история появления, эволюция и перспективы / Хабр
Привет, Хабр! Меня зовут Азат Якупов, я работаю Data Architect в компании Quadcode. Сегодня хочу поговорить о реляционных СУБД, которые играют важную роль в современном IT-мире. О том, что они собой представляют и для чего нужны, понимают, вероятно, большинство читателей.
Но вот как и почему появились реляционные СУБД? Об этом многие из нас знают лишь приблизительно. А ведь история создания технологии весьма интересна, она позволяет лучше понять основу цифрового мира. Если вам интересна эта тема — прошу под кат.
Как всё начиналось
В 60-х годах прошлого столетия появилась необходимость в надежной модели хранения и обработки данных. В первую очередь эти данные генерировались банками и финансовыми организациями. В то время не существовало единых стандартов работы с данными и моделями, да и работа как таковая заключалась в ручном упорядочении и организации хранящейся информации.
У банков худо-бедно получалось записывать информацию о транзакциях в виде файлов в заранее подготовленную структуру. У каждой организации было собственное понимание того, как все это должно выглядеть и работать. Не было таких понятий, как консистентность (англ. data consistency), целостности данных (англ. data integrity). В файлах часто встречались дубликаты данных клиентов и их транзакций, которые необходимо было каким-то образом уточнять и приводить в порядок, делалось это в основном вручную. В целом все проблемы того времени в отношении работы с данными можно разделить на несколько основных видов:
У каждой организации было собственное понимание того, как все это должно выглядеть и работать. Не было таких понятий, как консистентность (англ. data consistency), целостности данных (англ. data integrity). В файлах часто встречались дубликаты данных клиентов и их транзакций, которые необходимо было каким-то образом уточнять и приводить в порядок, делалось это в основном вручную. В целом все проблемы того времени в отношении работы с данными можно разделить на несколько основных видов:
Представление структуры в каждом файле было различным.
Необходимо было согласовывать данные в разных файлах, чтобы обеспечить непротиворечивость информации.
Сложность разработки и поддержки приложений, работающих с конкретными данными, и их обновления при изменении структуры файла.
По сути, здесь мы видим антипаттерн «чистой архитектуры», который был описан Робертом Мартином (Robert C. Martin).
Следует отметить, что были попытки создания моделей, позволяющих навести порядок в данных и их обработке. Одна из таких попыток — иерархическая модель, в которой данные были организованы в виде древовидной структуры. Иерархическая модель была востребованной, но не гибкой. В ней каждая запись могла иметь только одного «предка», даже если отдельные записи могли иметь несколько «потомков». Из-за этого базы данных представляли только отношения «один к одному» или «один ко многим». Невозможность реализации отношения «многие ко многим» могла привести к проблемам при работе с данными и усложняла модель. Более того, вопросы консистентности данных и отсутствия дублирования информации здесь вообще не стояли. Первая иерархическая СУБД называлась IMS от IBM.
Одна из таких попыток — иерархическая модель, в которой данные были организованы в виде древовидной структуры. Иерархическая модель была востребованной, но не гибкой. В ней каждая запись могла иметь только одного «предка», даже если отдельные записи могли иметь несколько «потомков». Из-за этого базы данных представляли только отношения «один к одному» или «один ко многим». Невозможность реализации отношения «многие ко многим» могла привести к проблемам при работе с данными и усложняла модель. Более того, вопросы консистентности данных и отсутствия дублирования информации здесь вообще не стояли. Первая иерархическая СУБД называлась IMS от IBM.
На помощь иерархической пришла сетевая модель данных, и уже новая концепция реализовала отношение «многие ко многим». Данный подход был предложен как спецификация модели CODASYL в рамках рабочей группы DBTG (Data Base Task Group).
Но всё это модели, которые сложно было поддерживать. Упростить задачу сбора и обработки данных смог Франк Кодд (Edgar F. Codd). Его фундаментальная работа привела к появлению реляционных баз данных, которые нужны практически всем отраслям. Кодд предложил язык Alpha для управления реляционными данными. Коллеги Кодда из IBM — Дональд Чемберлен (Donald Chamberlin) и Рэймонд Бойс (Raymond Boyce) — создали один из языков под влиянием работы Кодда. Они назвали свой язык SEQUEL (Structured English Query Language), но изменили название на SQL из-за существующего товарного знака.
