Проверка правописания в Pages на Mac
Можно выполнять проверку правописания в Pages во время ввода и автоматически исправлять ошибки. Также можно проверять грамматику в Pages и добавлять термины в словарь, чтобы они не выделялись как ошибка.
Если Вы хотите проверить правописание на другом языке, сначала измените язык словаря.
Проверить правописание и грамматику
Выполните одно из описанных ниже действий.
Нажмите на клавиатуре сочетание клавиш Command-точка с запятой (;) для отображения первого слова с ошибкой правописания. Продолжайте нажимать это сочетание клавиш для перехода к следующей ошибке правописания и далее.
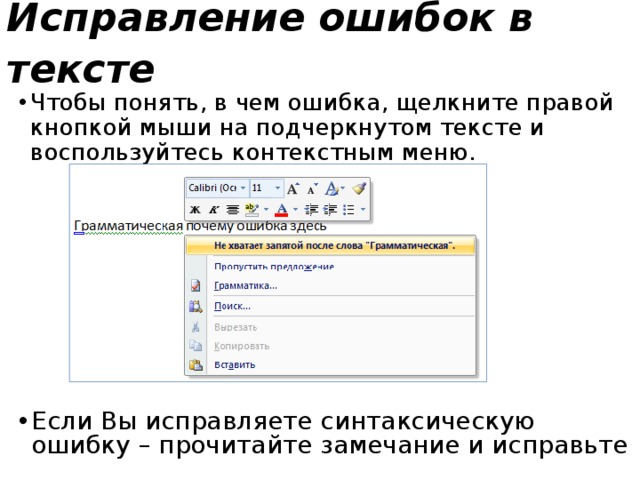
Выберите «Правка» > «Правописание и грамматика» > «Проверять грамматику и правописание» (флажок показывает, что проверка включена), затем выберите «Проверить документ». Выделяется первая ошибка правописания, а грамматически ошибки будут подчеркиваются зеленым.

Чтобы просмотреть предлагаемые исправления правописания или грамматики для слова, нажмите его при нажатой клавише Control, затем нажмите нужный вариант.
Чтобы пропустить ошибку, нажмите слово при нажатой клавише Control, затем выберите «Пропустить правописание».
Если слово повторно встретится в текущем документе, оно будет пропущено; в других документах оно будет выделено. Если Вы позже захотите удалить его из списка «Игнорируемые слова», выберите меню Pages > «Настройки» (меню Pages расположено у верхнего края экрана), нажмите «Автокоррекция», нажмите кнопку «Игнорируемые слова», затем удалите слово.
Чтобы показать следующую ошибку, нажмите сочетание клавиш Command-точка с запятой.

Использование автоисправления
Когда правописание проверяется автоматически, слова с ошибками подчеркиваются красным, а предлагаемые исправления отображаются синим цветом под словом. Если предлагаемые варианты автокоррекции отсутствуют, убедитесь, что автокоррекция включена.
Если предлагаемые варианты автокоррекции отсутствуют, убедитесь, что автокоррекция включена.
Выберите меню Pages > «Настройки» (меню Pages расположено у верхнего края экрана).
Нажмите «Автокоррекция» вверху окна настроек, затем установите или снимите флажок «Исправлять ошибки автоматически».
Когда автокоррекция включена, выполните любое из указанных ниже действий.
Принятие предложенного варианта. Если предлагается только один вариант, продолжайте ввод, и слово будет автоматически исправлено на этот вариант. Если предлагается несколько вариантов, выберите один из них.
Игнорирование предлагаемых вариантов. Нажмите клавишу Esc (Escape), затем продолжайте ввод.
Отмена автокоррекции. Автоматически исправленное слово кратковременно подчеркивается синей линией. Чтобы восстановить первоначальное написание, поместите точку вставки после слова для отображения первоначального написания, затем выберите свое написание.
 Можно также нажать слово, удерживая нажатой клавишу Control, чтобы отобразить первоначальное написание, а затем выбрать его.
Можно также нажать слово, удерживая нажатой клавишу Control, чтобы отобразить первоначальное написание, а затем выбрать его.
Добавление слов в словарь правописания и их удаление
Добавление слова. Удерживая клавишу Control, нажмите слово, затем выберите «Запомнить правописание» в контекстном меню. Слово добавляется в словарь macOS, используемый Pages и другими приложениями.
Удаление слова. Удерживая клавишу Control, нажмите слово, затем выберите «Не запоминать правописание» в контекстном меню. Слово удаляется из словаря macOS, используемого Pages и другими приложениями.
Определение слов для игнорирования в Pages. Выберите меню Pages > «Настройки» (меню Pages расположено у верхнего края экрана). Нажмите «Автокоррекция» вверху окна настроек, затем нажмите кнопку «Игнорируемые слова» в разделе «Правописание». Нажмите и введите слово, которое нужно игнорировать при проверке правописания в документах Pages.
 Когда будете готовы, нажмите «ОК».
Когда будете готовы, нажмите «ОК».
Примечание. Слово, добавленное в словарь правописания, добавляется для всех языков.
Работа с окном «Правописание и грамматика»
Можно открыть окно «Правописание и грамматика», чтобы проверить правописание и грамматику в документе.
Выберите «Правка» > «Правописание и грамматика» > «Показать правописание и грамматику» (меню «Правка» расположено у верхнего края экрана).
Чтобы проверить только определенный текст, сначала выберите этот текст.
