Раскодировать текст онлайн: сервисы для раскодировки
Весь текстовый контент, с которым мы работаем, хранится изначально в числовом виде. Для его преобразования используется кодирование. В различных системах одним и тем же значениям соответствуют различные буквенные, цифровые или просто символьные последовательности. Так иногда можно открыть документ или страничку и увидеть непонятные символы. Получается, что здесь данные были сохранены в другой кодировке. В таком случае можно раскодировать текст онлайн, с помощью специализированных сервисов. Все перечисленные ниже инструменты являются довольно популярными и функциональными.
СОДЕРЖАНИЕ СТАТЬИ:
Универсальный декодер
Сервис отлично справляется с кириллицей. Очень популярен среди юзеров рунета. Если вы выбрали его для работы, то необходимо сделать копию текста, нуждающегося в декодировании и вставить в специальное поле. Следует размещать отрывок так, чтобы уже на первой строчке были непонятные знаки.
Если вы хотите, чтобы ресурс автоматически смог раскодировать, придется отметить это в списке выбора. Но можно выполнять и ручную настройку, указав выбранный тип. Итоги можете найти в разделе «Результат». Вот только тут есть определенные ограничения. К примеру, если в поле вставить отрывок более 100 Кб, софт не обработает его, так что нужно будет выбирать кусочки.
Но можно выполнять и ручную настройку, указав выбранный тип. Итоги можете найти в разделе «Результат». Вот только тут есть определенные ограничения. К примеру, если в поле вставить отрывок более 100 Кб, софт не обработает его, так что нужно будет выбирать кусочки.
Как раскодировать текст онлайн с помощью Fox Tools
Здесь вы можете выбирать итоговый результат. Программа способна функционировать и в режиме «по умолчанию», который используется для неизвестных кодировок, но в таком случае необходимо отмечать самостоятельно вариант текстового объекта, подходящего больше всего. Инструмент простой и доступный, поэтому идеально подойдет даже новичкам.
Декодер Артемия Лебедева
Данный дешифратор способен взаимодействовать со всеми популярными кодировками. Приложение может предложить пользователю сложный и простой рабочий режим. В первом показывается не только исходник, но и преобразование. Еще можно указать кодировку, куда понадобилось перевести текст, из открывающегося списка.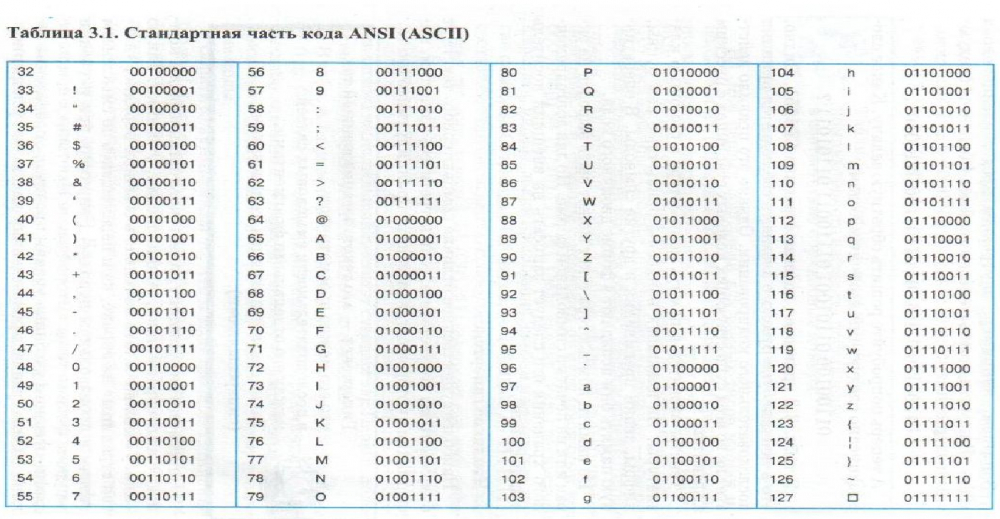 В правом блоке вы найдете результат для прочтения.
В правом блоке вы найдете результат для прочтения.
Translit.net
Этот инструмент имеет сложный внешний вид, но по принципу работы он не отличается от остальных. Необходимо ввести текстовый отрывок и в ручном режиме установить настройки.
Программа Штирлиц
Приложение, которым легко раскодировать онлайн, было создано для работы с русскоязычными объектами. Сюда можно текст копировать из буфера обмена, а также из самого текстового файла. Программа, позволяющая раскодировать текст онлайн, проверяет разные схемы. Если схема корректно не отображает все русские слова, используется следующая. Еще здесь можно создавать авторскую кодовую схему и пользоваться ей для работы. Для одновременной обработки нескольких файлов, нужно индивидуально открывать каждый из них.
Пользуемся стандартным Word
Этот редактор очень популярен, именно с ним работает большая часть пользователей. Так что они регулярно сталкиваются с некорректным отображением букв или невозможностью открыть участок с неподходящей кодировкой. Если документ Ворд открылся в режиме ограниченной функциональности, следует ее убрать. Если все еще отображаются непонятные знаки, укажите верную кодировку в программных настройках. Для этого идете по такому пути:
Если документ Ворд открылся в режиме ограниченной функциональности, следует ее убрать. Если все еще отображаются непонятные знаки, укажите верную кодировку в программных настройках. Для этого идете по такому пути:
Файл (Office)/Параметры/Дополнительно.
В разделе «Общие» установите галочку в спецнастройке «Подтверждать преобразование формата». Соглашаетесь с изменениями, закрываете прогу, а потом опять открываете файл. В окошке «Преобразование» выбираете «Кодированный текст». Ищите свой вариант.
Определение кодировки
Есть несколько способов определения:
- В Ворде во время открытия документа: если есть отличия от СР1251, редактор предлагает выбирать одну из самых подходящих кодировок. Оценить, насколько они аналогичны, можно по превью текстового образца;
- В утилите KWrite. Сюда загружаете объект с расширением .txt и используете настройки в меню «Кодирование»;
- Открываете объект в обозревателе Mozilla Firefox. При правильном отображении в разделе «Вид» ищите кодировку.
