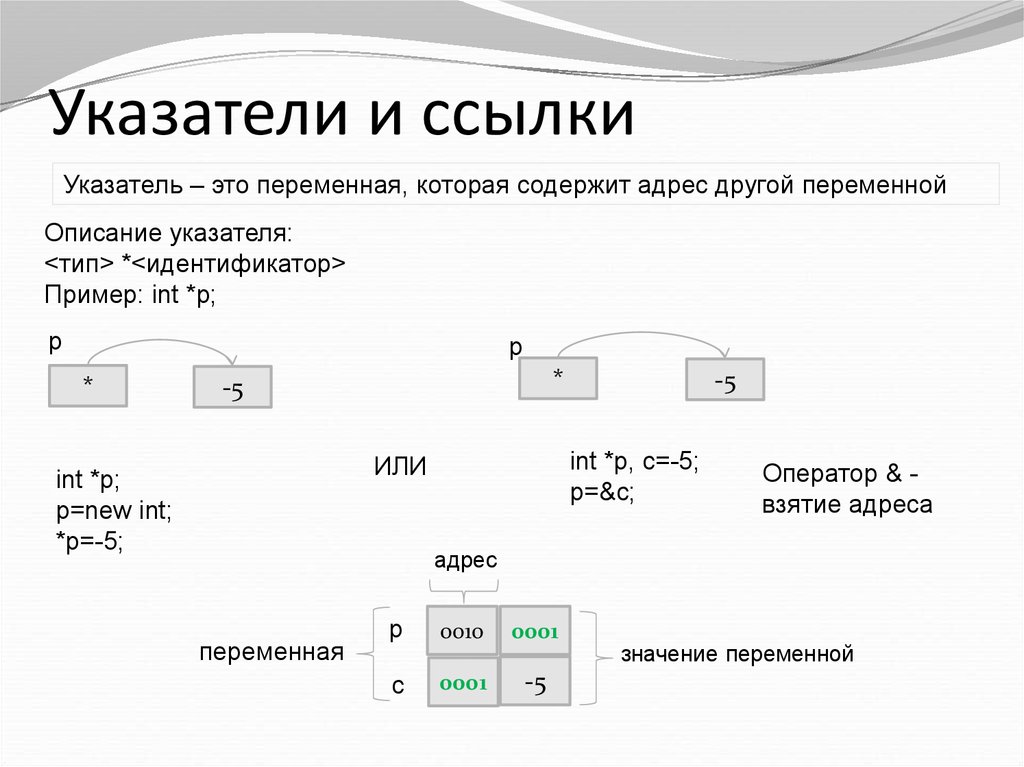 Я начал разбираться с этой темой и в результате написал небольшую статью: «Размышления над разыменованием нулевого указателя».
Я начал разбираться с этой темой и в результате написал небольшую статью: «Размышления над разыменованием нулевого указателя».
По всему выходило, что я был прав. Так писать нельзя. Однако я не смог окончательно обосновать свою позицию и привести нужные ссылки на стандарт.
После статьи вновь последовали письма с возражениями, и я понял, что надо разобраться с данной темой окончательно. Я обратился с вопросом к экспертам, чтобы узнать их мнение. Эта статья является их обобщенным ответом.
О языке Си
Выражение ‘&podhd->line6’ является неопределенным поведением в языке C в том случае, если ‘podhd’ — нулевой указатель.
Вот что говорится про оператор взятия адреса ‘&’ в стандарте C99 (Раздел 6.5.3.2 «Операторы взятия адреса и разыменовывания»):
Операнд унарного оператора & должен быть либо указателем функции, либо результатом оператора [] или унарного оператора *, либо lvalue-выражением, указывающим на объект, который не является битовым полем и не содержит в объявлении спецификатора регистрового класса памяти.
Выражение ‘podhd->line6’ однозначно не является указателем функции, результатом оператора [] или *. Это как раз lvalue-выражение. Однако, когда указатель ‘podhd’ равен нулю, выражение не указывает на объект, поскольку в Разделе 6.3.2.3 «Указатели» сказано следующее:
Если константа нулевого указателя приводится к типу указателей, то результирующий указатель, называемый нулевым, гарантированно будет не равен указателю на любой объект или функцию.
