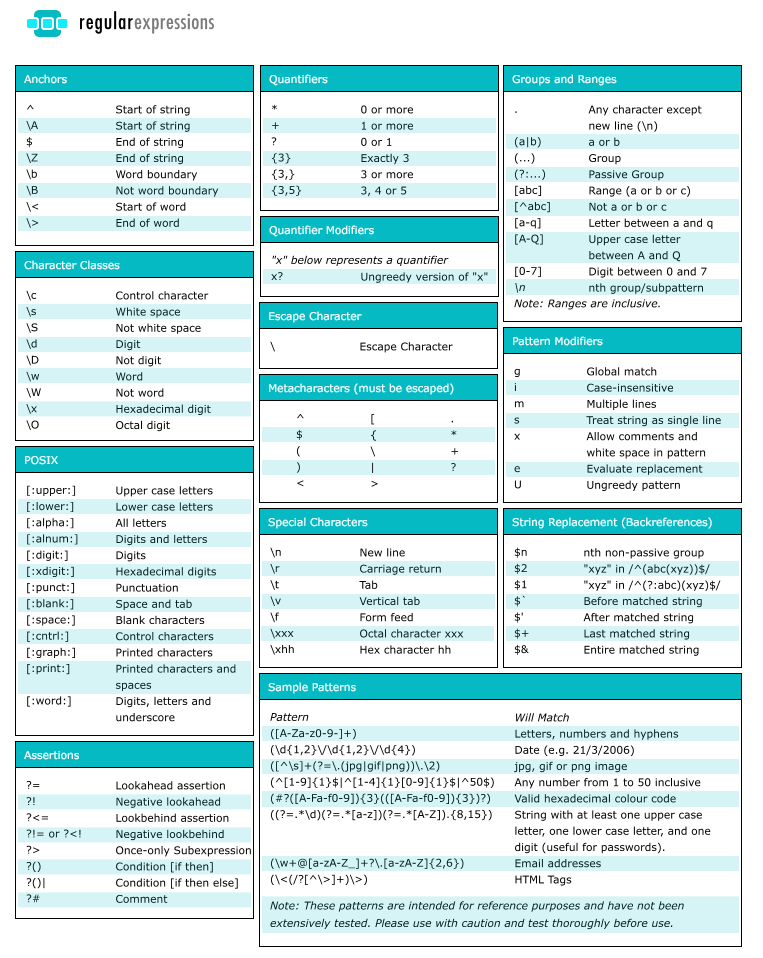
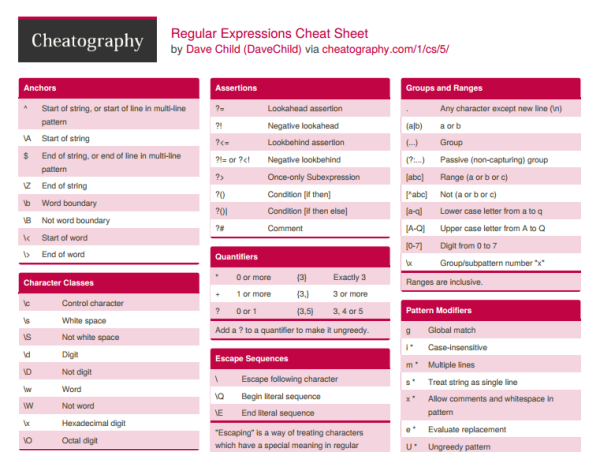
Определение регулярных выражения
Определение регулярного выражения, это создание🏗️ шаблона, на основе которого будет происходить работа со строками. В JavaScript регулярные выражения — это объект, который может быть определён двумя способами.
- Литерал
- Конструкция
Определение регулярных выражений с использованием литералов. Для регулярных выражений литералами выступают слеши / ... /, они играют ту же роль, что и скобки ' ... ' при создании🏗️ строк.
let regExp = /шаблон/
Если вы решили создавать🏗️ регулярные выражения при помощи литералов, то стоит учитывать, что такой метод создания🏗️ не допускает динамическое изменение задаваемых значений. Происходит это из-за того, что литералы регулярных выражения вызывают предварительную компиляцию при анализе скрипта. banana$/. Метод
banana$/. Метод .test() вернёт true ✅ только в том случае, если вся строка это banana.
Флаги
Флаги используются для расширения осуществляемого регулярными выражениями поиска.
g— при поиске ищет все совпадения;i— поиск не зависит от регистра[Z-z];m— многострочный режим;s— включает режим dotall, при котором точка.может соответствовать символу перевода строки;y— выполняет поиск начиная с символа, который находится на позиции свойства lastindex текущего регулярного выражения;u— включает поддержку Unicode.
Использование флагов при разных способах создания🏗️ шаблона регулярного выражения
- Литерал
- Конструкция
let regExp = /шаблон/флаг // prettier-ignore
Обратите внимание, что флаги являются неотъемлемой частью регулярного выражения. Флаги не могут быть добавлены или удалены позднее. Также флаги можно комбинировать.
Флаги не могут быть добавлены или удалены позднее. Также флаги можно комбинировать.
function learnJavaScript() { let regExp = /banana/i, str = ‘faNana RanaNA BaNanA’ return regExp.test(str) ? ‘Нашёл’ : ‘Нету’ }
Loading…
Попробуйте убрать флаг i из примера.
Итого
Тема очень обширная и нечасто используемая нами в разработке, поэтому если интересно, то подробней можно познакомиться с ней здесь, здесь и здесь.
Проблемы?
Пишите в Discord или телеграмм чат, а также подписывайтесь на наши новости
Вопросы
Для чего нужны регулярные выражения?
- Cоздание шаблонов
- Манипуляции со строками
- Редактирования строк
Какой символ используется для литерального создания регулярного выражения?
- Слеш
/ - Обратный слеш
\ - Квадратные скобки
[]
В каком способе создания регулярного выражения не допускается дальнейшее динамическое изменение задаваемых значений?
- В литеральном
- В конструкции
- При любом способе динамическое изменение допустимо
Для того чтобы понять насколько вы усвоили этот урок пройдите тест в мобильном приложении в нашей школы по этой теме.
