НОУ ИНТУИТ | Лекция | Кодировка букв русского алфавита
< Дополнительный материал 2 || Дополнительный материал 3 || Дополнительный материал 4 >
Ключевые слова: KOI8-R, UCS, CHARACTER SET, UTF-16, таблица, cyrillic, letter, capital, таблица кодировки, ASCII, mic
В настоящее время наиболее широко используются пять (!) различных таблиц кодировки для формального представления русских букв:
- I. ISO 8859-5 — международный стандарт;
- II. Кодовая страница 866 (Microsoft CP866) — используется в MS-DOS;
- III. Кодовая страница 1251 (Microsoft CP1251) для Microsoft Windows;
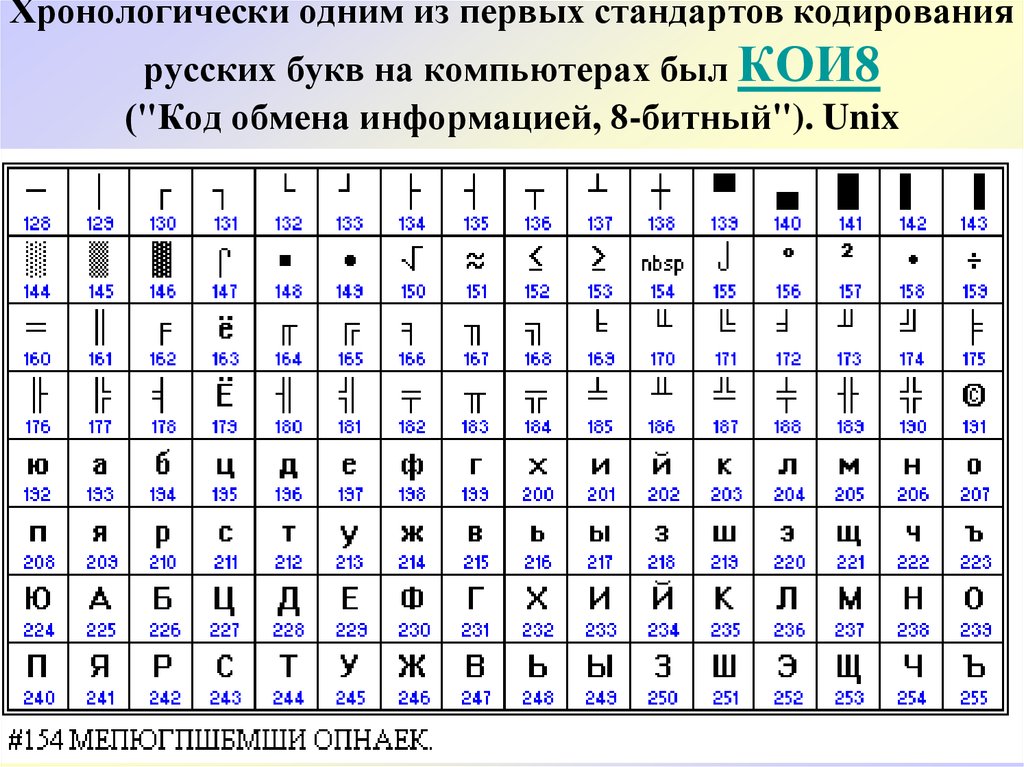
- IV. На базе ГОСТ КОИ-8, koi8-r — применяется в мире Unix;
- V. Unicode — используется в Microsoft Windows, Unix и клонах Unix.

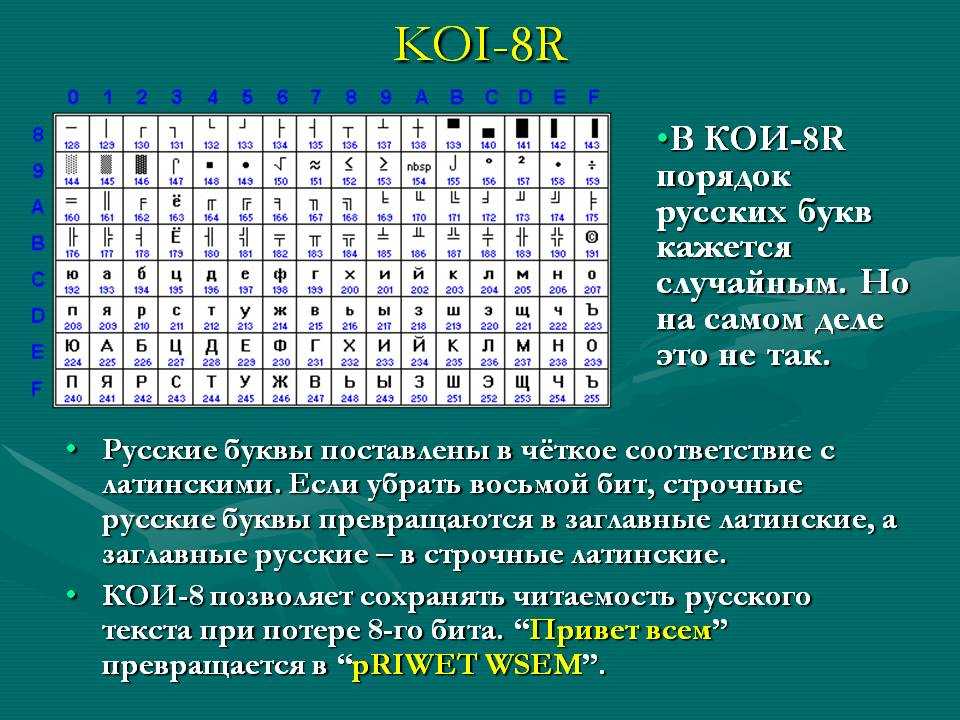
Основная кодировка ГОСТ (государственный стандарт СССР) от 1987 года создана на основе рекомендаций ISO и в дальнейшем стала основой для представления знаков русских букв в Unicode. В ней и в кодировках II, III и V все буквы кроме ё и Ё расположены в алфавитном порядке. На практике эту кодировку можно встретить только на старых IBM PC совместимых компьютерах ЕС-1840 и в некоторых принтерах. Internet браузеры обычно поддерживают ее наряду с кодировками II-IV.
Кодировка CP866, разработанная на основе альтернативной кодировки ГОСТ, создана специально для ОС MS-DOS, в которой часто используются символы псевдографики. В этой кодировке эти символы имеют те же коды, что и в стандартном IBM PC совместимом компьютере.
Альтернативная кодировка ГОСТ, которая имеет два варианта, совпадает с CP866 по позициям для букв русского алфавита и знакам псевдографики. Основная кодировка ГОСТ совпадает с ISO 8859-5 только по всем знакам русских букв, кроме заглавной буквы Ё.
