аргументы Марии Бурас и Максима Кронгауза
добавлен в корзину
type.today
ЖурналКириллический, а не кирилловский:аргументы Марии Бурас и Максима Кронгауза
Кириллица
Русскоязычное шрифтовое сообщество спорит о словоупотреблении: наши коллеги из журнала «Шрифт» считают, что вместо слова «кириллический» в некоторых случаях следует говорить «кирилловский», а многие с этим не соглашаются. Мы попросили лингвистов Марию Бурас и Максима Кронгауза высказать свое профессиональное мнение
29 сентября 2020 г.
- Мария Бурас
- Лингвист, журналист
- Максим Кронгауз
- Лингвист, профессор НИУ ВШЭ и РГГУ
Казалось бы, сугубо дизайнерский спор о словах кириллический и кирилловский Речь идёт о сочетании этих прилагательных со словами, связанными с двумя славянскими азбуками. Прочих сочетаний прилагательного кирилловский, например Кирилловский монастырь или Кирилловская улица, мы вообще не касаемся. представляет безусловный филологический, а точнее, даже лингвистический интерес. Почему вдруг в одном профессиональном сообществе решают заменить привычное слово на непривычное? Честно говоря, ни исторические, ни логические аргументы, приводимые в пользу этой замены, не выдерживают критики. Более того, квалицированное мнение филолога Сергея Монахова, высказавшегося против такой замены, даже не игнорируется, а как бы выворачивается наизнанку и приводится в качестве аргумента за.
Прочих сочетаний прилагательного кирилловский, например Кирилловский монастырь или Кирилловская улица, мы вообще не касаемся. представляет безусловный филологический, а точнее, даже лингвистический интерес. Почему вдруг в одном профессиональном сообществе решают заменить привычное слово на непривычное? Честно говоря, ни исторические, ни логические аргументы, приводимые в пользу этой замены, не выдерживают критики. Более того, квалицированное мнение филолога Сергея Монахова, высказавшегося против такой замены, даже не игнорируется, а как бы выворачивается наизнанку и приводится в качестве аргумента за.
Мы ещё вернёмся к этому, а пока просто приведём аргументы в пользу прилагательного кириллический.
Во-первых, оно соответствует более чем вековой традиции.
Вот пример из переписки великих славистов:
Смущают меня только кириллические юсы, предполагающие довольно продолжительный промежуток времени между изобретением глаголицы и изобретением кириллицы… Н. С. Трубецкой
С. Трубецкой
Письма H. H. Дурново (1925)
Во-вторых, прилагательное кириллический имеет прекрасную поддержку со стороны прилагательного глаголический, то есть составляет с ним пару прилагательных, образованных от пары существительных, обозначающих соответствующие алфавиты: кириллица и глаголица. Прилагательное кирилловский из этого ряда выбивается.
Наконец, в-третьих, имеется и логический аргумент. Его, в частности, приводит Сергей Монахов:
Упрощая, можно сказать, что главное смысловое различие между суффиксами -овск- и -ическ- при образовании с их помощью прилагательных от имён собственных заключается в том, что первый указывает непосредственно на деятеля, а второй — на некую абстрактную идею, с именем этого деятеля связанную.
Эту же мысль можно сформулировать и несколько иначе: прилагательное кирилловский отсылает к Кириллу непосредственно, а кириллический опосредованно — через кириллицу. Непосредственная отсылка к Кириллу была бы оправданна, если бы он изобрёл кириллицу, но сегодня практически всё научное сообщество считает иначе: Кирилл создал глаголицу, кириллица же появилась значительно позже и была создана учениками Кирилла и Мефодия, возможно Климентом Охридским. К сожалению, это мнение окончательно утвердилось в науке довольно поздно — в начале XX века, но Трубецкой в 1925 году (см. цитату выше) говорит об этом с абсолютной уверенностью.
Непосредственная отсылка к Кириллу была бы оправданна, если бы он изобрёл кириллицу, но сегодня практически всё научное сообщество считает иначе: Кирилл создал глаголицу, кириллица же появилась значительно позже и была создана учениками Кирилла и Мефодия, возможно Климентом Охридским. К сожалению, это мнение окончательно утвердилось в науке довольно поздно — в начале XX века, но Трубецкой в 1925 году (см. цитату выше) говорит об этом с абсолютной уверенностью.
Таким образом, с логической точки зрения кирилловской азбукой в буквальном смысле слова следовало бы называть глаголицу, изобретённую Кириллом, но это приведёт к совершенной путанице. Итак, употреблять прилагательное кириллический по отношению к азбуке, буквам, рукописи, шрифту и другим подобным словам логичнее, поскольку оно отсылает не непосредственно к Кириллу, а к кириллице, названной в честь него, но не созданной им.
На этом аргументацию можно было бы завершить, но интересно привести ещё и некоторые исторические сведения, свидетельствующие о том, что прилагательное кирилловский в этом употреблении (то есть применительно к словам, связанным с письмом) древнее.
Вот, например, какие слова присутствуют в Словаре В. И. Даля:
Кири́лловская грамота, кири́ллица, кири́лловщина, та, которую мы пишем.
Другая же азбука описывается у Даля ещё более странными словами:
Глаголи́та, глагóлица или азбука глагóльская, глаголи́тская, глаголити́ческая, южно-славянская древняя азбука и письмо, противопол. кириллица.
А вот ещё примеры из Национального корпуса русского языка со словом кирилловский, относящиеся к XIX веку (слово кириллический в корпусе для этого и более ранних веков не зафиксировано).
Исследователи по большей части шли от изобретения письмен Кириллом и Мефодием и пытались определить: какое письмо изобретено прежде,
Начало Руси (1876)
В кирилловской рукописи этой находятся следы глаголиты, именно две её страницы писаны до половины кирилловскими, дальше глаголитскими буквами, сверх того попадаются в тексте целые слова и выражения, напр. имя св. Климента, изображённое глаголитским начертанием. В. И. Григорович.
имя св. Климента, изображённое глаголитским начертанием. В. И. Григорович.
Очерк путешествия по Европейской Турции (1848)
Однако традиция подобного употребления слова кирилловский всё-таки прервалась, так же как и традиция слов глагольский или глаголитский, и сегодня оно воспринимается как очень архаичное. Прилагательные же глагольский и глаголитский, по-видимому, просто неизвестны и непонятны современному носителю русского языка. Нельзя исключать, кстати, что вытеснению прилагательного кирилловский прилагательным кириллический способствовал и упомянутый выше логический аргумент.
В заключение хочется вернуться к вопросу о том, почему всё-таки могла возникнуть идея возрождения слова кирилловский и довольно изысканного противопоставления понятий кирилловский и кириллический шрифт, а также обсудить, имеет ли она какие-то перспективы.
В журнале «Шрифт» предложение обосновывается следующим образом:
…слово «кирилловский» указывает на историческую перспективу или на конкретное явление.
и далее:
«Кирилловский шрифт» мы используем для глобализации описываемого явления, для взгляда в перспективу (как прошлого, так и будущего).
Упоминание «исторической перспективы» позволяет предположить, что сторонников нововведения привлекает как раз архаичность и непривычность слова. Это в общем-то понятный эффект высвобождения энергии нового слова, обращающего на себя внимание необычностью, в отличие от слова привычного и в каком-то смысле затёртого. Но надо понимать, что этот эффект очень краткосрочный, потому что новое слово, входя в обиход, быстро теряет энергию новизны, а содержательных аргументов, как мы постарались показать, за это слово просто нет. Иначе говоря, «перспектива» всё же направлена исключительно в прошлое, но не в будущее.
