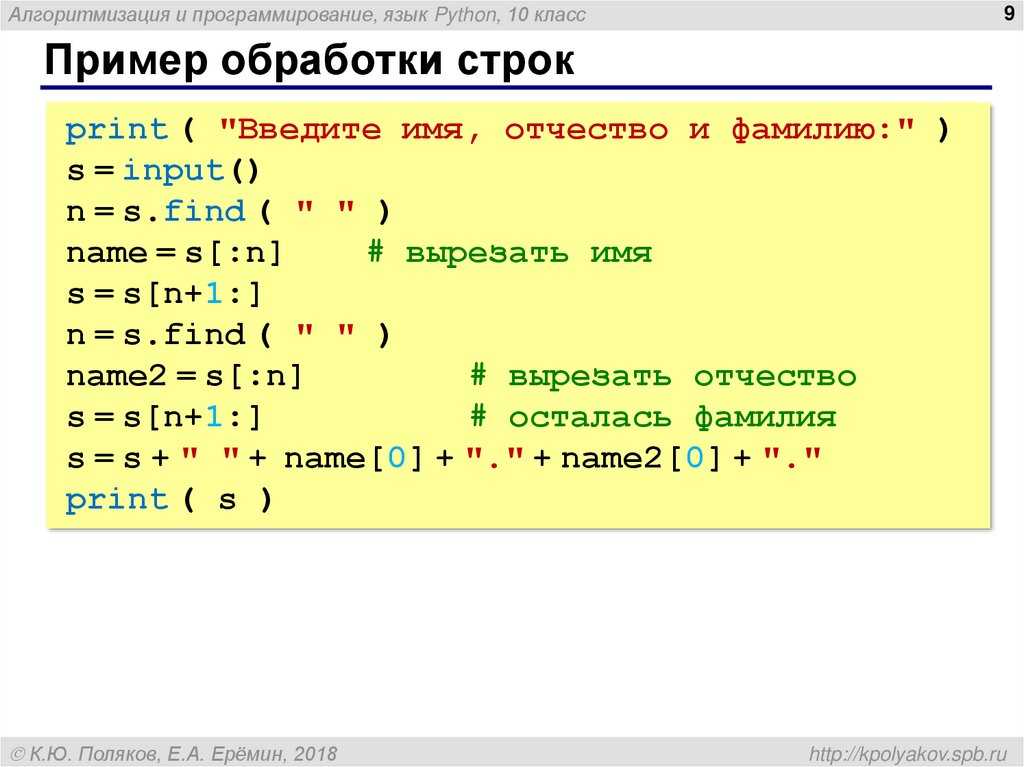
7 полезных строковых функций в Python
Как один из самых популярных языков программирования, Python позволяет разработчикам использовать строковые функции, которые помогают им выполнять различные операции. Для тех, кто не знает, строковые данные содержат значение 1 или 1> (это может быть любое число, уникальный символ и т. д.), а затем преобразуются в код ASCII, т. е. в американский стандартный код для обмена информацией и Unicode, чтобы машина могут понимать на своем языке.
Python использует один и тот же шаблон для своих строковых данных, которые выполняются для выполнения различных задач, таких как смещение верхнего или нижнего регистра и т. д. Это делает разработчиков более полезными, чтобы сэкономить свое время на различных задачах, не беспокоясь о небольших ошибках опечаток, и поэтому это Для вас искренне важно иметь технические знания о тех строковых функциях, которые были сужены в этой статье.
Содержание
- 7 полезных строковых функций в Python
- 1.
 Используйте заглавные буквы
Используйте заглавные буквы - 2. Count
- 3. Find
- 4. Lower
- 5. Upper
- 6. Replace
- 7. Join
 Используйте заглавные буквы
Используйте заглавные буквы1. Используйте заглавные буквы
Capitalize () используется в Python, где первая буква строки преобразуется в ПРОПИСНУЮ, а остальные символы остаются прежними. С другой стороны, если все символы написаны ПРОПИСНЫМИ буквами, строка вернет одно и то же значение (кроме первого символа).
Пример: mY name is YUVRAJ -> My name is yuvraj
Python3
sentence_1="mY name is YUVRAJ"
sentence_2="MY name is Ansul"
capitalized_string=sentence_1.capitalize()
("Sentence 1 output -> ", capitalized_string)
capitalized_string=sentence_2.capitalize()
("Sentence 2 output -> ", capitalized_string)
Выход:
Sentence 1 output -> My name is yuvraj Sentence 2 output -> My name is ansul
2. Count
Функция count() используется в Python для подсчета количества вхождений отдельного элемента или подстроки в строке. count() выдает числовое значение, которое предоставляет подробную информацию о фактическом количестве данной строки.
