Размер типов данных в C++ | Уроки С++
Обновл. 2 Сен 2020 |
Как мы уже знаем из урока №28, память на современных компьютерах, как правило, организована в блоки, которые состоят из байтов, причем каждый блок имеет свой уникальный адрес. До этого момента, память можно было сравнивать с почтовыми ящиками (с теми, которые находятся в каждом подъезде), куда мы можем поместить информацию и откуда мы её можем извлечь, а имена переменных — это всего лишь номера этих почтовых ящиков.
Тем не менее, эта аналогия не совсем подходит к программированию, так как переменные могут занимать больше 1 байта памяти. Следовательно, одна переменная может использовать 2, 4 или даже 8 последовательных адресов. Объем памяти, который использует переменная, зависит от типа данных этой переменной. Так как мы, как правило, получаем доступ к памяти через имена переменных, а не через адреса памяти, то компилятор может скрывать от нас все детали работы с переменными разных размеров.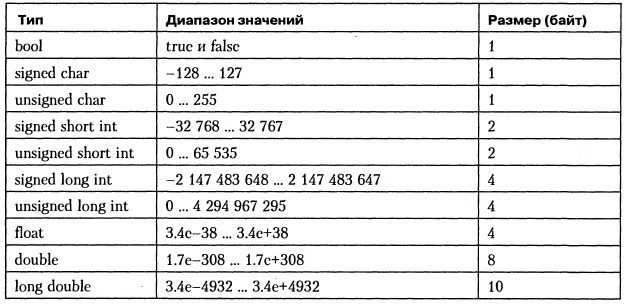
Есть несколько причин по которым полезно знать, сколько памяти занимает определенная переменная/тип данных.
Во-первых, чем больше она занимает, тем больше информации сможет хранить. Так как каждый бит содержит либо 0, либо 1, то 1 бит может иметь 2 возможных значения.
2 бита могут иметь 4 возможных значения:
| бит 0 | бит 1 |
| 0 | 0 |
| 0 | 1 |
| 1 | 0 |
| 1 | 1 |
3 бита могут иметь 8 возможных значений:
| бит 0 | бит 1 | бит 2 |
| 0 | 0 | 0 |
| 0 | 0 | 1 |
| 0 | 1 | 0 |
| 0 | 1 | 1 |
| 1 | 0 | 0 |
| 1 | 0 | 1 |
| 1 | 1 | 0 |
| 1 | 1 | 1 |
По сути, переменная с n-ным количеством бит может иметь 2n возможных значений. Поскольку байт состоит из 8 бит, то он может иметь 28 (256) возможных значений.
Поскольку байт состоит из 8 бит, то он может иметь 28 (256) возможных значений.
Размер переменной накладывает ограничения на количество информации, которую она может хранить. Следовательно, переменные, которые используют больше байт, могут хранить более широкий диапазон значений.
Во-вторых, компьютеры имеют ограниченное количество свободной памяти. Каждый раз, когда мы объявляем переменную, небольшая часть этой свободной памяти выделяется до тех пор, пока переменная существует. Поскольку современные компьютеры имеют много памяти, то в большинстве случаев это не является проблемой, особенно когда в программе всего лишь несколько переменных. Тем не менее, для программ с большим количеством переменных (например, 100 000), разница между использованием 1-байтовых или 8-байтовых переменных может быть значительной.
Размер основных типов данных в C++
Возникает вопрос: «Сколько памяти занимают переменные разных типов данных?». Вы можете удивиться, но размер переменной с любым типом данных зависит от компилятора и/или архитектуры компьютера!
Язык C++ гарантирует только их минимальный размер:
| Категория | Тип | Минимальный размер |
| Логический тип данных | bool | 1 байт |
| Символьный тип данных | char | 1 байт |
| wchar_t | 1 байт | |
| char16_t | 2 байта | |
| char32_t | 4 байта | |
| Целочисленный тип данных | short | 2 байта |
| int | 2 байта | |
| long | 4 байта | |
| long long | 8 байт | |
| Тип данных с плавающей запятой | float | 4 байта |
| double | 8 байт | |
| long double | 8 байт |
Фактический размер переменных может отличаться на разных компьютерах, поэтому для его определения используют оператор sizeof.
Оператор sizeof — это унарный оператор, который вычисляет и возвращает размер определенной переменной или определенного типа данных в байтах. Вы можете скомпилировать и запустить следующую программу, чтобы выяснить, сколько занимают разные типы данных на вашем компьютере:
#include <iostream> int main() { std::cout << «bool:\t\t» << sizeof(bool) << » bytes» << std::endl; std::cout << «char:\t\t» << sizeof(char) << » bytes» << std::endl; std::cout << «wchar_t:\t» << sizeof(wchar_t) << » bytes» << std::endl; std::cout << «char16_t:\t» << sizeof(char16_t) << » bytes» << std::endl; std::cout << «char32_t:\t» << sizeof(char32_t) << » bytes» << std::endl; std::cout << «short:\t\t» << sizeof(short) << » bytes» << std::endl; std::cout << «int:\t\t» << sizeof(int) << » bytes» << std::endl; std::cout << «long:\t\t» << sizeof(long) << » bytes» << std::endl; std::cout << «long long:\t» << sizeof(long long) << » bytes» << std::endl; std::cout << «float:\t\t» << sizeof(float) << » bytes» << std::endl; std::cout << «double:\t\t» << sizeof(double) << » bytes» << std::endl; std::cout << «long double:\t» << sizeof(long double) << » bytes» << std::endl; return 0; }
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
#include <iostream> int main() { std::cout << «bool:\t\t» << sizeof(bool) << » bytes» << std::endl; std::cout << «char:\t\t» << sizeof(char) << » bytes» << std::endl; std::cout << «wchar_t:\t» << sizeof(wchar_t) << » bytes» << std::endl; std::cout << «char16_t:\t» << sizeof(char16_t) << » bytes» << std::endl; std::cout << «char32_t:\t» << sizeof(char32_t) << » bytes» << std::endl; std::cout << «short:\t\t» << sizeof(short) << » bytes» << std::endl; std::cout << «int:\t\t» << sizeof(int) << » bytes» << std::endl; std::cout << «long:\t\t» << sizeof(long) << » bytes» << std::endl; std::cout << «long long:\t» << sizeof(long long) << » bytes» << std::endl; std::cout << «float:\t\t» << sizeof(float) << » bytes» << std::endl; std::cout << «double:\t\t» << sizeof(double) << » bytes» << std::endl; std::cout << «long double:\t» << sizeof(long double) << » bytes» << std::endl; return 0; } |
Вот результат, полученный на моем компьютере:
bool: 1 bytes
char: 1 bytes
wchar_t: 2 bytes
char16_t: 2 bytes
char32_t: 4 bytes
short: 2 bytes
int: 4 bytes
long: 4 bytes
long long: 8 bytes
float: 4 bytes
double: 8 bytes
long double: 8 bytes
Ваши результаты могут отличаться, если у вас другая архитектура, или другой компилятор. Обратите внимание, оператор sizeof не используется с типом void, так как последний не имеет размера.
