Как утащить простой сайт за 5 минут
Когда начинаешь практиковаться в вёрстке сайтов, может быть очень полезно разобраться, как устроены сайты у других ребят. Вот как это сделать.
👉 Всё, что мы делаем в этой статье, мы делаем в учебных целях. Если вы просто скопируете себе чужой сайт и будете выдавать его за свой, это может плохо кончиться.
💡 На самом деле всё сказанное в этой статье нужно для тех, кто боится отключения интернета и хочет сохранить у себя на компьютере самую важную информацию. Но эта мысль бредовая сразу на стольких уровнях, что мы стесняемся её произносить вслух. Разве что шёпотом.
В чём идея
Мы будем копировать чужой сайт, чтобы его можно было запустить на своём сервере или на домашнем компьютере. Задача — не просто открыть сайт в браузере и посмотреть его код, а забрать из него все важные файлы — и стили, и скрипты, и изображения. Чтобы было проще, мы будем практиковаться на одностраничном сайте, но всё то же самое будет работать и на многостраничном.
❌ Мы не сможем утащить чужие PHP-скрипты и страницы, связанные с данными пользователя (например, не сможем утащить из интернет-магазина рабочую версию корзины с покупками). Для этого нужен доступ к файлам сервера, а этого у нас нет.
Главный принцип этой работы: когда ваш браузер запрашивает страницу чужого сайта, веб-сервер отправляет ему эту страницу, в буквальном смысле. То же с картинками, стилями и скриптами: каждый раз, когда вы посещаете сайт, вы как будто делаете его копию у себя на компьютере. Браузер получает страницу от сервера и выводит её копию на экран, а в памяти держит исходный код. Разве что он не сохраняет эту страницу на диск, чтобы вы могли её редактировать.
Вот этот последний этап мы и исправим: теперь мы будем сохранять чужие сайты к себе на диск.
Весь процесс покажем на примере сайта ux-posters.ru – простом одностраничном сайте, где есть картинки, стили и скрипты. Автору этого текста пришлось помогать авторам этого сайта с похожей задачей, так что пример свеженький.
Быстрый путь: грабберы
Есть категория программ под названием «веб-грабберы», или «веб-рипперы». Они работают так:
- Ты говоришь программе, на какую страницу сайта зайти.
- Программа собирает все ссылки с этой страницы, переходит по этим ссылкам и строит себе виртуальную карту сайта — то есть пытается понять, сколько на этом сайте страниц и как они связаны.
- Потом граббер начинает ползать по этим страницам подряд, запрашивать их у сервера, получать ответы и сохранять ответы на вашем жёстком диске.
- В какой-то момент граббер останавливается, потому что он скачал все доступные ему страницы с этого сайта.
После работы граббер оставляет у вас на диске гору файлов, которые представляют собой статичный отпечаток чужого сайта. Эту гору можно загрузить на собственный сервер, и издалека это будет похоже на чужой сайт.
✅ Плюсы: граббер может быстро охватить много страниц и скачать из них огромное количество стилей, картинок и всего подряд.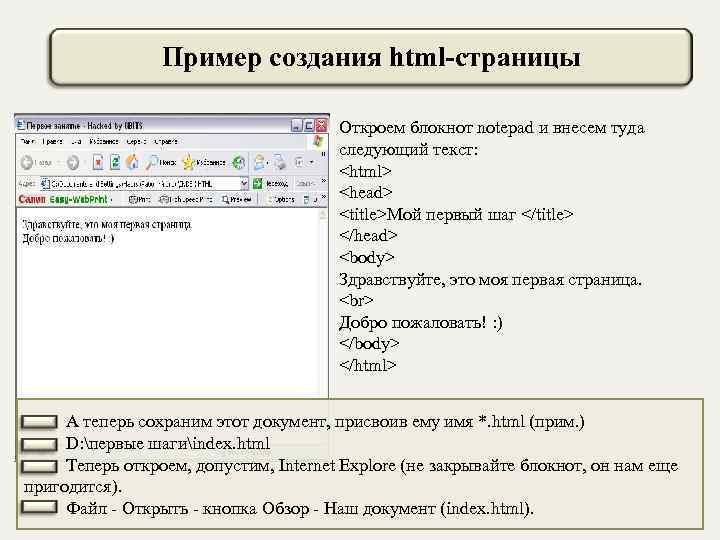 Работа очень быстрая и хорошо автоматизирована.
