Эффективность различных способов работы с файлами в языках С/С++
Библиографическое описание:Эффективность различных способов работы с файлами в языках С/С++ / Е. В. Коптенок, В. С. Лядов, М. Ю. Пескова [и др.]. — Текст : непосредственный // Техника. Технологии. Инженерия. — 2020. — № 1 (15). — С. 5-9. — URL: https://moluch.ru/th/8/archive/152/4839/ (дата обращения: 09.01.2023).
Главный объект, с которым работает любой компьютер — информация. Как и человек, компьютер обрабатывает разного рода информацию: текст, графику, звук, видео и т. д. Одним из способов хранения и обработки информации на компьютере является использование файлов. Файл представляет собой последовательный набор данных, хранящийся на каком-либо физическом устройстве и имеющий имя и расширение. Работа с файлами реализуется средствами самой операционной системой. Операционная система предоставляет приложениям набор некоторых функций, благодаря которым организуется работа с файлами.
Наиболее распространенные расширения:
– Текстовый документ: txt;
– Форматированный текстовый документ: rtx, rtf, pdf, doc, docm;
– Электронные таблицы: xls, xlsx, xlsm, ods;
– Графика: jpg, jpeg, gif, png;
– Видео: mpeg 263, avi;
– Архив: rar, zip, tg;
– Исполняемые файлы: exe, cmd, bat;
Как для пользователей, так и для разработчиков файл является одним из лучших способов хранения и обработки данных при разработке программного обеспечения. В этой статье мы рассмотрим несколько способов работы с файлами в таких языках программирования С/С++, а также проверим их эффективность.
Перед тем, как перейти к тому, какими же средствами в языках программирования C/C++ реализованы способы работы с файлами, стоит заметить, что существует два основных способа хранения в файлах, в виде:
– Текстовых файлов;
– Бинарных файлов;
Текстовый файл — является своим родом компьютерного файла, который структурирован как последовательность строк из электронного текста.
Преимущества:
– Универсальность — любая операционная система может прочитать файл, особенно если речь идет об однобайтных кодировках, которые не подвержены проблеме, характерной для других форматов файлов.
– Формат текстового файла простой, и он свободно может быть изменён обычным редактором текста, который в свою очередь есть в любом ОС.
– У текстовых файлов, имеющих большой объём, низкая информационная энтропия — эти файлы занимают больше места, нежели чем минимально необходимо.
– Некоторые операции производимыми над текстовыми файлами малоэффективны. К примеру, если в файле встретится число, вычислительная система до начала операций с ним должна будет перевести его в собственный внутренний формат, применив сравнительно сложную процедуру преобразования числа; чтобы перейти на 1000-ю строку, требуется пройти 999 строк, идущих до нее.
Двоичный (бинарный) файл — в широком смысле представляет собой набор последовательных произвольных байтов.
В узком смысле слова: двоичные файлы — противопоставляются текстовым файлам. При этом, если говорить о технической реализации на уровне аппаратного обеспечения, текстовые файлы являются частным случаем двоичных файлов, и следовательно, можно сказать, что абсолютно любой файл является «двоичным»
Целью данной статьи является выяснить производительность различных способов работы с файлами. В качестве способов обработки файлов рассматривались:
– Функции заголовочного файла стандартной библиотеки языка C, для файлового ввода и вывода.
– Потоковые классы языка C++: ifstream и ofstream.
В качестве способов хранения выступали текстовые и бинарные файлы.
Для проверки эффективности каждого способа обработки были получены значения времени, за которое происходит считывание и сохранение данных в файл. В качестве данных выступал массив структур, размерностью 1000 элементов, хранящий запись вида: “Строка, целое число, вещественное число”. Эксперименты, обсуждаемые в данной статье, проходили на ноутбуке (модель Intel Core i5 CPU P8300, 2.4*4 Ghz), работающий на Windows 10. Размер оперативной памяти 8 Гб. Для каждого способа эксперимент повторялся 20 раз, и учитывался средний показатель.