Обратите внимание, оператор sizeof не используется с типом void, так как последний не имеет размера.
Если вам интересно, что значит \t в коде, приведенном выше, то это специальный символ, который используется вместо клавиши TAB. Мы его использовали для выравнивания столбцов. Детально об этом мы еще поговорим на соответствующих уроках.
Интересно то, что sizeof — это один из 3-х операторов в языке C++, который является словом, а не символом (еще есть new и delete).
Вы также можете использовать оператор sizeof и с переменными:
#include <iostream> int main() { int x; std::cout << «x is » << sizeof(x) << » bytes» << std::endl; }
#include <iostream>
int main() { int x; std::cout << «x is » << sizeof(x) << » bytes» << std::endl; } |
Результат выполнения программы:
x is 4 bytes
На следующих уроках мы рассмотрим каждый из фундаментальных типов данных языка С++ по отдельности.
Оценить статью:
Загрузка…Поделиться в социальных сетях:
Типы данных Visual Basic
Visual Basic for Applications может управлять различными типами данных. Как и в большинстве других систем программирования Visual Basic разделяет обрабатываемые данные на числа, текст, даты и другие типы. Ниже будут приведены описания основных типов данных VBA, а также будет показан объем памяти занимаемый каждым типом и диапазоны значений, которые эти типы могут сохранять.
Типы данных для хранения целых чисел
Для хранения целых чисел используется один из трех численных типов данных.
Byte
Байт — это единица измерения компьютерной и дисковой памяти, состоящая из восьми битов или двоичных разрядов. Обычно один алфавитный символ требует для хранения одного байта памяти.
Тип данных Byte используется для хранения положительных чисел от 0 до 255 и занимает 1 байт памяти.
Integer
Integer — это целое число, число, не имеющее дробной части.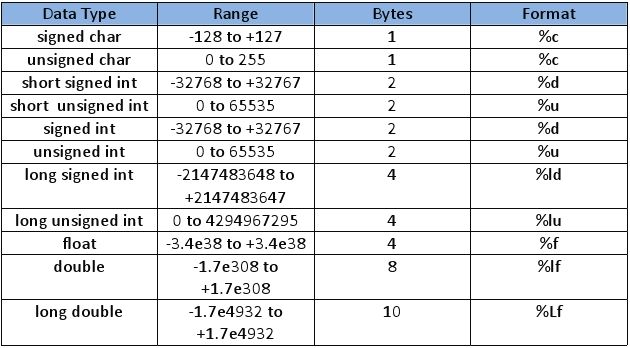 Целые числа не содержат десятичного знака, даже если дробная часть равна нулю.
Целые числа не содержат десятичного знака, даже если дробная часть равна нулю.
Тип данных Integer используется для хранения чисел от -32768 до 32767 и требует 2-х байтов памяти.
Long
Long — длинное целое число.
Тип данных Long используется для хранения чисел от -2147483648 до 2147483647 и требует 4-х байтов памяти.
Типы данных для хранения дробных чисел
Для хранения чисел, имеющих дробную часть используются типы данных с плавающей и с фиксированной точкой. Числа с плавающей точкой получили свое название вследствие того, что десятичная точка «плавает» в зависимости от того, насколько большое или маленькое значение сохраняется в памяти. VBA имеет два различных типа данных с плавающей точкой и один с фиксированной.
Single
Числа, сохраняемые с использованием типа Single, называют числами одинарной точности.
Тип данных Single используется для хранения отрицательных чисел от -3,402823*1038 до -1,401298*10-45, положительных чисел от 1,401298*10-45 до 3,402823*1038 и требует 4-х байтов памяти.
Double
Числа, сохраняемые с использованием типа Double, называют числами двойной точности.
Тип данных Double используется для хранения отрицательных числел от -1,79769313486232*10308 до -4,94065645841247*10-324, положительных от 4,94065645841247*10-324 до 1,79769313486232*10308 и требует 8-и байтов памяти.
Currency
Тип данных Currency используется для хранения чисел от -922337203685477,5808 до 922337203685477,5807 и требует 8-и байтов памяти.
Этот тип данных используется для хранения чисел с фиксированной точкой, десятичная точка всегда находится в одном и том же положении, справа от десятичной точки всегда имеется только четыре цифры. Числа типа Currency не имеют ошибок округления, используются при «денежных» вычислениях.
Типы данных для хранения дат, текстовых строк и логических значений
Date
Тип данных Date использует 8 байтов памяти для хранения дат и времени.
String
Любые текстовые данные, содержащие буквы алфавита, цифры, знаки пунктуации и различные символы называются строками. Существуют строки переменной и фиксированной длины.
Тип данных String (переменной длины) используется для хранения текста с количеством символов от 0 до 2 миллиардов и требует памяти в размере 10 байт+один байт на один символ.
Тип данных String (фиксированной длины) используется для хранения текста с количеством от 1 до 654000 символов и требует памяти в размере один байт на один символ.
Boolean
Логические значения True и False называют булевыми значениями. Булевы значения получают как результат операций сравнения.
Тип данных Boolean может иметь одно из двух значений True или False и требует 2-х байтов памяти.
Типы данных Variant и Object
Variant
Тип данных Variant — это особый тип данных, который используется для всех переменных с необъявленным явно типом. Не смотря на то, что типы Variant удобны, они требуют большого объема памяти, а математические операции и операции сравнения над данными этого типа выполняются медленнее.
Не смотря на то, что типы Variant удобны, они требуют большого объема памяти, а математические операции и операции сравнения над данными этого типа выполняются медленнее.
Тип данных Variant может хранить любой тип данных, за исключением типа Object. Диапазон для данных этого типа зависит от фактически сохраняемых данных и требует памяти в размере 16 байт + 1 байт на символ.
Object
Тип данных Object используется для доступа к любому объекту, распознаваемому VBA. Сохраняет адрес объекта и требует 4-х байтов памяти.
Учебник С++ — Типы данных. Преобразование типов
Переменная – ячейка памяти. Назначение типа определяет размер этой ячейки, какие операции можно выполнять с данной переменной, допустимые значения, которые может принимать переменная.
Классификация типов данных:
- Простые (скалярные) – целые, вещественные, логические (булевские).
- Структурированные – массивы, структуры, объединения, классы.

- Адресные – указатели, ссылки.
Простые типы данных
Целый тип
char – целый символьный тип;
short int – короткий целый тип;
int – целый тип;
long int – длинный целый тип.
Каждый из целочисленных типов может быть определён как знаковый (signed) или беззнаковый (unsigned) тип. При отсутствие ключевого слова, по умолчанию принимается знаковый тип.