Работа очень быстрая и хорошо автоматизирована.
❌ Минусы: часто он качает всё без разбора, оставляя на диске много дублей. Также он бессилен с сайтами, в которых контент выводится динамически или имеет нестандартную систему адресации.
💡 В целом грабберы можно использовать, чтобы скачивать сайты библиотек, архивов и других мест, где документов много и всё устроено логично. Например, с помощью граббера можно скачать какую-нибудь классическую книгу из онлайн-библиотеки.
Вот ссылки на грабберы для разных платформ:
- HTTrack — старый интерфейс из нулевых, но свою задачу выполняет полностью. Бесплатный и надёжный, работает везде.
- Getleft — мультиплатформенный граббер, который пытается выкачивать всё, до чего дотянется, включая PHP-скрипты.
- Cyotek WebCopy — для тех, кто любит только Windows, тоже бесплатный.
Сложный путь: ручное сохранение
Допустим, мы хотим сохранить какую-то отдельную страницу сайта или конкретные её части (например, картинки).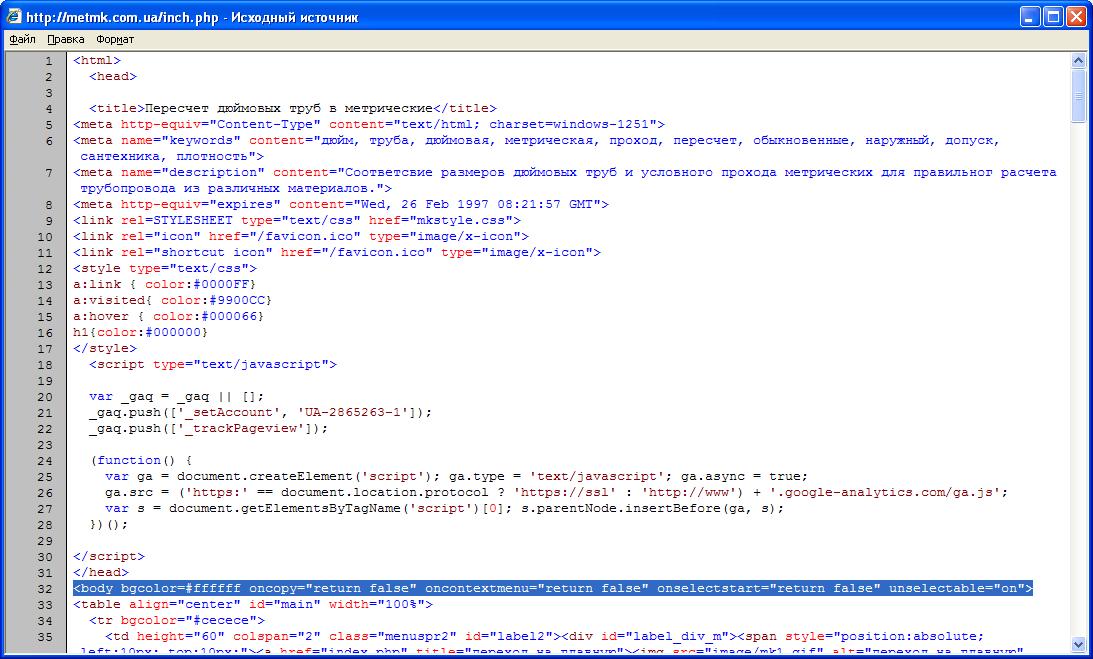 Но эти картинки как-то так хитро встроены, что вы не можете просто нажать «Сохранить картинку как…». Тогда потребуется ручной метод.