Использование CP1251 обусловлено почти исключительно влиянием на компьютерные технологии разработок фирмы Microsoft. В ней наиболее полно по сравнению с I, II, IV представлены такие символы как , , №, различные виды кавычек и тире и т. п.
Кодировка koi8-r основана на стандартах по обмену информацией, используемых на компьютерах под управлением ОС Unix, CP/M и некоторых других с середины 1970-х. В 1993 она стандартизирована в Internet документом RFC1489.
Кодировка Unicode опирается на каталог символов UCS (Universal Character Set) стандарта ISO 10646. UCS может содержать до 231 различных знаков. Коды UCS-2 — 2-байтные, UCS-4 — 4-байтные. Используются также коды переменной длины UTF-8 (Unicode Transfer Format) — 1 -6-байтные, наиболее совместимые с ASCII, и UTF-16 — 2 или 4-байтные. Unicode в прикладных программах реализуется лишь частично, и в полном объеме пока нигде не поддерживается. В Linux используется UTF-8.

Достаточно широко используется кодирование на основе ASCII:
- VI. На базе КОИ-7 — можно использовать при отсутствии кириллических шрифтов, код получается вычитанием 128 от соответствующего кода в koi8-r, что, как правило, дает код латинской буквы, близкой фонетически к русской.

В кодировке VI нет видимого символа для Ъ.
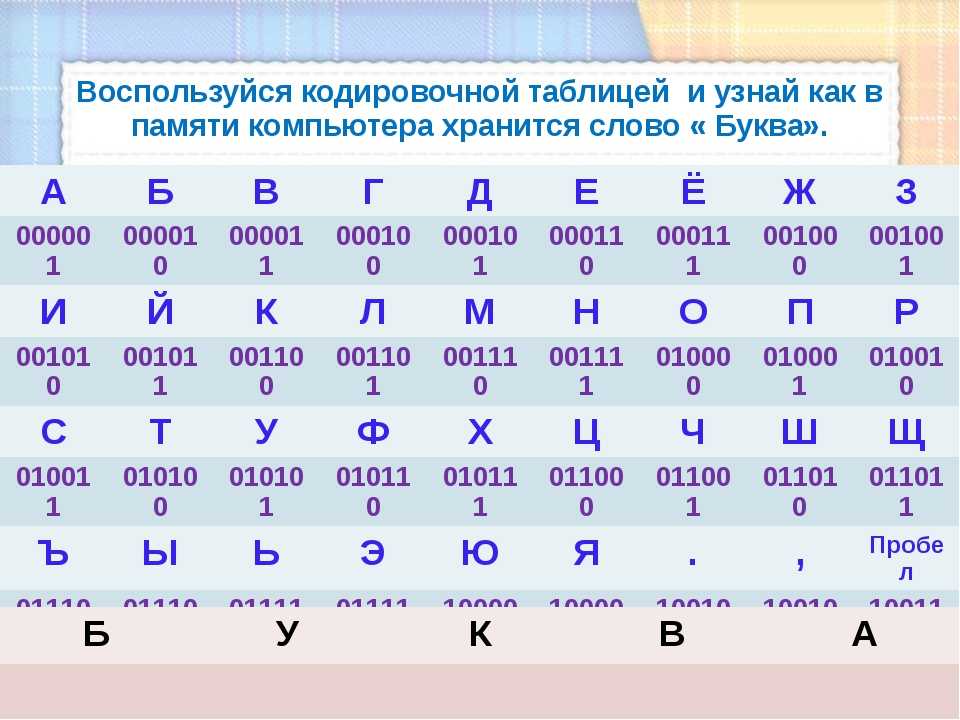
Далее следует таблица, в которой представлены все перечисленные способы
кодирования букв русского алфавита. В этой таблице в колонке 1 находятся
символы букв, в колонке 2 часть названия букв в Unicode 3.2 (названия
строчных кириллических букв начинается словами CYRILLIC SMALL LETTER, а
заглавных — CYRILLIC CAPITAL LETTER, т. о., полное название буквы Д —
CYRILLIC CAPITAL LETTER DE), в колонках с I по V коды десятичные и
шестнадцатеричные соответствующих таблиц кодировки, а в колонке VI — символ
ASCII для КОИ-7.
Кроме перечисленных можно встретить еще используемую до введения кодировок ГОСТ болгарскую кодировку, называемую также MIC, Interprog или «старый вариант ВЦ АН СССР». На компьютерах под управлением Macintosh OS используется также своя собственная таблица кодировки для русских букв, по своему набору знаков почти совпадающая с CP1251.
Дальше >>
< Дополнительный материал 2 || Дополнительный материал 3 || Дополнительный материал 4 >
python — Вместо русских букв выводится что-то другое
Вопрос задан
Изменён 3 месяца назад
Вместо русских букв выводится что-то другое в Pycharm!
При чем с английскими все нормально.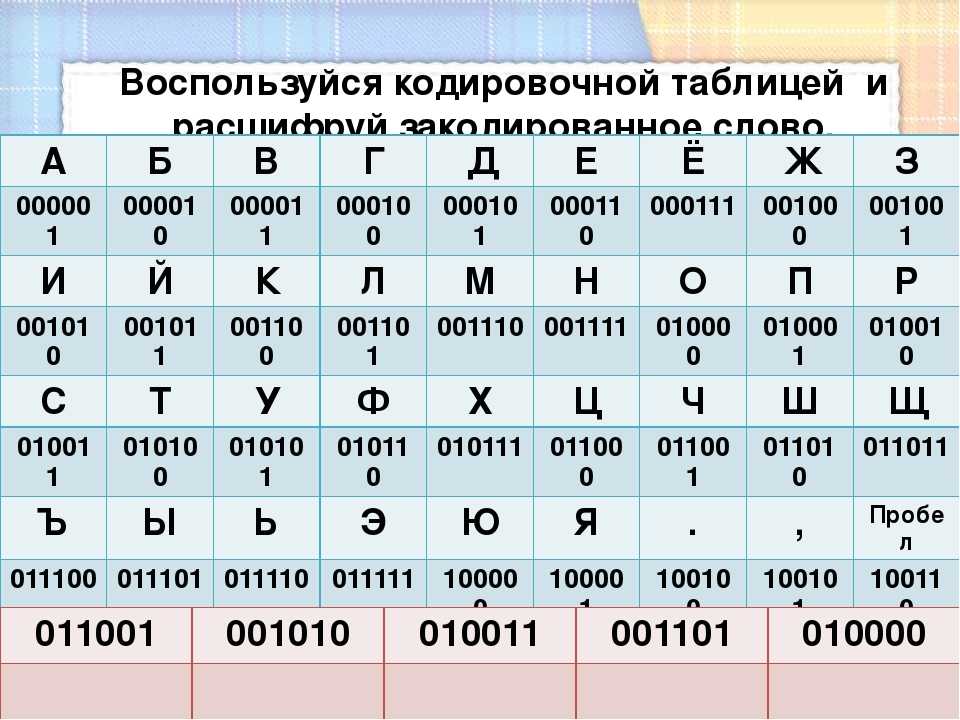
Вообще изначально я не добавлял в начале
#!/usr/bin/env python
и
# -*- coding: utf-8 -*
Но тогда у меня вообще была ошибка
SyntaxError: Non-ASCII character '\xd0' in file C:\Users\staykoks\PycharmProjects\pythonProject\task_1.py on line 9, but no encoding declared
Помогите пожалуйста)
- python
- pycharm
5
Судя по всему у вас кодировка консоли не соответствует UTF-8
По умолчанию pycharm ставит системную кодировку для консоли. Попробуйте выставить вручную.
