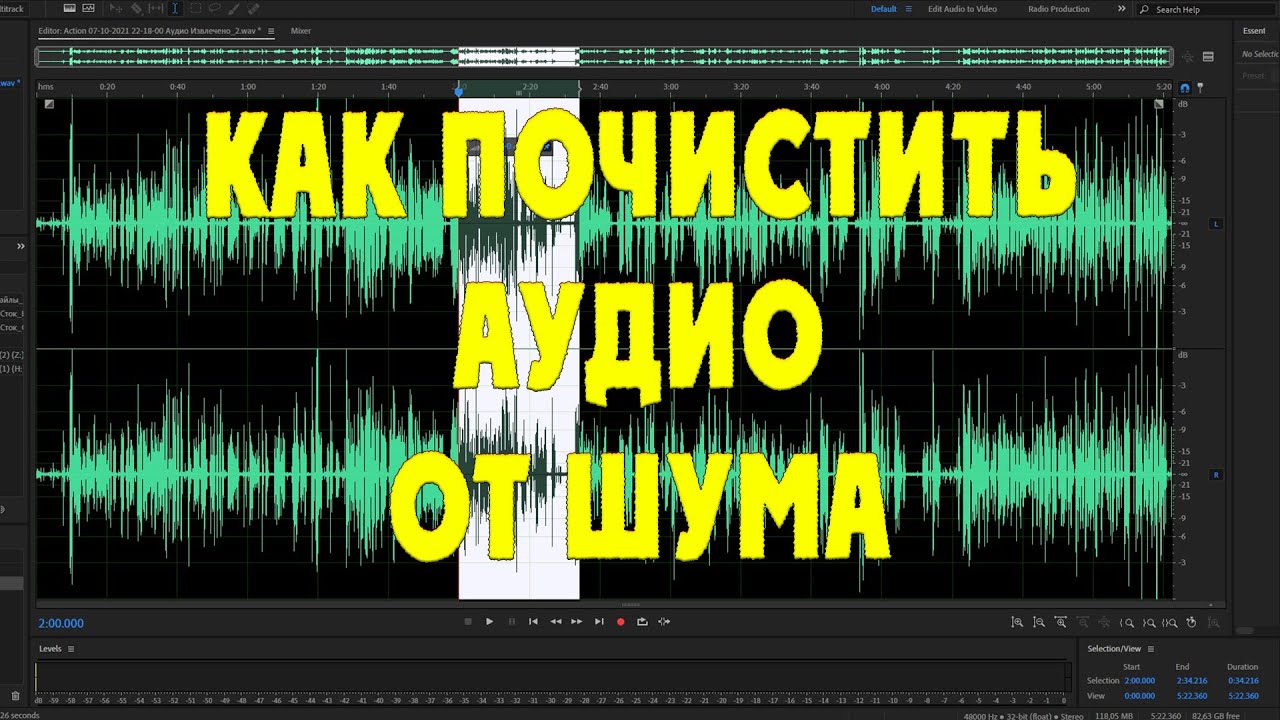
Разделение звука в видеозаписях / Хабр
Кадр из видео Super Mario Theme (Trumpet & Euphonium) https://youtu.be/o3a6F070Xt0Введение
Традиционно популярными и активно исследуемыми областями в Deep Learning являются задачи обработки изображений или текстов. Тем не менее, задачи, связанные с обработкой звуков и аудиодорожек, полезны и могут найти практические приложения во многих областях. Вот неполный перечень задач обработки звука, при решении которых используются подходы на основе глубокого обучения:
Классификация звуковых сигналов;
Speech3Text. Перевод речи в текстовое отображение;
Text2Speech. Обратная предыдущей задача. Генерация речи по заданному тексту;
Поиск похожих звуков;
Sound Separation. Разделение звуковой дорожки на составляющие звуки;
Beamforming. Разделение многоканальной звуковой дорожки на возможные составляющие с учетом пространственного расположения звукозаписывающих устройств.


В данной статье я расскажу о решении задачи Sound Separation, но с одним отличием — в качестве входных данных используются видеозаписи.
Для начала разберемся: что такое звук? Звук — это механические колебания, передающиеся в среде. Звуковые колебания характеризуются амплитудой и частотой. В среднем обычный человек может услышать звуки частотой 20Гц – 20000Гц. Для представления аудиоданных в цифровом формате микрофон с определенной частотой регистрирует амплитуду механических колебаний среды, затем полученные замеры преобразуются в цифровой формат. Таким образом, звук в вычислительных устройствах представляется как временной ряд. При этом, чем более высокая частота дискретизации, тем более высокие частоты получается сохранить.
Возможно представление аудио сигнала в виде трехмерной диаграммы, где на оси абсцисс изображено время, на оси ординат – частота звука. Третье измерение с указанием амплитуды на определенной частоте в конкретный момент времени представлено интенсивностью или цветом каждой точки изображения.
Такое представление позволяет применять двумерные сверточные нейронные сети в задачах обработки звука. Следует помнить, что в таком подходе не учитывается положение на изображении, хотя в случае спектрограмм это может быть важно. Например, в задаче классификации изображений совершенно неважно, находится объект внизу или вверху, при этом положение «внизу» и «вверху» на спектрограмме отвечает разным частотам, а значит разным звукам.
Задача разделения звуков заключается в получении аудиодорожек отдельных источников звука по одной аудиозаписи с несколькими источниками.
— исходная аудиодорожка, «смесь» отдельных звуков
– i-тая компонента звука
— число компонент звука
Задача локализации — поиск источников звука в кадре и отделение от общей аудиодорожки.
Локализация звуковПодобрать метрику, которая идеально оценивала качество модели, не так просто. Это связано со сложностью самих звуковых данных, а так же с тем, что восприятие результата может быть субъективно. Несколько человек могут по-разному оценить качество разделения в зависимости от их музыкального слуха и других факторов. Зачастую, в задачах разделения звука используют метрику SDR, дополнительно можно вычислять SIR и SAR.
Это связано со сложностью самих звуковых данных, а так же с тем, что восприятие результата может быть субъективно. Несколько человек могут по-разному оценить качество разделения в зависимости от их музыкального слуха и других факторов. Зачастую, в задачах разделения звука используют метрику SDR, дополнительно можно вычислять SIR и SAR.
