INNER JOIN, LEFT JOIN, RIGHT JOIN, FULL JOIN
Содержание:
Говоря про соединение таблиц в SQL, обычно подразумевают один из видов операции JOIN. Не стоит путать с объединением таблиц через операцию UNION. В этой статье я постараюсь простыми словами рассказать именно про соединение, чтобы после ее прочтения Вы могли использовать джойны в работе и не допускать грубых ошибок.
Соединение – это операция, когда таблицы сравниваются между собой построчно и появляется возможность вывода столбцов из всех таблиц, участвующих в соединении.
Придумаем 2 таблицы, на которых будем тренироваться.
Таблица «Сотрудники», содержит поля:
- id – идентификатор сотрудника
- Имя
- Отдел – идентификатор отдела, в котором работает сотрудник
| id | Имя | Отдел |
|---|---|---|
| 1 | Юлия | 1 |
| 2 | Федор | 2 |
| 3 | Алексей | NULL |
| 4 | Светлана | 2 |
Таблица «Отделы», содержит поля:
- id – идентификатор отдела
- Наименование
| id | Наименование |
|---|---|
| 1 | Кухня |
| 2 | Бар |
| 3 | Администрация |
Давайте уже быстрее что-нибудь покодим.
INNER JOIN
Самый простой вид соединения INNER JOIN – внутреннее соединение. Этот вид джойна выведет только те строки, если условие соединения выполняется (является истинным, т.е. TRUE). В запросах необязательно прописывать INNER – если написать только JOIN, то СУБД по умолчанию выполнить именно внутреннее соединение.
Давайте соединим таблицы из нашего примера, чтобы ответить на вопрос, в каких отделах работают сотрудники (читайте комментарии в запросе для понимания синтаксиса).
SELECT
-- Перечисляем столбцы, которые хотим вывести
Сотрудники.id,
Сотрудники.Имя,
Отделы.Наименование AS Отдел -- выводим наименование отдела и переименовываем столбец через as
FROM
-- таблицы для соединения перечисляем в предложении from
Сотрудники
-- обратите внимание, что мы не указали вид соединения, поэтому выполнится внутренний (inner) джойн
JOIN Отделы
-- условия соединения прописываются после ON
-- условий может быть несколько, записанных через and, or и т.п.
ON Сотрудники.Отдел = Отделы.id
Получим следующий результат:
| id | Имя | Отдел |
|---|---|---|
| 1 | Юлия | Кухня |
| 2 | Федор | Бар |
| 4 | Светлана | Бар |
Из результатов пропал сотрудник Алексей (id = 3), потому что условие «Сотрудники.Отдел = Отделы.id» не будет истинно для этой сроки из таблицы «Сотрудники» с каждой строкой из таблицы «Отделы». По той же логике в результате нет отдела «Администрация». Попробую это визуализировать (зеленные линии – условие TRUE, иначе линия красная):
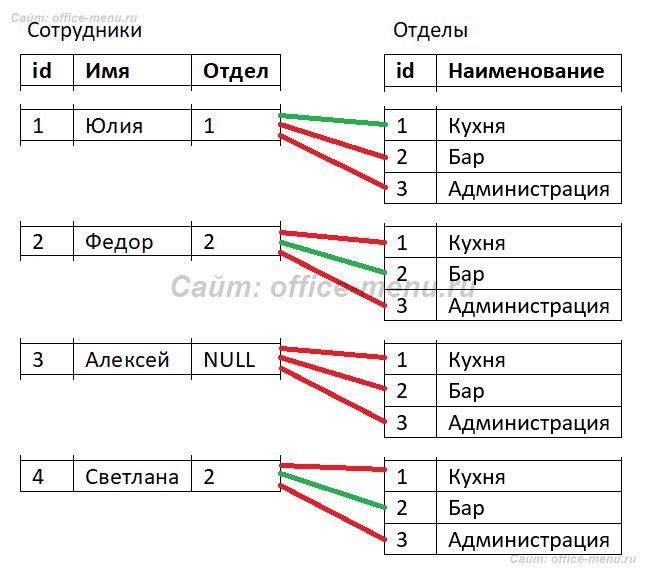
Если не углубляться в то, как внутреннее соединение работает под капотом СУБД, то происходит примерно следующее:
- Каждая строка из одной таблицы сравнивается с каждой строкой из другой таблицы
- Строка возвращается, если условие сравнения является истинным
Если для одной или нескольких срок из левой таблицы (в рассмотренном примере левой таблицей является «Сотрудники», а правой «Отделы») истинным условием соединения будут являться одна или несколько срок из правой таблицы, то строки умножат друг друга (повторятся). В нашем примере так произошло для отдела с id = 2, поэтому строка из таблицы «Отделы» повторилась дважды для Федора и Светланы.
SELECT *
FROM
Сотрудники
JOIN Отделы
ON 1=1
В результате получится 12 строк (4 сотрудника * 3 отдела), где для каждого сотрудника подтянется каждый отдел.
Также хочу сразу отметить, что в соединении может участвовать сколько угодно таблиц, можно таблицу соединить даже саму с собой (в аналитических задачах это не редкость). Какая из таблиц будет правой или левой не имеется значения для INNER JOIN (для внешних соединений типа LEFT JOIN или RIGHT JOIN это важно. Читайте далее). Пример соединения 4-х таблиц:
SELECT *
FROM
Table_1
JOIN Table_2
ON Table_1.Column_1 = Table_2.Column_1
JOIN Table_3
ON
Table_1.Column_1 = Table_3.Column_1
AND Table_2.Column_1 = Table_3.Column_1
JOIN Table_1 AS Tbl_1 -- Задаем алиас для таблицы, чтобы избежать неоднозначности
-- Если в Table_1.Column_1 хранится порядковый номер какого-то объекта,
-- то так можно присоединить следующий по порядку объект
ON Table_1.Column_1 = Tbl_1.Column_1 + 1
Как видите, все просто, прописываем новый джойн после завершения условий предыдущего соединения. Обратите внимание, что для Table_3 указано несколько условий соединения с двумя разными таблицами, а также Table_1 соединяется сама с собой по условию с использованием сложения.
Строки, которые выведутся запросом, должны совпасть по всем условиям. Например:
- Строка из Table_1 соединилась со строкой из Table_2 по условию первого JOIN. Давайте назовем ее «объединенной строкой» из двух таблиц;
- Объединенная строка успешно соединилась с Table_3 по условию второго JOIN и теперь состоит из трех таблиц;
- Для объединенной строки не нашлось строки из Table_1 по условию третьего JOIN, поэтому она не выводится вообще.
На этом про внутреннее соединение и логику соединения таблиц в SQL – всё. Если остались неясности, то спрашивайте в комментариях.
Далее рассмотрим отличия остальных видов джойнов.
LEFT JOIN и RIGHT JOIN
Левое и правое соединения еще называют внешними. Главное их отличие от внутреннего соединения в том, что строка из левой (для LEFT JOIN) или из правой таблицы (для RIGHT JOIN) попадет в результаты в любом случае.
Давайте до конца определимся с тем, какая таблица левая, а какая правая.
Левая таблица та, которая идет перед написанием ключевых слов [LEFT | RIGHT| INNER] JOIN, правая таблица – после них:
SELECT *
FROM
Левая_таблица AS lt
LEFT JOIN Правая_таблица AS rt
ON lt.c = rt.c
Теперь изменим наш SQL-запрос из самого первого примера так, чтобы ответить на вопрос «В каких отделах работают сотрудники, а также показать тех, кто не распределен ни в один отдел?»:
SELECT
Сотрудники.id,
Сотрудники.Имя,
Отделы.Наименование AS Отдел
FROM
Сотрудники
LEFT JOIN Отделы -- добавляем только left
ON Сотрудники.Отдел = Отделы.id
Результат запроса будет следующим:
| id | Имя | Отдел |
|---|---|---|
| 1 | Юлия | Кухня |
| 2 | Федор | Бар |
| 3 | Алексей | NULL |
| 4 | Светлана | Бар |
Как видите, запрос вернул все строки из левой таблицы «Сотрудники», дополнив их значениями из правой таблицы «Отделы». А вот строка для отдела «Администрация» не показана, т.к. для нее не нашлось совпадений слева.
Это мы рассмотрели пример для левого внешнего соединения. Для RIGHT JOIN будет все тоже самое, только вернутся все строки из таблицы «Отделы»:
| id | Имя | Отдел |
|---|---|---|
| 1 | Юлия | Кухня |
| 2 | Федор | Бар |
| 4 | Светлана | Бар |
| NULL | NULL | Администрация |
Алексей «потерялся», Администрация «нашлась».
Вопрос для Вас. Что надо изменить в последнем приведенном SQL-запросе, чтобы результат остался тем же, но вместо LEFT JOIN, использовался RIGHT JOIN?
Ответ. Нужно поменять таблицы местами:
SELECT
Сотрудники.id,
Сотрудники.Имя,
Отделы.Наименование AS Отдел
FROM
Отделы
RIGHT JOIN Сотрудники
ON Сотрудники.Отдел = Отделы.id
В одном запросе можно применять и внутренние соединения, и внешние одновременно, главное соблюдать порядок таблиц, чтобы не потерять часть записей (строк).
FULL JOIN
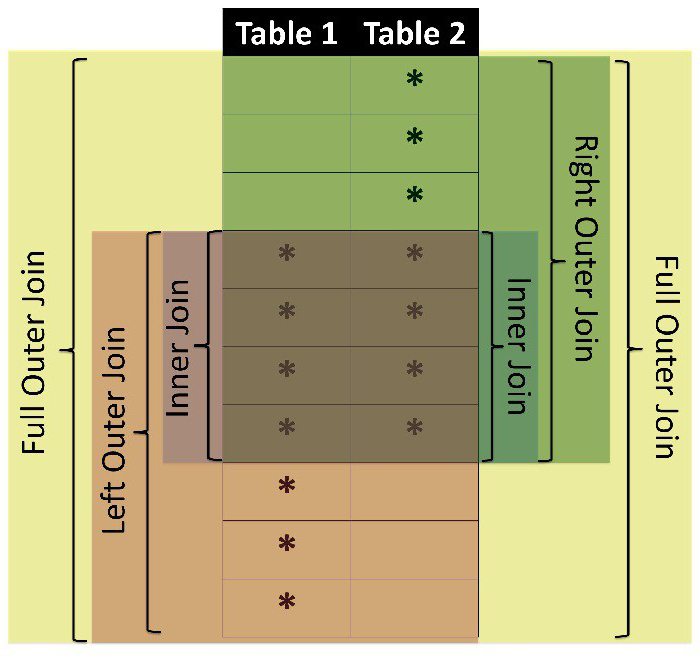
Еще один вид соединения, который осталось рассмотреть – полное внешнее соединение.
Этот вид джойна вернет все строки из всех таблиц, участвующих в соединении, соединив между собой те, которые подошли под условие ON.
Давайте посмотрим всех сотрудников и все отделы из наших тестовых таблиц:
SELECT
Сотрудники.id,
Сотрудники.Имя,
Отделы.Наименование AS Отдел
FROM
Сотрудники
FULL JOIN Отделы
ON Сотрудники.Отдел = Отделы.id
| id | Имя | Отдел |
|---|---|---|
| 1 | Юлия | Кухня |
| 2 | Федор | Бар |
| 3 | Алексей | NULL |
| 4 | Светлана | Бар |
| NULL | NULL | Администрация |
Теперь мы видим все, даже Алексея без отдела и Администрацию без сотрудников.
Вместо заключения
Помните о порядке выполнения соединений и порядке таблиц, если используете несколько соединений и используете внешние соединения. Можно выполнять LEFT JOIN для сохранения всех строк из самой первой таблицы, а последним внутренним соединением потерять часть данных. На маленьких таблицах косяк заметить легко, на огромных очень тяжело, поэтому будьте внимательны.
| id | Наименование |
|---|---|
| 1 | Банк №1 |
| 2 | Лучший банк |
| 3 | Банк Лидер |
В таблицу «Сотрудники» добавим столбец «Банк»:
| id | Имя | Отдел | Банк |
|---|---|---|---|
| 1 | Юлия | 1 | 2 |
| 2 | Федор | 2 | 2 |
| 3 | Алексей | NULL | 3 |
| 4 | Светлана | 2 | 4 |
Теперь выполним такой запрос:
SELECT
Сотрудники.id,
Сотрудники.Имя,
Отделы.Наименование AS Отдел,
Банки.Наименование AS Банк
FROM
Сотрудники
LEFT JOIN Отделы
ON Сотрудники.Отдел = Отделы.id
INNER JOIN Банки
ON Сотрудники.Банк = Банки.id
В результате потеряли информацию о Светлане, т.к. для нее не нашлось банка с id = 4 (такое происходит из-за неправильной проектировки БД):
| id | Имя | Отдел | Банк |
|---|---|---|---|
| 1 | Юлия | Кухня | Лучший банк |
| 2 | Федор | Бар | Лучший банк |
| 3 | Алексей | NULL | Банк Лидер |
Хочу обратить внимание на то, что любое сравнение с неизвестным значением никогда не будет истинным (даже NULL = NULL). Эту грубую ошибку часто допускают начинающие специалисты. Подробнее читайте в статье про значение NULL в SQL.
Пройдите мой тест на знание основ SQL. В нем есть задания на соединения таблиц, которые помогут закрепить материал.
Дополнить Ваше понимание соединений в SQL могут схемы, изображенные с помощью кругов Эйлера. В интернете много примеров в виде картинок.
Если какие нюансы джойнов остались не раскрытыми, или что-то описано не совсем понятно, что-то надо дополнить, то пишите в комментариях. Буду только рад вопросам и предложениям.
Привожу простыню запросов, чтобы Вы могли попрактиковаться на легких примерах, рассмотренных в статье:
-- Создаем CTE для таблиц из примеров
WITH Сотрудники AS(
SELECT 1 AS id, 'Юлия' AS Имя, 1 AS Отдел, 2 AS Банк
UNION ALL
SELECT 2, 'Федор', 2, 2
UNION ALL
SELECT 3, 'Алексей', NULL, 3
UNION ALL
SELECT 4, 'Светлана', 2, 4
),
Отделы AS(
SELECT 1 AS id, 'Кухня' AS Наименование
UNION ALL
SELECT 2, 'Бар'
UNION ALL
SELECT 3, 'Администрация'
),
Банки AS(
SELECT 1 AS id, 'Банк №1' AS Наименование
UNION ALL
SELECT 2, 'Лучший банк'
UNION ALL
SELECT 3, 'Банк Лидер'
)
-- Если надо выполнить другие запросы, то сначала закоментируй это запрос с помощью /**/,
-- а нужный запрос расскоментируй или напиши свой.
