Как легко определять шрифты на Android
Есть несколько способов определить шрифты на Android, одним из лучших является Какой шрифт Расширение Chrome. Он позволяет обнаруживать любой шрифт в Интернете одним касанием. Но что делать, если вы наткнетесь на шрифт на своем телефоне? Не волнуйся, есть выход. Вот как легко идентифицировать шрифты на Android.
Прочтите, как записывать звук в Chrome на ПК и Mac
Как легко определять шрифты на Android?
Для Android мы собираемся использовать приложение под названием Найди мой шрифт. У приложения очень простой пользовательский интерфейс, однако оно способно точно определять шрифты за время, которое я его тестировал. Итак, посмотрим, как это делается.
Программы для Windows, мобильные приложения, игры — ВСЁ БЕСПЛАТНО, в нашем закрытом телеграмм канале — Подписывайтесь:)
Во-первых, вы собираетесь открыть Google Play Store и выполнить поиск Find my Font в верхней строке поиска. Теперь выберите приложение, как показано ниже, или вы можете открыть эта ссылка если вы на телефоне, чтобы открыть его напрямую. Затем нажмите «Установить», чтобы загрузить и установить автоматически.
Затем нажмите «Установить», чтобы загрузить и установить автоматически.
Когда вы закончите, откройте приложение, чтобы вы могли ознакомиться с пользовательским интерфейсом. Приложение имеет очень простой интерфейс и два способа определения шрифтов на телефоне. Первый способ — использовать переднюю камеру для поиска шрифтов вокруг вас. Вы можете использовать его для журнала, любимой книги и других вещей, которые имеют любой текст.
Второй — использовать снимок экрана для определения шрифта, который мы собираемся использовать. Этот метод позволяет вам определять шрифты на любом веб-сайте, в приложении или даже в играх на вашем телефоне.
Для этого метода нажмите на значок галереи, как показано на рисунке ниже, на главной странице приложения. Затем просмотрите свою галерею и откройте снимок экрана, который хотите идентифицировать.
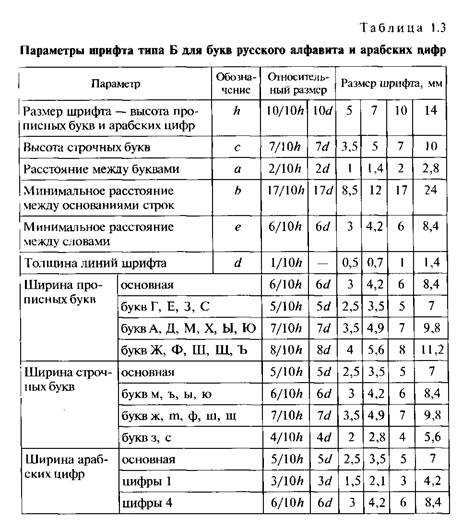
Вы получите прямоугольное наложение с выравниванием текста. Переместите / поверните телефон и попытайтесь уместить текст на этом оверлее (прямоугольное выделение). Когда вы закончите, нажмите на буквы (синие) и выберите самый четкий текст (я обычно выбираю все для лучшего предсказания). После того, как вы сделаете выбор, вы сможете увидеть его в верхнем белом поле с максимальным выбором семи слов. Нажмите на стрелку вправо, чтобы узнать больше.
Когда вы закончите, нажмите на буквы (синие) и выберите самый четкий текст (я обычно выбираю все для лучшего предсказания). После того, как вы сделаете выбор, вы сможете увидеть его в верхнем белом поле с максимальным выбором семи слов. Нажмите на стрелку вправо, чтобы узнать больше.
У вас также есть набор дополнительных инструментов выделения, таких как изменение фона выделения, поворот, настройка области выделения, рисование выделения, если текст разбросан, и т. Д.