Пример: GFG KARLO HO JAYEGA -> Count of ‘G’ = 3
Python3
message='GFG KARLO HO JAYEGA'
('Number of occurrence of G:', message.count('G'))
Выход:
Number of occurrence of G: 3
3.
 Find
FindФункция find() используется в Python для возврата наименьшего значения индекса из первого вхождения строки (только в случае, если она найдена): иначе значение будет равно −1.
Пример: Yuvraj is my name -> Position of ‘is’ = 7
Python3
message='Yuvraj is my name'
(message.find('is'))
Выход:
7
4. Lower
Нижний () используется в программировании на Python, чтобы гарантировать, что все символы в строке ВЕРХНЕГО РЕГИСТРА будут преобразованы в нижний регистр и извлечены с новой строкой в нижнем регистре, а исходная копия строки останется нетронутой.
Пример: bestprogrammer IS A COMPUTER SCIENCE PORTAL -> ‘bestprogrammer is a computer science portal’.
Python3
message='bestprogrammer IS A COMPUTER SCIENCE PORTAL'
(message.lower())
Выход:
bestprogrammer is a computer science portal
5. Upper
Функция upper() используется в программировании на Python, чтобы убедиться, что все строчные символы в строке преобразуются в ПРОПИСНЫЕ и извлекаются вместе с новой строкой, тогда как исходная копия строки остается нетронутой.
Пример: bestprogrammer is a computer science portal -> bestprogrammer IS A COMPUTER SCIENCE PORTAL.
Python3
message='bestprogrammer is a computer science portal'
(message.upper())
Выход:
bestprogrammer IS A COMPUTER SCIENCE PORTAL
6. Replace
Replace() используется в Python для замены любого нежелательного символа или текста и замены его новым желаемым выводом в строке. replace() можно использовать в Python с указанным ниже синтаксисом для выполнения действия:
string.replace(old, new, count)
Пример: subway surfer -> Replace ‘s’ with ‘t’ = tubway turfer/
Python3
text='subway surfer'
replaced_text=text.replace('s','t')
(replaced_text)
Выход:
tubway turfer
7.
 Join
JoinМетод join() используется в программировании на Python для объединения каждого элемента итерируемого объекта, такого как список, набор и т. д., а позже вы можете использовать разделитель строк для разделения значений. Таким образом, join() возвращает объединенную строку и выдает исключение TypeError, если итерируемый объект содержит любой нестроковый элемент.
Python3
text=['Anshul','is','my','only','friend']
(' '.join(text))
Выход:
Anshul is my only friend
Функция для удаления определенного символа в Python
Вопрос задан
Изменён 6 дней назад
Просмотрен 541 раз
Друзья, добрый день!
Мне нужно реализовать функцию.
def filter_string(text, char):
result = ''
for current_char in text:
if current_char.upper() != char.upper():
result += current_char
return result
Но к сожалению, он работает некорректно. Ожидается:
filter_string(text, 'i') # 'f look forward wn' filter_string(text, 'O') # 'If I lk frward I win
Ошибка:
def test():
text = 'I look back if you are lost'
assert filter_string(text, 'w') == 'I look back if you are lost' AssertionError: assert 'I' == 'I look back if you are lost'
- I look back if you are lost
+ I
tests/test_solution.py:6: AssertionError
short test summary info
FAILED tests/test_solution.py::test - AssertionError: assert 'I' == 'I look b...
Спасибо за помощь!
- python
16
Для начала покажу фикс на который многие и без меня указывали в комментариях
def filter_string(text, char):
result = ''
for current_char in text:
print(current_char)
if current_char. upper() != char.upper():
result += current_char
return result
upper() != char.upper():
result += current_char
return result
Если задача не учебная, и даже если она учебная то тем более хорошо знать строковые функции присутсвующие в языке. Эту задачу можно реализовать например строковой функцией replace()
Параметры
- old – это старая подстрока, которая будет заменена.
- new – это новая подстрока, которая заменит старую подстроку.
- max – это дополнительный аргумент, заменяется только первые max вхождений.
Возвращаемое значение
Эта функция возвращает копию строки со всеми вхождениями старой подстроки заменен новой. Если указывается дополнительный аргумент max, только заменяются только первые max вхождений. Пример
Следующий пример показывает использование функции replace().
