PySpark orderBy() и sort() объяснили
Вы можете использовать функцию sort() или orderBy() PySpark DataFrame для сортировки DataFrame по возрастанию или убыванию на основе одного или нескольких столбцов, вы также можете сделать сортировка с использованием функций сортировки PySpark SQL. В этой статье я объясню все эти различные способы на примерах PySpark.
- Использование функции sort()
- Использование функции orderBy()
- По возрастанию
- По убыванию
- Функции сортировки SQL
Связанные: Как сортировать DataFrame с помощью Scala
Прежде чем мы начнем, сначала давайте создадим DataFrame.
simpleData = [("Джеймс","Продажи","Нью-Йорк",,34,10000), \
("Майкл", "Продажи", "Нью-Йорк", 86000,56,20000), \
("Роберт", "Продажи", "CA", 81000,30,23000), \
("Мария","Финанс","ЦА",
,24,23000),\
("Раман", "Финанс", "СА",99000,40,24000), \
(«Скотт», «Финансы», «Нью-Йорк», 83000,36,19000), \
(«Джен», «Финансы», «Нью-Йорк», 79000,53,15000), \
("Джефф", "Маркетинг", "CA", 80000,25,18000), \
("Кумар","Маркетинг","NY",91000,50,21000)\
]
columns= ["имя_сотрудника","отдел","штат","зарплата","возраст","бонус"]
df = spark.
createDataFrame (данные = simpleData, схема = столбцы)
df.printSchema()
df.show (усечение = Ложь)

Это дает меньше выходной мощности.
корень |-- имя_сотрудника: строка (можно обнулить = истина) |-- отдел: строка (nullable = true) |-- состояние: строка (nullable = true) |-- зарплата: целое число (можно обнулить = ложь) |-- возраст: целое число (можно обнулить = ложь) |-- бонус: целое число (можно обнулить = ложь) +-------------+----------+-----+------+---+-----+ |employee_name|отдел|штат|зарплата|возраст|премия| +-------------+----------+-----+------+---+-----+ | Джеймс| Продажи| Нью-Йорк || 34|10000| | Майкл| Продажи| Нью-Йорк | 86000| 56|20000| | Роберт| Продажи| Калифорния| 81000| 30|23000| | Мария| Финансы| Калифорния|
| 24|23000| | Раман | Финансы| Калифорния| 99000| 40|24000| | Скотт| Финансы| Нью-Йорк | 83000| 36|19000| | Джен| Финансы| Нью-Йорк | 79000| 53|15000| | Джефф| Маркетинг| Калифорния| 80000| 25|18000| | Кумар| Маркетинг| Нью-Йорк | 91000| 50|21000| +-------------+----------+-----+------+---+-----+
Сортировка DataFrame с помощью функции sort()
Класс PySpark DataFrame предоставляет функцию sort() для сортировки по одному или нескольким столбцам. По умолчанию он сортируется по возрастанию.
По умолчанию он сортируется по возрастанию.
Синтаксис
sort(self, *cols, **kwargs):
Пример
df.sort ("отдел", "состояние"). показать (truncate = ложь)
df.sort(col("отдел"),col("состояние")).show(truncate=False)
Приведенные выше два примера возвращают один и тот же результат, показанный ниже: первый принимает имя столбца DataFrame в виде строки, а следующий — столбцы типа Column. Эта таблица отсортирована по первым состояния .
+-------------+----------+-----+------+---+-----+ |employee_name|отдел|штат|зарплата|возраст|премия| +-------------+----------+-----+------+---+-----+ |Мария |Финансы |CA ||24 |23000| |Раман |Финансы |CA |99000 |40 |24000| |Джен |Финансы |NY |79000 |53 |15000| |Скотт |Финансы |NY |83000 |36 |19000| |Джефф |Маркетинг |CA |80000 |25 |18000| |Кумар |Маркетинг |Нью-Йорк |91000 |50 |21000| |Роберт |Продажи |CA |81000 |30 |23000| |Джеймс |Продажи |NY |
|34 |10000| |Майкл |Продажи |NY |86000 |56 |20000| +-------------+----------+-----+------+---+-----+
Сортировка DataFrame с использованием функции orderBy()
PySpark DataFrame также предоставляет функцию orderBy() для сортировки по одному или нескольким столбцам. По умолчанию он упорядочивает по возрастанию.
По умолчанию он упорядочивает по возрастанию.
Пример
df.orderBy("отдел","состояние").show(truncate=False)
df.orderBy(столбец("отдел"),столбец("состояние")).show(truncate=False)
Это возвращает тот же вывод, что и предыдущий раздел.