Это последний шаг, на котором вы найдете результаты соответствия шрифту. Но перед этим вам также необходимо ввести текст, который вы хотите сопоставить (так же, как выделение), предварительный просмотр текста (текст, который вы хотите просмотреть с тем же шрифтом) и фильтр поиска, который вы должны оставить как есть.
Первый метод использует вашу камеру, которая также доступна с домашней страницы и использует тот же процесс.
Как только вы введете данные, вы автоматически получите несколько шрифтов, соответствующих стилю.
Особенности
- База шрифтов 150K
- 30 бесплатных прогнозов
- 2 Бесплатный запрос. каждые 48 часов
- Безлимитные запросы за 9 долларов
Получить Найди мой шрифт
Заключительные замечания
Вот как вы можете легко идентифицировать шрифты на Android. Это отличное приложение, очень точное. Если вы графический дизайнер, иллюстратор, выберите премиум-версию, которая пригодится с неограниченными предсказаниями. Кроме того, если определение шрифтов не является частью вашего профиля работы, бесплатной версии будет более чем достаточно.
Также прочтите, как отслеживать цену продукта для Amazon Mobile
Программы для Windows, мобильные приложения, игры — ВСЁ БЕСПЛАТНО, в нашем закрытом телеграмм канале — Подписывайтесь:)
Как легко распознавать шрифты на Android
Есть несколько способов определить Тип шрифта в браузере, и лучший из них — надстройка Какой шрифт для Chrome. Это позволяет одним щелчком мыши находить любой шрифт в Интернете. Но что делать, если во время использования телефона вы найдете шрифт, который вам нравится? Не волнуйтесь, есть способ спасти вас. Вот как легко определять шрифты на Android.
Это позволяет одним щелчком мыши находить любой шрифт в Интернете. Но что делать, если во время использования телефона вы найдете шрифт, который вам нравится? Не волнуйтесь, есть способ спасти вас. Вот как легко определять шрифты на Android.
Как легко распознавать шрифты на Android?
Для Android мы будем использовать приложение под названием Найди мой шрифт. Приложение имеет очень простой пользовательский интерфейс, однако за то время, когда я его тестировал, оно смогло точно определять шрифты. Итак, посмотрим, как это делается.
Сначала вы откроете Google Play Store и выполните поиск Find my Font, используя верхнюю панель поиска. Теперь выберите приложение, как показано ниже, или вы можете открыть эта ссылка Если вы используете свой телефон, чтобы разблокировать его напрямую. Затем нажмите Установка чтобы загрузить и установить его автоматически.
После этого откройте приложение, чтобы ознакомиться с пользовательским интерфейсом. Приложение имеет очень простой пользовательский интерфейс и два способа распознавания шрифтов с помощью телефона. Первый способ — использовать переднюю камеру, чтобы найти линии вокруг вас. Вы можете использовать его для своего журнала, любимой книги и других вещей с любым типом текста.
Первый способ — использовать переднюю камеру, чтобы найти линии вокруг вас. Вы можете использовать его для своего журнала, любимой книги и других вещей с любым типом текста.
Второй — использовать снимок экрана, чтобы определить, какой шрифт используется. Этот метод позволяет вам выбирать шрифты на любом веб-сайте, в приложении или даже в играх на вашем телефоне.
Чтобы использовать этот метод, щелкните значок галереи, как показано на изображении ниже, на главной странице приложения. Затем просмотрите свою галерею и откройте снимок экрана, на котором вы хотите выбрать тип отображаемого шрифта.
Вы получите прямоугольное наложение выравнивания текста. Переместите / поверните телефон и попробуйте уместить текст на этом оверлее (выберите прямоугольник). Когда закончите, нажмите на буквы (синие) и выберите наиболее заметный текст (я обычно выбираю все для лучшего результата). Сделав выбор, вы сможете увидеть его в верхнем белом поле, не более семи слов. Нажмите на стрелку вправо, чтобы узнать больше.