#!/usr/bin/python3
str = "это пример строки....wow!!! это действительно строка"
print (str.replace("wow", "поразительно"))
print (str.replace("это", "здесь", 3))
Результат выведет 2 строки
это пример строки....поразительно!!! это действительно строка здесь пример строки....wow!!! здесь действительно строка
Пример как использовать реплейс как удаление:
10
filter_string = lambda t, c: t.translate({ord(c): '', ord(c.swapcase()): ''})
filter_string('f lOok forward wn', 'o') # 'f lk frward wn'
Еще вариант:
def filter_string(text, char):
return ''.join(filter(lambda x: x.upper() != char.upper(), text))
text = 'I look back if you are lost'
print(filter_string(text, 'i'))
# look back f you are lost
знакомое задание, ты забыл обозначить, что «Итоговая строка также не должна содержать начальные и концевые пробелы»
return result.strip() и всё заработает
Новый участник
илья — новый участник сайта. Будьте снисходительны, задавая уточняющие вопросы, комментируя и отвечая. Почитайте про нормы поведения.
Почитайте про нормы поведения.
1
Зарегистрируйтесь или войдите
Регистрация через GoogleРегистрация через Facebook
Регистрация через почту
Отправить без регистрации
Почта
Необходима, но никому не показывается
Отправить без регистрации
Почта
Необходима, но никому не показывается
Нажимая на кнопку «Отправить ответ», вы соглашаетесь с нашими пользовательским соглашением, политикой конфиденциальности и политикой о куки
строковых функций в Python с примерами
 Для управления строками и символьными значениями в python есть несколько встроенных функций. Это означает, что вам не нужно импортировать или иметь зависимость от какого-либо внешнего пакета для работы со строковым типом данных в Python. Это одно из преимуществ использования Python по сравнению с другими инструментами обработки данных. Работа со строковыми значениями очень распространена в реальном мире. Предположим, у вас есть полное имя клиента, и ваш менеджер попросил вас извлечь имя и фамилию клиента. Или вы хотите получить информацию обо всех продуктах, код которых начинается с «QT».
Для управления строками и символьными значениями в python есть несколько встроенных функций. Это означает, что вам не нужно импортировать или иметь зависимость от какого-либо внешнего пакета для работы со строковым типом данных в Python. Это одно из преимуществ использования Python по сравнению с другими инструментами обработки данных. Работа со строковыми значениями очень распространена в реальном мире. Предположим, у вас есть полное имя клиента, и ваш менеджер попросил вас извлечь имя и фамилию клиента. Или вы хотите получить информацию обо всех продуктах, код которых начинается с «QT».Список часто используемых строковых функций
В таблице ниже показаны многие распространенные строковые функции вместе с описанием и эквивалентной функцией в MS Excel. Мы все используем MS Excel на своем рабочем месте и знакомы с функциями, используемыми в MS Excel. Сравнение строковых функций в MS EXCEL и Python поможет вам быстро изучить функции и набраться опыта перед собеседованием.
| Функция | Описание | MS EXCEL ФУНКЦИЯ |
|---|---|---|
| моя строка[:N] | Извлечь N символов из начала строки. | ЛЕВЫЙ( ) |
| моя строка[-N:] | Извлечь N символов из конца строки | ПРАВО( ) |
| моя строка[X:Y] | Извлечь символы из середины строки, начиная с позиции X и заканчивая Y | СРЕДНИЙ( ) |
| ул.split(sep=’ ‘) | Разделенные струны | — |
| ул.заменить (старая_подстрока, новая_подстрока) | Заменить часть текста другой подстрокой | ЗАМЕНИТЬ( ) |
| ул.нижний() | Преобразование символов в нижний регистр | НИЖНИЙ( ) |
| стр.верхний() | Преобразование символов в верхний регистр | ВЕРХНЯЯ( ) |
str. contains(‘шаблон’, case=False) contains(‘шаблон’, case=False) | Проверка соответствия шаблону (функция Pandas) | Оператор SQL LIKE |
| стр.экстракт(regular_expression) | Возврат совпадающих значений (функция Pandas) | — |
| количество ул(‘sub_string’) | Количество вхождений шаблона в строке | — |
| ул. найти() | Возврат позиции подстроки или шаблона | НАЙТИ() |
| улица isalnum() | Проверить, состоит ли строка только из буквенно-цифровых символов | — |
| улица islower() | Проверить, все ли символы в нижнем регистре | — |
| ул.верхний() | Проверить, все ли символы в верхнем регистре | — |
| числовая строка() | Проверить, состоит ли строка только из цифр | — |
ул. isspace() isspace() | Проверить, состоит ли строка только из пробельных символов | — |
| лен( ) | Вычислить длину строки | ДЛИН( ) |
| кот( ) | Объединение строк (функция Pandas) | СЦЕПИТЬ( ) |
| separator.join(str) | Объединить строки | СЦЕПИТЬ( ) |
Функции LEFT, RIGHT и MID
Если вы являетесь средним пользователем MS Excel, вы должны использовать функции ВЛЕВО, ВПРАВО и СРЕДНЯЯ. Эти функции используются для извлечения N символов или букв из строки.
