UTF-8 — что это и зачем нужна кодировка символов
Автор: RuWeb
Время чтения: 7 минут
Поделиться:
Машины и люди говорят «на разных языках», однако пользователи видят на экране компьютера понятный им текст, даже если в памяти устройства он хранится в виде чисел. При создании веб-сайта разработчику необходимо помнить, что возможность его использовать должна быть не только у сервера, но и у конечного пользователя. Для преобразования числового представления информации в ее символьный вид используют кодировки. Долгое время разработчики использовали разные схемы для трансформации текста, и если на другом устройстве работала иная кодировка, часть информации не могла быть распознана и терялась. Ситуация исправилась с появлением Юникода. В нашем материале отвечаем на вопросы: UTF-8 — что это? Для чего служит? Какие преимущества и недостатки имеет стандарт?
Что такое UTF-8
UTF-8 (Unicode Transformation Format, 8-bit) — это система кодирования, работающая по стандарту Unicode.
UTF-8 входит в семейство кодировок Unicode, каждая из которых уникальна. Особенность UTF-8 заключается в том, что она представляет символы в однобайтовых единицах. Один байт содержит в самом простом виде восемь бит информации, что нашло отражение в названии кодировки.
Для чего нужна кодировка символов
Компьютеры обрабатывают информацию в двоичной системе. Чтобы разобраться в текстовом сообщении, им необходимо обработать последовательность нулей и единиц. Например, английская литера А — это 01000001. Человеку для понимания текста этого недостаточно, он воспринимает данные, записанные с помощью букв, цифр и других символов, кроме того ему потребуется знание языка, на котором написано сообщение.
Компьютер говорит на языке битов и байтов. Информация в двоичной системе измеряется с помощью битов. Если объем данных достигает 8 битов, то для удобства подсчетов используют большую единицу измерения — байт, далее следуют килобайты, мега- и гигабайты. Каждый символ текста записывается в компьютерной системе в виде строки битов.
Человек говорит на языке символов. Одним из первых наиболее универсальных стандартов кодирования является ASCII. Он имеет библиотеки, в которых систематизированы элементы двух языков — байтового и символьного. Буквам, знакам пунктуации, цифрам присваиваются индивидуальные числовые коды. Например, литере «B» в верхнем регистре по стандарту кодирования ASCII присваивается код «066».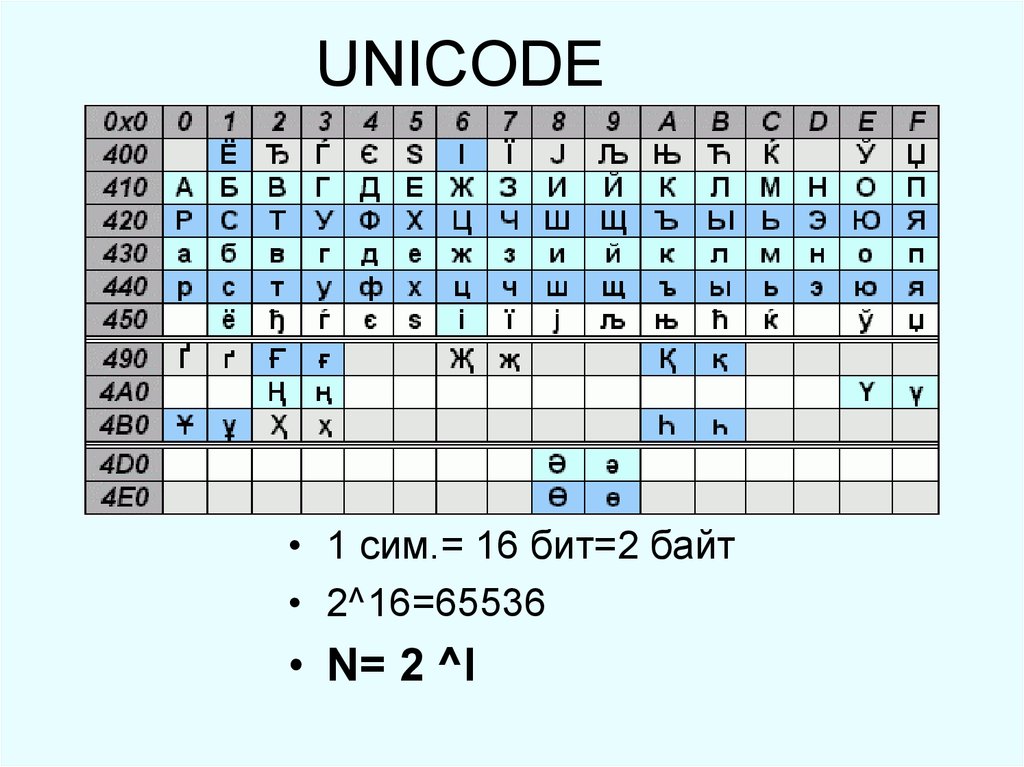 Затем данное обозначение соотносится с двоичной системой: «066» — это 01000010 при записи в нулях и единицах. В результате каждому идентификатору принадлежит свой символ и его байтовый аналог.
Затем данное обозначение соотносится с двоичной системой: «066» — это 01000010 при записи в нулях и единицах. В результате каждому идентификатору принадлежит свой символ и его байтовый аналог.
Стандарт ASCII содержит данные о самых востребованных символах и работает для передачи текста, написанного латинскими буквами. Однако пользователи веб-ресурсов, приложений, программного обеспечения и других ИТ-продуктов рассредоточены по всему миру. Поэтому для кодирования всех языков человечества и вообще любого символа, который когда-либо использовался, включая эмотиконы, появился стандарт с более широкими возможностями по хранению символов и соответствующих им кодов — Unicode. Его понимают большинство компьютеров на планете и носители основных мировых языков. Юникод хранит результаты преобразования информации, выполненного через систему кодирования UTF-8, UTF-16 или UTF-32.
