Отлично, для 128 символов достаточно 7 бит. С другой стороны, в байте 8 бит и каналы связи 8-битные (забудем про «доисторические» времена, когда в байте и каналах бит было меньше). По 8-ми битному каналу будем передавать 7 бит кода символа и 1 бит контрольный (для повышения надежности и распознавания ошибок). И все было замечательно, пока компьютеры не стали использоваться в других странах (где латиница содержит больше 26 символов или вообще используется не латинский алфавит). Вместо того, чтобы всем поголовно освоить английский, жители СССР, Франции, Германии, Грузии и десятков других стран захотели, чтобы компьютер общался с ними на их родном языке. Пути были разные (в зависимости от остроты проблемы): одно дело, если к 26 символам латиницы надо добавить 2-3 национальных символа (можно пожертвовать какими-то специальными) и другое дело, когда надо «вклинить» кириллицу.

 Текст с большими и маленькими буквами стал выглядеть вполне прилично. Все эти варианты более-менее работали на больших компьютерах, но после выпуска IBM PC началось массовое распространение персональных компьютеров по всему миру и надо было что-то решать централизовано.
Текст с большими и маленькими буквами стал выглядеть вполне прилично. Все эти варианты более-менее работали на больших компьютерах, но после выпуска IBM PC началось массовое распространение персональных компьютеров по всему миру и надо было что-то решать централизовано.Решением стала разработанная фирмой IBM технология кодовых страниц. К этому времени «контрольный символ» при передаче потерял свою актуальность и все 8-бит можно было использовать для кода символа. Вместо диапазона кодов 0-127 стал доступен диапазон 0-255. Кодовая страница (или кодировка)– это сопоставление кода из диапазона 0-255 некоему графическому образу (например, букве «Я» кириллицы или букве «омега» греческого). Нельзя сказать «символ с кодом 211 выглядит так», но можно сказать «символ с кодом 211 в кодовой странице CP1251 выглядит так: У, а в CP1253(греческая) выглядит так: Σ ». Во всех (или почти всех) кодовых таблица первые 128 кодов соответствуют таблице ASCII, только для первых 32 непечатных кодов IBM «назначила» свои картинки (которые показывается при выводе на экран монитора).

 От KOI8 тоже «отпочковывались» варианты — украинский, белорусский, таджикский, кавказский и др. Оборудование (принтеры, видеодаптеры) тоже надо было настраивать (или «прошивать») для работы со своими кодировками. Коммерсанты могли привезти дешевую партию принтеров (из эмиратов, например, по бартеру) а они не работали с русскими кодировками.
От KOI8 тоже «отпочковывались» варианты — украинский, белорусский, таджикский, кавказский и др. Оборудование (принтеры, видеодаптеры) тоже надо было настраивать (или «прошивать») для работы со своими кодировками. Коммерсанты могли привезти дешевую партию принтеров (из эмиратов, например, по бартеру) а они не работали с русскими кодировками.Тем не менее в целом кодовые страницы позволили решить проблему вывода национальных символов (устройство просто должно уметь работать с соответствующей кодовой страницей), но породили проблему множественности кодировок, когда почтовая программа отправляет данные в одной кодировке, а принимающая программа показывает их в другой. В результате пользователь видит так называемые «кракозябры» (вместо «привет» написано «ЏаЁўҐв» или «оПХБЕР»). Потребовались программы-перекодировщики, переводящие данные из одной кодировки в другую. Увы, порой письма при прохождении через почтовые серверы неоднократно автоматически перекодировались (или даже «обрезался» 8-й бит) и нужно было найти и выполнить всю цепочку обратных преобразований.
