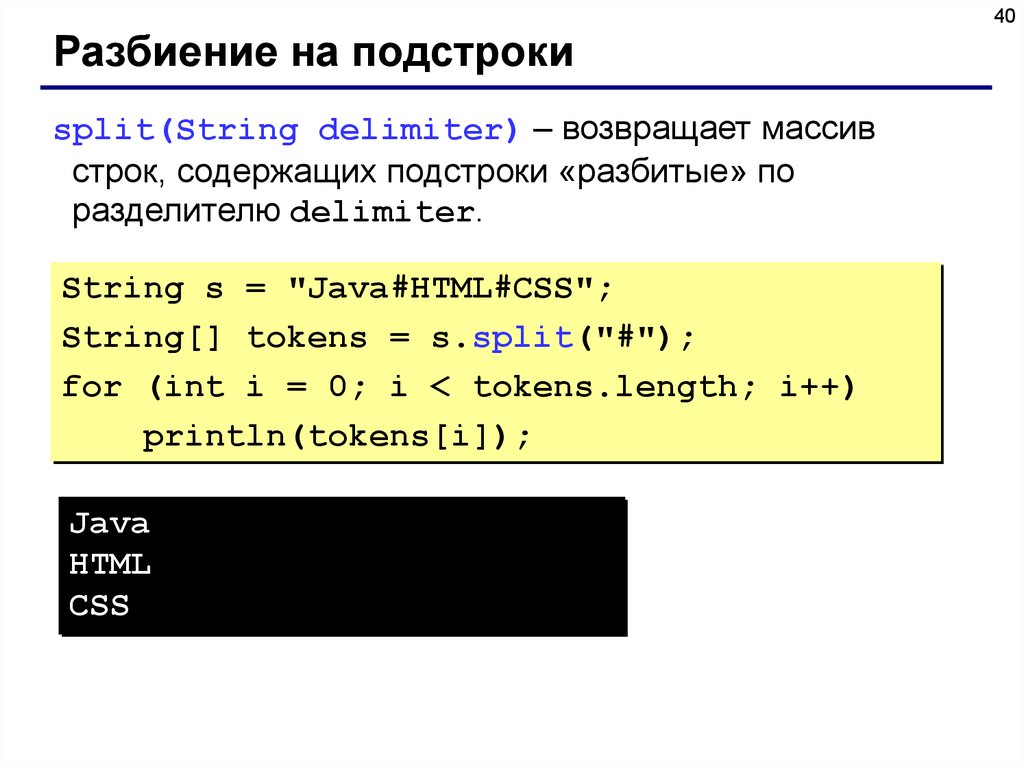
15 — Нахождение строк, соответствующих шаблону
- Сырые строки
r'' - Метод
group() - Запоминающие группы
- Ограничение жадности квантификаторов
Если в регулярном выражениии используются специальные значения с \, то лучше использовать синтаксис для «сырых» (raw) строк. Приведем простой пример использования «сырых» строк: предположим, что нужно написать строку, которая бы содержала два подряд идущих символа: \ и n. Мы уже знаем, что если просто написать '\n', то Python превратит это сочетание в символ переноса строки. Однако, если написать r'\n', то Python не будет производить никаких преобразований внутри этой строки.
Проверим, есть ли числа в строке:
if re.search(r'\d', 'Я родился 30 февраля 1930 года'):
print(True)
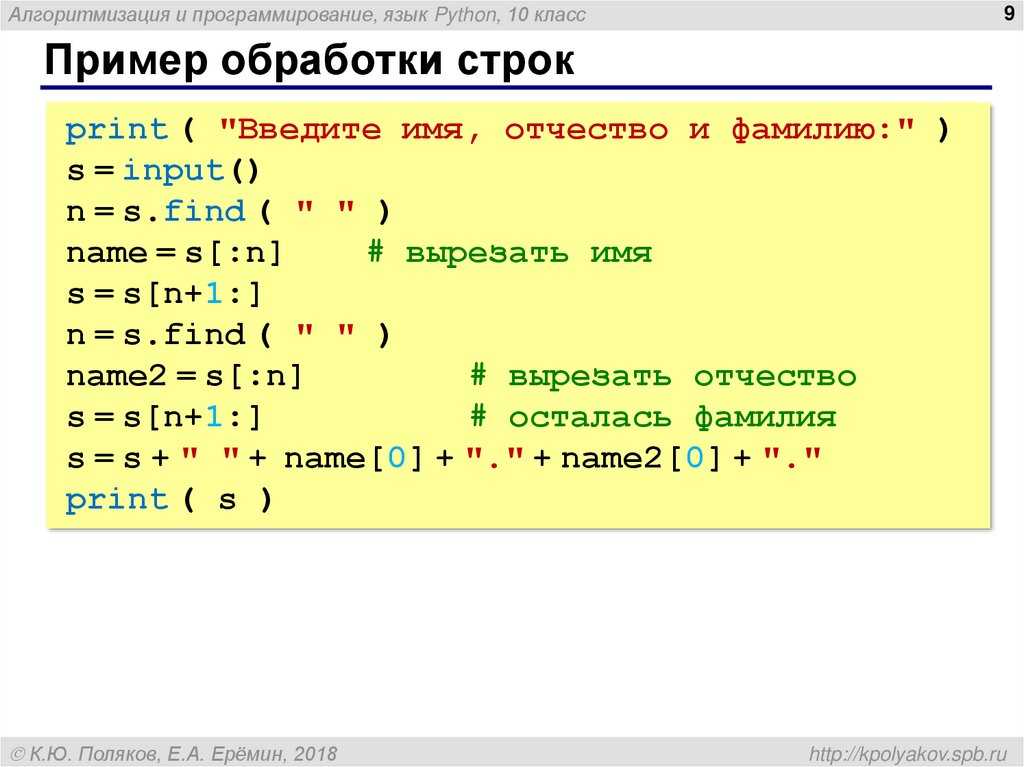
Часто нам не просто нужно узнать, находится ли что-то нас интересующее в строке, но и узнать, что именно нашлось. Но функция
Но функция
>>> s = 'abc'
>>> r = re.search('a', s)
>>> r
<_sre.SRE_Match object; span=(0, 1), match='a'>
Это такой объект, а нам хотелось бы саму найденную строку.
Чтобы получить найденную строку, существует метод group():
first_match = re.search('кот.', 'Кот пришёл к коту и спросил кота: «Бойкот, котелок или скотч?»')
if first_match:
first_match.group() # 'кот '
else:
print('Nothing found.')
Если нужно найти в строке несколько подстрок, то каждую из них можно выделить с помощью круглых скобок.
>>> s = 'корова молоко'
>>> r = re.search('(.+?оро.+?) (.+?оло.+)', s)
>>> r
<_sre.SRE_Match object; span=(0, 12), match='корова молоко'>
>>> r.group(1)
'корова'
>>> r.group(2)
'молоко'