Сортировка по возрастанию (ASC)
Если вы хотите явно указать восходящий порядок/сортировку в DataFrame, вы можете использовать метод asc функции Column . например
df.sort(df.department.asc(),df.state.asc()).show(truncate=False)
df.sort(col("отдел").asc(),col("состояние").asc()).show(truncate=False)
df.orderBy(col("отдел").asc(),col("состояние").asc()).show(truncate=False)
Приведенные выше три примера возвращают один и тот же результат.
+-------------+----------+-----+------+---+-----+ |employee_name|отдел|штат|зарплата|возраст|премия| +-------------+----------+-----+------+---+-----+ |Мария |Финансы |CA ||24 |23000| |Раман |Финансы |CA |99000 |40 |24000| |Джен |Финансы |NY |79000 |53 |15000| |Скотт |Финансы |NY |83000 |36 |19000| |Джефф |Маркетинг |CA |80000 |25 |18000| |Кумар |Маркетинг |Нью-Йорк |91000 |50 |21000| |Роберт |Продажи |CA |81000 |30 |23000| |Джеймс |Продажи |NY |
|34 |10000| |Майкл |Продажи |NY |86000 |56 |20000| +-------------+----------+-----+------+---+-----+
Сортировка по убыванию (DESC)
Если вы хотите указать сортировку по убыванию в DataFrame, вы можете использовать метод desc функции Column . Например. В нашем примере давайте используем desc для столбца состояния.
Например. В нашем примере давайте используем desc для столбца состояния.
df.sort(df.department.asc(),df.state.desc()).show(truncate=False)
df.sort(col("отдел").asc(),col("состояние").desc()).show(truncate=False)
df.orderBy(col("отдел").asc(),col("состояние").desc()).show(truncate=False)
Это дает приведенный ниже вывод для всех трех примеров.
+-------------+----------+-----+------+---+-----+ |employee_name|отдел|штат|зарплата|возраст|премия| +-------------+----------+-----+------+---+-----+ |Скотт |Финансы |NY |83000 |36 |19000| |Джен |Финансы |NY |79000 |53 |15000| |Раман |Финансы |CA |99000 |40 |24000| |Мария |Финансы |CA ||24 |23000| |Кумар |Маркетинг |Нью-Йорк |91000 |50 |21000| |Джефф |Маркетинг |CA |80000 |25 |18000| |Джеймс |Продажи |Нью-Йорк |
|34 |10000| |Майкл |Продажи |NY |86000 |56 |20000| |Роберт |Продажи |CA |81000 |30 |23000| +-------------+----------+-----+------+---+-----+
Помимо функций asc() и desc() , PySpark также предоставляет asc_nulls_first() и asc_nulls_last() и эквивалентные функции убывания.
Использование необработанного SQL
Ниже приведен пример сортировки DataFrame с использованием синтаксиса необработанного SQL.
df.createOrReplaceTempView("EMP")
spark.sql("выберите имя_сотрудника,отдел,штат,зарплату,возраст,бонус из EMP ORDER BY Department asc").show(truncate=False)
Приведенные выше два примера возвращают тот же результат, что и выше.
Пример завершения сортировки кадров данных
импортировать pyspark
из pyspark.sql импортировать SparkSession
из pyspark.sql.functions импортировать col, asc, desc
искра = SparkSession.builder.appName('SparkByExamples.com').getOrCreate()
