Как правило, при совместной работе с текстовыми файлами нет необходимости вникать в технические аспекты хранения текста. Однако если необходимо поделиться файлом с человеком, который работает с текстами на других языках, скачать текстовый файл из Интернета или открыть его на компьютере с другой операционной системой, может потребоваться задать кодировку при его открытии или сохранении.
Когда вы открываете текстовый файл в Microsoft Word или другой программе (например, на компьютере, язык операционной системы на котором отличается от того, на котором написан текст в файле), кодировка помогает программе определить, в каком виде нужно вывести текст на экран, чтобы его можно было прочитать.
В этой статье
-
Общие сведения о кодировке текста
-
Выбор кодировки при открытии файла
-
Выбор кодировки при сохранении файла
-
Поиск кодировок, доступных в Word
Общие сведения о кодировке текста
Текст, который отображается в виде текста на экране, на самом деле сохраняется как числовые значения в текстовом файле. Компьютер переводит числовые значения в видимые символы. Для этого используется стандарт кодировки.
Кодировка — это схема нумерации, согласно которой каждому текстовому символу в наборе соответствует определенное числовое значение. Кодировка может содержать буквы, цифры и другие символы. В различных языках часто используются разные наборы символов, поэтому многие из существующих кодировок предназначены для отображения наборов символов соответствующих языков.
Различные кодировки для разных алфавитов
Сведения о кодировке, сохраняемые с текстовым файлом, используются компьютером для вывода текста на экран. Например, в кодировке «Кириллица (Windows)» знаку «Й» соответствует числовое значение 201. Когда вы открываете файл, содержащий этот знак, на компьютере, на котором используется кодировка «Кириллица (Windows)», компьютер считывает число 201 и выводит на экран знак «Й».
Однако если тот же файл открыть на компьютере, на котором по умолчанию используется другая кодировка, на экран будет выведен знак, соответствующий числу 201 в этой кодировке. Например, если на компьютере используется кодировка «Западноевропейская (Windows)», знак «Й» из исходного текстового файла на основе кириллицы будет отображен как «É», поскольку именно этому знаку соответствует число 201 в данной кодировке.
Юникод: единая кодировка для разных алфавитов
Чтобы избежать проблем с кодированием и декодированием текстовых файлов, можно сохранять их в Юникоде. В состав этой кодировки входит большинство знаков из всех языков, которые обычно используются на современных компьютерах.
Так как Word работает на базе Юникода, все файлы в нем автоматически сохраняются в этой кодировке. Файлы в Юникоде можно открывать на любом компьютере с операционной системой на английском языке независимо от языка текста. Кроме того, на таком компьютере можно сохранять в Юникоде файлы, содержащие знаки, которых нет в западноевропейских алфавитах (например, греческие, кириллические, арабские или японские).
