Первая программа для AVR микроконтроллера на Ассемблере
Приведен и подробно разобран пример простой программы для AVR микроконтроллера на языке Ассемблер (Assembler). Собираем простую схему на микроконтроллере для мигания светодиодами, компилируем программу и прошиваем ее в микроконтроллер под ОС GNU Linux.
Содержание:
- Подготовка
- Принципиальная схема и макет
- Исходный код программы на Ассемблере
- Документация по Ассемблеру
- Работа с числами в Hex, Bin и Dec
- Компиляция и прошивка программы в МК
- Заключение
Подготовка
Итак, у нас уже есть настроенный и подключенный к микроконтроллеру программатор, также мы разобрались с программой avrdude, изучили ее настройки и примеры использования. Пришло время разработать свою первую программу, которая будет выполнять какие-то реальные действия с AVR микроконтроллером (МК).
Писать программу мы будем на языке программирования Ассемблер (Assembler, Asm). Основной ее задачей будет заставить поочередно и с установленной задержкой мигать два разноцветных светодиода (красный и синий), имитируя таким образом полицейскую мигалку.
Основной ее задачей будет заставить поочередно и с установленной задержкой мигать два разноцветных светодиода (красный и синий), имитируя таким образом полицейскую мигалку.
В результате у вас получится простая электронная схема, которую можно вмонтировать в какой-то пластмассовый макет полицейского автомобиля и подарить ребенку для забавы.
Понятное дело что подобную мигалку можно реализовать на основе простого мультивибратора на двух транзисторах с конденсаторами. Микроконтроллер же вам предоставляет намного больше возможностей.
Используя один чип можно оживить полицейскую мигалку + заставить раз в несколько секунд мигать модель авто фарами, добавить различные звуковые эффекты, научить модельку ездить реагируя на препятствия и многое другое.
Первый инструмент, который нам понадобится — редактор исходного кода, здесь можно использовать любой текстовый редактор. В одной из прошлых статей мы рассматривали настройку среды разработки программ Geany для программирования AVR микроконтроллеров с использованием языков Ассемблера и Си.
В принципе там уже все готово, останется написать код программы и поочередным нажатием двух кнопок (Compile-Flash) скомпилировать и прошить программу в микроконтроллер.
Несмотря на то что у вас уже может быть настроена среда Geany, я приведу все консольные команды которые необходимы для компиляции и прошивки нашей программы в МК.
Принципиальная схема и макет
Для понимания того что из себя представляет наша конструкция, для которой мы будем писать программу, приведу ниже принципиальную схему устройства.
Рис. 1. Принципиальная схема мигалки на светодиодах и микроконтроллере ATmega8.
Примечание: принципиальная схема нарисована за несколько минут в программе Eeschema, которая входит в комплекс программ EDA(Electronic Design Automation) KiCAD (для Linux, FreeBSD, Solaris, Windows). Очень мощный профессиональный инструмент, и что не мало важно — свободный!
Схема устройства состоит из микроконтроллера ATmega8 и двух светодиодов, которые подключены через гасящие резисторы. К микроконтроллеру подключен ISP-коннектор для осуществления программирования через программатор. Также предусмотрены клеммы для подключения внешнего источника питания напряжением 5В.
К микроконтроллеру подключен ISP-коннектор для осуществления программирования через программатор. Также предусмотрены клеммы для подключения внешнего источника питания напряжением 5В.
То как выглядит данная схема в сборе на макетной баспаечной панели (BreadBoard) можно посмотреть на рисунке ниже:
Рис. 2. Конструкция светодиодной мигалки на микроконтроллере ATmega8.
К микроконтроллеру подключен программатор USBAsp, используя ISP интерфейс, от него же и будет питаться наша экспериментальная конструкция. Если нужно запитать конструкцию от внешнего источника питания напряжением 5В то достаточно его подключить к + и — линиям питания панели.
Исходный код программы на Ассемблере
Разработанная нами программа будет попеременно зажигать и гасить два светодиода. Светодиоды подключены к двум пинам микроконтроллера, которые соответствуют каналам с названиями PD0 и PD1 (порт PORTD, D).
Ниже приведен исходный код программы на Ассебмлере(Assembler, Asm) для микроконтроллера ATmega8.
; Светодиодная мигалка на микроконтроллере ATmega8
; https://ph0en1x.net
.INCLUDEPATH "/usr/share/avra/" ; путь для подгрузки INC файлов
.INCLUDE "m8def.inc" ; загрузка предопределений для ATmega8
.LIST ; включить генерацию листинга
.CSEG ; начало сегмента кода
.ORG 0x0000 ; начальное значение для адресации
; -- инициализация стека --
LDI R16, Low(RAMEND) ; младший байт конечного адреса ОЗУ в R16
OUT SPL, R16 ; установка младшего байта указателя стека
LDI R16, High(RAMEND) ; старший байт конечного адреса ОЗУ в R16
OUT SPH, R16 ; установка старшего байта указателя стека
.equ Delay = 5 ; установка константы времени задержки
; -- устанавливаем каналы PD0 и PD1 порта PORTD (PD) на вывод --
LDI R16, 0b00000011 ; поместим в регистр R16 число 3 (0x3)
OUT DDRD, R16 ; загрузим значение из регистра R16 в порт DDRD
; -- основной цикл программы --
Start:
SBI PORTD, PORTD0 ; подача на пин с каналом PD0 высокого уровня
CBI PORTD, PORTD1 ; подача на пин сканалом PD1 низкого уровня
RCALL Wait ; вызываем подпрограмму задержки по времени
SBI PORTD, PORTD1 ; подача на пин с каналом PD1 высокого уровня
CBI PORTD, PORTD0
RCALL Wait
RJMP Start ; возврат к метке Start, повторяем все в цикле
; -- подпрограмма задержки по времени --
Wait:
LDI R17, Delay ; загрузка константы для задержки в регистр R17
WLoop0:
LDI R18, 50 ; загружаем число 50 (0x32) в регистр R18
WLoop1:
LDI R19, 0xC8 ; загружаем число 200 (0xC8, $C8) в регистр R19
WLoop2:
DEC R19 ; уменьшаем значение в регистре R19 на 1
BRNE WLoop2 ; возврат к WLoop2 если значение в R19 не равно 0
DEC R18 ; уменьшаем значение в регистре R18 на 1
BRNE WLoop1 ; возврат к WLoop1 если значение в R18 не равно 0
DEC R17 ; уменьшаем значение в регистре R17 на 1
BRNE WLoop0 ; возврат к WLoop0 если значение в R17 не равно 0
RET ; возврат из подпрограммы Wait
Program_name: .
