Индексы и срезы | Python 3 для начинающих и чайников
Сегодня мы поговорим об операциях взятия индекса и среза.
Взятие элемента по индексу
Как и в других языках программирования, взятие по индексу:
>>> a = [1, 3, 8, 7] >>> a[0] 1 >>> a[3] 7 >>> a[4] Traceback (most recent call last): File "<stdin>", line 1, in <module> IndexError: list index out of range
Как и во многих других языках, нумерация элементов начинается с нуля. При попытке доступа к несуществующему индексу возникает исключение IndexError.
В данном примере переменная a являлась списком, однако взять элемент по индексу можно и у других типов: строк, кортежей.
В Python также поддерживаются отрицательные индексы, при этом нумерация идёт с конца, например:
>>> a = [1, 3, 8, 7] >>> a[-1] 7 >>> a[-4] 1 >>> a[-5] Traceback (most recent call last): File "<stdin>", line 1, in <module> IndexError: list index out of range
Срезы
В Python, кроме индексов, существуют ещё и срезы.
item[START:STOP:STEP] — берёт срез от номера START, до STOP (не включая его), с шагом STEP. По умолчанию START = 0, STOP = длине объекта, STEP = 1. Соответственно, какие-нибудь (а возможно, и все) параметры могут быть опущены.
>>> a = [1, 3, 8, 7] >>> a[:] [1, 3, 8, 7] >>> a[1:] [3, 8, 7] >>> a[:3] [1, 3, 8] >>> a[::2] [1, 8]
Также все эти параметры могут быть и отрицательными:
>>> a = [1, 3, 8, 7] >>> a[::-1] [7, 8, 3, 1] >>> a[:-2] [1, 3] >>> a[-2::-1] [8, 3, 1] >>> a[1:4:-1] []
В последнем примере получился пустой список, так как START < STOP, а STEP отрицательный. То же самое произойдёт, если диапазон значений окажется за пределами объекта:
>>> a = [1, 3, 8, 7] >>> a[10:20] []
Также с помощью срезов можно не только извлекать элементы, но и добавлять и удалять элементы (разумеется, только для изменяемых последовательностей).
>>> a = [1, 3, 8, 7] >>> a[1:3] = [0, 0, 0] >>> a [1, 0, 0, 0, 7] >>> del a[:-3] >>> a [0, 0, 7]
pythonworld.ru
методы для форматирования и преобразование в строку
Строками в языках программирования принято называть упорядоченные последовательности символов, которые используются для представления любой текстовой информации. В Python они являются самостоятельным типом данных, а значит при помощи встроенных функций языка над ними можно производить различные операции и форматировать их для вывода.
Создание
Получить новую строку можно несколькими способами: при помощи соответствующего литерала либо же вызвав готовую функцию. Для начала рассмотрим первый метод, который продемонстрирован ниже. Здесь переменная string получает значение some text, благодаря оператору присваивания. Вывести на экран созданную строку помогает функция print.
string = 'some text' print(string) some text
Как видно из предыдущего примера, строковый литерал обрамляется в одиночные кавычки. Если необходимо, чтобы данный символ был частью строки, следует применять двойные кавычки, как это показано в следующем фрагменте кода. Из результатов его работы видно, что новая строка включает в себя текст some ‘new’ text, который легко выводится на экран.
string = "some 'new' text" print(string) some 'new' text
Иногда возникает потребность в создании объектов, включающих в себя сразу несколько строк с сохранением форматирования. Эту задачу поможет решить троекратное применение символа двойных кавычек для выделения литерала. Объявив строку таким образом, можно передать ей текст с неограниченным количеством абзацев, что показано в данном коде.
string = """some 'new' text with new line here""" print(string) some 'new' text with new line here
Специальные символы
Пользоваться тройными кавычками для форматирования строк не всегда удобно, так как это порой занимает слишком много места в коде. Чтобы задать собственное форматирование текста, достаточно применять специальные управляющие символы с обратным слэшем, как это показано в следующем примере. Здесь используется символ табуляции \t, а также знак перехода на новую строку \n. Метод print демонстрирует вывод нового объекта на экран.
string = "some\ttext\nnew line here" print(string) some text new line here
Служебные символы для форматирования строк выполняют свои функции автоматически, но иногда это мешает, к примеру, когда требуется сохранить путь к файлу на диске. Чтобы их отключить, необходимо применить специальный префикс r перед первой кавычкой литерала. Таким образом, обратные слэши будут игнорироваться программой во время ее запуска.
string = r"D:\dir\new"
Следующая таблица демонстрирует перечень всех используемых в языке Python служебных символов для форматирования строк. Как правило, большинство из них позволяют менять положение каретки для выполнения перевода строки, табуляции или возврата каретки.
| Символ | Назначение |
| \n | Перевод каретки на новую строку |
| \b | Возврат каретки на один символ назад |
| \f | Перевод каретки на новую страницу |
| \r | Возврат каретки на начало строки |
| \t | Горизонтальная табуляция |
| \v | Вертикальная табуляция |
| \a | Подача звукового сигнала |
| \N | Идентификатор базы данных |
| \u, \U | 16-битовый и 32-битовый символ Unicode |
| \x | Символ в 16-ричной системе исчисления |
| \o | Символ в 8-ричной системе исчисления |
| \0 | Символ Null |
Очень часто испльзуется \n. С помощью него осуществляется в Python перенос строки. Рассмотрим пример:
print('first\nsecond')
first
secondФорматирование
Выполнить форматирование отдельных частей строки, задав в качестве ее компонентов некие объекты программы позволяет символ %, указанный после литерала. В следующем примере показано, как строковый литерал включает в себя не только текст, но также строку и целое число. Стоит заметить, что каждой переменной в круглых скобках должен соответствовать специальный символ в самом литерале, обладающий префиксом % и подходящим значением.
string = "text" number = 10 newString = "this is %s and digit %d" % (string, number) print(newString) this is text and digit 10
В приведенном ниже фрагменте кода демонстрируется использование форматирования для вывода строки с выравниванием по правому краю (общая длина символов указана как 10).
string = "text" newString = "%+10s" % string print(newString) text
Данная таблица содержит в себе все управляющие символы для форматирования строк в Python, каждый из которых обозначает определенный объект: числовой либо же символьный.
| Символ | Назначение |
| %d, %i, %u | Число в 10-ричной системе исчисления |
| %x, %X | Число в 16-ричной системе исчисления с буквами в нижнем и верхнем регистре |
| %o | Число в 8-ричной системе исчисления |
| %f, %F | Число с плавающей точкой |
| %e, %E | Число с плавающей точкой и экспонентой в нижнем и верхнем регистре |
| %c | Одиночный символ |
| %s, %r | Строка из литерала и обычная |
| %% | Символ процента |
Более удобное форматирование выполняется с помощью функции format. Ей необходимо передать в качестве аргументов объекты, которые должны быть включены в строку, а также указать места их расположения с помощью числовых индексов, начиная с нулевого.
string = "text"
number = 10
newString = "this is {0} and digit {1}".format(string, number)
print(newString)
this is text and digit 10В следующем примере показано как можно отцентрировать строку, воспользовавшись методом format и специальными символами. Изначальный текст здесь перемещается в самый центр строки, в то время как пустое пространство заполняется символом *.
string = "text"
newString = "{:*^10}".format(string)
print(newString)
***text***Следующая таблица отображает специальные символы для выравнивания строк и вывода чисел с необходимым форматом знаков для положительных и отрицательных объектов.
| Символ | Назначение |
| ‘<‘ | Выравнивание строки по левому краю с символами-заполнителями справа |
| ‘>’ | Выравнивание строки по правому краю с символами-заполнителями слева |
| ‘=’ | Выравнивание с символами-заполнителями после знака числа, но перед его цифрами |
| ‘^’ | Выравнивание строки по центру с символами-заполнителями с обеих сторон |
| ‘+’ | Применение знака для любых чисел |
| ‘-‘ | Применение знака для отрицательных чисел и ничего для положительных |
| ‘ ‘ | Применение знака для отрицательных чисел и пробела для положительных |
Операции над строками
Прежде чем перейти к функциям для работы со строками, следует рассмотреть основные операции с ними, которые позволяют быстро преобразовывать любые последовательности символов. При помощи знака плюс можно производить конкатенацию строк, соединяя их вместе. В следующем примере продемонстрировано объединение this is new и text.