Подробную информацию о поиске и замене текста см. в разделе Поиск и замена текста в Pages на Mac.
Настройка проверки правописания для нескольких языков
В разделе «Системные настройки» на компьютере Mac можно задать автоматическую проверку правописания для нескольких языков.
Для изменения настроек проверки правописания выполните одно из указанных ниже действий.

В macOS Ventura 13 или новее. Выберите меню Apple > «Системные настройки» > «Клавиатура», нажмите «Изменить» справа от параметра «Источники ввода», затем во всплывающем меню «Правописание» выберите «Автоматически определять язык».
В macOS 12 или более ранних версиях. Выберите меню Apple > «Системные настройки» > «Клавиатура», нажмите «Текст», затем во всплывающем меню «Правописание» выберите «Автоматически определять язык».
Закройте окно настроек клавиатуры.
В Pages в окне «Правописание и грамматика» можно также выбрать язык для проверки правописания. Выберите «Правка» > «Правописание и грамматика» > «Показать правописание и грамматику». Нажмите всплывающее меню в нижней части окна и выберите язык.
См. такжеПоиск определений слов в Pages на MacПоиск и замена текста в Pages на MacАвтоматическая замена текста в Pages на Mac
проверка правописания — взгляд изнутри (часть 1) / Хабр
Читавшие мои предыдущие публикации знают, что пишу я достаточно редко, но обычно сериями. Хочется собраться с мыслями на заданную тему и разложить их по полочкам, не втискивая себя в прокрустово ложе одной короткой статейки.
Хочется собраться с мыслями на заданную тему и разложить их по полочкам, не втискивая себя в прокрустово ложе одной короткой статейки.
На сей раз появился новый повод поговорить об обработке текстов (natural language processing то бишь). Я разрабатываю модуль проверки правописания для одной конторы. На выходе должна получиться функциональность, аналогичная встроенной в MS Word, только лучше 🙂 Не могу пока назвать себя крупным специалистом в этой области, но стараюсь учиться. В заметках постараюсь рассказать о том, куда движется наш проект, как устроен тот или иной этап обработки текста. Может, в комментариях услышу что-нибудь новое/интересное и для себя. Если проекту с этого будет польза — прекрасно. Как минимум, устаканю данные у себя в голове, а это тоже неплохо.
Понятно, что без оглядки на существующие решения изобретать свою систему трудно. Однако гигантов вокруг нас как-то не особенно наблюдается. Есть MS Word, который все мы знаем, а ещё… а кто ещё? Вот пусть комментаторы поправят, но кроме модуля LanguageTool для Open Office (о нём мы ещё поговорим) даже в голову ничего не приходит. Штучный товар. (Да, вспомнил ещё о пакете Grammarian Pro X для макинтоша, но он тоже погоды не делает). Соответственно, ориентироваться на «отцов» сложновато. Проверка орфографии худо-бедно много где реализована, а вот с грамматикой совсем беда.
Штучный товар. (Да, вспомнил ещё о пакете Grammarian Pro X для макинтоша, но он тоже погоды не делает). Соответственно, ориентироваться на «отцов» сложновато. Проверка орфографии худо-бедно много где реализована, а вот с грамматикой совсем беда.
В языках программирования отчётливо видны две модели выявления ошибок в тексте. Во-первых, ошибки можно выявить на этапе компиляции, то есть при попытке соединить слова языка в осмысленные, допустимые в соответствии с языковой грамматикой конструкции. Во-вторых, можно произвести статический анализ кода, то есть разыскать в тексте программы некие паттерны, связываемые с потенциально опасными действиями.
В теории «модель компиляции», конечно, выглядит очень заманчиво: попытаемся «откомпилировать» текст. Если в нём присутствуют ошибки, анализируемый фрагмент попросту «не склеится», причём системе будет сразу же ясно почему — как это ясно компилятору компьютерного языка. К сожалению, на данный момент полноценных «компиляторов естественного языка» не существует. Это как раз то направление, которое я копаю на досуге, но пытаться встроить сырые идеи в коммерческий продукт я пока не готов. Лучше уж сделать хороший state-of-the-art модуль, заодно понять, как он в наши времена устроен.
Это как раз то направление, которое я копаю на досуге, но пытаться встроить сырые идеи в коммерческий продукт я пока не готов. Лучше уж сделать хороший state-of-the-art модуль, заодно понять, как он в наши времена устроен.
Если вы откроете настройки правописания в MS Word, то увидите, что грамматическая проверка действует как раз по принципу статического анализатора. Есть некий набор проверок, и система последовательно прогоняет через них текст:
По правде говоря, рассуждать о «модуле проверки правописания в MS Word» не совсем корректно: в действительности модули для разных языков делались разными командами и на различных алгоритмах. Однако общая идея «прогона» текста через сито проверок вроде как справделива для каждого модуля.
