Срезы строк | Python | CodeBasics
Когда мы работаем со строками в программировании, из них регулярно приходится извлекать некую часть. Например, нам нужно выяснить, присутствует ли меньшая строка внутри большей. В этом уроке мы разберемся, как это сделать.
Подстрока — это некоторая часть строки, которую нужно найти и извлечь.
Представим, что у нас есть дата в таком формате: 12-08-2034. Нам нужно извлечь из нее подстроку, в которую входит только год.
Если подумать логически, то нужно посчитать индекс символа, с которого начинается год, и затем извлечь четыре символа. Индексы в строке начинаются с нуля, значит, первый символ года доступен по индексу 6, а последний символ — по индексу 9. Проверим:
value = '12-08-2034' print(value[6]) # => 2 print(value[9]) # => 4
Зная эти индексы, мы можем воспользоваться срезами и получить нужную подстроку:
value = '12-08-2034' year = value[6:10] print(year) # => 2034
Срезы для строк
 В примере выше мы взяли подстроку с 6 индекса по 10 индекс, не включая, то есть с 6 по 9 включительно. Формула выглядит так:
В примере выше мы взяли подстроку с 6 индекса по 10 индекс, не включая, то есть с 6 по 9 включительно. Формула выглядит так:str[начальный индекс:конечный индекс] # Пара примеров value = '01-12-9873' # Срез строки это всегда строка, # даже если внутри строки было число. value[1:2] # '1' value[3:5] # '12'
Срезы — механизм с большим количеством вариаций. Например, если не указать вторую границу, то извлечение произойдет до конца строки. То же самое с первой границей — началом строки:
value = 'Hexlet' value[3:] # 'let' value[:3] # 'Hex'
Можно указать даже отрицательные индексы. В таком случае отсчет идет с обратной стороны:
value = 'Hexlet' # Правая граница отрицательная. Считаем -1 от конца строки value[3:-1] # 'le' # Левая граница отрицательная. Считаем -5 от конца строки value[-5:3] # 'ex'
У срезов два обязательных параметра, но иногда используется и третий.
У срезов есть третий необязательный параметр — шаг извлечения. По умолчанию он равен единице, но мы можем его изменить:
По умолчанию он равен единице, но мы можем его изменить:
value = 'Hexlet' value[1:5:2] # el # 1:5 это 'exle' # шаг 2 это каждый второй, то есть 'e' и 'l'
Все это можно комбинировать с открытыми границами, то есть без указания начала или конца:
value = 'Hexlet' value[:5:2] # 'Hxe' value[1::2] # 'elt'
Шаг может быть отрицательным, в таком случае он берется с конца. Из этого вытекает самый популярный способ использования шага — переворот строки:
value = 'Hexlet' # Пропускаем обе границы value[::-1] # 'telxeH'
Если используется отрицательный шаг, и элементы среза извлекаются в обратном порядке — тогда и границы среза тоже нужно указывать в обратном порядке. Первой указывается правая граница среза, второй — левая:
value = 'Hexlet' # Символ с индексом 1 не будет включен в подстроку value[4:1:-1] # 'elx'
Срезы можно указывать не только через числа, но и с использованием переменных:
value = 'Hexlet' start = 1 end = 5 value[start:end] # 'exle'
https://replit.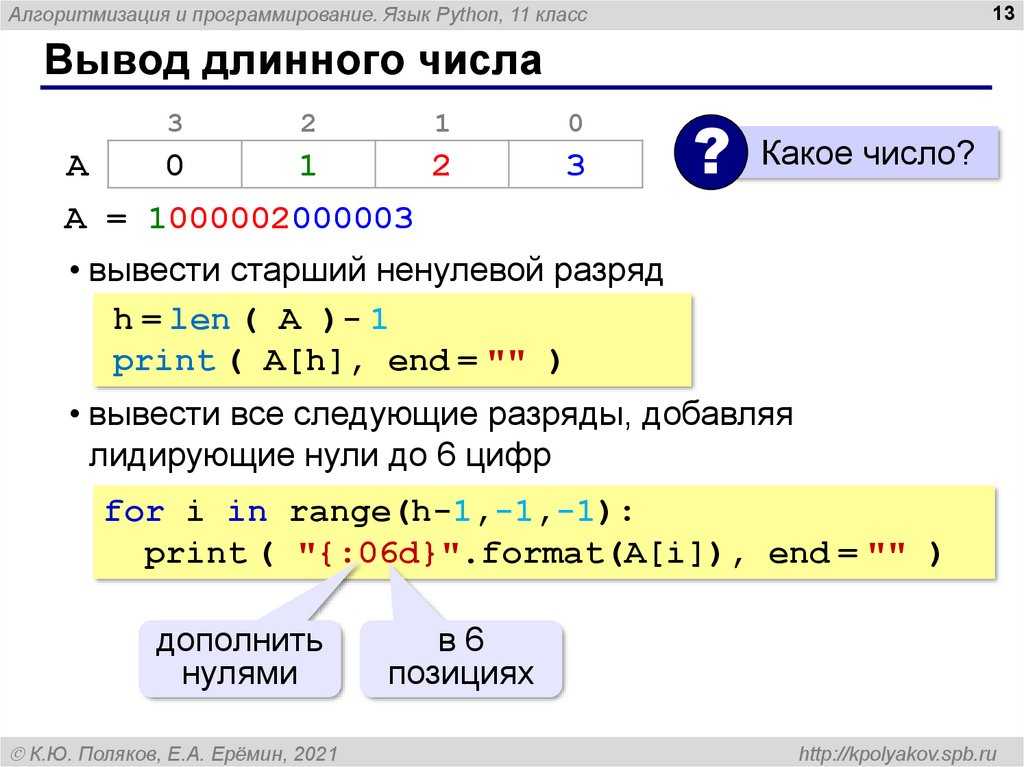 com/@hexlet/python-basics-advanced-strings-slices
com/@hexlet/python-basics-advanced-strings-slices
Как видите, срезы способны на многое. Не переживайте, если прямо сейчас не запомните все эти комбинации — это нормально. Со временем вы научитесь их использовать, не подглядывая в документацию.