В Settings(Ctrl+Alt+S) перейдите в Editor | General | Console.
Попробуйте поставить UTF-8 или windows-1251 в выпадающем меню «Default encoding»
OK для сохранения
1
Могу ошибаться, но, по-моему, у вас во второй строке после # лишний пробел.
Попробуйте проверить
#-*- coding: utf-8 -*-
В правом нижнем углу окна Pycharm видно, что вы используете Python 2.7. В Python 2 print — не функция, а оператор, параметры в него передаются без скобок. Он воспринимает параметр print("f(x) = ", f, "при x = ", x) как кортеж ("f(x) = ", f, "при x = ", x)
Варианты исправления:
- Настоятельно рекомендую установить и использовать Python 3 вместо Python 2
- Если все-таки по какой-то причину нужно использовать Python 2, то:
- можно убрать скобки:
print "f(x) = ", f, "при x = ", x - или добавить импорт
from __future__ import print_function, тогдаprintбудет работать как в Python 3 (но других современных возможностей Python 3, естественно, не будет).
- можно убрать скобки:
Зарегистрируйтесь или войдите
Регистрация через Google
Регистрация через Facebook
Регистрация через почту
Отправить без регистрации
Почта
Необходима, но никому не показывается
Отправить без регистрации
ПочтаНеобходима, но никому не показывается
Нажимая на кнопку «Отправить ответ», вы соглашаетесь с нашими пользовательским соглашением, политикой конфиденциальности и политикой о куки
Суп кириллических символов
Суп кириллических символов Несмотря на то, что ISO 8859 содержит стандарт Кириллическая кодировка, есть куча других кириллических кодировок используется на компьютерах по всему миру. Эта страница пытается объяснить, почему
это так, давая исторический обзор. Каждый набор символов проиллюстрирован
растровым GIF вместе с базовой таблицей отображения Unicode и
Шрифт BDF (X/Unix).
Эта страница пытается объяснить, почему
это так, давая исторический обзор. Каждый набор символов проиллюстрирован
растровым GIF вместе с базовой таблицей отображения Unicode и
Шрифт BDF (X/Unix).Кириллица
Братья и православные славянские монахи Кирилл и Мефодий изобрел глаголицу в Македонии в 863 г. зашифрованный греческий алфавит с расширениями для специальных славянских звуков. Их ученый Климент Охридский позже изобрел «кириллицу». более удобочитаемая преобразованная глаголица. В течение века кириллица распространялась и трансформировалась, был модернизирован в его нынешнюю романизированную форму (Гражданка) под Царь Петр Великий.
В настоящее время кириллица используется более чем в 70 языках.
начиная от восточноевропейских славянских языков русский (ru), украинский
(uk), белорусский (be), болгарский (bg), сербский (sr) и македонский
(мк) над алтайскими языками Центральной Азии, такими как азербайджанский (аз), туркменский (тк),
курдский (ku), узбекский (uz), казахский (kk), киргизский (ky) и другие, такие как
таджикский (тг) и монгольский (мн).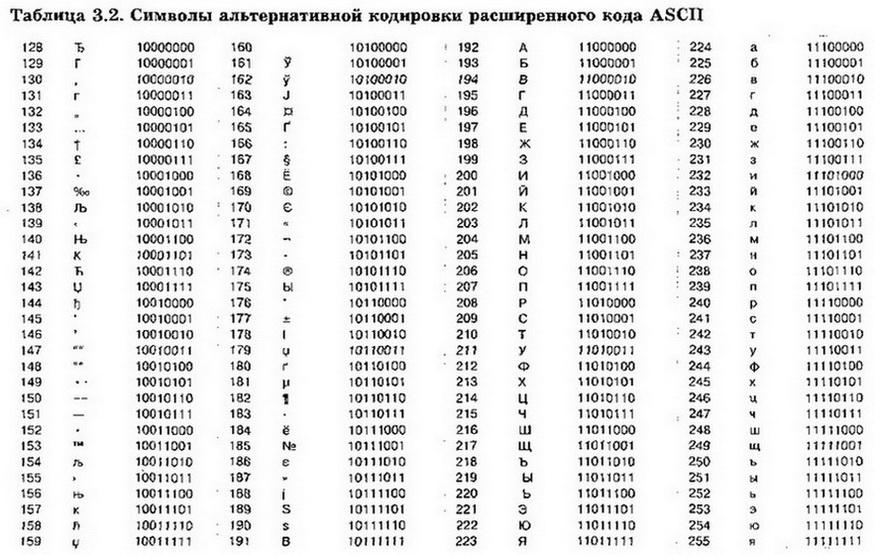 В вашей библиотеке может быть буклет
«Алфавиты языков народов СССР» Кенесбая Мусаевича Мусаева.
опубликовано в 1965.
В вашей библиотеке может быть буклет
«Алфавиты языков народов СССР» Кенесбая Мусаевича Мусаева.
опубликовано в 1965.
При маленьком безакцентном алфавите русский и болгарский казались так же хорошо подходит для компьютерной обработки, как и английский язык.
Самая старая стандартизированная кириллическая компьютерная кодировка, которую я нашел (в John Clews’ Language Automation Worldwide) является государственным стандартом. ГОСТ 13052, 7-битная кодировка, кодирующая буквы русского языка. алфавит (который также удовлетворяет все болгарские потребности) поверх соответствующие буквы ASCII напротив регистр (для распознавания русского текста типа «РУССКИЙ ТЕКСТ» по его регистру, когда представлены в ASCII. я буду называть это свойство соответствием KOI), пожертвовали точками, чтобы сократить алфавит до 32 букв. в два ряда и опустил редко необходимый ЗАГЛАВНЫЙ ТВЕРДЫЙ ЗНАК, чтобы предотвратить его столкновение с DELETE в позиции =7F или EOF=-1:
кодировка = кои-0
[ТЕКСТ]
[БДФ]
Тот факт, что болгарский язык использует ЗАГЛАВНУЮ ТВЕРДЫЙ ЗНАК намного чаще
побудил некоторых болгар закодировать свой твердый знак поверх
ненужные русские вместо ЕРЫ бИ.