А вот теперь обсудим вот такой важный вопрос: откуда берутся те самые проверки, о которых только что шла речь? Почему в MS Word встроен именно тот набор правил, который показан на скриншоте выше? Кстати, в справке доступна более развёрнутая информация по каждому виду анализа:
Качество проверки грамматики Вордом не пинал только ленивый. Достаточно изучить хотя бы вот эту известную подборку материалов, чтобы убедиться, что ваш негативный опыт разделяют многие 🙂 Я думаю, недостатки всех грамматических модулей вызваны тремя основными причинами. Во-первых, сам принцип «статической проверки» подразумевает неполное покрытие ошибок правописания. Имя этим ошибкам — легион, и надо обладать недюжинным талантом тестера, чтобы вбить в систему все мыслимые и немыслимые несуразности, потенциально возможные в предложениях. Во-вторых, наши технологии ещё не столь хороши, как хотелось бы. Многие ошибки тестер осознаёт, но не имеет возможности их запрограммировать. Понятно, что не все ошибки одинаково легко ловятся. В-третьих, по всей видимости, ошибки ищутся в соответствии с известной шуткой — «под фонарём», где светло, а не там, где они водятся на самом деле.
Достаточно изучить хотя бы вот эту известную подборку материалов, чтобы убедиться, что ваш негативный опыт разделяют многие 🙂 Я думаю, недостатки всех грамматических модулей вызваны тремя основными причинами. Во-первых, сам принцип «статической проверки» подразумевает неполное покрытие ошибок правописания. Имя этим ошибкам — легион, и надо обладать недюжинным талантом тестера, чтобы вбить в систему все мыслимые и немыслимые несуразности, потенциально возможные в предложениях. Во-вторых, наши технологии ещё не столь хороши, как хотелось бы. Многие ошибки тестер осознаёт, но не имеет возможности их запрограммировать. Понятно, что не все ошибки одинаково легко ловятся. В-третьих, по всей видимости, ошибки ищутся в соответствии с известной шуткой — «под фонарём», где светло, а не там, где они водятся на самом деле.
На сегодняшний день не так уж легко отыскать частотный перечень ошибок, встречающихся в обычной переписке. Одно из немногочисленных исследований перечисляет двадцать наиболее частых ошибок, замеченных в сочинениях студентов (на английском языке). Речь идёт о носителях языка, поэтому список может показаться нам неочевидным. Думаю, для иностранцев мы получим совершенно другую выборку (причём сильно зависящую от родного языка пишущего).
Речь идёт о носителях языка, поэтому список может показаться нам неочевидным. Думаю, для иностранцев мы получим совершенно другую выборку (причём сильно зависящую от родного языка пишущего).
Автор другой статьи не поленился и прогнал тексты с указанными ошибками через различные модули проверки грамматики. Результаты оказались совершенно неутешительными. Если вкратце, всё плохо (а Word 97 почему-то оказался гораздо лучше всех последующих версий; впрочем, для нас это не имеет значения). Тест наиболее популярных ошибкок либо слишком сложен для программирования, либо попросту упущен разработчиками по недосмотру.
Разумеется, заказчик хочет иметь самый лучший грамматический модуль в мире. По крайней мере, не хуже, чем у MS Word. И мы попытаемся это ему обеспечить, но я, по правде говоря, не надеюсь далеко уйти от нынешних стандартов качества. Слишком многое играет против нас. Действительно, не существует хорошей классификации возможных ошибок с указанием их реальной частотности (как для носителей, так и для иностранцев), а без такого списка любые проверки превращаются в стрельбу по хмурому небу в надежде попасть в пролетающую где-то за тучами дичь. Да и ошибки из списка (я их внимательно изучил) действительно по большей части сложны для отлова. Что ж, будем работать. Да, я не упомянул пока, что начинаем мы с английского, далее по плану немецкий, а там жизнь покажет.
Да и ошибки из списка (я их внимательно изучил) действительно по большей части сложны для отлова. Что ж, будем работать. Да, я не упомянул пока, что начинаем мы с английского, далее по плану немецкий, а там жизнь покажет.
В следующих частях перейду к техническим деталям того, как устроена наша система (на данный момент по большей части существующая только у меня в голове, но процесс движется быстро), а на сегодня предлагаю закончить.
Устранение неполадок при проверке орфографии и грамматики на нескольких языках
Проверка орфографии и грамматики на нескольких языках может создавать уникальные проблемы, например правильно написанные слова помечаются как неправильные или слова с ошибками на другом языке не помечаются как неправильные. В этой статье рассматриваются распространенные проблемы, и она поможет вам убедиться, что ваш текст указан на правильном языке; что для проверки правописания и грамматики используется правильный языковой словарь; и что автоматизированные языковые инструменты в Office включены.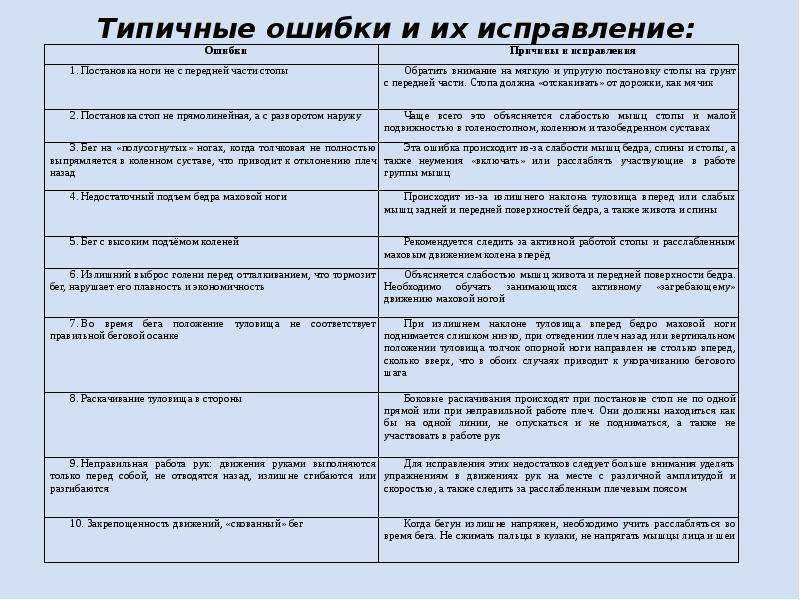
Примечание. Если вы хотите ввести всего несколько символов на другом языке, см. раздел Вставка галочки или другого символа.