После массового перехода на Windows к трем кодовым страницам добавилась четвертая (Windows-1251 она же CP1251 она же ANSI ) и пятая (CP866 она же OEM или DOS). Не удивляйтесь — Windows для работы с кириллицей в консоли по-умолчанию использует кодировку CP866 (русские символы такие же как в «альтернативной кодировке», только некоторые спецсимволы отличаются), для других целей — кодировку CP1251. Почему Windows понадобилось две кодировки, неужели нельзя было обойтись одной? Увы, не получается: DOS-кодировка используется в именах файлов (тяжелое наследие DOS) и консольные команды типа dir, copy должны правильно показывать и правильно обрабатывать досовские имена файлов. С другой стороны, в этой кодировке много кодов отведено символам псевдографики (различным рамкам и т.п.), а Windows работает в графическом режиме и ей (а точнее, windows-приложениям) не нужны символы псевдографики (но нужны занятые ими коды, которые в CP1251 использованы для других полезных символов). Пять кириллических кодировок поначалу еще больше усугубили ситуацию, но со временем наиболее популярными стали Windows-1251 и KOI8, а досовскими просто стали меньше пользоваться.
Решение проблемы кодировок пришло, когда повсеместно стала внедряться система Unicode (и для персональных ОС и для серверов). Unicode каждому национальному символу ставит в соответствие раз и навсегда закрепленное за ним 20-ти битовое число («точку» в кодовом пространстве Unicode, причем чаще всего хватает 16 бит, поскольку 20-битные коды используются для редких символов и иероглифов), поэтому нет необходимости перекодировать (подробнее об Unicode см следующую запись в журнале). Теперь для любой пары <код байта>+<кодовая страница> можно определить соответствующий ей код в Unicode (сейчас в кодовых страницах для каждого 8-битного кода показывается 16-битный код Unicode) и потом при необходимости вывести этот символ для любой кодовой страницы, где он присутствует. В настоящее время проблема кодировок и перекодировок для пользователей практически исчезла, но все же изредка приходят письма, где либо тема письма либо содержание «не в той» кодировке.

Юный читатель может спросить — а что помешало сразу использовать Unicode, зачем были придуманы эти заморочки с кодовыми страницами? Думаю, дело в финансовой стороне проблемы. Unicode требует в 2 раза больше памяти, а память стоит денег (и дисковая и ОЗУ). Стал бы американец покупать компьютер на 1-2 тыс дороже из-за того, что «теперь новая ОС требует больше памяти, но позволяет без проблем работать с русским, европейскими, арабскими языками»? Боюсь, простой англоязычный покупатель воспринял бы такой аргумент «неадекватно» (и обратился бы к другим производителям).
Лекция Кодирование текстовой информации
ТЕМА «Кодирование текстовой информации»
С точки зрения ЭВМ текст состоит из отдельных символов. К числу символов принадлежат не только буквы (заглавные или строчные, латинские или русские), но и цифры, знаки препинания, спецсимволы типа «=», «(«, «&» и т.п. и даже (обратите особое внимание!) пробелы между словами. Да, не удивляйтесь: пустое место в тексте тоже должно иметь свое обозначение.
Да, не удивляйтесь: пустое место в тексте тоже должно иметь свое обозначение.
Вся информация в компьютере хранится в двоичном коде. Поэтому надо научиться преобразовывать символы в двоичный код.
Множество символов, с помощью которых записывается текст, называется алфавитом.
Число символов в алфавите – это его мощность.
Формула определения количества информации:
N = 2b,
где N – мощность алфавита (количество символов),
b – количество бит (информационный вес символа).
В алфавит мощностью 256 символов можно поместить практически все необходимые символы. Такой алфавит называется достаточным.
Т.к. 256 = 28, то вес 1 символа – 8 бит.
Двоичный код каждого символа в компьютерном тексте занимает 1 байт памяти.
В оперативную память символы попадают в двоичном коде. Это значит, что каждый символ представляется 8-разрядным двоичным кодом.
