[Данные, строки] Преобразование кодировки ISO-8859-1 в Windows-1251
man_without_face
Новичок
- #1
Всем здравствуйте!
Со сканера штрих-кода, при чтении pdf417, содержащего кириллицу, на выходе имею текст в кодировке ISO-8859-1. Сторонними способами (онлайн декодирование, программы типа «Штирлиц», сменить кодировку можно. Но на целевом объекте, данные методы недоступны.
Для вноса этих данных в базу, данная кодировка не подходит. Можно ли сменить её средствами autoit? На входе имеем либо текстовый файл, сохраненный в юникоде или utf-8 через стандартный блокнот, либо эти данные в буфере обмена. На выходе нужен текстовый файл, читаемый в Windows.
Спасибо!
Naisho
Знающий
- #2
_WinAPI_MultiByteToWideChar _WinAPI_WideCharToMultiByte
ra4o
AutoIT Гуру
- #3
Строку расшифровывает функция «_Encoding_UTF8BOMDecode», правда на 99% — нет Букв Ёё,Ч,Ъъ,Я
Вот пример, пробуйте
#include <Encoding.Чуть дописал в функции «_Encoding_UTF8BOMDecode» строки, теперь всё раскодирует корректно .au3> $hFile = FileOpen(@ScriptDir & '\example.txt', 0) If $hFile = -1 Then MsgBox(4096, "Ошибка", "Невозможно открыть файл.") Exit EndIf $sLine = FileReadLine($hFile, 4) MsgBox(0, 'Результат', _Encoding_UTF8BOMDecode($sLine)) FileClose($hFile)
Замените эти две строки в функции «_Encoding_UTF8BOMDecode» в UDF Encoding.au3 :
Local $sDecodeStr = BinaryToString('0xC3A0C3A1C3A2C3A3C3A4C3A5C3A6C3A7C3A8C3A9C3AAC3ABC3ACC3ADC3AEC3AFC3B0C3B1C3B2C3B3C3B4C3B5C3B6C3B7C3B8C3B9C3BCC3BBC3BDC3BEC3BFC39FC2A8C2B8C397C39A', 4)
Local $sEncodeStr = 'абвгдежзийклмнопрстуфхцчшщьыэюяЯЁёЧъ'Во вложении UDF «Encoding.au3» уже с исправленными строками
man_without_face
Новичок
- #4
Спасибо, получилось.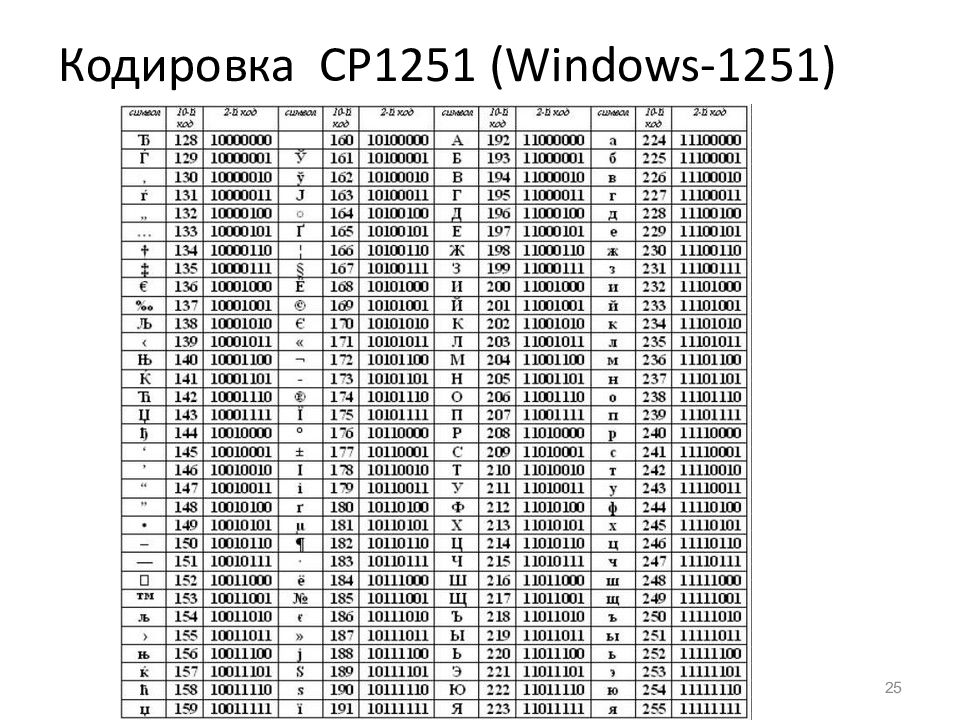 Пришлось немного помучаться, оказывается функция некорректно работает, если в тексте есть символы разрыва строки. Но т.к. текст все равно обрабатывается дальше, просто убрал все @CRLF из считанного файла.