string = "text" newString = "this is new " + string print(newString) this is new text
Пользуясь символом умножения, программист получает возможность дублировать строку любое количество раз. В данном коде слово text записывается в новую строку трижды.
string = "text " newString = string * 3 print(newString) text text text
Как и в случае с числами, со строками можно использовать операторы сравнения, например двойное равно. Очевидно, что литералы some text и some new text разные, поэтому вызов метода print выводит на экран булево значение False для строк string и newString.
string = "some text" newString = "some new text" print(string == newString) False
Операции над строками позволяют получать из них подстроки, делая срезы, как с обычными элементами последовательностей. В следующем примере, необходимо лишь указать нужный интервал индексов в квадратных скобках, помня, что нумерация осуществляется с нуля.
string = "some text" newString = string[2:4] print(newString) me
Отрицательный индекс позволяет обращаться к отдельным символами строки не с начала, а с конца. Таким образом, элемент под номером -2 в строке some text является буквой x.
string = "some text" print(string[-2]) x
Методы и функции
Очень часто используется для приведения типов к строковому виду функция str. С ее помощью можно создать новую строку из литерала, который передается в качестве аргумента. Данный пример демонстрирует инициализацию переменной string новым значением some text.
string = str("some text")
print(string)
some textАргументом этой функции могут быть переменные разных типов, например числа или списки. Эта функция позволяет в Python преобразовать в строку разные типы данных. Если вы создаете свой класс, то желательно определить для него метод __str__. Этот метод должен возвращать строку, которая будет возвращена в случае, когда в качестве аргумента str будет использован объект вашего класса.
В Python получения длины строки в символах используется функция len. Как видно из следующего фрагмента кода, длина объекта some text равняется 9 (пробелы тоже считаются).
string = "some text" print(len(string)) 9
Метод find позволяет осуществлять поиск в строке. При помощи него в Python можно найти одиночный символ или целую подстроку в любой другой последовательности символов. В качестве результата своего выполнения он возвращает индекс первой буквы искомого объекта, при этом нумерация осуществляется с нуля.
string = "some text"
print(string.find("text"))
5Метод replace служит для замены определенных символов или подстрок на введенную программистом последовательность символов. Для этого необходимо передать функции соответствующие аргументы, как в следующем примере, где пробелы заменяются на символ ‘-‘.
string = "some text"
print(string.replace(" ", "-"))
some-textДля того чтобы разделить строку на несколько подстрок при помощи указанного разделителя, следует вызвать метод split. По умолчанию его разделителем является пробел. Как показано в приведенном ниже примере, some new text трансформируется в список строк strings.
string = "some new text" strings = string.split() print(strings) ['some', 'new', 'text']
Выполнить обратное преобразование, превратив список строк в одну можно при помощи метода join. В следующем примере в качестве разделителя для новой строки был указан пробел, а аргументом выступил массив strings, включающий some, new и text.
strings = ["some", "new", "text"] string = " ".join(strings) print(string) some new text
Наконец, метод strip используется для автоматического удаления пробелов с обеих сторон строки, как это показано в следующем фрагменте кода для значения объекта string.
string = " some new text " newString = string.strip() print(newString) some new text
Ознакомиться с функциями и методами, используемыми в Python 3 для работы со строками можно из данной таблицы. В ней также приведены методы, позволяющие взаимодействовать с регистром символов.
| Метод | Назначение |
| str(obj) | Преобразует объект к строковому виду |
| len(s) | Возвращает длину строки |
| find(s, start, end), rfind(s, start, end) | Возвращает индекс первого и последнего вхождения подстроки в s или -1, при этом поиск идет в границах от start до end |
| replace(s, ns) | Меняет выбранную последовательность символов в s на новую подстроку ns |
| split(c) | Разбивает на подстроки при помощи выбранного разделителя c |
| join(c) | Объединяет список строк в одну при помощи выбранного разделителя c |
| strip(s), lstrip(s), rstrip(s) | Убирает пробелы с обоих сторон s, только слева или только справа |
| center(num, c), ljust(num, c), rjust(num, c) | Возвращает отцентрированную строку, выравненную по левому и по правому краю с длиной num и символом c по краям |
| lower(), upper() | Перевод всех символов в нижний и верхний регистр |
| startwith(ns), endwith(ns) | Проверяет, начинается ли или заканчивается строка подстрокой ns |
| islower(), isupper() | Проверяет, состоит ли строка только из символов в нижнем и верхнем регистре |
| swapcase() | Меняет регистр всех символов на противоположный |
| title() | Переводит первую букву каждого слова в верхний регистр, а все остальные в нижний |
| capitalize() | Переводит первую букву в верхний регистр, а все остальные в нижний |
| isalpha() | Проверяет, состоит ли только из букв |
| isdigit() | Проверяет, состоит ли только из цифр |
| isnumeric() | Проверяет, является ли строка числом |
Кодировка
Чтобы задать необходимую кодировку для используемых в строках символов в Python достаточно поместить соответствующую инструкцию в начало файла с кодом, как это было сделано в следующем примере, где используется utf-8. С помощью префикса u, который стоит перед литералом, можно помечать его соответствующей кодировкой. В то же время префикс b применяется для литералов строк с элементами величиной в один байт.
# coding: utf-8 string = u'some text' newString = b'text'
Производить кодирование и декодирование отдельных строк с заданной кодировкой позволяют встроенные методы decode и encode. Аргументом для них является название кодировки, как в следующем примере кода, где применяется наименование utf-8.
string = string.decode('utf8')
newString = newString.encode('utf8')all-python.ru
индексирование, срезы, сортировка / Habr
 Данная статья является продолжением моей статьи «Python: коллекции, часть 1: классификация, общие подходы и методы, конвертация».
Данная статья является продолжением моей статьи «Python: коллекции, часть 1: классификация, общие подходы и методы, конвертация».В данной статье мы продолжим изучать общие принципы работы со стандартными коллекциями (модуль collections в ней не рассматривается) Python.
Для кого: для изучающих Python и уже имеющих начальное представление о коллекциях и работе с ними, желающих систематизировать и углубить свои знания, сложить их в целостную картину.
ОГЛАВЛЕНИЕ:
- Индексирование
- Срезы
- Сортировка
1. Индексирование
1.1 Индексированные коллекции
Рассмотрим индексированные коллекции (их еще называют последовательности — sequences) — список (list), кортеж (tuple), строку (string).
Под индексированностью имеется ввиду, что элементы коллекции располагаются в определённом порядке, каждый элемент имеет свой индекс от 0 (то есть первый по счёту элемент имеет индекс не 1, а 0) до индекса на единицу меньшего длины коллекции (т.е. len(mycollection)-1).
1.2 Получение значения по индексу
Для всех индексированных коллекций можно получить значение элемента по его индексу в квадратных скобках. Причем, можно задавать отрицательный индекс, это значит, что будем находить элемент с конца считая обратном порядке.
При задании отрицательного индекса, последний элемент имеет индекс -1, предпоследний -2 и так далее до первого элемента индекс которого равен значению длины коллекции с отрицательным знаком, то есть (-len(mycollection).
| элементы | a | b | c | d | e |
|---|---|---|---|---|---|
| индексы | 0 (-5) | 1 (-4) | 2 (-3) | 3 (-2) | 4 (-1) |
my_str = "abcde"
print(my_str[0]) # a - первый элемент
print(my_str[-1]) # e - последний элемент
print(my_str[len(my_str)-1]) # e - так тоже можно взять последний элемент
print(my_str[-2]) # d - предпоследний элемент
Наши коллекции могут иметь несколько уровней вложенности, как список списков в примере ниже. Для перехода на уровень глубже ставится вторая пара квадратных скобок и так далее.
my_2lvl_list = [[1, 2, 3], ['a', 'b', 'c']]
print(my_2lvl_list[0]) # [1, 2, 3] - первый элемент — первый вложенный список
print(my_2lvl_list[0][0]) # 1 — первый элемент первого вложенного списка
print(my_2lvl_list[1][-1]) # с — последний элемент второго вложенного списка
1.3 Изменение элемента списка по индексу
Поскольку кортежи и строки у нас неизменяемые коллекции, то по индексу мы можем только брать элементы, но не менять их:
my_tuple = (1, 2, 3, 4, 5)
print(my_tuple[0]) # 1
my_tuple[0] = 100 # TypeError: 'tuple' object does not support item assignment
А вот для списка, если взятие элемента по индексу располагается в левой части выражения, а далее идёт оператор присваивания =, то мы задаём новое значение элементу с этим индексом.
my_list = [1, 2, 3, [4, 5]]
my_list[0] = 10
my_list[-1][0] = 40
print(my_list) # [10, 2, 3, [40, 5]]
UPD: Примечание: Для такого присвоения, элемент уже должен существовать в списке, нельзя таким образом добавить элемент на несуществующий индекс.
my_list = [1, 2, 3, 4, 5]
my_list[5] = 6 # IndexError: list assignment index out of range
2 Срезы
2.1 Синтаксис среза
Очень часто, надо получить не один какой-то элемент, а некоторый их набор ограниченный определенными простыми правилами — например первые 5 или последние три, или каждый второй элемент — в таких задачах, вместо перебора в цикле намного удобнее использовать так называемый срез (slice, slicing).