Преимущества и недостатки
Юникод — это набор символов, взятых из всех языков мира, глифов и эмодзи.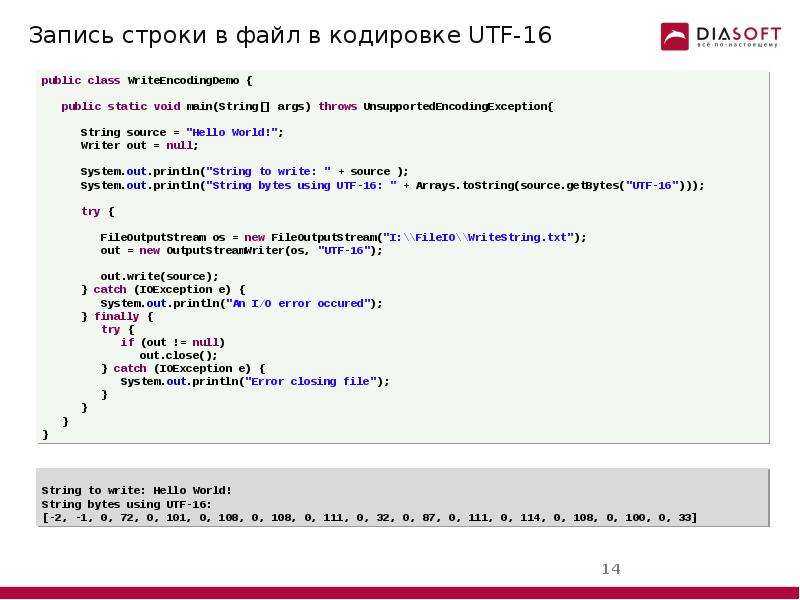 Семейство кодировок UTF определяет, как символ будет представлен в двоичной системе. UTF-8 позволяет пользователям работать в совместимой со всеобщими стандартами и принятой по всему миру многоязычной среде.
Семейство кодировок UTF определяет, как символ будет представлен в двоичной системе. UTF-8 позволяет пользователям работать в совместимой со всеобщими стандартами и принятой по всему миру многоязычной среде.
Языки программирования (ЯП) по-разному поддерживают и используют кодировки. Иногда они могут искажать Unicode. Недостатки Юникода для разных ЯП и программ:
- PHP. Данный язык программирования поддерживает 256 символов, то есть воспринимает 1 символ в строке за 1 байт информации. Так происходит, даже если символ в строке весит больше одного байта. Например, смайл может весить четыре байта, а для PHP все равно один. Однако это можно исправить, настроив многобайтовые функции. Тогда при подсчете длины строки PHP будет обращаться к памяти, а не считать символ за байт.
- JavaScript. Работает с кодировкой UTF-16. Сложные символы требуют две кодовых точки для ссылки.

- MySQL. Система управления базами данных не поддерживает UTF-8 в его стандартном виде. MySQL недостаточно 24 битов, чтобы представить один символ. СУБД поддерживает расширенную версию кодировки — UTF-8mb4.
Максимальный потенциал
С помощью UTF-8 можно записать код любой длины. Однако, для того чтобы работа алгоритма была эффективной и надежной, лучше ограничить размер кода. Unicode 6.х является действующим стандартом и предполагает использование кода до четырех байт в UTF-8.
Сравнение UTF-8 и UTF-16
UTF-8 и UTF-16 — две самые широко используемые кодировки в стандарте Unicode. Они обе обладают переменной длинной кодирования. Один символ в них может быть представлен разным количеством байт. В Юникоде все данные хранятся в таблице и отсортированы по количеству байт, которое они имеют в двоичной системе. В начале стандарта символы могут занимать всего 1 байт, поэтому и UTF-8 зашифрует их с помощью 1 байта.
UTF-16 оперирует данными из двух и четырех байт. Кодировка подходит для восточных языков.
Заключение
UTF-8 является самым распространенным методом кодирования в Сети, поскольку позволяет хранить текст, содержащий любой символ. Он способен перевести символы, содержащиеся в библиотеке Юникода, в байты, а затем выполнить обратный процесс.
Автор: RuWeb
Время чтения: 7 минут
Поделиться:
другие полезные статьи
- 09.01.
 2023
Автор: RuWeb
2023
Автор: RuWebWordPress (WP) — самая популярная бесплатная система управления контентом. Поэтому пользователи со всего мира ежедневно создают сайты на этой платформе.
16.01.2023 Автор: RuWeb
Регистрация доменного имени — задача, с которой рано или поздно сталкивается каждый веб-мастер, поскольку без этого пункта полноценно запустить сайт в интернете не получится.
23.01.2023 Автор: RuWeb
Доменное имя является важной частью продвижения сайта в интернете. Оно упрощает поиск ресурса для пользователей, влияет на его оптимизацию в поисковых системах и формирует первое впечатление о проекте — еще до того, как человек его посетит.