Таблица 1
Значение времени, за которое произошло считывание данных из файлов. ms— миллисекунды
Текстовый файл | Бинарный файл | |
Стандартная библиотека языка С | 3 ms | 1 ms |
Потоковые классы: ifstream, ofstream | 8 ms | 7 ms |
Таблица 2
Значение времени, за которое произошла запись данных вфайлов. ms— миллисекунды
ms— миллисекунды
Текстовый файл | Бинарный файл | |
Стандартная библиотека языка С | 3 ms | 1 ms |
Потоковые классы: ifstream, ofstream | 13 ms | 12 ms |
Рис. 1. Время, затраченное на считывание данных из файла
Рис. 2. Время, затраченное на запись данных в файл
Вывод:
Наиболее оптимальной по времени оказалась работа стандартной библиотеки языка С. Исследование показывает, что наилучшую скорость работы обеспечивают средства стандартной библиотеки языка С, описанные в заголовочном файле stdio.h при взаимодействии с бинарными файлами.
Литература:
- Страуструп, Б. Язык программирования C++ / Б. Страуструп. — М.: Радио и связь, 2011. — 350 c.
- Керниган, Б. Язык программирования C. / Б. Керниган, Д. М. Ритчи. — М.: Вильямс, 2016. — 288 c.
Основные термины (генерируются автоматически): файл, API, значение времени, стандартная библиотека языка С, текстовый файл, бинарный файл, заголовочный файл, операционная система, самая операционная система, файловая система.
Алгоритм сжатия
текстовых файлов | Статья в журнале…Алгоритм сжатия текстовых файлов. Авторы : Череданова Екатерина Максимовна , Мамченко Елизавета Андреевна.
Растущий в настоящее время объем текстовой информации требует разработки новых эффективных и надежных методов ее кодирования, закрытия и передачи.
Применение простой стеганографии при передаче
файлов…В данной статье описывается понятие стеганографии, а также показывается её применение на простейших примерах в операционной системе Windows. Ключевые слова: стеганография, скрытие, криптография, альтернативные потоки данных, rarjpeg.
Операционные системы мобильных мультимедиа устройств для…Наше исследование — рассмотрение операционных систем мобильных мультимедиа устройств и
В отличие от Android, операционная система iOS не используется на устройствах от других производителей и не
С технической точки зрения прошивка — это бинарный файл, который…
Применение графической
библиотеки SDL2.0 для. ..
..Для работы с аудио необходимо подключить заголовочный файл SDL_audio.h.
Использование средств библиотеки SFML для написания игровых проектов. Применение графической библиотеки SDL2.0 для программирования компьютерных игр на языке СИ.
Интеграция MS-DOS приложений в современные
операционные…Однако эта операционная система уже устарела, и использовать её становится неудобно, а порой даже не представляется
Первым и самым простым способом является использование самой операционной системы MS-DOS. Но такой способ обладает целым рядом недостатков.
Современные
системы автоматизированного динамического… Статья посвящена исследованию трех современных систем автоматизированного динамического анализа вредоносных файлов: Cuckoo Sandbox , Anubis и DRAKVUF . Показано значение подобных систем в области изучения функциональности вредоносных программ.
Показано значение подобных систем в области изучения функциональности вредоносных программ.
Сравнительный анализ методов Наивного Байеса и SVM…
В статье раскрывается понятие классификации текстовых документов для автоматического обнаружения категорий по текстам. Проводится сравнительный анализ двух самых главных алгоритмов, которыми являются методы наивного Байеса и SVM.
Системы сбора информации в аспекте кибербезопасности– Система должна иметь OS независимые агенты сбора и мониторинга. – В системе должен присутствовать Веб интерфейс. – Система должна иметь возможность извлекать данные анализа для визуализации через API или иметь средство визуализации данных анализа.
С++
библиотека компонентов генетических алгоритмовГотовый файл библиотеки теперь доступен для решения оптимизационных задач с помощью генетических алгоритмов. Чтобы решать задачи с помощью данной библиотеки, создается новый проект, подключается файл библиотеки Library.lib, подключаются заголовочные…
Чтобы решать задачи с помощью данной библиотеки, создается новый проект, подключается файл библиотеки Library.lib, подключаются заголовочные…
Чтение файлов в Ruby— Ruby Rush
В этом уроке вы научитесь работать с файлами в Ruby. Мы будем открывать файлы, читать их содержимое и работать с ним в удобной форме.
Мы узнаем о классе File и о том, как работают его методы new, dirname, exist? и методы его экземпляров read, readlines и close.
Мы научимся читать из файлов данные целиком и построчно, как выводить на экран произвольную строчку файла и как, а главное, для чего необходимо закрывать файлы.
План урока
- Файлы, что это такое и как программы с ними работают
- Чтение данных из файла в Ruby и не только
- Зачем нужно закрывать файлы и как это делать
Что такое файлы?
