Определение регулярных выражения
Определение регулярного выражения, это создание🏗️ шаблона, на основе которого будет происходить работа со строками. В JavaScript регулярные выражения — это объект, который может быть определён двумя способами.
- Литерал
- Конструкция
Определение регулярных выражений с использованием литералов. Для регулярных выражений литералами выступают слеши / ... /, они играют ту же роль, что и скобки ' ... ' при создании🏗️ строк.
let regExp = /шаблон/
Если вы решили создавать🏗️ регулярные выражения при помощи литералов, то стоит учитывать, что такой метод создания🏗️ не допускает динамическое изменение задаваемых значений. Происходит это из-за того, что литералы регулярных выражения вызывают предварительную компиляцию при анализе скрипта. banana$/. Метод
banana$/. Метод .test() вернёт true ✅ только в том случае, если вся строка это banana.
Флаги
Флаги используются для расширения осуществляемого регулярными выражениями поиска.
g— при поиске ищет все совпадения;i— поиск не зависит от регистра[Z-z];m— многострочный режим;s— включает режим dotall, при котором точка.может соответствовать символу перевода строки;y— выполняет поиск начиная с символа, который находится на позиции свойства lastindex текущего регулярного выражения;u— включает поддержку Unicode.
Использование флагов при разных способах создания🏗️ шаблона регулярного выражения
- Литерал
- Конструкция
let regExp = /шаблон/флаг // prettier-ignore
Обратите внимание, что флаги являются неотъемлемой частью регулярного выражения. Флаги не могут быть добавлены или удалены позднее. Также флаги можно комбинировать.
Флаги не могут быть добавлены или удалены позднее. Также флаги можно комбинировать.
function learnJavaScript() { let regExp = /banana/i, str = ‘faNana RanaNA BaNanA’ return regExp.test(str) ? ‘Нашёл’ : ‘Нету’ }
Loading…
Попробуйте убрать флаг i из примера.
Итого
Тема очень обширная и нечасто используемая нами в разработке, поэтому если интересно, то подробней можно познакомиться с ней здесь, здесь и здесь.
Проблемы?
Пишите в Discord или телеграмм чат, а также подписывайтесь на наши новости
Вопросы
Для чего нужны регулярные выражения?
- Cоздание шаблонов
- Манипуляции со строками
- Редактирования строк
Какой символ используется для литерального создания регулярного выражения?
- Слеш
/ - Обратный слеш
\ - Квадратные скобки
[]
В каком способе создания регулярного выражения не допускается дальнейшее динамическое изменение задаваемых значений?
- В литеральном
- В конструкции
- При любом способе динамическое изменение допустимо
Для того чтобы понять насколько вы усвоили этот урок пройдите тест в мобильном приложении в нашей школы по этой теме.
Ссылки
- Learn JavaScript
- MDN Web Docs
- JS RegExp
Contributors ✨
Thanks goes to these wonderful people (emoji key):
IIo3iTiv 📖 | Dmitriy Vasilev 💵 | Resoner2005 🐛 🎨 🖋 | Navernoss 🖋 🐛 🎨 |
Регулярные выражения + JS событие. Очередное обновление от Яндекс.Метрики — CMS Magazine
Яндекс.Метрика выкатила очередное обновление. Наконец-то возликуют те, кто не любит плодить по 100500 целей в интерфейсе! Теперь появилась возможность объединить js-события в одну цель, избегая настройки через составную цель. Ведь раньше приходилось задавать каждую цель через условие «или». Конечно, можно предварительно объединить все события в одном теге через GTM… Но что, если события для Метрики прописаны напрямую в коде сайта или частично настроены и в коде, и в GTM? В этом случае регулярные выражения упростят жизнь.
Регулярные выражения могут помочь ускорить вашу работу в инструментах аналитики, а также добавить дополнительную гибкость в работе с данными. Если вы только начинаете их изучать, то регулярные выражения могут показаться сложными, но помните, что вам не нужно их зазубривать, есть много ресурсов, которые могут вам помочь.
В Метрике регулярные выражения можно использовать при настройке сегментов, при настройке цели «Просмотр страницы», а также с недавних пор, при настройке js-событий.
Пример сегментации:
Что соответствует любому вхождению символов, как в начале, так и в конце
Пример использования при настройке цели «Посещение страниц»:
Например, здесь вы можете использовать регулярное выражение для сопоставления нескольких страниц благодарности при настройке цели
Разберем пример на основе js-событияДавайте представим такую ситуацию: у вас есть три тега в GTM, в которых предварительно настроена передача событий в Метрику. Каждый тег содержит разные идентификаторы js-события. Например,
Каждый тег содержит разные идентификаторы js-события. Например, Form_callback, Form_question, Form_calculator.
А также бывший подрядчик настроил для клиента передачу данных в Метрику напрямую через код сайта. В ID события он прописал произвольные названия: FormOrder, 1click_order. Но вы не хотите перенастраивать эти события через GTM.
Оптимальным вариантом объединить такие события раньше была составная цель:
Приходилось прописывать каждый шаг через условие «или»:
Как это выглядит сейчас:
Где в качестве условия мы выбираем «или», что соответствует вертикальной черте «|». И прописываем все наши идентификаторы:
1click_order|FormOrder|Form_calculator|Form_question|Form_callback
Что соответствует одному из вариантов: 1click_order, или FormOrder, или Form_calculator, или Form_question, или Form_callback. Form — это соответствует
Form — это соответствует FormOrder, FormCallback, FormFeedback, но не соответствует QuestionForm.
Знак доллара ($)
Значит, что-то заканчивается на …
Например: Click$ — это соответствует Click, Mail_Click, Phone_Click
Clicks, ClickPhone, ClickProduct.
Пока не выкатили полную инструкцию по применению регулярных выражений в настройках JS-событий. Предположительно, будет использоваться базовый синтаксис, который используется при работе с сегментами в Метрике.
Подробнее можно узнать тут: Регулярные выражения
Больше не нужно искать и обзванивать каждое диджитал-агентство
Создайте конкурс на workspace.ru – получите предложения от участников CMS Magazine по цене и срокам. Это бесплатно и займет 5 минут. В каталоге 15 617 диджитал-агентств, готовых вам помочь – выберите и сэкономьте до 30%.
В каталоге 15 617 диджитал-агентств, готовых вам помочь – выберите и сэкономьте до 30%.
