Вектора
ВектораСоздаем вектор:
- с помощью функции с()
v1 <- c(1, 2, 3, 1, 2, 9) v1
## [1] 1 2 3 1 2 9
- перечислением
v2 <- 7:12 v2
## [1] 7 8 9 10 11 12
- из векторов
v3 <- c(v1, v2) v3
## [1] 1 2 3 1 2 9 7 8 9 10 11 12
- с помощью функции rep
v6 <- rep(x = c(1, 2), each = 4) v6
## [1] 1 1 1 1 2 2 2 2
v7 <- rep(x = c(1, 2)) v7
## [1] 1 2
v8 <- rep(x = c(1, 2), times = 3) v8
## [1] 1 2 1 2 1 2
- создание случайного вектора из набора значений
v9 <- sample(c(1, 3, 5, 6), 10, replace = T) v9
## [1] 3 6 6 6 3 5 1 5 5 1
v11 <- sample(10) v11
## [1] 6 3 9 4 1 5 2 8 7 10
- seq — создает последовательность
v10 <- seq(from = 1, to = 10, by = 2) v10
## [1] 1 3 5 7 9
Сумма векторов
v4 <- v1 + v2 v4
## [1] 8 10 12 11 13 21
Произведение векторов
v5 <- v1 * v2 v5
## [1] 7 16 27 10 22 108
Скалярное произведение двух векторов (одинаковой длины!)
v1 %*% v2
## [,1] ## [1,] 190
Получение элементов вектора по индексу
- получить второй элемент вектора v1
v1[2]
## [1] 2
- получить с третьего по пятый элементы вектора v1
v1[3:5]
## [1] 3 1 2
- получить все элементы вектора v1, кроме первого
v1[-1]
## [1] 2 3 1 2 9
Сумма всех координат вектора v1
sum(v1)
## [1] 18
Среднее значение координат вектора v1
mean(v1)
## [1] 3
Медиана координат вектора v1
median(v1)
## [1] 2
Максимальное значение координат вектора v1
max(v1)
## [1] 9
Минимальное значение координат вектора v1
min(v1)
## [1] 1
Количество позиций в векторе
length(v1)
## [1] 6
Округление числа
round(2.45865, digits = 3)
 45865, digits = 3)
45865, digits = 3)
## [1] 2.459
Создание матрицы
m1 <- matrix(1:8, ncol = 2) m1
## [,1] [,2] ## [1,] 1 5 ## [2,] 2 6 ## [3,] 3 7 ## [4,] 4 8
m2 <- matrix(v1, nrow = 2) m2
## [,1] [,2] [,3] ## [1,] 1 3 2 ## [2,] 2 1 9
Произведение матриц. Количество строк одной матрицы должно быть равно количеству столбцов другой.
m3 <- m1 %*% m2 m3
## [,1] [,2] [,3] ## [1,] 11 8 47 ## [2,] 14 12 58 ## [3,] 17 16 69 ## [4,] 20 20 80
Вывести размер матрицы
dim(m3)
## [1] 4 3
Вывести количество строк в матрице
nrow(m3)
## [1] 4
Вывести количество столбцов в матрице
ncol(m1)
## [1] 2
Задать имена столбцов и строк в матрице
rownames(m3) <- c("Bio1", "Bio2", "Bio3", "Bio4")
colnames(m3) <- c("Col1", "Col2", "Col3")
m3
## Col1 Col2 Col3 ## Bio1 11 8 47 ## Bio2 14 12 58 ## Bio3 17 16 69 ## Bio4 20 20 80
Вывести названия строк и столбцов матрицы
rownames(m3)
## [1] "Bio1" "Bio2" "Bio3" "Bio4"
colnames(m3)
## [1] "Col1" "Col2" "Col3"
Получение элементов матрицы по индексам и именам строк и столбцов
- взять элемент матрицы на пересечении 1 строки и 2 столбца
m3[1, 2]
## [1] 8
- взять второй столбце матрицы
m3[, 2]
## Bio1 Bio2 Bio3 Bio4 ## 8 12 16 20
- взять первую строку матрицы
m3[1, ]
## Col1 Col2 Col3 ## 11 8 47
- взять элемент матрицы строки Bio1 и столбца Col3
m3["Bio1", "Col3"]
## [1] 47
Создать список
l1 <- list()
Добавить элемент в список
l1[[1]] <- 1:10 l1
## [[1]] ## [1] 1 2 3 4 5 6 7 8 9 10
l1[["matrix"]] <- matrix(1:10, nrow = 2) l1
## [[1]] ## [1] 1 2 3 4 5 6 7 8 9 10 ## ## $matrix ## [,1] [,2] [,3] [,4] [,5] ## [1,] 1 3 5 7 9 ## [2,] 2 4 6 8 10
l1[[3]] <- "test" l1
## [[1]] ## [1] 1 2 3 4 5 6 7 8 9 10 ## ## $matrix ## [,1] [,2] [,3] [,4] [,5] ## [1,] 1 3 5 7 9 ## [2,] 2 4 6 8 10 ## ## [[3]] ## [1] "test"
Создаем data frame
df1 <- data.frame(v11 = c(1, 2, 3, 4, 5), v12 = c("T1", "T2", "T3", "T4", "T5")) df1
## v11 v12 ## 1 1 T1 ## 2 2 T2 ## 3 3 T3 ## 4 4 T4 ## 5 5 T5
Загрузить таблицу