1. Извлечь первые два символа из начала строки
mystring = "Эй, приятель, как дела?" моя строка[:2]
Выход[1]: 'Он'
-
string[start:stop:step]означает начало элемента от 0 (по умолчанию) до (stop-1), шаг за шагом 1 (по умолчанию). -
mystring[:2]эквивалентноmystring[0:2] -
mystring[:2]сообщает Python, что нужно извлечь первые 2 символа из строкового объектаmystring.
- Индексирование начинается с нуля, поэтому оно включает первый, второй элемент и исключает третий.
2. Найти два последних символа строки
mystring[-2:]
Приведенная выше команда возвращает p? . -2 начинает диапазон от предпоследней позиции до максимальной длины строки.
3. Найти символы из середины строки
mystring[1:3]
Исходящий[1]: 'эй'
mystring[1:3] возвращает второй и третий символы. 1 относится ко второму символу, так как индекс начинается с 0.
4. Как перевернуть строку?
моя строка[::-1]
Out[1]: '?pussaw ,yddub yeH'
-1 говорит Python начать с конца и увеличить его на 1 справа налево.
5. Как извлечь символы из строковой переменной в Pandas DataFrame?
Давайте создадим поддельный фрейм данных для иллюстрации. В приведенном ниже коде мы создаем фрейм данных с именем
В приведенном ниже коде мы создаем фрейм данных с именем df , содержащий только 1 переменную с именем var1
.
импортировать панд как pd
df = pd.DataFrame({"var1": ["A_2", "B_1", "C_2", "A_2"]})
переменная1
0 А_2
1 Б_1
2 С_2
3 А_2
Для обработки текстовых данных в Python Pandas Dataframe мы можем использовать атрибут str . Его можно использовать для нарезки значений символов.
df['var1'].str[0]
В этом случае мы получаем первый символ из var1 переменная. См. вывод, показанный ниже.
Выход 0 А 1 Б 2 С 3 А
Извлечение слов из строки
Предположим, вам нужно вынуть слово(а) вместо символов из строки. Обычно мы рассматриваем один пробел как разделитель для поиска слов из строки.
1. Найти первое слово строки
mystring.split()[0]
Исх[1]: 'Эй'
Как это работает?
-
функция split()разбивает строку, используя пробел в качестве разделителя по умолчанию -
mystring.возвращает split()
split() ['Эй', 'приятель', 'как дела?'] -
0возвращает первый элемент или словоHey
2. Запятая как разделитель слов
mystring.split(',')[0]
Исходящий[1]: 'Эй, приятель'
3. Как извлечь последнее слово
mystring.split()[-1]
Out[1]: 'как дела?'
4. Как извлечь слово из DataFrame
Давайте создадим фиктивный фрейм данных, состоящий из имен клиентов, и назовем его переменной 9.0184 имя пользователя
mydf = pd.DataFrame({"custname": ["Priya_Sehgal", "David_Stevart", "Kasia_Woja", "Sandy_Dave"]})
пользовательское имя
0 Прия_Сегал
1 Дэвид_Стеварт
2 Кася_Воя
3 Сэнди_Дэйв
#Первое слово
mydf['fname'] = mydf['custname'].str.split('_').str[0]
#Последнее слово
mydf['lname'] = mydf['custname'].str.split('_').str[1]
Подробное объяснение
-
str.аналогичен split()
split() split(). Он используется для активации функции разделения во фрейме данных pandas в Python. - В приведенном выше коде мы создали два новых столбца с именами
fnameиlname, в которых хранятся имя и фамилия.
Выход
имя пользователя fname lname
0 Priya_Sehgal Прия Сегал
1 David_Stevart Дэвид Стюарт
2 Kasia_Woja Кася Воя
3 Сэнди_Дэйв Сэнди Дэйв
Оператор SQL LIKE в Pandas DataFrame
В SQL оператор LIKE используется, чтобы узнать, соответствует ли строка символов шаблону или содержит ли он его. Мы можем реализовать аналогичную функциональность в python, используя str.содержит( ) функцию.
df2 = pd.DataFrame({"var1": ["AA_2", "B_1", "C_2", "a_2"],
"var2": ["X_2", "Y_1", "Z_2", "X2"]})
вар1 вар2 0 АА_2 Х_2 1 Б_1 Д_1 2 C_2 Z_2 3 а_2 Х2
Как найти строки, содержащие либо A, либо B в переменной var1?
df2['var1'].str.contains('A|B')
str.contains(шаблон) используется для сопоставления шаблона в Pandas Dataframe.
