о кодировке символов — PowerShell
- Статья
- Чтение занимает 5 мин
Краткое описание
Описывает, как PowerShell использует кодировку символов для ввода и вывода строковых данных.
Подробное описание
Юникод — это глобальный стандарт кодировки символов. Система использует Юникод исключительно для обработки символов и строк. Подробное описание всех аспектов Юникода см. в статье Стандарт Юникода.
Windows поддерживает Юникод и традиционные наборы символов. Традиционные наборы символов, такие как кодовые страницы Windows, используют 8-разрядные значения или комбинации 8-разрядных значений для представления символов, используемых в определенных параметрах языка или географического региона.
По умолчанию PowerShell использует кодировку Юникода. Однако несколько командлетов имеют параметр
Следующие командлеты имеют параметр Encoding :
- Microsoft.PowerShell.Management
- Add-Content
- Get-Content
- Set-Content
- Microsoft.PowerShell.Utility
- Export-Clixml
- Export-Csv
- Export-PSSession
- Format-Hex
- Import-Csv
- Out-File
- Select-String
- Send-MailMessage
Метка порядка байтов
Метка порядка байтов (BOM) — это подпись Юникода в первых нескольких байтах файла или текстового потока, которая указывает, какая кодировка Юникода используется для данных. Дополнительные сведения см. в документации по метки порядка байтов .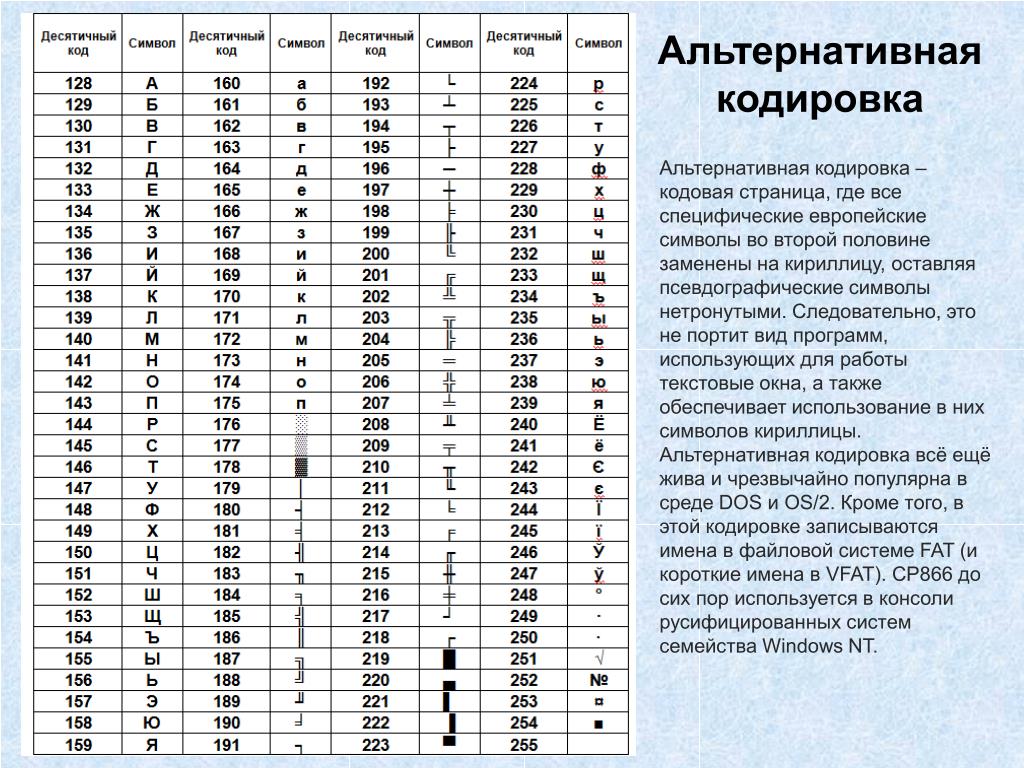
В Windows PowerShell любая кодировка Юникода, за исключением UTF7, всегда создает BOM. PowerShell (версии 6 и выше) по умолчанию использует значение для utf8NoBOM всех текстовых выходных данных.
Для обеспечения оптимальной общей совместимости не используйте BOM в файлах UTF-8. Платформы Unix и программы unix-heritage, которые также используются на платформах Windows, не поддерживают bom.
Аналогичным UTF7 образом следует избегать кодирования. UTF-7 не является стандартной кодировкой Юникода и записывается без BOM во всех версиях PowerShell.