Пришлось немного помучаться, оказывается функция некорректно работает, если в тексте есть символы разрыва строки. Но т.к. текст все равно обрабатывается дальше, просто убрал все @CRLF из считанного файла.
ra4o
AutoIT Гуру
- #5
Уберите все возвраты каретки функциейфункция некорректно работает, если в тексте есть символы разрыва строки.
Нажмите, чтобы раскрыть…
StringStripCR()
Конвертирование базы данных DLE из utf-8 в windows-1251 » DataLife Engine (DLE) — система управления сайтом и контентом. Официальный сайт.
О том, как перевести сайт и базу данных из кодировки windows-1251 в кодировку utf-8, уже рассказывалось неоднократно. Это можно сделать средствами самой DLE. Данная статья предназначена для тех, кто хочет перевести сайт из кодировки utf-8 в кодировку windows—1251. Cделать это сравнительно легко в «домашних» условиях без обращений к техподдержке хостинга или без самостоятельных дополнительных манипуляций на своем сервере. Надеюсь, она поможет тем, кто по каким-то причинам разочаровался в кодировке utf-8 и решил вернуться к windows-1251.
Это можно сделать средствами самой DLE. Данная статья предназначена для тех, кто хочет перевести сайт из кодировки utf-8 в кодировку windows—1251. Cделать это сравнительно легко в «домашних» условиях без обращений к техподдержке хостинга или без самостоятельных дополнительных манипуляций на своем сервере. Надеюсь, она поможет тем, кто по каким-то причинам разочаровался в кодировке utf-8 и решил вернуться к windows-1251.Для начала вам нужно сделать дамп базы данных вашего сайта (можно, и даже лучше, средствами самого движка через админпанель сайта), которые работают в кодировке utf-8, и скачать этот дамп себе на локальный компьютер.
Перед тем как начать заниматься базой данных, вам нужно будет удалить файлы дистрибутива старого сайта в кодировке utf-8 и проинсталлировать по новой дистрибутив DLE в кодировке windows-1251. От старого дистрибутива вам нужно оставить на хостинге (НЕ УДАЛЯТЬ!!!) папку uploads и все файлы в ней. Также, скачайте к себе на компьютер папку с вашим рабочим шаблоном и папку engine/data со всеми файлами конфигурации сайта — они вам понадобятся, чтобы не вводить все настройки заново после установки DLE в кодировке windows-1251.
Базу данных на хостинге можно оставить прежнюю, но из неё нужно будет удалить все таблицы, оставив её полностью пустой. Затем через phpmyadmin вам будет нужно на вкладке «Операции» выставить «Сравнение» cp1251_general_ci для этой базы данных.
Теперь займемся самой базой данных…
Распакуем архив с базой данных архиватором, например WinRAR. У вас получится файл с расширением .sql. Откроем его с помощью бесплатного текстового редактора Notepad++ (он поддерживает достаточно большие файлы, если кто-то беспокоится из-за размера своего дампа базы данных).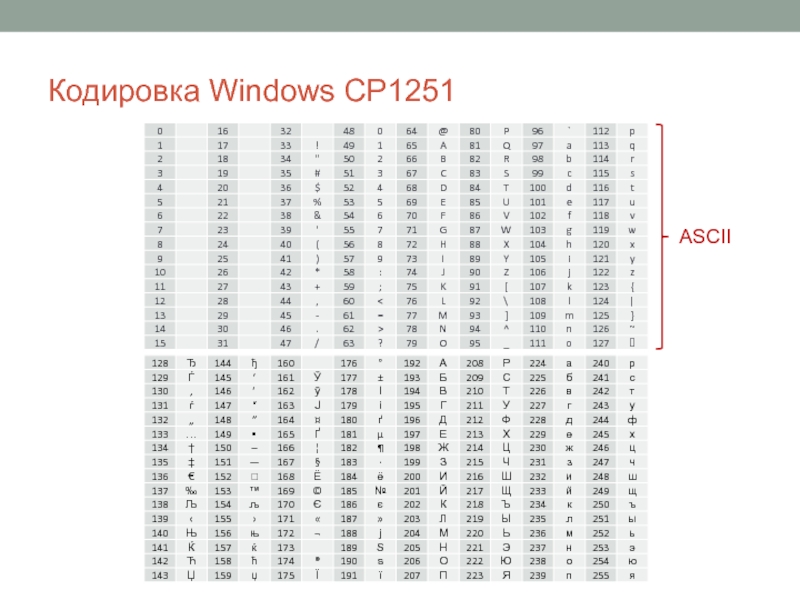
Конвертировать базу данных будем в два этапа.