Codd). Его фундаментальная работа привела к появлению реляционных баз данных, которые нужны практически всем отраслям. Кодд предложил язык Alpha для управления реляционными данными. Коллеги Кодда из IBM — Дональд Чемберлен (Donald Chamberlin) и Рэймонд Бойс (Raymond Boyce) — создали один из языков под влиянием работы Кодда. Они назвали свой язык SEQUEL (Structured English Query Language), но изменили название на SQL из-за существующего товарного знака.
Появление реляционных БД и их эволюция
Активное развитие технологий БД началось примерно в 1970 году, когда Кодд опубликовал свою работу, послужившую основой для создания реляционной модели данных. Среди достоинств этой модели стоит выделить:
Отсутствие дублирования данных.
Исключение ряда ошибок и аномалий данных, которые есть в других моделях.
Все данные представлены как факты, хранящиеся в виде отношений (relations) со столбцами (attributes) и строками (tuples).
Одной из первых РСУБД можно назвать dBase-II от компании Ashton-Tate, которая выпустила свой продукт в 1979 году. Она смогла поставить на рынок около 100 000 копий своего продукта. В итоге эта база данных стала самой популярной среди всех существовавших в то время продуктов. К слову, компанию Ashton-Tate позже приобрела фирма Borland. В целом реляционной СУБД этот продукт можно было назвать лишь с очень большой натяжкой.
Она смогла поставить на рынок около 100 000 копий своего продукта. В итоге эта база данных стала самой популярной среди всех существовавших в то время продуктов. К слову, компанию Ashton-Tate позже приобрела фирма Borland. В целом реляционной СУБД этот продукт можно было назвать лишь с очень большой натяжкой.
Но начало было положено — и другие компании стали представлять свои продукты. Так, например, появились Oracle, Ingress и Focus.
К 1980 году сформировалось архитектурное (высокоуровневое) и инженерное (низкоуровневое) понимание того, как должна функционировать РСУБД. И пришло решение о введении стандарта (SQL Standard ISO and ANSI).
Развитие баз данных усилилось после распространения локальных сетей, а затем и сети глобальной. Сеть позволяла совместно использовать оборудование. Также пользователи хотели совместно (параллельно) работать с РСУБД, что ускорило развитие многопользовательских приложений для локальных сетей. Была создана клиент-серверная архитектура обработки данных.
С 90-х годов технология стала более дружелюбной к пользователю. По словам маркетологов, в СУБД теперь мог разобраться любой человек. Конечно, это преувеличение, но в целом направление эволюции понятно.
В это же время стали появляться первые онлайн-сервисы (например, отправка цветов, подарков, открыток, ведение блогов и т. п.). Большинство этих сервисов стали (и продолжают) работать в связке PHP + MySQL.
Распространение сотовой связи и сотовых телефонов с 1996 года привело к созданию специализированных баз данных для обработки информации в мобильном устройстве. Сейчас они эволюционировали в отдельный стек баз данных (In-Memory) и применяются либо в качестве кэша данных, находясь перед основной базой данных, либо в качестве Warm / Hot логического слоя, используясь в Lambda / Kappa архитектуре.
По моему мнению, в 2000-х произошла своеобразная эволюция, когда нереляционная модель была интегрирована в реляционную базу данных (я говорю про интеграцию XML-формата). Можно было определять модель в модели (по сути, описать любую модель можно в одном столбце таблицы). Примерами технической реализации такого «фрактального моделирования» были Oracle Nested Tables, а также тип XML, а в последствии JSON. Такие модели назвали Post-Relational Models, и можно сказать, что начали появляться зачатки работы с noSQL-моделями формата «ключ-значение / ключ-документ».
Примерами технической реализации такого «фрактального моделирования» были Oracle Nested Tables, а также тип XML, а в последствии JSON. Такие модели назвали Post-Relational Models, и можно сказать, что начали появляться зачатки работы с noSQL-моделями формата «ключ-значение / ключ-документ».