Синтаксис среза похож на таковой для индексации, но в квадратных скобках вместо одного значения указывается 2-3 через двоеточие:
my_collection[start:stop:step] # старт, стоп и шагОсобенности среза:
Примеры срезов в виде таблицы:
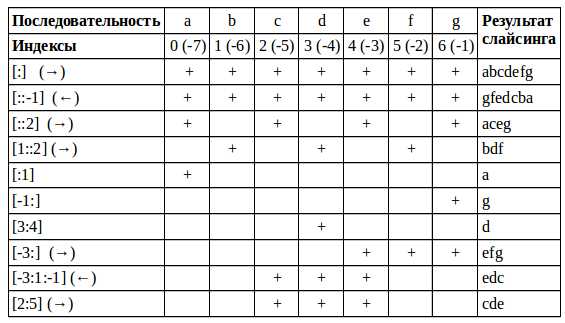
Код примеров из таблицы
col = 'abcdefg'
print(col[:]) # abcdefg
print(col[::-1]) # gfedcba
print(col[::2]) # aceg
print(col[1::2]) # bdf
print(col[:1]) # a
print(col[-1:]) # g
print(col[3:4]) # d
print(col[-3:]) # efg
print(col[-3:1:-1]) # edc
print(col[2:5]) # cde2.2. Именованные срезы
Чтобы избавится от «магических констант», особенно в случае, когда один и тот же срез надо применять многократно, можно задать константы с именованными срезами с пользованием специальной функции slice()()
Примечание: Nonе соответствует опущенному значению по-умолчанию. То есть [:2] становится slice(None, 2), а [1::2] становится slice(1, None, 2).
person = ('Alex', 'Smith', "May", 10, 1980)
NAME, BIRTHDAY = slice(None, 2), slice(2, None)
# задаем константам именованные срезы
# данные константы в квадратных скобках заменятся соответствующими срезами
print(person[NAME]) # ('Alex', 'Smith')
print(person[BIRTHDAY]) # ('May', 10, 1980)
my_list = [1, 2, 3, 4, 5, 6, 7]
EVEN = slice(1, None, 2)
print(my_list[EVEN]) # [2, 4, 6]
2.3 Изменение списка срезом
Важный момент, на котором не всегда заостряется внимание — с помощью среза можно не только получать копию коллекции, но в случае списка можно также менять значения элементов, удалять и добавлять новые.
Проиллюстрируем это на примерах ниже:
- Даже если хотим добавить один элемент, необходимо передавать итерируемый объект, иначе будет ошибка TypeError: can only assign an iterable
my_list = [1, 2, 3, 4, 5] # my_list[1:2] = 20 # TypeError: can only assign an iterable my_list[1:2] = [20] # Вот теперь все работает print(my_list) # [1, 20, 3, 4, 5] - Для вставки одиночных элементов можно использовать срез, код примеров есть ниже, но делать так не рекомендую, так как такой синтаксис хуже читать. Лучше использовать методы списка .append() и .insert():Срез аналоги .append() и insert()
my_list = [1, 2, 3, 4, 5] my_list[5:] = [6] # вставляем в конец — лучше использовать .append(6) print(my_list) # [1, 2, 3, 4, 5, 6] my_list[0:0] = [0] # вставляем в начало — лучше использовать .insert(0, 0) print(my_list) # [0, 1, 2, 3, 4, 5, 6] my_list[3:3] = [25] # вставляем между элементами — лучше использовать .insert(3, 25) print(my_list) # [0, 1, 2, 25, 3, 4, 5, 6] - Можно менять части последовательности — это применение выглядит наиболее интересным, так как решает задачу просто и наглядно.
my_list = [1, 2, 3, 4, 5] my_list[1:3] = [20, 30] print(my_list) # [1, 20, 30, 4, 5] my_list[1:3] = [0] # нет проблем заменить два элемента на один print(my_list) # [1, 0, 4, 5] my_list[2:] = [40, 50, 60] # или два элемента на три print(my_list) # [1, 0, 40, 50, 60] - Можно просто удалить часть последовательности
my_list = [1, 2, 3, 4, 5] my_list[:2] = [] # или del my_list[:2] print(my_list) # [3, 4, 5]
2.4 Выход за границы индекса
Обращение по индексу по сути является частным случаем среза, когда мы обращаемся только к одному элементу, а не диапазону. Но есть очень важное отличие в обработке ситуации с отсутствующим элементом с искомым индексом.
Обращение к несуществующему индексу коллекции вызывает ошибку:
my_list = [1, 2, 3, 4, 5]
print(my_list[-10]) # IndexError: list index out of range
print(my_list[10]) # IndexError: list index out of range
А в случае выхода границ среза за границы коллекции никакой ошибки не происходит:
my_list = [1, 2, 3, 4, 5]
print(my_list[0:10]) # [1, 2, 3, 4, 5] — отработали в пределах коллекции
print(my_list[10:100]) # [] - таких элементов нет — вернули пустую коллекцию
print(my_list[10:11]) # [] - проверяем 1 отсутствующий элемент - пустая коллекция, без ошибки
Примечание: Для тех случаев, когда функционала срезов недостаточно и требуются более сложные выборки, можно воспользоваться синтаксисом выражений-генераторов, рассмотрению которых посвещена 4 статья цикла.
3 Сортировка элементов коллекции
Сортировка элементов коллекции важная и востребованная функция, постоянно встречающаяся в обычных задачах. Тут есть несколько особенностей, на которых не всегда заостряется внимание, но которые очень важны.
3.1 Функция sorted()
Мы может использовать функцию sorted() для вывода списка сортированных элементов любой коллекции для последующее обработки или вывода.
- функция не меняет исходную коллекцию, а возвращает новый список из ее элементов;
- не зависимо от типа исходной коллекции, вернётся список (list) ее элементов;
- поскольку она не меняет исходную коллекцию, ее можно применять к неизменяемым коллекциям;
- Поскольку при сортировке возвращаемых элементов нам не важно, был ли у элемента некий индекс в исходной коллекции, можно применять к неиндексированным коллекциям;
- Имеет дополнительные не обязательные аргументы:
reverse=True — сортировка в обратном порядке
key=funcname (начиная с Python 2.4) — сортировка с помощью специальной функции funcname, она может быть как стандартной функцией Python, так и специально написанной вами для данной задачи функцией и лямбдой.
my_list = [2, 5, 1, 7, 3]
my_list_sorted = sorted(my_list)
print(my_list_sorted) # [1, 2, 3, 5, 7]
my_set = {2, 5, 1, 7, 3}
my_set_sorted = sorted(my_set, reverse=True)
print(my_set_sorted) # [7, 5, 3, 2, 1]
Пример сортировки списка строк по длине len() каждого элемента:
my_files = ['somecat.jpg', 'pc.png', 'apple.bmp', 'mydog.gif']
my_files_sorted = sorted(my_files, key=len)
print(my_files_sorted) # ['pc.png', 'apple.bmp', 'mydog.gif', 'somecat.jpg']
3.2 Функция reversed()
Функция reversed() применяется для последовательностей и работает по другому:
- возвращает генератор списка, а не сам список;
- если нужно получить не генератор, а готовый список, результат можно обернуть в list() или же вместо reversed() воспользоваться срезом [: :-1];
- она не сортирует элементы, а возвращает их в обратном порядке, то есть читает с конца списка;
- из предыдущего пункта понятно, что если у нас коллекция неиндексированная — мы не можем вывести её элементы в обратном порядке и эта функция к таким коллекциям не применима — получим «TypeError: argument to reversed() must be a sequence»;
- не позволяет использовать дополнительные аргументы — будет ошибка «TypeError: reversed() does not take keyword arguments».