Однажды программисты поняли, что хранить данные в памяти компьютера не надёжно, затратно, не выгодно и вообще, программа должна быть постоянно запущена. Было бы здорово, если бы можно было выключить программу, а потом начать с того же места.
Как-то так были придуманы файлы.
Абсолютно вся информация на вашем или любом другом компьютере когда он выключен, храниться в файлах.
Файлы есть как у вас на домашнем компьютере — ваши документы и фотографии или системные файлы Windows или Mac OS X, так и на любом сервере, к которому вы на самом деле обращаетесь, когда вводите в браузере адрес любого сайта. То, что вы видите как сайт — это тоже файл (чаще всего несколько файлов), подготовленных определённым образом.
Именно поэтому так важно и удобно уметь работать с файлами в ваших программах.
Как программы работают с файлами
Программы — они как люди. Только люди читают книги, когда им нужна какая-то информация, а программы могут читать не только книги, но и картинки, аудиозаписи, видеоролики и много-много другого.
Только люди читают книги, когда им нужна какая-то информация, а программы могут читать не только книги, но и картинки, аудиозаписи, видеоролики и много-много другого.
Когда программе сказали, что ей нужно прочесть какой-то файл, она ищет его в файловой системе вашего компьютера и достаёт его, подобно тому, как вы можете заказать книгу в ближайшей библиотеке.
После того, как файловая система предоставила ей этот файл (как заботливый библиотекарь), программа его открывает и может начать читать.
А потом, конечно же, файл нужно закрыть и вернуть на место, чтобы его могли читать другие программы (хотя, в отличие от библиотеки, один и тот же файл могут читать сразу несколько программ, копируя его себе в память или в специальное место на диске).
Чтение файлов в Ruby
Давайте напишем простенькую программку, решающую вот такую задачу:
Вывести на экран произвольный афоризм из файла со списком афоризмов.
Список будет храниться в файле quotes., по одному афоризму на одну строчку файла. txt
txt
Как обычно, файлы мы храним в нашей папке урока: с:\rubytut\lesson13.
Однако, для файлов с данными, не являющимися текстом программ, удобно всегда создавать вложенные подпапки. Наш файл с цитатами quotes.txt мы положим в подпапку data в нашей рабочей директории. Сам файл будет содержать вот это:
Учиться, учиться и еще раз учиться... программированию! // В. И. Ленин Слышь, пацан, либы есть? // Ванек со второго подъезда Я программирую, значит я существую // Фрэнсис Бэкон Кто не умеет программировать, тот лох :) // Билл Гейтс Тяжело в учении — легко в программировании // Народная мудрость Программировали, перепрограммировали, да не запрограммировали // Скороговорка
Вы можете взять наши цитаты или (что гораздо интереснее, придумать свои).
Теперь создадим нашу программу open_file.rb в рабочей папке урока с:\rubytut\lesson13.
В этой программе мы будем открывать файл data/quotes., брать из него произвольную строчку и выводить её на экран. txt
txt
Для пользователей Windows: убедитесь, что вы сохранили файл quotes.txt в кодировке UTF-8 (для этого тоже можно использовать редактор Sublime), как это делать мы обсуждали во втором уроке.
Открытие файла
Для работы с файлами в Ruby есть специальный встроенный класс File, который позволяет в программе создавать объекты для работы с файлами.
Любой экземпляр класса начинается с конструктора. Также и здесь, чтобы создать новый файловый объект, нам надо у класса File вызвать метод new, который вернёт нам экземпляр класса File.
Методу new нужно передать несколько параметров мы уже умеем это делать: первый параметр — путь (относительно текущей директории, из которой вы запускаете программу) к файлу, который нужно открыть, подробнее об этом в 2-м уроке, второй параметр — специальный ключ.
Этот ключ говорит классу File, как именно мы хотим открыть файл, и в какой кодировке мы этот файл хотим прочитать.
В нашем случае мы хотим открыть наш файл с афоризмами ./data/quotes.txt для чтения в кодировке UTF-8, поэтому пишем так:
file = File.new("./data/quotes.txt","r:UTF-8")
Обратите внимание на ключ "r:UTF-8", первая буква обозначает тип открытия файла:
r— только для чтения: мы будем только читать файл, писать в него мы так не сможемw— только для записи: мы не хотим знать, что в файле, мы просто перепишем его содержимоеa— только для записи, но дописывать будем в конец файла, сам файл не трогаем
Есть и другие ключи, но в этом блоке не будем ими морочить вам голову, в этом уроке нам понадобится только первый, так что все остальные — для любознательных. После указания способа открытия файла через двоеточие идёт кодировка, в нашем случае UTF-8.
