Как определить кодировку онлайн
Способ 1: 2cyr
Основное предназначение онлайн-сервиса 2cyr заключается в декодировании определенного отрывка текста, однако это не помешает использовать встроенные в него инструменты для определения кодировки, для чего потребуется только скопировать небольшую надпись.
Перейти к онлайн-сервису 2cyr
- В самом декодере вставьте скопированный текст в соответствующую форму, используя контекстное меню или горячую клавишу Ctrl + V.
- Убедитесь в том, что текст был успешно добавлен, а затем в поле «Выберите кодировку» установите значение «Автоматически (рекомендуется)». Подтвердите распознавание, нажав по кнопке «ОК», которая расположена справа.
- Остается только ознакомиться с названием кодировки в поле «Отображается как», чтобы узнать ее.
- Дополнительно вы можете посмотреть перевод ее в читаемый вид, если та нечитабельна, а также узнать, какая кодировка использовалась для этого.

- В 2cyr есть и другие читаемые варианты, которые можно использовать в своих целях, переключаясь между ними в соответствующих всплывающих меню.
Ничего не помешает сохранить или запомнить этот онлайн-сервис и обращаться к нему в те моменты, когда требуется перевести кодировку или снова определить ее. Если же этот вариант не подходит, переходите к рассмотрению следующих сайтов.
Способ 2: Online Decoder
Онлайн-сервис под названием Online Decoder тоже умеет определять кодировку текста в автоматическом режиме, а также переводить ее в читаемый вид или любые другие кодировки, если это требуется. Подбор символов на этом сайте осуществляется буквально в несколько кликов.
Перейти к онлайн-сервису Online Decoder
- Воспользуйтесь ссылкой выше или самостоятельно откройте главную страницу сайта Online Decoder, где сразу же активируйте поле для ввода и вставьте туда целевой текст.
- Напротив пункта «Раскодировать текст автоматически (рекомендуется)» нажмите по кнопке «Подбор» для запуска процесса распознавания.

- Та кодировка, в которую выполнен перевод, отображается второй.
- Исходная находится прямо после надписи «Я знаю нужные кодировки». Ее и надо узнать, если речь идет об определении стилистики символов.
- Перевод в выбранную конечную кодировку вы видите внизу, можете его изменить или скопировать.
- Используйте дополнительные инструменты сайта Online Decoder, если нужно продолжить взаимодействие с другими надписями.
Способ 3: FoxTools
FoxTools — еще один онлайн-сервис, основное предназначение которого заключается в декодировании текста, однако его функциональность можно использовать и для определения необходимого символьного набора, что происходит так:
Перейти к онлайн-сервису FoxTools
- Активируйте поле для ввода и вставьте туда скопированную ранее надпись.
- Снизу поля «Исходная кодировка» вы найдете кнопку «Определить», по которой и следует нажать для запуска процесса распознавания.
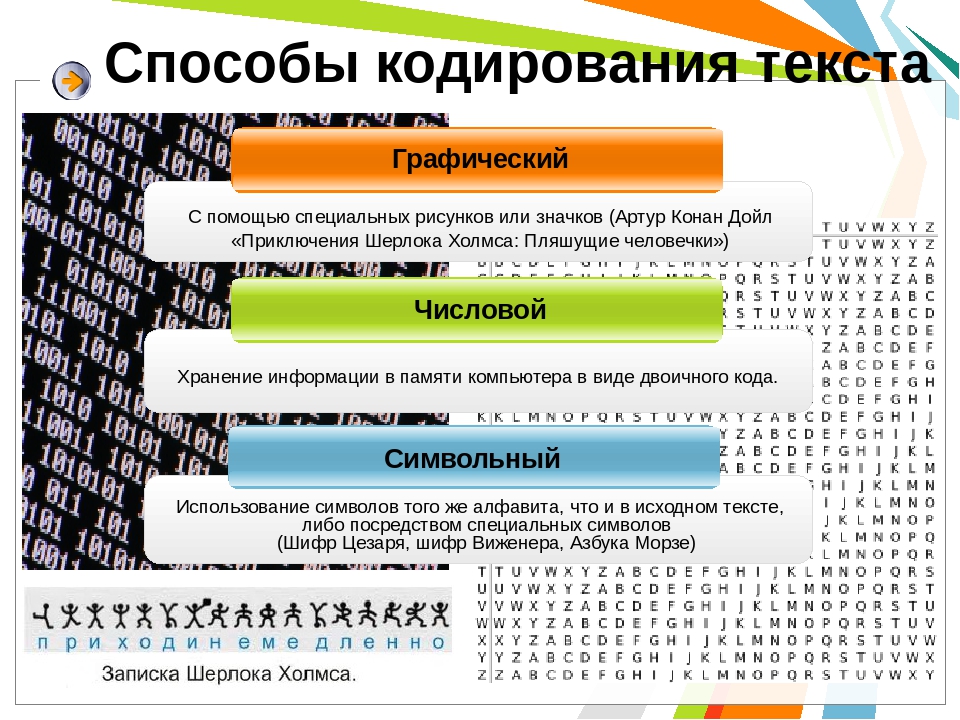
- Если параллельно осуществляется перевод в читаемый вид, выберите его из выпадающего меню сверху.
- Нажмите «Отправить», чтобы получить результат со всей необходимой информацией.
- Ознакомьтесь с параметром возле пункта «Исходная кодировка» для определения символьного набора. Если он отображен не в кодовом названии, найдите перевод через Википедию для общего понимания.
- Иногда FoxTools не распознает редко используемые кодировки, поэтому потребуется переключиться в режим «Все кодировки» и повторить процедуру подбора.
Опишите, что у вас не получилось. Наши специалисты постараются ответить максимально быстро.
Помогла ли вам эта статья?
