Объяснение PySpark orderBy() и sort()
Вы можете использовать функцию sort() или orderBy() PySpark DataFrame для сортировки DataFrame по возрастанию или убыванию на основе одного или нескольких столбцов, вы также можете сделать сортировка с использованием функций сортировки PySpark SQL,
В этой статье я объясню все эти различные способы на примерах PySpark. Обратите внимание, что pyspark.sql.DataFrame.orderBy() является псевдонимом для .sort()
- Использование функции sort()
- Использование функции orderBy()
- По возрастанию
- По убыванию
- Функции сортировки SQL
Связано: Как сортировать DataFrame с помощью Scala
Прежде чем мы начнем, сначала давайте создадим DataFrame.
simpleData = [("Джеймс","Продажи","Нью-Йорк",,34,10000), \
("Майкл", "Продажи", "Нью-Йорк", 86000,56,20000), \
("Роберт", "Продажи", "CA", 81000,30,23000), \
("Мария","Финанс","ЦА",
,24,23000),\
(«Раман», «Финансы», «ЦА», 99000,40,24000), \
(«Скотт», «Финансы», «Нью-Йорк», 83000,36,19000), \
("Джен", "Финансы", "Нью-Йорк", 79000,53,15000), \
("Джефф", "Маркетинг", "CA", 80000,25,18000), \
("Кумар","Маркетинг","NY",91000,50,21000)\
]
columns= ["имя_сотрудника","отдел","штат","зарплата","возраст","бонус"]
df = spark. createDataFrame (данные = simpleData, схема = столбцы)
df.printSchema()
df.show (усечение = Ложь)
createDataFrame (данные = simpleData, схема = столбцы)
df.printSchema()
df.show (усечение = Ложь)
 createDataFrame (данные = simpleData, схема = столбцы)
df.printSchema()
df.show (усечение = Ложь)
createDataFrame (данные = simpleData, схема = столбцы)
df.printSchema()
df.show (усечение = Ложь)
Этот выход ниже выходного.
корень |-- имя_сотрудника: строка (можно обнулить = истина) |-- отдел: строка (nullable = true) |-- состояние: строка (nullable = true) |-- зарплата: целое число (можно обнулить = ложь) |-- возраст: целое число (можно обнулить = ложь) |-- бонус: целое число (можно обнулить = ложь) +-------------+----------+-----+------+---+-----+ |employee_name|отдел|штат|зарплата|возраст|премия| +-------------+----------+-----+------+---+-----+ | Джеймс| Продажи| Нью-Йорк || 34|10000| | Майкл| Продажи| Нью-Йорк | 86000| 56|20000| | Роберт| Продажи| Калифорния| 81000| 30|23000| | Мария| Финансы| Калифорния|
| 24|23000| | Раман | Финансы| Калифорния| 99000| 40|24000| | Скотт| Финансы| Нью-Йорк | 83000| 36|19000| | Джен| Финансы| Нью-Йорк | 79000| 53|15000| | Джефф| Маркетинг| Калифорния| 80000| 25|18000| | Кумар| Маркетинг| Нью-Йорк | 91000| 50|21000| +-------------+----------+-----+------+---+-----+
Сортировка DataFrame с помощью функции sort()
Класс PySpark DataFrame предоставляет функцию sort() для сортировки по одному или нескольким столбцам. По умолчанию он сортируется по возрастанию.
По умолчанию он сортируется по возрастанию.
Синтаксис
sort(self, *cols, **kwargs):
Пример
df.sort ("отдел", "состояние"). показать (truncate = ложь)
df.sort(col("отдел"),col("состояние")).show(truncate=False)
Приведенные выше два примера возвращают один и тот же результат, показанный ниже: первый принимает имя столбца DataFrame в виде строки, а следующий — столбцы типа Column. Эта таблица отсортирована по первым состояния .
+-------------+----------+-----+------+---+-----+ |employee_name|отдел|штат|зарплата|возраст|премия| +-------------+----------+-----+------+---+-----+ |Мария |Финансы |CA ||24 |23000| |Раман |Финансы |CA |99000 |40 |24000| |Джен |Финансы |NY |79000 |53 |15000| |Скотт |Финансы |NY |83000 |36 |19000| |Джефф |Маркетинг |CA |80000 |25 |18000| |Кумар |Маркетинг |Нью-Йорк |91000 |50 |21000| |Роберт |Продажи |CA |81000 |30 |23000| |Джеймс |Продажи |NY |
|34 |10000| |Майкл |Продажи |NY |86000 |56 |20000| +-------------+----------+-----+------+---+-----+
Сортировка DataFrame с использованием функции orderBy()
PySpark DataFrame также предоставляет функцию orderBy() для сортировки по одному или нескольким столбцам.