Ссылки
- Learn JavaScript
- MDN Web Docs
- JS RegExp
Contributors ✨
Thanks goes to these wonderful people (emoji key):
IIo3iTiv 📖 | Dmitriy Vasilev 💵 | Resoner2005 🐛 🎨 🖋 | Navernoss 🖋 🐛 🎨 |
Онлайн-курс «Регулярные выражения для фронтендеров»
Онлайн-курс «Регулярные выражения для фронтендеров»Задать вопросНачать
Регулярные выражения помогают быстрее и эффективнее анализировать и искать информацию. В некоторых случаях их использование ускоряет написание кода и увеличивает скорость его работы.
Необходимые знания: JavaScript
В курс включено: регулярные выражения
Гибкие сроки: начинайте прямо сейчас и двигайтесь в комфортном режиме
Начать за 6 900 ₽Начать бесплатно
Находить оптимальные и быстрые пути решения задач
Успешно проходить собеседования в крупные продуктовые компании
Решать cложные задачи правильными методами
Приносить больше пользы продукту
Знание регулярных выражений — необходимый навык для разработчиков с опытом работы более года.
Оставьте email, чтобы получать свежую информацию:
- — даты выхода новых курсов по навыкам с карты компетенций;
- — специальные предложения для практикующих веб-разработчиков;
- — акции и скидки от HTML Academy.
Соглашаюсь на обработку персональных данных и получение рекламных и информационных сообщений в соответствии с «Политикой» и «Пользовательским соглашением».
Спасибо, что подписались!
Ждите новостей — обещаем не спамить.
Что-то пошло не так 🙁 Попробуйте ещё раз
Поиск по строке с плавающими условиями
Валидация данных на формат и значения
Генерация и очистка данных
Задачи по типографике текста
Гибкое редактирование в текстовом редакторе
Работа в командной строке и grep
Разделы построены таким образом, чтобы постепенно усложнять и углублять знания о регулярных выражениях.
Задача — не только научиться писать регулярные выражения, но и правильно и уместно их использовать.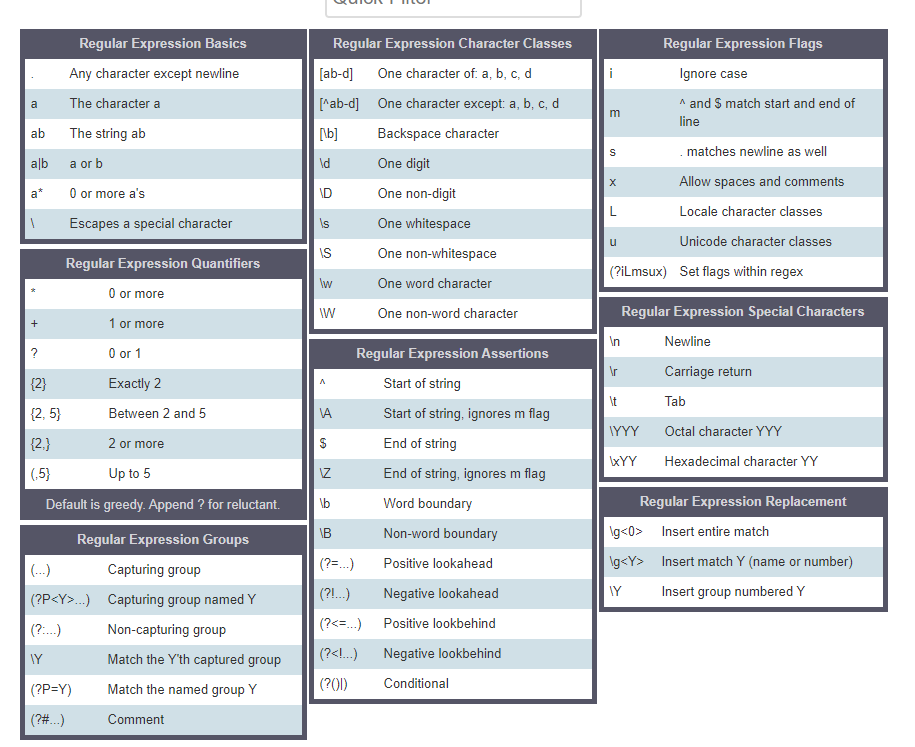
Раздел 1
бесплатно
Узнаем принципы работы регулярных выражений, познакомимся с основными терминами. Разберём механизм движения паттернов и возвраты.
— Основные принципы использования регулярных выражений
— Обзор базового инструментария и примеры использования
— Методы JavaScript для работы с регулярными выражениями
— Базовый синтаксис регулярных выражений
— Таблица метасимволов регулярных выражений для языка JavaScript
Получить доступ
Раздел 2
— Понятие символа и набора
— Работа с регистром
— Поиск с помощью символов и наборов
— Практическое задание
Раздел 3
— Разнообразие символьных селекторов и их отличия от символов
— Ограничения символьных селекторов
— Служебные символы
— Универсальный селектор
— Особенность работы в разных операционных системах
— Практическое задание
Раздел 4
— Что такое группировка и как она работает в регулярных выражениях
— Использование круглых и фигурных скобок
— Практическое задание
— Тест по пройденному материалу
Раздел 5
— Понятие квантификаторов
— Жадность и ограничение жадности
— Более глубокое использование регулярных выражений
— Практическое задание: описание уровня игры
— Тест по пройденному материалу
Раздел 6
— Что такое проверки и зачем они нужны
— Понятие и использование модификаторов
— Практическое задание
Раздел 7
— Различия RegExp в JavaScript и серверных языках на базе библиотеки PCRE (Perl Compatible Regular Expression)
— Плюсы и минусы регулярных выражений, скорость работы, обоснованность более точных паттернов
— Регулярные выражения в командной строке, работа с именами файлов
— Регулярные выражения в текстовых редакторах
— Финальный тест
Курс предполагает самостоятельное изучение материала в комфортном для вас режиме. Начать учиться можно прямо сейчас.
Начать учиться можно прямо сейчас.
Программа разбита на модули, каждый из которых позволяет постепенно осваивать навык от простых основ до сложных тонкостей.
В каждом модуле будет:
Структурированная информация, необходимая для усвоения части навыка
Примеры решения типовых задач, которые помогут понять, как теория превращается в практику
Для самостоятельного закрепления полученной теории. После выполнения каждого задания вы получите пошаговое эталонное решение и сможете сравнить его со своим вариантом.
Для финального закрепления материала. Позволит вам убедиться, что вы всё точно усвоили и можете двигаться дальше.
Вы можете приобрести несколько курсов по выгодной цене.
Навыки на курсах, входящих в пакет, объединены общей тематикой.