Слова с ошибками не помечаются как написанные с ошибками
Убедитесь, что:
Язык, который вы хотите, включен
Правильный язык применяется к тексту
Используется правильный языковой словарь
Установлен флажок «Определять язык автоматически».

Установлен флажок Автоматически переключать клавиатуру в соответствии с языком окружающего текста.
Флажок Не проверять орфографию и грамматику снят.
Слово с ошибкой не было случайно добавлено в пользовательский словарь.
Убедитесь, что нужный язык включен
Чтобы правильно проверять орфографию и грамматику на другом языке, этот язык должен быть включен в Office. Если вам нужен язык, который не указан в качестве языка редактирования в диалоговом окне Задайте языковые настройки Office , вам может потребоваться получить и установить языковой пакет, прежде чем вы сможете проверить правописание.
Верх страницы
Убедитесь, что к тексту применен правильный язык
Если средство проверки орфографии не проверяет слова, введенные вами на другом языке, или если оно помечает слова на другом языке, которые написаны правильно, как написанные с ошибками, возможно, эти слова относятся к неверному языку.
Чтобы вручную изменить язык определенных слов или части текста в Word, выполните следующие действия:
На вкладке Review в группе Language щелкните Language > Set Proofing Language .

(В Word 2007 щелкните Установить язык в группе Правописание .)
В диалоговом окне Language выберите нужный язык.
Важно: Если нужный язык не отображается над двойной линией, необходимо включить этот язык, чтобы он был доступен для проверки орфографии.
Начните печатать.
Примечание: Для ввода символов, таких как умлаут в немецком языке (ö), тильда в испанском языке (ñ), седилья в турецком языке (Ç) или даже символа, например галочки, на вкладыше
 org/ListItem»>
org/ListItem»>Чтобы вернуться к исходному языку или переключиться на другой язык, повторите шаги 1–3. На шаге 3 выберите следующий язык.
Верх страницы
Убедитесь, что используется правильный языковой словарь
Убедитесь, что для вашего текста выбран правильный язык словаря — например, английский (США) вместо английского (Великобритания).
Чтобы изменить словарь на определенный язык в Word , выполните следующие действия:
На вкладке Review в группе Language щелкните Language > Set Proofing Language .
(В Word 2007 щелкните Установить язык в группе Правописание .
 )
)В диалоговом окне Language выберите нужный язык.
Важно: Если нужный язык не отображается над двойной линией, необходимо включить этот язык, чтобы он был доступен для проверки орфографии.
Примечание. Если ваша версия Office не предоставляет средств проверки правописания, таких как средство проверки орфографии, для языка, который вы хотите использовать, вам может потребоваться языковой пакет. Дополнительные сведения см. в разделе Пакет языковых аксессуаров для Office.
Чтобы изменить словарь для выделенного текста, выполните следующие действия:
Выберите текст, для которого вы хотите изменить язык словаря.

На вкладке Review в группе Language щелкните Language > Set Proofing Language .
(В Word 2007 щелкните Установить язык в группе Правописание .)
В разделе Пометить выделенный текст как , щелкните язык, которым вы хотите идентифицировать часть текста. Если языки, которые вы используете, не отображаются над двойной линией, вы должны включить эти языки (включить параметры для конкретных языков), чтобы они были доступны.
Верх страницы
Убедитесь, что установлен флажок Определять язык автоматически
Чтобы установить флажок Определять язык автоматически в Word, выполните следующие действия:
На вкладке Review в группе Language нажмите Язык > Установить язык проверки .
(В Word 2007 щелкните Установить язык в группе Правописание .)
В диалоговом окне Язык установите флажок Определять язык автоматически .
Просмотрите языки, указанные над двойной линией в Пометить выбранный текст как 9список 0006. Word может обнаружить только те языки, которые перечислены над двойной чертой. Если нужные вам языки недоступны, вы должны включить язык редактирования, чтобы Word автоматически обнаруживал их.
 org/ItemList»>
org/ItemList»>Примечания:
 org/ListItem»>
org/ListItem»>Для автоматического определения языка требуется, чтобы текстовое предложение было написано на этом языке. В зависимости от длины ваших предложений вам может потребоваться ввести несколько предложений, прежде чем Word получит достаточно контекстной информации для автоматического определения языка и применения правильного словаря.
Слова, которые пишутся одинаково на нескольких языках, например, «центр» в английском (Великобритания) и французском (Франция) Флажок «Определять язык автоматически» может неправильно определять язык текста. Чтобы решить эту проблему, введите больше слов на нужном языке или снимите флажок
Верх страницы
Убедитесь, что установлен флажок Автоматически переключать клавиатуру в соответствии с языком окружающего текста
Флажок Автоматически переключать клавиатуру в соответствии с языком окружающего текста может быть включен и вызывать типографские ошибки, изменяя язык клавиатуры при вводе. Попробуйте ввести больше слов на нужном языке или снимите флажок 9.0005 Автоматически переключать клавиатуру в соответствии с языком окружающего текста флажок.