my_list = [2, 5, 1, 7, 3]
my_list_sorted = reversed(my_list)
print(my_list_sorted) # <listreverseiterator object at 0x7f8982121450>
print(list(my_list_sorted)) # [3, 7, 1, 5, 2]
print(my_list[::-1]) # [3, 7, 1, 5, 2] - тот же результат с помощью среза3.3 Методы списка .sort() и .reverse()
У списка (и только у него) есть особые методы .sort() и .reverse() которые делают тоже самое, что соответствующие функции sorted() и reversed(), но при этом:
- Меняют сам исходный список, а не генерируют новый;
- Возвращают None, а не новый список;
- поддерживают те же дополнительные аргументы;
- в них не надо передавать сам список первым параметром, более того, если это сделать — будет ошибка — не верное количество аргументов.
my_list = [2, 5, 1, 7, 3]
my_list.sort()
print(my_list) # [1, 2, 3, 5, 7]
Обратите внимание: Частая ошибка начинающих, которая не является ошибкой для интерпретатора, но приводит не к тому результату, который хотят получить.
my_list = [2, 5, 1, 7, 3]
my_list = my_list.sort()
print(my_list) # None
3.4 Особенности сортировки словаря
В сортировке словаря есть свои особенности, вызванные тем, что элемент словаря — это пара ключ: значение.
UPD: Так же, не забываем, что говоря о сортировке словаря, мы имеем ввиду сортировку полученных из словаря данных для вывода или сохранения в индексированную коллекцию. Сохранить данные сортированными в самом стандартном словаре не получится, они в нем, как и других неиндексированных коллекциях находятся в произвольном порядке.
- sorted(my_dict) — когда мы передаем в функцию сортировки словарь без вызова его дополнительных методов — идёт перебор только ключей, сортированный список ключей нам и возвращается;
- sorted(my_dict.keys()) — тот же результат, что в предыдущем примере, но прописанный более явно;
- sorted(my_dict.items()) — возвращается сортированный список кортежей (ключ, значение), сортированных по ключу;
- sorted(my_dict.values()) — возвращается сортированный список значений
my_dict = {'a': 1, 'c': 3, 'e': 5, 'f': 6, 'b': 2, 'd': 4}
mysorted = sorted(my_dict)
print(mysorted) # ['a', 'b', 'c', 'd', 'e', 'f']
mysorted = sorted(my_dict.items())
print(mysorted) # [('a', 1), ('b', 2), ('c', 3), ('d', 4), ('e', 5), ('f', 6)]
mysorted = sorted(my_dict.values())
print(mysorted) # [1, 2, 3, 4, 5, 6]
Отдельные сложности может вызвать сортировка словаря не по ключам, а по значениям, если нам не просто нужен список значений, и именно выводить пары в порядке сортировки по значению.
Для решения этой задачи можно в качестве специальной функции сортировки передавать lambda-функцию lambda x: x[1] которая из получаемых на каждом этапе кортежей (ключ, значение) будет брать для сортировки второй элемент кортежа.
population = {"Shanghai": 24256800, "Karachi": 23500000, "Beijing": 21516000, "Delhi": 16787941}
# отсортируем по возрастанию населения:
population_sorted = sorted(population.items(), key=lambda x: x[1])
print(population_sorted)
# [('Delhi', 16787941), ('Beijing', 21516000), ('Karachi', 23500000), ('Shanghai', 24256800)]
UPD от ShashkovS: 3.5 Дополнительная информация по использованию параметра key при сортировке
Допустим, у нас есть список кортежей названий деталей и их стоимостей.
Нам нужно отсортировать его сначала по названию деталей, а одинаковые детали по убыванию цены.
shop = [('каретка', 1200), ('шатун', 1000), ('седло', 300),
('педаль', 100), ('седло', 1500), ('рама', 12000),
('обод', 2000), ('шатун', 200), ('седло', 2700)]
def prepare_item(item):
return (item[0], -item[1])
shop.sort(key=prepare_item)
Результат сортировки
for det, price in shop:
print('{:<10} цена: {:>5}р.'.format(det, price))
# каретка цена: 1200р.
# обод цена: 2000р.
# педаль цена: 100р.
# рама цена: 12000р.
# седло цена: 2700р.
# седло цена: 1500р.
# седло цена: 300р.
# шатун цена: 1000р.
# шатун цена: 200р.
Перед тем, как сравнивать два элемента списка к ним применялась функция prepare_item, которая меняла знак у стоимости (функция применяется ровно по одному разу к каждому элементу. В результате при одинаковом первом значении сортировка по второму происходила в обратном порядке.
Чтобы не плодить утилитарные функции, вместо использования сторонней функции, того же эффекта можно добиться с использованием лямбда-функции.
# Данные скопировать из примера выше
shop.sort(key=lambda x: (x[0], -x[1]))Дополнительные детали и примеры использования параметра key:
UPD от ShashkovS: 3.6 Устойчивость сортировки
Допустим данные нужно отсортировать сначала по столбцу А по возрастанию, затем по столбцу B по убыванию, и наконец по столбцу C снова по возрастанию.
Если данные в столбце B числовые, то при помощи подходящей функции в key можно поменять знак у элементов B, что приведёт к необходимому результату.
А если все данные текстовые? Тут есть такая возможность.
Дело в том, что сортировка sort в Python устойчивая (начиная с Python 2.2), то есть она не меняет порядок «одинаковых» элементов.
Поэтому можно просто отсортировать три раза по разным ключам:
data.sort(key=lambda x: x['C'])
data.sort(key=lambda x: x['B'], reverse=True)
data.sort(key=lambda x: x['А'])
Дополнительная информация по устойчивости сортировки и примеры: wiki.python.org/moin/HowTo/Sorting#Sort_Stability_and_Complex_Sorts (на наглийском).
Приглашаю к обсуждению:
- Если я где-то допустил неточность или не учёл что-то важное — пишите в комментариях, важные комментарии будут позже добавлены в статью с указанием вашего авторства.
- Если какие-то моменты не понятны и требуется уточнение — пишите ваши вопросы в комментариях — или я или другие читатели дадут ответ, а дельные вопросы с ответами будут позже добавлены в статью.
habr.com
Строки. Урок 19 курса «Python. Введение в программирование»
Мы уже рассматривали строки как простой тип данных наряду с целыми и вещественными числами и знаем, что строка – это последовательность символов, заключенных в одинарные или двойные кавычки.
В Python нет символьного типа, т. е. типа данных, объектами которого являются одиночные символы. Однако язык позволяет рассматривать строки как объекты, состоящие из подстрок длинной в один и более символов. При этом, в отличие от списков, строки не принято относить к структурам данных. Видимо потому, что структуры данных состоят из более простых типов данных, а для строк в Python нет более простого (символьного) типа.
С другой стороны, строка, как и список, – это упорядоченная последовательность элементов. Следовательно, из нее можно извлекать отдельные символы и срезы.
>>> s = "Hello, World!" >>> s[0] 'H' >>> s[7:] 'World!' >>> s[::2] 'Hlo ol!'
В последнем случае извлечение идет с шагом, равным двум, т. е. извлекается каждый второй символ. Примечание. Извлекать срезы с шагом также можно из списков.
Важным отличием от списков является неизменяемость строк в Python. Нельзя перезаписать какой-то отдельный символ или срез в строке:
>>> s[-1] = '.' Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: 'str' object does not support item assignment
Интерпретатор сообщает, что объект типа str не поддерживает присвоение элементам.
Если требуется изменить строку, то следует создать новую из срезов старой:
>>> s = s[0:-1] + '.' >>> s 'Hello, World.'
В примере берется срез из исходной строки, соединяется с другой строкой. Получается новая строка, которая присваивается переменной s. Ее старое значение при этом теряется.