Если мы хотим выделить в шаблоне только часть строки и сделать её запоминающей группой, то у нас возможны случаи двойного толкования шаблона, как в примере выше:
>>> s = 'корова молоко' >>> r = re..+? ', s) >>> print(r.group()) Онегин,
Продолжаем делать задание по регуляркам
Python: поиск вхождений и замена в строках используя регулярки
Что такое регулярки?
Регулярные выражения (regex) позволяют вам выполнять сложный поиск подстроки в тексте для различных целей: проверка вхождения подстроки, удаление, замена и прочие действия.
В Python для этих целей предназначена библиотека re
import re
Базовый синтаксис регулярных варажений состоит из следующих операторов:
| . | Любой символ, кроме новой строки \n. |
| ? | Должен содержать 0 или 1 вхождение |
| + | Должен содержать 1 и более вхождений |
| * | Должен содержать 0 и более вхождений |
| \w | Любая цифра или буква (\W — все, кроме буквы или цифры) |
| \d | Любая цифра [0-9] (\D — все, кроме цифры) |
| \s | Любой пробельный символ (\S — любой непробельный символ) |
| \b | Граница слова |
[. и $ и $ | Начало и конец строки соответственно |
| {n,m} | От n до m вхождений ({,m} — от 0 до m) |
| a|b | Соответствует a или b |
| () | Группирует выражение и возвращает найденный текст |
| \t, \n, \r | Символ табуляции, новой строки и возврата каретки соответственно |
Поиск подстроки в тексте
В Python поиск подстроки осуществляется при помощи функций re.match(), re.search(), re.finditer() и re.findall().
Первые 3 метода возвращают None если ничего не найдено, и объект Match если что-то нашлось.
Объект Match
Чтобы работать с найденным результатом, полезно знать, что включает в себя объект Match.