Вещественный тип
float – вещественный тип одинарной точности;
doudle – вещественный тип двойной точности;
long double – вещественный тип расширенной точности;
Логический тип
bool – логический тип данных, принимает значение «истина» (true или 1),
или «ложь» (false или 0).
Тип данных | Размер, байт | Диапазон значений |
char | 1 | -128… +128 |
int | 2/4 | зависит от системы |
unsigned char | 1 | 0… 255 |
unsigned int | 2/4 | зависит от системы |
short int | 2 | -32768… 32767 |
unsigned short | 2 | 0… 65535 |
long int | 4 | -2147483648… 2147483648 |
unsigned long int | 4 | 0… 4294967295 |
float | 4 | ±(3.4Е-38… 3.4Е+38) |
double | 8 | ±(1.7Е-308… 1.7Е+308) |
long double | 10 | ±(3.4Е-4932… 1.1Е+4932) |
Анализируя данные таблицы, можно сделать следующие выводы:
если не указан базовый тип, то по умолчанию подразумевается int;
если не указан модификатор знаков, то по умолчанию подразумевается
signed;с базовым типом float модификаторы не употребляются;
модификатор short применим только к базовому типу int.
Приведением типов называется преобразование значения одного типа к значению другого типа, при этом возможно как сохранение величины этого значения, так и изменение этой величины. Приведение типов также называют преобразованием типов.
При деление двух переменных целого типа результат получится целый. Для получения вещественного результата, необходимо явное преобразование типа.
int a=5; int b=2; float t;
t=a/b (при этом t будет равняться 2)
t= (float)a/b (при этом t будет ровняться 2,5).
На момент вычисления изменили тип переменной а – это и есть явное приведение типов. Приведённый тип указывается в круглых скобках перед переменной.
Неявное преобразование типов используется когда в бинарной операции операнды имеют различные типы. В этом случае компилятор выполняет преобразование типов автоматически, т.е все они приводятся к типу с наибольшим диапазоном значений.
int a=5; float b=2; float t;
t=a/b (результат = 2,5)
При неявном преобразование типов выполняется правило переводов низших типов в высшие для точности представления данных и их непротиворечивости (низший тип – char, высший — long double; см.таблицу).
Типы данных JavaScript и структуры данных — JavaScript
Все языки программирования содержат встроенные типы данных, но они часто отличаются друг от друга в разных языках. Эта статья — попытка описать встроенные структуры (типы) данных, доступные в JavaScript, и их свойства. На их основе строятся другие структуры данных. Когда это возможно, то мы будем сравнивать типы данных в разных языках.
JavaScript является слабо типизированным или динамическим языком. Это значит, что вам не нужно определять тип переменной заранее. Тип определится автоматически во время выполнения программы. Также это значит, что вы можете использовать одну переменную для хранения данных различных типов:
var foo = 42;
foo = "bar";
foo = true;
Стандарт ECMAScript определяет 9 типов:
- 6 типов данных являющихся примитивами:
- Undefined (Неопределенный тип) :
typeof instance === "undefined" - Boolean (Булев, Логический тип) :
typeof instance === "boolean" - Number (Число) :
typeof instance === "number" - String (Строка) :
typeof instance === "string" - BigInt :
typeof instance === "bigint" - Symbol (в ECMAScript 6) :
typeof instance === "symbol"
- Undefined (Неопределенный тип) :
- Null (Null тип ) :
typeof instance === "object". Специальный примитив, используемый не только для данных но и в качестве указателя на финальную точку в Цепочке Прототипов; - Object (Объект) :
typeof instance === "object". Простая структура, используемая не только для хранения данных, но и для создания других структур, где любая структура создаётся с использованием ключевого словаnew: new Object, new Array, new Map, new Set, new WeakMap, new WeakSet, new Date и множество других структур; - и Function :
typeof instance === "function". Специальный случай, упрощающий определение типа для Функций, несмотря на то, что все функции конструктивно унаследованы от Object.
И здесь нам необходимо сделать предостережение относительно использования оператора typeof для определения типа структур, т.к. все структуры будут возвращать "object" при его использовании, так как назначение typeof — проверка типа данных, но не структур. Если проверить тип структуры всё же необходимо, то в этом случае желательно использовать оператор instanceof, так как именно он отвечает на вопрос о том, какой конструктор был использован для создания структуры.
Все типы данных в JavaScript, кроме объектов, являются иммутабельными (значения не могут быть модифицированы, а только перезаписаны новым полным значением). Например, в отличии от C, где строку можно посимвольно корректировать, в JavaScript строки пересоздаются только полностью. Значения таких типов называются «примитивными значениями».
Булевый тип данных
Булевый тип представляет логическую сущность и имеет два значения: true (истина) и false (ложь). Смотрите Boolean и Boolean для получения подробностей.
Null
Этот тип данных имеет всего одно значение: null. Смотрите null и Null для получения подробностей.
Undefined
Переменная, которой не было присвоено значение, будет иметь значение undefined. Смотрите undefined и undefined для получения подробностей.
Числа
В соответствии со стандартом ECMAScript, существует только один числовой тип, который представляет собой 64-битное число двойной точности согласно стандарту IEEE 754. Другими словами, специального типа для целых чисел в JavaScript нет. Это означает, что при числовых операциях вы можете получить неточное (округлённое) значение. В дополнение к возможности представлять числа с плавающей запятой, есть несколько символических значений: +Infinity (положительная бесконечность), -Infinity (отрицательная бесконечность), и NaN (не число).
Для получения самого большого или самого меньшего доступного значения в пределах +/-Infinity, можно использовать константы Number.MAX_VALUE или Number.MIN_VALUE. А начиная с ECMAScript 2015, вы также можете проверить, находится ли число в безопасном для целых чисел диапазоне, используя метод Number.isSafeInteger(), либо константы Number.MAX_SAFE_INTEGER и Number.MIN_SAFE_INTEGER. За пределами этого диапазона операции с целыми числами будут небезопасными, и возвращать приближённые значения.
Ноль в JavaScript имеет два представления: -0 и +0. («0» это синоним +0). На практике это имеет малозаметный эффект. Например, выражение +0 === -0 является истинным. Однако, это может проявиться при делении на ноль:
> 42 / +0
Infinity
> 42 / -0
-InfinityХотя число в большинстве случаев представляет только своё значение, JavaScript предоставляет несколько бинарных операций. Они могут использоваться для того, чтобы представлять число как несколько булевых значений, с помощью битовой маски. Это считается плохой практикой, так как JavaScript предлагает другие способы представления булевых значений (например, массив элементов с булевыми значениями или объект, содержащий набор булевых свойств). Кроме того, битовые маски часто делают код более трудным для чтения, понимания и дальнейшей поддержки. Эта техника может быть необходима в условиях технических ограничений, таких как объём локального хранилища данных, или в такой экстремальной ситуации, когда каждый бит передаваемый по сети на счету. Данный подход следует использовать как крайнюю меру, когда не остаётся других путей для необходимой оптимизации.