Методы строк
В Python для строк есть множество методов. Посмотреть их можно по команде dir(str), получить информацию по каждому – help(str.имя_метода). Рассмотрим наиболее интересные из них.
Методы split() и join()
Метод split() позволяет разбить строку по пробелам. В результате получается список слов. Если пользователь вводит в одной строке ряд слов или чисел, каждое из которых должно в программе обрабатываться отдельно, то без split() не обойтись.
>>> s = input() red blue orange white >>> s 'red blue orange white' >>> sl = s.split() >>> sl ['red', 'blue', 'orange', 'white'] >>> s 'red blue orange white'
Список, возвращенный методом split(), мы могли бы присвоить той же переменной s, т. е. s = s.split(). Тогда исходная строка была бы потеряна. Если она не нужна, то лучше не вводить дополнительную переменную.
Метод split() может принимать необязательный аргумент-строку, указывающей по какому символу или подстроке следует выполнить разделение:
>>> s.split('e')
['r', 'd blu', ' orang', ' whit', '']
>>> '40030023'.split('00')
['4', '3', '23']Метод строк join() выполняет обратное действие. Он формирует из списка строку. Поскольку это метод строки, то впереди ставится строка-разделитель, а в скобках — передается список:
>>> '-'.join(sl) 'red-blue-orange-white'
Если разделитель не нужен, то метод применяется к пустой строке:
>>> ''.join(sl) 'redblueorangewhite'
Методы find() и replace()
Данные методы строк работают с подстроками. Методы find() ищет подстроку в строке и возвращает индекс первого элемента найденной подстроки. Если подстрока не найдена, то возвращает -1.
>>> s
'red blue orange white'
>>> s.find('blue')
4
>>> s.find('green')
-1Поиск может производиться не во всей строке, а лишь на каком-то ее отрезке. В этом случае указывается первый и последний индексы отрезка. Если последний не указан, то ищется до конца строки:
>>> letters = 'ABCDACFDA'
>>> letters.find('A', 3)
4
>>> letters.find('DA', 0, 6)
3Здесь мы ищем с третьего индекса и до конца, а также с первого и до шестого. Обратите внимания, что метод find() возвращает только первое вхождение. Так выражение letters.find('A', 3) последнюю букву ‘A’ не находит, так как ‘A’ ему уже встретилась под индексом 4.
Метод replace() заменяет одну подстроку на другую:
>>> letters.replace('DA', 'NET')
'ABCNETCFNET'Исходная строка, конечно, не меняется:
Так что если результат надо сохранить, то его надо присвоить переменной:
>>> new_letters = letters.replace('DA', 'NET')
>>> new_letters
'ABCNETCFNET'Метод format()
Строковый метод format() уже упоминался при рассмотрении вывода на экран с помощью функции print():
>>> print("This is a {0}. It's {1}.".format("ball", "red"))
This is a ball. It's red.Однако к print() он никакого отношения не имеет, а применяется к строкам. Лишь потом заново сформированная строка передается в функцию вывода.
Возможности format() широкие, рассмотрим основные.
>>> size1 = "length - {}, width - {}, height - {}"
>>> size1.format(3, 6, 2.3)
'length - 3, width - 6, height — 2.3'Если фигурные скобки исходной строки пусты, то подстановка аргументов идет согласно порядку их следования. Если в фигурных скобках строки указаны индексы аргументов, порядок подстановки может быть изменен:
>>> size2 = "height - {2}, length - {0}, width - {1}"
>>> size2.format(3, 6, 2.3)
'height - 2.3, length - 3, width - 6'Кроме того, аргументы могут передаваться по слову-ключу:
>>> info = "This is a {subj}. It's {prop}."
>>> info.format(subj="table", prop="small")
"This is a table. It's small."Пример форматирования вещественных чисел:
>>> "{1:.2f} {0:.3f}".format(3.33333, 10/6)
'1.67 3.333'Практическая работа
Вводится строка, включающая строчные и прописные буквы. Требуется вывести ту же строку, заменив в ней строчные буквы прописными, а прописные – строчными. Например, исходная строка – «aB!cDEf», новая строка – «Ab!CdeF». В коде используйте цикл for, строковые методы upper() (преобразование к верхнему регистру) и lower() (преобразование к нижнему регистру), а также методы isupper() и islower(), проверяющие регистр строки или символа.
Строковый метод isdigit() проверяет, состоит ли строка только из цифр. Напишите программу, которая запрашивает с ввода два целых числа и выводит их сумму. В случае некорректного ввода программа не должна завершаться с ошибкой, а должна продолжать запрашивать числа. Обработчик исключений try-except использовать нельзя.
Примеры решения в android-приложении и pdf-версии курса.
younglinux.info
Python | Основные методы строк
Основные методы строк
Последнее обновление: 02.05.2017
Рассмотрим основные методы строк, которые мы можем применить в приложениях:
isalpha(str): возвращает True, если строка состоит только из алфавитных символов
islower(str): возвращает True, если строка состоит только из символов в нижнем регистре
isupper(str): возвращает True, если все символы строки в верхнем регистре
isdigit(str): возвращает True, если все символы строки — цифры
isnumeric(str): возвращает True, если строка представляет собой число
startswith(str): возвращает True, если строка начинается с подстроки str
endswith(str): возвращает True, если строка заканчивается на подстроку str
lower(): переводит строку в нижний регистр
upper(): переводит строку в вехний регистр
title(): начальные символы всех слов в строке переводятся в верхний регистр
capitalize(): переводит в верхний регистр первую букву только самого первого слова строки
lstrip(): удаляет начальные пробелы из строки
rstrip(): удаляет конечные пробелы из строки
strip(): удаляет начальные и конечные пробелы из строки
ljust(width): если длина строки меньше параметра width, то справа от строки добавляются пробелы, чтобы дополнить значение width, а сама строка выравнивается по левому краю
rjust(width): если длина строки меньше параметра width, то слева от строки добавляются пробелы, чтобы дополнить значение width, а сама строка выравнивается по правому краю
center(width): если длина строки меньше параметра width, то слева и справа от строки равномерно добавляются пробелы, чтобы дополнить значение width, а сама строка выравнивается по центру
find(str[, start [, end]): возвращает индекс подстроки в строке. Если подстрока не найдена, возвращается число -1
replace(old, new[, num]): заменяет в строке одну подстроку на другую
split([delimeter[, num]]): разбивает строку на подстроки в зависимости от разделителя
join(strs): объединяет строки в одну строку, вставляя между ними определенный разделитель
Например, если мы ожидаем ввод с клавиатуры числа, то перед преобразованием введенной строки в число можно проверить, с помощью метода isnumeric() введено ли в действительности число, и если так, то выполнить операцию преобразования:
string = input("Введите число: ")
if string.isnumeric():
number = int(string)
print(number)
Проверка, начинается или оканчивается строка на определенную подстроку:
file_name = "hello.py"
starts_with_hello = file_name.startswith("hello") # True
ends_with_exe = file_name.endswith("exe") # False
Удаление пробелов в начале и в конце строки:
string = " hello world! " string = string.strip() print(string) # hello world!