Кодирование и декодирование / Хабр
Причиной разобраться в том, как же работает UTF-8 и что такое Юникод заставил тот факт, что VBScript не имеет встроенных функций работы с UTF-8.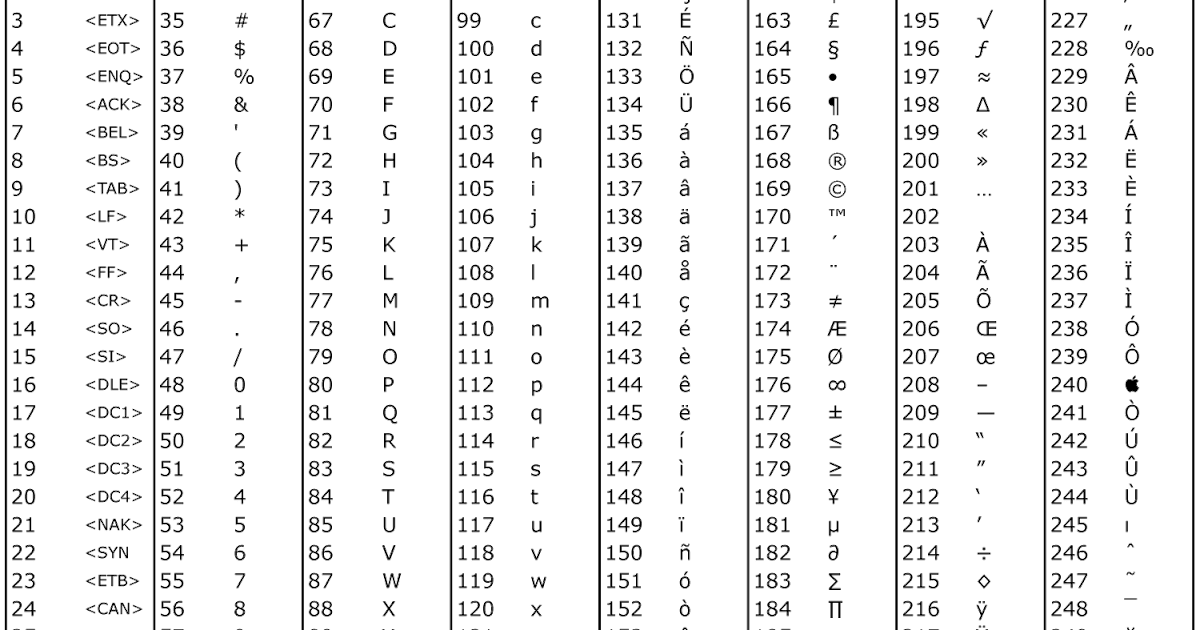 А так как ничего рабочего не нашел, то пришлось писть/дописывать самому. Опыт на мой взгляд полезный в любом случае. Для лучшего понимания начну с теории.
А так как ничего рабочего не нашел, то пришлось писть/дописывать самому. Опыт на мой взгляд полезный в любом случае. Для лучшего понимания начну с теории.
О Юникоде
До появления Юникода широко использовались 8-битные кодировки, главные минусы которых очевидны:
- Всего 255 символов, да и то часть из них не графические;
- Возможность открыть документ не с той кодировкой, в которой он был создан;
- Шрифты необходимо создавать для каждой кодировки.
Так и было решено создать единый стандарт «широкой» кодировки, которая включала бы все символы (при чем сначала хотели в нее включить только обычные символы, но потом передумали и начали добавлять и экзотические). Юникод использует 1 112 064 кодовых позиций (больше чем 16 бит). Начало дублирует ASCII, а дальше остаток латиницы, кирилица, другие европейские и азиатские символы. Для обозначений символов используют шестнадцатеричную запись вида «U+xxxx» для первых 65k и с большим количеством цифр для остальных.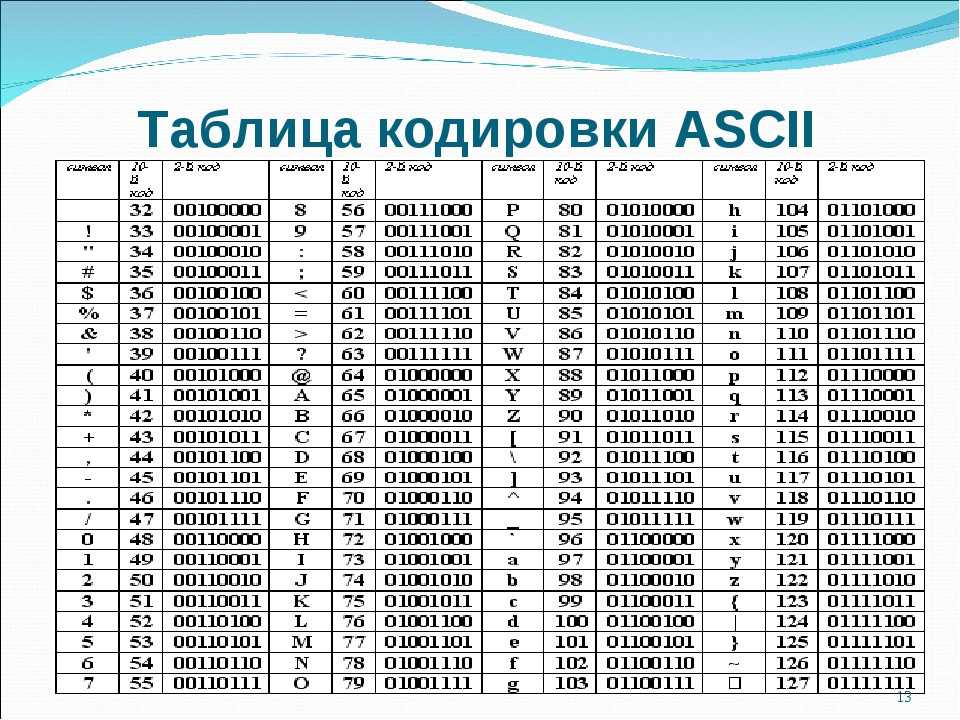
О UTF-8
Когда-то я думал что есть Юникод, а есть UTF-8. Позже я узнал, что ошибался.
UTF-8 является лишь представлением Юникода в 8-битном виде. Символы с кодами меньше 128 представляются одним байтом, а так как в Юникоде они повторяют ASCII, то текст написанный только этими символами будет являться текстом в ASCII. Символы же с кодами от 128 кодируются 2-мя байтами, с кодами от 2048 — 3-мя, от 65536 — 4-мя. Так можно было бы и до 6-ти байт дойти, но кодировать ими уже ничего.