Но эти картинки как-то так хитро встроены, что вы не можете просто нажать «Сохранить картинку как…». Тогда потребуется ручной метод.
Заходим на страницу и нажимаем в браузере Ctrl + I (в Виндоус) или ⌥ + ⌘ + I (если у вас мак). Появляется окно «Инспектора», где видна внутренняя структура страницы:
Мы видим, что текущий документ в браузере состоит:
- из страницы index.html;
- скрипта likely.js;
- четырёх таблиц стилей;
- шрифтов, подключённых через сервис Google;
- папки с картинками.
Шрифты нам скачивать необязательно — сайт и так их подключит с сервера гугла, а всё остальное скачать нужно. Чтобы не создавать хаос на компьютере, создадим сначала папку ux-posters — в ней будет храниться наш сайт. Потом в эту папку сохраняем все файлы таким способом:
- Нажимаем правой кнопкой мыши на очередной файл.
- Выбираем пункт Save as, или «Сохранить как».
- Пишем имя и расширение файла — точно так, как указано в списке.
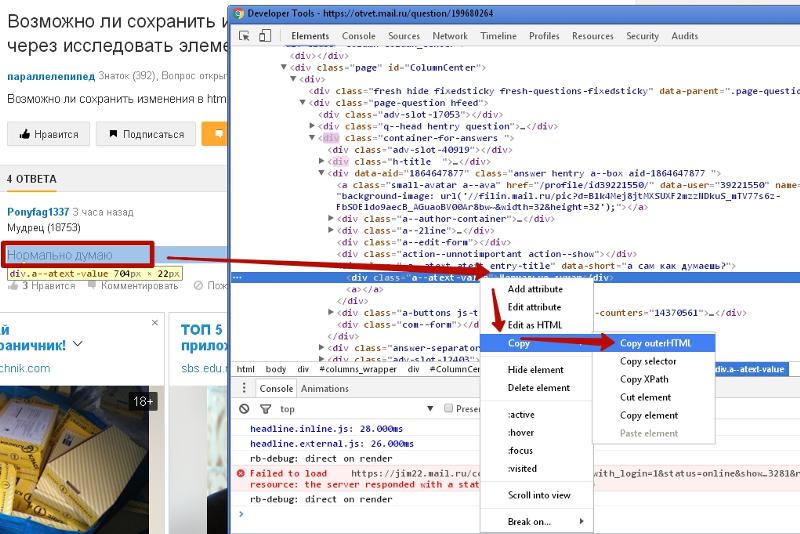
- Если лень писать самому — скопируйте перед этим название файла, нажав правую кнопку мыши и выбрав Copy file name, или «Скопировать имя файла».
- Чаще всего название файла подставится само, но если нет — смотрите пункт 4.
Исключения в названии файлов два:
- (index) — это index.html.
- В любом файле знак вопроса и всё, что после него, писать не нужно.
Скачать можно всё, а можно только то, что вам нужно для работы и экспериментов. Например, если вам нужны только стили и код страницы, сохраняйте файлы .css и (index). Если нужны картинки, заходите в папку pics и сохраняйте всё оттуда.
Щёлкаем на очередном файле и выбираем «Сохранить как»Выбираем нашу папку для сохранения и пишем имя файлаЧто в итоге
Если мы пройдёмся по всем папкам и сохраним в них всё нужное нам, у нас получится локальный слепок сайта. Теперь можно:
- Изучить, как он устроен, что-то отредактировать и увидеть результат у себя на компьютере.
- Открыть файл index.
 html в браузере, и будет ощущение, что вы зашли на сайт, но с локального компьютера. Сайт откроется по протоколу file:// — это так браузер говорит нам, что файл взялся с нашего компьютера, а не из интернета.
html в браузере, и будет ощущение, что вы зашли на сайт, но с локального компьютера. Сайт откроется по протоколу file:// — это так браузер говорит нам, что файл взялся с нашего компьютера, а не из интернета. - Запустить MAMP и завести на нём локальную копию сайта для экспериментов. Тогда браузер будет думать, что ходит за этим сайтом в интернет. Можно написать какие-нибудь php-скрипты и оживить сайт.
