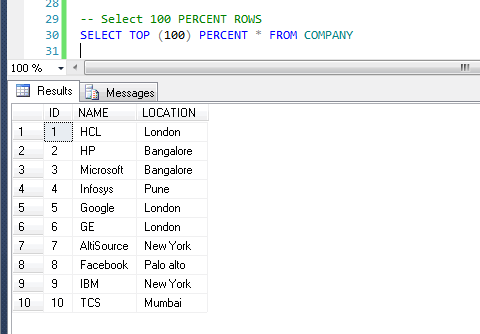
sql — Каков синтаксис для функционального аналога SELECT TOP(N) в Oracle?
Предположим, есть таблица TABLE
ID | DEF 1 | Один 2 | Два 3 | Три 4 | Четыре
Тогда запрос в MS SQL Server
SELECT TOP(2) * FROM TABLE ORDER BY ID DESC
Даст нам выдачу:
ID | DEF 4 | Четыре 3 | Три
А аналогичный запрос в Oracle (аналог, который мне предложился в интернетах)
SELECT * FROM TABLE WHERE ROWNUM <= 2 ORDER BY ID DESC
Даст нам выдачу:
ID | DEF 2 | Два 1 | Один
Как получить действительно аналогичный по функциональности синтаксис для Oracle?
- sql
- база-данных
- sql-server
- oracle
- plsql-developer
0
В оракле до 11-й версии включительно — через подзапрос с row_number:
select *
from (select t.*, row_number() over (order by id desc) rn
from t)
where rn <= 2
В 12-й версии появился синтаксис для первых N строк с OFFSET, почти как в постгресе (запрос скопипастил из интернета, 12-го оракла под рукой нет):
select * from t order by id desc OFFSET 5 ROWS FETCH NEXT 5 ROWS ONLY;
Дело в том, что Oracle сначала выполняет условие where и только потом производит сортировку. То есть в вашем случае сначала остаются строки с
То есть в вашем случае сначала остаются строки с id in (1, 2) и потом они и сортируются.
Для получения аналогичного результата сначала надо отсортировать все данные и потом обернув запрос получить нужное количество строк:
SELECT *
FROM (SELECT *
FROM TABLE
ORDER BY ID DESC)
WHERE ROWNUM <= 2
Вам придётся воспользоваться подзапросом. Т.е. ваш запрос с основными условиями и сортировкой перенесите в подзапрос, а ограничение на выбор поставьте в секцию WHERE внешнего запроса.
SELECT * FROM ( SELECT * FROM TABLE ORDER BY ID DESC ) WHERE ROWNUM <= 2
1
Начиная с версии 12.1.0.1 Oracle БД поддерживает введённый в стандарте SQL:2008 FETCH FIRST|NEXT синтаксис (см. row_limiting_clause для полного описания).
Воспроизводимый рабочий пример:
with tab (id, def) as (
select rownum, trim (column_value)
from xmlTable ('"Один", "Два", "Три", "Четыре"')
)
select *
from tab
order by id desc
fetch first 2 rows only;
Результат:
ID DEF
---------- ----------
4 Четыре
3 Три
Надо отметить, что поддерживаемый MS SQL Server SELECT TOP(N) синтаксис не является стандартным.
Зарегистрируйтесь или войдите
Регистрация через Facebook
Регистрация через почту
Отправить без регистрации
Почта
Необходима, но никому не показывается
Отправить без регистрации
Почта
Необходима, но никому не показывается
Нажимая на кнопку «Отправить ответ», вы соглашаетесь с нашими пользовательским соглашением, политикой конфиденциальности и политикой о куки
Подробнее о TOP / Хабр
В прошлой статье я писал об особом виде оператора TOP, известного как ROWCOUNT TOP.
В общем случае, ТОР — довольно приземленный оператор. Он просто подсчитывает и возвращает заданное количество строк. SQL Server 2005 включает в себя два усовершенствования этого оператора, которых не было в SQL Server 2000.