- group() или group(0) — возвращает найденную подстроку полностью, которая совпала с выражением,
- group(N) где N номер группы — вернет только подстроку соответствующей группы,
- groups() — вернет кортеж, элементы которого являются подстроками которые попали в соответствующие группы,
- groupdict() — вернет словарь, ключами которого являются имена групп, а их значения — соответствующие подстроки,
- start, end — вернет начальный и конечный индекс совпадения с регулярным выражением,
- span — вернет кортеж с начальным и конечным индексом совпадения с регулярным выражением.
re.match(pattern, string)
Данный метод позволяет искать по заданному шаблону только в начале строки. Если найдено, то возвращает объект Match с найденным совпадением, иначе (если не найдено) вернет None.
re.search(pattern, string)
В отличие от re.match() ищет по всей строки. Если найдено, то возвращает объект Match с первым найденным совпадением, иначе (если не найдено) вернет None.
re.findall(pattern, string)
Также как и re.search ищет вхождения по всей строке, но в ответе возвращает все вхождения в виде списка (list).
Примеры поиска подстроки
import re
# исходные строки
born1 = "27-11-1984 #ABC Дата рождения # 27-11-1984"
born2 = "ABC#27-11-1984 # Дата рождения # 27-11-1984"
# пример поиска при помощи match()
r1 = re.match(r'ABC', born1)
r2 = re.match(r'ABC', born2)
if r1:
print(f'r1: {r1. group()}')
if r2:
print(f'r2: {r2.group()}')
# РЕЗУЛЬТАТ ОТВЕТА:
> r2: ABC
# пример поиска при помощи search()
r1 = re.search(r'ABC', born1)
r2 = re.search(r'ABC', born2)
if r1:
print(f'r1: {r1.group()}')
if r2:
print(f'r2: {r2.group()}')
# РЕЗУЛЬТАТ ОТВЕТА:
> r1: ABC
> r2: ABC
# пример поиска при помощи findall()
born3 = "ABC#27-11-1984 #ABC Дата рождения # 27-11-1984"
r3 = re.findall(r'ABC', born3)
if r3:
print(f'r3: {r3}')
# РЕЗУЛЬТАТ ОТВЕТА:
> r3: ['ABC', 'ABC']
group()}')
if r2:
print(f'r2: {r2.group()}')
# РЕЗУЛЬТАТ ОТВЕТА:
> r2: ABC
# пример поиска при помощи search()
r1 = re.search(r'ABC', born1)
r2 = re.search(r'ABC', born2)
if r1:
print(f'r1: {r1.group()}')
if r2:
print(f'r2: {r2.group()}')
# РЕЗУЛЬТАТ ОТВЕТА:
> r1: ABC
> r2: ABC
# пример поиска при помощи findall()
born3 = "ABC#27-11-1984 #ABC Дата рождения # 27-11-1984"
r3 = re.findall(r'ABC', born3)
if r3:
print(f'r3: {r3}')
# РЕЗУЛЬТАТ ОТВЕТА:
> r3: ['ABC', 'ABC'] Разделение и замена подстрок
re.split(pattern, string, [maxsplit=0])Данный метод разделяет строку по заданному шаблону и формирует список (list). Параметр maxsplit позволяет ограничивать количество частей, на которые следует разделять строку.
import re born3 = "ABC#27-11-1984 #ABC Дата рождения # 27-11-1984" r3 = re.split(r'ABC', born3) if r3: print(f'r3: {r3}') # РЕЗУЛЬТАТ ОТВЕТА: r3: ['', '#27-11-1984 #', ' Дата рождения # 27-11-1984']
re.sub(pattern, repl, string)
Данный метод позволяет произвести замену одной подстроки в тексте на другую. Пример замены подстроки «ABC» на пустое значение.
born3 = "ABC#27-11-1984 #ABC Дата рождения # 27-11-1984"
r3 = re.sub(r'ABC', '', born3)
if r3:
print(f'r3: {r3}')
# РЕЗУЛЬТАТ ОТВЕТА:
r3: #27-11-1984 # Дата рождения # 27-11-1984Компиляция шаблона регулярного выражения
Иногда есть потребность один раз задать шаблон регулярного выражения, а дальше вызывать его в нескольких местах.
Для этого удобнее всего обернуть этот шаблон регулярки в объект при помощи метода re.compile.
import re # строка born3 = "ABC#27-11-1984 #ABC Дата рождения # 27-11-1984" # шаблон регулярки оборачиваем в объект при помощи compile regex = re.compile('ABC') # теперь из этого объекта мы можем вызывать все те же методы, при этом не указывая в их аргументе pattern r3 = regex.sub('', born3) if r3: print(f'r3: {r3}') # РЕЗУЛЬТАТ ОТВЕТА: r3: #27-11-1984 # Дата рождения # 27-11-1984
Методы проверки наличия подстроки в строке Python
В этом руководстве по Python мы рассмотрим, как можно проверить, содержит ли строка Python подстроку. Мы рассмотрим различные методы и подробно объясним варианты их использования.