ДА НЕТПоделиться статьей в социальных сетях:
Как проверить кодировку в текстовом файле? / Общая / SocialKit
Программный комплекс SocialKit корректно работает с кириллицей в текстовых файлах, кодировка которых соответствует стандарту Windows-1251 (кратко может быть записано как CP1251 или ANSI). В этой связи в задачах, поддерживающих указание внешнего файла с перечнем комментариев, сообщений, описаний и прочей информации, которая может содержать кириллицу, нужно указывать текстовые файлы, где русский текст задан в кодировке по стандарту Windows-1251 или же просто ANSI, или CP1251 — всё это, по сути, одно и то же.
В этой связи в задачах, поддерживающих указание внешнего файла с перечнем комментариев, сообщений, описаний и прочей информации, которая может содержать кириллицу, нужно указывать текстовые файлы, где русский текст задан в кодировке по стандарту Windows-1251 или же просто ANSI, или CP1251 — всё это, по сути, одно и то же.
Учитывая, что многие инструменты по работе с текстом не отображают, в какой именно кодировке задан текст в текстовом файле и/или не поддерживают преобразование кодировок, то у новичков часто возникает вопрос о том, как именно привести кодировку текстового файла с русским текстом к понятному для SocialKit формату CP1251.
Следует сразу отметить, что большинство текстовых редакторов для ОС Windows (например, встроенный Блокнот и Wordpad) по умолчанию создают текстовые файлы именно с кодировкой по стандарту Windows-1251. Однако, эта кодировка по умолчанию может быть изменена в следствие тех или иных действий.
Если вы не уверены в том, в какой именно кодировке задан текст, то проще всего этот текст пересохранить через стандартный Блокнот Windows. При пересохранении Блокнот также покажет, в каком формате текст сейчас.
При пересохранении Блокнот также покажет, в каком формате текст сейчас.
Опишем эту простую процедуру по шагам.
1. Открыть искомый текстовый файл в Блокноте Windows и выбрать пункт меню «Файл» -> «Сохранить как…».
Пример текстового файла, в котором русский текст задан в формате UTF, но это не очевидно при открытии.
2. В открывшемся диалоговом окне вы сразу видите, в какой кодировке был сохранён текст в текстовом файле.
Диалоговое окно пересохранения текстового файла, в котором можно сразу изменить кодировку.
Как видно, в примере текст в текстовом файле был ранее сохранён в кодировке UTF-8. Для изменения кодировке достаточно выбрать в выпадающем списке кодировку ANSI и нажать кнопку «Сохранить«.
При этом зрительно для вас ничего не изменится, но многое изменится для программы и алгоритмов, занимающихся обработкой текста в процессе отправки. Корректно Instagram’у будет отправлен только ANSI-текст.
Автоопределение кодировки текста
Введение
Я очень люблю программировать, я любитель и первый и последний раз заработал на программировании в далёком 1996 году. Но для автоматизации повседневных задач иногда что-то пишу. Примерно год назад открыл для себя golang. В качестве инструмента создания утилит golang оказался очень удобным. Итак.
Возникла потребность обработать большое количество (больше тысячи, так и вижу улыбки профи) архивных файлов со специальной геофизической информацией. Формат файлов текстовый, простой. Если вдруг интересно то это LAS формат.
LAS файл содержит заголовок и данные.
Данные практически CSV, только разделитель табуляция или пробелы.
А заголовок содержит описание данных и вот в нём обычно содержится русский текст. Это может быть название месторождение, название исследований записанных в файл и пр.
Файлы эти созданы в разное время и в разных программах, доходит до того что в одном файле часть в кодировке CP1251 а часть в CP866. Файлы эти мне нужно обработать, а значит понять. Вот и потребовалось определять автоматически кодировку файла.
Файлы эти мне нужно обработать, а значит понять. Вот и потребовалось определять автоматически кодировку файла.
В итоге изобрёл велосипед на golang и соответственно родилась маленькая библиотечка с возможностью детектировать кодовую страницу.
Про кодировки. Не так давно на хабре была хорошая статья про кодировки Как работают кодировки текста. Откуда появляются «кракозябры». Принципы кодирования. Обобщение и детальный разбор Если хочется понять что такое “кракозябры” или “кости” то стоит прочитать.
В начале я накидал своё решение. Потом пытался найти готовое работающее решение на golang, но не вышло. Нашлось два решения, но оба не работают.
- Первое “из коробки”— golang.org/x/net/html/charset функция DetermineEncoding()
- Второе библиотека — saintfish/chardet на github
Обе уверенно ошибаются на некоторых кодировках. Стандартная та вообще почти ничего определить не может по текстовым файлам, оно и понятно, её для html страниц делали.
При поиске часто натыкался на готовые утилиты из мира linux — enca. Нашёл её версию скомпилированную для WIN32, версия 1.12. Её я тоже рассмотрю, там есть забавности. Я прошу сразу прощения за своё полное незнание linux, а значит возможно есть ещё решения которые тоже можно попытаться прикрутить к golang коду, я больше искать не стал.
Сравнение найденных решений на автоопределение кодировки
Подготовил каталог softlandia\cpd тестовые данные с файлами в разных кодировках. Содержимое файлов очень короткое и одинаковое. Одна строка “Русский в кодировке CodePageName”. Дополнил файлами со смешением кодировок и некоторыми сложными случаями и попробовал определить.
Мне кажется получилось забавно.
Наблюдение 1
enca не определила кодировку у файла UTF-16LE без BOM — это странно, ну ладно. Я попробовал добавить больше текста, но результата не получил.
Наблюдение 2. Проблемы с кодировками CP1251 и KOI8-R
Строка 15 и 16. У команды enca есть проблемы.
У команды enca есть проблемы.
Здесь сделаю объяснение, дело в том, что кодировки CP1251 (она же Windows 1251) и KOI8-R очень близки если рассматривать только алфавитные символы.