Задание
В переменной value лежит значение Hexlet. Извлеките из него и выведите на экран срез, который получит подстроку xle. Это задание можно сделать разными способами.
Если вы зашли в тупик, то самое время задать вопрос в «Обсуждениях». Как правильно задать вопрос:
- Обязательно приложите вывод тестов, без него практически невозможно понять что не так, даже если вы покажете свой код. Программисты плохо исполняют код в голове, но по полученной ошибке почти всегда понятно, куда смотреть.
Тесты устроены таким образом, что они проверяют решение разными способами и на разных данных. Часто решение работает с одними входными данными, но не работает с другими. Чтобы разобраться с этим моментом, изучите вкладку «Тесты» и внимательно посмотрите на вывод ошибок, в котором есть подсказки.
Часто решение работает с одними входными данными, но не работает с другими. Чтобы разобраться с этим моментом, изучите вкладку «Тесты» и внимательно посмотрите на вывод ошибок, в котором есть подсказки.
Это нормально 🙆, в программировании одну задачу можно выполнить множеством способов. Если ваш код прошел проверку, то он соответствует условиям задачи.
В редких случаях бывает, что решение подогнано под тесты, но это видно сразу.
Создавать обучающие материалы, понятные для всех без исключения, довольно сложно. Мы очень стараемся, но всегда есть что улучшать. Если вы встретили материал, который вам непонятен, опишите проблему в «Обсуждениях». Идеально, если вы сформулируете непонятные моменты в виде вопросов. Обычно нам нужно несколько дней для внесения правок.
Кстати, вы тоже можете участвовать в улучшении курсов: внизу есть ссылка на исходный код уроков, который можно править прямо из браузера.
Полезное
Подробнее о срезах в Python
Определения
←Предыдущий
Следующий→
Нашли ошибку? Есть что добавить? Пулреквесты приветствуются https://github.com/hexlet-basics
Срезы строк | Основы Python
Зарегистрируйтесь для доступа к 15+ бесплатным курсам по программированию с тренажером
Когда мы работаем со строками в программировании, из них регулярно приходится извлекать некую часть. Например, нам нужно выяснить, присутствует ли меньшая строка внутри большей. В этом уроке мы разберемся, как это сделать.
Подстрока и срезы для строк
Подстрока — это некоторая часть строки, которую нужно найти и извлечь.
Представим, что у нас есть дата в таком формате: 12-08-2034. Нам нужно извлечь из нее подстроку, в которую входит только год.
Если подумать логически, то нужно посчитать индекс символа, с которого начинается год, и затем извлечь четыре символа. Индексы в строке начинаются с нуля, значит, первый символ года доступен по индексу 6, а последний символ — по индексу 9. Проверим:
Индексы в строке начинаются с нуля, значит, первый символ года доступен по индексу 6, а последний символ — по индексу 9. Проверим:
value = '12-08-2034' print(value[6]) # => 2 print(value[9]) # => 4
Зная эти индексы, мы можем воспользоваться срезами и получить нужную подстроку:
value = '12-08-2034' year = value[6:10] print(year) # => 2034
Срезы для строк в Python — это механизм, с помощью которого извлекается подстрока по указанным параметрам. В примере выше мы взяли подстроку с 6 индекса по 10 индекс, не включая, то есть с 6 по 9 включительно. Формула выглядит так:
str[начальный индекс:конечный индекс] # Пара примеров value = '01-12-9873' # Срез строки это всегда строка, # даже если внутри строки было число. value[1:2] # '1' value[3:5] # '12'
Срезы — механизм с большим количеством вариаций. Например, если не указать вторую границу, то извлечение произойдет до конца строки. То же самое с первой границей — началом строки:
value = 'Hexlet' value[3:] # 'let' value[:3] # 'Hex'
Можно указать даже отрицательные индексы. В таком случае отсчет идет с обратной стороны:
В таком случае отсчет идет с обратной стороны:
value = 'Hexlet' # Правая граница отрицательная. Считаем -1 от конца строки value[3:-1] # 'le' # Левая граница отрицательная. Считаем -5 от конца строки value[-5:3] # 'ex'
У срезов два обязательных параметра, но иногда используется и третий.