SDR — source to distortion ratio, общая оценка того, насколько хорошо источник звучит
SIR – source to interference ratio, оценка того, насколько хорошо звук отделен от остальных источников
SAR – source to artifact ratio, оценка того, насколько хорошо звук изолирован от нежелательных артефактов
Теперь, определившись с задачей и метриками, можно посмотреть как решать такую задачу.
Модель
Расскажу про подход, предложенный в статье Sound-of-Pixels. Модель состоит из нескольких частей: визуальная, аудио и синтезатор. Для начала определимся, что передается на вход в модели. Исходными данными для модели являются видеозаписи с источниками звука. Видеозапись можно представить как последовательность кадров и аудиодорожка. Аудиодорожку из одномерного представления можно перевести в спектрограмму. Таким образом, на вход модели будем подавать несколько кадров из видео и спектрограмму аудиодорожки.
Видеозапись можно представить как последовательность кадров и аудиодорожка. Аудиодорожку из одномерного представления можно перевести в спектрограмму. Таким образом, на вход модели будем подавать несколько кадров из видео и спектрограмму аудиодорожки.
Для вычисления признаков из кадров видео используется ResNet, для генерации аудио признаков из спектрограммы применяется U-Net подобная архитектура. После вычисления видео и аудио признаков они комбинируются с некоторыми обучаемыми весами и на выходе модели получаются сетка из масок. Маска — это одноканальное изображение с таким же размером, как и у входной спектрограммы, каждый пиксель маски принимает значения от 0 до 1. Впрочем, маска может быть бинарной, тогда значения — это 0 или 1. При поэлементном умножении маски на исходную спектрограмму смеси получается спектрограмма изолированного источника звука, а по спектрограмме можно восстановить аудиодорожку изолированного звука.
При вычисления визуальных признаков пространственные размерности уменьшаются в 16 раз. При использовании кадров размером 224х224 выходная пространственная размерность получается 14х14. И в каждой пространственной точке получается визуальный размер признаков размерности K (гиперпараметр, подбирается в зависимости от датасета). Сеть синтезатор для каждой пространственной точки совмещает визуальные признаки и аудио признаки и предсказывает маску для спектрограммы. Получается маска для звуков, источники которых находятся в соответствующем участке исходных кадров.
При использовании кадров размером 224х224 выходная пространственная размерность получается 14х14. И в каждой пространственной точке получается визуальный размер признаков размерности K (гиперпараметр, подбирается в зависимости от датасета). Сеть синтезатор для каждой пространственной точки совмещает визуальные признаки и аудио признаки и предсказывает маску для спектрограммы. Получается маска для звуков, источники которых находятся в соответствующем участке исходных кадров.
Обучить такую модель напрямую проблематично, поэтому авторы предлагают несколько трюков. Обучение проводится по видео с отдельными источниками звука. Если рассматривать музыкальный домен, то подойдут видео с соло исполнениями на музыкальных инструментах. Дополнительной разметки при этом не требуется, но при обучении делается несколько допущений. Во-первых, во время обучения не предсказывается сетка масок, после визуальной сети берется макспулинг по пространственным размерностям и маска вычисляется одна на весь кадр. Во-вторых, звук аддитивен, а это значит, что при сложении двух аудиозаписей в соло исполнении получается запись исполнения в дуете.
Во-вторых, звук аддитивен, а это значит, что при сложении двух аудиозаписей в соло исполнении получается запись исполнения в дуете.
Для обучения из выборки семплируется пара видеозаписей, т.е. объект для обучения — это две видеозаписи. Аудиодорожки складываются и получается дорожка с несколькими источниками звука. В аудио часть модели подается смесь, а по кадрам первого и второго видео вычисляются соответствующие вектора визуальных признаков. Теперь можно применить синтезатор к аудио признакам и видео признакам от первого и второго видео и получить на выходе маску для извлечения исходных аудиодорожек из смеси. Исходные аудиодорожки нам известны, можно посчитать функцию потерь между предсказанными дорожками и исходными и обновить веса модели.
Обучение моделиОстается вопрос — где взять данные для обучения? Для обучения на музыкальных инструментах использовался датасет MUSIC, для обобщения модели на общий звуковой домен использовался датасет VGGSound. Данные собраны из видео на youtube, но сами датасеты — это . csv файлы с id видео. Сбор, загрузку и предобработку записей нужно выполнять своими руками. MUSIC содержит ~600 видеозаписей с соло исполнением на 11 (есть часть с 21) музыкальных инструментах, а также видео с исполнениями в дуете. Все исполнения любительские, произведены в повседневной обстановке без использования профессионального оборудования. VGGSound намного больше, датасет содержит более 200 тысяч видеозаписей, а также разметку на 310 классов звуков (указывается временной отрезок в видео и метка звука, который звучит в этом отрезке)
csv файлы с id видео. Сбор, загрузку и предобработку записей нужно выполнять своими руками. MUSIC содержит ~600 видеозаписей с соло исполнением на 11 (есть часть с 21) музыкальных инструментах, а также видео с исполнениями в дуете. Все исполнения любительские, произведены в повседневной обстановке без использования профессионального оборудования. VGGSound намного больше, датасет содержит более 200 тысяч видеозаписей, а также разметку на 310 классов звуков (указывается временной отрезок в видео и метка звука, который звучит в этом отрезке)
Результаты
Давайте теперь посмотрим на результаты обученной модели. Сначала я покажу, как работает модель на музыкальных инструментах, затем на общих звуках из VGGSound.
Разберем разделение на этапе валидации на примере двух видео. Возьмем два видео с соло исполнениями, сложим их аудиодорожки и разделим обратно.
Разделение гитары и скрипкиПо полученным спектрограммам можно восстановить звук и получить финальный результат
Модель работала в режиме валидации, который приближен к обучению.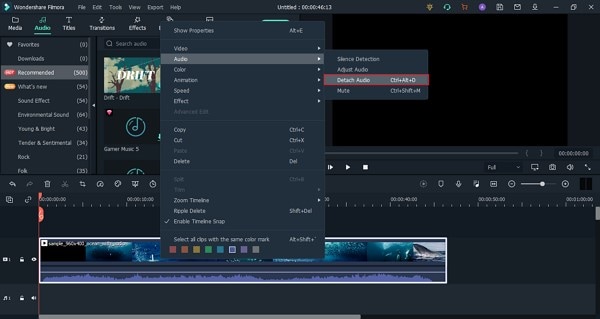 Визуальные признаки в этом случае считались по всему кадру, разбиения на регионы не было. Теперь можно посмотреть на результаты модели, которая не только разделяет источники, но и ищет их в кадре.