-- Это пример внутреннего соединения
SELECT
Сотрудники.id,
Сотрудники.Имя,
Отделы.Наименование AS Отдел
FROM
Сотрудники
JOIN Отделы
ON Сотрудники.Отдел = Отделы.id
/*
-- Пример левого джойна
SELECT
Сотрудники.id,
Сотрудники.Имя,
Отделы.Наименование AS Отдел
FROM
Сотрудники
LEFT JOIN Отделы
ON Сотрудники.Отдел = Отделы.id
*/
/*
-- Результат этого запроса будет аналогичен результату запроса выше, хотя соединение отличается
SELECT
Сотрудники.id,
Сотрудники.Имя,
Отделы.Наименование AS Отдел
FROM
Отделы
RIGHT JOIN Сотрудники
ON Сотрудники.Отдел = Отделы.id
*/
/*
-- Правое соединение
SELECT
Сотрудники.id,
Сотрудники.Имя,
Отделы.Наименование AS Отдел
FROM
Сотрудники
RIGHT JOIN Отделы
ON Сотрудники.Отдел = Отделы.id
*/
/*
-- Пример с использованием разных видов JOIN
SELECT
Сотрудники.id,
Сотрудники.Имя,
Отделы.Наименование AS Отдел
FROM
Отделы
RIGHT JOIN Сотрудники
ON Сотрудники.Отдел = Отделы.id
LEFT JOIN Банки
ON Банки.id = Сотрудники.Банк
*/
/*
-- Полное внешние соединение
SELECT
Сотрудники.id,
Сотрудники.Имя,
Отделы.Наименование AS Отдел
FROM
Сотрудники
FULL JOIN Отделы
ON Сотрудники.Отдел = Отделы.id
*/
/*
-- Пример с потерей строки из-за последнего внутреннего соединения
SELECT
Сотрудники.id,
Сотрудники.Имя,
Отделы.Наименование AS Отдел,
Банки.Наименование AS Банк
FROM
Сотрудники
LEFT JOIN Отделы
ON Сотрудники.Отдел = Отделы.id
INNER JOIN Банки
ON Сотрудники.Банк = Банки.id
*/
/*
-- Запрос с условием, которое всегда будет True
SELECT *
FROM
Сотрудники
JOIN Отделы
ON 1=1
*/
- < Назад
- Вперёд >
Если материалы office-menu.ru Вам помогли, то поддержите, пожалуйста, проект, чтобы я мог развивать его дальше.
Добавить комментарий
Разработка любой базы данных подразумевает не только создание и наполнение таблиц разнообразной информацией, но и дальнейшую работу с данными. Для корректного выполнения разнообразных задач по выбору данных из таблиц и формированию отчетов, используется стандартная конструкция Select.

Выборки данных из таблиц
Если рассматривать задачу выбора данных или построения некоторого отчета, можно определить уровень сложности данной операции. Как правило, при работе с серьезными (по объему информации) базами данных, которые формируются, например, в интернет-магазинах или крупных компаниях, выборка данных не будет ограничиваться лишь одной таблицей. Как правило, выборки могут быть из довольно большого количества не только связанных между собой таблиц, но и вложенных запросов/подзапросов, которые составляет сам программист, в зависимости от поставленной перед ним задачи. Для выборки из одной таблицы можно использовать простейшую конструкцию:
где Person – имя таблицы, из которой необходимо сделать выборку данных.
Если же будет необходимость выбрать данные из нескольких таблиц, можно использовать одну из стандартных конструкций для объединения нескольких таблиц.
Способы подключения дополнительных таблиц
Если рассматривать использование такого рода конструкций на начальном уровне, то можно выделить следующие механизмы подключения необходимого количества таблиц для выборки, а именно:
- Оператор Inner Join.
- Left Join или, это второй способ записи, Left Outer Join.
- Cross Join.
- Full Join.
Использование операторов объединения таблиц на практике можно усвоить, рассмотрев применение оператора SQL — Inner Join. Пример его использования будет выглядеть следующим образом:
Select * from Person Inner join Subdivision on Su_Person = Pe_ID |
Язык SQL и оператор Join Inner Join можно использовать не только для объединения двух и более таблиц, но и для подключения иных подзапросов, что значительно облегчает работу администраторов базы данных и, как правило, может значительно ускорить выполнение определенных, сложных по структуре запросов.
Объединение данных в таблицах построчно
Если рассматривать подключение большого количества подзапросов и сборку данных в единую таблицу строка за строкой, то можно использовать также операторы Union, и Union All.
Применение этих конструкций будет зависеть от поставленной перед разработчиком задачи и результата, которого он хочет достичь в итоге.
Описание оператора Inner Join
В большинстве случаев для объединения нескольких таблиц в языке SQL используется оператор Inner Join. Описание Inner Join в SQL довольно простое для понимания среднестатистического программиста, который только начинает разбираться в базах данных. Если рассмотреть описание механизма работы этой конструкции, то получим следующую картину. Логика оператора в целом построена на возможности пересечения и выборки только тех данных, которые есть в каждой из входящих в запрос таблиц.
Если рассмотреть такую работу с точки зрения графической интерпретации, то получим структуру оператора SQL Inner Join, пример которой можно показать с помощью следующей схемы:
К примеру, мы имеем две таблицы, схема которых показана на рисунке. Они в свою очередь, имеют разное количество записей. В каждой из таблиц есть поля, которые связаны между собой. Если попытаться пояснить работу оператора исходя из рисунка, то возвращаемый результат будет в виде набора записей из двух таблиц, где номера связанных между собой полей совпадают. Проще говоря, запрос вернет только те записи (из таблицы номер два), данные о которых есть в таблице номер один.
Синтаксис оператора Inner Join
Как уже говорилось ранее, оператор Inner Join, а именно его синтаксис, необычайно прост. Для организации связей между таблицами в пределах одной выборки достаточно будет запомнить и использовать следующую принципиальную схему построения оператора, которая прописывается в одну строчку программного SQL-кода, а именно:
- Inner Join [Имя таблицы] on [ключевое поле из таблицы, к которой подключаем] = [Ключевому полю подключаемой таблицы].
Для связи в данном операторе используются главные ключи таблиц. Как правило, в группе таблиц, которые хранят информацию о сотрудниках, ранее описанные Person и Subdivision имеют хотя бы по одной похожей записи. Итак, рассмотрим подробнее оператор SQL Inner Join, пример которого был показан несколько ранее.
Пример и описание подключения к выборке одной таблицы
У нас есть таблица Person, где хранится информация обо всех сотрудниках, работающих в компании. Сразу отметим, что главным ключем данной таблицы является поле – Pe_ID. Как раз по нему и будет идти связка.
Вторая таблица Subdivision будет хранить информацию о подразделениях, в которых работают сотрудники. Она, в свою очередь, связана с помощью поля Su_Person с таблицей Person. О чем это говорит? Исходя из схемы данных можно сказать, что в таблице подразделений для каждой записи из таблицы «Сотрудники» будет информация об отделе, в котором они работают. Именно по этой связи и будет работать оператор Inner Join.
Для более понятного использования рассмотрим оператор SQL Inner Join (примеры его использования для одной и двух таблиц). Если рассматривать пример для одной таблицы, то тут все довольно просто:
Select * from Person Inner join Subdivision on Su_Person = Pe_ID |
Пример подключения двух таблиц и подзапроса
Оператор SQL Inner Join, примеры использования которого для выборки данных из нескольких таблиц можно организовать вышеуказанным образом, работает по чуть усложненному принципу. Для двух таблиц усложним задачу. Скажем, у нас есть таблица Depart, в которой хранится информация обо всех отделах в каждом из подразделений. В в эту таблицу записан номер подразделения и номер сотрудника и нужно дополнить выборку данных названием каждого отдела. Забегая вперед, стоит сказать, что для решения этой задачи можно воспользоваться двумя методами.
Первый способ заключается в подключении таблицы отделов к выборке. Организовать запрос в этом случае можно таким образом:
Select Pe_ID, Pe_Name, Su_Id, Su_Name, Dep_ID, Dep_Name from Person Inner join Subdivision on Su_Person = Pe_ID Inner join Depart on Su_Depart = Dep_ID and Pe_Depart = Dep_ID |
Второй метод решения задачи – это использование подзапроса, в котором из таблицы отделов будет выбраны не все данные, а только необходимые. Это, в отличие от первого способа, позволит уменьшить время работы запроса.
Select Pe_ID, Pe_Name, Su_Id, Su_Name, Dep_ID, Dep_Name from Person Inner join Subdivision on Su_Person = Pe_ID Inner join (Select Dep_ID, Dep_Name, Pe_Depart from Depart) as T on Su_Depart = Dep_ID and Pe_Depart = Dep_ID |
Стоит отметить, что такая конструкция не всегда может ускорить работу запроса. Иногда бывают случаи, когда приходится использовать дополнительно выборку данных во временную таблицу (если их объем слишком большой), а потом ее объединять с основной выборкой.
Пример использования оператора Inner Join для выборок из большого количества таблиц
Построение сложных запросов подразумевает использование для выборки данных значительного количества таблиц и подзапросов, связанных между собой. Этим требованиям может удовлетворить SQL Inner Join синтаксис. Примеры использования оператора в данном случаем могут усложняться не только выборками из многих мест хранения данных, но и с большого количества вложенных подзапросов. Для конкретного примера можно взять выборку данных из системных таблиц (оператор Inner Join SQL). Пример — 3 таблицы — в этом случае будет иметь довольно сложную структуру.

В данном случае подключено (к основной таблице) еще три дополнительно и введено несколько условий выбора данных.
При использовании оператора Inner Join стоит помнить о том, что чем сложнее запрос, тем дольше он будет реализовываться, поэтому стоит искать пути более быстрого выполнения и решения поставленной задачи.
Заключение
В итоге хотелось бы сказать одно: работа с базами данных — это не самое сложное, что есть в программировании, поэтому при желании абсолютно каждый человек сможет овладеть знаниями по построению баз данных, а со временем, набравшись опыта, получится работать с ними на профессиональном уровне.
SQL оператор JOINS — Oracle PL/SQL •MySQL •MariaDB •SQL Server •SQLite
В этом учебном материале вы узнаете, как использовать SQL JOINS с синтаксисом и примерами.
Описание
SQL JOINS используются для извлечения данных из нескольких таблиц. SQL JOIN выполняется всякий раз, когда две или более таблицы перечислены в операторе SQL.
Существует 4 различных типа соединений SQL:
Итак, давайте обсудим синтаксис SQL JOIN, рассмотрим наглядные иллюстрации SQL JOINS и рассмотрим несколько примеров.
SQL INNER JOIN (простое соединение)
Скорее всего, вы уже писали SQL запрос, который использует SQL INNER JOIN. Это наиболее распространенный тип соединения SQL. INNER JOIN возвращает все строки из нескольких таблиц, где выполняется условие соединения.
Синтаксис
Синтаксис INNER JOIN в SQL:
SELECT columns
FROM table1
INNER JOIN table2
ON table1.column = table2.column;
Рисунок.
На этом рисунке SQL INNER JOIN возвращает затененную область: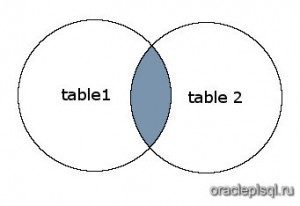
SQL INNER JOIN будет возвращать записи, где пересекаются table1 и table2.
Пример
Давайте рассмотрим пример использования INNER JOIN в запросе.
В этом примере у нас есть таблица customer и следующими данными:
| customer_id | first_name | last_name | favorite_website |
|---|---|---|---|
| 4000 | Justin | Bieber | google.com |
| 5000 | Selena | Gomez | bing.com |
| 6000 | Mila | Kunis | yahoo.com |
| 7000 | Tom | Cruise | oracle.com |
| 8000 | Johnny | Depp | NULL |
| 9000 | Russell | Crowe | google.com |
И таблица orders со следующими данными:
| order_id | customer_id | order_date |
|---|---|---|
| 1 | 7000 | 2019/06/18 |
| 2 | 5000 | 2019/06/18 |
| 3 | 8000 | 2019/06/19 |
| 4 | 4000 | 2019/06/20 |
| 5 | NULL | 2019/07/01 |
Выполним следующий SQL оператор:
SELECT customers.customer_id, orders.order_id, orders.order_date FROM customers INNER JOIN orders ON customers.customer_id = orders.customer_id ORDER BY customers.customer_id;
SELECT customers.customer_id, orders.order_id, orders.order_date FROM customers INNER JOIN orders ON customers.customer_id = orders.customer_id ORDER BY customers.customer_id; |
Будет выбрано 4 записи. Вот результаты, которые вы должны получить:
| customer_id | order_id | order_date |
|---|---|---|
| 4000 | 4 | 2019/06/20 |
| 5000 | 2 | 2019/06/18 |
| 7000 | 1 | 2019/06/18 |
| 8000 | 3 | 2019/06/19 |
В этом примере будут возвращены все строки из таблиц customers и orders, в которых совпадают значения поля customer_id в обоих таблицах.
Строки, где значение customer_id равен 6000 и 9000 в таблице customers, будут опущены, поскольку они не существуют в обеих таблицах. Строка, в которой значение order_id равно 5 из таблицы orders, будет опущена, поскольку customer_id со значением NULL не существует в таблице customers.
SQL LEFT OUTER JOIN
Другой тип соединения называется LEFT OUTER JOIN. Этот тип соединения возвращает все строки из таблиц с левосторонним соединением, указанным в условии ON, и только те строки из другой таблицы, где объединяемые поля равны (выполняется условие соединения).
Синтаксис
Синтаксис для LEFT OUTER JOIN в SQL:
SELECT columns
FROM table1
LEFT [OUTER] JOIN table2
ON table1.column = table2.column;
В некоторых базах данных ключевое слово OUTER опущено и записывается просто как LEFT JOIN.
Рисунок
На этом рисунке SQL LEFT OUTER JOIN возвращает затененную область: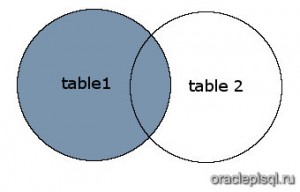
SQL LEFT OUTER JOIN возвращает все записи из table1 и только те записи из table2, которые пересекаются с table1.
Пример
Теперь давайте рассмотрим пример, который показывает, как использовать LEFT OUTER JOIN в операторе SELECT.
Используя ту же таблицу customers, что и в предыдущем примере:
| customer_id | first_name | last_name | favorite_website |
|---|---|---|---|
| 4000 | Justin | Bieber | google.com |
| 5000 | Selena | Gomez | bing.com |
| 6000 | Mila | Kunis | yahoo.com |
| 7000 | Tom | Cruise | oracle.com |
| 8000 | Johnny | Depp | NULL |
| 9000 | Russell | Crowe | google.com |
И таблицу orders со следующими данными:
| order_id | customer_id | order_date |
|---|---|---|
| 1 | 7000 | 2019/06/18 |
| 2 | 5000 | 2019/06/18 |
| 3 | 8000 | 2019/06/19 |
| 4 | 4000 | 2019/06/20 |
| 5 | NULL | 2019/07/01 |
Введите следующий SQL оператор:
SELECT customers.customer_id, orders.order_id, orders.order_date FROM customers LEFT OUTER JOIN orders ON customers.customer_id = orders.customer_id ORDER BY customers.customer_id;
SELECT customers.customer_id, orders.order_id, orders.order_date FROM customers LEFT OUTER JOIN orders ON customers.customer_id = orders.customer_id ORDER BY customers.customer_id; |
Будет выбрано 6 записей. Вот результаты, которые вы получите:
| customer_id | order_id | order_date |
|---|---|---|
| 4000 | 4 | 2019/06/20 |
| 5000 | 2 | 2019/06/18 |
| 6000 | NULL | NULL |
| 7000 | 1 | 2019/06/18 |
| 8000 | 3 | 2019/06/19 |
| 9000 | NULL | NULL |
Этот пример LEFT OUTER JOIN вернул бы все строки из таблицы customers и только те строки из таблицы orders, в которых объединенные поля равны.