Создать конкурс →
Регулярные выражения — это действительно то, что должен знать каждый аналитик, даже если вы не считаете себя техническим специалистом. Кроме того, если вы специалист в контекстной рекламе, вам также не помешают базовые навыки в работе с регулярными выражениями
Поэтому я рекомендую вам начать учиться и, что более важно, просто начать практиковаться в использовании регулярных выражений. Они не такие уж страшные.
Полезные материалы-
Регулярные выражения в Google Analytics
-
Как использовать регулярные выражения в Google Analytics и Google Tag Manager
-
Google Analytics RegEx: Cheat Sheet, Tips, & Mistakes To Avoid
-
Использования регулярных выражений в гугл аналитикс
-
Как регулярные выражения упрощают работу в Google Analytics и Google Tag Manager
Как ВЫ можете выучить достаточно регулярных выражений в JavaScript, чтобы быть опасными
Я пишу это самому себе из будущего.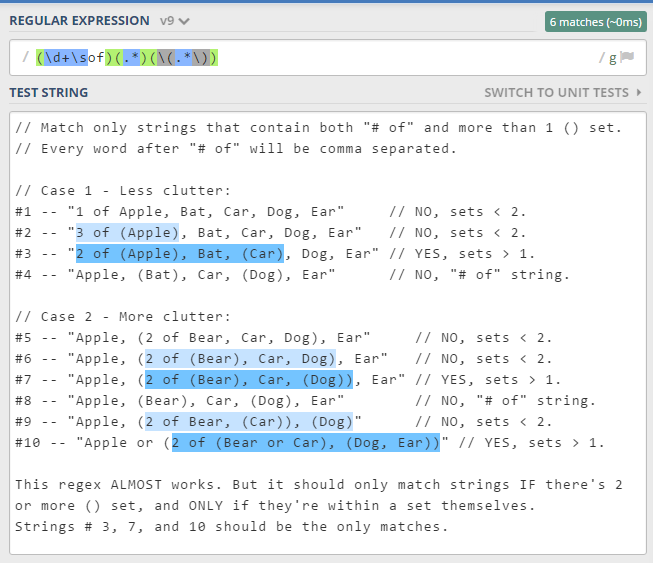 На самом деле, многие мои статьи обращены к самому себе в будущем, который забыл все о том, как что-то делать. RegEx, регулярные выражения — действительно мощный инструмент в нашем наборе инструментов. К сожалению, мы называем это черной магией, дьяволом и прочими прелестями. Это не должно быть так. RegEx, конечно, отличается от обычного программирования, но это действительно очень мощное средство. Давайте узнаем, как это работает и как на самом деле использовать и применять к повседневным проблемам, которые вы знаете.
На самом деле, многие мои статьи обращены к самому себе в будущем, который забыл все о том, как что-то делать. RegEx, регулярные выражения — действительно мощный инструмент в нашем наборе инструментов. К сожалению, мы называем это черной магией, дьяволом и прочими прелестями. Это не должно быть так. RegEx, конечно, отличается от обычного программирования, но это действительно очень мощное средство. Давайте узнаем, как это работает и как на самом деле использовать и применять к повседневным проблемам, которые вы знаете.
TLDR; Это долго? Да, но он проходит через основные конструкции в RegEx. Кроме того, в конце у меня есть несколько хороших рецептов о том, как делать такие вещи, как RegEx для электронной почты, пароли, преобразования формата даты и как обрабатывать URL-адреса. Если вы никогда раньше не работали с RegEx или вам трудно замечать всю эту странную магию — это для вас. Приятного чтения 🙂
использованная литература
Есть отличные ресурсы для RegEx, к которым я регулярно обращаюсь. Потратьте время, чтобы прочитать их. Иногда они объясняют, как обрабатывается RegEx, и могут объяснить, почему магия бывает:
Потратьте время, чтобы прочитать их. Иногда они объясняют, как обрабатывается RegEx, и могут объяснить, почему магия бывает:
- Информация о регулярных выражениях Хороший сайт с большим количеством информации о RegEx.
- Страницы документации Mozillas на RegEx Хороший сайт, подробные объяснения с примерами
- Информация о JavaScript Некоторые из лучших объяснений, которые я видел в группах RegEx.
- Именованные группы
- Документы по регулярным выражениям Несмотря на то, что это руководство по .NET, информация о регулярных выражениях является довольно общей и применимой .
Как практиковать
- Node.js REPL . Если у вас установлен Node.js, я рекомендую просто ввести
nodeв терминале. Это запустит REPL, это отличный способ протестировать паттерны . - JavaScript REPL , это расширение VS Code, которое оценивает то, что вы вводите. Вы получите мгновенную обратную связь о результатах
Браузер , открытие Dev Tools в браузере и использование консоли также будет работать нормально
Регулярное выражение 101
Отличная песочница. Спасибо за подсказку, Лукаш 🙂
Спасибо за подсказку, Лукаш 🙂
Обычные выражения
Регулярные выражения или RegEx предназначены для сопоставления с образцом. Многое из того, что мы делаем, на самом деле связано с сопоставлением с образцом, если подумать. RegEx действительно хорош для сопоставления шаблонов и извлечения значений из найденных шаблонов. Итак, какие проблемы мы можем решить?
- URL-адрес , URL-адрес содержит много интересной информации, такой как
имя хоста,маршрут,порт,параметры маршрутаипараметры запроса. Мы хотим иметь возможность извлекать эту информацию, а также проверять ее правильность. - Пароль , чем длиннее пароль, тем лучше, обычно это то, что нам нужно. Есть и другие измерения, такие как сложность. Под сложностью мы подразумеваем, что наш пароль должен содержать, например, цифры, специальные символы и многое другое.

- Поиск и извлечение данных , возможность поиска данных на веб-странице, например, может быть очень легко реализована с помощью пары хорошо написанных регулярных выражений. На самом деле существует целая категория компьютерных программ, посвященных этому, под названием 9.0015 скребки .
Регулярное выражение создается следующим образом:
/шаблон/Войти в полноэкранный режимВыйти из полноэкранного режима
Начинается и заканчивается / .
Или вот так, где мы создаем объект из класса RegEx :
new RegEx(/pattern/)Войти в полноэкранный режимВыйти из полноэкранного режима
Методы
Существует несколько разных методов, предназначенных для разных типов использования. Важно научиться использовать правильный метод.
-
exec(), Выполняет поиск совпадения в строке. Он возвращает массив информацииили нольпри несоответствии.
