Кодовые страницы — Win32 apps
- Статья
Большинство приложений, написанных сегодня, обрабатывают символьные данные в основном как Юникод, используя кодировку UTF-16. Однако во многих устаревших приложениях по-прежнему используются наборы символов на основе кодов. Даже новым приложениям иногда приходится работать с кодными страницами, часто по одной из следующих причин:
- Для взаимодействия с устаревшими приложениями.
- Для взаимодействия со старыми почтовыми серверами и серверами новостей, которые могут не всегда поддерживать Юникод.
- Взаимодействие с консолью Windows для устаревших целей.


Примечание
Новые приложения Windows должны использовать Юникод , чтобы избежать несоответствий различных кодовых страниц и упростить локализацию.
Каждая кодовая страница представлена идентификатором кодовой страницы, например 1252, и обрабатывается функциями API Юникода и кодировки. Список поддерживаемых идентификаторов кодовых страниц см. в разделе Идентификаторы кодовых страниц. Справочник по «Кодовые страницы» в Глобальном центре разработчиков Microsoft Go содержит полное описание многих кодовых страниц.
Кодовые страницы Windows, обычно называемые «кодовые страницы ANSI», — это кодовые страницы, для которых значения, отличные от ASCII (значения больше 127), представляют международные символы. Эти кодовы страницы используются изначально в Windows Me, а также доступны в Windows NT и более поздних версиях.
Примечание
Первоначально кодовая страница Windows 1252, кодовая страница, обычно используемая для английского и других западноевропейских языков, была основана на проекте Американского национального института стандартов (ANSI).
Многие функции API Windows имеют версии «A» (ANSI) и «W» (широкий, Юникод). Версия «A» обрабатывает текст на основе кодовых страниц Windows, а версия «W» — текст Юникода. См. статью Типы данных Windows для строк и соглашения для прототипов функций.
Кодовую страницу Windows также иногда называют «активными кодными страницами» или «системными активными кодами». В операционной системе Windows всегда есть одна активная в данный момент кодовая страница Windows. Все версии функций API ANSI используют текущую активную кодовую страницу.
Кодовые страницы изготовителя оборудования (OEM) — это кодовые страницы, для которых значения, отличные от ASCII, представляют собой символы рисования и пунктуации. Эти кодовые страницы изначально использовались для MS-DOS и по-прежнему используются для консольных приложений.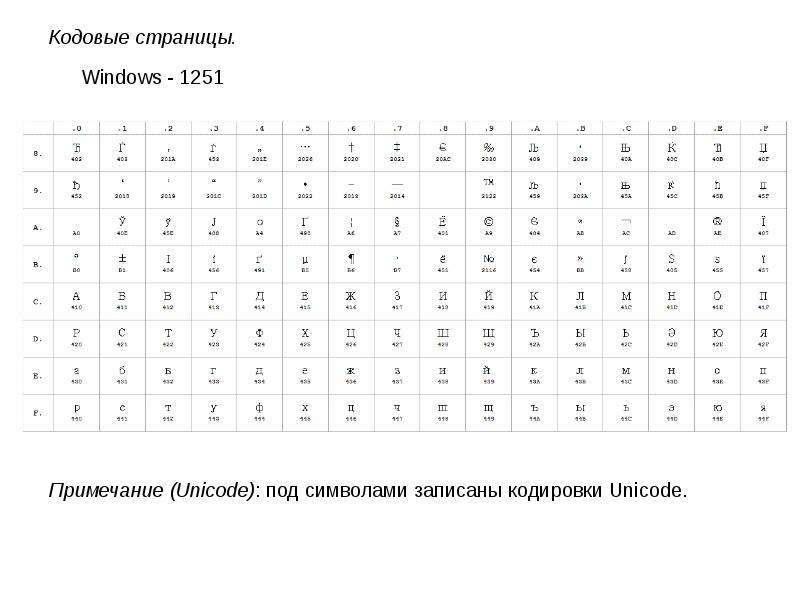 Они также используются для не расширенных имен файлов в файловых системах FAT12, FAT16 и FAT32, как описано в разделе Наборы символов, используемые в именах файлов. Обычная кодовая страница OEM для английского языка — кодовая страница 437.
