Как проверить текст на ошибки: топ-7 лучших онлайн-сервисов
Приветствую, уважаемые читатели!
Сегодня я расскажу, как проверить текст на ошибки. Грамотность – одно из главных требований, предъявляемых к копирайтеру. Она демонстрирует уровень образованности автора и степень владения языком. Желание предотвратить ошибки в тексте – это не только показатель профессионализма, но и демонстрация уважения к себе, к читателям и своему проекту.
Однако от опечаток, пунктуационных и грамматических ошибок не застрахован никто. Они могут быть связаны с усталостью, невнимательностью, спешкой. Чтобы не сдавать клиенту некачественную работу, нужно воспользоваться программами проверки правописания, которые помогут выявить орфографические ошибки, проверить пунктуацию, избавиться от словесного мусора.
В статье мы разберем лучшие, на мой взгляд, онлайн-сервисы, где можно проверить текст на наличие ошибок. У каждого инструмента есть свои преимущества и недостатки. Мы возьмем статью и проверим ее на всех сервисах, сравним их работу и сделаем выводы.
Содержание
- Топ-7 сервисов для проверки текстов на наличие ошибок
- 1. Орфограммка
- Как пользоваться сервисом
- 2. Text.ru
- Руководство по работе с сайтом
- 3. Текстовод
- Как проверить статью на ошибки в Текстоводе
- 4. Орфограф
- Как пользоваться инструментом
- 5. Яндекс.Спеллер
- Руководство по работе с сервисом
- 6. Главред
- Как пользоваться инструментом
- 7. LanguageTool
- Руководство по работе с инструментом
- Заключение
Топ-7 сервисов для проверки текстов на наличие ошибок
Улучшайте знание русского языка и исправляйте ошибки с помощью этих инструментов.
1. Орфограммка
Орфограммка – самый точный и информативный сервис, который обнаруживает смысловые, речевые, грамматические и орфографические ошибки, нарушение стилистических норм. Он способен находить и исправлять опечатки, помогает избавиться от тавтологии, подбирает синонимы. Сервис поясняет ошибки и дает ссылку на правила грамматики.
Недостатком Орфограммки я считаю то, что она платная. Бесплатно зарегистрированные пользователи могут проверить текст, объем которого не превышает 6 000 знаков с пробелами.
Кроме проверки правописания, сервис поможет сделать вашу статью качественнее. Он оценит читабельность, выявит излишне частотные сочетания и плеоназмы. Ресурс использует примерно 7 000 лингвистических алгоритмов для определения ошибок. Благодаря постоянному обновлению системы улучшаются алгоритмы проверки, расширяется системный словарь.
Как пользоваться сервисом
Для проверки необходимо выполнить всего несколько шагов:
1.Заходим на Орфограммку и в правом верхнем углу нажимаем на кнопку “Кабинет”.
2.Выполняем вход в систему любым удобным способом. Я зашла через соцсеть Вконтакте.
3.Прежде чем приступить к работе, указываем вариант лицензии. Поскольку у нас небольшой по объему пробный текст, ставим галочку на первом пункте.
4.Вставляем в поле текст и нажимаем на синюю кнопку в правом нижнем углу “Проверить грамотность”.
5.Получаем подробный результат.
Справа в столбик отмечены все ошибки, которые обнаружила Орфограммка. Среди них 7 орфографических, 1 грамматическая, примечания по семантике и типографике. Ниже видим, что уровень воды нашего текста равен 4,88 %, а под ним представлены рекомендации по улучшению качества материала. Не все советы бывают корректны, поэтому в спорных ситуациях рекомендую открывать пособия с правилами русского языка.
2. Text.ru
Text.ru – многофункциональный сервис для работы с SEO-текстами, на котором можно проверить как правильность написания статьи, так и ее уникальность. Кроме выявления ошибок, сервис предлагает возможные варианты корректного написания слова. Также он показывает количество знаков, измеряет заспамленность и водность, находит опечатки, лишние пробелы. Слова с ошибками подсвечиваются другим цветом.
Иногда сервис работает некорректно и сообщает, что ошибок в тексте не найдено. В таком случае нужно еще раз выполнить проверку, поскольку во второй раз неточности могут быть обнаружены.

Руководство по работе с сайтом
Чтобы узнать, какие ошибки допущены в тексте, выполняем следующие действия:
1.Открываем сайт Text.ru, находим кнопку “Проверка орфографии” и нажимаем на нее.
2.В окно вставляем текст и жмем на зеленую кнопку “Проверить орфографию”.
3.Сервис выявил 9 ошибок.
Пунктуационные ошибки программа не распознала, зато показала нам уровень воды и заспамленности (7 и 33 % соответственно).
После того как недочеты будут исправлены, можно открыть доступ к проверке и отправить ссылку на нее заказчику, если это прописано в требованиях ТЗ.
3. Текстовод
Текстовод – средство исправления морфологических, орфографических и грамматических ошибок. Гости сайта могут проверить до 10 000 знаков, зарегистрированные пользователи – до 100 000 знаков, а в режиме PRO-проверки – до 500 000 знаков.
На сервисе есть возможность автокоррекции мелких опечаток. Также он определяет предложения, начинающиеся не с заглавной буквы, дублирование слов, двойные запятые, неверное согласование подлежащего и сказуемого.
Все недочеты подсвечиваются ярким цветом. Чтобы узнать полную информацию, достаточно навести на них курсор мышки. Для исправления выберите правильный вариант из списка.
Текстовод производит автокорректировку знаков препинания, удаляет лишние пробелы. По умолчанию программа проверяет тексты на русском языке, но вы можете настроить и другой. Список включает более 30 языков.
Как проверить статью на ошибки в Текстоводе
Чтобы воспользоваться сервисом, нужно выполнить ряд действий:
1.Заходим на Текстовод.