Что нужно поставить на компьютер, чтобы делать сайты
💡 Важно понимать, что перед нами именно «слепок» — то, что мы бы увидели, если бы сервер сегодня ответил на наш запрос. Если завтра сервер будет отвечать по-другому, мы этого в своей локальной копии не увидим.
Когда ещё это пригодится
Защитить сайт перед наплывом пользователей. С помощью грабберов можно быстро создать неубиваемую статическую копию сайта и временно подменить ей динамическую версию сайта. Это полумера, но может сработать. А вообще вместо этого есть специальные надстройки, которые делают почти то же самое, но более умно, — поищите слово «кеширование».
Делаем неубиваемый сайт: статика и динамика
Сделать копию своего блога, личного сайта или ещё чего-то важного вам, если вы потеряли к нему доступ, но сайт всё ещё на ходу.
Если вы едете туда, где не будет интернета, а вам нужна информация с сайта (например, путеводитель по чужой стране). Помните, что динамические карты и видеоролики так не сохранятся.
Сделать собственный «веб-архив» — это сервис, который ползает по сайтам и делает их «слепки» для истории. Благодаря этому сервису можно посмотреть, как выглядели ваши любимые сайты много лет назад — например, Яндекс.
Текст:
Михаил Полянин
Редактор:
Максим Ильяхов
Художник:
Даня Берковский
Корректор:
Ирина Михеева
Вёрстка:
Кирилл Климентьев
Соцсети:
Олег Вешкурцев
Как отредактировать код страницы | REG.RU
В настройках REG.Site вы можете отредактировать код страницы — добавить свой скрипт или тег. Это можно сделать двумя способами: в настройках модуля или в админке сайта.
Это можно сделать двумя способами: в настройках модуля или в админке сайта.
Мы не рекомендуем добавлять код:
- через файлы сайта (например, function.php) — правки могут нарушить общую структуру сайта,
- сразу после обновления темы Divi — системные файлы будут перезаписаны и добавленные в код изменения автоматически удалятся,
- при работе на техническом домене — он подходит только для ознакомления с функционалом REG.Site.
В настройках конкретного модуля
Через настройки модуля можно разместить js или html-скрипты в любом месте на странице сайта. Так вы сможете добавить рекламный баннер, систему бронирования, онлайн-калькулятор и др. Для этого:
- 1.
Перейдите в редактор сайта.
Откройте настройки нужного модуля.
 org/HowToStep»>
3.
org/HowToStep»>
3.Перейдите на вкладку Дополнительно:
- 4.
В блоке «Пользовательский CSS» заполните поля «Перед», «Основной элемент» или «После». Чтобы сохранить настройки, кликните на галочку в зелёном прямоугольнике:
Через админку сайта
В настройках Divi код можно добавить:
В конкретную часть сайта (html-страницы)
Для этого:
- 1.
Перейдите в админку сайта.
- 2.
Откройте раздел Divi — Настройки темы:
- 3.
Перейдите на вкладку Интеграция. Добавьте код в нужную часть страницы, например, перед тегом /head или /body. После этого вверху страницы кликните Сохранить изменения:
 org/HowToStep»>
4.
org/HowToStep»>
4.Проверьте измененный внешний вид страницы.
Вставить CSS-стиль для всего сайта
Для этого:
- 1.
Перейдите в админку сайта.
- 2.
Откройте раздел Divi — Настройки темы:
Перейдите на вкладку Основное и добавьте нужный CSS-стиль в поле «Пользовательский CSS». После этого внизу страницы кликните Сохранить изменения:
- 4.
Проверьте измененный внешний вид страницы.
Помогла ли вам статья?