К началу страницы
Выбор кодировки при открытии файла
-
Откройте вкладку Файл.
-
Нажмите кнопку Параметры.
-
Нажмите кнопку Дополнительно.
-
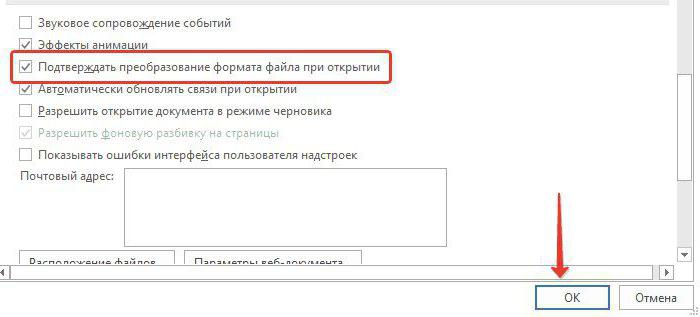
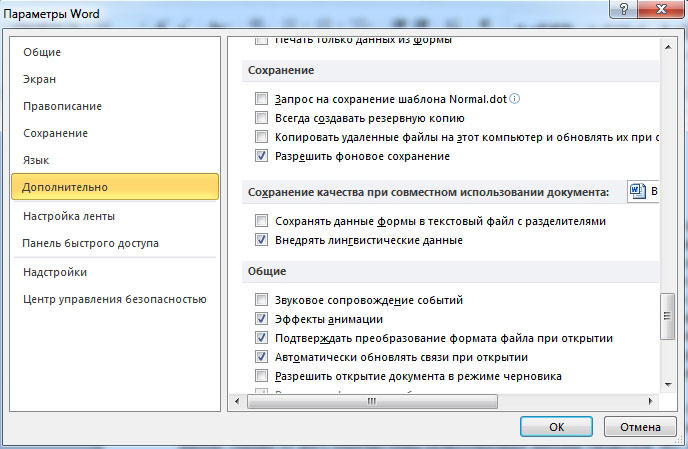
Перейдите к разделу Общие и установите флажокПодтверждать преобразование формата файла при открытии.
Примечание:
Если установлен этот флажок, Word отображает диалоговое окно Преобразование файла при каждом открытии файла в формате, отличном от формата Word (то есть файла, который не имеет расширения DOC, DOT, DOCX, DOCM, DOTX или DOTM). Если вы часто работаете с такими файлами, но вам обычно не требуется выбирать кодировку, не забудьте отключить этот параметр, чтобы это диалоговое окно не выводилось. -
Закройте, а затем снова откройте файл.
-
В диалоговом окне Преобразование файла выберите пункт Кодированный текст.
-
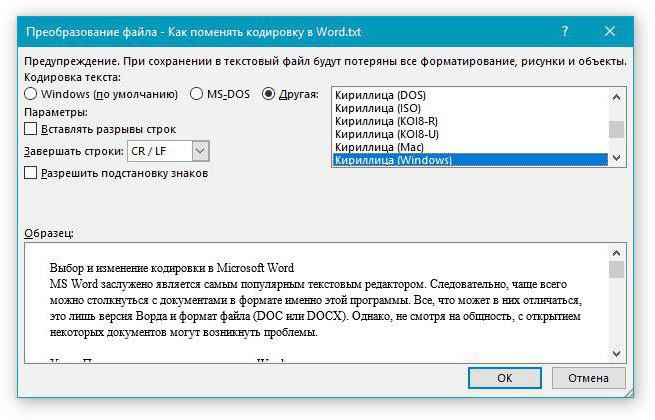
В диалоговом окне Преобразование файла установите переключатель Другая и выберите нужную кодировку из списка.
В области Образец можно просмотреть текст и проверить, правильно ли он отображается в выбранной кодировке.
Чтобы установить дополнительные шрифты, сделайте следующее:
-
Нажмите кнопку Пуск и выберите пункт Панель управления.
-
Выполните одно из указанных ниже действий.
В Windows 7
-
На панели управления выберите элемент Удаление программ.
-
В списке программ щелкните Microsoft Office или Microsoft Word, если он был установлен отдельно от пакета Microsoft Office, и нажмите кнопку Изменить.
В Windows Vista
-
На панели управления выберите раздел Удаление программы.
-
В списке программ щелкните Microsoft Office или Microsoft Word, если он был установлен отдельно от пакета Microsoft Office, и нажмите кнопку Изменить.
В Windows XP
-
На панели управления щелкните элемент
-
В списке Установленные программы щелкните Microsoft Office или Microsoft Word, если он был установлен отдельно от пакета Microsoft Office, и нажмите кнопку Изменить.
-
-
В группе Изменение установки Microsoft Office нажмите кнопку Добавить или удалить компоненты и затем нажмите кнопку Продолжить.
-
В разделе Параметры установки разверните элемент Общие средства Office, а затем — Многоязыковая поддержка.
-
Выберите нужный шрифт, щелкните стрелку рядом с ним и выберите пункт Запускать с моего компьютера.
Совет: При открытии текстового файла в той или иной кодировке в Word используются шрифты, определенные в диалоговом окне Параметры веб-документа. (Чтобы вызвать диалоговое окно Параметры веб-документа, нажмите кнопку Microsoft Office, затем щелкните Параметры Word и выберите категорию Дополнительно. В разделе Общие нажмите кнопку Параметры веб-документа.) С помощью параметров на вкладке Шрифты диалогового окна Параметры веб-документа можно настроить шрифт для каждой кодировки.
К началу страницы
Выбор кодировки при сохранении файла
Если не выбрать кодировку при сохранении файла, будет использоваться Юникод. Как правило, рекомендуется применять Юникод, так как он поддерживает большинство символов большинства языков.
