HTML кодировка страницы. В какой кодировке сохранять web-страницу? Урок №14
Бывали ли у вас ситуации, когда на web-странице вместо читабельного текста открывались кракозябры? Я уверен, что бывали или, по крайне мере, вы видели их на других сайтах. Если не видели, посмотрите на пример снизу:

Что такое HTML кодировка?
HTML кодировка – это таблицы соответствия кодов и символов алфавита. То есть, наш компьютер по кодировке поменяет код на понятные читабельные буквы.

Популярные кодировки.
На сегодняшний день существуют две самые популярные кодировки в русскоязычном интернете. Это кодировка windows-1251 и utf-8. Частенько веб-мастерам приходится выбирать, в какой кодировке делать им веб-страничку.
В какой кодировке следует сохранять HTML файл?
Большинство веб-мастеров выбирают кодировку utf-8. И это верный выбор, так как в кодировке utf-8 имеются различные знаки (→ ←↓↑ и т. д.), а также есть масса разнообразных специфических символов. Кстати, основная часть движков, как Joomla, WordPress, Drupal работает на кодировке utf-8.
Поэтому я рекомендую вам сохранять HTML файлы в кодировке utf-8.
Как задать кодировку UTF-8 для файла?
Чтобы задать кодировку для HTML файла, используют различные редакторы. Я пользуюсь текстовым редактором Notepad++.
Откройте текстовый редактор Notepad++.
Если нужно, создайте новый документ.
Перейдите в меню сверху по вкладке «Кодировки» => «Кодировать в UTF-8 (без BOM)»:

Чтобы сообщить браузеру, в какой кодировке HTML файл, существует специальный META-тег
<meta http-equiv="Content-Type" content="text/html; charset=utf-8">
В HTML документе это будет выглядеть вот так:
<html> <head> <title>кодировка HTML</title> <meta http-equiv="Content-Type" content="text/html; charset=utf-8"> </head> <body> </body> </html>
Как задать кодировку windows-1251 для файла?
Откройте текстовый редактор Notepad++.
Если нужно, создайте новый документ.
Перейдите в меню сверху по вкладке «Кодировки» => «Кодировать в ANSI»:

Чтобы сообщить браузеру, в какой кодировке HTML файл, существует специальный
<meta http-equiv="Content-Type" content="text/html; charset=windows-1251">
В HTML документе это будет выглядеть вот так:
<html> <head> <title>кодировка HTML</title> <meta http-equiv="Content-Type" content="text/html; charset=windows-1251"> </head> <body> </body> </html>
Пример перекодировки файла из windows-1251 в utf-8
Если в HTML документе был прописан код в кодировке windows-1251 (ANSI), а вам нужно перекодировать на utf-8 (или на оборот), тогда сделайте так:
Откройте текстовый редактор Notepad++. В текстовом редакторе перейдите в меню сверху по вкладке «Кодировки» => «Преобразовать в UTF-8 (без BOM)»:

Внимание, если бы вы нажали «Кодировать в UTF-8 (без BOM)», то в результате вы бы увидели вместо любимого русского текста, красивые караказябли ![]() .
.