Да
раз уже
помогла
Поисковая система для исходного кода
Найдите любой буквенно-цифровой фрагмент, подпись или ключевое слово в коде веб-страниц HTML, JS и CSS.
Синтаксис запроса : RegEx, ccTLD и т. д. Идет поиск…
488 738 970 веб-страниц
17 апреля 2023 г.
Идеальное решение для цифрового маркетинга и исследований партнерского маркетинга, PublicWWW позволяет вам выполнять поиск таким образом, то, что невозможно с другими обычными поисковыми системами:
- Любой HTML, JavaScript, CSS и обычный текст в исходном коде веб-страницы
- Ссылки на вопросы StackOverflow в HTML, .CSS и .JS-файлы
- Веб-дизайнеры и разработчики, ненавидящие IE
- Сайты с одинаковым идентификатором аналитики: «UA-19778070-»
- Сайты, использующие следующую версию nginx: «Сервер: nginx/1.4.7»
- Пользователи рекламных сетей: «adserver.adtech.de»
- Сайты, использующие одну и ту же учетную запись AdSense: «pub-9533414948433288»
- WordPress с темой: «/wp-content/themes/twentysixteen/»
- Поиск связанных веб-сайтов с помощью уникальных кодов HTML, которые они используют, т.
 е. идентификаторов виджетов и издателей
е. идентификаторов виджетов и издателей - Идентифицировать сайты с помощью определенных изображений или значков
- Узнайте, кто еще использует вашу тему
- Определите сайты, на которых вас упоминают
- Ссылки на использование библиотеки или платформы
- Найдите примеры кода в Интернете
- Выясните, кто какие JS-виджеты использует на своих сайтах.
Функции
- До 1 000 000 результатов на поисковый запрос
- API для разработчиков, которые хотят интегрировать наши данные
- Загрузить результаты в виде файла CSV
- Фрагменты результатов поиска
- Результаты отсортированы по популярности веб-сайта
- Поиск обычно выполняется в течение нескольких секунд
- 488 738 970 веб-страниц проиндексировано
- HTTP-заголовки ответа веб-сервера также индексируются
- Сайты из топ-1 000 000 открываются бесплатно
- Результаты из топ-3 000 000 по факту
регистрация,
остальные платные.

Usage Examples
«angular.min.js»
«bootstrap.min.js»
«addthis_widget.js»
«recaptcha/api.js»
«X-Akamai-Transformed»
«AlgoliaSearch»
узловая точка
«Begin comScore Tag»
«Histats.com START»
«cmdatatagutils.js»
«api.convertkit.com»
«app.adjust.com»
Больше примеров
90 Статистика и исследования
Вы можете взаимодействовать с нашей статистикой, основанной на нашей веб-аналитике, а также получать помощь в поиске, использовании и понимании данных.
Файлы .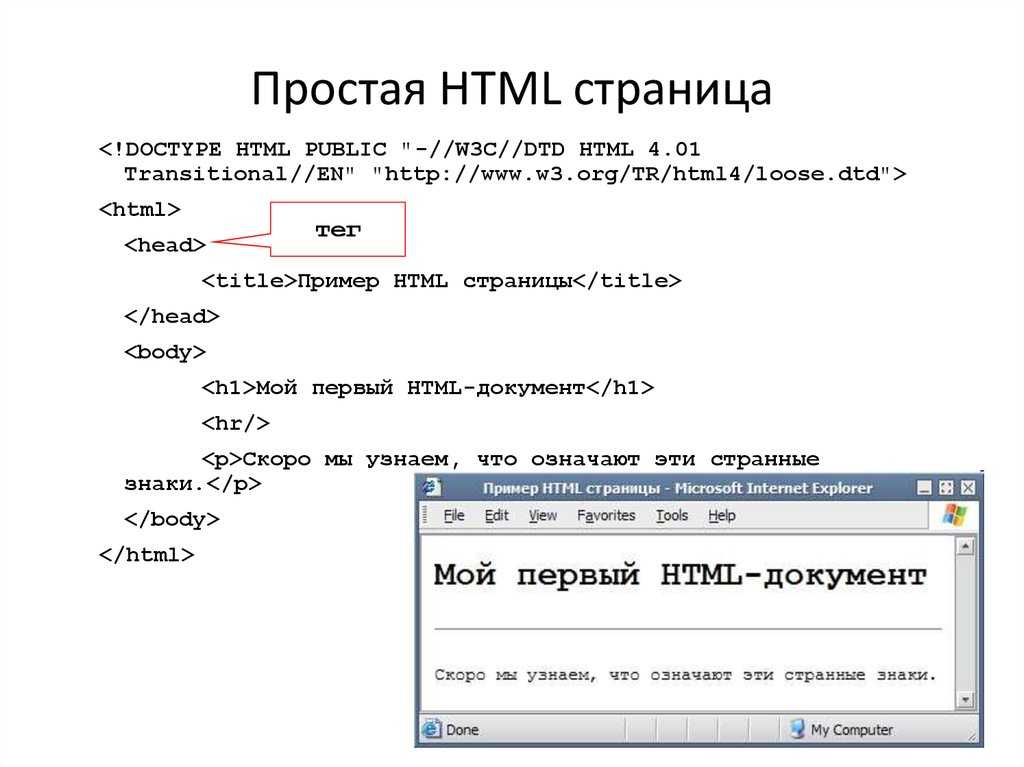 JS
JS
Файлы .CSS
Объекты Javascript
Свойства CSS
IMG-файлы
Заголовок HTTP-сервера
