postgresql — ORDER BY ASC в 300 раз быстрее, чем ORDER BY DESC
Задавать вопрос
спросил
Изменено 4 года, 7 месяцев назад
Просмотрено 773 раза
Сортировка по возрастанию в 300 раз быстрее, чем сортировка по убыванию для столбца с индексом B-Tree.
У меня есть таблица около 20 миллионов строк.
У меня есть индексы по столбцам insert_at и x .
Сортировка по возрастанию
выбрать
* из table_a где
a.insert_at >= '2018-09-01 00:00:00.0' и a.x in ('some_x_val')
порядок по a.inserted_at по возрастанию
смещение 0 предел 20;
Лимит (стоимость=0,44..2027,69 рядов=20 ширина=51) (фактическое время=418,529..464,558 рядов=20 петель=1)
-> Сканирование индекса с использованием table_a_inserted_at_index в table_a a (стоимость = 0,44.
.5406390,18 строк = 53337 ширина = 51) (фактическое время = 418,527..464,543 строк = 20 циклов = 1)
Состояние индекса: (inserted_at >= '2018-09-01 00:00:00'::отметка времени без часового пояса)
Фильтр: (event_type_id = ''some_x_val'::uuid)
Строки, удаленные фильтром: 4092
Время планирования: 0,177 мс
Время выполнения: 464,596 мс
объяснить (анализировать, подробно, буферы) select * from table_a a, где a.inserted_at >= '2018-09-01 00:00:00.0' и a.x в порядке ('some_x_val') на a.inserted_at asc offset 0 limit 20;
ПЛАН ЗАПРОСА
-------------------------------------------------- -------------------------------------------------- -------------------------------------------------- --------
Лимит (стоимость=0,44..2027,77 рядов=20 ширина=51) (фактическое время=527,032..575,516 рядов=20 петель=1)
Выход: х, у, г
Буферы: общий хит=2492 чтения=905
-> Сканирование индекса с использованием table_a_inserted_at_index в public. table_a a (стоимость = 0,44..5406596,96 строк = 53337 ширина = 51) (фактическое время = 527,029..575,496 строк = 20 циклов = 1)
Выход: х, у, г
Index Cond: (a.insert_at >= '2018-09-01 00:00:00'::timestamp без часового пояса)
Фильтр: (a.x = 'some_x_val'::uuid)
Строки, удаленные фильтром: 4092
Буферы: общее попадание=2492 чтение=905
Время планирования: 0,162 мс
Время выполнения: 575,550 мс
table_a a (стоимость = 0,44..5406596,96 строк = 53337 ширина = 51) (фактическое время = 527,029..575,496 строк = 20 циклов = 1)
Выход: х, у, г
Index Cond: (a.insert_at >= '2018-09-01 00:00:00'::timestamp без часового пояса)
Фильтр: (a.x = 'some_x_val'::uuid)
Строки, удаленные фильтром: 4092
Буферы: общее попадание=2492 чтение=905
Время планирования: 0,162 мс
Время выполнения: 575,550 мс

Сортировка по убыванию
выбрать
* из table_a где
a.insert_at >= '2018-09-01 00:00:00.0' и a.x in ('some_x_val')
заказ по a.insert_at desc
смещение 0 предел 20;
Лимит (стоимость=0,44..2027,69 рядов=20 ширина=51) (фактическое время=148377,757..148385,703 рядов=20 петель=1)