Таблица CP 1251
Таблица KOI8-r
В обеих кодировках алфавит расположен от 0xC0 до 0xFF, но там где у одной кодировки заглавные буквы у другой строчные. Судя по всему enca работает по строчным буквам. Вот и получается, если подать на вход программе enca строку “СТП” в кодировке CP1251, то она решит, что это строка “яро” в кодировке KOI8-r, о чём и сообщит. В обратную сторону также работает.
Наблюдение 3
Стандартной библиотеке html/charset можно доверить только определение UTF-8, но осторожно! Пользоваться следует именно charset.DetermineEncoding(), поскольку метод utf8.Valid(b []byte) на файлах в кодировке utf-16be возвращает true.
Собственный велосипед
Автоопределение кодировки возможно только эвристическими методами, не точно. Если мы не знаем на каком языке и в какой кодировке записан текстовый файл, то определить кодировку с высокой точночностью наверняка можно, но будет сложновато… и нужно будет достаточно много текста.
Для меня такая цель не стояла. Мне достаточно определять кодировки в предположении что там есть русский язык. И второе, определять нужно по небольшому количеству символов – на 10 символах должно быть достаточно уверенное определение, а желательно вообще на 5–6 символах.
Алгоритм
Когда я обнаружил совпадение кодировок KOI8-r и CP1251 по местоположению алфавита, то на пару дней загрустил… стало понятно, что чуть-чуть придётся подумать. Получилось так.
Основные решения:
- Работу будем вести со слайсом байтов, для совместимости с charset.DetermineEncoding()
- Кодировку UTF-8 и случаи с BOM проверяем отдельно
- Входные данные передаём по очереди каждой кодировке.
 Каждая сама вычисляет два целочисленных критерия. У кого сумма двух критериев больше, тот и выиграл.
Каждая сама вычисляет два целочисленных критерия. У кого сумма двух критериев больше, тот и выиграл.
Критерии соответствия
Первый критерий
Первым критерием является количество самых популярных букв русского алфавита.
Наиболее часто встречаются буквы: о, е, а, и, н, т, с, р, в, л, к, м, д, п, у. Данные буквы дают 82% покрытия. Для всех кодировок кроме KOI8-r и CP1251 я использовал только первые 9 букв: о, е, а, и, н, т, с, р, в. Этого вполне хватает для уверенного определения.
А вот для KOI8-r и CP1251 пришлось доработать напильником. Коды некоторых из этих букв совпадают, например буква о имеет в CP1251 код 0xEE при этом в KOI8-r этот код у буквы н. Для этих кодировок были взяты следующие популярные буквы.
Второй критерий
К сожалению для очень коротких случаев (общая длина русского текста 5-6 символов) встречаемость популярных букв на уровне 1-3 шт и происходит нахлёст кодировок KOI8-r и CP1251. Пришлось вводить второй критерий. Подсчёт количества пар согласная+гласная.
Пришлось вводить второй критерий. Подсчёт количества пар согласная+гласная.
Такие комбинации ожидаемо наиболее часто встречаются в русском языке и соответственно в той кодировке в которой число таких пар больше, та кодировка имеет больший критерий.
Вычисляются оба критерия, складываются и полученная сумма является итоговым критерием.
Особенности с которыми я столкнулся
Чуть коснусь прелестей и проблем связанных с golang. Раздел может быть интересен только начинающим писать на golang.
Проблемы
Лично походил по некоторым подводным камушкам из 50 оттенков Go: ловушки, подводные камни и распространённые ошибки новичков.
Что делать если интерфейс является входным параметром нашей функции? Например если мы принимаем io.Reader, проверить его на nil ведь надо. Проверить на существование переменной типа io.Reader мне удалось только с помощью рефлексии.
//CodePageDetect - detect code page of ascii data from reader 'r'
func CodePageDetect(r io. Reader, stopStr ...string) (IDCodePage, error) {
if !reflect.ValueOf(r).IsValid() {
return ASCII, fmt.Errorf("input reader is nil")
}
...
Reader, stopStr ...string) (IDCodePage, error) {
if !reflect.ValueOf(r).IsValid() {
return ASCII, fmt.Errorf("input reader is nil")
}
...Разок наступил на грабли с передачей массивов по значению. Немного тупанул на попытке изменять элементы хранящиеся в map пробегая по ним в range…
Прелести
Сложно сказать что конкретно, постоянное ли битьё по рукам от линтера и компилятора или активное использование range, или всё вместе, но практически отсутствуют залёты по выходу индекса за пределы.
Конечно очень приятно жить со сборщиком мусора. Полагаю мне ещё предстоит освоить грабли автоматизации выделения/освобождения памяти, но пока дебильная улыбка не покидает лица.
Строгая типизация — тоже кусочек счастья.
Переменные имеющие тип функции — соответственно лёгкая реализация различного поведения у однотипных объектов.
Странно мало пришлось сидеть в отладчике, перечитывание кода обычно быстро давало результат.
Щенячий восторг от наличия массы инструментов из коробки, это чудное ощущение когда компилятор, язык, библиотека и IDE Visual Studio Code работают на тебя вместе, слаженно.
Подбор читаемой кодировки с кириллицей онлайн
Пришло мне письмо с не читаемой кириллической кодировкой и встал вопрос о декодирование этой абракадабры в читаемый набор символов. Для этих целей под Windows есть хороший софт, который не раз помогал в таких случаях – Shtirlitz IV 4.01. Но в этот раз он не выдала даже приблизительно читаемый текст.
После непродолжительного googling around был найден Универсальный декодер кириллицы.
Вкратце о возможностях:
- Визуальный подбор исходной кодировки
- Программа проверяет максимум 4725 вариантов из двух и трех перекодировок: если имело место многократное перекодирование вроде koi8(utf(cp1251(utf))), оно не будет распознано или проверено. Если в вашем случае предполагается многократное преобразование – рекомендую воспользоваться выше упомянутым Shtirlitz, он иногда правильно понимает многократное преобразование.