Они также используются для не расширенных имен файлов в файловых системах FAT12, FAT16 и FAT32, как описано в разделе Наборы символов, используемые в именах файлов. Обычная кодовая страница OEM для английского языка — кодовая страница 437.
Для кодовых страниц Windows и кодовых страниц OEM значения кода 0x00 через 0x7F соответствуют 7-разрядной кодировке ASCII. Кодовые значения 0x00 0x19 и 0x7F всегда представляют стандартизированные управляющие символы, а 0x20 через 0x7E — стандартизированные отображаемые символы. Символы, представленные остальными кодами, 0x80 0xff, различаются в разных наборах символов. Каждая кодировка содержит различные специальные символы, обычно настраиваемые для определенного языка или группы языков. Кодовая страница Windows 1252 и кодовая страница OEM 437 обычно используются в США.
Помимо кодовых страниц Windows и OEM, приложения могут использовать не машинные кодовые страницы. Примерами могут быть кодовые страницы EBCDIC и Macintosh.
Две кодировки Юникода (UTF-7 и UTF-8) реализуются в виде кодовых страниц. Как и другие кодовые страницы, каждая страница известна по числовым идентификаторам и может обрабатываться с помощью многих одинаковых функций API Юникода и кодировки.
Как и другие кодовые страницы, каждая страница известна по числовым идентификаторам и может обрабатываться с помощью многих одинаковых функций API Юникода и кодировки.
Кодовые страницы могут быть однобайтовой кодировкой (SBCS) или двухбайтовой кодировкой (DBCS). На страницах SBCS каждый байт напрямую кодирует один символ, чтобы можно было представить ровно 256 различных символов (включая управляющие символы, буквы, цифры, знаки препинания, символы и т. д.). Кодовая страница DBCS используется для таких языков, как японский и китайский. В такой кодовой странице некоторые символы имеют двухбайтовые кодировки с определенными значениями байтов (всегда больше 127), которые служат в качестве «байтов свинца». Вместо того, чтобы кодировать символы самостоятельно, байты свинца можно сопоставить с символом только в сочетании с «байтом следа».
Некоторые устаревшие протоколы требуют использования кодовых страниц SBCS и DBCS. Каждая кодовая страница SBCS/DBCS поддерживает разные символы, но никакая кодовая страница не поддерживает полный набор символов, предоставляемых Юникодом. Каждая кодовая страница SBCS/DBCS поддерживает другое подмножество с разными кодировками.
Каждая кодовая страница SBCS/DBCS поддерживает другое подмножество с разными кодировками.
Примечание
Данные, преобразованные из одной кодовой страницы SBCS или DBCS в другую, могут быть повреждены, так как одно и то же значение данных на разных кодовых страницах может кодировать другой символ. Данные, преобразованные из Юникода в SBCS или DBCS, могут быть потеряны, так как данная кодовая страница может не представлять все символы, используемые в данных Юникода.
Помимо кодовых страниц SBCS и DBCS, в приложениях доступны многобайтовые кодовые страницы 52936, 54936, 51949 и 5022x, которые используют подход, аналогичный тому, который используется для DBCS. Однако кодовая страница многобайтовой кодировки выходит за рамки двухбайтовых кодировок некоторых символов. В UTF-7 и UTF-8 используется аналогичный подход для кодирования Юникода на основе 7- и 8-разрядных байтов соответственно. Дополнительные сведения см. в разделе Юникод.
Несколько функций Юникода и кодировки позволяют приложениям обрабатывать кодовые страницы.
Приложение может использовать функции MultiByteToWideChar и WideCharToMultiByte для преобразования строк на основе кодовых страниц Windows и строк Юникода. Хотя их названия относятся к «MultiByte», эти функции одинаково хорошо работают с кодовыми страницами SBCS, DBCS и многобайтовой кодировки.
Примечание
WideCharToMultiByte может потерять некоторые данные, если указанная кодовая страница не может представлять все символы в строке Юникода.
Приложение может преобразовывать кодовые страницы Windows и кодовые страницы OEM с помощью стандартных функций библиотеки среды выполнения C. Однако использование этих функций представляет риск потери данных, так как символы, которые могут быть представлены каждой кодовой страницей, не совпадают точно.