-> Сканирование индекса в обратном направлении с использованием table_a_inserted_at_index в table_a a (стоимость = 0,44..5406383,67 строк = 53337 ширина = 51) (фактическое время = 148377,756..148385,691 строк = 20 циклов = 1)
Index Cond: (inserted_at > = '2018-09-01 00:00:00'::timestamp без часового пояса)
Фильтр: (x = 'some_x_val'::uuid)
Строки, удаленные фильтром: 2737952
Время планирования: 0,663 мс
Время выполнения: 148385,756 мс
объяснить (анализировать, подробно, буферы) select * from table_a a, где a.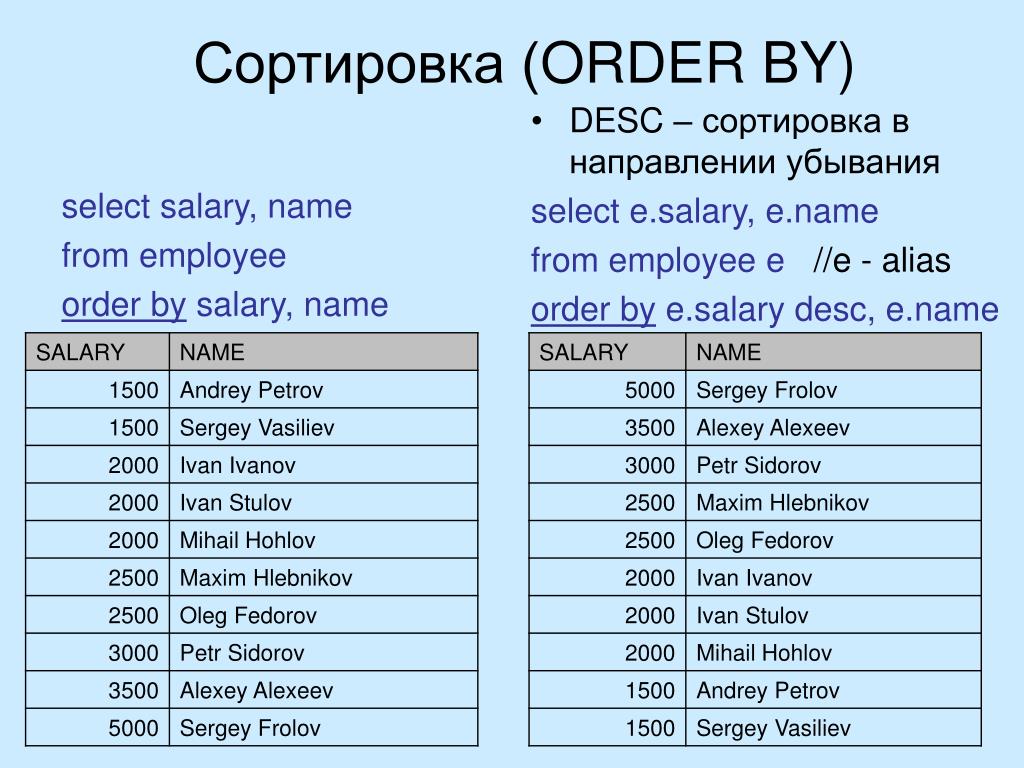 inserted_at >= '2018-09-01 00:00:00.0' и a.x в порядке ('some_x_val') на a.inserted_at desc offset 0 limit 20;
ПЛАН ЗАПРОСА
-------------------------------------------------- -------------------------------------------------- -------------------------------------------------- -----------------------
Лимит (стоимость=0,44..2027,77 строк=20 ширина=51) (фактическое время=168306,377..168312,296 рядов=20 петель=1)
Выход: х, у, г
Буферы: общее попадание = 2439002 чтение = 359523 загрязнение = 288
-> Сканирование индекса в обратном направлении с использованием table_a_inserted_at_index в public.table_a a (стоимость = 0,44..5406596,96 строк = 53337 ширина = 51) (фактическое время = 168306,375..168312,282 строк = 20 циклов = 1)
Выход: х, у, г
Index Cond: (a.insert_at >= '2018-09-01 00:00:00'::timestamp без часового пояса)
Фильтр: (a.x = 'some_x_val'::uuid)
Строки, удаленные фильтром: 2745418
Буферы: общий хит=2439002 прочитано=359523 загажено=288
Время планирования: 0,139 мс
Время выполнения: 168312,326 мс
inserted_at >= '2018-09-01 00:00:00.0' и a.x в порядке ('some_x_val') на a.inserted_at desc offset 0 limit 20;
ПЛАН ЗАПРОСА
-------------------------------------------------- -------------------------------------------------- -------------------------------------------------- -----------------------
Лимит (стоимость=0,44..2027,77 строк=20 ширина=51) (фактическое время=168306,377..168312,296 рядов=20 петель=1)
Выход: х, у, г
Буферы: общее попадание = 2439002 чтение = 359523 загрязнение = 288
-> Сканирование индекса в обратном направлении с использованием table_a_inserted_at_index в public.table_a a (стоимость = 0,44..5406596,96 строк = 53337 ширина = 51) (фактическое время = 168306,375..168312,282 строк = 20 циклов = 1)
Выход: х, у, г
Index Cond: (a.insert_at >= '2018-09-01 00:00:00'::timestamp без часового пояса)
Фильтр: (a.x = 'some_x_val'::uuid)
Строки, удаленные фильтром: 2745418
Буферы: общий хит=2439002 прочитано=359523 загажено=288
Время планирования: 0,139 мс
Время выполнения: 168312,326 мс
В чем может быть проблема?
