Какие существуют кодировки русских букв в компьютере
Статьи › Код › Какие коды соответствуют таким операциям как перевод строки ввод пробела и др
К сожалению, в настоящее время существуют пять различных кодировок кириллицы (КОИ8-Р, Windows. MS-DOS, Macintosh и ISO). Из-за этого часто возникают проблемы с переносом русского текста с одного компьютера на другой, из одной программной системы в другую.
- Какие кодировки с русскими буквами
- Какие бывают кодировки символов
- Какие кодовые таблицы используют для кодировки русских букв
- Какая кодировка в Windows
- Какая кодировка лучшая
- Как узнать какая кодировка стоит на компьютере
- Какие бывают кодировки в информатике
- Какие таблицы кодировок вы знаете
- Что такое UTF-16 и UTF-8 чем различаются эти кодировки
- Как кодируются буквы
- В чем различие между ASCII и Unicode
- Где используется UTF-8
- Что такое кодировка it
- Какая кодировка в Chrome
- Что за кодировка ANSI
- Как кодировать текст в UTF-8
- Как работает юникод
- Какая кодировка в Python
- Для чего нужно кодирование Юникод
- Сколько символов в кодировке
- Что означает знак х
- Какие стандарты кодирования символов в Интернете были зарегистрированы для представления на компьютере русских букв
- Что такое алфавит в кодировании
- Как указать кодировку UTF-8
- Как расшифровать кодировку UTF-8
- Как поставить кодировку UTF-8 в С ++
- Какие кодировки с русскими буквами используются в сети Интернет кодировка MS-DOS
Какие кодировки с русскими буквами
Наиболее распространёнными кодировками с поддержкой Русского языка (с использованием символов Кириллицы) являются: UTF-8, Windows-1251, CP-866, KOI-8R, ISO-8859-5.
Какие бывают кодировки символов
Распространённые кодировки:
- ISO 646. ASCII.
- BCDIC.
- EBCDIC.
- ISO 8859:
- Кодировки Microsoft Windows:
- MacRoman, MacCyrillic.
- КОИ8 (KOI8-R, KOI8-U…),
- Болгарская кодировка
Какие кодовые таблицы используют для кодировки русских букв
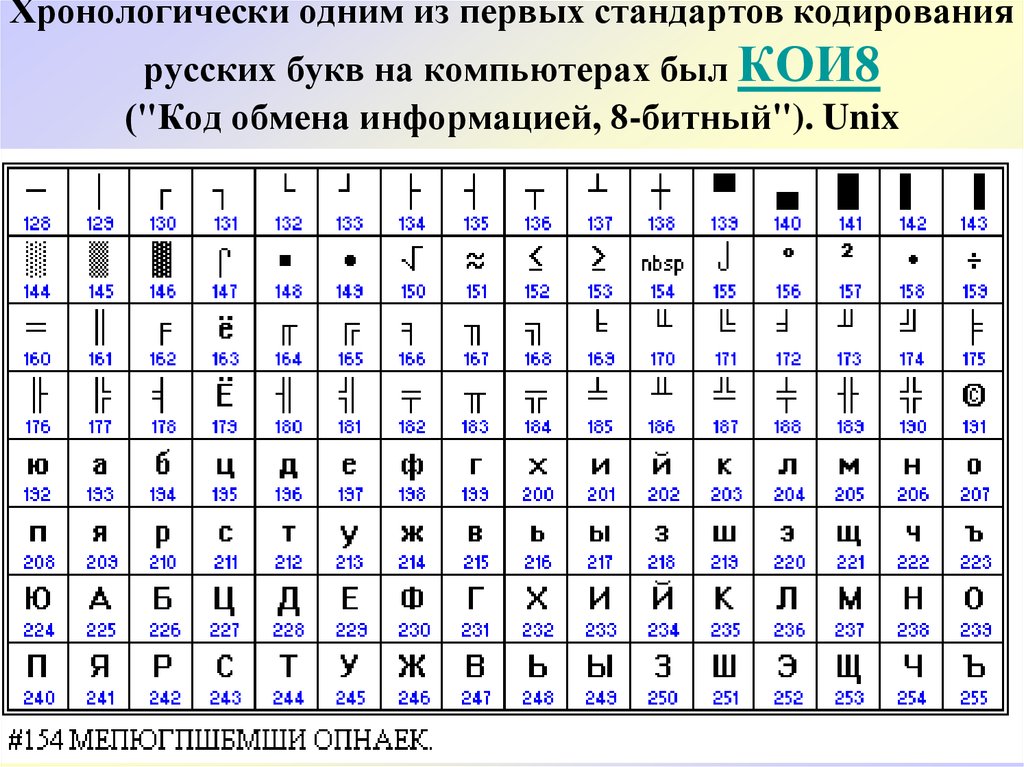
В настоящее время существует 5 кодовых таблиц для русских букв: Windows (СР(кодовая страница)1251), MS — DOS (СР(кодовая страница)866), KOИ — 8 (Код обмена информацией, 8-битный) (используется в OS UNIX), Mac (Macintosh), ISO (OS UNIX).
Какая кодировка в Windows
Windows-1251 — набор символов и кодировка, являющаяся стандартной 8-битной кодировкой для русских версий Microsoft Windows до 10-й версии. В прошлом пользовалась довольно большой популярностью. Была создана на базе кодировок, использовавшихся в ранних «самопальных» русификаторах Windows в 1990—1991 гг.
Какая кодировка лучшая
Медикаментозное кодирование: на сегодняшний день остается самым распространенным и эффективным методом, который гарантирует надёжное воздержание от алкоголя.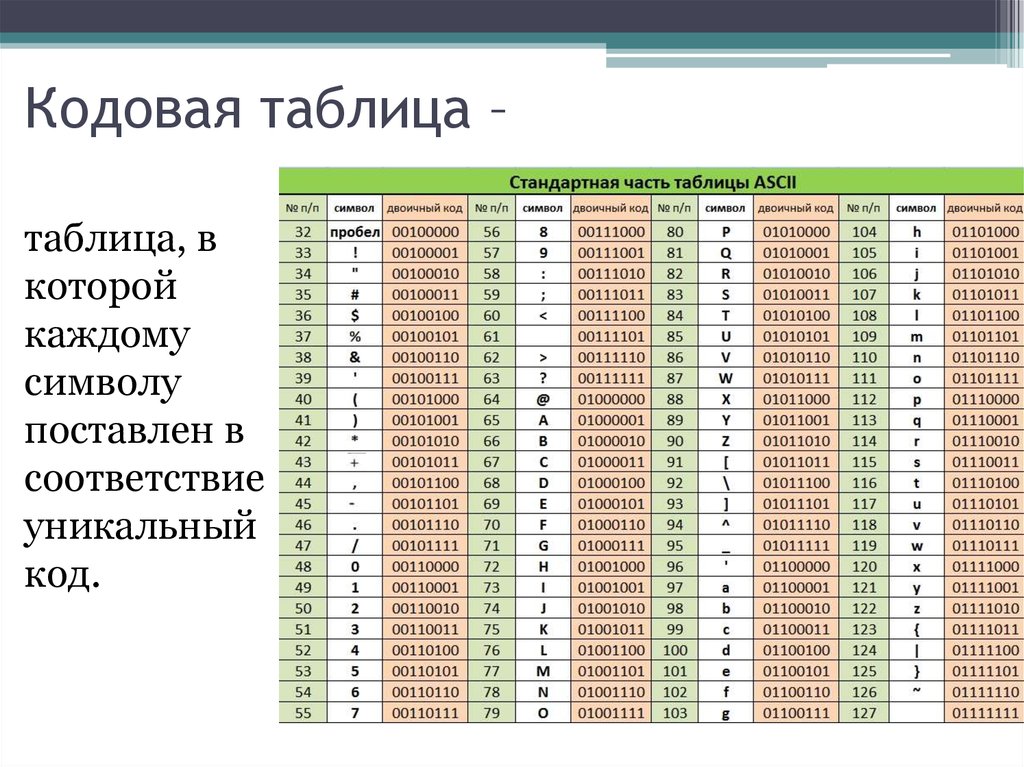 А самыми используемыми препаратами остается Эспераль и Дисульфирам.
А самыми используемыми препаратами остается Эспераль и Дисульфирам.