Если «lvalue-выражение не указывает на объект при своем вычислении, возникает неопределенное поведение» (Стандарт C99, Раздел 6.3.2.1 «Lvalue-выражения, массивы и указатели функций»):
lvalue — это выражение объектного типа или неполного типа, отличного от void; если lvalue-выражение не указывает на объект при своем вычислении, возникает неопределенное поведение.
Ещё раз кратко:
Когда оператор -> был применен к указателю, его результатом стало lvalue-выражение, для которого не существует объекта, и в результате мы имеем дело с неопределенным поведением.
О языке Си++
В языке С++ всё обстоит точно также. Выражение ‘&podhd->line6’ является неопределенным поведением в языке C++ в том случае, если ‘podhd’ — нулевой указатель.
С толку немного сбивает дискуссия на WG21 (232. Is indirection through a null pointer undefined behavior?), на которую я ссылался в предыдущей статье. Там настаивают, будто бы такое выражение не является неопределенным поведением. Однако никто так и не нашел никаких правил в стандартах C++, которые разрешали бы использовать «podhd->line6», когда «podhd» — нулевой указатель.
Указатель «podhd» нарушает основное ограничение (Раздел 5.2.5/4, второй пункт в списке) о том, что он должен указывать на объект. Ни один объект в C++ не может иметь адреса nullptr.
Итого
struct usb_line6 *line6 = &podhd->line6;
Этот код является некорректным в языке Си и Си++, если указатель podhd равен 0. Если указатель равен 0, то возникает неопределённое поведение.
То, что программа может работать, является везением. Неопределённое поведение может проявить себя, как угодно. В том числе, программа может работать так, как хотел программист. Это один из частных случаев, но не более того.
Неопределённое поведение может проявить себя, как угодно. В том числе, программа может работать так, как хотел программист. Это один из частных случаев, но не более того.
Так писать нельзя. Указатель должен быть проверен до разыменования.
Разное в дополнение
- При рассмотрении идиоматической реализации offsetof() следует учитывать, что компилятору разрешено использовать непереносимые приемы для реализации этой функциональности. Тот факт, что в реализации библиотеки в компиляторе используется константа нулевого указателя при реализации offsetof(), вовсе не означает, что в пользовательском коде можно без опаски применять ‘&podhd->line6′ в случае, когда’podhd’ является нулевым указателем.
- GCC может (и делает это) проводить оптимизацию, основываясь на предположении, что никакого неопределенного поведения возникнуть не может, и убрать в данном случае проверки указателей на ноль — поэтому ядро компилируется с набором ключей, указывающих компилятору не делать этого.
 Например, эксперты в качестве примера ссылаются на статью «What Every C Programmer Should Know About Undefined Behavior #2/3».
Например, эксперты в качестве примера ссылаются на статью «What Every C Programmer Should Know About Undefined Behavior #2/3». - Возможно, вам также будет интересно узнать, что подобным образом нулевой указатель был задействован в эксплойте ядра с помощью TUN/TAP-драйва. Подробности можно посмотреть по ссылке «Fun with NULL pointers». Некоторые могут решить, будто эти два примера имеют мало общего, поскольку во втором случае есть существенное отличие: в баге TUN/TAP-драйвера вместо простого взятия адреса поля структуры, к которому обращался нулевой указатель, это поле было явно взято в качестве значения для инициализации переменной. Однако с точки зрения стандарта C взятие адреса поля с помощью нулевого указателя также является неопределенным поведением.
- А есть ли какая-та ситуация, когда при P == nullptr мы напишем &P->m_foo и всё будет хорошо? Да, например это может быть аргументом оператора sizeof: sizeof(&P->m_foo).
Благодарности
В подготовке статьи мне помогли эксперты, сомневаться в компетенции которых нет повода. Я благодарен за помощь в написании статьи следующим людям:
Я благодарен за помощь в написании статьи следующим людям:
- Майкл Бёрр — горячий поклонник языка C/C++ и специалист по системному и встроенному ПО, в том числе службам Windows, работе с сетями и драйверам устройств. Активно участвует в жизни сообщества Stack Overflow, отвечая на вопросы программистов по C и C++ (а иногда и на некоторые простые вопросы по C#). Имеет 6 наград Microsoft MVP в номинации Visual C++.