 Нужный вариант – тот, возле которого установлен флажок. Если все отображается с ошибками, проверяете различные варианты в меню «Дополнительно»;
Нужный вариант – тот, возле которого установлен флажок. Если все отображается с ошибками, проверяете различные варианты в меню «Дополнительно»; - Пользователи Unix могут воспользоваться приложением Enca.
С помощью предложенных инструментов вы можете быстро и легко раскодировать текст онлайн. Если у вас мало знаний, воспользуйтесь утилитами с простым меню и функционалом.
Распознаём 50 видов текста на C++ с Plywood | by Novikov Ivan | NOP::Nuances of Programming
Посмотрим на скромный текстовый файл:
Этот файл может содержать удивительное количество различных форматов. Текст может быть закодирован как ASCII, UTF-8, UTF-16 (с прямым или обратным порядком байтов), Windows-1252, Shift JIS или любой из десятков других кодировок. Файл может начинаться или не начинаться с метки порядка байтов (BOM). Строки текста могут заканчиваться символом конца строки \n, типичным для UNIX, последовательностью \r\n, типичной для Windows или, если файл создан в старой системе, какой-то другой последовательностью символов. Иногда невозможно определить кодировку в конкретном текстовом файле. Предположим, файл содержит такие байты:
Иногда невозможно определить кодировку в конкретном текстовом файле. Предположим, файл содержит такие байты:
A2 C2 A2 C2 A2 C2
Это может быть:
- UTF-8, содержащий
¢¢¢; - UTF-16 с прямым порядком (или UCS-2) с символами
ꋂꋂꋂ; - UTF-16 обратного порядка байтов с
슢슢슢; - Windows-1252 с
¢¢¢.
Пример искусственный. Суть в том, что текстовые файлы в своей основе неоднозначны. Неясности создают проблему для программного обеспечения, загружающего текст. Она существует уже некоторое время. К счастью, ландшафт текстовых файлов со временем стал проще. UTF-8 одержал победу над другими кодировками. Более 95% Интернета использует UTF-8. Впечатляет скорость, с которой изменилась цифра: она составляла менее 10% в 2006 году.
Но UTF-8 ещё не захватил мир. Редактор реестра Windows по-прежнему сохраняет текстовые файлы в кодировке UTF-16. Когда же текстовый файл пишется в Python, кодировка по умолчанию зависит от платформы. На моей машине с Windows это Windows-1252. Говоря коротко, проблема неопределённости текста всё ещё актуальна. И даже если файл закодирован в UTF-8, всё равно есть вариации: он может начинаться или не начинаться с BOM; или может иметь разные стили окончания строк.
На моей машине с Windows это Windows-1252. Говоря коротко, проблема неопределённости текста всё ещё актуальна. И даже если файл закодирован в UTF-8, всё равно есть вариации: он может начинаться или не начинаться с BOM; или может иметь разные стили окончания строк.
Plywood — это кросс-платформенный фреймворк с открытым исходным кодом, выпущенный мной два месяца назад. При открытии текстового файла с помощью Plywood у вас есть несколько вариантов:
- Если вы знаете формат, вызывайте
FileSystem::openTextForRead(), передавая ожидаемый формат в структуруTextFormat. - Если вы не знаете формат, вызывайте
FileSystem::openTextForReadAutodetect(). Функция попытается определить формат и вернуть его.
Возвращаемый этими функциями входной поток никогда не начинается с BOM, всегда кодируется в UTF-8 и завершает каждую строку ввода одним символом возврата каретки \n, независимо от исходного формата входного файла. Преобразование выполняется налету, когда необходимо, позволяя приложениям Plywood работать с единственной внутренней кодировкой.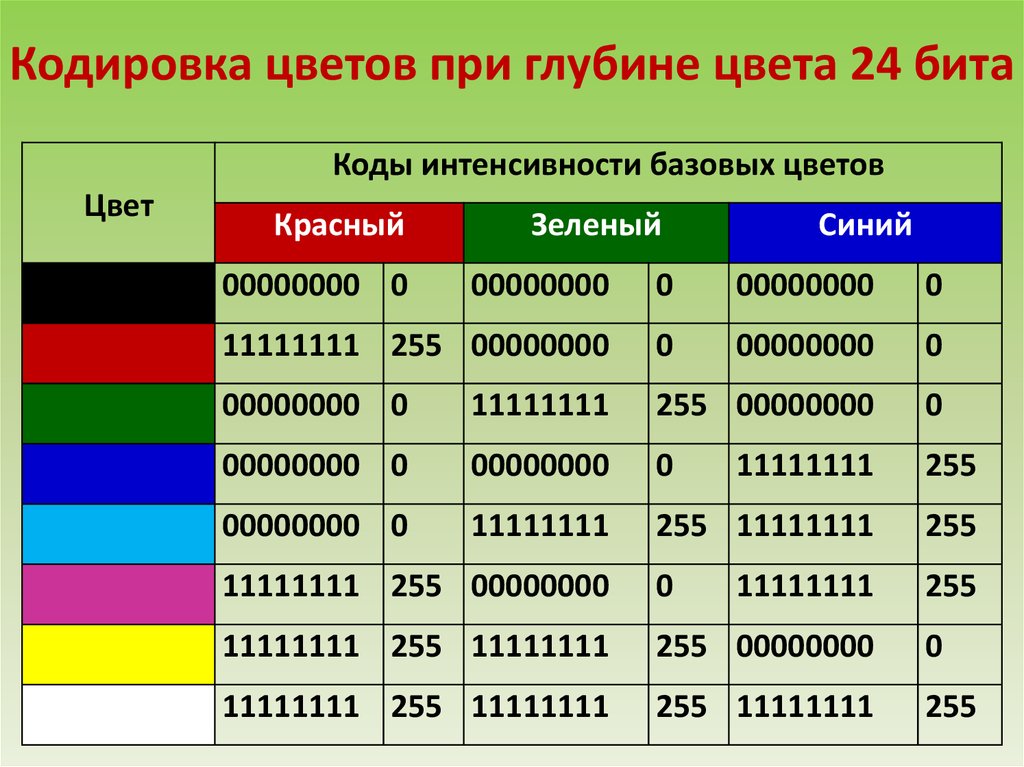
Вот так сейчас работает автоматическое определение формата текста в Plywood:
Plywood анализирует первые 4 КБ входного файла, чтобы предположить его формат. Двух начальных проверок достаточно подавляющему большинству текстовых файлов, с которыми я сталкивался. В UTF-8 есть много недопустимых последовательностей байтов, поэтому когда файл может быть декодирован как UTF-8 и не содержит никаких управляющих кодов, это почти наверняка UTF-8. Управляющий код — это код символа меньше 32, за исключением символов табуляции, перевода строки и возврата каретки.