- postgresql
- производительность
- postgresql-10
- сортировка
- postgresql-производительность
1
Я думаю, что проблема двоякая (или троекратная):
- отсутствует составной индекс в обоих отфильтрованных столбцах:
(x, insert_at) - неравномерное распределение
- старая статистика
Фильтр: (a.x = 'some_x_val'::uuid) Строки, удаленные фильтром: 2745418
Необычное распределение означает, что однократное сканирование индекса должно проделать большую работу, чтобы удалить строки, которые не соответствуют второму фильтру (по другому столбцу ( x )). Сканирование индекса для ORDER BY ASC просто повезло и находит 20 строк немного быстрее, только по счастливой случайности. С другими значениями в параметрах 9 могло быть и наоборот.0014 insert_at
x Таким образом, лучший способ решить эту проблему — добавить составной индекс. Вы можете последовать совету Эрвина по связанному вопросу и ответу, чтобы обновить статистику в таблице, но это может помочь решить проблему или нет. Это не точно.
0
Зарегистрируйтесь или войдите в систему
Зарегистрируйтесь с помощью Google
Зарегистрироваться через Facebook
Зарегистрируйтесь, используя адрес электронной почты и пароль
Опубликовать как гость
Электронная почта
Требуется, но не отображается
Опубликовать как гость
Требуется, но не отображается
Нажимая «Опубликовать свой ответ», вы соглашаетесь с нашими условиями обслуживания, политикой конфиденциальности и политикой использования файлов cookie
.
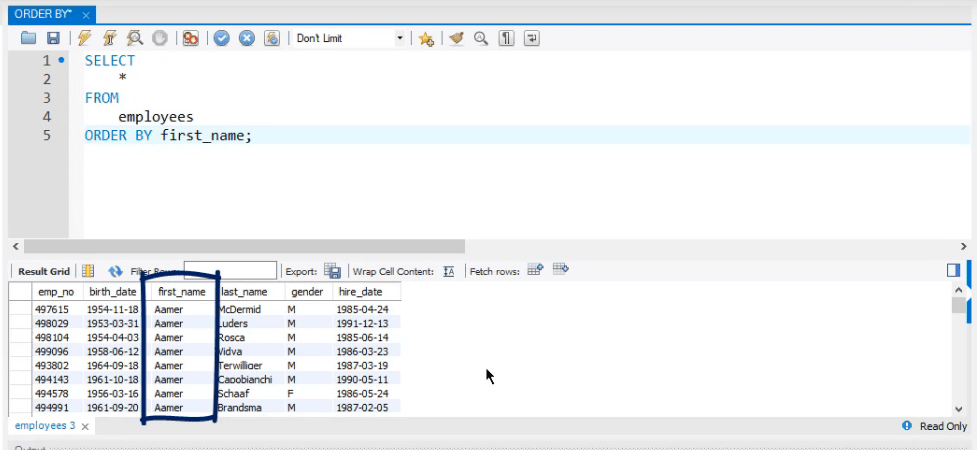
Использование предложений WHERE и ORDER BY в SQL
При выполнении запроса SELECT без каких-либо параметров сортировки сервер SQL возвращает записи в произвольном порядке. В большинстве случаев SQL-сервер возвращает записи в том же порядке, в котором они добавляются в базу данных. Нет гарантии, что записи будут возвращены в определенном порядке, если вы не используете параметры сортировки в SQL. В дополнение к сортировке вы также используете параметры фильтрации, чтобы возвращать только определенные записи, соответствующие вашим требованиям.
