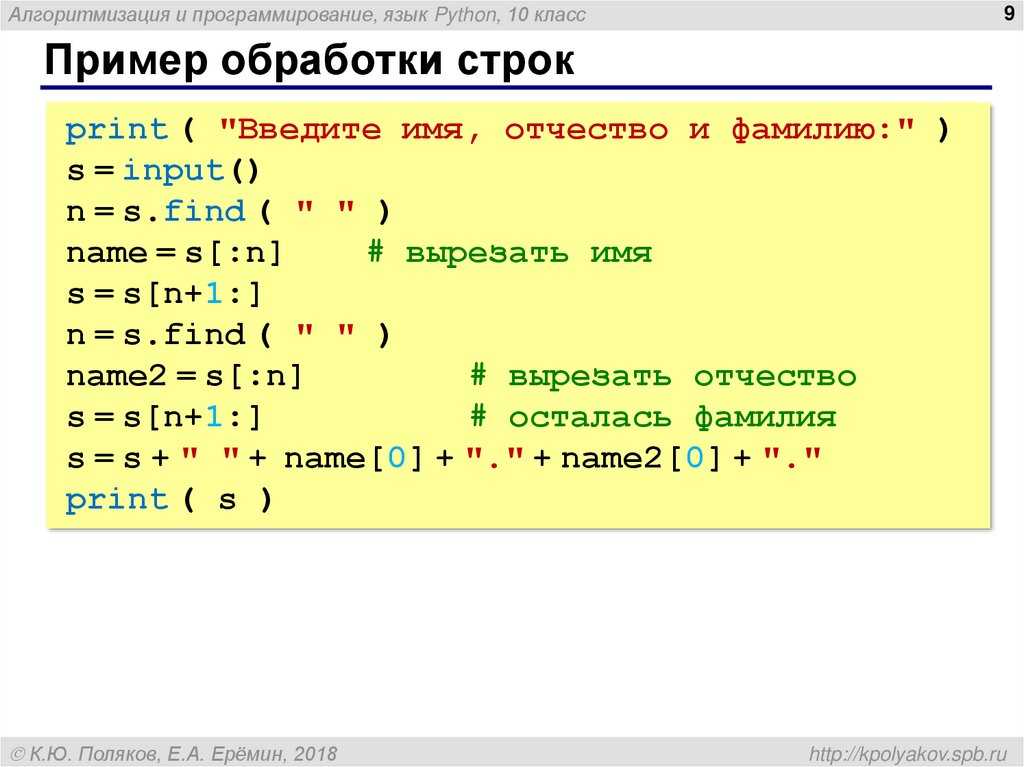
Как разделить строку в Python методом str.split(), примеры с пробелом, запятой и регулярными выражениями
Строки — отличный инструмент в руках Python-разработчиков. В Python строка —
это последовательность символов в кавычках. Она может включать числа, буквы и
символы. С помощью Python строку можно разделить на список подстрок по
определенному разделителю. Это делается с помощью метода split.
В этом материале разберем особенности его использования.
Что делает split в Python?
Функция split сканирует всю строку и разделяет ее в случае нахождения разделителя.
В строке должен быть как минимум один разделитель. Им может выступать в том
числе и символ пробела. Пробел — разделитель по умолчанию.
Если параметр на задать, то разделение будет выполнено именно по символу
пробела.
Синтаксис функции следующий:
string.split(separator*, maxsplit*)
Параметр separator — необязательный, но он позволяет задать разделитель
вручную.
Параметр maxsplit определяет максимальное количество разделений. Значение по
умолчанию — -1, будут выполнены все разделения.
Как разделить строку в Python
Метод .split() разделяет основную строку по разделителю и возвращает список строк.
Копировать Скопировано Use a different Browser
my_st = "Пример строки Python" print(my_st.split())
В примере выше была объявлена строка .split() разделяет ее на список таких строк:
['Пример', 'строки', 'Python']
Вывод содержит список подстрок.
Еще один пример разбиения строки:
Копировать Скопировано Use a different Browser
my_st = "синий,оранжевый,красный" print(my_st.split(","))
В приведенном выше примере мы создали строку my_st с 3 подстроками. В этом случае именно запятая выступит параметром разделения в функции. Вывод будет следующий:
Вывод будет следующий:
['синий', 'оранжевый', 'красный']
Примеры разделения строки в Python
Разделение сроки по пробелу
Если не передать параметр разделителя, то .split() выполнит разделение по пробелу.