Визуальные признаки в этом случае считались по всему кадру, разбиения на регионы не было. Теперь можно посмотреть на результаты модели, которая не только разделяет источники, но и ищет их в кадре.
Теперь, если взять полученную модель и обученный детектор объектов в кадре, то можно усреднять маски в предсказанных boundary box детектора и получать звуки, издаваемые объектами в кадре.
Приведу метрики, которые я получал в результате наиболее удачных экспериментов. За baseline я взял метрики, которые авторы указали в своей статье. В приведенных экспериментах я использовал размерность признаков K=16. В других экспериментах пробовал различные значения, но они дают худший результат. В статье же авторы указывают, что по их экспериментам размерность K=32 работает лучше.
SDR | SIR | SAR | |
baseline | 8.87 | 15.02 | 12.28 |
BCE loss, бинарная маска | 10. | 21.24 | 13.96 |
BCE loss, регуляризация сценами с тишиной | 8.27 | 17.69 | 12.07 |
L2 loss, непрерывная маска | 5.87 | 15.41 | 15.03 |
 56
56Перейдем к датасету VGGSound. Приведу пример разделения детского плача и шума от работы погрузчика.
Разделение общих звуковПо вычисленным спектрограммам можно собрать аудиодорожки.
Локализация работает, но не идеально. Например, в кадре с вертолетом в небе у модели получается выделить звук в центре кадра.
Локализация источника звука (вертолета)Есть и неудачные примеры.
Локализация источника звука (человек)Модель определяет источник звука в центре, но по краям кадра также дает ненулевые маски. В целом же, модель, обученная таким способом на звуках из общего домена, работает.
Наилучшая модель на валидации получилась со следующими метриками:
SDR | SIR | SAR | |
K=32, BCE loss | 3. | 9.43 | 11.78 |
 62
62Сравнивать напрямую метрики на MUSIC и VGGSound, как я считаю, не очень корректно, т.к. датасеты совсем разные, VGGSound гораздо больше и вариативнее. Из-за этого оптимальным значением для размерности вектора признаков оказалось 32.
Трудности
В процессе воспроизведения статьи я столкнулся с рядом трудностей, о которых хотел бы упомянуть.
Сбор данных — довольно трудоемкий процесс. Даже несмотря на то, что есть размеченные датасеты, загрузка данных из источников требует времени и аккуратности. Каждая видеозапись требует времени на скачивание, времени на обработку, а также объем на диске. Уместить весь VGGSound локально я не смог, поэтому после скачивания сразу вырезал из видео нужный участок, раскладывал его на кадры и аудиодорожку, приводил картинки к меньшему размеру и понижал частоту дискретизации аудио дорожки. Стоит также сказать, что youtube не дает открыто массово скачивать контент с ресурса, поэтому пришлось применить некоторые трюки. Помимо этого, нет никаких гарантий, что указанные в датасете видео будут доступны на видеохостинге всегда, и, конечно же, это не так. Некоторые видеозаписи из датасета скрыты, удалены, заблокированы.
Помимо этого, нет никаких гарантий, что указанные в датасете видео будут доступны на видеохостинге всегда, и, конечно же, это не так. Некоторые видеозаписи из датасета скрыты, удалены, заблокированы.
Авторы оригинальной работы опубликовали код, но он оказался неполным и немного устаревшим. Потребовалось обновить код для совместимости с современной версией PyTorch, исправить несколько неочевидных нюансов, а также дописать код для выполнения локализации и демо (локализация + детектор)
Архитектура модели довольно сложная, из-за чего появляется много гиперпараметров и похожих решений, которые можно попробовать и улучшить результат. Основной гиперпараметр — размерность вектора признаков K. Это значение крайне желательно подбирать. Сама модель состоит из нескольких, каждая из архитектур обладает своими особенностями и потенциалом для улучшения. Понятно, что посмотреть на все комбинации улучшений для каждой из модели очень трудоемко и можно смотреть на каждую модель по очереди.
Обучение модели занимает довольно много времени. На личном компьютере (Nvidia RTX 2070 Super) обучение на MUSIC занимает 4 суток, на VGGSound 6 суток. Из-за этого каждый эксперимент занимал много времени, по этой причине пункт выше становится еще более актуальным.
На личном компьютере (Nvidia RTX 2070 Super) обучение на MUSIC занимает 4 суток, на VGGSound 6 суток. Из-за этого каждый эксперимент занимал много времени, по этой причине пункт выше становится еще более актуальным.
Заключение
В статье я рассказал о том, как можно научить модель находить источники звука в видеозаписи без явной разметки. Это отличается от большинства существующих решений, требующих для обучения смесь звуков и разделенные звуки. Такие датасеты есть, но их немного и, что более важно, они небольшие и основаны на музыкальных композициях (MusDB, например). В рассмотренном подходе удалось научить модель разделять звуки из общего домена.
На практике такую модель можно применять, например, для удаления посторонних шумов в кадре, выделения речи людей и другие подобные задачи.
Полезные ссылки
https://github.com/MaximKsh/Sound-of-Pixels — репозиторий с кодом. Форк оригинального репозитория с изменениями и дополнениями
https://arxiv.
 org/abs/1804.03160 — оригинальная статья
org/abs/1804.03160 — оригинальная статьяhttps://github.com/hangzhaomit/Sound-of-Pixels — оригинальный репозиторий
https://github.com/roudimit/MUSIC_dataset — датасет MUSIC
https://github.com/hche11/VGGSound — датасет VGGSound
https://source-separation.github.io/tutorial/landing.html — хороший туториал по разделению звука.
Отделение и Отключение Звука и Настройка Громкости
- Добавление звуковых файлов
- Добавление закадрового голоса
- Разделение аудио
- Настройка элементов управления временной шкалы
- Настройка аудио
- Отключение звука в видеоклипе
- Отсоединение аудио от видео
- Обрезка аудиофайла
- Регулировка громкости аудио
- Затухание/Появление музыки
- Регулировка скорости и высоты тона
- Замена исходного аудио в видео
- Удаление шумов в аудио
- Аудио эквалайзер
- Аудиомикшер
1Добавление звуковых файлов
Filmora X для Mac предоставляет бесплатную музыкальную библиотеку, из которой вы можете выбирать файлы для собственного видео. Можно также импортировать свои аудио и применять файлы к видеопроекту.