Предложение ввести тонкое смысловое различие между этими прилагательными также не опирается ни на языковую практику, ни на языковую интуицию, к тому же довольно туманно и малопонятно обычному носителю языка.
Наконец, важное соображение, касающееся оценки перспектив нововведения. Дизайнеры, как и другие профессиональные сообщества, вольны менять и создавать свою терминологию, как им хочется, даже если это противоречит общим традициям и нормам. Но как раз узкую терминологию редакторы «Шрифта» предлагают сохранить:
Дизайнеры, как и другие профессиональные сообщества, вольны менять и создавать свою терминологию, как им хочется, даже если это противоречит общим традициям и нормам. Но как раз узкую терминологию редакторы «Шрифта» предлагают сохранить:
«Кириллический шрифт» — один из группы шрифтов, которые восходят к азбуке, носящей имя Кирилла. Сюда же относятся буквы, глифы, гарнитуры, лигатуры, всё наше дорогое хозяйство, вся наша кухня, то есть все частные случаи кирилловской письменности — кириллические.
Изменения должны коснуться сочетаний со словами алфавит, азбука, письменность и подобных, то есть общеупотребительных. Очевидно, что с этим не согласятся многочисленные лингвисты и филологи, да и все образованные носители языка, для которых языковая привычка — одна из главных составляющих речевого общения.
Контекст
#terminsrach 🤘 “Кирилловский” или “Кириллический”? // Type&Typography, 28 августа 2020 года
Обо всём «кириллическом». Владимир Кричевский // Журнал «Шрифт», 15 сентября 2020 года
Реплика Дениса Машарова // Type&Typography, 15 сентября 2020 года
Открытое письмо редакции Журнал и издательство «Шрифт»!
Илья Рудерман // 23 сентября 2020 года
Кирилловский алфавит и кириллическое завтра
(Открытый ответ Илья Рудерман от редакции журнала «Шрифт») // 25 сентября 2020 года
На заглавной иллюстрации: гражданская азбука с исправлениями Петра Первого
Относительно лёгкий способ определить качество кириллицы в шрифте
?- Относительно лёгкий способ определить качество кириллицы в шрифте
- oksigirl
- March 21st, 2014
На мысль написать этот пост меня натолкнуло письмо с вопросом «а что ты скажешь про шрифт NNN, хороший?»
Несмотря на то, что предыдущий пост из жанра «объяснить на пальцах» вызвал не самую однозначную реакцию, я по-прежнему считаю, что такие объяснения нужны и полезны.
 Однако на всякий случай заранее предупреждаю, что описанный ниже способ не гарантирует стопроцентного результата, результат всё равно зависит от насмотренности, начитанности и т.п., и если вы видите в моём способе неточности и вообще можете легко без него обойтись, то и не мучайтесь 🙂
Однако на всякий случай заранее предупреждаю, что описанный ниже способ не гарантирует стопроцентного результата, результат всё равно зависит от насмотренности, начитанности и т.п., и если вы видите в моём способе неточности и вообще можете легко без него обойтись, то и не мучайтесь 🙂
Если вы графический дизайнер и вдруг внезапно вам понадобился новый текстовый шрифт, а за новостями и дискуссиями на эту тему вы не особенно следите.
Во-первых, кому и зачем.
Если вы рисуете шрифты, но не разбираетесь в кириллице (да, я надеюсь перевести этот текст).
Если вы рисуете шрифты, думаете, что разбираетесь в кириллице и хотите проверить себя.
То
в том поле, где отображаются знаки шрифта и куда можно вбить свой текст
(например, на майфонтсе — вот так оно выглядит)
наберите комбинацию
БДабвджклмфя
(если хотите, можно ещё добавить з, э)
и внимательно смотрите на результат.Вот, например, скриншоты примерно со второй страницы поиска по тэгу Cyrillic:
Куда смотреть?
1.
 На рисунок отдельных знаков.
На рисунок отдельных знаков.
(примечание: чем больше вопросительных знаков, тем хуже, но всё-таки, возможно, немножко лучше, чем зачёркнутый вариант)и далее (большие горизонтальные картинки я делила пополам):
2. На ширину знаков.
Она должна выглядеть более-менее равномерной, не должно быть (в текстовом шрифте) явного дисбаланса по ширине.
сбалансированная ширина
сбалансированная ширина
несбалансированная ширина3. На расстояния между знаками и общий баланс строки.
На этой (случайно попавшейся мне на глаза) картинке видно, насколько строка, сделанная носителем языка, ровнее строк, сделанных не-носителями (смотрите на сочетания вд, кл, например). Хотя, возможно, это и не так очевидно, как если бы один или два из этих шрифтов были откровенно кривыми…P. S. Ну что, кто кинулся проверять свои шрифты? 🙂
Tags: правила, про буквы, шрифт, шрифтовой дизайн
Часто задаваемые вопросы — v5 и более ранние версии — латинские, кириллические и греческие шрифты
Предупреждение .
Этот документ устарел и актуален только для версии 5 и более ранних версий шрифтов. Он предназначен для пользователей, которые все еще могут использовать эти шрифты. Актуальные ответы на часто задаваемые вопросы см. в текущем разделе часто задаваемых вопросов.
ПРЕДУПРЕЖДЕНИЕ:
Этот документ устарел и актуален только для версии 5 и более ранних версий шрифтов. Он предназначен для пользователей, которые все еще могут использовать эти шрифты. Актуальные ответы на часто задаваемые вопросы см. в текущем разделе часто задаваемых вопросов 9.0006
О шрифтах / Использование шрифтов
На каких платформах и программах будут работать шрифты SIL?Шрифты SIL будут работать в Mac OS X, Linux и Windows. Однако имейте в виду, что более поздние версии (например, Mac OS x v10.8+ и Windows 7+) обеспечивают наилучшую поддержку. Другим ключом к успешному отображению сложных шрифтов является поддержка используемого вами приложения.
Что особенного в шрифтах SIL? Наши латинские, кириллические и греческие шрифты предназначены для работы с двумя передовыми технологиями шрифтов: Graphite и OpenType. Чтобы воспользоваться расширенными типографскими возможностями этого шрифта, вы должны использовать приложения, обеспечивающие адекватный уровень поддержки Graphite или OpenType. Эти расширенные возможности обеспечивают логику для комплексного рендеринга латинского, кириллического и греческого шрифтов и доступа к вариантным формам символов, используемым во многих языках.
Чтобы воспользоваться расширенными типографскими возможностями этого шрифта, вы должны использовать приложения, обеспечивающие адекватный уровень поддержки Graphite или OpenType. Эти расширенные возможности обеспечивают логику для комплексного рендеринга латинского, кириллического и греческого шрифтов и доступа к вариантным формам символов, используемым во многих языках.
Мы не можем предложить индивидуальную техническую поддержку. Лучшим ресурсом является этот веб-сайт, где мы надеемся предложить ограниченную помощь. Тем не менее, мы хотим услышать о любых проблемах, с которыми вы столкнетесь, чтобы мы могли добавить их в список ошибок для исправления в более поздних выпусках. Пожалуйста, перейдите на страницу поддержки, чтобы сообщить о любых проблемах. Пожалуйста, поймите, что мы не можем гарантировать личный ответ.
Лицензирование
Я хочу использовать один из ваших шрифтов в своей публикации. Могу ли я?
Могу ли я? Все наши латинские, кириллические и греческие шрифты выпущены в соответствии с лицензией SIL Open Font License, которая разрешает использование для любых публикаций, как электронных, так и печатных. Дополнительные ответы на вопросы об использовании см. в OFL-FAQ. Лицензия вместе с информацией, относящейся к шрифту, находится в каждом пакете выпуска шрифта.