DB "Simple LEDs blinking program"Кратко рассмотрим приведенный выше код и построчно разберем его структуру. Выполнение программы происходит по порядку — с верху кода и к низу, учитывая при этом метки, переходы с возвратами и условия.
Все строки и части строк, которые начинаются с символа «;» — это комментарии. При компиляции и выполнении программы такие строчки игнорируются, они служат для документирования и примечаний.
При помощи директивы «.INCLUDEPATH» мы указываем путь «/usr/share/avra/», по которому компилятору нужно искать файлы для включения их в текущий файл с использованием директив «.INCLUDE«. В нашем примере подключается файл, полный путь к которому будет выглядеть вот так: «/usr/share/avra/m8def.inc».Директива «.LIST» указывает компилятору о необходимости генерирования листинга с текущего места в коде, отключить генерирование можно директивой «.NOLIST». Листинг представляет собой файл в котором содержится комбинация ассемблерного кода, адресов и кодов операций. Используется для отладки и других полезных нужд.
Используется для отладки и других полезных нужд.
Директива «.CSEG» (CodeSEGment) определяет начало программного сегмента (код программы что записан во флешь-память) — сегмента кода. Соответственно все что размещено ниже этой директивы относится к программному коду.
Для определения сегмента данных (RAM, оперативная память) или памяти EEPROM используются директивы «.DSEG» и «.ESEG» соответственно. Таким образом выполняется распределение памяти по сегментам.
Каждый из сегментов может использоваться в программном коде только раз, по умолчанию если не указана ни одна из директив используется сегмент кода (CSEG).
При помощи директивы «.ORG» компилятору указывается начальный адрес «0x0000» сегмента, в данном случае мы указали начальный адрес сегмента кода. В данной программе эту директиву можно было бы и не использовать, поскольку по умолчанию адрес программного кода всегда 0x0000.
Дальше в коде происходит инициализация стека. Стек (Stack) — это область памяти (как правило у всех AVR чипов размещается в SRAM), которая используется микропроцессором для хранения и последующего считывания адресов возврата из подпрограмм, а также для других пользовательских нужд.
Стек (Stack) — это область памяти (как правило у всех AVR чипов размещается в SRAM), которая используется микропроцессором для хранения и последующего считывания адресов возврата из подпрограмм, а также для других пользовательских нужд.
При вызове подпрограммы flhtc nt записывается в стек и начинается выполнение кода подпрограммы. По завершению подпрограммы (директива RET)
Стек работает по принципу LIFO (Last In — First Out, последним пришёл — первым вышел). Для адресации вершины стека используется указатель стека — SP (Stack Pointer), это может быть однобайтовое или двухбайтовое значение в зависимости от доступного количества SRAM памяти в МК.
При помощи инструкции «LDI» мы загружаем в регистр R16 значение младшего байта конечного адреса ОЗУ «Low(RAMEND)» (предопределенная константа в файле m8def.inc что содержит адрес последней ячейки SRAM), а потом при помощи инструкции OUT выполняем загрузку данного значения из регистра R16 в порт SPL
 Таким же образом производится инициализация старшего байта адреса в указателе стека SPH.
Таким же образом производится инициализация старшего байта адреса в указателе стека SPH.Инструкция LDI используется для загрузки старшего и младшего значений из константы в регистр общего назначения. А инструкция OUT позволяет выполнить операцию загрузки с немного иной спецификой — из регистра общего назначения в регистр периферийного устройства МК, порт ввода-вывода и т.п.
Если не произвести инициализацию стека то возврат из подпрограмм станет невозможным, к примеру в приведенном коде после выполнения инструкции перехода к подпрограмме «RCALL Wait» возврат не будет выполнен и программа не будет работать как нужно.
Директива «.equ» выполняет присвоение указанному символьному имени «Delay» числового значения «5», по сути мы объявили константу. Имя константы должно быть уникальным, а присвоенное значение не может быть изменено в процессе работы программы.
Дальше мы устанавливает каналы PD0 и PD1 порта DDRD (PortD) на вывод, делается это загрузкой двоичного значения 0b00000011 (0x3, число 3) в регистр R16 с последующим выводом этого значения из него в порт DDRD при помощи команды OUT.
По умолчанию все каналы (и соответствующие им пины) порта настроены на ввод (input). При помощи двоичного числа 0b00000011, где последние биты установлены в 1, мы переводим каналы PD0 и PD1 в режим вывода.
Начиная с метки «Start:» начинается основной рабочий цикл нашей программы, эта метка послужит нам для обозначения начального адреса основного цикла и позже будет использована для возврата.
При помощи инструкции «
Используя инструкцию «CBI» (Clear Bit in I/o register) выполняется очистка бита PORTD1 в байте регистра для порта PORTD и тем самым устанавливается низкий уровень напряжения на пине с каналом PD1.
Дальше с помощью инструкции RCALL выполняем относительный вызов подпрограммы которая начинается с метки «Wait:«. Здесь для запоминания адреса возврата уже используется стек, который мы инициализировали в начале программы.
После завершения подпрограммы (в нашем случае ее функция — задержка по времени) программа вернется к позиции где был выполнен вызов подпрограммы (адрес возврата будет получен из стека) и с этого места продолжится выполнение последующих операторов.
После вызова подпрограммы задержки «Wait» следуют вызовы инструкций SBI и CBI в которых выполняется установка битов в байте регистра для порта PORTD таким образом, что теперь на пине с каналом PD0 у нас будет низкий уровень, а на пине с каналом PD1 — высокий.
По завершению этих инструкций следует еще один вызов подпрограммы задержки «Wait», а дальше следует инструкция «RJMP» которая выполнит относительный переход к указанной метке — «Start», после чего программа снова начнет установку битов в порте с задержками по времени.
Таким образом выполняется реализация бесконечного цикла в котором будут изменяться состояния битов в байте регистра для порта PORTD микроконтроллера и поочередно зажигаться/гаснуть светодиоды которые подключены к пинам что соответствуют каналам данного порта (PD0, PD1).
После основного цикла программы следует наша подпрограмма задержки по времени. Принцип ее работы заключается в выполнении трех вложенных циклов, в каждом из которых происходит вычитание (DEC, decrement) единички из числа которое хранится в отдельном регистре, и так до тех пор пока значение не достигнет нуля. Инструкция «DEC» декрементирует значение указанного регистра и требует для этого 1 рабочий такт процессора.
При помощи инструкций «BRNE» (условный переход) выполняется анализ нулевого бита статусных флагов процессора (Zero Flag, ZF). Переход на указанную в инструкции метку будет выполнен если после выполнения предыдущей команды нулевой флаг был установлен.
В данном случае проверяется значение нулевого флага после выполнения команд «DEC» над значениями которые хранится в регистрах общего назначения (R17, R18, R19). Инструкция «BRNE» требует 1/2 такта процессора.