Сделано для разработчиков, у которых мало времени на обучение.
Связывает теорию с типовыми задачами на рынке. У вас будет понимание того, где и как применить полученную теорию.
Построена от простого к сложному.
Вы легко погрузитесь в тему, даже если ничего про неё не знали раньше.
Актуальная и обновляемая теория, проверенная рынком. Никакой «воды» — вы получите только необходимые знания.
Поможет вам с ответами на вопросы и углублением знаний.
Хотите освоить конкретный навык, но не знаете как
Не хотите тратить время на поиск актуальной информации по теме
Вам нужна конкретная методика обучения и только необходимая информация
Хотите убедиться, что полученные знания усвоились на практике
9 лет выстраиваем связь с рынком коммерческой разработки. Обучаем начинающих разработчиков и видим, как они становятся опытными специалистами.
Перед запуском курса убеждаемся, что он даёт востребованный профессиональный навык.
Общаемся с сообществом веб-разработчиков и поэтому понимаем, как нужно учить. Максимально сокращаем время от изучения теории до решения типовых задач.
«Изучая материал самостоятельно, я получил теоретические представления о вопросе. Но для решения задач необходимы именно практические знания. И в HTML Academy именно на это ставка. Что ты руками осваиваешь, как работает. Даже если что-то не дочитал».
Но для решения задач необходимы именно практические знания. И в HTML Academy именно на это ставка. Что ты руками осваиваешь, как работает. Даже если что-то не дочитал».
«Если честно, мне лень искать по всему интернету какие-то статьи, учебники. А тут сразу теория, объяснение, задачи. И я знаю, что я их точно пройду, в отличие от каких-нибудь видеокурсов».
«Материал подан в том формате, в котором его лучше учить. Изучая самостоятельно, мы не всегда понимаем. В голове каша».
«Cамостоятельно всё это изучать можно, но довольно проблематично, потому что информации в интернете много. Она какая-то разрозненная, в некоторых местах противоречивая. А здесь, что мне понравилось, выжимки очень конкретные с объяснениями дают. Направляют куда нужно, дают вектор развития. И постепенно».
«Было ожидание, что будет больше разговорных видео, слушать преподавателя. По многим курсам есть такое в видео-формате. А пришлось читать учебник. Я бы не сказал, что это что-то испортило. Оказалось, что с учебником приятно работать. Думал, что будет сложнее. Оказалось — нет, всё прекрасно».
Думал, что будет сложнее. Оказалось — нет, всё прекрасно».
«Когда находишь правильное решение, и оно работает, ошибок не выдаёт, ты все равно сомневаешься, а правильно ли ты сделал. [На курсе] коллективная работа, авторитетное мнение. Это как компас, ориентир».
«У меня есть мнение, что HTML Academy делает курсы прикладные для специалистов. Что студент выйдет сразу с общим представлением о вопросе, уже имея набор практических решений».
Способы оплаты
Доступ к материалам:
демо, практика, кейсы
Постоянно обновляющийся контент
Комьюнити с авторами и экспертами курса
3 часа персональных консультаций с экспертом
Стоимость
Стоимость в рассрочку на 6 месяцев
Начать бесплатно
Начать
с экспертом
Начать
учиться
Regex в JS — как ВЫ можете изучить его и научиться любить его
Я пишу это самому себе из будущего. На самом деле, многие мои статьи обращены к самому себе в будущем, который забыл все о том, как что-то делать.
RegEx, регулярные выражения — действительно мощный инструмент в нашем наборе инструментов. К сожалению, мы называем это черной магией, дьяволом и прочими прелестями. Это не должно быть так. RegEx, конечно, отличается от обычного программирования, но это действительно очень мощное средство. Давайте узнаем, как это работает и как на самом деле использовать и применять к повседневным проблемам, которые вы знаете.
TLDR; Это долго? Да, но он проходит через основные конструкции в RegEx. Кроме того, в конце у меня есть несколько хороших рецептов о том, как делать такие вещи, как RegEx для электронной почты, пароли, преобразования формата даты и как обрабатывать URL-адреса. Если вы никогда раньше не работали с RegEx или вам трудно замечать всю эту странную магию — это для вас. Приятного чтения 😃
Ссылки
Есть несколько замечательных ресурсов для RegEx, к которым я регулярно обращаюсь. Потратьте время, чтобы прочитать их. Иногда они объясняют, как обрабатывается RegEx, и могут объяснить, почему magic случается:
- Информация о регулярных выражениях
Хороший сайт с большим количеством информации о RegEx.

- Страницы документов Mozilla на RegEx Хороший сайт, подробные объяснения с примерами
- Информация о JavaScript Некоторые из лучших объяснений, которые я видел в группах RegEx.
- Именованные группы
- Документы по регулярным выражениям Несмотря на то, что это руководство по .NET, информация о регулярных выражениях довольно общая и применимая
Практика
Node.js REPL . Если у вас установлен Node.js, я рекомендую просто ввести
nodeв терминале. Это запустит REPL, это отличный способ протестировать шаблоныJavaScript REPL , это расширение VS Code, которое оценивает то, что вы вводите. Вы получите мгновенную обратную связь о результатах
Браузер Отличная среда песочницы. Спасибо за совет Лукаш 😃
Регулярные выражения
Регулярные выражения или RegEx предназначены для сопоставления с образцом. Многое из того, что мы делаем, на самом деле связано с сопоставлением с образцом, если подумать. RegEx действительно хорош для сопоставления шаблонов и извлечения значений из найденных шаблонов. Итак, какие проблемы мы можем решить?
Многое из того, что мы делаем, на самом деле связано с сопоставлением с образцом, если подумать. RegEx действительно хорош для сопоставления шаблонов и извлечения значений из найденных шаблонов. Итак, какие проблемы мы можем решить?
- URL-адрес , URL-адрес содержит много интересной информации, такой как
имя хоста,маршрут,порт,параметры маршрутаипараметры запроса. Мы хотим иметь возможность извлекать эту информацию, а также проверять ее правильность. - Пароль , чем длиннее пароль, тем лучше, обычно это то, что нам нужно. Есть и другие измерения, такие как сложность. Под сложностью мы подразумеваем, что наш пароль должен содержать, например, цифры, специальные символы и многое другое.
- Поиск и извлечение данных , например, возможность поиска данных на веб-странице может быть очень легко реализована с помощью пары хорошо написанных регулярных выражений.