Пример
df.orderBy("отдел","состояние").show(truncate=False)
df.orderBy(столбец("отдел"),столбец("состояние")).show(truncate=False)
Это возвращает тот же вывод, что и в предыдущем разделе.
Сортировка по возрастанию (ASC)
Если вы хотите явно указать восходящий порядок/сортировку в DataFrame, вы можете использовать метод asc функции Column . например
df.sort(df.department.asc(),df.state.asc()).show(truncate=False)
df.sort(col("отдел").asc(),col("состояние").asc()).show(truncate=False)
df.orderBy(col("отдел").asc(),col("состояние").asc()).show(truncate=False)
Приведенные выше три примера возвращают один и тот же результат.
+-------------+----------+-----+------+---+-----+ |employee_name|отдел|штат|зарплата|возраст|премия| +-------------+----------+-----+------+---+-----+ |Мария |Финансы |CA |
|24 |23000| |Раман |Финансы |CA |99000 |40 |24000| |Джен |Финансы |NY |79000 |53 |15000| |Скотт |Финансы |NY |83000 |36 |19000| |Джефф |Маркетинг |CA |80000 |25 |18000| |Кумар |Маркетинг |Нью-Йорк |91000 |50 |21000| |Роберт |Продажи |CA |81000 |30 |23000| |Джеймс |Продажи |NY | |34 |10000| |Майкл |Продажи |NY |86000 |56 |20000| +-------------+----------+-----+------+---+-----+
Сортировка по убыванию (DESC)
Если вы хотите указать сортировку по убыванию в DataFrame, вы можете использовать метод desc функции Column . например. В нашем примере давайте используем desc для столбца состояния.
например. В нашем примере давайте используем desc для столбца состояния.
df.sort(df.department.asc(),df.state.desc()).show(truncate=False)
df.sort(col("отдел").asc(),col("состояние").desc()).show(truncate=False)
df.orderBy(col("отдел").asc(),col("состояние").desc()).show(truncate=False)
Это дает приведенный ниже вывод для всех трех примеров.
+-------------+----------+-----+------+---+-----+ |employee_name|отдел|штат|зарплата|возраст|премия| +-------------+----------+-----+------+---+-----+ |Скотт |Финансы |NY |83000 |36 |19000| |Джен |Финансы |NY |79000 |53 |15000| |Раман |Финансы |CA |99000 |40 |24000| |Мария |Финансы |CA ||24 |23000| |Кумар |Маркетинг |Нью-Йорк |91000 |50 |21000| |Джефф |Маркетинг |CA |80000 |25 |18000| |Джеймс |Продажи |Нью-Йорк |
|34 |10000| |Майкл |Продажи |NY |86000 |56 |20000| |Роберт |Продажи |CA |81000 |30 |23000| +-------------+----------+-----+------+---+-----+
Помимо функций asc() и desc() , PySpark также предоставляет asc_nulls_first() и asc_nulls_last() и эквивалентные функции убывания.
Использование необработанного SQL
Ниже приведен пример сортировки DataFrame с использованием синтаксиса необработанного SQL.
df.createOrReplaceTempView("EMP")
spark.sql("выберите имя_сотрудника,отдел,штат,зарплату,возраст,бонус из EMP ORDER BY Department asc").show(truncate=False)
Приведенные выше два примера возвращают тот же результат, что и выше.