Копировать Скопировано Use a different Browser
my_st = "Пример строки Python" print(my_st.split())
Код вернет: ['Пример', 'строки', 'Python'].
Обратите внимание, что мы не указали разделитель, который нужно использовать при вызове функции .split(), поэтому в качестве разделителя используется пробел.
Разделение строки по запятой
Разделителем может выступать запятая (","). Это вернет список строк, которые
изначально были окружены запятыми.
Копировать Скопировано Use a different Browser
my_st = "Например, строка Python" print(my_st.split(","))
Вывод: ['Например', ' строка Python']. Результатом является список подстрок, разделенных по запятым в исходной строке.
Результатом является список подстрок, разделенных по запятым в исходной строке.
Разделение строк по нескольким разделителям
В Python можно использовать даже несколько разделителей. Для этого просто требуется передать несколько символов в качестве разделителей функции split.
Возьмем в качестве примера ситуацию, где разделителями выступают одновременно ,. Задействуем функцию re.split().
Копировать Скопировано Use a different Browser
import re my_st = "Я\nучу; язык,программирования\nPython" print(re.split(";|,|\n", my_st))
Вывод:
['Я', 'учу', ' язык', 'программирования', 'Python']
Здесь мы используем модуль re и функции регулярных выражений. Переменной my_st была присвоена строка с несколькими разделителями, включая «\n», «;» и «,». А функция re.split() вызывается для этой строки с перечисленными выше разделителями.
Вывод — список подстрок, разделенных на основе оригинальной строки.
Как работает параметр maxsplit в функции split?
Этот параметр помогает задать максимальное число разделений. Разделить стоку можно, передав значение этого параметра. Например, если разделителем выступает символ пробела, а значение maxsplit — 1,
то строка будет разделена максимум на 2 подстроки.
Копировать Скопировано Use a different Browser
languages = "Python,Java,Perl,PHP,Swift" print(languages.split(",",1))
В строке languages хранится строка с перечислением разных языков. Функция split принимает запятую в качестве разделителя и значение 1 для параметра maxsplit. Это значит, что разделение будет выполнено только один раз.
['Python', 'Java,Perl,PHP,Swift']
Следующий пример показывает, как выполнить разделение два раза. Здесь разделителем выступает пробел, а значение maxplit равно 2.
Копировать Скопировано Use a different Browser
languages = "Python,Java,Perl,PHP,Swift" print(languages.split(",",2))
['Python', 'Java', 'Perl,PHP,Swift']
Как разделить строку посередине
Функция .split() не может разбить строку на две равных части.
Однако для этого можно использовать срезы (оператор :) и функцию len().
Копировать Скопировано Use a different Browser
languages = "Python,Java,Perl,PHP,Swift" mean_index = len(languages) // 2 print(f"Первая половина: {languages[:mean_index]}") print(f"Вторая половина: {languages[mean_index:]}")
Вывод:
Первая половина: Python,Java,P Вторая половина: erl,PHP,Swift
Значение languages было разбито на две равных части. Для работы был использован оператор целочисленного деления.
Вывод
Вот что вы узнали:
- Функция
splitразбивает строку на подстроки по разделителю. - Параметр
maxsplitпозволяет указать максимально количество разделений. - Если разделитель не задать, то по умолчанию будет выбрано значение пробела.
- Срезы используются для деления строк на равные части.
Разделение строки на списки в Python
В этой статье мы расскажем, как можно разбивать строки на списки. Вы узнаете, как при этом использовать разделители (в частности — как отделять часть строки только по первому разделителю и как быть с последовательно идущими разделителями) и регулярные выражения. Безусловно, эта информация будет особенно полезна начинающим питонистам, но, возможно, и более опытные найдут для себя кое-что интересное.
Мини-задача на разогрев: являются ли две строки анаграммами?
Простое разделение строки и получение списка ее составляющих
Если вы хотите разбить любую строку на подстроки и составить из них список, вы можете просто воспользоваться методом split(sep=None, maxsplit=-1). Этот метод принимает два параметра (опционально). Остановимся пока на первом из них — разделителе (sep).
Разделитель можно задать явно в
качестве параметра, но можно и не
задавать: в этом случае в его роли
выступает пробел.
Пример использования метода split() без указания разделителя:
print("Python2 Python3 Python Numpy".split()) print("Python2, Python3, Python, Numpy".split())
Результат:
['Python2', 'Python3', 'Python', 'Numpy'] ['Python2,', 'Python3,', 'Python,', 'Numpy']
Разделение строки с использованием разделителя
Python может разбивать строки по любому разделителю, указанному в качестве параметра метода split(). Таким разделителем может быть, например, запятая, точка или любой другой символ (или даже несколько символов).