X-Powered-By
Мета-генератор
IMG-домены
JavaScript-домены
CSS-код доменов
3
Нет файлов IMG3? | Каустубх Гупта | Культура гиков
Объяснение того, почему therickroll.com не показывает исходный код
Изображение автора, сделано в Canva Вы отличный веб-разработчик. Вы создали один из самых красивых веб-сайтов со всеми последними интеграциями. Вы опубликовали веб-сайт для широкой публики, и теперь кто-то хочет воспроизвести тот же внешний интерфейс, который вы создали.
Современные веб-сайты — это больше, чем просто текст, графика и мультимедиа. Они превратились в веб-приложения. Эти приложения могут делать гораздо больше, чем просто просмотр. Что касается вопроса, то человек просматривает исходный код и может или не может получить представление о вашей стратегии и коде в зависимости от того, как он разработан.
Но задумывались ли вы когда-нибудь о том, что можно полностью скрыть код? Здесь «полностью» означает, что не только исходный код скрыт на хостинговых платформах, таких как GitHub или Gitlab, но и при проверке вкладки «просмотреть исходный код» в любом браузере ничего не возвращается? Пустой экран. Возможно ли это сделать?
Технически, на момент написания этой статьи не существовало «официального» способа скрыть весь исходный код на вкладке просмотра исходного кода. Но есть один замечательный обходной путь, который позволяет скрыть код с этой вкладки!
Предположения
Прежде чем я начну с основного контекста, я хочу, чтобы вы знали несколько вещей, чтобы мы были на одной странице:
- Все объяснения здесь очень хорошо работают для браузера Firefox, а не для браузера Chrome, и причина поскольку это будет обсуждаться в следующем разделе статьи.

- Параметр вкладки «просмотр исходного кода» для браузеров покажет это как пустое, но инструменты разработчика будут отображать автоматический HTML, который вставляется каждым браузером, и, вероятно, предоставит обходной путь. (вы увидите это далее в статье)
Но тем не менее, даже с этими предположениями, я хочу обсудить этот обходной путь, поскольку он предоставит вам дополнительные сведения о том, как веб-сайты работают в бэкэнде.
Этот сайт является центром статьи. Если вы посетите этот веб-сайт в Firefox, он отобразит следующее:
Скриншот сайта therickroll.comНа сайте мало контента. В нем есть один GIF и текст под ним с мигающим курсором. Предположим, если вы хотите воспроизвести этот веб-сайт, то вы, должно быть, думаете, что в исходном коде должны быть элементы для изображения и текста, верно? Теперь проверьте исходный код веб-сайта в Firefox.