2.Вставляем текст в специальное окно и кликаем по кнопке “Орфография”.
3.Получаем результат.
Программа обнаружила 9 ошибок. Из них 6 орфографических, две запятые подряд и 1 опечатка с повтором слова “сроков”. Также прилагательное “отделочные” не согласуется с существительным “работ” по падежу.
Хочу отметить, что сервис не распознал пунктуационные ошибки, например, отсутствие запятой перед относительным местоимением “который”. Под окном проверки отображается информация о количестве знаков в тексте с пробелами и без них.
Под окном проверки отображается информация о количестве знаков в тексте с пробелами и без них.
4. Орфограф
Орфограф – приложение для проверки написанных на русском и английском языках текстов на наличие орфографических ошибок. Слова, которые не включены в словарь сервиса, выделяются другим цветом. Вы можете самостоятельно выбрать удобный для восприятия цвет в правом верхнем углу над рабочей областью.
На Орфографе можно проверять отдельные статьи или целые веб-страницы (достаточно указать ссылку). Также сервис предоставляет своим клиентам другие полезные дополнения: конвертер прописных букв в строчные, инструмент транскрибирования текстов, декодер.
Как пользоваться инструментом
Чтобы узнать, сколько ошибок в тексте, следует выполнить несколько действий:
1.Заходим на Орфограф.
2.В рабочую область вставляем текст. Проверка начинается автоматически.
3.Результат отображается ниже поля с текстом.
Инструмент нашел только орфографические казусы. Поиск пунктуационных, стилистических и грамматических ошибок здесь отсутствует.
Поиск пунктуационных, стилистических и грамматических ошибок здесь отсутствует.
Будет полезно! Писать без страха показаться неграмотным перед клиентами помогут курсы по русскому языку. На них вы сможете усовершенствовать свои знания, вспомните правила орфографии и пунктуации, закрепите материал на практике.
5. Яндекс.Спеллер
Яндекс.Спеллер помогает выявлять и исправлять орфографические ошибки. Он подмечает повторение слов (например, дорогие гости нашего нашего сайта), обнаруживает неправильное написание гласных и согласных (здраствуй, радосный, компютер). Кроме того, сервис распознает строчное/прописное написание, например, франция, СТраны.
Вы можете проверять тексты, написанные на русском, английском, украинском языке. Для обнаружения ошибок и подбора замен программа использует продвинутую библиотеку машинного обучения CatBoost, которая расшифровывает искаженные до неузнаваемости слова и учитывает контекст при поиске опечаток (например, не скучать картинку, а скачать картинку). Также Яндекс.Спеллер лояльно относится к новым словам, которые еще не добавлены в словари.
Также Яндекс.Спеллер лояльно относится к новым словам, которые еще не добавлены в словари.
Недостатками сервиса многие копирайтеры считают то, что он не замечает двойных пробелов, не находит пунктуационные и стилистические ошибки.
Руководство по работе с сервисом
Чтобы узнать количество ошибок в тексте, выполняем пару простых шагов:
1.Заходим на Яндекс.Спеллер.
2.Листаем ниже и находим рабочее поле.
3.Сохраняем отрывок в поле и нажимаем на желтую кнопку “Проверить текст”.
4.Спустя 4 секунды получаем результат.
В отличие от предыдущих сервисов Яндекс.Спеллер нашел всего 3 ошибки. Неточности пунктуации он не заметил, как и повтор слова “сроков”. Раньше программа работала намного эффективней. Могу предположить, что лучше выполнять проверку правописания, скачав плагин Яндекс.Спеллер.
6. Главред
Главред – инструмент, который находит в тексте стоп-слова. Создатель сервиса – известный копирайтер, редактор и блогер Максим Ильяхов.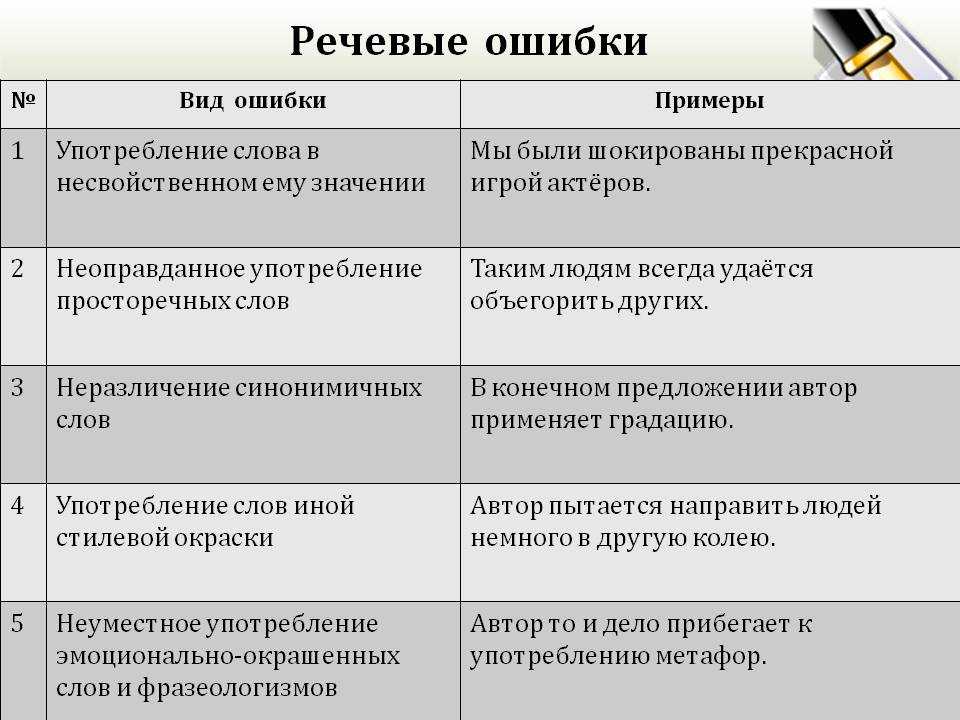 Он решил активно бороться со штампами вроде “всем известно”, “как говорится”, “на сегодняшний день”, канцеляризмами и прочим пустозвонством неопытных авторов. Также Главред против неопределенности. Если вы используете в статье слова “мало”, “много”, “несколько часов”, он потребует конкретики.