Приложения также могут вызывать функцию GetACP . Эта функция получает идентификатор текущей кодовой страницы Windows (ANSI).
Кодировки
Ошибка в Zabbix — Неподдерживаемая кодовая страница
Home » Мониторинг » Zabbix » Ошибка в Zabbix — Неподдерживаемая кодовая страница
Zerox Обновлено: 21.05.2020 Zabbix, Ошибки 10 комментариев 6,727 Просмотры
Некоторое время назад столкнулся с ошибкой в web интерфейсе Zabbix после очередного обновления сервера. Текст ошибки в веб интерфейсе — Неподдерживаемая кодовая страница или тип сравнения для таблиц. То же самое было на английском языке в логе — character set name or collation name that is not supported by Zabbix found in 379 column(s) of database «zabbix», only character set «utf8» and collation «utf8_bin» should be used in database
Если у вас есть желание научиться администрировать системы на базе Linux, рекомендую познакомиться с онлайн-курсом «Linux для начинающих» в OTUS. Курс для новичков, для тех, кто с Linux не знаком. Подробная информация.
Курс для новичков, для тех, кто с Linux не знаком. Подробная информация.
Выглядела ошибка вот так.
В принципе, по тексту ошибки все понятно. Таблицы в базе данных почему-то имеют не ту кодировку, которая нужна. Работает при этом все нормально. Операционная система — Centos 8.
Стал решать проблему в лоб. Взял и изменил кодировку у всех таблиц в базе данных Zabbix. На деле это оказалось не такой простой задачей, как виделось изначально. В итоге поступил следующим образом. Вводим в консоли Mysql следующую команду:
SELECT CONCAT( 'ALTER TABLE `', t.`TABLE_SCHEMA` , '`.`', t.`TABLE_NAME` , '` CONVERT TO CHARACTER SET utf8 COLLATE utf8_bin;' ) AS sqlcode FROM `information_schema`.`TABLES` t WHERE 1 AND t.`TABLE_SCHEMA` = ' zabbix' ORDER BY 1 LIMIT 0 , 180;
Работа этой команды сформирует на выходе набор из команд для перекодировки каждой таблицы в отдельности. Их нужно все запустить. Если делать все через phpmyadmin, то не возникает проблем. Все команды копируются разом и исполняются. Если будете делать через консоль сервера, то придется как-то обрабатывать вывод, чтобы подать его потом на вход. Надо будет от лишних символов очищать.
Все команды копируются разом и исполняются. Если будете делать через консоль сервера, то придется как-то обрабатывать вывод, чтобы подать его потом на вход. Надо будет от лишних символов очищать.
Не забудьте сделать бэкап базы данных перед тем, как начнете с ней что-то делать.
Если у вас есть желание научиться строить и поддерживать высокодоступные и надежные системы, рекомендую познакомиться с онлайн-курсом «Administrator Linux. Professional»
Помогла статья? Подписывайся на telegram канал автора
Анонсы всех статей, плюс много другой полезной и интересной информации, которая не попадает на сайт.Скачать pdf
Автор Zerox
Владимир, системный администратор, автор сайта. Люблю настраивать сервера, изучать что-то новое, делиться знаниями, писать интересные и полезные статьи.
Открыт к диалогу и сотрудничеству. Если вам интересно узнать обо мне побольше, то можете послушать интервью. Запись на моем канале — https://t.me/srv_admin/425 или на сайте в контактах.
Люблю настраивать сервера, изучать что-то новое, делиться знаниями, писать интересные и полезные статьи.
Открыт к диалогу и сотрудничеству. Если вам интересно узнать обо мне побольше, то можете послушать интервью. Запись на моем канале — https://t.me/srv_admin/425 или на сайте в контактах.
Предыдущая Percona Mysql server master — slave репликация
Следующая Удаленный доступ сотрудников и HelpDesk с помощью Veliam
Что такое кодовая страница?
Кодовая страница — это другое название кодировки символов. Большая часть нового программного обеспечения способна читать стандарт кодировки UTF-8 (Unicode). Тем не менее, некоторым старым программам для правильной работы может потребоваться определенная кодовая страница, например, Windows-1250 для польского языка.