Таким образом, использовав несколько вложенных циклов, ми заберем у ЦПУ некоторое количество тактов и реализуем нужную задержку по времени, которая будет зависеть от количества итераций в каждом цикле и от установленной частоты микропроцессора.
По умолчанию, без установки фьюзов что задают источник и частоту тактового генератора, в микроконтроллере ATmega8 используется откалиброванный внутренний RC-генератор с частотой 1МГц. Если же мы изменим частоту МК на 4Мгц то наши светодиоды начнут мигать в 4 раза быстрее, поскольку на каждую операцию вычитания и сравнения будет тратиться в 4 раза меньше времени.
Завершается подпрограмма инструкцией «RET«, которая выполняет возврат из подпрограммы и продолжение выполнения инструкций с того места, с которого эта подпрограмма была вызвана (на основе сохраненного адреса возвращения, который сохранился в стеке при вызове инструкции «RCALL»).
При помощи директивы «.DB» в памяти программ (флешь) резервируется цепочка из байтов под строчку данных «Simple LEDs blinking program», эти данные являются статичными и их нельзя изменять в ходе работы программы. Для резервирования слов (Double Word) нужно использовать директиву «.DW».
В данном случае, у нас во FLASH-память вместе с программным кодом будет записана строка «Simple LEDs blinking program«, которая содержит название программы. Данные из этой строчки нигде в программе не используются и приведены в качестве примера.
При каждом резервировании данных с использованием директивы «.DB» или «.DW» должна предшествовать уникальная метка, которая пригодится нам когда нужно будет получить адрес размещаемых данных в памяти для дальнейшего их использования, в нашем случае это «Program_name:«.
При построении программы важно чтобы счетчик выполняемых команд не добрался до адреса с зарезервированными данными, иначе процессор начнет выполнять эти строчки как программный код (поскольку они размещены в сегменте кода). В примере моей программы байты под название программы зарезервированы в конце сегмента кода и за пределами рабочих циклов программы, так что все ОК.
В примере моей программы байты под название программы зарезервированы в конце сегмента кода и за пределами рабочих циклов программы, так что все ОК.
Эти данные можно разместить и в начале кода, использовав операторы перехода для изоляции этих байтов от выполнения:
RJMP DataEnd Program_name: .DB "Simple LEDs blinking program" DataEnd:
Документация по Ассемблеру
Разобраться с основами языка программирования Ассемблер в пределах одной статьи достаточно сложно, без практики здесь никак, но тем не менее на начальном этапе и для нашего эксперимента приведенных знаний вполне достаточно. У вас уже будет базовое представление что такое программа на Ассемблере и как используются директивы и инструкции.
Процесс дальнейшего изучения Ассемблера для AVR микроконтроллеров полностью в ваших руках. Есть достаточно много полезных ресурсов в интернете, книг и материалов с примерами и пояснениями.
Приведу несколько полезных документов, которые вы можете скачать и использовать для справки при разработке программ на AVR ASM.
Справка по Ассемблеру для Atmel AVR (перевод Руслана Шимкевича): atmel-avr-assembler-quick-doc-ru.zip (16Кб, HTML, RU).
Справка по инструкциям Atmel Assembler: atmel-avr-instruction-set-manual-en.pdf.zip (700Кб, PDF, EN, 2015).
Работа с числами в Hex, Bin и Dec
В коде программы для загрузки значений в регистры используются числа и в скобках приведены их значения в шестнадцатеричной системе счисления, например: «50 (0x32, )». В двоичной системе счисления числа указываются в формате «0b00000011».
Для удобной переконвертации чисел из шестнадцатеричной системы счисления в десятичную, двоичную и наоборот отлично подходит программный калькулятор из среды рабочего окружения KDE — KCalc.
Рис. 3. KCalc — простое и эффективное решение для пересчета между разными системами счисления.
В настройках (Settings) нужно выбрать режим (Numeral System Mode), после чего программа приобретет вид что на рисунке выше. Переключаться между системами счисления можно устанавливая флажки в полях «Dec», «Hex», «Bin».
Для примера: переключаемся в Hex и набираем «FF», потом переключаемся в Dec и видим число в десятичной системе счисления — 255, просто и удобно.
В операционной системе GNU Linux с рабочей средой GNOME (например Ubuntu) также есть подобный калькулятор, это программа — galculator.
Компиляция и прошивка программы в МК
Итак, у нас уже есть полный код программы, который мы сохранили в файл с именем «leds_blinking.asm». Теперь самое время скомпилировать его, делается это нажатием кнопки «Compile» в предварительно настроенной среде Geany или же отдельной командой в консоли:
avra --includepath /usr/share/avra/ leds_blinking.asm
Если результат выполнения будет без ошибок то мы получим файл прошивки в формате Intel HEX — «leds_blinking.hex», который уже можно прошивать во флешь-память микроконтроллера.
Примечание: опцию «—includepath /usr/share/avra/» можно и не указывать, поскольку в файле с исходным кодом уже была указана директива «.INCLUDEPATH» для поиска файлов с предопределениями для разных моделей МК.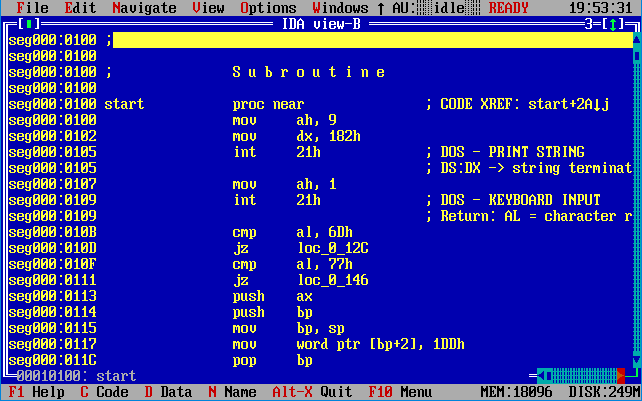
Осталось прошить микроконтроллер используя полученный файл «leds_blinking.hex». В примере я использую программатор USBAsp и микроконтроллер ATmega8, вот так выглядит команда для записи получившегося файла во флешь-память МК:
avrdude -p m8 -c usbasp -P usb -U flash:w:leds_blinking.hex
Примечание: в команде используется относительный путь к файлу leds_blinking.hex, поэтому для успешного выполнения команды нужно перейти в терминале(консоли) в директорию где находится данный файл.
Сразу же после прошивки флешь-памяти на микроконтроллер поступит команда сброса (RESET) и программа начнет выполняться, об єтом будут свидетельствовать два попеременно мелькающих светодиода.
