Работа с файлами в Python
В этой статье мы на примерах разберем такую важную тему, как работа с файлами в Python. Вы узнаете, как открыть и закрыть файл, как его прочитать и как записать в него новое содержимое.
Файл – это контейнер, используемый для хранения данных. Когда мы хотим читать из файла или записывать в него, нам нужно сначала открыть этот файл. После завершения работы с файлом его нужно закрыть, чтобы освободить связанные с ним ресурсы.
Таким образом, в Python операции с файлами выполняются в следующем порядке:
- Открытие файла
- Чтение или запись (выполнение операции)
- Закрытие файла
Дальше мы подробно разберем эти пункты, но если вы лучше воспринимаете видеоконтент, вот туториал от автора статьи:
Как открыть файл в Python
В Python для открытия файлов мы используем метод open(). Предположим, что у нас есть файл test.txt со следующим содержимым:
Давайте попробуем открыть данные из этого файла с помощью функции 
# Открыть файл в текущей директории
file1 = open("test.txt")Здесь мы создали файловый объект с именем file1. Этот объект можно использовать для работы с файлами и каталогами.
По умолчанию файлы открываются в режиме чтения (т.е. они не могут быть изменены). Следующий код эквивалентен предыдущему:
file1 = open("test.txt", "r")
Здесь мы явно указали режим, передав аргумент "r", что означает открытие файла для чтения.
Режимы открытия файла в Python
| Режим | Описание |
|---|---|
| r | Открыть файл для чтения (режим по умолчанию). |
| w | Открыть файл для записи. Если указанный файл не существует, он будет создан. Если существует, то его содержимое будет перезаписано. |
| x | Открыть файл исключительно для его создания. Если файл уже существует, операция завершается неудачно. |
| a | Открыть файл для добавления в конец файла без перезаписи содержимого. Создает новый файл, если он не существует. |
| t | Открыть в текстовом режиме (режим по умолчанию). |
| b | Открыть в двоичном режиме. |
| + | Открыть файл для обновления (чтение и запись). |
Вот несколько простых примеров того, как открыть файл в разных режимах:
file1 = open("test.txt") # эквивалентно 'r' или 'rt' file1 = open("test. txt",'w') # запись в текстовом режиме file1 = open("img.bmp",'r+b') # чтение и запись в бинарном режиме
Чтение файлов в Python
После открытия файла мы используем метод read() для чтения его содержимого. Например:
# Открыть файл
file1 = open("test.txt", "r")
# Прочитать файл
read_content = file1.read()
print(read_content)Вывод:
This is a test file. Hello from the test file.
В приведенном выше примере мы прочитали файл test.txt, который находится в нашем текущем каталоге. Обратите внимание на строку read_content = file1.read. Здесь file1.read() считывает файл test.txt и сохраняет его в переменной read_content.
Как закрыть файл в Python
Когда мы закончили выполнять операции над файлом, нам нужно правильно закрыть файл. Закрытие файла освобождает ресурсы, которые были связаны с ним. В Python это делается с помощью метода
Закрытие файла освобождает ресурсы, которые были связаны с ним. В Python это делается с помощью метода close(). Например:
# Открыть файл
file1 = open("test.txt", "r")
# Прочитать файл
read_content = file1.read()
print(read_content)
# Закрыть файл
file1.close()Вывод:
This is a test file. Hello from the test file.
Здесь мы использовали метод close() для закрытия файла.
После выполнения операции с файлом его обязательно нужно закрывать: это хорошая практика программирования.
Обработка исключений при работе с файлами
Если при выполнении какой-либо операции с файлом возникает исключение, код завершается без закрытия файла. Более безопасным способом является использование блока try…finally.
Примечание редакции: о том, что собой представляют исключения, можно почитать в статье “Ошибки и исключения в Python”, а о том, как их обрабатывать, – в статье “Как обрабатывать исключения в Python”.
Рассмотрим пример:
try:
file1 = open("test.txt", "r")
read_content = file1.read()
print(read_content)
finally:
# close the file
file1.close()Здесь мы закрыли файл в блоке finally, так как finally всегда выполняется, и файл будет закрыт, даже если произойдет исключение.
Использование синтаксиса with…open
В Python мы можем использовать синтаксис with…open для автоматического закрытия файла. Например,
with open("test.txt", "r") as file1:
read_content = file1.read()
print(read_content)Примечание: Поскольку это позволяет не беспокоиться о закрытии файла, возьмите за привычку использовать синтаксис with…open.