Шаг извлечения
У срезов есть третий необязательный параметр — шаг извлечения. По умолчанию он равен единице, но мы можем его изменить:
value = 'Hexlet' value[1:5:2] # el # 1:5 это 'exle' # шаг 2 значит через один, то есть 'e' и 'l'
Все это можно комбинировать с открытыми границами, то есть без указания начала или конца:
value = 'Hexlet' value[:5:2] # 'Hxe' value[1::2] # 'elt'
Шаг может быть отрицательным, в таком случае он берется с конца. Из этого вытекает самый популярный способ использования шага — переворот строки:
value = 'Hexlet' # Пропускаем обе границы value[::-1] # 'telxeH'
Если используется отрицательный шаг, и элементы среза извлекаются в обратном порядке — тогда и границы среза тоже нужно указывать в обратном порядке. Первой указывается правая граница среза, второй — левая:
Первой указывается правая граница среза, второй — левая:
value = 'Hexlet' # Символ с индексом 1 не будет включен в подстроку value[4:1:-1] # 'elx'
Срезы можно указывать не только через числа, но и с использованием переменных:
value = 'Hexlet' start = 1 end = 5 value[start:end] # 'exle'
Как видите, срезы способны на многое. Не переживайте, если прямо сейчас не запомните все эти комбинации — это нормально. Со временем вы научитесь их использовать, не подглядывая в документацию.
Остались вопросы? Задайте их в разделе «Обсуждение»
Вам ответят команда поддержки Хекслета или другие студенты.
Открыть доступ
Курсы программирования для новичков и опытных разработчиков. Начните обучение бесплатно
- 130 курсов, 2000+ часов теории
- 1000 практических заданий в браузере
- 360 000 студентов
Электронная почта *
Отправляя форму, вы принимаете «Соглашение об обработке персональных данных» и условия «Оферты», а также соглашаетесь с «Условиями использования»
Наши выпускники работают в компаниях:
Рекомендуемые программы
Профессия
с нуля
Python-разработчик
Разработка веб-приложений на Django
16 февраля 10 месяцев
Профессия
В разработке с нуля
Аналитик данныхСбор, анализ и интерпретация данных
16 марта 8 месяцев
Для перемещения по курсу нужно зарегистрироваться
1. Введение
↳
теория
Введение
↳
теория
2. Hello, World! ↳ теория / тесты / упражнение
3. Инструкции ↳ теория / тесты / упражнение
4. Арифметические операции ↳ теория / тесты / упражнение
5. Ошибки оформления — синтаксис и линтер ↳ теория / тесты / упражнение
6. Строки ↳ теория / тесты / упражнение
7. Переменные ↳ теория / тесты / упражнение
8. Выражения в определениях ↳ теория / тесты / упражнение
9. Именование ↳ теория / тесты / упражнение
10. Интерполяция ↳ теория / тесты / упражнение
11. Извлечение символов из строки ↳ теория / тесты / упражнение
12. Срезы строк ↳ теория / тесты / упражнение
13. Типы данных ↳ теория / тесты / упражнение
14. Неизменяемость и примитивные типы ↳ теория / тесты / упражнение
15. Функции и их вызов ↳ теория / тесты / упражнение
16. Сигнатура функции ↳ теория / тесты / упражнение
17. Вызов функции — выражение ↳ теория / тесты / упражнение
18. Детерминированность ↳ теория / тесты / упражнение
19. Стандартная библиотека
↳
теория
/
тесты
/
упражнение
Стандартная библиотека
↳
теория
/
тесты
/
упражнение
20. Свойства и методы ↳ теория / тесты / упражнение
21. Цепочка методов ↳ теория / тесты / упражнение
22. Определение функций ↳ теория / тесты / упражнение
23. Возврат значений ↳ теория / тесты / упражнение
24. Параметры функций ↳ теория / тесты / упражнение
25. Необязательные параметры функций ↳ теория / тесты / упражнение
26. Именованные аргументы ↳ теория / тесты / упражнение
27. Окружение ↳ теория / тесты / упражнение
28. Логика ↳ теория / тесты / упражнение
29. Логические операторы ↳ теория / тесты / упражнение
30. Результат логических операций ↳ теория / тесты / упражнение
31. Условные конструкции ↳ теория / тесты / упражнение
32. Оператор Match ↳ теория / тесты
33. Цикл while ↳ теория / тесты / упражнение
34. Агрегация данных ↳ теория / тесты / упражнение
35. Обход строк ↳ теория / тесты / упражнение
36. Условия внутри тела цикла ↳ теория / тесты / упражнение
37. Цикл for
↳
теория
/
тесты
/
упражнение
Цикл for
↳
теория
/
тесты
/
упражнение
38. Отладка ↳ теория / тесты / упражнение
39. Модули ↳ теория / тесты / упражнение
40. Модули поглубже ↳ теория / тесты / упражнение
41. Пакеты ↳ теория / тесты / упражнение
42. Модуль random ↳ теория / тесты / упражнение
43. Кортежи ↳ теория / тесты / упражнение
44. История развития языка Python ↳ теория / тесты
Испытания
1. Фибоначчи
2. Сумма двоичных чисел
3. Физзбазз
4. Классификация отрезков
5. Вращение троек
6. Разница углов
7. Степени тройки
8. Фасад
9. Счастливый билет
10. Идеальные числа
11. Инвертированный регистр
12. Счастливые числа
13. Шифрование
Порой обучение продвигается с трудом. Сложная теория, непонятные задания… Хочется бросить. Не сдавайтесь, все сложности можно преодолеть. Рассказываем, как
Не понятна формулировка, нашли опечатку?