Если же светодиоды не подают признаков жизни, значит что-то пошло не так. Посмотрите внимательно вывод команды для компиляции и прошивки МК, возможно что там увидите сообщения об ошибках которые нужно исправить.
Заключение
Увеличив значение константы «Delay» можно уменьшить частоту мерцания светодиодов, а уменьшив — увеличить частоту. Также можете попробовать добавить несколько светодиодов к свободным каналам порта (PD2-PD7) и модифицировать программу таким образом чтобы получить бегущий огонь из светодиодов.
Также можете попробовать добавить несколько светодиодов к свободным каналам порта (PD2-PD7) и модифицировать программу таким образом чтобы получить бегущий огонь из светодиодов.
В заключение приведу краткое видео работы рассмотренной схемы на двух светодиодах:
В следующей статье мы разберем программу с похожим функционалом, используя тот-же макет, только выполним ее на языке программирования Си.
Начало цикла статей: Программирование AVR микроконтроллеров в Linux на языках Asembler и C.
Учебный курс. Часть 2. Первая программа
Итак, поехали! Курс обучения любому языку программирования принято начинать с написания программы «Hello, world!». Однако мы этого делать не будем. Потому что «Hello, world!» на ассемблере придется долго объяснять и трудно понять сходу. А я хочу сделать курс из коротких понятных статей.
Поэтому мы напишем совсем простую программу. Сразу оговорюсь, что мы будем писать только COM-программы под DOS. Они проще, чем EXE, а подробно разбирать тонкости программирования под DOS мне не интересно, во всяком случае в учебном курсе.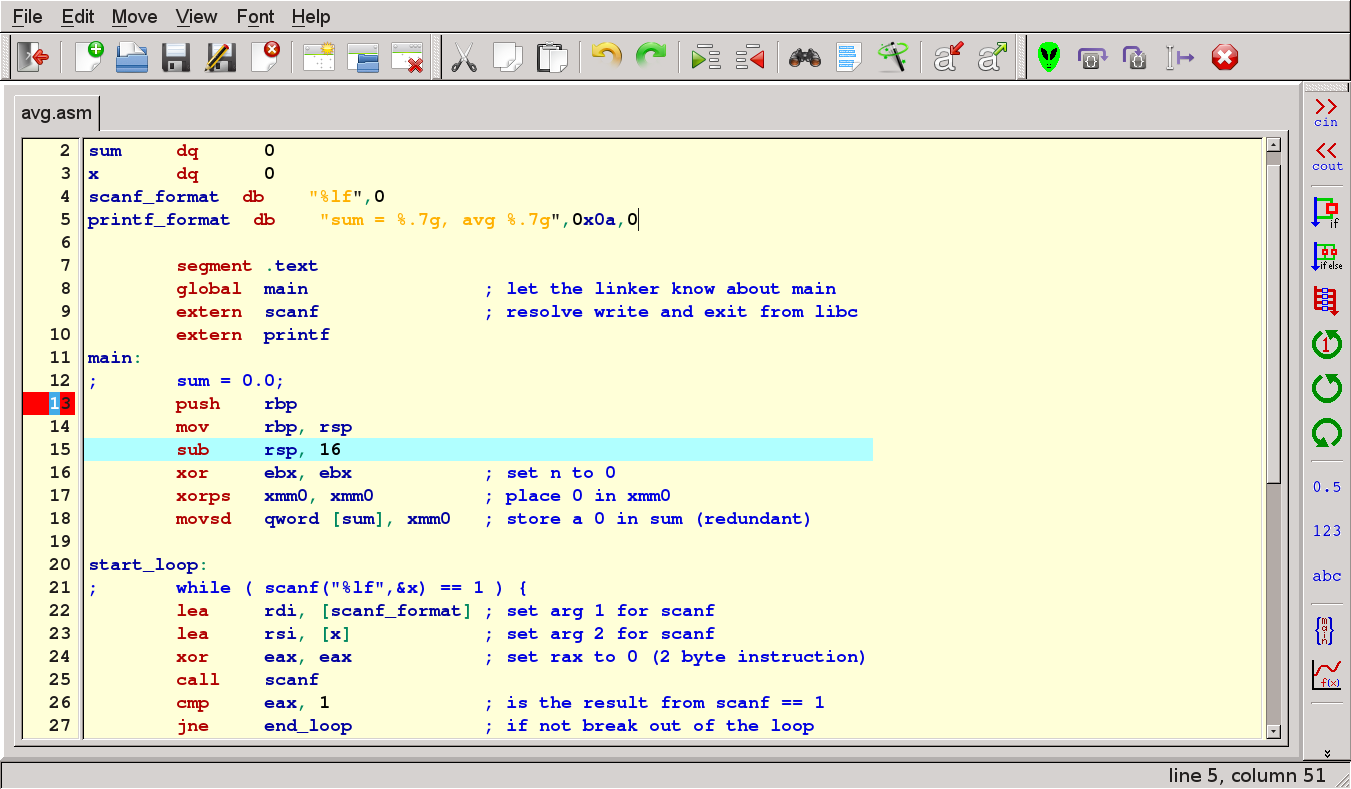
Для того, чтобы написать программу, нам надо запустить fasmw.exe. Откроется окошко, в которое можно смело набивать код:
В это окошко надо ввести следующее (я подробно объясню ниже, что значит каждая строчка):
1 2 3 4 5 6 7 8 9 10 | use16 ;Генерировать 16-битный код
org 100h ;Программа начинается с адреса 100h
mov ax,255 ;Поместить 255 в регистр AX
inc ax ;Увеличить содержимое AX на 1
nop ;Эта команда ничего не делает
mov bx,ax ;Поместить в BX содержимое AX
mov ax,4C00h ;\
int 21h ;/ Завершение программы |
Первая строка «use16» сообщает FASM’у, что нужно генерировать 16-битный код. Нам нужен именно такой для нашей первой программы. Точка с запятой — это символ комментария. Все что идет после «;» до конца строки игнорируется компилятором. Там можно писать все что угодно.
Вторая строка «org 100h» объясняет FASM’у, что следующие команды и данные будут располагаться в памяти, начиная с адреса 100h. Дело в том, что при загрузке нашей программы в память, DOS размещает в первых 256 байтах (с адресов 0000h — 00FFh) свои служебные данные. Нам эти данные изменять нежелательно.
Далее идут непосредственно команды! Программа на ассемблере состоит из команд процессора. Каждая команда обозначается мнемоникой (символическим именем). Например «mov», «inc», «nop» и т.д. После мнемоники могут идти операнды. Они отделяются одним или несколькими пробелами (или табуляцией).
Команды бывают без операндов, с одним или несколькими операндами. Если операндов больше одного, то они отделяются друг от друга запятыми.