Дополнение строки пробелами и выравнивание:
print("iPhone 7:", "52000".rjust(10))
print("Huawei P10:", "36000".rjust(10))
Консольный вывод:
iPhone 7: 52000 Huawei P10: 36000
Поиск в строке
Для поиска подстроки в строке в Python применяется метод find(), который возвращает индекс первого вхождения подстроки в строку и имеет три формы:
find(str): поиск подстроки str ведется с начала строки до ее концаfind(str, start): параметр start задает начальный индекс, с которого будет производиться поискfind(str, start, end): параметр end задает конечный индекс, до которого будет идти поиск
Если подстрока не найдена, метод возвращает -1:
welcome = "Hello world! Goodbye world!"
index = welcome.find("wor")
print(index) # 6
# поиск с 10-го индекса
index = welcome.find("wor",10)
print(index) # 21
# поиск с 10 по 15 индекс
index = welcome.find("wor",10,15)
print(index) # -1
Замена в строке
Для замены в строке одной подстроки на другую применяется метод replace():
replace(old, new): заменяет подстроку old на newreplace(old, new, num): параметр num указывает, сколько вхождений подстроки old надо заменить на new
phone = "+1-234-567-89-10"
# замена дефисов на пробел
edited_phone = phone.replace("-", " ")
print(edited_phone) # +1 234 567 89 10
# удаление дефисов
edited_phone = phone.replace("-", "")
print(edited_phone) # +12345678910
# замена только первого дефиса
edited_phone = phone.replace("-", "", 1)
print(edited_phone) # +1234-567-89-10
Разделение на подстроки
Метод split() разбивает строку на список подстрок в зависимости от разделителя. В качестве разделителя может выступать любой символ или последовательность символов. Данный метод имеет следующие формы:
split(): в качестве разделителя используется пробелsplit(delimeter): в качестве разделителя используется delimetersplit(delimeter, num): параметр num указывает, сколько вхождений delimeter используется для разделения. Оставшаяся часть строки добавляется в список без разделения на подстроки
text = "Это был огромный, в два обхвата дуб, с обломанными ветвями и с обломанной корой"
# разделение по пробелам
splitted_text = text.split()
print(splitted_text)
print(splitted_text[6]) # дуб,
# разбиение по запятым
splitted_text = text.split(",")
print(splitted_text)
print(splitted_text[1]) # в два обхвата дуб
# разбиение по первым пяти пробелам
splitted_text = text.split(" ", 5)
print(splitted_text)
print(splitted_text[5]) # обхвата дуб, с обломанными ветвями и с обломанной корой
Соединение строк
При рассмотрении простейших операций со строками было показано, как объединять строки с помощью операции сложения. Другую возможность для соединения строк представляет метод join(): он объединяет список строк. Причем текущая строка, у которой вызывается данный метод, используется в качестве разделителя:
words = ["Let", "me", "speak", "from", "my", "heart", "in", "English"] # разделитель - пробел sentence = " ".join(words) print(sentence) # Let me speak from my heart in English # разделитель - вертикальная черта sentence = " | ".join(words) print(sentence) # Let | me | speak | from | my | heart | in | English
Вместо списка в метод join можно передать простую строку, тогда разделитель будет вставляться между символами этой строки:
word = "hello" joined_word = "|".join(word) print(joined_word) # h|e|l|l|o
metanit.com
Python 3 — Строки
Строки являются одними из самых популярных типов в Python. Мы можем создать их, просто заключив символы в кавычках. Python рассматривает одиночные кавычки такие же, как и двойные кавычки. Создание строк так же просто, как и присвоение значения переменной. Например:var1 = 'Привет мир!' var2 = "программирование на Python"
Доступ к значениям в строках
Python не поддерживает тип символов; они рассматриваются как строки одной длины, таким образом, также считается подстроки.
Чтобы получить доступ к подстроки, используйте квадратные скобки вместе с индексом или индексами, чтобы получить вашу подстроку. Например:
#!/usr/bin/python3
var1 = 'Привет мир!'
var2 = "программирование на Python"
print ("var1[0]: ", var1[0])
print ("var2[1:5]: ", var2[1:5])
Когда код выполниться, он покажет следующий результат:
var1[0]: П var2[1:5]: ytho
Обновление строк
Вы можете «обновить» существующую строку c присваиванием переменной на другую строку. Новое значение может быть связано с его предыдущим значением или совершенно другой строкой. Например:
#!/usr/bin/python3
var1 = 'Привет мир!'
print ("Обновление строки :- ", var1[:6] + 'Python')
Когда код выполниться, получиться следующий результат:
Обновление строки :- Hello Python
Символ Escape
В следующей таблице приведен список escape или непечатаемых символов, которые могут быть представлены с представлением.
Символ escape интерпретируется: в одинарных кавычках, а также строки в двойных кавычках.
| Представление | Шестнадцатеричный символ | Описание |
|---|---|---|
| \a | 0x07 | Звонок или оповещение |
| \b | 0x08 | Backspace |
| \cx | Control-х | |
| \C-x | Control-х | |
| \e | 0x1b | Escape |
| \f | 0x0C | Formfeed |
| \M- \C-x | Meta-Control-x | |
| \n | 0x0a | Новая линия |
| \nnn | Восьмеричная запись, где п находится в диапазоне от 0,7 | |
| \r | 0x0d | Возврат каретки |
| \s | 0x20 | Пробел |
| \t | 0x09 | Табуляция |
| \v | 0x0B | Вертикальная табуляция |
| \x | Символ х | |
| \xnn | Шестнадцатеричное, где n находится в диапазоне от 0,9, a.f, или A.F |
Специальные строковые операторы
Предположим, переменная строка а, имеет «Hello» а переменная b равна «Python», тогда:
| оператор | Описание | пример |
|---|---|---|
| + | Конкатенация – Добавляет значения по обе стороны от оператора | A + B = HelloPython |
| * | Повторение – Создает новые строки, объединяя нескольких копий одной и той же строки | а * 2 = HelloHello |
| [] | Кусочек – Выдает символ из данного индекса | а [1] = е |
| [ : ] | Диапазон среза – Дает символы из заданного диапазона | а [1: 4] = ELL |
| in | Возвращает истину, если символ существует в данной строке | Н = 1 |
| not in | Возвращает истину, если символ не существует в данной строке | М <> 1 |
| r/R | Raw String – Подавляет фактическое значение символов Escape. Синтаксис для необработанных строк точно такой же, как и для обычных строк, за исключением raw строки оператора, буква «r», которая предшествует кавычки. «R» может быть в нижнем регистре (r) или в верхнем регистре (R) и должна быть размещена непосредственно предшествующей первой кавычки. | print r’\n’ печатает \n и print R’\n’печатает \n |
| % | Формат – Выполняет форматирование строк | См в следующем разделе |
Оператор форматирования строки
Одна из самых привлекательных особенностей языка Python является оператор форматирования строк %. Этот оператор является уникальным для строк и блоков, имеющие функции из языка C printf(). Ниже приведен простой пример:
#!/usr/bin/python3
print ("Меня зовут %s и мой вес равен %d кг!" % ('AndreyEx', 71))
Когда код выполниться, будет показан следующий результат:
Меня зовут AndreyEx и мой вес равен 71 кг!
Вот полный набор списка символов, которые могут быть использованы вместе с %:
| S.No. | Формат символов и преобразование |
|---|---|
| 1 | %c символ |
| 2 | %s преобразование строки с помощью str() до форматирования |
| 3 | %i десятичное число |
| 4 | %d десятичное число |
| 5 | %u беззнаковое десятичное целое |
| 6 | %o восьмеричное целое |
| 7 | %x шестнадцатеричное число (прописные буквы) |
| 8 | %X шестнадцатеричное число (заглавные буквы) |
| 9 | %e экспоненциальное (с строчной «х») |
| 10 | %E экспоненциальное (с «E» в верхнем регистре) |
| 11 | %f вещественное число с плавающей точкой |
| 12 | %g наименьшее из %f и %е |
| 13 | %G наименьшее из% F% и E |
Другие поддерживаемые символы и функции перечислены в следующей таблице:
| S.No. | Символ и функциональность |
|---|---|
| 1 | * аргумент определяет ширину или точность |
| 2 | – выравнивание по левому краю |
| 3 | + отобразить знак |
| 4 | <sp> поставить пробел перед положительным числом |
| 5 | # добавить восьмеричной ведущий ноль ( «0») или шестнадцатеричным ведущий «0x» или «0X», в зависимости от того, был использован «х» или «X». |
| 6 | 0 заместить слева нулями (вместо пробелов) |
| 7 | «%%» оставляет вас с одним буквальным «%» |
| 8 | (var) соотнесение переменных (словарные аргументы) |
| 9 | m.n. минимальная общая ширина и n число цифр, отображаемых после десятичной точки (если заявл.) |
Тройные кавычки
Тройные кавычки в Python приходят на помощь, позволяя строкам занимать несколько строк, в том числе стенографические символы новой строки, табуляции, а также любые другие специальные символы.
Синтаксис для тройных кавычек состоит из трех последовательных одиночных или двойных кавычек.