Кодирование заключается в том, что каждому символу ставится в соответствие уникальный десятичный код от 0 до 255 или соответствующий ему двоичный код от 00000000 до 11111111. Этот код просто порядковый номер символа в двоичной системе счисления. Таким образом, человек различает символы по их начертанию, а компьютер — по их коду.
Таблица, в которой всем символам компьютерного алфавита поставлены в соответствие порядковые номера, называется таблицей кодировки.Для разных типов ЭВМ используются различные таблицы кодировки.
Международным стандартом для ПК стала таблица ASCII (читается аски) (Американский стандартный код для информационного обмена).
Таблица кодов ASCII делится на две части (смотреть приложение 2).
Международным стандартом является лишь первая половина таблицы, т.е. символы с номерами от 0 (00000000), до 127 (01111111).
Структура таблицы кодировки ASCIIПорядковый номер | Код | Символ |
0 — 31 | 00000000 — 00011111 | Символы с номерами от 0 до 31 принято называть управляющими. Их функция – управление процессом вывода текста на экран или печать, подача звукового сигнала, разметка текста и т.п. |
32 — 127 | 00100000 — 01111111 | Стандартная часть таблицы (английский). Сюда входят строчные и прописные буквы латинского алфавита, десятичные цифры, знаки препинания, всевозможные скобки, коммерческие и другие символы. Символ 32 — пробел, т.е. пустая позиция в тексте. Все остальные отражаются определенными знаками. |
128 — 255 | 10000000 — 11111111 | Альтернативная часть таблицы (русская). Вторая половина кодовой таблицы ASCII, называемая кодовой страницей (128 кодов, начиная с 10000000 и кончая 11111111), может иметь различные варианты, каждый вариант имеет свой номер. Кодовая страница в первую очередь используется для размещения национальных алфавитов, отличных от латинского. В русских национальных кодировках в этой части таблицы размещаются символы русского алфавита. |

Обращаю ваше внимание на то, что в таблице кодировки буквы (прописные и строчные) располагаются в алфавитном порядке, а цифры упорядочены по возрастанию значений. Такое соблюдение лексикографического порядка в расположении символов называется принципом последовательного кодирования алфавита.
Для букв русского алфавита так же в основном соблюдается принцип последовательного кодирования.
С конца 90-х годов проблема стандартизации символьного кодирования решается введением нового международного стандарта, который называется Unicode. Это 16-разрядная кодировка, т.е. в ней на каждый символ отводится 2 байта памяти. Конечно, при этом объем занимаемой памяти увеличивается в 2 раза. Но зато такая кодовая таблица допускает включение до 65536 символов. Полная спецификация стандарта Unicode включает в себя все существующие, вымершие и искусственно созданные алфавиты мира, а также множество математических, музыкальных, химических и прочих символов.
Попробуем с помощью таблицы ASCII представить, как будут выглядеть слова в памяти компьютера.Слово 1 | Память ПК | Слово 2 | Память ПК | |||
file | f | 01100110 | disk | d | 01100100 | |
i | 01101001 | i | 01101001 | |||
l | 01101100 | s | 01110011 | |||
e | 01100101 | k | 01101011 | |||
Каждый символ текста кодируется восьмиразрядным двоичным кодом.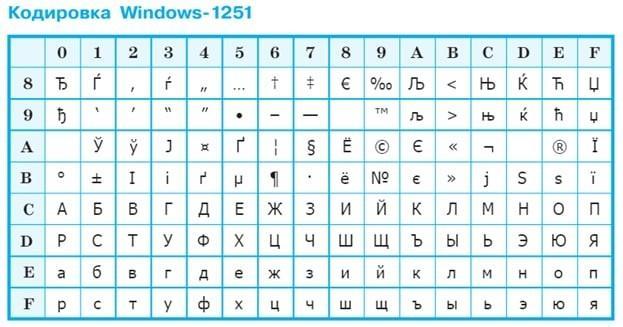 Для представления текстов в компьютере используется алфавит мощностью 256 символов.