0x00000000 — 0x0000007F: 0xxxxxxx 0x00000080 — 0x000007FF: 110xxxxx 10xxxxxx 0x00000800 — 0x0000FFFF: 1110xxxx 10xxxxxx 10xxxxxx 0x00010000 — 0x001FFFFF: 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
Кодируем в UTF-8
Порядок действий примерно такой:
- Каждый символ превращаем в Юникод.
- Проверяем из какого символ диапазона.
- Если код символа меньше 128, то к результату добавляем его в неизменном виде.

- Если код символа меньше 2048, то берем последние 6 бит и первые 5 бит кода символа. К первым 5 битам добавляем 0xC0 и получаем первый байт последовательности, а к последним 6 битам добавляем 0x80 и получаем второй байт. Конкатенируем и добавляем к результату.
- Похожим образом можем продолжить и для больших кодов, но если символ за пределами U+FFFF придется иметь дело с UTF-16 суррогатами.
Function EncodeUTF8(s)
Dim i, c, utfc, b1, b2, b3
For i=1 to Len(s)
c = ToLong(AscW(Mid(s,i,1)))
If c < 128 Then
utfc = chr( c)
ElseIf c < 2048 Then
b1 = c Mod &h50
b2 = (c - b1) / &h50
utfc = chr(&hC0 + b2) & chr(&h80 + b1)
ElseIf c < 65536 And (c < 55296 Or c > 57343) Then
b1 = c Mod &h50
b2 = ((c - b1) / &h50) Mod &h50
b3 = (c - b1 - (&h50 * b2)) / &h2000
utfc = chr(&hE0 + b3) & chr(&h80 + b2) & chr(&h80 + b1)
Else
' Младший или старший суррогат UTF-16
utfc = Chr(&hEF) & Chr(&hBF) & Chr(&hBD)
End If
EncodeUTF8 = EncodeUTF8 + utfc
Next
End Function
Function ToLong(intVal)
If intVal < 0 Then
ToLong = CLng(intVal) + &h20000
Else
ToLong = CLng(intVal)
End If
End Function
Декодируем UTF-8
- Ищем первый символ вида 11xxxxxx
- Считаем все последующие байты вида 10xxxxxx
- Если последовательность из двух байт и первый байт вида 110xxxxx, то отсекаем приставки и складываем, умножив первый байт на 0x40.
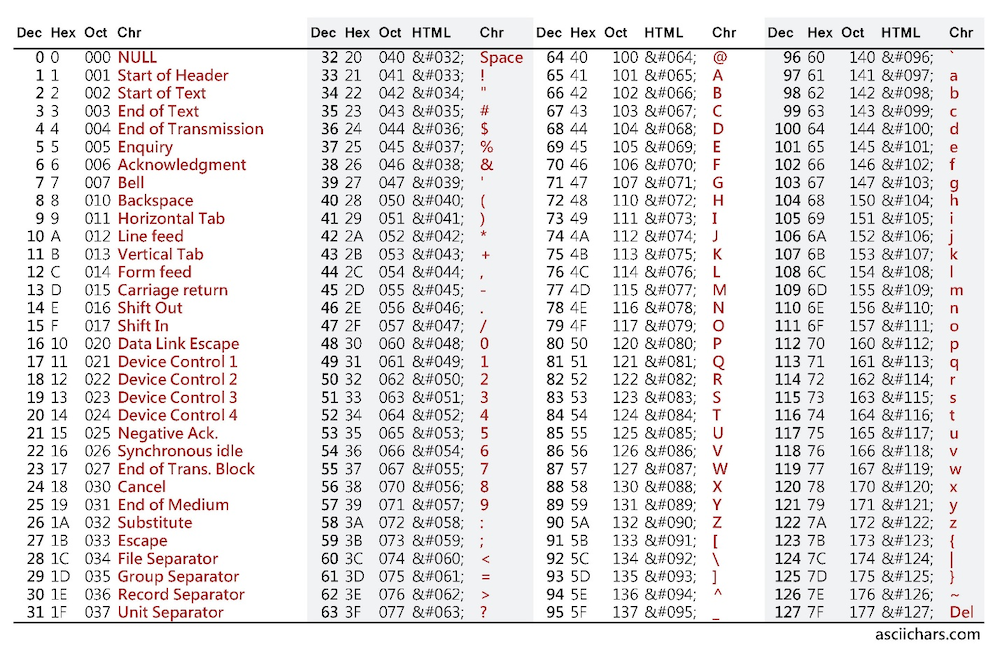
- Аналогично для более длинных последовательностей.
- Заменяем всю последовательность на нужный символ Юникода.
Function DecodeUTF8(s)
Dim i, c, n, b1, b2, b3
i = 1
Do While i <= len(s)
c = asc(mid(s,i,1))
If (c and &hC0) = &hC0 Then
n = 1
Do While i + n <= len(s)
If (asc(mid(s,i+n,1)) and &hC0) <> &h80 Then
Exit Do
End If
n = n + 1
Loop
If n = 2 and ((c and &hE0) = &hC0) Then
b1 = asc(mid(s,i+1,1)) and &h4F
b2 = c and &h2F
c = b1 + b2 * &h50
Elseif n = 3 and ((c and &hF0) = &hE0) Then
b1 = asc(mid(s,i+2,1)) and &h4F
b2 = asc(mid(s,i+1,1)) and &h4F
b3 = c and &h0F
c = b3 * &h2000 + b2 * &h50 + b1
Else
' Символ больше U+FFFF или неправильная последовательность
c = &hFFFD
End if
s = left(s,i-1) + chrw( c) + mid(s,i+n)
Elseif (c and &hC0) = &h80 then
' Неожидаемый продолжающий байт
s = left(s,i-1) + chrw(&hFFFD) + mid(s,i+1)
End If
i = i + 1
Loop
DecodeUTF8 = s
End Function
Ссылки
Юникод на Википедии
Исходник для ASP+VBScript
UPD: Обработка ошибочных последовательностей и ошибка с типом Integer, который возвращает AscW.
