Кодовые страницы — Школа N61 г.Ульяновска
Сервисы | МинПрос УО | Учебные предметы | Домашнее задание | Программирование | ГИА (ЕГЭ) | Я.Лицей ZooM |
На конец 20-го века существовало пять различных кодировок кириллицы (КОИ8-Р, Windows-1251, MS-DOS, Macintosh и ISO). Из-за этого часто возникали проблемы с переносом русского текста с одного компьютера на другой из одной программной системы в другую.
Хронологически одним из первых стандартов кодирования русских букв на компьютерах был КОИ8 («Код обмена информацией 8-битный»). Эта кодировка применялась еще в 70-ые годы на компьютерах серии ЕС ЭВМ а с середины 80-х стала использоваться в первых русифицированных версиях операционной системы UNIX.
От начала 90-х годов времени господства операционной системы MS DOS остается кодировка CP866 («CP» означает «Code Page» «кодовая страница»).
Компьютеры фирмы Apple работающие под управлением операционной системы Mac OS используют свою собственную кодировку

Кроме того Международная организация по стандартизации (International Standards Organization ISO) утвердила в качестве стандарта для русского языка еще одну кодировку под названием ISO 8859-5.
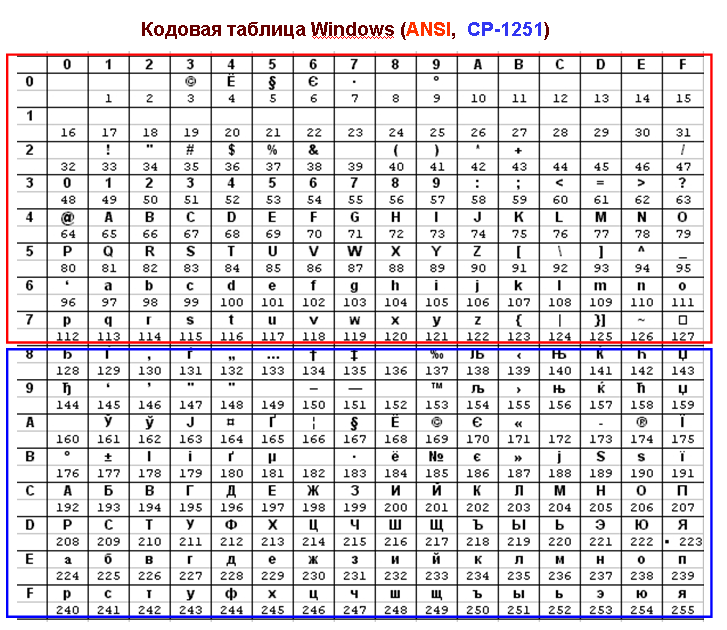
В конце 20-го века наиболее распространенной была кодировка Microsoft Windows обозначаемая сокращением CP1251. Введена компанией Microsoft; с учетом широкого распространения операционных систем (ОС) и других программных продуктов этой компании в Российской Федерации она нашла широкое распространение.
С конца 90-х годов проблема стандартизации символьного кодирования решается введением нового международного стандарта который называется Unicode.
Это 16-разрядная кодировка т.е. в ней на каждый символ отводится 2 байта памяти. Конечно при этом объем занимаемой памяти увеличивается в 2 раза. Но зато такая кодовая таблица допускает включение до 65536 символов. Полная спецификация стандарта Unicode включает в себя все существующие вымершие и искусственно созданные алфавиты мира а также множество математических музыкальных химических и прочих символов.
Внутреннее представление слов в памяти компьютера с помощью таблицы ASCII
|
Слова |
Память |
| file |
01100110 01101001 01101100 01100101 |
| disk |
01100100 01101001 01110011 01101011 |
Иногда бывает так что текст состоящий из букв русского алфавита полученный с другого компьютера невозможно прочитать — на экране монитора видна какая-то «абракадабра». Это происходит оттого что на компьютерах применяется разная кодировка символов русского языка.
Таким образом каждая кодировка задается своей собственной кодовой таблицей. Как видно из таблицы одному и тому же двоичному коду в различных кодировках поставлены в соответ-ствие различные символы.