Чтение информации из файла
Мы открыли файл, но пока ещё ничего с ним не сделали, мы просто получили некую переменную file с экземпляром класса File, которая знает, к какому файлу она относится и как ему с этим файлом нужно обращаться.
Мы можем получить всё содержимое файла в одной большой строке (со всеми словами, пробелами и переносами) с помощью метода read экземпляра класса File, то есть нашего объекта file.
content = file.read
Теперь по идее в переменной content у нас будут все цитаты одна за другой.
Чтение файла построчно
По условию задачи нам нужно прочитать только одну цитату, а не весь файл целиком. Поэтому нам нужно немного переписать нашу программу. Мы напишем новый файл read_lines.rb
file_path = "/data/aphorizmus.txt" f = File.new(file_path, "r:UTF-8") lines = f.readlines puts lines.sample
Обратите внимание, что мы сохранили путь к файлу в переменную file_path, чтобы каждый раз не писать его вручную.
Вместо file.read вызываем метод readlines, который в отличие от предыдущего возвращает не одну большую строку, а массив строк, разбитых по символам переноса.
Этот массив мы сохранили в переменную lines, поэтому чтобы вывести одну случайную строчку файла мы можем просто написать
puts lines.sample
Метод sample у массива возвращает один случайный элемент из этого массива — каждый раз разный.
Запуск программы
Программа написана и осталось её запустить, для этого как обычно переходим в нашу рабочую папку в консоли и запускаем программу с помощью команды ruby
cd c:\rubytut\lesson13\ ruby read_lines.rb
Что делать когда файл не найден?
Первое, с чем сталкивается любой программист, когда пишет программу, общающуюся с файлами — ситуация, когда файл не открылся. Не важно по какой-то причине.
Может, его стёрли, может, он опечатался и неправильно указал имя файла, может быть, диск, на котором хранился файл, не доступен. Мало ли чего в наше неспокойное время может произойти.
Запомните основное правило при работе с файлами: перед открытием файла всегда убедитесь, что он есть.
Проверить наличие файла можно с помощью метода exist? у класса File:
if File.exist?(file_path) # тут можно работать с файлом, не боясь, что он не откроется else puts "Файл не найден" end
Как вы видите, метод очень похож на new, только никакой ключ ему не нужен, потому что методу exist? не важно, как с этим файлом собрались работать, ему только нужно проверить, есть ли файл и если файл есть, то вернуть true, а если нет — вернуть false.
Именно поэтому очень удобно использовать этот метод в качестве условия в конструкции if-else, если файл есть, мы его откроем и прочитаем, если его нет, мы напишем об этом пользователю и либо пойдём дальше, либо прекратим выполнение программы.
Теперь можно переименовать файл quotes.txt в, например, quotes_.txt и убедиться, что при запуске программы, мы увидим строчку
Файл не найден
Как правильно указывать пути к файлам
При открытии файла мы считали, что он лежит в папке data, которая находится в той же папке, в которой мы запускаем программу.
Если мы в консоли поднимемся на уровень выше:
cd ../
и снова запустим нашу программу, дописав к её пути спереди название папки, в которой она лежит (мы не говорили, но так можно делать):
ruby lesson13/qoute.rb
то встретимся как раз с ситуацией, когда файл не найден.
Наша проверка обломалась, ведь файла уже нет рядом с нами, он лежит в другой папке, о чём программа не знает, она ищет его в c:\rubytut\data, то есть рассматривает путь data относительно текущей папки консоли.
Знак точки (.) в пути к файлу означает: «текущая папка, в которой мы находились в тот момент, когда запустили программу», то есть текущая папка консоли в нашем случае.
Но нам нужно, чтобы файл в подпапке data искался всегда относительно папки, в которой лежит программа, а не из которой она запущена.
Это легко исправить, ведь для этого в Ruby есть классная штука: специальный объект __FILE__ — он содержит путь к файлу программы относительно той папки, из которой программа запущена. То есть откуда бы мы не запустили, с помощью объекта
То есть откуда бы мы не запустили, с помощью объекта __FILE__ мы всегда можем восстановить правильный путь к файлам нашей программы.
Для того, чтобы из этой переменной получить путь к папке текущей программы, нам нужно снова обратиться к нашему классу File:
current_path = File.dirname(__FILE__)
Теперь в переменной current_path всегда (откуда бы мы ни запустили нашу программу) будет лежать путь к папке с этой программой.