Он решил активно бороться со штампами вроде “всем известно”, “как говорится”, “на сегодняшний день”, канцеляризмами и прочим пустозвонством неопытных авторов. Также Главред против неопределенности. Если вы используете в статье слова “мало”, “много”, “несколько часов”, он потребует конкретики.
Сервис считается одним из самых совершенных, поскольку он не только показывает проблемные места с высокой водностью, но и объясняет, почему их нужно отредактировать. Вы можете проверять информационные статьи, рекламные и новостные материалы, коммерческие предложения, пресс-релизы, письма. Сервис поможет очистить текст от заезженных фраз и изречений, необъективной оценки.
Минусом Главреда я могу назвать то, что им не проверить статью на грамотность. Максимум сервис выделит вам красным цветом ошибки правописания. Например, вместо “окно” вы написали “акно”. Грамматику рекомендую проверять на других сервисах.
Качество текста Главред оценивает по десятибалльной шкале. Чем больше использовано стоп-слов, тем ниже оценка. Плохим считается результат от 0 до 4,9, удовлетворительным – от 5 до 7,4, идеальным – от 7,5 до 10 баллов.
Плохим считается результат от 0 до 4,9, удовлетворительным – от 5 до 7,4, идеальным – от 7,5 до 10 баллов.
Как пользоваться инструментом
Чтобы проверить текст на наличие ошибок, выполняем несколько несложных действий:
1.Заходим на Главред.
2.Вставляем в окно текст. Через пару секунд сервис автоматически выделяет оранжевым цветом словесный мусор.
3.Получаем оценку по шкале Главреда 7,5 балла.
Сервис выявил 6 стоп-слов и повторы. Чтобы узнать больше о каждой ошибке, наводим на них курсор мышки. В правой части страницы видим подробное описание с вариантом замены слов.
7. LanguageTool
LanguageTool – популярная во всем мире платформа для проверки стилистики и грамматики текста. Подходит не только копирайтерам для анализа статей, но и тем, кто переписывается со знакомыми и не хочет показаться неграмотным.
Вы можете встроить сервис в браузер (Firefox, Chrome) или добавить инструмент в Google Docs, LibreOffice, Microsoft Word. Благодаря расширению вы будете автоматически получать подсказки по правописанию.
Благодаря расширению вы будете автоматически получать подсказки по правописанию.
Руководство по работе с инструментом
Чтобы воспользоваться системой, нам потребуется сделать всего 3 шага:
1.Открываем официальный сайт LanguageTool.
2.Вставляем документ в окошко и ждем, пока закончится проверка. Спустя 5–7 секунд получаем результат.
Программа обнаружила все орфографические ошибки и повтор слова, но не учла недочеты со знаками препинания.
Для более тщательного анализа и проверки статей объемом до 40 000 знаков рекомендую оформить платную подписку. Для индивидуальных пользователей стоимость составляет 3,93 $ в месяц или 47,20 $ в год, для команд – 7,87 $ в месяц или 94,40 $ в год.
Как платная, так и бесплатная версия LanguageTool может работать с 27 языками. Среди них даже есть китайский и японский.
Подробнее узнать о том, как найти и избавиться от грамматических ошибок в тексте, вы можете из видео.
Заключение
Работа с текстовым материалом не терпит суеты и рассеянности. Наличие ошибок в статьях может испортить ваше портфолио и профессиональную репутацию. Поэтому рекомендую пользоваться сервисами для проверки правописания, больше читать классической литературы, учить стихотворения, писать изложения. Так вы тренируете зрительную память и запоминаете написание слов. При любых затруднениях заглядывайте в орфографический словарь. Проанализируйте, где вы допускаете больше всего ошибок, и изучайте только нужные правила.
При работе с онлайн-сервисами учитывайте специфику каждого из них. Например, суть проверки по Главреду – не получить максимальное количество баллов, а заменить или удалить из статьи слова и фразы, которые не несут никакого смысла.
Если вам интересно больше узнать о профессии копирайтера и развиваться в этом направлении, то обратите внимание на статью о том, как стать копирайтером с нуля.
В ней описаны плюсы и минусы работы, где искать заказы, как создать портфолио и многое другое.
А как вы предпочитаете проверять пунктуацию и орфографию текстового контента? Расскажите в комментариях. Мне интересно узнать ваше мнение.
До встречи в следующей статье.
Пишем правильно: онлайн-сервисы для проверки орфографии
Иногда при составлении текстов мы просто не замечаем опечаток или ошибок, хотя они обязательно найдутся. Для исправления этого недоразумения существуют онлайн-сервисы проверки орфографии. Советуем пользоваться ими, особенно когда цена ошибки текста слишком велика: важный документ, большой тираж полиграфии и так далее.
Конечно, даже умный компьютер не идеален. Бывает сервис подчеркивают специфические термины, которые не знает и не указывает на смысловое содержание предложения. Но и это можно решить, если пользоваться сразу несколькими сайтами, так можно добиться максимального результата. Орфографические ошибки можно проверить Орфограммкой, Яндекс.Спеллером или Languagetool, подкорректировать оформление – Типографом, а об устранении стилистических ошибок позаботится Главред.