test <- read.table("annotation.ptt", header = T, sep = "\t", quote = "")
Узнать размер таблицы (кол-во строк х кол-во столбцов)
dim(test)
## [1] 763 10
Вывести шапку таблицы
head(test)
## Start End Strand Length PID Gene Synonym Code COG ## 1 1893 2681 + 262 294660181 parA MGA_0619 - COG1192D ## 2 2671 3147 + 158 294660182 - MGA_0621 - - ## 3 3163 4548 + 461 31544207 dnaA MGA_0622 - COG0593L ## 4 4939 5133 + 64 294660183 - MGA_1322d - COG1132V ## 5 5160 6077 + 305 294660184 - MGA_0625a - COG1132V ## 6 6393 8294 + 633 294660185 - MGA_0626 - COG1132V ## Product ## 1 ParA/Soj family protein ## 2 hypothetical protein ## 3 chromosomal replication initiator protein DnaA ## 4 ABC transporter ## 5 multidrug/protein/lipid ABC transporter ## 6 multidrug/protein/lipid ABC transporter
Вывести 2 верхние строки таблицы
head(test, 2)
## Start End Strand Length PID Gene Synonym Code COG ## 1 1893 2681 + 262 294660181 parA MGA_0619 - COG1192D ## 2 2671 3147 + 158 294660182 - MGA_0621 - - ## Product ## 1 ParA/Soj family protein ## 2 hypothetical protein
Вывести 2 последние строки таблицы
tail(test, 2)
## Start End Strand Length PID Gene Synonym Code COG ## 762 1010633 1011601 - 322 294660636 dnaJ_7 MGA_0617 - COG0484O ## 763 1011604 1012779 - 391 294660637 dnaN MGA_0618 - COG0592L ## Product ## 762 DnaJ-like molecular chaperone ## 763 DNA polymerase III beta subunit DnaN
Статистика по колонкам таблицы
summary(test)
## Start End Strand Length ## Min.: 1893 Min. : 2681 -:362 Min. : 37 ## 1st Qu.: 243677 1st Qu.: 245410 +:401 1st Qu.: 188 ## Median : 517500 Median : 519914 Median : 314 ## Mean : 505601 Mean : 506773 Mean : 390 ## 3rd Qu.: 756280 3rd Qu.: 757211 3rd Qu.: 539 ## Max. :1011604 Max. :1012779 Max. :1969 ## ## PID Gene Synonym Code COG ## Min. :3.15e+07 - :351 MGA_0001: 1 -:763 - :274 ## 1st Qu.:3.15e+07 cbiO : 2 MGA_0002: 1 COG0484O: 8 ## Median :2.95e+08 vlhA.3.0.1: 2 MGA_0004: 1 COG1132V: 6 ## Mean :1.92e+08 aceF : 1 MGA_0005: 1 COG3328L: 6 ## 3rd Qu.:2.95e+08 ach2 : 1 MGA_0008: 1 COG0561R: 5 ## Max. :2.95e+08 ackA : 1 MGA_0009: 1 COG1404O: 5 ## (Other) :405 (Other) :757 (Other) :459 ## Product ## hypothetical protein :220 ## DnaJ-like molecular chaperone : 7 ## putative transposase domain-containing protein: 6 ## HAD superfamily hydrolase Cof : 5 ## putative transposase : 5 ## ABC transporter permease : 4 ## (Other) :516
Структура таблицы
str(test)
## 'data.Вывести с третьего по пятое значения столбца Length таблицы testframe': 763 obs. of 10 variables: ## $ Start : int 1893 2671 3163 4939 5160 6393 8389 8574 8929 10080 ... ## $ End : int 2681 3147 4548 5133 6077 8294 8538 8924 10080 10886 ... ## $ Strand : Factor w/ 2 levels "-","+": 2 2 2 2 2 2 2 2 2 2 ... ## $ Length : int 262 158 461 64 305 633 49 116 383 268 ... ## $ PID : int 294660181 294660182 31544207 294660183 294660184 294660185 31544211 294660186 31544213 294660187 ... ## $ Gene : Factor w/ 411 levels "-","aceF","ach2",..: 190 1 56 1 1 1 244 240 411 151 ... ## $ Synonym: Factor w/ 763 levels "MGA_0001","MGA_0002",..: 349 350 351 731 352 353 732 354 355 356 ... ## $ Code : Factor w/ 1 level "-": 1 1 1 1 1 1 1 1 1 1 ... ## $ COG : Factor w/ 411 levels "-","COG0006E",..: 319 1 240 306 306 306 112 241 269 13 ... ## $ Product: Factor w/ 483 levels "1-acyl-sn-glycerol-3-phosphate acyltransferase",..: 261 220 105 65 250 250 55 356 315 137 ...