| Кодовая точка Unicode | символ | UTF-8 (шестнадцатеричный) | имя |
|---|---|---|---|
| U+0000 | 00 | <управление> | |
| U+0001 | 01 | <управление> | |
| U+0002 | 02 | <управление> | |
| U+0003 | 03 | <управление> | |
| U+0004 | 04 | <управление> | |
| U+0005 | 05 | <управление> | |
| U+0006 | 06 | <управление> | |
| U+0007 | 07 | <управление> | |
| U+0008 | 08 | <управление> | |
| U+0009 | 09 | <управление> | |
| U+000A | 0a | <управление> | |
| U+000B | 0b | <управление> | |
| U+000C | 0c | <управление> | |
| U+000D | 0d | <управление> | |
| U+000E | 0e | <управление> | |
| U+000F | 0f | <управление> | |
| U+0010 | 10 | <управление> | |
| U+0011 | 11 | <управление> | |
| U+0012 | 12 | <управление> | |
| U+0013 | 13 | <управление> | |
| U+0014 | 14 | <управление> | |
| U+0015 | 15 | <управление> | |
| U+0016 | 16 | <управление> | |
| U+0017 | 17 | <управление> | |
| U+0018 | 18 | <управление> | |
| U+0019 | 19 | <управление> | |
| U+001A | 1a | <управление> | |
| U+001B | 1b | <управление> | |
| U+001C | 1c | <управление> | |
| U+001D | 1d | <управление> | |
| U+001E | 1e | <управление> | |
| U+001F | 1f | <управление> | |
| U+0020 | 20 | ПРОБЕЛ | |
| U+0021 | ! | 21 | ВОСКЛИЦАТЕЛЬНЫЙ ЗНАК |
| U+0022 | » | 22 | КАвычки |
| U+0023 | # | 23 | НОМЕР ЗНАК |
| U+0024 | $ | 24 | ЗНАК ДОЛЛАРА |
| U+0025 | % | 25 | ЗНАК ПРОЦЕНТА |
| U+0026 | и | 26 | АМПЕРСАНД |
| U+0027 | ‘ | 27 | АПОСТРОФ |
| U+0028 | ( | 28 | ЛЕВАЯ СКОБКА |
| U+0029 | ) | 29 | ПРАВАЯ СКОБКА |
| U+002A | * | 2a | ЗВЕЗДОЧКА |
| U+002B | + | 2b | ЗНАК ПЛЮС |
| U+002C | , | 2c | ЗАПЯТАЯ |
| U+002D | — | 2d | ДЕФИС-МИНУС |
| U+002E | . | 2e | ПОЛНЫЙ СТОП |
| U+002F | / | 2f | SOLIDUS |
| U+0030 | 0 | 30 | ЦИФРА НОЛЬ |
| U+0031 | 1 | 31 | ЦИФРА ЕДИНИЦА |
| U+0032 | 2 | 32 | ДВА ЦИФРЫ |
| U+0033 | 3 | 33 | ЦИФРА ТРИ |
| U+0034 | 4 | 34 | ЧЕТВЕРТАЯ ЦИФРА |
| U+0035 | 5 | 35 | ПЯТАЯ ЦИФРА |
| U+0036 | 6 | 36 | ЦИФРА ШЕСТЬ |
| U+0037 | 7 | 37 | СЕДЬМАЯ ЦИФРА |
| U+0038 | 8 | 38 | ЦИФРА ВОСЕМЬ |
| U+0039 | 9 | 39 | ЦИФРА ДЕВЯТЬ |
| U+003A | : | 3a | ДВОРОЦ |
| U+003B | ; | 3b | ТОЧКА С ЗАПЯТОЙ |
| U+003C | < | 3c | ЗНАК МЕНЬШЕ |
| U+003D | = | 3d | ЗНАК РАВНО |
| U+003E | > | 3e | ЗНАК БОЛЬШЕ |
| U+003F | ? | 3f | ВОПРОСИТЕЛЬНЫЙ ЗНАК |
| U+0040 | @ | 40 | КОММЕРЧЕСКИЙ НОМЕР |
| U+0041 | A | 41 | ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА A |
| U+0042 | B | 42 | ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА B |
| U+0043 | C | 43 | ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА C |
| U+0044 | Д | 44 | ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА D |
| U+0045 | E | 45 | ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА E |
| U+0046 | F | 46 | ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА F |
| U+0047 | G | 47 | ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА G |
| U+0048 | H | 48 | ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА H |
| U+0049 | Я | 49 | ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА I |
| U+004A | J | 4a | ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА J |
| U+004B | K | 4b | ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА K |
| U+004C | L | 4c | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА L |
| U+004D | M | 4d | ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА M |
| U+004E | Н | 4e | ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА N |
| U+004F | O | 4f | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА O |
| U+0050 | P | 50 | ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА P |
| U+0051 | Q | 51 | ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА Q |
| U+0052 | R | 52 | ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА R |
| U+0053 | S | 53 | ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА S |
| U+0054 | T | 54 | ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА T |
| U+0055 | U | 55 | ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА U |
| U+0056 | V | 56 | ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА V |
| U+0057 | W | 57 | ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА W |
| U+0058 | X | 58 | ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА X |
| U+0059 | Y | 59 | ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА Y |
| U+005A | Z | 5a | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА Z |
| U+005B | [ | 5b | ЛЕВЫЙ КВАДРАТНЫЙ КРОНШТЕЙН |
| U+005C | \ | 5с | ОБРАТНЫЙ СОЛИДУС |
| U+005D | 95e | ЦИРКУМФЛЕКС АКЦЕНТ | |
| U+005F | _ | 5f | НИЗКАЯ ЛИНИЯ |
| U+0060 | ` | 60 | ГРЕЙВ АКЦЕНТ |
| U+0061 | a | 61 | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА A |
| U+0062 | b | 62 | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА B |
| U+0063 | в | 63 | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА C |
| U+0064 | d | 64 | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА D |
| U+0065 | e | 65 | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА E |
| U+0066 | f | 66 | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА F |
| U+0067 | g | 67 | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА G |
| U+0068 | h | 68 | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА H |
| U+0069 | i | 69 | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА I |
| U+006A | j | 6a | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА J |