Только при входе в нижнюю часть блок-схемы возникают некоторые догадки. Во-первых, Plywood решает, лучше ли интерпретировать файл как UTF-8 или как простые байты. Это делается, чтобы обработать, например, текст с ударениями в кодировке Windows-1252. В ней французское слово détail кодируется байтами 64 E9 74 61 69 6C, что вызывает ошибку декодирования UTF-8. UTF-8, в свою очередь, ожидает, что за байтом E9 следует байт в диапазоне от 80 до BF. После определённого количества ошибок Plywood делает выбор в пользу простого байта, а не UTF-8.
После определённого количества ошибок Plywood делает выбор в пользу простого байта, а не UTF-8.
Фреймворк пытается декодировать одни и те же данные, применяя 8-битный формат, little-endian UTF-16 и big-endian UTF-16. Он вычисляет балл для каждой кодировки таким образом:
- Каждый декодированный символ пробела добавляет 2,5 балла. Пробельные символы очень полезны для идентификации кодировок, поскольку пробелы UTF-8 не могут быть распознаны в UTF-16, а пробелы UTF-16 содержат управляющие коды при интерпретации в 8-битной кодировке.
- ASCII символы, за исключением управляющих, добавляют по 1 баллу.
- Ошибки декодирования влекут штраф в 100 баллов.
- Управляющие коды наказываются штрафами в 50 баллов.
- Коды символов, превышающие
U+FFFF, стоят 5 баллов, так как шансы столкнуться с такими символами в случайных данных невелики вне зависимости от кодировки. Яркий пример — эмоджи.
Яркий пример — эмоджи.
Баллы делятся на общее количество декодированных символов, затем выбирается лучший результат.
Откуда взялись 2,5, 1 и прочие значения? Я их выдумал. Они, вероятно, ещё не оптимальны. У алгоритма есть и другие слабые места. Plywood ещё не знает, как распознавать произвольные 8-битные кодировки. В настоящее время он интерпретирует каждый 8-битный текстовый файл UTF-8 как Windows-1252. Фреймворк также не поддерживает Shift JIS в настоящее время. Хорошая новость заключается в том, что Plywood — проект с открытым исходным кодом. Это означает, что улучшения могут публиковаться сразу после разработки.
В репозитории вы найдете папку, содержащую 50 текстовых файлов различных форматов. Все эти файлы корректно определяются и загружаются функцией FileSystem::openTextForReadAutodetect().
Многие современные текстовые редакторы, как и Plywood, определяют формат автоматически. Из любопытства я открывал этот набор в нескольких редакторах:
- Notepad++ корректно открывает 38 из 50 файлов.
 Он терпит неудачу на всех файлах UTF-16 без BOM, за исключением little-endian, состоящих в основном из символов ASCII.
Он терпит неудачу на всех файлах UTF-16 без BOM, за исключением little-endian, состоящих в основном из символов ASCII. - Sublime Text понимает 42 файла. Когда текст содержит ASCII, редактор делает верное предположение независимо от кодировки.
- Visual Studio Code видит 40 фалов. VSC близок к Sublime Text, но ошибается на Windows-1252 с ударениями.
- И самое впечатляющее: Блокнот Windows верно отображает 42 файла! Он правильно распознаёт все UTF-16 с прямым порядком без BOM, но не работает с UTF-16 обратного порядка байтов и без BOM.
По общему признанию это было нечестное соревнование: весь тестовый набор создан вручную специально для Plywood. Больше всего ошибок происходило на файле UTF-16 без BOM. Кажется, это редкий формат. Ни один из редакторов не позволяет сохранить такой файл.
Редакторы из списка выше в первую очередь вдохновляли стратегию автоматического обнаружения в Plywood. В C++ работа с Unicode всегда вызывала трудности. Ситуация весьма печальная: комитет по стандартизации C++ только недавно сформировал исследовательскую группу для решения проблемы. Между тем, я всегда задавался вопросом о том, почему загрузка текста в C++ не может быть такой же простой, как в современном текстовом редакторе? Если вам нравится направление движения Plywood и вы хотите, чтобы так и продолжалось, ваша поддержка на Patreon была бы признанием фреймворка.
Между тем, я всегда задавался вопросом о том, почему загрузка текста в C++ не может быть такой же простой, как в современном текстовом редакторе? Если вам нравится направление движения Plywood и вы хотите, чтобы так и продолжалось, ваша поддержка на Patreon была бы признанием фреймворка.
Если вы хотите сделать Plywood лучше любым из упомянутых способов, участвуйте на GitHub или на сервере Discord. Если вам нужен только исходный код, обнаруживающий кодировки, не стесняйтесь копировать исходник и изменять его, как посчитаете нужным.
Читайте также:
- Шаблон проектирования прототипов в современном C++
- Тест рабочего цикла C++ через написание кода для декодера base85
- Языки C и C++. Где их используют и зачем?
Читайте нас в телеграмме, vk и Яндекс.Дзен
Перевод статьи Jeff Preshing: Automatically Detecting Text Encodings in C++
NLP — кодирование текста: руководство для начинающих | Бишал Бозе | Analytics Vidhya
— В этом блоге мы разберемся, ЧТО такое кодирование текста ? КАК это сделать? А точнее ЗАЧЕМ его выполнять?
Источник: GoogleДавайте сначала попробуем понять несколько основных правил…
1.
Машина не понимает символы, слова или предложения.
2. Машины могут обрабатывать только числа.