Создание скриптов PowerShell на платформе, подобной Unix, или с помощью кроссплатформенного редактора в Windows, например Visual Studio Code, приводит к созданию файла, закодированного с помощью UTF8NoBOM. Эти файлы хорошо работают в PowerShell, но могут нарушить работу Windows PowerShell, если файл содержит символы, отличные от Ascii.
Если вам нужно использовать в скриптах символы, отличные от Ascii, сохраните их как UTF-8 с BOM. Без BOM Windows PowerShell неправильно интерпретирует скрипт как кодируемый в устаревшей кодовой строке ANSI. И наоборот, файлы, которые имеют спецификацию UTF-8, могут быть проблемными на unix-подобных платформах. Многие средства Unix, такие как
Без BOM Windows PowerShell неправильно интерпретирует скрипт как кодируемый в устаревшей кодовой строке ANSI. И наоборот, файлы, которые имеют спецификацию UTF-8, могут быть проблемными на unix-подобных платформах. Многие средства Unix, такие как cat, sed, awkи некоторые редакторы, например gedit , не знают, как обрабатывать спецификацию.
Кодировка символов в Windows PowerShell
В PowerShell 5.1 параметр Encoding поддерживает следующие значения:
AsciiИспользует набор символов Ascii (7 бит).BigEndianUnicodeИспользует UTF-16 с порядком байтов с большим порядком байтов.BigEndianUTF32Использует UTF-32 с порядком байтов с большим порядком байтов.ByteКодирует набор символов в последовательность байтов.DefaultИспользует кодировку, соответствующую активной кодовой странице системы (обычно ANSI).
OemИспользует кодировку, соответствующую текущей системной кодовой странице OEM.StringаналогиченUnicode.UnicodeИспользует UTF-16 с порядком байтов с минимальным порядком байтов.UnknownаналогиченUnicode.UTF32Использует UTF-32 с порядком байтов с минимальным порядком байтов.UTF7Использует UTF-7.UTF8Использует UTF-8 (с BOM).
Как правило, Windows PowerShell по умолчанию использует кодировку UTF-16LE в Юникоде. Однако кодировка по умолчанию, используемая командлетами в Windows PowerShell, не согласована.
Примечание
Использование любой кодировки Юникода, за исключением UTF7, всегда создает BOM.
Для командлетов, которые записывают выходные данные в файлы:
Out-Fileи операторы>перенаправления и>>создание UTF-16LE, который заметно отличается отSet-ContentиAdd-Content.
New-ModuleManifestаExport-CliXmlтакже создавать файлы UTF-16LE.Если целевой файл пуст или не существует,
Set-ContentиAdd-ContentиспользуйтеDefaultкодировку.Default— это кодировка, заданная устаревшей кодовой страницей ANSI активного языкового стандарта системы.
создаетExport-CsvAsciiфайлы, но использует другую кодировку при использовании параметра Append (см. ниже).Export-PSSessionпо умолчанию создает файлы UTF-8 с BOM.New-Item -Type File -Valueсоздает файл UTF-8 без BOM.Send-MailMessageиспользуетAsciiкодировку по умолчанию.Start-TranscriptсоздаетUtf8файлы с BOM. При использовании параметра Append кодировка может отличаться (см. ниже).
Для команд, которые добавляются к существующему файлу:
Out-File -Appendи оператор перенаправления>>не пытается сопоставить кодировку содержимого существующего целевого файла. Вместо этого они используют кодировку по умолчанию, если не используется параметрПри отсутствии явного параметра
Add-ContentEncoding обнаруживает существующую кодировку и автоматически применяет ее к новому содержимому. Если существующее содержимое не имеет BOM,Defaultиспользуется кодировка ANSI.Add-ContentПоведение в PowerShell (версии 6 и выше) одинаково, за исключением кодировки по умолчанию .Utf8Export-Csv -Appendсоответствует существующей кодировке, если целевой файл содержит BOM. При отсутствии BOM используетсяUtf8кодировка.
Start-Transcript -Appendсоответствует существующей кодировке файлов, включающих BOM. При отсутствии спецификации по умолчанию используется кодировкаAscii. Такая кодировка может привести к потере данных или повреждению символов, если данные в расшифровке содержат многобайтовые символы.
Для командлетов, которые считывают строковые данные при отсутствии BOM:
Get-ContentиImport-PowerShellDataFileиспользует кодировкуDefaultANSI. AnSI также используется подсистемой PowerShell при чтении исходного кода из файлов.Import-Csv,Import-CliXmlиSelect-StringпредполагаетсяUtf8при отсутствии спецификации.