Текстовые строки
В JavaScript для представления текстовых данных служит тип String. Он представляет собой цепочку «элементов» 16-битных беззнаковых целочисленных значений. Каждый такой элемент занимает свою позицию в строке. Первый элемент имеет индекс 0, следующий — 1, и так далее. Длина строки — это количество элементов в ней.
В отличие от языков подобных C, строки в JavaScript являются иммутабельными. Это означает, что после того, как строковое значение создано, его нельзя модифицировать. Остаётся лишь создать новую строку путём совершения некой операции над исходной строкой. Например:
- Получить часть исходной строки выборкой отдельных символов, либо применением метода
String.substr(). - Объединить две строки в одну, применив оператор (
+) или методString.concat().
Избегайте повсеместного использования строк в своем коде!
Иногда может показаться соблазнительным использование строк для представления сложных структур данных. Это даст небольшие краткосрочные выгоды:
- Легко соединять данные в кучу сложением строк.
- Легко отлаживать (данные выглядят «как есть», в читаемом текстовом виде).
- Строки — это распространённый формат данных, используемый разнообразными API (поля ввода, значения локального хранилища,
XMLHttpRequestвозвращает ответ в виде строки, и т. д.) и использовать только строки может показаться заманчивым.
Несмотря на то, что в строке можно выразить данные любой сложности, делать это — не самая лучшая идея. Например, используя разделитель, строку можно использовать как список элементов (массив JavaScript будет более подходящим решением). К сожалению, если такой сепаратор встретится в значении одного из элементов, такой список будет сломан. Выходом может стать добавление символа экранирования, и т. д. Всё это потребует добавления множества ненужных правил, и станет обременительным при поддержке.
Используйте строки только для текстовых данных. Для составных структур преобразуйте строки в подобающие конструкции.
Тип данных Символ (Symbol)
Символы являются нововведением JavaScript начиная с ECMAScript 2015. Символ — это уникальное и иммутабельное примитивное значение, которое может быть использовано как ключ для свойства объекта (смотрите ниже). В некоторых языках программирования символы называются атомами. Их также можно сравнить с именованными значениями перечисления (enum) в языке C. Подробнее смотрите Symbol и Symbol.
Тип данных Большое целое (BigInt)
BigInt является встроенным объектом, который предоставляет способ представления целых чисел, которые больше 2 53, что является наибольшим числом, которое JavaScript может надежно представить с помощью Number примитива.
> let bigInt = 19241924124n;
> console.log(bigInt);
19241924124n
> console.log(typeof bigInt);
"bigint"В компьютерной терминологии, объект — это значение в памяти, на которое возможно сослаться с помощью идентификатора.
Свойства
В JavaScript объект может расцениваться как набор свойств. Литеральная инициализация объекта задаёт определённое количество начальных свойств, и в процессе работы приложения поля могут добавляться и удаляться. Значения свойств могут иметь любой тип, включая другие объекты, что позволяет строить сложные, разветвлённые иерархии данных. Каждое свойство объекта идентифицируется ключом, в качестве которого может выступать значение с типом Строка или Символ.
Есть два типа свойств: свойство-значение и свойство-акцессор (свойство, обёрнутое в геттер и сеттер). Они отличаются определенными атрибутами.
Свойство-значение
Ассоциирует ключ со значением, и имеет следующие атрибуты:
| Атрибут | Тип | Описание | Значение по умолчанию |
|---|---|---|---|
| [[Value]] | Любой тип JavaScript | Значение, возвращаемое при обращении к свойству. | undefined |
| [[Writable]] | Boolean | Если false, то [[Value]] свойства не может быть изменено. | false |
| [[Enumerable]] | Boolean | Если true, свойство будет перечислено в цикле for…in. Смотрите подробнее Перечисляемость и владение свойствами. | false |
| [[Configurable]] | Boolean | Если false, то свойство не может быть удалено, а его атрибуты, кроме [[Value]] и [[Writable]] не могут быть изменены. | false |
| Атрибут | Тип | Описание |
|---|---|---|
| Read-only | Boolean | Зарезервировано по атрибуту [[Writable]] ES5. |
| DontEnum | Boolean | Зарезервировано по атрибуту [[Enumerable]] ES5. |
| DontDelete | Boolean | Зарезервировано по атрибуту [[Configurable]] ES5. |
Свойство-акцессор
Ассоциирует ключ с одной из двух функций-акцессоров (геттер и сеттер) для получения или изменения значения свойства, и имеет следующий атрибуты:
| Атрибут | Тип | Описание | Значение по умолчанию |
|---|---|---|---|
| [[Get]] | Function или undefined | Функция вызывается без параметров и возвращает значение свойства каждый раз, когда происходит чтение свойства. Смотрите также get. | undefined |
| [[Set]] | Function или undefined | Функция вызывается с одним аргументом, содержащим присваиваемое значение, каждый раз, когда происходит попытка присвоить свойству новое значение. Смотрите также set. | undefined |
| [[Enumerable]] | Boolean | Если true, свойство будет перечислено в цикле for…in. | false |
| [[Configurable]] | Boolean | Если false, то свойство не может быть удалено, и не может быть преобразовано в свойство-значение. | false |
Примечание: Атрибуты обычно используются движком JavaScript, поэтому вы не можете обратиться к ним напрямую (смотрите подробнее Object.defineProperty()). Вот почему в таблицах выше они помещены в двойные квадратные скобки вместо одиночных.
«Обычные» объекты и функции
Объект JavaScript — это таблица соотношений между ключами и значениями. Ключи — это строки (или Symbol), а значения могут быть любыми. Это делает объекты полностью отвечающими определению хеш-таблицы.
Функции — это обычные объекты, имеющие дополнительную возможность быть вызванными для исполнения.
Даты
Для работы с датами служит встроенный глобальный объект Date.
Массивы общие и типизированные
Массив — это обычный объект с дополнительной связью между целочисленными ключами его свойств и специальным свойством length. Вдобавок ко всему, массивы наследуют Array.prototype, предоставляющий исчерпывающий набор методов для манипуляции массивами. Например, метод indexOf (служит для поиска значения в массиве), push (добавляет элемент в конец массива) и т. д. Всё это делает массив идеальным кандидатом для представления списков и перечислений.