Выход 0 Верно 1 правда 2 Ложь 3 Ложь
Приведенная выше команда возвращает ЛОЖЬ для четвертой строки, поскольку функция чувствительна к регистру. Чтобы игнорировать чувствительность к регистру, мы можем использовать параметр case=False . См. рабочий пример ниже. df2['var1'].str.contains('A|B', case=False) Как фильтровать строки, содержащие определенный шаблон?
В следующей программе мы просим Python подмножить данные с условием — содержать символьные значения либо A, либо B. Это эквивалентно ключевому слову WHERE в SQL. 9 — это токен регулярного выражения, означающий начало с определенного элемента.
вар1 вар2 1 Б_1 Д_1 2 C_2 Z_2 3 а_2 Х2
Найти позицию определенного символа или ключевого слова
str. используется для поиска позиции подстроки. В этом случае подстрока ‘_’.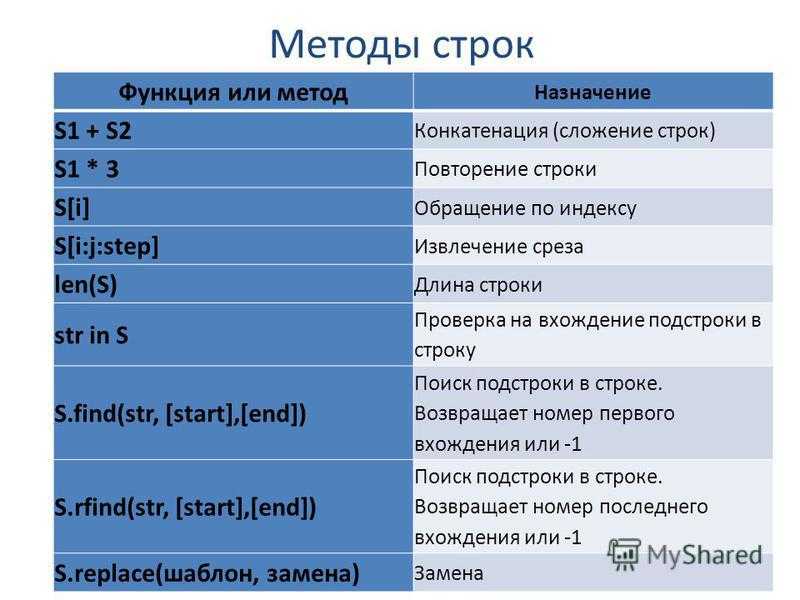 find(pattern)
find(pattern)
df2['var1'].str.find('_')
0 2 1 1 2 1 3 1
Заменить подстроку
str.replace(old_text,new_text,case=False) используется для замены определенного символа (символов) или шаблона на какое-либо новое значение или шаблон. В приведенном ниже коде мы заменяем _ на — в переменной var1.
df2['var1'].str.replace('_', '--', case=False)
Выход 0 АА--2 1 Б--1 2 С--2 3 А--2
Мы также можем создавать сложные шаблоны, подобные следующей программе. + означает, что элемент встречается один или несколько раз. В этом случае алфавит встречается 1 или более раз.
df2['var1'].str.replace('[A-Z]+_', 'X', case=False)
0 х2 1 х 1 2 х 2 3 х 2
Найти длину строки
len(string) используется для вычисления длины строки. Во фрейме данных pandas вы можете применить
Во фрейме данных pandas вы можете применить str.len() для того же.
df2['var1'].str.len()
Выход 0 4 1 3 2 3 3 3
Чтобы найти количество вхождений определенного символа (скажем, сколько раз «A» появляется в каждой строке), вы можете использовать функцию str.count(pattern) .
df2['var1'].str.count('A') Преобразование в нижний и верхний регистр
str.lower() и str.upper() Функции используются для преобразования строки в нижний и верхний регистр значения в верхнем регистре.