Если документ планируется открывать в программе, которая не поддерживает Юникод, вы можете выбрать нужную кодировку. Например, в операционной системе на английском языке можно создать документ на китайском (традиционное письмо) с использованием Юникода. Однако если такой документ будет открываться в программе, которая поддерживает китайский язык, но не поддерживает Юникод, файл можно сохранить в кодировке «Китайская традиционная (Big5)». В результате текст будет отображаться правильно при открытии документа в программе, поддерживающей китайский язык (традиционное письмо).
Примечание: Так как Юникод — это наиболее полный стандарт, при сохранении текста в других кодировках некоторые знаки могут не отображаться. Предположим, например, что документ в Юникоде содержит текст на иврите и языке с кириллицей. Если сохранить файл в кодировке «Кириллица (Windows)», текст на иврите не отобразится, а если сохранить его в кодировке «Иврит (Windows)», то не будет отображаться кириллический текст.
Если выбрать стандарт кодировки, который не поддерживает некоторые символы в файле, Word пометит их красным. Вы можете просмотреть текст в выбранной кодировке перед сохранением файла.
При сохранении файла в виде кодированного текста из него удаляется текст, для которого выбран шрифт Symbol, а также коды полей.
Выбор кодировки
-
Откройте вкладку Файл.
-
Выберите пункт Сохранить как.
Чтобы сохранить файл в другой папке, найдите и откройте ее.
-
В поле Имя файла введите имя нового файла.
-
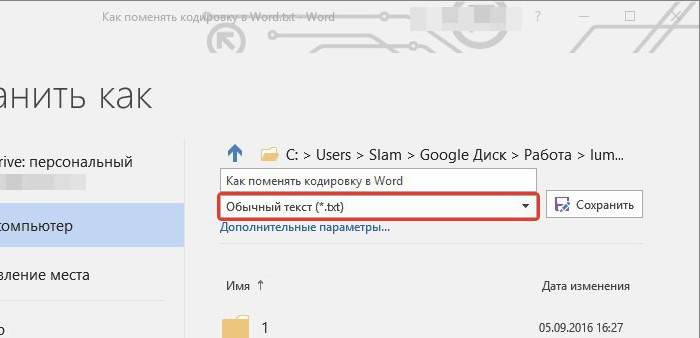
В поле Тип файла выберите Обычный текст.
-
Нажмите кнопку Сохранить.
-
Если появится диалоговое окно Microsoft Office Word — проверка совместимости, нажмите кнопку Продолжить.
-
В диалоговом окне Преобразование файла выберите подходящую кодировку.
-
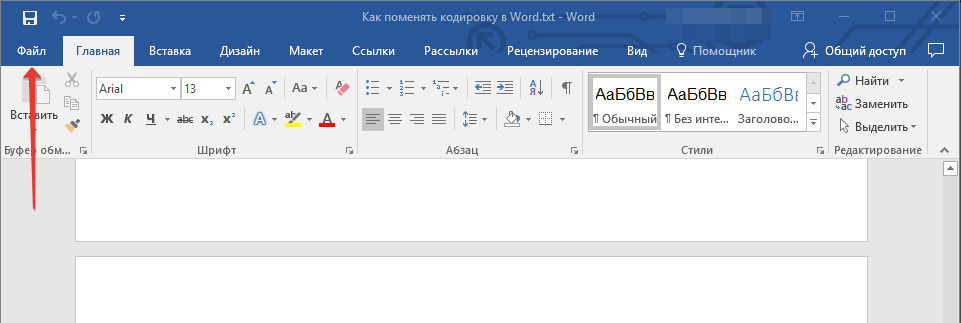
Чтобы использовать стандартную кодировку, выберите параметр Windows (по умолчанию).
-
Чтобы использовать кодировку MS-DOS, выберите параметр MS-DOS.
-
Чтобы задать другую кодировку, установите переключатель Другая и выберите нужный пункт в списке. В области Образец можно просмотреть текст и проверить, правильно ли он отображается в выбранной кодировке.
Примечание: Чтобы увеличить область отображения документа, можно изменить размер диалогового окна Преобразование файла.
-
-
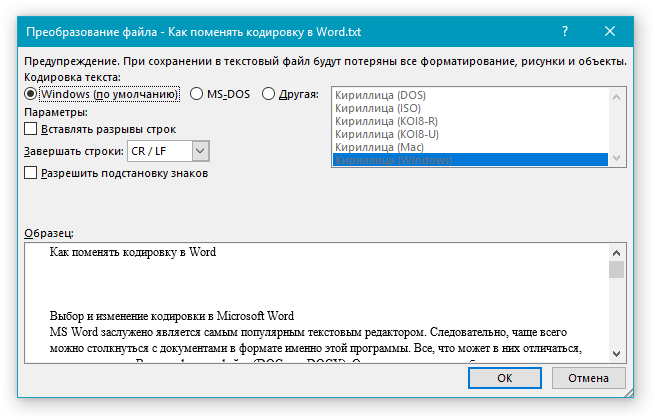
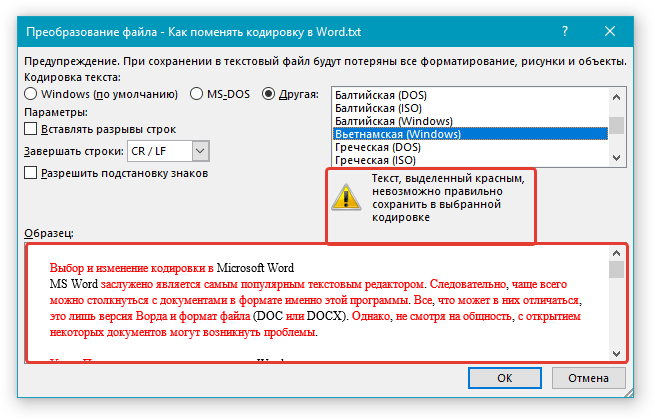
Если появилось сообщение «Текст, выделенный красным, невозможно правильно сохранить в выбранной кодировке», можно выбрать другую кодировку или установить флажок Разрешить подстановку знаков.
Если разрешена подстановка знаков, знаки, которые невозможно отобразить, будут заменены ближайшими эквивалентными символами в выбранной кодировке. Например, многоточие заменяется тремя точками, а угловые кавычки — прямыми.
