Модуль codecs в Python, реестр кодеков.
Модуль codecs определяет базовые классы для стандартных кодеков Python (кодировщик и декодировщик) и предоставляет доступ к внутреннему реестру кодеков Python, который управляет процессом поиска кодека и обработки ошибок.
Большинство стандартных кодеков — это текстовые кодировки, которые кодируют текст в байты, но есть также кодеки, которые кодируют текст в текст и байты в байты. В Python уже имеется большое количество стандартных кодеков и маловероятно, что приложению потребуется определять собственный кодировщик или декодировщик. Но иногда необходимо сделать свой кодек, для этих целей модуль codecs, предоставляет несколько базовых классов, чтобы упростить процесс.
Допустим надо сделать кодек, который будет инвертировать заглавные буквы в строчные, а строчные — в заглавные. Можно пойти простым путем и определить функцию кодирования, которая будет выполнять это преобразование для входной строки
import string
def invert(text):
"""Возвращает новую строку с преобразованными
заглавными буквами в строчные, а строчные - в заглавные
"""
return ''.
join(
c.upper() if c in string.ascii_lowercase
else c.lower() if c in string.ascii_uppercase
else c
for c in text
)
>>> invert('Hello World')
'hELLO wORLD'
>>> invert('hELLO wORLD')
'Hello World'

Такая реализация неэффективна, особенно для очень больших текстовых строк. Модуль codecs включает в себя некоторые вспомогательные функции для создания кодеков, основанных на карте символов. Карта символов состоит из двух словарей. Карта преобразует символьные значения из входной строки в байтовые значения на выходе, а карта декодирования — в обратном направлении. Сначала создадим карту декодирования, а затем с помощью функции make_encoding_map() преобразуйте ее в карту кодирования.
# encoding_decoding_map.py
import codecs
import string
# сопоставить символы самим себе
decoding_map = codecs.make_identity_dict(range(256))
# список пар порядковых номеров соответствий
# строчной букв - заглавной
pairs = list(zip(
[ord(c) for c in string. ascii_lowercase],
[ord(c) for c in string.ascii_uppercase],
))
# теперь изменим карту 'decoding_map' так чтобы номера
# строчных букв соответствовали заглавной и наоборот
decoding_map.update({
upper: lower
for (lower, upper)
in pairs
})
decoding_map.update({
lower: upper
for (lower, upper)
in pairs
})
# Создадим отдельную карту кодирования
encoding_map = codecs.make_encoding_map(decoding_map)
>>> codecs.charmap_encode('Hello World', 'strict', encoding_map)
# (b'hELLO wORLD', 11)
>>> codecs.charmap_encode(b'hELLO wORLD', 'strict', decoding_map)
('Hello World', 11)
ascii_lowercase],
[ord(c) for c in string.ascii_uppercase],
))
# теперь изменим карту 'decoding_map' так чтобы номера
# строчных букв соответствовали заглавной и наоборот
decoding_map.update({
upper: lower
for (lower, upper)
in pairs
})
decoding_map.update({
lower: upper
for (lower, upper)
in pairs
})
# Создадим отдельную карту кодирования
encoding_map = codecs.make_encoding_map(decoding_map)
>>> codecs.charmap_encode('Hello World', 'strict', encoding_map)
# (b'hELLO wORLD', 11)
>>> codecs.charmap_encode(b'hELLO wORLD', 'strict', decoding_map)
('Hello World', 11)
В данном случае карты кодирования и декодирования символов одинаковы, это может быть не всегда так. Функция None, чтобы пометить кодировку как неопределенную.
Созданные карты символов кодирования и декодирования поддерживают все стандартные обработчики ошибок, поэтому для соответствия этой части API не требуется никакой дополнительной работы.
Для создания полноценного кодека необходимо установить несколько дополнительных классов и зарегистрировать кодировщик и декодировщик. Функция codecs.register() добавляет функцию поиска в реестр кодеков, чтобы ее можно было найти. Функция поиска должна принимать один строковый аргумент с именем кодировки и возвращать объект codecs.CodecInfo()
None если нет.Экземпляр CodecInfo, возвращаемый функцией поиска, сообщает кодекам, как кодировать и декодировать, используя все различные поддерживаемые механизмы: кодирование и декодирование без сохранения состояния, инкрементное кодирование и декодирование и потоковое кодирование и декодирование.
from encoding_decoding_map import encoding_map, decoding_map
import codecs
class InvertCodec(codecs.Codec):
"кодирование/декодирование без сохранения состояния"
def encode(self, input, errors='strict'):
return codecs.charmap_encode(input, errors, encoding_map)
def decode(self, input, errors='strict'):
return codecs. charmap_decode(input, errors, decoding_map)
class InvertIncrementalEncoder(codecs.IncrementalEncoder):
def encode(self, input, final=False):
data, nbytes = codecs.charmap_encode(input,
self.errors, encoding_map)
return data
class InvertIncrementalDecoder(codecs.IncrementalDecoder):
def decode(self, input, final=False):
data, nbytes = codecs.charmap_decode(input,
self.errors, decoding_map)
return data
class InvertStreamReader(InvertCodec, codecs.StreamReader):
pass
class InvertStreamWriter(InvertCodec, codecs.StreamWriter):
pass
def find_invert(encoding):
"""Return the codec for 'invert'.
"""
if encoding == 'invert':
return codecs.CodecInfo(
name='invert',
encode=InvertCodec().encode,
decode=InvertCodec().decode,
incrementalencoder=InvertIncrementalEncoder,
incrementaldecoder=InvertIncrementalDecoder,
streamreader=InvertStreamReader,
streamwriter=InvertStreamWriter,
)
return None
codecs.
charmap_decode(input, errors, decoding_map)
class InvertIncrementalEncoder(codecs.IncrementalEncoder):
def encode(self, input, final=False):
data, nbytes = codecs.charmap_encode(input,
self.errors, encoding_map)
return data
class InvertIncrementalDecoder(codecs.IncrementalDecoder):
def decode(self, input, final=False):
data, nbytes = codecs.charmap_decode(input,
self.errors, decoding_map)
return data
class InvertStreamReader(InvertCodec, codecs.StreamReader):
pass
class InvertStreamWriter(InvertCodec, codecs.StreamWriter):
pass
def find_invert(encoding):
"""Return the codec for 'invert'.