А от него и до data/quotes.txt рукой подать, нужно просто склеить две строчки плюсиком, как мы это умеем делать:
file_path = current_path + "/data/quotes.txt"
Теперь откуда бы мы ни запустили нашу программу, она будет искать файл data/quotes.txt рядом с собой, а не в том месте, откуда её вызвали.
Это очень удобно. Можно в консоли перейти на папку выше и запустить программу вот так:
ruby lesson13/read_lines.rb
Тяжело в учении — легко в программировании!
Закрытие файлов
Если вкратце, то файлы нужно закрывать.
Ну во-первых, незакрытые файлы могут приводить к ошибкам в ваших и чужих программах, которые работают с этим же файлом.
Во-вторых, каждый открытый файл занимает у памяти какой-то её объём и чем больше таких открытых файлов, тем медленнее работает ваша программа. Хорошие программисты помнят об этом и стараются делать свои программы быстрее.
Для нашей маленькой программы это не так важно — Ruby сам закроет все файлы после выполнения программы.
Но усвоить эту привычку надо уже сейчас, когда ваши программы станут большими и навороченными, вы еще скажете нам спасибо за эту привычку.
Это как правило хорошего тона: подобно тому, как прилежный читатель всегда возвращает книгу туда, откуда он её взял — полка в собственном доме или библиотека, также и прилежный программист всегда должен помнить о том, что чем меньше на Земле незакрытых вовремя файлов, тем больше на Земле добра!
Делайте добро, Дамы и Господа, всегда закрывайте ваши файлы.
Закрывать файлы можно сразу после того, как вы сделали с файлом всё, для чего он был нужен. Прям вот сразу же.
Прям вот сразу же.
В нашей программе мы закроем файл ещё до того, как выведем строчку на экран.
current_path = File.dirname(__FILE__) file_path = current_path + "/data/aphorizmus.txt" if File.exist?(file_path) f = File.new(file_path, "r:UTF-8") lines = f.readlines f.close puts lines.sample else puts "Файл не найден" end
Итак, сегодня мы научились работать с файлами, узнали о классе File, как работают его методы new, dirname, exist? и методы его экземпляров read, readlines и close.
Узнали, как читать из файлов данные целиком и построчно, как выводить на экран произвольную строчку файла и как, а главное, для чего необходимо закрывать файлы.
А в следующем уроке нас ждёт третья версия нашей замечательной игры «Виселица», мы будем использовать полученные данные и будем открывать файлы с псевдографикой.
Компиляция файлов C с помощью gcc, шаг за шагом | Laura Roudge
Чтобы объяснить все этапы компиляции, нам нужно заранее прояснить несколько концепций программирования. В этой статье мы расскажем, что такое язык C, как его скомпилировать с помощью такого инструмента, как gcc, и что происходит при его компиляции.
В этой статье мы расскажем, что такое язык C, как его скомпилировать с помощью такого инструмента, как gcc, и что происходит при его компиляции.
Все программное обеспечение, программы, веб-сайты и приложения написаны на определенном языке программирования. По сути, все, что мы видим на экране своего компьютера или смартфона, — это просто множество кода, написанного на разных языках и определенным образом собранного воедино. Каждый язык программирования используется по-своему, и сегодня мы сосредоточимся на C.
C — это язык программирования, изобретенный Деннисом Ритчи, который впервые появился в 1972 году. Это то, что мы называем языком низкого уровня, что означает, что между C и машинным языком существует лишь небольшая абстракция, поэтому его можно считать более близким к компьютерному языку. аппаратное обеспечение. C также является скомпилированным языком , в отличие от интерпретируемого, что означает, что исходные файлы, написанные на C, должны быть скомпилированы, чтобы они были исполняемыми.
Прежде всего, давайте поговорим об инструментах, которые мы будем использовать в нашем примере. Мы будем работать с Unix-подобной операционной системой, поэтому примеры могут отличаться от Windows. Нам нужен доступ к shell , которая представляет собой «программу, которая берет команды с клавиатуры и передает их операционной системе для выполнения», согласно http://linuxcommand.org. Для этого нам понадобится терминал , или эмулятор терминала, который представляет собой просто окно, позволяющее нам взаимодействовать с оболочкой. Внутри терминала мы должны увидеть приглашение оболочки, содержащее ваше имя пользователя и имя машины, за которым следует переменная среды PS1, которая часто представляет собой символ «$». Мы можем вводить команды после этого символа в том, что мы называем 9.0011 командная строка. Нам также нужен текстовый редактор, такой как vi или emacs, для создания исходного файла.