Понравился пост? Помоги другим узнать об этой статье, кликни на кнопку социальных сетей ↓↓↓
Последние новости категории:
Похожие статьи
Популярные статьи:
Добавить комментарий
Метки: html, основы
bloggood.ru
Как перевести файлы в кодировку UTF-8
Как перевести файлы в кодировку UTF-8
Те, у кого старые сайты, могут столкнуться с такой проблемой, что необходимо перевести файлы в кодировку UTF-8. К их числу я смело могу назвать и себя. Начала делать сайты более 10 лет назад, когда об этой кодировке было мало что известно. На всех страницах у меня стояла кодировка:
<META http-equiv=content-type content=»text/html; charset=windows-1251″>
За эти годы некоторые мои сайты распухли до тысячи и более страниц и переделывать все эти тысячные страницы не хватит никаких сил и времени.
Сейчас уже так не пишут. На смену старому пришло новое — HTML5, где нужно прописать:
<meta charset=»UTF-8″>
Скажу честно, все же решила я все перелопатить вручную и вот как это у меня происходило:
- Открывала файл в Notepad++
- Выделяла весть текст
- Копировала весь текст
- Переводила кодировку в UTF-8
- Вставляла текст
- Проверяла опять — в той ли кодировке стоит?
- Сохраняла файл
И вот два дня я так долбила один свой сайт.
Можно, конечно же и не менять ничего. Но ведь старые сайты мои давно устарели, нужно переводить их и на современную верстку HTML5 и CSS3, плюс мобильную и адаптивную верстку. И лучше это делать в более продвинутых программах, а не в Notepad++.
Короче, приуныла я. Однако приехал сын-программист и все решил!
Оказывается все уже давно придумано. И если у Вас возникла такая же проблема — не отчаивайтесь! Есть прекрасная программа UTFCast Express
Эту программу можно скачать тут — http://www.rotatingscrew.com/utfcast-express.aspx — Это условно бесплатная программа, которая умеет конвертировать текст из разных кодировок в utf8. Доступна для ОС семейства Windows.
Запускаем UTFCast Express и указываем правильные пути: сверху — что конвертировать, снизу — куда складывать конвертированные файлы. Вам нужно просто выбрать нужные директории, программа сама перекодирует все нужные файлы из папки. Нажимаем «Start».
Единственно, заранее создайте новую папку, куда программа закачает все Ваши файлы из нужной папки.
Не забудьте также поставить галочку «Copy Unconverted». Нажимаете кнопочку «Start» и программа заработала!
Всего пара минут и все файлы волшебным образом перекодировались в нужную кодировочку!
Папку с прежними файлами можете просто удалить, чтобы не занимала место и работать дальше! Вперед, к новым высотам!
Ура, товарищи!!!
Что такое вообще UTF-8
Заметьте, что UTF-8 надо обязательно писать в верхнем регистре и через черточку, то есть никаких там utf-8, utf8 или UTF8. Пишите правильно!
UTF-8 (от англ. Unicode Transformation Format, 8-bit — «формат преобразования Юникода, 8-битный») — одна из общепринятых и стандартизированных кодировок текста, которая позволяет хранить символы Юникода, используя переменное количество байт (от 1 до 6).
Стандарт UTF-8 официально закреплён в документах RFC 3629 и ISO/IEC 10646 Annex D. Кодировка нашла широкое применение в UNIX-подобных операционных системах и веб-пространстве. Сам же формат UTF-8 был изобретён 2 сентября 1992 года Кеном Томпсоном и Робом Пайком и реализован в Plan 9. В качестве BOM использует последовательность байт EF16, BB16, BF16 (что у неё самой является трёхбайтовой реализацией символа FEFF16).
Одним из преимуществ является совместимость с ASCII — любые их 7-битные символы отображаются как есть, а остальные выдают пользователю мусор (шум). Поэтому в случае, если латинские буквы и простейшие знаки препинания (включая пробел) занимают существенный объём текста, UTF-8 даёт выигрыш по объёму по сравнению с UTF-16.
highstar.ru
Кодирование и декодирование / Habr
Причиной разобраться в том, как же работает UTF-8 и что такое Юникод заставил тот факт, что VBScript не имеет встроенных функций работы с UTF-8. А так как ничего рабочего не нашел, то пришлось писть/дописывать самому. Опыт на мой взгляд полезный в любом случае. Для лучшего понимания начну с теории.О Юникоде
До появления Юникода широко использовались 8-битные кодировки, главные минусы которых очевидны:
- Возможность открыть документ не с той кодировкой, в которой он был создан;
- Шрифты необходимо создавать для каждой кодировки.
Так и было решено создать единый стандарт «широкой» кодировки, которая включала бы все символы (при чем сначала хотели в нее включить только обычные символы, но потом передумали и начали добавлять и экзотические). Юникод использует 1 112 064 кодовых позиций (больше чем 16 бит). Начало дублирует ASCII, а дальше остаток латиницы, кирилица, другие европейские и азиатские символы. Для обозначений символов используют шестнадцатеричную запись вида «U+xxxx» для первых 65k и с большим количеством цифр для остальных.
О UTF-8
Когда-то я думал что есть Юникод, а есть UTF-8. Позже я узнал, что ошибался.
UTF-8 является лишь представлением Юникода в 8-битном виде. Символы с кодами меньше 128 представляются одним байтом, а так как в Юникоде они повторяют ASCII, то текст написанный только этими символами будет являться текстом в ASCII. Символы же с кодами от 128 кодируются 2-мя байтами, с кодами от 2048 — 3-мя, от 65536 — 4-мя. Так можно было бы и до 6-ти байт дойти, но кодировать ими уже ничего.
0x00000000 — 0x0000007F: 0xxxxxxx 0x00000080 — 0x000007FF: 110xxxxx 10xxxxxx 0x00000800 — 0x0000FFFF: 1110xxxx 10xxxxxx 10xxxxxx 0x00010000 — 0x001FFFFF: 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
Кодируем в UTF-8
Порядок действий примерно такой:
- Каждый символ превращаем в Юникод.
- Проверяем из какого символ диапазона.
- Если код символа меньше 128, то к результату добавляем его в неизменном виде.
- Если код символа меньше 2048, то берем последние 6 бит и первые 5 бит кода символа. К первым 5 битам добавляем 0xC0 и получаем первый байт последовательности, а к последним 6 битам добавляем 0x80 и получаем второй байт. Конкатенируем и добавляем к результату.
- Похожим образом можем продолжить и для больших кодов, но если символ за пределами U+FFFF придется иметь дело с UTF-16 суррогатами.
Function EncodeUTF8(s)
Dim i, c, utfc, b1, b2, b3
For i=1 to Len(s)
c = ToLong(AscW(Mid(s,i,1)))
If c < 128 Then
utfc = chr( c)
ElseIf c < 2048 Then
b1 = c Mod &h50
b2 = (c - b1) / &h50
utfc = chr(&hC0 + b2) & chr(&h80 + b1)
ElseIf c < 65536 And (c < 55296 Or c > 57343) Then
b1 = c Mod &h50
b2 = ((c - b1) / &h50) Mod &h50
b3 = (c - b1 - (&h50 * b2)) / &h2000
utfc = chr(&hE0 + b3) & chr(&h80 + b2) & chr(&h80 + b1)
Else
' Младший или старший суррогат UTF-16
utfc = Chr(&hEF) & Chr(&hBF) & Chr(&hBD)
End If
EncodeUTF8 = EncodeUTF8 + utfc
Next
End Function
Function ToLong(intVal)
If intVal < 0 Then
ToLong = CLng(intVal) + &h20000
Else
ToLong = CLng(intVal)
End If
End Function
Декодируем UTF-8
- Ищем первый символ вида 11xxxxxx
- Считаем все последующие байты вида 10xxxxxx
- Если последовательность из двух байт и первый байт вида 110xxxxx, то отсекаем приставки и складываем, умножив первый байт на 0x40.
- Аналогично для более длинных последовательностей.
- Заменяем всю последовательность на нужный символ Юникода.
Function DecodeUTF8(s)
Dim i, c, n, b1, b2, b3
i = 1
Do While i <= len(s)
c = asc(mid(s,i,1))
If (c and &hC0) = &hC0 Then
n = 1
Do While i + n <= len(s)
If (asc(mid(s,i+n,1)) and &hC0) <> &h80 Then
Exit Do
End If
n = n + 1
Loop
If n = 2 and ((c and &hE0) = &hC0) Then
b1 = asc(mid(s,i+1,1)) and &h4F
b2 = c and &h2F
c = b1 + b2 * &h50
Elseif n = 3 and ((c and &hF0) = &hE0) Then
b1 = asc(mid(s,i+2,1)) and &h4F
b2 = asc(mid(s,i+1,1)) and &h4F
b3 = c and &h0F
c = b3 * &h2000 + b2 * &h50 + b1
Else
' Символ больше U+FFFF или неправильная последовательность
c = &hFFFD
End if
s = left(s,i-1) + chrw( c) + mid(s,i+n)
Elseif (c and &hC0) = &h80 then
' Неожидаемый продолжающий байт
s = left(s,i-1) + chrw(&hFFFD) + mid(s,i+1)
End If
i = i + 1
Loop
DecodeUTF8 = s
End Function
Ссылки
Юникод на Википедии
Исходник для ASP+VBScript
UPD: Обработка ошибочных последовательностей и ошибка с типом Integer, который возвращает AscW.
habr.com
Кодировка — Проблемы с кодировкой — utf-8 — windows-1251
В этой статье я постараюсь поставить все точки над «и» (а так же над «i») в вопросе выбора кодировки для создаваемой HTML-страницы.
Когда я только начинал заниматься сайтостроительством у меня постоянно возникали проблемы из-за этих кодировок. Сохранишь HTML-страницу, выгрузишь на сервер, открываешь, бах, а там кракозябры. Ну вот и здравствуйте, приехали.
Или в среде отладки (например, локальная среда разработки «Денвер») все нормально, а с хостинга опять они, кракозябры проклятые, нагло на меня смотрят.
С движками сколько мучений было. Вдруг, непонятно почему, родные русские буквы превращаются в …
Сейчас мы с этим делом подробно разберемся и вы будете четко знать в какую кодировку сохранять HTML-страницу и посредством каких инструментов.