Для представления текстов в компьютере используется алфавит мощностью 256 символов.
В таблице кодировки каждому символу алфавита поставлен в соответствие порядковый номер и восьмиразрядный двоичный код.
Все символы кодируются одинаковым числом бит (алфавитный подход)
Международным стандартом является код ASCII — американский стандартный код для информационного обмена.
Чаще всего используют кодировки, в которых на символ отводится 8 бит (8-битные ASCII) или 16 бит (16-битные Unicode)
После знака препинания внутри (не в конце!) текста ставится пробел
При измерении количества информации принимается, что в одном байте 8 бит, а в одном килобайте (1 Кбайт) – 1024 байта, в мегабайте (1 Мбайт) – 1024 Кбайта
Чтобы найти информационный объем текста I, нужно умножить количество символов N на число бит на символ K :
I=N*K
Примеры решения задач
Пример 1 Закодируйте кодом ASCII слово MOSCOW.
Решение:
Составим таблицу и поместим туда слово MOSCOW. Используя таблицу ASCII кодов, закодируем все буквы слова:
M | O | S | C | O | W |
01001101 | 01001111 | 01010011 | 01000011 | 01001111 | 01110111 |
ОТВЕТ:
100110110011111010011100001110011111110111
Пример 2
Задача 1. Информационный объём сообщения составляет 8,5 Кбайт (I). Данное сообщение содержит 8704 символа (N). Какое минимально возможное количество символов содержится в использованном алфавите?
Решение задачи 1.
Информационный объём сообщения 8,5 Кбайт = 8,5 * 1024 = 8704 байта
I / N = K (число бит на символ)
8704 байта / 8704 символа = Одному символу сообщения соответствует 1 байт = 8 бит
С помощью 8 бит (1 байта) можно закодировать 28 = 256 символов, это меньше количества символов, содержащихся в сообщении.
Ответ:
В использованном алфавите содержится 256 символов, что соответствует полному алфавиту ASCII.
Пример 3
Задача 2.
Автоматическое устройство осуществило перекодировку информационного сообщения, первоначально записанного в 7-битном коде ASCII, в 16-битную кодировку Unicode. При этом информационное сообщение увеличилось на 108 бит.
Какова длина сообщения в символах?
1) 12
2) 27
3) 6
4) 62
Решение задачи 2.
Изменение кодировки с 7 бит на 16 бит, равно 16 — 7 = 9 бит. Следовательно информационный объем каждого символа сообщения увеличился на 9 бит. По условиям задачи информационный объем сообщения после кодировки составил 108 бит, следовательно количество символов в сообщении = 108/9 = 12.
Ответ: 1) 12 символов.
Пример 4
Задача 3.
В одной из кодировок Unicode каждый символ кодируется 16 битами.
Определите размер следующего предложения в данной кодировке:
«Тише едешь – дальше будешь!»
216 бит
27 байт
54 байта
46 байт
Решение задачи 3:
Каждый символ кодируется 16 битами. Значит общее количество бит во всем предложении равно количеству символов умноженному на 16. Аккуратно подсчитаем количество символов в предложении, не забывая при этом пробелы между словами. Получаем 27 символов, умножаем 27 на 16, получаем 432 бита. Такого ответа нет среди предлагаемых вариантов. Переведем полученную величину в байты. То есть поделим 432 на 8 (или изначально можно было умножить 27 на 2, а не на 8). Получаем 54 байта.
Аккуратно подсчитаем количество символов в предложении, не забывая при этом пробелы между словами. Получаем 27 символов, умножаем 27 на 16, получаем 432 бита. Такого ответа нет среди предлагаемых вариантов. Переведем полученную величину в байты. То есть поделим 432 на 8 (или изначально можно было умножить 27 на 2, а не на 8). Получаем 54 байта.
Ответ: 3) 54 байта.
ЗАКРЕПЛЕНИЕ МАТЕРИАЛА.