Если значение customer_id в таблице customers не существует в таблице orders, все поля таблицы orders будут отображаться как NULL в наборе результатов. Как вы можете видеть, строки, где customer_id равен 6000 и 9000, будут включены в LEFT OUTER JOIN, но поля order_id и order_date отображают NULL.
SQL RIGHT OUTER JOIN JOIN
Другой тип соединения называется SQL RIGHT OUTER JOIN. Этот тип соединения возвращает все строки из таблиц с правосторонним соединением, указанным в условии ON, и только те строки из другой таблицы, где объединяемые поля равны (выполняется условие соединения).
Синтаксис
Синтаксис для RIGHT OUTER JOIN в SQL:
SELECT columns
FROM table1
RIGHT [OUTER] JOIN table2
ON table1.column = table2.column;
В некоторых базах данных ключевое слово OUTER опущено и записывается просто как RIGHT JOIN.
Рисунок
На этом рисунке SQL RIGHT OUTER JOIN возвращает затененную область:
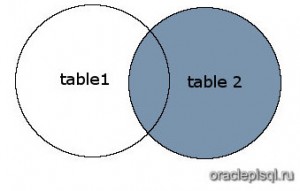
SQL RIGHT OUTER JOIN возвращает все записи из table2 и только те записи из table1, которые пересекаются с table2.
Пример
Теперь давайте рассмотрим пример, который показывает, как использовать RIGHT OUTER JOIN в операторе SELECT.
| customer_id | first_name | last_name | favorite_website |
|---|---|---|---|
| 4000 | Justin | Bieber | google.com |
| 5000 | Selena | Gomez | bing.com |
| 6000 | Mila | Kunis | yahoo.com |
| 7000 | Tom | Cruise | oracle.com |
| 8000 | Johnny | Depp | NULL |
| 9000 | Russell | Crowe | google.com |
И таблицу orders со следующими данными:
| order_id | customer_id | order_date |
|---|---|---|
| 1 | 7000 | 2019/06/18 |
| 2 | 5000 | 2019/06/18 |
| 3 | 8000 | 2019/06/19 |
| 4 | 4000 | 2019/06/20 |
| 5 | NULL | 2019/07/01 |
Введите следующий SQL оператор:
SELECT customers.customer_id, orders.order_id, orders.order_date FROM customers RIGHT OUTER JOIN orders ON customers.customer_id = orders.customer_id ORDER BY customers.customer_id;
SELECT customers.customer_id, orders.order_id, orders.order_date FROM customers RIGHT OUTER JOIN orders ON customers.customer_id = orders.customer_id ORDER BY customers.customer_id; |
Будет выбрано 5 записей. Вот результаты, которые вы должны получить:
| customer_id | order_id | order_date |
|---|---|---|
| NULL | 5 | 2019/07/01 |
| 4000 | 4 | 2019/06/20 |
| 5000 | 2 | 2019/06/18 |
| 7000 | 1 | 2019/06/18 |
| 8000 | 3 | 2019/06/19 |
Этот пример RIGHT OUTER JOIN вернул бы все строки из таблицы orders и только те строки из таблицы customers, где объединенные поля равны.
Если значение customer_id в таблице orders не существует в таблице customers, то все поля в таблице customers будут отображаться как NULL в наборе результатов. Как видите, строка, где order_id равен 5, будет включена в RIGHT OUTER JOIN, но в поле customer_id отображается NULL.
SQL FULL OUTER JOIN
Другой тип объединения называется SQL FULL OUTER JOIN. Этот тип объединения возвращает все строки из LEFT таблицы и RIGHT таблицы со значениями NULL в месте, где условие соединения не выполняется.
Синтаксис
Синтаксис для SQL FULL OUTER JOIN:
SELECT columns
FROM table1
FULL [OUTER] JOIN table2
ON table1.column = table2.column;
В некоторых базах данных ключевое слово OUTER опускается и записывается просто как FULL JOIN.
Рисунок
На этом рисунке SQL FULL OUTER JOIN возвращает затененную область: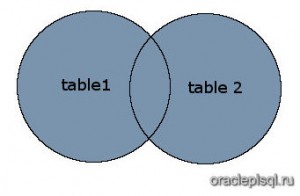
SQL FULL OUTER JOIN возвращает все записи из таблиц table1 и table2.
Пример
Давайте рассмотрим пример, который показывает, как использовать FULL OUTER JOIN в операторе SELECT.
Используя ту же таблицу customers, что и в предыдущем примере:
| customer_id | first_name | last_name | favorite_website |
|---|---|---|---|
| 4000 | Justin | Bieber | google.com |
| 5000 | Selena | Gomez | bing.com |
| 6000 | Mila | Kunis | yahoo.com |
| 7000 | Tom | Cruise | oracle.com |
| 8000 | Johnny | Depp | NULL |
| 9000 | Russell | Crowe | google.com |
И таблицу orders со следующими данными:
| order_id | customer_id | order_date |
|---|---|---|
| 1 | 7000 | 2019/06/18 |
| 2 | 5000 | 2019/06/18 |
| 3 | 8000 | 2019/06/19 |
| 4 | 4000 | 2019/06/20 |
| 5 | NULL | 2019/07/01 |
Введите следующий SQL оператор:
SELECT customers.customer_id,
orders.order_id,
orders.order_date
FROM customers
FULL OUTER JOIN orders
ON customers.customer_id = orders.customer_id
ORDER BY customers.customer_id;
Будет выбрано 7 записей. Вот результаты, которые вы получите:
| customer_id | order_id | order_date |
|---|---|---|
| NULL | 5 | 2019/07/01 |
| 4000 | 4 | 2019/06/20 |
| 5000 | 2 | 2019/06/18 |
| 6000 | NULL | NULL |
| 7000 | 1 | 2019/06/18 |
| 8000 | 3 | 2019/06/19 |
| 9000 | NULL | NULL |
Это пример FULL OUTER JOIN будет возвращать все строки из таблицы orders и все строки из таблицы customers. Всякий раз, когда условие соединения не выполняется, значение NULL будет распространяться на эти поля в наборе результатов. Это означает, что если значение customer_id в таблице customers не существует в таблице orders, то все поля в таблице orders будут отображаться в наборе результатов как NULL Кроме того, если значение customer_id в таблице orders не существует в таблице customers, то все поля в таблице customers будут отображаться в наборе результатов как NULL.
Как видите, строки, где customer_id равен 6000 и 9000, будут включены, но поля order_id и order_date для этих записей содержат значение NULL. Строка, где order_id равен 5, также будет включена, но поле customer_id для этой записи имеет значение NULL.
SQL JOIN — соединение таблиц базы данных
Оператор языка SQL JOIN предназначен для соединения двух или более таблиц базы данных по совпадающему условию. Этот оператор существует только в реляционных базах данных. Именно благодаря JOIN реляционные базы данных обладают такой мощной функциональностью, которая позволяет вести не только хранение данных, но и их, хотя бы простейший, анализ с помощью запросов. Разберём основные нюансы написания SQL-запросов с оператором JOIN, которые являются общими для всех СУБД (систем управления базами данных). Для соединения двух таблиц оператор SQL JOIN имеет следующий синтаксис:
SELECT ИМЕНА_СТОЛБЦОВ (1..N) FROM ИМЯ_ТАБЛИЦЫ_1 JOIN ИМЯ_ТАБЛИЦЫ_2 ON УСЛОВИЕ
После одного или нескольких звеньев с оператором JOIN может следовать необязательная секция WHERE или HAVING, в которой, также, как в простом SELECT-запросе, задаётся условие выборки. Общим для всех СУБД является то, что в этой конструкции вместо JOIN может быть указано INNER JOIN, LEFT OUTER JOIN, RIGHT OUTER JOIN, FULL OUTER JOIN, CROSS JOIN (или, как вариант, запятая).
Запрос с оператором INNER JOIN предназначен для соединения таблиц и вывода результирующей таблицы, в которой данные полностью пересекаются по условию, указанному после ON.
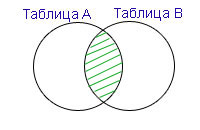
То же самое делает и просто JOIN. Таким образом, слово INNER — не обязательное.
Есть база данных портала объявлений — 2. В ней есть таблица Categories (категории объявлений) и Parts (части, или иначе — рубрики, которые и относятся к категориям). Например, части Квартиры, Дачи относятся к категории Недвижимость, а части Автомобили, Мотоциклы — к категории Транспорт.
Если вы хотите выполнить запросы к базе данных из этого урока на MS SQL Server, но эта СУБД не установлена на вашем компьютере, то ее можно установить, пользуясь инструкцией по этой ссылке.
Скрипт для создания базы данных портала объявлений — 2, её таблиц и заполения таблиц данными — в файле по этой ссылке.
Таблицы этой базы данных с заполненными данными имеют следующий вид.
Таблица Categories:
| Catnumb | Cat_name | Price |
| 10 | Стройматериалы | 105,00 |
| 505 | Недвижимость | 210,00 |
| 205 | Транспорт | 160,00 |
| 30 | Мебель | 77,00 |
| 45 | Техника | 65,00 |
Таблица Parts:
| Part_ID | Part | Cat |
| 1 | Квартиры | 505 |
| 2 | Автомашины | 205 |
| 3 | Доски | 10 |
| 4 | Шкафы | 30 |
| 5 | Книги | 160 |
Заметим, что в таблице Parts Книги имеют Cat — ссылку на категорию, которой нет в таблице Categories, а в таблице Categories Техника имеет номер категории Catnumb — значение, ссылки на которое нет в таблице Parts.
Пример 1. Требуется соединить данные этих двух таблиц так, чтобы в результирующей таблице были поля Part (Часть), Cat (Категория) и Price (Цена подачи объявления) и чтобы данные полностью пересекались по условию. Условие — совпадение номера категории (Catnumb) в таблице Categories и ссылки на категорию в таблице Parts. Для этого пишем следующий запрос:
SELECT Parts.Part, Categories.Catnumb AS Cat, Categories.Price FROM Parts INNER JOIN Categories ON Parts.Cat = Categories.Catnumb
Результатом выполнения запроса будет следующая таблица:
| Part | Cat | Price |
| Квартиры | 505 | 210,00 |
| Автомашины | 205 | 160,00 |
| Доски | 10 | 105,00 |
| Шкафы | 30 | 77,00 |
В результирующей таблице нет Книг, так как эта запись ссылается на категорию, которой нет в таблице Categories, и Техники, так как эта запись имеет внешний ключ в таблице Categories, на который нет ссылки в таблице Parts.
В ряде случаев при соединениях таблиц составить менее громоздкие запросы можно с помощью предиката EXISTS и без использования JOIN.
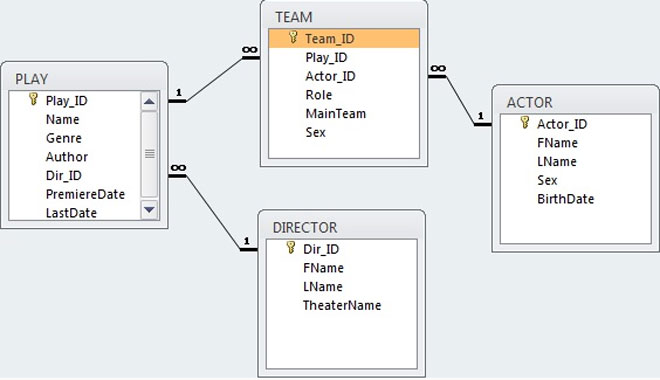
Есть база данных «Театр». Таблица Play содержит данные о постановках. Таблица Team — о ролях актёров. Таблица Actor — об актёрах. Таблица Director — о режиссёрах. Поля таблиц, первичные и внешние ключи можно увидеть на рисунке ниже (для увеличения нажать левой кнопкой мыши).
Пример 2. Определить самого востребованного актёра за последние 5 лет.
Оператор JOIN использовать 2 раза. Использовать COUNT(), CURDATE(), LIMIT 1.
Правильное решение и ответ.
Пример 3. Вывести список актеров, которые в одном спектакле играют более одной роли, и количество их ролей.
Оператор JOIN использовать 1 раз. Использовать HAVING, GROUP BY.
Подсказка. Оператор HAVING применяется к числу ролей, подсчитанных агрегатной функцией COUNT.
Правильное решение и ответ.
Запрос с оператором LEFT OUTER JOIN предназначен для соединения таблиц и вывода результирующей таблицы, в которой данные полностью пересекаются по условию, указанному после ON, и дополняются записями из первой по порядку (левой) таблицы, даже если они не соответствуют условию. У записей левой таблицы, которые не соответствуют условию, значение столбца из правой таблицы будет NULL (неопределённым).
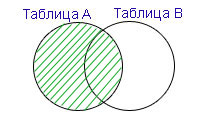
Пример 4. База данных и таблицы — те же, что и в примере 1.
Для получения результирующей таблицы, в которой данные из двух таблиц полностью пересекаются по условию и дополняются всеми данными из таблицы Parts, которые не соответствуют условию, пишем следующий запрос:
SELECT Parts.Part, Categories.Catnumb AS Cat, Categories.Price FROM Parts LEFT OUTER JOIN Categories ON Parts.Cat = Categories.Catnumb
Результатом выполнения запроса будет следующая таблица:
| Part | Cat | Price |
| Квартиры | 505 | 210,00 |
| Автомашины | 205 | 160,00 |
| Доски | 10 | 105,00 |
| Шкафы | 30 | 77,00 |
| Книги | 160 | NULL |
В результирующей таблице, в отличие от таблицы из примера 1, есть Книги, но значение столбца Цены (Price) у них — NULL, так как эта запись имеет идентификатор категории, которой нет в таблице Categories.
Запрос с оператором RIGHT OUTER JOIN предназначен для соединения таблиц и вывода результирующей таблицы, в которой данные полностью пересекаются по условию, указанному после ON, и дополняются записями из второй по порядку (правой) таблицы, даже если они не соответствуют условию. У записей правой таблицы, которые не соответствуют условию, значение столбца из левой таблицы будет NULL (неопределённым).
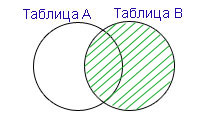
Пример 5. База данных и таблицы — те же, что и в предыдущих примерах.
Для получения результирующей таблицы, в которой данные из двух таблиц полностью пересекаются по условию и дополняются всеми данными из таблицы Categories, которые не соответствуют условию, пишем следующий запрос:
SELECT Parts.Part, Categories.Catnumb AS Cat, Categories.Price FROM Parts RIGHT OUTER JOIN Categories ON Parts.Cat = Categories.Catnumb
Результатом выполнения запроса будет следующая таблица:
| Part | Cat | Price |
| Квартиры | 505 | 210,00 |
| Автомашины | 205 | 160,00 |
| Доски | 10 | 105,00 |
| Шкафы | 30 | 77,00 |
| NULL | 45 | 65,00 |
В результирующей таблице, в отличие от таблицы из примера 1, есть запись с категорией 45 и ценой 65,00, но значение столбца Части (Part) у неё — NULL, так как эта запись имеет идентификатор категории, на которую нет ссылок в таблице Parts.