#!/usr/bin/python3 para_str = """это длинная строка, которая состоит из несколько строк и непечатаемых символов, таких как TAB ( \t ) и они показывают тот путь, когда отображается. Символы новой строки в строке, прямо как в скобках [ \n ], или просто новую строку с присваиванием переменной также будет отображаться. """ print (para_str)
Когда приведенный выше код выполнится, он произведет следующий результат. Обратите внимание, что каждый специальный символ был преобразован в печатный вид, вплоть до последней новой строки в конце строки между «вверх». и закрытие тройные кавычки. Также отметим, что новая строка происходит либо с явным возвратом каретки в конце строки либо escape кодом (\n):
это длинная строка, которая состоит из несколько строк и непечатаемых символов, таких как TAB ( ) и они показывают тот путь, когда отображается. Символы новой строки в строке, прямо как в скобках [ ], или просто новую строку с присваиванием переменной также будет отображаться.
Неочищенные строки не относятся к обратной косой черты как к специальному символу. Каждый символ, который вы поместили в строку остается так, как вы его написали:
#!/usr/bin/python3
print ('C:\\nowhere')
Когда код выполниться, он выдаст следующий результат:
C:\nowhere
Теперь давайте используем строку. Мы укажем выражение следующим образом:
#!/usr/bin/python3 print (r'C:\\nowhere')
Когда код выполниться, он выдаст следующий результат:
C:\\nowhere
Строки Юникода
В Python 3 все строки представлены в Unicode. В Python 2 хранятся в виде 8-битного ASCII, следовательно, требуется указать «u», чтобы сделать его Unicode. Больше нет необходимости в настоящее время.
Встроенные методы строк
Python включает в себя следующие встроенные методы манипулирования строками:
| S.No. | Методы и описание |
|---|---|
| 1 | capitalize() – Прописная первая буква строки |
| 2 | center(width, fillchar) – Возвращает строку, заполненную с FillChar от исходной строки с центром в общем столбце width. |
| 3 | count(str, beg = 0,end = len(string)) – Считает, сколько раз str имеет вхождение в строке или в подстроках строки, начиная с индекса str и заканчивается индексом end. |
| 4 | decode(encoding = ‘UTF-8’,errors = ‘strict’) – Декодирует строку, используя кодек, зарегистрированный для кодирования. кодирования по умолчанию строки по умолчанию кодировке. |
| 5 | encode(encoding = ‘UTF-8’,errors = ‘strict’) – Возвращает закодированные строки версии строки; при ошибке, по умолчанию вызывает исключение ValueError, если ошибки не указываются с ‘ignore’ or ‘replace’. |
| 6 | endswith(suffix, beg = 0, end = len(string)) – Определяет, является ли строка или подстроку строки (если начальный индекс нач и заканчивая концом индекса приведены) заканчивается суффиксом; возвращает истину, если так и ложь в противном случае. |
| 7 | expandtabs(tabsize = 8) – Расширяет вкладки в строке на несколько пробелов; по умолчанию 8 пространств на вкладке, если TabSize не предусмотрено. |
| 8 | find(str, beg = 0 end = len(string)) – Определить, встречается ли строка в строке или в подстроки строки, если начинается с индекса beg и заканчивается индексом end, индекс возвращается, если найден и -1 в противном случае. |
| 9 | index(str, beg = 0, end = len(string)) – То же действие, что find(), но вызывает исключение, если строка не найдена. |
| 10 | isalnum() – Возвращает истину, если строка имеет по крайней мере 1 символ и все символы являются алфавитно-цифровыми и ложью в противном случае. |
| 11 | isalpha() – Возвращает истину, если строка имеет по крайней мере 1 символ и все символы буквенные и ложь в противном случае. |
| 12 | isdigit() – Возвращает истину, если строка содержит только цифры и ложь в противном случае. |
| 13 | islower() – Возвращает истину, если строка имеет по крайней мере 1 символ в нижнем регистре и все символы в нижнем регистре и ложь в противном случае. |
| 14 | isnumeric() – Возвращает истину, если строка Юникода содержит только числовые символы и ложь в противном случае. |
| 15 | isspace() – Возвращает истину, если строка содержит только символы пробелов и ложь в противном случае. |
| 16 | istitle() – Возвращает истину, если строка имеет«titlecased» и ложь в противном случае. |
| 17 | isupper() – Возвращает истину, если строка имеет по крайней мере один символ в верхнем регистре или все символы в верхнем регистре и ложь в противном случае. |
| 18 | join(seq) – Слияния (Объединяет) строковых элементов в последовательности seq в строку со строкой разделителя. |
| 19 | len(string) – Возвращает длину строки |
| 20 | ljust(width[, fillchar]) – Возвращает space-padded строку в исходную строку с выравниванием влево на итоговую ширину столбцов. |
| 21 | lower() – Преобразует все прописные буквы в строке в нижний регистр. |
| 22 | lstrip() – Удаляет начальные пробелы в строке. |
| 23 | maketrans() – Возвращает таблицу перевода для использования в функции перевода. |
| 24 | max(str) – Возвращает максимальный алфавитный символ из строки str. |
| 25 | min(str) – Возвращает минимальный алфавитный символ из строки str. |
| 26 | replace(old, new [, max]) – Заменяет все вхождения old в строке на new или в большинстве случаев, если max задано. |
| 27 | rfind(str, beg = 0,end = len(string)) – То же, что find(), но поиск в обратном направлении в строке. |
| 28 | rindex( str, beg = 0, end = len(string)) – То же, что index(), но поиск в обратном направлении в строке. |
| 29 | rjust(width,[, fillchar]) – Возвращает space-padded строку из исходной строки, выравнивается по правому краю в количестве width столбцов. |
| 30 | rstrip() – Удаляет все конечные пробелы из строки. |
| 31 | split(str=””, num=string.count(str)) – Разделяет строку в соответствии с разделителем str (пробел, если не предусмотрено) и возвращает список из подстроке; разделяет на num подстроку, если дано. |
| 32 | splitlines( num=string.count(‘\n’)) – Разбивает строку на все (или числа) строки и возвращает список каждой строки с удаленными символами новой строки. |
| 33 | startswith(str, beg=0,end=len(string)) – Определяет, является ли строка или подстрока в строке (если начальный индекс нач и заканчивается указанием на конец) начинается с подстроки str; возвращает истину, если так и ложь в противном случае. |
| 34 | strip([chars]) – Выполняет как lstrip() и rstrip() в строке |
| 35 | swapcase() – Инверсия для всех букв в строке. |
| 36 | title() – Возвращает «titlecased» версию строки, то есть, все слова начинаются с верхним регистром, а остальное в нижнем регистре. |
| 37 | translate(table, deletechars=””) – Переводит строку согласно таблице перевода str(256 символов), убрав deletechars. |
| 38 | upper() – Преобразование строчных букв в строке в верхний регистр. |
| 39 | zfill (width) – Возвращает исходную строку добавленную слева с нулями с указанной шириной символов; предназначенный для чисел, zfill() сохраняет любой данный знак (менее один ноль). |
| 40 | isdecimal() – Возвращает истину, если строка содержит только десятичные знаки и ложь в противном случае. |
Если вы нашли ошибку, пожалуйста, выделите фрагмент текста и нажмите Ctrl+Enter.
andreyex.ru
Некоторые понятия в Python, Преобразование типов данных, срезы, строки
Основные понятия: функции, методы, объекты, итерация
Разберем несколько понятий, воизбежание путаницы в дальнейшем. Мы уже сталкивались с функциями, когда использовали команду, которая возвращает длину(размерность списка, кортежа или строки — len().
Некая команда, справа от которой стоят круглые скобочки, имеет название — функция. Между скобочками мы можем указать некую информацию, в случае с len(), мы указываем список, кортеж или строку, длину которого мы хотим узнать, или переменную, которая на них ссылается. Также есть функции, куда мы ничего не передаем, про это будет дальше.
Что такое объекты? Список, кортеж, словарь, строка, число — это все объекты. Это условное название некой завершенной структуры в Python, но давайте проведем более тонкую грань. Просто строка — это тип данных. Объектом оно станет только тогда, когда вы физически создадите строку в Python. Какая-то строка, находящаяся между кавычками «»(») — это объект. Также и с остальными типами данных. Создали какой-то вполне конкретный список — это объект.