Страница исходного кода для therickroll.com Хм, исходный код пуст! Кроме того, если вы остаетесь на этом сайте более 5 секунд, он перенаправляет вас на знаменитое видео rickroll на YouTube. Странно да? Вашей следующей мыслью будет, как все это работает, если исходный код пуст? Откроем волшебство!
С самого начала нас учат, что веб-сайт — это набор веб-страниц, которые обслуживаются из центрального места (серверов) через Интернет. Эта подача контента контролируется с помощью интернет-протоколов, таких как HTTP. На веб-страницах, с которыми мы познакомились, не упоминались ответы HTTP и метаданные заголовков или файлы конфигурации, связанные с этими веб-сайтами.
Всякий раз, когда веб-сайт обслуживается с сервера, он обслуживается с ответом HTTP вместе с HTML, CSS и другими соответствующими файлами. Этот HTTP-ответ содержит метаданные заголовка, за которыми следует тело, представляющее собой фактический контент веб-сайта (HTML). Этот ответ можно легко просмотреть в пользовательском интерфейсе с помощью команды «http» в Linux. См. пример ниже для моего веб-сайта портфолио (kaustubhgupta.me):
HTTP-ответ возвращен для веб-сайта моего портфолио Из приведенного выше вывода видно, что в HTTP-ответе возвращается много метаданных, и после этих метаданных тело содержит фактический HTML-код веб-страницы. Это HTML-код, который мы видим на вкладке «Просмотр исходного кода» в браузерах.
Это HTML-код, который мы видим на вкладке «Просмотр исходного кода» в браузерах.
Что, если мы каким-то образом включим код нашего веб-сайта в этот ответ HTTP-заголовка? Таким образом, веб-сайт будет отображаться, а код не будет отображаться на вкладке исходного кода!
Именно это и было сделано на сайте therickroll.com! Создатель использовал заголовок «Ссылка» HTTP-ответа для прикрепления таблицы стилей CSS. Этот файл CSS смог отобразить текущую версию веб-сайта. На абстрактном уровне файл CSS сделал следующее:
- Элемент head был сделан в виде блока, чтобы он был виден на экране. GIF был прикреплен здесь с использованием свойства «background-image» CSS.
- Для добавления текста на экран использовалось свойство CSS «content». Это свойство использовалось в элементе body «до».
- CSS-элемент HTML отображает цвет фона веб-страницы.
Прежде чем писать комментарий о том, что «исходного кода HTML не было», нужно понять эту вещь. Браузеры автоматически вставляют элементы HTML, head и body для каждой веб-страницы, независимо от того, указали ли мы элементы на нашей веб-странице, и поэтому в этом случае сработал CSS.
Браузеры автоматически вставляют элементы HTML, head и body для каждой веб-страницы, независимо от того, указали ли мы элементы на нашей веб-странице, и поэтому в этом случае сработал CSS.
Вопрос 1. Почему этот метод не работает в браузере Chrome?
Просто заголовок «Ссылка» не поддерживается в Chrome, и поэтому, когда кто-то заходит на этот сайт в Chrome, он возвращается с пустой версией сайта.
Qs 2: Как веб-сайт перенаправляет на rickroll видео YouTube через 5 секунд?
Создатель использовал заголовок «обновить», который принимает время ожидания и ссылку для перенаправления. Поэтому через 5 секунд сайт автоматически перенаправляет на ссылку YouTube песни rickroll!
Вот HTTP-ответ для therickroll.com:
HTTP-ответ для therickroll.comЭто полное объяснение того, как веб-сайт therickroll.com отображает содержимое, скрывая код!
Эта статья основана исключительно на этом видео на YouTube, и все кредиты на все исследования и реализацию этого веб-сайта принадлежат этому каналу YouTube!
Цель этой статьи не вводить никого в заблуждение.