test$Length[1:5]
## [1] 262 158 461 64 305
Вывести начало столбца Length таблицы test
head(test$Length)
## [1] 262 158 461 64 305 633
Вывести последние значения столбца Length таблицы test
tail(test$Length)
## [1] 210 420 846 648 322 391
Вывести элемент первой строки и второго столбца таблицы test
test[1, 2]
## [1] 2681
Вывести название строк и столбцов таблицы test
colnames(test)
## [1] "Start" "End" "Strand" "Length" "PID" "Gene" "Synonym" ## [8] "Code" "COG" "Product"
rownames(test)
## [1] "1" "2" "3" "4" "5" "6" "7" "8" "9" "10" "11" ## [12] "12" "13" "14" "15" "16" "17" "18" "19" "20" "21" "22" ## [23] "23" "24" "25" "26" "27" "28" "29" "30" "31" "32" "33" ## [34] "34" "35" "36" "37" "38" "39" "40" "41" "42" "43" "44" ## [45] "45" "46" "47" "48" "49" "50" "51" "52" "53" "54" "55" ## [56] "56" "57" "58" "59" "60" "61" "62" "63" "64" "65" "66" ## [67] "67" "68" "69" "70" "71" "72" "73" "74" "75" "76" "77" ## [78] "78" "79" "80" "81" "82" "83" "84" "85" "86" "87" "88" ## [89] "89" "90" "91" "92" "93" "94" "95" "96" "97" "98" "99" ## [100] "100" "101" "102" "103" "104" "105" "106" "107" "108" "109" "110" ## [111] "111" "112" "113" "114" "115" "116" "117" "118" "119" "120" "121" ## [122] "122" "123" "124" "125" "126" "127" "128" "129" "130" "131" "132" ## [133] "133" "134" "135" "136" "137" "138" "139" "140" "141" "142" "143" ## [144] "144" "145" "146" "147" "148" "149" "150" "151" "152" "153" "154" ## [155] "155" "156" "157" "158" "159" "160" "161" "162" "163" "164" "165" ## [166] "166" "167" "168" "169" "170" "171" "172" "173" "174" "175" "176" ## [177] "177" "178" "179" "180" "181" "182" "183" "184" "185" "186" "187" ## [188] "188" "189" "190" "191" "192" "193" "194" "195" "196" "197" "198" ## [199] "199" "200" "201" "202" "203" "204" "205" "206" "207" "208" "209" ## [210] "210" "211" "212" "213" "214" "215" "216" "217" "218" "219" "220" ## [221] "221" "222" "223" "224" "225" "226" "227" "228" "229" "230" "231" ## [232] "232" "233" "234" "235" "236" "237" "238" "239" "240" "241" "242" ## [243] "243" "244" "245" "246" "247" "248" "249" "250" "251" "252" "253" ## [254] "254" "255" "256" "257" "258" "259" "260" "261" "262" "263" "264" ## [265] "265" "266" "267" "268" "269" "270" "271" "272" "273" "274" "275" ## [276] "276" "277" "278" "279" "280" "281" "282" "283" "284" "285" "286" ## [287] "287" "288" "289" "290" "291" "292" "293" "294" "295" "296" "297" ## [298] "298" "299" "300" "301" "302" "303" "304" "305" "306" "307" "308" ## [309] "309" "310" "311" "312" "313" "314" "315" "316" "317" "318" "319" ## [320] "320" "321" "322" "323" "324" "325" "326" "327" "328" "329" "330" ## [331] "331" "332" "333" "334" "335" "336" "337" "338" "339" "340" "341" ## [342] "342" "343" "344" "345" "346" "347" "348" "349" "350" "351" "352" ## [353] "353" "354" "355" "356" "357" "358" "359" "360" "361" "362" "363" ## [364] "364" "365" "366" "367" "368" "369" "370" "371" "372" "373" "374" ## [375] "375" "376" "377" "378" "379" "380" "381" "382" "383" "384" "385" ## [386] "386" "387" "388" "389" "390" "391" "392" "393" "394" "395" "396" ## [397] "397" "398" "399" "400" "401" "402" "403" "404" "405" "406" "407" ## [408] "408" "409" "410" "411" "412" "413" "414" "415" "416" "417" "418" ## [419] "419" "420" "421" "422" "423" "424" "425" "426" "427" "428" "429" ## [430] "430" "431" "432" "433" "434" "435" "436" "437" "438" "439" "440" ## [441] "441" "442" "443" "444" "445" "446" "447" "448" "449" "450" "451" ## [452] "452" "453" "454" "455" "456" "457" "458" "459" "460" "461" "462" ## [463] "463" "464" "465" "466" "467" "468" "469" "470" "471" "472" "473" ## [474] "474" "475" "476" "477" "478" "479" "480" "481" "482" "483" "484" ## [485] "485" "486" "487" "488" "489" "490" "491" "492" "493" "494" "495" ## [496] "496" "497" "498" "499" "500" "501" "502" "503" "504" "505" "506" ## [507] "507" "508" "509" "510" "511" "512" "513" "514" "515" "516" "517" ## [518] "518" "519" "520" "521" "522" "523" "524" "525" "526" "527" "528" ## [529] "529" "530" "531" "532" "533" "534" "535" "536" "537" "538" "539" ## [540] "540" "541" "542" "543" "544" "545" "546" "547" "548" "549" "550" ## [551] "551" "552" "553" "554" "555" "556" "557" "558" "559" "560" "561" ## [562] "562" "563" "564" "565" "566" "567" "568" "569" "570" "571" "572" ## [573] "573" "574" "575" "576" "577" "578" "579" "580" "581" "582" "583" ## [584] "584" "585" "586" "587" "588" "589" "590" "591" "592" "593" "594" ## [595] "595" "596" "597" "598" "599" "600" "601" "602" "603" "604" "605" ## [606] "606" "607" "608" "609" "610" "611" "612" "613" "614" "615" "616" ## [617] "617" "618" "619" "620" "621" "622" "623" "624" "625" "626" "627" ## [628] "628" "629" "630" "631" "632" "633" "634" "635" "636" "637" "638" ## [639] "639" "640" "641" "642" "643" "644" "645" "646" "647" "648" "649" ## [650] "650" "651" "652" "653" "654" "655" "656" "657" "658" "659" "660" ## [661] "661" "662" "663" "664" "665" "666" "667" "668" "669" "670" "671" ## [672] "672" "673" "674" "675" "676" "677" "678" "679" "680" "681" "682" ## [683] "683" "684" "685" "686" "687" "688" "689" "690" "691" "692" "693" ## [694] "694" "695" "696" "697" "698" "699" "700" "701" "702" "703" "704" ## [705] "705" "706" "707" "708" "709" "710" "711" "712" "713" "714" "715" ## [716] "716" "717" "718" "719" "720" "721" "722" "723" "724" "725" "726" ## [727] "727" "728" "729" "730" "731" "732" "733" "734" "735" "736" "737" ## [738] "738" "739" "740" "741" "742" "743" "744" "745" "746" "747" "748" ## [749] "749" "750" "751" "752" "753" "754" "755" "756" "757" "758" "759" ## [760] "760" "761" "762" "763"
Вывести элемент третьей строки столбца End