Запрос с оператором FULL OUTER JOIN предназначен для соединения таблиц и вывода результирующей таблицы, в которой данные полностью пересекаются по условию, указанному после ON, и дополняются записями из первой (левой) и второй (правой) таблиц, даже если они не соответствуют условию. У записей, которые не соответствуют условию, значение столбцов из другой таблицы будет NULL (неопределённым).
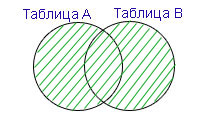
Пример 6. База данных и таблицы — те же, что и в предыдущих примерах.
Для получения результирующей таблицы, в которой данные из двух таблиц полностью пересекаются по условию и дополняются всеми данными как из таблицы Parts, так и из таблицы Categories, которые не соответствуют условию, пишем следующий запрос:
SELECT Parts.Part, Categories.Catnumb AS Cat, Categories.Price FROM Parts FULL OUTER JOIN Categories ON Parts.Cat = Categories.Catnumb
Результатом выполнения запроса будет следующая таблица:
| Part | Cat | Price |
| Квартиры | 505 | 210,00 |
| Автомашины | 205 | 160,00 |
| Доски | 10 | 105,00 |
| Шкафы | 30 | 77,00 |
| Книги | 160 | NULL |
| NULL | 45 | 65,00 |
В результирующей таблице есть записи Книги (из левой таблицы) и с категорией 45 (из правой таблицы), причём у первой из них неопределённая цена (столбец из правой таблицы), а у второй — неопределённая часть (столбец из левой таблицы).
В предыдущих запросах мы указывали с названиями извлекаемых столбцов из разных таблиц полные имена этих таблиц. Такие запросы выглядят громоздко: одно и то же слово повторяется несколько раз. Нельзя ли как-то упростить конструкцию? Оказывается, можно. Для этого следует использовать псевдонимы таблиц — их сокращённые имена. Псевдоним может состоять и из одной буквы. Возможно любое количество букв в псевдониме, главное, чтобы запрос после сокращения был понятен Вам самим. Общее правило: в секции запроса, определяющей соединение, то есть вокруг слова JOIN нужно указать полные имена таблиц, а за каждым именем должен следовать псевдоним таблицы.
Пример 7. Переписать запрос из примера 1 с использованием псевдонимов соединяемых таблиц.
Запрос будет следующим:
SELECT P.Part, C.Catnumb AS Cat, C.Price FROM Parts P INNER JOIN Categories C ON P.Cat = C.Catnumb
Запрос вернёт то же самое, что и запрос в примере 1, но он гораздо компактнее.
Реляционные базы данных должны подчиняться требованиям целостности и неизбыточности данных, в связи с чем данные об одном бизнес-процессе могут содержаться не только в одной, двух, но и в трёх и более таблицах. В этих случаях для анализа данных используются цепочки соединённых таблиц: например, в одной (первой) таблице содержится некоторый количественный показатель, вторую таблицу с первой и третьей связывают внешние ключи — данные пересекаются, но только третья таблица содержит условие, в зависимости от которого может быть выведен количественный показатель из первой таблицы. И таблиц может быть ещё больше. При помощи оператора SQL JOIN в одном запросе можно соединить большое число таблиц. В таких запросах за одной секцией соединения следует другая, причём каждый следующий JOIN соединяет со следующей таблицей таблицу, которая была второй в предыдущем звене цепочки. Таким образом, синтаксис SQL запроса для соединения более двух таблиц следующий:
SELECT ИМЕНА_СТОЛБЦОВ (1..N) FROM ИМЯ_ТАБЛИЦЫ_1 JOIN ИМЯ_ТАБЛИЦЫ_2 ON УСЛОВИЕ JOIN ИМЯ_ТАБЛИЦЫ_3 ON УСЛОВИЕ … JOIN ИМЯ_ТАБЛИЦЫ_M ON УСЛОВИЕ
Пример 8. База данных — та же, что и в предыдущих примерах. К таблицам Categories и Parts в этом примере добавится таблица Ads, содержащая данные об опубликованных на портале объявлениях. Приведём фрагмент таблицы Ads, в котором среди записей есть записи о тех объявлениях, срок публикации которых истекает 2018-04-02.
| A_Id | Part_ID | Date_start | Date_end | Text |
| 21 | 1 | ‘2018-02-11’ | ‘2018-04-20’ | «Продаю…» |
| 22 | 1 | ‘2018-02-11’ | ‘2018-05-12’ | «Продаю…» |
| … | … | … | … | … |
| 27 | 1 | ‘2018-02-11’ | ‘2018-04-02’ | «Продаю…» |
| 28 | 2 | ‘2018-02-11’ | ‘2018-04-21’ | «Продаю…» |
| 29 | 2 | ‘2018-02-11’ | ‘2018-04-02’ | «Продаю…» |
| 30 | 3 | ‘2018-02-11’ | ‘2018-04-22’ | «Продаю…» |
| 31 | 4 | ‘2018-02-11’ | ‘2018-05-02’ | «Продаю…» |
| 32 | 4 | ‘2018-02-11’ | ‘2018-04-13’ | «Продаю…» |
| 33 | 3 | ‘2018-02-11’ | ‘2018-04-12’ | «Продаю…» |
| 34 | 4 | ‘2018-02-11’ | ‘2018-04-23’ | «Продаю…» |
Представим, что сегодня ‘2018-04-02’, то есть это значение принимает функция CURDATE() — текущая дата. Требуется узнать, к каким категориям принадлежат объявления, срок публикации которых истекает сегодня. Названия категорий есть только в таблице CATEGORIES, а даты истечения срока публикации объявлений — только в таблице ADS. В таблице PARTS — части категорий (или проще, подкатегории) опубликованных объявлений. Но внешним ключом Cat_ID таблица PARTS связана с таблицей CATEGORIES, а таблица ADS связана внешним ключом Part_ID с таблицей PARTS. Поэтому соединяем в одном запросе три таблицы и этот запрос можно с максимальной корректностью назвать цепочкой.
Запрос будет следующим:
SELECT C.Cat_name FROM Categories C JOIN Parts P ON P.Cat=C.Catnumb JOIN ads A ON A.Part_id=P.Part_id WHERE A.Date_end=CURDATE()
Результат запроса — таблица, содержащая названия двух категорий — «Недвижимость» и «Транспорт»:
| Cat_name |
| Недвижимость |
| Транспорт |
Использование оператора SQL CROSS JOIN в наиболее простой форме — без условия соединения — реализует операцию декартова произведения в реляционной алгебре. Результатом такого соединения будет сцепление каждой строки первой таблицы с каждой строкой второй таблицы. Таблицы могут быть записаны в запросе либо через оператор CROSS JOIN, либо через запятую между ними.
Пример 9. База данных — всё та же, таблицы — Categories и Parts. Реализовать операцию декартова произведения этих двух таблиц.
Запрос будет следующим:
SELECT (*) Categories CROSS JOIN Parts
Или без явного указания CROSS JOIN — через запятую:
SELECT (*) Categories, Parts
Запрос вернёт таблицу из 5 * 5 = 25 строк, фрагмент которой приведён ниже:
| Catnumb | Cat_name | Price | Part_ID | Part | Cat |
| 10 | Стройматериалы | 105,00 | 1 | Квартиры | 505 |
| 10 | Стройматериалы | 105,00 | 2 | Автомашины | 205 |
| 10 | Стройматериалы | 105,00 | 3 | Доски | 10 |
| 10 | Стройматериалы | 105,00 | 4 | Шкафы | 30 |
| 10 | Стройматериалы | 105,00 | 5 | Книги | 160 |
| … | … | … | … | … | … |
| 45 | Техника | 65,00 | 1 | Квартиры | 505 |
| 45 | Техника | 65,00 | 2 | Автомашины | 205 |
| 45 | Техника | 65,00 | 3 | Доски | 10 |
| 45 | Техника | 65,00 | 4 | Шкафы | 30 |
| 45 | Техника | 65,00 | 5 | Книги | 160 |
Как видно из примера, если результат такого запроса и имеет какую-либо ценность, то это, возможно, наглядная ценность в некоторых случаях, когда не требуется вывести структурированную информацию, тем более, даже самую простейшую аналитическую выборку. Кстати, можно указать выводимые столбцы из каждой таблицы, но и тогда информационная ценность такого запроса не повысится.
Но для CROSS JOIN можно задать условие соединения! Результат будет совсем иным. При использовании оператора «запятая» вместо явного указания CROSS JOIN условие соединения задаётся не словом ON, а словом WHERE.
Пример 10. Та же база данных портала объявлений, таблицы Categories и Parts. Используя перекрестное соединение, соединить таблицы так, чтобы данные полностью пересекались по условию. Условие — совпадение идентификатора категории в таблице Categories и ссылки на категорию в таблице Parts.
Запрос будет следующим:
SELECT P.Part, C.Catnumb AS Cat, C.Price FROM Parts P, Categories C WHERE P.Cat = C.Cat_ID
Запрос вернёт то же самое, что и запрос в примере 1:
| Part | Cat | Price |
| Квартиры | 505 | 210,00 |
| Автомашины | 205 | 160,00 |
| Доски | 10 | 105,00 |
| Шкафы | 30 | 77,00 |
И это совпадение не случайно. Запрос c перекрестным соединением по условию соединения полностью аналогичен запросу с внутренним соединением — INNER JOIN — или, учитывая, что слово INNER — не обязательное, просто JOIN.
Таким образом, какой вариант запроса использовать — вопрос стиля или даже привычки специалиста по работе с базой данных. Возможно, перекрёстное соединение с условием для двух таблиц может представляться более компактным. Но преимущество перекрестного соединения для более чем двух таблиц (это также возможно) весьма спорно. В этом случае WHERE-условия пересечения перечисляются через слово AND. Такая конструкция может быть громоздкой и трудной для чтения, если в конце запроса есть также секция WHERE с условиями выборки.
Поделиться с друзьями
Реляционные базы данных и язык SQL
Оператор JOIN используется для соединения двух или нескольких таблиц. Соединение таблиц может быть внутренним (INNER) или внешним (OUTER), причем внешнее соединение может быть левым (LEFT), правым (RIGHT) или полным (FULL). Далее на примере двух таблиц рассмотрим различные варианты их соединения.
Синтаксис соединения таблиц оператором JOIN имеет вид:
FROM <таблица 1>
[INNER]
{{LEFT | RIGHT | FULL } [OUTER]} JOIN <таблица 2>
[ON <предикат>]Предикат в этой конструкции определяет условие соединения строк из разных таблиц.
Допустим есть две таблицы (Auto слева и Selling справа), в каждой по четыре записи. Одна таблица содержит названия марок автомобилей (Auto), вторая количество проданных автомобилей (Selling):
id name id sum -- ---- -- ---- 1 bmw 1 250 2 opel 5 450 3 kia 3 300 4 audi 6 400
Далее соединим эти таблицы по полю id несколькими различными способами. Совпадающие значения выделены красным для лучшего восприятия.
1. Внутреннее соединение (INNER JOIN) означает, что в результирующий набор попадут только те соединения строк двух таблиц, для которых значение предиката равно TRUE. Обычно используется для объединения записей, которые есть и в первой и во второй таблице, т. е. получения пересечения таблиц:

Красным выделена область, которую мы должны получить.
Итак, сам запрос:
SELECT * FROM 'Auto' INNER JOIN 'Selling' ON 'Auto'.id = 'Selling'.id
И результат:
id name id sum -- ---- -- ---- 1 bmw 1 250 3 kia 3 300
Ключевое слово INNER в запросе можно опустить.
В итоге запрос отбирает и соединяет те записи, у которых значение поля id в обоих таблицах совпадает.
2. Внешнее соединение (OUTER JOIN) бывает нескольких видов. Первым рассмотрим полное внешнее объединение (FULL OUTER JOIN), которое объединяет записи из обоих таблиц (если условие объединения равно true) и дополняет их всеми записями из обоих таблиц, которые не имеют совпадений. Для записей, которые не имеют совпадений из другой таблицы, недостающее поле будет иметь значение NULL. Граф выборки записей будет иметь вид:

Переходим к запросу:
SELECT * FROM 'Auto' FULL OUTER JOIN 'Selling' ON 'Auto'.id = 'Selling'.id
Результат:
id name id sum -- ---- -- ---- 1 bmw 1 250 2 opel NULL NULL 3 kia 3 300 4 audi NULL NULL NULL NULL 5 450 NULL NULL 6 400
То есть мы получили все записи, которые есть в обоих таблицах. Записи у которых значение поля id совпадает соединяются, а у записей для которых совпадений не найдено недостающие поля заполняются значением NULL.
Ключевое слово OUTER можно опустить.
3. Левое внешнее объединение (LEFT OUTER JOIN). В этом случае получаем все записи удовлетворяющие условию объединения, плюс все оставшиеся записи из внешней таблицы, которые не удовлетворяют условию объединения. Граф выборки:

Запрос:
SELECT * FROM 'Auto' LEFT OUTER JOIN 'Selling' ON 'Auto'.id = 'Selling'.id
Результат:
id name id sum -- ---- -- ---- 1 bmw 1 250 2 opel NULL NULL 3 kia 3 300 4 audi NULL NULL
Запрос также можно писать без ключевого слова OUTER.
В итоге здесь мы получили все записи таблицы Auto. Записи для которых были найдены совпадения по полю id в таблице Selling соединяются, для остальных недостающие поля заполняются значением NULL.
Еще существует правое внешнее объединение (RIGHT OUTER JOIN). Оно работает точно также как и левое объединение, только в качестве внешней таблицы будет использоваться правая (в нашем случае таблица Selling или таблица Б на графе).
Далее рассмотрим остальные возможные выборки с использованием объединения двух таблиц.
4. Получить все записи из таблицы А, которые не имеют объединения из таблицы Б. Граф:

То есть в нашем случае, нам надо получить все автомобили из таблицы Auto, которые не имеют продаж в таблице Selling.
Запрос:
SELECT * FROM 'Auto' LEFT OUTER JOIN 'Selling' ON 'Auto'.id = 'Selling'.id WHERE 'Selling'.id IS null
Результат:
id name id sum -- ---- -- ---- 2 opel NULL NULL 4 audi NULL NULL
5. И последний вариант, получить все записи из таблицы А и Таблицы Б, которые не имеют объединений. Граф:

В нашем случае мы должны получить все записи из таблицы Auto, которые не связаны с таблицей Selling, и все записи из таблицы Selling, которые не имеют сопоставления из таблицы Auto.
Запрос:
SELECT * FROM 'Auto' FULL OUTER JOIN 'Selling' ON 'Auto'.id = 'Selling'.id WHERE 'Auto'.id IS null OR 'Selling'.id IS null
Результат:
id name id sum -- ---- -- ---- 2 opel NULL NULL 4 audi NULL NULL NULL NULL 5 450 NULL NULL 6 400
На этом все, до новых встреч на страницах блога.
SQL join в примерах с описанием
Присоединение таблиц в запросах — это базовый инструмент в работе с базами данных. Давайте рассмотрим какие присоединения (JOIN) бывают, и что от этого меняется в результатах запроса.