Как записать файл в Python
При записи в файл необходимо помнить две вещи:
- Если файл, который мы пытаемся открыть, не существует, он будет создан
- Если файл уже существует, его содержимое стирается, а в файл добавляется новое содержимое
Чтобы записать что-то в файл, нам нужно открыть его в режиме записи, передав "w" методу open() в качестве второго аргумента.
Предположим, у нас нет файла с именем test2.txt. Давайте посмотрим, что произойдет, если мы запишем содержимое в файл test2.txt.
with open('test2.txt', 'w') as file2:
# Записать текст в файл test2.txt
file2.write('Programming is Fun.')
file2.write('Programiz for beginners')Здесь создается новый файл test2.txt с содержимым, переданным в методе write().
Методы файлов Python
Для работы с файловыми объектами есть много разных методов. Некоторые из них вы уже видели в приведенных выше примерах. В этой таблице приведен полный список методов с кратким описанием:
| Метод | Описание |
|---|---|
| close() | Закрывает открытый файл. Не имеет эффекта, если файл уже закрыт. |
| detach() | Отделяет базовый двоичный буфер от TextIOBase и возвращает его. |
| fileno() | Возвращает целочисленный номер (дескриптор) файла. |
| flush() | Очищает буфер записи файлового потока. |
| isatty() | Возвращает True, если файловый поток является интерактивным. |
| read(n) | Читает не более n символов из файла. Читает до конца файла, если n — отрицательное число или None. |
| readable() | Возвращает True, если из файлового потока можно читать. |
| readline(n=-1) | Читает и возвращает одну строку из файла. Считывает не более n байт, если передан параметр n. Считывает не более n байт, если передан параметр n. |
| readlines(n=-1) | Читает и возвращает список строк из файла. Считывается не более n байт/символов, если передан параметр n. |
| seek(offset,from=SEEK_SET) | Перемещает указатель текущей позиции в файле на offset байтов по отношению к from. |
| seekable() | Возвращает True, если файловый поток поддерживает произвольный доступ. |
| tell() | Возвращает целое число, представляющее текущую позицию файлового объекта. |
| truncate(size=None) | Изменяет размер файлового потока до указанного размера в байтах. Если размер не указан, он изменяется до текущего местоположения. |
| writable() | Возвращает True, если в файловый поток можно записывать данные. |
| write(s) | Записывает строку s в файл и возвращает количество записанных символов. |
| writelines(lines) | Записывает список строк в файл.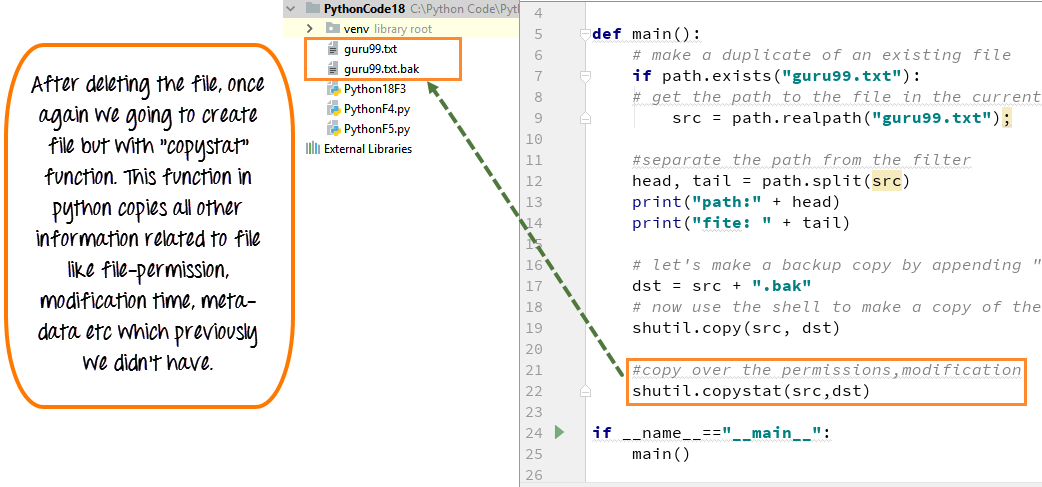 |
Перевод статьи «Python File I/OPython File Operation».
Работа с файлами в Python
| Введение | |
| Основы | |
| Более сложные примеры | |
| glob | |
| shutil | |
| os | |
| pathlib | |
| Похожие статьи |
Введение
В этой статье вы узнаете как организовать работать с файлами в Python 3.
Создайте файл files.py и копируйте туда код из примеров.