"""
if encoding == 'invert':
return codecs.CodecInfo(
name='invert',
encode=InvertCodec().encode,
decode=InvertCodec().decode,
incrementalencoder=InvertIncrementalEncoder,
incrementaldecoder=InvertIncrementalDecoder,
streamreader=InvertStreamReader,
streamwriter=InvertStreamWriter,
)
return None
codecs.
register(find_invert)
Для кодирования/декодирования без сохранения состояния переопределяем Codec.encode() и Codec.decode() с новой реализацией, вызывая функции charmap_encode() и charmap_decode() соответственно. Каждый метод должен возвращать кортеж, содержащий преобразованные данные и количество использованных входных байтов или символов.
IncrementalEncoder и IncrementalDecoder служат в качестве базовых классов для дополнительных интерфейсов. Методы encode() и decode() инкрементных классов определены таким образом, что они возвращают только фактические преобразованные данные. Любая информация о буферизации сохраняется как внутреннее состояние. Созданный кодек invert не требует буферизации данных, т.к. использует взаимно однозначное отображение.
StreamWriter также нуждаются в методах encode() и decode () т. к. они должны возвращать то же значение, что и версия из кодека, для реализации может использоваться множественное наследование.
к. они должны возвращать то же значение, что и версия из кодека, для реализации может использоваться множественное наследование.
# Stateless encoder/decoder
encoder = codecs.getencoder('invert')
text = 'Hello Word'
encoded_text, consumed = encoder(text)
print('Encoded "{}" to "{}", consuming {} characters'.format(
text, encoded_text, consumed))
# Stream writer
import io
buffer = io.BytesIO()
writer = codecs.getwriter('invert')(buffer)
print('StreamWriter for io buffer: ')
print(' writing "abcDEF"')
writer.write('abcDEF')
print(' buffer contents: ', buffer.getvalue())
# Incremental decoder
decoder_factory = codecs.getincrementaldecoder('invert')
decoder = decoder_factory()
decoded_text_parts = []
for c in encoded_text:
decoded_text_parts.append(
decoder.decode(bytes([c]), final=False)
)
decoded_text_parts.append(decoder.decode(b'', final=True))
decoded_text = ''.join(decoded_text_parts)
print('IncrementalDecoder converted {!r} to {!r}'. format(
encoded_text, decoded_text))
# Encoded "Hello Word" to "b'hELLO wORLD'", consuming 6 characters
# StreamWriter for io buffer:
# writing "Hello Word"
# buffer contents: b'hELLO wORLD'
# IncrementalDecoder converted b'hELLO wORLD' to 'Hello Word'
format(
encoded_text, decoded_text))
# Encoded "Hello Word" to "b'hELLO wORLD'", consuming 6 characters
# StreamWriter for io buffer:
# writing "Hello Word"
# buffer contents: b'hELLO wORLD'
# IncrementalDecoder converted b'hELLO wORLD' to 'Hello Word'
Текстовые строки str в Python.
Тип 'str' — текстовые строки представляют собой неизменяемые последовательности Юникода. Текстовые данные в Python обрабатываются с помощью встроенного класса str().
Тип str — текстовые строки можно создать различными способами:
- Одинарные кавычки: ‘позволяет вставлять «двойные» кавычки’
- Двойные кавычки: «позволяет использовать встроенные ‘одинарные’ кавычки».
- Тройные кавычки:
- »’три одинарные кавычки»’,
- «»»три двойные кавычки»»»
- Могут быть созданы из других объектов с помощью класса
str().
Текстовые строки в тройных кавычках могут занимать несколько строк — все связанные пробелы будут включены в итоговую строку.
Строки, которые являются частью одного выражения и имеют только пробелы между собой, будут неявно преобразованы в одну строку. То есть выражение ("hello" 'world') == "helloworld". Эту функцию можно использовать для уменьшения необходимого количества обратных слэшей при форматировании строки. Обратите внимание, что конкатенация литералов может использовать разные стили кавычек для каждого компонента, например можно смешивать необработанные строки и строки с тройными кавычками. А форматированные строковые литералы могут быть объединены с обычными строковыми литералами.
Для текстовых строк доступны следующие операции:
- общие операции c последовательностями;
- дополнительные методы встроенного класса
str().
Текстовые строки поддерживают различные формы строковых литералов, включая escape-последовательности, а также префикс r"строка" — ‘raw’ необработанная (сырая) строка, который отключает обработку большинства escape-последовательностей.
В Python не существует отдельного типа «символ», поэтому для непустой строки string[0] == string[0:1].
Также нет изменяемого строкового типа, но str.join() или io.StringIO можно использовать для эффективного построения строк из нескольких фрагментов.
Строки также поддерживают два стиля форматирования строк, один из которых обеспечивает большую степень гибкости и настройки str.format() и другой, основанный на форматировании строк в стиле printf языка C. Стиль форматирования printf обрабатывает более узкий диапазон типов, его немного сложнее использовать, но он быстрее, чем str.format().
Изменено в Python-3.3: для обратной совместимости с Python-2 префикс u'строка' (строка Юникода) снова разрешен. Он не влияет на значение строковых литералов и не может быть объединен с префиксом r'строка' (сырая строка).
Примеры использования создания строк и преобразования объектов к типуДополнительно смотрите материалы:
- Использование текстовых строк
strв Python.- Создание пользовательского класса строк str в Python.
str:>>> 'позволяет вставлять "двойные" кавычки' # 'позволяет вставлять "двойные" кавычки' >>> "позволяет использовать встроенные 'одинарные' кавычки" # "позволяет использовать встроенные 'одинарные' кавычки" >>> '''три одинарные кавычки''' # 'три одинарные кавычки' >>> """три двойные кавычки""" # 'три двойные кавычки' >>> '''"двойные кавычки" и 'одинарные кавычки' в строке с тройными кавычками''' # '"двойные кавычки" и \'одинарные кавычки\' в строке с тройными кавычками' # преобразование объекта к строке # получим читаемое значение объекта >>> str(65) # '65' >>> str(65,20) # '65,20' >>> str([1, 6, 3, 5]) # '[1, 6, 3, 5]'
Стандартная библиотека Python предоставляет огромные возможности по обработке строк:
- общие строковые операции,
- обтекание и заполнение текста,
- сравнения файлов и каталогов,
- регулярные выражения,
- интерфейс GNU readline.

Чтение, запись и создание файлов в Python (с помощью и open())
В Python функция open() позволяет читать файл как строку или список, а также создавать, перезаписывать или добавлять файл .