simpleData = [("Джеймс","Продажи","Нью-Йорк",,34,10000), \
("Майкл", "Продажи", "Нью-Йорк", 86000,56,20000), \
("Роберт", "Продажи", "CA", 81000,30,23000), \
("Мария","Финанс","ЦА",
,24,23000),\
(«Раман», «Финансы», «ЦА», 99000,40,24000), \
(«Скотт», «Финансы», «Нью-Йорк», 83000,36,19000), \
("Джен", "Финансы", "Нью-Йорк", 79000,53,15000), \
("Джефф", "Маркетинг", "CA", 80000,25,18000), \
("Кумар","Маркетинг","NY",91000,50,21000)\
]
columns= ["имя_сотрудника","отдел","штат","зарплата","возраст","бонус"]
df = spark.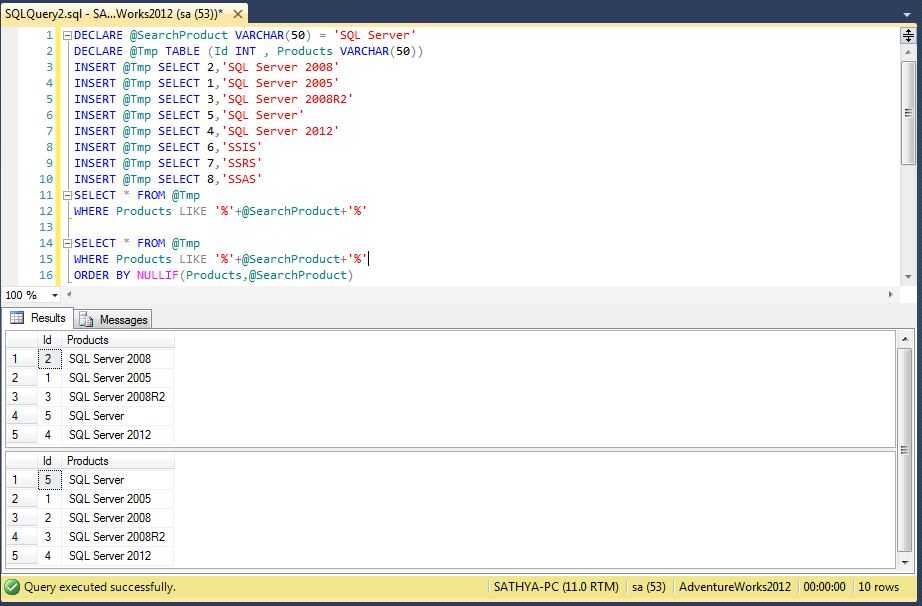 createDataFrame (данные = simpleData, схема = столбцы)
df.printSchema()
df.show (усечение = Ложь)
df.sort ("отдел", "состояние"). показать (truncate = ложь)
df.sort(col("отдел"),col("состояние")).show(truncate=False)
df.orderBy("отдел","состояние").show(truncate=False)
df.orderBy(столбец("отдел"),столбец("состояние")).show(truncate=False)
df.sort(df.department.asc(),df.state.asc()).show(truncate=False)
df.sort(col("отдел").asc(),col("состояние").asc()).show(truncate=False)
df.orderBy(col("отдел").asc(),col("состояние").asc()).show(truncate=False)
df.sort(df.department.asc(),df.state.desc()).show(truncate=False)
df.sort(col("отдел").asc(),col("состояние").desc()).show(truncate=False)
df.orderBy(col("отдел").asc(),col("состояние").desc()).show(truncate=False)
df.createOrReplaceTempView("EMP")
spark.sql("выберите имя_сотрудника,отдел,штат,зарплату,возраст,бонус из EMP ORDER BY Department asc").show(truncate=False)
createDataFrame (данные = simpleData, схема = столбцы)
df.printSchema()
df.show (усечение = Ложь)
df.sort ("отдел", "состояние"). показать (truncate = ложь)
df.sort(col("отдел"),col("состояние")).show(truncate=False)
df.orderBy("отдел","состояние").show(truncate=False)
df.orderBy(столбец("отдел"),столбец("состояние")).show(truncate=False)
df.sort(df.department.asc(),df.state.asc()).show(truncate=False)
df.sort(col("отдел").asc(),col("состояние").asc()).show(truncate=False)
df.orderBy(col("отдел").asc(),col("состояние").asc()).show(truncate=False)
df.sort(df.department.asc(),df.state.desc()).show(truncate=False)
df.sort(col("отдел").asc(),col("состояние").desc()).show(truncate=False)
df.orderBy(col("отдел").asc(),col("состояние").desc()).show(truncate=False)
df.createOrReplaceTempView("EMP")
spark.sql("выберите имя_сотрудника,отдел,штат,зарплату,возраст,бонус из EMP ORDER BY Department asc").show(truncate=False)
Этот полный пример также доступен в проекте PySpark sorting GitHub для справки.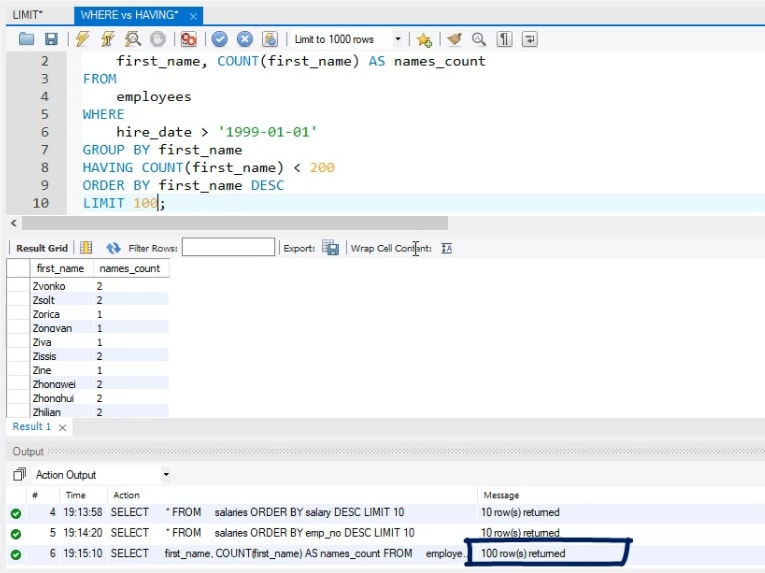
Заключение
Здесь вы узнали, как сортировать столбцы PySpark DataFrame, используя sort() , orderBy() и используя функции сортировки SQL, и использовали эту функцию с PySpark SQL вместе с порядком сортировки по возрастанию и убыванию.