— Первый этап
Для начала нам нужно сменить название кодировки с utf-8 на windows-1251 по всей базе данных для всех таблиц. Для этого вызываем диалог поиска и замены в Notepad++ и будем менять текст в базе данных сutf8 наcp1251, как на скриншоте. Нажимаем «Заменить всё» и после нажимаем «Сохранить изменения» (иконка дискеты). Для DLE 9.5 на данный момент таблиц должно быть 35 и столько же должно быть произведено замен (см. скриншот).— Второй этап
Теперь нам нужно конвертировать саму базу данных в windows-1251. Чтобы сохранить кириллицу кириллицей, без всяких крякозяблов, делаем следующее…
Нажимаем кнопку «Кодировка» в меню Notepad++ и затем в выпадающем меню выбираем «Преобразовать в ANSI». Ждем пока Notepad++ закончит эту операцию (на больших базах это может занять время) и после этого нажимаем снова «Сохранить изменения» (иконка дискеты).

Если вы сделали все именно так, то кириллица в вашей базе данных сохранилась без изменений, а в правом нижнем углу окна Notepad++ будет видна кодировка «UNIX ANSI».Ваша новая база данных в кодировке windows-1251 готова. Теперь вы можете упаковать её в zip архив, чтобы уберечь от возможных повреждений при загрузке на хостинг, и загрузить в папку backup вашего свежеустановленного сайта, где уже распакуете этот архив через панель управления хостингом (ISPManager или аналогичные). После этого вы сможете восстановить базу данных стандартными средствами движка через админпанель сайта в разделе «Управление базой данных». После восстановления базы данных не забудьте в разделе «Категории» нажать кнопку «Отсортировать категории». Вот, собственно, и все премудрости, теперь у вас и сайт, и база данных в кодировке windows-1251.
Для того, чтобы вам вернуть все настройки (не зря я говорил о необходимости сохранить все файлы из папки engine/data), откройте сохраненный файл config.php, найдите строчку
'charset' => "utf-8",и замените её на
'charset' => "windows-1251",и затем нажимаем «Сохранить изменения» (иконка дискеты). Чтобы перевести этот файл с настройками из кодировки utf-8 в windows-1251 проделываем все то же самое, как и с базой данных, и после снова нажимаем «Сохранить изменения» (иконка дискеты). В правом нижнем углу окна Notepad++ будет видна кодировка «UNIX ANSI». Можете загрузить теперь этот файл config.php к себе на сайт в папку data — все настройки и кодировка будут сохранены. Если остальные файлы из старой папки data у вас тоже изменялись на хостинге, то проделываете с каждым нужным вам из них все те же действия, а после загружаете к себе на сайт в папку data.
С шаблоном нужно сделать то же самое — все файлы стилей .css и шаблонов .tpl нужно перевести в кодировку windows-1251 при помощи Notepad++ по тому же принципу, а после загрузить к себе на сайт в папку с шаблонами. Не забудьте выставить права на файлы в соответствии с документацией к DLE.
Не забудьте выставить права на файлы в соответствии с документацией к DLE.
Ну вот и все. Надеюсь, что эта информация будет для кого-то полезной. Помните, что чтобы избежать ошибок с конвертированием файлов и базы данных, все операции нужно делать с точностью и в два этапа, как описано выше.
Проблема обнаружения кодировки файла | Блокнот++ Сообщество
Ваш браузер не поддерживает JavaScript. В результате ваши впечатления от просмотра будут уменьшены, и вы будете переведены в режим только для чтения .