Для начала создадим две таблицы, над которыми будем проводить опыты. Это таблица с именами сотрудников и словарь с перечнем должностей.
Persons (Сотрудники)
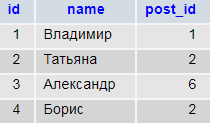
Positions (должности)
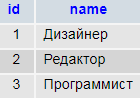
Т.е. чтобы узнать должность сотрудника, нужно присоединить соответствующие данные. Далее мы рассмотрим все варианты присоединений. Данные специально подобраны так, чтобы продемонстрировать отличия в результатах разных запросов.
INNER JOIN
Внутреннее присоединение. Равносильно просто JOIN или CROSS JOIN.
SELECT p.id, p.name `Имя сотрудника`, ps.id `pos.id`, ps.name `Должность` FROM `persons` p INNER JOIN `positions` ps ON ps.id = p.post_id
SELECT p.id, p.name `Имя сотрудника`, ps.id `pos.id`, ps.name `Должность` FROM `persons` p INNER JOIN `positions` ps ON ps.id = p.post_id |
Такое присоединение покажет нам данные из таблиц только если условие связывания соблюдается — т.е. для сотрудника указан существующий в словаре идентификатор должности.
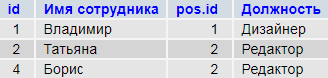
Если поменять порядок соединения таблиц — получим тот же результат.
Условно представим себе эти таблицы, как пересекающиеся множества, где пересечение — это наличие связи между таблицами. Получим картинку:
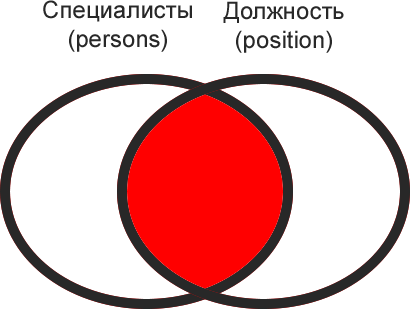
Далее проследим как получить разные части (подмножества) данного множества.
OUTER JOIN
Внешнее присоединение. Различают LEFT OUTER JOIN и RIGHT OUTER JOIN, и обычно опускают слово «OUTER».
Внешнее присоединение включает в себя результаты запроса INNER и добавляются «неиспользованные» строки из одной из таблиц. Какую таблицу использовать в качестве «добавки» — указывает токен LEFT или RIGHT.
LEFT JOIN
Внешнее присоединение «слева».
SELECT p.id, p.name `Имя сотрудника`, ps.id `pos.id`, ps.name `Должность` FROM `persons` p LEFT OUTER JOIN `positions` ps ON ps.id = p.post_id
SELECT p.id, p.name `Имя сотрудника`, ps.id `pos.id`, ps.name `Должность` FROM `persons` p LEFT OUTER JOIN `positions` ps ON ps.id = p.post_id |
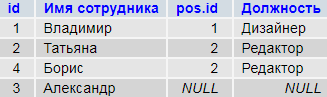
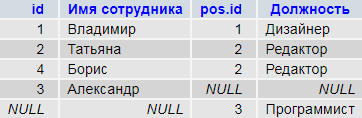
«Левая» таблица persons, содержит строку id#3 — «Александр», где указан идентификатор должности, отсутствующей в словаре.
На картинке это можно показать вот так:

RIGHT JOIN
Присоединение «справа».
SELECT p.id, p.name `Имя сотрудника`, ps.id `pos.id`, ps.name `Должность` FROM `persons` p RIGHT OUTER JOIN `positions` ps ON ps.id = p.post_id
SELECT p.id, p.name `Имя сотрудника`, ps.id `pos.id`, ps.name `Должность` FROM `persons` p RIGHT OUTER JOIN `positions` ps ON ps.id = p.post_id |
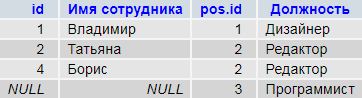
Словарь должностей (правая таблица) содержит неиспользуемую запись с id#3 — «программист». Теперь она попала в результат запроса.
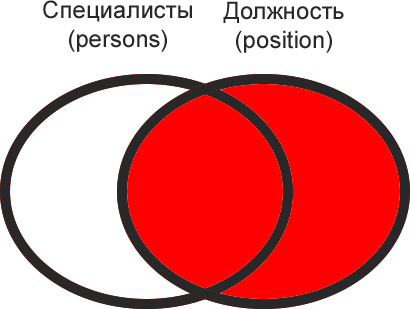
Полное множество
MySQL не знает соединения FULL OUTER JOIN. Что если нужно получить полное множество?
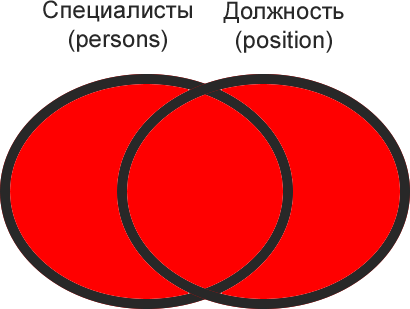
Первый способ — объединение запросов LEFT и RIGHT.
(SELECT p.id, p.name `Имя сотрудника`, ps.id `pos.id`, ps.name `Должность` FROM `persons` p LEFT OUTER JOIN `positions` ps ON ps.id = p.post_id) UNION (SELECT p.id, p.name `Имя сотрудника`, ps.id `pos.id`, ps.name `Должность` FROM `persons` p RIGHT OUTER JOIN `positions` ps ON ps.id = p.post_id)
(SELECT p.id, p.name `Имя сотрудника`, ps.id `pos.id`, ps.name `Должность` FROM `persons` p LEFT OUTER JOIN `positions` ps ON ps.id = p.post_id) UNION (SELECT p.id, p.name `Имя сотрудника`, ps.id `pos.id`, ps.name `Должность` FROM `persons` p RIGHT OUTER JOIN `positions` ps ON ps.id = p.post_id) |
При таком вызове UNION, после слияния результатов, SQL отсечет дубли (как DISTINCT). Для отсечения дублей SQL прибегает к сортировке. Это может сказываться на быстродействии.
Второй способ — объединение LEFT и RIGHT, но в одном из запросов мы исключаем часть, соответствующую INNER. А объединение задаём как UNION ALL, что позволяет движку SQL обойтись без сортировки.
(SELECT p.id, p.name `Имя сотрудника`, ps.id `pos.id`, ps.name `Должность` FROM `persons` p LEFT OUTER JOIN `positions` ps ON ps.id = p.post_id) UNION ALL (SELECT p.id, p.name `Имя сотрудника`, ps.id `pos.id`, ps.name `Должность` FROM `persons` p RIGHT OUTER JOIN `positions` ps ON ps.id = p.post_id WHERE p.id IS NULL)
(SELECT p.id, p.name `Имя сотрудника`, ps.id `pos.id`, ps.name `Должность` FROM `persons` p LEFT OUTER JOIN `positions` ps ON ps.id = p.post_id) UNION ALL (SELECT p.id, p.name `Имя сотрудника`, ps.id `pos.id`, ps.name `Должность` FROM `persons` p RIGHT OUTER JOIN `positions` ps ON ps.id = p.post_id WHERE p.id IS NULL) |
Этот пример показывает нам как исключить пересечение и получить только левую или правую часть множества.
Левое подмножество
LEFT JOIN ограничиваем проверкой, что данных из второй таблицы нет.
SELECT p.id, p.name `Имя сотрудника`, ps.id `pos.id`, ps.name `Должность` FROM `persons` p LEFT OUTER JOIN `positions` ps ON ps.id = p.post_id WHERE ps.id is NULL
SELECT p.id, p.name `Имя сотрудника`, ps.id `pos.id`, ps.name `Должность` FROM `persons` p LEFT OUTER JOIN `positions` ps ON ps.id = p.post_id WHERE ps.id is NULL |

В нашем примере — это специалисты, у которых не задана должность или нет должности с указанным ключом.

Правое подмножество
Точно также выделяем правую часть.
SELECT p.id, p.name `Имя сотрудника`, ps.id `pos.id`, ps.name `Должность` FROM `persons` p RIGHT OUTER JOIN `positions` ps ON ps.id = p.post_id WHERE p.id is NULL
SELECT p.id, p.name `Имя сотрудника`, ps.id `pos.id`, ps.name `Должность` FROM `persons` p RIGHT OUTER JOIN `positions` ps ON ps.id = p.post_id WHERE p.id is NULL |


В нашем случае получим должности, которые никому не назначены.
Всё кроме пересечения
Остался один вариант, тот когда исключено пересечение множеств. Его можно сложить из двух предыдущих запросов через UNION ALL (т.к. подмножества не пересекаются).
(SELECT p.id, p.name `Имя сотрудника`, ps.id `pos.id`, ps.name `Должность` FROM `persons` p LEFT OUTER JOIN `positions` ps ON ps.id = p.post_id WHERE ps.id is NULL) UNION ALL (SELECT p.id, p.name `Имя сотрудника`, ps.id `pos.id`, ps.name `Должность` FROM `persons` p RIGHT OUTER JOIN `positions` ps ON ps.id = p.post_id WHERE p.id is NULL)
(SELECT p.id, p.name `Имя сотрудника`, ps.id `pos.id`, ps.name `Должность` FROM `persons` p LEFT OUTER JOIN `positions` ps ON ps.id = p.post_id WHERE ps.id is NULL) UNION ALL (SELECT p.id, p.name `Имя сотрудника`, ps.id `pos.id`, ps.name `Должность` FROM `persons` p RIGHT OUTER JOIN `positions` ps ON ps.id = p.post_id WHERE p.id is NULL) |

Данная запись опубликована в 19.09.2017 20:19 и размещена в mySQL. Вы можете перейти в конец страницы и оставить ваш комментарий.
Многотабличные запросы, оператор JOIN
Многотабличные запросы
В предыдущих статьях описывалась работа только с одной таблицей базы данных. В реальности же очень часто приходится делать выборку из нескольких таблиц, каким-то образом объединяя их. В данной статье вы узнаете основные способы соединения таблиц.
Общая структура многотабличного запроса
SELECT поля_таблиц
FROM таблица_1
[INNER] | [[LEFT | RIGHT | FULL][OUTER]] JOIN таблица_2
ON условие_соединения
[[INNER] | [[LEFT | RIGHT | FULL][OUTER]] JOIN таблица_n
ON условие_соединения]Эту же структуру можно переписать следующим образом:
SELECT поля_таблиц
FROM таблица_1
[INNER] | [[LEFT | RIGHT | FULL][OUTER]] JOIN таблица_2[ JOIN таблица_n]
ON условие_соединения [AND условие_соединения]В большинстве случаев условием соединения является равенство столбцов таблиц (таблица_1.поле = таблица_2.поле), однако точно так же можно использовать и другие операторы сравнения.
Соединение бывает внутренним (INNER) или внешним (OUTER), при этом внешнее соединение делится на левое (LEFT), правое (RIGHT) и полное (FULL).
INNER JOIN
По умолчанию, если не указаны какие-либо параметры, JOIN выполняется как INNER JOIN, то есть как внутреннее (перекрёстное) соединение таблиц.
Внутреннее соединение — соединение двух таблиц, при котором каждая запись из первой таблицы соединяется с каждой записью второй таблицы, создавая тем самым все возможные комбинации записей обеих таблиц (декартово произведение).
Например, объединим таблицы покупок (Payments) и членов семьи (FamilyMembers) таким образом, чтобы дополнить каждую покупку данными о том, кто её совершил.
Данные в таблице Payments:
| payment_id | date | family_member | good | amount | unit_price |
|---|---|---|---|---|---|
| 1 | 2005-02-12 00:00:00 | 1 | 1 | 1 | 2000 |
| 2 | 2005-03-23 00:00:00 | 2 | 1 | 1 | 2100 |
| 3 | 2005-05-14 00:00:00 | 3 | 4 | 5 | 20 |
| 4 | 2005-07-22 00:00:00 | 4 | 5 | 1 | 350 |
| 5 | 2005-07-26 00:00:00 | 4 | 7 | 2 | 150 |
| 6 | 2005-02-20 00:00:00 | 5 | 6 | 1 | 100 |
| 7 | 2005-07-30 00:00:00 | 2 | 6 | 1 | 120 |
| 8 | 2005-09-12 00:00:00 | 2 | 16 | 1 | 5500 |
| 9 | 2005-09-30 00:00:00 | 5 | 15 | 1 | 230 |
| 10 | 2005-10-27 00:00:00 | 5 | 15 | 1 | 230 |
| 11 | 2005-11-28 00:00:00 | 5 | 15 | 1 | 250 |
| 12 | 2005-12-22 00:00:00 | 5 | 15 | 1 | 250 |
| 13 | 2005-08-11 00:00:00 | 3 | 13 | 1 | 2200 |
| 14 | 2005-10-23 00:00:00 | 2 | 14 | 1 | 66000 |
| 15 | 2005-02-03 00:00:00 | 1 | 9 | 5 | 8 |
| 16 | 2005-03-11 00:00:00 | 1 | 9 | 5 | 7 |
| 17 | 2005-03-18 00:00:00 | 2 | 9 | 3 | 8 |
| 18 | 2005-04-20 00:00:00 | 1 | 9 | 8 | 8 |
| 19 | 2005-05-13 00:00:00 | 1 | 9 | 5 | 7 |
| 20 | 2005-06-11 00:00:00 | 2 | 9 | 3 | 150 |
| 21 | 2006-01-12 00:00:00 | 3 | 10 | 1 | 100 |
| 22 | 2006-03-12 00:00:00 | 1 | 5 | 3 | 10 |
| 23 | 2005-06-05 00:00:00 | 1 | 8 | 1 | 300 |
| 24 | 2005-06-20 00:00:00 | 3 | 6 | 8 | 150 |
Данные в таблице FamilyMembers:
| member_id | status | member_name | birthday |
|---|---|---|---|
| 1 | father | Headley Quincey | 1960-05-13 00:00:00 |
| 2 | mother | Flavia Quincey | 1963-02-16 00:00:00 |
| 3 | son | Andie Quincey | 1983-06-05 00:00:00 |
| 4 | daughter | Lela Quincey | 1985-06-07 00:00:00 |
| 5 | daughter | Annie Quincey | 1988-04-10 00:00:00 |
| 6 | father | Ernest Forrest | 1961-09-11 00:00:00 |
| 7 | mother | Constance Forrest | 1968-09-06 00:00:00 |
Для того, чтобы решить поставленную задачу выполним запрос, который объединяет поля строки из одной таблицы с полями другой, если выполняется условие, что покупатель товара (family_member) совпадает с идентификатором члена семьи (member_id):
SELECT *
FROM Payments
JOIN FamilyMembers ON family_member = member_id;В результате вы можете видеть, что каждая строка из таблицы Payments дополнилась данными о члене семьи, который совершил покупку. Обратите внимание на поля family_member и member_id — они одинаковы, что и было отражено в запросе.