Можно также импортировать свои аудио и применять файлы к видеопроекту.
Бесплатная музыкальная библиотека: Нажмите на кнопку «Audio», откроется бесплатная музыкальная библиотека, там выберите нужный трек. Всего в один клик, музыка будет загружена и показана на звуковой дорожке.
Использование музыки с Mac: Чтобы импортировать музыку из локальной папки на вашем Mac, вы можете нажать кнопку «Импорт» над панелью «Медиатека» и выбрать аудиофайл на вашем компьютере. Затем вы можете импортировать выбранные аудиофайлы в программу и перетаскивать музыкальные и аудиофайлы на аудиодорожку на временной шкале.
2Добавление закадрового голоса
Под панелью «Media» нажмите на кнопку «Record» и выберите опцию «Record voiceover». Или вы можете нажать на значок «Record» на панели инструментов и открыть меню записи.
Теперь вы можете поместите точку воспроизведения в то место на временной шкале, где вы хотите добавить закадровый голос, а затем нажмите на значок «Microphone» для начала записи. Нажмите на значок «Stop», чтобы остановить запись. Наконец, новый созданный файл закадрового голоса будет автоматически показан на звуковой дорожке.
Нажмите на значок «Stop», чтобы остановить запись. Наконец, новый созданный файл закадрового голоса будет автоматически показан на звуковой дорожке.
3Разделение аудио
Переместите ползунок в часть аудио, которую вы хотите отделить, щелкните правой кнопкой мыши на музыкальной дорожке на временной шкале, а затем выберите «Split». Вы также можете нажать на значок «Ножницы» для разделения аудио.
4Настройка элементов управления временной шкалы
Добавление нового трека: Нажмите на значок «+» в левой части над временной шкалой и выберите опцию «Add video track» или «Add audio track». Новый трек будет добавлен поверх или под существующими треками.
Добавление нескольких новых треков: После того, как вы нажмете на значок «+», выберите опцию «Open Tracker Manager», чтобы открыть меню «Track manager». В окне вы можете вставить нужное количество треков в поле «Add box».
Удаление пустых треков:
Если вы хотите удалить пустой трек, выберите опцию «Delete Empty Tracks» из выпадающего списка после того, как вы нажмете на иконку «+».Регулировка высоты трека: Нажмите на значок «+» и выберите опцию «Adjust Track Height», затем выберите одну из опций «Small», «Normal» или «Big», чтобы настроить высоту дорожки в соответствии с вашими потребностями.
5Настройка аудио
Filmora X для Mac позволяет настраивать параметры звука по умолчанию. Щелкните дважды на аудио на временной шкале, откроется панель управления звуком. Вы можете настроить скорость, громкость, затухание/появление и высоту тона.
6Отключение звука в видеоклипе
Щелкните правой кнопкой мыши на видео на временной шкале и выберите «Mute».
7Отсоединение аудио от видео
Щелкните правой кнопкой мыши на видео на временной шкале и выберите опцию «Audio Detach».
8Обрезка аудиофайла
После отключения аудио, оно будет автоматически добавлено на временную шкалу. И тогда вы можете поместить курсор в начале или в конце звуковой дорожки для обрезки.
9Регулировка громкости аудио
Дважды щелкните на аудио на временной шкале, чтобы включить окно Audio Inspector > перейдите на вкладку Volume. Там вы сможете настроить громкость звука. Вы можете регулировать громкость от 1 до 100.
10Затухание/Появление музыки
Дважды щелкните на аудио на временной шкале, в окне Audio Inspector перетаскивайте ползунок на вкладке Fade in/out, чтобы применить эффект Затухания или Появления.
11Регулировка скорости и высоты тона
Сначала нажмите на аудио на временной шкале, и найдите опцию Speed (скорости) и Pitch (высоты тона) в окне Audio inspector. Отрегулируйте скорость и высоту тона звука, перемещая ползунок. Для подтверждения нажмите «OK».
12Замена исходного аудио в видео
Filmora X для Mac позволяет заменять исходный звуковой файл в видео. Для этого:
1. Импортируйте видео и аудио файлы в медиатеку программы. И перетащите видео на временную шкалу.
2. Щелкните правой кнопкой мыши на видео и выберите опцию «Detect Audio». Тогда видео и аудио будут разделены.
3. Нажмите на аудио на временной шкале и нажмите кнопку «Delete» для удаления исходного аудио.
4. Перетащите аудио из медиатеки на временную шкалу. Затем экспортируйте видео с новым аудио.
13Удаление шумов в аудио
Дважды щелкните на аудио на временной шкале. В открывшемся окне Audio inspector установите флажок рядом с «Remove background noise» и перемещайтесь между режимами слабым, средним и сильным для уменьшения шума.
14Аудио эквалайзер
Функция аудио эквалайзера в Filmora Video Editor позволяет настраивать звук для достижения идеального сочетания аудио.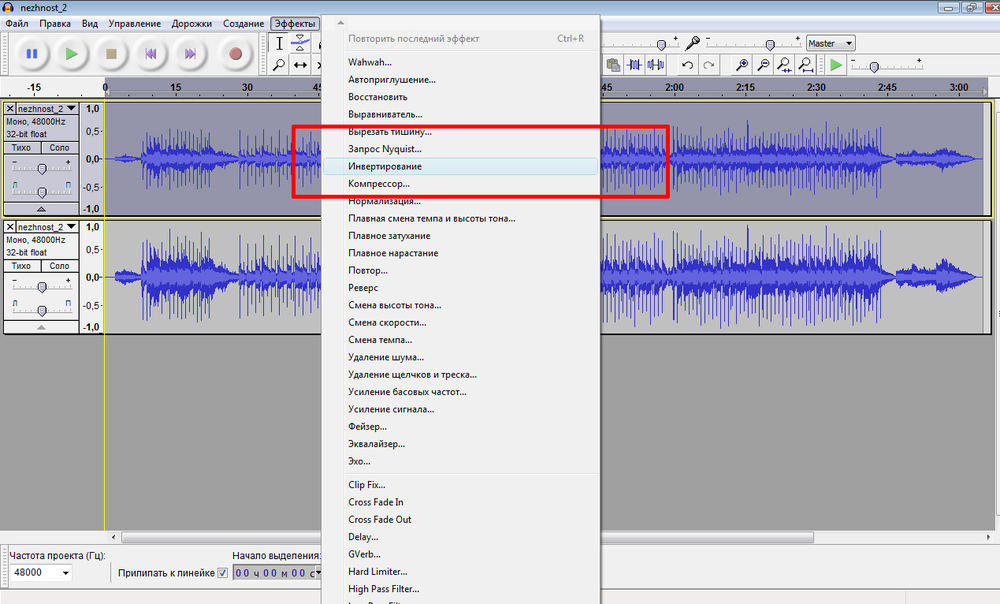
Чтобы настроить эквалайзер, откройте окно Audio Inspector, дважды щелкнув по аудио на временной шкале. А затем во вкладке «Equalizer» выберите параметры, включая по умолчанию, поп, рок-н-ролл, мягкий, классика, низкий бас, оживленно, кантри, техно, хард-рок, акустика, фольк, блюз. Вы также можете нажать на кнопку «Customize», чтобы сделать дополнительные настройки.