Содержание: проверьте, содержит ли строка Python подстроку
- Зачем проверять, содержит ли строка Python подстроку?
- Использование оператора in
- Использование строковых методов
- Ограничения и предостережения
Зачем проверять, содержит ли строка Python подстроку?
Мы проверяем, содержит ли строка Python подстроку по нескольким причинам, однако чаще всего она используется в условных операторах.
В этом случае запускается определенный код. Другое распространенное использование — поиск индекса подстроки в строке.
Скорее всего, вы сталкивались с функцией contains в других языках программирования. Python также поддерживает метод __contains__ . Он также поддерживает несколько более быстрых и удобочитаемых методов, чтобы проверить, содержит ли строка Python подстроку. Мы собираемся изучить их ниже.
Использование оператора
‘in’ : Оператор in — это самый простой и точный способ проверить, содержит ли строка Python подстроку.
в и не в являются операторами принадлежности, они принимают два аргумента и оценивают, является ли один членом другого. Они возвращают логическое значение. Это эффективная альтернатива методу __contains__ , и его также можно использовать для проверки существования элемента в списке.
Метод in можно использовать только для проверки того, содержит ли строка Python подстроку. Если вы хотите вернуть индекс подстроки, следующее решение обеспечивает это.
Если вы хотите вернуть индекс подстроки, следующее решение обеспечивает это.
Синтаксис в :
подстрока в строке
Синтаксис для не в такой же.
Код для проверки наличия подстроки в строке Python:
, если «Нанять» в «Нанять лучших фрилансеров»:
распечатать("Существует")
еще:
печатать("Не существует")
#Вывод - существует
Оператор in чувствителен к регистру, и приведенный выше код вернул бы false, если бы подстрока была «hire», поэтому рекомендуется использовать его с методом .lower() .
Этот метод преобразует строку в нижний регистр. Поскольку строки неизменяемы, это не повлияет на исходную строку.
, если "нанять" в "Нанять лучших фрилансеров".lower():
распечатать("Существует")
еще:
печатать("Не существует")
#Вывод - существует
Использование строковых методов:
Python поставляется с несколькими строковыми методами, которые можно использовать для проверки того, содержит ли строка Python подстроку.
find() и Index() .Эти методы находят и возвращают индекс подстроки. Однако у них есть несколько минусов, о которых мы подробно поговорим.
Использование index()
Метод string.index() возвращает начальный индекс подстроки, переданной в качестве параметра.
Однако основной недостаток заключается в том, что он возвращает ValueError в случае, если подстрока не существует. Мы можем решить эту проблему, используя Try Except.
Синтаксис index():
string.index(значение, начало, остановка)
Здесь строка относится к строке Python, а значение — подстроке.
Синтаксис также содержит два необязательных параметра start и stop. Они принимают значения индекса и помогают искать подстроку в определенном диапазоне индексов.
Код с использованием index():
попытка:
"Нанять лучших фрилансеров". index("Нанять")
кроме ValueError:
печатать("Не существует")
еще:
печать (жало.индекс (сти))
#Вывод = 0
index("Нанять")
кроме ValueError:
печатать("Не существует")
еще:
печать (жало.индекс (сти))
#Вывод = 0
index() чувствителен к регистру, убедитесь, что вы используете функцию .lower() , чтобы избежать ошибок.
попытка:
"Наймите лучших фрилансеров".lower().index("нанять")
кроме ValueError:
печатать("Не существует")
еще:
печать (жало.индекс (сти))
#Вывод = 0
Использование find():
string.find() — это еще один метод, который можно использовать для проверки нашего запроса.
Подобно методу index() , find() также возвращает начальный индекс подстроки. Однако find() возвращает -1, если подстрока не существует. -1 — это отрицательный индекс крайнего левого символа.
Синтаксис find():
string.find(значение, начало, конец)
Синтаксис и параметры find() такие же, как index()
Код, использующий find():
, если "Нанять лучших фрилансеров".find("Нанять") != -1: print("Нанять лучших фрилансеров".find("Нанять")) еще: печатать("Не существует")
И снова find() также чувствителен к регистру и должен использоваться метод .lower() .
если "Нанять лучших фрилансеров".lower().find("нанять") != -1:
print("Нанять лучших фрилансеров".find("Нанять"))
еще:
печатать("Не существует")
Проверить, содержит ли строка Python подстроку — Ограничения и предостережения:
- Не забудьте использовать методы
.lower(), так как все методы чувствительны к регистру. - Который использует метод
index(), чтобы убедиться, что он помещен в условие попытки и исключения.