Задание 1. Расшифруйте сообщение, используя таблицу ASCII.
1001001 | |
1101110 | |
1100110 | |
1101111 | |
1110010 | |
1101101 | |
1100001 | |
1110100 | |
1101001 | |
1101111 | |
1101110 |
Задание 2.
Задача. Считая, что каждый символ кодируется одним байтом, оцените информационный объем следующего предложения:
Один пуд – около 16,4 килограмм.
ПРИЛОЖЕНИЕ 1
Аналогичные (Базовой таблице кодировки ASCII) системы кодирования текстовых данных были разработаны и в других странах.
Так, например, в СССР в этой области действовала система кодирования КОИ-7 (код обмена информацией, семизначный). Однако поддержка производителей оборудования и программ вывела американский код ASCII на уровень международного стандарта, и национальным системам кодирования пришлось «отступить» во вторую, расширенную часть системы кодирования, определяющую значения кодов со 128 по 255. Отсутствие единого стандарта в этой области привело к множественности одновременно действующих кодировок. Только в России можно указать три действующих стандарта кодировки и еще два устаревших.
Так, например, кодировка символов русского языка, известная как кодировка Windows-1251, была введена «извне» — компанией Microsoft, но, учитывая широкое распространение операционных систем и других продуктов этой компании в России, она глубоко закрепилась и нашла широкое распространение (таблица 1.2). Эта кодировка используется на большинстве локальных компьютеров, работающих на платформе Windows.
Другая распространенная кодировка носит название КОИ-8 (код обмена информацией, восьмизначный) — ее происхождение относится ко временам действия Совета Экономической Взаимопомощи государств Восточной Европы (таблица 1.3). Сегодня кодировка КОИ-8 имеет широкое распространение в компьютерных сетях на территории России и в российском секторе Интернета.
Международный стандарт, в котором предусмотрена кодировка символов русского алфавита, носит название кодировки /50 (International Standard Organization — Международный институт стандартизации). На практике данная кодировка используется редко (таблица 1.4).
На практике данная кодировка используется редко (таблица 1.4).
На компьютерах, работающих в операционных системах MS—DOS, могут действовать еще две кодировки (кодировка ГОСТ и кодировка ГОСТ-альтернативная). Первая из них считалась устаревшей даже в первые годы появления персональной вычислительной техники, но вторая используется и по сей день (см. таблицу 1.5).
В связи с изобилием систем кодирования текстовых данных, действующих в России, возникает задача межсистемного преобразования данных — это одна из распространенных задач информатики.
Если проанализировать организационные трудности, связанные с созданием единой системы кодирования текстовых данных, то можно прийти к выводу, что они вызваны ограниченным набором кодов (256). В то же время очевидно, что если, например, кодировать символы не восьмиразрядными двоичными числами, а числами с большим количеством разрядов, то и диапазон возможных значений кодов станет намного больше. Такая система, основанная на 16-разрядном кодировании символов, получила название универсальной — UNICODE. Шестнадцать разрядов позволяют обеспечить уникальные коды для 65 536 различных символов — этого поля достаточно для размещения в одной таблице символов большинства языков планеты.
Такая система, основанная на 16-разрядном кодировании символов, получила название универсальной — UNICODE. Шестнадцать разрядов позволяют обеспечить уникальные коды для 65 536 различных символов — этого поля достаточно для размещения в одной таблице символов большинства языков планеты.
8
Таблицы наборов символов— проект Kermit
Франк да КрузСледующие ссылки относятся к таблицам наборов символов в едином формате, в котором каждый символ включен буквально, его код показан в четырех способами (десятичными, строками/столбцами, восьмеричными, шестнадцатеричными) и его именем. из соответствующего стандарта (если есть), либо его Имя Unicode или в противном случае краткое имя.
10 марта 2011 г.