ISO/IEC 8859
ISO 8859-1 : Latin-1 или западноевропейский
ISO 8859-2 : Latin-1 или восточноевропейский
ISO 8859-3 : Latin-3 или Южно-Европейский
ISO 8859-4 : Latin-4 или североевропейский
ISO 8859-5: латиница/кириллица
ISO 8859-6: латинский/арабский
ISO 8859-7: латинский/греческий
ISO 8859-8: латинский/иврит
ISO 8859-9: латиница-5 или турецкий
ISO 8859-10: Latin-6 или скандинавские языки
ISO 8859-13 : Latin-7 или Балтийский край
ISO 8859-15: Latin-9 или Western European (включая дополнительные символы)
ISO 2022-JP: японский
ISO 2022-JP-2: японский язык
ISO 2022-KR: корейский
IBM PC
IBM037: набор символов Latin-1, используемый в мейнфреймах IBM
IBM273 : Германия, Австрия
IBM277 : Дания
IBM278 : Швеция
IBM280 : Италия
IBM284 : Испания
IBM285 : Великобритания, Ирландия
IBM297 : Франция
IBM420 : арабский
IBM423 : греческий
IBM424 : иврит
IBM437 : исходная кодовая страница IBM PC
. IBM500 : латиница 1
IBM500 : латиница 1
IBM775 : эстонский, литовский и латышский
IBM850 : «Многоязычный (латиница-1)» (западноевропейские языки)
IBM852 : «Славянский (латиница-2)» (языки Центральной и Восточной Европы)
IBM855 : Кириллица
IBM857 : Турецкий
IBM860 : португальский
IBM861 : исландский
IBM863 : французский (Квебек, французский)
IBM864 : арабский
IBM865 : датский/норвежский
IBM869 : греческий
IBM870 : латинский 2
IBM871 : Исландия
IBM880 : Русская кириллица
IBM905 : Турецкий
IBM1026 : Турция
MS-DOS
CP 866 : Кириллица
CP 875 : греческий
CP 1025 : Кириллица
WINDOWS
windows-1250 : Центрально- и восточноевропейская латиница
windows-1251 : Кириллица
windows-1252 : западноевропейская латиница
windows-1253: греческий
windows-1254 : турецкий
windows-1255 : иврит
windows-1256: арабский
окна-1257 : Балтика
windows-1258 : вьетнамский
windows-874: тайский
KOI
KOI8-R: русский,
KOI8-U: украинский
Расширенный код Unix (EUC)
EUC-CN: упрощенные китайские символы
EUC-JP: стандарты японского набора символов
EUC-KR: текст на корейском языке
Unicode/ISO/IEC 10646
UTF-7
УТФ-8
UTF-16
UTF-32
UTF-32BE
Первые телекоммуникации
US-ASCI: английский алфавит
Другое
Johab: корейский
Макинтош
CSISO2022JP: японский
арабский
Shift_JIS : японский
ASMO 708 : арабский
GB 18030 : упрощенный китайский
ГБ 2312: китайский
BIG 5: кодировка китайских символов
Дополнительные сведения см. на странице: http://msdn.microsoft.com/en-us/library/windows/desktop/dd317756(v=vs.85).aspx 9.0003
на странице: http://msdn.microsoft.com/en-us/library/windows/desktop/dd317756(v=vs.85).aspx 9.0003
Набор символов, кодовые страницы, кодировки, нажатием кнопки
Набор символов, кодовые страницы, кодировки, нажатием кнопкиКодовые страницы, кодировки символов от поставщиков программного обеспечения и органов по стандартизации
Здесь вы можете найти информацию о наборе символов и кодовой странице от поставщиков программного обеспечения. (Microsoft, HP, IBM, Sun и т. д.) и международных организаций по стандартизации (например, ISO, ECMA, INCITS и т. д.). Нажмите любую «кнопку» и вы попадете либо на таблицу кодовой страницы предоставленный поставщиком, или веб-страницу поставщика со ссылками на диаграммы кодовых страниц. Это дает вам быстрый доступ к популярным кодовым страницам, а также доступ к более полным спискам диаграмм кодовых страниц.
Организация
Ссылки (в основном) организованы поставщиком или стандартной организацией. Некоторые кодовые страницы перечислены избыточно, обычно потому, что кодовая страница описывается разными поставщиками.