Во-первых, в SQL Server 2000 можно указать только константу в виде целого числа возвращаемых строк. В SQL Server 2005 мы можем указать произвольное выражение, включая выражение, содержащее переменные или параметры T-SQL.
Во-вторых, SQL Server 2000 допускает только TOP в операторе SELECT (хотя он поддерживает ROWCOUNT TOP в операторах INSERT, UPDATE и DELETE). SQL Server 2005 допускает TOP с операторами SELECT, INSERT, UPDATE и DELETE.
В этой статье мы сосредоточимся на нескольких простых примерах с оператором SELECT. Для начала создадим небольшую таблицу:
CREATE TABLE T (A INT, B INT)
CREATE CLUSTERED INDEX TA ON T(A)
SET NOCOUNT ON
DECLARE @i INT
SET @i = 0
WHILE @i < 100
BEGIN
INSERT T VALUES (@i, @i)
SET @i = @i + 1
END
SET NOCOUNT OFFПлан простейшего запроса с TOP не нуждается в пояснениях:
SELECT TOP 5 * FROM T
Rows Executes 5 1 |--Top(TOP EXPRESSION:((5))) 5 1 |--Clustered Index Scan(OBJECT:([tempdb].[dbo].[T].[TA]))
TOP часто используется в сочетании с ORDER BY. Сочетание TOP с ORDER BY способствует детерминированности выборки. Без ORDER BY выборка зависит от плана запроса и даже может меняться от выполнения к выполнению. Если у нас есть подходящий индекс для поддержки выбранного порядка строк, план запроса останется простым (обратите внимание на ключевые слова ORDERED FORWARD):
SELECT TOP 5 * FROM T ORDER BY A
Rows Executes 5 1 |--Top(TOP EXPRESSION:((5))) 5 1 |--Clustered Index Scan(OBJECT:([tempdb].[dbo].[T].[TA]), ORDERED FORWARD)
Обратите внимание что, если нет подходящего индекса для выборки первых 5 строк SQL Server должен просмотреть все 100 строк таблицы. Также обратите внимание, что сортировка в этом сценарии будет «TOP sort». Такая сортировка обычно использует меньше памяти, чем обычная сортировка, поскольку ей нужно прокрутить через алгоритм сортировки только несколько топовых строк, а не всю таблицу.
Теперь давайте рассмотрим, что произойдет, если мы запросим TOP 5% строк. Чтобы это определить. Для получения результата SQL Server должен подсчитать все строки и вычислить 5%. Это делает запросы, использующие TOP PERCENT, менее эффективными, чем запросы, использующие TOP с абсолютным числом строк.
Чтобы это определить. Для получения результата SQL Server должен подсчитать все строки и вычислить 5%. Это делает запросы, использующие TOP PERCENT, менее эффективными, чем запросы, использующие TOP с абсолютным числом строк.
SELECT TOP 5 PERCENT * FROM T
Rows Executes 5 1 |--Top(TOP EXPRESSION:((5.000000000000000e+000)) PERCENT) 5 1 |--Table Spool 100 1 |--Clustered Index Scan(OBJECT:([tempdb].[dbo].[T].[TA]))
Как и в предыдущем примере, SQL Server будет просматривать все 100 строк таблицы. Тут SQL Server использует «жадную» очередь (Eager Spool), которая буферизует и подсчитывает все входные строки, прежде чем что-либо возвращать. Затем TOP запрашивает число строк в очереди, вычисляет 5% и продолжает работу, как любой другой TOP.
Если SQL Server в плане запроса должен выполнять сортировку, этим он также может обеспечить подсчёт затронутых строк. Однако только обычная сортировка умеет подсчитывать их количество. Сортировка «TOP sort» должна знать какое число строк необходимо вернуть с самого начала.
Сортировка «TOP sort» должна знать какое число строк необходимо вернуть с самого начала.