-
test(), проверяет совпадение в строке, ответы сtrueилиfalse -
match(), Возвращает массив, содержащий все совпадения, включая захваченные группы, илиnull, если совпадений не найдено. -
matchAll(), Возвращает итератор, содержащий все совпадения, включая группы захвата. -
search(), Проверяет совпадение в строке. Он возвращает индекс совпадения или -1, если поиск не удался. -
replace(), Выполняет поиск совпадения в строке и заменяет совпадающую подстроку замещающей подстрокой. -
split(), Использует регулярное выражение или фиксированную строку для разбиения строки на массив подстрок.
Давайте покажем несколько примеров с учетом описанных выше методов.
test() , тестовая строка для true/false Давайте рассмотрим пример с использованием test() :
/\w+/.Войти в полноэкранный режимВыйти из полноэкранного режимаtest('abc123') // true
Выше мы проверяем строку abc123 на наличие всех буквенных символов \w+ и отвечаем на вопрос, содержите ли вы буквенные символы.
match() , найти совпадения Рассмотрим пример:
'заказы/элементы'.match(/\w+/) // [ 'заказы', группы: не определены, индекс: 0, ввод]Войти в полноэкранный режимВыйти из полноэкранного режима
Приведенный выше ответ массива говорит нам, что мы можем сопоставить заказов с нашим шаблоном \w+ . Мы не захватили ни одной группы, на что указывает groups:undefined , и наше совпадение было найдено по адресу index:0 . Если бы мы хотели сопоставить все буквенные символы в строке, нам пришлось бы использовать флаг g . г указывает глобальное соответствие , например:
'orders/items'.Войти в полноэкранный режимВыйти из полноэкранного режимаmatch(/\w+/g) // ['orders', 'items']
Группы
У нас также есть понятие групп. Чтобы начать использовать группы, нам нужно заключить наш шаблон в круглые скобки следующим образом:
const matchedGroup = 'orders/114'.match(/(?Войти в полноэкранный режимВыйти из полноэкранного режима\d+)/) // [114, 114, groups: { порядок: 114 }]
Использование конструкции ? создает так называемую именованную группу.
Флаги
Есть разные флаги. Перечислим некоторые из них. Все флаги добавляются в конце регулярного выражения. Таким образом, типичное использование выглядит так:
var re = /pattern/flags;Войти в полноэкранный режимВыйти из полноэкранного режима
-
g, вы говорите, что хотите сопоставить всю строку, а не только первое вхождение -
i, это означает, что нам нужно совпадение без учета регистра 9 словотест.
Обратное будет выглядеть так:
/test$/.test('123test')Войти в полноэкранный режимВыйти из полноэкранного режимаКлассы персонажей
Классы символов относятся к различным типам символов, таким как буквы и цифры. Перечислим некоторые из них:
-
., соответствует любому одиночному символу, кроме разделителей строк, таких как\nили\r -
\d, соответствует цифрам, эквивалентным 9[0-9] -
\w, соответствует любому буквенному символу, включая_. Эквивалент[a-zA-Z0-9_] -
\W, отрицание вышесказанного. Соответствует%например -
\s, соответствует пробельным символам -
\t, соответствует вкладке -
\r, соответствует возврату каретки -
\n, соответствует переводу строки -
\, escape-символ. Его можно использовать для соответствия
Его можно использовать для соответствия /вот так\/. Также используется для придания символам особого значения
квантификаторы
Квантификаторы — это количество символов для соответствия:
-
*, от 0 до многих символов -
+, от 1 до многих символов -
{n}, соответствует n символам -
{n,}, совпадение >= n символов -
{n,m}, совпадение >= n && =< m символов -
?, нежадное соответствие
Рассмотрим несколько примеров
/\w*/.test('abc123') // true /\w*/.test('') // верно. * = от 0 до многихВойти в полноэкранный режимВыйти из полноэкранного режимаВ следующем примере мы используем
?:/\/продукты\/?/.test('/products') ///продукты\/?/.test('/products/')Войти в полноэкранный режимВыйти из полноэкранного режимаВыше мы можем видеть, как используется
?дает окончание/необязательны, когда мы используем этот тип соответствия\/?.
ДЕМО
Хорошо, это много теории, смешанной с некоторыми примерами. Далее давайте рассмотрим некоторые реалистичные сопоставления, сопоставления, которые мы действительно будем использовать в производстве.
Если вы используете JavaScript на бэкенде, вы, вероятно, уже используете какие-то фреймворки, такие как Express, Koa или Nest.js. Знаете ли вы, что эти фреймворки делают для вас с точки зрения сопоставления маршрутов, параметров и многого другого? Что ж, пора это выяснить.
Сопоставление маршрута
Такой же простой маршрут, как
/products, как нам его сопоставить?. Ну, мы знаем, что наш URL-адрес должен содержать эту часть, поэтому написать регулярное выражение для этого довольно просто. Давайте также учтем, что некоторые будут вводить/products, а некоторые другие будут вводить/products/:/\products\/?$/.test('/products')Войти в полноэкранный режимВыйти из полноэкранного режима0036 / с\/для соответствия необязательным/в конце с\/?.
Извлечь/сопоставить параметр маршрута
Хорошо, возьмем аналогичный случай.
/продукты/112. Маршрут/productsс номером в конце. Начнем проверять, соответствует ли входящий маршрут://products\/\d+$/.test('/products/112') // true //продукты\/\d+$/.test('/products/') // ложьВойти в полноэкранный режимВыйти из полноэкранного режимаЧтобы извлечь параметр маршрута, мы можем ввести следующее:
const [ productId] = '/products/112'.match(/\/products\/(\d+)/) // идентификатор продукта = 112
Войти в полноэкранный режимВыйти из полноэкранного режимаСопоставление/извлечение нескольких параметров маршрута
Хорошо, допустим, у вас есть маршрут, похожий на этот
/orders/113/items/55. Это примерно соответствует заказу с идентификатором113и идентификатору позиции заказа55. Сначала мы хотим убедиться, что наш входящий URL-адрес совпадает, поэтому давайте посмотрим на RegEx для этого:/\orders\/\d+\/items\/\d+\/?/.
Войти в полноэкранный режимВыйти из полноэкранного режима test('/orders/99/items/22') // true
test('/orders/99/items/22') // true
Приведенное выше регулярное выражение выглядит следующим образом: сопоставьте
/orders/[1-n цифр]/items/[1-n цифр][необязательно /]Теперь мы знаем, что можем сопоставить указанный выше маршрут. Давайте возьмем эти параметры дальше. Мы можем сделать это, используя именованные группы:
var { groups: {orderId, itemId } } = '/orders/99/items/22'.match(/(?Войти в полноэкранный режимВыйти из полноэкранного режима\d+)\/items\/( ? \d+)\/?/) // идентификатор заказа = 99 // элементы = 22 Приведенное выше выражение вводит группы путем создания именованных групп
orderIdиitemIdс конструкциями(?и\d+) (?соответственно. Шаблон очень похож на тот, который используется с методом\d+) test().Классификатор маршрутов
Я уверен, вы видели, как маршрут был разделен на несколько частей, как
протокол,хост,маршрут,портипараметры запроса.