Как узнать какая кодировка стоит на компьютере
Открыть искомый текстовый файл в Блокноте Windows и выбрать пункт меню «Файл» -> «Сохранить как». Пример текстового файла, в котором русский текст задан в формате UTF, но это не очевидно при открытии. 2. В открывшемся диалоговом окне вы сразу видите, в какой кодировке был сохранён текст в текстовом файле.
Способы кодирования информации: при помощи чисел — числовой. Кодирование при помощи знаков того же алфавита, что и исходный текст — символьный. Кодирование при помощи рисунков и значков — графический.
Какие таблицы кодировок вы знаете
Существует множество разнообразных кодировок, наиболее распространённой и универсальной на данный момент является кодировка UTF-8. Также существуют такие таблицы, как ASCII, UNICODE и многие другие.
Что такое UTF-16 и UTF-8 чем различаются эти кодировки
UTF-8 — стандарт кодирования, преобразующий номера ячеек таблицы Юникод в бинарные коды с использованием переменного количества бит: 8, 16, 24 или 32. UTF-16 — стандарт кодирования, преобразующий номера ячеек таблицы Юникод в бинарные коды с использованием переменного количества бит:16 или 32.
UTF-16 — стандарт кодирования, преобразующий номера ячеек таблицы Юникод в бинарные коды с использованием переменного количества бит:16 или 32.
Как кодируются буквы
Каждая буква также кодируется своим номером в алфавите, НО номер всегда записывается двумя цифрами: к записи однозначных чисел слева добавляется 0. Например, код А — 01, код Б — 02 и т. д. В этом случае кодом текста АББА будет 01020201.
В чем различие между ASCII и Unicode
Важно не путать ее с ASCII — эти понятия не идентичны. ASCII появилась раньше и включает в себя меньше символов. В стандартной таблице их всего 128, если не считать расширений для других языков. А в «Юникоде», который реализуют кодировки UTF-8 и UTF-32, сейчас 2²¹ символов — это больше чем два миллиона.
Где используется UTF-8
Кодировка UTF-8 сейчас является доминирующей в веб-пространстве. Она также нашла широкое применение в UNIX-подобных операционных системах. Формат UTF-8 был разработан 2 сентября 1992 года Кеном Томпсоном и Робом Пайком, и реализован в Plan 9.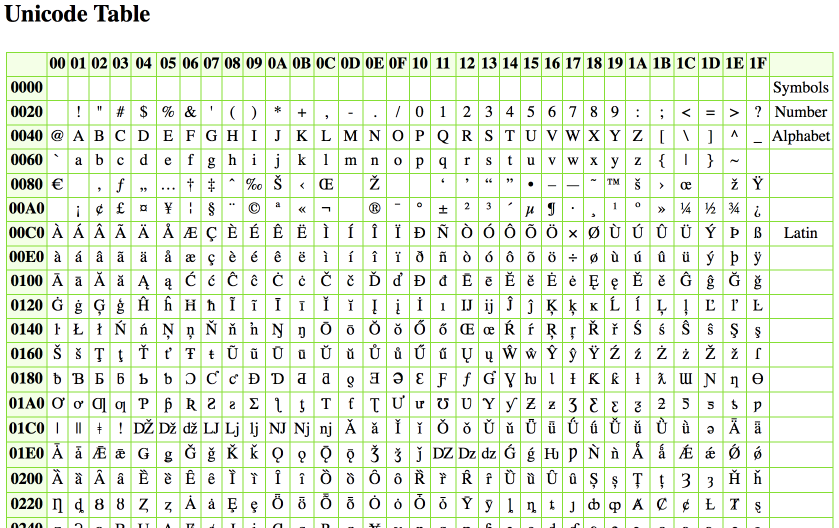 Идентификатор кодировки в Windows — 65001.
Идентификатор кодировки в Windows — 65001.
Что такое кодировка it
Кодировка — это набор правил, описывающий способ перевода одного представления в другое. Прочие термины, заслуживающие прояснения: Набор символов, чарсет, charset — Набор символов, который может быть закодирован. «Кодировка ASCII включает набор из 128 символов».
Какая кодировка в Chrome
Откройте меню «Вид» в верхней части браузера. Нажмите «Кодировка текста». Выберите Unicode (UTF-8) в раскрывающемся меню.
Что за кодировка ANSI
ANSI-графика — расширение ASCII-графики. Этот вид цифровой графики создаёт картинку из символов, но использует не только символы, предлагаемые кодировкой ASCII, а все 224 печатных символа, 16 цветов шрифта и 8 фоновых цветов, поддерживаемых драйвером ANSI. SYS, который использовался в системе MS-DOS.
Как кодировать текст в UTF-8
Кодируем в UTF-8:
- Каждый символ превращаем в Юникод.
- Проверяем из какого символ диапазона.

- Если код символа меньше 128, то к результату добавляем его в неизменном виде.
- Если код символа меньше 2048, то берем последние 6 бит и первые 5 бит кода символа.
Как работает юникод
Юникод постулирует чёткое разграничение между символами, их представлением в компьютере и их отображением на устройстве вывода. Юникод-символы не всегда соответствуют символу в традиционно-наивном понимании, например букве, цифре, пунктуационному знаку или иероглифу.
Какая кодировка в Python
По умолчанию Python использует кодировку utf-8, но видимо запись в файл происходила не с её помощью. Здесь нам придёт на помощь дополнительный параметр функции open — параметр encoding, который позволяет указать конкретную кодировку, в которой следует прочитать файл (или записывать в него).
Для чего нужно кодирование Юникод
Применение этого стандарта позволяет закодировать очень большое число символов из разных систем письменности: в документах, закодированных по стандарту Юникод, могут соседствовать китайские иероглифы, математические символы, буквы греческого алфавита, латиницы и кириллицы, символы музыкальной нотной нотации, при этом
Сколько символов в кодировке
Unicode содержит 1,114,112 кодовых значений; на настоящий момент времени, для них назначено более 96,000 символов.
Что означает знак х
Буквой X часто обозначают неизвестное значение или неизвестный объект (в математике, литературе, разговорной речи). В польском, финском, румынском и ряде других языков эта буква используется только в заимствованных словах.
Какие стандарты кодирования символов в Интернете были зарегистрированы для представления на компьютере русских букв
Первые русские ЭВМ использовали 7-битную кодировку символов КОИ-7 (Код Обмена Информацией семибитный — рисунок 1.3), в которой присутствовали прописные латинские буквы, а на месте строчных латинских были русские прописные буквы (кириллица).
Что такое алфавит в кодировании
Алфавитное кодирование — вид кодирования, построенный на взаимной однозначности кодирования слов некоторого алфавита при помощи замены каждой буквы некоторым словом того же или какого-либо другого алфавита.
Как указать кодировку UTF-8
Откройте меню «Вид» в верхней части браузера. Нажмите «Кодировка текста». Выберите Unicode (UTF-8) в раскрывающемся меню.
Как расшифровать кодировку UTF-8
Unicode Transformation Format, 8-bit — «формат преобразования Юникода, 8-бит») — распространённый стандарт кодирования символов, позволяющий более компактно хранить и передавать символы Юникода, используя переменное количество байт (от 1 до 4), и обеспечивающий полную обратную совместимость с 7-битной кодировкой ASCII.
Как поставить кодировку UTF-8 в С ++
Выберите страницу свойствC/C++>Command Lineсвойства> конфигурации. В разделе Дополнительные параметры добавьте /utf-8 параметр, чтобы указать предпочитаемую кодировку. Выберите ОК для сохранения внесенных изменений.
Какие кодировки с русскими буквами используются в сети Интернет кодировка MS-DOS
Кодировки русских букв:
- CP-866. Кодировка 866 (альтернативная). Используется в системе MS-DOS, а также в текстовой консоли Windows.
- KOI-8. Кодировка KOI-8 используется в операционных системах семейства UNIX. Русские буквы одним старшим битом отличаются от созвучных им латинских букв.

- CP-1251. Кодировка 1251 (Windows).