Будут ли шрифты SIL Unicode Roman бесплатными?Мы не собираемся взимать плату с пользователей за использование шрифтов SIL Unicode Roman. Текущие версии распространяются по лицензии SIL Open Font License (OFL), и будущие версии будут аналогичными.
Я хочу связать один из шрифтов SIL Unicode Roman с моим приложением. Могу ли я?Лицензия SIL Open Font License позволяет объединять приложения, даже коммерческие, с некоторыми ограничениями.
См. веб-страницу OFL.
Могу ли я использовать на своем веб-сайте один из шрифтов SIL Unicode Roman? Да. Вы можете создавать веб-страницы, запрашивающие использование шрифтов SIL Unicode Roman для их отображения (если этот шрифт доступен в системе пользователя). Согласно лицензии, вам даже разрешено размещать шрифт на своем сайте, чтобы люди могли его скачать. Однако мы настоятельно рекомендуем вам направлять пользователей на наш сайт для загрузки шрифта. Это гарантирует, что они всегда используют самую последнюю версию с исправлениями ошибок и т. д.
Вы можете создавать веб-страницы, запрашивающие использование шрифтов SIL Unicode Roman для их отображения (если этот шрифт доступен в системе пользователя). Согласно лицензии, вам даже разрешено размещать шрифт на своем сайте, чтобы люди могли его скачать. Однако мы настоятельно рекомендуем вам направлять пользователей на наш сайт для загрузки шрифта. Это гарантирует, что они всегда используют самую последнюю версию с исправлениями ошибок и т. д.
В пакете загрузки «веб» для каждого шрифта мы предоставляем шрифт WOFF. Инструкции по использованию шрифтов на веб-страницах см. в разделе Использование шрифтов SIL на веб-страницах.
Модификация
Могу ли я внести изменения в ваши шрифты?Да! Это разрешено, если вы соблюдаете условия лицензии SIL Open Font License.
Я заметил, что в ваших латинских, кириллических и греческих шрифтах отсутствует ряд символов, которые мне бы хотелось. Вы добавите это? Если у вас есть специальный символ, который вам нужен (скажем, для определенной системы транскрипции), лучшим способом сделать это будет убедиться, что символ включен в стандарт Unicode. Мы не можем добавить каждый глиф, который желает каждый человек, но мы уделяем первостепенное внимание добавлению почти всего, что попадает в определенные диапазоны Unicode (расширенная латиница, кириллица). Вы можете присылать нам свои запросы, но, пожалуйста, поймите, что мы вряд ли добавим символы там, где пользовательская база очень мала, если только они не будут приняты в Unicode.
Мы не можем добавить каждый глиф, который желает каждый человек, но мы уделяем первостепенное внимание добавлению почти всего, что попадает в определенные диапазоны Unicode (расширенная латиница, кириллица). Вы можете присылать нам свои запросы, но, пожалуйста, поймите, что мы вряд ли добавим символы там, где пользовательская база очень мала, если только они не будут приняты в Unicode.
Да! См. FONTLOG для получения информации о том, как стать участником.
Технический
Как использовать функцию? Например, я вижу четыре варианта Eng (U+014A Ŋ). Как выбрать отображаемый вариант?Ответ зависит от рассматриваемого приложения:
- Приложения с поддержкой Graphite: Предполагая, что они поддерживают функции, вы можете выбрать нужный вариант Eng из Меню Формат/Шрифт/Функция (или как устроен интерфейс).

LibreOffice с Graphite: В LibreOffice функции шрифта можно включить, выбрав шрифт (например, Charis SIL), за которым следует двоеточие, идентификатор функции, а затем настройка функции. Так, например, если желательна альтернатива «Заглавная N с хвостом» в верхнем регистре, выбор шрифта будет «Charis SIL:Engs=2». Если вы хотите применить две (или более) функции, вы можете разделить их знаком «&». Таким образом, «Charis SIL:Engs=2&smcp=1» применит «Заглавную букву N с хвостиком» плюс функцию «Маленькие заглавные».
InDesign и аналогичные приложения Adobe: Выберите Eng в своем тексте, а затем используйте палитру глифов (выберите Type / Glyphs / Access All Alternates ), чтобы выбрать альтернативу. (Доступные функции будут зависеть от выбранного шрифта.)
Word и другие приложения на основе Uniscribe: Извините, но в настоящее время нет механизма выбора функций или альтернативных глифов.

С системой набора XeTeX: Включить пары «feature=setting» в спецификацию шрифта в исходном документе или таблице стилей; например,
fontbodytext="Doulos SIL/GR:Uppercase Eng alters=Large eng on. Синтаксис для этого можно получить из документа «Функции шрифтов» для конкретного используемого вами шрифта.
baseline" at 12pt
Итак, предвидя ваш (или чей-то) следующий вопрос: что мне делать, если я использую Word или другие приложения на основе Uniscribe?
- В долгосрочной перспективе мы надеемся, что будущие версии ОС Windows и прикладного программного обеспечения обеспечат архитектуру и пользовательский интерфейс, которые поддерживают некоторую форму выбираемого пользователем механизма функций шрифта. Посмотрим.
Тем временем единственной альтернативой является создание производных шрифтов, у которых желаемое поведение (например, альтернативные глифы) «включено» по умолчанию. Таким образом, можно представить себе шрифт, такой как «Doulos SIL Eng4», который точно такой же, как Doulos SIL, за исключением того, что он отображает Eng, используя 4-й вариант.
 Мы создали инструмент под названием TypeTuner Web, который вы можете использовать для создания производных шрифтов.
Мы создали инструмент под названием TypeTuner Web, который вы можете использовать для создания производных шрифтов.
Функция Small Caps — это функция OpenType и Graphite, которую можно включить в шрифте. Как его использовать будет варьироваться от одного приложения к другому.
- Adobe InDesign будет использовать функцию OpenType Small Caps. Выделите текст, затем выберите палитру символов, затем щелкните маленькую стрелку вниз в правом верхнем углу и выберите Opentype/All Small Caps.
Приложения FieldWorks — малые прописные буквы можно выбрать, выбрав Формат / Шрифт / Функции шрифта / Капитель.
LibreOffice может использовать прописные буквы, выделив текст, выбрав имя шрифта (например, «Charis SIL»), а затем после имени шрифта введите «:smcp=1». Таким образом, ваша запись шрифта будет «Charis SIL:smcp=1».
 Если вы хотите использовать более одной функции, вы можете ввести «&» между ними. Таким образом, «Charis SIL:smcp=1&Engs=1» даст вам альтернативный eng плюс маленькие заглавные буквы. 9textsc становится маленькими заглавными буквами.
Если вы хотите использовать более одной функции, вы можете ввести «&» между ними. Таким образом, «Charis SIL:smcp=1&Engs=1» даст вам альтернативный eng плюс маленькие заглавные буквы. 9textsc становится маленькими заглавными буквами.Другие приложения — Microsoft Word и Publisher не используют функцию OpenType или Graphite Small Caps. Они делают маленькие заглавные буквы на лету. Другие приложения, такие как RenderX, требуют использования отдельного шрифта для прописных букв. В обеих этих ситуациях, если вы хотите использовать настоящие прописные буквы, вам нужно будет создать отдельный шрифт с помощью TypeTuner Web. Мы создали инструмент под названием TypeTuner Web, который вы можете использовать для создания производных шрифтов. Просто выберите шрифт, нажмите «Выбрать функции», измените настройку «Маленькие прописные» на «True», а затем загрузите и установите шрифт. Это даст вам шрифт с маленькими прописными буквами, и вы будете применять этот шрифт, когда он вам понадобится.