| payment_id | date | family_member | good | amount | unit_price | member_id | status | member_name | birthday |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 2005-02-12 00:00:00 | 1 | 1 | 1 | 2000 | 1 | father | Headley Quincey | 1960-05-13 00:00:00 |
| 2 | 2005-03-23 00:00:00 | 2 | 1 | 1 | 2100 | 2 | mother | Flavia Quincey | 1963-02-16 00:00:00 |
| 3 | 2005-05-14 00:00:00 | 3 | 4 | 5 | 20 | 3 | son | Andie Quincey | 1983-06-05 00:00:00 |
| 4 | 2005-07-22 00:00:00 | 4 | 5 | 1 | 350 | 4 | daughter | Lela Quincey | 1985-06-07 00:00:00 |
| 5 | 2005-07-26 00:00:00 | 4 | 7 | 2 | 150 | 4 | daughter | Lela Quincey | 1985-06-07 00:00:00 |
| 6 | 2005-02-20 00:00:00 | 5 | 6 | 1 | 100 | 5 | daughter | Annie Quincey | 1988-04-10 00:00:00 |
| 7 | 2005-07-30 00:00:00 | 2 | 6 | 1 | 120 | 2 | mother | Flavia Quincey | 1963-02-16 00:00:00 |
| 8 | 2005-09-12 00:00:00 | 2 | 16 | 1 | 5500 | 2 | mother | Flavia Quincey | 1963-02-16 00:00:00 |
| 9 | 2005-09-30 00:00:00 | 5 | 15 | 1 | 230 | 5 | daughter | Annie Quincey | 1988-04-10 00:00:00 |
| 10 | 2005-10-27 00:00:00 | 5 | 15 | 1 | 230 | 5 | daughter | Annie Quincey | 1988-04-10 00:00:00 |
| 11 | 2005-11-28 00:00:00 | 5 | 15 | 1 | 250 | 5 | daughter | Annie Quincey | 1988-04-10 00:00:00 |
| 12 | 2005-12-22 00:00:00 | 5 | 15 | 1 | 250 | 5 | daughter | Annie Quincey | 1988-04-10 00:00:00 |
| 13 | 2005-08-11 00:00:00 | 3 | 13 | 1 | 2200 | 3 | son | Andie Quincey | 1983-06-05 00:00:00 |
| 14 | 2005-10-23 00:00:00 | 2 | 14 | 1 | 66000 | 2 | mother | Flavia Quincey | 1963-02-16 00:00:00 |
| 15 | 2005-02-03 00:00:00 | 1 | 9 | 5 | 8 | 1 | father | Headley Quincey | 1960-05-13 00:00:00 |
| 16 | 2005-03-11 00:00:00 | 1 | 9 | 5 | 7 | 1 | father | Headley Quincey | 1960-05-13 00:00:00 |
| 17 | 2005-03-18 00:00:00 | 2 | 9 | 3 | 8 | 2 | mother | Flavia Quincey | 1963-02-16 00:00:00 |
| 18 | 2005-04-20 00:00:00 | 1 | 9 | 8 | 8 | 1 | father | Headley Quincey | 1960-05-13 00:00:00 |
| 19 | 2005-05-13 00:00:00 | 1 | 9 | 5 | 7 | 1 | father | Headley Quincey | 1960-05-13 00:00:00 |
| 20 | 2005-06-11 00:00:00 | 2 | 9 | 3 | 150 | 2 | mother | Flavia Quincey | 1963-02-16 00:00:00 |
| 21 | 2006-01-12 00:00:00 | 3 | 10 | 1 | 100 | 3 | son | Andie Quincey | 1983-06-05 00:00:00 |
| 22 | 2006-03-12 00:00:00 | 1 | 5 | 3 | 10 | 1 | father | Headley Quincey | 1960-05-13 00:00:00 |
| 23 | 2005-06-05 00:00:00 | 1 | 8 | 1 | 300 | 1 | father | Headley Quincey | 1960-05-13 00:00:00 |
| 24 | 2005-06-20 00:00:00 | 3 | 6 | 8 | 150 | 3 | son | Andie Quincey | 1983-06-05 00:00:00 |
Использование WHERE для соединения таблиц
Для внутреннего соединения таблиц также можно использовать оператор WHERE. Например, вышеприведённый запрос, написанный с помощью INNER JOIN, будет выглядеть так:
SELECT *
FROM Payments, FamilyMembers
WHERE family_member = member_id;OUTER JOIN
Внешнее соединение может быть трёх типов: левое (LEFT), правое (RIGHT) и полное (FULL). По умолчанию оно является полным.
Главным отличием внешнего соединения от внутреннего является то, что оно обязательно возвращает все строки одной (LEFT, RIGHT) или двух таблиц (FULL).
Внешнее левое соединение (LEFT OUTER JOIN)
Соединение, которое возвращает все значения из левой таблицы, соединённые с соответствующими значениями из правой таблицы если они удовлетворяют условию соединения, или заменяет их на NULL в обратном случае.
Для примера получим из базы данных расписание звонков объединённых с соответствующими занятиями в расписании занятий:
SELECT *
FROM Timepair
LEFT JOIN Schedule ON Schedule.number_pair = Timepair.id;Данные в таблице Timepair (расписание звонков):
| id | start_pair | end_pair |
|---|---|---|
| 1 | 08:30:00 | 09:15:00 |
| 2 | 09:20:00 | 10:05:00 |
| 3 | 10:15:00 | 11:00:00 |
| 4 | 11:05:00 | 11:50:00 |
| 5 | 12:50:00 | 13:35:00 |
| 6 | 13:40:00 | 14:25:00 |
| 7 | 14:35:00 | 15:20:00 |
| 8 | 15:25:00 | 16:10:00 |
Данные в таблице Schedule (расписание занятий):
| id | date | class | number_pair | teacher | subject | classroom |
|---|---|---|---|---|---|---|
| 1 | 2019-09-01 | 9 | 1 | 11 | 1 | 47 |
| 4 | 2019-09-02 | 9 | 1 | 4 | 3 | 13 |
| 7 | 2019-09-03 | 9 | 1 | 5 | 6 | 36 |
| 10 | 2019-09-04 | 9 | 1 | 9 | 9 | 39 |
| 13 | 2019-09-05 | 9 | 1 | 3 | 13 | 43 |
| 16 | 2019-08-30 | 9 | 1 | 2 | 4 | 34 |
| 2 | 2019-09-01 | 9 | 2 | 8 | 2 | 13 |
| 5 | 2019-09-02 | 9 | 2 | 2 | 4 | 34 |
| 8 | 2019-09-03 | 9 | 2 | 13 | 7 | 37 |
| 11 | 2019-09-04 | 9 | 2 | 10 | 10 | 40 |
| 14 | 2019-09-05 | 9 | 2 | 11 | 1 | 47 |
| 17 | 2019-08-30 | 9 | 2 | 8 | 2 | 13 |
| 3 | 2019-09-01 | 9 | 3 | 4 | 3 | 13 |
| 6 | 2019-09-02 | 9 | 3 | 6 | 5 | 35 |
| 9 | 2019-09-03 | 9 | 3 | 6 | 8 | 38 |
| 12 | 2019-09-04 | 9 | 3 | 3 | 11 | 41 |
| 15 | 2019-09-05 | 9 | 3 | 5 | 6 | 36 |
| 18 | 2019-08-30 | 9 | 3 | 6 | 5 | 35 |
| 19 | 2019-08-30 | 9 | 4 | 10 | 1 | 47 |
В выборку попали все строки из левой таблицы, дополненные данными о занятиях. Примечательно, что в конце таблицы есть строки с полями, заполненными NULL. Это те строки, для которых не нашлось соответствующих занятий, однако они присутствуют в левой таблице, поэтому тоже были выведены.
| timepair.id | start_pair | end_pair | schedule.id | date | class | number_pair | teacher | subject | classroom |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 08:30:00 | 09:15:00 | 4 | 2019-09-02 | 9 | 1 | 4 | 3 | 13 |
| 1 | 08:30:00 | 09:15:00 | 7 | 2019-09-03 | 9 | 1 | 5 | 6 | 36 |
| 1 | 08:30:00 | 09:15:00 | 16 | 2019-08-30 | 9 | 1 | 2 | 4 | 34 |
| 1 | 08:30:00 | 09:15:00 | 10 | 2019-09-04 | 9 | 1 | 9 | 9 | 39 |
| 1 | 08:30:00 | 09:15:00 | 1 | 2019-09-01 | 9 | 1 | 11 | 1 | 47 |
| 1 | 08:30:00 | 09:15:00 | 13 | 2019-09-05 | 9 | 1 | 3 | 13 | 43 |
| 2 | 09:20:00 | 10:05:00 | 2 | 2019-09-01 | 9 | 2 | 8 | 2 | 13 |
| 2 | 09:20:00 | 10:05:00 | 5 | 2019-09-02 | 9 | 2 | 2 | 4 | 34 |
| 2 | 09:20:00 | 10:05:00 | 17 | 2019-08-30 | 9 | 2 | 8 | 2 | 13 |
| 2 | 09:20:00 | 10:05:00 | 8 | 2019-09-03 | 9 | 2 | 13 | 7 | 37 |
| 2 | 09:20:00 | 10:05:00 | 11 | 2019-09-04 | 9 | 2 | 10 | 10 | 40 |
| 2 | 09:20:00 | 10:05:00 | 14 | 2019-09-05 | 9 | 2 | 11 | 1 | 47 |
| 3 | 10:15:00 | 11:00:00 | 12 | 2019-09-04 | 9 | 3 | 3 | 11 | 41 |
| 3 | 10:15:00 | 11:00:00 | 18 | 2019-08-30 | 9 | 3 | 6 | 5 | 35 |
| 3 | 10:15:00 | 11:00:00 | 15 | 2019-09-05 | 9 | 3 | 5 | 6 | 36 |
| 3 | 10:15:00 | 11:00:00 | 9 | 2019-09-03 | 9 | 3 | 6 | 8 | 38 |
| 3 | 10:15:00 | 11:00:00 | 6 | 2019-09-02 | 9 | 3 | 6 | 5 | 35 |
| 3 | 10:15:00 | 11:00:00 | 3 | 2019-09-01 | 9 | 3 | 4 | 3 | 13 |
| 4 | 11:05:00 | 11:50:00 | 19 | 2019-08-30 | 9 | 4 | 10 | 1 | 47 |
| 5 | 12:50:00 | 13:35:00 | NULL | NULL | NULL | NULL | NULL | NULL | NULL |
| 6 | 13:40:00 | 14:25:00 | NULL | NULL | NULL | NULL | NULL | NULL | NULL |
| 7 | 14:35:00 | 15:20:00 | NULL | NULL | NULL | NULL | NULL | NULL | NULL |
| 8 | 15:25:00 | 16:10:00 | NULL | NULL | NULL | NULL | NULL | NULL | NULL |
Внешнее правое соединение (RIGHT OUTER JOIN)
Соединение, которое возвращает все значения из правой таблицы, соединённые с соответствующими значениями из левой таблицы если они удовлетворяют условию соединения, или заменяет их на NULL в обратном случае.
Внешнее полное соединение (FULL OUTER JOIN)
Соединение, которое выполняет внутреннее соединение записей и дополняет их левым внешним соединением и правым внешним соединением.
Алгоритм работы полного соединения:
- Формируется таблица на основе внутреннего соединения (INNER JOIN).
- В таблицу добавляются значения не вошедшие в результат формирования из левой таблицы (LEFT OUTER JOIN).
- В таблицу добавляются значения не вошедшие в результат формирования из правой таблицы (RIGHT OUTER JOIN).
SELECT *
FROM левая_таблица
LEFT JOIN правая_таблица
ON правая_таблица.ключ = левая_таблица.ключ
UNION ALL
SELECT *
FROM левая_таблица
RIGHT JOIN правая_таблица
ON правая_таблица.ключ = левая_таблица.ключ
WHERE левая_таблица.key IS NULLБазовые запросы для разных вариантов объединения таблиц
Группировка данных, оператор GROUP BY, оператор HAVING
mysql — оператор ON в sql для объединений
Переполнение стека- Товары
- Клиенты
- Случаи использования
- Переполнение стека Публичные вопросы и ответы
- Команды Частные вопросы и ответы для вашей команды
- предприятие Частные вопросы и ответы для вашего предприятия
- работы Программирование и связанные с ним технические возможности карьерного роста
- Талант Нанимать технический талант
- реклама Связаться с разработчиками по всему миру
Вы когда-нибудь замечали оператор SET NOCOUNT ON в операторах T-SQL или хранимых процедурах в SQL Server? Я видел разработчиков, не использующих это утверждение set, потому что не знал его.
В этой статье мы рассмотрим, почему рекомендуется использовать SET NOCOUNT ON с операторами T-SQL. Мы также узнаем о преимуществах производительности, которые вы можете получить.
Введение
Прежде чем исследовать этот оператор, давайте создадим образец таблицы в базе данных SQL Server с помощью следующего сценария.
USE SQLShackDemo; GO CREATE TABLE tblEmployeeDemo (Id INT ПЕРВИЧНЫЙ КЛЮЧ, EmpName NVARCHAR (50), Пол NVARCHAR (10), ); |
Давайте вставим несколько записей данных в эту таблицу, используя следующий скрипт.
1 2 3 4 5 6 7 8 9 10 11 12 13 160003 140003 14000000 18 19 20 21 22 | USE [SQLShackDemo] GO INSERT [dbo].[tblEmployeeDemo] ([Id], [EmpName], [Gender]) ЗНАЧЕНИЯ (1, N’Grace ‘, N’Female’) GO INSERT [dbo]. [tblEmployeeDemo] ([Id], [EmpName ], [Gender]) VALUES (2, N’Gordon ‘, N’Male’) GO INSERT [dbo]. [TblEmployeeDemo] ([Id], [EmpName], [Gender]) VALUES (3, N’Jaime ‘, N’Female’) GO INSERT [dbo]. [TblEmployeeDemo] ([Id], [EmpName], [Gender]) ЗНАЧЕНИЯ (4, N’Ruben ‘, N’Female’) GO INSERT [dbo]. [TblEmployeeDemo] ([Id], [EmpName], [Gender]) ЗНАЧЕНИЯ (5, N’Makayla ‘, N’Male’) GO INSERT [dbo].[tblEmployeeDemo] ([Id], [EmpName], [Gender]) ЗНАЧЕНИЯ (6, N’Barry ‘, N’Female’) GO INSERT [dbo]. [tblEmployeeDemo] ([Id], [EmpName ], [Gender]) VALUES (7, N’Ramon ‘, N’Male’) GO INSERT [dbo]. [TblEmployeeDemo] ([Id], [EmpName], [Gender]) VALUES (8, N’Douglas ‘, N’Male’) GO INSERT [dbo]. [TblEmployeeDemo] ([Id], [EmpName], [Gender]) ЗНАЧЕНИЯ (9, N’Julian ‘, N’Female’) GO INSERT [dbo]. [TblEmployeeDemo] ([Id], [EmpName], [Gender]) ЗНАЧЕНИЯ (10, N’Sarah ‘, N’Female’) GO |
Выполнив команду, вы получите следующее сообщение в SSMS.Для каждой строки вы получаете сообщение « затронут 1-й ряд».
Предположим, вы вставили миллион строк в таблицу, и для каждой записи вы получите это сообщение. Как видите, это не полезное сообщение и не содержит соответствующей информации.
Теперь давайте выберем записи из этой таблицы.