# Преобразовать в нижний регистр mydf['имя пользователя'].str.lower() # Преобразовать в верхний регистр mydf['имя пользователя'].str.upper()
Удалить начальные и конечные пробелы
-
str.strip()удаляет как начальные, так и конечные пробелы. -
стр.lstrip()удаляет начальные пробелы (в начале).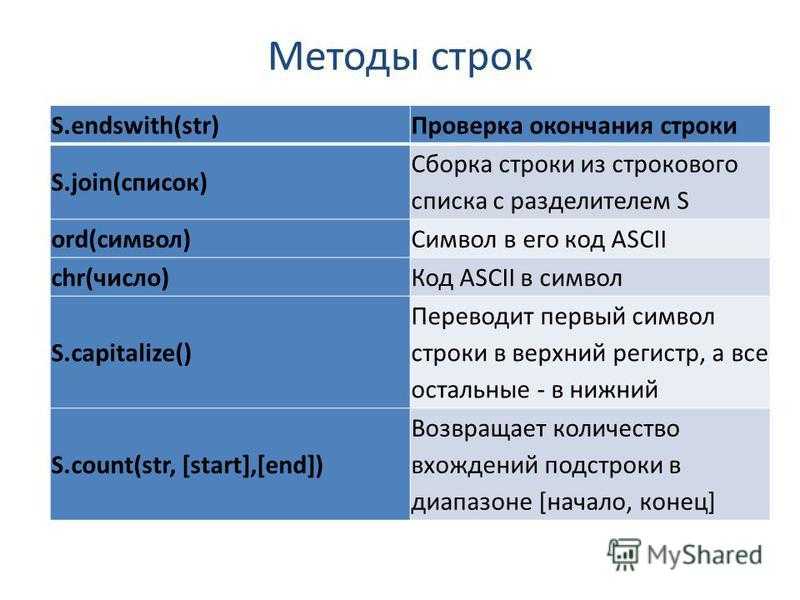
-
str.rstrip()удаляет конечные пробелы (в конце).
df1 = pd.DataFrame({'y1': ['Джек', 'Джилл', 'Джесси', 'Фрэнк']})
df1['оба']=df1['y1'].str.strip()
df1['left']=df1['y1'].str.lstrip()
df1['право']=df1['y1'].str.rstrip()
y1 оба слева направо
0 джек джек джек джек
1 Джилл Джилл Джилл Джилл
2 Джесси Джесси Джесси Джесси
3 Фрэнк Фрэнк Фрэнк Фрэнк
Преобразование числа в строку
С помощью функции str() вы можете преобразовать числовое значение в строку.
моя переменная = 4 mystr = str (моя переменная)
Объединение или объединение строк
Просто используя + , вы можете соединить два строковых значения.
х = "Дипаньшу" у = "Бхалла" х+у
ДипаншуБхалла
Если вы хотите добавить пробел между двумя строками, вы можете использовать это — x+' '+y возвращает Дипаншу Бхалла Предположим, у вас есть список, содержащий несколько строковых значений, и вы хотите их объединить. Вы можете использовать функцию join() .
Вы можете использовать функцию join() .
string0 = ['Рам', 'Кумар', 'Сингх'] ' .присоединиться (строка0)
Выход 'Рам Кумар Сингх'
Предположим, вы хотите объединить или объединить два столбца фрейма данных pandas.
mydf[‘полное имя’] = mydf[‘fname’] + ‘ ‘ + mydf[‘lname’]
ИЛИ
mydf[‘полное имя’] = mydf[[‘fname’, ‘lname’]].apply(лямбда x: ‘ ‘.join(x), ось=1)
пользовательское имя fname lname полное имя
0 Priya_Sehgal Прия Сегал Прия Сегал
1 David_Stevart Дэвид Стюарт Дэвид Стюарт
2 Kasia_Woja Kasia Woja Kasia Woja
3 Sandy_Dave Сэнди Дэйв Сэнди Дэйв
Оператор SQL IN в Pandas
Мы можем использовать функцию isin(list) , чтобы включить несколько значений в наши критерии фильтрации или подмножества.
mydata = pd.DataFrame({'продукт': ['A', 'B', 'B', 'C','C','D','A']})
мои данные[мои данные['продукт']. isin(['A', 'B'])]
9[A-Z]_)').dropna()
isin(['A', 'B'])]
9[A-Z]_)').dropna()
Встроенные строковые функции в Python
В следующей таблице перечислены все функции, которые можно использовать со строковым типом в Python 3.