У вас также есть набор инструментов выделения, таких как изменение фона выделения, поворот, настройка области выделения, рисование выделения, если текст разбросан, и т. Д.
Это последний шаг, на котором вы найдете результаты, соответствующие строке. Но перед этим вам также необходимо ввести текст, который вы хотите сопоставить (например, выделение), текст предварительного просмотра (текст, который вы хотите просмотреть с тем же шрифтом) и фильтр поиска, который вы должны оставить как есть.
Первый метод использует вашу собственную камеру, которая также доступна с домашней страницы и использует тот же процесс.
После ввода данных вы автоматически получите несколько шрифтов, соответствующих шаблону. В данном случае это строка Джек Фрост. Приложение также отображает точность совпадения и тип шрифта. Кроме того, вы также можете щелкнуть значок (i), чтобы загрузить шрифт на свое устройство, если он находится в свободном доступе.
Функции
- База данных включает 150 тысяч строк.
- 30 бесплатных прогнозов.
- 2 бесплатных заказа. каждые 48 часов.
- Безлимитные заказы за 9 долларов.
Получающий Найди мой шрифт
заключительные замечания
Вот как вы можете легко идентифицировать шрифты на Android. Это отличное и очень точное приложение. Если вы работаете графическим дизайнером или иллюстратором, выберите премиум-версию, которая пригодится с неограниченными прогнозами. Кроме того, если определение шрифтов не является частью вашего профиля работы, бесплатной версии будет более чем достаточно.
Источник
Распознавание шрифтов с помощью глубокого обучения | Джехад Мохамед | MLearning.ai
Сканируется каллиграфия А. Это основано на DeepFont Paper, методе, созданном Adobe.Inc для обнаружения шрифта на изображениях с использованием глубокого обучения. Они опубликовали свою работу в виде документа для общественности, и реализованный код является производным от того же. В этом блоге обсуждаются необходимые шаги, а также дается обзор кода.
Ключевые точки DeepFont:
- Он обучен на наборе данных AdobeVFR, который содержит 2383 Шрифт Категории!
- Его CNN адаптирована к предметной области (Нажмите здесь, чтобы узнать больше)
- Его обучение основано на сжатии модели
Прежде чем мы начнем — давайте начнем с того, какие библиотеки нам нужны.
Из Matplotlib.pyplot Import Imshow
Импорт Matplotlib.cm AS CM
Импорт MATPLOTLIB.PYLAB AS
от KERAS.PYLAB AS
от KERS.PLABS .0006 ImageDataGenerator
import numpy as np
import PIL
from PIL import ImageFilter
import cv2
import itertools
import random
import keras
import imutils
из imutils импорт путей
импорт os
из keras импорт оптимизаторы
from keras.preprocessing.image import img_to_array
from sklearn.model_selection import train_test_split
from keras.utils import to_categorical
from keras import callbacks
from keras.models импорт последовательный
из keras.layers.normalization импорт BatchNormalization
из keras.layers Импорт Плотный, выпадающий, выбросить
из Keras.layers Import Conv2d, MaxPooling2d, Upsampling2d, Conv2dtranspose
с Ceras Import .Will Will Will Will Will Will Will in
Will Will Will Will Will Will in
.
Will Will Will Will in
.
. манипулировать изображениями, давайте возьмем PIL (библиотеку изображений Python) и создадим функцию для чтения изображения из каталога и изменения размера по мере необходимости.
 деф pil_image(img_path):
деф pil_image(img_path):
пил_им = пил . Изображение . открыть (img_path) . convert('L')
pil_im = pil_im . resize((105,105))
#imshow(np.asarray(pil_im))
return pil_imТеперь мы разобьем всю работу на 4 шага или этапа.
Шаг 1: Набор данных
Поскольку ссылка на набор данных AdobeVFR имеет огромный размер и содержит множество категорий шрифтов, простой способ обойти это — создать собственный набор данных на основе необходимых исправлений шрифтов с помощью TextRecognitionDataGenerator github.