Это очень легко сделать. Предположим, мы смотрим на URL-адрес, который выглядит так:
http://localhost:8000/products?page=1&pageSize=20. Мы хотим разобрать этот URL и в идеале получить что-то удобное для работы, например:{ протокол: 'http', хост: «локальный хост», маршрут: '/products?page=1&pageSize=20', порт: 8000 }Войти в полноэкранный режимВыйти из полноэкранного режимаКак нам туда добраться? Что ж, то, что вы видите, следует очень предсказуемому образцу, и RegEx — это Mjolnir of Hammers , когда дело доходит до сопоставления с образцом. Давайте сделаем это 🙂
var http = 'http://localhost:8000/products?page=1&pageSize=20' .match(/(?<протокол>\w+):\/{2}(?<хост>\w+):(?<порт>\d+)(?<маршрут>.*)/) // http.groups = {протокол: 'http', хост: 'localhost', порт: 8000, маршрут: '?page=1&pageSize=20' }Войти в полноэкранный режимВыйти из полноэкранного режимаДавайте возьмем вышеизложенное и разберем его:
-
(?<протокол>\w+):, это соответствует n количеству буквенных символов, которые заканчиваются на:. Кроме того, он помещается в именованную группу
Кроме того, он помещается в именованную группу , протокол. -
\/{2}, это просто говорит о том, что у нас есть//, обычно послеhttp://. -
(?, это соответствует n количеству буквенных символов, заканчивающихся на\w+): :, поэтому в данном случае он соответствуетlocalhost. Кроме того, он помещается в именованную группухост. -
(?, это соответствует некоторым цифрам, которые следуют после хоста, который будет портом. Кроме того, он помещается в именованную группу\d+) порт. -
(?, наконец, у нас есть сопоставление маршрута, которое просто соответствует любым символам, что гарантирует, что мы получим часть.*) ?page=1&pageSize=20. Кроме того, он помещается в именованную группуroute.
Чтобы разобрать параметры запроса, нам просто нужно регулярное выражение и один вызов
reduce(), например:const queryMatches = http.
Войти в полноэкранный режимВыйти из полноэкранного режима groups.route.match(/(\w+=\w+)/g ) // ['page=1', 'pageSize=20']
const queryParams = queryMatches.reduce((acc, curr) => {
const [ключ, значение] = curr.split('=')
обр[...обр, [ключ]: значение]
}, {}) // {страница: 1, размер страницы: 20}
groups.route.match(/(\w+=\w+)/g ) // ['page=1', 'pageSize=20']
const queryParams = queryMatches.reduce((acc, curr) => {
const [ключ, значение] = curr.split('=')
обр[...обр, [ключ]: значение]
}, {}) // {страница: 1, размер страницы: 20}
Выше мы работаем с ответом от нашего первого сопоставления шаблона
http.groups.route. Теперь мы создаем шаблон, который будет соответствовать следующему[любой символ алфавита]=[любой символ алфавита]. Кроме того, поскольку у нас есть глобальное совпадениеg, мы получаем массив ответов. Это соответствует всем параметрам нашего запроса. Наконец, мы вызываемreduce()и превращаем массив в объект.Сложность пароля
Сложность пароля заключается в том, что он поставляется с различными критериями, такими как:
- длина , должно быть больше n символов и может быть меньше m символов
- числа , должно содержать число
- специальный символ , должен содержать специальные символы
Значит, мы в безопасности? Что ж, безопаснее, не забывайте о двухфакторной аутентификации в приложении, а не о вашем номере телефона.

Давайте посмотрим на RegEx для этого:
// проверка хотя бы 1 номера var pwd = /\d+/.test('пароль1') // проверка хотя бы на 8 символов var pwdNCharacters = /\w{8,}/.test('пароль1') // проверка хотя бы одного из &, ?, !, - var specialCharacters = /&|\?|\!|\-+/.test('password1-')Войти в полноэкранный режимВыйти из полноэкранного режимаКак вы можете видеть, я строю каждое требование как собственное сопоставление с образцом. Вам нужно пройти через каждый из паролей, чтобы убедиться, что он действителен.
Идеальное свидание
На моей нынешней работе я сталкиваюсь с коллегами, которые все думают, что их формат даты — это тот, который следует использовать всем нам. В настоящее время это означает, что моему бедному мозгу приходится иметь дело с:
// ГГ/ММ/ДД , европейский стандарт ISO. // ДД/ММ/ГГ, британский // ММ/ДД/ГГ, Америка, США
Войти в полноэкранный режимВыйти из полноэкранного режимаИтак, вы можете себе представить, что мне нужно знать национальность того, кто прислал мне электронное письмо каждый раз, когда я получаю электронное письмо с датой в нем.
 Это больно :). Итак, давайте создадим регулярное выражение, чтобы мы могли легко менять его по мере необходимости.
Это больно :). Итак, давайте создадим регулярное выражение, чтобы мы могли легко менять его по мере необходимости.Допустим, мы получаем дату в США, например,
ММ/ДД/ГГ. Мы хотим извлечь важные части и поменять местами дату, чтобы кто-то из европейцев/британцев мог это понять. Давайте также предположим, что наш ввод ниже американский:var toBritish = '12/22/20'.replace(/(?
Войти в полноэкранный режимВыйти из полноэкранного режима\d{2})\/(? \d{2} )\/(?<год>\d{2})/, '$2/$1/$3') var toEuropeanISO = '22/12/20'.replace(/(?<месяц>\д{2})\/(?<день>\д{2})\/(?<год>\д{2} )/, '3 доллара/1 доллар/2 доллара') Наверху мы можем сделать именно это. В нашем первом параметре
replace()мы даем ему наше регулярное выражение. Наш второй параметр — это то, как мы хотим его поменять местами. Для британского свидания мы просто меняем месяц и день, и все счастливы. Для европейской даты нам нужно сделать немного больше, так как мы хотим, чтобы она начиналась с года, затем месяца и дня.
Эл. адрес
Хорошо, поэтому для электронной почты нам нужно подумать о нескольких вещах
-
@, должен иметь символ@где-то посередине -
имя, у людей могут быть длинные имена, с тире/дефисом и без них. А значит людям можно звонить,на,на альбинаи так далее -
фамилия, им нужна фамилия, или электронная почта просто фамилия или имя -
домен, нам нужно внести в белый список несколько доменов, таких как.com,.gov,.edu
Имея все это в виду, я даю вам мать всего RegEx: 9 , это означает, что он начинается с.