Кодировка символов в PowerShell
В PowerShell (версии 6 и выше) параметр Encoding поддерживает следующие значения:
ascii: использует кодировку для 7-разрядной кодировки ASCII.
bigendianunicodeoem: использует кодировку по умолчанию для MS-DOS и консольных программ.unicode: кодирует в формате UTF-16 с использованием порядка байтов с маленьким порядком байтов.utf7: кодирует в формате UTF-7.utf8: кодирует в формате UTF-8 (без BOM).utf8BOM: кодирует в формате UTF-8 с меткой порядка байтов (BOM)utf8NoBOM: кодирует в формате UTF-8 без метки порядка байтов (BOM)utf32: кодирует в формате UTF-32.
PowerShell по умолчанию использует значение для utf8NoBOM всех выходных данных.
Начиная с PowerShell 6.2, параметр Encoding также разрешает числовые идентификаторы зарегистрированных кодовых страниц (например -Encoding 1251, ) или строковые имена зарегистрированных кодовых страниц (например -Encoding "windows-1251", ). Дополнительные сведения см. в документации по .NET для Encoding.CodePage.
Дополнительные сведения см. в документации по .NET для Encoding.CodePage.
Изменение кодировки по умолчанию
В PowerShell есть две переменные по умолчанию, которые можно использовать для изменения поведения кодирования по умолчанию.
$PSDefaultParameterValues$OutputEncoding
Дополнительные сведения см. в разделе about_Preference_Variables.
Начиная с PowerShell 5.1 операторы перенаправления (> и >>) вызывают Out-File командлет . Поэтому вы можете задать кодировку по умолчанию для них с помощью переменной $PSDefaultParameterValues предпочтения, как показано в этом примере:
$PSDefaultParameterValues['Out-File:Encoding'] = 'utf8'
Используйте следующую инструкцию, чтобы изменить кодировку по умолчанию для всех командлетов с параметром Encoding
$PSDefaultParameterValues['*:Encoding'] = 'utf8'
Важно!
Если поместить эту команду в профиль PowerShell, этот параметр будет глобальным параметром сеанса, который влияет на все команды и скрипты, которые явно не указывают кодировку.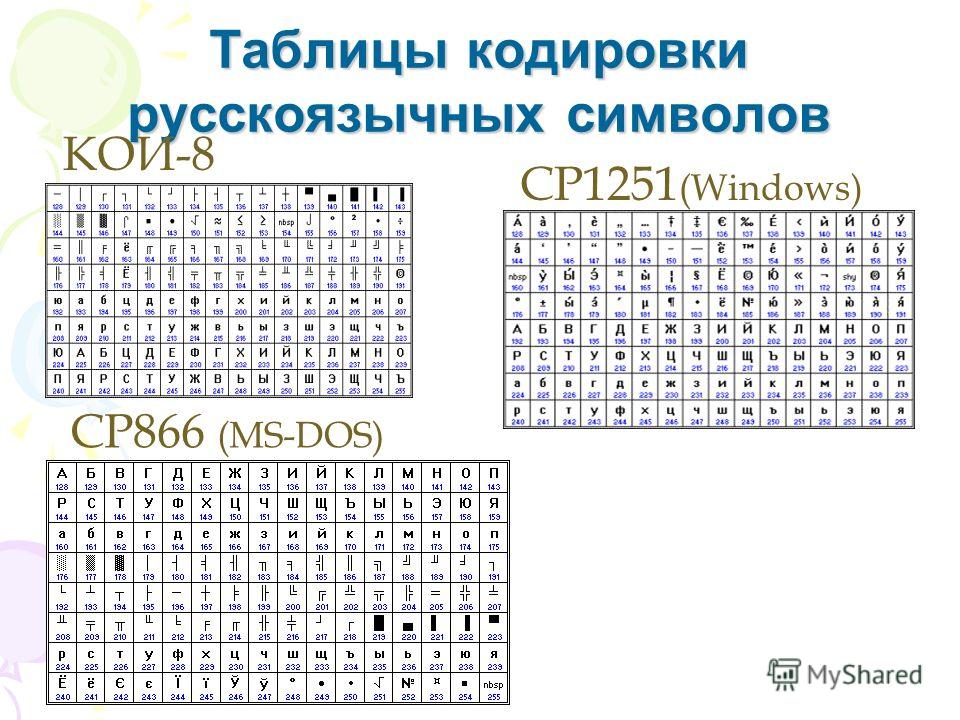
Аналогичным образом следует включить в скрипты или модули такие команды, которые должны вести себя одинаково. Использование этих команд гарантирует, что командлеты работают одинаково даже при выполнении другим пользователем, на другом компьютере или в другой версии PowerShell.
Автоматическая переменная $OutputEncoding влияет на кодирование, используемое PowerShell для взаимодействия с внешними программами. Она не влияет на кодировку, которую операторы перенаправления выходных данных и командлеты PowerShell используют для сохранения в файлы.