| U+006B | k | 6b | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА K |
| U+006C | l | 6c | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА L |
| U+006D | m | 6d | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА M |
| U+006E | n | 6e | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА N |
| U+006F | o | 6f | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА O |
| U+0070 | p | 70 | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА P |
| U+0071 | q | 71 | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА Q |
| U+0072 | r | 72 | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА R |
| U+0073 | s | 73 | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА S |
| U+0074 | t | 74 | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА T |
| U+0075 | u | 75 | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА U |
| U+0076 | v | 76 | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА V |
| U+0077 | w | 77 | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА W |
| U+0078 | x | 78 | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА X |
| U+0079 | y | 79 | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА Y |
| U+007A | z | 7a | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА Z |
| U+007B | { | 7b | ЛЕВАЯ ФИГУРНАЯ СКОБКА |
| U+007C | | | 7c | ВЕРТИКАЛЬНАЯ ЛИНИЯ |
| U+007D | } | 7d | ПРАВАЯ ФИГУРНАЯ СКОБКА |
| U+007E | ~ | 7e | ТИЛЬДА |
| U+007F | 7f | <управление> | |
| U+0080 | c2 80 | <управление> | |
| U+0081 | c2 81 | <управление> | |
| U+0082 | c2 82 | <управление> | |
| U+0083 | c2 83 | <управление> | |
| U+0084 | c2 84 | <управление> | |
| U+0085 | c2 85 | <управление> | |
| U+0086 | c2 86 | <управление> | |
| U+0087 | c2 87 | <управление> | |
| U+0088 | c2 88 | <управление> | |
| U+0089 | c2 89 | <управление> | |
| U+008A | c2 8a | <управление> | |
| U+008B | c2 8b | <управление> | |
| U+008C | c2 8c | <управление> | |
| U+008D | c2 8d | <управление> | |
| U+008E | c2 8e | <управление> | |
| U+008F | c2 8f | <управление> | |
| U+0090 | c2 90 | <управление> | |
| U+0091 | c2 91 | <управление> | |
| U+0092 | c2 92 | <управление> | |
| U+0093 | c2 93 | <управление> | |
| U+0094 | c2 94 | <управление> | |
| U+0095 | c2 95 | <управление> | |
| U+0096 | c2 96 | <управление> | |
| U+0097 | c2 97 | <управление> | |
| U+0098 | c2 98 | <управление> | |
| U+0099 | c2 99 | <управление> | |
| U+009A | c2 9a | <управление> | |
| U+009B | c2 9b | <управление> | |
| U+009C | c2 9c | <управление> | |
| U+009D | c2 9d | <управление> | |
| U+009E | c2 9e | <управление> | |
| U+009F | c2 9f | <управление> | |
| U+00A0 | c2 a0 | НЕРАЗРЫВНЫЙ ПРОБЕЛ | |
| U+00A1 | ¡ | c2 a1 | ПЕРЕВЕРНУТЫЙ ВОСКЛИЦАТЕЛЬНЫЙ ЗНАК |
| U+00A2 | ¢ | c2 a2 | ЗНАК ЦЕНТА |
| U+00A3 | £ | c2 a3 | ЗНАК ФУНТА |
| U+00A4 | ¤ | c2 a4 | ЗНАК ВАЛЮТЫ |
| U+00A5 | ¥ | c2 a5 | ЗНАК ЙЕНЫ |
| U+00A6 | ¦ | c2 a6 | СЛОМАННЫЙ БАР |
| U+00A7 | § | c2 a7 | ЗНАК СЕКЦИИ |
| U+00A8 | ¨ | c2 a8 | ДИЭРЕЗИС |
| U+00A9 | © | c2 a9 | ЗНАК АВТОРСКИХ ПРАВ |
| U+00AA | ª | c2 aa | ЖЕНСКИЙ ОРДИНАЛ ИНДИКАТОР |
| U+00AB | « | c2 ab | ДВУХУГОЛЬНАЯ КАВАЧКА, УКАЗЫВАЮЩАЯ ВЛЕВО |
| U+00AC | ¬ | c2 ac | НЕ ЗНАК |
| U+00AD | c2 объявление | МЯГКИЙ ДЕФЕС | |
| U+00AE | ® | c2 ae | ЗАРЕГИСТРИРОВАННЫЙ ЗНАК |
| U+00AF | ¯ | c2 af | Макрон |
| U+00B0 | ° | c2 b0 | ЗНАК СТЕПЕНИ |
| U+00B1 | ± | c2 b1 | ЗНАК ПЛЮС-МИНУС |
| U+00B2 | ² | c2 b2 | НАДПИСЬ ДВА |
| U+00B3 | ³ | c2 b3 | НАДСТРОЙКА ТРИ |
| U+00B4 | ´ | c2 b4 | ОСТРЫЙ АКЦЕНТ |
| U+00B5 | µ | c2 b5 | МИКРОЗНАК |
| U+00B6 | ¶ | c2 b6 | ЗНАК ПОДШИВКИ |
| U+00B7 | · | c2 b7 | СРЕДНЯЯ ТОЧКА |
| U+00B8 | ¸ | c2 b8 | СЕДИЛЬЯ |
| U+00B9 | ¹ | c2 b9 | НАДПИСЬ ОДИН |
| U+00BA | º | c2 ba | МУЖСКОЙ ОРДИНАЛ |
| U+00BB | » | c2 bb | ДВУХУГОЛЬНАЯ КАВАЧКА, УКАЗЫВАЮЩАЯ ВПРАВО |
| U+00BC | ¼ | c2 bc | ОБЫЧНАЯ Дробь ЧЕТВЕРТЬ |
| U+00BD | ½ | c2 bd | ВУЛГАРНАЯ Дробь ОДНА ПОЛОВИНА |
| U+00BE | ¾ | c2 be | ОБЫЧНАЯ Дробь ТРИ ЧЕТВЕРТИ |
| U+00BF | ¿ | c2 bf | ПЕРЕВЕРНУТЫЙ ВОПРОСИТЕЛЬНЫЙ ЗНАК |
| U+00C0 | À | c3 80 | ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА A С ГРАВОЙ |
| U+00C1 | Á | c3 81 | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА A С АКТРОЙ |
| U+00C2 | Â | c3 82 | ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА A С CIRCUMFLEX |
| U+00C3 | Ã | c3 83 | ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА A С ТИЛЬДОЙ |
| U+00C4 | Ä | c3 84 | ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА A С ДИЕРЕЗИСОМ |
| U+00C5 | Å | c3 85 | ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА A С КОЛЬЦОМ НАД |
| U+00C6 | Æ | c3 86 | ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА AE |
| U+00C7 | Ç | c3 87 | ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА C С СЕДИЛЬЕЙ |
| U+00C8 | È | c3 88 | ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА E С ГРАВОЙ |
| U+00C9 | É | c3 89 | ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА E С ОСТРОЙ СТОЙКОЙ |
| U+00CA | Ê | c3 8a | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА E С CIRCUMFLEX |
| U+00CB | Ë | c3 8b | ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА E С ДИЭРЕЗИСОМ |
| U+00CC | Ì | c3 8c | ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА I С ГРАВОЙ |
| U+00CD | Í | c3 8d | ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА I С ОСТРОЙ |