Если в выбранной кодировке нет эквивалентных знаков для символов, выделенных красным цветом, они будут сохранены как внеконтекстные (например, в виде вопросительных знаков).
-
Если документ будет открываться в программе, в которой текст не переносится с одной строки на другую, вы можете включить в нем жесткие разрывы строк. Для этого установите флажок Вставлять разрывы строк и укажите нужное обозначение разрыва (возврат каретки (CR), перевод строки (LF) или оба значения) в поле Завершать строки.
К началу страницы
Поиск кодировок, доступных в Word
Word распознает несколько кодировок и поддерживает кодировки, которые входят в состав системного программного обеспечения.
Ниже приведен список письменностей и связанных с ними кодировок (кодовых страниц).
Система письменности | Кодировки | Используемый шрифт |
|---|---|---|
|
Многоязычная |
Юникод (UCS-2 с прямым и обратным порядком байтов, UTF-8, UTF-7) |
Стандартный шрифт для стиля «Обычный» локализованной версии Word |
|
Арабская |
Windows 1256, ASMO 708 |
Courier New |
|
Китайская (упрощенное письмо) |
GB2312, GBK, EUC-CN, ISO-2022-CN, HZ |
SimSun |
|
Китайская (традиционное письмо) |
BIG5, EUC-TW, ISO-2022-TW |
MingLiU |
|
Кириллица |
Windows 1251, KOI8-R, KOI8-RU, ISO8859-5, DOS 866 |
Courier New |
|
Английская, западноевропейская и другие, основанные на латинице |
Windows 1250, 1252-1254, 1257, ISO8859-x |
Courier New |
|
Греческая |
Windows 1253 |
Courier New |
|
Иврит |
Windows 1255 |
Courier New |
|
Японская |
Shift-JIS, ISO-2022-JP (JIS), EUC-JP |
MS Mincho |
|
Корейская |
Wansung, Johab, ISO-2022-KR, EUC-KR |
Malgun Gothic |
|
Тайская |
Windows 874 |
Tahoma |
|
Вьетнамская |
Windows 1258 |
Courier New |
|
Индийские: тамильская |
ISCII 57004 |
Latha |
|
Индийские: непальская |
ISCII 57002 (деванагари) |
Mangal |
|
Индийские: конкани |
ISCII 57002 (деванагари) |
Mangal |
|
Индийские: хинди |
ISCII 57002 (деванагари) |
Mangal |
|
Индийские: ассамская |
ISCII 57006 |
|
|
Индийские: бенгальская |
ISCII 57003 |
|
|
Индийские: гуджарати |
ISCII 57010 |
|
|
Индийские: каннада |
ISCII 57008 |
|
|
Индийские: малаялам |
ISCII 57009 |
|
|
Индийские: ория |
ISCII 57007 |
|
|
Индийские: маратхи |
ISCII 57002 (деванагари) |
|
|
Индийские: панджаби |
ISCII 57011 |
|
|
Индийские: санскрит |
ISCII 57002 (деванагари) |
|
|
Индийские: телугу |
ISCII 57005 |
-
Для использования индийских языков необходима их поддержка в операционной системе и наличие соответствующих шрифтов OpenType.
-
Для непальского, ассамского, бенгальского, гуджарати, малаялам и ория доступна только ограниченная поддержка.
К началу страницы
Как поменять кодировку в Word
Когда человек работает с программой «MS Word», у него редко возникает потребность вникать в нюансы кодировки. Но как только появляется необходимость поделиться документом с коллегами, существует вероятность того, что отправленный пользователем файл может просто-напросто не быть прочитан получателем. Это случается из-за несовпадения настроек, а конкретно кодировок в разных версиях программы.