test[3, "End"]
## [1] 4548
Вывести с третье по пятую строки всех столбцов
test[3:5, ]
## Start End Strand Length PID Gene Synonym Code COG ## 3 3163 4548 + 461 31544207 dnaA MGA_0622 - COG0593L ## 4 4939 5133 + 64 294660183 - MGA_1322d - COG1132V ## 5 5160 6077 + 305 294660184 - MGA_0625a - COG1132V ## Product ## 3 chromosomal replication initiator protein DnaA ## 4 ABC transporter ## 5 multidrug/protein/lipid ABC transporter
Посчитать среднее значение столбца Length
mean(test$Length)
## [1] 389.8
Добавить новый столбец к таблице
test$new <- 0 head(test)
## Start End Strand Length PID Gene Synonym Code COG ## 1 1893 2681 + 262 294660181 parA MGA_0619 - COG1192D ## 2 2671 3147 + 158 294660182 - MGA_0621 - - ## 3 3163 4548 + 461 31544207 dnaA MGA_0622 - COG0593L ## 4 4939 5133 + 64 294660183 - MGA_1322d - COG1132V ## 5 5160 6077 + 305 294660184 - MGA_0625a - COG1132V ## 6 6393 8294 + 633 294660185 - MGA_0626 - COG1132V ## Product new ## 1 ParA/Soj family protein 0 ## 2 hypothetical protein 0 ## 3 chromosomal replication initiator protein DnaA 0 ## 4 ABC transporter 0 ## 5 multidrug/protein/lipid ABC transporter 0 ## 6 multidrug/protein/lipid ABC transporter 0
Записать в новый столбец значения разницы двух столбцов
test$new <- test$End - test$Start head(test)
## Start End Strand Length PID Gene Synonym Code COG ## 1 1893 2681 + 262 294660181 parA MGA_0619 - COG1192D ## 2 2671 3147 + 158 294660182 - MGA_0621 - - ## 3 3163 4548 + 461 31544207 dnaA MGA_0622 - COG0593L ## 4 4939 5133 + 64 294660183 - MGA_1322d - COG1132V ## 5 5160 6077 + 305 294660184 - MGA_0625a - COG1132V ## 6 6393 8294 + 633 294660185 - MGA_0626 - COG1132V ## Product new ## 1 ParA/Soj family protein 788 ## 2 hypothetical protein 476 ## 3 chromosomal replication initiator protein DnaA 1385 ## 4 ABC transporter 194 ## 5 multidrug/protein/lipid ABC transporter 917 ## 6 multidrug/protein/lipid ABC transporter 1901
Удалить столбец new
test$new <- NULL head(test)
## Start End Strand Length PID Gene Synonym Code COG ## 1 1893 2681 + 262 294660181 parA MGA_0619 - COG1192D ## 2 2671 3147 + 158 294660182 - MGA_0621 - - ## 3 3163 4548 + 461 31544207 dnaA MGA_0622 - COG0593L ## 4 4939 5133 + 64 294660183 - MGA_1322d - COG1132V ## 5 5160 6077 + 305 294660184 - MGA_0625a - COG1132V ## 6 6393 8294 + 633 294660185 - MGA_0626 - COG1132V ## Product ## 1 ParA/Soj family protein ## 2 hypothetical protein ## 3 chromosomal replication initiator protein DnaA ## 4 ABC transporter ## 5 multidrug/protein/lipid ABC transporter ## 6 multidrug/protein/lipid ABC transporter
Выбор из таблицы с условием
a <- test[test$Strand == "+" & test$Length > 1300, ] a
## Start End Strand Length PID Gene Synonym Code COG ## 21 24273 28358 + 1361 31544225 - MGA_0654 - - ## 94 110558 115042 + 1494 294660232 polC MGA_0791 - COG2176L ## 228 303943 308115 + 1390 294660312 rpoB MGA_1000 - COG0085K ## 265 364332 369059 + 1575 294660333 - MGA_1079 - - ## 337 448671 454466 + 1931 31544525 hlp2 MGA_1203 - COG1196D ## Product ## 21 ABC transporter permease ## 94 DNA polymerase III subunit alpha polC/Gram positive-type ## 228 DNA-directed RNA polymerase subunit beta ## 265 hypothetical protein ## 337 cytadherence-associated protein Hlp2
Aggregate
Функция aggregate. ищем среднее значение по столбцу Length для строк, имеющих одно значение столбца Strand
ищем среднее значение по столбцу Length для строк, имеющих одно значение столбца Strand
agg <- aggregate(x = test$Length, by = list(test$Strand), FUN = mean) agg
## Group.1 x ## 1 - 377.2 ## 2 + 401.2
Задаем имена полей
colnames(agg) <- c("Strand", "MeanLength")
agg
## Strand MeanLength ## 1 - 377.2 ## 2 + 401.2
Назвать только 2 столбец таблицы
colnames(agg)[2] <- "NewName" agg
## Strand NewName ## 1 - 377.2 ## 2 + 401.2
Merge
Соединить 2 таблицы
test.agg <- merge(test, agg, by.x = "Strand", by.y = "Strand") head(test.agg)
## Strand Start End Length PID Gene Synonym Code COG ## 1 - 193268 195040 590 31544361 metG_2 MGA_0893 - COG0143J ## 2 - 384996 386495 499 31544468 - MGA_1107 - COG1322S ## 3 - 180028 180384 118 31544347 himA/hup_1 MGA_0869 - COG0776L ## 4 - 149313 150758 481 31544321 - MGA_0829a - - ## 5 - 57481 59649 722 31544247 nrdA MGA_0695 - COG0209F ## 6 - 197100 197741 213 294660276 - MGA_0901 - - ## Product ## 1 methionyl-tRNA synthetase ## 2 hypothetical protein ## 3 histone-like DNA-binding superfamily protein HimA/HU/Integration host factor ## 4 hypothetical protein ## 5 ribonucleotide-diphosphate reductase subunit alpha ## 6 hypothetical protein ## NewName ## 1 377.2 ## 2 377.2 ## 3 377.2 ## 4 377.2 ## 5 377.2 ## 6 377.2
Apply. Lapply. Tapply