Обновлено 1 августа 2021 г.:
FTP-ссылки преобразованы в HTTP; HTML4 в HTML5; проверка W3C; небольшие улучшения контента.
 «C1 Safe» сообщает, соответствует ли набор символов
международным стандартам и резервирует область 0x80-0x9ф для контроля
персонажи. Наборы символов , а не C1-Safe не подходят.
для межплатформенного обмена данными.
«C1 Safe» сообщает, соответствует ли набор символов
международным стандартам и резервирует область 0x80-0x9ф для контроля
персонажи. Наборы символов , а не C1-Safe не подходят.
для межплатформенного обмена данными.Каждая таблица включает файл HTML с диктором для ее набор символов, поэтому символы должны правильно отображаться в вашем веб-браузере если он поддерживает объявления набора символов HTML следующего вида:
в котором имена «charset» взяты из IANA/MIME реестр. В HTML5 это будет:
<МЕТА-кодировка="iso-8859-1">
или (предпочтительнее, так как все страницы теперь должны быть закодированы в UTF-8):
<МЕТА-кодировка="utf-8">
Если символы отображаются неправильно в вашем браузере, это означает, что ваш
браузер не понимает объявление или не поддерживает его
набор символов или у вас нет подходящего шрифта.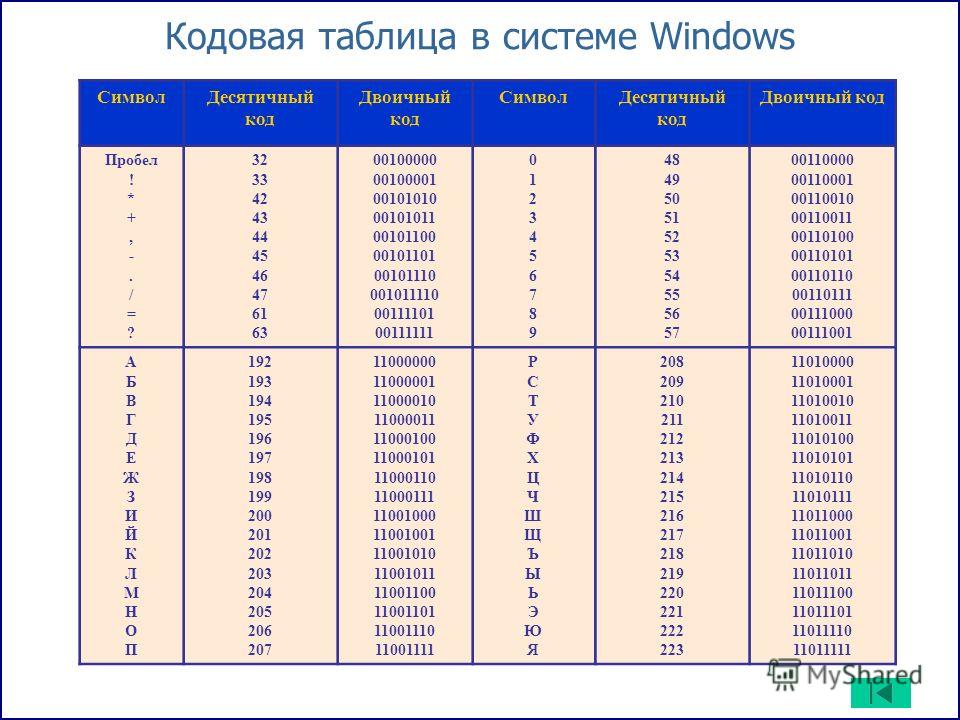 Тем не менее, вы все еще можете
сохраните файл и используйте его локально.
Тем не менее, вы все еще можете
сохраните файл и используйте его локально.
Если вы сохраните таблицу, вы сможете ее использовать (возможно, вы захотите сохранить только часть между
и) для проверки набора символов осведомленное программное обеспечение. Например, если сохранить на хосте, то сделать терминал соединение (ssh, telnet, коммутируемое соединение, что угодно) с вашего настольного компьютера на host, вы можете увидеть, работают ли ваши определения набора символов, и/или если вы используют подходящий шрифт.