 На самом деле существует целая категория компьютерных программ, посвященных этому, под названием 9.0011 скребки .
На самом деле существует целая категория компьютерных программ, посвященных этому, под названием 9.0011 скребки .
Регулярное выражение создается следующим образом:
/шаблон/
1
Начинается и заканчивается на /.
Или вот так, где мы создаем объект из класса RegEx :
new RegEx(/pattern/)
1
Методы
Существует несколько различных методов, предназначенных для различных типов использования. Важно научиться использовать правильный метод.
-
exec(), Выполняет поиск совпадения в строке. Возвращает массив информацииили нольпри несоответствии. -
test(), проверяет совпадение в строке, отвечаетtrueилиfalse -
match(), возвращает массив, содержащий все совпадения, включая группы захвата, илиnull, если совпадений не найдено.
-
matchAll(), Возвращает итератор, содержащий все совпадения, включая группы захвата. -
search(), Проверяет соответствие в строке. Он возвращает индекс совпадения или -1, если поиск не удался. -
replace(), Выполняет поиск совпадения в строке и заменяет совпадающую подстроку замещающей подстрокой. -
split(), Использует регулярное выражение или фиксированную строку для разбиения строки на массив подстрок.
Давайте покажем несколько примеров с учетом вышеуказанных методов.
тест() , тестовая строка для истинности/ложности Давайте рассмотрим пример с использованием test() :
/\w+/.test('abc123') // true
1
Выше мы проверяем строку abc123 на наличие всех буквенных символов \w+ и отвечаем на вопрос, содержите ли вы буквенные символы.
match() , найти совпаденияРассмотрим пример:
'orders/items'.match(/\w+/) // [ 'orders', groups: undefined, index: 0, input ]
1
Приведенный выше ответ массива говорит нам, что мы можем сопоставить заказа с нашим шаблоном \w+ . Мы не захватили ни одной группы, на что указывает groups:undefined , и наше совпадение было найдено по адресу index:0 . Если бы мы хотели сопоставить все буквенные символы в строке, нам пришлось бы использовать флаг g . g указывает глобальное соответствие
'orders/items'.match(/\w+/g) // ['orders', 'items']
1
Группы
У нас также есть понятие групп. Чтобы начать использовать группы, нам нужно заключить наш шаблон в круглые скобки следующим образом:
const matchedGroup = 'orders/114'.match(/(?\d+)/) // [114, 114, groups: { order : 114 }]
1
Использование конструкции ? создает так называемую именованную группу.
Флаги
Есть разные флаги. Перечислим некоторые из них. Все флаги добавляются в конце регулярного выражения. Таким образом, типичное использование выглядит так:
var re = /шаблон/флаги;
1
-
g, вы говорите, что хотите сопоставить всю строку, а не только первое вхождение i, это означает, что мы хотим совпадение без учета регистра