Значение и ценность данных стал постепенно осознавать бизнес, в результате чего возросла необходимость в соответствующих специалистах. Технологии БД стали использовать далеко не только для OLTP и OLAP-трафиков, но и для глубоких исследований в данных (поиск аномалий, корреляций, использование статистического аппарата и т. д.).
С 2006 года начал работать облачный сервис Amazon AWS, по словам его представителей, сейчас он насчитывает уже свыше 20 000 частных Data Lakes, построенных внутри облака.
Ну а сейчас роль баз данных возросла еще больше. Ведь данные генерирует любое умное устройство, а их становится всё больше. Это уже не только телевизоры или смартфоны, но и зубные щетки и даже чайники (IOT-трафик, не путать с Index-Organized Tables! 😉
Правда, с увеличением объема данных стало больше и узконаправленных баз данных, которые специализируются на работе с разными типами информации и моделями.
Реляционных СУБД не так много (по сравнению с нереляционными базами данных), но архитектура каждой из них уникальна. У каждой есть свои плюсы и минусы. Также можно отметить, что в мире не существует РСУБД, которая полностью бы описывала математическую реляционную модель Франка Кодда, кроме одной с именем Rel и языком Tutorial-D. Почему это так? Неужели сложность в технической реализации реляционной теории? Нет, конечно. По моему мнению, на самом деле все проще: бизнес неявно диктует свои условия реализации хранения и обработки данных. Давайте вспомним некоторые основные свойства отношений (relations) в рамках реляционной теории и сравним их с реальной жизнью.
“All tuples are unique“. Это значит, что необходимо хранить один факт о свершившимся событии из реального мира. Данное утверждение также поддерживает определение простейшего уникального ключа для отношения, который должен включать весь набор атрибутов отношения.
2. “The order of the lines is irrelevant”. Зачем нам вообще вводить такое понятие, как сортировка строк, а тем более по конкретным атрибутам, да еще в возрастании / убывании или на основании формулы? Хм, вообще, это требование недопустимо!
Зачем нам вообще вводить такое понятие, как сортировка строк, а тем более по конкретным атрибутам, да еще в возрастании / убывании или на основании формулы? Хм, вообще, это требование недопустимо!
3.“The order of the columns is irrelevant”. Столбцы (attributes) мы можем переставлять как угодно, так как R(A,B,C) = R(B,C,A).
4.“Each attribute has a unique name within a table”. Каждый атрибут отношения должен иметь уникальное имя.
5.“Each column represents a single data element”. С одной стороны — вопрос нормализации. С другой — вопрос денормализации и ускорения работы модели.
6.“NULL value support”. NULL (𝒘) означает информацию, непригодную для употребления, а в действительности мы можем использовать значение NULL как статус значения в нашей модели.
Более того, каждая РСУБД по-своему интерпретирует NULL значения. Попробуйте выполнить команду ниже для PostgreSQL / MySQL:
SELECT 'Hello' || NULL || ' world!';
и команду для Oracle:
SELECT 'Hello' || NULL || ' world!' FROM dual;
Просто Oracle использует тождество NULL ~ » (пустая строка), и именно эта фича принесла немало боли во время миграций кодовой базы из Oracle в PostgreSQL (особенно если у вас на проекте витрины данных с материализациями на основании сортировок в оконных функциях и сами оконные функции, основанные на конкатенациях атрибутов).
Что дальше
Каждый виток спирали в IT-индустрии знаменуется очередным открытием модели или подходом в реализации. Так было с реляционными базами данных, затем на сцене появились объектно-ориентированные базы данных, после ворвались noSQL с лозунгом «Долой жесткие структуры отношений!». Я уверен, что эта история будет повторяться снова и снова в зависимости от вызовов, которые стоят уже сейчас и будут появляться перед IT-сообществом.
Но тем не менее сейчас следует обратить внимание на то, что в топ-5 баз данных 4 первых места занимают реляционные базы данных (по данным исследования Solid IT).
Почему это так? Как, учитывая полувековую историю, РСУБД может претендовать на такое высокое место в современном мире? Может быть, причина в legacy кода и созданных структурах моделей, которые нужно поддерживать в рамках реляционных баз данных? Или же причина в том, что переходить на более современные движки слишком дорого?