Компиляция — это перевод исходного кода (кода, который мы пишем) в объектный код (последовательность операторов на машинном языке) компилятором .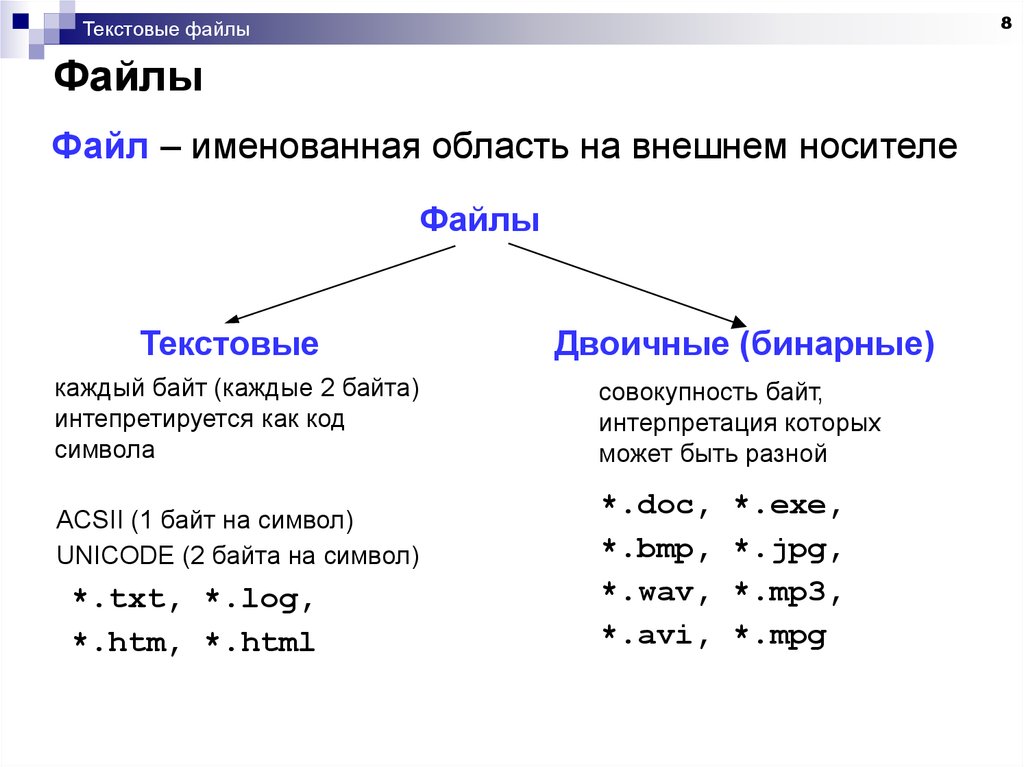
Процесс компиляции состоит из четырех различных этапов:
- Предварительная обработка
- Компиляция
- Сборка
- Связывание
В качестве примера мы будем использовать компилятор gcc , что означает Сборник компиляторов GNU . Проект GNU — это проект свободного программного обеспечения и массового сотрудничества, запущенный Ричардом Столлманом в 1983 году и позволяющий разработчикам бесплатно получить доступ к мощным инструментам.
Gcc поддерживает различные языки программирования, включая C, полностью бесплатен и является компилятором для большинства Unix-подобных операционных систем. Чтобы использовать его, мы должны установить его на свой компьютер, если его еще нет.
В нашем примере давайте посмотрим на исходный код внутри файла с именем «main.c», где «.c» — это расширение файла, которое обычно означает, что файл написан на C. Это изображение находится внутри текстового редактора. ви:
ви:
Розовым цветом выделена директива препроцессора #include, которая указывает компилятору включить заголовочный файл stdio.h, но мы вернемся к этому позже.
Синим цветом выделены комментарии к коду, они полезны для запоминания того, что на самом деле делает ваш код спустя месяцы после его создания. Нам они не особо нужны в такой маленькой программе, но ставить их — хорошая практика.
Далее у нас есть точка входа, функция main(). Это означает, что программа начнется с выполнения операторов, которые находятся внутри блока этой функции, то есть между фигурными скобками. Здесь есть только два оператора: один, который напечатает предложение «Hello, World» на терминале, и другой, который говорит программе «вернуть» 0, если она вышла или завершилась правильно. Итак, после того, как мы скомпилировали его, если мы запустим эту программу, мы увидим только фразу «Hello, World».