- Чтение и запись файлов с помощью open() и
- Спецификация кодирования: кодировка
- Чтение текстовых файлов
- Открытие файла для чтения: mode=’r’
- Прочитать весь файл как строку: read()
- Прочитать весь файл в виде списка: readlines()
- Прочитать файл построчно: readline()
- Запись текстовых файлов
- Открыть файл для записи: mode=’w’
- Запись строки: write()
- Написать список: writelines()
- Создать пустой файл: передать
- Создать файл, только если он не существует
- Открыть файл для монопольного создания: mode=’x’
- Проверить, существует ли файл перед открытием
- Добавить в файл
- Открыть файл для добавления: mode=’a’
- Вставка в начале или в середине
- Чтение и запись двоичных файлов
Чтение и запись файлов с помощью
open() и с помощью open() , чтобы открыть файл.
- Встроенные функции — open() — Документация по Python 3.11.3
Файловый объект, на который указывает строка пути, указанная в первом аргументе, открыт. Используйте режим аргумент для указания чтения или записи, текстового или двоичного. Подробности описаны ниже.
Пути могут быть как абсолютными, так и относительными относительно текущего каталога. Вы можете проверить текущий каталог с помощью os.getcwd() и изменить его с помощью os.chdir() .
- Получить и изменить текущий рабочий каталог в Python
Текстовые файлы считываются как объект io.TextIOWrapper .
путь = 'данные/src/test.txt' f = открыть (путь) печать (тип (е)) # <класс '_io.TextIOWrapper'> е.закрыть()
источник: file_io_with_open.py
Как показано в примере выше, вам нужно закрыть файловый объект с помощью метода close() . В качестве альтернативы, блок с автоматически закрывает файл, когда блок заканчивается, обеспечивая более удобный подход.
с открытым (путем) как f:
печать (тип (е))
# <класс '_io.TextIOWrapper'>
источник: file_io_with_open.py
Вы можете использовать любое имя переменной для xxx в с open() как xxx: . Он представляет собой файловый объект, открытый с помощью open() , названный xxx и используемый внутри блока. Хотя обычно используется f , допустимы и другие названия.
Спецификация кодировки:
encoding Укажите кодировку для чтения или записи текстовых файлов с аргументом encoding функции open() . Строка кодирования может быть в верхнем или нижнем регистре и может использовать либо дефис - , либо символ подчеркивания 9.0003 _ . Например, разрешены как 'UTF-8' , так и 'utf_8' .
См. официальную документацию по кодировкам, поддерживаемым Python.
- кодеки — Стандартные кодировки — Реестр кодеков и базовые классы — Документация по Python 3.
 11.3
11.3
Значение по умолчанию для , кодирующего , зависит от платформы. Вы можете проверить это с помощью locale.getpreferredencoding() .
регион импорта печать (locale.getpreferredencoding()) # UTF-8
источник: locale_getpreferredencoding.py
Чтение текстовых файлов
Открытие файла для чтения:
mode='r' Чтобы открыть файл для чтения, установите режим аргумент функции open() 900 от 04 до режима 'р' . Значение по умолчанию для аргумента равно 'r' , поэтому его можно опустить. В следующих примерах он опущен.
Если вы укажете несуществующий путь в mode='r' , вы получите ошибку ( FileNotFoundError ).
# с open('data/src/test_error.txt') как f:
# печать (тип (f))
# FileNotFoundError: [Errno 2] Нет такого файла или каталога: 'data/src/test_error.txt'
источник: file_io_with_open. py
py
Прочитать весь файл как строку:
read() Чтобы прочитать весь файл в одну строку, используйте метод read() для файлового объекта.
с открытым (путем) как f:
с = f.read ()
печать (тип (ы))
печать(и)
# <класс 'ул'>
# линия 1
# строка 2
# строка 3
источник: file_io_with_open.py
Хотя файловый объект закрывается в конце блока с , назначенная переменная остается доступной вне блока.
с открытым (путем) как f:
с = f.read ()
печать(и)
# линия 1
# строка 2
# строка 3
источник: file_io_with_open.py
Чтение всего файла в виде списка:
readlines() Чтобы прочитать весь файл в виде списка строк, используйте метод readlines() . Все строки, кроме последней, включают символ новой строки \n в конце.
с открытым (путем) как f:
л = f.readlines()
печать (тип (л))
печать (л)
# <класс 'список'>
# ['строка 1\n', 'строка 2\n', 'строка 3']
источник: file_io_with_open. py
py
Если вы хотите удалить завершающий символ новой строки, вы можете использовать понимание списка и вызывать rstrip() для каждого элемента.
- Удалить часть строки (подстроку) в Python
- Понимание списков в Python
с открытым (путем) как f:
l_strip = [s.rstrip() для s в f.readlines()]
печать (l_strip)
# ['строка 1', 'строка 2', 'строка 3']
источник: file_io_with_open.py
Чтение файла построчно:
readline() При переборе файлового объекта с помощью цикла for вы можете получить каждую строку как строку (включая символ новой строки в конец). Здесь repr() используется для отображения символа новой строки как есть.
- Встроенные функции — repr() — Документация по Python 3.11.3
с открытым (путем) как f:
для s_line в f:
печать (представление (s_line))
# 'строка 1\n'
# 'строка 2\n'
# 'строка 3'
источник: file_io_with_open. py
py
Чтобы читать по одной строке, используйте next() . Ошибка возникает, если нет больше строк для чтения.
- Встроенные функции — next() — Документация по Python 3.11.3
с открытым (путем) как f:
распечатать (представить (следующий (f)))
распечатать (представить (следующий (f)))
распечатать (представить (следующий (f)))
# print(repr(следующий(f)))
# Остановить итерацию:
# 'строка 1\n'
# 'строка 2\n'
# 'строка 3'
источник: file_io_with_open.py
метод readline() файлового объекта также может извлекать по одной строке за раз, но он не вызывает ошибку после EOF (конец файла) и продолжает возвращать пустую строку '' .
с открытым (путем) как f:
печать (представление (f.readline ()))
печать (представление (f.readline ()))
печать (представление (f.readline ()))
печать (представление (f.readline ()))
печать (представление (f.readline ()))
# 'строка 1\n'
# 'строка 2\n'
# 'строка 3'
# ''
# ''
источник: file_io_with_open. py
py
Запись текстовых файлов
Открыть файл для записи:
mode='w' Чтобы открыть файл для записи, установите аргумент mode функции open() на 'w' . Содержимое файла будет перезаписано, если оно существует, или будет создан новый файл, если его нет.
Не указывайте несуществующий каталог для нового файла, так как это приведет к ошибке ( FileNotFoundError ).