- Если части текста закодированы в разных кодировках, программа сможет распознать только одну часть за раз.

- На преобразуемый текст есть ограничения – 20 Кб
Что сразу понравилось, так это комбобокс Выберите кодировку, в котором перечислен примерный вид исходного текста, т.е. не надо гадать какая правильная исходная и желаемая кодировка, а можно определить примерно по внешней последовательности символов.
Если в списке не было найдено примерно совпавшей кодировки можно воспользоваться Испробовать все комбинации. После нажатия кнопки OK страница перезагрузиться и в выпадающем списке можно будет просмотреть список всех возможных преобразований, среди них я нашел более-менее читаемый текст для своего случая. Правда, некоторые символы не были правильно преобразованы, но текст стал разборчивым и можно было понять смысл письма.
Есть возможность и полностью управляемого декодирования с выбором исходной кодировки, предполагаемой кодировкой и методом кодирования символов (Content-Transfer-Encoding для MIME).
Еще варианты:
Как узнать кодировку сайта и проверить, указана ли кодировка сайта в коде страницы?
24. 06.2014.
06.2014.
Для того, что бы браузеры посетителей вашего сайта корректно отображали текстовое содержимое сайта, нужно на каждой странице указывать кодировку. Делается это, как правило, в файле вашего шаблона, отвечающего за вывод «хедера» (верхней части сайта, шапки).Узнать кодировку сайта можно, посмотрев ответы вашего сервера, их можно посмотреть, используя специальные сервисы. Мы сделали такой сервис для наших посетителей (пункт «Заголовки»):
Найти альтернативные сервисы можно, задав поисковой системе запрос, типа:
проверить ответы сервера
О используемой кодировке нам сообщает строка Content-Type: text/html; charset=UTF-8 — то есть, проверяемая страница закодирована при помощи кодировки UTF-8.
Теперь мы знаем, в какой кодировке сайт отдает страницы, и нужно убедиться, что на всех страницах указана нужная кодировка. Для этого можно открыть исходный код страницы сайта (правый клик на пустом месте страницы — исходный код или CTRL+U — в разных браузерах по разному) и найти строку, содержащую слово charset внутри тега head (между <head> и </head>). Строка может выглядеть по-разному:
Строка может выглядеть по-разному:
<meta charset=»UTF-8″>
<meta http-equiv=»Content-Type» content=»text/html; charset= UTF-8 » />
Главное, что бы она была, и была одна (не должно быть несколько строк с указанием кодировки). Если есть, и кодировка, указанная в коде страницы совпадает с кодировкой, полученной с сервера — то всё хорошо, проверяем ещё несколько страниц, что бы убедиться, что все страницы выдают правильную кодировку.
Если же такой строчки нет, то необходимо указать кодировку сайта в файле шаблона, используемого на сайте (вставить строчку с кодировкой между открывающим и закрывающим тегом head).
Понравилась статься? Подпишитесь на обновления:
Как определить кодировку? Зачем это нужно? :: SYL.ru
Каждая программа пишется с помощью специального кода, который является базовой частью программирования. Сегодня мы расскажем о том, как определить кодировку, с помощью которой была написана та или иная программа.
Что собой представляет кодировка
Кодировкой (одна из частей языка программирования) является некий последовательный набор цифр и знаков, благодаря которым можно создавать новые файлы и программы. Она является базовым элементом каждого языка программирования и может подстраиваться под любую платформу благодаря конвертированию исходного варианта. После полного написания определить кодировку практически невозможно или же очень даже сложно, все это зависит от того, какими программами ее записывали. Не стоит кодировку в программировании путать с ее аналогом в других программах, которые всего лишь зашифровывают некую информацию или ее определенные части.
Как определить кодировку файла
Распознавать язык программирования нужно только в двух случаях: во-первых, когда необходимо дописать программу или переделать ее; во-вторых, когда нужно написать полностью противоположную версию к уже имеющейся. Желательно, чтобы всем этим занимался один и тот же специалист, но если такой возможности нет, то следует владеть знаниями о том, как определить кодировку.
Программы
Определить кодировку можно с помощью определенного ряда программ. Давайте же о них поговорим. Одной из таковых является программа Штирлиц. Она не только сможет определить кодировку, но также подберет необходимый код для изменения данных. Также хорошей программой является Notepad++. С ее помощью вы сможете проанализировать нужный вам файл всего за пять-десять минут в зависимости от его размера. Особенностью программы есть то, что она может конвертировать необходимые документы на разные языки программирования и сохранять уже в таком виде. Следующей является программа UltraEdit, которая не только определит кодировку файла, но также сможет его конвертировать. Ее особенностью есть то, что она кодирует не только пакет в целом, но и его текст в отдельности. Некоторые документы могут показывать кодировку самостоятельно. Для этого на ярлыке документа откройте контекстное меню, выберите функцию «Кодировка» и посмотрите, что вам предоставит данный файл. Если редактор хороший, то он также сможет изменить текущий код, конвертируя пакет для разных языков программирования. Существуют и другие программы, предназначением которых есть кодирование файлов, их конвертация и возможность подстраивать файл под несколько языков программирования одновременно, но мы предоставили только те, работа с которыми требует всего лишь базовых навыков.
Существуют и другие программы, предназначением которых есть кодирование файлов, их конвертация и возможность подстраивать файл под несколько языков программирования одновременно, но мы предоставили только те, работа с которыми требует всего лишь базовых навыков.
Подведем итоги
Благодаря данной статье вы узнали о том, что собой являет кодировка, где и зачем она используется, а также какими способами ее можно узнать. Немного мы затронули разговор и о том, что кодировочная программа может изменять код файла, подстраивая его под разные языки программирования.