Орфографические ошибки можно проверить Орфограммкой, Яндекс.Спеллером или Languagetool, подкорректировать оформление – Типографом, а об устранении стилистических ошибок позаботится Главред.
Главред (glvrd.ru)
Один из самых популярных сервисов. Его функционал разработан для усовершенствования рекламных, информационных, новостных материалов, писем, коммерческих предложений, пресс-релизов. Нормальным текстом считается значение от 7 баллов и выше. Советы Главреда помогают очистить текст от словесного мусора, необъективной оценки, клише или фраз, которыми пользуются только провинциальные журналисты. Примерно то же самое умеет созданная автором Главреда программа test-the-text, а автор – небезызвестный Максим Ильяхов.
На сайте можно провести онлайн работу над ошибками и узнать, насколько в лучшую (или худшую) сторону изменился текст. Пользуйтесь без фанатизма и без погони за максимальной оценкой. Опытные копирайтеры говорят, что после проверки и правок текст становится более информативным и понятным.
Орфограммка (orfogrammka.ru)
Платный сервис, который выявляет орфографические, грамматические, пунктуационные, стилистические, речевые и смысловые ошибки. Он поможет избавиться от тавтологии, варваризмов, найти и исправить опечатки, подобрать синонимы и даже расставить буквы «ё». За один раз можно проверить сразу текст объемом до 40 тысяч символов.
Languagetool (languagetool.org)
Расширение устанавливается в браузер для проверки орфографии и грамматики. Умеет работать с документами в MS Word, LibreOffice, Google Docs, браузерами Firefox и Chrome.
Этот инструмент, предназначенный для выявления орфографических, грамматических, стилистических и других ошибок, удобен своей простотой, а также многоязычностью. Он поддерживает более 20 языков.
Яндекс.Спеллер (tech.yandex.ru/speller/)
Яндекс.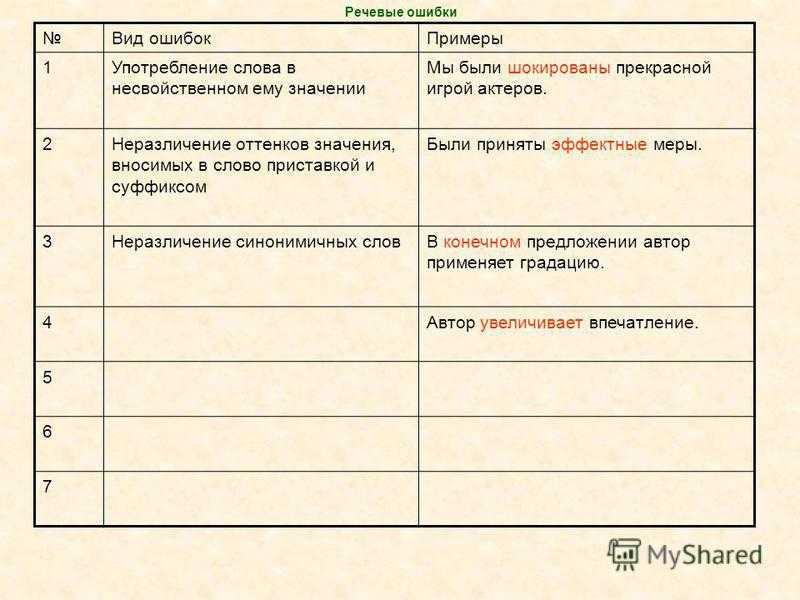 Спеллер находит и выделяет орфографические ошибки в текстах на русском, украинском и английском языках. Система узнает слова с несколькими ошибками, а при анализе правильности написания слов учитывает контекст. Можно работать онлайн или встроить его в браузер.
Спеллер находит и выделяет орфографические ошибки в текстах на русском, украинском и английском языках. Система узнает слова с несколькими ошибками, а при анализе правильности написания слов учитывает контекст. Можно работать онлайн или встроить его в браузер.
Орфограф (artlebedev.ru/orfograf/)
Созданный студией Артемия Лебедева «Орфограф» проверяет правильность текстов, написанных на русском и английском языках. Не включенные в словарь приложения слова выделяются цветом, который можно выбрать самостоятельно. Проверяются отдельные тексты или целые веб-страницы. Артемий плохого не посоветует.
Meta.ua (translate.meta.ua/ru/orthography/)
Сервис от meta.ua бесплатно проверяет русские, украинские и английские тексты на правописание и предлагает варианты замены неизвестных ему слов. Простая и удобная программка.
Типограф (typograf. ru)
ru)
Типограф помогает готовить тексты к размещению на сайтах: исправляет кавычки, неразрывные пробелы, спецсимволы, корректирует опечатки, проверяет правильность слов. Авторы заверяют, что программа способна автоматически исправлять около 95–99% неточностей. Бесплатным сервисом можно пользоваться до 1 июня, потом он станет платным.
И бонусом для проверки уникальности советуем Контент-Вотч, Текст.ру.
Правила русского языка, которые мы не можем запомнить: как решить эту проблему?