Счастливого обучения!!
SQL ORDER BY DESC
В этом разделе мы описали ORDER BY DESC с подробным примером.
Оператор ORDER BY DESC используется для сортировки данных в результирующем наборе в порядке убывания. Оператор ORDER BY DESC используется в операторе SELECT.
Синтаксис —
SELECT столбец1, столбец2, …, столбецN ОТ имя_таблицы [ ГДЕ состояние ] ORDER BY имя_столбца DESC;
- столбец1, столбец2, …, столбецN — указывает имена столбцов из таблицы.
- имя_таблицы — Указывает имя таблицы.
- имя_столбца — указывает столбец, используемый для выполнения операции ORDER BY DESC.
Пример —
Давайте рассмотрим приведенную ниже таблицу (таблицы) в качестве примера таблицы (таблиц) для создания SQL-запроса для получения желаемых результатов.
employee_details —
| emp_id | emp_name | обозначение | manager_id | date_of_hire | зарплата | dept_id |
|---|---|---|---|---|---|---|
| 001 | Сотрудник1 | Директор | 11.07.2019 | 45000.00 | 1000 | |
| 002 | Сотрудник2 | Директор | 11.07.2019 | 40000.00 | 2000 | |
| 003 | Сотрудник3 | Менеджер | Сотрудник1 | 11.07.2019 | 27000.00 | 1000 |
| 004 | Сотрудник4 | Менеджер | Сотрудник2 | 2019-10-08 | 25000,00 | 2000 |
| 005 | Сотрудник5 | Аналитик | Сотрудник3 | 11.07.2019 | 20000.00 | 1000 |
| 006 | Сотрудник6 | Аналитик | Сотрудник3 | 2019-10-08 | 18000. 00 00 | 1000 |
| 007 | Сотрудник7 | Клерк | Сотрудник3 | 11.07.2019 | 15000.00 | 1000 |
| 008 | Сотрудник8 | Продавец | Сотрудник4 | 09.09.2019 | 14000.00 | 2000 |
| 009 | Сотрудник9 | Продавец | Сотрудник4 | 2019-10-08 | 13000.00 | 2000 |
Сценарий — выборка строк в порядке убывания одного столбца.
Требование — Получить emp_name, manager_id всех сотрудников из таблицы employee_details в порядке убывания manager_id. Запрос был следующим –
ВЫБЕРИТЕ emp_name, manager_id ИЗ employee_details ORDER BY manager_id DESC;
Выполнив вышеуказанный запрос, мы можем получить результаты, как показано ниже —
| emp_name | manager_id |
|---|---|
| Сотрудник9 | Сотрудник4 |
| Сотрудник8 | Сотрудник4 |
| Сотрудник7 | Сотрудник3 |
| Сотрудник6 | Сотрудник3 |
| Сотрудник5 | Сотрудник3 |
| Сотрудник4 | Сотрудник2 |
| Сотрудник3 | Сотрудник1 |
| Сотрудник2 | |
| Сотрудник1 |
Сценарий — выборка строк путем сортировки нескольких строк в порядке убывания.
Требование — Получить все сведения о сотрудниках, чей dept_id равен 2000 и в порядке убывания date_of_hire, зарплаты. Запрос был такой —
ВЫБЕРИТЕ * ИЗ сведения о_сотруднике ГДЕ dept_id = 2000 ЗАКАЗ ПО зарплате DESC, дате_найма DESC;
Выполнив вышеуказанный запрос, мы можем получить результаты, как показано ниже —
| emp_id | emp_name | обозначение | manager_id | date_of_hire | зарплата | dept_id |
|---|---|---|---|---|---|---|
| 002 | Сотрудник2 | Директор | 11.07.2019 | 40000.00 | 2000 | |
| 004 | Сотрудник4 | Менеджер | Сотрудник2 | 2019-10-08 | 25000,00 | 2000 |
| 008 | Сотрудник8 | Продавец | Сотрудник4 | 09.09.2019 | 14000.00 | 2000 |
| 009 | Сотрудник9 | Продавец | Сотрудник4 | 2019-10-08 | 13000. Оставить комментарий
|