15Аудиомикшер
Чтобы включить функцию «Аудиомикшер» в Filmora Video Editor, нажмите кнопку «Audio Mixer » на панели инструментов. Во всплывающем окне дорожки будут подсвечивается фиолетовым цветом. Вы можете крутить небольшой кружок на панели для того, чтобы переключить звук. Или вы можете нажать на кнопку «Master», чтобы сделать общую громкость больше или меньше.
Далее: Редактирование изображений
Как разделить аудио в Premiere Pro: пошаговое руководство
Марко Себастьяно Алесси
10 октября 2022 г.
Существует множество причин, по которым вам может понадобиться разделить звук в ваших проектах: работать с аудио и видео по отдельности, редактировать звук поверх разных видеоклипов, улучшать звук, обрезать или обрезать часть аудио или видео. клип, не затрагивая всю последовательность.
Или, может быть, вы только что узнали, как удалить фоновый шум в Premier Pro, и не хотите рисковать испортить весь файл.
Вы можете использовать программное обеспечение, чтобы разделить звук, отредактировать его, а затем снова объединить; однако это означает, что вам нужно будет установить различные аудиопрограммы, познакомиться с ними и, возможно, потратить много дополнительного времени на обработку своих проектов. Зачем мучиться, если Adobe Premiere Pro позволяет нам делать все на одной платформе?
Зачем мучиться, если Adobe Premiere Pro позволяет нам делать все на одной платформе?
Adobe Premiere Pro более известен как программное обеспечение для редактирования видео. Хотя у него не так много инструментов для редактирования звука, как у специального аудиоредактора или DAW, он предлагает достаточно инструментов для оптимизации звука для видео.
Он даже позволяет нам обрезать, вырезать, добавлять звуковые эффекты и нормализовать звук.
В этой статье вы узнаете, как разделить аудио из видео и как разделить стереофоническую звуковую дорожку на две монодорожки.
Это простой процесс, если вы научитесь это делать, поэтому я создал это пошаговое руководство, чтобы помочь как новичкам, так и тем, кто знаком с Adobe Premiere Pro, а также опытным пользователям, которым требуется краткое руководство.
Прежде чем мы начнем, убедитесь, что на вашем ПК или Mac установлена программа Adobe Premiere Pro. Вы можете загрузить и установить его с веб-сайта Adobe, если вы еще этого не сделали.
Давайте узнаем, как разделить аудио в Premiere Pro
Давайте начнем с того, что вам очень понадобится в процессе редактирования видео. Возможно, вам потребуется отделить звуковую волну от видео, чтобы создать различные эффекты и переходы.
Отделить звук от видео с помощью Premiere Pro очень просто.
Шаг 1. Импорт клипов
Создайте новый проект в Adobe Premiere и импортируйте файл, который хотите разделить. Или, если вы уже работаете над проектом, перетащите видеоклип на панель «Таймлайн», чтобы начать работу.
- Перейдите в строку меню «Файл» и выберите «Импорт», чтобы открыть видеофайл. Или перетащите файл в Premiere Pro.
Шаг 2. Создайте последовательность
Теперь, когда ваш видеоклип находится на панели «Проект», вы можете создать новую последовательность или добавить клип к существующей.
- Щелкните клип правой кнопкой мыши и выберите «Новый эпизод из клипа», создав новый эпизод и добавив видеоклип, который мы хотим разделить.

- Если вы уже работали над эпизодом, вы можете просто перетащить видео на панель временной шкалы.
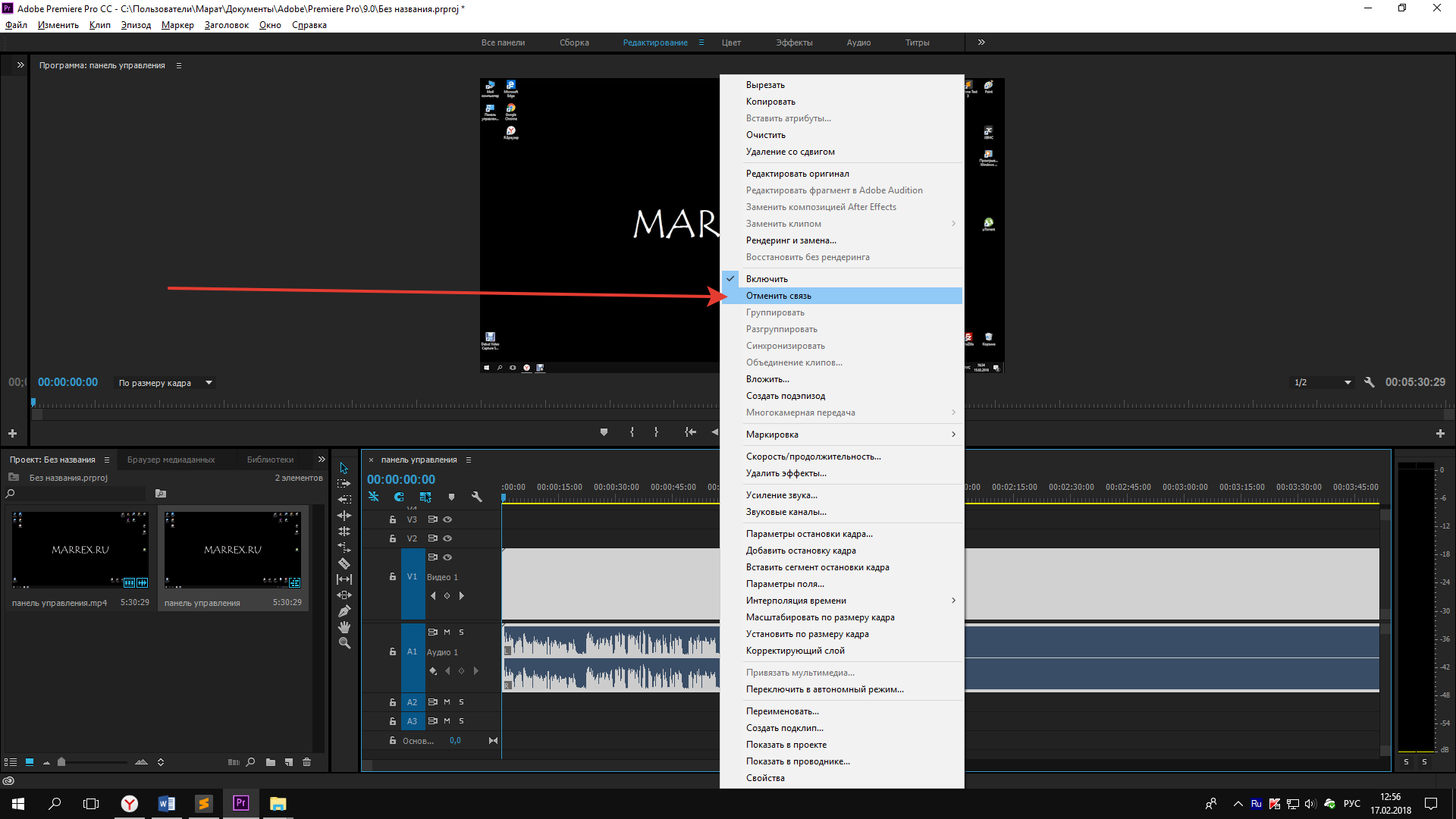
Шаг 3. Отсоедините аудио от видео
Когда вы импортируете видеоклип на панель «Таймлайн» в Premiere Pro, вы видите, что аудио и видеоклип имеют свои независимые дорожки, но они связаны друг с другом.
Все ваши действия по редактированию будут относиться к связанному клипу; если вы нажмете на любой из них и перетащите, связанные клипы будут перемещаться как один.