Давайте рассмотрим пример, где в качестве разделителя выступает запятая и точка с запятой (это можно использовать для работы с CSV-файлами).
print("Python2, Python3, Python, Numpy". split(','))
print("Python2; Python3; Python; Numpy".split(';'))
split(','))
print("Python2; Python3; Python; Numpy".split(';'))Результат:
['Python2', ' Python3', ' Python', ' Numpy'] ['Python2', ' Python3', ' Python', ' Numpy']
Как видите, в результирующих списках отсутствуют сами разделители.
Если вам нужно получить список, в который войдут и разделители (в качестве отдельных элементов), можно разбить строку по шаблону, с использованием регулярных выражений (см. документацию re.split). Когда вы берете шаблон в захватывающие круглые скобки, группа в шаблоне также возвращается как часть результирующего списка.
import re
sep = re.split(',', 'Python2, Python3, Python, Numpy')
print(sep)
sep = re.split('(,)', 'Python2, Python3, Python, Numpy')
print(sep)Результат:
['Python2', ' Python3', ' Python', ' Numpy'] ['Python2', ',', ' Python3', ',', ' Python', ',', ' Numpy']
Если вы хотите, чтобы разделитель был частью каждой подстроки в списке, можно обойтись без регулярных выражений и использовать list comprehensions:
text = 'Python2, Python3, Python, Numpy' sep = ',' result = [x+sep for x in text.split(sep)] print(result)
Результат:
['Python2,', ' Python3,', ' Python,', ' Numpy,']
Разделение многострочной строки (построчно)
Создать список из отдельных строчек многострочной строки можно при помощи того же метода split(), указав в качестве разделителя символ новой строки \n. Если текст содержит лишние пробелы, их можно удалить при помощи методов strip() или lstrip():
str = """
Python is cool
Python is easy
Python is mighty
"""
list = []
for line in str.split("\n"):
if not line.strip():
continue
list.append(line.lstrip())
print(list)Результат:
['Python is cool', 'Python is easy', 'Python is mighty']
Разделение строки-словаря и преобразование ее в списки или словарь
Допустим, у нас есть строка, по сути являющаяся словарем и содержащая пары ключ-значение в виде key => value.
dictionary = """\
key1 => value1
key2 => value2
key3 => value3
"""
mydict = {}
listKey = []
listValue = []
for line in dictionary.split("\n"):
if not line.strip():
continue
k, v = [word.strip() for word in line.split("=>")]
mydict[k] = v
listKey.append(k)
listValue.append(v)
print(mydict)
print(listKey)
print(listValue)Результат:
{'key3': 'value3', 'key2': 'value2', 'key1': 'value1'}
['key1', 'key2', 'key3']
['value1', 'value2', 'value3']Отделение указанного количества элементов
Метод split() имеет еще один опциональный параметр — maxsplit. С его помощью можно указать, какое максимальное число «разрезов» нужно сделать. По умолчанию
По умолчанию maxsplit=-1, это означает, что число разбиений не ограничено.
Если вам нужно отделить от строки несколько первых подстрок, это можно сделать, указав нужное значение maxsplit. В этом примере мы «отрежем» от строки первые три элемента, отделенные запятыми:
str = "Python2, Python3, Python, Numpy, Python2, Python3, Python, Numpy"
data = str.split(", ",3)
for temp in data:
print(temp)Результат:
Python2 Python3 Python Numpy, Python2, Python3, Python, Numpy
Разделение строки при помощи последовательно идущих разделителей
Если вы для разделения строки используете метод split() и не указываете разделитель, то разделителем считается пробел. При этом последовательно идущие пробелы трактуются как один разделитель.
Но если вы указываете определенный разделитель, ситуация меняется. При работе метода будет считаться, что последовательно идущие разделители разделяют пустые строки. Например, '1,,2'.split(',') вернет ['1', '', '2'].
Если вам нужно, чтобы последовательно идущие разделители все-таки трактовались как один разделитель, нужно воспользоваться регулярными выражениями. Разницу можно видеть в примере:
import re
print('Hello1111World'.split('1'))
print(re.split('1+', 'Hello1111World' ))Результат:
['Hello', '', '', '', 'World'] ['Hello', 'World']
regex — Разобрать строку в python
спросил
Изменено 6 месяцев назад
Просмотрено 15 тысяч раз
Я хотел бы превратить это:
mystr = 'foo1 (foo2 foo3 (foo4))'
в:
['foo1','foo2 foo3 (foo4)']
Итак, в основном мне приходится разбивать на основе количества пробелов/табуляций и скобок.