Сравнительная таблица части кодов разных кодировок русского языка
|
Кодовая старница |
Код символа |
cим вол | … |
65 / 97 193 / 225 |
66 / 98 194 / 226 |
67 / 99 195 / 227 |
68 / 100 196 / 228 |
69 / 101 197 / 229 |
70 / 102 198 / 230 |
71 / 103 199 / 231 |
72 / 104 200 / 232 | … | ||||||||||
| ASCII | 0000 0000 | :) |
. .. ..
| 65 | 0100 0001 | A | 0100 0010 | B | 0100 0011 |
C
| 0100 0100 | D | 0100 0101 | E | 0100 0110 | F | 0100 0111 | G | 0100 1000 | H | … | |
| koi8-r | 1000 0000 | - | … | 193 | 1100 0001 | а | 1100 0010 | б | 1100 0011 | ц | 1100 0100 | д | 1100 0101 | е | 1100 0110 | ф | 1100 0111 | г | 1100 1000 | х |
. .. ..
| |
| ASCII | 0000 0000 | … | 97 | 0110 0001 | a | 0110 0010 | b | 0110 0011 | c | 0110 0100 | d | 0110 0101 | e | 0110 0110 | f | 0110 0111 | g | 0110 1000 | h | … | ||
| koi8-r | 1000 0000 |
. .. ..
| 225 | 1110 0001 | А | 1110 0010 | Б | 1110 0011 | Ц | 1110 0100 | Д | 1110 0101 | Е | 1110 0110 | Ф | 1110 0111 | Г | 1110 1000 | Х | … | ||
| CP866 | 1000 0000 | А | Б | … | 225 | 1110 0001 | с | 1110 0010 | т | 1110 0011 | у | 1110 0100 |
| 1110 0101 | х | 1110 0110 | ц | 1110 0111 | ч | 1110 1000 | ш |
. .. ..
|
| ISO 8859-5 | 1000 0000 | [] | … | 225 | 1110 0001 | с | 1110 0010 | т | 1110 0011 | у | 1110 0100 | ф | 1110 0101 | х | 1110 0110 | ц | 1110 0111 | ч | 1110 1000 | ш | … | |
| MAC | 1000 0000 | А | Б |
. .. ..
| 225 | 1110 0001 | б | 1110 0010 | в | 1110 0011 | г | 1110 0100 | д | 1110 0101 | е | 1110 0110 | ж | 1110 0111 | з | 1110 1000 | и | … |
| CP1251 | 1000 0000 | Á | à | … | 225 | 1110 0001 | б | 1110 0010 | в | 1110 0011 | г | 1110 0100 | д | 1110 0101 | е | 1110 0110 | ж | 1110 0111 | з | 1110 1000 | и |
. .. ..
|
- http://uom.mv.ru:3000/
- ГосВэб
- ГосВэб
- Группа Школы 61 ВКонтакте
- Школьный клуб «Гелиос»
- Программирование
1. Работа с текстом и кодировки
Лекция
Исходный текст.
- Создайте свой каталог на учебном компьютере.
- В этом каталоге создайте текстовый файл и откройте его в редакторе.
- Переключите кодировку текста на «CP 866».
- Наберите в текстовом файле фразу «Hello, мир-25!» и сохраните его.
Шестнадцатеричное представление текста
- Откройте набранный файл в программе «Frhed».
- Допишите справа от текста цифры 0, 1 и 2. Чему равны шестнадцатеричные коды этих символов?
- Найдите в шестнадцатеричном представлении код запятой, дефиса и восклицательного знака. Чему они равны в десятичной системе счисления?
Кодировки символов
- Клинув в строке статуса в программе «Frhed» по надписи «OEM» измените кодировку.
 Как изменился текст в правой половине окна и почему? Верните исходную кодировку.
Как изменился текст в правой половине окна и почему? Верните исходную кодировку. - В текстовом редакторе измените кодировку на «Windows 1251» (основная кодировка операционной системы windows) и сохраните файл. Какие варианты изменения кодировки поддерживаются в текстовом редакторе?