3. Текстовые данные должны быть закодированы как числа для ввода или вывода для любой машины.
ЗАЧЕМ кодировать текст?
Как упоминалось в предыдущих пунктах, мы не можем передавать необработанный текст в машины в качестве входных данных до тех пор, пока мы не преобразуем его в числа, поэтому нам необходимо выполнить кодирование текста.
ЧТО такое кодировка текста?
Кодирование текста — это процесс преобразования осмысленного текста в числовое/векторное представление с целью сохранения контекста и отношений между словами и предложениями, чтобы машина могла понять шаблон, связанный с любым текстом, и могла разобрать контекст предложений .
КАК кодировать текст для любой задачи НЛП?
Существует множество методов преобразования текста в числовые векторы, а именно:
— Кодирование на основе индексов
— Сумка слов (BOW)
— Кодирование Word2Vector
— Кодирование BERT
Поскольку это базовое объяснение кодирования текста НЛП, мы пропустим последние 2 метода, то есть Word2Vector и BERT, поскольку они являются довольно сложными и мощными реализациями Deep.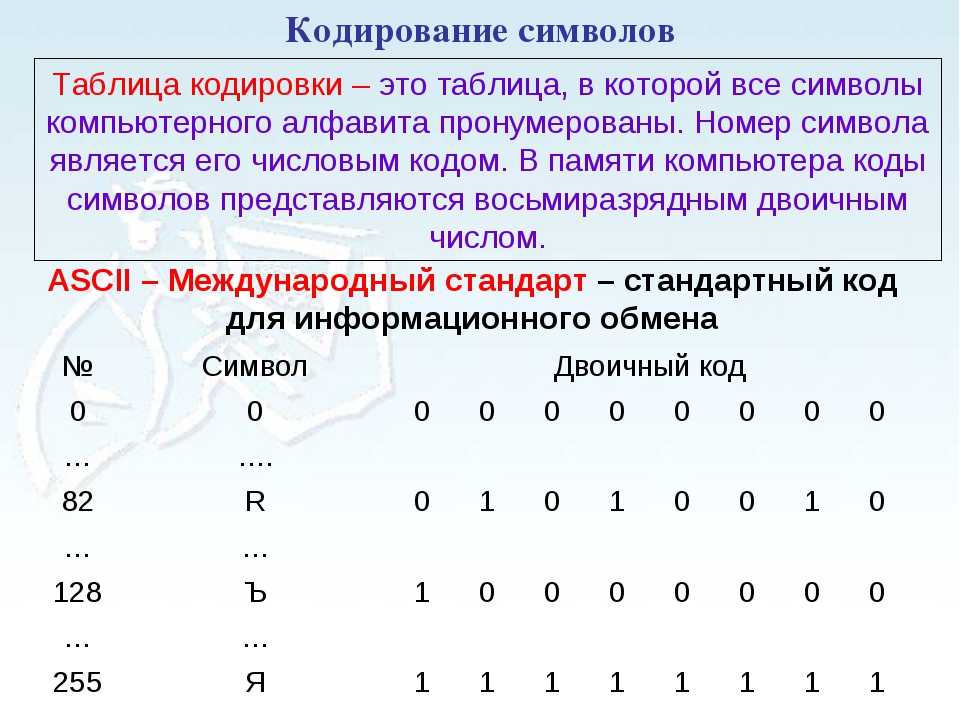 Метод обучения на основе встраивания текста для преобразования текста в векторное кодирование.
Метод обучения на основе встраивания текста для преобразования текста в векторное кодирование.
Вы можете найти подробную информацию о Word2Vector в другом моем блоге, указанном здесь: НЛП — кодировка текста: Word2Vec
Прежде чем мы углубимся в каждый метод, давайте приведем несколько основных примеров, чтобы упростить его выполнение.
Корпус документа: Это весь набор текста, который у нас есть, в основном наш текстовый корпус, может быть чем угодно, например, новостными статьями, блогами и т. д.… и т. д.…
Пример: У нас есть 5 предложений, а именно: [“это хороший телефон», «это плохой мобильный», «она хорошая кошка», «у него плохой характер», «этот мобильный телефон плохой»]
Корпус данных: это набор уникальных слов в нашем корпусе документов, т.е. в нашем случае это выглядит так:
[«а», «плохой», «кот», «хороший», «имеет», » он», «есть», «мобильный», «не», «телефон», «она», «нрав», «это»]
Мы будем придерживаться этих предложений, чтобы понять каждый метод встраивания.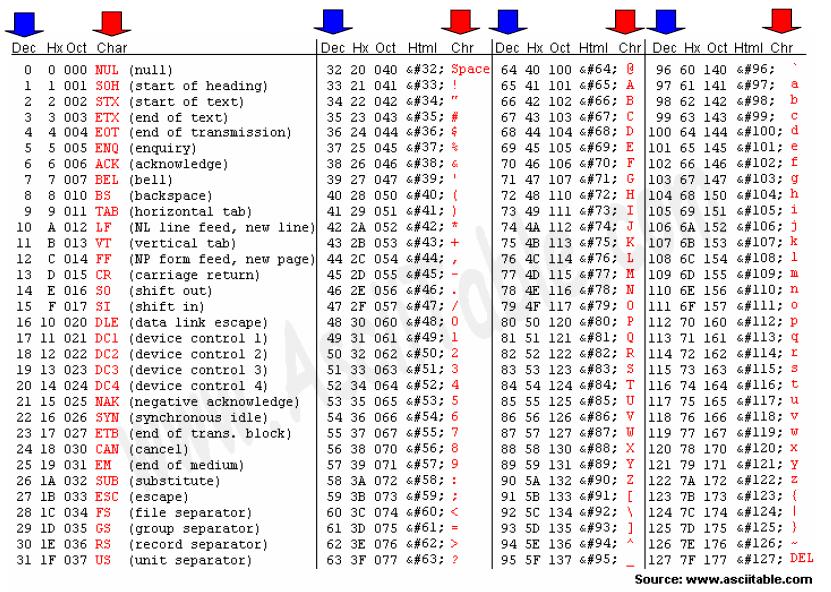
Это облегчит понимание и понимание интуиции, стоящей за этими методами.