-
-
(\w+\-?\w+\.)*, это означает слово с нашим без-так как у нас есть шаблон-?и заканчивая., значитчел.,пер-альбин.. Кроме того, мы заканчиваем*, поэтому 0 для многих из них.
-
(\w+){1}, это означает ровно одно слово, например электронное письмо, состоящее только из фамилии или только имени. Это открывается для комбинации 1) + 2), поэтомуper-albin.hanssonилиper.hanssonили 2) отдельно, что соответствует per илиhansson. -
@, нам нужно сопоставить один@символ -
\w+\., здесь мы сопоставляем имя, оканчивающееся на ., например,Швеция. -
(\w+\.)*, здесь мы открываем несколько поддоменов или ни одного, учитывая*, например sthlm.region. и т. д. -
(edu|gov|com), доменное имя, здесь мы перечисляем разрешенные домены:edu,govилиcom -
$, должно заканчиваться, это означает, что мы гарантируем, что кто-то не введет какую-то чушь после доменного имени - Информация о регулярных выражениях
Хороший сайт с большим количеством информации о RegEx.
- Страницы документов Mozilla на RegEx Хороший сайт, подробные объяснения с примерами
- Информация о JavaScript Некоторые из лучших объяснений, которые я видел в группах RegEx.
- Именованные группы
- Документы по регулярным выражениям Несмотря на то, что это руководство по .NET, информация о регулярных выражениях довольно общая и применимая
Node.js REPL . Если у вас установлен Node.js, я рекомендую просто ввести
nodeв терминале. Это запустит REPL, это отличный способ протестировать шаблоныJavaScript REPL , это расширение VS Code, которое оценивает то, что вы вводите. Вы получите мгновенную обратную связь о результатах
Браузер Отличная среда песочницы. Спасибо за совет Лукаш 😃
- URL-адрес , URL-адрес содержит много интересной информации, такой как
имя хоста,маршрут,порт,параметры маршрутаипараметры запроса. Мы хотим иметь возможность извлекать эту информацию, а также проверять ее правильность. - Пароль , чем длиннее пароль, тем лучше, обычно это то, что нам нужно. Есть и другие измерения, такие как сложность. Под сложностью мы подразумеваем, что наш пароль должен содержать, например, цифры, специальные символы и многое другое.
- Поиск и извлечение данных , например, возможность поиска данных на веб-странице может быть очень простой с помощью пары хорошо написанных регулярных выражений.
 На самом деле существует целая категория компьютерных программ, посвященных этому, под названием 9.0015 скребки .
На самом деле существует целая категория компьютерных программ, посвященных этому, под названием 9.0015 скребки .
Резюме
Вы дошли до конца. Мы действительно рассмотрели много вопросов по теме RegEx. Надеюсь, теперь вы лучше понимаете, из каких компонентов он состоит. Кроме того, я надеюсь, что примеры из реальной жизни заставили вас понять, что вам может просто не понадобиться устанавливать этот дополнительный модуль node. Надеюсь, после небольшой практики вы почувствуете, что RegEx полезен и действительно может сделать ваш код намного короче, элегантнее и даже читабельнее. Да, я сказал читабельно. RegEx вполне удобочитаем, как только вы поймете, как оцениваются вещи. Вы обнаружите, что чем больше времени вы тратите на это, тем больше оно окупается. Перестаньте пытаться изгнать его обратно в измерение Демонов и дайте ему шанс 🙂
Мы действительно рассмотрели много вопросов по теме RegEx. Надеюсь, теперь вы лучше понимаете, из каких компонентов он состоит. Кроме того, я надеюсь, что примеры из реальной жизни заставили вас понять, что вам может просто не понадобиться устанавливать этот дополнительный модуль node. Надеюсь, после небольшой практики вы почувствуете, что RegEx полезен и действительно может сделать ваш код намного короче, элегантнее и даже читабельнее. Да, я сказал читабельно. RegEx вполне удобочитаем, как только вы поймете, как оцениваются вещи. Вы обнаружите, что чем больше времени вы тратите на это, тем больше оно окупается. Перестаньте пытаться изгнать его обратно в измерение Демонов и дайте ему шанс 🙂
Regex в JS — как ВЫ можете изучить его и научиться любить его
Я пишу это самому себе из будущего. На самом деле, многие мои статьи обращены к самому себе в будущем, который забыл все о том, как что-то делать. RegEx, регулярные выражения — действительно мощный инструмент в нашем наборе инструментов.
К сожалению, мы называем это черной магией, дьяволом и прочими прелестями. Это не должно быть так. RegEx, конечно, отличается от обычного программирования, но это действительно очень мощное средство. Давайте узнаем, как это работает и как на самом деле использовать и применять к повседневным проблемам, которые вы знаете.
TLDR; Это долго? Да, но он проходит через основные конструкции в RegEx. Кроме того, в конце у меня есть несколько хороших рецептов о том, как делать такие вещи, как RegEx для электронной почты, пароли, преобразования формата даты и как обрабатывать URL-адреса. Если вы никогда раньше не работали с RegEx или вам трудно замечать всю эту странную магию — это для вас. Приятного чтения 😃
Ссылки
Есть несколько замечательных ресурсов для RegEx, к которым я регулярно обращаюсь. Потратьте время, чтобы прочитать их. Иногда они объясняют, как обрабатывается RegEx, и могут объяснить, почему magic происходит:
Практика
Регулярные выражения
Регулярные выражения или RegEx предназначены для сопоставления с образцом.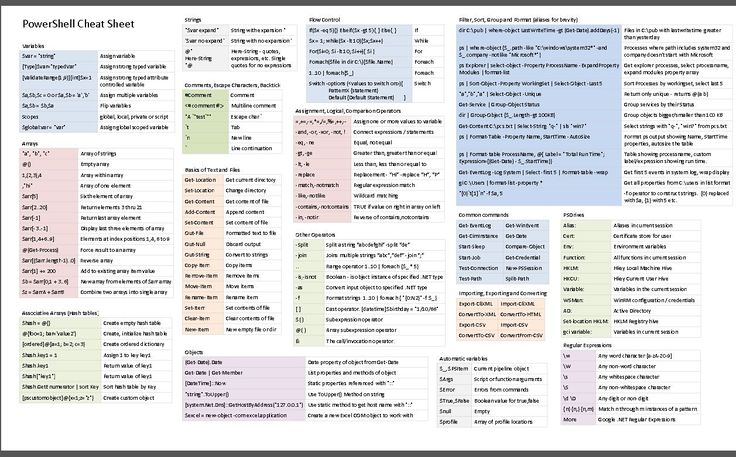 Многое из того, что мы делаем, на самом деле связано с сопоставлением с образцом, если подумать. RegEx действительно хорош для сопоставления шаблонов и извлечения значений из найденных шаблонов. Итак, какие проблемы мы можем решить?