Можно вспомнить, что у реляционных баз данных есть принцип ACID и фундаментальный математический аппарат.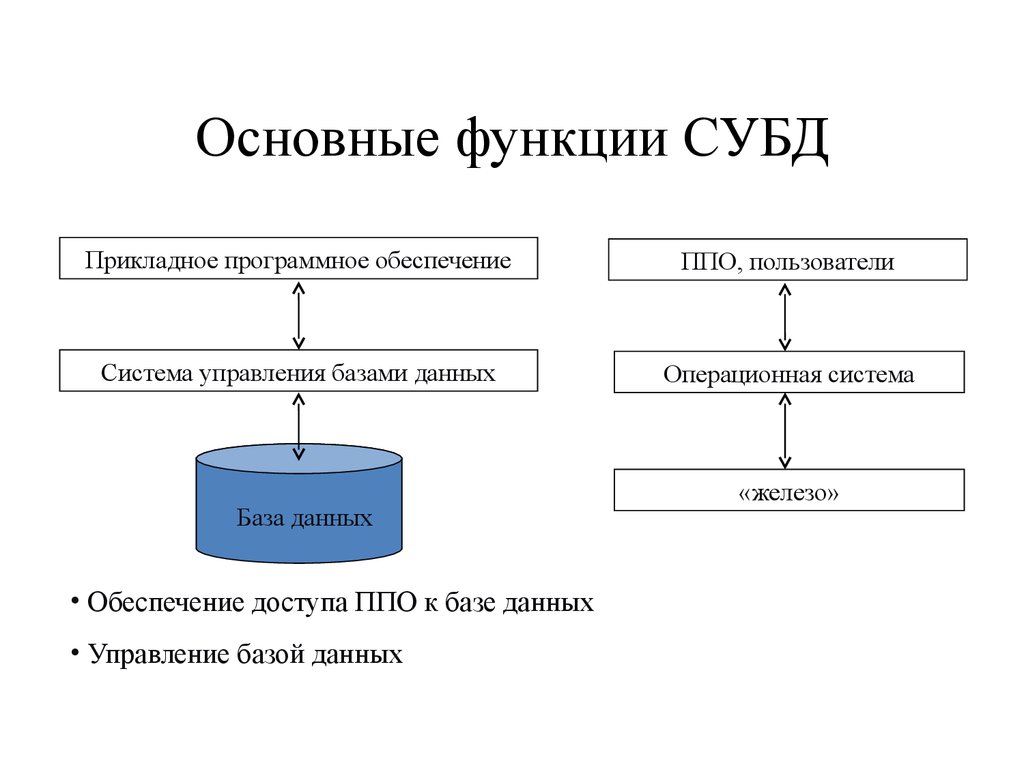 А у нереляционных баз данных есть BASE-семантика с более «мягкими» условиями функционирования и моделирования, а также набор алгоритмов, поддерживающих работу с данными. Семантика против Принципа, иногда хочется жить по Принципам без аномалий в данных и в режиме SERIALIZABLE.
А у нереляционных баз данных есть BASE-семантика с более «мягкими» условиями функционирования и моделирования, а также набор алгоритмов, поддерживающих работу с данными. Семантика против Принципа, иногда хочется жить по Принципам без аномалий в данных и в режиме SERIALIZABLE.
Но все-таки истина лежит где-то посередине, и это видно в разных архитектурах проектов, когда используется «зоопарк» (в хорошем смысле слова) гетерогенных баз данных и их интеграция между собой. А особенно это прослеживается при создании общих хранилищ данных (DWH + Data Lake) в корпорациях.
Как совместить OLAP и OLTP и получить полноценные «диагональные» базы данных? Почему бы не посмотреть в сторону дедуктивных баз данных? Наконец, почему бы полноценно не привлечь весь аппарат Data Science в движки оптимизаторов и обработки информации?