| Метод | Описание |
|---|---|
| капитализировать () | Возвращает копию строки с заглавной буквой первого символа и строчными буквами остальных букв. |
| чехол() | Возвращает строку в нижнем регистре. Он похож на метод lower(), но метод casefold() преобразует больше символов в нижний регистр. |
| центр() | Возвращает новую центрированную строку указанной длины, дополненную указанным символом. Символ по умолчанию — пробел. Символ по умолчанию — пробел. |
| считать() | Ищет (с учетом регистра) указанную подстроку в заданной строке и возвращает целое число, указывающее вхождения подстроки. |
| заканчивается() | Возвращает True, если строка заканчивается указанным суффиксом (с учетом регистра), в противном случае возвращает False. |
| расширить вкладки () | Возвращает строку, в которой все символы табуляции \t заменены одним или несколькими пробелами, в зависимости от количества символов перед \t и указанного размера табуляции. |
| найти() | Возвращает индекс первого вхождения подстроки в заданной строке (с учетом регистра). Если подстрока не найдена, возвращается -1. Если подстрока не найдена, возвращается -1. |
| показатель() | Возвращает индекс первого вхождения подстроки в заданной строке. |
| Изальнум () | Возвращает True, если все символы в строке являются буквенно-цифровыми (буквами или цифрами). Если нет, возвращается False. |
| альфа() | Возвращает True, если все символы в строке являются буквенными (как строчными, так и прописными), и возвращает False, если хотя бы один символ не является алфавитом. |
| isascii () | Возвращает True, если строка пуста или все символы в строке ASCII. |
| десятичный() | Возвращает True, если все символы в строке являются десятичными. Если нет, возвращается False. |
| isdigit() | Возвращает True, если все символы в строке являются цифрами или символами Unicode цифры. Если нет, возвращается False. |
| идентификатор() | Проверяет, является ли строка допустимой строкой идентификатора или нет. Он возвращает True, если строка является допустимым идентификатором, в противном случае возвращает False. |
| ниже() | Проверяет, все ли символы данной строки в нижнем регистре или нет. Он возвращает True, если все символы в нижнем регистре, и False, даже если один символ в верхнем регистре. Он возвращает True, если все символы в нижнем регистре, и False, даже если один символ в верхнем регистре. |
| числовой() | Проверяет, все ли символы строки являются числовыми или нет. Он вернет True, если все символы являются числовыми, и вернет False, даже если один символ не является числовым. |
| печатаемый () | Возвращает True, если все символы данной строки являются Printable. Он возвращает False, даже если один символ является непечатаемым. |
| isspace() | Возвращает True, если все символы заданной строки являются пробелами.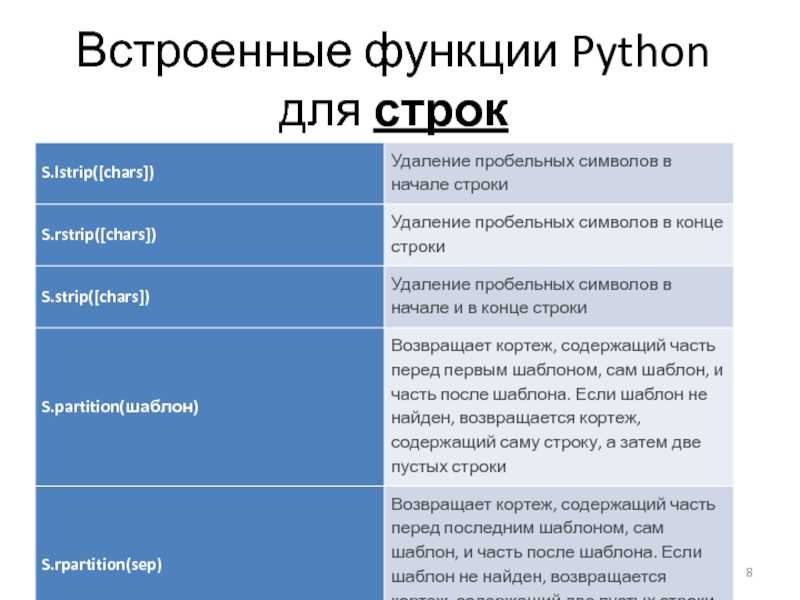 Он возвращает False, даже если один символ не является пробелом. Он возвращает False, даже если один символ не является пробелом. |
| istitle() | Проверяет, является ли первый символ каждого слова прописным, а остальные строчными или нет. Он возвращает True, если строка имеет заглавный регистр; в противном случае возвращается False. Символы и цифры игнорируются. |