Первой была еще одна 7-битная кодировка с именем KOI-7, состоящая только из заглавных букв. буквы:
кодировка = кои-7
[ТЕКСТ]
[БДФ]
кодировка = koi8-a
[ТЕКСТ]
[БДФ]
KOI-8 использовался на многих сетевых узлах Unix. Естественно, знак доллара ASCII $ прижился. вместо знака международной валюты, хотя это не было политкорректный. И точка (йо) была добавлена в столбец 3, поэтому что такие слова, как e (yeyo), больше не нужно было писать без ударения э.
Вернее, последний шаг не происходил, пока компания Demos не начала портировать
Поддержка кириллицы для ПК Unix, таких как Xenix в конце 1980-х и
разработал новую русскую кодовую страницу КОИ-8, которая позже стала известна как
KOI8-R с пунктиром на его позиции от
первый проект ДИС-6937-8/ДИС-8859-5 и
все нерусские буквы вычищены и заменены блочной графикой.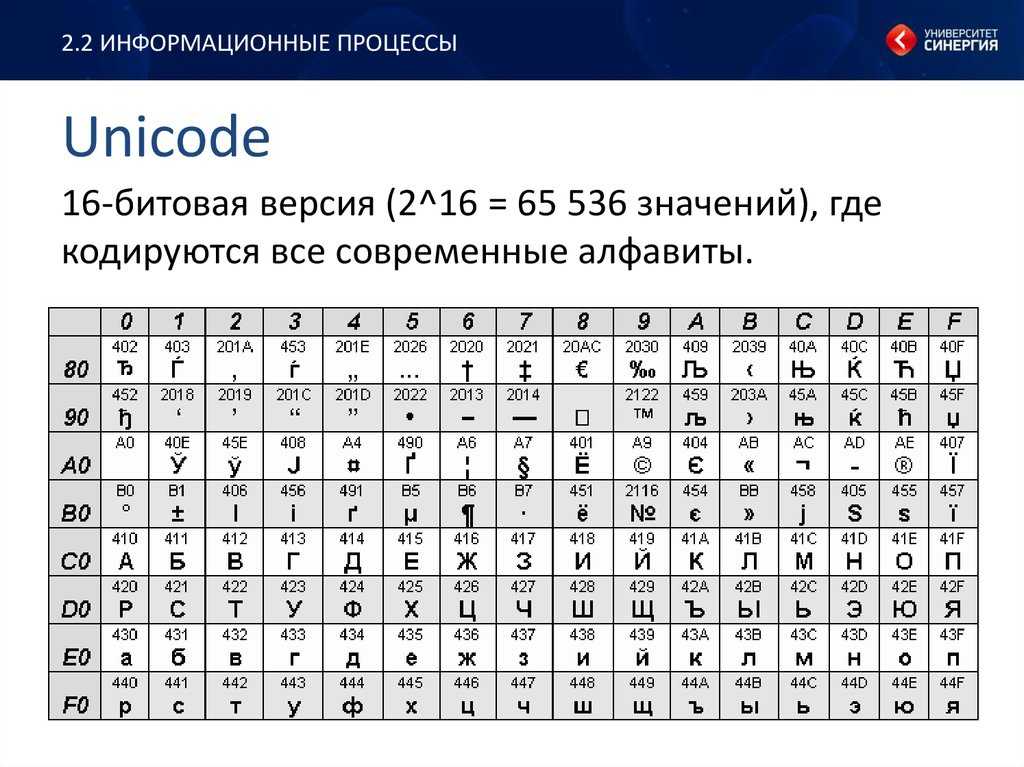
Но многие поставщики шрифтов реализовали только подмножество букв. Позволь нам назовите его КОИ8-Б, это расширенная (большая) база КОИ-8, содержащая буквы (буквы) общие (басы) для всех современных вариантов КОИ-8:
кодировка = koi8-b
[ТЕКСТ]
[БДФ]
В середине 1980-х годов ECMA комитет по разработке серии ISO-8859 а его кириллица ISO-8859-5 хотела сохранить совместимость с установил базу десятилетнего стандарта КОИ-8, и изящно добавил недостающие украинские, белорусские, Сербские и македонские буквы в неиспользуемых кодовых точках. Их черновик был опубликован как 1-е издание стандарта ECMA-113 в 1986 году. проект международного стандарта DIS-8859-5 в 1987 году и был зарегистрирован с номером 111 в Международном реестре ISO наборов символов, которые будут использоваться с экранированием (ISO-2022) последовательностей, отсюда и название ISO-IR-111 и прозвище ECMA-кириллица:
кодировка = koi8-e
[ТЕКСТ]
[БДФ]
ISO-IR-111 так и не был принят в качестве окончательного ISO-8859-5 потому что за это время ГОСТ надышался перестройкой и задекларировал установленную базу и КОИ соответствие менее важно и пересмотрел свой стандарт 19768 года с 1974 по 1987 год в несовместим с новым ГОСТ 19768-87, который переместил русские буквы на один ряд составил и упорядочил их в порядке словаря родного русского языка (АБВГД) вместо корреспонденции KOI (ABCDE):
кодировка=ГОСТ-19768-87
[ТЕКСТ]
[БДФ]
ECMA сразу же последовал за ходом ГОСТ
по совету своих советских экспертов, пересмотрев свои первые
предложение и изменение их ISO-IR-111
символов на кодовые позиции нового ГОСТ 19768-87. Дизайнеры не стали до конца еще и сортировать
нерусские буквы в русский алфавит для обеспечения правильного
порядок словаря для всех языков, как вы найдете его, например, в
Стандарт ISO 9 (транслитерация кириллицы). Пересмотренное предложение
опубликовано как 2-е издание ECMA-113:1988 (заменяет оригинал
ECMA-113:1986, который прижился
(популярен благодаря сочетанию нерусских букв с КОИ-8
совместимости) под псевдонимом ECMA-Cyrillic (хотя ECMA ссылается
вам ISO-8859-5 сейчас) или ISO-IR-111) и принят в ISO 8859 (несмотря на то, что Советский Союз проголосовал против
его знак доллара) как окончательный ISO-8859-5 (ISO-IR-144) в 1988 году. Многие
люди, включая меня, считают, что это избавило бы нас от многих
проблема, если исходный KOI8-совместимый DIS-8859-5: 1987 также был выбран ISO-8859-5:1988. Сейчас мы
есть международный стандарт ISO-8859-5, который настолько нестандартен
что почти никто не любит и не использует его:
Дизайнеры не стали до конца еще и сортировать
нерусские буквы в русский алфавит для обеспечения правильного
порядок словаря для всех языков, как вы найдете его, например, в
Стандарт ISO 9 (транслитерация кириллицы). Пересмотренное предложение
