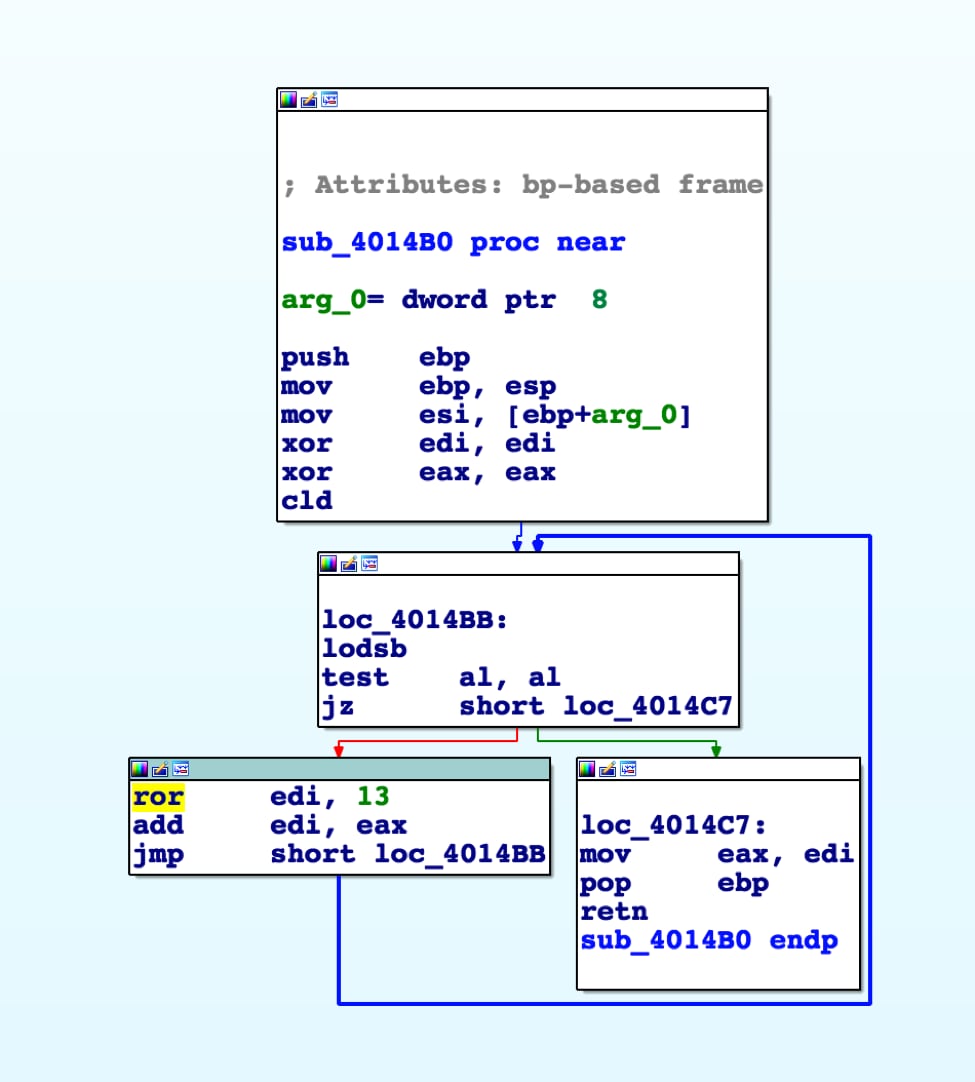
Команды управления циклами (loop, loope, loopz, loopne, loopnz) имеют следующие форматы в мнемонике ассемблера:
LOOP disp,
LOOPE disp,
LOOPZ disp,
LOOPNE disp,
LOOPNZ disp,
где disp – адресное выражение типа метки с атрибутом NEAR, значение которого лежит в интервале от –128 до 127 от адреса следующей за циклом команды.
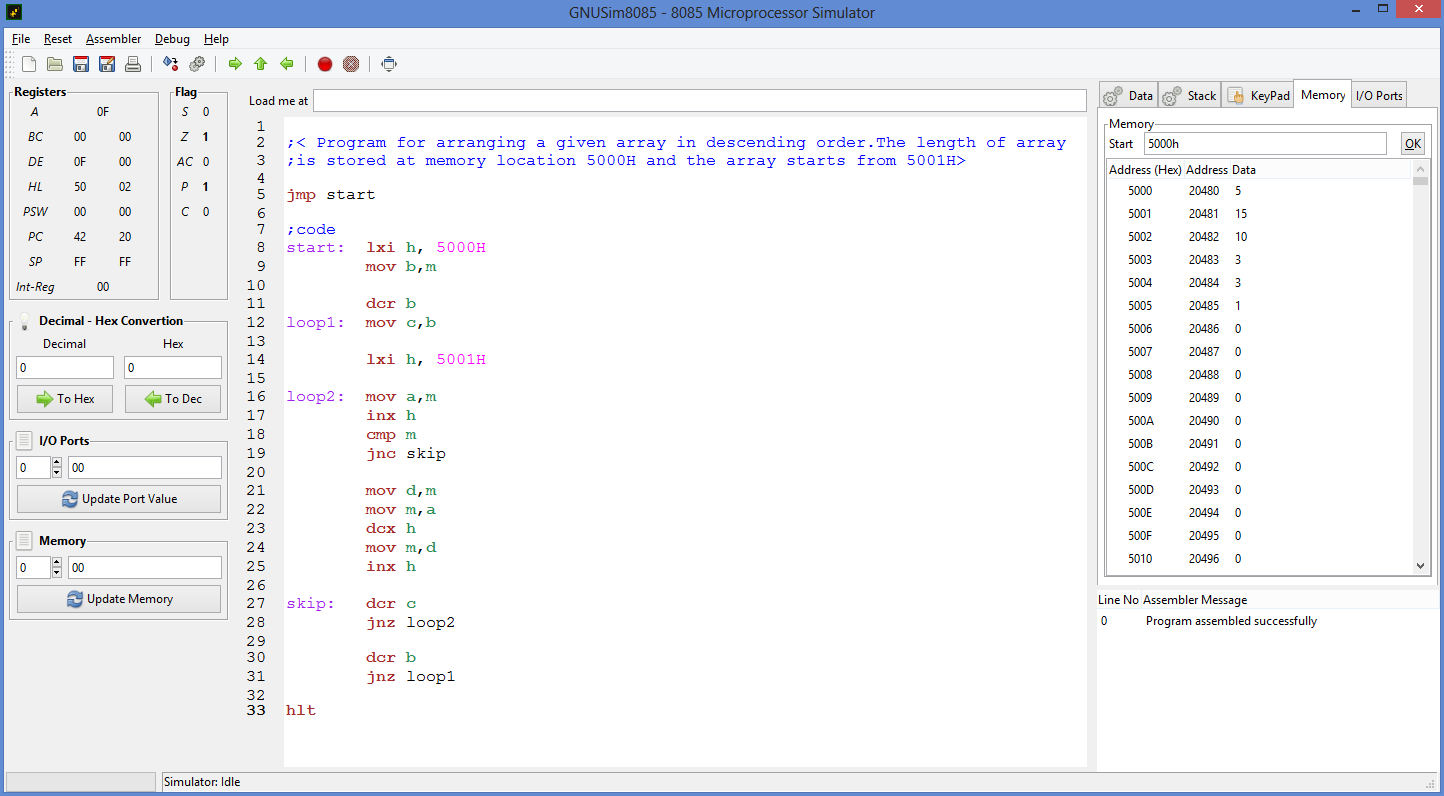
Все эти команды декрементируют значение
регистра CX. Если после
этого значение CX не
равно нулю, то LOOP передает управление по адресу своего
операнда. Эквивалентные друг другу
команды LOOPE и LOOPZ передают управление по адресу своего
операнда, если CX не
равно нулю и значение флага ZF равно 1. Эквивалентные друг другу команды LOOPNE и LOOPNZ передают управление по адресу своего
операнда, если CX не
равно нулю и ZF = 0. Эти
действия позволяют легко реализовать
цикл с заданным количеством повторений,
которое задается в CX.
Эти
действия позволяют легко реализовать
цикл с заданным количеством повторений,
которое задается в CX.
Команды управления циклами имеют следующий формат машинных кодов:
LOOP: | 11100010 | disp |
LOOPE/LOOPZ: | 11100001 | disp |
LOOPNE/LOOPNZ: | 11100000 | disp |
Примеры использования команд управления циклами:
; Пример 1: вычисление суммы элементов массива из 10 байт | ||
XOR AX,AX | ; обнуление суммы | |
XOR SI,SI | ; обнуление индекса | |
MOV CX,0Ah | ; загрузка количества элементов | |
NEXT: | ; начало цикла | |
ADD AL, [SI + 20] | ; сложение очередного элемента с | |
ADC AH,0 | ; учет возможного переноса | |
INC SI | ; увеличение индекса | |
LOOP NEXT | ; возврат в цикл, ; если массив не исчерпан | |
; Пример 2: поиск первого ненулевого элемента в массиве из 10 байт | ||
MOV SI, -1 | ; установить значение индекса | |
MOV CX, 0Ah | ; установить количество элементов | |
NEXT: | ; начало цикла | |
INC SI | ; увеличить индекс | |
CMP [SI + 20], 0 | ; сравнить текущий элемент с нулем | |
LOOPE NEXT | ; возврат в цикл, ; если элемент не найден и массив еще ; не исчерпан | |
JNE YES | ; если элемент найден, то переход ; к метке YES | |
. | ; действия, если элемент не найден | |
… | ; массив содержит только нули | |
JMP short END | ; переход к метке END | |
YES: | … | ; действия, если элемент найден |
… | ; SI указывает на ненулевой элемент | |