Как поменять кодировку в Word
Что представляет собой кодировка и от чего она зависит?
Для каждого региона кодировка может в значительной степени разниться. Для понимания кодировки необходимо знать то, что информация в текстовом документе сохраняется в виде некоторых числовых значений. Персональный компьютер самостоятельно преобразует числа в текст, используя при этом алгоритм отдельно взятой кодировки. Для стран СНГ используется кодировка файлов с названием «Кириллица», а для других регионов, таких как Западная Европа, применяется «Западноевропейская (Windows)». Если текстовый документ был сохранен в кодировке кириллицы, а открыт с использованием западноевропейского формата, то символы будут отображаться совершенно неправильно, представляя собой бессмысленный набор знаков.

При открытии документа, сохраненного одним типом кодировки, в другом формате кодировки невозможно будет прочитать
Во избежание недоразумений и облегчения работы разработчики внедрили специальную единую кодировку для всех алфавитов – «Юникод». Этот общепринятый стандарт кодировки содержит в себе практически все знаки большинства письменных языков нашей планеты. К тому же он преобладает в интернете, где так необходима подобная унификация для охвата большего количества пользователей и удовлетворения их потребностей.

Тип кодировок, которые используются, как стандартные для всех языков
«Word 2013» работает как раз на основе Юникода, что позволяет обмениваться текстовыми файлами без применения сторонних программ и исправления кодировок в настройках. Но нередко пользователи сталкиваются с ситуацией, когда при открытии вроде бы простого файла вместо текста отображаются только знаки. В таком случае программа «Word» неправильно определила существующую первоначальную кодировку текста.
Справка! Некоторые кодировки применяются к определенным языкам. Для японского языка специально была разработана кодировка «Shift JIS», для корейского – «EUC-KR», а для китайского «ISO-2022» и «EUC».
Изменение кодировки текста в «Word 2013»
Первый способ изменения кодировки в «Word»
Для исправления текстового документа, которому была неправильно определена изначальная кодировка, необходимо:
Шаг 1. Запустить текстовый документ и открыть вкладку «Файл».