Python: найти подстроку в строке и вернуть индекс подстроки
спросил
Изменено 2 года, 9несколько месяцев назад
Просмотрено 259 тысяч раз
У меня есть:
функция:
def find_str(s, char)и строка:
"С Днем Рождения",
По сути, я хочу ввести "py" и вернуть 3 , но вместо этого я продолжаю получать 2 .
Код:
def find_str(s, char):
индекс = 0
если символ в s:
символ = символ [0]
для вп с:
если ch в s:
индекс += 1
если ч == символ:
возвращаемый индекс
еще:
возврат -1
print(find_str("С днем рождения", "py"))
Не знаю, что случилось!
- python
- строка
- индексация
- подстрока
1
Есть встроенный метод find для строковых объектов.
с = "С днем рождения" с2 = "ру" печать (s.find (s2))
Python — это «язык, работающий от батареек», в нем уже написан код, который делает большую часть того, что вы хотите (все, что вы хотите).. если это не домашнее задание 🙂
find возвращает -1, если строка не найдена.
3
В идеале вы должны использовать str. find или str.index , как сказал сумасшедший ёжик. Но вы сказали, что не можете…
find или str.index , как сказал сумасшедший ёжик. Но вы сказали, что не можете…
Ваша проблема в том, что ваш код ищет только первый символ вашей строки поиска, которая (первая) находится в индексе 2.
Вы в основном говорите, если char[0] находится в s , приращение индекса до ch == char[0] , который вернул 3, когда я тестировал его, но он все еще был неправильным. Вот как это сделать.
определение find_str(s, char):
индекс = 0
если символ в s:
с = символ [0]
для вп с:
если ч == с:
если s[index:index+len(char)] == char:
возвращаемый индекс
индекс += 1
возврат -1
print(find_str("С днем рождения", "py"))
print(find_str("С днем рождения", "rth"))
print(find_str("С днем рождения", "rh"))
Результат:
3 8 -1
4
В регулярном выражении есть еще одна опция, поиск метод
импорт ре строка = 'С Днем Рождения' шаблон = 'ру' print(re.search(pattern, string).span()) ## печатает начальный и конечный индексы print(re.search(pattern, string).span()[0]) ## это делает то, что вы хотели
Кстати, если вы хотите найти все вхождения шаблона, а не только первое, вы можете использовать finditer метод
импорт повторно string = 'я думаю, что то, что там написал тот студент, не совсем так' шаблон = 'это' print([match.start() для совпадения в re.finditer(шаблон, строка)])
, который напечатает все начальные позиции матчей.
Добавление ответа @demented hedgehog при использовании find()
С точки зрения эффективности
Возможно, стоит сначала проверить, находится ли s1 в s2, прежде чем вызывать find() .
Это может быть более эффективно, если вы знаете, что в большинстве случаев s1 не будет подстрокой s2
Поскольку оператор в очень эффективен
s1 в s2
Преобразование может быть более эффективным:
index = s2.find(s1)
до
индекс = -1 если s1 в s2: индекс = s2.find(s1)
Это полезно, когда find() будет часто возвращать -1.
Я обнаружил, что это значительно быстрее с find() вызывалась много раз в моем алгоритме, поэтому я подумал, что стоит упомянуть
Вот простой подход:
my_string = 'abcdefg'
печать (текст. найти ('def'))
Вывод:
3
Если подстроки нет, вы получите -1 . Например:
my_string = 'abcdefg'
печать (текст. найти ('xyz'))
Вывод:
-1
Иногда вам может понадобиться создать исключение, если подстроки нет:
my_string = 'abcdefg'
print(text.index('xyz')) # Возвращает индекс, только если он присутствует
Вывод:
Трассировка (последний последний вызов):
Файл «test. py», строка 6, в print(text.index(‘xyz’))
py», строка 6, в print(text.index(‘xyz’))
ValueError: подстрока не найдена
опоздала на вечеринку, искала то же самое, поскольку «in» недействительно, я только что создал следующее.
по определению find_str(полный, дополнительный):
индекс = 0
суб_индекс = 0
позиция = -1
для ch_i, ch_f в перечислении (полное):
если ch_f.lower() != sub[sub_index].lower():
позиция = -1
суб_индекс = 0
если ch_f.lower() == sub[sub_index].lower():
если sub_index == 0 :
позиция = ch_i
если (len(sub) - 1) <= sub_index :
перерыв
еще:
суб_индекс += 1
обратная позиция
print(find_str("С днем рождения", "py"))
print(find_str("С днем рождения", "rth"))
print(find_str("С днем рождения", "rh"))
который производит
3 8 -1
удалить нижний() в случае, если поиск без учета регистра не требуется.