Кодировки русского текста | Практическая информатика
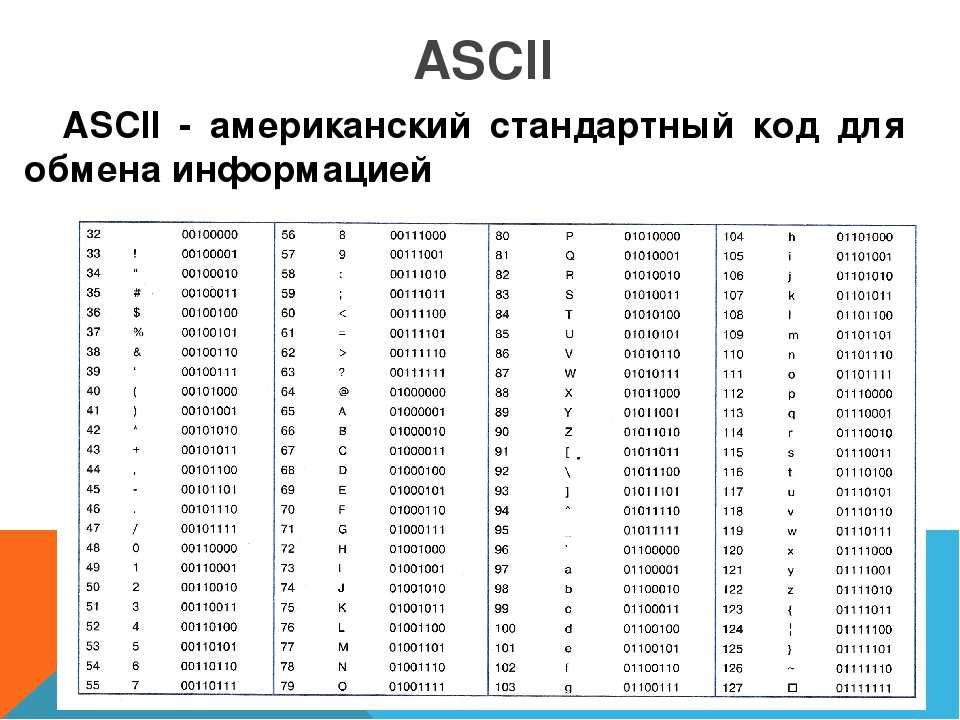
Исторически сложилось так, что для представления печатных символов (кодирования текста) в первых ЭВМ отвели 7 бит. 27=128. Этого количества вполне хватало для кодирования всех строчных и прописных букв латинского алфавита, десяти цифр и различных знаков и скобок. Именно такой, 7-битной, является таблица символов ASCII (американский стандартный код для обмена информацией), подробную информацию о которой вы можете получить при помощи команды man ascii операционной системы Linux.
Когда возникла необходимость кодировать национальные алфавиты, то 128 символов стало недостаточно. Было решено перейти на кодирование с помощью 8 бит (т. е. одного байта). В результате количество символов, которые можно закодировать таким образом стало равно 28=256. При этом символы национальных алфавитов располагались во второй половине кодовой таблицы, т. е.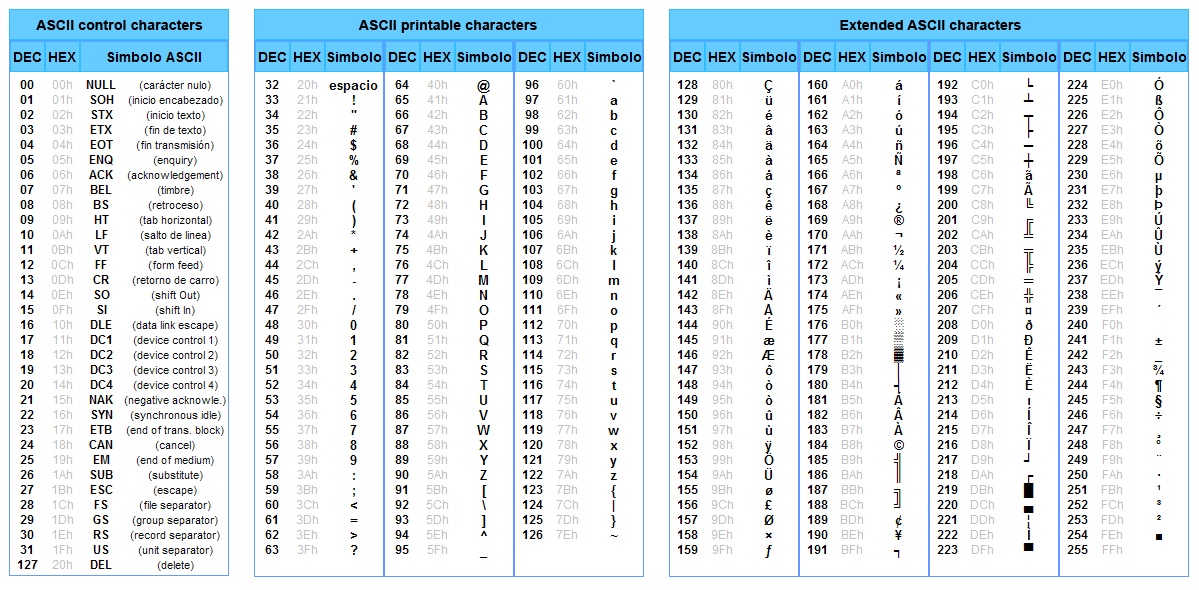 содержали единицу в старшем разряде байта, отведенного для кодирования символа. Так появился стандарт ISO 8859, содержащий множество кодировок для наиболее распространенных языков.
содержали единицу в старшем разряде байта, отведенного для кодирования символа. Так появился стандарт ISO 8859, содержащий множество кодировок для наиболее распространенных языков.
Среди них была и одна из первых таблиц для кодировки русских букв — ISO 8859-5 (воспользуйтесь командой man iso_8859_1 для получения кодов русских букв в этой таблице).
Задачи передачи текстовой информации по сети вынудили разработать еще одну кодировку для русских букв, названную Koi8-R (код отображения информации 8-битный, русифицированный). Рассмотрим ситуацию, когда письмо, содержащее русский текст, отправлено по электронной почте. Случалось, что в процессе путешествия по сетям письмо обрабатывалось программой, которая работала с 7-битной кодировкой и обнуляла восьмой бит. В результате такого преобразования код символа уменьшался на 128, превращаясь в код символа латинского алфавита. Возникла необходимость повысить устойчивость передаваемой текстовой информации к обнулению 8 бита.
К счастью, значительное число букв кириллицы имеет фонетические аналоги в латинском алфавите. Например, Ф и F, Р и R. Есть несколько букв, совпадающих даже по начертанию. Расположив русские буквы в кодовой таблице таким образом, чтобы их код превышал код аналогичных латинских на число 128, добились того, что потеря 8-го бита превращала текст хотя и в состоящий из одной латиницы, но все равно понимаемый русскоязычным пользователем.
Так как из всех операционных систем, распространенных в то время, самыми удобными средствами работы с сетью обладали различные клоны операционной системы Unix, то эта кодировка стала фактическим стандартом в этих системах. Таковой она является и сейчас в ОС Linux. И именно эта кодировка чаще всего применяется для обмена почтой и новостями в Интернет.
Далее наступила эра персональных компьютеров и операционной системы MS DOS. Как выяснилось, кодировка Koi8-R для нее не подходила (так же, как и ISO 8859-5), в ее таблице некоторые русские буквы находились на тех местах, которые многие программы предполагали заполненными псевдографикой (горизонтальные и вертикальные черточки, уголки и т.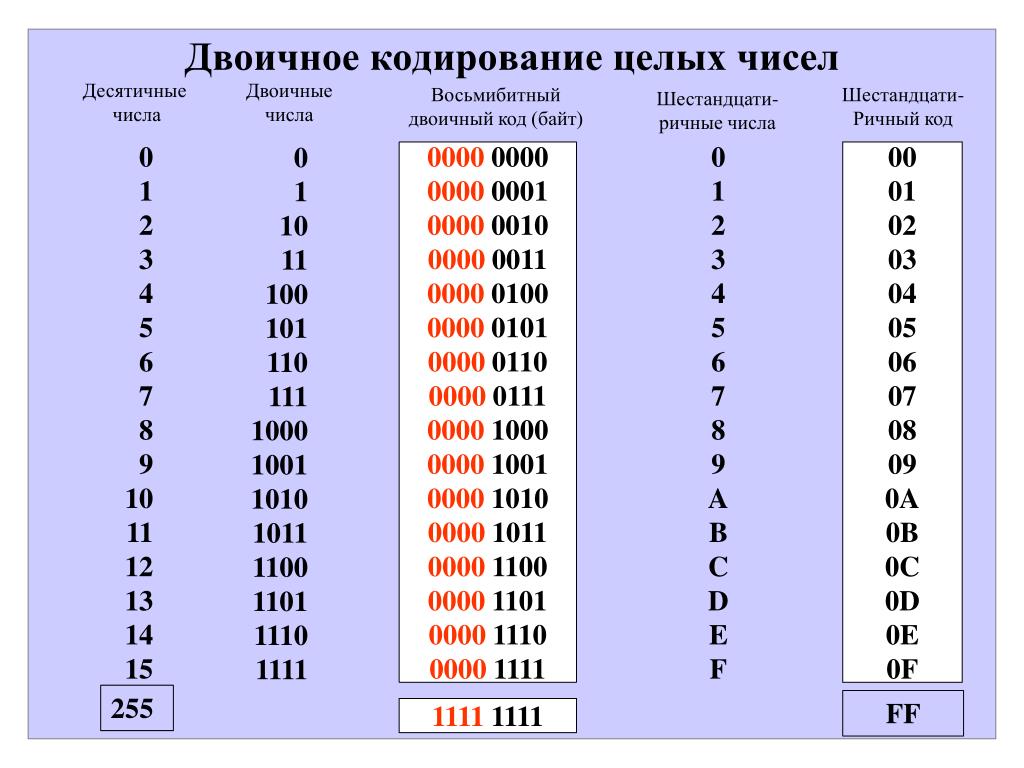 д.). Поэтому была придумана еще одна кодировка кириллицы, в таблице которой русские буквы «обтекали» со всех сторон графические символы. Назвали эту кодировку альтернативной (alt), поскольку она была альтернативой официальному стандарту — кодировке ISO-8859-5. Неоспоримым достоинством этой кодировки является то, что русские буквы в ней расположены в алфавитном порядке.