# с open('data/src/new_dir/test_w.txt', mode='w') как f:
# f.запись(и)
# FileNotFoundError: [Errno 2] Нет такого файла или каталога: 'data/src/new_dir/test_w.txt'
источник: file_io_with_open.py
Запись строки:
write() Чтобы записать строку в файл, используйте метод write() для файлового объекта.
path_w = 'данные/temp/test_w.txt'
с = 'Новый файл'
с open(path_w, mode='w') как f:
f.написать (ы)
с open(path_w) как f:
печать (f.read())
# Новый файл
источник: file_io_with_open. py
py
Строки, содержащие символы новой строки, записываются без каких-либо изменений.
s = 'Новая строка 1\nНовая строка 2\nНовая строка 3'
с open(path_w, mode='w') как f:
f.написать (ы)
с open(path_w) как f:
печать (f.read())
# Новая строка 1
# Новая строка 2
# Новая строка 3
источник: file_io_with_open.py
Дополнительные сведения о строках с разрывами строк см. в следующей статье:
- Обработка разрывов строк (переводов строк) в строках в Python
Метод write() принимает только строки в качестве аргументов. Передача другого типа, например целого числа ( int ) или числа с плавающей запятой ( float ), приведет к ошибке TypeError . Чтобы записать нестроковое значение, преобразуйте его в строку с помощью str() перед передачей в write() .
Написать список:
writelines() Чтобы записать список строк в файл, используйте метод writelines() . Обратите внимание, что этот метод не вставляет разрывы строк автоматически.
Обратите внимание, что этот метод не вставляет разрывы строк автоматически.
л = ['Один', 'Два', 'Три']
с open(path_w, mode='w') как f:
f.writelines(l)
с open(path_w) как f:
печать (f.read())
# Один два три
источник: file_io_with_open.py
Чтобы записать каждый элемент списка в отдельной строке, создайте строку, содержащую символы новой строки, используя метод join() .
- Объединение строк в Python (оператор +, объединение и т. д.)
с open(path_w, mode='w') как f:
f.write('\n'.join(l))
с open(path_w) как f:
печать (f.read())
# Один
# Два
# Три
источник: file_io_with_open.py
Метод writelines() принимает только списки, содержащие строки в качестве элементов. Если вы хотите написать список с элементами других типов, такими как целые числа ( int ) или числа с плавающей запятой ( float ), вам нужно преобразовать список в список строк. См. следующую статью:
- Преобразование списка строк и списка чисел друг в друга в Python
Создать пустой файл:
pass Чтобы создать пустой файл, откройте новый файл в режиме записи ( mode='w' ) без записи содержимого.
Поскольку блок с требует написания некоторого оператора, используйте оператор pass , который ничего не делает.
- Оператор pass в Python
с открытым('temp/empty.txt', 'w'):
проходить
источник: pass_with_open.py
Создать файл, только если он не существует
Использование mode='w' может случайно перезаписать существующий файл.
Для записи в файл только в том случае, если он не существует, т. е. создать новый файл без перезаписи, вы можете использовать один из следующих двух методов:
Открыть файл для монопольного создания:
mode='x' Чтобы создать новый файл, только если он еще не существует, установите аргумент режима функции open() на 'x' . Если указанный файл существует, будет выдано сообщение об ошибке FileExistsError .
# с open(path_w, mode='x') как f: # f.запись(и) # FileExistsError: [Errno 17] Файл существует: 'data/src/test_w.txt'
источник: file_io_with_open.py
Используя try и кроме для обработки исключений, вы можете создать новый файл, если он не существует, и не предпринимать никаких действий, если он уже существует.
- Обработка исключений в Python (попробуйте, кроме, иначе, наконец)
попробуйте:
с open(path_w, mode='x') как f:
f.написать (ы)
кроме FileExistsError:
проходить
источник: file_io_with_open.py
Проверить, существует ли файл перед открытием
Используйте функцию os.path.isfile() из модуля os в стандартной библиотеке, чтобы проверить, существует ли файл.
- Проверить, существует ли файл или каталог в Python
импорт ОС
если не os.path.isfile(path_w):
с open(path_w, mode='w') как f:
f.написать (ы)
источник: file_io_with_open.py
Добавление к файлу
Открытие файла для добавления:
mode='a' Чтобы открыть файл для добавления, установите mode аргумент функции open() по 'а' .
write() и writelines() будут добавляться в конец существующего файла.
с open(path_w, mode='a') как f:
f.write('Четыре')
с open(path_w) как f:
печать (f.read())
# Один
# Два
# Три четыре
источник: file_io_with_open.py
Если вы хотите добавить последнюю строку, добавьте символ новой строки при добавлении.
с open(path_w, mode='a') как f:
f.write('\nЧетыре')
с open(path_w) как f:
печать (f.read())
# Один
# Два
# Три четыре
# Четыре
источник: file_io_with_open.py
Обратите внимание, что если файл не существует, он будет создан как новый файл, как и при использовании mode='w' .
Вставка в начале или в середине
mode='r+' Когда аргументу mode функции open() присвоено значение 'r+' , файл открывается в режиме обновления.
write() и writelines() перезапишет существующий файл с самого начала.
с open(path_w, mode='r+') как f:
е.написать('12345')
с open(path_w) как f:
печать (f.read())
№ 12345wo
# Три четыре
# Четыре
источник: file_io_with_open.py
В приведенном выше примере One\nTwo перезаписывается на 12345 с самого начала, в результате получается 12345wo . \n рассматривается как один символ.
Вы также можете переместить позицию с помощью метода seek() файлового объекта, но вам нужно указать позицию в символах, а не в строках. Это также будет перезаписано.