Пример завершения сортировки кадров данных
импортировать pyspark
из pyspark.sql импортировать SparkSession
из pyspark.sql.functions импортировать col, asc, desc
искра = SparkSession.builder.appName('SparkByExamples.com').getOrCreate()
simpleData = [("Джеймс","Продажи","Нью-Йорк",,34,10000), \
("Майкл", "Продажи", "Нью-Йорк", 86000,56,20000), \
("Роберт", "Продажи", "CA", 81000,30,23000), \
("Мария","Финанс","ЦА",
,24,23000),\
(«Раман», «Финансы», «ЦА», 99000,40,24000), \
(«Скотт», «Финансы», «Нью-Йорк», 83000,36,19000), \
("Джен", "Финансы", "Нью-Йорк", 79000,53,15000), \
("Джефф", "Маркетинг", "CA", 80000,25,18000), \
("Кумар","Маркетинг","NY",91000,50,21000)\
]
columns= ["имя_сотрудника","отдел","штат","зарплата","возраст","бонус"]
df = spark. createDataFrame (данные = simpleData, схема = столбцы)
df.printSchema()
df.show (усечение = Ложь)
df.sort ("отдел", "состояние"). показать (truncate = ложь)
df.sort(col("отдел"),col("состояние")).show(truncate=False)
df.orderBy("отдел","состояние").show(truncate=False)
df.orderBy(столбец("отдел"),столбец("состояние")).show(truncate=False)
df.sort(df.department.asc(),df.state.asc()).show(truncate=False)
df.sort(col("отдел").asc(),col("состояние").asc()).show(truncate=False)
df.orderBy(col("отдел").asc(),col("состояние").asc()).show(truncate=False)
df.sort(df.department.asc(),df.state.desc()).show(truncate=False)
df.sort(col("отдел").asc(),col("состояние").desc()).show(truncate=False)
df.orderBy(col("отдел").asc(),col("состояние").desc()).show(truncate=False)
df.createOrReplaceTempView("EMP")
spark.sql("выберите имя_сотрудника,отдел,штат,зарплату,возраст,бонус из EMP ORDER BY Department asc").show(truncate=False)
createDataFrame (данные = simpleData, схема = столбцы)
df.printSchema()
df.show (усечение = Ложь)
df.sort ("отдел", "состояние"). показать (truncate = ложь)
df.sort(col("отдел"),col("состояние")).show(truncate=False)
df.orderBy("отдел","состояние").show(truncate=False)
df.orderBy(столбец("отдел"),столбец("состояние")).show(truncate=False)
df.sort(df.department.asc(),df.state.asc()).show(truncate=False)
df.sort(col("отдел").asc(),col("состояние").asc()).show(truncate=False)
df.orderBy(col("отдел").asc(),col("состояние").asc()).show(truncate=False)
df.sort(df.department.asc(),df.state.desc()).show(truncate=False)
df.sort(col("отдел").asc(),col("состояние").desc()).show(truncate=False)
df.orderBy(col("отдел").asc(),col("состояние").desc()).show(truncate=False)
df.createOrReplaceTempView("EMP")
spark.sql("выберите имя_сотрудника,отдел,штат,зарплату,возраст,бонус из EMP ORDER BY Department asc").show(truncate=False)
Этот полный пример также доступен в проекте PySpark sorting GitHub для справки.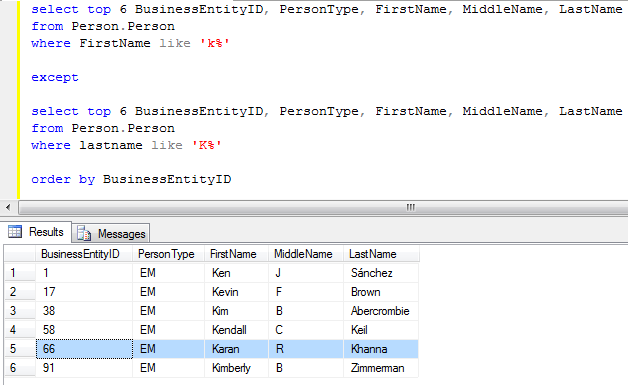
Заключение
Здесь вы узнали, как сортировать столбцы PySpark DataFrame, используя sort() , orderBy() и используя функции сортировки SQL, и использовали эту функцию с PySpark SQL вместе с порядком сортировки по возрастанию и убыванию.
Счастливого обучения!!