Итак, давайте попробуем разобраться в каждом из них по порядку:
1. Кодирование на основе индекса:Как следует из названия, на основе индекса нам обязательно нужно дать всем уникальным словам индекс, как мы отделили наш корпус данных, теперь мы можем индексировать их по отдельности, например …
a : 1
bad : 2
…
this : 13
Теперь, когда мы присвоили всем словам уникальный индекс, чтобы на основе индекса мы могли их однозначно идентифицировать, мы можем преобразовать наши предложения используя этот метод на основе индекса.
Очень просто понять, что мы просто заменяем слова в каждом предложении их соответствующими индексами.
Наш корпус документов становится следующим:
[13 7 1 4 10], [13 7 1 2 8], [11 7 1 4 3], [6 5 1 2 12], [13 8 10 7 9 4]
Теперь мы закодировали все слова порядковыми номерами, и это можно использовать в качестве входных данных для любой машины, поскольку машина понимает числа.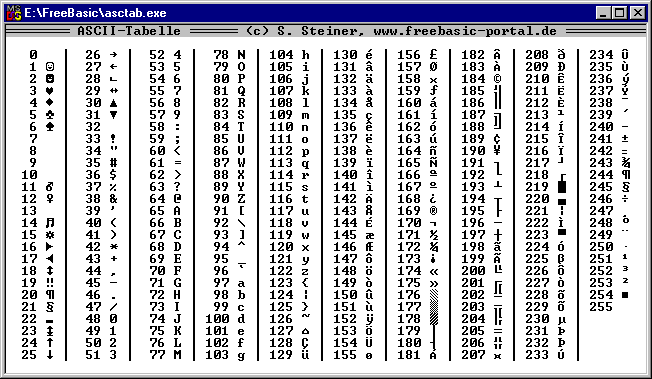
Но есть небольшая проблема, которую необходимо решить в первую очередь, а именно непротиворечивость ввода. Наши входные данные должны иметь ту же длину, что и наша модель, они не могут меняться. В реальном мире он может отличаться, но о нем нужно позаботиться, когда мы используем его в качестве входных данных для нашей модели.
Теперь, когда мы видим, что в первом предложении 5 слов, а в последнем предложении 6 слов, это вызовет дисбаланс в нашей модели.
Итак, чтобы решить эту проблему, мы делаем максимальное заполнение, что означает, что мы берем самое длинное предложение из нашего корпуса документов и дополняем другое предложение, чтобы оно было таким же длинным. Это означает, что если все мои предложения состоят из 5 слов, а одно предложение состоит из 6 слов, я составлю все предложения из 6 слов.
Как теперь добавить сюда это лишнее слово? Как в нашем случае добавить сюда этот дополнительный индекс?
Если вы заметили, мы не использовали 0 в качестве индекса, и желательно, чтобы он нигде не использовался, даже если у нас есть корпус данных длиной 100000 слов, поэтому мы используем 0 в качестве индекса заполнения. Это также означает, что мы ничего не добавляем к нашему фактическому предложению, поскольку 0 не представляет какое-либо конкретное слово, поэтому целостность наших предложений не нарушена.
Это также означает, что мы ничего не добавляем к нашему фактическому предложению, поскольку 0 не представляет какое-либо конкретное слово, поэтому целостность наших предложений не нарушена.
Итак, наконец, наши кодировки на основе индекса выглядят следующим образом:
[13 7 1 4 10 0],
[13 7 1 2 8 0],
[11 7 1 4 3 0],
[ 6 5 1 2 12 0 ] ,
[ 13 8 10 7 9 4 ]
Таким образом мы сохраняем целостность нашего ввода и не нарушаем контекст наших предложений.
Кодирование на основе индекса учитывает информацию о последовательности в текстовом кодировании.
2. Пакет слов (BOW):Пакет слов или BoW — это еще одна форма кодирования, при которой мы используем весь корпус данных для кодирования наших предложений. Это будет иметь смысл, когда мы на самом деле увидим, как это сделать.
Корпус данных:
[«а», «плохой», «кошка», «хороший», «имеет», «он», «есть», «мобильный», «не», «телефон», «она». ” , “temper” , “this”]
” , “temper” , “this”]
Поскольку мы знаем, что наш корпус данных никогда не изменится, поэтому, если мы используем это в качестве основы для создания кодировок для наших предложений, тогда мы будем иметь преимущество, чтобы не дополнять лишние слова.
Итак, первое предложение, которое у нас есть, звучит так: «это хороший телефон»
Как мы можем использовать весь корпус для представления этого предложения?
Таким образом, наше первое предложение становится комбинацией всех слов, которые у нас есть, и тех, которых у нас нет.
[1,0,0,1,0,0,1,0,0,1,0,0,1]
Вот как представлено наше первое предложение.
Теперь есть 2 вида ЛУК:
1. Бинарный ЛУК.
2. BOW
Разница между ними в том, что в Binary BOW мы кодируем 1 или 0 для каждого слова, появляющегося или не появляющегося в предложении. Мы не учитываем частоту появления слова в этом предложении.
В BOW мы также учитываем частоту появления каждого слова в этом предложении.
Допустим, наше текстовое предложение звучит так: «Это хороший телефон, это хороший мобильный телефон» (к вашему сведению, просто для справки)
Если вы посмотрите внимательно, мы посчитали, сколько раз слова «этот», «а», « есть» и «хорошо».
Это единственная разница между Binary BOW и BOW.
BOW полностью отбрасывает информацию о последовательности наших предложений.
3. Кодировка TF-IDF:Частота термина — обратная частота документа
Как следует из названия, здесь мы даем каждому слову относительную частотность кодирования по отношению к текущему предложению и всему документу.
Частота термина: Встречаемость текущего слова в текущем предложении по отношению к общему количеству слов в текущем предложении.
Обратная частота данных: логарифм общего количества слов во всем корпусе данных по отношению к общему количеству предложений, содержащих текущее слово.