с open(path_w, mode='r+') как f:
f.искать(3)
f.write('---')
с open(path_w) как f:
печать (f.read())
# 123---о
# Три четыре
# Четыре
источник: file_io_with_open.py
readlines() и insert() Если текстовый файл небольшой, проще прочитать весь файл в виде списка с помощью readlines() и обработать его . Метод insert() списка позволяет вставлять новые строки в начало или в середину строк.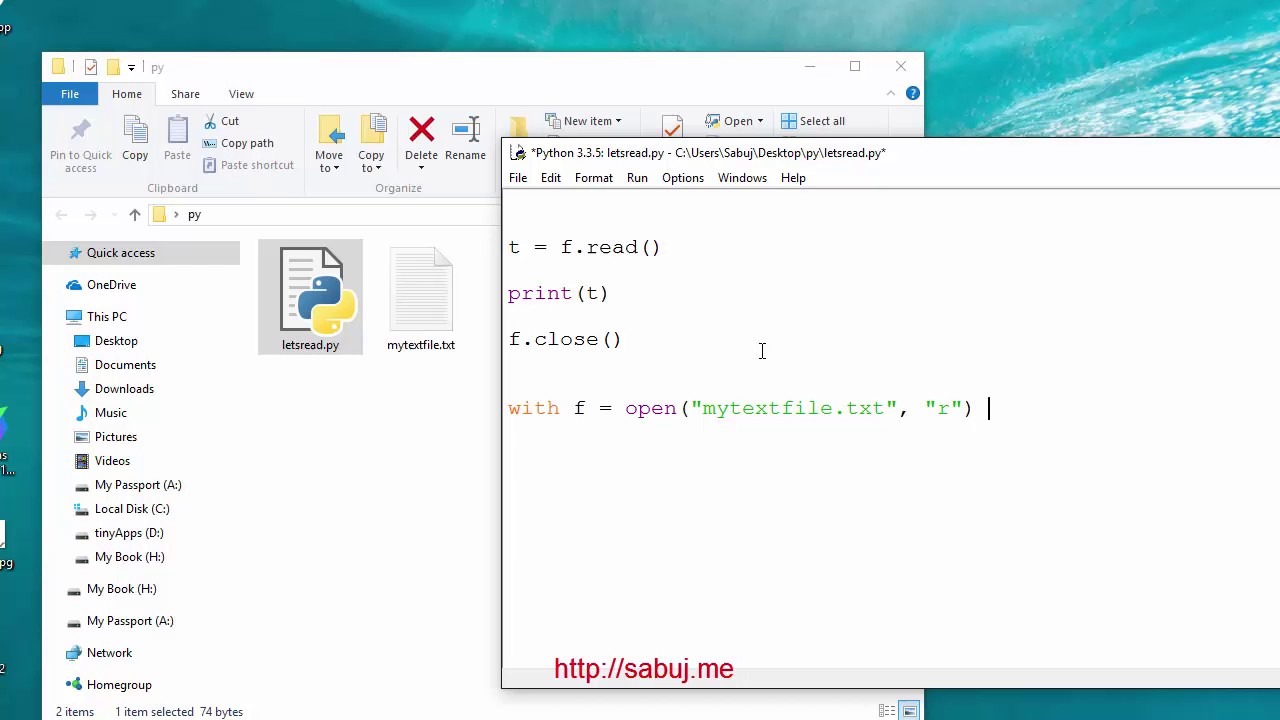
Прочитайте файл как список с помощью readlines() , вставьте элемент с помощью insert() , а затем запишите обновленный список с помощью строки записи() .
Вы можете указать количество строк для вставки в первый аргумент insert() .
с открытым (path_w) как f:
л = f.readlines()
l.insert(0, 'ПЕРВЫЙ\n')
с open(path_w, mode='w') как f:
f.writelines(l)
с open(path_w) как f:
печать (f.read())
# ПЕРВЫЙ
# 123---о
# Три четыре
# Четыре
источник: file_io_with_open.py
Сведения о добавлении, вставке и удалении элементов в список см. в следующих статьях:
- Добавить элемент в список в Python (добавить, расширить, вставить)
- Удалить элемент из списка в Python (очистить, вытолкнуть, удалить, удалить)
Чтение и запись двоичных файлов
Добавление b в конец аргумента режима позволяет читать и записывать двоичные файлы. Например,
Например, mode='rb' предназначен для чтения двоичных файлов, а mode='ab' — для добавления в конец двоичных файлов.
Подобно текстовым файлам, двоичные файлы также поддерживают read() , readline() , readlines() , write() и writelines() как методы файлового объекта.
Для открытия, обработки и сохранения файлов изображений используйте такие библиотеки, как Pillow или OpenCV.
- Как использовать Pillow (PIL: Python Imaging Library)
- Чтение и сохранение файлов изображений с помощью Python, OpenCV (imread, imwrite)
Открыть файл в Python — PYnative
В этом руководстве вы узнаете, как открыть файл в Python.
Данные могут быть в виде файлов, таких как текст, csv и двоичные файлы. Для извлечения данных из этих файлов Python поставляется со встроенными функциями для открытия файла, а затем для чтения и записи содержимого файла.
Прочитав этот учебник, вы можете узнать : –
- Как открыть файл в Python, используя как относительный, так и абсолютный путь
- Различные режимы доступа к файлу для открытия файла
- Как открыть файл для чтения, написание и добавление.
- Как открыть файл с помощью оператора
с - Важность закрытия файла
Содержание
- Режимы доступа для открытия файла
- Шаги для открытия файла в Python 9000 8
- Пример: открытие файла в режиме чтения
- Открытие файла с относительным путем
- Обработка FileNotFoundError
Режимы доступа для открытия файл
Параметр режима доступа в функции open() в первую очередь упоминает цель открытия файла или тип операции, которую мы планируем выполнить с файлом после открытия. в Python следующие символы используются для обозначения режимов открытия файлов.
в Python следующие символы используются для обозначения режимов открытия файлов.
| Режим файла | Значение |
|---|---|
r | Открывает файл для чтения (по умолчанию) 9066 4 |
w | Открыть файл для записи. Если файл уже существует, он удаляет все существующее содержимое и добавляет новое содержимое с начала файла. |
x | Откройте файл для монопольного создания. Если файл уже существует, эта операция завершится ошибкой. |
a | Открытие файла в режиме добавления и добавление нового содержимого в конец файла. |
b | Открыть файл в двоичном режиме. |
t | Открывает файл в текстовом режиме (по умолчанию). |
+ | Открыть файл для обновления (чтения и записи). |
Действия по открытию файла в Python
Чтобы открыть файл в Python, выполните следующие действия:
- Найдите путь к файлу
Мы можем открыть файл, используя как относительный, так и абсолютный путь.
 Путь — это расположение файла на диске.
Путь — это расположение файла на диске.
Абсолютный путь содержит полный список каталогов, необходимых для поиска файла.
Относительный путь содержит текущий каталог, а затем имя файла. - Определите режим доступа
Режим доступа определяет операцию, которую вы хотите выполнить с файлом, например чтение или запись. Чтобы открыть и прочитать файл, используйте
rрежим доступа. Чтобы открыть файл на запись, используйте режимw. - Передать путь к файлу и режим доступа функции open()
fp= open(r"File_Name", "Access_Mode"). Например, чтобы открыть и прочитать :fp = open('sample.txt', 'r') - Чтение содержимого из файла.