Типизированный массив является новинкой ECMAScript Edition 6 и является массивоподобным представлением для лежащего в его основе бинарного буфера памяти. Следующая таблица поможет вам найти соответствующие типы языка C:
Объекты TypedArray
| Размер (байты) | |||||
Int8Array | -128 до 127 | 1 | 8-битное целое со знаком с дополнением до двух | byte | int8_t |
Uint8Array | 0 до 255 | 1 | 8-битное беззнаковое целое | octet | uint8_t |
Uint8ClampedArray | 0 до 255 | 1 | 8-битное беззнаковое целое (фиксированное от 0 до 255) | octet | uint8_t |
Int16Array | -32768 до 32767 | 2 | 16-битное целое со знаком с дополнением до двух | short | int16_t |
Uint16Array | 0 до 65535 | 2 | 16-битное беззнаковое целое | unsigned short | uint16_t |
Int32Array | -2147483648 до 2147483647 | 4 | 32-битное целое со знаком с дополнением до двух | long | int32_t |
Uint32Array | 0 до 4294967295 | 4 | 32-битное беззнаковое целое | unsigned long | uint32_t |
Float32Array | 1.2×10-38 to 3.4×1038 | 4 | 32-битное число с плавающей точкой IEEE-стандарта (7 значащих цифр, нпример 1.123456) | unrestricted float | float |
Float64Array | 5.0×10-324 to 1.8×10308 | 8 | 64-битное число с плавающей точкой IEEE-стандарта (16 значащих цифр, например, 1.123…15) | unrestricted double | double |
Коллекции: Maps, Sets, WeakMaps, WeakSets
Эти наборы данных используют ссылку на объект в качестве ключа, и введены в JavaScript с приходом ECMAScript Edition 6. Set и WeakSet являют собой набор уникальных объектов, в то время как Map и WeakMap ассоциируют с объектом (выступающим в качестве ключа) некоторое значение. Разница между Map и WeakMap заключается в том, что только у Map ключи являются перечисляемыми. Это позволяет оптимизировать сборку мусора для WeakMap.
Можно было бы написать собственную реализацию Map и Set на чистом ECMAScript 5. Однако, так как объекты нельзя сравнивать на больше или меньше, то производительность поиска в самодельной реализации будет вынужденно линейной. Нативная реализация (включая WeakMap) имеет производительность логарифмически близкую к константе.
Обычно, для привязки некоторых данных к узлу DOM, приходится устанавливать свойства этому узлу непосредственно, либо использовать его атрибуты data-*. Обратной стороной такого подхода является то, что эти данные будут доступны любому скрипту, работающему в том же контексте. Maps и WeakMaps дают возможность приватной привязки данных к объекту.
Структурированные данные: JSON
JSON (JavaScript Object Notation) — это легковесный формат обмена данными, происходящий от JavaScript, но используемый во множестве языков программирования. JSON строит универсальные структуры данных. Смотрите JSON и JSON для детального изучения.
Больше объектов и стандартная библиотека
JavaScript имеет стандартную библиотеку встроенных объектов. Пожалуйста, обратитесь к справочнику, чтобы найти описание всех объектов доступных для работы.
Оператор typeof может помочь определить тип вашей переменной. Смотрите страницу документации, где приведены его детали и случаи использования.
Тип данных Long
Пакет javafx.beans. | 61 |
public void addListener(ChangeListener<? super java.lang.Number> listener) —
присоединяет слушателя событий изменения значения свойства;
public void removeListener(InvalidationListener listener) — удаляет слуша-
теля событий недействительности значения свойства;
public void removeListener(ChangeListener<? super java.lang.Number> listener) —
удаляет слушателя событий изменения значения свойства.
Реализация для длинных чисел состоит из следующих классов:
абстрактного класса ReadOnlyLongProperty, который реализует интерфейс
ReadOnlyProperty<java.lang.Number> и расширяет класс javafx.beans.binding.LongExpression;
абстрактного класса LongProperty, который реализует интерфейсы
Property<java.lang.Number>, javafx.beans.value.WritableLongValue, расширяет класс ReadOnlyLongProperty и имеет конструктор public LongProperty() и методы:
public void setValue(java.lang.Number v) — устанавливает значение свойства;
public void bindBidirectional(Property<java.lang.Number> other) — создает
двунаправленное связывание;
public void unbindBidirectional(Property<java.lang.Number> other) — удаляет
двунаправленное связывание;
public java.lang.String toString() — возвращает строковое представление
объекта;
абстрактного класса LongPropertyBase, который расширяет класс LongProperty и является базовой реализацией JavaFX Beans-свойства со следующими конструкторами:
public LongPropertyBase()
public LongPropertyBase(long initialValue)
и методами:
public void addListener(InvalidationListener listener) — присоединяет слу-
шателя событий недействительности значения свойства;
public void addListener(ChangeListener<? super java.lang.Number> listener) —
присоединяет слушателя событий изменения значения свойства;
public void removeListener(InvalidationListener listener) — удаляет слуша-
теля событий недействительности значения свойства;
public void removeListener(ChangeListener<? super java.lang.Number>
listener) — удаляет слушателя событий изменения значения свойства; public long get() — возвращает значение свойства;
62 | javafx.beans.property |
|
|
public void set(long v) — устанавливает значение свойства;
public boolean isBound() — возвращает true, если свойство связано;
public void bind(ObservableValue<? extends java.lang.Number> rawObservable) —
создает однонаправленное связывание;
public void unbind() — удаляет однонаправленное связывание;
public java.lang.String toString() — возвращает строковое представление
объекта;
класса SimpleLongProperty, который расширяет класс LongPropertyBase и является конечной реализацией JavaFX Beans-свойства со следующими конструкторами:
public SimpleLongProperty()
public SimpleLongProperty(long initialValue)
public SimpleLongProperty(java.lang.Object bean, java.lang.String name)
public SimpleLongProperty(java.lang.Object bean, java.lang.String name, long initialValue)
и методами:
public java.lang.Object getBean() — возвращает объект, содержащий данное свойство;
public java.lang.String getName() — возвращает имя данного свойства;
класса ReadOnlyLongWrapper, который расширяет класс SimpleLongProperty, обеспе-
чивает свойство, доступное только для чтения, и имеет следующие конструкторы:
public ReadOnlyLongWrapper()
public ReadOnlyLongWrapper(long initialValue)
public ReadOnlyLongWrapper(java.lang.Object bean, java.lang.String name)
public ReadOnlyLongWrapper(java.lang.Object bean, java.lang.String name, long initialValue)
и методы:
public ReadOnlyLongProperty getReadOnlyProperty() — возвращает свойство,
доступное только для чтения;
public void addListener(InvalidationListener listener) — присоединяет слу-
шателя событий недействительности значения свойства;
public void addListener(ChangeListener<? super java.lang.Number> listener) —
присоединяет слушателя событий изменения значения свойства;
public void removeListener(InvalidationListener listener) — удаляет слуша-
теля событий недействительности значения свойства;
public void removeListener(ChangeListener<? super java.lang.Number>
listener) — удаляет слушателя событий изменения значения свойства;
Пакет javafx.beans. | 63 |
абстрактного класса ReadOnlyLongPropertyBase, который расширяет класс
ReadOnlyLongProperty и имеет конструктор public ReadOnlyLongPropertyBase()
и методы:
public void addListener(InvalidationListener listener) — присоединяет слу-
шателя событий недействительности значения свойства;
public void addListener(ChangeListener<? super java.lang.Number> listener) —
присоединяет слушателя событий изменения значения свойства;
public void removeListener(InvalidationListener listener) — удаляет слуша-
теля событий недействительности значения свойства;
public void removeListener(ChangeListener<? super java.lang.Number>
listener) — удаляет слушателя событий изменения значения свойства.