TF:
Term-FrequencyIDF:
Inverse-Data-Frequency Здесь следует отметить одну вещь: мы должны рассчитать частотность каждого слова для этого конкретного предложения, потому что в зависимости от того, сколько раз слово встречается в предложение, значение TF может измениться, тогда как значение IDF остается постоянным до тех пор, пока не будут добавлены новые предложения.
Попробуем разобраться, экспериментируя:
Корпус данных: [«а», «плохой», «кот», «хороший», «имеет», «он», «есть», «мобильный», » не», «телефон», «она», «характер», «это»]
TF-IDF: «это» в предложении1: количество слов «это» в предложении1 / общее количество слов в предложении1
IDF: log(общее количество слов во всем корпусе данных/общее количество предложений, содержащих «это» слово)
TF : 1/5 = 0,2
IDF : loge(13/3) = 1,4663
TF-IDF : 0,2 * 1,4663 = 0,3226
Итак, мы связываем «это»: 0,3226; аналогичным образом мы можем найти TF-IDF для каждого слова в этом предложении, а затем остальная часть процесса остается такой же, как и BOW, здесь мы заменяем слово не частотой его появления, а скорее значением TF-IDF для этого слова.
Итак, давайте попробуем закодировать наше первое предложение: «это хороший телефон»
Как мы видим, мы заменили все слова, встречающиеся в этом предложении, на их соответствующие значения tf-idf, здесь следует отметить одну вещь: у нас есть аналогичные значения tf-idf для нескольких слов. Это редкий случай, который произошел с нами, так как у нас было мало документов, и почти все слова имели примерно одинаковые частоты.
Это редкий случай, который произошел с нами, так как у нас было мало документов, и почти все слова имели примерно одинаковые частоты.
И вот как мы достигаем кодирования текста TF-IDF.
Теперь попробуем реализовать их самостоятельно:
Это наш корпус документов, о котором говорилось выше. Я подправил данные, чтобы сделать их более понятными, это даст больше смысла в кодировках.
Вот как мы создаем наш корпус данных на основе любого имеющегося у нас корпуса документов.
Сначала мы узнаем максимальную длину предложения, а затем, используя наш корпус данных, мы кодируем весь наш текст с помощью схемы на основе индекса.
Внедрение бинарного BoW, где мы ставим 1 для каждого слова, встречающегося в предложении в корпусе данных, и 0 для остальных.
Реализуя BoW, здесь мы должны закодировать количество каждого вхождения слова в этом конкретном предложении в корпус данных и 0 для остальных.
Первое вычисление частоты каждого элемента в предложениях.
Создание функции для вычисления tf-idf для каждого слова в конкретном предложении, которая использует ссылку на созданные выше частоты.
Наконец-то созданы векторы tf-idf для нашего модуля.
CountVectorizer из модуля Scikit-Learn дает нам представление текста BoW. Мы можем использовать различные параметры для расчета бинарного BoW или BoW и многих других настроек.
TfidfVectorizer из модуля Scikit-Learn дает нам представления TF-IDF кодировки текста, подобно CountVectorizer, мы можем установить множество параметров для преобразования.
Значения будут немного отличаться, так как мы реализовали базовую версию TF-IDF. В библиотеке Scikit-learn они реализуют TF-IDF разными методами, поэтому мы видим такие различия, в остальном более-менее одно и то же.
Итак, вот оно: основные реализации кодирования текста НЛП.
Вы можете найти код по моей ссылке на GitHub здесь .
Следующий раздел: НЛП — Кодировка текста: Word2Vec
Вы можете поддержать меня, купив некоторые цифровые продукты в моем магазине Etsy или помогая мне распространять информацию среди ваших друзей и семьи.
Вот ссылка: InfoDigitalProducts
Также вы можете помочь мне хотя бы подписавшись на мой канал YouTube здесь: TheSoulTranquilizer
Что такое система кодирования символов?
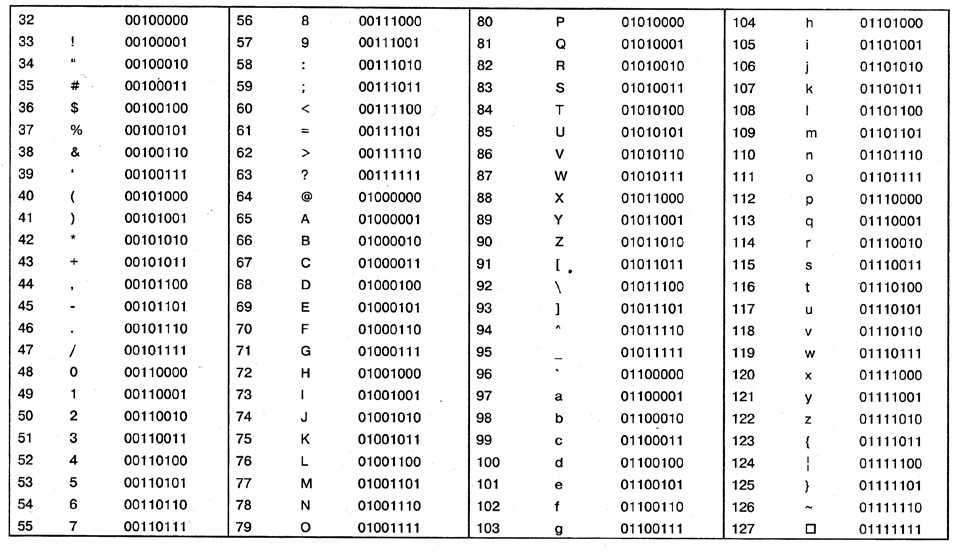
Как мы все знаем, компьютеры не понимают английский алфавит, числа, кроме 0 и 1, или текстовые символы. Мы используем кодирование для их преобразования. Итак, кодирование — это метод или процесс преобразования последовательности символов, т. е. букв, цифр, знаков препинания и символов, в специальный или уникальный формат для передачи или хранения в компьютерах. Данные представлены в компьютерах с использованием схем кодирования ASCII, UTF8, UTF32, ISCII и Unicode. Компьютеры могут обрабатывать все типы данных, включая числа, текст, фотографии, аудио- и видеофайлы. Например, 65 представляется как A, потому что всем символам, символам, числам присваивается некоторый уникальный код стандартными схемами кодирования. Некоторые из часто используемых схем кодирования описаны ниже:
1. ASCII: ASCII известен как Американский стандартный код для обмена информацией. Группа X3, входящая в состав ASA, впервые произвела и опубликовала ASCII в 1963 г. (Американская ассоциация стандартов). Стандарт ASCII был впервые опубликован в 1963 году как ASA X3.4-1963 и пересматривался десять раз в период с 1967 по 1986 год. ASCII — это стандарт 8-битного кода, который делит 256 слотов на буквы, цифры и другие символы. Десятичное число ASCII (Dec) создается с использованием двоичного кода, который является универсальным компьютерным языком. Десятичное значение символа «h» в нижнем регистре (char) равно 104, что соответствует «01101000» в двоичном формате.