Загрузите браузер, поддерживающий JavaScript, или включите его, если он отключен (например, NoScript).
Эта тема была удалена. Его могут видеть только пользователи с правами управления темами.
 org/Comment»>
org/Comment»> Notepad++ имеет проблемы с определением правильной кодировки файлов. Обычно я храню текстовые файлы в кодировке Windows-1251 (кириллица). Но часто для файлов, содержащих не только латинские символы, программа выбирает кодировку Macintosh. Это раздражает, чтобы выбрать правильный.
Можешь починить или ты так любишь яблоки? 🙂
-
@Артём ,
К сожалению, во вселенной нет алгоритма, который всегда будет правильно угадывать кодировку для всех этих древних кодировок Windows-125x. Вот и вся причина, по которой Unicode и кодировки Unicode, такие как UTF-8 и UTF-16, существуют: чтобы вывести нас за пределы 19Технология 80-х годов, позволяющая иметь десятки или сотни кодировок, не позволяющая внешне сказать, не интерпретируя байты как каждую индивидуальную кодировку, и посмотреть, «имеют ли байты смысл» при выполнении этого кодирования.
 Но если вы застряли, имея дело с древней технологией старомодных кодировок, то вы застряли, и превосходство кодировок UTF-* не имеет значения.
Но если вы застряли, имея дело с древней технологией старомодных кодировок, то вы застряли, и превосходство кодировок UTF-* не имеет значения.Если ваши файлы почти всегда в одной кодировке. вы, вероятно, можете отключить MISC> Autodetect Character Encoding, который, по мнению некоторых людей, работает лучше, когда их файлы обычно имеют одну и ту же кодировку.
Если вам нужен способ быстро изменить кодировку на Windows-1251, вы можете использовать Shortcut Mapper на главной вкладке, отфильтровать 1251, а затем ИЗМЕНИТЬ ярлык для Windows-1251 на то, что вы можете запомнить. Затем вы можете просто нажать это нажатие клавиши, чтобы изменить кодировку, если он загружает файл с использованием неправильной кодировки.
-
@Артём
Следите за этой ТЕМОЙ.
 Надеюсь, я скоро закончу сценарий, над которым работал, чтобы «решить» очень похожую проблему.
Надеюсь, я скоро закончу сценарий, над которым работал, чтобы «решить» очень похожую проблему.
Откуда мы знаем, какую кодировку использовать с pd.read_csv? charde не помогает — Курсы DQ
DnaData 1
Управляемый проект: анализ сделок по сбору средств для стартапов от Crunchbase
Ссылка на экран: https://app.dataquest.io/m/167/guided-project%3A-analyzing-startup-fundraising-deals-from-crunchbase/1/introduction
Попытка прочитать некоторые строки из файла csv (с кодировкой UTF-8 по умолчанию) не сработала. Он выдает ниже UnicodeDecodeError
Мой код:
Fivek_rows = pd.read_csv(csvfile, nrows=5000)
Что на самом деле произошло:
UnicodeDecodeError: кодек 'utf-8' не может декодировать байт 0x8e в позиции 6: недопустимый начальный байт
Я попытался использовать chardet, прочитав 128 байт, чтобы определить кодировку, но кажется, что возвращаемая кодировка ненадежна, т. е. возвращает ascii , и это все равно не сработало.
е. возвращает ascii , и это все равно не сработало.
После некоторых догадок и гугления я использовал кодировку = ‘ISO-8859-1’, и это сработало.
Как мы сможем окончательно найти и применить правильную кодировку, используемую в подобных случаях?
Спасибо
1 Нравится
2
По-видимому, правильно определить кодировку с уверенностью невозможно — https://stackoverflow.com/questions/436220/how-to-determine-the-encoding-of-text
Использование chardet , как вы уже пробовали, это один из способов, который может помочь. Но, конечно, это не гарантия.
Рекомендуется попробовать некоторые из наиболее распространенных вариантов —
- UTF-8
- Latin-1 (также известный как ISO-8859-1)
- Windows-1251
ДнкДата 3
Правильно, я использовал, как уже упоминал, encoding=’ISO-8859-1’ и это сработало.
Но мне кажется, что это стрельба в темноте, не так ли?