SELECT TOP 5 PERCENT * FROM T ORDER BY B
Rows Executes 5 1 |--Top(TOP EXPRESSION:((5.000000000000000e+000)) PERCENT) 5 1 |--Sort(ORDER BY:([tempdb].[dbo].[T].[B] ASC)) 100 1 |--Clustered Index Scan(OBJECT:([tempdb].[dbo].[T].[TA]))
TOP WITH TIES также несовместим с «TOP sort». TOP WITH TIES не позволяет узнать наверняка, сколько строк будет получено, пока не будет вычитаны все «привязки». В нашем примере давайте сделаем «привязку» для пятой строки:
INSERT T VALUES (4, 4) SELECT TOP 5 WITH TIES * FROM T ORDER BY B
Rows Executes 6 1 |--Top(TOP EXPRESSION:((5))) 7 1 |--Sort(ORDER BY:([tempdb].[dbo].[T].[B] ASC)) 101 1 |--Clustered Index Scan(OBJECT:([tempdb].[dbo].[T].[TA]))
В этом представлении плана нет TOP WITH TIES, но при SHOWPLAN_ALL или STATISTICS PROFILE можно увидеть следующее: «TIE COLUMNS:([T].
Наконец, есть пара вырожденных случаев, когда оптимизатор знает, что TOP 0 и TOP 0 PERCENT никогда ничего не возвращают, и заменяет любой такой план запроса на сканирование константы:
SELECT TOP 0 * FROM T
|--Constant Scan
Оптимизатор также знает, что TOP 100 PERCENT всегда возвращает все строки и удаляет оператор TOP из плана запроса:
SELECT TOP 100 PERCENT * FROM T
|--Clustered Index Scan(OBJECT:([tempdb].[dbo].[T].[TA]))
Для этих случаев требуется, чтобы количество строк было постоянным. Например, использование выражения, включающего переменную или параметр T-SQL, приведёт к тому, что план запроса будет такой же, как в общем случае. Оба описанных упрощения плана также работают и с операторами INSERT, UPDATE и DELETE.
Обратите внимание, что не рекомендуется использовать TOP для обхода ограничений языка SQL на использование ORDER BY в подзапросах или представлениях или для принудительного определенных порядка использования операторов в плане запроса.
SQL Выберите Верх | Укажите предел с помощью оператора Top в SQL
Мы можем получить набор результатов из запросов, указав максимальное количество записей, которые могут быть извлечены из запроса с помощью оператора top в SQL. При работе с огромными базами данных, включающими запросы к таблицам, которые содержат огромный набор записей, а результирующий набор результатов также включает слишком много записей, так что системе становится тяжело справляться, и это может даже привести к зависанию системы на долгое время.
Мы можем указать предел, используя оператор top в SQL. Однако многие СУБД не поддерживают использование основных операторов, таких как MySQL и oracle. Они предоставляют альтернативный способ, такой как предложение LIMIT и ROWNUM в MySQL и Oracle соответственно. В этой статье мы изучим общий синтаксис предложения TOP в SQL и рассмотрим его использование и реализацию с помощью определенных примеров.
Синтаксис:
Синтаксис верхней части выбора показан ниже –
SELECT TOP (числовое_выражение) [ПРОЦЕНТ]
[СО СВЯЗЬМИ]
FROM
name_of_table
ORDER BY
name_of_column;
Числовое выражение может быть числом строк, которые должны быть извлечены в конечном наборе результатов после выполнения оператора запроса. Использование ключевого слова PERCENT является необязательным, и если оно указано, числовое выражение рассматривается как значение с плавающей запятой, указывающее процент результирующего набора, который должен быть извлечен, вместо количества строк. Когда PERCENT не используется, числовое выражение представляет собой значение BIGINT, указывающее количество записей, которые необходимо извлечь из запроса на выборку. Имя_таблицы — это имя таблицы, из которой должны быть извлечены записи, а имя столбца — это имя столбца, по которому должен быть отсортирован результат.
Когда PERCENT не используется, числовое выражение представляет собой значение BIGINT, указывающее количество записей, которые необходимо извлечь из запроса на выборку. Имя_таблицы — это имя таблицы, из которой должны быть извлечены записи, а имя столбца — это имя столбца, по которому должен быть отсортирован результат.