Чтобы наш код main.c был исполняемым, нам нужно ввести команду «gcc main.c», и процесс компиляции пройдет все четыре этапа, которые он содержит. Конечно, у gcc есть опции, которые позволяют нам останавливать процесс компиляции после каждого шага. Давайте посмотрим на них.
Конечно, у gcc есть опции, которые позволяют нам останавливать процесс компиляции после каждого шага. Давайте посмотрим на них.
1. Препроцессор
Препроцессор имеет несколько ролей:
- он избавляется от всех комментариев в исходных файлах
- он включает код заголовочный файл (файлы) , который представляет собой файл с расширением .h, который содержит объявления функций C и определения макросов
- он заменяет все макросы (фрагменты кода, которым было присвоено имя) их значениями
Результат этого шага будет сохранен в файле с расширением «.i», поэтому здесь он будет в main.i.
Чтобы остановить компиляцию сразу после этого шага, мы можем использовать опцию «-E» с командой gcc в исходном файле и нажать Enter.
Вот как должен выглядеть конец файла main.i:
2. Компилятор
Компилятор возьмет предварительно обработанный файл и сгенерирует IR-код (промежуточное представление), так что это создаст «. s» файл. При этом другие компиляторы могут создавать ассемблерный код на этом этапе компиляции.
s» файл. При этом другие компиляторы могут создавать ассемблерный код на этом этапе компиляции.
После этого шага мы можем остановиться с опцией «-S» в команде gcc и нажать Enter.
Вот как должен выглядеть файл main.s:
3. Ассемблер
Ассемблер берет ИК-код и преобразует его в объектный код, то есть код на машинном языке (т.е. двоичный). Это создаст файл, оканчивающийся на «.o».
Мы можем остановить процесс компиляции после этого шага, используя опцию «-c» с командой gcc и нажав Enter.
Наш файл main.o должен выглядеть так (нет, он не читается человеком):
4. Компоновщик
Компоновщик создает окончательный исполняемый файл в двоичном виде и может играть две роли:
- связывает вместе все исходные файлы, то есть все остальные коды объектов в проекте. Например, если я хочу скомпилировать main.c с другим файлом с именемsecondary.c и превратить их в одну программу, на этом шаге объектный код вторичного.c (т.е.secondary.
 o) будет связан с Код объекта main.c (main.o).
o) будет связан с Код объекта main.c (main.o). - связывание вызовов функций с их определениями. Компоновщик знает, где искать определения функций в статических библиотеках или динамические библиотеки. Статические библиотеки являются «результатом того, что компоновщик копирует все используемые библиотечные функции в исполняемый файл», согласно geeksforgeeks.org, а динамические библиотеки «не требуют копирования кода, это делается путем простого размещения имя библиотеки в бинарном файле». Обратите внимание, что gcc по умолчанию использует динамические библиотеки. В нашем примере это когда компоновщик найдет определение нашей функции «помещает» и свяжет ее.
По умолчанию после этого четвертого и последнего шага, то есть когда вы вводите всю команду «gcc main.c» без каких-либо параметров, компилятор создаст исполняемую программу с именем a.out, , который мы можем запустить, набрав «./a.out» в командной строке.
Мы также можем создать исполняемую программу с желаемым именем, добавив параметр «-o» в команду gcc, поместив после имени файла или файлов, которые мы компилируем, и нажав Enter:
Итак, теперь мы можем либо ввести «./a.out», если вы не использовали параметр -o, либо «./my_program» для выполнения скомпилированного кода, вывод будет «Hello, World», а за ним следует приглашение оболочки появится снова.
Сборник компиляторов GNU предлагает гораздо больше замечательных инструментов для компиляции и работы с нашими программами, о которых стоило бы написать, но эта статья была посвящена основным шагам компиляции. Может быть в следующий раз!