Apply — матрицы Создаем случайную матрицу
m <- matrix(sample(1:100, 100), ncol = 10) m
## [,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8] [,9] [,10] ## [1,] 90 4 8 24 50 15 71 33 35 74 ## [2,] 23 73 99 14 54 70 30 22 26 61 ## [3,] 97 34 49 45 91 28 96 20 60 53 ## [4,] 82 32 94 75 72 85 3 2 25 47 ## [5,] 93 81 12 44 62 17 66 46 29 64 ## [6,] 95 36 37 41 7 56 18 63 6 88 ## [7,] 16 27 42 87 92 1 86 40 39 31 ## [8,] 5 98 78 76 48 58 89 84 55 80 ## [9,] 57 59 52 79 67 19 77 69 51 65 ## [10,] 100 83 9 21 38 10 68 13 43 11
Находим среднее по строкам
apply(X = m, MARGIN = 1, FUN = mean)
## [1] 40.4 47.2 57.3 51.7 51.4 44.7 46.1 67.1 59.5 39.6
Находим среднее по столбцам
apply(m, 2, mean)
## [1] 65.8 52.7 48.0 50.6 58.1 35.9 60.4 39.2 36.9 57.4
Lapply — списки Создаем список из 3 векторов. Находим максимальное значение для каждого из векторов списка
l <- list() l[[1]] <- 1:10 l[[2]] <- seq(1, 20, 2) l[[3]] <- sample(1:30, size = 10, replace = F) l
## [[1]] ## [1] 1 2 3 4 5 6 7 8 9 10 ## ## [[2]] ## [1] 1 3 5 7 9 11 13 15 17 19 ## ## [[3]] ## [1] 15 1 7 4 16 26 22 11 27 12
lapply(X = l, FUN = max)
## [[1]] ## [1] 10 ## ## [[2]] ## [1] 19 ## ## [[3]] ## [1] 27
Tapply — таблицы Считаем среднее значений столбца Length для строк, сргуппированных по значениям столбца Strand
tapply(X = test$Length, INDEX = test$Strand, FUN = mean)
## - + ## 377.2 401.2
Unique
Выбор уникальных значений из столбца таблицы
unique(test$Strand)
## [1] + - ## Levels: - +
Графика
t.cover <- read.table("metagenomic_coverage_distributions.txt", header = T, sep = " ") t.groups <- read.table("sample_groups.txt", header = T, sep = " ") t.all <- merge(t.cover, t.groups, by.x = "names", by.y = "names")
Гистограмма
hist(t.all$length, breaks = 30, main = "Histogram", col = "lightgreen", xlab = "Length",
ylab = "Freq")
Точки
plot(x = t.all$length, y = t.all$cover, col = t.all$country, cex = 0.6, main = "Coverage by length",
xlab = "Length", ylab = "Coverage", pch = 16)
legend(1e+06, 5e+06, levels(t.all$country), col = 1:3, pch = 16)
Боксплот
boxplot(data = t.all, cover ~ country, col = "lightblue", main = "Coverage by country",
xlab = "Country", ylab = "Coverage")
График плотности
plot(density(t.all$length), col = "red", main = "Length density", xlab = "Length")
Барплот
barplot(c(1:30), col = heat.colors(30))
m1 <- matrix(sample(30), ncol = 5)
colnames(m1) <- c("M1", "M2", "M3", "M4", "M5")
m1
## M1 M2 M3 M4 M5 ## [1,] 24 16 23 3 7 ## [2,] 4 25 8 30 18 ## [3,] 1 2 6 26 17 ## [4,] 22 14 19 13 29 ## [5,] 15 9 28 11 10 ## [6,] 27 21 5 20 12
barplot(m1, col = rainbow(6), beside = TRUE)
Несколько линий создаем матрицу со случайными данными
m2 <- matrix(c(1:5, sample(20)), nrow = 5)
colnames(m2) <- c("x", "y1", "y2", "y3", "y4")
m2
## x y1 y2 y3 y4 ## [1,] 1 4 19 6 9 ## [2,] 2 16 1 14 15 ## [3,] 3 2 7 11 18 ## [4,] 4 13 17 10 8 ## [5,] 5 5 20 12 3
Рисуем первую линию. Задаем границы графика
Добавляем новые линии других цветов и типов
Задаем границы графика
Добавляем новые линии других цветов и типов
plot(x = m2[, 1], y = m2[, 2], type = "l", col = "red", ylim = c(min(m2), max(m2)),
lty = 1, xlab = "x", ylab = "y")
lines(x = m2[, 1], y = m2[, 3], type = "l", col = "blue", lty = 2)
lines(x = m2[, 1], y = m2[, 4], type = "l", col = "green", lty = 3, lwd = 3)
lines(x = m2[, 1], y = m2[, 5], type = "l", col = "orange", lty = 4)
lines(x = m2[, 1], y = m2[, 5], type = "l", col = "orange", lty = 4, lwd = 2)
Несколько графиков на одном листе
layout(mat = matrix(1:4, ncol = 2)) plot(sample(5)) plot(sample(5)) plot(sample(5)) plot(sample(5)) layout(mat = matrix(1:8, ncol = 4))
for (i in 1:8) {
plot(sample(100), col = i, pch = 16)
}
Условия
If
x <- 4
if (x == 4) print("yes") else print("no")
## [1] "yes"
if (x < 2) {
print("x <= 2")
} else if (x <= 3) {
print("x <= 3")
} else {
print("x > 3")
}
## [1] "x > 3"
Switch
switch(3, "A", "B", "C", "D", "E")
## [1] "C"
switch("T", A = print("A"), T = {
m <- 1
m <- m + 2
}, C = print("C"))
print(m)
## [1] 3
switch("T", A = print("A"), B = print("B"), print("not eq"))
## [1] "not eq"
Циклы
Repeat
i <- 1
repeat {
i <- i + 1
if (i >= 5)
break
}
print(i)
## [1] 5
While
i <- 1
while (i <= 5) {
i <- i + 1
}
print(i)
## [1] 6
For
for (i in 1:5) {
print(i)
}
## [1] 1 ## [1] 2 ## [1] 3 ## [1] 4 ## [1] 5
for (i in c("A", "B", "C", "D")) {
print(i)
}
## [1] "A" ## [1] "B" ## [1] "C" ## [1] "D"
Функции
myFunc <- function(x) {
x <- x + 2
return(x)
}
myFunc(2)
## [1] 4
x <- 2 myFunc(x)
## [1] 4
x
## [1] 2
myFunc2 <- function(x, y) {
return(x + y)
}
myFunc2(x = 3, y = 5)
## [1] 8
myFunc2(3, 5)
## [1] 8
plotVec <- function(vec = rep(1, 5)) {
plot(vec)
}
plotVec(vec = c(1, 2, 3, 4, 5))
plotVec()
m <- matrix(1:10, nrow = 2, byrow = T) m
## [,1] [,2] [,3] [,4] [,5] ## [1,] 1 2 3 4 5 ## [2,] 6 7 8 9 10
apply(m, 1, FUN = function(x) {
x + 2
})
## [,1] [,2] ## [1,] 3 8 ## [2,] 4 9 ## [3,] 5 10 ## [4,] 6 11 ## [5,] 7 12
apply(m, 2, FUN = function(x) {
x[1]
})
## [1] 1 2 3 4 5
1.