опубликовано как 2-е издание ECMA-113:1988 (заменяет оригинал
ECMA-113:1986, который прижился
(популярен благодаря сочетанию нерусских букв с КОИ-8
совместимости) под псевдонимом ECMA-Cyrillic (хотя ECMA ссылается
вам ISO-8859-5 сейчас) или ISO-IR-111) и принят в ISO 8859 (несмотря на то, что Советский Союз проголосовал против
его знак доллара) как окончательный ISO-8859-5 (ISO-IR-144) в 1988 году. Многие
люди, включая меня, считают, что это избавило бы нас от многих
проблема, если исходный KOI8-совместимый DIS-8859-5: 1987 также был выбран ISO-8859-5:1988. Сейчас мы
есть международный стандарт ISO-8859-5, который настолько нестандартен
что почти никто не любит и не использует его:
кодировка = ISO-8859-5
[ТЕКСТ]
[БДФ]
После RFC 1341
(MIME) предложил использовать кириллицу ISO-8859-5 в электронной почте.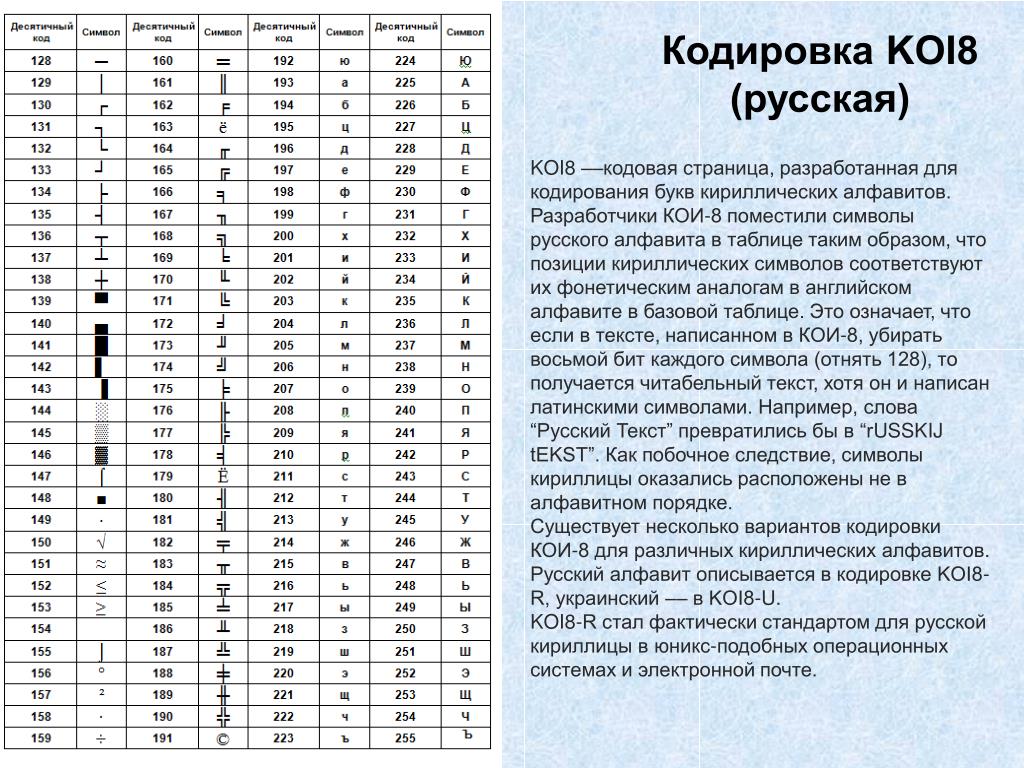 общение, в то время как русский раздел Интернета (группы новостей relcom.*) все еще использовал KOI-8,
Андрей Чернов отправился в
опубликовать его RFC
1489 Регистрация кириллического набора символов «КОИ8-Р» и
установил KOI8-R как стандарт де-факто в Интернете.
KOI8-R, который позже также получил номер CP878, содержит KOI8 с точками и многое другое.
символов рисования коробки:
общение, в то время как русский раздел Интернета (группы новостей relcom.*) все еще использовал KOI-8,
Андрей Чернов отправился в
опубликовать его RFC
1489 Регистрация кириллического набора символов «КОИ8-Р» и
установил KOI8-R как стандарт де-факто в Интернете.
KOI8-R, который позже также получил номер CP878, содержит KOI8 с точками и многое другое.
символов рисования коробки:
кодировка=koi8-r
[ТЕКСТ]
[БДФ]
Андрей Чернов предлагает много практической информации о KOI8-R на его сайте.
При всех этих кодировках есть особая украинская проблема. Украинцы читают букву GHE со штрихом вниз как хе. Чтобы написать правильно гхе им нужна украинская буква ГЕ С ВВЕРХОМ которая была был подавлен сталинскими чиновниками и восстановлен в 1990 году.
Можно злоупотреблять GHE с акцентом (македонский GJE) в ISO-IR-111 или ISO-8859-5, чтобы представить GHE С ВВЕРХОМ, но это не похоже на
быть предпочтительным вариантом. Украинцы, кажется, предпочитают кодировки, которые
включайте настоящий GHE С ПОДЪЕМОМ. GHE WITH UPTURN присутствует в
CP1251 от Microsoft, KOI8-Unified от Fingertip и, конечно же, в Unicode. Тем не менее, эти варианты не казались близкими
достаточно для KOI8-R, чтобы помешать украинским почтмейстерам разработать
новый КОИ8-У и его издание
как RFC2319 в
Апрель 1998. КОИ8-У добавлены только украинские буквы в позициях
совместим с ISO-IR-111, используемым многими
украинцев и сохранили как можно больше рисунков, потому что
многие пользователи в этом районе все еще застряли в MS-DOS. Из-за этого
предпочтения, в нем отсутствуют короткое U с белорусским акцентом, а также сербский и
Македонская поддержка:
GHE WITH UPTURN присутствует в
CP1251 от Microsoft, KOI8-Unified от Fingertip и, конечно же, в Unicode. Тем не менее, эти варианты не казались близкими
достаточно для KOI8-R, чтобы помешать украинским почтмейстерам разработать
новый КОИ8-У и его издание
как RFC2319 в
Апрель 1998. КОИ8-У добавлены только украинские буквы в позициях
совместим с ISO-IR-111, используемым многими
украинцев и сохранили как можно больше рисунков, потому что
многие пользователи в этом районе все еще застряли в MS-DOS. Из-за этого
предпочтения, в нем отсутствуют короткое U с белорусским акцентом, а также сербский и
Македонская поддержка:
кодировка = koi8-u
[ТЕКСТ]
[БДФ]
Я предполагаю, что спецификация RFC2319 и RFC1489 пули KOI8-R является математической.