Затем прочитайте файл, используя метод
read(). Например,content = fp.read(). Вы также можете использоватьreadline()иreadlines() - Запись содержимого в файл
Если вы открыли файл в режиме записи, вы можете записать или добавить текст в файл, используя
write()метод. Например,
Например, fp.write('content'). Вы также можете использовать методwriteine(). - Закрыть файл после завершения операции
Нам нужно убедиться, что файл будет правильно закрыт после завершения операции с файлом. Используйте
fp.close(), чтобы закрыть файл.
Следующий код показывает , как открыть текстовый файл для чтения в Python. В этом примере мы открываем файл, используя абсолютный путь .
Абсолютный путь содержит полный путь к файлу или каталогу, к которому нам нужно получить доступ. Он включает в себя полный список каталогов, необходимых для поиска файла.
Например, /home/reports/samples.txt — это абсолютный путь к файлу sample.txt. Вся информация, необходимая для поиска файла, содержится в строке пути.
См. прикрепленный файл, используемый в примере, и изображение, показывающее содержимое файла для справки.
# Открытие файла с абсолютным путем fp = open(r'E:\demos\files\sample.txt', 'r') # прочитать файл печать (fp.read()) # Закрываем файл после прочтения fp.close() # путь, если вы используете MacOs # fp = open(r"/Users/myfiles/sample.txt", "r")
Выход
Добро пожаловать на PYnative.com Это пример.txt
Открытие файла с относительным путем
Относительный путь — это путь, который начинается с рабочего каталога или текущего каталога, а затем начинается поиск файла из этого каталога по имени файла.
Например, reports/sample.txt — это относительный путь. В относительном пути он будет искать файл в каталоге, в котором запущен этот скрипт.
# Открытие файла с относительным путем
пытаться:
fp = открыть ("sample.txt", "r")
печать (fp.read())
fp.close()
кроме FileNotFoundError:
print("Пожалуйста, проверьте путь.") Обработка
FileNotFoundError Если мы пытаемся открыть файл, которого нет по указанному пути, мы получим FileNotFoundError .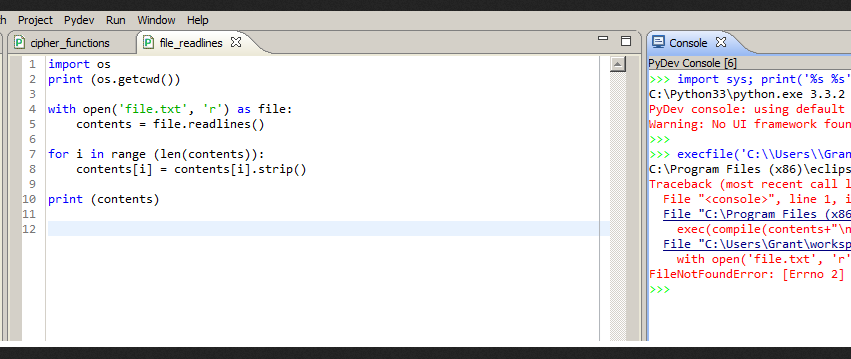
fp = открыть (r'E:\demos\files\reports.txt', 'r') print(f.read())
Вывод
FileNotFoundError: [Errno 2] Нет такого файла или каталога: «E:\demos\files\reports.txt»
Мы можем обработать ошибку «файл не найден» внутри блока try-except. Давайте посмотрим на пример того же. Используйте блок, кроме блока, чтобы указать действие, которое должно быть выполнено, когда указанный файл отсутствует.
попробуйте:
fp = open(r'E:\PYnative\reports\samples.txt', 'r')
печать (fp.read())
fp.close()
кроме IOError:
print("Файл не найден. Пожалуйста, проверьте путь.")
окончательно:
печать ("Выход") Вывод
Файл не найден. Пожалуйста, проверьте путь. Выход
Функция File open()
Python предоставляет набор встроенных функций, доступных в интерпретаторе, и он всегда доступен. Для этого нам не нужно импортировать какой-либо модуль. Мы можем открыть файл с помощью встроенной функции open().
Синтаксис файла open() function
open(file, mode='r', buffering=-1, encoding=None, errors=None, newline=None, closefd=True, opener=None)
Возвращает файловый объект, который мы можем использовать для чтения или записи в файл.
Параметры :
Давайте посмотрим, какие параметры мы можем передать функции open() для улучшения работы с файлами.
| Параметр | Описание |
|---|---|
файл | Значение этого параметра указывает путь (абсолютный или относительный к текущему рабочий каталог) открываемого файла. |
режим | Это необязательная строка, указывающая режим, в котором будет открыт файл. Значение по умолчанию — 'r' для чтения текстового файла. Мы можем обсудить другие режимы в следующем разделе. |
буферизация | Это необязательное целое число, используемое для установки политики буферизации. Передайте 0, чтобы отключить буферизацию (разрешено только в двоичном режиме), 1, чтобы выбрать буферизацию строк (можно использовать только в текстовом режиме), и целое число > 1, чтобы указать размер в байтах буфера фрагмента фиксированного размера. Передайте 0, чтобы отключить буферизацию (разрешено только в двоичном режиме), 1, чтобы выбрать буферизацию строк (можно использовать только в текстовом режиме), и целое число > 1, чтобы указать размер в байтах буфера фрагмента фиксированного размера. |
кодировка | Это имя кодировки, используемой для декодирования или кодирования файла. Значение по умолчанию зависит от платформы. |
ошибки | Это необязательная строка, обозначающая, как должны обрабатываться стандартные ошибки кодирования и декодирования. |
новая строка | Это параметр, который указывает, как работает режим новой строки (он применяется только к текстовому режиму). Это может быть Нет , '' , '\n' , '\r' и '\r\n' . |
closefd | Этот параметр указывает, закрывать дескриптор файла или нет. Значение по умолчанию верно. Если Значение по умолчанию верно. Если closefd равно False и был задан файловый дескриптор, а не имя файла, базовый файловый дескриптор останется открытым при закрытии файла. |
Открытие файла в режиме чтения
Мы можем открыть файл для чтения содержимого файла, используя функцию open() и передав режим r . Это откроет файл только для чтения содержимого, и мы не сможем использовать его ни для чего другого, например для написания нового содержимого.
Файл может быть в основном двух категорий: плоские файлы и неплоские файлы.
- Плоские файлы — это файлы, которые не проиндексированы должным образом, например .csv (значения, разделенные запятыми), где каждая запись имеет разные значения, разделенные запятыми. Но они не упорядочены с индексом. Как правило, они имеют одну запись в строке и, как правило, имеют фиксированный набор значений в каждой записи.