Итак, если вы хотите использовать определенный фрагмент аудио, а не всю запись, или просто хотите избавиться от одного клипа, но сохранить другой, вам нужно создать связанный клип, разъединив их.
Вы также можете связывать клипы несколько раз, предоставляя еще больше возможностей для редактирования звука в соответствии с визуальными эффектами.
1. Выберите клип, который хотите разделить.
2. Нажмите на него правой кнопкой мыши и выберите Отключить во всплывающем меню.
3. Аудиофайлы и видео теперь разделены, а видео остается выбранным после разделения. Если мы хотим работать с этим клипом, мы можем двигаться дальше. Но если вы хотите отредактировать аудио, вам нужно выбрать теперь независимый аудиоклип.
4. После разделения аудио и видео теперь вы можете редактировать и перемещать клипы по отдельности, что означает, что вы можете создать последовательность со звуком из первого видео в конце или наоборот.
Что делать, если вы разделили не тот клип?
Если вы разделили аудио, а затем передумали, вы можете связать его обратно за считанные секунды:
1. Выберите клипы, которые хотите связать. Использование Shift-клика позволит вам выбрать несколько клипов.
2. Нажмите правой кнопкой мыши на выбранные клипы и выберите «Ссылка» во всплывающем меню.
3. Ваши клипы будут снова связаны.
Если вы повторно свяжете клипы, Premiere Pro автоматически синхронизирует клипы, если обнаружит, что они рассинхронизированы.
Функция Link также полезна, когда вы записываете звук с помощью внешнего микрофона, чтобы получить лучшее качество, чем звук с вашей камеры.
Вы можете отделить звук от видео, а затем связать аудиоклип с внешнего микрофона с видео и синхронизировать его.
Разделение стереозвука на двойное моно
Звук можно записывать по-разному, например, стерео и моно. Это будет зависеть от микрофона, который вы используете для записи. Давайте посмотрим разницу между стерео и моно.
· Стереомикрофон использует два канала для индивидуальной записи слева и справа. Он помогает создавать окружающие звуки, а также используется для акустических выступлений.
· Мономикрофоны используют только один канал, поэтому все, что вы записываете, будет выводиться на одной дорожке.
Камеры иногда записывают звук в стерео вместо моно, и когда мы импортируем видео в Premiere Pro, мы получаем аудиоклип с двумя звуковыми дорожками.
Обычно это не проблема, если вы используете встроенный микрофон камеры; вы по-прежнему можете редактировать свой аудиофайл, как если бы вы использовали монофоническую звуковую дорожку.
Проблемы могут возникнуть, если вы используете стереомикрофон и используете его каналы для разных целей и не записываете один источник звука.
Стереомикрофоны обычно используются для записи интервью с интервьюером на одном канале и интервьюируемым на другом.
Вам нужно разделить эту стереодорожку, чтобы вы могли редактировать каждую отдельно и повышать или понижать уровень громкости каждого динамика.
Еще одно применение разделения — подкастинг. Запись эпизода для двух человек со стереомикрофоном, чтобы позже отредактировать фоновые звуки, которые один канал выбрал больше, чем другой, или отключить звук одного динамика, пока другой говорит, чтобы улучшить качество звука.
Если вы находитесь в одном из двух сценариев, вы можете разделить звук, разделив стереодорожку на двойную монофоническую дорожку. Прежде чем вы начнете, вам нужно выполнить следующие шаги, прежде чем добавлять клип, который вы хотите разделить, на временную шкалу.
Если он у вас уже есть, вам нужно удалить его, иначе вы не сможете разделить аудиоканал.
Шаг 1. Импортируйте файл или откройте свой проект
Во-первых, нам нужно получить стерео звуковую дорожку, которую мы хотим разделить.
1. Откройте меню «Файл» и найдите пункт «Импорт» в раскрывающемся меню.
2. Выберите файл и оставьте его на панели «Проект».
Шаг 2. Измените аудиоканалы и разделите аудио
Здесь все усложнится, поэтому внимательно выполняйте каждый шаг.