См. также раздел
- about_Preference_Variables
- Метка порядка байтов
- Кодовые страницы — приложения Win32
- Encoding.CodePage
- Общие сведения о кодировании символов в .NET
- Стандарт Юникода
- UTF-16LE
Представление нечисловой информации в компьютере
Планирование уроков на учебный год
Главная | Информатика и информационно-коммуникационные технологии | Планирование уроков и материалы к урокам | 10 классы | Планирование уроков на учебный год | Представление текстовой информации в компьютере
Изучив эту тему, вы узнаете и повторите:
— как в компьютере представляется текстовая информация;
— что такое ASCII и Unicode;
— как в компьютере представляется графическая информация;
— какие форматы используются при хранении графических файлов;
— как в компьютере представляется звуковая информация;
— какие форматы используются при хранении звуковых файлов.
Компьютеры не с самого рождения могли обрабатывать символьную информацию. Лишь с конца 60-х годов они стали использоваться для обработки текстов и в настоящее время большинство пользователей ПК занимаются вводом, редактированием и форматированием текстовой информации.
1. Таблица кодирования ASCII.
А теперь «заглянем» в память компьютера и разберемся, как же представлена в нем текстовая информация.
Текстовая информация состоит из символов: букв, цифр, знаков препинания, скобок и других. Мы уже говорили, что множество всех символов, с помощью которых записывается текст, называется алфавитом, а число символов в алфавите — его мощностью.
Для представления текстовой информации в компьютере используется алфавит мощностью 256 символов. Мы знаем, что один символ такого алфавита несет 8 битов информации: 2 в 8 степени равно 256. 8 битов = 1 байт, следовательно:
Один символ в компьютерном тексте занимает 1 байт памяти.
Как мы выяснили, традиционно для кодирования одного символа используется 8 бит. И, когда люди определились с количеством бит, им осталось договориться о том, каким кодом кодировать тот или иной символ, чтобы не получилось путаницы, т.е. необходимо было выработать стандарт – все коды символов сохранить в специальной таблице кодов. В первые годы развития вычислительной техники таких стандартов не существовало, а сейчас наоборот, их стало очень много, но они противоречивы. Первыми решили эти проблемы в США, в институте стандартизации. Этот институт ввел в действие таблицу кодов ASCII (AmericanStandardCodeforInformationInterchange – стандартный код информационного обмена США).
Рассмотрим таблицу кодов ASCII.
Пояснение: раздать учащимся распечатанную таблицу кодов ASCII.
Таблица ASCII разделена на две части. Первая – стандартная – содержит коды от 0 до 127. Вторая – расширенная – содержит символы с кодами от 128 до 255.
Первые 32 кода отданы производителям аппаратных средств и называются они управляющие, т.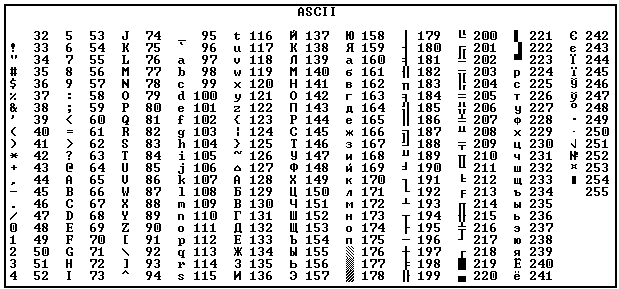 к. эти коды управляют выводом данных. Им не соответствуют никакие символы.
к. эти коды управляют выводом данных. Им не соответствуют никакие символы.
Коды с 32 по 127 соответствуют символам английского алфавита, знакам препинания, цифрам, арифметическим действиям и некоторым вспомогательным символам.
Коды расширенной части таблицы ASCII отданы под символы национальных алфавитов, символы псевдографики и научные символы.
Стандартная часть таблицы кодов ASCII
Если вы внимательно посмотрите на обе части таблицы, то увидите, что все буквы расположены в них по алфавиту, а цифры – по возрастанию. Этот принцип последовательного кодирования позволяет определить код символа, не заглядывая в таблицу.
Коды цифр берутся из этой таблицы только при вводе и выводе и если они используются в тексте. Если же они участвуют в вычислениях, то переводятся в двоичную систему счисления.
Коды национального (русского) алфавита расширенной частитаблицы ASCII
Альтернативные системы кодирования кириллицы.

Тексты, созданные в одной кодировке, не будут правильно отображаться в другой.В настоящее время для поддержки букв русского алфавита (кириллицы) существует несколько кодовых таблиц (кодировок), которые используются различными операционными системами, что является существенным недостатком и в ряде случаев при-водит к проблемам, связанным с операциями декодирования числовых значений символов.