Попробуйте ввести больше слов на нужном языке или снимите флажок 9.0005 Автоматически переключать клавиатуру в соответствии с языком окружающего текста флажок.
Чтобы установить флажок Автоматически переключать клавиатуру в соответствии с языком окружающего текста (в Office 2010, Office 2013 и Office 2016):
Открыть Ворд.
Щелкните Файл > Параметры > Дополнительно .
В разделе Параметры редактирования установите флажок Автоматически переключать клавиатуру в соответствии с языком окружающего текста .
Примечание. Флажок Автоматически переключать клавиатуру в соответствии с языком окружающего текста отображается только после включения раскладки клавиатуры для языка. Если вы не видите эту опцию, включите раскладку клавиатуры для языка, который вы хотите использовать.
Верх страницы
Убедитесь, что флажок Не проверять орфографию и грамматику снят.
Если установлен флажок Не проверять орфографию и грамматику , правописание в ваших документах не проверяется.
Чтобы снять флажок Определять язык автоматически в Word, выполните следующие действия:
На вкладке Review в группе Language щелкните Language > Set Proofing Language .

(В Word 2007 щелкните Установить язык в группе Правописание .)
В диалоговом окне Язык снимите флажок Не проверять орфографию или грамматику .
Узнайте больше о проверке орфографии и грамматики на разных языках.
Верх страницы
Убедитесь, что слово с ошибкой не было случайно добавлено в пользовательский словарь
Если в пользовательский словарь было добавлено слово с ошибкой, вам необходимо найти и удалить это слово. Сведения о том, как проверить пользовательский словарь на наличие слов с ошибками, см. в разделе Использование пользовательских словарей для добавления слов в средство проверки орфографии. Сведения о том, как удалить слово из словаря, см. в разделе Добавление или изменение слов в словаре проверки орфографии.
Сведения о том, как удалить слово из словаря, см. в разделе Добавление или изменение слов в словаре проверки орфографии.
Верх страницы
Язык словаря, который мне нужен, не указан в диалоговом окне «Язык»
Наиболее распространенными причинами того, что язык словаря не отображается в списке Язык словаря в диалоговом окне Язык , является то, что этот язык не был включен в качестве языка редактирования или этот язык не включен в установлена версия Office, и необходимо установить языковой пакет для этого языка. Сведения о том, как включить язык редактирования, см. в разделе Изменение языка, который Office использует в своих меню и средствах проверки правописания.
Верх страницы
Все еще нужна помощь?
Свяжитесь с нами с вашим вопросом или проблемой.
Дополнительная информация об орфографии и грамматике
Проверьте орфографию и грамматику
Добавление или изменение слов в словаре проверки орфографии
Проверка орфографии и грамматики не работает должным образом
Добавление языка или настройка языковых параметров в Office
Проверка орфографии и грамматики на другом языке
Исправление грамматических ошибок с помощью глубокого обучения | PUSHAP GANDHI
Изображение из Unsplash- Введение
- Определение задач
- Пререквизиты
- Источник данных
- Понимание данных
- Анализ данных
- Предварительная обработка данных .
- Вывод (жадный поиск VS поиск BEAM)
- Результаты и сравнение моделей
- Развертывание модели и прогнозы
- Будущая работа
- Репозиторий Github и Linkedin
- Ссылки
 Внимание
ВниманиеИсправление грамматических ошибок, как следует из названия, — это процесс, посредством которого выполняется обнаружение и исправление ошибки в тексте. Проблема кажется простой для понимания, но на самом деле она сложна из-за разнообразия словарного запаса и набора правил в языке. Кроме того, мы собираемся не только выявить ошибку, но и требуется ее исправление.
Применение:
- У этой проблемы есть множество применений, потому что письмо — очень распространенный способ обмена идеями и информацией. Это может помочь писателю ускорить свою работу с минимальной вероятностью ошибки.
- Кроме того, может быть много людей, которые не владеют каким-либо языком. Таким образом, эти типы моделей гарантируют, что язык не является барьером в общении.

Теперь мы определим поставленную задачу как задачу машинного обучения. Проблема, с которой мы имеем дело, относится к типу проблем НЛП (обработки естественного языка). NLP — это область машинного обучения, которая занимается взаимодействием между человеческими языками и компьютерами. Я бы рекомендовал просмотреть этот документ, чтобы узнать о прогрессе подходов, используемых для решения проблемы.
Подход, который мы собираемся рассмотреть, — это модель «Последовательность за последовательностью». Короче говоря, модель глубокого обучения получит последовательность (в данном случае неправильный текст) и выведет другую последовательность (в данном случае исправленный текст).