Когда у вас есть набор образцов, вы готовы к работе!
Шаг 2: Предварительная обработка данных
Шрифты не похожи на объекты, и для классификации их функций требуется огромная пространственная информация. Чтобы определить очень незначительное изменение характеристик, DeepFont использует определенные методы предварительной обработки, а именно:
- Шум
- Размытие
- Перспективное вращение
- Затенение (градиентное освещение)
- Переменный интервал между символами
- Переменное соотношение сторон
Исходя из этого — у нас есть функции для каждого из шагов аугментации:
def Noise_image(pil_im):
# Добавление шума к изображению
img_array 0 ASARRAY (PIL_IM)
Среднее = 0,0 # Некоторая постоянная
Std = 5 # Некоторая постоянная (стандартное отклонение)
NOISY_IMG = IMG_ARRAY + NP .случайное . нормальное (среднее, станд., img_array . форма)
noisy_img_clipped = np . клип(noisy_img, 0, 255)
шум_img = PIL . Изображение . fromarray(np . uint8(noisy_img_clipped))
шум_изображения = шум_изображения . resize((105,105))
return Noise_img
def blur_image(pil_im):
#Добавление размытия к изображению
blur_img = pil_im3 .
filter(ImageFilter . GaussianBlur(радиус = 3))
blur_img = blur_img . resize((105,105))
return blur_img
def affine_rotation(img):
строк, столбцов = img . shapepoint1 = np .
float32([[10, 10], [30, 10], [10, 30]])
point2 = np . float32([[20, 15], [40, 10], [20, 40]])A = cv2 . getAffineTransform(point1, point2)
вывод = cv2 . warpAffine(img, A, (столбцы, строки))
affine_img = PIL . Изображение . fromarray (np . uint8 (выход))
affine_img = affine_img . изменить размер ((105,105))
вернуть affine_img
def градиент_заполнить (изображение):
лапласиан = cv2 . Лапласиан (изображение, cv2 . CV_64F)
лапласиан = cv2 . изменение размера (лапласиан, (105, 105))
return laplacianТеперь, когда они готовы, мы можем подготовить набор данных.
data_path = "font_patch/" #Ссылка на все созданные образцы случайный . семян(42)
случайных . shuffle(imagePaths)#Это были 5 шрифтов, взятых за образец def conv_label(label):
IF Метка == 'LATO':
Возврат 0
ELIF Метка == 'Raleway':
return 1
ELIF Label == 'Roboto':
7 ELIF = 'Roboto'
ELIF = = ':
70003 . return 2
ELIF Метка == 'Sansation':
return 3
ELIF Метка == 'Проходная дорожка':
return 4augument = ["Blur" ","аффинный","градиент"]
a = itertools .комбинаций (дополнение, 4)
для i в list(a):
print(list(i))Теперь, основываясь на a, мы перебираем изображения, используя только что сгенерированные комбинации, добавляя вывод данных и меток каждый раз.
counter = 0.0003 == 'Blur':
для imagePath в imagePaths:
label = imagePath . split(os . path . sep)[ - 2]
Метка = Conv_label (метка)
PIL_IMG = PIL_IMAGE (ImagePath)
#IMSHOW (PIL_IMG)#Добавление оригинального изображения
org_img = IMG_TO_ARRAP )
данные . append(org_img)
ярлыков . добавление(метка)дополнение = ["шум","размытие","аффинный","градиент"]
для l в диапазоне (0,len(дополнение)):a = itertools .