 Заполнить вектор а размерности n по правилу:
Заполнить вектор а размерности n по правилу:где В и С — заданные векторы той же размерности.
Для отладки программы контрольный пример выбрать самостоятельно. 2. Пересчитать элементы матрицы К размерности m*n, разделив каждый из них на элемент, расположенный в той же строке в первом столбце.
Проанализировать выполнение программы на примере:
Вариант 18
1. Пересчитать элементы вектора N размерности L по правилу:
Ni=(Ni-1+Ni+1)/2, где 2 i L-1 Проанализировать выполнение программы на примере:
N={1; 2; 4; 8; 16; 32}
2. Заполнить в памяти эвм матрицу:
Для контроля напечатать третий столбец.
Вариант 19
1. Заполнись одномерный массив
S
размерности 13 значениями функции
Заполнись одномерный массив
S
размерности 13 значениями функции
Sin2 X, где Х меняется от О до 2 с шагом /6.
Полученный массив напечатать в столбец.
2. Транспонировать матрицу В размерности n. Напечатать матрицу В и полученную матрицу ВТ.
Проанализировать выполнение программы на примере.
Вариант 20
1. Пересчитать значения элементов одномерного массива К размерности n по правилу:
Кj=Кj / K1, К10, где j > 1.
Для отладки программы, вектор выбрать самостоятельно.
2. Заполнить в памяти ЭВМ матрицу В размерности m*n так, чтобы каждый элемент был равен сумме его индексов: строки и столбца. Полученную матрицу напечатать.
Проанализировать выполнение программы на примере:
m=3;
n=4.
Вариант 21
1. Пересчитать элементы вектора Р размерности n по правилу:
Pi=Pi+P1
Исходный и полученный векторы напечатать. Для отладки программы принять n=6, вектор Р выбрать самостоятельно.
2. Заполнить в памяти ЭВМ матричную единицу размерности n. (Матричная единица — квадратная матрица, значения элементов которой равны 1). Проанализировать выполнение программы на примере: n=5.
Вариант 22
1. Заполнить в памяти машины одномерный массив:
K={1, 2, 3, 4, 5, 6, …, 20}
2. Пересчитать квадратную матрицу Р размерности n так, чтобы поменялись местами первая и последняя строки. Напечатать исходную и полученную матрицы.
Для отладки программы значения n и Р выбрать самостоятельно.
Вариант 23
1. Заполнить вектор М размерности КЗ по
правилу:
Заполнить вектор М размерности КЗ по
правилу:
Mi=|i-3|
Проанализировать выполнение программы на примере К3==10
2. Пересчитать матрицу К размерности m*n так, чтобы поменялись местами первый и последний столбец.Для отладки программы контрольный пример выбрать самостоятельно.
Вариант 24
1. Заполнись одномерный массив С размерности 13 значениями функции Cos 2X, где Х меняется от О до 2 с шагом /6.
Полученный массив напечатать в столбец.
Пересчитать элементы матрицы Q по правилу:
Qij = |Qij| + 10
Для контроля напечатать вторую строку исходной матрицы и вновь полученную матрицу. Матрицу Q задать самостоятельно.
Вариант 25
1. Пересчитать элементы вектора а размерности n по правилу:
где В — вектор той же размерности
Для
отладки программы контрольный
пример
выбрать самостоятельно.
2. Заполнить матрицу L размерности m no правилу:
Lki=k-j
Проанализировать выполнение программы на примере m=3.
Вариант 26
1. Заполнить в памяти машины одномерный вектор вида:
N={0; 1; 0; 1; 0; 1}
2. Задана матрица А размерности К*l_, состоящая из целыx десятичных чисел. Транспонировать ее в матрицу В. Для контроля напечатать первый столбец исходной матрицы и первую строку полученной.
Вариант 27
Заполнить в памяти машины матрицу вида:
2. Пересчитать элементы вектора Q размерности L так, чтобы поменялись местами первый и последний элемент, второй и предпоследний и т. д. Вектор задать самостоятельно.
Вариант 28
Пересчитать элементы матрицы Т размерности K*l, умножив каждый из них на элемент, расположенный в том же столбце в последней строке.

Заполнить вектор В размерности 9 значениями функции 1gх, где х изменяется от 0,1 до 0,9 с шагом 0,1.
Вариант 29
1. Заполнить вектор С размерности N диагональными элементами квадратной матрицы А той же размерности.