- Билли О’Нил — разработчик ПО на C++ (преимущественно) и активный участник сообщества Stack Overflow. Является инженером-разработчиком ПО в подразделении по совершенствованию систем безопасности Microsoft (Trustworthy Computing Team). До этого работал в нескольких компаниях, занимающихся безопасностью ПО, в числе которых — Malware Bytes и PreEmptive Solutions.
- Джованни Диканио — программист, специализирующийся на разработке ОС Windows. Автор статей для программистов по C++, OpenGL и другим темам в ряде итальянских компьютерных журналов.
 Также писал код для некоторых открытых проектов. Джованни помогает коллегам, давая советы по решению программистских проблем, связанных с C и C++, на форумах Microsoft MSDN, а с некоторых пор — и на Stack Overflow. Имеет 8 наград Microsoft MVP в номинации Visual C++.
Также писал код для некоторых открытых проектов. Джованни помогает коллегам, давая советы по решению программистских проблем, связанных с C и C++, на форумах Microsoft MSDN, а с некоторых пор — и на Stack Overflow. Имеет 8 наград Microsoft MVP в номинации Visual C++. - Габриэль Дус Рейс — главный инженер-разработчик ПО Microsoft. Также является исследователем и долгосрочным участником C++-сообщества. Одно из направлений его научных интересов и исследований — средства разработки надежного ПО. До того, как прийти в Microsoft, работал старшим преподавателем в Техасском Университете A&M (Texas A&M University). В 2012 году Доктор Дус Рейс был отмечен премией Национального Научного Фонда (National Science Foundation CAREER Award) за проведенное им исследование компиляторов надежного ПО в области вычислительной математики и за образовательную деятельность. Является членом комитета по стандартизации языка C++.
Дополнительные ссылки
- Wikipedia.
 Неопределённое поведение.
Неопределённое поведение. - A Guide to Undefined Behavior in C and C++. Part 1, 2, 3.
- Wikipedia. offsetof.
- LLVM Blog. What Every C Programmer Should Know About Undefined Behavior #2/3.
- LWN. Fun with NULL pointers. Part 1, 2.
- Дискуссия на сайте Stack Overflow. Is dereferencing a pointer that’s equal to nullptr undefined behavior by the standard?
#Cpp #Knowledge
ПОДЕЛИТЬСЯ
Теги:
#Cpp#Knowledge
Присылаем лучшие статьи раз в месяц
НОУ ИНТУИТ | Лекция | Основы языка Си: структура Си-программы, базовые типы и конструирование новых типов, операции и выражения
< Лекция 12 || Лекция 8: 1234567
Аннотация: Лекция посвящена введению в язык Си. Объясняются общие принципы построения Си-программы: разбиение проекта на h- и c-файлы, т. е. разделение интерфейса и реализации, использование препроцессора. Приводятся базовые типы языка Си, конструкции массива и указателя, позволяющие строить новые типы, а также модификаторы типов. Рассматриваются всевозможные операции и выражения языка Си.
е. разделение интерфейса и реализации, использование препроцессора. Приводятся базовые типы языка Си, конструкции массива и указателя, позволяющие строить новые типы, а также модификаторы типов. Рассматриваются всевозможные операции и выражения языка Си.
Ключевые слова: Си, Java, указатель, адрес, массив, программа, контроль, операционная система, API, application program, interface, компилятор, слово, оператор DEFINE, файл, прототип функции, имя функции, константы, переменная, представление, standard input, препроцессор, директива, символическое имя, понимание текста, функция, алгоритм, значение, аргумент, вещественное число, вычисленное значение, вызов функции, стандартный поток вывода, логический тип, класс, тело оператора, специальный тип данных, volatility, Intel 80286, операции, сложение, умножение, оператор присваивания, префиксные операции, сумма элементов массива, аргумент операции, эквивалентное выражение, type cast, неявное преобразование
Основы языка Си
 intuit.ru/2010/edi»>В настоящее время язык Си и объектно-ориентированные языки
его группы (прежде всего C++, а также Java и C#) являются основными
в практическом программировании. Достоинство языка Си — это,
прежде всего, его простота и лаконичность. Язык Си легко учится.