- Граница , это для сопоставления элементов в начале и конце слова
- Другие утверждения 9 слово
тест.Обратное будет выглядеть так:
/test$/.test('123test')1
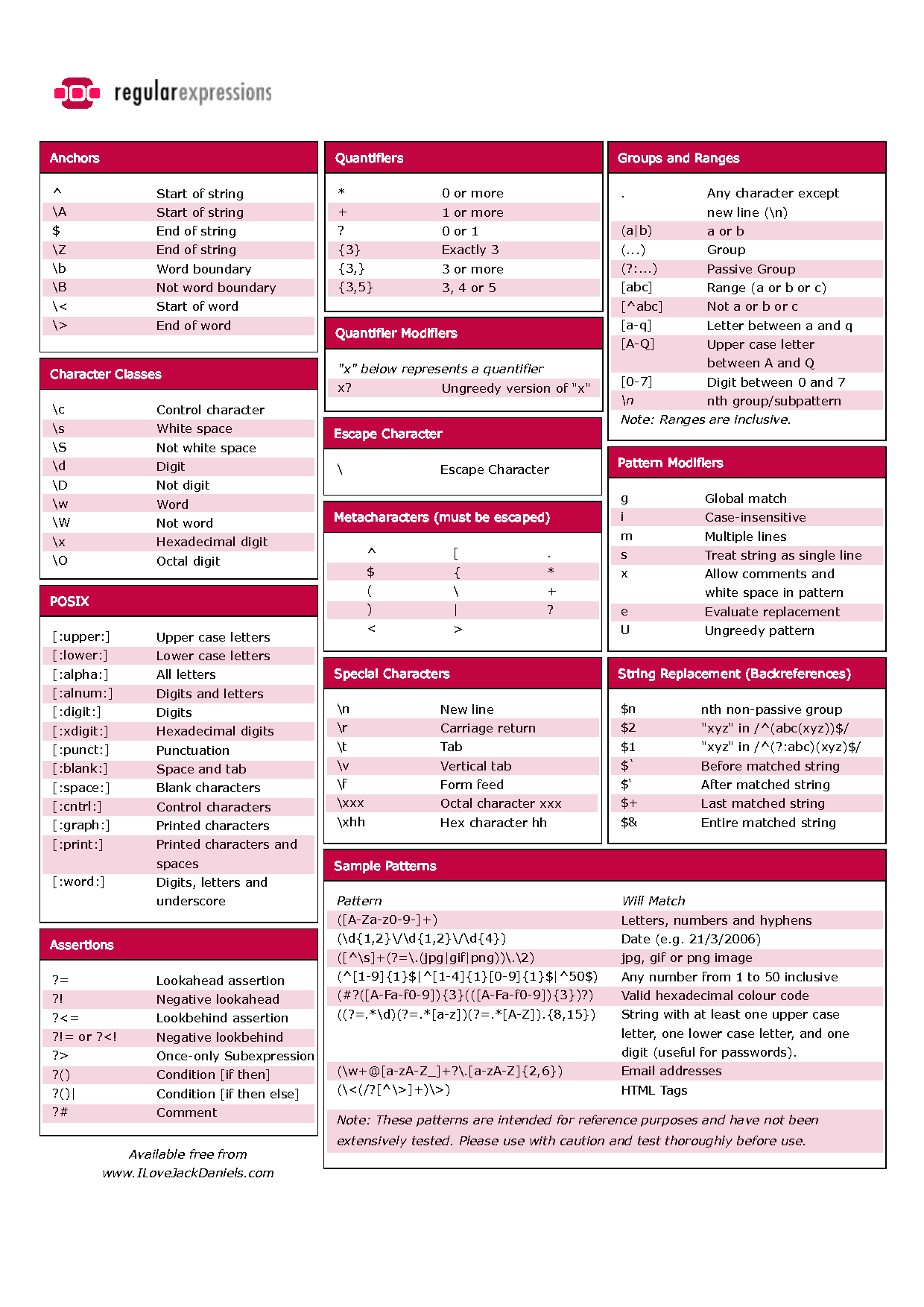
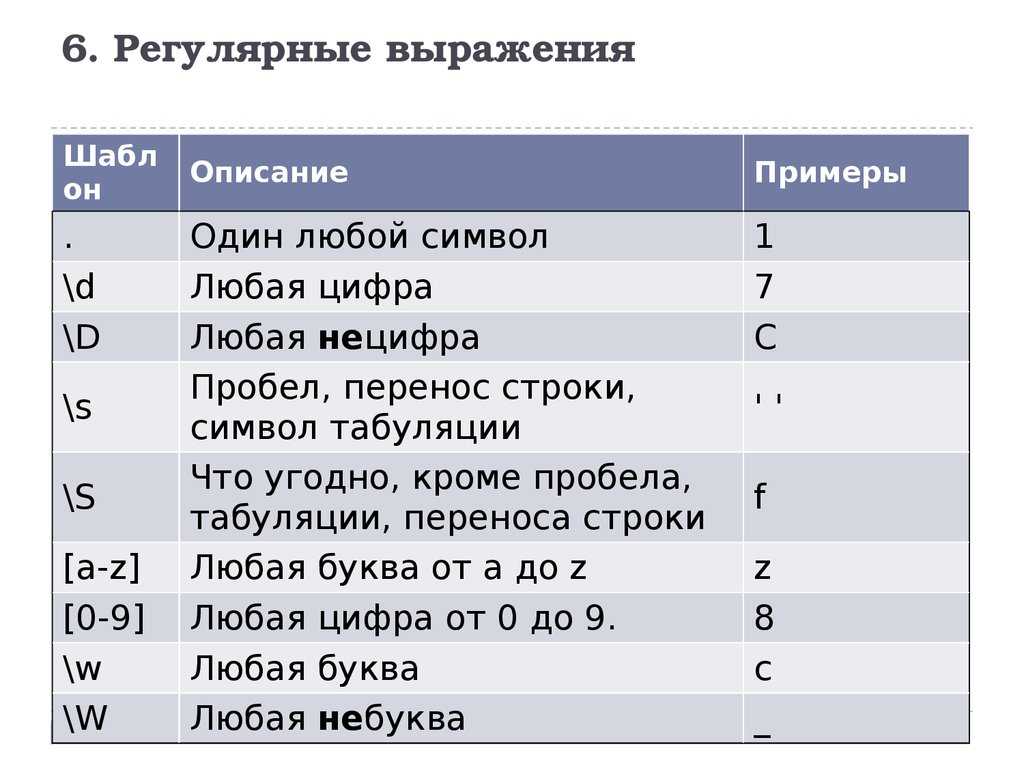
Классы символов
Классы символов относятся к различным типам символов, таким как буквы и цифры. Перечислим некоторые из них:
-
., соответствует любому одиночному символу, кроме разделителей строк, таких как\nили\r -
\d, соответствует цифрам, эквивалентным[0-9[0-9] -
\w, соответствует любому буквенному символу, включая_. Эквивалент
Эквивалент [a-zA-Z0-9_] -
\W, отрицание вышесказанного. Соответствует%например -
\s, соответствует пробельным символам -
\t, соответствует табуляции -
\r, соответствует возврату каретки \n переводу строки 5 -
\, управляющий символ. Его можно использовать для соответствия/вот так\/. Также используется для придания символам специального значения.
Квантификаторы
Квантификаторы определяют количество совпадающих символов:
-
*, от 0 до многих символов -
+, от 1 до многих символов 90} , совпадение n символов -
{n,}, совпадение >= n символов -
{n,m}, совпадение >= n && =< m символов -
?, нежадное сопоставление
Рассмотрим несколько примеров
/\w*/.
 test('abc123') // true
/\w*/.test('') // верно. * = от 0 до многих
test('abc123') // true
/\w*/.test('') // верно. * = от 0 до многих
1
2В следующем примере мы используем
?:/\/продукты\/?/.test('/products') ///продукты\/?/.test('/products/')1
2Выше мы можем видеть, как используется
?делает окончание/необязательным, когда мы используем этот тип соответствия\/?.DEMO
Хорошо, это много теории, смешанной с некоторыми примерами. Далее давайте рассмотрим некоторые реалистичные сопоставления, сопоставления, которые мы действительно будем использовать в производстве.
Если вы используете JavaScript на бэкенде, вы, вероятно, уже используете какие-то фреймворки, такие как Express, Koa или, возможно, Nest.js. Знаете ли вы, что эти фреймворки делают для вас с точки зрения сопоставления маршрутов, параметров и многого другого? Что ж, пора это выяснить.
Соответствие маршруту
Такой же простой маршрут, как
/products, как нам его сопоставить?. Ну, мы знаем, что наш URL-адрес должен содержать эту часть, поэтому написать регулярное выражение для этого довольно просто. Давайте также учтем, что некоторые будут вводить
Ну, мы знаем, что наш URL-адрес должен содержать эту часть, поэтому написать регулярное выражение для этого довольно просто. Давайте также учтем, что некоторые будут вводить /products, а некоторые другие будут вводить/products/:/\products\/?$/.test('/products')1
Вышеупомянутое регулярное выражение удовлетворяет всем нашим потребностям от сопоставления
/с\/до сопоставления необязательного/в конце с\/?.Хорошо, возьмем аналогичный случай.