Использование предложения ORDER BY в верхней части выбора необязательно. Однако рекомендуется использовать оператор TOP вместе с предложением order by, так как это заставит запрос получить упорядоченный набор результатов, содержащий ограниченное количество записей, которые появляются первыми в последовательности порядка.
Предложение WITH TIES также является необязательным, в нем упоминается, что все связанные записи упорядоченного набора результатов также должны быть извлечены. Использование WITH TIES может увеличить число извлеченных наборов результатов, чем указано в числовом выражении. Например, если мы пытаемся получить человека с наибольшим количеством баллов в классе, а вы используете TOP 1, то, если вы не используете WITH LIES, набор результатов даст только одну запись, даже если существуют те же самые люди с оценкой, которые имеют достигли наивысших результатов. А при использовании TOP1 вместе с предложением «WITH LIES» это приведет к извлечению всех записей, имеющих самые высокие баллы в классе.
А при использовании TOP1 вместе с предложением «WITH LIES» это приведет к извлечению всех записей, имеющих самые высокие баллы в классе.
Примеры SQL Select Top
Рассмотрим одну существующую таблицу с именем educba_articles в нашей базе данных с именем educba. Содержимое и структуру таблицы можно получить, выполнив следующий запрос:
SELECT * FROM `educba_articles`;
Выполнение приведенного выше оператора запроса дает результат, показанный ниже.
Теперь мы можем заметить, что таблица educba_articles состоит из 20 записей. Мы хотим получить только первые 10 записей, которым назначена максимальная ставка. Для этого мы можем использовать предложение select top в SQL, используя следующий оператор запроса, который извлекает имя, автора и рейтинг статьи.
ВЫБЕРИТЕ ТОП 10
ИМЯ,
автор,
рейтинг
ИЗ
educba.`educba_articles`
ORDER BY Rate DESC ;
Выполнение приведенного выше оператора запроса дает результат, показанный ниже.
Использование предложения WITH TIES
Предположим, что у нас есть шесть самых первых записей статей, перечисленных в соответствии с их оценками, и мы должны найти из них статьи с наивысшим рейтингом. Если мы просто используем оператор top, как показано в приведенном выше операторе запроса, мы будем использовать следующий запрос.
ВЫБЕРИТЕ ТОП 6
ИМЯ,
автор,
рейтинг
ИЗ
educba.`educba_articles`
ORDER BY Rate DESC ;
Выполнение приведенного выше оператора запроса дает результат, показанный ниже.
Но мы можем заметить, что еще две статьи оцениваются так же, как ставки извлеченных целых записей, и в которых таблица educba_article. Поскольку мы хотим получить самые высокооплачиваемые записи, которые находятся в первых шести позициях, они также должны быть получены, поскольку им также назначена одинаковая ставка. Эту проблему можно решить, просто используя WITH TIES в том же операторе запроса, как показано ниже.
ВЫБЕРИТЕ ТОП-6 СО СВЯЗЯМИ
ИМЯ,
автор,
рейтинг
ИЗ
educba.`educba_articles`
СОРТИРОВАТЬ ПО рейтингу DESC ;
Выполнение приведенного выше оператора запроса дает результат, который показан ниже:
Здесь NOT NULL и где именованные статьи извлекаются из-за использования WITH TIES в предложении top в нашем операторе запроса select.
Использование PERCENT
Предположим, что мы хотим получить только 1/4 набора результатов оператора запроса. Для таких случаев мы можем использовать предложение PERCENT. 1/4 суммы чего-либо означает скидку 25% на эту вещь. Следовательно, упомянув 25 PERCENT в верхнем предложении, мы можем получить 1/4 записей исходного набора результатов запроса. Так как наша таблица содержит 20 записей. 25 процентов записей из 20 записей будут составлять 5 записей. Следовательно, использование следующего оператора запроса должно привести к извлечению первых пяти записей, упорядоченных на основе их скоростей в порядке убывания.