Метрика производительности
Теперь, когда мы определили нашу проблему как проблему машинного обучения, есть еще одна очень важная идея, с которой необходимо разобраться, — это метрика производительности. Метрика производительности — это математическая мера, которая помогает понять производительность нашей модели машинного обучения.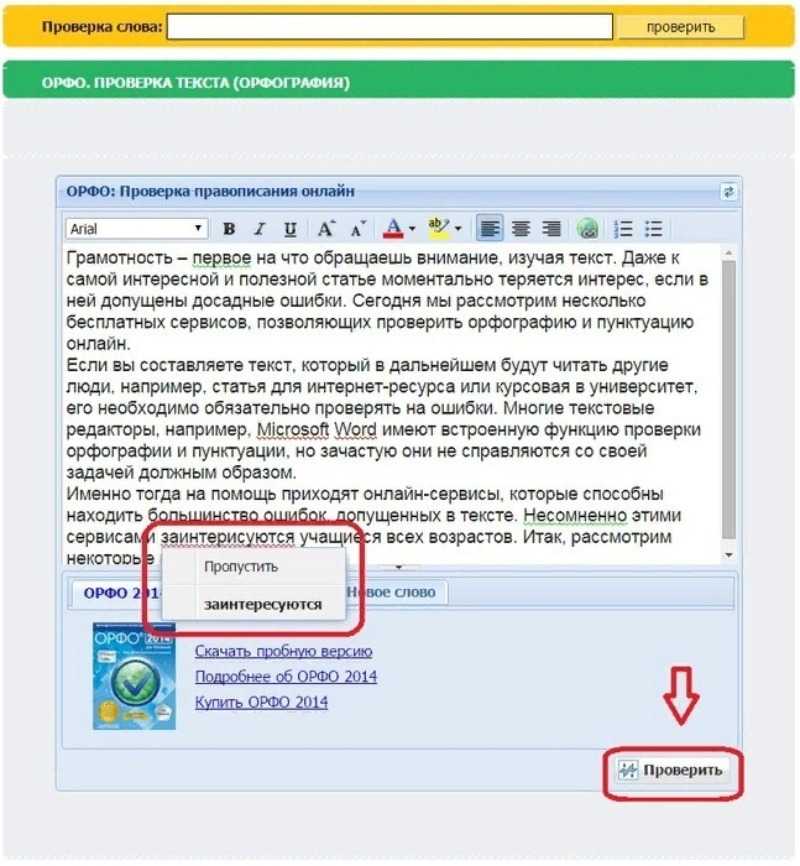
Очень популярной метрикой производительности для задач NLP является BLEU (двуязычная оценка дублера) Score , поэтому мы собираемся использовать ее и для нашей модели. Вы можете обратиться к этому видео, чтобы узнать больше о баллах BLEU.
Прежде чем мы углубимся в детали этого тематического исследования, я предполагаю, что читатели знакомы с концепциями машинного обучения и глубокого обучения. Чтобы быть конкретным, идеи LSTM, кодеров-декодеров, механизма внимания должны быть знакомы.
Я постараюсь предоставить несколько хороших рекомендаций по пути.
Как я упоминал выше, решить проблему сложно, одной из причин которой является отсутствие набора данных хорошего качества. В своем исследовании я нашел некоторые из них полезными и рассмотрел следующие два набора данных.
- Набор данных Lang-8
- Корпус нормализации и перевода текстов социальных сетей NUS
Оба эти набора данных находятся в открытом доступе, если вы заинтересованы в работе с ними.
5.1 Набор данных Lang-8
Это японский веб-сайт, предназначенный для изучения языка. Пользователи могут публиковать сообщения на языке(ах), которые они изучают, и этот пост будет виден носителям этого языка для исправления. Набор данных с этого веб-сайта содержит данные в следующем столбце, разделенном \t :
- Номер исправления
- Серийный номер
- Номер предложения
- 0 является заголовком
- Предложение, написанное изучающим английский язык исправлено предложение пар для тех точек данных, для которых существуют оба этих предложения.
5.2 Корпус нормализации и перевода текстов социальных сетей NUS
Это набор данных Национального университета Сингапура (NUS), который представляет собой текстовые данные данных социальных сетей. Размер набора данных составляет 2000 точек данных. Данные в необработанном виде имеют три строки для каждой точки данных.
- Первая строка представляет собой текст социальных сетей
- Вторая строка представляет собой правильный формальный текст, переведенный на английский язык
- Третья строка представляет собой данные, переведенные на китайский язык.

Из них мы можем использовать первые две строки каждой точки данных для нашей задачи.
После того, как мы извлекли данные в требуемой форме, теперь наступает очень неотъемлемый шаг, который представляет собой исследовательский анализ данных, который дает возможность понять и развить хорошее представление о наборе данных.
Я извлек и предварительно обработал набор данных в требуемой форме, которая будет обсуждаться в следующем разделе.
6.1 Базовая статистика
Сначала мы соберем общую информацию о наборе данных, такую как количество точек данных, типы данных, средние или медианные значения числовых данных и т. д. ЗНАЧЕНИЯ
df.info()Таким образом, имеется около 500 тыс. точек данных и отсутствуют нулевые значения.
У нас есть два столбца в наборе данных, один из которых является входным, а другой — выходным или целевым. Давайте посмотрим один за другим анализ для каждого столбца.
6.2 Длина текста и количество слов Анализ распределения
Неправильный текст
Ввод представляет собой текстовую функцию, которую мы можем проанализировать по длине текста и распределению количества слов.
- Распределение длины символов и количества слов во входных данных сильно искажено.
- Оба дистрибутива почти одинаковы.
- Количество символов во вводе может достигать 2000, а количество слов — до 400.
- Соотношение большей длины слов или символов значительно меньше.
- Более 99 процентов входных данных имеют количество символов менее 200 и количество слов менее 50.
Исправленный текст
То же самое делается и для выходного текста.
И, что удивительно, наблюдения для входного текста верны и для выходного текста.
6.3 Анализ облака слов на неправильный и исправленный текст
Облако слов — отличная визуализация для определения наиболее часто встречающихся слов в тексте.