Отступы не обязательны, но желательны — с ними код гораздо легче читать. Пустые строки игнорируются. Регистр символов значения не имеет. Можно писать большими буквами, или маленькими, или в перемешку.
Четвертая строка определяет команду «поместить число 255 в регистр AX». «mov» — это мнемоника команды (от английского «MOVe»). AX — первый операнд — приёмник. 255 — второй операнд — источник. Первый операнд является регистром. Второй операнд — константа 255.
Пятая строка. Тут команда «inc» с одним операндом. Она заставит процессор выполнить инкремент, то есть увеличение на единицу. Единственный операнд — это регистр AX, содержимое которого и будет увеличено на 1.
Шестая строка. Команда «nop» — без операндов. Эта команда ничего не делает 🙂 Зачем она нужна я ещё расскажу как-нибудь.
Седьмая строка. Снова команда «mov», но на этот раз оба операнда являются регистрами. Команда скопирует в BX содержимое AX.
Две последние строки — это стандартное завершение процесса в DOS. Так мы будем завершать все наши программы. Команда «mov» должна быть вам понятна, а про команду «int» я ещё расскажу, это отдельная тема.
Чтобы откомпилировать программу надо выбрать меню Run->Compile. FASM предложит сохранить файл, если вы этого ещё не сделали, а затем скомпилирует. То есть переведет текст, набранный нами, в машинный код и сделает его программой. Файл с расширением .asm — это исходный код или исходник, обычный текстовый файл. При желании его можно открыть блокнотом )
Отлично! Целых 12 байт получилось 😀
В каталоге с asm-файлом появился файл .com — это и есть наша прога!
Если в коде что-то неправильно, то в этом окне вы увидите сообщение об ошибке.
В общем, наша программа ничего не делает 🙂 Но в следующей статье я расскажу как работать с отладчиком. И мы её отладим и увидим как она работает! 🙂
Следующая часть »
Сборка— Были ли первые ассемблеры написаны на машинном коде?
спросил
Изменено 2 месяца назад
Просмотрено 32к раз
Я читаю книгу «Элементы вычислительных систем: создание современного компьютера из первых принципов», в которой содержатся проекты, охватывающие сборку компьютера от логических элементов до приложений высокого уровня (именно в таком порядке). Текущий проект, над которым я работаю, — это написание ассемблера с использованием языка высокого уровня по моему выбору для перевода ассемблерного кода Hack в машинный код Hack (Hack — это название аппаратной платформы, созданной в предыдущих главах). Хотя все аппаратное обеспечение было построено в симуляторе, я попытался сделать вид, что на самом деле конструирую каждый уровень, используя только инструменты, доступные мне на тот момент в реальном процессе.
Текущий проект, над которым я работаю, — это написание ассемблера с использованием языка высокого уровня по моему выбору для перевода ассемблерного кода Hack в машинный код Hack (Hack — это название аппаратной платформы, созданной в предыдущих главах). Хотя все аппаратное обеспечение было построено в симуляторе, я попытался сделать вид, что на самом деле конструирую каждый уровень, используя только инструменты, доступные мне на тот момент в реальном процессе.
Тем не менее, это заставило меня задуматься. Использование языка высокого уровня для написания моего ассемблера, безусловно, удобно, но для самого первого ассемблера, когда-либо написанного (т.е. в истории), не нужно ли было писать его в машинном коде, поскольку это все, что существовало в то время?
И связанный с этим вопрос… как насчет сегодняшнего дня? Если появится совершенно новая архитектура ЦП с совершенно новым набором инструкций и совершенно новым синтаксисом ассемблера, как будет построен ассемблер? Я предполагаю, что вы все еще можете использовать существующий язык высокого уровня для создания двоичных файлов для программы на ассемблере, поскольку, если вы знаете синтаксис как ассемблера, так и машинного языка для вашей новой платформы, то задача написания ассемблера на самом деле просто задача анализа текста и не связана по своей сути с этой платформой (т. е. должна быть написана на машинном языке этой платформы)… что является той самой причиной, по которой я могу «обмануть» при написании моего ассемблера Hack в 2012 году и использовать некоторые ранее существовавшие язык высокого уровня, чтобы помочь мне.
е. должна быть написана на машинном языке этой платформы)… что является той самой причиной, по которой я могу «обмануть» при написании моего ассемблера Hack в 2012 году и использовать некоторые ранее существовавшие язык высокого уровня, чтобы помочь мне.
- сборка
- низкоуровневая
для самого первого ассемблера, когда-либо написанного (т.е. в истории), разве его не нужно было бы писать в машинном коде
Не обязательно. Конечно, самая первая версия ассемблера v0.00 должна была быть написана на машинном коде, но она не была бы достаточно мощной, чтобы называться ассемблером. Он не будет поддерживать и половины функций «настоящего» ассемблера, но его будет достаточно, чтобы написать следующую версию самого себя. Затем вы можете переписать v0.00 на подмножестве языка ассемблера, назвать его v0.01, использовать его для создания следующего набора функций вашего ассемблера v0.02, затем использовать v0. 02 для сборки v0.03, и так далее, пока не доберетесь до версии 1.00. В результате в машинном коде будет только первая версия; первые выпущенная версия будет на ассемблере.
02 для сборки v0.03, и так далее, пока не доберетесь до версии 1.00. В результате в машинном коде будет только первая версия; первые выпущенная версия будет на ассемблере.
Используя этот прием, я запустил разработку компилятора языка шаблонов. Моя первоначальная версия использовала операторы printf , но первая версия, которую я применил в своей компании, использовала тот самый обработчик шаблонов, который он обрабатывал. Фаза начальной загрузки длилась менее четырех часов: как только мой процессор мог выдавать едва ли полезный вывод, я переписал его на его родном языке, скомпилировал и выбросил версию без шаблона.
Согласно Википедии, первый в истории ассемблер/язык ассемблера был реализован для IBM 701 Натаниэлем Рочестером. (Даты немного неопределенны из статьи в Википедии. В ней говорится, что Рочестер присоединился к IBM в 1948 году, но на другой странице Википедии говорится, что 701 был публично анонсирован в 1952 году. А на этой странице IBM говорится, что «настоящая разработка началась 1 февраля 1951 г. и завершено через год» .)
А на этой странице IBM говорится, что «настоящая разработка началась 1 февраля 1951 г. и завершено через год» .)
Однако в «Ассемблере и загрузчиках» Дэвида Саломона говорится (на стр. 7), что у EDSAC также был ассемблер:
«Одним из первых компьютеров с хранимой программой был EDSAC (автоматический калькулятор электронного хранения с задержкой), разработанный в Кембриджском университете в 1949 году Морис Уилкс и У. Ренвик. С первых дней существования EDSAC был ассемблер под названием Initial Orders. Он был реализован в постоянной памяти, сформированной из набора поворотных телефонных селекторов, и принимал символические инструкции. Каждая инструкция состояла из мнемоники из одной буквы, десятичного адреса и третьего поля, которое было буквой. Третье поле вызывало добавление к адресу во время сборки одной из 12 предустановленных программистом констант».0030 (Ссылки опущены… см. оригинал.)