SELECT * ОТ tblEmployeeDemo; |
В результате мы получаем две вкладки Результаты и Сообщения.
- На вкладке «Результат» отображается запись из таблицы.
- Вкладка сообщений показывает количество строк, затронутых сообщением
Давайте создадим хранимую процедуру для получения записей из указанной таблицы.
СОЗДАТЬ ПРОЦЕДУРУ SP_tblEmployeeDemo AS НАЧАТЬ ВЫБРАТЬ * ОТ tblEmployeeDemo; КОНЕЦ; |
Выполните эту хранимую процедуру, и вы получите похожий вывод на следующем снимке экрана.
SET NOCOUNT ON / OFF Оператор управляет поведением в SQL Server, чтобы показать количество затронутых строк в запросе T-SQL.
- SET NOCOUNT OFF — По умолчанию SQL Server показывает количество затронутых строк в области сообщений
- SET NOCOUNT ON — Мы можем указать этот оператор set в начале оператора. Как только мы включим его, мы не получим количество затронутых строк в выводе
Давайте попробуем выполнить предыдущие запросы с помощью оператора NOCOUNT.
Выполните оператор вставки после включения NOCOUNT
1
2
3
4
5
6
7
8
9
10
11
12
13
160003
140003
14000000
18
19
20
21
22
23
24
25
TRUNCATE TABLE tblEmployeeDemo;
GO
SET NOCOUNT ON
USE [SQLShackDemo]
GO
INSERT [dbo].[tblEmployeeDemo] ([Id], [EmpName], [Gender]) ЗНАЧЕНИЯ (1, N’Grace ‘, N’Female’)
GO
INSERT [dbo]. [tblEmployeeDemo] ([Id], [EmpName ], [Gender]) VALUES (2, N’Gordon ‘, N’Male’)
GO
INSERT [dbo]. [TblEmployeeDemo] ([Id], [EmpName], [Gender]) VALUES (3, N’Jaime ‘, N’Female’)
GO
INSERT [dbo]. [TblEmployeeDemo] ([Id], [EmpName], [Gender]) ЗНАЧЕНИЯ (4, N’Ruben ‘, N’Female’)
GO
INSERT [dbo]. [TblEmployeeDemo] ([Id], [EmpName], [Gender]) ЗНАЧЕНИЯ (5, N’Makayla ‘, N’Male’)
GO
INSERT [dbo].[tblEmployeeDemo] ([Id], [EmpName], [Gender]) ЗНАЧЕНИЯ (6, N’Barry ‘, N’Female’)
GO
INSERT [dbo]. [tblEmployeeDemo] ([Id], [EmpName ], [Gender]) VALUES (7, N’Ramon ‘, N’Male’)
GO
INSERT [dbo]. [TblEmployeeDemo] ([Id], [EmpName], [Gender]) VALUES (8, N’Douglas ‘, N’Male’)
GO
INSERT [dbo]. [TblEmployeeDemo] ([Id], [EmpName], [Gender]) ЗНАЧЕНИЯ (9, N’Julian ‘, N’Female’)
GO
INSERT [dbo]. [TblEmployeeDemo] ([Id], [EmpName], [Gender]) ЗНАЧЕНИЯ (10, N’Sarah ‘, N’Female’)
GO
Как только мы выполним вышеупомянутые запросы, мы не получим сообщения 1 затронутой строки.Это дает следующее сообщение.
Выполните оператор Select с NOCOUNT ON, и вы получите следующий вывод
SET NOCOUNT ON
SELECT *
FROM tblEmployeeDemo;
Подобно оператору вставки, мы не получили количество строк, затронутых сообщением в выводе оператора выбора.
Выполнить хранимую процедуру
Мы не можем напрямую выполнить хранимую процедуру с помощью инструкции SET NOCOUNT ON. Вышеуказанное утверждение не работает с хранимой процедурой.
SET NOCOUNT ON
Exec SP_tblEmployeeDemo
Нам нужно либо создать новую хранимую процедуру, либо изменить процедуру и добавить инструкцию SET NOCOUNT согласно следующему сценарию.
ALTER PROCEDURE SP_tblEmployeeDemo
AS
BEGIN
SET NOCOUNT ON;
SELECT *
ОТ tblEmployeeDemo;
КОНЕЦ;
Выполните хранимую процедуру, и мы получим требуемый вывод без сообщения о количестве затронутых строк.
Настроить поведение NOCOUNT на уровне экземпляра
SET NOCOUNT ON работает на уровне сеанса.Нам нужно указывать это с каждой сессией. В хранимых процедурах мы указываем сам код. Следовательно, он не требует явного указания в сеансе.
Мы можем использовать опцию конфигурации sp_configure, чтобы использовать ее на уровне экземпляра. Следующий запрос устанавливает поведение SET NOCOUNT ON на уровне экземпляра.
EXEC sys.sp_configure ‘user options’, ‘512’; RECONFIGURE |
Если мы указываем NOCOUNT ON / OFF в отдельном сеансе, мы можем переопределить поведение, настроенное на уровне экземпляра.
SET NOCOUNT и функция @@ ROWCOUNT
Мы можем использовать функцию @@ ROWCOUNT, чтобы получить количество затронутых строк в SQL Server. Функция NOCOUNT ON не влияет на функцию @@ ROWCOUNT.
Выполните следующий запрос, и мы получим количество строк, затронутых оператором Insert.
TRUNCATE TABLE tblEmployeeDemo; GO USE [SQLShackDemo] GO SET NOCOUNT ON INSERT[dbo].[tblEmployeeDemo] ([Id], [EmpName], [Gender]) ЗНАЧЕНИЯ (1, N’Grace ‘, N’Female’), (2, N’Gordon ‘, N’Male’) Выбрать @@ ROWCOUNT как строка |
SET NOCOUNT ON и SQL Trigger
Давайте проверим влияние оператора NOCOUNT на триггеры SQL.
Следующая команда вставляет две записи в таблицу tblEmployeeDemo.
TRUNCATE TABLE tblEmployeeDemo; GO USE [SQLShackDemo] GO SET NOCOUNT ON INSERT[dbo].[tblEmployeeDemo] ([Id], [EmpName], [Gender]) ЗНАЧЕНИЯ (1, N’Grace ‘, N’Female’), (2, N’Gordon ‘, N’Male’) Выбрать @@ ROWCOUNT как строка |
Создайте другую таблицу для хранения записей записей транзакций, вставленных с использованием триггера.
CREATE TABLE Audit_tblEmployee (Обновлено ID INT, Обновлено значение NVARCHAR (10), Audit_Timestamp DATETIME default getdate () ); |
Давайте создадим SQL INSERT, триггер обновления, чтобы захватить записи для вставки, обновить значения.
CREATE TRIGGER TR_tblEmployeeDemo ON dbo.tblEmployeeDemo ПОСЛЕ ВСТАВКИ, ОБНОВЛЕНИЕ КАК НАЧАЛА ВСТАВИТЬ В Audit_tblEmployee iGID2000000000000000000000000000000050ОТ вставлено как я; КОНЕЦ; |
Выполните следующий запрос, чтобы обновить существующее значение в таблице tblEmployeeDemo, и он вызывает триггер SQL для вставки записи в таблицу Audit_tblEmployee.
Обновление tblEmployeeDemo set Пол = ‘Мужской’, где ID = 1 |
Оператор обновления обновляет только одну запись; однако в следующем сообщении SSMS оно показывает две затронутые строки.
Это может создать проблемы для нас, если дальнейший код зависит от количества строк, затронутых сообщением. Мы получаем это сообщение из-за обновления записи tblEmployeeDemo и вставки записи в таблицу Audit_tblEmployee.
Мы не хотим, чтобы результат «затронут 1 строка» для вставки данных в таблицу аудита. Мы должны использовать триггер с SET NOCOUNT ON для подавления этого сообщения.
Давайте изменим триггер с помощью следующего скрипта:
alter TRIGGER TR_tblEmployeeDemo ON dbo.tblEmployeeDemo ПОСЛЕ ВСТАВКИ, ОБНОВЛЕНИЕ AS НАЧАЛО НАСТРОЙКА INSERT ИСПОЛНЕНИЕ ИСПОЛН.ID,i.Gender ИЗ вставлен AS i; КОНЕЦ; |
Перезапустите оператор обновления, и мы получим ожидаемый результат и получим только количество затронутых строк, используя оператор обновления.
Влияние на производительность оператора NOCOUNT
Согласно документации Microsoft, использование опции NOCOUNT может обеспечить значительное улучшение производительности.
Давайте рассмотрим это преимущество в производительности на следующем примере.
Создайте две разные хранимые процедуры с разными свойствами NOCOUNT.
Выполните обе хранимые процедуры с различным числом строк 1000, 10000, 100000 и 1000000. Мы хотим получить статистику клиента для этих выполнений. В окне запроса SSMS перейдите в «Редактировать» и включите «Включить статистику клиента» .
Давайте сравним статистику клиента
с выключенным SET NOCOUNT
С SET NOCOUNT ON
Давайте соединим оба скриншота клиентской статистики, чтобы увидеть разницу
Мы видим огромную разницу в упаковщиках TDS, полученных от сервера, байтах, полученных от сервера, и времени обработки клиентом.Номер оператора select также показывает значительное улучшение. Мы не указали оператор Select в хранимой процедуре, но, тем не менее, SQL Server рассматривает оператор SET как оператор выбора со значением NOCOUNT по умолчанию. Мы можем уменьшить пропускную способность сети с помощью опции SET NOCOUNT ON в хранимых процедурах или инструкциях T-SQL. Это может существенно не повысить производительность запросов, но определенно влияет на время обработки, уменьшая пропускную способность сети и время обработки клиента.
Заключение
В этой статье мы исследовали поведение операторов T-SQL и хранимых процедур, используя SET NOCOUNT ON. Мы должны рассмотреть эту опцию SET и исключить ненужные сообщения, чтобы уменьшить сетевой трафик и повысить производительность.
Раджендра обладает более чем 8-летним опытом администрирования баз данных. Он увлечен оптимизацией производительности баз данных, мониторингом, технологиями высокой доступности и аварийного восстановления, изучением новых вещей, новых функций. Работая старшим консультантом DBA для крупных клиентов и пройдя сертификацию MCSA SQL 2012, он любит делиться знаниями в различных блогах.
С ним можно связаться по адресу [email protected]
Просмотреть все сообщения Раджендра Гупта
Последние сообщения Раджендра Гупта (посмотреть все) ,ОператорCASE в SQL
Оператор case в SQL возвращает значение по указанному условию. Мы можем использовать оператор Case в запросах выбора вместе с предложениями Where, Order By и Group By. Он также может быть использован в операторе вставки. В этой статье мы рассмотрим оператор CASE и различные варианты его использования.
Предположим, у вас есть таблица, в которой хранится ProductID для всех продуктов в мини-магазине. Вы хотите получить Productname для определенного ProductID.
Посмотрите на следующий пример; Мы объявили переменную @ProductID и указали для нее значение 1. В заявлении Case мы определили условия. Как только условие выполнено, возвращается соответствующее ему значение.
Точно так же, если мы изменим условие в операторе Case в SQL, оно возвращает соответствующее выражение. В следующем примере мы хотим получить имя продукта для ProductID 4. оно не удовлетворяет условию оператора Case; следовательно, это дало вывод из выражения Else.
Давайте рассмотрим несколько примеров оператора Case в SQL. Прежде чем мы продолжим, создайте образец таблицы и вставьте в нее несколько записей.
1 2 3 4 5 6 7 8 9 10 11 12 13 140003 160003 14000000 18 19 20 21 22 23 24 25 26 27 28 9 000 3435 36 37 | USE [SQLShackDemo] GO CREATE TABLE dbo.EmployeeID ( EmployeeID INT IDENTITY PRIMARY KEY, EmployeeName VARCHAR (100) NOT NULL, Пол VARCHAR (1) NOT NULL, StateCode VARCHAR (20) NOT NULL, ) GO ИСПОЛЬЗОВАНИЕ [SQLShackDemo] GO SET IDENTITY_INSERT [dbo]. [Employee] ON GO INSERT [dbo]. [Employee] ([EmployeeID], [EmployeeID], Employee ], [StateCode], [Salary]) VALUES (201, N’Jerome ‘, N’M’, N’FL ‘, 83000.0000) GO INSERT [dbo]. [Employee] ([EmployeeID], [EmployeeName], [Gender], [StateCode], [Salary]) ЗНАЧЕНИЯ (202, N’Ray ‘, N’M’, N’AL ‘, 88000.0000) GO INSERT [dbo]. [Employee] ([EmployeeID], [EmployeeName], [Gender], [StateCode], [Salary]) VALUES (203, N’Stella’, N’F ‘, N’AL’, 76000.0000) GO INSERT [dbo]. [Employee] ([EmployeeID], [EmployeeName], [Gender], [StateCode], [Salary]) VALUES (204, N’Gilbert ‘, N’M’, N’Ar ‘, 42000.0000) GO INSERT [dbo].[Employee] ([EmployeeID], [EmployeeName], [Gender], [StateCode], [Salary]) ЗНАЧЕНИЯ (205, N’Edward ‘, N’M’, N’FL ‘, 93000.0000) GO INSERT [dbo]. [Employee] ([EmployeeID], [EmployeeName], [Gender], [StateCode], [Salary]) ЗНАЧЕНИЯ (206, N’Ernest ‘, N’F’, N’Al ‘, 64000.0000) GO INSERT [dbo]. [Employee] ([EmployeeID], [EmployeeName], [Gender], [StateCode], [Salary]) ЗНАЧЕНИЯ (207, N’Jorge ‘, N’F’, N ‘ IN ‘, 75000.0000) GO INSERT [dbo]. [Employee] ([EmployeeID], [EmployeeName], [Gender], [StateCode], [Salary]) ЗНАЧЕНИЯ (208, N’Nicholas’, N ‘ F ‘, N’Ge’, 71000.0000) GO INSERT [dbo]. [Employee] ([EmployeeID], [EmployeeName], [Gender], [StateCode], [Salary]) ЗНАЧЕНИЯ (209, N’Lawrence ‘, N’M’, N’IN ‘, 95000.0000) GO INSERT [dbo]. [Employee] ([EmployeeID], [EmployeeName], [Gender], [StateCode], [Salary]) VALUES (210, N’Salvador’), N’M ‘, N’Co’, 75000.0000) GO SET IDENTITY_INSERT [dbo]. [Сотрудник] OFF GO |
У нас есть следующие записи в таблице сотрудников.
Различные форматы операторов CASE
Простое выражение оператора CASE
В этом формате мы оцениваем одно выражение по нескольким значениям. В простом утверждении case он оценивает условия одно за другим. Как только условие и выражение совпадают, возвращается выражение, упомянутое в предложении THEN.
У нас есть следующий синтаксис для оператора case в SQL с простым выражением
SELECT CASE Выражение Когда выражение1 затем результат1 Когда выражение2 затем результат2 … ELSE Результат END |
Обычно мы храним сокращения в таблице вместо ее полной формы. Например, в моей таблице Employee я использовал сокращения в Gender и StateCode. Я хочу использовать оператор Case для возврата значений Мужской и Женский на выходе вместо M и F .
Выполните следующий код и обратите внимание, что мы хотим оценить CASE Gender в этом запросе.