Запустить файл можно командой
python3 files.py
| Создать |
| open(): Открыть |
| close(): Закрыть |
| with: Менеджер контекста |
| read(): чтение файла |
| readline(): построчное чтение |
| Очистить файл |
| Копировать файл |
| Запись в файл |
| Дописать к файлу |
| seek(0): перемещение в начало файла |
| Записать json в файл |
| Удалить первые несколько строк файла |
| Запись вывода программы в файл |
| Определить кодировки файлов |
| Прочитать файл из другой директории |
| Найти строку |
| Удалить определённую строку |
| Удалить всё между тегами |
| Основы glob |
| Поиск по шаблону |
| Поиск по нескольким директориям |
| Поиск по вложенным директориям |
| Поиск скрытых файлов |
| Варианты копирования |
| copyfile |
| copy |
| move |
| getcwd() и chdir() |
| listdir(): Содержимое директории |
| Создать директорию |
| Удалить директорию |
| rename(): Переименовать файл |
os. stat(): информация о файле stat(): информация о файле |
| os.walk(): обход директорий |
| os.environ() |
| os.path(): |
| join() |
| dirname() |
| split(), splitext() |
| exists(), isdir, isfile |
| cwd() |
| stat(): Метаданные |
| exists(): Проверка существования |
| Python | |
| Основы работы с файлами | |
| Продвинутые приёмы | |
| glob: Работа с несколькими файлами | |
| shutil: Работа с несколькими файлами | |
| os | |
| pathlib | |
| Скачать файл по сети | |
| psutil: cистемные ресурсы | |
| Обучение программированию на Python |
Поиск по сайту
Подпишитесь на Telegram канал @aofeed чтобы следить за выходом новых статей и обновлением старых
Перейти на канал
@aofeed
Задать вопрос в Телеграм-группе
@aofeedchat
IT
Образование
Актуально сейчас
Разное
Поиск по сайту
Подпишитесь на Telegram канал @aofeed чтобы следить за выходом новых статей и обновлением старых
Перейти на канал
@aofeed
Задать вопрос в Телеграм-группе
@aofeedchat
Рекомендую наш хостинг beget. ru ru |
| Пишите на [email protected] если Вы: |
| 1. Хотите написать статью для нашего сайта или перевести статью на свой родной язык. |
| 2. Хотите разместить на сайте рекламу, подходящуюю по тематике. |
| 3. Реклама на моём сайте имеет максимальный уровень цензуры. Если Вы увидели рекламный блок недопустимый для просмотра детьми школьного возраста, вызывающий шок или вводящий в заблуждение — пожалуйста свяжитесь с нами по электронной почте |
| 4. Нашли на сайте ошибку, неточности, баг и т.д. … ……. |
| 5. Статьи можно расшарить в соцсетях, нажав на иконку сети: |
Понимание работы с файлами в Python с примерами — SitePoint
В этой статье об обработке файлов с помощью Python вы узнаете, как использовать pathlib и модули ОС для навигации по локальным файлам и каталогам. Вы также узнаете, как открывать, читать, записывать и закрывать файлы в Python.
Вы также узнаете, как открывать, читать, записывать и закрывать файлы в Python.
Обработка файлов — хороший способ сохранить данные после завершения программы. Данные из компьютерной программы сохраняются в файл и могут быть доступны позже. Python, как и многие другие языки программирования, предоставляет удобные методы для создания, открытия, чтения и записи данных в файл.
Содержание:
- Обработка файлов в Python: файлы и пути к файлам
- Использование модуля pathlib
- Как получить текущий рабочий каталог
- Абсолютные и относительные пути
- Как создать каталог в Python
- Как изменить текущий рабочий каталог
- Как удалить файлы или каталоги в Python
- Как составить список файлов и каталогов в Python
- Обработка файлов в Python: чтение и запись данных
- Как открыть файл в Python
- Как закрыть файл в Python
- С выпиской
- Как прочитать файл в Python
- Как записать файл в Python
Обработка файлов в Python: файлы и пути к файлам
Файлы — это быстрая альтернатива сохранению данных из компьютерной программы. Оперативная память может хранить данные только временно, так как все предыдущие данные теряются сразу после выключения компьютерной системы. Файлы предпочтительнее, потому что они являются более постоянным местом хранения данных на компьютере. А файл — это место на локальном диске, где хранятся данные. У него есть два основных свойства: имя файла и путь к нему.
Оперативная память может хранить данные только временно, так как все предыдущие данные теряются сразу после выключения компьютерной системы. Файлы предпочтительнее, потому что они являются более постоянным местом хранения данных на компьютере. А файл — это место на локальном диске, где хранятся данные. У него есть два основных свойства: имя файла и путь к нему.