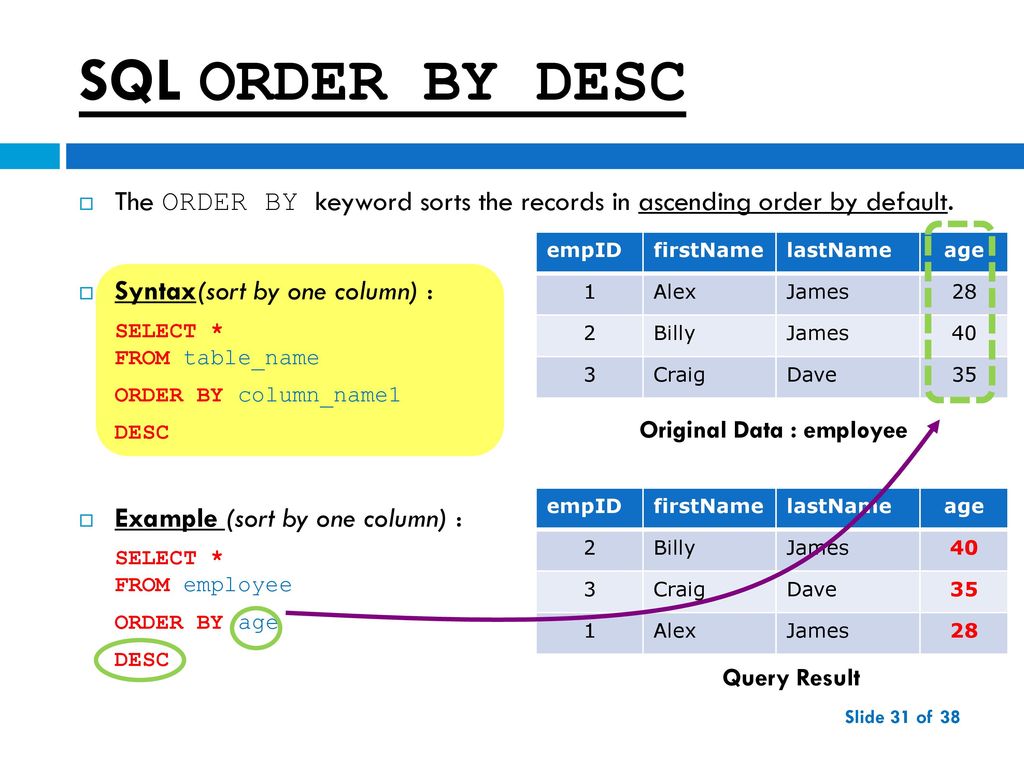
SQL ORDER BY Пункт
Предложение ORDER BY можно использовать в запросе SELECT для сортировки результата по возрастанию или убыванию одного или нескольких столбцов.
Синтаксис:
ВЫБЕРИТЕ столбец1, столбец2,... столбецN ОТ имя_таблицы [ГДЕ] [ГРУППА ПО] [ИМЕЮЩИЙ] [ORDER BY столбцы [ASC|DESC]]
- Предложение ORDER BY используется для получения отсортированных записей по одному или нескольким столбцам в порядке возрастания или убывания.
- Предложение ORDER BY должно стоять после предложений WHERE, GROUP BY и HAVING, если они присутствуют в запросе.

- Используйте ASC или DESC, чтобы указать порядок сортировки после имени столбца. Используйте ASC для сортировки записей по возрастанию или используйте DESC для убывания. По умолчанию предложение ORDER BY сортирует записи в порядке возрастания, если порядок не указан.
Для демонстрационных целей мы будем использовать следующий Сотрудник во всех примерах.
| Эмпирид | Имя | Фамилия | Электронная почта | Телефон № | Зарплата | ИД отдела |
|---|---|---|---|---|---|---|
| 1 | ‘Джон’ | ‘[электронная почта защищена]’ | ‘650. 127.1834′ 127.1834′ | 33000 | 1 | |
| 2 | ‘Джеймс’ | «Бонд» | 1 | |||
| 3 | ‘Нина’ | ‘Кочхар’ | ‘[электронная почта защищена]’ | ‘123.456.4568’ | 17000 | 2 |
| 4 | ‘Лекс’ | ‘Де Хаан’ | ‘[электронная почта защищена]’ | ‘123.000.4569’ | 15000 | 1 |
| 5 | ‘Амит’ | ‘Патель’ | 18000 | 1 | ||
| 6 | ‘Абдул’ | ‘Калам’ | ‘[электронная почта защищена]’ | ‘123. 123.0000′ 123.0000′ | 25000 | 2 |
Следующий запрос извлечет все записи из таблицы Сотрудник и отсортирует результат в порядке возрастания значений Имя .
ВЫБЕРИТЕ * ОТ Сотрудника ЗАКАЗАТЬ ПО Имени;
| Эмпирид | Имя | Фамилия | Электронная почта | Телефон № | Зарплата | ИД отдела |
|---|---|---|---|---|---|---|
| 6 | ‘Абдул’ | ‘Калам’ | ‘[электронная почта защищена]’ | ‘123.123.0000’ | 25000 | 2 |
| 5 | ‘Амит’ | ‘Патель’ | 18000 | 1 | ||
| 2 | ‘Джеймс’ | «Бонд» | 1 | |||
| 1 | ‘Джон’ | ‘Король’ | ‘[электронная почта защищена]’ | ‘650. 127.1834′ 127.1834′ | 33000 | 1 |
| 4 | ‘Лекс’ | ‘Де Хаан’ | ‘[электронная почта защищена]’ | ‘123.456.4569’ | 15000 | 1 |
| 3 | ‘Нина’ | ‘Кочхар’ | ‘[электронная почта защищена]’ | ‘123.456.4568’ | 17000 | 2 |
Следующий запрос вернет строки в порядке убывания значения Имя .