Обратите внимание, что непечатаемые символы, такие как мягкий дефис, скорее всего, будут занимать нет места на дисплее. Несмотря на то, что скобки кажутся пустыми, действительно является характером между ними.
Если вам нужен стол, которого здесь нет, дайте мне знать, и я добавлю его.
Стол IANA/MIME Скрипт С1 Сейф Примечания US ASCII/ISO 646 IRV US-ASCII Латинский Н/Д США КОИ-7 / Короткий КОИ Кириллица Н/Д СССР ISO 8859-1 Латинский алфавит 1 ISO-8859-1 Латинский Да Западная Европа ISO 8859-2 Латинский алфавит 2 ISO-8859-2 Латинский Да Восточная Европа ISO 8859-3 Латинский алфавит 3 ISO-8859-3 Латинский Да Западная Европа/Турция ISO 8859-4 Латинский алфавит 4 ISO-8859-4 Латинский Да Северная и Западная Европа ISO 8859-5 Латинский/кириллица ISO-8859-5 Кириллица Да ISO 8859-6 Латинский/арабский алфавит ISO-8859-6 Арабский Да ISO 8859-7 Латинский/греческий алфавит ISO-8859-7 Греческий Да ISO 8859-8 Латинский/ивритский алфавит ISO-8859-8 Иврит Да ISO 8859-15 Латинский алфавит 9 ISO-8859-15 Латинский Да Западная Европа Многонациональная компания DEC (MCS) DEC-MCS Латинский Да Западная Европа ПК Кодовая страница 437 IBM437 Латинский Нет Западная Европа Кодовая страница ПК 850 IBM850 Латинский Нет Западная Европа ПК Кодовая страница 852 IBM852 Латинский Нет Восточная Европа ПК Кодовая страница 856 (нет) Кириллица Нет ПК Кодовая страница 861 IBM861 Латинский Нет Исландия ПК Кодовая страница 862 IBM862 Иврит Нет ПК Кодовая страница 866 IBM866 Кириллица Нет Кодовая страница Microsoft Windows 1250 windows-1250 латиница Нет Восточная Европа Кодовая страница Microsoft Windows 1251 windows-1251 кириллица Нет Кодовая страница Microsoft Windows 1252 окна-1252 Латинский Нет Западная Европа Кодовая страница Microsoft Windows 1254 окна-1254 Латинский Нет Турция Юникод UTF-8 U+0020-28FF UTF-8 (много) Нет (Все, кроме CJK) (БОЛЬШОЙ!) Юникод Готика U+10330-1034F UTF-8 Готика Нет Юникод 3. 1 Уровень 1
Вы можете найти текстовые (не встроенные в HTML) версии этих таблиц (и многое другое) в архиве проекта Kermit: http://www.columbia.edu/kermit/archivefiles/charsets.html; передавать их только в ДВОИЧНОМ режиме. Для любой пары файлов xxx .c и xxx .txt, первая — программа на C для создания таблицы, вторая — это сама таблица. ПРИМЕЧАНИЕ: эти таблицы не будут правильно отображаться в вашем браузере, потому что это обычный текст, который не может объявить свою кодировку символов. Чтобы загрузить любую из этих таблиц, щелкните правой кнопкой мыши его имя (крайний правый столбец) и выберите «Сохранить» или «Загрузить».
кодовых страниц | Alteryx Help
Кодовая страница (также называемая набором символов или кодировкой) представляет собой таблицу значений, в которой каждому символу присвоено числовое представление. Кодовая страница позволяет компьютеру правильно идентифицировать символы и отображать текст.