Использование модуля pathlib
Python предоставляет модуль pathlib для выполнения таких операций, как навигация по каталогам и файлам, создание папок, определение путей к файлам и т. д. Модуль pathlib стал доступен в Python 3.4 и обеспечивает объектно-ориентированный подход к программированию для обработки путей файловой системы.
Модуль pathlib имеет Path Класс для навигации по путям файловой системы. Вы импортируете его в свою программу следующим образом:
из pathlib import Path
Как получить текущий рабочий каталог
Вы можете получить текущий рабочий каталог («cwd») в Python, используя метод cwd() объекта Path . Этот метод возвращает путь к каталогу, в котором мы сейчас работаем, в виде строки, как показано во фрагменте кода ниже:
Этот метод возвращает путь к каталогу, в котором мы сейчас работаем, в виде строки, как показано во фрагменте кода ниже:
из pathlib import Path р = Путь.cwd() печать (р)
Вот вывод этого кода:
/home/ini/Dev/Tutorial/sitepoint
Абсолютные и относительные пути
Пути к файлам можно указать двумя способами: либо их абсолютный путь, либо их относительный путь. Оба пути указывают на текущее местоположение файла.
Абсолютный путь к файлу объявляет его путь, начиная с корневой папки. Абсолютный путь выглядит так:
/home/ini/Dev/Tutorial/sitepoint/filehandling.py
Корневая папка (как показано в приведенном выше коде) — это домашняя папка в ОС Linux.
Относительный путь файла объявляет его путь относительно текущего рабочего каталога. Давайте посмотрим на пример:
./sitepoint/filehandling.py
Приведенный выше код показывает относительный путь к файлу Python filehandling. . py
py
Как создать каталог в Python
Класс Path имеет метод mkdir() для создания новых папок или каталогов в Python. 9Метод 0057 mkdir() принимает три аргумента: режим , родители и exists_ok .
Для родителей и exists_ok по умолчанию установлено значение False . Если установлено значение False , аргумент parents вызывает исключение FileNotFoundError , если родительский элемент по указанному пути не существует. exists_ok выдает FileExistsError по умолчанию, если целевой каталог уже существует.
Вот пример:
из pathlib import Path path = '/home/ini/Dev/Tutorial/sitepoint/projects' р = путь (путь) p.mkdir()
В приведенном выше примере у нас есть переменная path , задающая расположение для нового каталога. Объект Path p был создан со строковым аргументом пути, и метод mkdir() вызывается для p . Если мы сейчас проверим папку
Если мы сейчас проверим папку sitepoint , мы найдем только что созданный 9Папка 0057 проектов .
Как изменить текущий рабочий каталог
Модуль pathlib не поддерживает смену каталогов. Если мы хотим сделать это, мы должны использовать модуль ОС — еще один встроенный модуль для взаимодействия с операционной системой нашего компьютера.
Чтобы использовать модуль ОС, мы импортируем его в нашу программу, как показано ниже:
import os
Для переключения между каталогами используйте метод chdir() модуля ОС. Новый путь передается в качестве аргумента методу для перехода из текущего рабочего каталога в другой.
После создания новой папки в предыдущем примере кода мы можем изменить каталог на папку проектов :
import os
os.chdir('/home/ini/Dev/Tutorial/sitepoint/projects')
Чтобы подтвердить изменение каталога, используйте метод cwd() объекта Path , который возвращает строку текущего рабочего каталога: /home/ini/Dev/Tutorial/sitepoint/projects .
Как удалить файлы или каталоги в Python
Мы можем удалять файлы и каталоги в Python, используя методы объекта Path unlink() и rmdir() соответственно.
Чтобы удалить файлы в Python, создайте экземпляр файла Path и примените метод unlink() . (При удалении файлов программа выдаст исключение FileNotFoundError , если файл не существует.)
Рассмотрим пример кода:
из pathlib import Path path = '/home/ini/Dev/Tutorial/sitepoint/file_handling.txt' р = путь (путь) p.unlink ()
Файл file_handling.txt удален из каталога sitepoint . Если мы попытаемся удалить файл снова, мы получим исключение FileNotFoundError .
Чтобы удалить или удалить каталог, примените метод rmdir() к удаляемому объекту Path , например:
from pathlib import Path path = '/home/ini/Dev/Tutorial/projects' р = путь (путь) p.rmdir()
Папка проектов удалена из папки Папка Tutorial .