| U+00CE | Î | c3 8e | ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА I С CIRCUMFLEX |
| U+00CF | Ï | c3 8f | ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА I С ДИЭРЕЗИСОМ |
| U+00D0 | Ð | c3 90 | ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА ETH |
| U+00D1 | Ñ | c3 91 | ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА N С ТИЛЬДОЙ |
| U+00D2 | Ò | c3 92 | ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА O С ГРАВОЙ |
| U+00D3 | Ó | c3 93 | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА O С ОСТРОЙ |
| U+00D4 | Ô | c3 94 | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА O С CIRCUMFLEX |
| U+00D5 | Õ | c3 95 | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА O С ТИЛЬДОЙ |
| U+00D6 | Ö | c3 96 | ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА O С ДИЕРЕЗИСОМ |
| U+00D7 | × | c3 97 | ЗНАК УМНОЖЕНИЯ |
| U+00D8 | Ø | c3 98 | ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА O С ШТРИХОМ |
| U+00D9 | Ù | c3 99 | ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА U С ГРАВОЙ |
| U+00DA | Ú | c3 9a | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА U С ОСТРОЙ |
| U+00DB | Û | c3 9b | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА U С CIRCUMFLEX |
| U+00DC | Ü | c3 9c | ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА U С ДИЕРЕЗИСОМ |
| U+00DD | Ý | c3 9d | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА Y С ОСТРОЙ БУКВОЙ |
| U+00DE | Þ | c3 9e | ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА THORN |
| U+00DF | ß | c3 9f | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА SHARP S |
| U+00E0 | à | c3 a0 | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА A С ГРАВОЙ |
| U+00E1 | á | c3 a1 | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА A С ОСТРОЙ БУКВОЙ |
| U+00E2 | â | c3 a2 | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА A С CIRCUMFLEX |
| U+00E3 | ã | c3 a3 | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА A С ТИЛЬДОЙ |
| U+00E4 | ä | c3 a4 | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА A С ДИЭРЕЗИСОМ |
| U+00E5 | å | c3 a5 | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА A С КОЛЬЦОМ НАД |
| U+00E6 | æ | c3 a6 | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА AE |
| U+00E7 | ç | c3 a7 | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА C С СЕДИЛЬЕЙ |
| U+00E8 | и | c3 a8 | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА E С ГРАВОЙ |
| U+00E9 | é | c3 a9 | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА E С ОСТРОЙ ЧАСТЬЮ |
| U+00EA | ê | c3 aa | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА E С CIRCUMFLEX |
| U+00EB | ë | c3 ab | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА E С ДИЭРЕЗИСОМ |
| U+00EC | ì | c3 ac | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА I С ГРАВОЙ |
| U+00ED | í | c3 ad | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА I С ОСТРОЙ БУКВОЙ |
| U+00EE | î | c3 ae | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА I С CIRCUMFLEX |
| U+00EF | ï | c3 af | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА I С ДИЭРЕЗИСОМ |
| U+00F0 | ð | c3 b0 | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА ETH |
| У+00Ф1 | – | c3 b1 | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА N С ТИЛЬДОЙ |
| U+00F2 | ò | c3 b2 | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА O С ГРАВОЙ |
| U+00F3 | ó | c3 b3 | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА O С ОСТРОЙ БУКВОЙ |
| U+00F4 | ô | c3 b4 | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА O С CIRCUMFLEX |
| U+00F5 | х | c3 b5 | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА O С ТИЛЬДОЙ |
| U+00F6 | ö | c3 b6 | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА O С ДИЕРЕЗИСОМ |
| U+00F7 | ÷ | c3 b7 | ЗНАК РАЗДЕЛА |
| U+00F8 | ø | c3 b8 | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА O С ШТРИХОМ |
| U+00F9 | ù | c3 b9 | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА U С ГРАВОЙ |
| U+00FA | ú | c3 ba | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА U С ОСТРОЙ |
| U+00FB | û | c3 bb | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА U С CIRCUMFLEX |
| U+00FC | ü | c3 bc | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА U С ДИЭРЕЗИСОМ |
| U+00FD | ý | c3 bd | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА Y С ОСТРОЙ |
| U+00FE | þ | c3 be | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА THORN |
| U+00FF | ÿ | c3 bf | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА Y С ДИЭРЕЗИСОМ |
Разница между кодировкой символов UTF-8, UTF-16 и UTF-32? Пример
Основное различие между кодировками символов UTF-8, UTF-16 и UTF-32 заключается в том, сколько байтов требуется для представления символа в памяти. UTF-8 использует минимум один байт, а UTF-16 использует минимум 2 байта. Кстати, если кодовая точка символа больше 127, максимальное значение байта тогда UTF-8 может занимать 2, 3 или 4 байта, но UTF-16 будет занимать только два или четыре байта. С другой стороны, UTF-32 представляет собой схему кодирования с фиксированной шириной и всегда использует 4 байта для кодирования кодовой точки Unicode. Теперь давайте начнем с того, что такое кодировка символов и почему это важно? Что ж, кодирование символов — важное понятие в процессе преобразования потоков байтов в символы, которые можно отобразить.