- Запустите еще один экземпляр программы «Frhed» и откройте в нем новую версию файла. Сравните шестнадцатеричные коды версий текстовых файлов в различных кодировках. Для каких символов коды совпадают?
- Проделайте аналогичные операции с текстом для кодировки «UTF-8». Определите, почему текст в этой кодировке занимает больше символов.
- Наберите текст из букв русского алфавита: «абвгдеёжзийклмнопрстуфхцчшщъыьэюя АБВГДЕЁЖЗИЙКЛМНОПРСТУФХЦЧШЩЪЫЬЭЮЯ». Посмотрите его шестнадцатеричное представление в трех рассмотренных кодировках. Какие кодировки можно использовать для сортировки русских слов по алфавиту и с какими ограничениями?
- Клинув в строке статуса в программе «Frhed» по надписи «OEM» измените кодировку.
Специальные символы
- В меню «View» текстового редактора установите галочки «Render Whitespace» и «Render Control Characters».
 Установите расширение «code-eol». Вставьте в текстовый файл символ конца строки (нажмите «Enter») и табуляции (возьмите тут: « »). Как отображаются эти символы в vs code?
Установите расширение «code-eol». Вставьте в текстовый файл символ конца строки (нажмите «Enter») и табуляции (возьмите тут: « »). Как отображаются эти символы в vs code? - Откройте текстовый файл в программе «Frhed». Какие коды имеют набранные символы?
- В правом нижнем углу, левее символов текущей кодировки, найдите обозначение текущего способа обозначение конца строки: «LF» (используется по умолчанию в Linux) или «CR LF» (Windows). Поменяйте способ обозначение конца строки и опишите, что произошло с текстом.
- Из List of Unicode characters возьмите символы длинного (—) и короткого тире (–) и символы принятых в русском языке кавычек елочек (как, например, в предыдущих предложениях). Составьте предложение, включающее эти символы. Определите коды этих символов.
- Откройте окно «Keyboard Shortcuts», в дополнительных операциях этого окна нажмите найдите команду «Open Keyboard Shortcuts(JSON)». По образцу для длинного тире создайте горячие клавиши для ввода символов из предыдущего параграфа (в параметре «key» указывается сочетание клавиш, в «text» — символ):
[ { "key": "alt+k m", "command": "type", "args": { "text": "—" } }, // Другие горячие клавиши ]- В меню «View» текстового редактора установите галочки «Render Whitespace» и «Render Control Characters».
о кодировке символов — PowerShell
- Статья
- 6 минут на чтение
Краткое описание
Описывает, как PowerShell использует кодировку символов для ввода и вывода строки. данные.
Подробное описание
Юникод — это всемирный стандарт кодирования символов. В системе используется Юникод. исключительно для манипуляций с символами и строками. Подробное описание обо всех аспектах Unicode см. Стандарт Юникод.
Windows поддерживает Unicode и традиционные наборы символов. Традиционный персонаж наборы, такие как кодовые страницы Windows, используют 8-битные значения или комбинации 8-битных значения для представления символов, используемых в определенном языке или географическом настройки региона.
PowerShell по умолчанию использует набор символов Unicode. Однако несколько командлетов
иметь параметр Encoding , который может указывать кодировку для другого
набор символов. Этот параметр позволяет выбрать конкретного персонажа
кодирование, необходимое для взаимодействия с другими системами и приложениями.
Следующие командлеты имеют параметр Encoding :
- Microsoft.PowerShell.Management
- Дополнительный контент
- Получить-контент
- Set-Content
- Microsoft.PowerShell.Утилита
- Экспорт-Clixml
- Экспорт-CSV
- Экспорт-PSSession
- Формат-Hex
- Импорт-CSV
- Исходящий файл
- Строка выбора
- Отправить-MailMessage
Знак порядка байтов
Знак порядка байтов (BOM) представляет собой подпись Unicode в первых нескольких байтах файл или текстовый поток, которые указывают, какая кодировка Unicode используется для данных. Для дополнительную информацию см. Документация по меткам порядка байтов.