Комбинации (Augument, L + 1)
для I в списке (A):
Комбинации = Список (I)
Печать (LEN (Комбинации))
TEMP_IMG = PIL_IMG
)
TEMP_IMG = 669 Для J в Комбинациях:, если J == 'Noise':
# Добавление шума изображения
Temp_img = rower_image (temp_img)ELIF J
# Добавление изображения размытия
Temp_img = BLUR_IMAGE (TEMP_IMG)
#IMSHOW (BLUR_IMG)ELIF j == 'Affine Offine:
77 ELIF j == ' Affine '
77 elif j == 9000' affine '7 . нп . Array (PIL_IMG)
# Добавление аффинного ротационного изображения
Temp_img = Affine_Rotation (OPEN_CV_AFFINE)ELIF J == 'GRADIENT':
array(pil_img)
OPEN_CV_GRADIent = Н.0003 .
# Добавление градиентного изображения добавить (temp_img)
меток . append(label)

Наш следующий шаг очень прост — мы разделяем данные, чтобы мы могли использовать 75% для обучения и оставшиеся 25% для тестирования. Затем мы конвертируем метки из целых чисел в векторы.
данные = нп . asarray(data, dtype = "float") / 255.0
labels = np . array(метки)
print("Успех")(trainX, testX, trainY, testY) = train_test_split(данные,
меток, test_size = 0,25, random_state = 42)trainY3 =
3 trainY, num_classes = 5)
testY = to_categorical(testY, num_classes = 5)авг = ImageDataGenerator(rotation_range = 30, width_shift_range = 0.1, height_shift_range = 0,1, shear_range = 0,2, Zoom_range = 0,2, Horizontal_flip = True )
. Классификация сети CNN, они следовали новой схеме, такой как две подсети,
- Низкоуровневая подсеть : извлечены из составного набора синтетических и реальных данных.
- Подсеть высокого уровня : Изучает глубокий классификатор на низкоуровневых функциях. Для получения более подробной информации и пояснений прочитайте их документ
Мы создаем модель, как указано в документе, и компилируем ее.
K.set_image_data_format('channels_last') def create_model():
модель = Sequential() # Cu Layers
модель . добавить(Conv2D(64, размер ядра = (48, 48), активация = 'relu', input_shape = (105,105,1)))
модель . добавить(Пакетная нормализация())
добавить(Пакетная нормализация())
модель . добавить(MaxPooling2D(pool_size = (2, 2)))
модель . добавить(Conv2D(128, размер ядра = (24, 24), активация = 'relu'))
модель . добавить(Пакетная нормализация())
модель . добавить(MaxPooling2D(pool_size = (2, 2)))