Сортировка записей
SQL использует оператор ORDER BY для сортировки записей. Вы можете сортировать записи по возрастанию или убыванию, а также сортировать записи по нескольким столбцам. SQL позволяет сортировать в алфавитном, числовом или хронологическом порядке.
Например, предположим, что вы хотите получить список своих клиентов, и вам нужен список в алфавитном порядке по штатам. Ниже приведен ваш текущий список клиентов.
Ниже приведен ваш текущий список клиентов.
идентификатор клиента | Имя | Фамилия | Город | Состояние |
321 | Фрэнк | Лоэ | Даллас | ТХ |
455 | Эд | Томпсон | Атланта | Г.А. |
456 | Эд | Томпсон | Атланта | Г.А. |
457 | Джо | Смит | Майами | FL |
458 | Фрэнк | Доу | Даллас | ТХ |
Если у вас тысячи клиентов и вы хотите просмотреть список клиентов в определенном состоянии без исключения других состояний, было бы слишком сложно просмотреть ваши данные без какой-либо возможности сортировки. Вы можете отсортировать данные по состоянию, используя следующую инструкцию SQL.
Вы можете отсортировать данные по состоянию, используя следующую инструкцию SQL.
SELECT * FROM Customer
ORDER BY State
В приведенном выше выражении ваши данные возвращаются и сортируются в алфавитном порядке по штатам. Данные сортируются в порядке возрастания. Восходящий порядок установлен по умолчанию, но вы также можете добавить ключевое слово «ASC» в свое заявление. Следующая инструкция SQL аналогична приведенной выше инструкции.
SELECT * FROM Customer
ORDER BY State ASC
Обратите внимание, что разница заключается в ASC, поскольку он подразумевается, когда вы исключаете его из операторов SQL.
Ваши данные по-прежнему хранятся без сортировки, но оператор SELECT показывает вам следующий набор данных.
идентификатор клиента | Имя | Фамилия | Город | Состояние |
457 | Джо | Смит | Майами | FL |
455 | Эд | Томпсон | Атланта | Г. |
456 | Эд | Томпсон | Атланта | Г.А. |
321 | Фрэнк | Лоэ | Даллас | ТХ |
458 | Фрэнк | Доу | Даллас | ТХ |
 А.
А.Вы также можете перечислить данные в порядке убывания. Ключевое слово DESC или DESCENDING перечисляет данные в порядке убывания. Взяв тот же набор данных, который вы использовали для отчета о заказе ASC, давайте поменяем местами клиентов. Следующий код показывает, как вы пишете оператор DESC SQL.
SELECT * FROM Customer
ORDER BY State DESC
SQL позволяет упорядочивать записи на основе нескольких столбцов. Например, вы можете отсортировать записи по состоянию, а затем по фамилии. В результате вы получите список людей, сгруппированных по состоянию клиента, а затем упорядоченных по их фамилиям. Вы разделяете столбцы, добавляя запятую, а затем добавляя другой параметр столбца в операторе ORDER BY. Следующая инструкция SQL является примером.
В результате вы получите список людей, сгруппированных по состоянию клиента, а затем упорядоченных по их фамилиям. Вы разделяете столбцы, добавляя запятую, а затем добавляя другой параметр столбца в операторе ORDER BY. Следующая инструкция SQL является примером.
ВЫБЕРИТЕ * ОТ Заказчика
ORDER BY State DESC, Last_name ASC
Фраза ASC используется в приведенном выше заявлении для ясности. Когда вы читаете заявление, вы знаете, что ваш набор записей упорядочен в порядке убывания, а затем упорядочен в порядке возрастания по фамилии. Ваш набор данных превращается в следующее.
идентификатор клиента | Имя | Фамилия | Город | Состояние |
457 | Джо | Смит | Майами | FL |
455 | Эд | Томпсон | Атланта | Г. |
456 | Эд | Томпсон | Атланта | Г.А. |
458 | Фрэнк | Доу | Даллас | ТХ |
321 | Фрэнк | Лоэ | Даллас | ТХ |
 А.
А.Запись уведомления номер 321 и 458 поменялись местами, так как фамилии были отсортированы по состоянию.