Проанализировать выполнение программы на примере:
Пересчитать элементы матрицы Р размерности M*N по правилу:
Pij=Pij+0,5
Вариант 30
1. Пересчитать элементы вектора D1 по правилу:
2. Заполнить в памяти машины матрицу TS вида:
Векторы и индексирование — наука о данных с R
R имеет специальную структуру данных, называемую вектором. Вектор — это одномерный набор объектов одного типа. Чаще всего вектор будет просто последовательностью чисел. Мы можем создать последовательность чисел, используя оператор
Чаще всего вектор будет просто последовательностью чисел. Мы можем создать последовательность чисел, используя оператор : .
чисел <- 1:10 числа
## [1] 1 2 3 4 5 6 7 8 9 10
Обратите внимание, что векторы обрабатываются так же, как один элемент. Все, что работает с одним числом, работает точно так же и с вектором. Это называется векторизацией. 9числа
## [1] 2 4 8 16 32 64 128 256 512 1024
sin(числа)
## [1] 0,8414710 0,9092974 0,1411200 -0,7568 025 -0,9589243 -0,2794155 ## [7] 0.6569866 0.9893582 0.4121185 -0.5440211
Мы также можем создать вектор с помощью функции c() ( c означает объединение, если вам интересно).
concat <- c(4, 17, -1, 55, 2) concat
## [1] 4 17 -1 55 2
Индексирование
Часто мы не хотим получать весь вектор. Возможно, нам нужен только один элемент или набор определенных элементов. Мы делаем это с помощью индексации (используются скобки [] ).
Чтобы получить первый элемент вектора, мы могли бы сделать следующее. В R индексы массивов начинаются с 1 — 1-й элемент имеет индекс 1. Это отличается от языков на основе 0, таких как C, Python или Java, где первый элемент имеет индекс 0.
concat[1]
# # [1] 4
Чтобы получить другие элементы, мы могли бы сделать следующее:
concat[2] # второй элемент
## [1] 17
concat[length(concat)] # последний элемент
## [1] 2
Обратите внимание, что для второго примера мы поместили функцию внутри квадратных скобок. В этом случае length() используется для получения длины вектора, а поскольку длина вектора будет равна индексу его последнего элемента, это отличный способ получить последний элемент вектора. .
В квадратных скобках можно поместить что угодно. Например, помещение другого вектора в скобки дает нам несколько значений.
concat[1:4]
## [1] 4 17 -1 55
concat[c(3, 5)]
## [1] -1 2
Мы можем использовать эту технику для переназначения определенные значения внутри вектора. Например, мы можем изменить 3-е и 5-е значения на 76 с помощью следующего кода:
Например, мы можем изменить 3-е и 5-е значения на 76 с помощью следующего кода:
concat[c(3, 5)] <- 76 concat
## [1] 4 17 76 55 76
Можно даже индексировать за пределами вектора. Обратите внимание, что R «заполняет пробелы» NA значений. NA — это заполнитель R для «нет данных» (поскольку 0 часто появляется в реальных данных).
concat[10] <- 4.3 concat
## [1] 4.0 17.0 76.0 55.0 76.0 NA NA NA NA 4.3
НИКОГДА НЕ ДЕЛАЙТЕ ЭТОГО. Хотя на самом деле это допустимый код в R (индексирование за пределами размера вектора является ошибкой в большинстве других языков), это сказывается на производительности. Позже мы более подробно рассмотрим, почему.
Матрицы
Матрица представляет собой двумерный вектор. Давайте создадим матрицу с матрица() функция. Одно важное замечание: функции часто имеют необязательные, «дополнительные» аргументы, которые указываются в нотации имя=значение .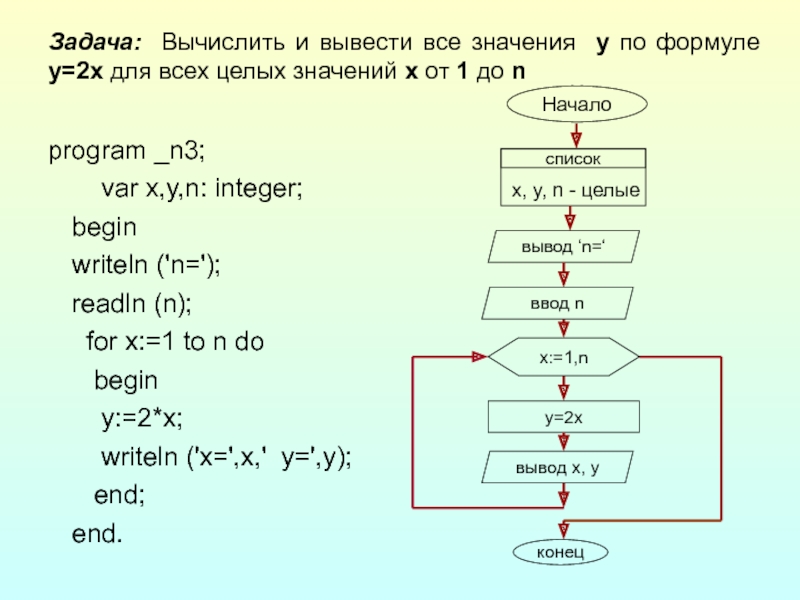 В этом случае мы создаем матрицу с 2 строками и 5 столбцами.
В этом случае мы создаем матрицу с 2 строками и 5 столбцами.
мат <- матрица (1:10, nrow=2, ncol=5) мат
## [1] [2] [3] [4] [5] ## [1,] 1 3 5 7 9 ## [2,] 2 4 6 8 10
Все те же операции, которые работают с векторами, также работают и с матрицами.