д.). Поэтому была придумана еще одна кодировка кириллицы, в таблице которой русские буквы «обтекали» со всех сторон графические символы. Назвали эту кодировку альтернативной (alt), поскольку она была альтернативой официальному стандарту — кодировке ISO-8859-5. Неоспоримым достоинством этой кодировки является то, что русские буквы в ней расположены в алфавитном порядке.
После появления ОС Windows от фирмы Microsoft выяснилось, что альтернативная кодировка по некоторым причинам для нее не подходит. Снова передвинув русские буквы в таблице (появилась возможность — ведь псевдографика в Windows не требуется), получили кодировку Windows 1251 (Win-1251).
Но компьютерные технологии постоянно совершенствуются и в настоящее время все большее число программ начинает поддерживать стандарт Unicode, который позволяет кодировать практически все языки и диалекты жителей Земли.
Итак, в различных ОС предпочтение отдается разным кодировкам. Для того чтобы стало возможным чтение и редактирования текста, набранного в другой кодировке, используются программы перекодирования русского текста. Некоторые текстовые редакторы содержат встроенные перекодировщики, позволяющие читать текст в различных кодировках (Word и др.). Мы для перекодировки файлов будем использовать ряд утилит в ОС Linux, назначение которых ясно из названия: alt2koi, win2koi, koi2win, alt2win, win2alt, koi2alt (откуда, куда, цифра 2 (two) схожа по звучанию с предлогом to, указывающим направление). Эти команды имеют одинаковый синтаксис: команда <входной_файл >выходной_файл.
Некоторые текстовые редакторы содержат встроенные перекодировщики, позволяющие читать текст в различных кодировках (Word и др.). Мы для перекодировки файлов будем использовать ряд утилит в ОС Linux, назначение которых ясно из названия: alt2koi, win2koi, koi2win, alt2win, win2alt, koi2alt (откуда, куда, цифра 2 (two) схожа по звучанию с предлогом to, указывающим направление). Эти команды имеют одинаковый синтаксис: команда <входной_файл >выходной_файл.
Пример
Перекодируем текст, набранный в редакторе Edit в среде MS DOS, в кодировку Koi8-R. Для этого выполним команду
alt2koi file1.txt > filenew
Так как в MS DOS и Linux по разному кодируется перевод строки, рекомендуется выполнить еще команду «fromdos»:
fromdos filenew > file2.txt
Команда с обратным действием называется «todos» и имеет такой же синтаксис.
Пример
Отсортируем файл List.txt, содержащий список фамилий и подготовленный в кодировке Koi8-R, в алфавитном порядке.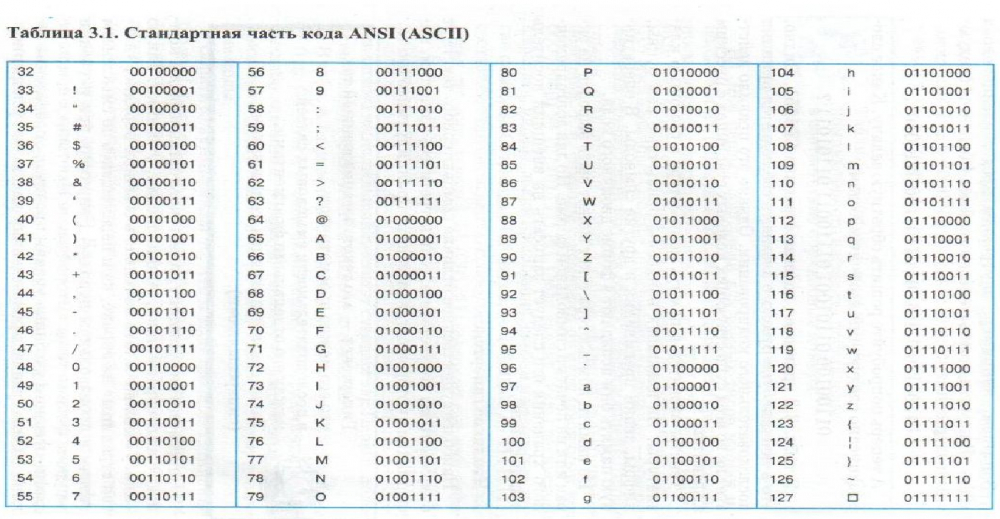 Воспользуемся командой sort, которая сортирует текстовый файл по возрастанию или убыванию кодов символов. Если применить ее сразу, то, например, буква В окажется в конце списка, аналогично соответствующей ей букве латинского алфавита V. Вспомнив, что в альтернативной кодировке русские буквы расположены строго по алфавиту, выполним ряд операций: перекодируем текст в альтернативную кодировку, отсортируем его и снова вернем в кодировку Koi8-R. С использованием конвейера команд получаем
Воспользуемся командой sort, которая сортирует текстовый файл по возрастанию или убыванию кодов символов. Если применить ее сразу, то, например, буква В окажется в конце списка, аналогично соответствующей ей букве латинского алфавита V. Вспомнив, что в альтернативной кодировке русские буквы расположены строго по алфавиту, выполним ряд операций: перекодируем текст в альтернативную кодировку, отсортируем его и снова вернем в кодировку Koi8-R. С использованием конвейера команд получаем
koi2alt List.txt | sort | alt2koi > List_Sort.txt
В современных дистрибутивах ОС Linux решены многие проблемы, связанные с локализацией программного обеспечения. В частности утилита sort теперь учитывает особенности кодировки Koi8-R и для сортировки файла в алфавитном порядке достаточно выполнить команду
sort List.txt > List_Sort.txt
php — Проблема с отображением русских букв в браузере, несмотря на то, что установлена кодировка UTF-8
У вас настроен Apache для поддержки переопределения кодировки ? По умолчанию он использует ISO-8859-1 для по умолчанию и игнорирует любые переопределения, которые появляются на веб-страницах, которые он обслуживает.
Решение №1 из 3
Например, вы можете поместить это в свой файл .htaccess для вложенного каталога, и теперь ваши веб-страницы будут иметь свои переопределяет:
AddDefaultCharset Off ДобавитьШарсет UTF-8 .html
В документации Apache указано:
Эта директива задает значение по умолчанию для параметра charset типа мультимедиа (имя кодировки символов), которое будет добавлено к ответу тогда и только тогда, когда
Например:тип содержимого ответаимеет значениеtext/plainилиtext/html.. Это должно переопределить любой набор символов, указанный в теле ответа через элемент META, хотя точное поведение часто зависит от конфигурации клиента пользователя. НастройкаAddDefaultCharset Offотключает эту функцию.AddDefaultCharset Onвключает кодировку по умолчаниюiso-8859-1. Предполагается, что любое другое значение является используемой кодировкой, которая должна быть одной из зарегистрированных IANA значений кодировки для использования в типах носителей MIME.адддефаултчарсет utf-8
AddDefaultCharsetследует использовать только тогда, когда известно, что все текстовые ресурсы, к которым он применяется, находятся в этой кодировке символов, и слишком неудобно маркировать их наборы символов по отдельности. Одним из таких примеров является добавление параметра charset к ресурсам, содержащим сгенерированное содержимое, например устаревшие сценарии CGI, которые могут быть уязвимы для атак с использованием межсайтовых сценариев из-за того, что предоставленные пользователем данные включаются в выходные данные. Обратите внимание, однако, что лучшим решением будет просто исправить (или удалить) эти сценарии, поскольку установка кодировки по умолчанию не защищает пользователей, которые включили функцию «автоматического определения кодировки символов» в своем браузере.