END: | … | ; завершающие действия |
; Пример 3: поиск заданного значения в массиве из 10 байт | ||
MOV AL, 5Dh | ; загрузить искомое значение | |
MOV SI, -1 | ; установить значение индекса | |
MOV CX, 0Ah | ; установить количество элементов | |
NEXT: | ; начало цикла | |
INC SI | ; увеличить индекс | |
CMP [SI + 20], AL | ; сравнить текущий элемент ; с искомым значением | |
LOOPNE NEXT | ; возврат в цикл, ; если элемент не найден ; и массив еще не исчерпан | |
JCXZ NO | ; если элемент не найден, то переход ; к метке NO | |
. | ; действия, если элемент найден. | |
… | ; SI указывает на этот элемент | |
NO: | JMP short END | ; переход к метке END |
… | ; действия, если элемент не найден | |
END: | … | ; завершающие действия |
 ..
.. ..
..СОДЕРЖАНИЕ РАБОТЫ
1. Ознакомиться с теоретическим материалом.
2. С помощью программы debug
исследовать выполнение всех арифметических
команд с любым возможным типом их
операндов.
3. В соответствии со своим вариантом решить поставленные задачи и с помощью DEBUG установить правильность их решения.
Флаги, переходы, макрокоманды условий, циклы, битовые операции, стек, подпрограммы, сдвиги в MASM
1. ЭВМ и Периферийные устройства
2. Вопрос с флагами
Пусть мы работает с 8-битныи операндом. Например, мы работает сAL
OF ( Overflow Flag, флаг переполнения) срабатывает если результат
слишком велик для помещения в 8-битный операнд. То есть:
• Сумма двух положительных знаковых превышает 127;
• Разность двух знаковых отрицательных операндов меньше -128.
CF (Carry Flag, флаг переноса) срабатывает если сумма двух
беззнаковых операндов превышает 255;
SF (Sign Flag, флаг переноса) срабатывает, если результат
становится меньше нуля
Естественно, это просто пример для 8 битных операндов. Для 16
битных и далее логика будет той же, только допустимые размеры
изменятся.
3. Программа на Ассемблере под Win32
. 386
386.model flat,stdcall ; плоская модель памяти, соглашение о вызове процедур
option casemap:none ; регистр команд неважен
;набор подключаемых библиотек
include \masm32\include\windows.inc
include \masm32\include\kernel32.inc
include \masm32\include\user32.inc
includelib \masm32\lib\kernel32.lib
includelib \masm32\lib\user32.lib
.data
dig dd 123456890d
MsgBoxCaption db «Программа»,0 ; заголовок она сообщения
MsgBoxText
db “HELLO WORLD!»,0
ifrmt db «%d», 0
buf db ?