мат + 20
## [1] [2] [3] [4] [5] ## [1,] 21 23 25 27 29 ## [2,] 22 24 26 28 30
dim(mat) # получить размеры матрицы
## [1] 2 5
length(mat) # количество элементов в матрице
## [ 1] 10
Однако индексация матрицы немного отличается от индексации вектора. Теперь у нас есть не одно, а два измерения на выбор. При индексировании с использованием объекта с несколькими измерениями мы используем , для их разделения. В R строки находятся слева от запятой, а столбцы — справа (третье измерение будет после второй запятой и так далее…). Обратите внимание, что R на самом деле пытается нам помочь. Когда мы напечатали нашу матрицу, в строках было [#,] рядом с ними, а столбцы имеют [#] . Это фактически показывает нам точный синтаксис, который нам нужен для получения каждого элемента.
Это фактически показывает нам точный синтаксис, который нам нужен для получения каждого элемента.
Таким образом, используя выходные данные матрицы, mat[1,] должны дать нам первую строку, а mat[4] должны дать нам четвертый столбец. Давайте проверим это:
mat[1,]
## [1] 1 3 5 7 9
mat[4]
## [1] 7 8
Мы можем индексировать как строки, так и столбцы в в то же время, чтобы получить определенный элемент.
mat[1, 1] # взять первый ряд, первый столбец
## [1] 1
mat[2, 1:3] # элементы 1-3 второго ряда
## [1] 2 4 6
Упражнение. Захват несвязанных элементов
Попробуйте получить столбцы 1, 4 и 5 первой строки одной командой.
Упражнение. Чтение документации
Создайте матрицу 8x5, используя числа 1:40. Посмотрите, сможете ли вы заполнить его по строкам, а не по столбцам.
Подсказка: вы должны проверить документацию для матрица() .
Различные типы данных
В большинстве языков программирования текст называется строкой. Чтобы создать текст в R, мы просто заключаем его в двойные ( " ) или одинарные ( ' ) кавычки. Мы уже видели пример строки ( print('hello world!') ).
"это строка"
## [1] "это строка"
paste('мы можем комбинировать строки', 'с помощью функции paste()') ## [1] "мы может объединять строки с помощью функции paste()"
Что произойдет, если мы добавим строку к вектору чисел?
чисел <- c(1, 4, 9, 10) числа
## [1] 1 4 9 10
числа[3] <- "тестирование..." числа
## [1] "1" "4" "тестирование..." "10"
Весь наш вектор чисел превратился в строки! Это важное свойство векторов и матриц: они могут содержать только один тип данных! Если мы попытаемся поместить другой тип в вектор, R преобразует весь вектор в новый тип данных.
Опять же, это преобразование оказывает сильное влияние на производительность, особенно для больших векторов или матриц. R необходимо создать новый вектор с нуля, а затем скопировать и преобразовать каждый элемент.
R необходимо создать новый вектор с нуля, а затем скопировать и преобразовать каждый элемент.
Итак, давайте узнаем о различных типах данных R. Есть еще несколько типов, которые мы не рассматриваем здесь или рассмотрим позже (например, факторы). Это просто наиболее распространенные типы данных, с которыми мы столкнемся.
Числовые
Числовые переменные могут содержать любое десятичное число, положительное или отрицательное. В других языках они называются поплавками. Обратите внимание, что это тип числа по умолчанию в R.
Чтобы создать числовое значение, все, что нам нужно сделать, это ввести его как обычно.
1
## [1] 1
-3.5
## [1] -3.5
Мы можем преобразовать другую переменную в числовую с помощью функции as.numeric() . Это работает только со значениями, которые можно легко преобразовать.
as.numeric("456") # это работает ## [1] 456
as.numeric("seven") # это не работает 1] нет данных Целые числа
Целые числа представляют любое целое число, положительное или отрицательное.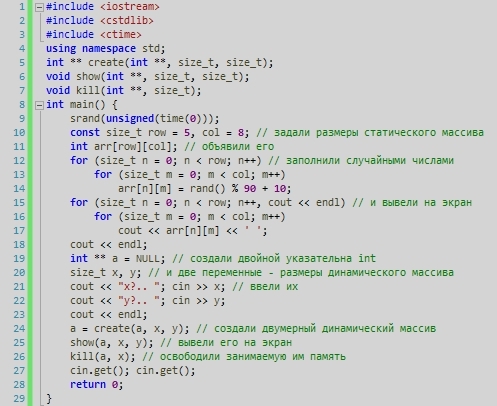 Они не могут хранить десятичные числа.
Они не могут хранить десятичные числа.
Чтобы создать число явно как целое число, добавьте после него L .
15L
## [1] 15
Мы можем преобразовать набор данных в целое число с помощью функции as.integer() .
as.integer(c("65.3", "4")) ## [1] 65 4
Символы (строки)
Как упоминалось ранее, строки представляют собой наборы текста. Мы можем превратить что-то в строку с помощью as.character() функция.
as.character(TRUE)
## [1] "TRUE"
Логические (логические) значения
Есть только два логических значения: TRUE и FALSE . Они используются в буквальном смысле для обозначения того, является ли утверждение истинным или ложным.
Как обычно, мы можем преобразовать что-либо в логическое/логическое значение с помощью функции as.logical() . Важно отметить, что это очень хорошо демонстрирует, что происходит, когда мы превращаем один тип данных в другой. Если один тип данных не может содержать дополнительную информацию из другого, эта информация теряется во время преобразования.
Если один тип данных не может содержать дополнительную информацию из другого, эта информация теряется во время преобразования.
пятьдесят <- as.logical(50) пятьдесят
## [1] TRUE
as.numeric(fifty)
## [1] 1
Определение типов данных
тип данных с функцией class() :
class(14)
## [1] "numeric"
class(1L)
## [1] "integer"
class (ИСТИНА)
## [1] "логический"
class("текст") ## [1] "character"
class(NA)
## [1] "logical"
Обратите внимание, что NA могут быть любого типа и часто используются в качестве заполнителей для отсутствующих данных .
Упражнение. Преобразование типов данных
Посмотрите, сможете ли вы заставить работать следующие выражения:
5 + "10" - В результате получите 15.
3 + 3,7 - Получим в результате 6.