Как определить кодировку файла в Mac OS из командной строки
Вы можете определить кодировку файлов и набор символов через командную строку в Mac OS (и Linux) с помощью команды «файл», которая помогает получить общую и конкретную информацию о типе файла.
Это, вероятно, не будет уместным советом для многих пользователей, но если вам необходимо работать с определенным набором символов для чего-либо или нужно знать, какой тип файла, кодировка или набор символов введенного элемента способ командной строки, то это поможет.
Команда file работает в Mac OS и Mac OS X, а также в Linux и многих других вариантах UNIX, что делает этот трюк полезным для скриптов и других подобных целей.
Определение кодировки файла и набора символов через командную строку в Mac OS
Основной синтаксис следующий:
файл -I (входной файл)
(если это не было очевидно, это заглавная буква «i» в качестве флага в -I, а не строчная L)
Нажатие return с правильным именем файла в качестве входных данных покажет набор символов, например UTF-8, us-ascii, binary, 8bit и т. Д.
Например, предположим, что мы проверяем набор символов и кодировку файла с именем «text.txt», тогда синтаксис будет выглядеть следующим образом:
$ файл -I text.txt
text.txt: text / plain; charset = unknown-8bit
Где «text / plain» — тип файла, а «unknown-8bit» — кодировка файла набора символов.
Вы также можете выполнить команду file буквально для любого другого файла, будь то изображения, архивы, исполняемые файлы или что-нибудь еще, на что вы хотите указать команду. Это может быть удобно, если вы что-то автоматизируете, чтобы определить тип файла, чтобы затем запустить соответствующую команду, возможно, после того, как файл был загружен с помощью curl, и тип архива необходимо определить, прежде чем можно будет выполнить правильную команду.
Это может быть удобно, если вы что-то автоматизируете, чтобы определить тип файла, чтобы затем запустить соответствующую команду, возможно, после того, как файл был загружен с помощью curl, и тип архива необходимо определить, прежде чем можно будет выполнить правильную команду.
$ файл -I DownloadedFile.zip
DownloadedFile.zip: application / zip; charset = двоичный
Есть много других применений для проверки набора символов, кодировки файла и типа файла через командную строку с помощью команды «файл», а флаг -I — лишь одна из множества доступных опций.Просмотрите страницу руководства для файла, чтобы узнать больше, если вы заинтересованы, и не забудьте ознакомиться с нашими многими другими советами по работе с командной строкой (или перечислить все команды терминала, доступные на Mac, и немного повеселиться).
Знаете ли вы другой или лучший способ проверить кодировку файла и набор символов через командную строку в Mac OS? Дайте нам знать об этом в комментариях!
Связанные
Объявление кодировки символов в HTML
Целевая аудитория:
Авторы HTML (с помощью редакторов или сценариев), разработчики сценариев (PHP, JSP и т. Д.)), Менеджеров веб-проектов и всех, кому нужно введение в объявление кодировки символов в своем HTML-файле.
Д.)), Менеджеров веб-проектов и всех, кому нужно введение в объявление кодировки символов в своем HTML-файле.
Как мне объявить кодировку моего файла HTML?
Вы всегда должны указывать кодировку, используемую для страницы HTML или XML. Если вы этого не сделаете, вы рискуете, что символы в вашем контенте будут неправильно интерпретированы. Это не только вопрос удобочитаемости человека, все чаще машинам необходимо понимать и ваши данные. Объявление кодировки символов также необходимо для обработки символов, отличных от ASCII, вводимых пользователем в формы, в URL-адресах, сгенерированных сценариями, и т. Д.В этой статье описывается, как это сделать для файла HTML.
Если вам нужно лучше понять, что такое символы и кодировки символов, см. Статью Кодировки символов для начинающих . Для получения информации об объявлении кодировок для таблиц стилей CSS см. Объявления кодировки символов CSS .
Всегда объявляйте кодировку вашего документа с помощью элемента meta с атрибутом charset или с помощью атрибутов http-Equ и content (так называемая директива pragma). Объявление должно полностью помещаться в первые 1024 байта в начале файла, поэтому лучше всего поместить его сразу после открывающего тега
Объявление должно полностью помещаться в первые 1024 байта в начале файла, поэтому лучше всего поместить его сразу после открывающего тега head .
...
.. .
Неважно, что вы используете, но проще набрать первое. Также не имеет значения, набираете ли вы UTF-8 или utf-8 .
Всегда следует использовать кодировку символов UTF-8. (Помните, что это означает, что вам также необходимо сохранить вашего контента как UTF-8.) Посмотрите, что вам следует учитывать, если вы действительно не можете использовать UTF-8.
Если у вас есть доступ к настройкам сервера, вам также следует подумать, имеет ли смысл использовать заголовок HTTP. Однако обратите внимание на , что, поскольку заголовок HTTP имеет более высокий приоритет, чем мета-объявления в документе
Однако обратите внимание на , что, поскольку заголовок HTTP имеет более высокий приоритет, чем мета-объявления в документе , авторы контента всегда должны учитывать, объявлена ли уже кодировка символов в заголовке HTTP. Если это так, должен быть установлен мета-элемент для объявления той же кодировки.
Вы можете обнаружить любые кодировки, отправленные заголовком HTTP, с помощью средства проверки интернационализации.
А как насчет отметки байтового порядка?
Если у вас есть метка порядка байтов (BOM) UTF-8 в начале вашего файла, то последние версии браузера, отличные от Internet Explorer 10 или 11, будут использовать это, чтобы определить, что кодировка вашей страницы - UTF-8.Он имеет более высокий приоритет, чем любое другое объявление, включая заголовок HTTP.
Вы можете пропустить объявление кодировки meta , если у вас есть спецификация, но мы рекомендуем вам сохранить его, поскольку это помогает людям, просматривающим исходный код, выяснить, какая кодировка страницы.
Подробнее о метке порядка байтов.
Следует ли указывать кодировку в заголовке HTTP?