Для разных типов ЭВМ используются различные кодировки:
В настоящее время существует 5 кодовых таблиц для русских букв: Windows (СР(кодовая страница)1251), MS – DOS (СР(кодовая страница)866), KOИ – 8 (Код обмена информацией, 8-битный) (используется в OS UNIX), Mac (Macintosh), ISO (OS UNIX).
Одним из первых стандартов кодирования кириллицы на компьютерах был стан-дарт КОИ-8.
Национальная часть кодовой таблицы стандарта КОИ8-Р
В настоящее время применяется и кодовая таблица, размещенная на странице СР866 стандарта кодирования текстовой информации, которая используется в операционной системе MS DOS или сеансе работы MS DOS для кодирования кириллицы.
Национальная часть кодовой таблицы СР866
В настоящее время для кодирования кириллицы наибольшее распространение получила кодовая таблица, размещенная на странице СР1251 соответствующего стандарта, которая используется в операционных системах семейства Windows фирмы Microsoft.
Национальная часть кодовой таблицы СР1251
Во всех представленных кодовых таблицах, кроме таблицы стандарта Unicode, для кодирования одного символа отводится 8 двоичных разрядов (8 бит).
В мире существует примерно 6800 различных языков. Если прочитать текст, напечатанный в Японии на компьютере в России или США, то понять его будет нельзя. Чтобы буквы любой страны можно было читать на любом компьютере, для их кодировки стали использовать 2 байта (16 бит).
N = 2i
2i = 216 = 65536
N = 65536
N – мощность алфавита символов в кодовой таблице Unicode.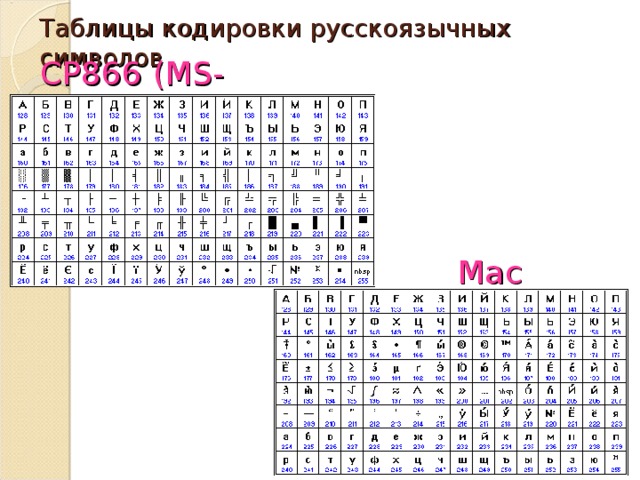
i – информационный вес символа
Основополагающая таблица использования кодового пространства Unicode
Использование Unicode значительно упрощает создание многоязычных документов, публикаций и программных приложений.
Рассмотрим примеры.
1) Представьте в форме шестнадцатеричного кода слово «ЭВМ» во всех пяти кодировках. Воспользуемся компьютерным калькулятором для перевода чисел из десятичной в шестнадцатеричную систему счисления.