Новое отдельное направление — Data Engineering дает сильный толчок в исследованиях не только данных, но и в поиске архитектуры / интеграции / валидации данных для конкретного бизнес-домена. Появляются стандарты определения данных / информации / знаний / мудрости, что перерастает в обобщенное логическое восприятие информации через разные логические слои данных (тут я могу сослаться на книгу DAMA-DMBOK) при помощи новых инженерных ролей и разграничения ответственности в направлении Data Engineering:
Появляются стандарты определения данных / информации / знаний / мудрости, что перерастает в обобщенное логическое восприятие информации через разные логические слои данных (тут я могу сослаться на книгу DAMA-DMBOK) при помощи новых инженерных ролей и разграничения ответственности в направлении Data Engineering:
Если у вас есть интересные идеи по поводу перспектив развития баз данных, моделей, стандартов и Data Engineering в целом — давайте обсудим в комментариях.
РСУБД | это… Что такое РСУБД?
ТолкованиеПеревод
- РСУБД
Реляционная СУБД (РСУБД; иначе Система управления реляционными базами данных, СУРБД) — СУБД, управляющая реляционными базами данных.
Понятие реляционный (англ. relation — отношение) связано с разработками известного английского специалиста в области систем баз данных Эдгара Кодда (Edgar Codd).

Эти модели характеризуются простотой структуры данных, удобным для пользователя табличным представлением и возможностью использования формального аппарата алгебры отношений и реляционного исчисления для обработки данных.
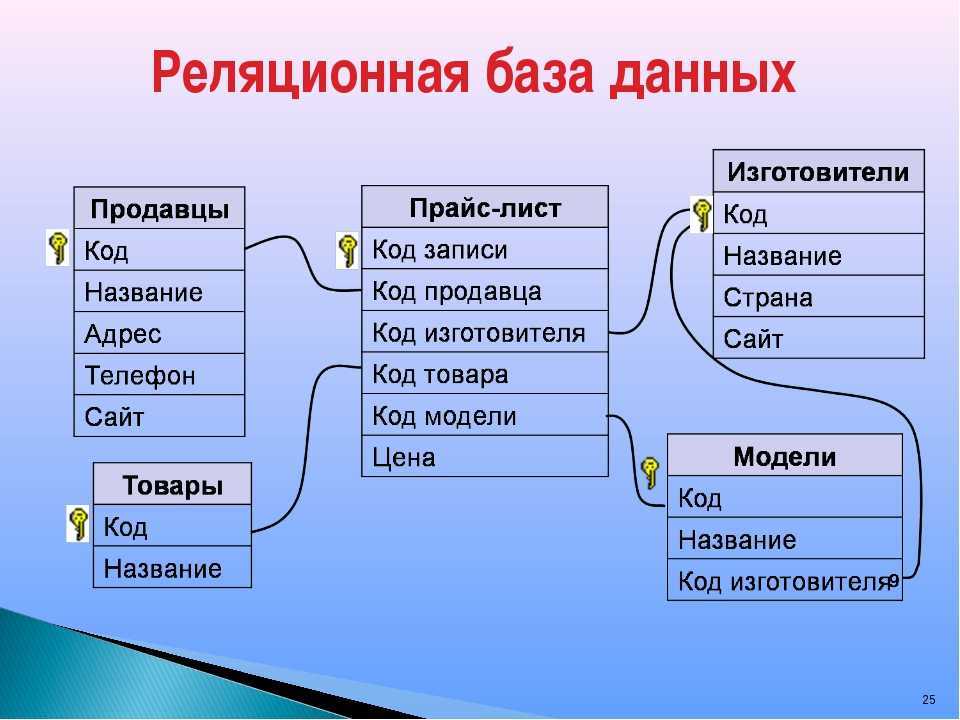
Реляционная модель ориентирована на организацию данных в виде двумерных таблиц. Каждая реляционная таблица представляет собой двумерный массив и обладает следующими свойствами:
- каждый элемент таблицы — один элемент данных
- все ячейки в столбце таблицы однородные, то есть все элементы в столбце имеют одинаковый тип (числовой, символьный и т. д.)
- каждый столбец имеет уникальное имя
- одинаковые строки в таблице отсутствуют
- порядок следования строк и столбцов может быть произвольным
Базовыми понятиями реляционных СУБД являются:
- атрибут
- отношения
- кортеж
Литература
- К. Дж. Дейт. Введение в системы баз данных = Introduction to Database Systems.