ВЫБЕРИТЕ ТОП 25 ПРОЦЕНТОВ
ИМЯ,
автор,
рейтинг
ИЗ
educba.`educba_articles`
ORDER BY Rate DESC ;
Выполнение приведенного выше оператора запроса дает результат, который соответствует ожидаемому и показан ниже.
Заключение
Использование оператора SELECT TOP в SQL помогает ограничить количество записей, которые будут извлечены из оператора запроса в SQL. Многие СУБД, такие как MySQL и oracle, не поддерживают его использование, но предоставляют альтернативы, такие как LIMIT и ROWNUM, которые можно использовать для ограничения набора результатов.
Рекомендуемые статьи
Это руководство по SQL Select Top. Здесь мы также обсудим введение и синтаксис sql select top вместе с различными примерами и реализацией кода. Вы также можете ознакомиться со следующими статьями, чтобы узнать больше:
- MySQL CEIL
- Виртуальная таблица SQL
- Синхронизация MySQL
- Сопоставление шаблонов SQL
SQL Select Top
В этом разделе мы описали Select Top с подробным примером.
При работе с большим количеством строк в таблице мы можем получить несколько строк в наборе результатов. Если мы хотим получить только определенные строки, мы можем использовать оператор SELECT TOP. Используя оператор SELECT TOP, мы можем получить столько строк из набора результатов, сколько нужно.
Синтаксис —
SELECT TOP Number| Процент Столбец1, Столбец2,.. FROM Имя_таблицы [WHERE Condition];
Пример —
Давайте рассмотрим приведенную ниже таблицу (таблицы) в качестве примера таблицы (таблиц) для создания SQL-запроса для получения желаемых результатов.
employee_details —
| emp_id | emp_name | обозначение | manager_id | date_of_hire | зарплата | dept_id |
|---|---|---|---|---|---|---|
| 001 | Сотрудник1 | Директор | 11.07.2019 | 45000.00 | 1000 | |
| 002 | Сотрудник2 | Директор | 11. 07.2019 07.2019 | 40000,00 | 2000 | |
| 003 | Сотрудник3 | Менеджер | Сотрудник1 | 11.07.2019 | 27000.00 | 1000 |
| 004 | Сотрудник4 | Менеджер | Сотрудник2 | 08.10.2019 | 25000,00 | 2000 |
| 005 | Сотрудник5 | Аналитик | Сотрудник3 | 11.07.2019 | 20000.00 | 1000 |
| 006 | Сотрудник6 | Аналитик | Сотрудник3 | 08.10.2019 | 18000.00 | 1000 |
| 007 | Сотрудник7 | Клерк | Сотрудник3 | 11.07.2019 | 15000.00 | 1000 |
| 008 | Сотрудник8 | Продавец | Сотрудник4 | 2019—09-09 | 14000.00 | 2000 |
| 009 | Сотрудник9 | Продавец | Сотрудник4 | 08. 10.2019 10.2019 | 13000.00 | 2000 |
Сценарий – Получение указанных строк из таблицы.
Требование — Получить первые 4 строки из таблицы employee_details. Запрос был следующим —
SELECT TOP 4 * FROM employee_details;
Выполнив вышеуказанный запрос, мы можем получить первые 4 строки из таблицы employee_details. Результат был таким, как показано ниже:
| emp_id | .emp_name | обозначение | manager_id | date_of_hire | зарплата | dept_id |
|---|---|---|---|---|---|---|
| 001 | Сотрудник1 | Директор | 11.07.2019 | 45000.00 | 1000 | |
| 002 | Сотрудник2 | Директор | 11.07.2019 | 40000,00 | 2000 | |
| 003 | Сотрудник3 | Менеджер | Сотрудник1 | 11. 07.2019 07.2019 | 27000.00 | 1000 |
| 004 | Сотрудник4 | Менеджер | Сотрудник2 | 08.10.2019 | 25000,00 | 2000 |
Сценарий — Получить указанные строки с указанными столбцами из таблицы.