Как получить список файлов и каталогов в Python
Чтобы получить обзор всего содержимого каталога, используйте метод iterdir() для объекта файла Path . Этот метод возвращает объект генератора. Теперь мы можем перебрать объект генератора, чтобы получить все существующие файлы и каталоги в этой конкретной папке:
из pathlib import Path
path = '/home/ini/Dev/Tutorial/sitepoint'
р = путь (путь)
для файла в p.itrdir():
распечатать файл)
Вот результат кода выше:
/home/ini/Dev/Tutorial/sitepoint/array.py /home/ini/Dev/Tutorial/sitepoint/unittesting.py /home/ini/Dev/Учебник/sitepoint/код /home/ini/Dev/Tutorial/sitepoint/search_replace.py /home/ini/Dev/Tutorial/sitepoint/__pycache__ /home/ini/Dev/Tutorial/sitepoint/pangram.txt /home/ini/Dev/Tutorial/sitepoint/random.txt /home/ini/Dev/Учебник/sitepoint/.pytest_cache /home/ini/Dev/Tutorial/sitepoint/exception.py /home/ini/Dev/Tutorial/sitepoint/files.py /home/ini/Dev/Tutorial/sitepoint/regex.py /home/ini/Dev/Tutorial/sitepoint/filehandling.py
Работа с файлами в Python: чтение и запись данных
Работа с файлами в Python проста и не так сложна, как иногда в других языках программирования. Существуют различные режимы доступа к файлам при открытии файла Python для любой операции:
r: открывает файл для чтения. Режим чтения выдает ошибку, когда файл не существует.r+: открывает файл для чтения и записи данных в файловый объект. Выдается ошибка, если файл не существует.w: в этом режиме открывается файл для записи данных. Режим записи переопределяет существующие данные и создает новый файловый объект, если он не существует.w+: открывает файл для чтения и записи данных. Существующие данные в файле переопределяются при открытии в этом режиме.
a: режим добавления добавляет к файлу, если файл существует. Он также создает новый файл, если существующего файла нет. Он не отменяет существующие данные.a+: этот режим открывает файл для добавления и чтения данных.x: режим создания используется для создания файлов в Python. Выдается ошибка, если файл существует.
Добавление b к любому из режимов доступа изменяет его текстовый формат по умолчанию на двоичный формат (например, rb , rb+ , wb и т. д.).
Как открыть файл в Python
Чтобы открыть файл в Python, мы можем использовать функцию open() . Он принимает как минимум два аргумента — имя файла и описание режима — и возвращает файловый объект. По умолчанию файл открывается для чтения в текстовом режиме, но мы можем указать, хотим ли мы вместо этого двоичный режим.
Вот простой код для открытия файла:
f = open(file, mode='r', encoding=None)
После этого шага, как показано в приведенном выше коде, мы можем начать операции чтения-записи над файловым объектом. По умолчанию файлы всегда обрабатываются в текстовом режиме. Метод open() принимает как минимум два аргумента: путь к файлу и режим.
Как закрыть файл в Python
После открытия файлового объекта и выполнения операций по обработке файла нам необходимо закрыть файл. Часто это последний шаг в чтении или записи файлов в Python. Метод объекта файла close() используется для закрытия ранее открытых файлов.
Закрытие файлов в Python выглядит так:
f = open('filename', 'mode', encoding=None)
// файловые операции, чтение, запись или добавление
е.закрыть()
Оператор with
Стандартной практикой является закрытие файлов после их открытия и выполнения файловых операций. Некоторые файлы можно забыть закрыть после того, как они были открыты.
Оператор with автоматически закрывает файлы после завершения последней операции обработки файлов в своей области. Например:
с open('random.txt', 'r', encoding='UTF-8') как f:
печать (f.read())
Вот результат кода выше:
Привет, мир! Привет, мир!
Как видно из фрагмента кода выше, инструкция with неявно закрывает файл после инструкции print . (Мы будем использовать оператор с оператором в оставшейся части этого руководства.)
Как прочитать файл в Python
Есть несколько способов прочитать данные из файла в Python. Мы можем прочитать содержимое файла, используя read() , readline() и readlines() 9.0058 методы.
Метод read()
Метод read() возвращает строку всех символов читаемого файла. Указатель помещается в начало содержимого файла. Режим по умолчанию — чтение с начала файла до конца, за исключением случаев, когда указано количество символов.
Взгляните на фрагмент кода ниже:
с open('random.txt', 'r', encoding='UTF-8') как f:
печать (f.read())
Вот результат этого кода:
Это случайный текст. Вот вторая строчка. Небо голубое. Розы красные.
Мы можем указать, сколько символов читать из текстового файла. Просто передайте количество символов в качестве аргумента методу read() :
с open('random.txt', 'r', encoding='UTF-8') как f:
печать (f.read (12))
Вот вывод этого кода:
Это немного
Как видно из приведенного выше примера, интерпретатор считывает только 12 символов из всего файла.