Облако слов для ввода TextWord Cloud для вывода текстаНаиболее часто встречающиеся слова в обоих текстах:
- думаю
- хочу
- сегодня
- Япония
- английский
8 6.
 4 неправильных слов — это те слова, которые присутствуют во входных данных, но отсутствуют в целевых предложениях, а исправленных слов — это те слова, которые присутствуют в целевых предложениях, но отсутствуют во входных предложениях. Я извлек все эти слова и провел для них анализ облака слов.
4 неправильных слов — это те слова, которые присутствуют во входных данных, но отсутствуют в целевых предложениях, а исправленных слов — это те слова, которые присутствуют в целевых предложениях, но отсутствуют во входных предложениях. Я извлек все эти слова и провел для них анализ облака слов.- После просмотра изображений неправильных и исправленных слов мы можем наблюдать изменение формы используемого глагола.
идти ==> идти
идти ==> идти
учиться ==> учиться
использовать ==> использовать6.5 Маркировка POS
В этой части анализа мы свяжем слова с их частями речи и нарисуйте 10 наиболее часто встречающихся частей речи. Ниже приведены графики:
Top 10 POS for Input TextTop 10 POS for Output Text- Это показывает, что часть речи, используемая максимальное количество раз, — это существительное (NN), за которым следует предлог (IN).
- Общее количество частей речи остается одинаковым для входных и выходных предложений, но числа различаются в NNS (существительное, множественное число) и PRP (личные местоимения)
Теперь мы посмотрим, как удалить ненужные данные из нашего набора данных.
 . Мы знаем, что данные в текстовом формате, поэтому необходимо удалить все специальные символы, ненужные пробелы и выполнить деконтракцию сокращенных слов. Мы также собираемся преобразовать весь текст в более низкий, чтобы уменьшить сложность задачи. Для выполнения всех вышеупомянутых операций используется следующий код:
. Мы знаем, что данные в текстовом формате, поэтому необходимо удалить все специальные символы, ненужные пробелы и выполнить деконтракцию сокращенных слов. Мы также собираемся преобразовать весь текст в более низкий, чтобы уменьшить сложность задачи. Для выполнения всех вышеупомянутых операций используется следующий код:После этого мы также можем выполнить некоторые другие операции, такие как удаление нулевых значений и дедупликация, которые доступны в библиотеке pandas.
Перед тем как передать наши данные в модель глубокого обучения, их необходимо преобразовать в форму, понятную машине. Итак, для этой проблемы мы собираемся использовать токенизацию и заполнение, чтобы преобразовать набор данных в последовательность целых чисел одинаковой длины.
При формировании конвейера данных для модели мы собираемся дополнить последовательность, чтобы длина всех точек данных была одинаковой. Максимальная длина, используемая для заполнения, составляет 99-й процентиль распределения количества слов.

Конвейер данных
Данные должны быть преобразованы в пакеты, чтобы ввести их в модель глубокого обучения. Следующий код используется для формирования конвейера для набора данных. Эта модель принимает входные данные в форме последовательности и предсказывает другую последовательность в качестве выходных данных. Благодаря этому он имеет множество приложений в задачах машинного перевода.
Изображение из статьи Эффективные подходы к нейронному машинному переводу на основе вниманияСледующий код используется для формирования слоев кодировщика-декодера в модели.
Это действительно хороший блог, чтобы получить представление о моделях Encoder-Decoder.
Я пробовал множество вариантов моделей Vanilla Encoder-Decoder, таких как использование предварительно обученных вложений Word2Vec и FastText, вы можете проверить их в моем профиле GitHub.
Поэкспериментировав с этими моделями, я обнаружил, что для моего случая обучаемые встраивания работают лучше, чем предварительно обученные, поэтому его следует использовать для продвинутых моделей.
СИНИЙ балл, полученный для кодировщика-декодера для нашего набора данных, равен 0,4603.
Механизм внимания — очень гениальная идея машинного обучения, которая клонирует гуманистический способ восприятия информации. Кроме того, существуют определенные недостатки простой модели кодер-декодер, которые преодолевает модель внимания. Некоторые из популярных техник механизма внимания, используемых сегодня, — это механизм внимания Багданау, механизм внимания Лоунга.
Позвольте мне дать краткую информацию об этапах механизма медленного внимания, который я широко использовал в своем тематическом исследовании. Если быть точным, эта идея известна как Глобальный механизм внимания.
Изображение из статьи Эффективные подходы к нейронному машинному переводу на основе вниманияЧасть кодировщика остается такой же, как обычный кодер-декодер, который выводит скрытые состояния входной последовательности. Теперь в части декодера для каждого временного шага мы должны вычислить нечто, называемое Context Vector .
 Этот вектор контекста содержит соответствующую информацию от кодера о словах, которые должны быть предсказаны на этом временном шаге. Это может показаться сложным, но как только вы узнаете, как это вычисляется, все встанет на свои места.
Этот вектор контекста содержит соответствующую информацию от кодера о словах, которые должны быть предсказаны на этом временном шаге. Это может показаться сложным, но как только вы узнаете, как это вычисляется, все встанет на свои места.- Во-первых, когда мы получаем все скрытые состояния кодировщика (ht) и предыдущие скрытые состояния декодера (hs) из RNN, мы находим альфа-значения ().
В статье Лунг и другие предложили три варианта расчета оценки.