U+2219 BULLET OPERATOR — это ошибка, унаследованная от RFC1345 и должна
быть исправлена на U+2022 BULLET, как в собственных таблицах Келда Симонсена для
IBM437 или KOI8-R. Вообще
обратите внимание, что RFC1345 и все, что основано на нем, например GNU recode 3.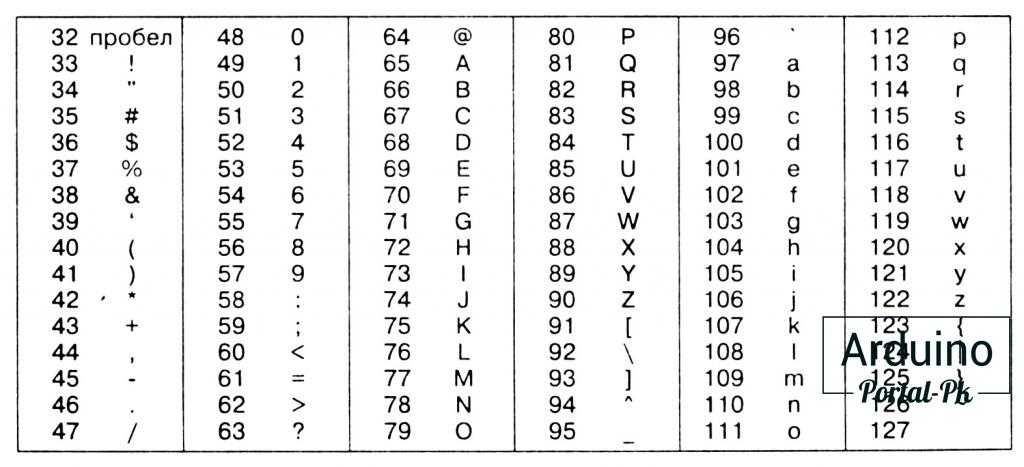 4.1
содержал ряд ошибок, особенно в области кириллицы:
isoir111 больше похож на cp1251, чем на koi8. RFC2319 содержит
дополнительная ошибка, что он кодирует ЗАГЛАВНУЮ БУКВУ УКРАИНСКОГО IE как
U+0403 вместо U+0404.
4.1
содержал ряд ошибок, особенно в области кириллицы:
isoir111 больше похож на cp1251, чем на koi8. RFC2319 содержит
дополнительная ошибка, что он кодирует ЗАГЛАВНУЮ БУКВУ УКРАИНСКОГО IE как
U+0403 вместо U+0404.
кодировка = koi8-f
[ТЕКСТ]
[БДФ]
Вы можете использовать этот шрифт koi8-f для отображения всего текста koi8-* и всех буквы будут отображаться правильно, но некоторые из менее используемых графических символы в koi8-r могут отображаться неправильно.
Еще один серьезный игрок на поле — WinCyrillic Windows от Microsoft. кодовая страница CP1251, для которой Microsoft зарегистрировала метку «Windows-1251», которая не должна ошибочно принимают за предшественника сегодняшней Windows95 13-го века.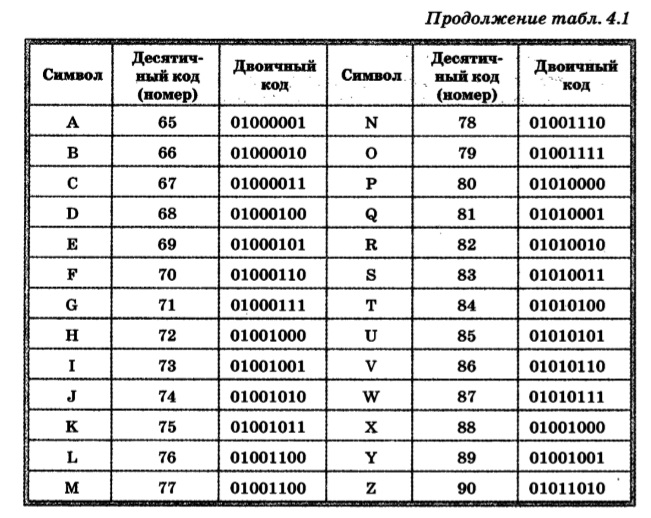 По состоянию на
Декабрь 1997 года, даже новый веб-сервер ГОСТа (Lotus Notes) приветствует вас
with charset=WINDOWS-1251 — ГОСТ (российская стандартизация
органа и организации-члена ISO) не
даже следуя собственным стандартам любой
более!
CP1251 имеет богатый репертуар в порядке, несовместимом ни с ISO-IR-111 (KOI8), ни с ISO-8859.-5:
По состоянию на
Декабрь 1997 года, даже новый веб-сервер ГОСТа (Lotus Notes) приветствует вас
with charset=WINDOWS-1251 — ГОСТ (российская стандартизация
органа и организации-члена ISO) не
даже следуя собственным стандартам любой
более!
CP1251 имеет богатый репертуар в порядке, несовместимом ни с ISO-IR-111 (KOI8), ни с ISO-8859.-5:
кодировка = Windows-1251
[ТЕКСТ]
[БДФ]
charset=MacУкраинский
[ТЕКСТ]
[БДФ]
кодировка=cp866
[ТЕКСТ]
[БДФ]
кодировка=болгарский-мик
[ТЕКСТ]
[БДФ]
Вам надоело это изобилие наборов символов, при этом ни один из них не
лучшее? Хотели бы вы иметь одну хорошую кодировку, способную
заменит все вышеперечисленное и будет принят везде? Не могли бы вы
тоже любите писать на неславянских кириллических языках? Вы получаете все
это и многое другое с Unicode
(ISO-10646), который просто кодирует
все персонажи мира.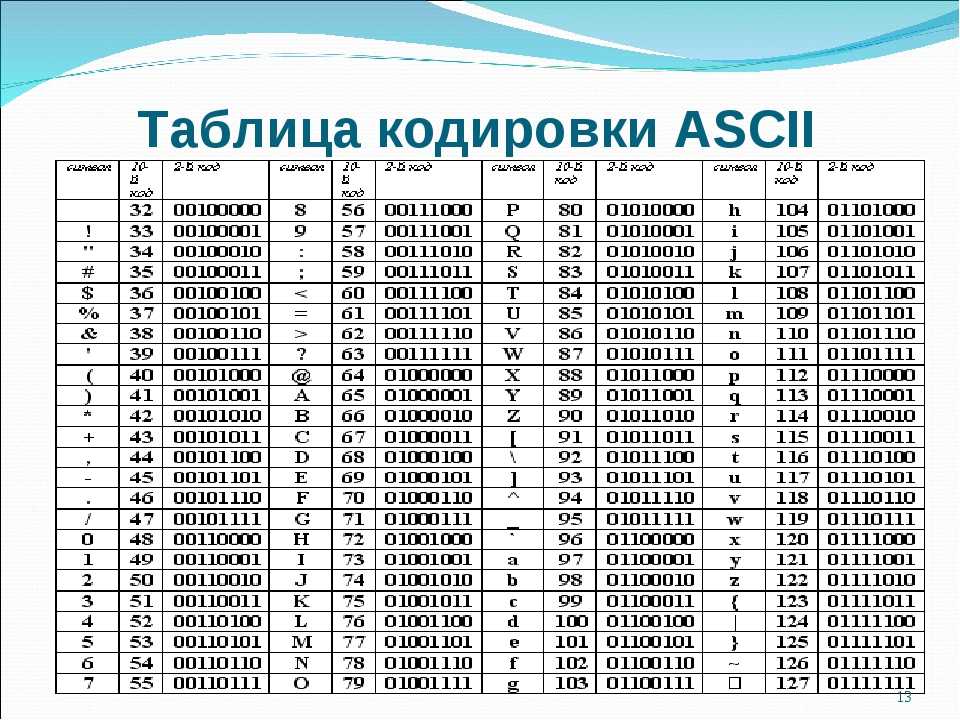
Это блок кириллицы U+0400 в Unicode. Это следует за порядком ISO-8859-5:
кодировка = Юникод-2-1
[ТЕКСТ]
[БДФ]
Ольга Лапко утверждает на страницах 175 и 179 блестящего выпуска TUGboat 17-2 (Материалы Ежегодная встреча группы пользователей TeX в 1996 г. в Дубне, Россия), в которой приняло участие около 100 Кириллические буквы по-прежнему отсутствуют в Юникоде. Большинство из них кажутся кодируется с комбинацией акцентов, а остальные могут быть добавлены с помощью процедуры, описанной в Приложение B. Отправка новых символов стандарта Unicode.