.code
start: ; стартовая метка. Она должна присутствовать
invoke MessageBox, NULL, ADDR MsgBoxText, ADDR MsgBoxCaption, MB_OK; Выводим HELLO WORLD
invoke wsprintf, ADDR buf, ADDR ifrmt, dig ; перевод числа dig в строку и помещение её в buf
invoke MessageBox, NULL, ADDR buf, ADDR MsgBoxCaption, MB_OK; выводим число 1234567890
invoke ExitProcess, NULL; Завершить процесс
end start ; конец программы
4. ExitProcess
Завершает работы программы с кодом результата.
invoke ExitProcess, код_результата_работы_in
5. MessageBox
Показывает информационной сообщение.invoke MessageBox,
дескриптор_родительского_окна_in,
адрес_текста_in,
адрест_текста_заголовка_in,
константа_обозначающая_набор_кнопок_окна_in
6. wsprintf
Преобразует число в строку.invoke wsprint,
адрес_результирующей_строки_out,
адрес_формата_строки_in,
Число1_in,число 2_in, …
Некоторые варианты формата:
• %d или %i – знаковый целый;
• %u – без знаковый целый.
7. Программа на Ассемблере под Win32 (консоль)
.386…
BSIZE equ 14 ; заводим псевдооператор . BSIZE заменится 14
.data
helloworld db «HELLO WORLD!»,13,10
ifrmt db «%d», 0
dig dd 123456890d
stdout dd ? ; поместим туда дескриптор консоли
cWritten dd ? ; Будет хранить количество выведенных на экран символов
buf db BSIZE dup (?)
.code
start:
invoke GetStdHandle, STD_OUTPUT_HANDLE ; Получить дескриптор для вывода данных и поместить его в eax
mov stdout,eax ; stdout= значение eax
invoke WriteConsole, stdout, ADDR helloworld, SIZEOF helloworld, ADDR cWritten, NULL
invoke wsprintf, ADDR buf, ADDR ifrmt, dig ; перевод числа dig в строку
invoke WriteConsole, stdout, ADDR buf, SIZEOF buf, ADDR cWritten, NULL ; Теперь выводим число
invoke Sleep, 3000d ; Пауза на 3 сек
invoke ExitProcess, NULL; Завершить процесс
end start
8.
 WriteConsoleПишет строку в консоль.
WriteConsoleПишет строку в консоль.invoke WriteConsole,
декскриптор_устройства_вывода_in, адрес_сообщения_in,
размер_сообщения_in,
адрес_колличества_выведеных_символов_out,
зарезервировано
9. GetStdHandle
Получает дескриптор стандартного устройства и помещает его в EAXinvoke GetStdHandle, константа_номера_стандартного_устройства_in
Вместо константы номера стандартного устройства можно использовать
обычное число. Для консоли это -11. Или STD_OUTPUT_HANDLE
10. «equ» или «=»
Эти псевдооператоры предназначен для присвоения некоторомувыражению символического имени или идентификатора.
Впоследствии, когда в ходе трансляции этот идентификатор
встретится в теле программы, ассемблер подставит вместо него
соответствующее выражение.
Иными словами это просто что-то вроде автозамены.
имя_идентификатора
equ
строка или числовое_выражение
имя_идентификатора
=
строка или числовое_выражение
11.
 «equ» или «=»Псевдооператор “=” удобно использовать для определения
«equ» или «=»Псевдооператор “=” удобно использовать для определенияпростых абсолютных (то есть не зависящих от места загрузки
программы в память) математических выражений.
Главное условие то, чтобы транслятор мог вычислить эти
выражения во время трансляции.
.data
adr1 db 5 dup (0)
adr2 dw 0
len = 43
len = len+1 ;можно и так, через предыдущее определение len = adr2-adr1
Ещё раз подчёркиваю – это автозамена ещё на этапе трансляции.
12. Обмен данными XCHG
Команда XCHG меняет значения регистров или регистров ипамяти:
mov eax , 237h
mov ecx, 978h
xchg eax, ecx
В результате
eax = 978h
ecx = 237h
13. Переходы (прыжки)
Условный переход это такая команда процессору, при которой взависимости от состояния регистра флагов производится
передача управления по некоторому адресу иначе говоря прыжок.
Этот адрес может быть ближним или дальним. Прыжок считается
ближним, если адрес, на который делается прыжок, находится не
дальше чем 128 байт назад и 127 байт вперёд от следующей
команды.

Дальний прыжок это прыжок дальше, чем на [-128,127] байт.
14. Безусловный переход jmp
jmp – команда прыжка к указанной метке. Не трогает стек в отличии отcall. Может осуществлять и коротки и длинные прыжки.
jmp метка
start:
jmp metka1
invoke ExitProcess, NULL; Сюда не попадёт
metka1: ; попадёт сюда
mov ax,77d
invoke ExitProcess, NULL;
end start
Проще говоря, это аналог GOTO.
15. Условные переходы. cmp.
cmp – команда сравнения двух операндов.cmp операнд1, операнд2
Выставляет флаги в зависимости от результата. Фактически вычитает
операнд1 из операнда2 . В этот момент, естественно, выставляются
флаги.
Замечу, что один из операндов запросто можно сделать 0 для ряда
целей.
16. Условные переходы. cmp + je…
КодРеальное
команды условие
JA
JAE
JNC
JB
JC
JBE
CF=0 и
ZF=0
Условие для CMP
Код
Реальное
команды условие
если выше
CF=0
если выше или равно
если нет переноса
CF=1
если ниже
если перенос
Условие для CMP
JG
ZF=0 и
SF=OF
если больше
JGE
SF=OF
если больше или равно
JL
CF=1 или
если ниже или равно
ZF=1
JLE
SF<>OF если меньше
ZF=1 или
если меньше или равно
SF<>OF
JE
JZ
ZF=1
если равно
если ноль
JNE
JNZ
ZF=0
если не равно
если не ноль
JO
OF=1
если есть переполнение
JNO
OF=0
если нет переполнения
JS
SF=1
если есть знак
SF=0
если нет знака
PF=1
если есть четность
JNS
JP
JNP
PF=0
если нет четности
Пример.