Alteryx поддерживает множество кодовых страниц, которые можно выбрать при вводе и выводе файлов данных с помощью инструментов «Вводные данные» и «Вывод данных» или при преобразовании типов данных с помощью инструмента «Преобразование больших двоичных объектов». Кроме того, функции
Кроме того, функции ConvertFromCodepage и ConvertToCodepage (доступные в инструментах с редактором выражений) могут использовать идентификаторы кодовых страниц для преобразования строк между кодовыми страницами и Unicode®, универсальным стандартом кодирования для всех письменных символов, созданным Консорциум Юникод.
Alteryx предполагает, что широкая строка представляет собой строку Unicode®, а узкая строка — строку Latin 1. Если вы преобразуете строку в кодовую страницу, она не будет отображаться правильно. Поэтому кодовые страницы следует использовать только для переопределения проблем с кодировкой текста в файле. Кодовые страницы могут быть разными на разных компьютерах или могут быть изменены для одного компьютера, что приводит к повреждению данных. Для наиболее согласованных результатов используйте Unicode®, например кодировку UTF-8 или UTF-16, вместо определенной кодовой страницы, которая позволяет кодировать разные языки в одном потоке данных.
UTF-8 — самый портативный и компактный способ хранения любых символов, который используется чаще всего. И UTF-8, и UTF-16 представляют собой кодировку с переменной шириной, но UTF-8 совместим с ASCII, и файлы, как правило, меньше, чем с UTF-16.
Дополнительные сведения о кодовых страницах см. в библиотеке MSDN.
Для поддержки той же функциональности в Linux Alteryx использует библиотеку ICU. Мы используем те же идентификаторы, что и в Windows, конвертируя их с помощью конвертеров ICU. ICU не поддерживает весь список кодировок Windows или могут быть различия при преобразовании данных из одной кодовой страницы в другую.
Эти идентификаторы кодовых страниц поддерживаются функциями ConvertFromCodepage и ConvertToCodepage . Перейдите в раздел «Функции» для получения дополнительной информации.
| ID | Описание | Опора |
| 37 | IBM EBCDIC — США/Канада | Оригинальный двигатель и усилитель. |
| 500 | IBM EBCDIC — международный | Оригинальный двигатель и усилитель. |
| 932 | ANSI/OEM — Японский Shift-JIS | Оригинальный двигатель и усилитель. |
| 949 | ANSI/OEM — корейский EUC-KR | Оригинальный двигатель и усилитель. Не поддерживается для скачивания и преобразования BLOB-объектов. |
| 1250 | ANSI — Центральная Европа | Оригинальный двигатель и усилитель. |
| 1251 | ANSI — Кириллица | Оригинальный двигатель и усилитель. |
| 1252 | ANSI — латиница I | Оригинальный двигатель и усилитель. |
| 1253 | ANSI — греческий | Оригинальный двигатель и усилитель. |
| 1254 | ANSI — турецкий | Оригинальный двигатель и усилитель. |
| 1255 | ANSI — иврит | Оригинальный двигатель и усилитель. |
| 1256 | ANSI — арабский | Оригинальный двигатель и усилитель. |
| 1257 | ANSI — Прибалтика | Оригинальный двигатель и усилитель. |
| 1258 | ANSI/OEM — вьетнамский | Оригинальный двигатель и усилитель. |
| 10000 | MAC — Роман | Оригинальный двигатель и усилитель. |
| 28591 | ISO 8859-1 латиница I | Оригинальный двигатель и усилитель. |
| 28592 | ISO 8859-2 Центральная Европа | Оригинальный двигатель и усилитель. |
| 28593 | ISO 8859-3 латиница 3 | Оригинальный двигатель и усилитель. |
| 28594 | ISO 8859-4 Балтика | Оригинальный двигатель и усилитель. |
| 28595 | ISO 8859-5 Кириллица | Оригинальный двигатель и усилитель. |
| 28596 | ISO 8859-6 Арабский | Оригинальный двигатель и усилитель. Оставить комментарий
|