Тщательное изучение репертуара Unicode показывает, что, например, символ U+0157 СТРОЧНАЯ ЛАТИНСКАЯ БУКВА R С СЕДИЛЬЕЙ (которая распадается на ) обычно рисуется в форме запятой, а не в форме седиллы. Это происходит для ряда символов, включая g/G, k/K, l/L, n/N и r/R. (Интересно: обратите внимание, что для нижнего регистра g седилья, нарисованная в виде запятой, на самом деле отображается выше g)
Кроме того, s/S и t/T с cedilla иногда отображаются с запятой — таким образом, у нас есть функция в коде Graphite (румынский стиль) и специфичное для языка поведение в OpenType код (прикрепленный к языку «Румынский»), который заставляет эти комбинации отображаться со стилем запятой. (Это альтернативное отображение предшествовало введению в Unicode 3. 0 символов s/S и t/T с запятой ниже (U+0218, U+0219, U+021A и U+021B), которые теперь являются предпочтительным способом различать эти символы) .
0 символов s/S и t/T с запятой ниже (U+0218, U+0219, U+021A и U+021B), которые теперь являются предпочтительным способом различать эти символы) .
В Microsoft Word кажется, что вы должны включить «Лигатуры», чтобы получить позиции вьетнамских диакритических знаков. Выберите свой текст (или свой стиль), а затем перейдите к Font / Advanced и выберите OpenType Features / Ligatures: / Standard Only. Это должно решить проблему.
Почему между тональными панелями в Word есть пробел?В Microsoft Word необходимо включить кернинг, чтобы панели тона располагались правильно. Перейдите к Font / Advanced и установите Kerning для шрифтов на 1 Points и выше.
Почему у моих тональных планок нет лигатуры? См. «Почему мои диакритические знаки расположены неправильно?»
«Почему мои диакритические знаки расположены неправильно?»
См. «Почему мои диакритические знаки расположены неправильно?»
Почему мои диакритические знаки расположены неправильно?Причина 1: Приложение, которое вы используете, не поддерживает ни Graphite, ни OpenType, или вы используете символы из области частного использования (PUA) в приложении OpenType.
Дополнительная информация: Для того чтобы сложные функции, такие как расположение диакритических знаков и лигатуры, работали, приложение должно иметь возможность использовать таблицы Graphite или OpenType в шрифте. Например, до выпуска Microsoft Office 2003 не существовало версий Microsoft Office и системного компонента Uniscribe, в которых можно было бы использовать любой из них для латиницы. К сожалению, даже последние версии Uniscribe игнорируют информацию OpenType для символов из области PUA, поэтому ни позиционирование диакритических знаков, ни связывание не выполняются. Microsoft говорит, что это сделано специально.
К сожалению, даже последние версии Uniscribe игнорируют информацию OpenType для символов из области PUA, поэтому ни позиционирование диакритических знаков, ни связывание не выполняются. Microsoft говорит, что это сделано специально.
Причина 2: Хотя некоторые из этих проблем связаны с ошибками шрифтов (о которых мы хотим знать), другой распространенной причиной являются проблемы с форматированием в приложении. Чтобы позиционирование диакритических знаков или лигатур работало правильно, приложение должно отображать всю последовательность символов за одну операцию. Наиболее распространенная причина, по которой это условие не выполняется, заключается в том, что некоторые символы в последовательности имеют другое форматирование (или даже другой шрифт), чем другие. Если есть какая-либо разница в форматировании (например, в межсимвольном интервале или цвете, названиях или размерах шрифтов и т. д.), приложению, возможно, придется разбить последовательность на отдельные прогоны.
Решение: Чтобы исключить проблемы с форматированием, убедитесь, что символы в последовательности имеют одинаковый формат. Некоторые приложения позволяют копировать затронутый текст в буфер обмена, а затем использовать Edit/Paste Special для вставки неформатированного текста обратно в документ. Другой подход, доступный в Microsoft Word, заключается в том, чтобы выделить текст и нажать Ctrl — пробел , чтобы сбросить форматирование всех символов до значения по умолчанию для абзаца. (Это предполагает, что ваш стиль абзаца по умолчанию отформатирован с использованием одного из наших шрифтов SIL Unicode Roman).
Примечание: В Word даже параметры форматирования, такие как шрифт Complex Scripts и параметры шрифта азиатского текста, должны точно совпадать для всей последовательности, даже если эти параметры фактически не используются для отображения латинского текста.
Почему диакритические знаки, расположенные над или под символами, не отображаются на экране, но отображаются при печати? Вертикальные метрики для наших шрифтов были установлены для соответствия большинству ситуаций, но в некоторых сценариях, особенно с наложением диакритических знаков, вы можете получить вырезание на экране. Вы можете решить эту проблему, отрегулировав межстрочный интервал в приложении. Например, в Microsoft Word выберите Format / Paragraph и установите межстрочный интервал, чтобы использовать настройку Exactly и значение, примерно вдвое превышающее размер шрифта. Например, если размер шрифта составляет 12 пунктов, выберите межстрочный интервал Ровно 24 пункта. Вы можете увеличить или уменьшить значение в зависимости от того, сколько диакритических знаков вам нужно сложить.
Вы можете решить эту проблему, отрегулировав межстрочный интервал в приложении. Например, в Microsoft Word выберите Format / Paragraph и установите межстрочный интервал, чтобы использовать настройку Exactly и значение, примерно вдвое превышающее размер шрифта. Например, если размер шрифта составляет 12 пунктов, выберите межстрочный интервал Ровно 24 пункта. Вы можете увеличить или уменьшить значение в зависимости от того, сколько диакритических знаков вам нужно сложить.
Большинство приложений OpenType игнорируют сложное поведение, которое было предусмотрено в шрифтах для символов PUA, поэтому в приложениях на основе OpenType, таких как Paratext и Microsoft Word, символы PUA отображаются неправильно.
Я не могу найти букву «о с правым хуком» в шрифте. Где это? Комбинации базовых букв с диакритическими знаками часто называют составными, или предварительно составленными глифами. В наших шрифтах их сотни (те, что включены в Unicode). Однако есть много общих комбинаций, которые не представлены одним композитом. Их можно ввести в документ, но только как отдельные компоненты. Таким образом, «о с правым хуком» следует вводить как «о», а затем «правый хук». Хотя в некоторых случаях это может выглядеть не очень хорошо, мы не можем предвидеть все возможные комбинации. Наши латинские, кириллические и греческие шрифты включают поддержку «умных шрифтов» для OpenType и Graphite.
В наших шрифтах их сотни (те, что включены в Unicode). Однако есть много общих комбинаций, которые не представлены одним композитом. Их можно ввести в документ, но только как отдельные компоненты. Таким образом, «о с правым хуком» следует вводить как «о», а затем «правый хук». Хотя в некоторых случаях это может выглядеть не очень хорошо, мы не можем предвидеть все возможные комбинации. Наши латинские, кириллические и греческие шрифты включают поддержку «умных шрифтов» для OpenType и Graphite.
В сочетании с некоторыми узкими глифами (например, «i») широкие диакритические знаки (например, тильда) могут конфликтовать с соседними глифами. Во многих случаях это не проблема (иногда глифы могут конфликтовать). Если это вызывает трудности с разборчивостью текста, вручную разнесите эти буквы в тексте, используя ручной кернинг или настройки межсимвольного интервала в вашем приложении. У нас нет общедоступного решения этой проблемы, но мы продолжим его искать.