модель . add(Conv2DTranspose(128, (24,24), шаги = (2,2), активация = 'relu', заполнение = 'такой же', kernel_initializer = 'однородный'))
модель . добавить(UpSampling2D(размер = (2, 2)))
модель . add(Conv2DTranspose(64, (12,12), шаги = (2,2), активация = 'relu', заполнение = 'то же самое', kernel_initializer = 'униформа'))
модель . add(UpSampling2D(size = (2, 2)))
add(UpSampling2D(size = (2, 2)))
#Cs Layers
модель . добавить(Conv2D(256, размер ядра = (12, 12), активация = 'relu'))
модель . добавить(Conv2D(256, размер ядра = (12, 12), активация = 'relu'))
модель . добавить(Conv2D(256, размер ядра = (12, 12), активация = 'relu'))
модель . добавить(свести())
модель . add(Dense(4096, активация = 'relu'))
модель . добавить(Выпадение(0.5))
модель . добавить(Dense(4096,активация = 'relu'))
модель . добавить(Выпадение(0.5))
модель . add(Dense(2383,активация = 'relu'))
модель .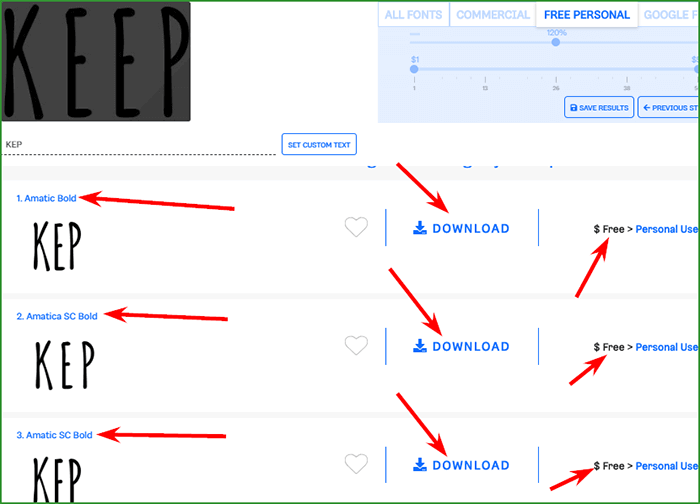 add(Dense(5, активация = 'softmax'))
add(Dense(5, активация = 'softmax'))
return model
batch_size = 128
epochs = 50
model= create_model()
sgd = tensorflow.keras.optimizers.0.SGD0(l. , распад = 1e-6, импульс = 0,9, нестеров = True)
model.compile (потеря = 'mean_squared_error', оптимизатор = sgd, metrics = ['точность']) Early_stopping = обратных вызовов . Раннее (Монитор = 'val_loss', min_delta = 0, терпение = 10, Verbose = 0, режим = 'мин.) контрольная точка = обратных вызовов . ModelCheckpoint(путь к файлу, монитор = 'val_loss', подробный = 1, save_best_only = True , режим = 'мин')
callbacks_list = pping]0007
Теперь мы подогнали модель и проверили на потери и точность.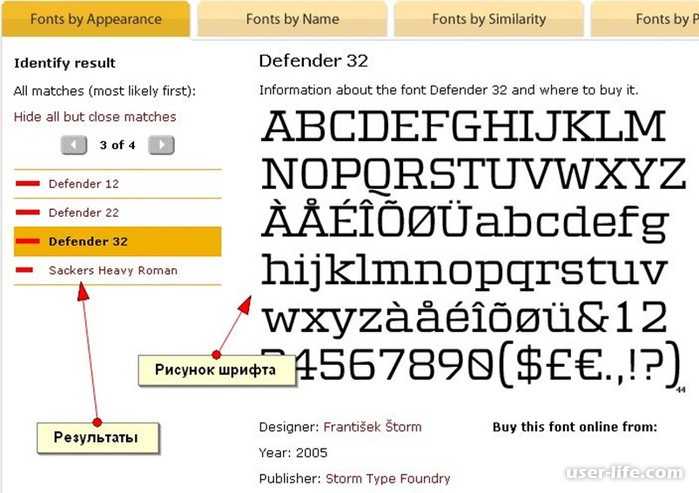
модель . FIT (Trainx, Trainy, Shuffle = True ,
BATCH_SIZE = BATCH_SIZE,
EPOCHS = EPOCHS,
VERBOSE = 1,
Validation_DATA = (TESTX, TELTY),
Validation_DATA = (testx, testy), callbacks = (testx, testy), callbacks = (testx, testy), callbacks = (testx, testy), callbacks wardation_data = (testx, testy). )счет = модель . оценить(testX, testY, verbose = 0)
print('Потеря теста:', оценка[0])
print('Точность теста:', оценка[1])
Потеря теста: 0,1341324895620346
Точность теста: 0,6410256624221802
Шаг 4: рамка
в качестве прототипа, мы используем KERAS.