FastCorrect: модель быстрой коррекции ошибок для распознавания речи
Исправление ошибок — это важный метод постобработки в распознавании речи, который направлен на обнаружение и исправление ошибок в результатах распознавания речи, тем самым повышая точность распознавания речи. Многие модели исправления ошибок используют авторегрессионные модели с высокой задержкой, но службы распознавания речи предъявляют строгие требования к задержке моделей.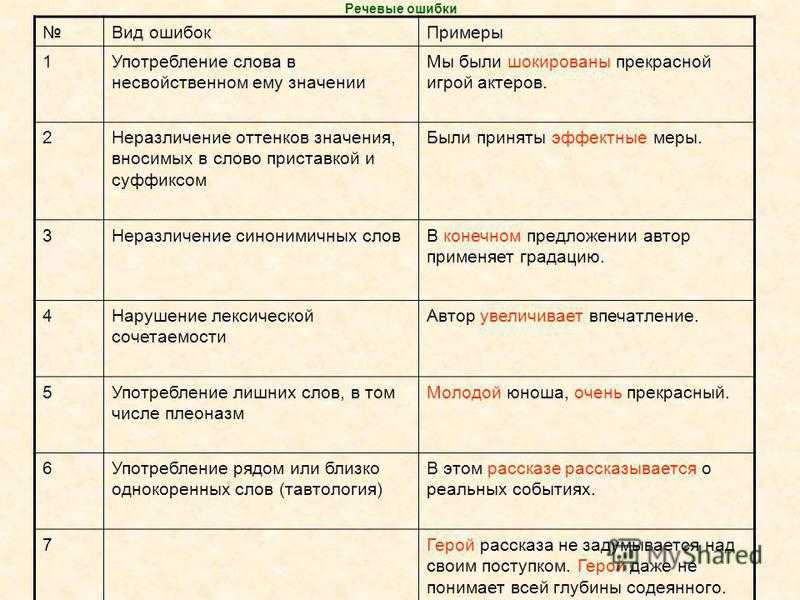 В сценариях распознавания речи в реальном времени авторегрессионные модели исправления ошибок нельзя использовать для онлайн-развертывания.
В сценариях распознавания речи в реальном времени авторегрессионные модели исправления ошибок нельзя использовать для онлайн-развертывания.
Чтобы ускорить модель исправления ошибок при распознавании речи, исследователи Microsoft Research Asia и Microsoft Azure Speech предложили FastCorrect, неавторегрессионную модель исправления ошибок, основанную на Edit Alignment, которая может ускорить авторегрессионную модель в шесть-девять раз. при сохранении сопоставимой способности исправления ошибок. Поскольку модели распознавания речи часто могут предоставлять несколько альтернативных результатов распознавания, исследователи также предложили FastCorrect 2, в котором несколько результатов используются для подтверждения друг друга и повышения производительности. Исследовательские работы по FastCorrect 1 и 2 были приняты NeurIPS 2021 и EMNLP 2021 соответственно.
FastCorrect
Редактировать выравнивание
FastCorrect использует неавторегрессионную генерацию с редактированием выравнивания для ускорения вывода модели авторегрессионной коррекции. В FastCorrect исследователи сначала вычисляют расстояние редактирования между распознанным текстом (исходным предложением) и текстом, достоверным (целевым предложением). Поскольку исходные и целевые токены выравниваются монотонно в автоматическом распознавании речи (ASR) (в отличие от ошибки перетасовки в нейронном машинном переводе), путем анализа операций вставки, удаления и замены на расстоянии редактирования количество целевых токенов, соответствующих каждому источнику токен после редактирования (т. е. 0 означает удаление, 1 означает неизменность или замену и ≥2 означает вставку), как показано на рисунке 1. В некоторых случаях может быть несколько возможных выравниваний пары исходное-целевое предложение, и будет выбрано окончательное выравнивание на основе оценки соответствия пути (количество совпадающих токенов в выравнивании) и оценки частоты (отражающей достоверность выравнивания в языковой модели).
В FastCorrect исследователи сначала вычисляют расстояние редактирования между распознанным текстом (исходным предложением) и текстом, достоверным (целевым предложением). Поскольку исходные и целевые токены выравниваются монотонно в автоматическом распознавании речи (ASR) (в отличие от ошибки перетасовки в нейронном машинном переводе), путем анализа операций вставки, удаления и замены на расстоянии редактирования количество целевых токенов, соответствующих каждому источнику токен после редактирования (т. е. 0 означает удаление, 1 означает неизменность или замену и ≥2 означает вставку), как показано на рисунке 1. В некоторых случаях может быть несколько возможных выравниваний пары исходное-целевое предложение, и будет выбрано окончательное выравнивание на основе оценки соответствия пути (количество совпадающих токенов в выравнивании) и оценки частоты (отражающей достоверность выравнивания в языковой модели).

Архитектура модели
FastCorrect использует неавторегрессивную структуру кодер-декодер с предсказателем длины для преодоления несоответствия длины между кодером (исходное предложение) и декодером (целевое предложение). Как показано на рисунке 2, кодировщик принимает исходное предложение в качестве входных данных и выводит скрытую последовательность, которая: 1) подается в предиктор длины для предсказания количества целевых токенов, соответствующих каждому исходному токену (т. е. выравнивание редактирования, полученное в предыдущий подраздел), и 2) используется декодером посредством внимания кодера-декодера. Метка предиктора длины получается в результате выравнивания редактирования, а подробная архитектура предиктора длины показана на правом подрисунке рисунка 2.
Рисунок 2: Архитектура модели FastCorrect.Экспериментальные результаты
Исследователи сообщили о точности и задержке различных моделей коррекции ошибок на AISHELL-1 и на внутреннем наборе данных, как показано в таблице 1. Мы сделали несколько наблюдений: 1) Модель авторегрессионной (AR) коррекции может уменьшить слово коэффициент ошибок (WER) (измеряемый снижением частоты ошибок в словах (WERR)) модели ASR на 15,53% и 8,50% соответственно на тестовом наборе AISHELL-1 и внутреннем наборе данных. 2) LevT, типичная неавторегрессионная модель от NMT, достигает незначительного WERR на AISHELL-1 и даже приводит к увеличению WER на внутреннем наборе данных. Между тем, LevT может ускорить вывод модели AR только в два-три раза на GPU/CPU. 3) FELIX достигает только 4,14% WERR на AISHELL-1 и 0,27% WERR на внутреннем наборе данных, что значительно хуже, чем у FastCorrect, хотя ускорение вывода аналогично. 4) Модель FastCorrect ускоряет вывод модели AR в шесть-девять раз на двух наборах данных на GPU/CPU и достигает 8-14% WERR, что почти сравнимо с моделью коррекции AR по точности.