1. На панели «Проект» щелкните правой кнопкой мыши аудиофайл, который хотите разделить. Вы можете выбрать несколько клипов одновременно, если у вас есть несколько клипов для разделения.
2. В меню найдите «Изменить» и выберите «Аудиоканалы».
3. Откроется окно «Изменить клип».
Шаг 3. Работа с окном Modify Clip
Не бойтесь всех доступных здесь опций. Все, что вам нужно, находится на вкладке «Аудиоканалы».
1. В формате канала клипа выберите моно в раскрывающемся меню.
2. Перейдите вниз к количеству аудиоклипов и измените его на 2.
Перейдите вниз к количеству аудиоклипов и измените его на 2.
3. Внизу на канале источника мультимедиа вы должны увидеть два аудиоканала, указывающих, что один правый, а другой левый. Оставьте все как есть.
4. Нажмите «ОК».
5. Теперь вы можете перетащить аудиоклип на временную шкалу.
6. Мы можем получить предупреждающее сообщение о том, что клип не соответствует настройкам последовательности. Это из-за изменений, которые мы только что сделали. Щелкните Сохранить существующие настройки.
7. Клип будет отображаться на временной шкале в виде двух отдельных звуковых дорожек.
Шаг 4. Панорамирование разделенных клипов
Как только мы получим наши отдельные дорожки, мы можем отредактировать их по своему усмотрению. Но осталось сделать кое-что существенное. Прямо сейчас у нас есть наши аудиоклипы точно такие же, как в стереоклипе.
Если мы будем слушать их по отдельности, мы услышим звук только с одной стороны. Нам нужно панорамировать эти аудиоклипы, чтобы слушать их как с правой, так и с левой стороны.
Нам нужно панорамировать эти аудиоклипы, чтобы слушать их как с правой, так и с левой стороны.
1. Перейдите к микшеру аудиоклипов на панели аудиоэффектов. Если вы его не видите, перейдите в «Окно» в строке меню и отметьте «Микшер аудиоклипов».
2. Нажмите на вкладку рядом с аудиоэффектами, чтобы открыть микшер.
3. Выберите каждый аудиоклип и переместите виртуальную ручку вверху. Вы увидите L и R, обозначающие лево и право. Просто отцентрируйте его так, чтобы вы могли слышать звук слева и справа.
4. Теперь вы можете продолжить редактирование остальной части клипа.
Как настроить стереодорожки по умолчанию в режиме двойного моно
Если вы постоянно делаете разделение стереодорожек, есть способ сделать это с помощью настройки по умолчанию:
левое меню.
2. В области «Аудиодорожки по умолчанию» измените в меню параметр «Стерео медиа» на «Моно».
3. Нажмите «ОК».
С этими изменениями каждый раз, когда вы импортируете стереоклип, он будет «переведен» в двойной моноканал.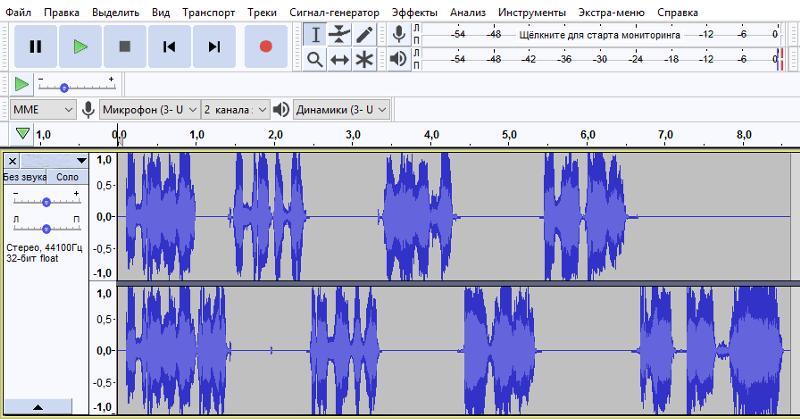 Вам не нужно будет повторять эти шаги с каждым проектом.
Вам не нужно будет повторять эти шаги с каждым проектом.
Final Words
Adobe Premiere Pro отлично подходит для редактирования, и как только вы к нему привыкнете, я уверен, что разделение аудио станет для вас пустяком. Если нет, убедитесь, что вы всегда держите это руководство под рукой!
Часто задаваемые вопросы
Чем разделение отличается от обрезки?
Разделение означает, что вы отделяете часть клипа для независимого редактирования или перемещения. Вы можете разделить видео несколько раз, используя инструмент бритвы, но общая продолжительность видео останется прежней.
Когда вы обрезаете клип, вы вырезаете его часть: это способ сократить клип, удалив часть видео. Знание того, как обрезать звук, полезно, если вы хотите сделать видео более плавным или профессиональным.
Чем разделение отличается от кадрирования?
Обрезка означает удаление областей из видеоизображения без его растяжения. Он обычно используется для изменения соотношения сторон или центрирования изображения на чем-то конкретном в видео.
С другой стороны, разделение — это процесс разделения клипа на несколько клипов.
Послушайте сами
CrumplePop удаляет шум и повышает качество вашего голоса. Включите / выключите его, чтобы услышать разницу.
Удаление ветра
Удалить шум
 mov.mp4″> Удалить шипучку и взрывчатку
mov.mp4″> Удалить шипучку и взрывчатку
Уровень аудио
Удалить шорох
Удалить эхо
Удалить ветер
Попробуйте CrumplePop бесплатноКак разделить аудио и видео в Davinci Resolve
Если вы видеоредактор, скорее всего, придет время, когда вам нужно будет отделить звук от видео. Возможно, вам нужно использовать только звук из определенного клипа или, может быть, вам нужно использовать только видео из определенного клипа. Какой бы ни была причина, разделение аудио и видео в Davinci Resolve — это относительно простой процесс, который можно выполнить всего за несколько шагов.
Возможно, вам нужно использовать только звук из определенного клипа или, может быть, вам нужно использовать только видео из определенного клипа. Какой бы ни была причина, разделение аудио и видео в Davinci Resolve — это относительно простой процесс, который можно выполнить всего за несколько шагов.
Чтобы разделить аудио и видео в Davinci Resolve, щелкните правой кнопкой мыши клип в медиапуле и выберите «Извлечь аудио». Теперь DaVinci Resolve создаст отдельный файл WAV, содержащий исключительно ваш звук.
Как всегда, мы используем последнюю версию DaVinci Resolve 18. Мы настоятельно рекомендуем вам как можно скорее обновить программное обеспечение DaVinci Resolve, если вы еще этого не сделали.