Для укрепления нашего взаимопонимания определимся с понятием кодировка. Так вот, кодировка — это таблица соответствия машинных кодов и символов алфавита. Есть какая-то последовательность машинных символов, которую умный компьютер, в соответствии с выбранной кодовой таблицей, заменяет на понятные нам буквы.
В 90-е годы прошлого века (древность какая, а я как сейчас помню календарь 1991 года на стене) существовало 4-е кодировки для PC и еще одна, своя собственная, для Мака. Ирония судьбы заключается в том, что во всех этих кодировках символы латиницы ставились в соответствие машинным кодам по одному и тому же алгоритму, а вот по поводу кирилицы каждая из кодировок имела свое собственное мнение.
Вся эта путаница и привела к появлению кракозябров. Например, если слово «Вопрос», набранное в кодировке windows-1251, отобразить кодировкой KOI8-R, получится слово «бНОПНЯ».
Слава Богу, 90-е годы уже далеко позади и из пяти бредокодировок осталось всего 2-е нормальных. Но этого вполне достаточно, чтобы начинающий веб-мастер заблудился в двух соснах. Ничего, не переживайте, сейчас я вас выведу из этого леса!
На данный момент выбор для кодировки HTML-документа стоит между windows-1251 и utf-8. А теперь внимание: utf-8 гораздо богаче, мощнее и за ней будущее. Так что наши HTML-файлы мы будем сохранять именно в utf-8.
Обосную свои слова ;). UTF-8 содержит в своей таблице соответствия такие знаки, как → ←↓↑. А в windws-1251 вместо этих символов вот что: > <v^. А еще в utf-8 есть знак «евро»; а еще utf-8 позволяет в одном HTML-файле совмещать кучу разнообразных специфических символов, используемых в таких языках как грузинский, иврит, китайский, японский; а еще utf-8 в кодировках HTML — это правило хорошего тона.
Надеюсь я вас убедил и вы будете использовать Юникод (кстати «utf-8» и «Юникод» — это синонимы или, если быть более точным, utf-8 — это одна из кодировок семейства Юникод, которая снискала популярность в среде веб-разработчиков).
Теперь пристально посмотрим на инструменты перекодирования файлов, которые я рекомендую вам использовать, уважаемый читатель.
Инструменты для работы с кодировками HTML файлов
Собственно, их всего три:
- PSPad. Бесплатный текстовый редактор, мой любимый.
- Notepad++. Еще один хороший текстовый редактор и тоже бесплатный.
- Dreamweaver. Ну с Dreamweaver-ом вы с вами знакомы из моих видеоуроков по верстке сайта.
Загружаем какой-то HTML-файл в PSPad. И как же нам понять, что за кодировка у загруженного подопытного? Очень просто в строке состояния (внизу) все четко написано.
Кодировка открытого HTML-файла windows-1251
А у этого файла HTML кодировка utf-8
А теперь, создавая новый HTML-документ, позаботимся о его кодировке.
Идем в меню моего любимого PSPad-а. Нас интересует пункт Формат. В нем-то мы и поставим галку напротив кодировки utf-8.
Кодировка будущего HTML-файла будет utf-8
А так кодировка будующего файла — windows-1251
Теперь о том как изменить кодировку файла HTML. Да оказывается очень просто:
Пример перекодирования файла из кодировки windows-1251 в utf-8
Нужно кликнуть по требуемой кодировке в пункте меню Формат и кодировка сменится. После этого сохраняйте файл, он перекодирован, дело сделано.
Что касается Notepad++ все очень похоже на вышеописанную ситуацию. Только для работы с кодировками нужно использовать пункт меню Кодировки.
Вся разница заключается в том, что в случае Notepad++ появляются, специально разработанные для преобразования кодировок, пункты меню Преобразовать... (лишние на мой взгляд, в PSPad все проще и поэтому я им пользуюсь). Соответственно, именно по ним и нужно кликать при желании поменять кодировки у нашего HTML-файла.
Кроме всего прочего, при сохранении в utf-8 у нас есть выбор: без BOM или с BOM. Нам, как веб-мастерам, нужно использовать кодировку UTF-8 (без BOM).
Вот что нам ответит Википедия на вопрос «что такое BOM»
Для определения формата представления Юникода в текстовом файле используется приём, по которому в начале текста записывается символ U+FEFF (неразрывный пробел с нулевой шириной), также именуемый меткой порядка байтов (англ. Byte Order Mark, BOM). Этот способ позволяет различать UTF-16LE и UTF-16BE, поскольку символа U+FFFE не существует. Также он иногда применяется для обозначения формата UTF-8, хотя к этому формату и неприменимо понятие порядка байтов.
Если прочитать приведенный текст 10 раз, почесать затылок, то становится понятно: для utf-8 BOM нам НЕ нужен. Кроме того, если сохранить файл с php-скриптом в кодировку utf-8 с BOM, то он не будет работать, потому что обработчик не поймет, что это за ерунда такая написана в начале файла-скрипта (я имею ввиду тот самый неразрывный пробел с нулевой шириной).
Так-так, осталось пристально взглянуть на Dreamweaver.
Создавая новый файл, обращайте внимание на то, в какой кодировке он будет создан. Для этого в окне создания нового документа File → New (Ctrl+N) воспользуйтесь кнопкой Preferences…
И посмотрите, что задано в качестве кодировки по умолчанию:
Кодировка создаваемого HTML-файла по умолчанию в Dreamweaver
Перекодировать открытый HTML-файл в Dreamweaver можно в диалоге Page Properties, который запускается из меню Modify → Page Properties (Ctrl + J).
Выбирайте требуемую кодировку, нажимайте ОК и все, задача по перекодированию выполнена (а вот BOM все так же ненужен, не ставьте галку).
Определение кодировки браузерами
Итак, наш HTML-файл сохранен в выбранную нами кодировку. Теперь давайте разберемся с вопросом: каким образом браузер узнает о применяемой в данном HTML-файле кодировке?
Здесь есть три варианта:
1. Мы сами сообщаем браузеру о том, какая кодировка установлена для данного HTML файла. Делается это посредством META-тега
<meta http-equiv="Content-Type" content="text/html; charset=utf-8">
В приведенном примере браузеру дается указание, что загруженный HTML-файл сохранен в кодировке utf-8.
Если HTML-файл сохранен в кодировку windows-1251, то:
<meta http-equiv="Content-Type" content="text/html; charset=windows-1251">
Кстати, при перекодировке файлов не забывайте изменять директивы в META-теге на актуальные. Dreamweaver, при изменении кодировки, делает это автоматически, а в других текстовых редакторах вам нужно самим ставить в соответствие примененную кодировку и директиву META-тега.
Полный HTML выглядит следующим образом (привожу его для понимания вопроса «в каком месте указывается META-тег с директивой кодировки» внимание на 4-ю строку):
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose.dtd"> <html> <head> <meta http-equiv="Content-Type" content="text/html; charset=utf-8"> <title>Untitled Document</title> </head> <body> Ну и т.д.
2. При помощи файла .htaccess. Иногда сервер насильно передает заголовки для загружаемых HTML-файлов и сообщает браузеру кодировку по умолчанию. В этом случае браузер не обращает внимания на директивы в META-теге, а отображает HTML-файл в той кодировки, которую сообщил сервер. Чтобы файл загружалсяв той кодировке, которая нужна вам (часто хостинг насильно указывает кодировку windows-1251), в корне хостинг-директории создается файл с именем «.htaccess».
Файл этот предназначен для дополнительной конфигурации сервера. Действие .htaccess-директив распространяется на все файлы и подкаталоги, которые находятся в том каталоге, куда вы сохранили файл .htaccess.
Создать этот файл можно, например, в Total Commander-е, нажав горячее сочетание клавиш Shift+F4 и указав имя создаваемому файлу .htaccess. Далее в текстовом редакторе указываются директивы дополнительных настроек кодировки по умолчанию.
Для HTML-файлов в кодировке utf-8 в .htaccess нужно написать одну строку:
AddDefaultCharset UTF-8
Для HTML-файлов в кодировке Windows-1251:
AddDefaultCharset Windows-1251
Если ваш хостинг хитро-мудрый и не обращает внимания на эти директивы, то можно попробовать:
charsetdisable on
AddDefaultCharset Off
Если и это не дало результата, то просто спросите у своего хостера, чего вам делать, чтобы отключить кодировку по умолчанию :). Все это зависит от конкретных настроек сервера у хостинг-провайдера.
3. PHP-инструкция, указывающая кодировку по умолчанию. В файле, который нужно отобразить в желаемой кодировке, не смотря на настройки сервера хостинг-провайдера, в самом начале указывается директива с php-кодом:
<?php header('Content-type: text/html; charset=utf-8')?>Этот php-код отправит заголовок сервера с указанием кодировки по умолчанию для браузера. В приведенном примере, для отображения страницы, будет применяться кодировка utf-8.
Против такого лома, обычно, приемов в настройках сервера хостинг-провайдера не остается.
Хочу заметить, что для обработки php-инструкций сервером, html-файл должен иметь расширение .php (например index.php).
Есть еще вопросы по кодировкам? Пишите в комментарии. Нужно решить эти проблемы раз и на всегда 🙂
С уважением, Андрей Морковин.
www.sdelaysite.com
Проблемы с кодировкой на сайте
Вы здесь: Главная — PHP — PHP Основы — Проблемы с кодировкой на сайте