В Windows PowerShell любая кодировка Unicode, кроме UTF7 , всегда создает
Спецификация PowerShell (v6 и выше) по умолчанию использует utf8NoBOM для всего вывода текста.
Для лучшей общей совместимости избегайте использования спецификаций в файлах UTF-8. Unix-платформы и утилиты наследия Unix, также используемые на платформах Windows, не поддерживают спецификации.
Точно так же следует избегать кодирования UTF7 . UTF-7 не является стандартным Unicode
кодировке и записывается без спецификации во всех версиях PowerShell.
Создание сценариев PowerShell на Unix-подобной платформе или с использованием кроссплатформенного
редактор в Windows, такой как Visual Studio Code, приводит к созданию файла, закодированного с использованием UTF8NoBOM . Эти файлы отлично работают в PowerShell, но могут сломаться в Windows.
PowerShell, если файл содержит символы, отличные от Ascii.
Если вам нужно использовать символы, отличные от Ascii, в сценариях, сохраните их как UTF-8.
с спецификацией. Без спецификации Windows PowerShell неправильно интерпретирует ваш сценарий как
кодируются в устаревшей кодовой странице «ANSI». И наоборот, файлы, которые имеют
Спецификация UTF-8 может быть проблематичной на Unix-подобных платформах. Многие инструменты Unix, такие как
И наоборот, файлы, которые имеют
Спецификация UTF-8 может быть проблематичной на Unix-подобных платформах. Многие инструменты Unix, такие как cat , sed , awk , и некоторые редакторы, такие как gedit не знают как лечить
спецификация.
Кодировка символов в Windows PowerShell
В PowerShell 5.1 параметр Encoding поддерживает следующие значения:
-
AsciiИспользует набор символов Ascii (7-разрядный). -
BigEndianUnicodeИспользует UTF-16 с прямым порядком байтов. -
BigEndianUTF32Использует UTF-32 с порядком байтов от старшего к старшему. -
БайтКодирует набор символов в последовательность байтов. -
По умолчаниюИспользует кодировку, соответствующую активной кодовой странице системы. (обычно ANSI). -
OEMИспользует кодировку, соответствующую текущему OEM-коду системы. страница.
страница. -
СтрокаТо же, что иUnicode. -
UnicodeИспользует UTF-16 с прямым порядком байтов. -
НеизвестноТо же, что иЮникод. -
UTF32Использует UTF-32 с прямым порядком байтов. -
UTF7Использует UTF-7. -
UTF8Использует UTF-8 (со спецификацией).
Обычно Windows PowerShell использует Unicode Кодировка UTF-16LE по умолчанию. Однако, кодировка по умолчанию, используемая командлетами в Windows PowerShell, несовместима.
Примечание
При использовании любой кодировки Unicode, кроме UTF7 , всегда создается спецификация.
Для командлетов, записывающих вывод в файлы:
Out-Fileи операторы перенаправления>и>>создают кодировку UTF-16LE, которая заметно отличается отSet-ContentиAdd-Content.
New-ModuleManifestиExport-CliXmlтакже создают файлы UTF-16LE.Когда целевой файл пуст или не существует,
Set-ContentиAdd-Contentиспользовать кодировкупо умолчанию.По умолчанию— это кодировка, указанная устаревшая кодовая страница ANSI локали активной системы.Export-Csvсоздаетфайл Ascii, но использует другую кодировку при использовании Добавить параметр (см. ниже).Export-PSSessionпо умолчанию создает файлы UTF-8 с BOM.New-Item -Type File -Valueсоздает файл UTF-8 без спецификации.Send-MailMessageпо умолчанию использует кодировкуAscii.Start-Transcriptсоздаетфайлы Utf8со спецификацией. Когда добавить используется параметр, кодировка может быть другой (см. ниже).
ниже).