Главные понятия языка Си, такие, как статические и локальные
переменные, массивы, указатели, функции и т.д., максимально приближены
к архитектуре реальных компьютеров. Так, указатель — это просто адрес
памяти, массив — непрерывная область памяти, локальные переменные — это
переменные, расположенные в аппаратном стеке,
статические — в статической памяти. Программист,
пишущий на Си, всегда достаточно точно представляет себе, как
созданная им программа будет работать на любой конкретной архитектуре.
Другими словами, язык Си предоставляет программисту
полный контроль над компьютером.
intuit.ru/2010/edi»>В настоящее время язык Си и объектно-ориентированные языки
его группы (прежде всего C++, а также Java и C#) являются основными
в практическом программировании. Достоинство языка Си — это,
прежде всего, его простота и лаконичность. Язык Си легко учится.
Главные понятия языка Си, такие, как статические и локальные
переменные, массивы, указатели, функции и т.д., максимально приближены
к архитектуре реальных компьютеров. Так, указатель — это просто адрес
памяти, массив — непрерывная область памяти, локальные переменные — это
переменные, расположенные в аппаратном стеке,
статические — в статической памяти. Программист,
пишущий на Си, всегда достаточно точно представляет себе, как
созданная им программа будет работать на любой конкретной архитектуре.
Другими словами, язык Си предоставляет программисту
полный контроль над компьютером.
Первоначально язык Си задумывался как заменитель Ассемблера
для написания операционных систем.
Тем не менее, область применения языка Си не ограничилась разработкой операционных систем. Язык Си оказался очень удобен в программах обработки текстов и изображений, в научных и инженерных расчетах. Объектно-ориентированные языки на основе Си отлично подходят для программирования в оконных средах.
В данном разделе будут приведены лишь основные понятия языка
Си (и частично C++). Это не заменяет чтения полного учебника по
Си или C++, например, книг [6] и [8].
Это не заменяет чтения полного учебника по
Си или C++, например, книг [6] и [8].
Мы будем использовать компилятор C++ вместо Cи. Дело в том, что язык Си почти целиком входит в C++, т.е. нормальная программа, написанная на Си, является корректной C++ программой. Слово «нормальная» означает, что она не содержит неудачных конструкций, оставшихся от ранних версий Си и не используемых в настоящее время. Компилятор C++ предпочтительнее, чем компилятор Си, т.к. он имеет более строгий контроль ошибок. Кроме того, некоторые конструкции C++, не связанные с объектно-ориентированным программированием, очень удобны и фактически являются улучшением языка Си. Это, прежде всего, комментарии //, возможность описывать локальные переменные в любой точке программы, а не только в начале блока, и также задание констант без использования оператора #define препроцесора. Мы будем использовать эти возможности C++, оставаясь по существу в рамках языка Си.
Структура Си-программы
 intuit.ru/2010/edi»>Любая достаточно большая программа на Си (программисты используют термин проект ) состоит из файлов. Файлы транслируются Си-компилятором независимо друг от друга и затем объединяются программой-построителем задач, в результате чего создается файл с программой, готовой к выполнению. Файлы, содержащие тексты Си-программы, называются исходными.
intuit.ru/2010/edi»>Любая достаточно большая программа на Си (программисты используют термин проект ) состоит из файлов. Файлы транслируются Си-компилятором независимо друг от друга и затем объединяются программой-построителем задач, в результате чего создается файл с программой, готовой к выполнению. Файлы, содержащие тексты Си-программы, называются исходными.
В языке Си исходные файлы бывают двух типов:
- заголовочные, или h-файлы;
Имена заголовочных файлов имеют расширение » .h «. Имена файлов реализации имеют расширения » .c » для языка Си и » .cpp «, » .cxx » или » .cc » для языка C++.
К сожалению, в отличие от языка Си, программисты не сумели договориться о едином расширении имен для файлов, содержащих программы на C++. Мы будем использовать расширение » .h » для заголовочных файлов и расширение » .cpp » для файлов реализации.
Мы будем использовать расширение » .h » для заголовочных файлов и расширение » .cpp » для файлов реализации.