Многое из того, что мы делаем, на самом деле связано с сопоставлением с образцом, если подумать. RegEx действительно хорош для сопоставления шаблонов и извлечения значений из найденных шаблонов. Итак, какие проблемы мы можем решить?
Регулярное выражение создается следующим образом:
/шаблон/
1
Начинается и заканчивается на / .
Или вот так, где мы создаем объект из класса RegEx :
new RegEx(/pattern/)
1
Методы
Существует несколько различных методов, предназначенных для различных типов использования. Важно научиться использовать правильный метод.
-
exec(), Выполняет поиск совпадения в строке. Он возвращает массив информацииили нольпри несоответствии. -
test(), проверяет совпадение в строке, отвечаетtrueилиfalse -
match(), возвращает массив, содержащий все совпадения, включая группы захвата, илиnull, если совпадений не найдено.
-
matchAll(), Возвращает итератор, содержащий все совпадения, включая группы захвата. -
search(), Проверяет соответствие в строке. Он возвращает индекс совпадения или -1, если поиск не удался. -
replace(), Выполняет поиск совпадения в строке и заменяет совпадающую подстроку замещающей подстрокой. -
split(), Использует регулярное выражение или фиксированную строку для разбиения строки на массив подстрок.
Давайте покажем несколько примеров с учетом вышеуказанных методов.
тест() , тестовая строка для истинности/ложности Давайте рассмотрим пример с использованием test() :
/\w+/.test('abc123') // true
1
Выше мы проверяем строку abc123 на наличие всех буквенных символов \w+ и отвечаем на вопрос, содержите ли вы буквенные символы.
match() , найти совпаденияРассмотрим пример:
'orders/items'.match(/\w+/) // [ 'orders', groups: undefined, index: 0, input ]
1
Приведенный выше ответ массива говорит нам, что мы можем сопоставить заказов с нашим шаблоном \w+ . Мы не захватили ни одной группы, на что указывает groups:undefined , и наше совпадение было найдено по адресу index:0 . Если бы мы хотели сопоставить все буквенные символы в строке, нам пришлось бы использовать флаг g . g указывает глобальное совпадение , например:
'orders/items'.match(/\w+/g) // ['orders', 'items']
1
Группы
У нас также есть понятие групп. Чтобы начать использовать группы, нам нужно заключить наш шаблон в круглые скобки следующим образом:
const matchedGroup = 'orders/114'.match(/(?\d+)/) // [114, 114, groups: { order : 114 }]
1
Использование конструкции ? создает так называемую именованную группу.
Флаги
Есть разные флаги. Перечислим некоторые из них. Все флаги добавляются в конце регулярного выражения. Таким образом, типичное использование выглядит так:
var re = /шаблон/флаги;
1
-
g, вы говорите, что хотите сопоставить всю строку, а не только первое вхождение -
i, это означает, что мы хотим совпадение без учета регистра 3
120 Assertions Существуют различные типы утверждений:
- Граница , это для сопоставления элементов в начале и конце слова
- Другие утверждения 9 слово
тест.Обратное будет выглядеть так:
/test$/.test('123test')1
Классы символов
Классы символов относятся к различным типам символов, таким как буквы и цифры. Перечислим некоторые из них:
-
., соответствует любому одиночному символу, кроме разделителей строк, таких как\nили\r -
\d, соответствует цифрам, эквивалентным[0-9[0-9] -
\w, соответствует любому буквенному символу, включая_. Эквивалент
Эквивалент [a-zA-Z0-9_] -
\W, отрицание вышесказанного. Соответствует%, например -
\s, соответствует пробельным символам -
\t, соответствует табуляции -
\r, соответствует возврату каретки 7 и
, соответствует строке -
-
\, управляющий символ. Его можно использовать для соответствия/вот так\/. Также используется для придания символам специального значения
Квантификаторы
Квантификаторы — это количество символов, которым необходимо соответствовать:
-
*, от 0 до многих символов -
+, от 1 до многих символов 90} , совпадение n символов -
{n,}, совпадение >= n символов -
{n,m}, совпадение >= n && =< m символов -
?, нежадное сопоставление
Рассмотрим несколько примеров
/\w*/.test('abc123') // true /\w*/.test('') // верно. * = от 0 до многих
1
2
В следующем примере мы используем ? :
/\/продукты\/?/.test('/products')
///продукты\/?/.test('/products/')
1
2
Выше мы можем видеть, как используется ? делает окончание / необязательным, когда мы используем этот тип соответствия \/? .
DEMO
Хорошо, это много теории, смешанной с некоторыми примерами. Далее давайте рассмотрим некоторые реалистичные сопоставления, сопоставления, которые мы действительно будем использовать в производстве.
Если вы используете JavaScript на бэкенде, вы, вероятно, уже используете какие-то фреймворки, такие как Express, Koa или Nest.js. Знаете ли вы, что эти фреймворки делают для вас с точки зрения сопоставления маршрутов, параметров и многого другого? Что ж, пора это выяснить.
Соответствие маршруту
Такой же простой маршрут, как /продукты , как нам его сопоставить?. Ну, мы знаем, что наш URL-адрес должен содержать эту часть, поэтому написать регулярное выражение для этого довольно просто. Давайте также учтем, что некоторые будут вводить
Ну, мы знаем, что наш URL-адрес должен содержать эту часть, поэтому написать регулярное выражение для этого довольно просто. Давайте также учтем, что некоторые будут вводить /products , а некоторые другие будут вводить /products/ :
/\products\/?$/.test('/products')
1
Вышеупомянутое регулярное выражение удовлетворяет всем нашим потребностям от сопоставления / с \/ до сопоставления необязательного / в конце с \/? .