Пока я не отключил AddDefaultCharset , я не мог заставить работать свои теги .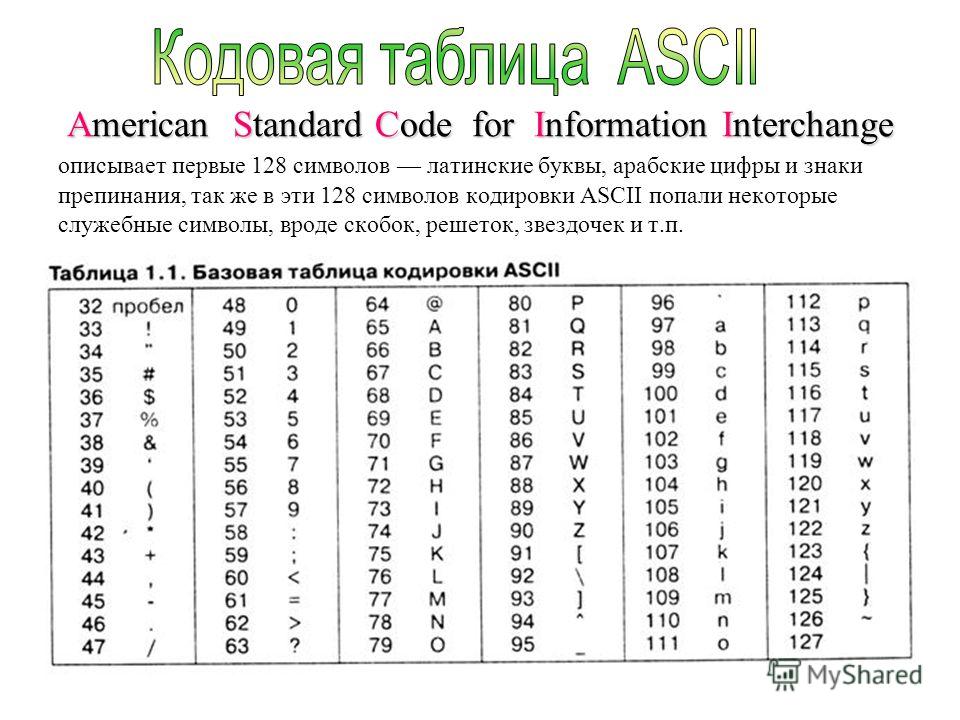 Это было довольно загадочно и неприятно. Однако, когда я это сделал, все работало гладко.
Это было довольно загадочно и неприятно. Однако, когда я это сделал, все работало гладко.
Решение № 2 из 3
Если у вас есть доступ на запись к файлам конфигурации Apache, вы можете изменить сам сервер. Однако вы должны убедиться, что больше ничего не зависит от старой непереопределяемой настройки. Это еще одна причина использовать .htaccess .
Если вы не можете ни изменить общую конфигурацию сервера, ни создать .htaccess , чьи собственные настройки будут соблюдаться для всего, что находится под ним, тогда ваш единственный вариант — использовать числовые объекты для всех кодовых точек свыше 127. Например, вместо
Целль-ам-Зее
вместо этого необходимо использовать
Целль-ам-Зее
или
Целль-ам-Зее
Преимущество этого в том, что больше не требуется переопределение и возня с сервером или файлами .. Недостатком является то, что требуется дополнительный проход перевода, что мешает возможности напрямую редактировать файл с помощью редактора, который буквально понимает кодировку UTF-8. htaccess
htaccess
Объекты игнорируют кодировки
Причина, по которой это работает, заключается в том, что весь HTML всегда находится в Unicode, поэтому номер символа 1062 всегда равен CYRILLIC CAPITAL LETTER TSE и т. д. Номера объектов всегда представляют собой номера кодовых точек Unicode; они никогда не являются числами из кодировки документа. В кодировке сервера или страницы учитываются только закодированные байты, а не незакодированные числа кодовых точек, которые всегда являются Unicode.
Вот почему мы можем использовать что-то вроде é , а всегда означает СТРОЧНАЯ ЛАТИНСКАЯ БУКВА E С ОСТРОЙ , потому что кодовая точка 233 всегда является этим символом, даже если сама веб-страница должна быть в какой-то другой кодировке (например, 142 в MacRoman или 221 в NextStep).
Количество символов всегда является числом Unicode, и не обращайте внимания на кодировку. Это связано с тем, что языки разметки, такие как HTML, XHTML и XML, всегда используют логические номера кодовых точек Unicode, как и языки программирования, такие как Perl и Go. (PHP на самом деле представляет собой просто байты с некоторыми API-интерфейсами UTF-8 поверх него, но, как вы сами узнали, с ним все еще есть проблемы. Это связано как с его внутренней моделью, так и с веб-серверами и даже веб-клиентами. все это делает все в PHP более сложным, чем в большинстве других языков.)
Даже если вы закодировали свою веб-страницу в кодировке ISO-8859-1 для кириллицы, где буквальный байт 0xC6 кодирует Unicode U+0426, CYRILLIC CAPITAL LETTER TSE , в качестве объекта символа вы должны использовать Ц или Ц — а не Æ , что было бы неправильно, поскольку U+00C6 — это ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА AE .
Точно так же, если бы вы использовали кодировку MacCyrillic, буквальный байт 0x96 был бы CYRILLIC CAPITAL LETTER TSE , но поскольку числовое значение всегда в Unicode, вы должны использовать Ц или Ц — а не – .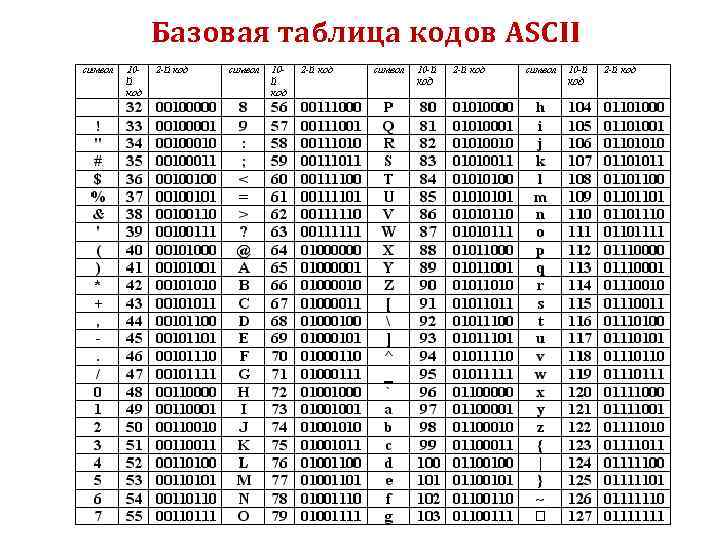
Я предпочитаю использовать только кодировку UTF-8 для всех веб-страниц. Ну, для новых, то есть. Я признаю, что существуют устаревшие страницы, не поддерживающие Unicode. Те я просто оставлю как есть.
О кодировании латинского, греческого, кириллического и ханьского алфавитов
Техническое примечание Unicode® № 26
Резюме
В этом документе обсуждается справочная информация и кодирование решения, касающиеся латинских, греческих, кириллических и ханьских символов в Unicode.
СтатусЭтот документ является Техническим примечанием Unicode . Исключительная ответственность за его содержание принадлежит автору (авторам). Публикация не означает одобрения со стороны Консорциум Юникод.
Информацию о технических примечаниях Unicode, включая критерии принятия, см. https://www.unicode.org/notes/.
Содержание
- Кодировка латинского, греческого и кириллического письма
- Кодировка ханьского письма
- Группа идеографических исследований
- Модификации
Кодирование латинского, греческого и кириллического шрифтов
Существует ряд очень веских причин, по которым латинский, греческий,
и кириллические шрифты были закодированы отдельно, а не
кодируется как единый скрипт.