ASCII: ASCII известен как Американский стандартный код для обмена информацией. Группа X3, входящая в состав ASA, впервые произвела и опубликовала ASCII в 1963 г. (Американская ассоциация стандартов). Стандарт ASCII был впервые опубликован в 1963 году как ASA X3.4-1963 и пересматривался десять раз в период с 1967 по 1986 год. ASCII — это стандарт 8-битного кода, который делит 256 слотов на буквы, цифры и другие символы. Десятичное число ASCII (Dec) создается с использованием двоичного кода, который является универсальным компьютерным языком. Десятичное значение символа «h» в нижнем регистре (char) равно 104, что соответствует «01101000» в двоичном формате.
Таблица ASCII разбита на три раздела.
- Non-printable, system codes between 0 and 31.
- Lower ASCII, between 32 and 127.
- Higher ASCII, between 128 and 255.
ASCII Table for characters:
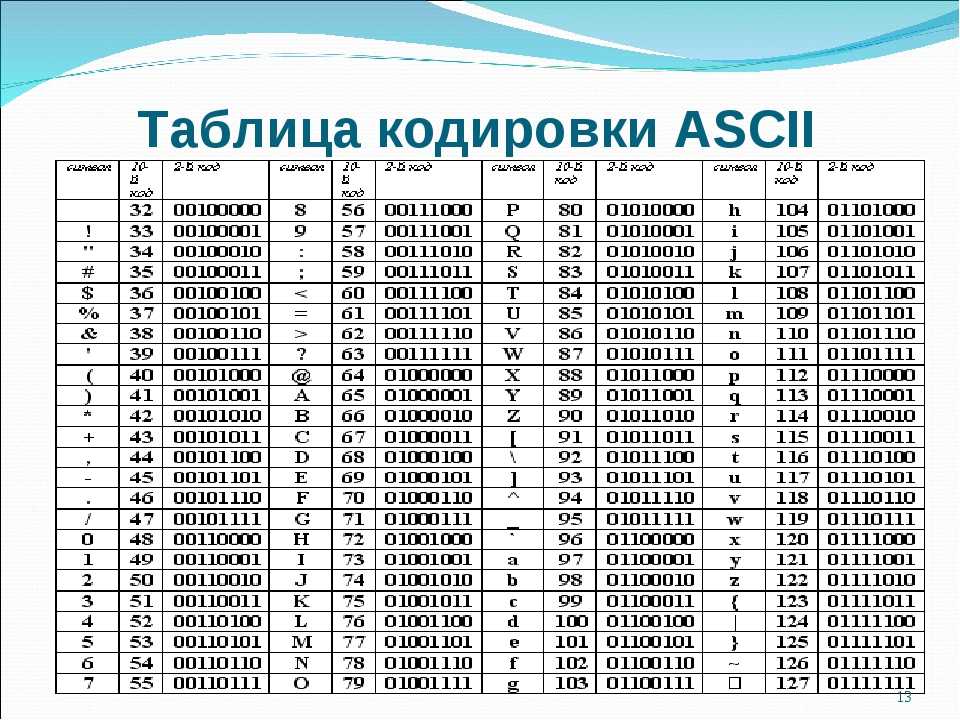
| Letter | Код ASCII | Буква | Код ASCII | ||
|---|---|---|---|---|---|
| A | 97 | A | 65 | 98 | B | 66 |
| c | 99 | C | 67 | ||
| d | 100 | D | 68 | ||
| e | 101 | E | 69 | ||
| F | 102 | F | 0302 | H | 72 |
| i | 105 | I | 73 | ||
| j | 106 | J | 74 | ||
| k | 107 | K | 75 | ||
| l | 108 | L | 76 | ||
| m | 109 | M | 77 | ||
| n | 110 | N | 78 | ||
| o | 111 | O | 79 | ||
| p | 112 | P | 80 | ||
| q | 113 | Q | 81 | ||
| r | 114 | R | 82 | ||
| s | 115 | S | 83 | ||
| t | 116 | T | 84 | ||
| u | 117 | U | 85 | ||
| v | 118 | V | 86 | ||
| w | 119 | W | 87 | ||
| x | 120 | X | 88 | ||
| y | 121 | Y | 89 | ||
| z | 122 | Z | 90 |
2.
ISCII была создана в 1991 году Бюро индийских стандартов (BIS). Он имеет примерно 256 символов и использует 8-битную технику кодирования. От 0 до 127 первые 128 символов такие же, как в ASCII. Следующие символы в диапазоне от 128 до 255 представляют собой символы из индийского письма.
Преимущества включают в себя:
- В этом представлено подавляющее большинство индийских языков.
- Набор символов прост и понятен.
- Можно легко транслитерировать между языками.
К недостаткам относятся:
- Требуется специальная клавиатура с символьными клавишами ISCII.

- Поскольку Unicode был создан позже, а Unicode включал в себя символы ISCII, ISCII устарел. ISCII (код индийской письменности для обмена информацией) — это код индийской письменности для обмена информацией.
- ISCII — это метод кодирования, который может кодировать широкий спектр индийских языков, как письменных, так и устных. Для облегчения транслитерации в нескольких системах письма ISCII использует единый механизм кодирования.