Предполагая, что мы согласны с тем, что «Первоначальные заказы» имеют приоритет, у нас есть четкие доказательства того, что первый ассемблер был реализован в машинном коде.
Этот шаблон (написание начальных ассемблеров в машинном коде) был бы нормой еще в 1950-х годах. Однако, согласно Википедии, «[a] ассемблеры были первыми языковыми инструментами, которые самозагрузились». См. также этот раздел, в котором объясняется, как изначальный машинный код, написанный на ассемблере, использовался для начальной загрузки более продвинутого ассемблера, написанного на языке ассемблера.
В наши дни ассемблеры и компиляторы пишутся на языках более высокого уровня, а ассемблер или компилятор для новой машинной архитектуры обычно разрабатывается на другой архитектуре и подвергается кросс-компиляции.
(FWIW — написание и отладка нетривиальных программ в машинном коде — чрезвычайно трудоемкий процесс. Кто-то, разрабатывающий ассемблер в машинном коде, скорее всего, как можно скорее загрузится на ассемблер, написанный на ассемблере.)
Эта страница Википедии на загрузку компиляторов и ассемблеров стоит прочитать… если все это вас сбивает с толку.
Я предполагаю, что первые ассемблеры были написаны на машинном коде, потому что, как вы говорите, тогда ничего другого не было.
Однако сегодня, когда выходит совершенно новая архитектура ЦП, мы используем так называемый кросс-компилятор, который представляет собой компилятор, создающий машинный код не для той архитектуры, на которой он работает, а для другой архитектуры.
(На самом деле, как я уверен, вы узнаете позже из книги, которую читаете, нет абсолютно ничего, что делало бы компилятор более подходящим для создания машинного кода для архитектуры, на которой он работает, чем на любой другой архитектуре.Вопрос только в том, на какую архитектуру вы, как создатель компилятора, собираетесь ориентироваться.)
Итак, сегодня даже возможно (по крайней мере, в теории) создать совершенно новую архитектуру и использовать компиляторы языка высокого уровня, работающие на ней (скомпилированные на других архитектурах с использованием кросс-компиляторов), прежде чем у вас будет даже ассемблер для этого. архитектура.
архитектура.
Сначала «сборка» писалась на бумаге, а потом вручную «собиралась» на перфокарты.
Мой дедушка работал с ZRA1 (извините, страница существует только на немецком языке, но с переводом Google все в порядке, и вы действительно можете подобрать самые важные факты :D).
Метод работы заключался в том, чтобы записать ваш код на бумаге на языке ассемблера, а секретарь фактически сделал транскрипцию на перфокарты, затем передал их оператору, и результат был возвращен на следующее утро.
Все это было по существу до того, как программисты смогли позволить себе роскошь вводить данные с клавиатуры и просматривать их на экране.
1 Трудно быть уверенным в самый первый ассемблер (трудно даже определить, что это было). Много лет назад, когда я написал несколько ассемблеров для машин, на которых не было ассемблеров, я все еще писал код на ассемблере. Затем, когда у меня был достаточно законченный участок кода, я вручную перевел его в машинный код. Тем не менее, это были две совершенно разные фазы — когда я писал код, я вообще не работал и не думал на уровне машинного кода.
Тем не менее, это были две совершенно разные фазы — когда я писал код, я вообще не работал и не думал на уровне машинного кода.
Должен добавить, что в нескольких случаях я пошел еще дальше: я написал большую часть кода на языке ассемблера, который мне показался более простым в использовании, затем написал крошечное ядро (более или менее то, что мы сейчас называем виртуальным машине) для интерпретации этого на целевом процессоре. Это было смертельно медленно (особенно на 8-разрядном процессоре с тактовой частотой 1 МГц), но это не имело большого значения, поскольку обычно оно запускалось только один раз (или, самое большее, несколько раз).
Вам не нужен ассемблер, чтобы вручную ассемблировать код на языке ассемблера в машинный код. Так же, как вам не нужен редактор для написания кода на ассемблере.
Исторический взгляд
Первые ассемблеры, вероятно, были написаны на языке ассемблера, а затем вручную собраны в машинный код. Даже если у процессора не было официального «языка ассемблера», программисты, вероятно, выполняли большую часть работы по программированию, используя какой-то псевдокод, прежде чем переводить этот код в машинные инструкции.
Даже на заре вычислительной техники программисты писали программы в своего рода символической записи и переводили их в машинный код перед тем, как ввести его в свой компьютер. В случае с Августой Адой Кинг ей пришлось бы перевести их в перфокарты для аналитической машины Бэббиджа, но, увы, она так и не была построена.
Личный опыт
Первым моим компьютером был Sinclair ZX81 (Timex 1000 в США). На обратной стороне руководства была вся информация, необходимая для перевода языка ассемблера Z80 в машинный код (даже включая все странные коды операций индексного режима, которые были у Z80).
Я бы написал программу (на бумаге) на ассемблере и прогнал код. Когда я был счастлив, что в моей программе нет ошибок, я искал каждую инструкцию в конце руководства, переводил ее в машинный код и тоже записывал машинный код на бумаге. Наконец, я набирал все инструкции машинного кода в свой ZX81, прежде чем сохранять его на ленту и пытаться запустить.
Если бы это не сработало, я бы перепроверил свою ручную сборку и, если бы какой-либо перевод был неправильным, я бы исправил байты, загруженные с ленты, перед повторным сохранением и повторной попыткой запустить программу.
По своему опыту могу сказать, что гораздо легче отлаживать свой код, если он написан на ассемблере, чем на машинном коде — отсюда и популярность дизассемблеров. Даже если у вас нет ассемблера, ручная сборка менее подвержена ошибкам, чем попытка написать машинный код напрямую, хотя я думаю, что настоящий программист, такой как Мел, может не согласиться. *8′)
Нет разницы тогда или сейчас. Вы хотите изобрести новый язык программирования, вы выбираете один из языков, доступных вам сегодня, чтобы сделать первый компилятор. в течение некоторого периода времени, если это цель проекта, вы создаете компилятор на этом языке, и затем он может размещаться самостоятельно.
Если все, что у вас было, это карандаш, бумага и несколько переключателей или перфокарт в качестве пользовательского интерфейса для первого или следующего нового набора инструкций, вы использовали один или все доступные вам элементы. Вы вполне могли бы написать язык ассемблера на бумаге, а затем использовать ассемблер, вы, чтобы преобразовать его в машинный код, может быть, в восьмеричный, а затем в какой-то момент это вошло в интерфейс к машине.