- После вычисления альфа-значений вектор контекста рассчитывается как средневзвешенное значение по всем скрытым состояниям кодировщика, где весами являются альфа-значения.
- Учитывая целевое скрытое состояние и контекстный вектор исходной стороны, слои простой конкатенации используются для объединения информации из обоих векторов для получения скрытого состояния внимания следующим образом:
- Затем вектор внимания h˜t проходит через слой softmax для создания следующего слова в последовательности.

Этот тип механизма внимания называется Глобальным механизмом внимания, потому что все скрытые состояния кодера учитываются на каждом временном шаге декодера для создания вектора контекста.
В этом примере я реализовал механизм Loung Attention Mechanism с нуля с помощью подклассов моделей. Ниже приведен код слоя «Внимание» для Оценка типа Dot . Полный код вы можете найти в моем профиле на GitHub.
Показатели производительности для моделей Attention значительно лучше, чем у наших эталонных моделей.
BLEU Score
Dot Scoring 0,5055
General Scoring 0,5545
Concat Score 0,5388Прежде чем мы углубимся в детали монотонного внимания, давайте рассмотрим некоторые недостатки простого механизма внимания и необходимость монотонного внимания.
Мы знаем, что в механизмах внимания на каждом временном шаге декодера необходимо обращаться ко всем скрытым состояниям кодировщика. Это создает квадратичную временную сложность , что препятствует ее использованию в онлайн-настройках .
Поэтому, чтобы преодолеть этот недостаток, вводится концепция монотонного внимания, которая просто говорит, что нет необходимости проверять все веса внимания на каждом временном шаге. Мы собираемся проверять скрытые состояния в определенном порядке (слева направо на английском языке), и одно из скрытых состояний выбирается в качестве вектора контекста на каждом временном шаге. После проверки конкретной записи она не будет проверяться на следующем временном шаге.
Softmax Внимание: изображение из этого блогаМонотонное внимание: изображение из этого блогаНаиболее важным преимуществом этого подхода является линейная временная сложность, поэтому его можно использовать для онлайн-настроек.
Здесь мы собираемся реализовать очень простой тип монотонного внимания, как описано в этом блоге и статье. Следует иметь в виду, что изменения будут происходить только на уровне внимания, но уровни кодировщика и декодера останутся прежними. Вот шаги для монотонного внимания:
- Учитывая предыдущие скрытые состояния, мы собираемся вычислить счет или энергию, для которой мы собираемся использовать те же методы, которые использовались выше в механизме внимания Лунга.

- После того, как счет подсчитан, он преобразуется в вероятности с помощью сигмовидной функции.
- Внимание для текущего временного шага вычисляется по следующей формуле: декодер для прохождения через слой softmax.
В этом примере я реализовал только один вариант монотонного уровня внимания. Для получения дополнительной информации обратитесь к блогу и коду Колина Раффела, где он дал полную реализацию этого слоя.
Производительность монотонного внимания сравнима с простым вниманием, но, как упоминалось в статье, оно дает некоторое преимущество во временной сложности.
Если вы знаете о последовательности для моделей, то вы знаете, что мы должны внести определенные изменения в модель, чтобы предсказать требуемый результат во время вывода.
Опять же, для этого у нас есть два варианта: один известен как жадный поиск, а другой — поиск по лучу. Давайте посмотрим на них обоих один за другим.
Жадный поиск
При жадном поиске для каждого временного шага мы рассматриваем токен с максимальной вероятностью и игнорируем все оставшиеся токены, даже если они имеют сопоставимые значения вероятностей после слоя softmax.

В коде вы можете увидеть функцию argmax на выходе плотного слоя активации softmax.
Прогнозы с жадным поискомУ этого есть недостаток, потому что, если какое-либо из предсказанных слов на временном шаге неверно, это также повлияет на результат будущих временных шагов.
BEAM Search
Лучшим способом прогнозирования является BEAM Search, в котором на каждом временном шаге предоставляется выбор для наиболее вероятных токенов, которые имеют номера, равные BEAM Width , а общий балл для каждой из предсказанных последовательностей равен равно произведению вероятностей каждого слова в последовательности.
Для этого примера я взял ширину луча, равную 3. Для получения дополнительной информации вы можете просмотреть этот блог.
Справочник по коду. Предсказание с помощью BEAM SearchДля этого примера я попробовал в общей сложности 12 моделей с определенными вариациями. Ниже приведены результаты.
- Результаты механизма внимания лучше, чем у простого кодировщика-декодера, и среди моделей внимания производительность не сильно отличается.

- Мы также можем заметить, что оценка BLEU для луча лучше, чем для жадного поиска, как и ожидалось.
Я выполнил развертывание модели для модели Monotonic Attention , которая вычисляет оценку с помощью скалярного произведения . Ознакомиться с моделью можно по этой ссылке.
Ниже приведены некоторые прогнозы для приведенной выше модели:
- Для будущей работы я хотел бы поработать с другими вариантами механизма монотонного внимания.
- Если лучший набор данных станет общедоступным, это действительно может улучшить производительность модели.
Я попытался вкратце рассказать о работе, которую я проделал в этом проекте. Если вы хотите увидеть полный подробный код, где я прокомментировал каждую строку, загляните в мой репозиторий Github. Не стесняйтесь подключаться к Linkedin.
Если вы дошли до этого момента, помогите мне улучшить содержание, оставив комментарий. Для меня это много значит 🙂
- https://colinraffel.