Открываем вкладку «Файл»
Шаг 2. Перейти в меню настроек «Параметры».

Переходим в меню настроек «Параметры»
Шаг 3. Выбрать пункт «Дополнительно» и перейти к разделу «Общие».

Выбираем пункт «Дополнительно»

Прокрутив список вниз, переходим к разделу «Общие»
Шаг 4. Активируем нажатием по соответствующей области настройку в графе «Подтверждать преобразование формата файла при открытии».

Отмечаем галочкой графу «Подтверждать преобразование формата файла при открытии», нажимаем «ОК»
Шаг 5. Сохраняем изменения и закрываем текстовый документ.
Шаг 6. Повторно запускаем необходимый файл. Перед пользователем появится окно «Преобразование файла», в котором необходимо выбрать пункт «Кодированный текст», и сохранить изменения нажатием «ОК».

Выбираем пункт «Кодированный текст», сохраняем изменения нажатием «ОК»
Шаг 7. Всплывет еще одна область, в которой необходимо выбрать пункт кодировки «Другая» и выбрать в списке подходящую. Поле «Образец» поможет пользователю подобрать необходимую кодировку, отображаемую изменения в тексте. После выбора подходящей сохраняем изменения кнопкой «ОК».

Отмечаем пункт кодировки «Другая», выбираем в списке подходящую, нажимаем «ОК»
Второй способ изменения кодировки в «Word»
- Производим запуск файла, кодировку текста которого необходимо произвести.
- Переходим во вкладку «Файл».
Открываем вкладку «Файл»
- Кликаем «Сохранить как».

Кликаем «Сохранить как»
- В области «Тип файла» необходимо выбрать «Обычный текст» и нажать «Сохранить».

В области «Тип файла» выбираем «Обычный текст», нажимаем «Сохранить»
- В появившемся «Преобразование файла» выбираем кодировку «Другая» и в списке активируем нужную.

Отмечаем опцию «Другая», в списке активируем нужную, нажимаем «ОК»
Читайте полезную информацию, как работать в ворде
для чайников, в новой статье на нашем портале.
Изменение кодировки в программе «Notepad ++»
Подобное приложение используется многими программистами для создания сайтов, различных приложений и многого другого. Поэтому очень важно сохранять и создавать файлы, используя необходимую кодировку. Для того, чтобы настроить нужный вариант для пользователя, следует:
Шаг 1. Запустить программу и в верхнем контекстном меню выбрать вкладку «Кодировки».

Выбираем вкладку «Кодировки»
Шаг 2. В выпадающем списке пользователю требуется выбрать из списка необходимую для него кодировку и щелкнуть на нее.

Выбираем из списка необходимую кодировку, щелкаем на ней
Шаг 3. Правильность проведения процедуры легко проверить, обратив внимание на нижнюю панель программы, которая будет отображать только что измененную кодировку.

В нижней панели программы можно увидеть измененную кодировку
Важно! Перед началом работы в «Notepad ++» в первую очередь рекомендуется проверить установленную кодировку. При необходимости ее нужно изменить при помощи инструкции, приведенной ранее.
Корректировка кодировки веб-страниц
Кодировка символов – неотъемлемая часть работы браузеров для серфинга в интернете. Поэтому каждому из пользователей просто необходимо уметь ее настраивать. Чтобы быстро изменить кодировку «Google Chrome», необходимо будет установить дополнительное расширение, так как разработчики убрали возможность изменения данного параметра.
Для того, чтобы сменить кодировку на необходимую, нужно:
- Запустить браузер.
- Перейти по ссылке chrome://extensions/.

В адресную строку вводим указанный адрес, нажимаем «Enter»
- Затем кликнуть в левом верхнем углу по опции «Расширения».

Нажимаем по опции «Расширения» в левом верхнем углу страницы
- Внизу найти и открыть интернет-магазин браузера Хром.

В левом нижнем углу щелкаем по ссылке «Открыть Интернет-магазин Chrome»
- В поиске найти расширение и установить «Set Character Encoding», нажать «Enter».

В поле для поиска вводим Set Character Encodin, нажимаем «Enter»
- Рядом с приложением нажать «Установить».