ВЫБЕРИТЕ EmpId, Имя, Фамилию ОТ Сотрудника ЗАКАЗАТЬ ПО ИМЕНИ DESC;
| Эмпирид | Имя | Фамилия |
|---|---|---|
| 3 | ‘Нина’ | ‘Кочхар’ |
| 4 | ‘Лекс’ | ‘Де Хаан’ |
| 1 | ‘Джон’ | ‘Король’ |
| 2 | ‘Джеймс’ | «Бонд» |
| 5 | ‘Амит’ | ‘Патель’ |
| 6 | ‘Абдул’ | ‘Калам’ |
Сортировка по нескольким столбцам
Предложение ORDER BY может включать несколько столбцов в разном порядке сортировки (по возрастанию или по убыванию). Когда вы включаете несколько столбцов с предложением ORDER BY, оно сортирует записи на основе первого столбца, и если любые две или более записей имеют одинаковое значение в первом столбце ORDER BY, они сортируются по второму столбцу ORDER BY. .
Когда вы включаете несколько столбцов с предложением ORDER BY, оно сортирует записи на основе первого столбца, и если любые две или более записей имеют одинаковое значение в первом столбце ORDER BY, они сортируются по второму столбцу ORDER BY. .
Чтобы понять это, сначала отсортируйте результат по столбцу DeptId , как показано ниже.
ВЫБЕРИТЕ * ОТ Сотрудника ЗАКАЗАТЬ ПО DeptId;
Приведенный выше запрос выдаст следующий результат.
| Эмпирид | Имя | Фамилия | Телефон № | Дата найма | Зарплата | ИД отдела |
|---|---|---|---|---|---|---|
| 1 | ‘Джон’ | ‘Король’ | ‘[электронная почта защищена]’ | ‘650.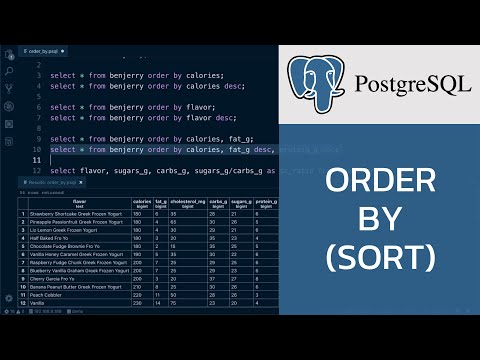 127.1834′ 127.1834′ | 33000 | 1 |
| 2 | ‘Джеймс’ | «Бонд» | 1 | |||
| 4 | ‘Лекс’ | ‘Де Хаан’ | ‘[электронная почта защищена]’ | ‘123.000.4569’ | 15000 | 1 |
| 5 | ‘Амит’ | ‘Патель’ | 18000 | 1 | ||
| 3 | ‘Нина’ | ‘Кочхар’ | ‘[электронная почта защищена]’ | ‘123. 456.4568′ 456.4568′ | 17000 | 2 |
| 6 | ‘Абдул’ | ‘Калам’ | ‘[электронная почта защищена]’ | ‘123.123.0000’ | 25000 | 2 |
Теперь включите столбец FirstName в предложение ORDER BY.
ВЫБЕРИТЕ * ОТ Сотрудника ЗАКАЗАТЬ ПО DeptId, Имя;
Приведенный выше запрос сначала отсортирует результат по DeptId , а затем строки с одинаковым DeptId будут отсортированы по FirstName . Помните, что мы не включили ASC или DESC, поэтому по умолчанию результат будет отсортирован в порядке возрастания, как показано ниже.
| Эмпирид | Имя | Фамилия | Телефон № | Дата найма | Зарплата | ИД отдела |
|---|---|---|---|---|---|---|
| 5 | ‘Амит’ | ‘Патель’ | 18000 | 1 | ||
| 2 | ‘Джеймс’ | «Бонд» | 1 | |||
| 1 | ‘Джон’ | ‘Король’ | ‘[электронная почта защищена]’ | ‘650. 127.1834′ 127.1834′ | 33000 | 1 |
| 4 | ‘Лекс’ | ‘Де Хаан’ | ‘[электронная почта защищена]’ | ‘123.000.4569’ | 15000 | 1 |
| 6 | ‘Абдул’ | ‘Калам’ | ‘[электронная почта защищена]’ | ‘123.123.0000’ | 25000 | 2 |
| 3 | ‘Нина’ | ‘Кочхар’ | ‘[электронная почта защищена]’ | ‘123.456.4568’ | 17000 | 2 |
Сортировка группы записей
Следующий запрос сортирует группу записей.