Одной из самых частых проблем, с которой сталкивается начинающий Web-мастер (да и не только начинающие), это проблемы с кодировкой на сайте. Даже у меня постоянно появляется при создании сайтов «абракадабра«. Но, благо, я прекрасно знаю, как эту проблему решить, поэтому всё привожу в порядок в течение нескольких секунд. И в этой статье я постараюсь научить Вас также быстро решать проблемы, связанные с кодировкой на сайте.
Первое, что стоит отметить, это то, что все проблемы с появлением «абракадабры» связаны с несовпадением кодировки документа и кодировки, выставляемой браузером. Допустим, документ в windows-1251, а браузер почему-то выставляет UTF-8. А уже источником такого несовпадения могут быть следующие причины.
Первая причина
Неправильно прописан мета-тег content-type. Будьте внимательны, в нём всегда должна находиться та кодировка, в котором написан Ваш документ.
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
Вторая причина
Вроде бы, мета-тег прописан так, как Вы хотите, и браузер выставляет именно то, что Вы хотите, но почему-то всё равно с кодировкой проблемы. Здесь, почти наверняка, виновато то, что сам документ имеет отличную кодировку. Если Вы работаете в Notepad++, то внизу справа есть название кодировки текущего документа (например, ANSI). Если Вы ставите в мета-теге UTF-8, а сам документ написан в ANSI, то сделайте преобразование в UTF-8 (через меню «Кодировки» и пункт «Преобразовать в UTF-8 без BOM«).
Третья причина
Мета-тег написан правильно, кодировка документа верная, но браузер почему-то настойчиво выбирает другую кодировку. Это уже связано с настройками сервера. Способ решения данной проблемы можно прочитать здесь: как задать кодировку в htaccess.
Четвёртая причина
И, наконец, последняя популярная причина — это проблема с кодировкой в базе данных. Во-первых, убедитесь, что все Ваши таблицы и поля написаны в одной кодировке, которая совпадает с кодировкой остального сайта. Если это не помогло, то сразу после подключения в скрипте выполните следующий запрос:
SET NAMES 'utf8'
Вместо «utf8» может стоять другая кодировка. После этого все данные из базы должны выходить в правильной кодировке.
В данной статье я, надеюсь, разобрал, как минимум, 90% проблем, связанных с появлением «абракадабры» на сайте. Теперь Вы должны расправляться с такой популярной и простой проблемой, как неправильная кодировка, в два счёта.
-
 Создано 21.05.2012 13:43:04
Создано 21.05.2012 13:43:04 -
 Михаил Русаков
Михаил Русаков
Копирование материалов разрешается только с указанием автора (Михаил Русаков) и индексируемой прямой ссылкой на сайт (http://myrusakov.ru)!
Добавляйтесь ко мне в друзья ВКонтакте: http://vk.com/myrusakov.
Если Вы хотите дать оценку мне и моей работе, то напишите её в моей группе: http://vk.com/rusakovmy.
Если Вы не хотите пропустить новые материалы на сайте,
то Вы можете подписаться на обновления: Подписаться на обновления
Если у Вас остались какие-либо вопросы, либо у Вас есть желание высказаться по поводу этой статьи, то Вы можете оставить свой комментарий внизу страницы.
Порекомендуйте эту статью друзьям:
Если Вам понравился сайт, то разместите ссылку на него (у себя на сайте, на форуме, в контакте):
-
Кнопка:
<a href=»https://myrusakov.ru» target=»_blank»><img src=»https://myrusakov.ru/images/button.gif» alt=»Как создать свой сайт» /></a>Она выглядит вот так:

-
Текстовая ссылка:
<a href=»https://myrusakov.ru» target=»_blank»>Как создать свой сайт</a>Она выглядит вот так: Как создать свой сайт
- BB-код ссылки для форумов (например, можете поставить её в подписи):
[URL=»https://myrusakov.ru»]Как создать свой сайт[/URL]
myrusakov.ru
Как поменять кодировку в Excel

С потребностью менять кодировку текста часто сталкиваются пользователи, работающие браузерах, текстовых редакторах и процессорах. Тем не менее, и при работе в табличном процессоре Excel такая необходимость тоже может возникнуть, ведь эта программа обрабатывает не только цифры, но и текст. Давайте разберемся, как изменить кодировку в Экселе.
Урок: Кодировка в Microsoft Word
Работа с кодировкой текста
Кодировка текста – эта набор электронных цифровых выражений, которые преобразуются в понятные для пользователя символы. Существует много видов кодировки, у каждого из которых имеются свои правила и язык. Умение программы распознавать конкретный язык и переводить его на понятные для обычного человека знаки (буквы, цифры, другие символы) определяет, сможет ли приложение работать с конкретным текстом или нет. Среди популярных текстовых кодировок следует выделить такие:
- Windows-1251;
- KOI-8;
- ASCII;
- ANSI;
- UKS-2;
- UTF-8 (Юникод).
Последнее наименование является самым распространенным среди кодировок в мире, так как считается своего рода универсальным стандартом.
Чаще всего, программа сама распознаёт кодировку и автоматически переключается на неё, но в отдельных случаях пользователю нужно указать приложению её вид. Только тогда оно сможет корректно работать с кодированными символами.