Используйте объявления кодировки символов в заголовках HTTP, если это имеет смысл, и если вы можете, для любого типа содержимого, , но в сочетании с объявление в документе.
Авторы контента всегда должны обеспечивать соответствие деклараций HTTP декларациям в документе.
Плюсы и минусы использования HTTP-заголовка
Одним из преимуществ использования HTTP-заголовка является то, что пользовательские агенты могут быстрее находить информацию о кодировке символов, когда она отправляется в HTTP-заголовке.
Информация заголовка HTTP имеет наивысший приоритет, когда она конфликтует с декларациями в документе, отличными от отметки порядка байтов.Средний
серверы, которые перекодируют данные (т. е. конвертируют в другую кодировку), могут воспользоваться этим, чтобы изменить кодировку документа перед его отправкой на небольшие устройства, которые распознают только несколько
кодировки. Неясно, широко ли используется эта перекодировка в настоящее время. Если это так, и он преобразует контент в кодировку, отличную от UTF-8, существует высокий риск потери данных, и это не является хорошей практикой.
Неясно, широко ли используется эта перекодировка в настоящее время. Если это так, и он преобразует контент в кодировку, отличную от UTF-8, существует высокий риск потери данных, и это не является хорошей практикой.
С другой стороны, есть ряд потенциальных недостатков:
Авторам контента может быть сложно изменить информацию о кодировке для статических файлов на сервере, особенно при работе с интернет-провайдером.Авторам потребуются знания и доступ к настройкам сервера.
Настройки сервера могут по тем или иным причинам не синхронизироваться с документом. Это может произойти, например, если вы полагаться на сервер по умолчанию, и это значение по умолчанию будет изменено. Это очень плохая ситуация, поскольку более высокий приоритет информации HTTP по сравнению с объявление в документе может сделать документ нечитаемым.
Существуют потенциальные проблемы как для статических, так и для динамических документов, если они не читаются с сервера; например, если они сохранены в место, такое как компакт-диск или жесткий диск.
 В этих случаях информация о кодировке из заголовка HTTP недоступна.
В этих случаях информация о кодировке из заголовка HTTP недоступна.Аналогичным образом, если кодировка символов объявлена только в заголовке HTTP, эта информация больше не доступна для файлов во время редактирования или когда они обрабатываются такими вещами, как XSLT или скрипты, или когда они отправляются на перевод и т. д.
Так следует ли мне использовать этот метод?
Если файлы обслуживаются через HTTP с сервера, никогда не будет проблемой отправить информацию о кодировке символов документа в заголовке HTTP, если эта информация верна.
С другой стороны, из-за перечисленных выше недостатков мы рекомендуем всегда объявлять информацию о кодировке также внутри документа. Объявление в документе также помогает разработчикам, тестировщикам или руководителям отдела переводов, которые хотят визуально проверить кодировку документа.
(Некоторые люди утверждают, что объявлять кодировку в заголовке HTTP редко бывает целесообразно, если вы собираетесь повторить ее в
содержание документа. В этом случае они предлагают, чтобы HTTP-заголовок ничего не говорил о кодировке документа. Обратите внимание, что это обычно означает
принятие мер, чтобы отключить все настройки сервера по умолчанию.)
В этом случае они предлагают, чтобы HTTP-заголовок ничего не говорил о кодировке документа. Обратите внимание, что это обычно означает
принятие мер, чтобы отключить все настройки сервера по умолчанию.)
Работа с полиглотами и форматами XML
XHTML5: Документ XHTML5 обслуживается как XML и имеет синтаксис XML.Парсеры XML не распознают объявления кодировки в мета-элементах . Они распознают только декларацию XML. Вот пример:
Объявление XML требуется только в том случае, если страница не обслуживается как UTF-8 (или UTF-16), но может быть полезно включить его, чтобы разработчики, тестировщики или менеджеры по производству переводов могли визуально проверить кодировку документ, посмотрев на источник.
Разметка полиглота: Страница, использующая разметку полиглота, использует подмножество HTML с синтаксисом XML, которое может быть проанализировано с помощью синтаксического анализатора HTML или XML. Он описан в Polyglot Markup: надежный профиль словаря HTML5 .
Он описан в Polyglot Markup: надежный профиль словаря HTML5 .
Поскольку документ полиглота должен быть в UTF-8, вам не нужно и даже не следует использовать объявление XML. С другой стороны, если файл должен читаться как HTML, вам нужно будет объявить кодировку, используя мета-элемент , метку порядка байтов или заголовок HTTP.
Поскольку объявление в элементе meta будет распознаваться только анализатором HTML, если вы используете подход с атрибутом content , его значение должно начинаться с text / html; .
Если вы используете мета-элемент с атрибутом charset , это не то, что вам нужно учитывать.
Информация в этом разделе относится к вещам, о которых вам обычно не нужно знать, но которые включены сюда для полноты.
Работа с кодировками, отличными от UTF-8
Использование UTF-8 не только упрощает создание страниц, но и позволяет избежать неожиданных результатов при отправке формы и кодировках URL-адресов, которые по умолчанию используют кодировку символов документа. Если вы действительно не можете избежать использования кодировки символов, отличной от UTF-8, вам нужно будет выбрать из ограниченного набора имен кодировки, чтобы обеспечить максимальную совместимость и максимально длительный срок читабельности вашего контента.
Хотя обычно они называются кодировкой именами , в действительности они относятся к кодировкам, а не к наборам символов.Например, набор символов Unicode или «репертуар» может быть закодирован в трех различных схемах кодирования.
До недавнего времени реестр IANA был местом, где можно было найти имена для кодировок. Реестр IANA обычно включает несколько имен для одной и той же кодировки. В этом случае вы должны использовать имя, обозначенное как
«предпочтительный».