Последовательности десятичных кодов слова «ЭВМ» в различных кодировках составляем на основе кодировочных таблиц:
КОИ8-Р: 252 247 237
СР1251: 221 194 204
СР866: 157 130 140
Мас: 157 130 140
ISO: 205 178 188
Переводим с помощью калькулятора последовательности кодов из десятичной системы в шестнадцатеричную:
КОИ8-Р: FCF7 ED
СР1251: DDC2 CC
СР866: 9D 82 8C
Мас: 9D 82 8C
ISO: CDB2 BC
2) Определить числовой код символа в кодировке Unicode с помощью тексто-вого редактора MicrosoftWord.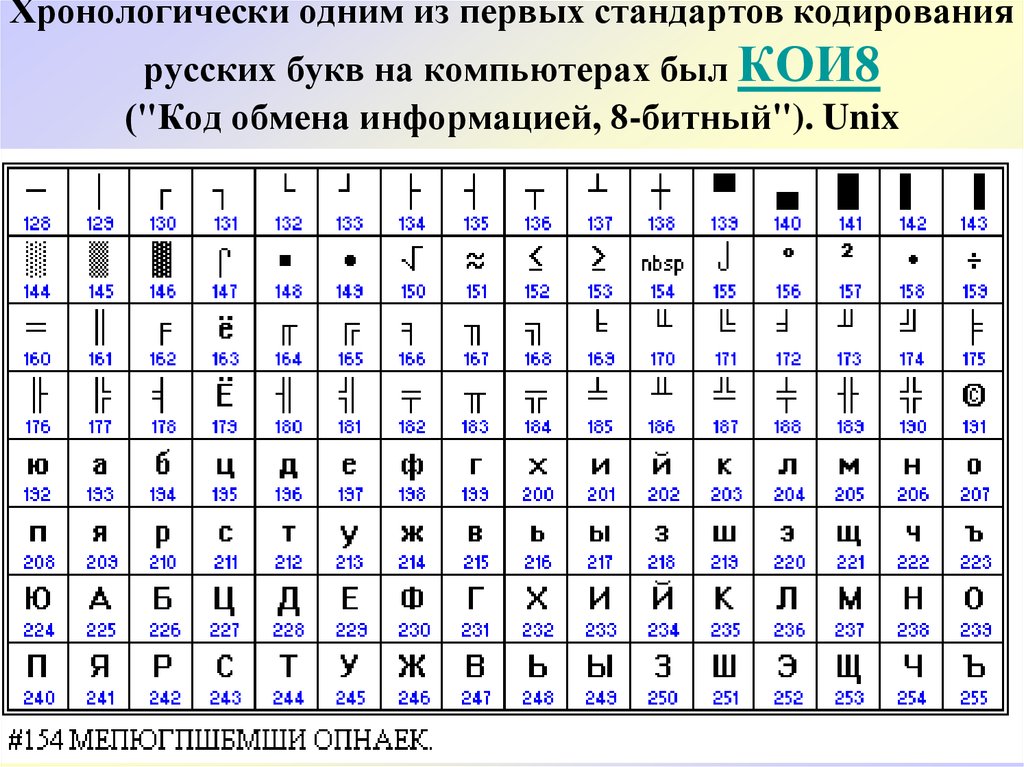
1. В операционной системе Windows запустить текстовый редактор MicrosoftWord.
2. В текстовом редакторе MicrosoftWord ввести команду [Вставка-Символ…]. На экране появится диалоговое окно Символ. Центральную часть диалогового окна занимает фрагмент таблицы символов.
3. Для определения числового кола знака кириллицы с помощью раскрывающегося списка Набор: выбрать пункт кириллица.
4. Для определения шестнадцатеричного числового кода символа в кодировке Unicode с помощью раскрывающегося списка из: выбрать тип кодировки Юникод (шестн.).
5. В таблице символов выбрать символ Э. В текстовом поле кодзнака : появится его шестнадцатеричный числовой код (в данном случае 042D).
Решите задачи:
№1. Закодируйте с помощью таблицы ASCII слова: А) Excel; Б) Access; В) Windows; Г) ИНФОРМАЦИЯ.
№2. Буква «i» в таблице кодов имеет код 105.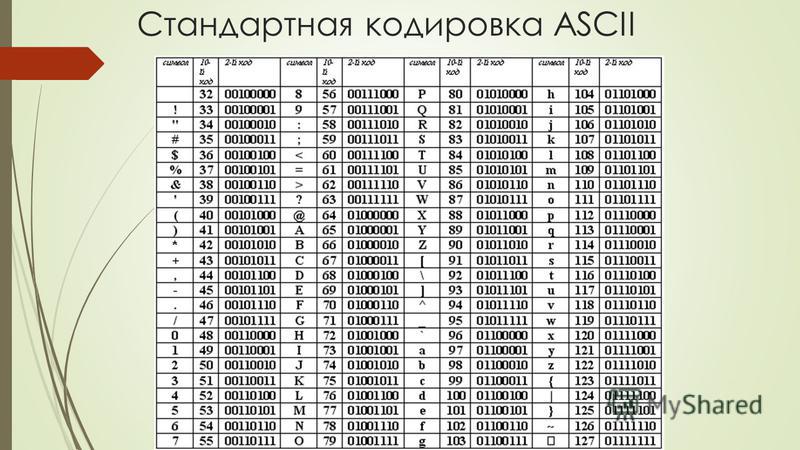 Не пользуясь таблицей, расшифруйте следующую последовательность кодов: 102, 105, 108, 101.
Не пользуясь таблицей, расшифруйте следующую последовательность кодов: 102, 105, 108, 101.
№3. Десятичный код буквы «е» в таблице ASCII равен 101. Не пользуясь таблицей, составьте последовательность кодов, соответствующих слову help.
№4. Десятичный код буквы «i» в таблице ASCII равен 105. Не пользуясь таблицей, составьте последовательность кодов, соответствующих слову link.
№5. Декодируйте следующие тексты, заданные десятичным кодом:
А) 192 235 227 238 240 232 242 236;
Б) 193 235 238 234 45 241 245 229 236 224;
В) 115 111 102 116 119 97 114 101.