/продукты/112. Маршрут/productsс номером в конце. Начнем проверять, соответствует ли входящий маршрут://products\/\d+$/.test('/products/112') // true //продукты\/\d+$/.test('/products/') // ложь1
2Чтобы извлечь параметр маршрута, мы можем ввести следующее:
const [ productId] = '/products/112'.match(/\/products\/(\d+)/) // идентификатор продукта = 112
1
2Хорошо, допустим, у вас есть маршрут, похожий на этот
/orders/113/items/55. Это примерно соответствует заказу с идентификатором
Это примерно соответствует заказу с идентификатором 113и идентификатору позиции заказа55. Сначала мы хотим убедиться, что наш входящий URL-адрес совпадает, поэтому давайте посмотрим на RegEx для этого:/\orders\/\d+\/items\/\d+\/?/.test('/orders/99/items/ 22') // верно1
Приведенное выше регулярное выражение выглядит следующим образом, соответствует
/orders/[1-n цифр]/items/[1-n цифр][необязательно /]Теперь мы знаем, что можем сопоставить указанный выше маршрут. Давайте возьмем эти параметры дальше. Мы можем сделать это, используя именованные группы:
var { groups: { orderId, itemId } } = '/orders/99/items/22'.match(/(?\d+)\/items\/(? \d+)\/?/) // идентификатор заказа = 99 // элементы = 22 1
2
3Приведенное выше выражение вводит группы путем создания именованных групп
orderIdиitemIdс конструкциями(?и\d+) \d+)  Шаблон очень похож на тот, который используется с методом
Шаблон очень похож на тот, который используется с методом test().Классификатор маршрутов
Я уверен, вы видели, как маршрут был разделен на несколько частей, таких как
протокол,хост,маршрут,портипараметры запроса.Это очень легко сделать. Предположим, мы смотрим на URL-адрес, который выглядит так:
http://localhost:8000/products?page=1&pageSize=20. Мы хотим разобрать этот URL и в идеале получить что-то удобное для работы, например:{ протокол: 'http', хост: «локальный хост», маршрут: '/products?page=1&pageSize=20', порт: 8000 }1
2
3
4
5
6Как туда добраться? Что ж, то, что вы видите, следует очень предсказуемому шаблону, а RegEx — это Mjolnir of Hammers , когда дело доходит до сопоставления с шаблоном. Давайте сделаем это 😃
var http = 'http://localhost:8000/products?page=1&pageSize=20' .
 match(/(?<протокол>\w+):\/{2}(?<хост>\w+):(?<порт>\d+)(?<маршрут>.*)/)
// http.groups = {протокол: 'http', хост: 'localhost', порт: 8000, маршрут: '?page=1&pageSize=20' }
match(/(?<протокол>\w+):\/{2}(?<хост>\w+):(?<порт>\d+)(?<маршрут>.*)/)
// http.groups = {протокол: 'http', хост: 'localhost', порт: 8000, маршрут: '?page=1&pageSize=20' }
1
2
3
4Давайте разберем приведенное выше и разберем его:
-
(?<протокол>\w+):, это соответствует n количеству буквенных символов, оканчивающихся на 4 :3 . Кроме того, он помещается в именованную группу
протокол -
\/{2}, это просто говорит, что у нас есть//, обычно послеhttp://. -
(?, это соответствует n количеству буквенных символов, заканчивающихся на\w+): :, поэтому в данном случае он соответствуетlocalhost. Кроме того, он помещается в именованную группухост. -
(?, это соответствует некоторым цифрам, которые следуют после хоста, который будет портом. Кроме того, он помещается в именованную группу\d+) порт.
-
(?, наконец, у нас есть сопоставление маршрута, которое просто соответствует любым символам, что гарантирует, что мы получим часть.*) ?page=1&pageSize=20. Кроме того, он помещается в именованную группуroute.
Чтобы проанализировать параметры запроса, нам просто нужно регулярное выражение и один вызов
reduce(), например:const queryMatches = http.groups.route.match(/(\w+=\w+)/g ) // ['page=1', 'pageSize=20'] const queryParams = queryMatches.reduce((acc, curr) => { const [ключ, значение] = curr.split('=') обр[...обр, [ключ]: значение] }, {}) // {страница: 1, размер страницы: 20}1
2
3
4
5
6Выше мы работаем с ответом от нашего первого сопоставления шаблона
http.groups.route. Теперь мы создаем шаблон, который будет соответствовать следующему[любой символ алфавита]=[любой символ алфавита]. Кроме того, поскольку у нас есть глобальное совпадениеg, мы получаем массив ответов. Это соответствует всем параметрам нашего запроса. Наконец, мы вызываем
Это соответствует всем параметрам нашего запроса. Наконец, мы вызываем reduce()и превращаем массив в объект.Сложность пароля
Сложность пароля заключается в том, что он поставляется с различными критериями, такими как:
- длина , он должен быть больше n символов и, возможно, меньше m символов
- цифры , должен содержать число
- специальный символ , должен содержать специальные символы
Тогда мы в безопасности? Что ж, безопаснее, не забывайте о двухфакторной аутентификации в приложении, а не о вашем номере телефона.
Давайте посмотрим на RegEx для этого:
// проверка хотя бы 1 номера var pwd = /\d+/.test('пароль1') // проверка хотя бы на 8 символов var pwdNCharacters = /\w{8,}/.test('пароль1') // проверка хотя бы одного из &, ?, !, - var specialCharacters = /&|\?|\!|\-+/.test('password1-')1
2
3
4
5
6
7
8
9Как видите, каждое требование я строю как сопоставление с собственным образцом.
 Вам нужно пройти через каждый из паролей, чтобы убедиться, что он действителен.
Вам нужно пройти через каждый из паролей, чтобы убедиться, что он действителен.Идеальное свидание
На моей нынешней работе я сталкиваюсь с коллегами, которые все думают, что их формат даты — тот, который следует использовать всем нам. В настоящее время это означает, что моему бедному мозгу приходится иметь дело с:
// YY/MM/DD , европейский стандарт ISO. // ДД/ММ/ГГ, британский // ММ/ДД/ГГ, Америка, США
1
2
3Итак, вы можете себе представить, что мне нужно знать национальность того, кто прислал мне электронное письмо каждый раз, когда я получаю электронное письмо с датой в нем. Это больно 😃. Итак, давайте создадим регулярное выражение, чтобы мы могли легко менять его по мере необходимости.