 Прыжок на metka произойдет если eax=777h:
Прыжок на metka произойдет если eax=777h:cmp eax, 777h
jz metka
Условные переходы могут делать только ближний прыжок.
17. Макрокоманды условного оператора.
В MASM существуют макроскрипты, упрощающие написание условий.IF eax==1
;eax равен 1
.ELSEIF eax==3
; eax равен 3
.ELSE
; eax не равен 1 и 3
.ENDIF
Эта конструкция очень полезна. Вам не нужно вставлять сравнения и
переходы, а только вставьте директиву .IF (не забудьте точку
перед .IF и .ELSE и т.д.). Директива .ENDIF нужна для определения ещё
одного сравнения, если предыдущие сравнения были ложными.
Инструкции после директивы .ELSE выполняются только в том случае,
если все сравнения были ложными.
18. Макрокоманды условного оператора.
Также доступна вложенность:.IF eax==1
.IF ecx!=2
; eax= 1 и ecx не равно 2
.ENDIF
.ENDIF
Доступны также привычные вам логические операторы. Вышенаписанное,
например, можно записать как:
.
 IF (eax==1 && ecx!=2)
IF (eax==1 && ecx!=2); eax = 1 и ecx не равно 2
.ENDIF
Подчеркиваю, что это не команды ассемблера, а макрокоманды, которые
впоследствии раскладываются на команды ассемблера. Важно помнить об
этом.
19. Макрокоманды условного оператора.
==равно
!=
не равно
>
больше
<
меньше
>=
больше или равно
<=
меньше или равно
&
проверка бита
!
инверсия ( NOT )
&&
логическое ‘И’ ( AND )
||
логическое ‘ИЛИ’ ( OR )
CARRY?
флаг переноса (cf) установлен
OVERFLOW?
флаг переполнения (of) установлен
PARITY
флаг паритета (pf) установлен
SIGN?
флаг знака (sf) установлен
ZERO?
флаг нуля (zf) установлен
20. Организация циклов. loop
loop проверяет, равен ли регистр ECX нулю, еслион не равен нулю, то значение регистра ECX уменьшается на 1 и
совершается ближний прыжок на указанное смещение (или метку)
mov ecx, 023h
repeat:
…; обязательно ближнее расстояние
Loop repeat
Тело цикла выполнится 23h раза.

Команда loope делает то же самое, но перед прыжком проверяет,
установлен ли флаг ZF, если он установлен, то прыжок совершается.
Точно тоже самое делает команда loopz. Команды loopne и loopnz
делают то же самое что и loope, но прыгают, если флаг ZF сброшен.
21. Макрокоманды циклов.
.REPEAT — Эта конструкция выполняет блок, пока условие не истинно:.REPEAT
; код здесь
.UNTIL eax==1
Эта конструкция повторяет код между .REPEAT и .UNTIL, пока eax не
станет равным 1.
Вы можете использовать директиву .BREAK, чтобы прервать цикл и
выйти.
.WHILE edx==1
inc eax ; увеличивает eax на 1
.IF eax==7
.BREAK
.ENDIF
.ENDW
Если eax=7, цикл while будет прерван.
22. Логические битовые операции
Логические операции с битами — OR, XOR, AND, NOT. Эти командыработают с приемником (операнд1) и источником(операнд2),
исключение команда NOT (там только один операнд)
Каждый бит в приемнике сравнивается с тем же самым битом в
источнике, и в зависимости от команды, 0 или 1 помещается в
бит приемника:
23.
 Логические битовые операции. AND, ORAND (логическое И) устанавливает бит результата в 1, если оба бита,
Логические битовые операции. AND, ORAND (логическое И) устанавливает бит результата в 1, если оба бита,бит источника и бит приемника установлены в 1.
приемник
источник
результат
1010
1100
1000
OR (логическое ИЛИ) устанавливает бит результата в 1, если один из
битов, бит источника или бит приемника установлен в 1.
приемник
источник
результат
1010
1100
1110
24. Логические битовые операции. XOR, OR
XOR (НЕ ИЛИ) устанавливает бит результата в 1, если бит источникаотличается от бита приемника.
приемник
источник
результат
1010
1100
0110
NOT инвертирует бит источника.
приемник
результат
1010
0101
XOR позволяет быстро
обнулять что-либо
xor eax, eax ; eax=0
25. Логические битовые операции. Пример.
mov ax, 3406dmov dx, 13EAh
xor ax, dx
ax = 3406 (десятичное), в двоичном — 0000110101001110.
dx = 13EA (шестнадцатиричное), в двоичном — 0001001111101010.

Выполнение операции XOR на этими битами:
Приемник = 0000110101001110 (ax)
Источник = 0001001111101010 (dx)
Результат = 0001111010100100 (новое значение в ax)
26. Стек. push, pop
Процессор имеет аппаратную поддержку стека. При этом стек,хранится в оперативной памяти
push – поместить значение (2 или 4 байта) в стек
pop – достать значение из стека (2 или 4 байта)
push
Стек растёт в сторону уменьшения адресов памяти.
Значение, помещенное в стек последним,
извлекается первым.
Регистр ESP хранит адрес вершины стека.
Стек используется для хранения параметров процедур
И их локальных переменных.
Естественно, вы можете использовать стек в своих целях,
но вы отвечаете за его содержимое
pop
27. Стек. push
Пусть стек находится в следующем состоянии.(стек здесь заполнен нулями, но в действительности это не так, как
здесь). ESP стоит в том месте, на которое он указывает)
mov ax, 4560h
push ax
mov ax, 0FFFFh
push ax
28.
 Стек. popС момента предыдущего слайда стек находится в таком состоянии
Стек. popС момента предыдущего слайда стек находится в таком состоянииpop edx
edx теперь равно 4560FFFF
Обратите внимание, что команда pop не чистит стек
29. Подпрограммы. Call.