Новая спецификация Encoding теперь предоставляет список, который был протестирован против реальных реализаций браузеров. Вы можете найти список в таблице в разделе «Кодировки».Лучше всего использовать имена из левого столбца этой таблицы.
Обратите внимание на , однако, что наличие имени в любом из этих источников не обязательно означает, что использовать эту кодировку можно. Некоторые кодировки проблематичны. Если вы действительно не можете использовать UTF-8, вам следует внимательно изучить совет из статьи Выбор и применение кодировки символов .
Не придумывайте свои собственные имена кодировок, которым предшествует x-. Это плохая идея, поскольку она
ограничивает совместимость.
Работа с устаревшими форматами HTML
HTML 4.01 не определяет использование атрибута charset с мета-элементом , но любой недавний крупный браузер все равно обнаружит его и будет использовать, даже если страница объявлена как HTML4, а не HTML5. Этот раздел актуален только в том случае, если у вас есть другая причина, кроме обслуживания браузера для соответствия более старому формату HTML. Он описывает любые отличия от раздела ответов выше.
Этот раздел актуален только в том случае, если у вас есть другая причина, кроме обслуживания браузера для соответствия более старому формату HTML. Он описывает любые отличия от раздела ответов выше.
Информацию о страницах, обслуживаемых как XML, см. В разделе Работа с многоязычными форматами и XML.
HTML4: Как уже упоминалось выше, для полного соответствия HTML 4.01 вам необходимо использовать директиву pragma, а не атрибут charset .
XHTML 1.x служил как text / html: Для полного соответствия HTML 4.01 требуется директива pragma, а не атрибут charset . Вам не нужно использовать объявление XML, поскольку файл обслуживается как HTML.
XHTML 1.x служит XML: Используйте объявление в кодировке объявления XML в первой строке страницы.Убедитесь, что перед ним ничего нет, включая пробелы (хотя отметка порядка байтов в порядке).
Атрибут charset ссылки
HTML5 не рекомендует использовать атрибут charset в элементе a или link , поэтому вам следует избегать его использования. Он возник в спецификации HTML 4.01 для использования с элементами
Он возник в спецификации HTML 4.01 для использования с элементами a , link и script и должен был указывать кодировку документа, на который вы ссылаетесь.
Он был предназначен для использования во встроенном элементе ссылки, например:
Плохой код. Не копируйте! См. Наш список публикаций .
Идея заключалась в том, что браузер сможет применить правильную кодировку к документу, который он извлекает, если никакая другая кодировка не указана для документа.
Всегда были проблемы с использованием этого атрибута. Во-первых, он плохо поддерживается основными браузерами.Одна из причин не поддерживать этот атрибут заключается в том, что, если браузеры делают это без специальных дополнительных правил, это будет вектор атаки XSS. Во-вторых, трудно гарантировать, что информация верна в любой момент времени. Автор указанного документа вполне может изменить кодировку документа без вашего ведома. Если автор все еще не указал кодировку своего документа, вы теперь попросите браузер применить неправильную кодировку. И, в-третьих, в этом нет необходимости, если люди следуют рекомендациям, изложенным в этой статье, и правильно размечают свои документы.Это гораздо лучший подход.
Автор указанного документа вполне может изменить кодировку документа без вашего ведома. Если автор все еще не указал кодировку своего документа, вы теперь попросите браузер применить неправильную кодировку. И, в-третьих, в этом нет необходимости, если люди следуют рекомендациям, изложенным в этой статье, и правильно размечают свои документы.Это гораздо лучший подход.
Этот способ указания кодировки документа имеет самый низкий приоритет (т. Е. Если кодировка объявлена каким-либо другим способом, это будет проигнорировано). Это означает, что вы также не можете использовать это для исправления неверных объявлений.
Работа с UTF-16
Согласно результатам выборки Google из нескольких миллиардов страниц, менее 0,01% страниц в Интернете закодированы в UTF-16. UTF-8 составляет более 80% всех веб-страниц, если вы включаете его подмножество, ASCII, и более 60%, если вы этого не делаете.Настоятельно не рекомендуется использовать UTF-16 в качестве кодировки страницы.
Если по какой-то причине у вас нет выбора, вот несколько правил объявления кодировки. Они отличаются от кодировок для других кодировок.
Спецификация HTML5 запрещает использование элемента meta для объявления UTF-16, поскольку значения должны быть совместимы с ASCII. Вместо этого вы должны убедиться, что у вас всегда есть метка порядка байтов в самом начале файла в кодировке UTF-16. По сути, это декларация в документе.
Кроме того, если ваша страница закодирована как UTF-16, не объявляйте файл как «UTF-16BE» или «UTF-16LE», используйте только «UTF-16». Отметка порядка байтов в начале вашего файла укажет, является ли схема кодирования прямым или обратным порядком байтов. (Это связано с тем, что содержимое, явно закодированное, например, как UTF-16BE, не должно использовать метку порядка байтов; но HTML5 требует метки порядка байтов для страниц в кодировке UTF-16.)
Unicode HOWTO — документация Python 3.9.1
Определения
Современные программы должны уметь обрабатывать широкий спектр
символы. Приложения часто интернационализированы для отображения
сообщения и вывод на различных языках, выбираемых пользователем; в
той же программе может потребоваться вывести сообщение об ошибке на английском, французском,
Японский, иврит или русский. Веб-контент может быть написан на любом из
эти языки, а также могут включать в себя различные символы эмодзи.
Строковый тип Python использует стандарт Unicode для представления
символов, что позволяет программам Python работать со всеми этими разными
возможные персонажи.
Приложения часто интернационализированы для отображения
сообщения и вывод на различных языках, выбираемых пользователем; в
той же программе может потребоваться вывести сообщение об ошибке на английском, французском,
Японский, иврит или русский. Веб-контент может быть написан на любом из
эти языки, а также могут включать в себя различные символы эмодзи.