1. Традиционная графология всегда рассматривала их как отдельные письменности, признавая при этом, что они, конечно, исторически связанный. Простое историческое родство не является достаточным основанием для однако унифицировать письменность, поскольку латиница, греческий и кириллица в конечном итоге могут все прослеживают свои корни до финикийского, и сам финикийский затем связан с арамейским и всеми его потомками, от иврита от арабского до далеких аборигенов, таких как согдийский, уйгурский и даже монгольский.
2. В случае латинского и греческого языков различие существовало с классических времен. Кириллица более тесно связана с греческий, а в средневековых рукописях имеется изрядное количество совпадения в греческой и ранней кириллической письменности, но ко времени развития современной типографики, Греческое письмо и кириллица явно различаются, и их текущие проявления в использовании печати очень разные.
3. Грамотные пользователи латинского, греческого и кириллического алфавитов
не иметь культурных условностей отношения друг к другу
алфавиты и буквы как часть их собственных систем письма.
4. Еще более важно, с точки зрения
проблема кодирования символов для цифрового текстового представления
в информационных технологиях ранее существовавшая идентификация
латыни, греческого и кириллического алфавита в качестве отдельных шрифтов.
в кодировку символов, с самых ранних экземпляров
таких кодировок.
5. Исходя из пункта №4, любая универсальная кодировка символов должен различать латинский, греческий и кириллический шрифты. Если это не так, это будет иметь непреодолимую интероперабельность проблемы, связанные с любым из огромного количества устаревших данных которые уже отличали сценарии. Обратите внимание, что мультискрипт (частично) универсальные кодировки символов, предшествующие Unicode Стандарт
 Сообщество библиотек поддерживает те же различия в сценариях в своих собственных
форматы данных: MARC 21 (опубликовано Библиотекой Конгресса) и UNIMARC.
(опубликовано ИФЛА).
Даже восточноазиатские кодировки символов по мере их развития также различают латиницу, греческий язык и кириллицу. Смотрите, для
например, сам JIS X 0208, который отдельно кодирует греческий
и кириллицы из ASCII Latin.
Сообщество библиотек поддерживает те же различия в сценариях в своих собственных
форматы данных: MARC 21 (опубликовано Библиотекой Конгресса) и UNIMARC.
(опубликовано ИФЛА).
Даже восточноазиатские кодировки символов по мере их развития также различают латиницу, греческий язык и кириллицу. Смотрите, для
например, сам JIS X 0208, который отдельно кодирует греческий
и кириллицы из ASCII Latin. 6. Несколько кодировок символов, которые на самом деле пытаются сделать
объединение латиницы и греческого или кириллицы очень специфично
и ограничены в использовании и не могут хорошо взаимодействовать с
подавляющее большинство инфраструктуры обработки текста. Хороший пример
это GSM 03.38 ETSI, который пытается адресовать
проблема отображение греческого языка в верхнем регистре на латинском устройстве с
7-битный набор символов путем объединения всех заглавных греческих букв
со своими латинскими двойниками и отказавшись от какой-либо поддержки
для нижний регистр греческий.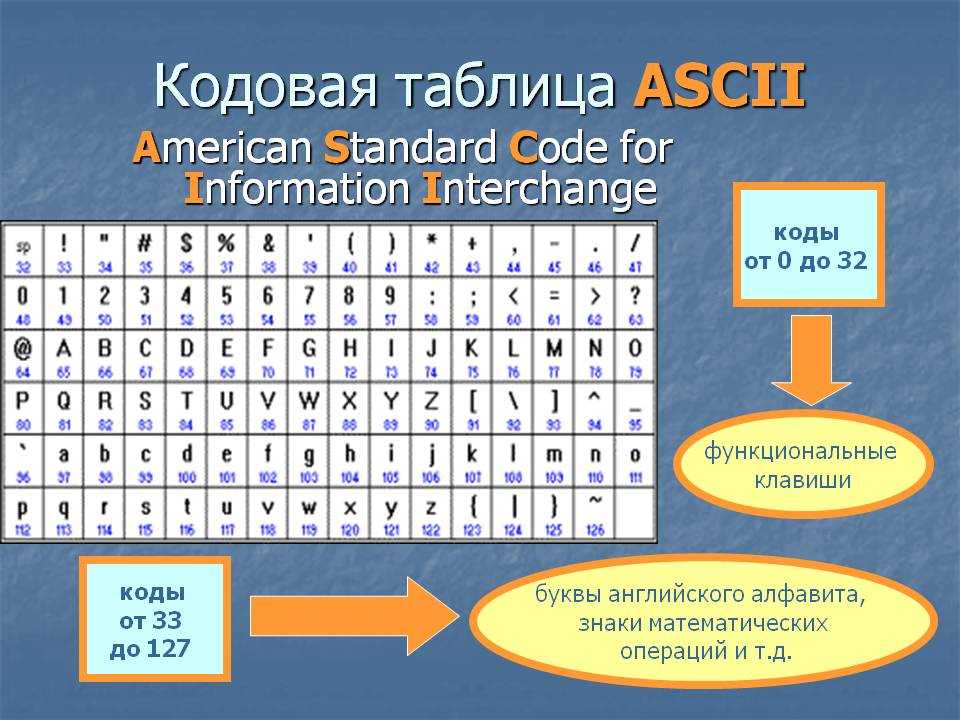 Такие схемы по унификации греческого (или кириллического)
с латынью никогда не распространялись за пределы своего первоначального, ограниченного назначения.
контекстах просто потому, что они не могут справиться с требованиями для
более универсальная обработка.
Такие схемы по унификации греческого (или кириллического)
с латынью никогда не распространялись за пределы своего первоначального, ограниченного назначения.
контекстах просто потому, что они не могут справиться с требованиями для
более универсальная обработка.
7. Что касается вопросов реализации, любая попытка унификации латынь, греческий и кириллица нанесли бы ущерб некоторым необходимые текстовые процессы. В частности, унифицированное кодирование Латинский, греческий и кириллица сделали бы операции с корпусами нечестивыми. беспорядок, фактически делающий все операции с корпусом контекстно-зависимыми в способ, который теперь ограничен несколькими проблемными пограничными случаями (турецкие i, греческие сигмы).
Кодирование ханьского письма
Теперь, в качестве контраста, рассмотрим проблему с ханьским письмом.
1. Графологически ханьское письмо («китайские иероглифы»)
долгое время считался единым шрифтом , адаптированным для использования
соседние культуры, но не разделены на отдельные сценарии
таким использованием.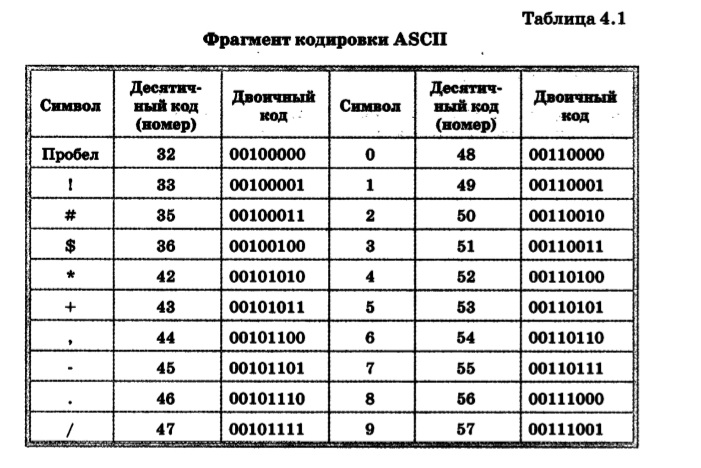 Исторически очень ранние версии китайского
использование символов (например, скрипт Small Seal), вероятно, правильно
квалифицировать как отдельные сценарии, но такие различия
не имеет отношения к статусу Хань синхронно.
Исторически очень ранние версии китайского
использование символов (например, скрипт Small Seal), вероятно, правильно
квалифицировать как отдельные сценарии, но такие различия
не имеет отношения к статусу Хань синхронно.
2. Эта идентичность ханьского письма была увековечена
исторически более или менее продолжительное культурное превосходство
Китай в Восточной Азии на протяжении тысячелетий, и к
политический обычай, который сменявшие друг друга китайские империи вкладывали
Китайское письмо — с использованием единственной письменной формы китайского языка.