Выделите текст, нажмите ctrl + enter и опишите проблему, затем отправьте нам. В течение нескольких дней мы улучшим формулировку или исправим опечатку
В течение нескольких дней мы улучшим формулировку или исправим опечатку
Что-то не получается в уроке?
Загляните в раздел «Обсуждение»:
- Изучите вопросы, которые задавали по уроку другие студенты — возможно, ответ на ваш уже есть
- Если вопросы остались, задайте свой. Расскажите, что непонятно или сложно, дайте ссылку на ваше решение. Обратите внимание — команда поддержки не отвечает на вопросы по коду, но поможет разобраться с заданием или выводом тестов
- Мы отвечаем на сообщения в течение 2-3 дней. К «Обсуждениям» могут подключаться и другие студенты. Возможно, получится решить вопрос быстрее!
Подробнее о том, как задавать вопросы по уроку
Разрезание строк в Python | phoenixNAP KB
Введение
Python — превосходный язык программирования для работы с текстовыми данными. Поскольку Python рассматривает строки как массив символов, нарезка строк — это метод в Python, который позволяет извлекать подстроки, что удобно при работе с длинными строками.
В этой статье показаны различные способы нарезки строки и некоторые полезные приемы при работе с нарезкой.
Предпосылки
- Python 3 установлен.
- Текстовый редактор или IDE для написания кода.
- Терминал или IDE для запуска кода.
Python предлагает два способа разделения строк:
- Метод
slice()разделяет массив в соответствии с предоставленными параметрами диапазона. - Обозначение среза массива выполняет ту же задачу, что и метод
slice(), но использует другое обозначение.
В обоих случаях возвращаемое значение представляет собой диапазон из символов . Каждая строка ведет себя как массив символов, элементы которого доступны через индексы. Есть два способа доступа к элементам массива в Python:
- Обычная индексация обеспечивает доступ к символам от первого до последнего (начиная с 0).

- Отрицательная индексация осуществляет доступ к символам в обратном порядке (начиная с -1).
Ниже приводится подробное объяснение обоих методов и их поведения.
Метод 1: использование slice()
Метод Python slice() представляет собой встроенную функцию для извлечения определенной части строки. Метод работает с любым массивоподобным объектом, таким как строка, список или кортеж.
Синтаксис:
slice(start,stop,step)
Аргументы являются индексами со следующим поведением:
- Значение
startявляется индексом первого символа в подпоследовательности. Значение по умолчанию – 9.00070илиНет. - Значение
stopявляется индексом первого символа, не включенного в последовательность. Значение по умолчанию:Нет.
- Окончательное значение
шага— это количество символов, которое необходимо пропустить между индексамиstartиstop. Значение по умолчанию:1илиНет.
Метод возвращает объект, содержащий массив символов подстроки.
Используйте метод slice() , чтобы сделать следующее:
- Извлечь часть строки с шагом . Укажите значения
start,stopиstep, как в следующем примере кода:
quote = «Нет места лучше дома». печать (цитата [срез (0,-1,2)])
Метод извлекает каждый второй символ с начала до (но не включая) последнего символа.