Допустим, мы получаем дату в США, например,
ММ/ДД/ГГ. Мы хотим извлечь важные части и поменять местами дату, чтобы кто-то из европейцев/британцев мог это понять. Давайте также предположим, что наш ввод ниже американский:var toBritish = '12/22/20'.
 replace(/(?
replace(/(?\d{2})\/(? \d{2}) \/(?<год>\d{2})/, '$2/$1/$3') var toEuropeanISO = '22/12/20'.replace(/(?<месяц>\д{2})\/(?<день>\д{2})\/(?<год>\д{2} )/, '3 доллара/1 доллар/2 доллара') 1
2Выше мы можем сделать именно это. В нашем первом параметре
replace()мы даем ему наше регулярное выражение. Наш второй параметр — это то, как мы хотим его поменять местами. Для британского свидания мы просто меняем месяц и день, и все счастливы. Для европейской даты нам нужно сделать немного больше, так как мы хотим, чтобы она начиналась с года, затем месяца и дня.Электронная почта
Хорошо, поэтому для электронной почты нам нужно подумать о нескольких вещах
-
@, должен быть@символ где-то посередине -
имя, у людей могут быть длинные имена, с тире/дефисом и без них. Это означает, что людям можно звонить,на,на альбинаи так далее -
фамилия, им нужна фамилия, или электронная почта просто фамилия или имя -
домен, нам нужно внести в белый список несколько доменов, таких как., com
com .gov,.edu
Имея все это в виду, я даю вам регулярное выражение: 9 , это означает, что он начинается с.
-
-
(\w+\-?\w+\.)*, это означает слово с нашим без-так как у нас есть шаблон-?и заканчивая., значитчел.,пер-альбин.. Кроме того, мы заканчиваем*, поэтому 0 для многих из них. -
(\w+){1}, это означает ровно одно слово, например электронное письмо, состоящее только из фамилии или только имени. Это открывается для комбинации 1) + 2), поэтомуper-albin.hanssonилиper.hanssonили 2) отдельно, что соответствует per илиhansson. -
@, нам нужно сопоставить один символ@ -
\w+\., здесь мы сопоставляем имя, оканчивающееся на ., например,Швеция. -
(\w+\., здесь мы открываем несколько поддоменов или никого, учитывая )*
)* *, например sthlm.region. и т. д. -
(edu|gov|com), доменное имя, здесь мы перечисляем разрешенные домены:edu,govилиcom -
$, это означает, что мы гарантируем, что кто-то не введет какую-нибудь чушь после доменного имени
Резюме
. Мы действительно рассмотрели много вопросов по теме RegEx. Надеюсь, теперь вы лучше понимаете, из каких компонентов он состоит. Кроме того, я надеюсь, что примеры из реальной жизни заставили вас понять, что вам может просто не понадобиться устанавливать этот дополнительный модуль узла. Надеюсь, после небольшой практики вы почувствуете, что RegEx полезен и действительно может сделать ваш код намного короче, элегантнее и даже читабельнее. Да, я сказал читабельно. RegEx вполне удобочитаем, как только вы поймете, как оцениваются вещи. Вы обнаружите, что чем больше времени вы тратите на это, тем больше оно окупается. Перестаньте пытаться изгнать его обратно в измерение Демонов и дайте ему шанс 😃
Перестаньте пытаться изгнать его обратно в измерение Демонов и дайте ему шанс 😃
Регулярные выражения — Scala.js
Регулярные выражения JavaScript отличаются от регулярных выражений Java.
Для java.util.regex.Pattern (и его производных, таких как scala.util.matching.Regex и метод .r ) Scala.js реализует семантику регулярных выражений Java, хотя и с некоторыми ограничениями.
Семантика и набор функций регулярных выражений JavaScript доступны через js.RegExp , как и любой другой API JavaScript.
Поддержка
Набор поддерживаемых функций для Pattern зависит от целевой версии ECMAScript, указанной в ESFeatures.esVersion .
По умолчанию Scala.js нацелен на ECMAScript 2015.
Эту цель можно изменить с помощью следующей настройки:
scalaJSLinkerConfig ~= (_.withESFeatures(_.withESVersion(ESVersion.ES2018)))
Внимание! Хотя это позволяет использовать больше функций регулярных выражений, ваше приложение ограничивается средами, поддерживающими последние функции JavaScript. Если вы поддерживаете библиотеку, это ограничение применяется ко всем нижестоящим библиотекам и приложениям.
Поэтому мы рекомендуем стараться избегать дополнительных функций и отдавать предпочтение дополнительной логике в коде, если это возможно.
Если вы поддерживаете библиотеку, это ограничение применяется ко всем нижестоящим библиотекам и приложениям.
Поэтому мы рекомендуем стараться избегать дополнительных функций и отдавать предпочтение дополнительной логике в коде, если это возможно.
В частности, мы рекомендуем избегать флага MULTILINE , также известного как (?m) , для которого требуется ES2018.
Ниже мы дадим несколько советов, как этого избежать.
Не поддерживается
Следующие функции никогда не поддерживаются:
- флаг
CANON_EQ, -
\X,\b{g}и\N{...}выражения, -
\p{In𝘯𝘢𝘮𝘦}классов символов, представляющих блоков Unicode , -
\Gсопоставление границ, кроме , если оно появляется в самом начале регулярного выражения (например,\Gfoo), - встроенных флаговых выражений с внутренними группами, т.
 е. конструкции вида
е. конструкции вида (?idmsuxU-idmsuxU:𝑋), - встроенных флаговых выражений без внутренних групп, т. е. конструкций вида
(?idmsuxU-idmsuxU), кроме , если они появляются в самом начале регулярного выражения (например,(?i)abcпринимается, аab(?i)c– нет), а - числовых «обратных» ссылок на группы, которые определены позже в шаблоне (обратите внимание, что даже Java не поддерживает именованных обратных ссылок, подобных этому).
Поддерживается условно
Следующие функции требуют esVersion >= ESVersion.ES2015 (по умолчанию верно):
- флаг
UNICODE_CASE.
Следующие функции требуют esVersion >= ESVersion.ES2018 (по умолчанию false):
- флаги
MULTILINEиUNICODE_CHARACTER_CLASS, - ретроспективных утверждений
(?<=𝑋)и(? , - выражения
\bи\B, используемые вместе с флагомUNICODE_CASE, -
\p{𝘯𝘢𝘮𝘦}выражения, где𝘯𝘢𝘮𝘦не является одним из классов символов POSIX.