№6. Во сколько раз увеличится информационный объем страницы текста при его преобразовании из кодировки Windows 1251 (таблица кодировки содержит 256 символов) в кодировку Unicode (таблица кодировки содержит 65536 символов)?
№7. Каков информационный объем текста, содержащего слово ПРОГРАММИРОВАНИЕ:
Каков информационный объем текста, содержащего слово ПРОГРАММИРОВАНИЕ:
А) в 16-битной кодировке;
Б) в 8-битной кодировке.
№8. Текст занимает ¼ Кбайта. Какое количество символов он содержит?
№9. Текст занимает полных 6 страниц. На каждой странице размещается 30 строк по 80 символов. Определить объем оперативной памяти, который займет этот текст.
№10. Свободный объем оперативной памяти компьютера 320 Кбайт. Сколько страниц книги поместится в ней, если на странице:
А) 32 строки по 32 символа;
Б) 64 строки по 64 символа;
В) 16 строк по 32 символа.
№11. Текст занимает 20 секторов на двусторонней дискете объемом 360 Кбайт. Дискета разбита на 40 дорожек по 9 секторов. Сколько символов содержит текст?
ascii, таблица ascii, кодовая страница, кодовая страница, расширенная
Кодовые страницы / таблица Ascii :: ascii, таблица ascii, кодовая страница, кодовая страница, расширенная
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
 с. Роман-8
с. Роман-8 Таблицы наборов символов — проект Kermit
Франк да Круз
10 марта 2011 г.
Обновлено 1 августа 2021 г.:
FTP-ссылки преобразованы в HTTP; HTML4 в HTML5; проверка W3C; небольшие улучшения контента.
Следующие ссылки относятся к таблицам наборов символов в едином формате, в котором каждый символ включен буквально, его код показан в четырех способами (десятичными, строками/столбцами, восьмеричными, шестнадцатеричными) и его именем. из соответствующего стандарта (если есть), либо его Имя Unicode или в противном случае краткое имя. «C1 Safe» сообщает, соответствует ли набор символов международным стандартам и резервирует область 0x80-0x9ф для контроля персонажи. Наборы символов , а не C1-Safe не подходят. для межплатформенного обмена данными.
Каждая таблица включает файл HTML с диктором для ее набор символов, поэтому символы должны правильно отображаться в вашем веб-браузере если он поддерживает объявления набора символов HTML следующего вида:
в котором имена «charset» взяты из
IANA/MIME
реестр.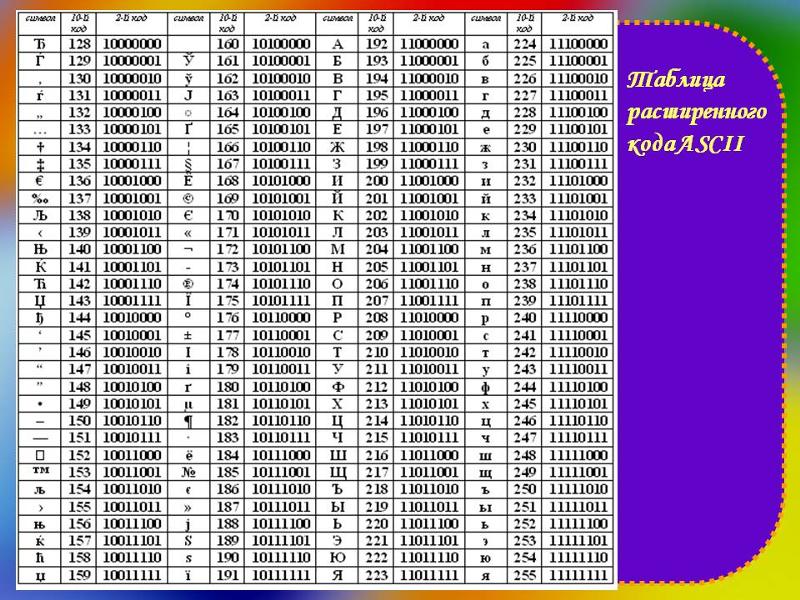 В HTML5 это будет:
В HTML5 это будет:
<МЕТА-кодировка="iso-8859-1">
или (предпочтительнее, так как все страницы теперь должны быть закодированы в UTF-8):
<МЕТА-кодировка="utf-8">
Если символы отображаются неправильно в вашем браузере, это означает, что ваш браузер не понимает объявление или не поддерживает его набор символов или у вас нет подходящего шрифта. Тем не менее, вы все еще можете сохраните файл и используйте его локально.
Если вы сохраните таблицу, вы сможете ее использовать (возможно, вы захотите сохранить только часть между
и) для проверки набора символов осведомленное программное обеспечение. Например, если сохранить на хосте, то сделать терминал соединение (ssh, telnet, коммутируемое соединение, что угодно) с вашего настольного компьютера на host, вы можете увидеть, работают ли ваши определения набора символов, и/или если вы используют подходящий шрифт.