Проверьте, установлен ли параметр Инструменты/Параметры/Сложные сценарии/Показать диакритические знаки . Если у вас нет вкладки Сложные сценарии в разделе Инструменты/Параметры, , вам следует:
- Закрыть все приложения Office
- Если у вас нет апплета Microsoft Office 2003 Language Settings (обычно в Start/Programs/Microsoft Office 2003/Microsoft Office Tools ), используйте Установка и удаление программ , чтобы добавить этот компонент в конфигурацию Microsoft Office 2003 (в категории Office Tools , это Language Settings Tool )
- Запустите Microsoft Office 2003 Language Settings апплет и включите язык, например арабский или иврит. После нажатия ОК, вы должны найти вкладку Сложные сценарии , доступную в разделе Инструменты/Опции.

- После того, как вы установите флажок и подтвердите, что это устраняет проблему, вы можете удалить эти языки (из апплета Microsoft Office 2003 Language Settings ), если хотите.
Несмотря на то, что это относится к более старой версии Office, в новых версиях решение может быть аналогичным.
Почему наложенные комбинированные знаки неправильно отображаются в шрифте?Следующие наложенные комбинированные знаки — это , присутствующие в шрифте, но не имеющие точек присоединения, поэтому они не будут отображаться должным образом:
- U+0334 ОБЪЕДИНЕНИЕ НАКЛАДКИ ТИЛЬДЫ
- U+0335 КОМБИНИРОВАННАЯ НАКЛАДКА ДЛЯ КОРОТКОГО ХОДА
- U+0336 КОМБИНИРОВАННАЯ НАКЛАДКА ДЛЯ ДЛИННОГО ХОДА
- U+0337 ОБЪЕДИНЕНИЕ КОРОТКОЙ НАКЛАДКИ SOLIDUS
- U+0338 ОБЪЕДИНЕНИЕ ДЛИННОЙ НАКЛАДКИ SOLIDUS
- U+20E5 ОБЪЕДИНЕНИЕ ОБРАТНОЙ СОЛИДУСНОЙ НАКЛАДКИ
Причина: Это задумано.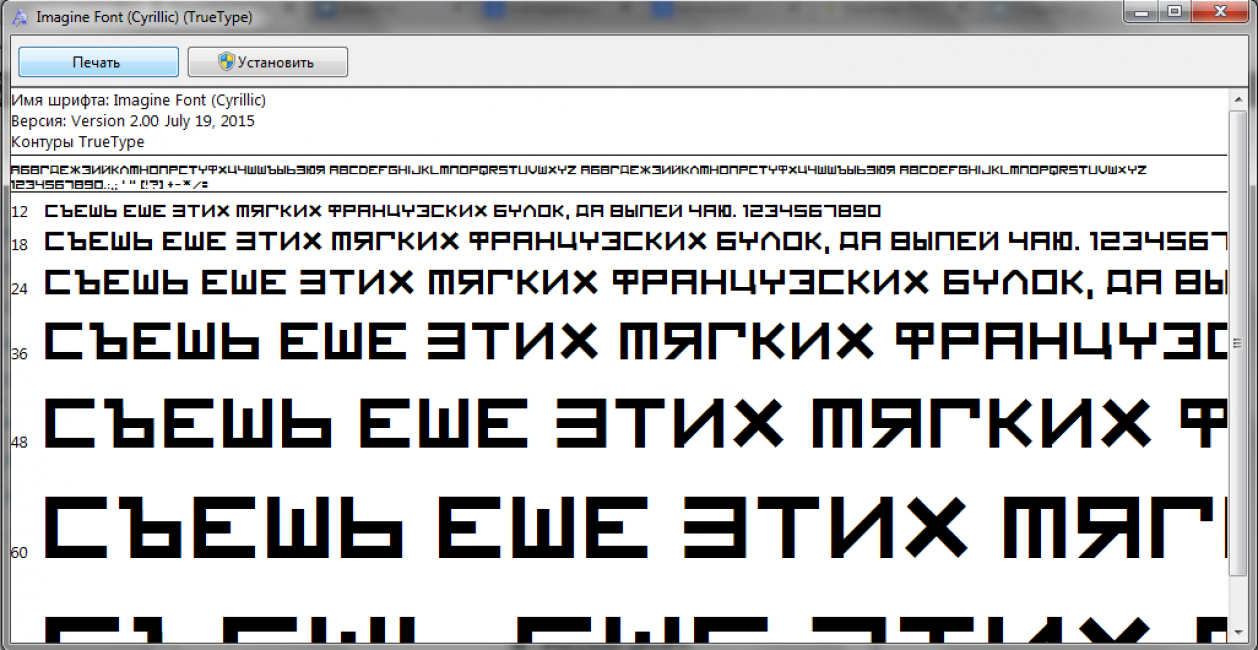 По различным техническим причинам лучше избегать использования наложенных комбинированных меток. Вот почему, например, Unicode не определяет разложение U+026B ЛАТИНСКОЙ СТРОЧНОЙ БУКВЫ L СО СРЕДНЕЙ ТИЛЬДОЙ в U+006C ЛАТИНСКУЮ СТРОЧНУЮ БУКВУ L + U+0334 КОМБИНИРОВАННОЕ НАЛОЖЕНИЕ ТИЛЬДЫ.
По различным техническим причинам лучше избегать использования наложенных комбинированных меток. Вот почему, например, Unicode не определяет разложение U+026B ЛАТИНСКОЙ СТРОЧНОЙ БУКВЫ L СО СРЕДНЕЙ ТИЛЬДОЙ в U+006C ЛАТИНСКУЮ СТРОЧНУЮ БУКВУ L + U+0334 КОМБИНИРОВАННОЕ НАЛОЖЕНИЕ ТИЛЬДЫ.
По причинам, аналогичным наложенным диакритическим знакам, U+0321 и U+0322 отсутствуют в шрифте… по задумке. В этом случае и в случае с наложенным диакритическим знаком Unicode обеспечивает большинство случаев использования этих знаков через предварительно составленные символы.
Стандарт Unicode не поддерживает комбинации U+0340 и U+0341, поэтому мы их пропустили. Метки U+0342..U+0345 предназначены в первую очередь для греческого языка, поэтому единственным шрифтом, который поддерживает эти кодовые точки, является Gentium.
Следующие комбинированные знаки не присутствуют в шрифте:
- U+0321 КОМБИНИРОВАННЫЙ ПАЛАТАЛИЗОВАННЫЙ КРЮЧОК НИЖЕ
- U+0322 СОЕДИНИТЕЛЬНЫЙ КРЮК RETROFLEX НИЖЕ
- U + 0340 ОБЪЕДИНЕНИЕ ЗНАКА ТОНА GRAVE
- U + 0341 ОБЪЕДИНЕНИЕ ЗНАКА ОСТРОГО ТОНА
- U+0342 ОБЪЕДИНЕНИЕ ГРЕЧЕСКОГО ПЕРИСПОМЕНА
- U+0343 ОБЪЕДИНЕНИЕ ГРЕЧЕСКОГО КОРОНИС
- U+0344 ОБЪЕДИНЕНИЕ ГРЕЧЕСКОЙ ДИАЛИТИКА ТОНОС
- U + 0345 ОБЪЕДИНЕНИЕ ГРЕЧЕСКОГО ИПОГЕГРАММЕНИ
Межстрочный интервал и показатели шрифта
Почему междустрочный интервал намного меньше, чем в других шрифтах, таких как Times New Roman? Наши шрифты SIL Unicode Roman включают символы с несколькими расположенными друг над другом диакритическими знаками, для которых требуется значительно меньшее межстрочное расстояние (например, U+1EA8 Ẩ). Мы не можем уменьшить межстрочный интервал, не испытывая «отсечения» этих символов. Вы можете решить эту проблему, отрегулировав межстрочный интервал в приложении. Например, в Microsoft Word выберите Format / Paragraph и установите межстрочный интервал, чтобы использовать параметр Exactly и значение, более подходящее для ваших нужд. Например, если размер шрифта составляет 12 пунктов, выберите межстрочный интервал Ровно 13 пунктов. Это даст более плотный межстрочный интервал. Вы можете увеличить или уменьшить значение в зависимости от того, сколько диакритических знаков вам нужно сложить. В HTML вы также должны иметь возможность изменять межстрочный интервал; добавьте в тег свойство line-height («
Мы не можем уменьшить межстрочный интервал, не испытывая «отсечения» этих символов. Вы можете решить эту проблему, отрегулировав межстрочный интервал в приложении. Например, в Microsoft Word выберите Format / Paragraph и установите межстрочный интервал, чтобы использовать параметр Exactly и значение, более подходящее для ваших нужд. Например, если размер шрифта составляет 12 пунктов, выберите межстрочный интервал Ровно 13 пунктов. Это даст более плотный межстрочный интервал. Вы можете увеличить или уменьшить значение в зависимости от того, сколько диакритических знаков вам нужно сложить. В HTML вы также должны иметь возможность изменять межстрочный интервал; добавьте в тег свойство line-height (« line-height:105%; » или « line-height: 12pt; «) и поэкспериментируйте со значением, пока не получите желаемый интервал.