Процедуры задаются директивами proc и endp. Proc обозначаетначало процедуры, а endp конец процедуры. Вот пример
объявления
процедуры:
SomeProc proc
…ещё код…
Ret ; обязательно
SomeProc endp
Вызов процедуры
Call SomeProc
Параметры процедуры должны быть выложены в стек перед её
вызовом в обратном порядке.
30. Подпрограммы. Invoke.
Существует улучшенный способ вызова и задания процедур.Invoke <функция>, <параметр1>, <параметр2>, <параметр3>
Для этого нужно сначала объявить прототип:
PROTO STDCALL testproc :DWORD, :DWORD, :DWORD
STDCALL указывать необязательно. DWORD тип. Возможны
типы, например WORD, BYTE и т. д..
Вызов процедуры:
Invoke testproc, 1, 2, 3,
При этом ещё на этапе компиляции будут проверено количество
параметров и их тип.
31. Подпрограммы. 2 способа.
MyProc PROTO :DWORD,:DWORD.code
MySimpleProc proc
mov eax, dword ptr [esp+4]
mov ecx, dword ptr [esp+8]
ret
MySimpleProc endp
MyProc proc myparam1:DWORD, myparam2:DWORD
LOCAL var1:DWORD ; локальная переменная 1
LOCAL var2:BYTE,var3:WORD ; локальные переменные 2 и 3
mov eax,myparam1
mov ecx,myparam2
ret
MyProc endp
start:
xor eax,eax
xor ecx,ecx
push 2h
push 1h
call MySimpleProc
invoke MyProc ,1h,2h
invoke ExitProcess, NULL; Завершить процесс
end start
32. Сдвиги. Логический сдвиг.
Логический свдиг – новые биты заполняются нулями, ушедшиеисчезают.
SHL операнд, количество_сдвигов
SHR операнд, количество_сдвигов
SHL и SHR сдвигают биты операнда (регистр/память) влево или
вправо соответственно на один разряд:
; al =
01011011 (двоичное)
shr al, 3 ; al= 00001011
Это означает: сдвиг всех битов регистра al на 3 разряда вправо.

Так что al станет 00001011.
Биты слева заполняются нулями, а биты справа выдвигаются
(исчезают). Последний выдвинутый бит, становится значением
флага переноса CF.
Семейная вечеринка | 11. Дополнительная сборка: ветвление и циклы
« 10. Графика спрайтов 12. Практические циклы »
Содержание:
- Управление потоком в сборке
- Ветвление
- Обзор циклических/ветвящихся опкодов
- Другой пример ветвления
- Сравнивать
- Использование сравнений в циклах
В конце прошлой главы мы успешно нарисовали на экране один спрайт,
но для этого потребовалось большое количество кода. В этой главе мы узнаем некоторые новые
коды операций сборки, которые помогут нам отделить данные от логики и, как побочный эффект,
сделать наш код намного более эффективным и легким для чтения и анализа.
Управление потоком в сборке
За исключением JMP , все сборки, которые мы видели до сих пор
был полностью линейным: процессор считывает байт со следующего адреса памяти
и обрабатывает его, двигаясь от начала нашего ROM-файла к концу. Управление потоком относится к способности писать код, который может оценивать определенные условия и
изменить код, который будет выполняться следующим, в зависимости от результата. Для 6502 есть
две формы управления потоком. JMP «безусловный» прыжок в другую точку ПЗУ (никаких тестов или оценок не выполняется).
Другая форма управления потоком называется «ветвлением», потому что она выполняет тест
а затем переходит к одной из двух разных «ветвей» кода в зависимости от результата.
Регистр состояния процессора
Ключ к ветвлению является частью 6502, называемой регистром состояния процессора ,
часто упоминается как P . Регистр состояния, как и все остальные регистры 6502,
имеет размер восемь бит. В отличие от других регистров, регистр состояния напрямую не
доступны для программиста. Каждый раз, когда процессор выполняет операцию, статус
зарегистрируйте изменения, чтобы отразить результаты этой операции. Каждый бит в регистре состояния
дает информацию о конкретном аспекте последней операции.
В отличие от других регистров, регистр состояния напрямую не
доступны для программиста. Каждый раз, когда процессор выполняет операцию, статус
зарегистрируйте изменения, чтобы отразить результаты этой операции. Каждый бит в регистре состояния
дает информацию о конкретном аспекте последней операции.
Для наших целей два самых важных бита (или «флаги») регистра состояния процессора — это Z («ноль») и C («перенос») биты. Нулевой флаг установлен (1) если результат последней операции был равен нулю. Нулевой флаг очищается (0), если
результат последней операции был совсем не нулевой. Точно так же устанавливается флаг переноса
если результат последней операции вызвал «перенос», и очищается в противном случае.
Переноска
В то время как нулевой флаг не вызывает затруднений, флаг переноса требует некоторых дополнительных пояснений.
Рассмотрим, что произойдет, если мы сложим десятичные числа 13 и 29. Если бы мы выполнили это
сложение вручную, мы бы сначала добавили «3» из 13 к «9» из 29. Результат 12,
что слишком велико, чтобы уместиться в одну десятичную цифру. Итак, записываем цифру 2 и переносим на .
«1» в следующую колонку слева. Здесь мы складываем «1» из 13, «2» из 29.,
и «1», которую мы перенесли. Результат равен 4, который мы записываем под этой колонкой, для
всего 42.
Если бы мы выполнили это
сложение вручную, мы бы сначала добавили «3» из 13 к «9» из 29. Результат 12,
что слишком велико, чтобы уместиться в одну десятичную цифру. Итак, записываем цифру 2 и переносим на .
«1» в следующую колонку слева. Здесь мы складываем «1» из 13, «2» из 29.,
и «1», которую мы перенесли. Результат равен 4, который мы записываем под этой колонкой, для
всего 42.