Метод readline()
Этот метод считывает из файла по одной строке за раз. Он читает с начала файла и останавливается там, где встречается символ новой строки. См. пример кода ниже:
с open('random.txt', 'r', encoding='UTF-8') как f:
печать (f.readline())
Приведенный выше код выводит следующее:
Это случайный текст.
Метод readlines()
Этот метод возвращает список всех строк из существующего читаемого файла. См. фрагмент кода ниже:
с open('random.txt', 'r', encoding='UTF-8') как f:
печать (f.readlines())
Вот результат:
['Это какой-то случайный текст.\n', 'Вот вторая строка.\n', 'Небо голубое.\n', 'Розы красные.']
Примечание: все методы чтения файлового потока возвращают пустое значение при достижении конца файла. Метод seek() возвращает файловый курсор в начало файла.
Как записать в файл в Python
Метод write() в Python полезен при попытке записать данные в файл. Для записи в открытый файл необходимо установить один из следующих режимов доступа: w , w+ , a , a+ и так далее. Опять же, по умолчанию используется текстовый режим, а не двоичный.
Метод
write() Передайте строковый аргумент этому методу, когда мы хотим записать данные в текстовый файл. Помните, что режим записи переопределит существующие данные, если файл существует:
Помните, что режим записи переопределит существующие данные, если файл существует:
с open('random.txt', 'w', encoding='UTF-8') как f:
f.write("Привет, мир!")
Новый строковый аргумент, переданный методу write() , перезапишет наш предыдущий текст в файле random.txt , и у нас останется следующее:
Привет, мир!
Метод writelines()
Этот метод помогает нам вставить сразу несколько строк в текстовый файл. Мы можем записать несколько строк строк в файл за один раз, передав список в качестве аргумента метода:
words = ['Небо голубое.\n', 'Розы красные.']
с open('random.txt', 'w', encoding='UTF-8') как f:
f.writelines(слова)
В приведенном выше коде показано, как открывается файл random.txt и вставляется в него список строк. Содержимое random.txt теперь будет выглядеть так:
Небо голубое. Розы красные.
Заключение
У файла есть два важных атрибута: имя файла и его путь . Модули pathlib и os помогают нам перемещаться по каталогам и выполнять определенные операции. Обработка файлов Python включает использование нескольких методов для открытия , создания , чтения и записи данных о файловых объектах.
Модули pathlib и os помогают нам перемещаться по каталогам и выполнять определенные операции. Обработка файлов Python включает использование нескольких методов для открытия , создания , чтения и записи данных о файловых объектах.
Также важно понимать обработку файлов в Python, если мы хотим взаимодействовать с содержимым внутри текстовых или двоичных файлов. Всегда закрывайте файлы после выполнения над ними операций. с 9Оператор 0058 упрощает работу с файлами в Python, поскольку он неявно закрывает файловые объекты после того, как мы закончим.
Связанное чтение:
- Понимание функций регулярных выражений Python с примерами
- Руководство по лямбда-функциям Python с примерами
- Понимание декораторов Python с примерами
День 21: Разделение кода на несколько файлов
Добро пожаловать в 21-й день серии «30 дней Python»! Сегодня мы узнаем, как (и зачем) разбивать наш код Python из одного файла на несколько файлов.
Но сначала мы быстро повторим, как импорт работает в Python. Давайте начнем!
Резюме импорта в Python
В этом случае полезно сделать краткий обзор, потому что важно понять несколько моментов, прежде чем приступить к созданию большого количества файлов для наших программ!
Если вам нужно что-то более подробное, не стесняйтесь перечитать пост дня 18, где мы впервые рассмотрели импорт.
Импорт добавляет имя к
globals() Если у вас есть файл Python и вы вводите это:
импорт json печать (глобальные значения ())
Затем отображаются имен , которые в настоящее время находятся в глобальном пространстве имен. Имя модуля будет находиться в глобальном пространстве имен и готово для использования.
Импорт позволяет нам получить доступ к элементам импортированного модуля
После импорта мы можем сделать что-то вроде этого, чтобы получить доступ к чему-то внутри модуля:
импорт математики print(math.pi) # 3.14
Мы получили доступ к pi имени внутри модуля math . В данном случае это значение математической константы пи.
Другие способы импорта
Вы можете использовать ключевое слово as , чтобы дать импортированному модулю другое имя в вашем коде. Я не рекомендую вам делать это, хотя время от времени вы будете видеть, как это делается!
Вы также можете использовать * , чтобы добавить почти все из модуля в ваше глобальное пространство имен. Это может «загрязнить» глобальное пространство имен, заполнив его переменными. В большинстве случаев это сильно обескураживает.