Наибольшее количество проблем с расшифровкой кодировки у программы Excel встречается при попытке открытия файлов CSV или экспорте файлов txt. Часто, вместо обычных букв при открытии этих файлов через Эксель, мы можем наблюдать непонятные символы, так называемые «кракозябры». В этих случаях пользователю нужно совершить определенные манипуляции для того, чтобы программа начала корректно отображать данные. Существует несколько способов решения данной проблемы.
Способ 1: изменение кодировки с помощью Notepad++
К сожалению, полноценного инструмента, который позволял бы быстро изменять кодировку в любом типе текстов у Эксель нет. Поэтому приходится в этих целях использовать многошаговые решения или прибегать к помощи сторонних приложений. Одним из самых надежных способов является использование текстового редактора Notepad++.
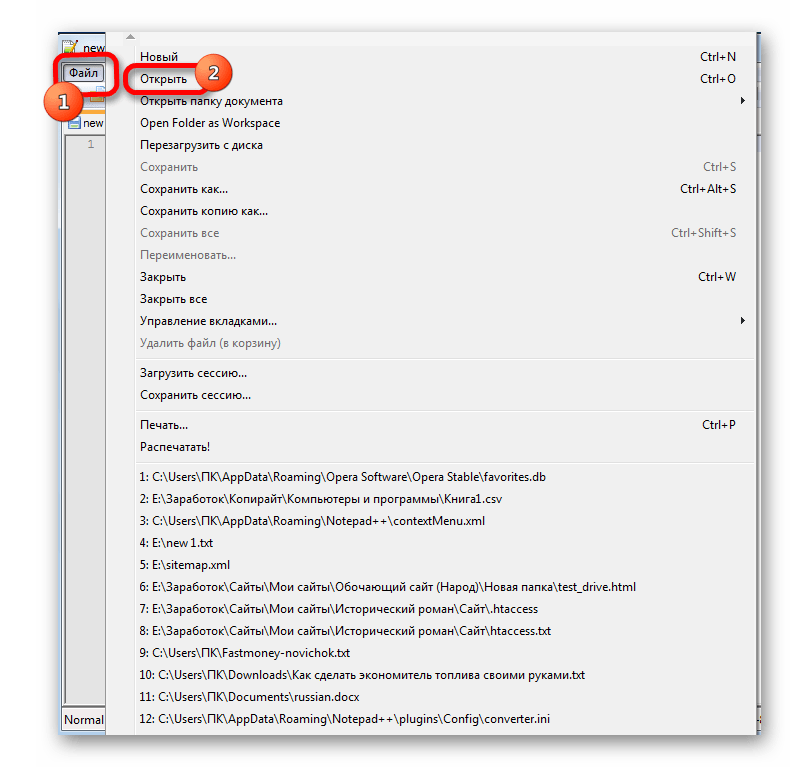
- Запускаем приложение Notepad++. Кликаем по пункту «Файл». Из открывшегося списка выбираем пункт «Открыть». Как альтернативный вариант, можно набрать на клавиатуре сочетание клавиш Ctrl+O.
- Запускается окно открытия файла. Переходим в директорию, где расположен документ, который некорректно отобразился в Экселе. Выделяем его и жмем на кнопку «Открыть» в нижней части окна.
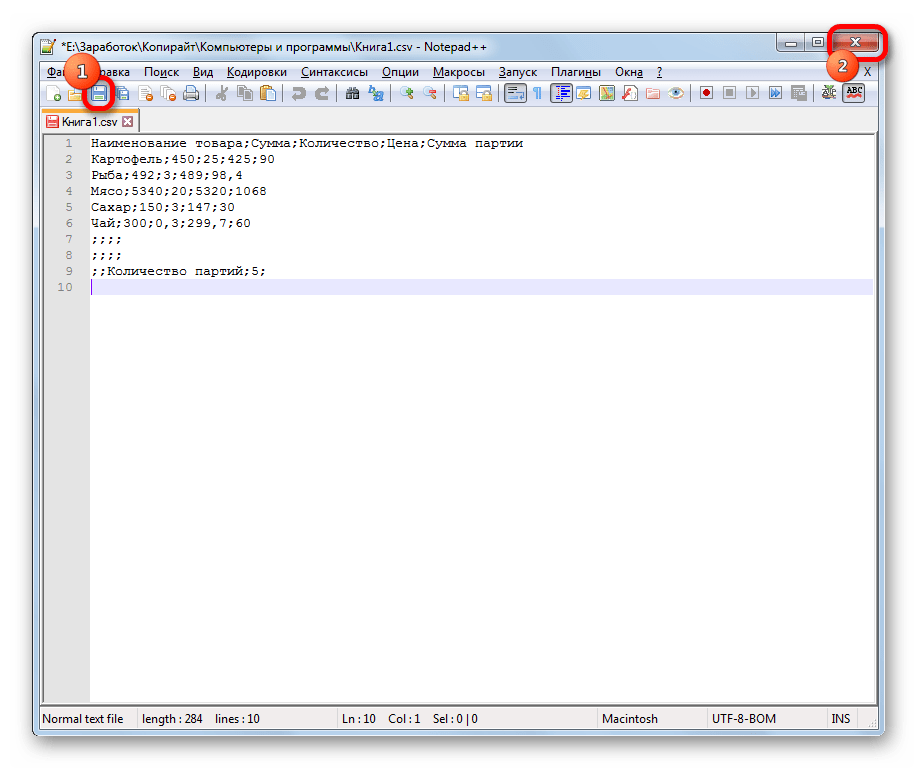
- Файл открывается в окне редактора Notepad++. Внизу окна в правой части строки состояния указана текущая кодировка документа. Так как Excel отображает её некорректно, требуется произвести изменения. Набираем комбинацию клавиш Ctrl+A на клавиатуре, чтобы выделить весь текст. Кликаем по пункту меню «Кодировки». В открывшемся списке выбираем пункт «Преобразовать в UTF-8». Это кодировка Юникода и с ней Эксель работает максимально корректно.
- После этого, чтобы сохранить изменения в файле жмем на кнопку на панели инструментов в виде дискеты. Закрываем Notepad++, нажав на кнопку в виде белого крестика в красном квадрате в верхнем правом углу окна.
- Открываем файл стандартным способом через проводник или с помощью любого другого варианта в программе Excel. Как видим, все символы теперь отображаются корректно.