Флаг переноса на 6502 выполняет ту же функцию, но для байтов. Операция сложения будет
привести к установке флага переноса, если результат сложения больше, чем может поместиться
в одном байте (т.е. если результат больше 255). Обычно мы будем использовать код операции, который
принудительно очищает флаг переноса перед выполнением добавления, чтобы избежать установки переноса
предыдущая операция сохраняется в текущем дополнении.⊕
Зачем вам сохранять предыдущий флаг переноса перед выполнением добавления? Не очистка флага переноса позволяет вам складывать многобайтовые числа, сначала
добавив младшие байты двух чисел и позволив этому добавлению установить перенос
флаг, если нужно. Когда вы добавляете следующие младшие байты двух чисел, флаг переноса
будут автоматически добавлены.
Когда вы добавляете следующие младшие байты двух чисел, флаг переноса
будут автоматически добавлены.
Вычитание работает аналогично сложению, за исключением того, что мы обычно устанавливаем флаг переноса перед выполнением вычитания. Операция вычитания приводит к переносу флаг очищается , если вычитаемое число больше, чем число, которое оно вычисляет. вычитается из. Например, если из 15 вычесть 17, получится -2. Это число меньше чем ноль, поэтому для выполнения вычитания нам нужно «позаимствовать» из следующего наименьшего столбец, используя флаг переноса, который мы установили перед началом вычитания.
Здесь важно отметить, что так же, как и одноразрядные десятичные числа, байты «переходят по кругу».
при добавлении за пределы 255 или вычитании за пределы нуля. Если байт (или регистр, или значение памяти)
в настоящее время 253, и вы добавляете 7, результат не 260 — это 4, с установленным флагом переноса.
Точно так же, если значение байта равно 4, и вы вычитаете 7, результат будет 253 с очищенным флагом переноса,
не -3.
Мы расскажем, как на самом деле выполнять сложение и вычитание, в следующей главе; на данный момент, все, что вам нужно знать, это то, что инструкции, которые выполняет процессор, изменят значения флагов нуля и переноса в регистре состояния процессора.
Разветвление
Теперь, когда вы знаете о регистре состояния процессора, мы можем использовать результаты операций для перехода к различным частям нашего кода. Самый простой способ использовать ветвление — построить цикл, который делает что-то 256 раз. В самом простом виде это выглядит так:
LDX #$00 Начало цикла: ; сделай что-нибудь ИНКС BNE LoopStart ; конец цикла
Прежде чем мы рассмотрим, как на самом деле работает цикл, давайте обсудим два новых опкода. INX означает «приращение X»; он добавляет единицу к значению регистра X
и сохраняет его обратно в регистр X. BNE означает «Ветвь, если не равно
на ноль»; он изменяет нормальный поток выполнения кода, если нулевой флаг в процессоре
регистр состояния очищается (т. е. результат последней операции не равен нулю).
е. результат последней операции не равен нулю).
Цикл начинается с загрузки непосредственного значения $00 в регистр X.
Далее у нас есть метка ( LoopStart ), которая будет использоваться нашим ответвлением.
инструкция в конце цикла. После лейбла мы делаем то, что мы
хотим, чтобы наш цикл выполнялся, тогда мы увеличиваем регистр X. Как и все, что связано с математикой
операции, это обновит флаги в регистре состояния процессора. Финал
строка цикла проверяет значение нулевого флага. Если установлен нулевой флаг, ничего
случается что-то особенное — программа просто продолжает работать, что бы ни происходило после ; конец цикла выполняется следующим. Если нулевой флаг снят, то BNE LoopStart указывает процессору найти LoopStart вместо этого пометить и выполнить все, что находится там дальше — другими словами,
выполнение следующей итерации цикла.
В реальной работе этот цикл будет выполняться 256 раз. На первой итерации цикла
значение регистра X равно нулю. После
На первой итерации цикла
значение регистра X равно нулю. После INX значение регистра X
это один. Так как результат INX не был нулем, флаг нуля будет
очищено. Когда мы доберемся до BNE LoopStart , поскольку нулевой флаг снят,
процессор вернется к метке LoopStart и запустит цикл
снова. На этот раз регистр X станет двойным, что все еще не равно нулю, и цикл
снова побежит. В конце концов, значение регистра X будет равно 255. Когда мы запустим INX на этот раз регистр X «обнулится» и будет установлен флаг переноса.
Обратите внимание, что в этом случае мы могли бы выполнить разветвление либо на основе нулевого флага,
или флаг переноса. Когда регистр X «переворачивается» с 255 на 0, оба
флаги нуля и переноса будут установлены.
Теперь, когда последняя операция привела к нулю, BNE LoopStart не будет
больше не будет запускаться, и процессор продолжит работу со всем, что следует после
петля.
Прежде чем мы двинемся дальше, следует отметить еще одну вещь. После запуска этого кода
через наш ассемблер и компоновщик все наши метки (например
После запуска этого кода
через наш ассемблер и компоновщик все наши метки (например LoopStart )
будут удалены и заменены реальными адресами памяти. Чтобы убедиться, что
ветки не занимают чрезмерное количество процессорного времени, данные, которые следуют
команда перехода — это не адрес памяти, а однобайтовое число со знаком, которое добавляется
на любой адрес памяти в программном счетчике. В результате код, который вы
к которому нужно перейти, должно быть менее 127 байт до или менее 128 байт после,
инструкция вашей ветки. Если вам нужно перейти к чему-то, что находится дальше,
вам нужно JMP вместо этого на этот ярлык. Это, наверное, не пойдет
быть обычным явлением, если только вы не пишете довольно сложный код, но
это интересная деталь реализации, которая может привести к сложному отслеживанию
ошибка где-то внизу.
Обзор циклических/ветвящихся опкодов
Мы уже видели INX и BNE , но это только два
кодов операций, которые вы, вероятно, будете использовать для создания циклов. Давайте посмотрим на
десять новых кодов операций, которые вы должны добавить в свой набор инструментов.
Давайте посмотрим на
десять новых кодов операций, которые вы должны добавить в свой набор инструментов.
Увеличение и уменьшение кодов операций
Эти коды операций позволяют прибавлять или вычитать на единицу в одном коде операции. Есть нет необходимости явно устанавливать или очищать флаг переноса перед использованием одного из этих кодов операций.
INX и INY добавит единицу («приращение») к X или Y
зарегистрироваться соответственно. В обратном направлении DEX и DEY вычитает единицу из регистра X или Y («уменьшает на единицу»).