- Определить диапазон для подстроки . Для этого используйте два значения:
quote = «Нет места лучше дома».print(quote[slice(5,10)])
Метод 6. При положительном индексировании отображаются первые пять символов, а при отрицательном — до последних пяти. Python использует синтаксис срезов массивов для выполнения срезов строк по-разному. Нарезка массива вызывает функцию slice() Примечание: Думайте о нарезке массива как о диапазоне . Один индекс извлекает символ по предоставленному индексу, а диапазон нарезает строку в соответствии с указанным диапазоном. Синтаксис для нарезки массива: Используйте нарезку массива для выполнения следующих задач: Нарезка начинается с четвертого символа и идет до конца, печатая каждый второй символ. Код извлекает подстроку, начиная с индекса три и заканчивая индексом десять. Значение шага Нарезка начинается с пятого до последнего символа и идет до конца. Значение шага Заключение После изучения примеров в этом руководстве вы знаете, как разрезать строку. Предоставляя значение Slicing — ценный инструмент для программистов Python, работающих со строковыми типами данных. Python стал одним из самых популярных языков программирования в мире благодаря своей интуитивной и простой природе. Среди его привлекательных особенностей — мощная библиотека для разбора и обработки строковых объектов. Python предоставляет инструменты для индексации строк и создания подстрок из больших строк, что известно как slicing 9.0310 . В этом руководстве обсуждается, как использовать индексирование строк Python и как нарезать строку в Python. Все структуры данных Python, включая строки, являются объектами. Можно получить доступ к любому символу в строке Python, используя индексацию на основе массива. Строками также можно манипулировать и преобразовывать с помощью встроенных строковых методов и операций. Нарезка строки — мощная операция для создания подстроки из исходной строки. В дополнение к извлечению строки, состоящей из последовательных символов, срез строки может выбирать каждую n-ю букву или даже работать в обратном порядке. Строки можно нарезать в Python, используя либо объект Если вы еще этого не сделали, создайте учетную запись Linode и вычислительный экземпляр. Следуйте нашему руководству по настройке и защите вычислительного экземпляра, чтобы обновить свою систему. Вы также можете установить часовой пояс, настроить имя хоста, создать ограниченную учетную запись пользователя и усилить доступ по SSH. Пока не выполняйте раздел Настройка брандмауэра . Это руководство включает правила брандмауэра специально для сервера OpenVPN. Убедитесь, что Python правильно установлен на Linode, и вы можете запускать и использовать среду программирования Python. Для получения информации о том, как использовать Python, см. наше руководство по установке Python 3. Шаги в этом руководстве написаны для пользователей без полномочий root. Команды, требующие повышенных привилегий, имеют префикс Строки Python работают как массивы. Отдельные символы в строке можно получить с помощью системы индексации с отсчетом от нуля. Это означает, что первый символ в строке длины n имеет позицию Традиционный метод индексации строк заключается в восходящем счете с нуля, начиная с крайнего левого символа в строке. Индекс увеличивается на единицу с каждым символом, поскольку строки читаются слева направо. Это называется положительной индексацией . В следующем примере показано, как работает индексация строк с использованием реального кода Python. Используйте индексацию строк, чтобы выбрать третий символ из Символы в строке также можно индексировать, считая в обратном порядке с конца строки. Это известно как отрицательное индексирование . Последний символ строки имеет отрицательный индекс Отрицательная индексация использует те же обозначения, что и положительная индексация. Предпоследний символ извлекается с помощью Индексация строк Python также может использоваться для извлечения подстроки из большей строки. Этот процесс называется нарезкой . Чтобы использовать Python для нарезки строки из родительской строки, укажите диапазон среза, используя начальный и конечный индексы. Разделите начальный и конечный индексы двоеточием и заключите весь диапазон в квадратные скобки, используя формат 9. slice() извлекает подстроку из индекса с пятого по десятый, тогда как значение step по умолчанию равно 1 . Начальный и конечный индексы используют одну и ту же систему нумерации, начинающуюся с нуля. Оба аргумента должны быть целыми числами. quote = "Нет места лучше дома".
печать (цитата [кусок (5)])
print(quote[slice(-5)])
. Например: quote = «Нет места лучше дома».
print(quote[slice(None,None,-1)])
START и Стоп Поля Используют значения по умолчанию из -за Параметр , в то время как Шаг 8.
-1 9008. Код считывает строку в обратном направлении и меняет порядок символов. Способ 2: использование срезов массивов [::]
9.0026 и выполняет ту же задачу. Однако синтаксис более гибкий. Вместо записи None для неуказанных индексов поле остается пустым, чтобы указать значения по умолчанию. строка[начало:стоп:шаг]
quote = «Нет места лучше дома».
 print(quote[3:-1:2])
print(quote[3:-1:2]) начало и остановить значений для определения диапазона. Например: quote = «Нет места лучше дома».
print(quote[3:10])
по умолчанию равно 1 , если оно не указано. quote = «Нет места лучше дома».
печать(цитата[-5:])
по умолчанию равно 1 , если оно не указано.
start , stop и step , нарезка строк позволяет извлекать различные значения из массива символов. Как разрезать и индексировать строки в Python |
Linode
Введение в срезы строк в Python
 Как объект строка имеет набор встроенных атрибутов и функций, также известных как методы. Строка — это массив, состоящий из упорядоченной последовательности одного или нескольких символов. Поскольку Python не имеет символьного типа или типа данных «char», одиночный символ считается строкой длиной, равной единице. Символы в строке могут быть буквами, цифрами, пробелами или не буквенно-цифровыми символами.