Мы сделали несколько наблюдений: 1) Модель авторегрессионной (AR) коррекции может уменьшить слово коэффициент ошибок (WER) (измеряемый снижением частоты ошибок в словах (WERR)) модели ASR на 15,53% и 8,50% соответственно на тестовом наборе AISHELL-1 и внутреннем наборе данных. 2) LevT, типичная неавторегрессионная модель от NMT, достигает незначительного WERR на AISHELL-1 и даже приводит к увеличению WER на внутреннем наборе данных. Между тем, LevT может ускорить вывод модели AR только в два-три раза на GPU/CPU. 3) FELIX достигает только 4,14% WERR на AISHELL-1 и 0,27% WERR на внутреннем наборе данных, что значительно хуже, чем у FastCorrect, хотя ускорение вывода аналогично. 4) Модель FastCorrect ускоряет вывод модели AR в шесть-девять раз на двух наборах данных на GPU/CPU и достигает 8-14% WERR, что почти сравнимо с моделью коррекции AR по точности.

FastCorrect 2
Ключевой задачей исправления ошибок ASR является обнаружение и исправление маркеров ошибок. Поскольку поиск луча обычно используется в ASR, обычно генерируются несколько кандидатов, которые доступны для исправления ошибок. Мы утверждаем, что несколько кандидатов могут выполнять эффект голосования, а это означает, что токены из нескольких предложений могут проводить проверку друг друга.
Например, если кандидатами на поиск луча являются три предложения «У меня есть кошка», «У меня есть шляпа» и «У меня есть летучая мышь», то первые два токена трех предложений, скорее всего, будут правильными, поскольку они то же самое среди всех кандидатов в лучи. Несоответствие в последнем токене показывает, что: 1) этот токен может нуждаться в исправлении, и 2) произношение наземного токена может заканчиваться на «æt». Эффект голосования можно использовать для повышения коррекции ASR, помогая модели обнаруживать маркер ошибки и давая подсказки о произношении маркера истинности.
Чтобы лучше использовать эффект голосования, исследователи предложили специальные конструкции алгоритма выравнивания и архитектуры модели.
Выравнивание на основе произношения
Поскольку длины нескольких кандидатов обычно различаются, а токены из разных предложений не выровнены по положению, нетривиально выровнять этих кандидатов по токенам, чтобы использовать эффект голосования. Если мы просто используем левое или правое заполнение, чтобы обеспечить одинаковую длину для выравнивания, информация о каждой позиции в разных кандидатах не выравнивается, и поэтому эффект голосования нежизнеспособен. Чтобы воспользоваться эффектом голосования, исследователи предложили новый алгоритм выравнивания, основанный на оценке совпадения токенов и оценке схожести произношения, который может обеспечить максимально возможное совпадение токенов в одной и той же позиции или произношение токенов в одной и той же позиции. насколько это возможно, если токены не совпадают.
Как показано на рисунке 3, по сравнению с простым методом выравнивания (заполнение справа) новый метод выравнивания может: 1) выравнивать одни и те же токены («B», «D» и «F») в одной и той же позиции, 2) изолировать дополнительную лексему, встречающуюся только в одном кандидате («C»), и 3) поддерживать как можно более высокое сходство произношения лексем в одной и той же позиции.
Предсказатель-кандидат для выбора кандидата для декодера
Кандидатов может быть несколько (такое же, как количество исходных предложений), но декодер может принять только одно скорректированное исходное предложение в качестве входных данных. (Поскольку прогнозируемая продолжительность может быть разной для разных кандидатов во время вывода, нецелесообразно подавать в декодер все скорректированные варианты с разной длиной.) Таким образом, необходимо выбрать подходящее исходное предложение для настройки и принять его в качестве входных данных для декодера. . Поэтому исследователи разработали предиктор-кандидат, чтобы выбрать наиболее подходящее исходное предложение. В частности, исследователи хотят выбрать кандидата, который может привести к наименьшим потерям (то есть кандидата, которого легче всего исправить) в модели коррекции.
Как показано на рис. 4, результаты поиска выровненного луча объединяются вдоль каждой позиции, преобразуются линейным слоем, а затем передаются в кодировщик. Выходные данные кодировщика объединяются с исходным внедрением токена и передаются в предиктор для прогнозирования продолжительности каждого исходного токена (с помощью предсказателя длительности) и потери кандидатов (с помощью предсказателя-кандидата). Исходный токен корректируется в соответствии с предсказателем длительности и затем подается в декодер. Наконец, потеря декодера используется как метка кандидата-предсказателя.
4, результаты поиска выровненного луча объединяются вдоль каждой позиции, преобразуются линейным слоем, а затем передаются в кодировщик. Выходные данные кодировщика объединяются с исходным внедрением токена и передаются в предиктор для прогнозирования продолжительности каждого исходного токена (с помощью предсказателя длительности) и потери кандидатов (с помощью предсказателя-кандидата). Исходный токен корректируется в соответствии с предсказателем длительности и затем подается в декодер. Наконец, потеря декодера используется как метка кандидата-предсказателя.
Экспериментальные результаты
В таблице 2 показаны точность коррекции и задержка вывода для различных моделей коррекции, на основании которых мы сделали следующие наблюдения:
По сравнению с базовой линией FastCorrect, FastCorrect 2 может повысить точность коррекции на 2,55 % и 3,22 % с точки зрения снижения WER для AISHELL-1 и внутреннего набора данных соответственно, что показывает эффективность использования информации о нескольких кандидатах. Более того, FastCorrect 2 в пять раз быстрее авторегрессионной модели, что свидетельствует об эффективности логического вывода.