Фильтрация записей и WHERE
Мы использовали предложение WHERE несколько раз, чтобы показать вам, как фильтровать записи при использовании операторов SELECT, UPDATE и DELETE. Вы можете использовать предложение WHERE с оператором ORDER BY или без него. Вы можете фильтровать записи по конечным значениям, значениям сравнения или с помощью операторов sub-SELECT. Предложение WHERE дает вам несколько вариантов фильтрации данных.
Мы использовали несколько примеров со знаком равенства (=). Вы также можете использовать сравнения. Например, вам может понадобиться получить список клиентов с идентификаторами от 300 до 400. Эти значения отображаются в следующей инструкции SQL.
SELECT * FROM Customer
WHERE CustomerId >=200 AND CustomerId <= 300
ORDER BY State
Обратите внимание, что используются фразы >= и <=. Знак равенства включает значения, находящиеся справа от них. Другими словами, в поиск включены 200 и 300. В этом примере таблицы Customer нет ни 200, ни 300, поэтому эти значения не возвращаются. Обратите внимание, что синтаксис также включает в себя «И» в операторе SQL. Ключевое слово AND включает фильтр из следующего оператора SQL, в данном случае это «Клиент <= 300». Когда вы используете ключевое слово AND, вы указываете оператору SQL фильтровать записи с обоими параметрами.
Приведенный выше оператор SELECT возвращает следующий набор данных.
идентификатор клиента | Имя | Фамилия | Город | Состояние |
321 | Фрэнк | Лоэ | Даллас | ТХ |
В нашем примере таблица Customer имеет только одну запись в заданном диапазоне.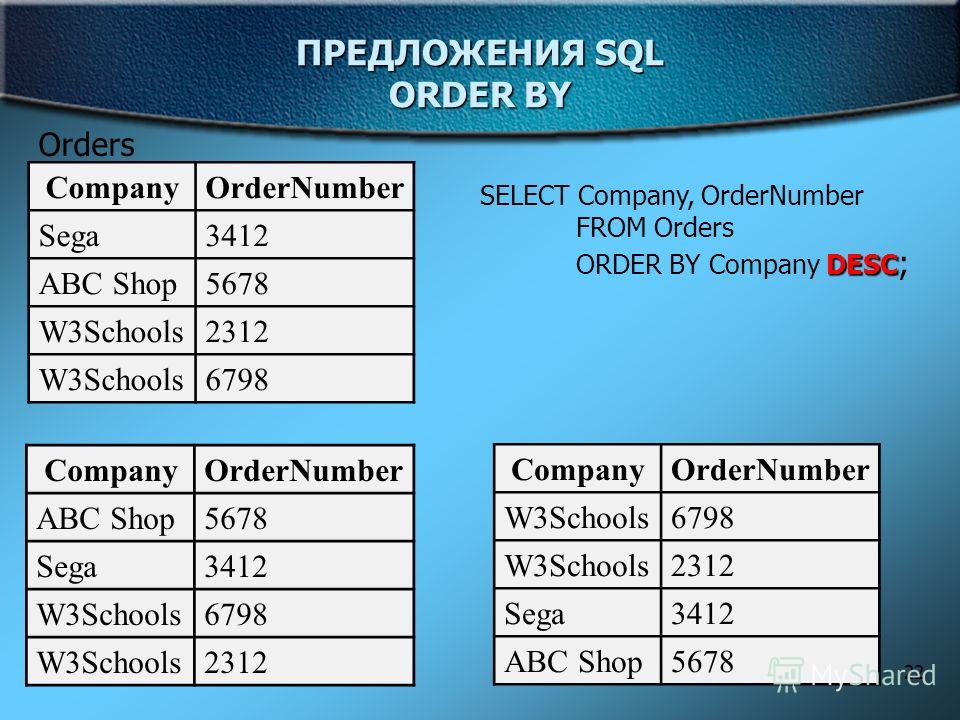
В предложении WHERE можно использовать фразу ИЛИ вместо фразы И. В следующем операторе И заменяется на ИЛИ.
SELECT * FROM Customer
WHERE CustomerId >=200 ИЛИ CustomerId <= 300
ORDER BY State
В приведенном выше заявлении говорится: «вернуть всех клиентов с идентификатором больше 200 или идентификатором меньше 300». Приведенный выше оператор SELECT возвращает следующие результаты.