Как объект строка имеет набор встроенных атрибутов и функций, также известных как методы. Строка — это массив, состоящий из упорядоченной последовательности одного или нескольких символов. Поскольку Python не имеет символьного типа или типа данных «char», одиночный символ считается строкой длиной, равной единице. Символы в строке могут быть буквами, цифрами, пробелами или не буквенно-цифровыми символами. slice , либо индексацию строк. Прежде чем начать
Примечание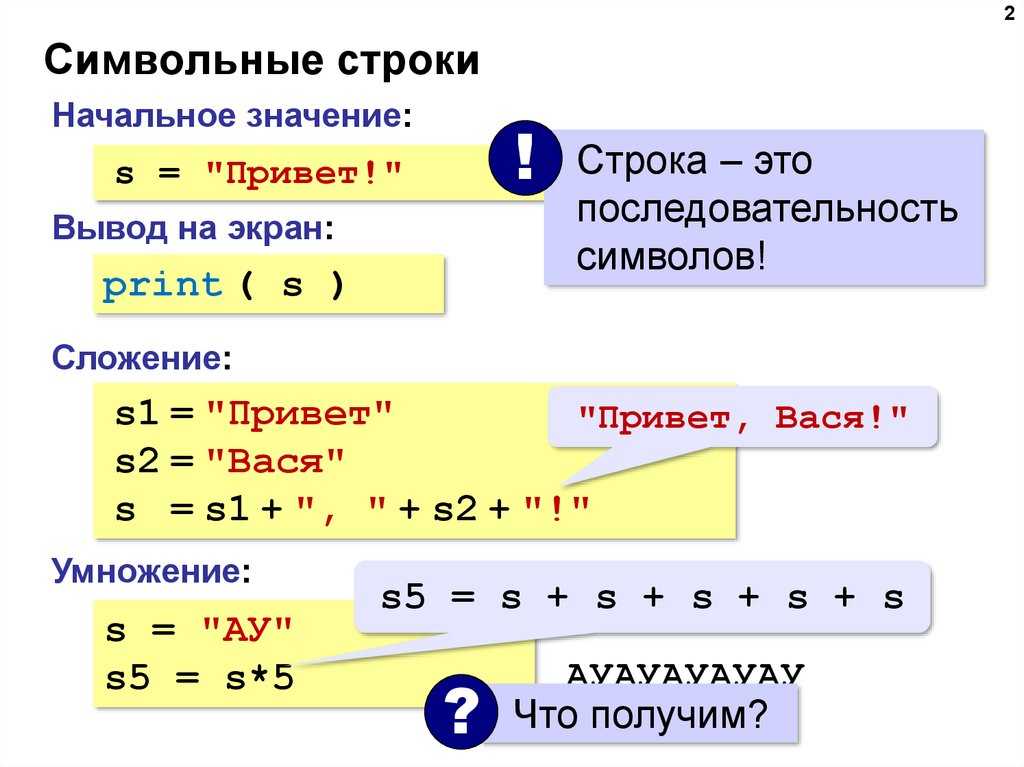 См. наши руководства «Начало работы с Linode» и «Создание вычислительного экземпляра».
См. наши руководства «Начало работы с Linode» и «Создание вычислительного экземпляра». sudo . Если вы не знакомы с командой sudo , см.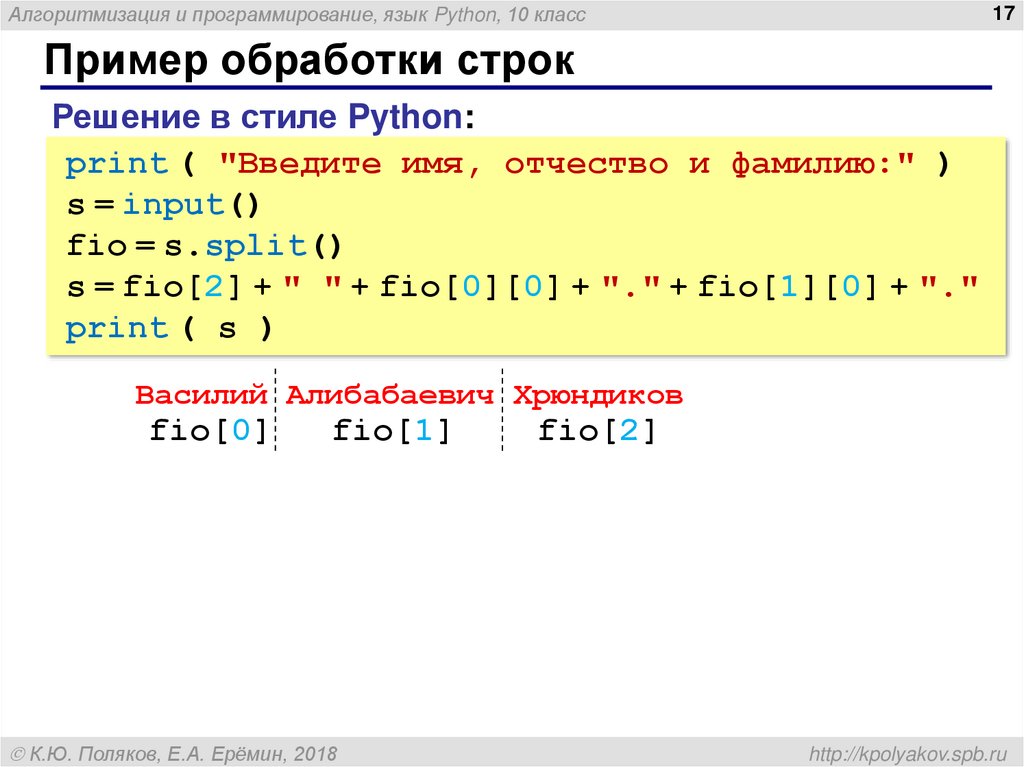 руководство «Пользователи и группы Linux».