Поддерживается всегда
Следует отметить, что, помимо прочего, следующие функции поддерживаются во всех случаях, даже если в ECMAScript вообще нет эквивалентной функции или в целевой версии ECMAScript:
- правильная обработка суррогатных пар (изначально поддерживается в ES 2015+),
- граничный сопоставитель
\G, когда он находится в начале шаблона (соответствует флагу «y», изначально поддерживается в ES 2015+), - именованных групп и именованных обратных ссылок (изначально поддерживается в ES 2018+),
- флаг
DOTALL(изначально поддерживается в ES 2018+), - Сопоставление без учета регистра ASCII (
CASE_INSENSITIVEвключено, ноUNICODE_CASEвыключено), - комментариев с флагом
COMMENTS, - Классы символов POSIX в режиме ASCII или их вариант Unicode с
UNICODE_CHARACTER_CLASS(если последний поддерживается, см. выше), 9г-р]] ),
выше), 9г-р]] ), - атомных групп
(?>𝑋), - притяжательные квантификаторы
𝑋*+,𝑋++и𝑋?+, -
\A,\Zи\zграничные согласователи, - выражение
\R, - встроенных цитат с
\Qи\E, как вне, так и внутри классов символов.
Все поддерживаемые функции имеют правильную семантику из Java.
Это верно даже для функций, существующих в JavaScript, но с другой семантикой, среди которых: 9 и $ граничные сопоставители с флагом MULTILINE (при поддержке последнего),
\h , \s , \v , \w и их инвертированные варианты с учетом флага UNICODE_CHARACTER_CLASS , \b и \B с учетом флага UNICODE_CHARACTER_CLASS , \p{𝘯𝘢𝘮𝘦} класса символов, включая \p{java𝘔𝘦𝘵𝘩𝘰𝘥𝘕𝘢𝘮𝘦} класса,
Гарантии
Если функция не поддерживается, во время Pattern.compile() выдается исключение PatternSyntaxException .
Если Pattern.compile() выполняется успешно, регулярное выражение гарантированно будет вести себя точно так же, как на JVM, за исключением для захвата групп в повторяющихся сегментах (как для их обратных ссылок, так и для последующих вызовов group , start и end ):
- на JVM группа захвата всегда фиксирует любую подстроку, которая была успешно сопоставлена последней этой группой во время обработки регулярного выражения:
- , даже если это было в предыдущей итерации повторяющегося сегмента, и последняя итерация не имела совпадения для этой группы, или
- , если это было во время более поздней итерации повторяющегося сегмента, для которого впоследствии был выполнен возврат;
- в JS и, следовательно, в Scala.
 js, захват групп в повторяющихся сегментах всегда захватывает то, что было сопоставлено (или нет) во время последней итерации, что в конечном итоге было сохранено.
js, захват групп в повторяющихся сегментах всегда захватывает то, что было сопоставлено (или нет) во время последней итерации, что в конечном итоге было сохранено.
Поведение JavaScript более «функционально», тогда как поведение JVM более «императивно».
Эта императивная природа также отражена в методах hitEnd() и requireEnd() Matcher , которые не поддерживаются (они не связываются).
Поведение JVM не указано и вызывает сомнения. Есть несколько открытых вопросов, которые утверждают, что это глючит:
- JDK-8027747
- ДДК-8187083
- ДДК-8187080
- ДДК-8187082
Scala.js сохраняет поведение JavaScript и не пытается воспроизвести поведение JVM (что может привести к большим затратам).
Избегайте использования флага
MULTILINE , также известного как (?m) Флаг «m» в регулярном выражении в JavaScript немного отличается от флага в Java Pattern .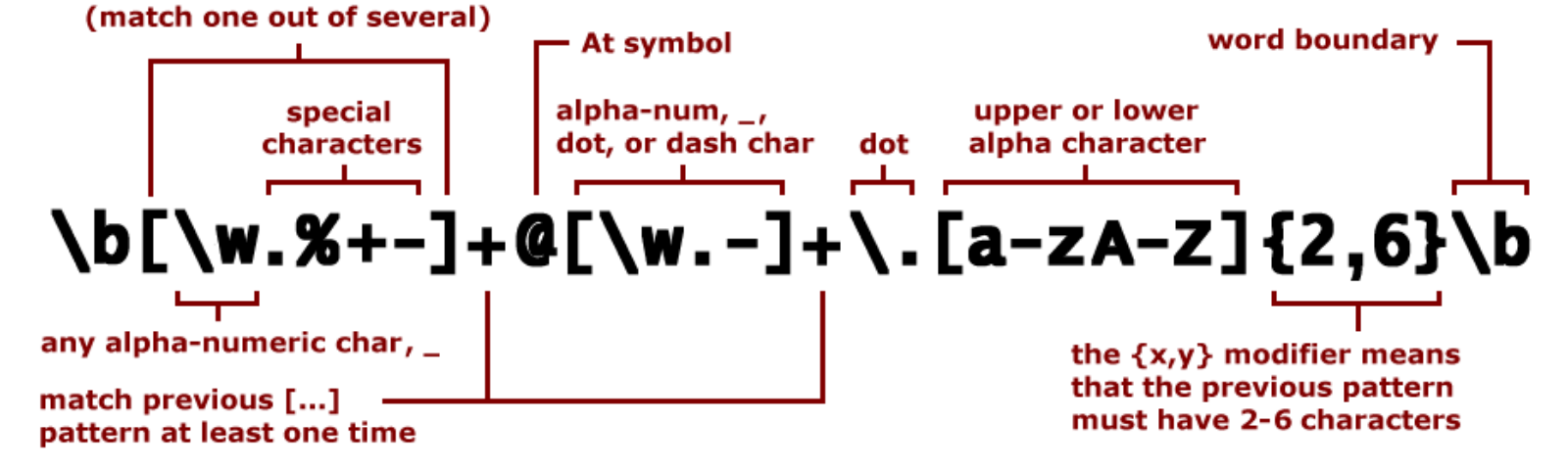 Он считает, что позиция в середине
Он считает, что позиция в середине \r\n последовательность является и началом, и концом строки, тогда как Pattern считает, что ни то, ни другое не верно.
Семантика Pattern соответствует рекомендациям Unicode.
Как правило, мы не можем реализовать поведение Pattern без обратных утверждений ( (?<=𝑋) ), которые доступны только в ECMAScript 2018+.
Однако в большинстве конкретных случаев можно заменить использование флага «m» комбинацией а) более сложных шаблонов и б) некоторой специальной логики в коде с использованием регулярного выражения. 9|\n)(foo|bar|)(?=\n|$)""".r
regex2 имеет ровно одно совпадение для каждого совпадения regex , и поэтому может использоваться вместо него.
Однако конкретная совпадающая строка изменяется, поскольку символы новой строки включаются в совпадающие подстроки.
Окружающий код может компенсировать это несоответствие, используя группу захвата в середине:
for (m <- regex2.