 — 8-е изд. — М.: «Вильямс», 2006. — С. 1328. — ISBN 0-321-19784-4
— 8-е изд. — М.: «Вильямс», 2006. — С. 1328. — ISBN 0-321-19784-4
См. также
- Сюръекция
- Инъекция (математика)
Типы СУБД Иерархическая СУБД | Сетевая СУБД | Реляционная СУБД | Объектно-ориентированная СУБД СУБД Концепции (Эдгар Кодд, Кристофер Дейт, …)
База данных | Модель данных | Реляционные базы данных | Реляционная модель данных | Реляционная алгебра
Первичный ключ — Внешний ключ — Суррогатный ключ — Superkey — Возможный ключ
Нормальная форма | Ссылочная целостность | Реляционные СУБД | Распределённые СУБД |Объекты
Триггер (Trigger) | Представление (View) | Таблица (Table) | Курсор (Cursor) | Журнал транзакций | Транзакция | Индекс | Хранимая процедура | PartitionDDL, SELECT | INSERT | UPDATE | MERGE | DELETE | JOIN | UNION | CREATE | ALTER | DROP
Сравнение синтаксисаРеализации систем управления базами данных Типы реализаций
Flat file | Deductive | Dimensional | Иерархическая | Объектно-ориентированная | TemporalСвободные системы
Ingres | PostgreSQL | Sav Zigzag |Компоненты
Язык запросов | Оптимизатор запросов | План выполнения запроса | ODBC | JDBC
Wikimedia Foundation.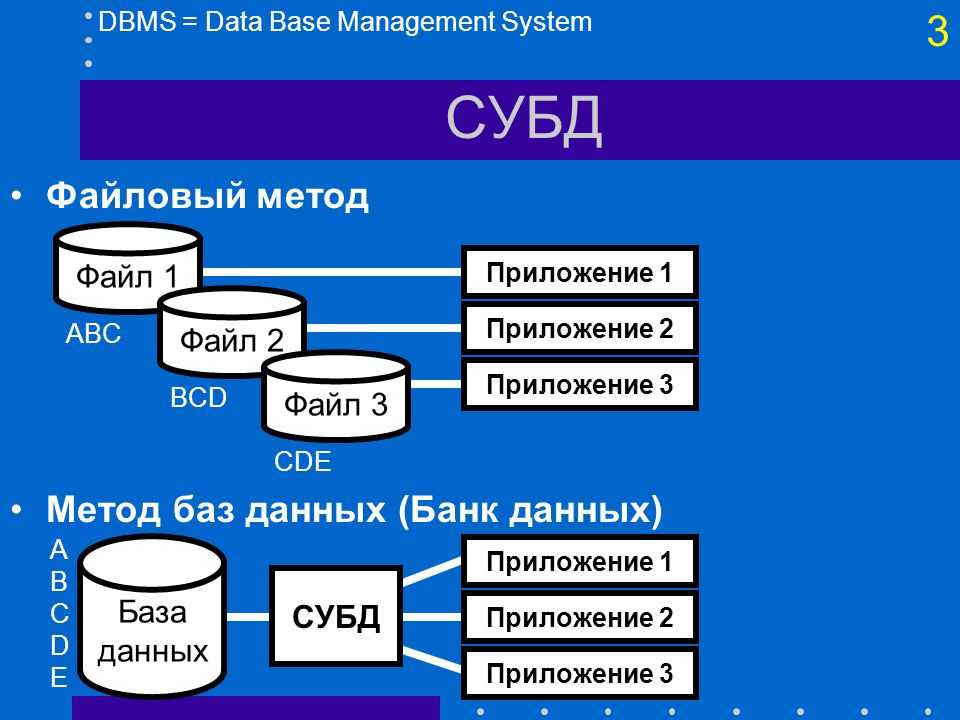 2010.
2010.
Поможем решить контрольную работу
- РСУ
- РСЭИ
Полезное
RF10S — Поля справки для экранов SAPMF10S
- Главная
- Ресурсы
- Таблицы SAP
- RF10S — Поля справки для экранов SAPMF10S
RF10S (Поля справки для экранов SAPMF10S) — это стандартная таблица в системах SAP R\3 ERP. Ниже вы можете найти технические детали полей, которые составляют эту таблицу. Ключевые поля отмечены синим цветом.