Хорошо, возьмем аналогичный случай. /продукты/112 . Маршрут /products с номером в конце. Начнем проверять, соответствует ли входящий маршрут:
//products\/\d+$/.test('/products/112') // true
//продукты\/\d+$/.test('/products/') // ложь
1
2
Чтобы извлечь параметр маршрута, мы можем ввести следующее:
const [ productId] = '/products/112'.match(/\/products\/(\d+)/) // идентификатор продукта = 112
1
2
Хорошо, допустим, у вас есть маршрут, похожий на этот /orders/113/items/55 .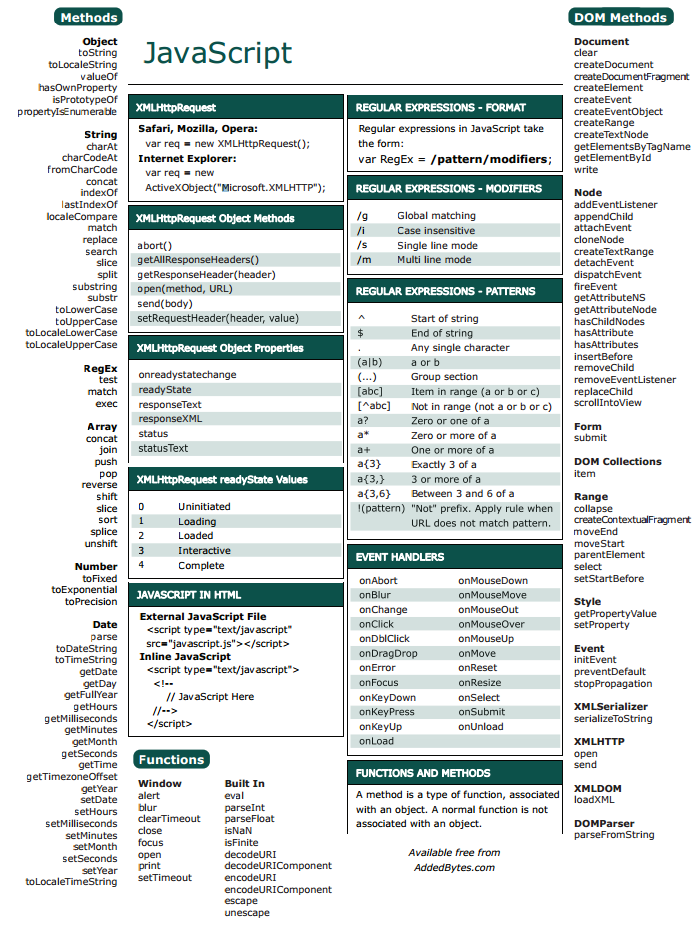 Это примерно соответствует заказу с идентификатором
Это примерно соответствует заказу с идентификатором 113 и идентификатору позиции заказа 55 . Сначала мы хотим убедиться, что наш входящий URL-адрес совпадает, поэтому давайте посмотрим на RegEx для этого:
/\orders\/\d+\/items\/\d+\/?/.test('/orders/99/items/ 22') // верно
1
Приведенное выше регулярное выражение выглядит следующим образом, соответствует /orders/[1-n цифр]/items/[1-n цифр][необязательно /]
Теперь мы знаем, что можем сопоставить указанный выше маршрут. Давайте возьмем эти параметры дальше. Мы можем сделать это, используя именованные группы:
var { groups: { orderId, itemId } } = '/orders/99/items/22'.match(/(?\d+)\/items\/(? \d+)\/?/)
// идентификатор заказа = 99
// элементы = 22
1
2
3
Приведенное выше выражение вводит группы путем создания именованных групп orderId и itemId с конструкциями (? и (? соответственно. Шаблон очень похож на тот, который используется с методом
Шаблон очень похож на тот, который используется с методом test() .
Классификатор маршрутов
Я уверен, вы видели, как маршрут был разделен на несколько частей, таких как протокол , хост , маршрут , порт и параметры запроса .
Это очень легко сделать. Предположим, мы смотрим на URL-адрес, который выглядит так: http://localhost:8000/products?page=1&pageSize=20 . Мы хотим проанализировать этот URL-адрес и в идеале получить что-то удобное для работы, например:
{
протокол: 'http',
хост: «локальный хост»,
маршрут: '/products?page=1&pageSize=20',
порт: 8000
}
1
2
3
4
5
6
Как туда добраться? Что ж, то, что вы видите, следует очень предсказуемому образцу, и RegEx — это Mjolnir of Hammers , когда дело доходит до сопоставления с образцом. Давайте сделаем это 😃
var http = 'http://localhost:8000/products?page=1&pageSize=20' .match(/(?<протокол>\w+):\/{2}(?<хост>\w+):(?<порт>\d+)(?<маршрут>.*)/) // http.groups = {протокол: 'http', хост: 'localhost', порт: 8000, маршрут: '?page=1&pageSize=20' }
1
2
3
4
Давайте разберем приведенное выше и разберем его:
-
(?<протокол>\w+):, это соответствует n буквенным символам, оканчивающимся на 7 3 :6 . Кроме того, он помещается в именованную группупротокол -
\/{2}, это просто говорит, что у нас есть//, обычно послеhttp://. -
(?, это соответствует n количеству буквенных символов, заканчивающихся на\w+): :, поэтому в данном случае он соответствуетlocalhost. Кроме того, он помещается в именованную группухост. -
(?, это соответствует некоторым цифрам, которые следуют после хоста, который будет портом. Кроме того, он помещается в именованную группу\d+) порт.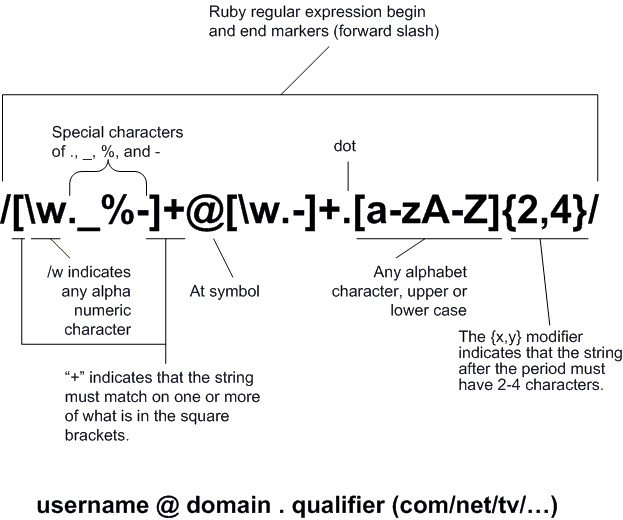
-
(?, наконец, у нас есть сопоставление маршрута, которое просто соответствует любым символам, что гарантирует, что мы получим часть.*) ?page=1&pageSize=20. Кроме того, он помещается в именованную группуroute.