из keras.models импорт load_model
модель = load_model('top_model.h5')
оценка = модель . оценить(testX, testY, verbose = 0)
print('Потеря теста:', оценка[0])
Печать («Точность теста:», оценка [1])
Потеря теста: 0,12708203494548798
Точность теста: 0,5833333134651184
Теперь We Trake A We Trak To Do Do Do Do Do Do Do Do Do Do Do Do Do Do Do Do Do Do Do Do Do Do Do Do Do Do Do Do Do Do Do Do Do Do Do DO результаты, достижения!img_path="sample/sample.jpg"
pil_im =PIL.Image.open(img_path).convert('L')
pil_im=blur_image(pil_im)
org_img = img_to_array(pil_im) def rev_conv_label(метка) :
если метка == 0:
Возврат 'Lato'
ELIF Метка == 1:
Возврат 'Raleway'
ELIF Лейбл == 2:
return ' ELIF Метка == 3:
Возврат 'Sansation'
ELIF Метка == 4:
Данные 'Walwway'data = []
Data .добавить (org_img)
данные = np . asarray(data, dtype = "float") / 255.0y = model.predict(data)
y = np.round(y).astype(int)label = rev_conv_label(y[0,0 ]))
рис, ax = plt . участков (1)
акселерометров . imshow(pil_im, интерполяция = 'ближайший', cmap = см . серый)
ах . text(5, 5, label , bbox = {'facecolor': 'white', 'pad': 10})
plt . show()
Вот и все, ребята! Распознавание шрифтов с помощью DeepFont.
Mlearning.ai Предложения по представлению
Как стать писателем на Mlearning.ai
medium.com
Как программное обеспечение для поиска шрифтов может повысить производительность магазина вывесок
9007 Продукты и процессы для получения прибыли Инструменты выпрямления, поворота и коррекции изображения встроены в программное обеспечение для более быстрого редактирования. В начале 90s, когда я начинал в индустрии вывесок, количество шрифтов, которые мы обычно выбирали для наших макетов, исчислялось десятками. В настоящее время мы имеем дело с тысячами возможных вариантов шрифтов, что затрудняет сопоставление существующих дизайнов, когда клиент не может предоставить иллюстрацию. Иногда у клиента есть логотип, который он может предоставить, но у него нет шрифтов, используемых в логотипе, и вам нужно набрать другой текст для его графики. В других случаях вам нужно воссоздать их логотип и нужны оригинальные шрифты. В любом случае вы должны быть в состоянии точно и быстро сопоставить их шрифты. Прокрутка списка шрифтов вручную в поисках подходящего шрифта не только отнимает много времени, но и может быть пустой тратой времени, если у вас даже не установлен шрифт на вашем компьютере. В таких случаях пригодится программное обеспечение для поиска шрифтов. Существует довольно много программ, позволяющих искать шрифт.

Программное обеспечение для шрифтов, которое использует наша компания, называется Find My Font. Это программное обеспечение для идентификации шрифтов, которое использует загруженное изображение. Вы нажимаете на пиксели в загруженном .jpeg, а затем вводите, какие буквы представляют эти пиксели. Затем вы запускаете сканирование, которое ищет совпадающие шрифты и составляет список.
Вы можете выбрать из списка шрифты, которые уже есть на вашем компьютере (локальный поиск), или шрифты, которые есть в сети (онлайн-поиск). Вы можете запускать локальный и онлайн-поиск отдельно или одновременно. Система разделяет их по цвету.

В программу встроено несколько дополнительных инструментов. Инструмент «Вращение базовой линии» позволяет провести параллельную линию вдоль основания букв, чтобы автоматически повернуть изображение под углом к горизонтали, чтобы можно было выбрать соответствующие буквы.
Другим удобным инструментом является инструмент «Разделитель букв», который отлично подходит для изображений, которые могут быть немного размытыми, или логотипов, где буквы соединены. Чтобы отсканировать шрифт, вам нужно начать с отдельных букв, поэтому, разделив их, вы сможете ввести то, что представляют пиксели.
Когда буквы на изображении идут вместе, встроенный инструмент разделения позволяет разделить пиксели и выбрать соответствующие буквы. Есть также инструменты вращения и инструмент коррекции и деформации изображения. Это позволяет вам настраивать импортированное изображение в программном обеспечении, поэтому вам не нужно тратить кучу времени, пытаясь выпрямить и обработать изображение в отдельном программном обеспечении, таком как Photoshop, перед его импортом.