идентификатор клиента | Имя | Фамилия | Город | Состояние |
457 | Джо | Смит | Майами | FL |
455 | Эд | Томпсон | Атланта | Г.А. |
456 | Эд | Томпсон | Атланта | Г. |
321 | Фрэнк | Лоэ | Даллас | ТХ |
458 | Фрэнк | Доу | Даллас | ТХ |
 А.
А.Обратите внимание, что все записи были возвращены. Чтобы понять, почему возвращаются все записи, вы должны разбить предложение WHERE на части. Первая часть — «CustomerId >=200». Все ваши записи имеют идентификатор выше 200, поэтому первая часть вашего предложения WHERE возвращает все записи.
Следующей частью является оператор ИЛИ, который является важным отличием от оператора И. Оператор OR говорит сохранить исходный набор данных, но также вернуть клиентов с идентификатором меньше 300. У вас нет клиентов с идентификатором меньше 300, поэтому вторая часть не возвращает записей. Трудная для понимания часть этого оператора SQL заключается в том, почему первый оператор с И возвращает 1 запись, а второй возвращает все записи. Оператор AND говорит, что вторая часть вашего предложения WHERE также должна применяться, поэтому ваши записи должны отвечать true для обоих условий. Второй оператор SQL возвращает записи, которые возвращают истину для или первое условие или второе условие. Логика этих двух утверждений совершенно разная. Поскольку все ваши записи соответствуют первому условию, оператор OR позволяет этим записям проходить и отображаться в результатах.
Оператор AND говорит, что вторая часть вашего предложения WHERE также должна применяться, поэтому ваши записи должны отвечать true для обоих условий. Второй оператор SQL возвращает записи, которые возвращают истину для или первое условие или второе условие. Логика этих двух утверждений совершенно разная. Поскольку все ваши записи соответствуют первому условию, оператор OR позволяет этим записям проходить и отображаться в результатах.
Оператор IN использовался в предыдущих главах, но вы также можете указать значения, которые хотите вернуть в своем операторе IN. В предыдущих главах использовался запрос sub-SELECT. Вы также можете использовать IN для указания таких значений, как состояние, которое вы хотите вернуть. Следующая инструкция SQL является примером.
SELECT * FROM Customer
WHERE State IN («tx», «fl»)
Фраза IN упрощает чтение кода SQL вместо использования оператора ИЛИ. В приведенном выше заявлении говорится: «получить всех клиентов, состояние которых равно TX ИЛИ FL. В следующей таблице приведены ваши результаты.
В следующей таблице приведены ваши результаты.
идентификатор клиента | Имя | Фамилия | Город | Состояние |
321 | Фрэнк | Лоэ | Даллас | ТХ |
457 | Джо | Смит | Майами | FL |
458 | Фрэнк | Доу | Даллас | ТХ |
Сложность предложения WHERE возрастает по мере того, как вы используете больше условий.
Даты обычно используются в операторах SQL. Пример таблицы не содержит дат, но представьте, что в таблице есть столбец даты с именем «SignupDate». В столбце SignupDate указано, когда клиент зарегистрировался на вашем веб-сайте. Затем вы можете запускать отчеты на основе даты, когда клиент зарегистрировался на вашем сайте. Следующий код является примером.
В столбце SignupDate указано, когда клиент зарегистрировался на вашем веб-сайте. Затем вы можете запускать отчеты на основе даты, когда клиент зарегистрировался на вашем сайте. Следующий код является примером.
SELECT * FROM Customer
WHERE SignupDate МЕЖДУ «1/1/2014» И «31/12/2014»
ORDER BY State
Приведенный выше оператор SQL получает записи, имеющие дату между первым днем года в 2014 и последний день года. Со значениями даты SQL включает даты, перечисленные в параметрах. Приведенное выше утверждение также можно записать следующим образом.
SELECT * FROM Customer
WHERE SignupDate >= ‘1/1/2014’ AND SignupDate <= ‘31/12/2014’
ORDER BY State
Предложение WHERE позволяет использовать оператор LIKE. Вы используете оператор LIKE, когда вам нужен список клиентов на основе части значений. Например, предположим, что у вас есть несколько клиентов в Далласе, но также есть клиенты в городах, названия которых начинаются с «Да», и вам необходимо их увидеть.