- Неплоские файлы — это файлы с правильными значениями индекса. Каждая запись будет иметь одно значение индекса, и мы можем легко найти его, используя значение индекса.
Учтите, что у нас есть файл с именем «sample.txt», и мы открываем его для чтения его содержимого.
попробуйте:
fp = открыть ("sample.txt", "r")
# Чтение содержимого файла и закрытие
печать (fp.read())
fp.close()
кроме IOError:
print("Пожалуйста, проверьте путь.") Вывод
Добро пожаловать на PYnative.com Это sample.txt
Подробнее : Полное руководство по чтению файлов в Python
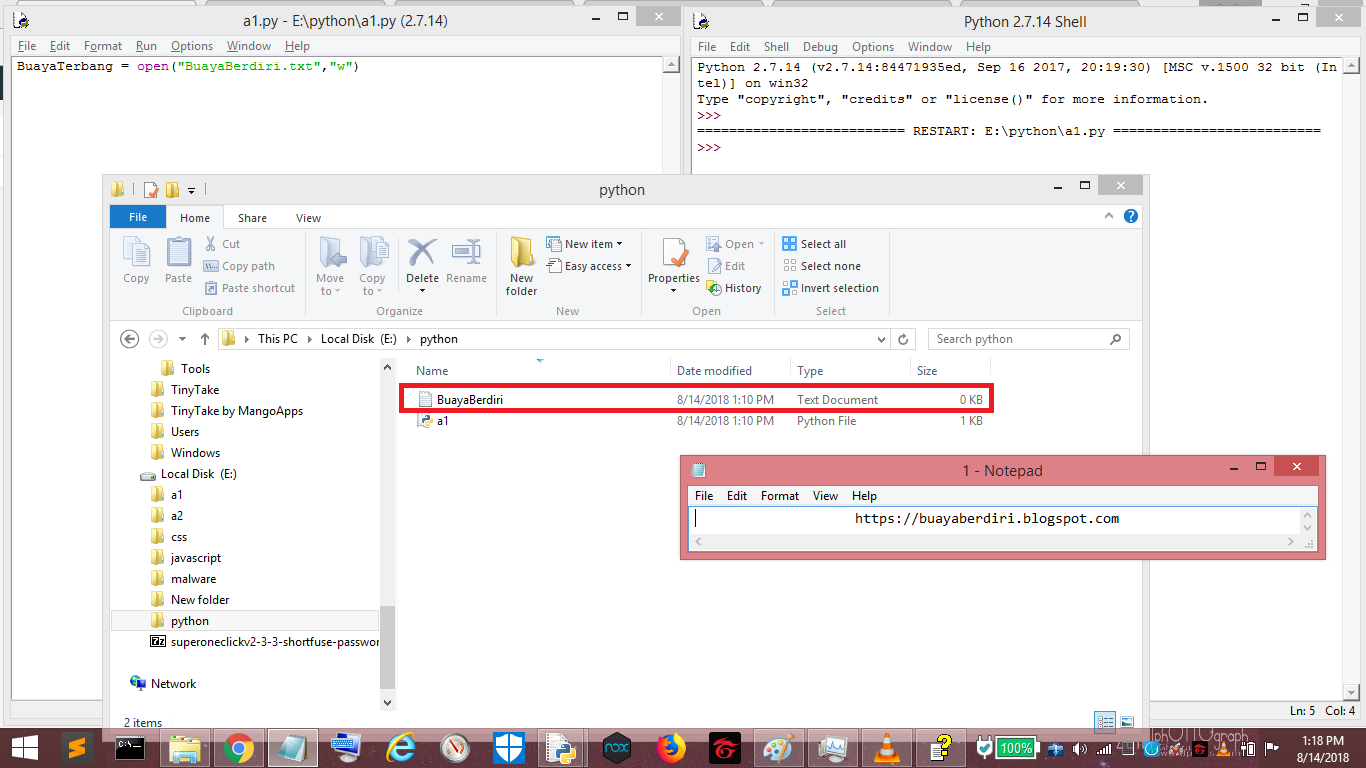
Открытие файла в режиме записи
Мы можем открыть файл для записи нового содержимого в файл с помощью функции open() с w как режим доступа . Курсор или указатель файла будет помещен в начало файла .
Примечание : Если файл уже существует, он будет усечен, что означает, что все содержимое, ранее находившееся в файле, будет удалено, а новое содержимое будет добавлено в файл.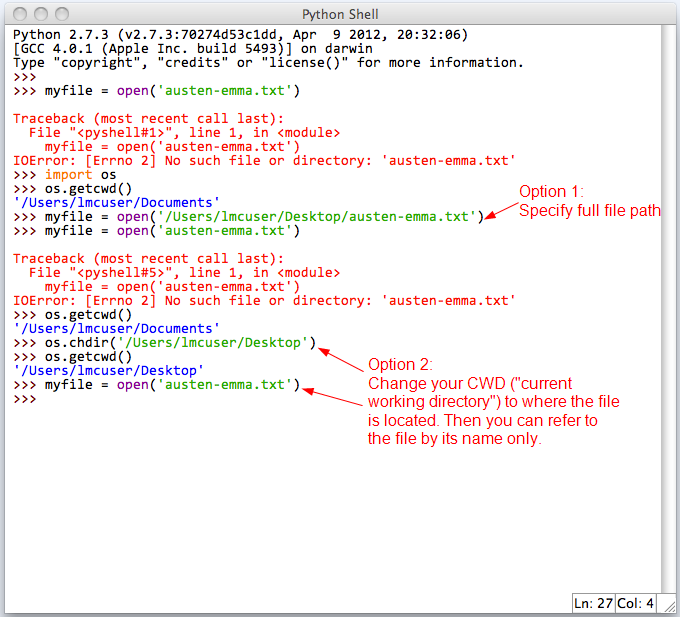
fp = открыть ("sample2.txt", "w")
# Написание контента
fp.write("Новая строка")
# Снова открываем файл для чтения содержимого
fp = открыть ("sample2.txt", "r")
# Чтение содержимого файла и закрытие
печать (fp.read())
fp.close() Вывод
Новая строка
Подробнее : Полное руководство по записи в файл в Python
Открытие файла в режиме добавления
Мы можем добавить некоторый контент в конец файл используя open() , передав символ a в качестве режима доступа . Курсор будет помещен в конец файла , а новый контент будет добавлен в конец.
Разница между этим режимом и режимом записи заключается в том, что в этом режиме содержимое файла не будет обрезано или удалено.