Мы также предоставляем для скачивания «компактные» версии наших шрифтов (например, Charis SIL Compact и Doulos SIL Compact). Эти шрифты обеспечивают межстрочный интервал, аналогичный межстрочному интервалу в Times New Roman.
Эти шрифты обеспечивают межстрочный интервал, аналогичный межстрочному интервалу в Times New Roman.
Мы не гарантируем стабильность метрик в будущих версиях. Практический результат этого означает, что вы должны ожидать разную длину строк, длину абзаца и межстрочный интервал. Не следует ожидать, что ваш документ будет иметь тот же макет страницы, что и при использовании текущего шрифта.
Печать
У меня проблемы с созданием PDF-файлов — почему мой документ не обрабатывается?Шрифты SIL Unicode Roman — это большие шрифты с большим количеством глифов. В результате некоторые принтеры могут отказываться от PDF-файлов, в которые встроен полный шрифт. Самый простой способ избежать этого — использовать подмножество шрифта в Acrobat/Distiller. Как правило, это хорошая идея (с любым шрифтом) и может уменьшить размер ваших файлов.
Устаревшие шрифты
Будут ли документы, созданные с использованием более ранних (устаревших) шрифтов, таких как шрифты SIL IPA и IPA93, быть совместимыми с новой (Unicode) версией?
Документы, созданные (закодированные) с использованием устаревших шрифтов, несовместимы со шрифтами Unicode. Вам нужно будет преобразовать ваши данные в Unicode. Для этого процесса можно использовать преобразователи TECkit или SIL. У нас есть файлы сопоставления (которые работают с TECkit) для преобразования документов, в которых использовались шрифты IPA SIL, в Unicode. Инструкции см. в SIL IPA9.3 Преобразование данных.
Вам нужно будет преобразовать ваши данные в Unicode. Для этого процесса можно использовать преобразователи TECkit или SIL. У нас есть файлы сопоставления (которые работают с TECkit) для преобразования документов, в которых использовались шрифты IPA SIL, в Unicode. Инструкции см. в SIL IPA9.3 Преобразование данных.
Клавиатура
Предоставляете ли вы клавиатуру для использования с латинскими, кириллическими и греческими шрифтами?Наши шрифты на латинице, кириллице и греческом языке не содержат вспомогательных средств или утилит для работы с клавиатурой. Если вы не можете использовать встроенные клавиатуры операционной системы, вам необходимо установить соответствующую клавиатуру и метод ввода для символов языка, который вы хотите использовать. Если вы хотите ввести символы, которые не поддерживаются какой-либо системной клавиатурой, программа Keyman может быть полезна в системах Windows. Для других платформ могут быть полезны XKB или Ukelele.
Если вы хотите вводить символы, которые не поддерживаются какой-либо системной клавиатурой, и получить доступ ко всему диапазону Unicode, мы предлагаем вам использовать gucharmap, kcharselect в Ubuntu или подобное программное обеспечение. Другой способ ввода некоторых символов предоставляется несколькими приложениями, такими как Adobe InDesign. Они могут отображать палитру глифов, которая показывает все глифы (символы) в шрифте и позволяет вам вводить их, щелкая нужный глиф.
Другой способ ввода некоторых символов предоставляется несколькими приложениями, такими как Adobe InDesign. Они могут отображать палитру глифов, которая показывает все глифы (символы) в шрифте и позволяет вам вводить их, щелкая нужный глиф.
Чтобы набирать символы IPA, вам необходимо загрузить и установить клавиатуру IPA со страницы клавиатур IPA. Клавиатуры доступны для компьютеров с Windows, Mac и Ubuntu (Linux).
Если вы не знакомы с процессом установки клавиатуры, сначала прочитайте эти инструкции для Windows и Mac.
Более ранняя версия этого документа (с устаревшими вопросами и известными проблемами) доступна здесь: Шрифты SIL Unicode Roman — часто задаваемые вопросы и известные проблемы
Языковая система LCD | Прошивка Marlin
В этом документе описываются изменения, внесенные в систему шрифтов для Marlin 1.1.
Marlin имеет дело с множеством различных дисплеев и должен отображать на них много разных языков в разных скриптах, в пределах своих возможностей. Описанная здесь система решает некоторые связанные проблемы, которые необходимо решить в ограниченной среде.
Описанная здесь система решает некоторые связанные проблемы, которые необходимо решить в ограниченной среде.
В настоящее время Marlin поддерживает две технологии отображения:
Символьные дисплеи:
- Имеют в ПЗУ фиксированный набор символов (набор символов — шрифт).
- Все они имеют одинаковые (не идентичные) первые 127 символов, аналогичные US-ASCII.
С другой стороны, символы 128 и выше имеют значительные отличия от одного дисплея к другому.
Marlin 1.0 и 1.1 в настоящее время поддерживают:
- HD44780 (и подобные) с кодировкой кана A00 HD44780 (стр. 17) Они очень распространены, но, к сожалению, не очень полезны при написании на европейских языках.
- HD44780 (и аналогичный) с западной кодировкой A02 HD44780 (стр. 18). Они редки, но довольно полезны для европейских языков. Также доступно ограниченное количество кириллических символов.
- HD44780 (и аналогичные) с кириллической кодировкой (стр. 14).
 Некоторые из наших русских друзей используют их.
Некоторые из наших русских друзей используют их.
На всех этих дисплеях вы можете определить 8 пользовательских символов для одновременного отображения. В Marlin эти символы используются на экране загрузки и на экране информации для температуры кровати, символа градуса, термометра, «FR» (скорость подачи), часов и индикатора выполнения. На экранах списка SD-карт некоторые из этих символов снова используются для повышения уровня, папки и обновления.
Полноценные графические дисплеи
Графические дисплеи дают полную свободу отображать все, что мы хотим, если мы предоставляем для этого программу. В настоящее время мы имеем дело с дисплеями 128×64 пикселей и делим эту область на ~ 5 строк с ~ 22 столбцами. Поэтому нам нужны моноширинные шрифты с ограничительной рамкой примерно 6×10.
- До сих пор мы использовали пользовательский шрифт Marlin, похожий на ISO10646-1, но со специальными символами в конце, которые делали «ü» и «ä» недоступными при размере 6×10.