Обратите внимание, что непечатаемые символы, такие как мягкий дефис, скорее всего, будут занимать
нет места на дисплее.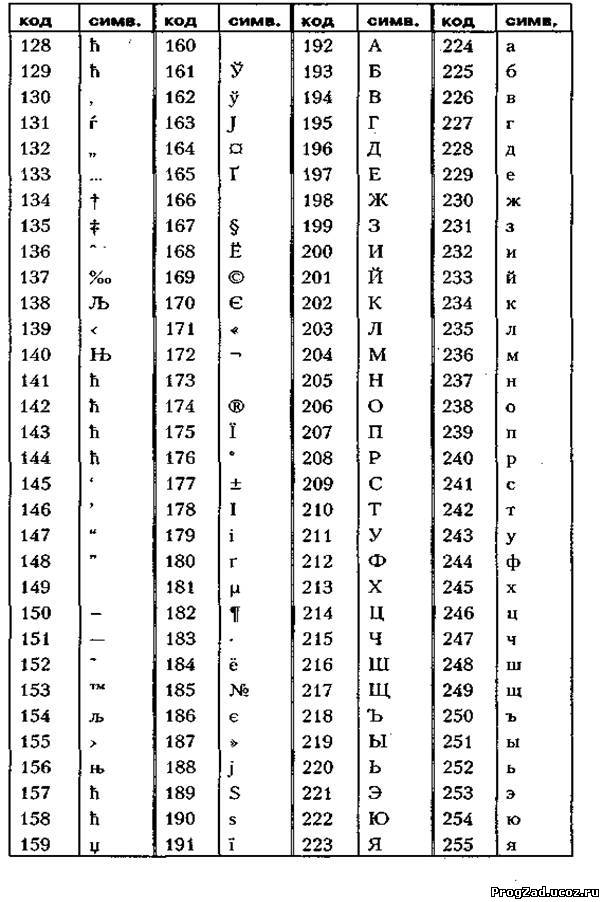 Несмотря на то, что скобки кажутся пустыми,
действительно является характером между ними.
Несмотря на то, что скобки кажутся пустыми,
действительно является характером между ними.
Если вам нужен стол, которого здесь нет, дайте мне знать, и я добавлю его.
Стол IANA/MIME Скрипт С1 Сейф Примечания US ASCII/ISO 646 IRV US-ASCII Латинский Н/Д США КОИ-7 / Короткий КОИ Кириллица Н/Д СССР ISO 8859-1 Латинский алфавит 1 ISO-8859-1 Латинский Да Западная Европа ISO 8859-2 Латинский алфавит 2 ISO-8859-2 Латинский Да Восточная Европа ISO 8859-3 Латинский алфавит 3 ISO-8859-3 Латинский Да Западная Европа/Турция ISO 8859-4 Латинский алфавит 4 ISO-8859-4 Латинский Да Северная и Западная Европа ISO 8859-5 Латинский/кириллица ISO-8859-5 Кириллица Да ISO 8859-6 Латинский/арабский алфавит ISO-8859-6 Арабский Да ISO 8859-7 Латинский/греческий алфавит ISO-8859-7 Греческий Да ISO 8859-8 Латинский/ивритский алфавит ISO-8859-8 Иврит Да ISO 8859-15 Латинский алфавит 9 ISO-8859-15 Латинский Да Западная Европа Многонациональная компания DEC (MCS) DEC-MCS Латинский Да Западная Европа ПК Кодовая страница 437 IBM437 Латинский Нет Западная Европа Кодовая страница ПК 850 IBM850 Латинский Нет Западная Европа ПК Кодовая страница 852 IBM852 Латинский Нет Восточная Европа ПК Кодовая страница 856 (нет) Кириллица Нет ПК Кодовая страница 861 IBM861 Латинский Нет Исландия ПК Кодовая страница 862 IBM862 Иврит Нет ПК Кодовая страница 866 IBM866 Кириллица Нет Кодовая страница Microsoft Windows 1250 windows-1250 латиница Нет Восточная Европа Кодовая страница Microsoft Windows 1251 windows-1251 кириллица Нет Кодовая страница Microsoft Windows 1252 окна-1252 Латинский Нет Западная Европа Кодовая страница Microsoft Windows 1254 окна-1254 Латинский Нет Турция Юникод UTF-8 U+0020-28FF UTF-8 (много) Нет (Все, кроме CJK) (БОЛЬШОЙ!) Юникод Готика U+10330-1034F UTF-8 Готика Нет Юникод 3. Оставить комментарий