Несмотря на то, что данный способ основан на использовании стороннего программного обеспечения, он является одним из самых простых вариантов для перекодировки содержимого файлов под Эксель.
Способ 2: применение Мастера текстов
Кроме того, совершить преобразование можно и с помощью встроенных инструментов программы, а именно Мастера текстов. Как ни странно, использование данного инструмента несколько сложнее, чем применение сторонней программы, описанной в предыдущем методе.
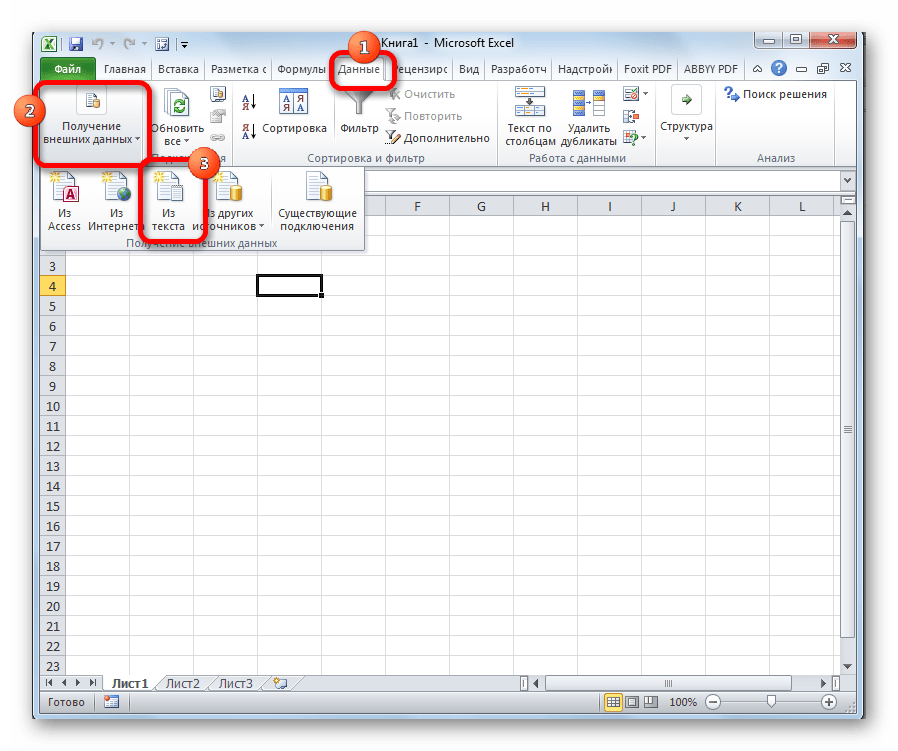
- Запускаем программу Excel. Нужно активировать именно само приложение, а не открыть с его помощью документ. То есть, перед вами должен предстать чистый лист. Переходим во вкладку «Данные». Кликаем на кнопку на ленте «Из текста», размещенную в блоке инструментов «Получение внешних данных».
- Открывается окно импорта текстового файла. В нем поддерживается открытие следующих форматов:
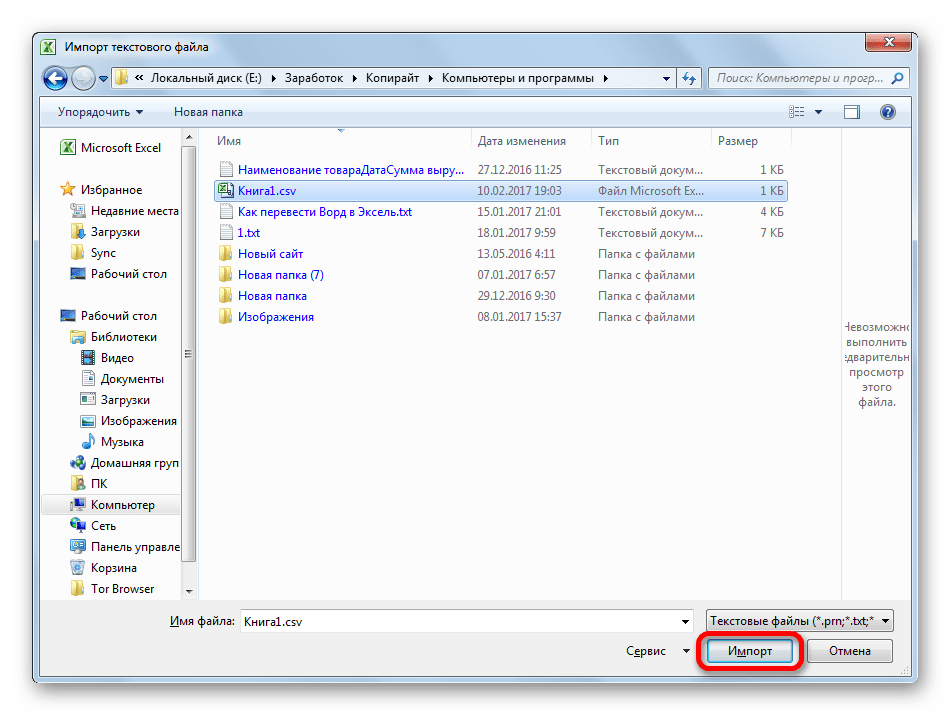
Переходим в директорию размещения импортируемого файла, выделяем его и кликаем по кнопке «Импорт».
- Открывается окно Мастера текстов. Как видим, в поле предварительного просмотра символы отображаются некорректно. В поле «Формат файла» раскрываем выпадающий список и меняем в нем кодировку на «Юникод (UTF-8)».

Если данные отображаются все равно некорректно, то пытаемся экспериментировать с применением других кодировок, пока текст в поле для предпросмотра не станет читаемым. После того, как результат удовлетворит вас, жмите на кнопку «Далее».
- Открывается следующее окно Мастера текста. Тут можно изменить знак разделителя, но рекомендуется оставить настройки по умолчанию (знак табуляции). Жмем на кнопку «Далее».
- В последнем окне имеется возможность изменить формат данных столбца:
- Общий;
- Текстовый;
- Дата;
- Пропустить столбец.
Тут настройки следует выставить, учитывая характер обрабатываемого контента. После этого жмем на кнопку «Готово».
- В следующем окне указываем координаты левой верхней ячейки диапазона на листе, куда будут вставлены данные. Это можно сделать, вбив адрес вручную в соответствующее поле или просто выделив нужную ячейку на листе. После того, как координаты добавлены, в поле окна жмем кнопку «OK».
- После этого текст отобразится на листе в нужной нам кодировке. Остается его отформатировать или восстановить структуру таблицы, если это были табличные данные, так как при переформатировании она разрушается.