Быстрый способ: с помощью клавиши Shift
Вы можете без дополнительных усилий использовать только звук из видеоклипа в своем медиапуле.
Удерживая клавишу Shift на клавиатуре, выберите видеоклип, звук из которого вы хотите использовать, и перетащите его на временную шкалу, удерживая клавишу Shift.
Будет использоваться только звук из клипа из вашего пула мультимедиа.
Пошаговые руководства по разделению аудио и видео в DaVinci Resolve
У нас есть несколько способов разделения аудио и видео в DaVinci Resolve. Не стесняйтесь выбирать свой любимый метод или самый быстрый для выполнения работы.
Метод извлечения аудио
Это один из самых быстрых способов разделения аудио и видео в DaVinci Resolve. Мы рассмотрим это в кратких деталях.
1. Найдите файл в пуле носителей
Пул носителей находится на вкладке меню мультимедиа в нижней части программного обеспечения DaVinci Resolve. Оказавшись здесь, перейдите к своему файлу, используя пул носителей в верхней левой части программного обеспечения.
2. Щелкните правой кнопкой мыши и выберите «Извлечь аудио».
Щелкните правой кнопкой мыши клип, из которого нужно извлечь аудио, и выберите параметр « Извлечь аудио ». Теперь DaVinci Resolve создаст WAV-файл, содержащий исключительно звук из вашего клипа.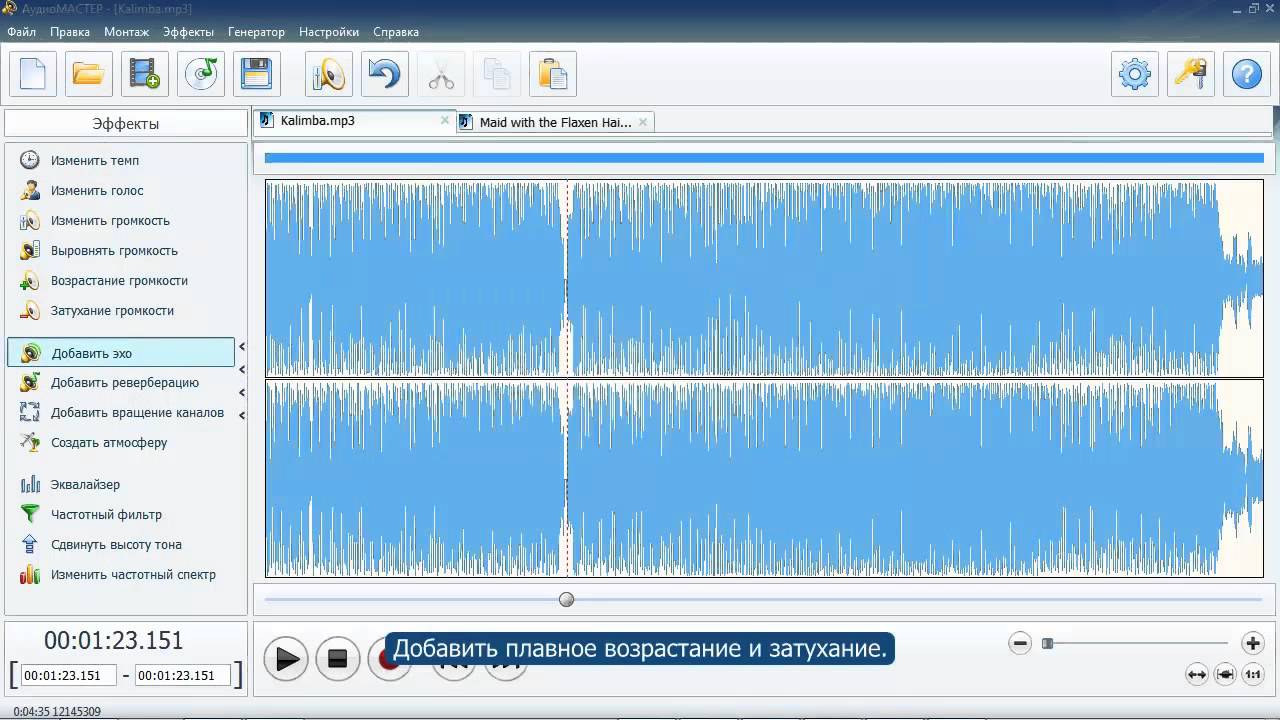
Поздравляем, теперь вы закончили извлечение звука из видеофайла.
Метод связывания/удаления клипов
Совет: Если у вас уже есть видеоклип на временной шкале, вы можете перейти к шагу 3.
1. Запустите проект, над которым вы хотите работать
первый шаг в разделении аудио и видео в Davinci Resolve. Таким образом, вы сможете получить доступ ко всем файлам и элементам, необходимым для вашего проекта редактирования видео.
Вот шаги для запуска проекта:
- Откройте программу Davinci Resolve на своем компьютере.
- Щелкните вкладку « Project Manager » в разделе « File ».
- Нажмите кнопку « Новый проект », чтобы запустить новый проект или выбрать существующий проект.
- Назовите проект и нажмите «Сохранить» при создании нового проекта.
2. Загрузите видеоклип, с которым вы хотите работать
Когда ваш проект открыт, пришло время загрузить видеоклип, из которого вы хотите извлечь звук. Вот шаги:
Вот шаги:
- Щелкните вкладку « Носитель » в интерфейсе Davinci Resolve.
- Перейдите к местоположению вашего файла, затем щелкните его, чтобы выбрать.
- Нажмите « Import », чтобы загрузить файл в Davinci Resolve.
3. Щелкните правой кнопкой мыши видеоклип на временной шкале.
После того, как видеоклип будет помещен на временную шкалу в Davinci Resolve, вы можете отделить звук от видео и выделить для него отдельную дорожку.
- Щелкните правой кнопкой мыши видеоклип на временной шкале
- Выберите «Связать клипы» . Эта опция больше не должна иметь галочку после того, как вы ее выбрали.
Теперь клипсы должны быть разделены, и вы правильно выполнили описанные выше шаги.
Необязательный шаг: добавление нового аудиоклипа в ваш медиапул
Вы можете добавить уже отделенный аудиоклип в свой медиапул, щелкнув клип правой кнопкой мыши и выбрав опцию « New Compound Clip ».