Тип данных Object
Реализация для объектов состоит из следующих классов:
абстрактного класса ReadOnlyObjectProperty<T>, который реализует интерфейс
ReadOnlyProperty<T> и расширяет класс javafx.beans.binding.ObjectExpression<T>;
абстрактного класса ObjectProperty<T>, который реализует интерфейсы
Property<T>, javafx.beans.value.WritableObjectValue<T>, расширяет класс ReadOnlyObjectProperty<T> и имеет конструктор public ObjectProperty() и методы:
public void setValue(T v) — устанавливает значение свойства;
public void bindBidirectional(Property<Т> other) — создает двунаправленное
связывание;
public void unbindBidirectional(Property<Т> other) — удаляет двунаправлен-
ное связывание;
public java.lang.String toString() — возвращает строковое представление
объекта;
абстрактного класса ObjectPropertyBase<T>, который расширяет класс ObjectProperty<T> и является базовой реализацией JavaFX Beans-свойства со следующими конструкторами:
public ObjectPropertyBase()
public ObjectPropertyBase(T initialValue)
и методами:
public void addListener(InvalidationListener listener) — присоединяет слу-
шателя событий недействительности значения свойства;
public void addListener(ChangeListener<? super Т> listener) — присоединяет
слушателя событий изменения значения свойства;
public void removeListener(InvalidationListener listener) — удаляет слуша-
теля событий недействительности значения свойства;
64 javafx.beans.property
public void removeListener(ChangeListener<? super Т> listener) — удаляет
слушателя событий изменения значения свойства; public T get() — возвращает значение свойства;
public void set(T v) — устанавливает значение свойства;
public boolean isBound() — возвращает true, если свойство связано;
public void bind(ObservableValue<? extends T> observable) — создает однона-
правленное связывание;
public void unbind() — удаляет однонаправленное связывание;
public java.lang.String toString() — возвращает строковое представление
объекта;
класса SimpleObjectProperty<T>, который расширяет класс ObjectPropertyBase<T> и
является конечной реализацией JavaFX Beans-свойства со следующими конструкторами:
public SimpleObjectProperty()
public SimpleObjectProperty(T initialValue)
public SimpleObjectProperty(java.lang.Object bean, java.lang.String name)
public SimpleObjectProperty(java.lang.Object bean, java.lang.String name, T initialValue)
и методами:
public java.lang.Object getBean() — возвращает объект, содержащий данное свойство;
public java.lang.String getName() — возвращает имя данного свойства;
класса ReadOnlyObjectWrapper<T>, который расширяет класс SimpleObjectProperty<T>, обеспечивает свойство, доступное только для чтения, и имеет следующие конструкторы:
public ReadOnlyObjectWrapper()
public ReadOnlyObjectWrapper(T initialValue)
public ReadOnlyObjectWrapper(java.lang.Object bean, java.lang.String name)
public ReadOnlyObjectWrapper(java.lang.Object bean, java.lang.String name, T initialValue)
и методы:
public ReadOnlyObjectProperty<T> getReadOnlyProperty() — возвращает свойст-
во, доступное только для чтения;
public void addListener(InvalidationListener listener) — присоединяет слу-
шателя событий недействительности значения свойства;
public void addListener(ChangeListener<? super Т> listener) — присоединяет
слушателя событий изменения значения свойства;
Длинный тип данных — Visual Basic
- 2 минуты на чтение
В этой статье
Содержит 64-битные (8-байтовые) целые числа со знаком в диапазоне значений от -9,223,372,036,854,775,808 до 9,223,372,036,854,775,807 (9,2 … E + 18).
Замечания
Используйте тип данных Long , чтобы содержать целые числа, которые слишком велики для размещения в типе данных Integer .
Значение по умолчанию Long — 0.
Буквальные присвоения
Вы можете объявить и инициализировать переменную Long , назначив ей десятичный литерал, шестнадцатеричный литерал, восьмеричный литерал или (начиная с Visual Basic 2017) двоичный литерал. Если целочисленный литерал находится за пределами диапазона Long (то есть, если он меньше Int64.MinValue или больше Int64.MaxValue, возникает ошибка компиляции.
В следующем примере целые числа, равные 4 294 967 296, которые представлены как десятичные, шестнадцатеричные и двоичные литералы, присваиваются значениям Long .
Dim longValue1 As Long = 4294967296
Console.WriteLine (longValue1)
Dim longValue2 As Long = & h200000000
Console.WriteLine (longValue2)
Dim longValue3 As Long = & B1_0000_0000_0000_0000_0000_0000_0000_0000
Console.WriteLine (longValue3)
'В этом примере отображается следующий вывод:
'4294967296
'4294967296
'4294967296
Примечание
Вы используете префикс & h или & H для обозначения шестнадцатеричного литерала, префикс & b или & B для обозначения двоичного литерала и префикс & o или & O для обозначения восьмеричного литерала.Десятичные литералы не имеют префикса.
Начиная с Visual Basic 2017, вы также можете использовать символ подчеркивания _ в качестве разделителя цифр для повышения удобочитаемости, как показано в следующем примере.
Dim longValue1 As Long = 4_294_967_296
Console.WriteLine (longValue1)
Dim longValue2 As Long = & h2_0000_0000
Console.WriteLine (longValue2)
Dim longValue3 As Long = & B1_0000_0000_0000_0000_0000_0000_0000_0000
Console.WriteLine (longValue3)
'В этом примере отображается следующий вывод:
'4294967296
'4294967296
'4294967296
Начиная с Visual Basic 15.5, вы также можете использовать символ подчеркивания ( _ ) в качестве ведущего разделителя между префиксом и шестнадцатеричными, двоичными или восьмеричными цифрами. Например:
Размерное число As Long = & H_0FAC_0326_1489_D68C
Чтобы использовать символ подчеркивания в качестве ведущего разделителя, необходимо добавить в файл проекта Visual Basic (* .vbproj) следующий элемент:
15.5
Дополнительные сведения см. В разделе «Настройка языковой версии Visual Basic».
Числовые литералы также могут включать в себя символ типа L для обозначения типа данных Long , как показано в следующем примере.
Размер размера = & H_0FAC_0326_1489_D68CL
Советы по программированию
Рекомендации по взаимодействию. Если вы взаимодействуете с компонентами, написанными не для .NET Framework, например с объектами автоматизации или COM, помните, что
Longимеет другую ширину данных (32 бита) в других средах.Если вы передаете 32-битный аргумент такому компоненту, объявите его какIntegerвместоLongв новом коде Visual Basic.Расширение. Тип данных
Longрасширяется доDecimal,SingleилиDouble. Это означает, что вы можете преобразоватьLongв любой из этих типов без возникновения ошибки System.OverflowException.Тип символов. Добавление символа типа литерала
Lк литералу приводит его к типу данныхLong. Добавление символа типа идентификатораик любому идентификатору приводит к установкеLong.Тип каркаса. Соответствующим типом в .NET Framework является структура System.Int64.