Над объектами, мы можем выполнять некоторые действия, обычно эти действия зависят от того, что хранится в объекте. Со строкой, мы можем выполнять одни действия, со списком другие. Эти действия, мы называем методами. По сути, метод — это та же самая функция, но она закреплена за конкретным объектом, что мы увидим далее в этой теме.. Пока мы не дойдем до парадигмы объектно-ориентированного программирования, будем представлять себе это так, как я описал выше.
Новое и интересное слово — итерация. Итерация — это возможность разобрать какой-то объект по элементам. Мы можем по индексу обратиться к определенному элементу списка? Да. Значит список итерируемый. Мы можем вызвать по индексу букву из строки? И опять таки да, а значит и строка итерируемая. А вот с числа, мы не можем взять отдельный элемент и соответственно объект числа неитерируемый. Словари, списки, кортежи, строки — это итерируемые объекты. Посути, итерация означает возможность перебрать тот или иной объект по элементам в том порядке, в котором нам необходимо, но есть исключения, когда мы можем итерировать что-то только в той последовательности, которая предусмотрена в каком-то объекте.
Преобразование типов данных
Довольно часто, нам необходимо перевести один тип данных в другой, зачем? Кпримеру у нас есть строка, где будет записано какое-то число. У нас будет необходимость совершать какие-то математические действия с этим числом, но поскольку мы не можем совершать математические действия со строкой, нам будет нужно перевести строчный тип данных в числовой. Для преобразования типов, у нас есть функции, которые отвечают за это действие:
str() — Переведет что-то в строку, если это возможно.
int() — Переведет строчный тип в целое число.
float() — Переведет строчный тип в число с плавающей точкой.
list() — Переведет что-то в список, если это возможно.
tuple() — Переведет что-то в кортеж, если это возможно.
dict() — Переведет что-то в словарь, если это возможно.
Давайте посмотрим, как это работает. Объявим переменную a и присвоим ей строчное значение 123.
>>> a = ‘123’
>>>
Есть замечательная функция, которая позволит нам посмотреть тип данных какого-то объекта.
>>> type(a)
>>>
Как мы видем — это действительно строка. Давайте переведем эту строку в число при помощи функции int() и сохраним результат в переменную b.
>>> b = int(a)
>>> b
123
>>> type(b)
>>>
Как нам подсказывает функция type(), при помощи функции int(), на выходе мы получили числовой, а точнее целочисленный тип данных. Как нам подсказывает логика, чтобы получить число с плавающей точкой, мы можем использовать функцию float()
>>> b = float(a)
>>> type(b)
>>> b
123.0
>>>
И действительно, тут очевидно, что функция float(), перевела строчный тип в число с
плавающей точкой.
Необходимо учитывать, что функция int(), не переведет записанное в строке десятичное число.
>>> a = «123.0»
>>> a
‘123.0’
>>> int(a)
Traceback (most recent call last):
File «», line 1, in
ValueError: invalid literal for int() with base 10: ‘123.0’
>>>
Если в строке записано число с плавающей точкой, его необходимо преобразовывать в десятичную дробь при помощи команды float(). Это значит, что если в теории, мы подразумеваем то, что в строке может быть десятичная дробь, мы всегда должны использовать для преобразования функцию float().
Преобразование целочисленного типа или числа с плавающей точкой в строку, происходит аналогично при помощи функции str().
>>> a = 123
>>> type(a)
>>> b = str(a)
>>> b
‘123’
>>> type(b)
>>>
Преобразования типа float в str, ничем не отличается от преобразования int в str. На выходе, мы получим строку с записанным числом.
Срезы
Срез позволяет нам обратиться к ряду элементов строки, списка или кортежа от какого-то начального элемента, который мы можем указать самостоятельно, до какого-то элемента, который мы тоже можем указать явно. Также мы можем указать шаг этого обращения, скажем если нам необходимо, вывести не все элементы подряд, а каждый третий. Формула среза примерно такая: [Индекс элемента с которого мы начнем:Индекс элемента до которого мы хотим пройтись не включая его:шаг с которым мы хотим пройтись]. Для более наглядного примера, посмотрим на следующее.
>>> a = «012345»
>>> a[0:5] # Элементы от начала до индекса 5, не включая его
‘01234’
>>> a[2:6] #С элемента под индексом 2, до конца
‘2345’
>>> # Если мы имеем ввиду начало или конец списка элементов, мы можем пропустить 0 вначале или номер индекса в конце
>>> a[:5]
‘01234’
>>> a[2:]
‘2345’
>>> a[::2] # Пробежимся по элементам от начала до конца с шагом в 2 элемента
‘024’
>>> a[::3] # Пробежимся по элементам от начала до конца с шагом в 3 элемента
’03’
>>> a[1:5:2] # Пробежимся от элемента с индексом 1, до индекса 5, не включая его
с шагом в 2 элемента
’13’
>>>
Взаимодействие со строкой, несколько методов
Рассмотрим несколько часто используемых методов для строки. Вы помните о чем я писал раньше? Метод — это функция, которая закреплена за конкретным объектом. Формат обращения к методам объектов такой: Объект.метод(). Где объект, там или непосредственный объект в виде списка, строки, кортежа и Т.Д. Или переменная, которая ссылается на этот объект. Рассмотрим метод split(), который позволяет разбить строку по определенному символу. Скажем строку из нескольких слов, мы можем превратить в список отдельных слов, разбив ее по пробелу.
>>> a = «Code is poetry»
>>> a.split(» «)
[‘Code’, ‘is’, ‘poetry’]
>>>
По характерным квадратным скобочкам, мы можем сказать, что строка была разбита по пробелам на отдельные слова и преобразована в список. Давайте проверим.
>>> b = a.split(» «)
>>> type(b)
>>>
Теперь мы можем обращаться к отдельным словам по их индексу в списке.
Также есть обратный split(), метод, он позволяет собрать список в строку, разделив каким-то знаком элементы списка в строке. Допустим был у нас список [‘Red’, ‘green’, ‘black’], а нам нужно свести этот список в строку, таким образом, чтобы каждый элемент списка был разделен пробелом. Для этого мы используем метод join().
>>> a = [‘Red’, ‘Green’, ‘Black’]
>>> ‘ ‘.join(a)
‘Red Green Black’
>>>
Я сказал, что мы обращаемся к объекту, затем через точку указываем метод, а тут все происходит наоборот? Сначала мы указываем символ которым элементы списка будут разделены в строке, потом через точку указываю метод, а потом в скобочках передаю переменную списка. Кажется, что все наоборот, но нет. Дело в том, что метод join() — метод строки а не списка и его нужно читать примерно так: Мы просим строку принять в себя список и разделить его элементы тем символом, который мы показали строке. Строка-строка, вот тебе пробел ‘ ‘. А теперь отделяя каждый элемент списка вот тем пробелом, собери в строку список ().
Еще один из самых часто используемых методов строки — это поиск подстроки, слова или нескольких слов. Метод find(), позволяет найти указанный набор символов в строке. Этот метод, возвращает индекс первого символа того, что вы ему укажете Т.Е. Он скажет индекс откуда начинается слово/фраза/набор символов, который вы передали методу find() для поиска.
>>> a = «Code is poetry»
>>> a.find(«is»)
5
>>> a[5:7] # проверим, что с 5 до 7 индекса, действительно находится слово is
‘is’
>>> a.find(» is «) # Поскольку сочитание букв is, может быть в другом слове, явно окружили is пробелами
4
>>> a[4:8]
‘ is ‘
>>>
Если find() ничего не найдет в строке, вернет -1.
Давайте, используя метод find(), выведем при помощи среза, строку от is до конца.
>>> a[a.find(» is «):]
‘ is poetry’
>>> a[a.find(» is «)+1:] # Приплюсуем 1 к индексу от find, чтобы в начале выводимой строки не болтался пробел
‘is poetry’
>>>
Метод find(), имеет 2 необязательных(опциональных) аргумента:
find(«что ищем», С какого индекса начинать поиск, до какого индекса производить поиск)
Также есть метод index(), в Python 2.7, он выполняет такуюже функцию как и метод find(), но при случае отсутствия искомого в строке, выдаст не -1, а ошибку.
>>> a.find(«blablabla»)
-1
>>> a.index(«blablabla»)
Traceback (most recent call last):
File «», line 1, in
ValueError: substring not found
>>>
magicofpython.blogspot.com