Иногда разница важна. Например, представление кодовой страницы одним поставщиком может отличаться от
чужой. Конечно, таблицы преобразования символов или сопоставления могут быть очень разными. Иногда кодовая страница была
обновлен, и один поставщик все еще ссылается на более раннюю версию кодовой страницы.
Некоторые кодовые страницы перечислены избыточно, обычно потому, что кодовая страница описывается разными поставщиками.
Иногда разница важна. Например, представление кодовой страницы одним поставщиком может отличаться от
чужой. Конечно, таблицы преобразования символов или сопоставления могут быть очень разными. Иногда кодовая страница была
обновлен, и один поставщик все еще ссылается на более раннюю версию кодовой страницы.
Кодировки символов, форматы преобразования, двухбайтовые, многобайтовые, UTF…
Обратите внимание, что «кодовая страница» также известна под другими именами:
кодовая страница, кодировка, набор символов, набор символов, набор закодированных символов, (CCS),
набор графических символов, карта символов и др. Некоторые из них имеют
более конкретные имена DBCS (набор двухбайтовых символов), MBCS
(многобайтовый набор символов). Некоторые кодировки являются результатом
преобразования и известны как форматы преобразования,
примеры включают Unicode UTF-8, UTF-16, UTF-32.
Суррогатные кодовые точки Unicode UTF-16 или дополнительные символы
Если вас интересуют суррогатные кодовые точки UTF-16 или дополнительные символы, см.
Настройка Microsoft Windows NT, 2000 или Windows XP для поддержки дополнительных символов Unicode
и
Таблица преобразования: суррогаты Unicode в скалярное значение/UTF-32.
Другие страницы Unicode на этом сайте, которые могут представлять интерес, включают: Памятка: Исходный код Microsoft C/C++ с поддержкой Unicode, Хирагана Персонажи, еврейские символы, Преимущества стандарта Unicode и Убедительная демонстрация Unicode.
Unicode Организации по стандартизации Различные веб-страницы The Go To Guys Czyborra’s Site Great Sites China’s GB18030 Гонконгский дополнительный набор символов (HKSCS) Машиночитаемый каталог Библиотеки Конгресса (MARC) | Кодовые страницы Microsoft ISO Кодовые страницы Microsoft Windows Двухбайтовые наборы символов Microsoft Кодовые страницы Microsoft DOS | Данные преобразования символов IBM ICU Кодовые страницы IBM ISO Кодовые страницы IBM Windows Кодовые страницы IBM для азиатских стран Кодовые страницы IBM DOS |
Различные веб-страницыI18n Таблица Unicode для хираганы I18n Гая История набора символов Дика Винтера Сайт польской кодовой страницы Петра Тржёнковского (на польском языке) Наборы символов Cyrillic. Страница с наборами символов I18nGuru VT320, VT102, VT52, Heath-19 Терминалы DEC VT100, VT220, VT320 Наборы символов Костиса Apple Macintosh Костиса Roman Японская кодировка Различия Таблицы персонажей Коити Ясуоки | Таблицы UnicodeТаблицы Unicode Указатель имен символов Unicode UTF-32 (TR-19) Модель кодирования символов (TR-17) Базовая латиница Латиница-1 дополнительная Расширенная латиница-A Комбинация диакритических знаков Греческий Кириллица Иврит I18n Таблица Unicode для иврита Гая Арабский Символы валюты Хангул Джамо Хирагана Таблица Unicode хираганы I18n Guy Катакана | Организации по стандартизацииISO INCITS Стандарты ECMA ISO 6429 = ECMA-48 (pdf) Международный регистр ISO/IEC кодированных наборов символов для использования с управляющими последовательностями Реестр набора символов IANA Указатель RFC RFC 1555 Кодировка символов иврита для интернет-сообщений RFC 1556 Обработка двунаправленных текстов в MIME RFC 1556 определяет ISO-8859-6-e, ISO-8859-6-i, ISO-8859-8-e, ISO-8859-8-i. Армянские наборы символов ArmSCII Тайский TIS 620-2533 Аннотированная ссылка на тайские реализации |
The Go To GuysСайт Майкла Эверсона CJK.inf Кена Лунде Сервер набора символов Кена Лунде Сайт Марка Дэвиса | Сайт ЧиборрыСайт www.czyborra.com/charsets недоступен. К счастью, у Кевина Аткинсона есть отразил его на aspell.net/charsets. Эти кнопки теперь связаны с его зеркалом. Спасибо, Кевин.Сайт Roman Czyborra Кодовые страницы поставщиков Czyborra Страница Czyborra на вьетнамском языке ASCII/ISO 646 страница Czyborra ISO 8859 Alphabet Soup 9 0003 Так ватный юникод? Куриный суп? | Великие сайтыНаборы символов Франка да Круза Таблицы наборов символов Франка да Круза Учебник Корпелы по вопросам кодирования символов Сайт Корпелы по символам и кодированию |
GB18030 Веб-страницыМаркус Шерер из ICU на GB18030 Sun на GB18030-2000 Пакет поддержки Microsoft GB18030 (в GB2312) (Adobe) Dirk Me Ваше резюме GB18030 | Гонконгский дополнительный набор символов (HKSCS)Гонконгский дополнительный набор символов (HKSCS) Hong Kong ITF on ISO 10646 | MARC БиблиографическийMARC 21 MARC-8 MARC UCS (Unicode) Кодовые таблицы MARC |
Здесь много таблиц транскодирования, выраженных в XML-файлах с использованием
Язык разметки отображения символов
(CharMapML, УТР 22). IBM ICUДанные преобразования символов Символьные данные IBMКодовые страницы IBM (Приложение F) Списки символов IBM (Приложение I) IBM Sort Sequences (Приложение C) | IBMКодовые страницы ISO CP 00819 (ISO 8859-1) Латинский алфавит № 1 CP 00813 (ISO 8859-7) Греция CP 00916 (ISO 8859-8) Иврит 90 003 СР 00920 (ИСО 8859 -9) Турция | IBMКодовые страницы Windows CP 01250 (Windows) Латинский 2 CP 01252 (Windows) Латинский 1 CP 01253 (Windows) Греческий CP 01254 (Windows) Турецкий 9 0003 CP 01255 (Windows) Иврит CP 01256 (Windows) Арабский CP 01257 (Windows) Балтийский край |
На следующих веб-страницах лидбайты обозначены светом
затенение серого фона. Оставить комментарий
|
 com
com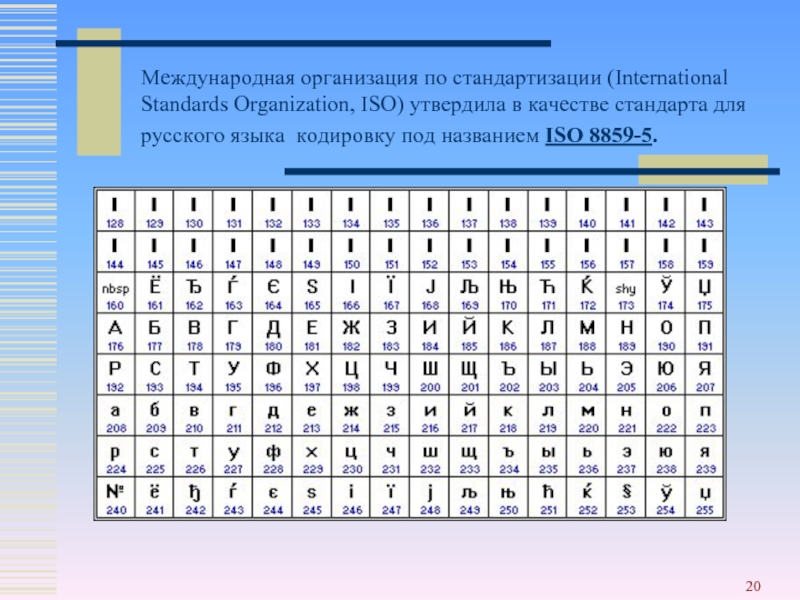 Данные преобразования кодирования используются в
Компоненты интернационализации для библиотеки с открытым исходным кодом Unicode (ICU).
Данные преобразования кодирования используются в
Компоненты интернационализации для библиотеки с открытым исходным кодом Unicode (ICU).