- Поскольку эти буквы были слишком большими для некоторых позиций на информационном экране, мы используем полный шрифт ISO10646-1 размером 6×9 (3200 байт).
- Когда мы определяем
USE_BIG_EDIT_FONT, мы используем дополнительный шрифт ISO10646-1 9×18, потребляя еще 3120 байт PROGMEM — но читаемый без очков!
В настоящее время Marlin поддерживает 34 различных языковых варианта:
| Код | Язык | Код | Язык | |
|---|---|---|---|---|
| en | Английский | an | Арагонский | |
| bg 9053 1 | Болгарский | ок. 31 | Чехия | |
| cz_utf8 | Чешский (UTF8) | de | Немецкий | |
| el | 9 0530 Греческийel-gr | Греческий (Греция) | ||
| es | Испанский | ЕС | Basque-Euskera | |
| fi | Финский | fr | Французский | |
| fr_utf8 | Французский (UTF8) | gl | Галисийский | |
| hr | Хорватский | 90 530ху | Венгерский | |
| it | Итальянский | Кана | Японский | |
| kana_utf8 | Японский (UTF8) | nl | Голландский | |
| pl | Польский | pt | Португальский | |
| pt-br | Португальский (бразильский) | pt-br_utf8 | Португальский (бразильский) (UTF8) | |
| pt_utf8 | Португальский (UTF8) | ru | Русский | |
| sk | 9 0530 Словацкий (UTF8)tr | Турецкий | ||
| Великобритания | Украинский | zh_CN | Китайский (упрощенный) | |
| zh_TW | Китайский (Тайвань) | vi | Вьетнамский |
Все эти языки (кроме английского) обычно используют расширенные символы, не содержащиеся в US-ASCII. Даже в английском переводе используются некоторые символы, отличные от US-ASCII (, например, ‘
Даже в английском переводе используются некоторые символы, отличные от US-ASCII (, например, ‘ \002 ’ для термометра, STR_h4 для ‘³’). В самом коде символы могут использоваться без учета дисплея, на котором они написаны.
В результате на западных дисплеях вы увидите « ~ », а на кириллице — «стрелку, идущую сверху и указывающую влево» (что совершенно противоположно тому, что хотел программист). Немцы хотят использовать « ÄäÖöÜüß », финский минимум « äö ». Другие европейские языки тоже хотят видеть свои акценты. Для других шрифтов, таких как кириллица, японский, греческий, иврит и т. д., вам придется найти совершенно другие наборы символов.
Японский переводчик имел дело с двумя сценариями, вводя специальный шрифт для графических дисплеев и используя японские расширенные символы. Таким образом, он получил два довольно нечитаемых файла language.h , полных определений ‘ \xxx ’. Другие языки либо старались избегать слов, содержащих специальные символы, либо просто использовали основные символы без акцентов, точек и т. д.
Другие языки либо старались избегать слов, содержащих специальные символы, либо просто использовали основные символы без акцентов, точек и т. д.
Эта система была создана для решения этих проблем.
В полнофункциональной настольной системе, такой как Windows или Linux, мы могли бы установить unifont.ttf и некоторый код библиотеки, и все было бы готово. Но встроенные системы имеют очень ограниченные ресурсы! Таким образом, мы должны найти способы ограничить используемое пространство ( unifont.ttf сам по себе составляет ~12 МБ!), требуя некоторого компромисса.
Цели
- Сделать ввод для переводчиков максимально удобным. (Юникод UTF8)
- Сделайте так, чтобы на дисплеях отображались сценарии как можно лучше. (шрифты, таблицы сопоставления)
- Не уничтожать существующие языковые файлы.
- Не использовать больше ресурсов ЦП.
- Не используйте слишком много памяти.
Действия
- Объявите оборудование дисплея, которое мы используем.
 (
( Configuration.h) - Объявить язык или сценарий, который мы используем. (
Configuration.h) - Объявить тип ввода, который мы используем. Эфирные прямые указатели на шрифт (
\xxx) или UTF-8 и шрифт для использования на графических дисплеях. (language_xx.h) - Объявить переводы. (
language_xx.h) - Создайте
strlen(), который работает с UTF8. (ultralcd.cpp) - Разделите символы Marlin на их собственный шрифт. (
dogm_font_data_Marlin_symbols.h) - Функция fontswitch запоминает последний использовавшийся шрифт. (
ultralcd_impl_DOGM.h) - Создайте функции вывода, которые подсчитывают количество записанных символов и переключают шрифт на символы Marlin и обратно, когда это необходимо. (
ultralcd_impl_DOGM.h) (ultralcd_impl_HD44780.h) - Создайте три шрифта для имитации кодировок HD44780 на дисплеях dogm.
 С помощью этих шрифтов переводчик может проверить, как перевод будет выглядеть на символьных дисплеях.
С помощью этих шрифтов переводчик может проверить, как перевод будет выглядеть на символьных дисплеях. - Сделать шрифты ISO для кириллицы и катаканы, потому что им не нужна таблица сопоставления, с ними быстрее работать и они имеют лучшую кодировку, чем шрифты HD44780. (Меньше компромиссов!)
- Создание функций сопоставления и таблиц для преобразования UTF8 в шрифты и их интеграция в новые функции вывода. (
utf_mapper.h) - Удалить устаревшие файлы
LiquidCrystalRus.xxxи их вызовы в ‘ultralcd_implementation_HD44780.h’. - Разделить ‘
dogm_font_data_Marlin.h’ на отдельные шрифты и удалить. (+dogm_font_data_6x9_marlin.h, +dogm_font_data_Marlin_symbols.h, —dogm_font_data_Marlin.h) - Немного магии препроцессора, чтобы сопоставить дисплеи — шрифты и преобразователи в 9 0123 utf_mapper.h .
- Сначала проверьте, существует ли файл
language_xx.для вашего языка (-> b.) или нет (-> e.). h
h - Либо объявлен
MAPPER_NON(-> c.), либо какой-либо другой преобразователь (-> d.)
Direct HD44780 Translation
- Символы вне нормального ASCII-диапазона (32-128) записываются как “
\xxx» и указать непосредственно на шрифт оборудования, указанный вConfiguration.h. - Дисплеи HD44780 имеют один из трех шрифтов (
JAPANESE,WESTERN,CYRILLIC), установленных параметромDISPLAY_CHARSET_HD44780. - Даже на полноэкранных дисплеях можно использовать один из этих наборов символов, определив
SIMULATE_ROMFONT. - Если вы не используете расширенный набор символов, ваш файл будет выглядеть как
language_en.h, и ваш языковой файл будет работать на всех дисплеях. - При интенсивном использовании ваш файл будет выглядеть как
language_kana.hи ваш языковой файл будет работать только на одном из дисплеев (в данном случаеDISPLAY_CHARSET_HD44780==ЯПОНСКИЙ).
- Будьте осторожны с символами
0x5C = '\'и0x7B - 0x7F«{|}». Они не одинаковы для всех вариантов.
Картографы
-
MAPPER_NON— самый быстрый и наименее требовательный к памяти вариант. Языковые файлы без акцентов используют это. - Если вы хотите использовать несколько символов, не входящих в стандартную ASCII, или хотите улучшить переносимость на другие типы дисплеев, используйте ввод UTF-8. Это означает определение другого картографа.
- Ввод UTF-8 используется для преобразователей, отличных от
MAPPER_NON. С помощью маппера вместо «\xe1» (ЯПОНСКИЙ) илиSTR_aeвы можете просто ввести «ä». «ä» расширяется до «\xc3\xa4». «Я» заменяется на «\xd0\xaf» … «ホ» заменяется на «9».0123 \xe3\x83\x9b ” … и т. д. - Из-за ограничений памяти мы не можем использовать каждый глиф UTF-8 сразу, поэтому мы захватываем только подмножество, содержащее нужные нам символы:
-
MAPPER_C2C3хорошо соответствует с западноевропейскими языками. Возможные символы перечислены на этой странице Latin-1.