Требование — Получить emp_id, emp_name, обозначение первых четырех строк из таблицы employee_details. Запрос был такой —
ВЫБЕРИТЕ ПЕРВЫЕ 4 emp_id, emp_name, назначение ИЗ employee_details;
Выполнив вышеуказанный запрос, мы можем получить первые 4 строки с указанными столбцами из таблицы employee_details. Результат был таким, как показано ниже:
| emp_id | .emp_name | обозначение |
|---|---|---|
| 001 | Сотрудник1 | Директор |
| 002 | Сотрудник2 | Директор |
| 003 | Сотрудник3 | Менеджер |
| 004 | Сотрудник4 | Менеджер |
Сценарий — Получить указанные процентные строки из таблицы.
Требование — Получить первые 50% от общего числа строк из таблицы employee_details. Запрос был следующим:
ВЫБЕРИТЕ ВЕРХНИЕ 50 ПРОЦЕНТОВ * ОТ employee_details;
Выполнив вышеуказанный запрос, мы можем получить первые 50% строк из таблицы employee_details. Результат был таким, как показано ниже —
| emp_id | emp_name | обозначение | manager_id | date_of_hire | зарплата | dept_id |
|---|---|---|---|---|---|---|
| 001 | Сотрудник1 | Директор | 11.07.2019 | 45000.00 | 1000 | |
| 002 | Сотрудник2 | Директор | 11.07.2019 | 40000,00 | 2000 | |
| 003 | Сотрудник3 | Менеджер | Сотрудник1 | 11.07.2019 | 27000.00 | 1000 |
| 004 | Сотрудник4 | Менеджер | Сотрудник2 | 08. 10.2019 10.2019 | 25000,00 | 2000 |
| 005 | Сотрудник5 | Аналитик | Сотрудник3 | 11.07.2019 | 20000.00 | 1000 |
Сценарий — Получить указанные процентные строки с указанными столбцами из таблицы.
Требование — Получить столбцы emp_id, emp_name, обозначение из первых 50% от общего числа строк в таблице employee_details. Запрос был следующим —
SELECT TOP 50 PERCENT emp_id, emp_name, обозначение ОТ employee_details;
Выполнив вышеуказанный запрос, мы можем получить 50 процентов строк указанных столбцов из таблицы employee_details. Результат был таким, как показано ниже:
| emp_id | .emp_name | обозначение |
|---|---|---|
| 001 | Сотрудник1 | Директор |
| 002 | Сотрудник2 | Директор |
| 003 | Сотрудник3 | Менеджер |
| 004 | Сотрудник4 | Менеджер |
| 005 | Сотрудник5 | Аналитик |
Сценарий — Получить указанные процентные строки с указанными столбцами с предложением WHERE.
Требование — Получить 50% строк emp_id, emp_name, сведения о назначении из таблицы employee_details из отдела 1000. Запрос был следующим —
SELECT TOP 50 PERCENT emp_id, emp_name, обозначение ОТ employee_details ГДЕ dept_id = 1000;
Выполнив вышеуказанный запрос, мы можем получить 50 процентов строк из таблицы employee_details под dept_id 1000. Вывод был таким, как показано ниже:
| emp_id | emp_name | обозначение |
|---|---|---|
| 001 | Сотрудник1 | Директор |
| 003 | Сотрудник3 | Менеджер |
| 005 | Сотрудник5 | Аналитик |
Сценарий — Получить указанные строки с указанными столбцами из таблицы с помощью предложения WHERE.
Требование — Получить первые 2 emp_id, emp_name, сведения о назначении из таблицы employee_details из отдела 2000. Запрос был следующим —
SELECT TOP 2 emp_id, emp_name, обозначение ОТ employee_details ГДЕ dept_id = 2000;
Выполнив вышеуказанный запрос, мы можем получить первые 2 строки с emp_id, emp_name, сведениями о назначении из таблицы employee_details, принадлежащей dept_id 2000.