Компиляция программы на C: — За кулисами — GeeksforGeeks
C — это язык высокого уровня, и ему нужен компилятор для преобразования его в исполняемый код, чтобы программу можно было запустить…
www.geeksforgeeks.org
CS 11: Компиляция программ C
Важно понимать, что хотя некоторые компьютерные языки (например, Scheme или Basic) обычно используются с… простыми и легкими шагами, начиная с базовых концепций и заканчивая продвинутыми с примерами…
www. tutorialspoint.com
tutorialspoint.com
Промежуточное представление — Википедия
Промежуточное представление (IR) — это структура данных или код, используемый внутри компилятора или виртуального машина до…
en.wikipedia.org
Надлежащее использование файлов .h и .c
Недавно я работал с некоторыми командами разработчиков встраиваемых систем, которые пытались найти лучший способ использования файлов .c и .h для своего исходного кода. Когда я это делал, я вспомнил, что когда я учился программировать, мне потребовалось довольно много времени, чтобы понять все это! Итак, вот несколько рекомендаций по разумному использованию файлов .c и .h для организации исходного кода. Они перечислены в виде свода правил, но также помогают применять здравый смысл:
- Используйте несколько файлов .c, а не только один файл «main.c». Каждый файл .c должен иметь набор переменных и функций, которые тесно связаны друг с другом и лишь слабо связаны с другими файлами .
 c. «Main.c» должен содержать только основной цикл.
c. «Main.c» должен содержать только основной цикл. - Файлы .C выделяют память и определяют исполняемый код. Только файлы .c имеют определенную в них функцию. Только файлы .c выделяют хранилище для переменных
- Файлы .H определяют внешнее хранилище и определяют прототипы функций. Файлы .h предоставляют другим модулям информацию, необходимую им для работы с определенным файлом .c, но на самом деле не определяют хранилище и не определяют код. Ключевое слово «extern» обычно должно отображаться только в файлах .h.
- Каждый файл .c должен иметь соответствующий файл .h. Файл .h предоставляет информацию о внешнем интерфейсе другим модулям для использования соответствующего файла .c.
Вот пример того, как это работает. Допустим, у вас есть файлы: main.c adc.c output.c process.c watchdog.c
main.c будет основной цикл, который опрашивает аналого-цифровой преобразователь, обрабатывает значения, отправляет выходные данные и обрабатывает сторожевой таймер. Это будет выглядеть как последовательность последовательных вызовов подпрограмм в бесконечном цикле. Будет соответствующий main.h, в котором могут быть глобальные определения (у вас также может быть «globals.h», хотя я предпочитаю не делать этого сам). Main.c будет #include main.h, adc.h, output.h, process.h и watchdog.h, потому что ему нужно вызывать функции из всех соответствующих файлов .c.
Это будет выглядеть как последовательность последовательных вызовов подпрограмм в бесконечном цикле. Будет соответствующий main.h, в котором могут быть глобальные определения (у вас также может быть «globals.h», хотя я предпочитаю не делать этого сам). Main.c будет #include main.h, adc.h, output.h, process.h и watchdog.h, потому что ему нужно вызывать функции из всех соответствующих файлов .c.
adc.c будет иметь код аналого-цифрового преобразователя и функции для опроса аналого-цифрового преобразователя и сохранения самых последних значений аналого-цифрового преобразования в структуре данных. Соответствующий файл adc.h будет иметь объявления extern и прототипы функций для любой другой подпрограммы, использующей вызовы A/D (например, вызов для поиска недавнего значения A/D из опроса). Adc.c будет #include adc.h и, возможно, ничего больше.
output.c будет принимать значения и отправлять их на выходы. Соответствующий файл output.h будет содержать информацию для вызова функций вывода. Output.c, вероятно, просто #include output.h. (То, действительно ли main.c вызывает что-то в output.c, зависит от вашей конкретной структуры кода, но я предполагаю, что выходные данные состоят из двух шагов: process.c ставит выходные данные в очередь, а вызов main.c фактически отправляет их.)
Output.c, вероятно, просто #include output.h. (То, действительно ли main.c вызывает что-то в output.c, зависит от вашей конкретной структуры кода, но я предполагаю, что выходные данные состоят из двух шагов: process.c ставит выходные данные в очередь, а вызов main.c фактически отправляет их.)
process.c будет принимать значения A/D, вычислять их и ставить результаты в очередь для вывода. Возможно, потребуется вызвать функции в adc.c для получения последних значений и функции в output.c для отправки результатов. По этой причине #include process.h, adc.h, output.h
watchdog.c будет устанавливать и обслуживать сторожевой таймер. Это будет #include watchdog.h
Одна проблема заключается в том, что некоторые компиляторы могут оптимизировать только в одном файле .c (например, делать «встроенные» только в одном файле). Это не причина помещать все в один файл .c! Вместо этого вы можете просто включить #include все остальные файлы .c из main.c. (Возможно, вам придется убедиться, что вы включаете каждый файл .