как способ охвата многих, многих различных китайских языков
в единой ханьской культурной идентичности. Имперское распространение Хань
писать через зеркала Восточной Азии, во многих отношениях, имперский
распространение латиницы в западном мире, где распространились
латинского алфавита от языка к языку и этническому
группа к этнической группе, сначала Римской империи, а гораздо позже
западноевропейскими империями, не привело к дроблению
сам сценарий, а скорее широкое использование одного
сценарий и его доработку добавлением новых идеограмм
(для ханьцев) и новые буквы (для латыни), поскольку новые требования были
размещены на нем.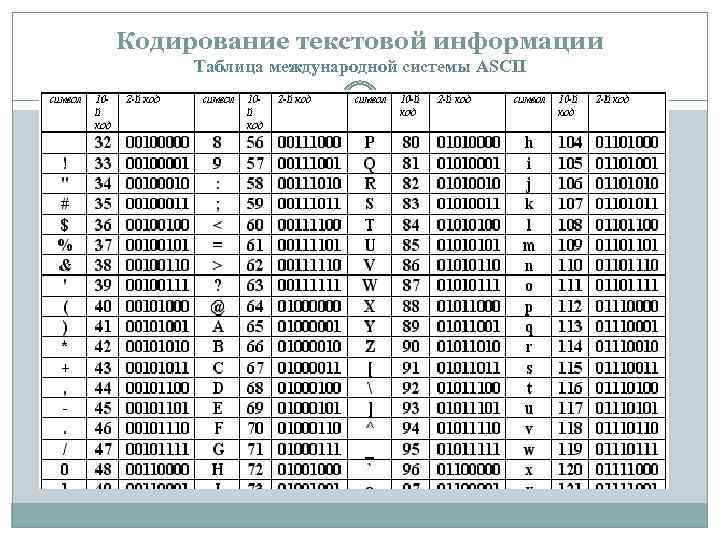 (Аналогичную картину можно увидеть в развороте
арабского письма по всему миру.)
(Аналогичную картину можно увидеть в развороте
арабского письма по всему миру.)
3. Основные неханьские народы, адаптировавшие китайскую письменность. в своей собственной культуре (особенно в Корее, Японии и Вьетнаме) продолжал рассматривать иероглифы хань как китайских письма, о чем свидетельствует даже название сценария в каждом из эти страны, будучи буквально «китайским иероглифом». И вместо того, чтобы просто принять сценарий в какой-то момент, а затем развивая его в каком-то независимом направлении, типичном Образцом для каждой из этих культур было то, что на протяжении столетий продолжайте пополнять запас иероглифов хань, которые они использовали продолжающееся заимствование больших новых наборов из них непосредственно у Китай.
4. Основное исключение в этой модели развития, в Японии,
фактически говорит, наоборот, о продолжающемся унитарном
природа самой ханьской письменности. В Японии очень скоропись
стиль написания китайских иероглифов для японских звуков,
в отличие от заимствованной китайской лексики, стиль, называемый
manyooshuu, был упрощен до набора обычных
слоговые символы только для японского языка. Этот явно был
разработка нового сценария, получившего название
Хирагана из ханьского письма. Но по отдельности и одновременно,
в Японии сами иероглифы хань («кандзи» на японском языке)
продолжали писать в традиционном китайском стиле.
Этот явно был
разработка нового сценария, получившего название
Хирагана из ханьского письма. Но по отдельности и одновременно,
в Японии сами иероглифы хань («кандзи» на японском языке)
продолжали писать в традиционном китайском стиле.
5. В отличие от латиницы, греческого языка и кириллицы, здесь равно .
давняя культурная традиция в Японии, Китае и Вьетнаме,
рассматривать «китайские иероглифы» как имеющие общую идентичность
по всему региону. Японец не может «читать» по-китайски — после
все, это совсем другой и совсем чужой язык
для носителей японского языка — так же, как носители английского языка не могут
читайте тагальский, написанный латинским алфавитом. Но они делают признать, что сами китайские иероглифы являются общими
и на самом деле могут распознавать большую часть общего словарного запаса, который
первоначально был заимствован японским языком из китайского, в
точно так же, как носители английского языка узнают большую часть французской лексики.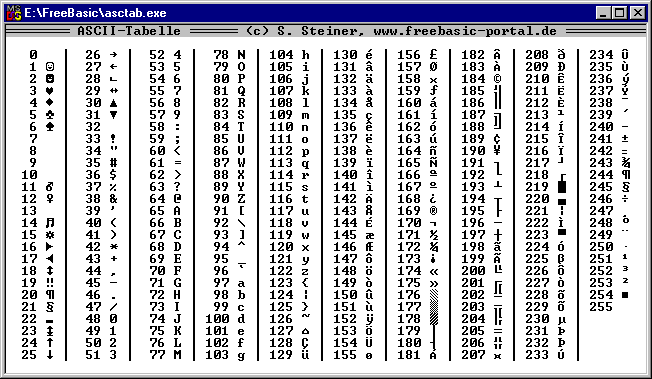
6. Существует много путаницы, которая возникает среди тех, кто не хорошо знаком с восточноазиатскими языками и системами письма из-за того, что системы письма для Японии, Кореи, Китай, а Вьетнам это совершенно разные, при этом время, которое они все разделяют, как части этих систем письма, общий одиночный ханьский сценарий. Нет сомнений в том, что Японская система письма в целом очень и очень отличается от китайская система письма. Но японский кандзи как часть японской письменности составляют один и тот же сценарий как китайский hanzi , функционирующий как основная часть китайской письменности.
7. Еще одна проблема, вызывающая споры по поводу «ханьского объединения».
в Восточной Азии, как правило, возникает из соображений стиля шрифта
и варианты персонажей. Проблема стиля возникает в основном из-за того, что
что Япония традиционно
была крайне консервативной страной, пережившей долгий,
преднамеренно изоляционистский период до реформ Мэйдзи. В результате Япония стремилась сохранить в своих буддийских и других
литературные традиции, формы китайского языка, которые восходят к
вернуться к материалам династий Тан, Сун и Мин. Тем временем Китай
сама была занята огромными революциями и потрясениями и
смена правителей с одной национальности на совершенно другую
(Монголы правили Китаем в одной династии, маньчжуры в другой). В течение
на этот раз китайское письмо продолжало обновляться, а формы
перенесенные в Японию, как правило, оставались более консервативными.
В результате Япония стремилась сохранить в своих буддийских и других
литературные традиции, формы китайского языка, которые восходят к
вернуться к материалам династий Тан, Сун и Мин. Тем временем Китай
сама была занята огромными революциями и потрясениями и
смена правителей с одной национальности на совершенно другую
(Монголы правили Китаем в одной династии, маньчжуры в другой). В течение
на этот раз китайское письмо продолжало обновляться, а формы
перенесенные в Японию, как правило, оставались более консервативными.
Несмотря на систематические колебания, иногда наблюдаемые между
более консервативные формы символов в Японии и типографски
различные формы, наблюдаемые в Китае, типичный диапазон вариаций
среди глифов во всех сообществах пользователей CJK находится в пределах
границы типичных вариаций, наблюдаемых в других сценариях. Этот
факт, отмеченный в самом стандарте JIS X 0208, формирует
основа принципов, по которым идентифицируются персонажи
как «один и тот же иероглиф» в японском, китайском и корейском языках. источники.
источники.
8. В ХХ веке мы сталкиваемся с самой крайней формой стилистического
инновации в Китае, когда в качестве
результат образовательной политики после коммунистической революции в
КНР, преднамеренный и очень широко распространенный процесс орфографического
упрощение и реформы были навязаны всему Китаю. Те
изменения не были приняты за пределами Китая в Японии, и даже
на Тайване и в Гонконге. Это привело
в резком расколе в использовании ханьского письма («упрощенное» и
«традиционный»). Но даже , что нельзя считать достаточным для
создали новый, отличный ханьский сценарий. Причина в том, что
даже в КНР к новым, упрощенным формам всегда относились
как альтернативные формы традиционных символов, часто
напечатаны рядом с ними в справочниках. Был
постоянная корректировка письма в Китае, так как все больше символов упрощаются,
но от некоторых упрощений отказываются в пользу более традиционных
формы и так далее. Многие китайцы по какой-то причине или
другой, просто нужно научиться оба традиционный и
упрощенные формы символов и читать их как альтернативные
глифы для одного и того же символа — неявно внутри одного и того же
общий ханьский сценарий.