Заголовочные файлы содержат только описания. Прежде всего, это прототипы функций. Прототип функции описывает имя функции, тип возвращаемого значения, число и типы ее аргументов. Сам текст функции в h-файле не содержится. Также в h-файлах описываются имена и типы внешних переменных, константы, новые типы, структуры и т.п. В общем, h-файлы содержат лишь интерфейсы, т.е. информацию, необходимую для использования программ, уже написанных другими программистами (или тем же программистом раньше). Заголовочные файлы лишь сообщают информацию о других программах. При трансляции заголовочных файлов, как правило, никакие объекты не создаются. Например, в заголовочном файле нельзя определить глобальную переменную. Строка описания
int x;
определяющая целочисленную переменную x, является ошибкой. Вместо этого следует использовать описание
Вместо этого следует использовать описание
extern int x;
означающее, что переменная x определена где-то в файле реализации (в каком — неизвестно). Слово extern (внешняя) лишь сообщает информацию о внешней переменной, но не определяет эту переменную.
Файлы реализации, или Cи-файлы, содержат тексты функций и определения глобальных переменных. Говоря упрощенно, Си-файлы содержат сами программы, а h-файлы — лишь информацию о программах.
Представление исходных текстов в виде заголовочных файлов и файлов реализации необходимо для создания больших проектов, имеющих модульную структуру. Заголовочные файлы служат для передачи информации между модулями. Файлы реализации — это отдельные модули, которые разрабатываются и транслируются независимо друг от друга и объединяются при создании выполняемой программы.
 intuit.ru/2010/edi»>Файлы реализации могут подключать описания, содержащиеся в заголовочных файлах. Сами заголовочные файлы также могут использовать другие заголовочные файлы. Заголовочный файл подключается с помощью директивы препроцессора #include. Например, описания стандартных функций ввода-вывода включаются с помощью строки
intuit.ru/2010/edi»>Файлы реализации могут подключать описания, содержащиеся в заголовочных файлах. Сами заголовочные файлы также могут использовать другие заголовочные файлы. Заголовочный файл подключается с помощью директивы препроцессора #include. Например, описания стандартных функций ввода-вывода включаются с помощью строки
#include <stdio.h>
(stdio — от слов standard input/output). Имя h-файла записывается в угловых скобках, если этот h-файл является частью стандартной Си-библиотеки и расположен в одном из системных каталогов. Имена h-файлов, созданных самим программистом в рамках разрабатываемого проекта и расположенных в текущем каталоге, указываются в двойных кавычках, например,
#include "abcd.h"
Препроцессор — это программа предварительной обработки текста
непосредственно перед трансляцией. Команды препроцессора называются директивами. Директивы препроцессора содержат символ диез # в начале
строки. Препроцессор используется в основном для подключения h-файлов.
В Си также очень часто используется директива #define для задания
символических имен констант. Так, строка
Препроцессор используется в основном для подключения h-файлов.
В Си также очень часто используется директива #define для задания
символических имен констант. Так, строка
#define PI 3.14159265
задает символическое имя PI для константы 3.14159265. После этого имя PI можно использовать вместо числового значения. Препроцессор находит все вхождения слова PI в текст и заменяет их на константу. Таким образом, препроцессор осуществляет подмену одного текста другим. Необходимость использования препроцессора всегда свидетельствует о недостаточной выразительности языка. Так, в любом Ассемблере средства препроцессирования используются довольно интенсивно. В Си по возможности следует избегать чрезмерного увлечения командами препроцессора — это затрудняет понимание текста программы и зачастую ведет к трудно исправляемым ошибкам. В C++ можно обойтись без использования директив #define для задания констант. Например, в C++ константу PI можно задать с помощью нормального описания
const double PI = 3.14159265;
Это является одним из аргументов в пользу применения компилятора C++ вместо Си даже при трансляции программ, не содержащих конструкции класса.
Дальше >>
< Лекция 12 || Лекция 8: 1234567
Сборка— куда указывает указатель SI, когда указано, что он указывает на смещение?
спросил
Изменено 3 года, 8 месяцев назад
Просмотрено 78 раз
Заранее извиняюсь, если вопрос дублируется. Меня немного смущает следующий код:
список БД 80ч, 70ч, 60ч, 50ч, 40ч, 30ч, 20ч
mov si, офсетный список
двигаться аль, [си]
повторять: вкл си
добавить al,[si]
ООО Репит
плавник:
Я знаю, что jnc указывает на то, что мы выйдем из этого цикла, когда не будет переполнения переноса, т. е.