Для команд, которые добавляются к существующему файлу:
Out-File -Appendи оператор перенаправления>>не пытаются сопоставить кодировка содержимого существующего целевого файла. Вместо этого они используют кодировка по умолчанию, если только Используется параметр кодировки . Вы должны использовать оригинальная кодировка файлов при добавлении содержимого.При отсутствии явного параметра Encoding
Add-Contentобнаруживает существующую кодировку и автоматически применяет ее к новому содержимому. Если существующее содержимое не имеет спецификации,По умолчанию используется кодировкаANSI. ПоведениеAdd-Content— это то же самое в PowerShell (v6 и выше), за исключением значения по умолчанию. кодировкаUtf8.Export-Csv -Appendсоответствует существующей кодировке, когда целевой файл содержит спецификацию. При отсутствии спецификации используется кодировка
При отсутствии спецификации используется кодировка Utf8.Start-Transcript -Appendсоответствует существующей кодировке файлов, которые включить спецификацию. При отсутствии спецификации по умолчанию используется кодировкаAscii. Этот кодирование может привести к потере данных или повреждению символов, когда данные в расшифровка содержит многобайтовые символы.
Для командлетов, которые считывают строковые данные в отсутствие спецификации:
Get-ContentиImport-PowerShellDataFileиспользуетImport-Csv,Import-CliXmlиSelect-StringпредполагаютUtf8в отсутствие спецификации.
Кодировка символов в PowerShell
В PowerShell (v7. 1 и выше) параметр Encoding поддерживает
следующие значения:
1 и выше) параметр Encoding поддерживает
следующие значения:
-
ascii: Использует кодировку для набора символов ASCII (7-бит). -
bigendianunicode: Кодирует в формате UTF-16 с использованием порядка байтов с прямым порядком байтов. -
bigendianutf32: Кодирует в формате UTF-32 с использованием порядка байтов с прямым порядком байтов. -
oem: Использует кодировку по умолчанию для MS-DOS и консольных программ. -
unicode: Кодирует в формате UTF-16 с использованием порядка байтов с прямым порядком байтов. -
utf7: Кодирует в формате UTF-7. -
utf8: Кодирует в формате UTF-8 (без спецификации). -
utf8BOM: Кодирует в формате UTF-8 с меткой порядка байтов (BOM) -
utf8NoBOM: Кодирует в формате UTF-8 без метки порядка байтов (BOM) -
utf32: Кодирует в формате UTF-32, используя обратный порядок байтов.
PowerShell по умолчанию использует utf8NoBOM для всех выходных данных.
Начиная с PowerShell 6.2, параметр Encoding также разрешает числовые значения.
Идентификаторы зарегистрированных кодовых страниц (например, -Encoding 1251 ) или строковые имена
зарегистрированные кодовые страницы (например, -Кодировка "windows-1251" ). Для дополнительной информации,
см. документацию .NET для
Кодировка.Кодовая Страница.
Изменение кодировки по умолчанию
PowerShell имеет две переменные по умолчанию, которые можно использовать для изменения кодировки по умолчанию. поведение при кодировании.
-
$PSDefaultParameterValues -
$OutputEncoding
Для получения дополнительной информации см. about_Preference_Variables.
Начиная с PowerShell 5.1 операторы перенаправления ( > и >> ) вызывают Командлет Out-File . Поэтому вы можете установить для них кодировку по умолчанию, используя
привилегированная переменная
Поэтому вы можете установить для них кодировку по умолчанию, используя
привилегированная переменная $PSDefaultParameterValues , как показано в этом примере:
$PSDefaultParameterValues['Out-File:Encoding'] = 'utf8'
Используйте следующую инструкцию, чтобы изменить кодировку по умолчанию для всех командлетов, которые иметь параметр Encoding .
$PSDefaultParameterValues['*:Кодировка'] = 'utf8'
Important
Помещение этой команды в ваш профиль PowerShell делает параметр глобальная настройка сеанса, влияющая на все команды и сценарии, которые не явно указать кодировку.
Точно так же вы должны включать в свои скрипты или модули такие команды, которые вы хотите вести себя так же. Использование этих команд гарантирует, что командлеты вести себя так же, даже когда запускается другим пользователем на другом компьютере, или в другой версии PowerShell.
Автоматическая переменная $OutputEncoding влияет на кодировку, используемую PowerShell.