Я видел, что функция повторного разделения пакетов может обрабатывать несколько разделителей (Python: разделить строку с несколькими разделителями), но я не могу понять правильный подход к анализу таких строк.
Что было бы лучшим, самым питоническим и простым подходом?
- питон
- регулярное выражение
7
Насколько я понимаю, это соответствует тому, что вы хотите, и довольно просто. Он просто использует некоторую нарезку, чтобы изолировать первое слово и часть в скобках. Он также должен использовать полосу пару раз из-за лишних пробелов. Это может показаться немного многословным, но, честно говоря, если задачу можно выполнить с помощью таких простых строковых операций, мне кажется, что сложный синтаксический анализ не нужен (хотя, возможно, я ошибся). Обратите внимание, что этот является гибким в отношении количества пробелов для разделения.
mystr = 'foo1 (foo2 foo3 (foo4))' mystr = mystr.strip() я = mystr.index(' ') a = mystr[:i].strip() b = mystr[i:].strip()[1:-1] распечатать ([а, б])
с выводом
['foo1', 'foo2 foo3 (foo4)']
Хотя мне до сих пор не совсем ясно, нужно ли вам это. Дайте мне знать, если это работает или что нужно изменить.
3
Если структура вашей строки так жестко определена, как вы говорите, вы можете использовать регулярное выражение для ее довольно легкого разбора:
импорт повторно
mystr = 'foo1 (foo2 foo3 (foo4))'
шаблон = r'(\S+)\s+\((.*)\)'
match = re.search(шаблон, mystr)
results = match.groups() # ('foo1', 'foo2 foo3 (foo4)')
Будьте осторожны с этим подходом, если ваш реальный вклад не так хорошо определен, как вы предложили свой вопрос. Регулярные выражения могут анализировать только обычные языки, а скобки обычно работают не так, как обычно. В этом вопросе вы заботились только об обработке скобок с одним набором (самых внешних), поэтому работает простое жадное совпадение. Адаптировать это решение к другим форматам ввода может быть сложно или даже невозможно, даже если они кажутся очень похожими!
Адаптировать это решение к другим форматам ввода может быть сложно или даже невозможно, даже если они кажутся очень похожими!
[mystr.split(' ')[0].strip(),mystr.split(' ')[1][1:-1]]
Простой однострочный. Вывод:
['foo1', 'foo2 foo3 (foo4)']
Зарегистрируйтесь или войдите в систему
Зарегистрируйтесь с помощью Google
Зарегистрироваться через Facebook
Зарегистрируйтесь, используя электронную почту и пароль
Опубликовать как гость
Электронная почта
Требуется, но не отображается
Опубликовать как гость
Электронная почта
Требуется, но не отображается
Python, анализ строки путем извлечения подстроки символов и цифр
спросил
Изменено 1 год, 3 месяца назад
Просмотрено 2к раз
У меня есть строка, полученная в результате выполнения некоторого алгоритма машинного обучения, которая обычно состоит из нескольких строк. В начале и в конце могут быть несколько строк, не содержащих никаких символов (кроме пробелов), а между ними должно быть 2 строки, каждая из которых содержит слово, за которым следуют некоторые числа и (иногда) другие символы.
В начале и в конце могут быть несколько строк, не содержащих никаких символов (кроме пробелов), а между ними должно быть 2 строки, каждая из которых содержит слово, за которым следуют некоторые числа и (иногда) другие символы.
Примерно так
первое_слово 3 5 7 @ 4 второе_слово 4 5 67| 5 [
Мне нужно извлечь 2 слова и числовые символы.
Я могу удалить пустые строки, выполнив что-то вроде:
lines_list = initial_string.split("\n")
для строки в lines_list:
если len(line) > 0, а не line.isspace():
печать (строка)
но теперь мне интересно:
- если есть более надежный, общий способ
- как разобрать каждую из оставшихся 2 центральных строк, извлекая слова и цифры (и отбрасывая другие символы, смешанные между цифрами, если они есть)
Я полагаю, что reg-выражения могут быть полезны, но я никогда ими не пользовался, поэтому сейчас немного борюсь
- python
- string
- text-parsing
1
Здесь я бы использовал re.