руководство «Пользователи и группы Linux». Как работает индексирование строк в Python 3
0 , а последний символ имеет индекс n - 1 . Чтобы извлечь символ из строки на основе его индекса, заключите индекс символа в квадратные скобки, используя формат строка[индекс] . Индекс всегда должен быть целым числом. В этом разделе описывается, как извлекать символы из строки, используя положительное или отрицательное индексирование. Извлечение определенного символа по индексу
Положительная индексация
 Первый символ имеет индекс
Первый символ имеет индекс 0 , символ в позиции x имеет индекс x - 1 , а последний символ в строке имеет индекс длина_строки - 1 . Если индекс больше string_length - 1 , Python возвращает ошибку IndexError: индекс строки вне диапазона . На следующей диаграмме показано, как работает строковый индекс Python, на примере строки из шести символов Linode . L i n o d e 0 1 2 3 4 5 L . Он имеет индекс 0 и доступен с использованием [0] . n . Он имеет индекс 2 и доступен с использованием [2] . e . Он имеет индекс
Он имеет индекс 5 и доступен с помощью [5] . тестовая строка . Символ, полученный выражением testString[2] , присваивается indexChar и распечатывается. testString = "Линод"
indexChar = тестовая строка[2]
печать (indexChar)
n
Отрицательное индексирование
-1 . Предпоследний символ занимает позицию -2 и так далее. Если индекс не существует в строке, Python возвращает ошибку. В следующей таблице показано, как строка Linode индексируется с использованием отрицательного индексирования.
L i n o d e -6 -5 -4 -3 -2 -1 строка[-2] . В следующем примере показано, как использовать отрицательное индексирование. печать (тестовая строка [-2])
d
Как разрезать строки в Python 3
Создать подстроку
 0025 строка[начальный_индекс:конечный_индекс]
0025 строка[начальный_индекс:конечный_индекс]
Начальная позиция включительно. Он отмечает позицию, где начинается подстрока и где находится первый символ новой строки. Конечная позиция является эксклюзивной. Он указывает первый символ, который является , а не частью подстроки. Последний символ подстроки находится в индексе, непосредственно предшествующем конечному индексу.
Чтобы разрезать строку с диапазоном от позиции 2 до позиции 4 , используйте нотацию string[2:5] . Поскольку запись строки начинается с нуля, срез подстроки содержит символы исходной строки с третьего по пятый. Вот несколько примеров:
Чтобы разрезать подстроку с позиции 2 на позицию 4 , используйте следующий синтаксис:
testString = "Linode" печать (тестовая строка [2: 5])
узел
Подстрока может содержать пробел или небуквенный символ. В этом примере результирующая подстрока содержит
В этом примере результирующая подстрока содержит ! и пробел.
testString2 = "Линод! Система" печать (тестовая строка2 [4:10])
де! Sy
Чтобы разделить все символы от начала строки до определенной точки в середине, опустите начальный индекс. Укажите конечный индекс, как обычно. Диапазон простирается от первого символа до символа непосредственно перед конечным индексом. Синтаксис для этой записи строка[:конечная_позиция] . Чтобы нарезать первые пять символов из строки, используйте string[:5] . В результате получается подстрока, которая простирается от индекса 0 до индекса 4 .
testString2 = "Линод! Система" печать (тестовая строка2 [: 5])
Linod
Python использует тот же метод, чтобы разрезать строку с конца. Используйте начальный индекс, чтобы указать первый символ, который нужно включить, и опустите конечный индекс. Синтаксис этой операции: string[start_position:] .
testString2 = "Линод! Система" печать (тестовая строка2 [5:])
е! Система
Нарезка также может работать с отрицательной индексацией. Это удобно для извлечения второго и третьего последних символов из строки без выполнения ряда логических операций. Нарезка с отрицательными индексами работает точно так же, как и с положительной индексацией. Начальная позиция является включительной и отмечает начало подстроки. Конечная позиция является исключающей и отмечает первый символ, исключаемый из новой подстроки.
testString2 = "Линод! Система" печать (тестовая строка2 [-3:-1])
te
Реализовать шаг при разрезании строки
Во всех примерах до сих пор подстрока извлекалась в последовательном порядке слева направо. Однако также возможно инвертировать строку или создать подстроку из не следующих друг за другом символов. Этого можно добиться с помощью шага . Шаг n возвращает каждый n-й символ. Он указывает, как Python должен проходить по строке при генерации подстроки. Шаг
Шаг 2 указывает Python выбирать каждый второй символ. Однако шаг -2 указывает, что каждую вторую букву следует выбирать справа налево.
Шаг указывается как необязательный третий аргумент операции среза в формате строка[начальная_позиция:конечная_позиция:шаг] . Шаг по умолчанию равен 1 , что приводит к поведению, наблюдаемому в предыдущих операциях среза.