е. CF = 0 . Поскольку si должен указывать на индекс первого элемента списка, не будет ли это 80h? И затем, если si увеличивается, он должен указывать на 70h. Если сложить их вместе, ответ должен быть F0, верно? Однако, когда я запускаю фрагмент кода, я получаю значение AL равным 50. Как это возможно? Что мне не хватает? Спасибо всем заранее!
- указатели
- сборка
- индексация
- x86
- память-сегментация
1
Я знаю, что jnc указывает, что мы выйдем из этого цикла, когда не будет переполнения переноса, т. е. CF = 0.
Это неверно. JNC будет прыгать, если CF=0, что значит будет прыгать, если нет беззнакового переполнения .
Поскольку предполагается, что si указывает на индекс первого элемента списка, не будет ли это 80h? И затем, если si увеличивается, он должен указывать на 70h.
Если сложить их вместе, ответ должен быть F0, верно?
Пока да.
Однако, когда я запускаю фрагмент кода, я получаю значение AL равным 50. Как это возможно?
Что я упускаю?
Возвращаемое значение 50h равно
80h + 70h + 60h = 50h + флаг CARRY (беззнаковое переполнение).
Пошагово это
80h + 70h = F0h (CF = 0 = JUMP) F0h + 60h = 50h (CF = 1 = НЕТ ПЕРЕХОДА = ВЫХОД ЦИКЛ)
Итак, последнее добавление устанавливает флаг CARRY на 1 из-за беззнаковое переполнение из FFh в 00h (F0h + 0Fh в F0h + 10h (и, наконец, 60h — 10h = 50h)). Поскольку флаг CARRY установлен, условный переход JNC проходит, а AL содержит «переполненное» значение 50h.
Чтобы ответить на вопрос заголовка (который почти не связан с остальной частью вашего вопроса):
Куда указывает указатель SI, если указано, что он указывает на смещение?
В модели сегментированной памяти x86 рядом с указателями — это смещений относительно базы сегмента.
mov si, символ OFFSET устанавливает SI в часть смещения seg:off адреса символа .
Если символ является меткой в разделе данных вашей программы, и вы используете [SI] , в то время как база сегмента DS = начало этого раздела, тогда [SI] дает вам байт(ы) ) по адресу символ в качестве операнда памяти.
СИ не указывает на смещение, это содержит смещение после mov si, символ OFFSET . Этот является указателем.
В простой плоской модели памяти (например, 32- или 64-битном коде) все использует основание = 0, поэтому смещение = линейный адрес.
В 16-битном коде с «крошечной» моделью памяти (например, .com ) CS=DS=ES=SS, поэтому все ссылки на память используют одну и ту же базу. Опять же, только 16-битное смещение работает как полный указатель. Фактическая база сегмента не имеет значения, потому что все относительно нее.
Зарегистрируйтесь или войдите в систему
Зарегистрируйтесь с помощью Google
Зарегистрироваться через Facebook
Зарегистрируйтесь, используя адрес электронной почты и пароль
Опубликовать как гость
Электронная почта
Обязательно, но не отображается
Опубликовать как гость
Электронная почта
Требуется, но не отображается
Сборка— В чем практическая разница между регистрами SI и DI?
спросил
Изменено 9лет, 2 месяца назад
Просмотрено 62к раз
Не понимаю в чем разница.
- сборка
- x86
- регистры процессора
0
Когда вы используете такие инструкции, как movsb, si считается регистром нашего источника s , а di — регистром назначения d . Но они оба являются обычными регистрами x86.
Моя сборка немного заржавела, но у одного индекс источника, у другого индекс назначения. Такая инструкция, как movsb , скопирует байт из ячейки памяти, на которую указывает SI , и переместит его в ячейку памяти, на которую указывает DI , а затем увеличит оба байта, поэтому, если вы хотите скопировать байт, хранящийся в SI+1 до DI+1 требуется только дополнительная инструкция movsb.
SI означает исходный индекс. Исходный индекс используется в качестве указателя на текущий символ, считываемый в строковой инструкции (LODS, MOVS или CMPS).