См. Также
Длинный тип данных — Visual Basic
- 2 мин. Лес
Í essari grein
Содержит 64-битные (8-байтовые) целые числа со знаком в диапазоне значений от -9,223,372,036,854,775,808 до 9,223,372,036,854,775,807 (9.2 … E + 18).
Замечания
Используйте тип данных Long , чтобы содержать целые числа, которые слишком велики для размещения в типе данных Integer .
Значение по умолчанию Long — 0.
Буквальные присвоения
Вы можете объявить и инициализировать переменную Long , назначив ей десятичный литерал, шестнадцатеричный литерал, восьмеричный литерал или (начиная с Visual Basic 2017) двоичный литерал. Если целочисленный литерал находится за пределами диапазона Long (то есть если он меньше Int64.MinValue или больше Int64.MaxValue, возникает ошибка компиляции.
В следующем примере целые числа, равные 4 294 967 296, которые представлены как десятичные, шестнадцатеричные и двоичные литералы, присваиваются значениям Long .
Dim longValue1 As Long = 4294967296
Console.WriteLine (longValue1)
Dim longValue2 As Long = & h200000000
Console.WriteLine (longValue2)
Dim longValue3 As Long = & B1_0000_0000_0000_0000_0000_0000_0000_0000
Console.WriteLine (longValue3)
'В этом примере отображается следующий вывод:
'4294967296
'4294967296
'4294967296
Примечание
Вы используете префикс & h или & H для обозначения шестнадцатеричного литерала, префикс & b или & B для обозначения двоичного литерала и префикс & o или & O для обозначения восьмеричного литерала.Десятичные литералы не имеют префикса.
Начиная с Visual Basic 2017, вы также можете использовать символ подчеркивания _ в качестве разделителя цифр для повышения удобочитаемости, как показано в следующем примере.
Dim longValue1 As Long = 4_294_967_296
Console.WriteLine (longValue1)
Dim longValue2 As Long = & h2_0000_0000
Console.WriteLine (longValue2)
Dim longValue3 As Long = & B1_0000_0000_0000_0000_0000_0000_0000_0000
Console.WriteLine (longValue3)
'В этом примере отображается следующий вывод:
'4294967296
'4294967296
'4294967296
Начиная с Visual Basic 15.5, вы также можете использовать символ подчеркивания ( _ ) в качестве ведущего разделителя между префиксом и шестнадцатеричными, двоичными или восьмеричными цифрами. Например:
Размерное число As Long = & H_0FAC_0326_1489_D68C
Чтобы использовать символ подчеркивания в качестве ведущего разделителя, необходимо добавить в файл проекта Visual Basic (* .vbproj) следующий элемент:
15.5
Дополнительные сведения см. В разделе «Настройка языковой версии Visual Basic».
Числовые литералы также могут включать в себя символ типа L для обозначения типа данных Long , как показано в следующем примере.
Размер размера = & H_0FAC_0326_1489_D68CL
Советы по программированию
Рекомендации по взаимодействию. Если вы взаимодействуете с компонентами, написанными не для .NET Framework, например с объектами автоматизации или COM, помните, что
Longимеет другую ширину данных (32 бита) в других средах.Если вы передаете 32-битный аргумент такому компоненту, объявите его какIntegerвместоLongв новом коде Visual Basic.Расширение. Тип данных
Longрасширяется доDecimal,SingleилиDouble. Это означает, что вы можете преобразоватьLongв любой из этих типов без возникновения ошибки System.OverflowException.Тип символов. Добавление символа типа литерала
Lк литералу приводит его к типу данныхLong. Добавление символа типа идентификатораик любому идентификатору приводит к установкеLong.Тип каркаса. Соответствующим типом в .NET Framework является структура System.Int64.
См. Также
Размер типа данных «длинное целое число» (C ++) на различных архитектурах и ОС
Размер «длинного» целого числа зависит от архитектуры и операционной системы.
Компилятор Intel® совместим и взаимодействует с Microsoft * Visual C ++ в Windows * и с gcc * в Linux * и Mac OS X *. Следовательно, размеры основных типов такие же, как у этих компиляторов. Размер «длинного» целого числа, в частности, зависит от операционной системы и целевой архитектуры следующим образом:
| OS | Архитектура | Размер «длинного» типа |
| Окна | IA-32 | 4 байта |
| Intel® 64 | 4 байта | |
| Linux | IA-32 | 4 байта |
| Intel® 64 | 8 байт | |
| Mac OS | Intel® 64 | 8 байт |
Следовательно, когда программы, использующие «длинный» целочисленный тип данных, переносятся из IA-32 Linux в Intel® 64 Linux или из Intel® 64 Windows в Intel® 64 Linux, поведение может измениться.(Обратите внимание, что размер указателей, как ожидается, изменится между IA-32 и Intel® 64).
Кроме того, размер «длинного двойника» также зависит от операционной системы.
В Windows * размер по умолчанию составляет 8 байт. В Linux или Mac OS X 10 байтов используются для представления длинного числа двойной точности, хотя выделенный размер может быть больше (12 байтов в IA-32 Linux; 16 байтов в других местах).
Предложение: Если для вас важно, чтобы целочисленные типы имели одинаковый размер на всех платформах Intel, подумайте о замене long на int или long long.Размер целочисленного типа «int» составляет 4 байта, а размер целочисленного типа «long long» составляет 8 байтов для всех вышеуказанных комбинаций операционной системы и архитектуры.
В Windows представление «длинного двойника» можно увеличить до 10 байтов с помощью переключателя командной строки / Qlong-double. Соответствующее выделение памяти составляет 16 байтов.