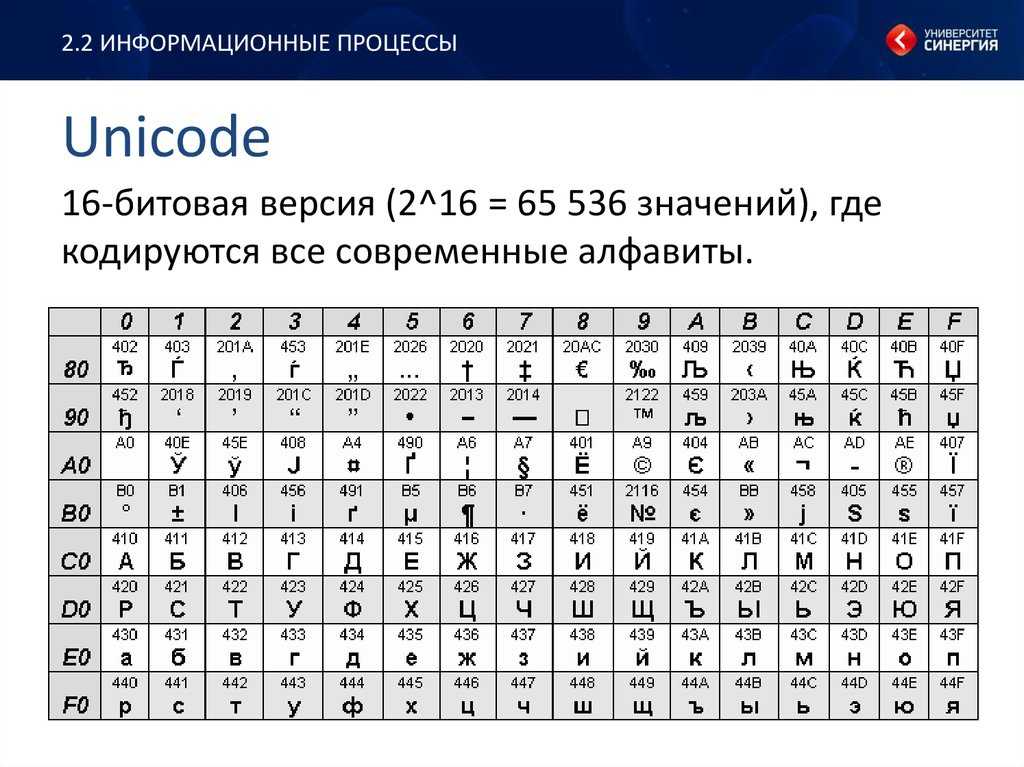
3. Юникод: Символы Юникода переводятся и хранятся в компьютерных системах как числа (битовые последовательности), которые может обрабатывать процессор. В Unicode кодовая страница — это система кодирования, которая преобразует набор битов в представление символов. Сотни различных методов кодирования присваивали номер каждой букве или символу на земном шаре до Unicode. Многие из этих методов использовали кодовые страницы только с 256 символами, каждая из которых требовала 8 бит памяти.
- Unicode позволяет создавать единый программный продукт или веб-сайт для нескольких платформ, языков и стран (без реорганизации), что приводит к значительной экономии средств по сравнению со старыми наборами символов.
- Данные Unicode можно использовать без повреждения данных в различных системах.
- Unicode — это универсальный метод кодирования, который можно использовать для кодирования любого языка или буквы независимо от устройств, операционных систем или программного обеспечения.
- Unicode — это стандарт кодировки символов, который позволяет выполнять преобразование между несколькими системами кодировки символов. Поскольку Unicode является расширенным набором всех других основных систем кодирования символов, вы можете преобразовать одну схему кодирования в Unicode, а затем из Unicode в другую схему кодирования.
- Наиболее широко используемой кодировкой является Unicode.
- Применимые версии стандарта ISO/IEC 10646, который определяет кодировку символов универсального набора символов, полностью совместимы и синхронизированы с версиями стандарта Unicode. Или мы можем сказать, что он включает в себя 96 447 кодов символов, которых достаточно для декодирования любого символа, присутствующего в мире.

4. UTF-8: Это кодировка символов переменной ширины, используемая в электронной связи. С помощью от одного до четырех однобайтовых (8-битных) кодовых единиц он может кодировать все 1 112 064 [nb 1] допустимых кодовых точек символов Unicode. Кодовые точки с более низкими числовыми значениями кодируются меньшим количеством байтов, поскольку они встречаются чаще. Когда он был создан, создатели удостоверились, что эта схема кодирования совместима с ASCII, а первые 128 символов Unicode, которые являются однозначными для ASCII, закодированы с использованием одного байта с тем же двоичным значением, что и ASCII, и убедитесь, что текст ASCII также действительный Unicode в кодировке UTF-8.
Converting Symbols to Binary:
| Character | ASCII | Byte | ||
|---|---|---|---|---|
| A | 65 | 1000001 | ||
| a | 97 | 1100001 | ||
| B | 66 | 1000010 | ||
| б | 98 | 1100010 | 90 | 1011010 |
| 0 | 48 | 110000 | ||
| 57 | 11001930139797979798989798989898989898989899898989899898989899898989989899897989898998979899899899897989989989989989989989979789н. | 33 | 100001 | |
| ? | 63 | 111111 |
5. UTF-32: UTF-32 известен как 32-битный формат преобразования Unicode. Это кодировка фиксированной длины, которая кодирует кодовые точки Unicode, используя 32 бита на код. Он использует 4 байта на символ, и мы можем подсчитать количество символов в строке UTF-32, просто подсчитав байты. Основное преимущество использования UTF-32 заключается в том, что кодовые точки Unicode могут быть проиндексированы напрямую (хотя буквы в целом, такие как «кластеры графем» или некоторые эмодзи, не могут быть проиндексированы напрямую, поэтому определение отображаемой ширины строки является более сложным) . Операцией с постоянным временем является нахождение N-й кодовой точки в последовательности кодовых точек. С другой стороны, код переменной длины требует последовательного доступа для нахождения N-й кодовой точки в строке. В результате UTF-32 является прямой заменой кода ASCII, который проверяет каждую проблему в строке, используя числа, увеличивающиеся на единицу.