Учтите, что файл «sample2.txt» уже создан и в нем есть содержимое. Теперь мы открываем файл в режиме добавления и пытаемся добавить содержимое в конец файла.
# Открыть и добавить наконец
fp = открыть ("sample2.txt", "а")
fp.write("Добавил эту строку, открыв файл в режиме добавления")
# Снова открываем файл для чтения
fp = открыть ("sample2.txt", "r")
печать (fp.read())
fp.close() Вывод
Новая строка Добавил эту строку, открыв файл в режиме добавленияОбразец текстового файла после записи
Закрытие файла
Нам нужно убедиться, что файл будет правильно закрыт после завершения файловой операции. Оставлять файлы открытыми — плохая практика.
В Python очень важно закрыть файл после завершения работы в основном по следующим причинам: –
- Это освобождает ресурсы, которые были связаны с файлом. Благодаря этому пространство в ОЗУ может быть лучше использовано и обеспечивает лучшую производительность.
- Обеспечивает лучшую сборку мусора.
- Существует ограничение на количество открытых файлов в приложении. Всегда лучше закрыть файл, чтобы убедиться, что лимит не превышен.

- Если вы открываете файл в режиме записи или чтения-записи, вы не знаете, когда данные сбрасываются.
Файл можно закрыть, просто вызвав функцию close() следующим образом.
# Открытие файла для чтения содержимого
f = открыть ("sample2.txt", "r")
печать (f.read())
# Закрытие файла после завершения нашей работы
f.close() Мы можем открыть файл, используя оператор with вместе с функцией открытия. Общий синтаксис следующий.
с открытым (__file__, режим доступа) как f:
Ниже приведены основные преимущества открытия файла с помощью оператора with .
- Оператор with упрощает обработку исключений, инкапсулируя общие задачи подготовки и очистки.
- Это также обеспечивает автоматическое закрытие файла после выхода из блока.
- Поскольку файл закрывается автоматически, это гарантирует освобождение всех ресурсов, связанных с файлом.
Давайте посмотрим, как мы можем использовать оператор with для открытия файла на примере. Предположим, что есть два файла «sample.txt» и «sample2.txt», и мы хотим скопировать содержимое первого файла во второй.
Предположим, что есть два файла «sample.txt» и «sample2.txt», и мы хотим скопировать содержимое первого файла во второй.
# Открытие файла
с open('sample.txt', 'r', encoding='utf-8') в качестве входного файла, open('sample2.txt', 'w') в качестве внешнего файла:
# прочитать sample.txt и записать его содержимое в sample2.txt
для строки в файле:
outfile.write(строка)
# Открытие файла для чтения содержимого
f = открыть ("Sample2.txt", "r")
печать (f.read())
f.close() Вывод
Добро пожаловать на PYnative.com Файл, созданный для демонстрации работы с файлами в Python
Здесь мы видим, что содержимое файла sample2.txt было заменено содержимым файла sample.txt.
Создание нового файла
Мы можем создать новый файл, используя функцию open() , установив режим x . Этот метод гарантирует, что файл еще не существует, а затем создает новый файл. Это вызовет ошибку FileExistsError , если файл уже существует.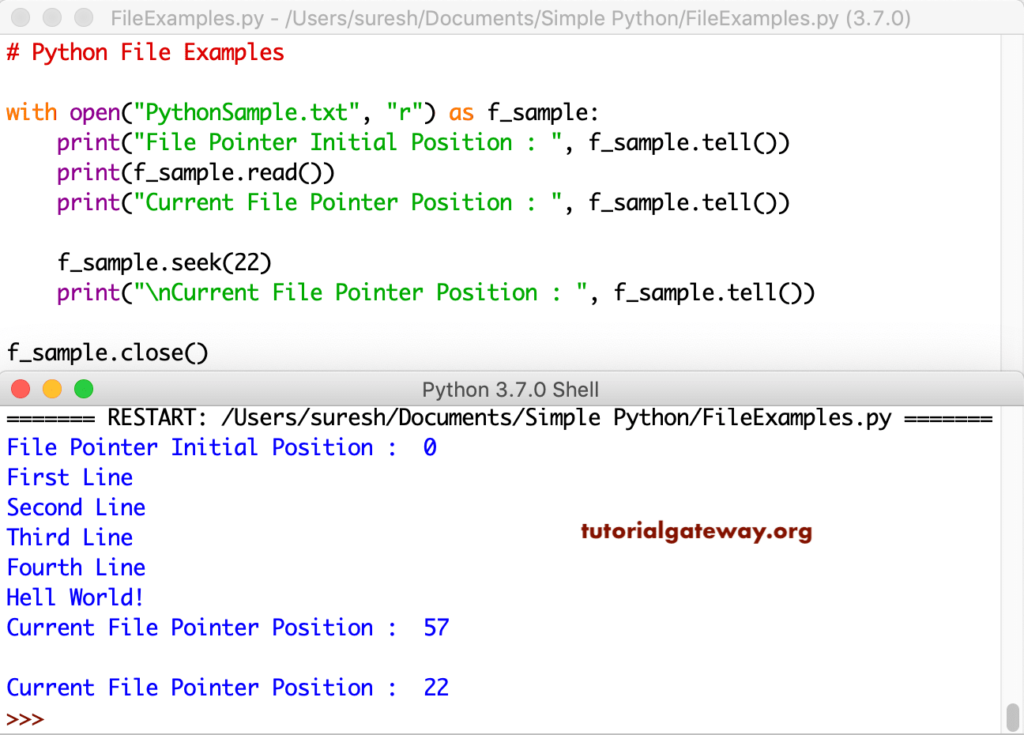
Пример : Создание нового файла.
попробуйте:
# Создание нового файла
с open("sample3.txt", "x") как fp:
fp.write("Привет, мир! Я новый файл")
# чтение содержимого нового файла
fp = открыть ("sample3.txt", "r")
печать (fp.read())
кроме FileExistsError:
print("Файл уже существует") Выход
Привет, мир! Я новый файл
Открытие файла для нескольких операций
В Python мы можем открыть файл для одновременного выполнения нескольких операций с помощью оператора '+' . Когда мы пройдем режим r+ , тогда в файле будут доступны как чтение, так и запись. Давайте посмотрим на это на примере.
с открытым ("Sample3.txt", "r+") как fp:
# чтение содержимого перед записью
печать (fp.read())
# Запись нового содержимого в этот файл
fp.write("\nДобавление нового контента") Открытие двоичного файла
Двоичные файлы в основном содержат данные в байтовом формате (0 и 1).