Наиболее распространенная причина использования отрицательного шага в Python — это реализация обратного среза строки. Укажите шаг -1 и оставьте начальную и конечную позиции пустыми. Формат прямого обращения строки — string[::-1] .
testString2 = "Линод! Система" печать (тестовая строка2 [:: -1])
metsyS !edoniL
Шаг можно использовать вместе с начальным и конечным индексами. В следующем примере показано, как построить подстроку из каждого второго символа в основной строке, начиная с индекса 3 . Python добавляет символы в позиции
Python добавляет символы в позиции 3 , 5 и 7 к подстроке и продолжается таким образом, пока не достигнет конца строки.
testString2 = "Линод! Система" печать (тестовая строка2 [3:: 2])
oe ytm
Для более глубокого изучения реверсирования строки в Python с использованием срезов и других методов см. наше руководство Реверсирование строки в Python
Использование объекта среза для упрощения повторяющихся задач
Python позволяет программистам определять срез объект с использованием констант для начального индекса, конечного индекса и шага. Программисты могут применять этот объект вместо обычного синтаксиса нарезки. Объект среза особенно удобен, если одна и та же операция среза требуется в разных обстоятельствах. Предопределенный объект среза помогает избежать ошибок кодирования, а также обеспечивает модульность и удобство сопровождения.
Чтобы создать подстроку с помощью функции среза Python, сначала создайте объект slice с помощью конструктора slice . Передайте начальный индекс, конечный индекс и шаг в качестве аргументов конструктору. Заключите объект среза в квадратные скобки
Передайте начальный индекс, конечный индекс и шаг в качестве аргументов конструктору. Заключите объект среза в квадратные скобки [] и используйте его для создания подстроки из родительской строки следующим образом.
testString2 = "Линод! Система" sliceObj1 = срез (2,8,2) подстрока = testString2[sliceObj1] печать (подстрока)
-й!
Как совместить индексирование с другими строковыми функциями
Индексирование и нарезка строк способны решать еще более сложные задачи в сочетании с другими строковыми функциями. Например, вы можете извлечь все символы, расположенные до или после определенной буквы, или разрезать строку пополам в зависимости от ее длины. Вот несколько примеров того, как совместить индексацию и нарезку с другими строковыми функциями.
Функция len определяет длину строки. Вы можете использовать его, чтобы разрезать строку на определенную часть ее длины. В следующем примере создается подстрока, состоящая из второй половины родительской строки. Длина исходной строки вычисляется с использованием
Длина исходной строки вычисляется с использованием len и разделить на два, чтобы определить среднюю точку. Средняя точка становится начальным индексом для операции нарезки. Это хороший пример того, как индекс может быть представлен довольно сложным выражением.
Оператор среза Python принимает только целые значения. Следовательно, начальный индекс должен быть преобразован в целое число, прежде чем его можно будет использовать в операции среза. Функция int округляет действительное число до ближайшего целого числа, которое называется 9.0309 этаж . Поскольку начальная точка является инклюзивной, эта подстрока всегда гарантированно будет не менее половины длины исходной строки. В последних версиях Python вы можете использовать оператор // для выполнения целочисленного деления.
testString3 = "Линод! Система отличная" print(testString3[(int(len(testString3)/2)):])
tem is great
Метод string. находит первый экземпляр подстроки (из одного или нескольких символов) в родительской строке. Индекс первого экземпляра  find
find char в строке можно найти с помощью string.find(char) . При использовании в сочетании с нарезкой строк find позволяет использовать подстроку в качестве разделителя. В следующем примере создается фрагмент из всех букв, предшествующих ! символов. Конечный индекс всегда является исключающим, поэтому разделитель исключается из результирующей подстроки.
String.find возвращает -1 , если символ не найден. Это приводит к разрезанию пустой строки. Вы также можете реализовать специальную обработку для этого случая. В любом случае важно тестировать крайние случаи в любом производственном сценарии.
testString3 = "Линод! Система отличная"
print(testString3[:(testString3.find("!"))])
Linode
Хотя операция нарезки в Python очень мощная, важно не злоупотреблять ею. Могут быть более подходящие альтернативы. Например, возьмем проблему определения того, сколько экземпляров определенного символа встречается в строке. Это потенциально может быть написано с использованием нарезки строк, метода
Могут быть более подходящие альтернативы. Например, возьмем проблему определения того, сколько экземпляров определенного символа встречается в строке. Это потенциально может быть написано с использованием нарезки строк, метода string.find , цикла, счетчика и значительной обработки ошибок. Но есть гораздо более простой и менее подверженный ошибкам способ сделать это. 9Метод 0025 string.count принимает подстроку в качестве параметра и определяет, сколько раз она встречается внутри строки .
testString3 = "Линод! Система отличная"
количество = testString3.count ("е")
распечатать (количество)
3
Полный список строковых методов см. в документации по работе со строками организации Python.
Краткий обзор индексации и нарезки строк Python
Python обрабатывает все строки, включая отдельные символы, как объекты с собственным набором встроенных функций. Строковый объект представляет собой массив символов, с которым можно обращаться так же, как и с другими массивами.