9. Когда речь идет о решениях по кодировке символов, принятых в Восточной Азии, также ясно, что ханьские персонажи почти считалось, что все случаи составляют единый сценарий, а не чем отдельные сценарии для каждой страны Восточной Азии. японские стандарты изначально были посвящены кодированию тех китайских иероглифов, которые необходимы на японский . И китайские стандарты ориентированы на это подмножество китайских иероглифов, необходимых для китайских . Но позже, стандарты с обеих сторон расширились по мере добавления японских стандартов иероглифы из Китая и китайские стандарты добавили иероглифы из Японии. Ни в том, ни в другом случае эти дополнения не следовали образец, наблюдаемый, когда греческий или кириллица были добавлены к ранним Кодировки латинских символов. Вместо этого в обоих случаях было просто вопрос добавления еще X тысяч ханьских символов в большие таблицы, которые уже состояли из тысяч иероглифов хань.
10. Попытка «унифицировать» кодировку ханьских символов в
10646, и стандарт Unicode был неправильно понят
некоторые как попытку смешать принципиально разные
Японская система письма и китайская система письма, как бы
имело место какое-то принудительное смешение рас.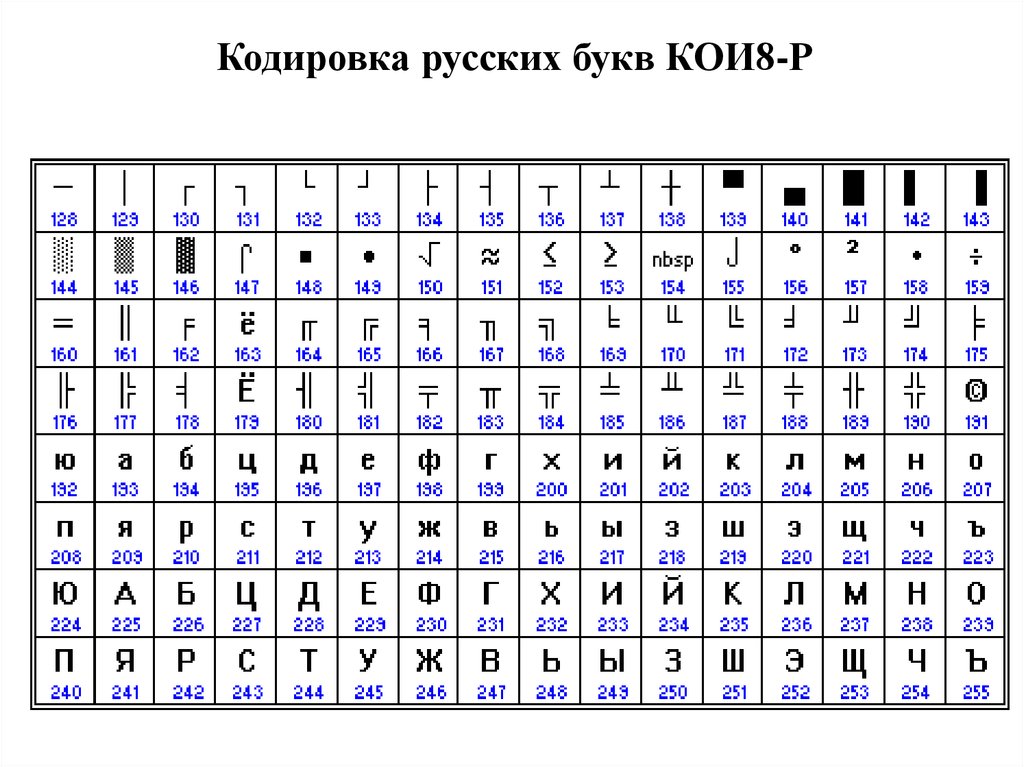 Но правильный способ интерпретировать то, что происходило, был довольно простым. предотвращение дублирования кодирования одних и тех же ханьских символов
представлен в нескольких различных стандартах Восточной Азии. Этот
процесс был хорошо понят фактическими национальными стандартами
участники из Японии, Кореи, Китая и других стран,
которые все время выполняли основную работу, связанную с
сводя к минимуму количество дублирующих кодов того, что все
члены комитета полностью согласны с тем, что тот же символ.
Но правильный способ интерпретировать то, что происходило, был довольно простым. предотвращение дублирования кодирования одних и тех же ханьских символов
представлен в нескольких различных стандартах Восточной Азии. Этот
процесс был хорошо понят фактическими национальными стандартами
участники из Японии, Кореи, Китая и других стран,
которые все время выполняли основную работу, связанную с
сводя к минимуму количество дублирующих кодов того, что все
члены комитета полностью согласны с тем, что тот же символ.
Аналогия, используемая при рассмотрении вопроса об «объединении ханьцев».
это не попытка унифицировать латинскую кодировку, а
Греческая кодировка и кириллическая кодировка на основе символа
форму, но вместо этого, объединяя кодировку ASCII (латиницу),
кодировка EBCDIC (латиница), латинская часть
Японский стандарт JIS X 0208 и латинская часть
Китайский стандарт ГБ 2312. Нет смысла кодировать
один и тот же латинский символ 4 раза в Unicode просто потому что
он появился в ASCII, кодовой странице EBCDIC 300, JIS X 0208,
и GB 2312. Точно такая же логика применялась к иероглифам хань.
в различных стандартах Восточной Азии при кодировании решений
были взяты о кодировании ханьского письма.
Точно такая же логика применялась к иероглифам хань.
в различных стандартах Восточной Азии при кодировании решений
были взяты о кодировании ханьского письма.
11. Что касается вопросов реализации, подход кодирования к Ханьские персонажи, которые не объединяли одни и те же персонажи из Японские, китайские, корейские (и другие) исходные стандарты будут нужно возить дорого (и по стоимости памяти, и по обслуживанию стоимость) таблицы эквивалентности вокруг только для того, чтобы сделать унификацию происходит на лету, перед поиском текста или почти любым другим текстовый процесс, представляющий интерес, может быть выполнен.
12. Для получения дополнительной информации о том, как ханьские персонажи из разных Унаследованные восточноазиатские стандарты источников были определены как тот же символ для целей кодирования в Unicode Стандарт, см. подробное обсуждение в Раздел 18.1, «Хань».
Идеографическая исследовательская группа
Информация об Идеографической исследовательской группе, которая основная ответственность за развитие репертуара Идеографические символы хань для кодирования в 10646 (и стандарт Unicode):
Группа идеографических исследований (IRG) — это группа, подотчетная
ИСО/МЭК СТК1/ПК2/РГ2. Основное внимание уделяется развитию идеографических знаков (хань
символы, используемые в Китае, Японии, Корее и других частях Азии) в ISO/IEC
Стандарт 10646. Его миссия состоит в том, чтобы представить идеографические символы для
включение в стандарт ISO/IEC 10646. IRG разработала CJK Unified
Блок идеографов и унифицированные расширения идеографов CJK от A до H.
В состав IRG входят Китай, САР Гонконг, САР Макао, Тайбэй Компьютер
Ассоциация, Сингапур, Япония, SAT (Комитет по текстовой базе данных Saṃgaṇikīkṛtaṃ Taiśotripiṭakaṃ Daizōkyō), Южная Корея, Северная Корея, Вьетнам, Великобритания и США.
Представители Консорциума Юникод также
посещать собрания IRG для координации синхронизации между ISO/IEC
10646 и стандарт Unicode. См. IRG для
подробнее.
Основное внимание уделяется развитию идеографических знаков (хань
символы, используемые в Китае, Японии, Корее и других частях Азии) в ISO/IEC
Стандарт 10646. Его миссия состоит в том, чтобы представить идеографические символы для
включение в стандарт ISO/IEC 10646. IRG разработала CJK Unified
Блок идеографов и унифицированные расширения идеографов CJK от A до H.
В состав IRG входят Китай, САР Гонконг, САР Макао, Тайбэй Компьютер
Ассоциация, Сингапур, Япония, SAT (Комитет по текстовой базе данных Saṃgaṇikīkṛtaṃ Taiśotripiṭakaṃ Daizōkyō), Южная Корея, Северная Корея, Вьетнам, Великобритания и США.
Представители Консорциума Юникод также
посещать собрания IRG для координации синхронизации между ISO/IEC
10646 и стандарт Unicode. См. IRG для
подробнее.
Ниже приводится сводка изменений по сравнению с предыдущей версией этого документ.
3
- Очистка стиля.
- Обновлены ссылки на https.
- Обновлена ссылка на раздел 18.1 Han в основной спецификации.