Возможные символы перечислены на этой странице Latin-1. -
MAPPER_D0D1хорошо соответствует кириллическим языкам. См. эту кириллицу. -
MAPPER_E382E383работает с японским письмом катакана. См. эту страницу катаканы. - Есть несколько других картографов для конкретных языков, и в настоящее время разрабатываются другие.
-
Функции картографа будут улавливать только вводную часть, описанную в имени картографа ( например, C2C3 ). Если входные данные не совпадают, картограф выведет «?» или мусор.
Последний байт в эфире последовательности указывает непосредственно на соответствующий шрифт ISO10646 или (через mapper_table) на один из шрифтов HD44780.
Таблицы mapper_tables делают все возможное, чтобы найти похожий символ в HD44780 (например, замена строчных букв соответствующими заглавными буквами). Но они могут не найти совпадения и выведут «?». Есть комбинации языка и дисплея, у которых просто нет соответствующих символов — например, кириллица на японском дисплее или наоборот . В этих случаях компилятор выдаст ошибку.
В этих случаях компилятор выдаст ошибку.
Вкратце: выберите картограф, который работает с символами, которые вы хотите использовать. Используйте только символы, соответствующие картографу. На полноэкранных дисплеях все символы должны быть в порядке. Используя графический дисплей, вы можете проверить наличие неправильных замен или вопросительных знаков, которые могут появиться на символьных дисплеях, определив SIMULATE_ROMFONT и пробуем разные варианты.
Если вы получаете много вопросительных знаков на дисплеях Hitachi с вашим новым переводом, возможно, стоит создать дополнительный языковой файл в формате language_xx_utf8.h .
Mapper Notes
- Как уже упоминалось,
MAPPER_NONявляется самым быстрым и наименее требовательным к памяти вариантом. В то время как языковые файлыMAPPER_NONуродливы и утомительны в обслуживании для нелатинских языков, для романских языков тривиально создатьMAPPER_NONфайл без диакритических знаков. Картографы
Картографы - вместе со шрифтом
ISO10646_*являются вторым лучшим выбором с точки зрения скорости и потребления памяти. Только несколько решений принимаются для каждого персонажа. - Помимо пространства, используемого для шрифта, преобразователи используют дополнительные ~128 байтов для
mapping_table. - Создать новый языковой файл несложно!
- Создайте новый файл в формате ‘
language_xx.h’ (или ‘language.xx_utf8.h‘) - В этом файле укажите маппер ( например,
MAPPER_NON) и шрифт ( например,DISPLAY_CHARSET_ISO1064 6_1) и перевести некоторые строки, определенные вlanguage_en.h. (Удалите#ifndef#endifиз определений.) - Вам не нужно переводить все строки. Пропущенные определения будут просто использовать английские строки в
language_en.h.
- Создайте новый файл в формате ‘
- Если для вашего языка нет картографа, все становится немного сложнее.
 С дисплеями на базе Hitachi вы не сможете сделать что-то полезное без соответствующей кодировки. Для графического отображения… возьмем пример греческого языка:
С дисплеями на базе Hitachi вы не сможете сделать что-то полезное без соответствующей кодировки. Для графического отображения… возьмем пример греческого языка:- Найдите соответствующую кодировку. (греческий и коптский)
- Предоставьте растровый шрифт, содержащий символы нужного размера (рекомендуется от 5×9 до 6×10). Обычные символы ASCII должны занимать от 1 до 127, а верхние 128 мест должны быть заполнены вашими специальными символами.
- Напишите преобразователь, который перехватывает — в данном случае —
0xCDв0xCFи добавьте его вutf_mapper.h. - В случае шрифта ISO10646 у нас есть
MAPPER_ONE_TO_ONEи нам не нужно создавать таблицу. - Если вы обнаружите достаточно полезных символов в одном из шрифтов HD44780, вы можете предоставить таблицу соответствия. Например,
WESTERNсодержит «альфа», «бета», «пи», «сигма», «омега» и «моя» — этого, я думаю, недостаточно для составления ПОЛЕЗНОЙ таблицы.
- Если вы хотите интегрировать совершенно новый вариант дисплея на базе Hitachi. Добавьте его в
Configuration.hи определите таблицы сопоставления вutf_mapper.h. Возможно, вам потребуется добавить новую функцию сопоставления.
Длина строк (для заголовков меню, меток редактирования и т. д.) ограничена. «17 символов» было грубым эмпирическим правилом. Очевидно, что 17 слишком долго для дисплея 16×2. Таким образом, языковые файлы могут свободно проверять ширину ЖК-дисплея и предоставлять более короткие строки следующим образом:
#если LCD_WIDTH <= 16 #define MSG_SPRING_LABEL "Весна" #еще #define MSG_SPRING_LABEL "Пружинность" #endif
На дисплеях 16x2 строки, подходящие для дисплея 20x4, будут обрезаны по размеру. Так что, если более короткая строка не предоставляется, по крайней мере сделайте похожие строки разными в начале строки. (‘ Someverylongoptionname x ’ -> ‘ x Somverylongoptionname ’)
Все переводимые строки сначала объявляются в language_en., а затем сопровождающие языки предоставляют переводы на свои языки. Марлин включает в себя сценарий под названием  h
h findMissingTranslations.sh , в котором перечислены строки, требующие перевода на один или несколько языков.
Строки в language.h предназначены для последовательного вывода, поэтому не требуют перевода. Строки основных ошибок всегда должны быть на английском языке, чтобы соответствовать протоколам хоста.
Информацию о шрифтах см. в файле buildroot/share/fonts/README.md .
Определите свое оборудование и желаемый язык в Configuration.h .
Чтобы узнать, какой набор символов использует ваше оборудование, установите #define LCD_LANGUAGE test и скомпилируйте Marlin. В меню вы увидите две строки из верхней половины набора символов:
-
ЯПОНСКИЙотображает «バパヒビピフブプヘベペホボポマミ» 900 98 -
ЗАПАДотображает “ÐÑÒÓÔÕÖ×ØÙÚÛÜÝÞß» -
CYRILLICвыводит «РСТУФХЦЧШЩЪЫЬЭЮЯ»
Если при компиляции выдает ошибку про «отсутствующие мапперы» - соврите про аппаратный шрифт вашего дисплея, чтобы увидеть хоть какой-то мусор, или выберите другой язык .
Английский работает на всем оборудовании.
LCD_LANGUAGE : Язык ЖК-дисплея и кодировка для компиляции. Например, pt-br_utf8 указывает португальский (Бразилия) в формате UTF-8 с преобразователем. Для более быстрого, легкого, но без акцента перевода вы можете вместо этого выбрать pt-br .
MAPPER_C2C3 : это преобразователь, установленный некоторыми языковыми файлами, и указывает, что Marlin должен использовать преобразователь для страниц Unicode C2 и C3. В этом преобразователе строки преобразуются из необработанного ввода UTF-8 в отдельные символы ASCII от 0 до 127 и индексы от 0 до 127 в объединенных двух 64-глифовых страницах C2 и C3.
SIMULATE_ROMFONT : Языки могут использовать специальные символы шрифта HD44780 ROM на графическом дисплее. Этот метод можно использовать для акцентированных западных, катаканских и кириллических шрифтов, если они не предоставляют свои собственные шрифты, или только для тестирования символьных преобразователей на графическом дисплее.