На следующем рисунке вы можете заметить разницу в выводе, используя оператор Case в SQL.
Оператор CASE и оператор сравнения
В этом формате оператора CASE в SQL мы можем оценить условие, используя операторы сравнения. Как только это условие выполнено, мы получаем выражение из соответствующего THEN в выводе.
Мы можем увидеть следующий синтаксис для оператора Case с оператором сравнения.
CASE WHEN ComparsionCondition THEN результат WHEN ComparsionCondition THEN результат ELSE прочее END |
Предположим, у нас есть диапазон зарплаты для каждого назначения. Если зарплата сотрудника находится между определенным диапазоном, мы хотим получить обозначение с помощью оператора Case.
В следующем запросе мы используем оператор сравнения и вычисляем выражение.
Выберите имя сотрудника, ПРИМЕР КОГДА Зарплата> = 80000 И ИСПОЛНЕНИЕ <= 100000 ТО «Директор» КОГДА Зарплата> = 50000 И зарплата <80000 ТО «Старший консультант» Остальное «Директор» END AS Обозначение от сотрудника |
На следующем изображении мы видим обозначение согласно условию, указанному в инструкции CASE.
Заявление о ситуации с приказом по пункту
Мы также можем использовать оператор Case с order by claus. В SQL мы используем предложение Order By для сортировки результатов в порядке возрастания или убывания.
Предположим, в следующем примере; Мы хотим отсортировать результат следующим способом.
- Для работницы зарплата должна быть в порядке убывания
- Для работника мужского пола, мы должны получать зарплату работника в порядке возрастания
Мы можем определить это условие с помощью комбинации Order by и Case.В следующем запросе вы можете видеть, что мы указали Order By и Case вместе. Мы определили условия сортировки в выражении case.
Выберите EmployeeName, Пол, Заработная плата от Сотрудника ЗАКАЗАТЬ ПО СЛУЧАЮ Пол КОГДА ‘F’ THEN Окончание зарплаты DESC, Дело, КОГДА Пол = М ‘THEN Зарплата END |
На выходе мы выполнили наше требование сортировки в порядке возрастания или убывания
- Для работницы зарплата отображается в порядке убывания
- Для работника мужского пола зарплата появляется в порядке возрастания
Case Case в SQL с группировкой по пункту
Мы также можем использовать оператор Case с предложением Group By.Предположим, мы хотим сгруппировать сотрудников по их зарплате. Далее мы хотим рассчитать минимальную и максимальную зарплату для определенного круга сотрудников.
В следующем запросе вы можете видеть, что у нас есть предложение Group By, и оно содержит i с условием получения требуемого вывода.
Выберите ПРИМЕР КОГДА Заработная плата> = 80000 И зарплата <= 100000 ТО «Директор» КОГДА Зарплата> = 50000 И зарплата <80000 ТО «Старший консультант» Остальное «Директор» END AS Обозначение, мин. (Зарплата) как минимальная зарплата, макс. (Зарплата) как максимальная зарплата от сотрудника группа по ДЕЛО КОГДА зарплата> = 80000 И зарплата <= 100000 ТО «Директор» КОГДА зарплата> 50000 AND Зарплата <80000 THEN «Старший консультант» Остальное «Директор» END |
У нас есть следующий вывод этого запроса.В этом выводе мы получаем минимальную и максимальную зарплату для определенного назначения.
Обновление оператора с оператором CASE
Мы также можем использовать оператор Case в SQL с обновлением DML. Предположим, мы хотим обновить Statecode сотрудников на основе условий выписки Case.
В следующем коде мы обновляем код состояния со следующим условием.
- Если код штата сотрудника — AR, , тогда обновите до FL
- Если код штата сотрудника GE, , тогда обновите до AL
- Для всех остальных кодов состояния обновите значение до IN
Выполните следующую команду обновления, чтобы выполнить наше требование, используя оператор Case.
ОБНОВЛЕНИЕ сотрудника SET StateCode = CASE StateCode КОГДА ‘Ar’ THEN ‘FL’ ЕСЛИ ‘GE’ THEN ‘AL’ ELSE ‘IN’ END |
В следующем выводе вы можете увидеть старый Statcode (слева) и обновленный Statecode для сотрудников на основе наших условий в инструкции Case.
Вставить выписку с выпиской CASE
Мы также можем вставить данные в таблицы SQL с помощью оператора Case в SQL.Предположим, у нас есть приложение, которое вставляет данные в таблицу Employees. Мы получаем следующие значения для пола.
Значение | Описание | Обязательное значение в таблице сотрудников |
0 | Мужской работник | M |
| 9952 1 0002 9952 9952 9952 9952 9952 9952 9952 9952 9952 9952 9952 9952 9952 9952 9952 9952 9952 9952 9952 Сотрудник | F |
Мы не хотим вставлять значения 0 и 1 для сотрудников мужского и женского пола.Нам нужно ввести необходимые значения M и F для пола сотрудника.
В следующем запросе мы указали переменные для хранения значений столбцов. В операторе вставки вы можете использовать оператор Case, чтобы определить соответствующее значение для вставки в таблицу сотрудников. В операторе Case он проверяет необходимые значения и вставляет в таблицу значения из выражения THEN .
1 2 3 4 5 6 7 8 9 10 11 12 13 140003 160003 14000000 18 | Объявление @EmployeeName varchar (100) Объявление @Gender int Объявление @Statecode char (2) Объявление @ зарплаты Set @ EmployeeName = ‘Raj’ Set @ Gender = 0 Код штата = ‘FL’ set @ salary = 52000 Вставить в сотрудника значения (@EmployeeName, CASE @Gender КОГДА 0 TH ‘M’ WHEN 1 THEN ‘F’ end , @Statecode, @salary) |
На следующем скриншоте мы видим, что вновь вставленная строка содержит пол M вместо значения 0.
Ограничения выписки по делу
- Мы не можем контролировать поток выполнения хранимых процедур, функций, используя оператор Case в SQL
- У нас может быть несколько условий в выражении Case; однако, это работает в последовательной модели. Если выполняется одно условие, он прекращает проверку дальнейших условий
- Мы не можем использовать оператор Case для проверки значений NULL в таблице
Заключение
Оператор Case в SQL обеспечивает гибкость в написании t-SQL для запросов DDL и DML.Это также добавляет универсальность запросам SQL Server. Вы должны практиковать утверждение Case в своих запросах.
Раджендра обладает более чем 8-летним опытом администрирования баз данных. Он увлечен оптимизацией производительности баз данных, мониторингом, технологиями высокой доступности и аварийного восстановления, изучением новых вещей, новых функций. Работая старшим консультантом DBA для крупных клиентов и пройдя сертификацию MCSA SQL 2012, он любит делиться знаниями в различных блогах.
С ним можно связаться по адресу [email protected]
Просмотреть все сообщения от Rajendra Gupta
Последние сообщения от Rajendra Gupta (просмотреть все) ,SQL IF Введение оператора и обзор
В этой статье рассматривается полезная функция SQL IF Statement в SQL Server.
Введение
В реальной жизни мы принимаем решения исходя из условий. Например, посмотрите на следующие условия.
- Если я получу бонус за результат в этом году, я поеду на международные каникулы, или же я возьму отпуск внутри страны.
- Если погода станет хорошей, я планирую поехать на велосипеде, иначе я не буду
В этих примерах мы решаем согласно условиям.Например, если я получу бонус, то только я поеду на международные каникулы, иначе я поеду на домашние каникулы. Нам необходимо также включить эти решения на основе условий в логику программирования. SQL Server предоставляет возможность выполнять логику программирования в реальном времени с помощью оператора SQL IF.
Синтаксис
В следующем операторе SQL IF он вычисляет выражение и, если условие истинно, выполняет оператор, упомянутый в блоке IF, в противном случае выполняются операторы в предложении ELSE.
IF (Выражение) BEGIN — Если условие TRUE, выполнить следующий оператор True Statements; END ELSE BEGIN — если условие ложно, выполнить следующий оператор ложные утверждения END |
Мы можем понять SQL IF Statement, используя следующую блок-схему.
- Условие в выражении SQL IF должно возвращать логическое значение для оценки
- Мы также можем указать оператор Select в логическом выражении, но он должен заключаться в скобки
- Мы можем использовать BEGIN и END в операторе IF для идентификации блока оператора
- Условие ELSE необязательно для использования
Давайте рассмотрим SQL IF Statement, используя примеры.
Пример 1: оператор IF с числовым значением в логическом выражении
В следующем примере мы указали числовое значение в логическом выражении, которое всегда TRUE. Он печатает оператор для оператора If, потому что условие истинно.
IF (1 = 1) PRINT ‘Выполнен оператор, поскольку условие TRUE’; ELSE PRINT ‘Выполнен оператор, поскольку условие равно FALSE’; |
Если мы изменим условие в логическом выражении, чтобы оно возвращало FALSE, оно напечатает инструкцию внутри ELSE.
IF (2 <= 0) PRINT ‘Выполнен оператор, поскольку условие TRUE’; ELSE PRINT ‘Выполнен оператор, поскольку условие равно FALSE’; |
Пример 2: оператор IF с переменной в логическом выражении
В следующем примере мы используем переменную в логическом выражении для выполнения инструкции на основе условия.Например, если студент набрал более 80% оценок, он сдает экзамен, в противном случае он не сдал экзамен.
ОБЪЯВИТЬ @StudentMarks INT = 91; IF @StudentMarks> = 80 PRINT ‘Passed, Поздравляем !!’; ELSE ПЕЧАТЬ ‘Ошибка, попробуйте еще раз’; |
Пример 3. Несколько операторов IF с переменной в логическом выражении
Мы можем указать несколько операторов SQL IF и выполнить оператор соответствующим образом.Посмотрите на следующий пример
- Если студент получает более 90% оценок, он должен отобразить сообщение из первого утверждения IF
- Если студент получает более 80% оценок, он должен отобразить сообщение из второго утверждения IF
- В противном случае он должен напечатать сообщение, указанное в выражении ELSE.
ОБЪЯВИТЬ @StudentMarks INT = 91; IF @StudentMarks> = 90 PRINT ‘Поздравляем, вы в списке заслуг !!’; IF @StudentMarks> = 80 PRINT ‘Поздравляем, вы в списке первого дивизиона !!’; ELSE ПЕЧАТЬ ‘Ошибка, попробуйте еще раз’; |
В этом примере оценки ученика 91% удовлетворяют условиям для обоих операторов SQL IF, и он печатает сообщение для обоих операторов SQL IF.
Мы не хотим, чтобы условие удовлетворяло обоим операторам SQL IF. Мы должны определить условие соответствующим образом.
ОБЪЯВИТЬ @StudentMarks INT = 91; IF @StudentMarks> = 90 PRINT ‘Поздравляем, вы в списке заслуг !!’; IF @StudentMarks> = 80 и @StudentMarks <90 ПЕЧАТЬ ‘Поздравляем, вы в списке первого подразделения !!’; ELSE ПЕЧАТЬ ‘Ошибка, попробуйте еще раз’; |
На следующем снимке экрана мы видим, что второе условие ЕСЛИ равно ИСТИНА, если оценки учеников больше или равны 80% и меньше 90%.
На выходе мы видим следующее
- Во-первых, условие оператора IF ИСТИНА. Он печатает сообщение внутри блока оператора IF
- Во-вторых, условие оператора IF — FALSE, оно не печатает сообщение внутри блока оператора IF.
- Он выполняет оператор ELSE и печатает для него сообщение. В этом случае у нас есть два оператора SQL IF. Второй оператор IF оценивается как ложный, поэтому он выполняет соответствующий оператор ELSE
Мы должны быть осторожны при указании условий в множественном операторе SQL IF.Мы можем получить неожиданный набор результатов без правильного использования оператора SQL IF.
Пример 4: оператор IF без оператора ELSE
Выше мы указали, что утверждение Else необязательно для использования. Мы также можем использовать оператор SQL IF без ELSE.
Далее выражение оценивается как ИСТИНА; следовательно, он печатает сообщение.
ОБЪЯВИТЬ @StudentMarks INT = 95; IF @StudentMarks> = 90 PRINT ‘Поздравляем, вы в списке заслуг !!’; |
Если выражение оценивается как FALSE, оно не возвращает никакого вывода.Мы должны использовать инструкцию ELSE, чтобы, если оценка не TRUE, мы могли установить вывод по умолчанию.
Пример 5: оператор IF для выполнения сценариев
В приведенных выше примерах мы печатаем сообщение, если условие имеет значение ИСТИНА или ЛОЖЬ. Мы также можем захотеть выполнить сценарии, как только условие выполнено.
В следующем примере, если объем продаж превышает 100000000, он должен выбрать записи из таблицы SalesOrderDtails.
Если объем продаж меньше 100000000, он должен выбрать записи из таблицы SalesOrderHeader.
ОБЪЯВИТЬ @sales INT; SELECT @sales = SUM (OrderQty * UnitPrice) ОТ [AdventureWorks2017]. [Sales]. [SalesOrderDetail]; IF @sales> 100000000 SELECT * FROM [AdventureWorks2017]. [Sales]. [SalesOrderDetail]; ELSE SELECT * ОТ [AdventureWorks2017].[Продажи] [SalesOrderHeader]. |
Пример 6: ЕСЛИ с блоком BEGIN и END
Мы можем использовать блок операторов BEGIN и END в операторе SQL IF. Как только условие выполнено, он выполняет код внутри соответствующего блока BEGIN и End.
ОБЪЯВИТЬ @StudentMarks INT = 70; IF @StudentMarks> = 90 НАЧАЛО ПЕЧАТЬ ‘Поздравляем, вы в списке заслуг !!’; КОНЕЦ; ELSE НАЧАЛО ПЕЧАТЬ ‘Failed, Try again’; КОНЕЦ; |
Мы также можем указать несколько операторов с помощью оператора SQL IF и блоков BEGIN END.В следующем запросе мы хотим напечатать сообщение из двух операторов print после выполнения условия.
- Примечание : У нас должен быть оператор END с соответствующим блоком BEGIN.
ОБЪЯВИТЬ @StudentMarks INT = 70; IF @StudentMarks> = 90 НАЧАЛО ПЕЧАТЬ ‘Поздравляем, вы в списке заслуг !!’; Распечатать ‘Второе утверждение.’ КОНЕЦ; ELSE НАЧАЛО ПЕЧАТЬ ‘Failed, Try again’; Распечатать «Второе заявление ELSE» END; |
Заключение
В этой статье мы рассмотрели оператор SQL IF и его использование на примерах. Мы можем написать код, основанный на условиях в реальном времени, используя операторы SQL IF. Если у вас есть комментарии или вопросы, не стесняйтесь оставлять их в комментариях ниже.
Раджендра обладает более чем 8-летним опытом администрирования баз данных. Он увлечен оптимизацией производительности баз данных, мониторингом, технологиями высокой доступности и аварийного восстановления, изучением новых вещей, новых функций. Работая старшим консультантом DBA для крупных клиентов и пройдя сертификацию MCSA SQL 2012, он любит делиться знаниями в различных блогах.
С ним можно связаться по адресу [email protected]
Посмотреть все сообщения Раджендра Гупта
Последние сообщения Раджендра Гупта (посмотреть все) ,