Строковый тип Python использует стандарт Unicode для представления
символов, что позволяет программам Python работать со всеми этими разными
возможные персонажи.
Unicode (https: // www.unicode.org/) — это спецификация, направленная на перечислите все символы, используемые в человеческих языках, и дайте каждому символу собственный уникальный код. Спецификации Unicode постоянно переработан и обновлен, чтобы добавить новые языки и символы.
Символ — наименьший возможный компонент текста. «А», «В», «С»,
и т.д., все разные персонажи. Таковы ‘’ и ‘’. Персонажи различаются
в зависимости от языка или контекста, на котором вы говорите
около. Например, для «римской цифры один» есть символ «», то есть
отдельно от заглавной буквы «I».Обычно они выглядят одинаково,
но это два разных персонажа, которые имеют разные значения.
Например, для «римской цифры один» есть символ «», то есть
отдельно от заглавной буквы «I».Обычно они выглядят одинаково,
но это два разных персонажа, которые имеют разные значения.
Стандарт Unicode описывает, как символы представлены кодовых точек . Значение кодовой точки — это целое число в диапазоне от 0 до
0x10FFFF (около 1,1 миллиона значений,
фактический присвоенный номер
меньше этого). В стандарте и в этом документе написана кодовая точка
используя обозначение U + 265E для обозначения символа со значением 0x265e (9822 в десятичной системе).
Стандарт Unicode содержит множество таблиц, в которых перечислены символы и их соответствующие кодовые точки:
0061 'а'; ЛАТИНСКАЯ СТРОЧНАЯ БУКВА A
0062 'b'; ЛАТИНСКАЯ СТРОЧНАЯ БУКВА B
0063 'c'; ЛАТИНСКАЯ СТРОЧНАЯ БУКВА C
...
007B '{'; КРОНШТЕЙН ЛЕВЫЙ
...
2167 'Ⅷ'; РИМСКОЕ ЧИСЛО ВОСЕМЬ
2168 'Ⅸ'; РИМСКОЕ ЧИСЛО ДЕВЯТЬ
...
265E '♞'; ЧЕРНЫЙ ШАХМАТНЫЙ РЫЦАРЬ
265F '♟'; ЧЕРНАЯ ШАХМАТНАЯ ПАПКА
. ..
1F600 '😀'; УЛИЧАЮЩЕЕ ЛИЦО
1F609 '😉'; Подмигивающее лицо
...
..
1F600 '😀'; УЛИЧАЮЩЕЕ ЛИЦО
1F609 '😉'; Подмигивающее лицо
...
Строго говоря, эти определения подразумевают, что бессмысленно говорить «это
символ U + 265E ’. U + 265E — это кодовая точка, которая представляет собой
персонаж; в данном случае это символ «ЧЕРНЫЙ ШАХМАТНЫЙ РЫЦАРЬ»,
‘♞’. В
неформальных контекстах, это различие между кодовыми точками и символами будет
иногда забывают.
Персонаж представлен на экране или на бумаге набором графических элементы, которые называются глифом . Глиф для прописной буквы A, например, это два диагональных штриха и горизонтальный штрих, хотя точные детали будут зависят от используемого шрифта.Большинству кода Python не нужно беспокоиться о глифы; определение правильного глифа для отображения обычно является задачей графического интерфейса. инструментарий или средство визуализации шрифтов терминала.
Кодировки
Подводя итог предыдущему разделу: строка Unicode — это последовательность
кодовые точки, которые представляют собой числа от 0 до 0x10FFFF (1,114,111
десятичный). Эта последовательность кодовых точек должна быть представлена в
память как набор кодовых единиц и кодовых единиц затем отображаются
в 8-битные байты.Правила перевода строки Unicode в
последовательность байтов называется кодировкой символов , или просто
кодировка .
Эта последовательность кодовых точек должна быть представлена в
память как набор кодовых единиц и кодовых единиц затем отображаются
в 8-битные байты.Правила перевода строки Unicode в
последовательность байтов называется кодировкой символов , или просто
кодировка .
Первая кодировка, о которой вы можете подумать, использует 32-битные целые числа в качестве код, а затем с использованием представления ЦП 32-битных целых чисел. В этом представлении строка «Python» может выглядеть так:
P y t h o n 0x50 00 00 00 79 00 00 00 74 00 00 00 68 00 00 00 6f 00 00 00 6e 00 00 00 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23
Это прямое представление, но его использование дает ряд проблемы.
Непереносной; разные процессоры по-разному упорядочивают байты.
Очень расточительно места. В большинстве текстов большинство кодовых точек меньше 127 или меньше 255, поэтому много места занимает
0x00байты. Приведенная выше строка занимает 24 байта по сравнению с 6 байтами, необходимыми для
Представление ASCII. Увеличенное использование ОЗУ не имеет большого значения (настольный компьютер
у компьютеров есть гигабайты оперативной памяти, и строки обычно не такие большие), но
увеличение использования диска и пропускной способности сети в 4 раза — это
невыносимо.
Приведенная выше строка занимает 24 байта по сравнению с 6 байтами, необходимыми для
Представление ASCII. Увеличенное использование ОЗУ не имеет большого значения (настольный компьютер
у компьютеров есть гигабайты оперативной памяти, и строки обычно не такие большие), но
увеличение использования диска и пропускной способности сети в 4 раза — это
невыносимо.Он несовместим с существующими функциями C, такими как
strlen (), поэтому новый необходимо использовать семейство широких строковых функций.
Таким образом, эта кодировка используется нечасто, и люди вместо этого выбирают другую более эффективные и удобные кодировки, например UTF-8.
UTF-8 — одна из наиболее часто используемых кодировок, а Python часто
по умолчанию использует его. UTF означает «Формат преобразования Unicode»,
а «8» означает, что при кодировании используются 8-битные значения.(Там
также являются кодировками UTF-16 и UTF-32, но реже
используется, чем UTF-8.