Зачем разбивать код на файлы?
Теперь, когда мы быстро повторили тему импорта, давайте поговорим о том, почему нам может понадобиться разделить наш код на несколько файлов!
Первый вопрос, который возникает у нас, когда мы начинаем обсуждать это: «А не проще ли хранить код в одном файле?».
Ведь тогда не надо заниматься импортом!
Хранение вашего кода в одном файле может облегчить написание (для начала!), но по мере того, как вы будете писать больше, его будет намного сложнее читать и изменять.
В программировании удобочитаемость и ремонтопригодность превосходят скорость записи в любой день!
Разделение задач и простота организации
Когда мы разделяем код на файлы, важно, чтобы у нас была причина помещать какой-то код в определенный файл. Обычно мы идем по касается . Код, который делает одно, помещается в один файл, а код, который делает что-то другое, помещается в другой файл.
Например, у нас может быть один файл для взаимодействия с пользователем (печать и ввод), а другой файл для хранения данных (сохранение и извлечение данных из файла).
В настоящий момент различные аспекты приложения Python могут быть вам не очевидны. Это нормально! Со временем вы узнаете об этом больше. С большим опытом станет яснее, когда что-то выиграет от разделения на файлы.
Разделение файлов по проблемам, предполагая, что мы даем файлам хорошие имена, также помогает нам легче находить код. Если у вас есть два файла с именами data_storage.py и user_menu.py , вы знаете, что найдете в каждом из них!
Использование файлов и папок также творит чудеса с организацией. Например, в одну папку можно поместить файлы, связанные с работой с разными типами хранилищ данных.
Улучшенная читаемость
По мере роста файлов их становится все труднее читать. У вас может быть много функций и переменных, и поиск нужной информации может потребовать много прокрутки.
В современных редакторах есть функции, облегчающие поиск определений, но это не идеальное решение.
Разделение кода на несколько файлов — отличный способ создавать более мелкие и целенаправленные файлы. Навигация по этим небольшим файлам будет проще, а также понимание содержимого каждого из этих файлов.
Легче повторно использовать код
Если у вас есть несколько файлов меньшего размера, сфокусированных, проще повторно использовать содержимое одного файла в нескольких других файлах путем импорта.
Слишком много файлов
Также возможно иметь слишком много файлов! Не стремитесь сделать ваши файлы как можно меньше. Вместо этого сделайте их сфокусированными.
Если каждый файл связан с одним аспектом вашего приложения и каждый файл имеет хорошее имя, навигация по вашему проекту будет легкой!
Как разделить файл Python на несколько файлов
Начнем с создания нового проекта Python (или repl.it repl) и создания двух файлов. Назовем их main.py и myfile.py .
Помните, что repl.it всегда будет запускать main.py , когда вы нажимаете кнопку «Выполнить», как мы упоминали в сообщении дня 0.
Поскольку оба файла находятся в одной папке, вы можете импортировать один из другого.
Давайте введем это в main.py :
импортировать мой файл
Обратите внимание, что мы импортируем не myfile.py , а только myfile . Python сделает все остальное!
Python сделает все остальное!
Что происходит при импорте
Когда мы импортируем файл, Python запускает файл. Он должен сделать это, чтобы определить, какие имен существуют в этом файле.
Затем он делает этот файл доступным для нас в main.py , помещая ссылку на модуль в глобальное пространство имен.
Давайте добавим печать в myfile.py :
print("Привет, мир!")
И еще один в main.py :
импортировать мой файл
print("Что происходит?")
Попробуйте запустить это.
Вы увидите, что мы распечатали две вещи:
Привет, мир! Что происходит?
Это потому, что файл myfile.py был выполнен. Он содержит вызов print , поэтому Python распечатывает все!
Вы редко будете писать такой код. Вместо этого файлы, которые вы импортируете, обычно содержат переменных и функций , поэтому при их импорте ничего не происходит, пока вы на самом деле не используете эти переменные и функции.
Давайте добавим что-нибудь более реалистичное к 9.0057 myfile.py . Может быть что-то вроде этого:
myfile.py def get_user_age():
return int(input("Введите свой возраст: "))
Теперь в main.py мы можем использовать функцию get_user_age , которую мы определили в myfile.py .
импортировать мой файл
пытаться:
мой файл.get_user_age()
кроме ValueError:
print("Это недопустимое значение для вашего возраста!")
Отлично!
В этом и суть: разделите вещи на файлы и импортируйте их!
Как (не) называть ваши файлы
Не давайте своим файлам те же имена, что и встроенным модулям.