Кроме того, мы предоставляем обзор отношений внешнего ключа, если таковые имеются, которые связывают RF10S с другими таблицами SAP.
Поля таблицы RF10S
| Поле | Элемент данных | Контрольная таблица | Тип данных | Длина | Десятичные числа | |||
|---|---|---|---|---|---|---|---|---|
| ГОЛУБОЙ | финансовый год | ГОЛУБОЙ | НУМК | 4 | 0 | |||
| РСУБД | Подгруппа | руб. | Т852 | СИМВОЛ | 3 | 0 | ||
| ПЕРИД | Период | ПЕРИОД | НУМК | 3 | 0 | |||
| РВЕРС | Версия консолидации | RVERS_GC | Т858 | СИМВОЛ | 3 | 0 | ||
| НОМЕР | Ссылка на подгруппу | RSUBD_REF | Т852 | СИМВОЛ | 3 | 0 | ||
| ВОНГ | Компания «От» | RCOMP_FROM | Т880 | СИМВОЛ | 6 | 0 | ||
| БИСГС | Компания «К» | RCOMP_TO | Т880 | СИМВОЛ | 6 | 0 | ||
| ЦЕНТРАЛЬНЫЙ | Ключ страны | ЦЕНТРАЛЬНЫЙ | Т005 | СИМВОЛ | 3 | 0 | ||
| РЕФВЕРС | Ссылка на версию | RVERS_REF | СИМВОЛ | 3 | 0 | |||
| WK_REF | Справочное поле для шаблонов | WF_REF | СИМВОЛ | 79 | 0 | |||
| CTYPPTXT | Краткий пояснительный текст | ДДТЕКСТ | СИМВОЛ | 60 | 0 | |||
| ЦТИПГТХТ | Краткий пояснительный текст | ДДТЕКСТ | СИМВОЛ | 60 | 0 | |||
| ТХТ001 | Краткий пояснительный текст | ДДТЕКСТ | СИМВОЛ | 60 | 0 | |||
| ТХТ002 | Краткий пояснительный текст | ДДТЕКСТ | СИМВОЛ | 60 | 0 | |||
| ТХТ003 | Краткий пояснительный текст | ДДТЕКСТ | СИМВОЛ | 60 | 0 | |||
| ТХТ004 | Пояснительный краткий текст | ДДТЕКСТ | СИМВОЛ | 60 | 0 | |||
Отношения внешнего ключа RF10S
| Таблица | Поле | Таблица внешних ключей | Поле внешнего ключа | Контрольный стол | Проверить поле | |
|---|---|---|---|---|---|---|
| РФ10С | БИСГС | СИСТЕМА | МАНДТ | Т880 | Глобальные данные компании (для KONS Ledger) | МАНДТ |
| РФ10С | БИСГС | РФ10С | БИСГС | Т880 | Глобальные данные компании (для KONS Ledger) | РКОМП |
| РФ10С | ЦЕНТРАЛЬНЫЙ | СИСТЕМА | МАНДТ | Т005 | стран | МАНДТ |