| выше() | Возвращает True, если все символы в верхнем регистре, и False, даже если один символ не в верхнем регистре. |
| присоединиться() | Возвращает строку, которая представляет собой конкатенацию строки (для которой она вызывается) со строковыми элементами указанного итерируемого объекта в качестве аргумента. |
| просто() | Возвращает выровненную по левому краю строку с указанной шириной. Если указанная ширина больше длины строки, то оставшаяся часть строки заполняется указанным fillchar. |
| ниже() | Возвращает копию исходной строки, в которой все символы преобразованы в нижний регистр. |
| lstrip() | Возвращает копию строки, удаляя начальные символы, указанные в качестве аргумента. |
| сделатьтранс() | Возвращает таблицу сопоставления, которая сопоставляет каждый символ в заданной строке с символом во второй строке в той же позиции. Эта таблица сопоставления используется с методом translate(), который заменяет символы в соответствии с таблицей сопоставления. Эта таблица сопоставления используется с методом translate(), который заменяет символы в соответствии с таблицей сопоставления. |
| раздел() | Разбивает строку при первом появлении указанного аргумента разделителя строк и возвращает кортеж, содержащий три элемента: часть перед разделителем, сам разделитель и часть после разделителя. |
| заменять() | Возвращает копию строки, в которой все вхождения подстроки заменены другой подстрокой. |
| найти() | Возвращает наивысший индекс указанной подстроки (последнее вхождение подстроки) в данной строке.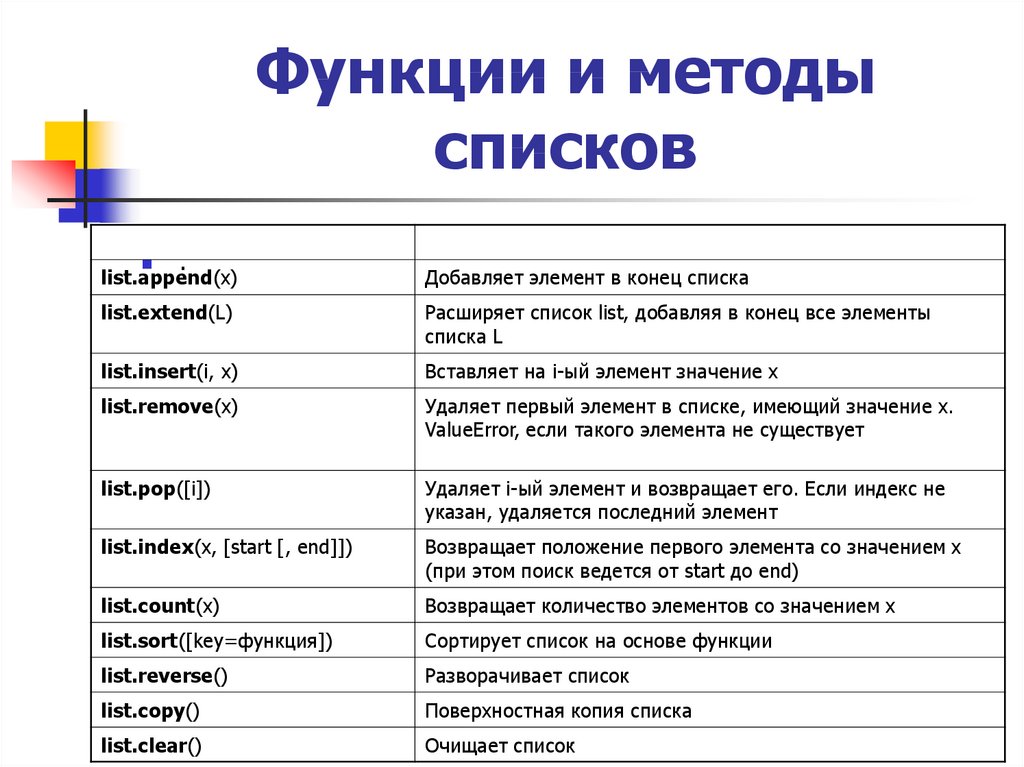 |
| риндекс() | Возвращает индекс последнего вхождения подстроки в заданной строке. |
| просто() | Возвращает выровненную по правому краю строку с указанной шириной. Если указанная ширина больше длины строки, то оставшаяся часть строки заполняется указанным заполняющим символом. |
| рраздел() | Разбивает строку в последнем вхождении указанного аргумента sep разделителя строк и возвращает кортеж, содержащий три элемента: часть перед разделителем, сам разделитель и часть после разделителя. |
| rsplit() | Разделяет строку с указанным разделителем и возвращает объект списка со строковыми элементами. |
| рстрип() | Возвращает копию строки, удаляя конечные символы, указанные в качестве аргумента. |
| расколоть() | Разделяет строку с указанным разделителем и возвращает объект списка со строковыми элементами. |
| линии разделения() | Разбивает строку по границам строк и возвращает список строк в строке. |
| начинается с() | Возвращает True, если строка начинается с указанного префикса. Если нет, возвращается False. Если нет, возвращается False. |
| полоска() | Возвращает копию строки, удаляя как начальные, так и конечные символы. |
| свопкейс() | Возвращает копию строки с преобразованием символов верхнего регистра в нижний регистр и наоборот. Символы и буквы игнорируются. |
| название () | Возвращает строку, в которой каждое слово начинается с символа верхнего регистра, а остальные символы — строчными. |
| переводить() | Возвращает строку, в которой каждый символ сопоставляется с соответствующим символом в таблице перевода. Оставить комментарий
|