Например, если вы создадите новый файл и назовете его json.py , у вас возникнут проблемы!
Это потому, что если другой файл попытается импортировать json , вы не будете импортировать встроенный модуль json , который позволяет нам работать с файлами JSON. Вместо этого вы будете импортировать файл
Вместо этого вы будете импортировать файл json.py !
Python всегда ищет импорт в папке проекта до , глядя на встроенные или установленные пакеты.
Ваши файлы работают так же, как модули
Все, что мы могли сделать с внешними модулями, мы можем сделать с нашими собственными файлами:
- Импорт всего файла с помощью
import myfileи обращение к вещам какmyfile.x. - Импорт определенных вещей с помощью
из myfile import x. - Псевдоним импорта.
- Мы можем сделать
из myfile mport *(хотя это не рекомендуется).
Использование файлов и папок
Вы можете создавать папки для своих файлов, если считаете, что это поможет организовать их. По моему опыту, обычно так и бывает.
Например, создайте папку в своем проекте с именем user_interactions и переместите в нее myfile.py . Теперь структура ваших файлов/папок будет выглядеть так:
- main.py - user_interactions/ | - мой файл.py
Из main.py теперь вам нужно использовать немного другой синтаксис для импорта myfile.py :
из user_interactions.myfile import get_user_age
пытаться:
get_user_age()
кроме ValueError:
print("Это недопустимое значение для вашего возраста!")
При импорте точка ( . ) означает что-то вроде «внутри».
Таким образом, в приведенном выше примере мы импортируем myfile из внутри user_interactions .
Если у вас есть несколько подпапок, вам нужно будет использовать несколько . для разделения разных уровней папок и файлов, например:
из папки.подпапка.модуль импортировать что-то_в_модуле
Когда вы импортируете таким образом, вы либо импортируете определенные вещи, как это сделали мы, либо используете импорт с псевдонимом. Любой из этих двух хорош (первый вообще лучше):
-
из user_interactions. myfile import get_user_age
myfile import get_user_age -
импортировать user_interactions.myfile как взаимодействия
Обычно вы не будете делать ничего подобного в приведенном ниже примере, потому что ввод может занять довольно много времени:
импортировать user_interactions.myfile user_interactions.myfile.get_user_age()
Вам нужно обратиться к полному импорту, когда вы хотите что-то использовать, так что вы будете много печатать user_interactions.myfile в своем коде!
Это можно сделать, если вы не будете часто использовать файл.
Режим сценария по сравнению с режимом модуля
Когда мы запускаем файл (например, в repl.it, это main.py ), мы говорим, что файл запускается в «режиме сценария».
Когда мы импортируем файл, этот файл работает в «режиме модуля».
На данный момент структура нашего проекта такова:
- main.py
- user_interactions/
| - мой файл.py
Я удалю содержимое обоих файлов и помещу это в myfile. : py
py
print(__name__)
И я сделаю это в main.py :
импортировать user_interactions.myfile печать (__имя__)
Вы увидите этот вывод:
user_interactions.myfile __основной__
Помните, что при импорте мы запускаем файл. Поэтому первая строка вывода принадлежит myfile.py , а вторая строка вывода принадлежит main.py .
Файл, который мы запускаем, всегда имеет переменную __name__ со значением "__main__" . Это просто то, как Python сообщает нам, что мы запустили этот файл .
Был импортирован любой файл, у которого __name__ не равно "__main__" .
Попробуйте переместить объекты и посмотреть, как изменится вывод, созданный myfile.py !
Запуск кода только в режиме сценария
Иногда мы хотим включить некоторый код в файл, но мы хотим, чтобы этот код выполнялся только в том случае, если мы выполнили этот файл напрямую, а не в том случае, если мы импортировали файл.
Поскольку мы знаем, что __name__ должно быть равно "__main__" , чтобы файл был запущен, мы можем использовать оператор if.
Мы могли бы ввести это в myfile.py :
def get_user_age():
return int(input("Введите свой возраст: "))
если __name__ == "__main__":
get_user_age()
Это может позволить нам запустить myfile.py (мы не можем сделать это в repl.it без дополнительной настройки) и посмотреть, будут ли Функция get_user_age() работает.
Это один из ключевых вариантов использования этой конструкции: помочь нам увидеть, работает ли материал в файле, когда мы обычно не хотим, чтобы он запускался.
Другой вариант использования — файлы, которые вы обычно не запускаете самостоятельно. Иногда вы можете написать файл, например, для использования другой программой.
Использование этой конструкции позволит вам запустить файл для тестирования, не влияя при этом на его функциональность, когда он импортируется другой программой.