Способ 3: сохранение файла в определенной кодировке
Бывает и обратная ситуация, когда файл нужно не открыть с корректным отображением данных, а сохранить в установленной кодировке. В Экселе можно выполнить и эту задачу.
- Переходим во вкладку «Файл». Кликаем по пункту «Сохранить как».
- Открывается окно сохранения документа. С помощью интерфейса Проводника определяем директорию, где файл будет храниться. Затем выставляем тип файла, если хотим сохранить книгу в формате отличном от стандартного формата Excel (xlsx). Потом кликаем по параметру «Сервис» и в открывшемся списке выбираем пункт «Параметры веб-документа».
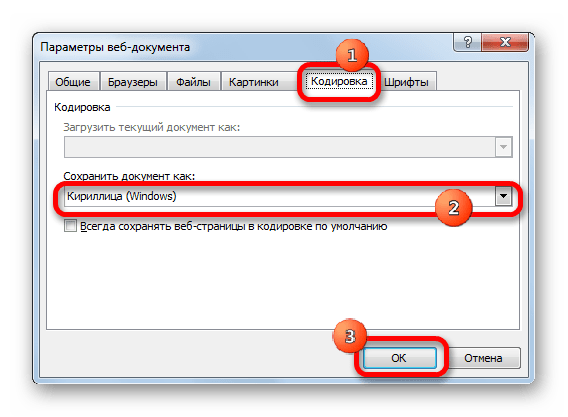
- В открывшемся окне переходим во вкладку «Кодировка». В поле «Сохранить документ как» открываем выпадающий список и устанавливаем из перечня тот тип кодировки, который считаем нужным. После этого жмем на кнопку «OK».
- Возвращаемся в окно «Сохранения документа» и тут жмем на кнопку «Сохранить».


Документ сохранится на жестком диске или съемном носителе в той кодировке, которую вы определили сами. Но нужно учесть, что теперь всегда документы, сохраненные в Excel, будут сохраняться в данной кодировке. Для того, чтобы изменить это, придется опять заходить в окно «Параметры веб-документа» и менять настройки.
Существует и другой путь к изменению настроек кодировки сохраненного текста.
- Находясь во вкладке «Файл», кликаем по пункту «Параметры».
- Открывается окно параметров Эксель. Выбираем подпункт «Дополнительно» из перечня расположенного в левой части окна. Центральную часть окна прокручиваем вниз до блока настроек «Общие». Тут кликаем по кнопке «Параметры веб-страницы».
- Открывается уже знакомое нам окно «Параметры веб-документа», где мы проделываем все те же действия, о которых говорили ранее.


Теперь любой документ, сохраненный в Excel, будет иметь именно ту кодировку, которая была вами установлена.
Как видим, у Эксель нет инструмента, который позволил бы быстро и удобно конвертировать текст из одной кодировки в другую. Мастер текста имеет слишком громоздкий функционал и обладает множеством не нужных для подобной процедуры возможностей. Используя его, вам придется проходить несколько шагов, которые непосредственно на данный процесс не влияют, а служат для других целей. Даже конвертация через сторонний текстовый редактор Notepad++ в этом случае выглядит несколько проще. Сохранение файлов в заданной кодировке в приложении Excel тоже усложнено тем фактом, что каждый раз при желании сменить данный параметр, вам придется изменять глобальные настройки программы.
 Мы рады, что смогли помочь Вам в решении проблемы.Опишите, что у вас не получилось.
Наши специалисты постараются ответить максимально быстро.
Мы рады, что смогли помочь Вам в решении проблемы.Опишите, что у вас не получилось.
Наши специалисты постараются ответить максимально быстро.Помогла ли вам эта статья?
ДА НЕТlumpics.ru
Как сменить кодировку с UTF-8 на кириллицу — artisteer-rus.com
Чтобы поменять кодировку страницы, напимер с UTF-8 на Windows-1251(кириллицу), можно использовать несколько способов. Для всех надо использовать текстовый редактор Notepad++, или любой подобный.
 Споб первый, самый простой, но не всегда действенный. Открыть нужную Вам страницу HTML или PHP и проделать следующее. В верху страницы между тегами <head> и </head> заменить в строке :
Споб первый, самый простой, но не всегда действенный. Открыть нужную Вам страницу HTML или PHP и проделать следующее. В верху страницы между тегами <head> и </head> заменить в строке :
<meta http-equiv=»content-type» content=»text/html; charset=utf-8″/>
кодировку с utf-8 на Windows-1251 так:
<meta http-equiv=»content-type» content=»text/html; charset=Windows-1251″/>
Дальше выделяем весь код в странице и открываем в Notepad++ вкладку вверху «кодировки»—>еще «кодировки»—> кириллица—>Windows-1251. Смотрим, что получилось. Иногда такой способ помогает, иногда приходится проделать более сложную процедуру. Проделываем все перечисленное выше, до выделения текста, дальше Выделенный код, копируем в простой блакнот Windows (это обязательно, в простой блокнот). Создаем в Notepad++ новую страницу сохраняем её как .html или .php и выбираем для этой новой страницы кодировку, так как описано Выше. После этого обратно копируем текст из простого блакнота Windows (очень важный момент, имено копируем опять из блокнота, а не просто вставляем тот, что находится в буфере обмена (что мы скопировали из Notepad)) Теперь все должно получиться. В описанных процедурах главное понять принип и не запутаться. При проделовании операции, один-два раза вы легко сможете менять кодировку. Аналогичный принцип используется и при обратном преобразовании. Так же иногда нужно преобразовать UTF-8 в UTF-8 без БОМ, Обратите внимание, что кодировки UTF-8 и UTF-8 без БОМ это в принципе очень разные вещи.
artisteer-rus.com