Для преобразования байтов в символы важны две вещи: набор символов и кодировка . Поскольку в мире так много символов и символов, требуется набор символов для поддержки всех этих символов. Набор символов — это не что иное, как список символов, где каждый символ или символ сопоставлен с числовым значением, также известным как кодовые точки.
С другой стороны UTF-16, UTF-32 и UTF-8 являются схемами кодирования , которые описывают , как эти значения (кодовые точки) сопоставляются с байтами (с использованием различных битовых значений в качестве основы; например, 16-битный для UTF-16, 32-битный для UTF-32 и 8-битный для UTF-8). UTF означает преобразование Unicode, которое определяет алгоритм для сопоставления каждой кодовой точки Unicode с уникальной последовательностью байтов.
Например, для символа A, который представляет собой латинскую заглавную букву A, кодовая точка Unicode — U+0041, байты в кодировке UTF-8 — 41, кодировка UTF-16 — 0041, а символьный литерал Java — ‘\u0041’. Короче говоря, вам просто нужна схема кодировки символов для интерпретации потока байтов, при отсутствии кодировки символов вы не сможете их правильно показать. Язык программирования Java имеет обширную поддержку различных кодировок и кодировок символов, по умолчанию он использует UTF-8.
Как я уже говорил ранее, UTF-8, UTF-16 и UTF-32 — это всего лишь несколько способов хранения кодовых точек Unicode, то есть тех магических чисел U+, использующих 8, 16 и 32 бита в памяти компьютера. После преобразования символа Unicode в байты его можно легко сохранить на диске, передать по сети и воссоздать на другом конце.
Фундаментальное различие между UTF-32 и UTF-8, UTF-16 заключается в том, что в первом используется схема кодирования с фиксированной шириной, а в более позднем дуэте используется кодирование с переменной длиной. Кстати, несмотря на как UTF-8, так и UTF-16 используют символы Unicode и кодировку переменной ширины , между ними также есть некоторые различия.
1. UTF-8 использует минимум один байт для кодирования символов, а UTF-16 использует минимум два байта.
В UTF-8 каждая кодовая точка от 0 до 127 хранится в одном байте. Только кодовые точки 128 и выше хранятся с использованием 2,3 или фактически до 4 байтов. Короче говоря, UTF-8 представляет собой кодировку переменной длины и занимает от 1 до 4 байтов, в зависимости от кодовой точки. UTF-16 также является кодировкой символов переменной длины, но занимает 2 или 4 байта. С другой стороны, UTF-32 имеет фиксированные 4 байта.
2.
UTF-8 совместим с ASCII, а UTF-16 несовместим с ASCIIUTF-8 имеет преимущество там, где чаще всего используются символы ASCII, в этом случае большинству символов требуется только один байт. Файл UTF-8, содержащий только символы ASCII, имеет ту же кодировку, что и файл ASCII, что означает, что текст на английском языке выглядит в UTF-8 точно так же, как и в ASCII. Учитывая доминирование ASCII в прошлом, это было основной причиной первоначального принятия Unicode и UTF-8.
Вот пример, показывающий, как разные символы сопоставляются с байтами в разных схемах кодирования символов, например. UTF-16, UTF-8 и UTF-32. Вы можете видеть, как разные схемы занимают разное количество байтов для представления одного и того же символа.
Резюме
1) UTF16 не имеет фиксированной ширины. Он использует 2 или 4 байта. Единственный UTF32 имеет фиксированную ширину и, к сожалению, его никто не использует. Кроме того, стоит знать, что строки Java представлены с использованием битовых символов UTF-16, ранее они использовали USC2, который имеет фиксированную ширину.
2) Вы можете подумать, что из-за того, что UTF-8 занимает меньше байтов для многих символов, потребуется меньше памяти, чем UTF-16, ну, это действительно зависит от того, на каком языке находится строка. Для неевропейских языков UTF-8 требует больше памяти, чем UTF-16.
3) ASCII строго быстрее, чем многобайтовая схема кодирования, потому что меньше данных для обработки = быстрее.
Это все о кодировке символов Unicode, UTF-8, UTF-32 и UTF-16 . Как мы узнали, Unicode представляет собой набор различных символов, а UTF-8, UTF-16 и UTF-32 — это разные способы их представления в байтовом формате. И UTF-8, и UTF-16 являются кодировками переменной длины, где количество используемых байтов зависит от кодовых точек Unicode.
С другой стороны, UTF-32 — это кодировка с фиксированной шириной, в которой каждая кодовая точка занимает 4 байта. Unicode содержит кодовые точки почти для всех представляемых графических символов в мире и поддерживает все основные языки, например.