Более того, FastCorrect 2 в пять раз быстрее авторегрессионной модели, что свидетельствует об эффективности логического вывода.
И FastCorrect, и FastCorrect 2 находятся в открытом доступе здесь: https://github.com/microsoft/NeuralSpeech. Исследователи разрабатывают FastCorrect 3 для повышения точности коррекции при высокой скорости логического вывода.
Paper Link:
FastCorrect: быстрое исправление ошибок с редактированием выравнивания для автоматического распознавания речи
https://arxiv.org/abs/2105.03842
FastCorrect 2:Быстрая коррекция ошибок нескольких кандидатов для автоматического распознавания речи
https://arxiv.org/abs/2109.14420
заметки, созданные с помощью онлайн- и офлайн-технологий распознавания речи и написанные от руки: интервенционное исследование
Сохранить цитату в файл
Формат: Резюме (текст)PubMedPMIDAbstract (текст)CSV
Добавить в коллекции
- Создать новую коллекцию
- Добавить в существующую коллекцию
Назовите свою коллекцию:
Имя должно содержать менее 100 символов
Выберите коллекцию:
Невозможно загрузить вашу коллекцию из-за ошибки
Повторите попытку
Добавить в мою библиографию
- Моя библиография
Не удалось загрузить делегатов из-за ошибки
Повторите попытку
Ваш сохраненный поиск
Название сохраненного поиска:
Условия поиска:
Тестовые условия поиска
Эл.
Который день? Первое воскресеньеПервый понедельникПервый вторникПервая средаПервый четвергПервая пятницаПервая субботаПервый деньПервый будний день
Который день? воскресеньепонедельниквторниксредачетвергпятницасуббота
Формат отчета: SummarySummary (text)AbstractAbstract (text)PubMed
Отправить максимум: 1 шт. 5 шт. 10 шт. 20 шт. 50 шт. 100 шт. 200 шт.
Отправить, даже если нет новых результатов
Необязательный текст в электронном письме:
Создайте файл для внешнего программного обеспечения для управления цитированием
. 2022 8 апреля; 22 (1): 96.

Сахар Пейванди 1 , Лейла Ахмадян 2 , Джамиле Фарохзадян 3 , Юнес Джахани 4
Принадлежности
Принадлежности
- 1 Кафедра медицинской информации, Факультет менеджмента и медицинской информации, Керманский университет медицинских наук, Керман, Иран.
- 2 Кафедра медицинской информации, Факультет менеджмента и медицинской информации, Керманский университет медицинских наук, Керман, Иран. [email protected].
- 3 Научно-исследовательский центр сестринского дела, Керманский университет медицинских наук, Керман, Иран.
- 4 Центр исследований в области моделирования в области здравоохранения, Институт перспективных исследований в области здравоохранения, Керманский университет медицинских наук, Керман, Иран.
- PMID: 35395798
- PMCID: PMC8994328
- DOI: 10.1186/с12911-022-01835-4
Бесплатная статья ЧВК
Сахар Пейванди и др. БМС Мед Информ Децис Мак. .
Бесплатная статья ЧВК
. 2022 8 апреля; 22 (1): 96.
2022 8 апреля; 22 (1): 96.
дои: 10.1186/с12911-022-01835-4.
Авторы
Сахар Пейванди 1 , Лейла Ахмадян 2 , Джамиле Фарохзадян 3 , Юнес Джахани 4
Принадлежности
- 1 Кафедра медицинской информации, Факультет менеджмента и медицинской информации, Керманский университет медицинских наук, Керман, Иран.
- 2 Кафедра медицинской информации, Факультет менеджмента и медицинской информации, Керманский университет медицинских наук, Керман, Иран. [email protected].
- 3 Научно-исследовательский центр сестринского дела, Керманский университет медицинских наук, Керман, Иран.

- 4 Центр исследований в области моделирования в области здравоохранения, Институт перспективных исследований в области здравоохранения, Керманский университет медицинских наук, Керман, Иран.
- PMID: 35395798
- PMCID: PMC8994328
- DOI: 10.1186/с12911-022-01835-4
Абстрактный
Задний план: Несмотря на быстрое распространение электронных медицинских карт, использование компьютерной мыши и клавиатуры затрудняет ввод данных в эти системы. Программное обеспечение для распознавания речи является одной из заменителей мыши и клавиатуры. Цель этого исследования состояла в том, чтобы оценить использование программного обеспечения для распознавания речи онлайн и офлайн на орфографических ошибках в отчетах медсестер и сравнить их с ошибками в рукописных отчетах.
Цель этого исследования состояла в том, чтобы оценить использование программного обеспечения для распознавания речи онлайн и офлайн на орфографических ошибках в отчетах медсестер и сравнить их с ошибками в рукописных отчетах.
Методы: Для этого исследования было выбрано и настроено онлайн- и офлайн-программное обеспечение для распознавания речи на основе нераспознаваемых терминов этим программным обеспечением. Две группы из 35 медицинских сестер предоставили записи госпитализированных пациентов по их прибытии, используя три метода ввода данных (используя рукописный метод или два типа программного обеспечения для распознавания речи). По крайней мере, через месяц они создали те же отчеты, используя другие методы. Определялось количество орфографических ошибок в каждом методе. Эти ошибки сравнивались между бумажным методом и двумя электронными методами до и после исправления ошибок.
Результаты: Самая низкая точность была связана с онлайн-программным обеспечением с точностью 96,4%. В среднем на отчет онлайн-метод 6,76 и офлайн-метод 4,56 генерировали больше ошибок, чем бумажный метод. После исправления ошибок участниками количество ошибок в онлайн-отчетах уменьшилось на 94,75%, а количество ошибок в офлайн-отчетах уменьшилось на 97,20%. Наибольшее количество отчетов с ошибками было связано с отчетами, созданными программным обеспечением в Интернете.