Когда сегодня изобретается совершенно новый набор инструкций, ничем не отличается, в зависимости от компании/отдельных лиц, практики и т. д. вполне вероятно, что инженер по аппаратному обеспечению, вероятно, программирует на verilog или vhdl, пишет первые несколько тестовых программ вручную на машинный код (вероятно, в шестнадцатеричном или двоичном формате). в зависимости от прогресса разработчиков программного обеспечения они могут очень быстро или не очень долго переходить на язык ассемблера, а затем на компилятор.
Первые вычислительные машины не были машинами общего назначения, которые можно было использовать для создания ассемблеров и компиляторов. Вы запрограммировали их, переместив несколько проводов между выходом предыдущего алюминиевого сплава и входом следующего. В конце концов у вас появился процессор общего назначения, так что вы могли написать ассемблер на ассемблере, собрать его вручную, передать как машинный код, затем использовать его для разбора ebcdic, ascii и т. д., а затем самостоятельно разместить. сохраните двоичный файл на каком-либо носителе, который вы могли бы позже прочитать / загрузить, не переключая переключатели на машинный код с ручной подачей.
д., а затем самостоятельно разместить. сохраните двоичный файл на каком-либо носителе, который вы могли бы позже прочитать / загрузить, не переключая переключатели на машинный код с ручной подачей.
Подумайте о перфокартах и бумажной ленте. Вместо того, чтобы переключать переключатели, вы определенно могли бы сделать полностью механическую машину, устройство для экономии труда, которое создавало бы носитель, который компьютер читал. Вместо того, чтобы вводить биты машинного кода с помощью переключателей, таких как Altair, вы могли вместо этого подавать бумажную ленту или перфокарты (используя что-то механическое, не управляемое процессором, которое питало память или процессор, ИЛИ используя небольшой загрузчик, написанный машинным кодом). Это была неплохая идея, потому что вы могли сделать что-то под управлением компьютера, который также мог бы механически производить бумажные ленты или перфокарты, а затем подавать их обратно. Два источника перфокарт, механическое устройство для экономии труда, не основанное на компьютере. , и машина с компьютерным управлением. оба производят «двоичные файлы» для компьютера.
, и машина с компьютерным управлением. оба производят «двоичные файлы» для компьютера.
В компьютерном зоопарке Брука есть один или два случая, когда он сказал что-то вроде «мнемоника — это наше изобретение, дизайнер просто использовал числовой код операции или символ, код которого был кодом операции», так что там, где машины, для которых не было даже не язык ассемблера.
Ввод программ завершает отладку на передней панели (для тех, кто не делал, это был способ настройки памяти, одни переключатели устанавливаешь на адрес, какие-то на значение и нажимаешь кнопку, или другое кнопку, чтобы прочитать значение) было распространено намного позже. Некоторые старожилы хвастаются, что они по-прежнему смогут вводить загрузочный код для машин, которые они активно использовали.
Сложность написания непосредственно машинного кода и чтения программ из дампа памяти сильно зависит от машинного языка, некоторые из них относительно просты (самая сложная часть — отслеживание адресов), x86 — один из худших.
Анекдот:
Когда я изучал язык ассемблера, на Apple ][ в ПЗУ была включена программа под названием микроассемблер. Он делал немедленный перевод ассемблерной инструкции в байты, как только вы их вводили. Это означает, что не было меток — если вы хотите прыгнуть или загрузиться, вам нужно было рассчитать смещения самостоятельно. Это было намного проще, чем искать схемы инструкций и вводить шестнадцатеричные значения.
Несомненно, настоящие ассемблеры сначала писались на микроассемблере или какой-то другой не совсем полной среде.
Я построил компьютер в 1975 году. Он был намного продвинутее своего современника Altair, потому что у него был «монитор ПЗУ», который позволял мне вводить программы, вводя машинный код в шестнадцатеричном формате и просматривая этот код на видеомониторе, где как в Altair каждую машинную инструкцию нужно было вводить понемногу с помощью ряда переключателей.
Так что да, на заре компьютеров, а затем снова на заре персональных компьютеров люди писали приложения в машинном коде.
Первыми «ассемблёрами» были люди. Язык ассемблера был изобретен как символьная нотация, полезная для программистов, но изначально ожидалось, что программист вручную переведет символический код в числовой машинный код, который можно будет ввести в машину. (Если вам небезразлична история, вы можете прочитать эту увлекательную статью 1947 года о том, как программировать компьютер. В ней используется ассемблерная символическая запись, которая вручную переводится в числовые машинные коды. Это за несколько лет до появления первого примитивного ассемблера программного обеспечения. .)
В то время программы тщательно разрабатывались ручкой и бумагой. Программист может начать с блок-схемы или какой-либо символической записи, но в конечном итоге закончит числовым машинным кодом. Только после этого код будет передан помощнику, который введет код в машину. В первые годы путем прямого подключения проводов или тумблеров на машине, позже путем создания перфокарт на каком-то механическом устройстве, похожем на пишущую машинку. Затем партия перфокарт помещалась в очередь, и в какой-то момент оператор вводил перфокарты в машину. Когда программа завершала работу, распечатка возвращалась программисту.
Затем партия перфокарт помещалась в очередь, и в какой-то момент оператор вводил перфокарты в машину. Когда программа завершала работу, распечатка возвращалась программисту.
Вручную преобразовать в числовой машинный код на самом деле не так уж и сложно. Самые ранние машины имели ограниченный набор инструкций, поэтому вы быстро выучили числовой код наизусть. Самая утомительная часть — управление адресами: например. для инструкции перехода вам нужно вычислить адрес для перехода. Если вам нужно изменить программу, вам нужно пересчитать все адреса.
Были некоторые промежуточные шаги между необработанным двоичным кодом и ассемблером. Самые ранние компьютеры программировались прямой настройкой тумблеров или проводов. Когда была изобретена «хранимая программа» (самый значительный прорыв в истории вычислительной техники), программы обычно печатались на перфокартах, а затем загружались в память машины. Перфокарта представляет собой двоичный формат, но устройство «keypunch», используемое для перфорации карт, может механически преобразовывать цифровые или буквенно-цифровые клавиши в битовую конфигурацию. Таким образом, уже на этом уровне программистам не нужно было работать с необработанным двоичным кодом, но они могли работать с более удобными восьмеричными или шестнадцатеричными кодами.
Таким образом, уже на этом уровне программистам не нужно было работать с необработанным двоичным кодом, но они могли работать с более удобными восьмеричными или шестнадцатеричными кодами.