Каждая кириллическая буква кодируется двумя байтами в UTF-8. Стандартная схема сжатия для Unicode (SCSU) позволяет уменьшить это до традиционного одного байта на букву.
Я все еще занят написанием своего Unicode-HOWTO для Linux. я добавил Cyrillic.kmap, злоупотребляющий ISO 9 в качестве метода ввода в текстовый редактор Yudit Unicode для системы X Window.
Я призываю вас присылать свои комментарии по адресу roman@czyborra. com. я благодарен
Кристофер Неханив, Андреас Прилоп, Питер Кассетта
com. я благодарен
Кристофер Неханив, Андреас Прилоп, Питер Кассетта
Роман Чиборра
1998-05-25 .. 1998-11-30
Буква кириллицы в URL — Кодировка | SEO Форум
Ваш браузер не поддерживает JavaScript. В результате ваши впечатления от просмотра будут уменьшены, и вы будете переведены в режим только для чтения .
Загрузите браузер, поддерживающий JavaScript, или включите его, если он отключен (например, NoScript).
- Дом
 org/ListItem»> SEO-тактика
org/ListItem»> SEO-тактика- Техническое SEO
- Буква кириллицы в URL — Кодировка
Эта тема была удалена. Его могут видеть только пользователи с правами управления вопросами.
-
Привет всем
Мы запускаем наш сайт в России.
Насколько я вижу по поиску в гугле, все сайты имеют адреса латинскими буквами.
Есть ли для этого особая причина? — Вроде и кириллица тоже работает.
Мой технический персонал говорит, что это может привести к проблемам с кодировкой.

Может ли кто-нибудь дать мне некоторое представление об этом?
Заранее спасибо..
/ Кеннет
-
Привет,
У меня точно такая же проблема, как описано выше. Что-то изменилось с 2012 года? Каково эмпирическое правило, когда речь идет о русских URL-адресах, лучше ли оставить кириллицу или преобразовать их в латиницу?
Я заметил, что URL-адреса на кириллице ломаются при их копировании и вставке, а сканеры Moz обнаруживают их слишком длинными. А как насчет поисковых роботов Google, видят ли они это по-другому?
Спасибо,
Аня
 org/Comment»>
org/Comment»> Если вы ориентируетесь на русские запросы на Google.ru, и ваша целевая аудитория в основном вводит запросы с кириллическими символами, то кириллические URL-адреса должны быть в порядке. Раньше поддержка нелатинских символов была плохой, но я думаю, что за последние пару лет ситуация сильно изменилась.
Вот соответствующая ветка поддержки Google, в которой участвует Джон Мью:
http://www.google.com.ag/support/forum/p/Webmasters/thread?tid=489ece0479e0d33d&hl=en
Технически Google может сканировать /индексировать эти страницы. Например, русская версия Википедии, кажется, использует кириллические URL-адреса:
http://ru.wikipedia.org/wiki/%D0%9A%D0%BE%D0%BC%D0%BF%D1%8C% D1%8E%D1%82%D0%B5%D1%80
(к сожалению, этот URL не работает, когда я вырезаю/вставляю)
Большой вопрос для меня будет заключаться в том, имеют ли поисковики привычку использовать латинские символы в поиске, и привлекают ли эти поиски больше объема, чем кириллицу.
 К сожалению, у нас здесь нет русскоязычных сотрудников, поэтому я не могу прокомментировать это. Я немного говорю по-китайски, и на этом рынке я тоже видел смесь. В некоторых URL-адресах используются упрощенные символы, а в некоторых — пиньинь (латинизированная версия). Технически любой из них должен работать, но все еще есть некоторые устаревшие эффекты времен, когда поддерживались только латинские символы.
К сожалению, у нас здесь нет русскоязычных сотрудников, поэтому я не могу прокомментировать это. Я немного говорю по-китайски, и на этом рынке я тоже видел смесь. В некоторых URL-адресах используются упрощенные символы, а в некоторых — пиньинь (латинизированная версия). Технически любой из них должен работать, но все еще есть некоторые устаревшие эффекты времен, когда поддерживались только латинские символы.
У вас есть животрепещущий вопрос по SEO?
Подпишитесь на Moz Pro, чтобы получить полный доступ к вопросам и ответам, отвечать на вопросы и задавать свои.
Начать бесплатную пробную версию
Есть вопрос?