| РФ10С | ЦЕНТРАЛЬНЫЙ | РФ10С | ЦЕНТРАЛЬНЫЙ | Т005 | стран | ЗЕМЛЯ1 |
| РФ10С | ССЫЛКИ | СИСТЕМА | МАНДТ | Т852 | Подгруппы | МАНДТ |
| РФ10С | ССЫЛКИ | РФ10С | ССЫЛКИ | Т852 | Подгруппы | руб. |
| РФ10С | руб. | СИСТЕМА | МАНДТ | Т852 | Подгруппы | МАНДТ |
| РФ10С | руб. | РФ10С | руб. | Т852 | Подгруппы | руб. |
| РФ10С | РВЕРС | РФ10С | РВЕРС | Т858 | Версии консолидации | РВЕРС |
| РФ10С | РВЕРС | СИСТЕМА | МАНДТ | Т858 | Версии консолидации | МАНДТ |
| РФ10С | ВОНГ | СИСТЕМА | МАНДТ | Т880 | Глобальные данные компании (для KONS Ledger) | МАНДТ |
| РФ10С | ВОНГ | РФ10С | ВОНГ | Т880 | Глобальные данные компании (для KONS Ledger) | РКОМП |
FILCC — FI-LC: поля для таблицы FILCT, связанные с транзакциями
- Главная
- Ресурсы
- Таблицы SAP
- FILCC — FI-LC: поля, связанные с транзакциями, для таблицы FILCT
FILCC (FI-LC: поля, связанные с транзакциями, для таблицы FILCT) — это стандартная таблица в системах SAP R\3 ERP.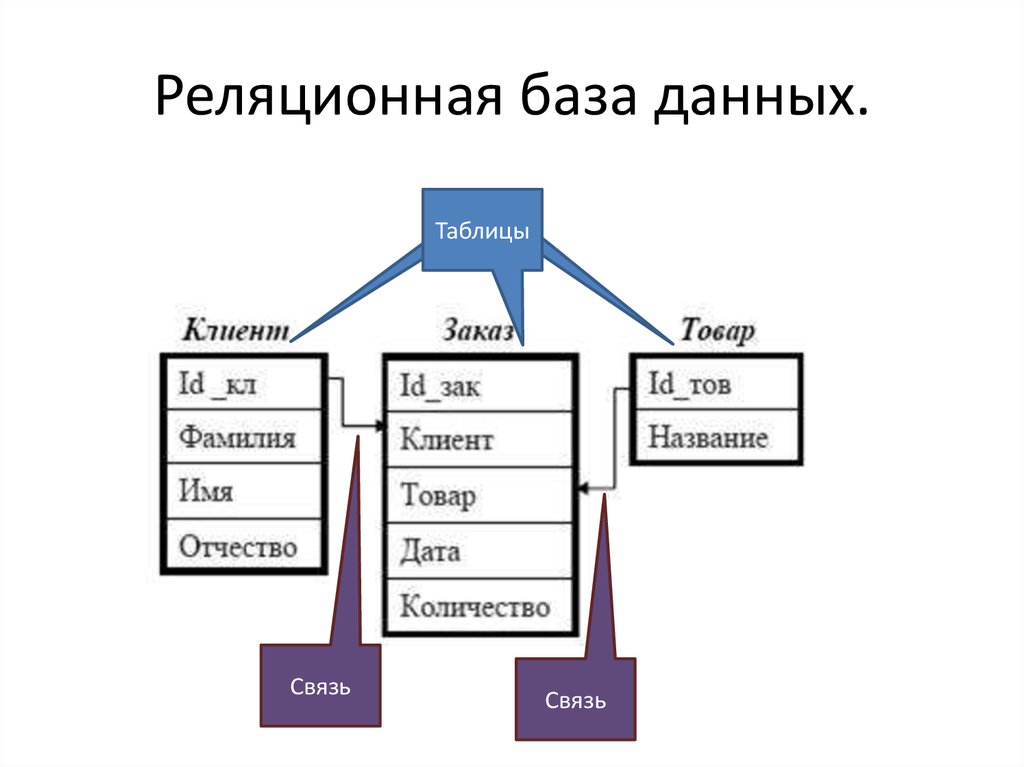 Ниже вы можете найти технические детали полей, которые составляют эту таблицу. Ключевые поля отмечены синим цветом.
Ниже вы можете найти технические детали полей, которые составляют эту таблицу. Ключевые поля отмечены синим цветом.
Кроме того, мы предоставляем обзор отношений внешнего ключа, если таковые имеются, которые связывают FILCC с другими таблицами SAP.
Поля таблицы FILCC
| Поле | Элемент данных | Контрольная таблица | Тип данных | Длина | Десятичные числа | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| МАНДТ | Клиент | МАНДТ | Т000 | КЛНТ | 3 | 0 | ||||||||||
| OBJNR | Номер объекта для таблиц FI-SL | GOBJNR | СИМВОЛ | 18 | 0 | |||||||||||
| РЭВЛ | Уровень публикации | РЭВЛ | СИМВОЛ | 1 | 0 | Возможные значения
| ||||||||||