Первая программа на ассемблере была очень простой — она принимала однобуквенные коды инструкций, за которыми следовал числовой параметр. Большой прорыв произошел, когда была добавлена поддержка меток перехода. Отсюда каждая итерация упрощала написание более сложных программ и, следовательно, улучшала ассемблер — следующим прорывом были макросы, в которых вы определяли ключевое слово, которое расширялось до нескольких инструкций ассемблера.
В то время как ассемблер все еще используется для низкоуровневого программирования, почти никто не программирует на чистом числовом машинном коде. При написании ассемблера или компилятора для нового набора инструкций это обычно делается на другом компьютере. Если вам нужен ассемблер для совершенно нового процессора, вы можете написать его на языке более высокого уровня, таком как C, а затем написать серверную часть C-компилятора, генерирующую этот язык ассемблера. Затем вы передаете ассемблер C-компилятору, и вуаля, у вас есть программа на ассемблере в виде двоичного файла, который можно перенести на новый компьютер и выполнить.
Затем вы передаете ассемблер C-компилятору, и вуаля, у вас есть программа на ассемблере в виде двоичного файла, который можно перенести на новый компьютер и выполнить.
сборка — Как собирается первый ассемблер? (без кросс-компиляции)
Задавать вопрос
спросил
Изменено 4 года, 3 месяца назад
Просмотрено 781 раз
Я знаю, что есть много тем по этой теме, но я не могу найти ответ именно на эту тему:
Прежде всего, под «первым ассемблером» я подразумеваю программу, которая переводит, скажем, инструкцию «mov» в определенный машинный код, понятный АЛУ, 1100111 или любое другое двоичное число.
Между этими двумя шагами есть некоторый разрыв, на который я не могу найти ответы.
Я понимаю, что процесс выглядит примерно так: у вас есть чип процессора, построенный с определенной микроархитектурой, которая реализует N инструкций. Доступ к каждой инструкции осуществляется внутри ALU с помощью двоичного числа или кода операции (000 mov, 001 add и т. д.). В какой-то исторический момент инструкции загружались в ЦП с помощью перфокарт, лент и т. д.
Но тогда вы хотите поднять уровень абстракции и вам нужен ассемблер для программирования на более высоком языке вместо опкодов, и это именно то, где я что-то упускаю.
На данный момент, я думаю, для перехода от кодов операций к ассемблеру используется некоторая начальная загрузка, но как? Как вы пишете ассемблер v0.00 для данного нового процессора? Есть ли какой-либо чип, жестко кодирующий эти инструкции, может быть, первый ассемблер аппаратный?
В «Ассемблере и загрузчиках» кажется, что первый ассемблер был создан с использованием ПЗУ, жестко связывающего телефонные селекторы с адресами памяти.
«Одним из первых компьютеров с хранимой программой был EDSAC (автоматический калькулятор электронного хранения с задержкой), разработанный в Кембриджском университете в 1949 году Морисом Уилксом и У. Ренвиком. С первых дней своего существования EDSAC имел ассемблер под названием Initial Orders. была реализована в постоянной памяти, сформированной из набора поворотных телефонных селекторов, и принимала символьные инструкции.Каждая инструкция состояла из одной буквенной мнемоники, десятичного адреса и третьего поля, которое было буквой.Третье поле вызывало одно из 12 предустановленных программистом констант, которые будут добавлены к адресу во время сборки.»
- в сборе
Вы пишете программу на ассемблере в машинном коде, то есть в виде ряда чисел. Может быть, вы пишете код на ассемблере на листе бумаги, а затем вручную переводите каждую инструкцию в соответствующий номер машинного кода.
1Вопрос напоминает мне анекдот, рассказанный о Джоне фон Неймане:
Дональд Жиль, один из учеников фон Неймана в Принстоне, преподаватель Иллинойского университета, вспоминал, что аспирантов «использовали» для ручной сборки программ в двоичный файл для их ранней машины (вероятно, машины IAS).
Он взял время для создания ассемблера, но когда фон Нейман узнал о это он был очень зол, говоря (перефразируя): «Это пустая трата ценный научный вычислительный инструмент, чтобы использовать его для канцелярских работа»
Таким образом, на заре вычислительной техники ручное преобразование машинного кода было настолько рутинной практикой, что оспаривалась даже потребность в инструментах.
Точно так же на заре микрокомпьютеров программисты нередко запоминали шестнадцатеричные значения для большинства инструкций (даже в тех случаях, когда у них были ассемблеры, доступные отладчики не всегда имели дизассемблеры).
В настоящее время, как правило, нет причин не использовать кросс-ассемблер.
2Примитивный ассемблер написать не так уж сложно. Например, я написал простой ассемблер/дизассемблер в Excel — на самом деле просто набор операций поиска.
Все, что вам нужно, это очень простой синтаксический анализатор для каждой строки, простой словарь для меток и список прямых ссылок, которые требуют последующих исправлений.
Существует также много возможностей для сокращений, т. е. требование, чтобы имя кода операции однозначно определяло ожидаемые аргументы, минимальное количество псевдоинструкций или их отсутствие, отсутствие арифметических выражений и т. д.
Упрощением является то, что ранние машины имели меньше инструкций и более простые режимы адресации. В случае, который вы цитируете, используются даже однобуквенные коды операций с тем, что выглядит как фиксированный набор аргументов.
Исходный код ассемблера даже не должен быть эффективным или устойчивым к размеру входных данных, поэтому он может использовать массивы фиксированного размера (в которых не хватило бы места при слишком больших входных данных) и линейный поиск (вместо хэш-таблиц или даже связанные списки), например. Обработка ошибок и сообщения также не должны быть хорошими. Как только вы освоите основные мнемоники, вы, по сути, загрузите ассемблер.
Как написать ассемблер v0.00 для данного нового процессора?
Это относительно просто, вы просто используете более старую машину, на которой уже есть язык программирования.
Написание ассемблера в любой момент времени аналогично написанию любой другой программы. Если бы вы имели дело с новым чипом с совершенно новой архитектурой, которая не была бинарно совместима ни с одним другим чипом, то вы бы использовали спецификацию этого чипа для создания отображения строк языка высокого уровня в строки машинного кода. . В противном случае вы бы основывали свою программу на ассемблере для какого-то подобного чипа.
Эта картографическая программа может быть реализована на любом языке на любом компьютере. Люди сделали это в Excel, а я сделал это в Python, используя регулярные выражения. В прошлом они написали бы это перфокартами, переключателями, молотком и зубилом или чем-то еще.
В руководстве по архитектуре чипа описаны регистры процессора, поддерживаемые операции, коды операций и т. д. Задачи написания ассемблера — это задача перевода высокоуровневого описания алгоритма в описание, совместимое с тем, что описано в руководство.