Чтобы проанализировать параметры запроса, нам просто нужно регулярное выражение и один вызов reduce() , например:
const queryMatches = http.groups.route.match(/(\w+=\w+)/g ) // ['page=1', 'pageSize=20']
const queryParams = queryMatches.reduce((acc, curr) => {
const [ключ, значение] = curr.split('=')
обр[...обр, [ключ]: значение]
}, {}) // {страница: 1, размер страницы: 20}
1
2
3
4
5
6
Выше мы работаем с ответом от нашего первого сопоставления шаблона http.groups.route . Теперь мы создаем шаблон, который будет соответствовать следующему [любой символ алфавита]=[любой символ алфавита] . Кроме того, поскольку у нас есть глобальное совпадение g , мы получаем массив ответов. Это соответствует всем параметрам нашего запроса. Наконец, мы вызываем
Это соответствует всем параметрам нашего запроса. Наконец, мы вызываем reduce() и превращаем массив в объект.
Сложность пароля
Сложность пароля заключается в том, что он поставляется с различными критериями, такими как:
- длина , он должен быть более n символов и, возможно, менее m символов
- числа , должен содержать число
- специальный символ , должен содержать специальные символы
Тогда мы в безопасности? Что ж, безопаснее, не забывайте о двухфакторной аутентификации в приложении, а не о вашем номере телефона.
Давайте посмотрим на RegEx для этого:
// проверка хотя бы 1 номера
var pwd = /\d+/.test('пароль1')
// проверка хотя бы на 8 символов
var pwdNCharacters = /\w{8,}/.test('пароль1')
// проверка хотя бы одного из &, ?, !, -
var specialCharacters = /&|\?|\!|\-+/.test('password1-')
1
2
3
4
5
6
7
8
9
Как видите, каждое требование я строю как сопоставление с собственным образцом. Вам нужно пройти через каждый из паролей, чтобы убедиться, что он действителен.
Вам нужно пройти через каждый из паролей, чтобы убедиться, что он действителен.
Идеальное свидание
На моей нынешней работе я сталкиваюсь с коллегами, которые все думают, что их формат даты — тот, который следует использовать всем нам. В настоящее время это означает, что моему бедному мозгу приходится иметь дело с:
// YY/MM/DD , европейский стандарт ISO. // ДД/ММ/ГГ, британский // ММ/ДД/ГГ, Америка, США
1
2
3
Итак, вы можете себе представить, что мне нужно знать национальность того, кто прислал мне электронное письмо каждый раз, когда я получаю электронное письмо с датой в нем. Это больно 😃. Итак, давайте создадим регулярное выражение, чтобы мы могли легко менять его по мере необходимости.
Допустим, мы получаем дату в США, например, ММ/ДД/ГГ . Мы хотим извлечь важные части и поменять местами дату, чтобы кто-то из европейцев/британцев мог это понять. Давайте также предположим, что наш ввод ниже американский:
var toBritish = '12/22/20'.replace(/(?
\d{2})\/(? \d{2}) \/(?<год>\d{2})/, '$2/$1/$3') var toEuropeanISO = '22/12/20'.replace(/(?<месяц>\д{2})\/(?<день>\д{2})\/(?<год>\д{2} )/, '3 доллара/1 доллар/2 доллара')
1
2
Выше мы можем сделать именно это. В нашем первом параметре replace() мы даем ему наше регулярное выражение. Наш второй параметр — это то, как мы хотим его поменять местами. Для британского свидания мы просто меняем месяц и день, и все счастливы. Для европейской даты нам нужно сделать немного больше, так как мы хотим, чтобы она начиналась с года, затем месяца и дня.
Электронная почта
Хорошо, поэтому для электронной почты нам нужно подумать о нескольких вещах
-
@, должен быть@символ где-то посередине -
имя, у людей могут быть длинные имена, с тире/дефисом и без них. Это означает, что людям можно звонить,на,на альбинаи так далее -
фамилия, им нужна фамилия, или электронная почта просто фамилия или имя -
домен, нам нужно внести в белый список несколько доменов, таких как.,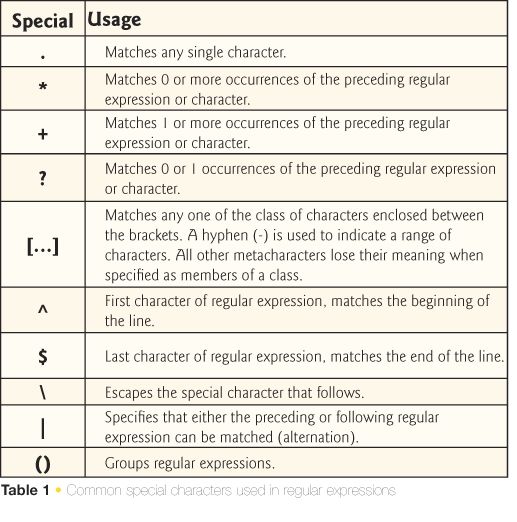 com
com .gov,.edu
Имея все это в виду, я даю вам регулярное выражение: 9 , это означает, что он начинается с.
(\w+\-?\w+\.)* , это означает слово с нашим без - так как у нас есть шаблон -? и заканчивая . , значит чел. , пер-альбин. . Кроме того, мы заканчиваем * , поэтому 0 для многих из них. (\w+){1} , это означает ровно одно слово, например электронное письмо, состоящее только из фамилии или только имени. Это открывается для комбинации 1) + 2), поэтому per-albin.hansson или per.hansson или 2) отдельно, что соответствует per или hansson . @ , нам нужно сопоставить один символ @ \w+\. , здесь мы сопоставляем имя, оканчивающееся на ., например, Швеция. (\w+\. )*
)* , здесь мы открываем несколько поддоменов или никого, учитывая * , например sthlm.region. и т. д. (edu|gov|com) , доменное имя, здесь мы перечисляем разрешенные домены: edu , gov или com $ , должен заканчиваться на, это означает, что мы гарантируем, что кто-то не введет какую-нибудь чушь после доменного имениРезюме
Вы получили все здесь . Мы действительно рассмотрели много вопросов по теме RegEx. Надеюсь, теперь вы лучше понимаете, из каких компонентов он состоит. Кроме того, я надеюсь, что примеры из реальной жизни заставили вас понять, что вам может просто не понадобиться устанавливать этот дополнительный модуль node. Надеюсь, после небольшой практики вы почувствуете, что RegEx полезен и действительно может сделать ваш код намного короче, элегантнее и даже читабельнее. Да, я сказал читабельно. RegEx вполне удобочитаем, как только вы поймете, как оцениваются вещи.