Типы данных — NumPy v1.13 Manual
Типы массивов и преобразования между типами
NumPy поддерживает гораздо большее разнообразие числовых типов, чем Python.В этом разделе показано, какие из них доступны и как изменить тип данных массива.
| Тип данных | Описание |
|---|---|
bool_ | Логическое значение (Истина или Ложь) хранится как байт |
внутр. | Целочисленный тип по умолчанию (такой же, как C long ; обычно либо int64 или int32 ) |
| intc | Идентично C int (обычно int32 или int64 ) |
| внутр | Целое число, используемое для индексации (то же, что и C ssize_t ; обычно
либо int32 , либо int64 ) |
| внутр8 | Байт (от -128 до 127) |
| внутренний 16 | Целое число (от -32768 до 32767) |
| int32 | Целое число (от -2147483648 до 2147483647) |
| внут64 | Целое число (от -9223372036854775808 до 9223372036854775807) |
| uint8 | Целое число без знака (от 0 до 255) |
| uint16 | Целое число без знака (от 0 до 65535) |
| uint32 | Целое число без знака (от 0 до 4294967295) |
| uint64 | Целое число без знака (от 0 до 18446744073709551615) |
float_ | Сокращение для float64 . |
| float16 | с плавающей запятой половинной точности: знаковый бит, 5-битная экспонента, 10 бит мантисса |
| float32 | с плавающей точкой одинарной точности: знаковый бит, 8-битная экспонента, 23 бита мантисса |
| float64 | с плавающей запятой двойной точности: знаковый бит, 11-битная экспонента, 52 бита мантисса |
комплекс_ | Сокращение для комплекса 128 . |
| комплекс 64 | Комплексное число, представленное двумя 32-битными числами с плавающей запятой (действительное и мнимые составляющие) |
| комплекс 128 | Комплексное число, представленное двумя 64-битными числами с плавающей запятой (действительное и мнимые составляющие) |
Дополнительно к intc зависимые от платформы целые типы C короткие ,
Определены long , longlong и их беззнаковые версии.
Числовые типы NumPy — это экземпляры объектов dtype (тип данных), каждый
обладающие уникальными характеристиками. После того, как вы импортировали NumPy с помощью
типы dtypes доступны как np.bool_ , np.float32 и т. Д.
Расширенные типы, не указанные в таблице выше, рассматриваются в раздел Структурированные массивы.
Существует 5 основных числовых типов, представляющих логические значения (bool), целые числа (int),
целые числа без знака (uint) с плавающей точкой (float) и комплексные.Те, у кого есть числа
в их названии указывают битовый размер типа (т.е. сколько бит необходимо
для представления единственного значения в памяти). Некоторые типы, такие как int и intp , имеют разные биты, в зависимости от платформ (например, 32-битный
против 64-битных машин). Это следует учитывать при сопряжении
с низкоуровневым кодом (например, C или Fortran), где адресуется необработанная память.
Типы данных могут использоваться как функции для преобразования чисел Python в скаляры массива (см. раздел скалярных массивов для объяснения), последовательности чисел Python для массивов этого типа или в качестве аргументов ключевого слова dtype, которое многие numpy функции или методы принимают.Некоторые примеры:
>>> импортировать numpy как np >>> x = np.float32 (1.0) >>> х 1.0 >>> y = np.int _ ([1,2,4]) >>> у массив ([1, 2, 4]) >>> z = np.arange (3, dtype = np.uint8) >>> г массив ([0, 1, 2], dtype = uint8)
Типы массивов могут также обозначаться кодами символов, в основном для сохранения обратная совместимость со старыми пакетами, такими как Numeric. Несколько документация все еще может ссылаться на них, например:
>>> нп.массив ([1, 2, 3], dtype = 'f') array ([1., 2., 3.], dtype = float32)
Вместо этого мы рекомендуем использовать объекты dtype.
Чтобы преобразовать тип массива, используйте метод .astype () (предпочтительно) или сам тип как функция. Например:
>>> z.astype (float) массив ([0., 1., 2.]) >>> np.int8 (z) array ([0, 1, 2], dtype = int8)
Обратите внимание, что выше мы используем объект float Python как dtype. NumPy знает
что int относится к np.int_ , bool означает np.bool_ ,
что float — это np.float_ и complex — это np.complex_ .
Остальные типы данных не имеют эквивалентов Python.
Чтобы определить тип массива, посмотрите атрибут dtype:
>>> z.dtype
dtype ('uint8')
объекты dtype также содержат информацию о типе, такую как его разрядность. и его порядок байтов. Тип данных также может косвенно использоваться для запроса свойства типа, например, является ли это целым числом:
>>> d = np.dtype (число)
>>> d
dtype ('int32')
>>> np.issubdtype (d, int)
Правда
>>> np.issubdtype (d, float)
Ложь
Скаляры массива
NumPy обычно возвращает элементы массивов как скаляры массива (скаляр
со связанным dtype). Скаляры массива отличаются от скаляров Python, но
по большей части они могут использоваться взаимозаменяемо (основной
исключение — для версий Python старше v2.x, где целочисленный массив
скаляры не могут действовать как индексы для списков и кортежей).Есть некоторые
исключения, например, когда код требует очень специфических атрибутов скаляра
или когда он специально проверяет, является ли значение скаляром Python. В общем-то,
проблемы легко решаются путем явного преобразования скаляров массива
в скаляры Python, используя соответствующую функцию типа Python
(например, int , float , complex , str , unicode ).
Основным преимуществом использования скаляров массива является то, что
они сохраняют тип массива (Python может не иметь соответствующего скалярного типа
в наличии, e.г. int16 ). Следовательно, использование скаляров массива обеспечивает
одинаковое поведение массивов и скаляров, независимо от того,
значение находится внутри массива или нет. Скаляры NumPy также имеют много одинаковых
методы массивы делают.
Повышенная точность
Числа с плавающей запятой Python обычно представляют собой 64-битные числа с плавающей запятой,
почти эквивалентно np.float64 . В некоторых необычных ситуациях это может быть
полезно использовать числа с плавающей запятой с большей точностью.Будь это
возможно в numpy, зависит от оборудования и от разработки
среда: в частности, машины x86 предоставляют аппаратное обеспечение с плавающей запятой
с 80-битной точностью, и хотя большинство компиляторов C предоставляют это как свои long double type, MSVC (стандартный для сборок Windows) делает long double идентично double (64 бита). NumPy делает
компилятор long double доступен как np.longdouble (и np.clongdouble для комплексных чисел).Вы можете узнать, что у вас
numpy предоставляет « np.finfo (np.longdouble) ».
NumPy не предоставляет dtype с большей точностью, чем C длинные двухместные; в частности, 128-битная четырехъядерная точность IEEE
тип данных (FORTRAN's `` REAL * 16 ») недоступен.
Для эффективного выравнивания памяти обычно сохраняется np.longdouble дополнены нулевыми битами до 96 или 128 бит. Что более эффективно
зависит от оборудования и среды разработки; обычно на 32-битном
системы они дополнены до 96 бит, а в 64-битных системах они
обычно дополняется до 128 бит. np.longdouble добавлен к системе
по умолчанию; np.float96 и np.float128 предназначены для пользователей, которые
нужно конкретное дополнение. Несмотря на названия, np.float96 и np.float128 обеспечивает такую же точность, как np.longdouble ,
то есть 80 бит на большинстве машин x86 и 64 бит в стандартном
Сборки Windows.
Имейте в виду, что даже если np.longdouble обеспечивает большую точность, чем
python float , эту дополнительную точность легко потерять, поскольку
Python часто заставляет значения проходить через float .Например,
оператор форматирования % требует преобразования своих аргументов
к стандартным типам python, поэтому сохранить
повышенная точность, даже если требуется много десятичных знаков.