Просмотр вопросов
Посмотреть Все вопросыНовые (нет ответов)ОбсуждениеОтветыПоддержка продуктаБез ответа
От Все времяПоследние 30 днейПоследние 7 днейПоследние 24 часа
Сортировка по Последние вопросыНедавняя активностьБольше всего лайковБольшинство ответовМеньше всего ответовСамые старые вопросы
С категорией All CategoriesAffiliate MarketingAlgorithm UpdatesAPIBrandingCommunityCompetitive ResearchContent DevelopmentConversion Rate OptimizationDigital MarketingFeature RequestsGetting StartedImage & Video OptimizationIndustry EventsIndustry NewsIntermediate & Advanced SEOInternational SEOJobs and OpportunitiesKeyword ExplorerKeyword ResearchLink BuildingLink ExplorerLocal ListingsLocal SEOLocal Website OptimizationMoz BarMoz LocalMoz NewsMoz ProMoz ToolsOn-Page OptimizationOther SEO ToolsPaid Search MarketingProduct SupportReporting & AnalyticsResearch & TrendsReviews and RatingsSearch BehaviorSEO ТактикаТренды поисковой выдачиСоциальные сетиТехническое SEOВеб-дизайнБелое/черное SEO
Связанные вопросы
- Я изо всех сил пытаюсь понять (и исправить), почему я получаю ошибку 404. URL-адрес включает этот «%5Bnull%20id=43484%5D», но я не могу найти его нигде в URL-адресе ссылки. Кто-нибудь знает, почему, пожалуйста? Спасибо
Можете ли вы помочь с тем, как исправить эту ошибку 404, пожалуйста? Похоже, у меня есть перенаправление с одной страницы на другую, хотя URL-адрес ссылающейся страницы работает, но, похоже, это ссылка на другой URL-адрес с этим кодом в конце URL-адреса — %5Bnull%20id=43484%5D, который Я изо всех сил пытаюсь найти и исправить. Спасибо
Техническое SEO | | Николь.
 wynter2020
wynter2020 0
- Как удалить конкретный URL?
Я только что провел диагностику и попытался удалить такие страницы, как «к сожалению, эта страница не найдена» или «404 (не найдено_ страницы ответа об ошибке). Кто-нибудь может помочь?
Техническое SEO | | распиловка
0
- Удаление URL
Здравствуйте! Я обнаружил, что на некоторых страницах сайта есть два разных URL-адреса, указывающих на одну и ту же страницу, что создает дублированный контент, заголовок и описание.
 Есть ли способ заблокировать один из них?
ваше здоровье
Есть ли способ заблокировать один из них?
ваше здоровьеТехническое SEO | | ПремиоОскар
0
- Дружественные URL-адреса (URL-адреса SEO)
Здравствуйте! У меня есть сайт электронной коммерции с более чем 5 000 продуктов, URL-адреса продуктов: www.site.com/index.php?route=product/product&path=61_87&product_id=266 Я думаю о том, чтобы сделать его другом для SEO site.com/category/product-brand Вот мой вопрос, потеряю ли я ранги за это изменение? Мне очень важно это знать Большое спасибо!
Техническое SEO | | матив
0
 org/ListItem»> Формат содержимого URL — любое влияние на поисковую оптимизацию
org/ListItem»> Формат содержимого URL — любое влияние на поисковую оптимизацию Я понимаю, что существует рекомендуемая максимальная длина URL, чтобы поисковые системы не наказывали его. Мне интересно, должен ли я оптимизировать наши категории электронной торговли, чтобы они были описательными, или использовать сокращения, чтобы свести длину URL к минимуму? Наши продукты разделены на множество категорий, поэтому URL-адреса многих продуктов довольно длинные, если мы пойдем описательным путем. Я также слышал, что можно рассмотреть возможность полного удаления компонента категории из URL-адреса продукта. Я новичок во всех этих SEO-вещах, поэтому я надеюсь, что сообщество может поделиться своими знаниями о влиянии этих опций. Ваше здоровье, Стив
Техническое SEO | | Стив Магуайр
0
 org/ListItem»> Должны ли мои URL быть в верхнем или нижнем регистре
org/ListItem»> Должны ли мои URL быть в верхнем или нижнем регистре Я делаю кучу 301 редиректов для своего сайта. Должен ли я сделать их строчными, прописными или это имеет значение? Кроме того, хочу ли я использовать дефисы (-) или символы подчеркивания (_)? Любые другие советы? БЫВШИЙ: http://www.stupid.com/golf-slippers.html ИЛИ ЖЕ http://www.stupid.com/Golf-Slippers.html
Техническое SEO | | ДжастинГлупый
0
- URL-адреса: менять или не менять
Здравствуйте! Недавно, в декабре прошлого года, мы запустили обновленный сайт на Drupal.
 Мы экотуристическая компания. Мой текущий URL-адрес выглядит следующим образом:
/Африка-и-Ближний-Восток/Кения-Танзания
/центральная-южная-америка/галапагосские острова
Мои страницы имеют хорошие оценки таргетинга по терминам, а рейтинги по ключевым словам, на которые мы ориентируемся — «сафари по Кении и Танзании» и «круизы по галапагосским островам» — приличные, но не высокие — большинство находится на странице 2 или 3. Единственный URL, где я нацелен на наш самый важный термин «круизы по реке Амазонке», я все еще на странице 2.
/центральная-южная-америка/амазонские-речные-круизы
Мои вопросы:
Я упустил возможность с остальными URL-адресами, и должен ли я подумать об изменении остальных на более целевые термины с 301? Поскольку новый сайт был запущен в январе, возможно, я не уделил достаточно времени, чтобы мои новые URL-адреса проиндексировались и созрели. Не проще ли создать целевые страницы с уникальным содержанием статей, ориентированных на такие термины, как «круизы на Галапагосские острова» и «сафари в Кении и Танзании»? Если да, то как сделать так, чтобы не «конкурировать» со страницами, на которые я хочу их вести?
Это также поднимает вопрос о перенаправлении одного и того же URL-адреса дважды, т.
Мы экотуристическая компания. Мой текущий URL-адрес выглядит следующим образом:
/Африка-и-Ближний-Восток/Кения-Танзания
/центральная-южная-америка/галапагосские острова
Мои страницы имеют хорошие оценки таргетинга по терминам, а рейтинги по ключевым словам, на которые мы ориентируемся — «сафари по Кении и Танзании» и «круизы по галапагосским островам» — приличные, но не высокие — большинство находится на странице 2 или 3. Единственный URL, где я нацелен на наш самый важный термин «круизы по реке Амазонке», я все еще на странице 2.
/центральная-южная-америка/амазонские-речные-круизы
Мои вопросы:
Я упустил возможность с остальными URL-адресами, и должен ли я подумать об изменении остальных на более целевые термины с 301? Поскольку новый сайт был запущен в январе, возможно, я не уделил достаточно времени, чтобы мои новые URL-адреса проиндексировались и созрели. Не проще ли создать целевые страницы с уникальным содержанием статей, ориентированных на такие термины, как «круизы на Галапагосские острова» и «сафари в Кении и Танзании»? Если да, то как сделать так, чтобы не «конкурировать» со страницами, на которые я хочу их вести?
Это также поднимает вопрос о перенаправлении одного и того же URL-адреса дважды, т.
 schema.org/ItemList» data-nextstart=»» data-set=»»>
schema.org/ItemList» data-nextstart=»» data-set=»»>