Наконец, вы можете использовать INC и DEC для увеличения
или уменьшить содержимое адреса памяти. В качестве примера вы можете
используйте INC $05 , чтобы добавить единицу ко всему, что хранится по адресу памяти. $05 и сохранить результат обратно в $05 .
Все коды операций увеличения/уменьшения будут обновлять значения
ноль и несут флаги регистра состояния процессора.
Коды операций ветвления
Для каждого флага регистра состояния процессора существуют коды операций ветвления. У каждого флага есть два кода операции: один разветвляется, если флаг установлен, а другой который разветвляется, если флаг снят. Для наших целей единственным разветвлением коды операций, которые вам нужно будет использовать, проверьте значения флагов нуля и переноса.
BEQ («Перейти, если равно нулю») и BNE («Перейти, если
Not Equals zero») изменит поток программы, если установлен нулевой флаг.
установлен или очищен соответственно. BCS («Ветвь при переносе набора») и BCC («Ветвь, если перенос очищен») сделайте то же самое для флага переноса.
То, что следует за каждым кодом операции, обычно должно быть меткой для того, какой код должен
выполняться следующим, если выполняются условия кода операции ветвления.
Другой пример ветвления
Приведу еще один пример ветвления. На этот раз наша петля
будет выполняться восемь раз вместо 256.
LDY #$08 LoopTwo: ; сделай что-нибудь ДЭЙ BNE LoopTwo ; конец цикла
Как и в предыдущем примере цикла, здесь мы сначала устанавливаем предварительные условия
нашего цикла, установив для регистра Y значение $08 . Тогда у нас есть
метка, которую наш код операции ветвления будет использовать позже. После того, как мы сделали
независимо от того, что мы хотим, чтобы наш цикл делал на каждой итерации, мы уменьшаем
регистр Y, а затем вернуться к началу цикла, если флаг нуля
очищается.
В более современном C-подобном языке программирования (таком как JavaScript) все это цикл можно было бы переписать следующим образом:
для (y = 8; y != 0; y--) {
// сделай что-нибудь
}
Сравнение
Хотя циклы, которые мы видели до сих пор, полезны, они требуют тщательной настройки.
Циклы выше полагаются на то, что наш счетчик циклов становится равным нулю, чтобы завершить цикл.
Чтобы сделать более гибкие и мощные циклы, нам нужна возможность сделать
произвольные сравнения. В ассемблере 6502 опкоды, позволяющие это сделать
В ассемблере 6502 опкоды, позволяющие это сделать CMP , «Сравнить (с аккумулятором)», CPX , «Сравнить
с регистром X» и CPY , «Сравнить с регистром Y».
Каждый из этих кодов операций работает, выполняя вычитание, устанавливая ноль и переносить соответствующие флаги, а затем отбрасывать результат вычитание. Помните, что когда мы выполняем вычитание, мы сначала установить флаг переноса. Это означает, что у нас есть три возможных результата из сравнения на основе значения регистра и значения, которое мы сравниваем это до:
- Регистр больше значения для сравнения : Флаг переноса установлен, флаг нуля очищен
- Регистр равен значению сравнения : установлен флаг переноса, установлен нулевой флаг
- Регистр меньше значения для сравнения : Флаг переноса сброшен, флаг нуля сброшен
Мы можем использовать эту информацию для создания более сложной логики программы. Рассмотрим случай
где мы загружаем значение из памяти, а затем проверяем, больше ли оно, равно ли
или меньше 80 долларов .
LDA $06 CMP #$80 БЭК reg_was_80 БКС reg_gt_80 ; ни одна из ветвей не взята; регистрация менее $80 ; сделай что-нибудь здесь JMP done_with_comparison ; перейти, чтобы пропустить код конкретной ветки reg_was_80: ; регистр равнялся $80 ; сделай что-нибудь здесь JMP done_with_comparison ; пропустить следующую ветку reg_gt_80: ; регистр был больше $80 ; сделай что-нибудь здесь ; не нужно прыгать, потому что done_With_comparison идет следующим done_with_comparison: ; продолжить оставшуюся часть программы
Этот вид трехстороннего ответвления довольно распространен. Обратите внимание на наличие
метка, обозначающая конец всего кода ответвления, чтобы более ранний код
может JMP по коду конкретной ветки, который не должен быть
выполняется, если ветвь не была взята.
Использование сравнений в циклах
Чтобы закрыть эту главу, давайте посмотрим, как сравнения могут
использоваться для создания более сложных циклов. Вот такая петля
запускается восемь раз, но считает с нуля вместо подсчета
вниз с восьми.
Вот такая петля
запускается восемь раз, но считает с нуля вместо подсчета
вниз с восьми.
LDX #$00 цикл_старт: ; сделай что-нибудь ИНКС СРХ #$08 BNE loop_start ; цикл закончен здесь
Здесь мы устанавливаем регистр X в ноль перед запуском цикла. После каждого
цикл, мы увеличиваем регистр X, а затем сравниваем X с $08 . Если регистр X не равен восьми, ноль
флаг не будет установлен, и мы вернемся к loop_start .
В противном случае CPX установит нулевой флаг (поскольку восемь
минус восемь равно нулю), и цикл завершится.
Для обзора в этой главе мы изучили следующие коды операций:
-
INX -
ИНИ -
ИНК -
ДЕКС -
ДЕЙ -
ДЕК -
БНЭ -
БЭК -
КБК -
БКС -
СМР -
СРХ -
Копия
Это еще 13 опкодов, которые можно добавить в свой набор инструментов!
В следующей главе мы реорганизуем наш код, чтобы воспользоваться преимуществами
циклов и сравнений, при подготовке к созданию
фоновая графика.