В среднем на отчет онлайн-метод 6,76 и офлайн-метод 4,56 генерировали больше ошибок, чем бумажный метод. После исправления ошибок участниками количество ошибок в онлайн-отчетах уменьшилось на 94,75%, а количество ошибок в офлайн-отчетах уменьшилось на 97,20%. Наибольшее количество отчетов с ошибками было связано с отчетами, созданными программным обеспечением в Интернете.
Заключение: Хотя два программного обеспечения имели относительно высокую точность, они создавали больше ошибок, чем бумажный метод, который можно снизить за счет оптимизации и обновления этих программ. Результаты показали, что исправление ошибок пользователями значительно уменьшило количество ошибок документации, вызванных программным обеспечением.
Ключевые слова: Документация; Электронная медицинская карта; Ошибки; Медсестры; записка по уходу; Бумажная записка; ПО для распознавания речи; Распознавание голоса.
© 2022. Автор(ы).
Заявление о конфликте интересов
У авторов нет конфликта интересов в отношении данного исследования.
Похожие статьи
Частота ошибок распознавания речи в отделении неотложной помощи.
Госс Ф.Р., Чжоу Л., Вайнер С.Г. Госс Ф.Р. и соавт. Int J Med Inform. 2016 Сентябрь; 93:70-3. doi: 10.1016/j.ijmedinf.2016.05.005. Эпаб 2016 26 мая. Int J Med Inform. 2016. PMID: 27435949 Бесплатная статья ЧВК.
Использование врачом распознавания речи по сравнению с набором текста в клинической документации: контролируемое обсервационное исследование.

Блэкли С.В., Шуберт В.Д., Госс Ф.Р., Аль Асад В., Гарабедян П.М., Чжоу Л. Блэкли С.В. и соавт. Int J Med Inform. 2020 Сентябрь; 141: 104178. doi: 10.1016/j.ijmedinf.2020.104178. Эпаб 2020 15 мая. Int J Med Inform. 2020. PMID: 32521449
Анализ ошибок в продиктованных клинических документах с помощью программного обеспечения для распознавания речи и профессиональных транскрипционистов.
Чжоу Л., Блэкли С.В., Ковальски Л., Доан Р., Акер В.В., Ландман А.Б., Контриент Э., Мак Д., Метеер М., Бейтс Д.В., Госс Ф.Р. Чжоу Л. и др. JAMA Сеть открыта. 2018 июль;1(3):e180530. doi: 10.1001/jamanetworkopen.2018.0530. Epub 2018 6 июля. JAMA Сеть открыта. 2018. PMID: 30370424 Бесплатная статья ЧВК.
Простая система классификации ошибок для понимания источников ошибок при автоматическом распознавании речи и транскрипции человека.

Зафар А., Мамлин Б., Перкинс С., Белсито А.М., Оверхейдж Дж.М., Макдональд С.Дж. Зафар А. и др. Int J Med Inform. 2004 г., сен; 73 (9-10): 719-30. doi: 10.1016/j.ijmedinf.2004.05.008. Int J Med Inform. 2004. PMID: 15325329
Эффективность и безопасность распознавания речи для документации в электронной медицинской карте.
Ходжсон Т., Маграби Ф., Койера Э. Ходжсон Т. и соавт. J Am Med Inform Assoc. 2017 1 ноября; 24 (6): 1127-1133. doi: 10.1093/jamia/ocx073. J Am Med Inform Assoc. 2017. PMID: 2
71 Бесплатная статья ЧВК.
Посмотреть все похожие статьи
Цитируется
Интеллектуальные речевые технологии для транскрипции, диагностики заболеваний и интерактивного управления медицинским оборудованием в умных больницах: обзор.

Чжан Дж, Ву Дж, Цю Ю, Сонг А, Ли В, Ли Х, Лю Ю. Чжан Дж. и др. Компьютер Биол Мед. 2023 фев; 153:106517. doi: 10.1016/j.compbiomed.2022.106517. Epub 2023 5 января. Компьютер Биол Мед. 2023. PMID: 36623438 Бесплатная статья ЧВК. Обзор.
использованная литература
- Мэн Ф., Тайра Р.К., Буй А.А., Кангарлу Х., Черчилль Б.М. Автоматическое создание повторяющейся информации о пациенте для адаптации клинических заметок. Int J Med Inform. 2005; 74 (7–8): 663–673. doi: 10.1016/j.ijmedinf.2005.03.008. — DOI — пабмед
- Поллард С.
 Е., Нери П.М., Уилкокс А.Р., Волк Л.А., Уильямс Д.Х., Шифф Г.Д. и соавт. Как врачи документируют записи амбулаторных посещений в электронной медицинской карте. Int J Med Inform. 2013;82(1):39–46. doi: 10.1016/j.ijmedinf.2012.04.002.
—
DOI
—
пабмед
Е., Нери П.М., Уилкокс А.Р., Волк Л.А., Уильямс Д.Х., Шифф Г.Д. и соавт. Как врачи документируют записи амбулаторных посещений в электронной медицинской карте. Int J Med Inform. 2013;82(1):39–46. doi: 10.1016/j.ijmedinf.2012.04.002.
—
DOI
—
пабмед
- Поллард С.
- Эль-Карех Р., Ганди Т.К., Пун Э.Г., Ньюмарк Л.П., Унгар Дж., Липсиц С. и др. Тенденции в восприятии врачами первичного звена новой электронной медицинской карты. J Gen Intern Med. 2009;24(4):464–468. doi: 10.1007/s11606-009-0906-z. — DOI — ЧВК — пабмед
- Джонсон К.

- Джонсон К.