мобосомто 4
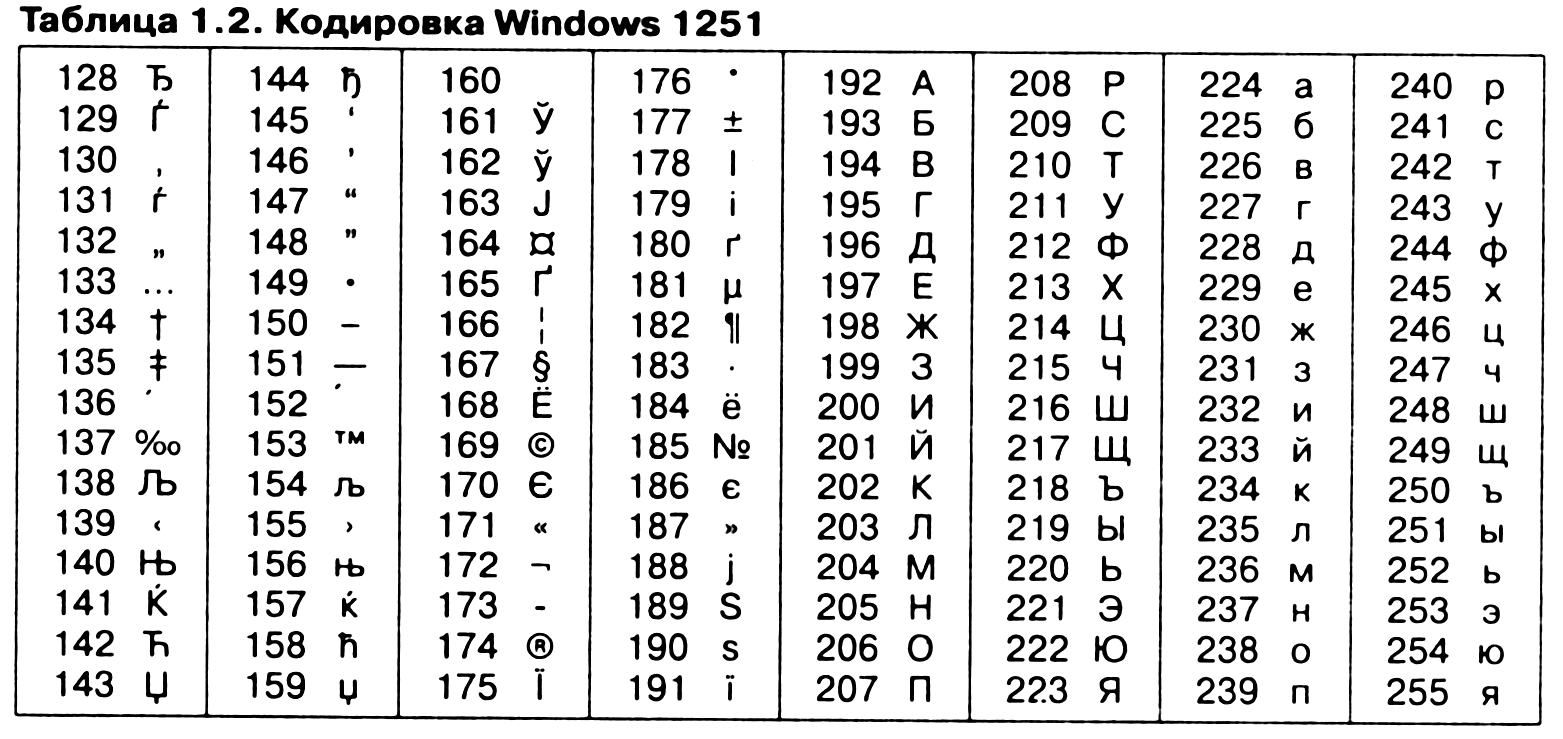
Эй, Дурга, очень сложно точно определить, в каком формате закодирован файл. Так что, как сказал @the_doctor, наиболее жизнеспособные форматы, в которых обычно кодируются файлы, в основном имеют один из следующих:
- UTF-8
- Latin-1 (также известный как ISO-885901)
- Windows-1251
В большинстве случаев шансы обычно находятся между UTF-8 и Latin-1 , поскольку Windows-1251 является подмножеством Latin-1 .
Стивен Румбалски