« 10. Графика спрайтов 12. Практические циклы »
Если, циклы и инструкция DBRA
Если, циклы и инструкция DBRAЕСЛИ
Простой IF
а)ГЛЛ б) 68К
x:=x+1 ADDQ.W #1,X
ЕСЛИ A=7, ТО CMPI.W #7,A
Б:=3; БНЭ СЛЕДУЮЩИЙ
С:=4; МОВЭК #3,Б
КОНЕЦ, ЕСЛИ ДВИЖЕНИЕ #4,C
х:=Х+2; СЛЕДУЮЩИЙ:
ДОБАВИТЬQ.W #2,X
б) на ГВУ
ЕСЛИ Х=2, ТО КОД:=2;
КОД:=1; изменить на ЕСЛИ X=2 ТО
ДРУГОЙ КОД:=1;
КОД:=2; КОНЕЦ ЕСЛИ
КОНЕЦ ЕСЛИ
Это упрощает код.
в) ОБЩИЙ КОНТУР
ХЛЛ 68К
ЕСЛИ (I>GT> 0), ТО CMPI.W #0,I
КОД(A) ДРУГОЕ
ДРУГОЙ КОД(А)
КОД(B) БЮСТГАЛЬТЕР NEXT
КОНЕЦ, ЕСЛИ ЕЩЕ:
КОД(В)
СЛЕДУЮЩИЙ СЛЕДУЮЩИЙ:
г) Я никогда не хочу видеть:
ВЕЩИ
БЮСТГАЛЬТЕР NEXT заменить на NEXT:
СЛЕДУЮЩИЙ:
Вы хотите уменьшить количество веток, не ставя лишние.
Петли
В мире существует два типа циклов — циклы ПОВТОР и циклы ПОКА. Повторяющиеся циклы всегда выполняются один раз, что является редкостью для циклов. Вы должны
всегда проверяйте себя, чтобы увидеть, безопасно ли использовать повторяющийся цикл. Какое-то время
цикл может быть выполнен ноль раз и всегда безопасен и очень распространен в
программирование.
Вы должны
всегда проверяйте себя, чтобы увидеть, безопасно ли использовать повторяющийся цикл. Какое-то время
цикл может быть выполнен ноль раз и всегда безопасен и очень распространен в
программирование.ПОВТОР Циклы
а) Стандартный повторяющийся цикл
ПОВТОР: Чтение с часовым
JSR DECIN подходит для повторной петли.
ЦМП.В '-1',d0
ПОВТОР БНЭ
б) Общий цикл
Петля:
CODE(A) Так как CODE(A) всегда выполнял это
CMPI.W #0,I — повторяющийся цикл.
БЛТ СЛЕДУЮЩИЙ
КОД(В)
БЮСТГАЛЬТЕР
Пока Цикл
а) ОК ВЕРСИЯ б) Лучшая версия
ПРЕДЫДУЩИЙ КОД ПРЕДЫДУЩИЙ КОД
Петля: БЮСТГАЛЬТЕР CHECK
CMP --- ЦИКЛ:
BEQ ENDLOOP CODE(C)
ПРОВЕРКА КОД(С):
БЮСТГАЛЬТЕР LOOP CMP ---
КОНЕЦ ПЕТЛИ: BNE LOOP
СЛЕДУЮЩИЙ КОД СЛЕДУЮЩИЙ КОД
Некоторые общие сведения о циклах
- Большинство циклов проходят «высшее тестирование» (например, циклы WHILE в Pascal или С). Это верно в большинстве случаев.
- Условие цикла должно быть проверено перед выполнением тела
петли в первый раз, а не после.
 Это позволяет телу цикла
выполняться 0 раз, если это уместно. В некоторых случаях
цикл повторения до тех пор, пока цикл выбора.
Это позволяет телу цикла
выполняться 0 раз, если это уместно. В некоторых случаях
цикл повторения до тех пор, пока цикл выбора. - В языке ассемблера условный переход будет проверять условие цикла.
- Это не означает, что условная ветвь должна появляться в хотя начало цикла на ассемблере. Обычно это должно быть размещается внизу, и должна быть безусловная ветвь к нижней части цикла, чтобы начать. Иногда, если петля очень долго эта процедура не соблюдается.
- Какая разница?
- В первом внутри цикла есть две ветви.
- Во втором внутри цикла всего одна ветвь. Другой один находится вне цикла, где он выполняется только один раз, а не на каждой итерации.
- Особенно в современных конвейерных процессорах очень важно чтобы свести к минимуму количество ветвей и упростить структуру петель.
Инструкция DBRA 68000k
- Синтаксис инструкции dbra (уменьшение и переход) следующий:
дБ Ди, Адрес
- Эта инструкция уменьшает Di.
 w и переходит к Addr, если результат
не -1.
w и переходит к Addr, если результат
не -1. - Эквивалент следующих 3 инструкций
sub.w #1, Di cmp.w #-1, Di bne Адрес
- Это очень типичная инструкция CISC. В программе для RISC-машины вы бы использовали три отдельные инструкции.
- Его цель — упростить «циклы, контролируемые счетом». (Что то есть, если вы заранее точно знаете, сколько раз должен выполняться цикл, воспользуйтесь этой инструкцией.)
- Чтобы выполнить цикл ровно N раз, используйте этот код:
move.w N,D2 ;Поместите N в D-рег, если это еще не сделано bra EndL ;Начните с инструкции dbra внизу Петля: ... ... EndL: dbra D2, петля
- Это «правильный» тип петли, только с одной ветвью в оно, внизу. Цикл вводится путем перехода к «dbra» внизу.
- Это также объясняет, почему инструкция dbra проверяет -1, а не 0.

- Если вы хотите использовать значения в регистре, они Н-1,Н-2,…1,0.
- Вот два неверных способа сделать это:
ход.w N,D1 Петля: ... ... dbra петля
- Приведенный выше цикл выполняется N+1 раз, а не N раз.
- Итак, как насчет того, чтобы сначала уменьшить N, чтобы решить эту проблему?
ход.w N,D1 sub.w #1,D1 Петля: ... ... dbra петля
- Приведенный выше цикл содержит огромную ошибку . Если N=0, цикл не будет
быть выполнено 0 раз (что правильно). Вместо этого будет выполнено 65536
раз!! (В первый раз «dbra» будет уменьшаться на -1
и получите -2. Это не -1, поэтому он будет продолжаться. Значение в D1 будет
нужно считать до -32768, переполнить до +32767 и продолжить
вниз, пока он, наконец, не достигнет -1 трудным путем.