Нажимаем по кнопке «Установить»
- Для того, чтобы с легкостью поменять значение кодировки, необходимо убедится в работоспособности расширения, после чего на любом сайте на пустой области правой кнопкой мыши вызвать контекстное меню. В нем следует перейти в «Set Character Encoding» и выбрать необходимое значение.

На пустой области нажимаем правой кнопкой мышки, левой кнопкой по пункту «Set Character Encoding», выбираем необходимое значение
Как поменять кодировку в «Mozilla Firefox»
Для этого пользователю потребуется:
Шаг 1. Запустить браузер и открыть меню, нажав по иконке трех линий левой клавишей мыши в правом верхнем углу страницы.

Нажимаем по иконке из трех линий в правом верхнем углу
Шаг 2. В контекстном меню запустить «Настройки».

Открываем «Настройки»
Шаг 3. Перейти во вкладку «Содержимое».

Переходим во вкладку «Содержимое»
Шаг 4. В разделе «Шрифты и цвета» нажать на блок «Дополнительные».

В разделе «Шрифты и цвета» нажимаем по блоку «Дополнительно»
Шаг 5. Перед пользователем отобразится специальная панель, на которой будет указана использующаяся кодировка. Для ее изменения потребуется нажать на название кодировки и выбрать нужную.

Нажимаем на название кодировки

Выбираем подходящую кодировку, нажимаем «ОК»
Установка кодировки в интерфейсе Блокнота
Тем юзерам, кому необходимо пользоваться стандартным приложением «Блокнот»  , будет полезно знать о том, что изменить кодировку можно следующим образом:
, будет полезно знать о том, что изменить кодировку можно следующим образом:
- Открыть текстовый документ и повторно сохранить его, нажав «Файл» и затем «Сохранить как».

Нажимаем по вкладке «Файл», затем по опции «Сохранить как»
- В появившемся окне помимо директории следует выбрать и кодировку, найдя необходимый формат, нажать «Сохранить».

В параметре «Кодировка» выбираем подходящий формат, нажимаем «Сохранить»
После этого без труда можно открывать необходимый текст в нужной кодировке.
Благодаря правильно подобранной и установленной кодировке пользователь может избежать неприятностей при отправке файла другим юзерам. Все, что для этого требуется, – это выставлять перед началом работы необходимое значение.
Видео — Как изменить кодировку в Word
Два способа, как поменять кодировку в Word
Ввиду того, что текстовый редактор «Майкрософт Ворд» является самым популярным на рынке, именно форматы документов, которые присущи ему, можно чаще всего встретить в сети. Они могут отличаться лишь версиями (DOCX или DOC). Но даже с этими форматами программа может быть несовместима или же совместима не полностью.

Случаи некорректного отображения текста
Конечно, когда в программе наотрез отказываются открываться, казалось бы, родные форматы, это поправить очень сложно, а то и практически невозможно. Но, бывают случаи, когда они открываются, а их содержимое невозможно прочесть. Речь сейчас идет о тех случаях, когда вместо текста, кстати, с сохраненной структурой, вставлены какие-то закорючки, «перевести» которые невозможно.
Эти случаи чаще всего связаны лишь с одним — с неверной кодировкой текста. Точнее, конечно, будет сказать, что кодировка не неверная, а просто другая. Не воспринимающаяся программой. Интересно еще то, что общего стандарта для кодировки нет. То есть, она может разниться в зависимости от региона. Так, создав файл, например, в Азии, скорее всего, открыв его в России, вы не сможете его прочитать.
В этой статье речь пойдет непосредственно о том, как поменять кодировку в Word. Кстати, это пригодится не только лишь для исправления вышеописанных «неисправностей», но и, наоборот, для намеренного неправильного кодирования документа.
Определение
Перед рассказом о том, как поменять кодировку в Word, стоит дать определение этому понятию. Сейчас мы попробуем это сделать простым языком, чтобы даже далекий от этой тематики человек все понял.
Зайдем издалека. В «вордовском» файле содержится не текст, как многими принято считать, а лишь набор чисел. Именно они преобразовываются во всем понятные символы программой. Именно для этих целей применяется кодировка.
Кодировка — схема нумерации, числовое значение в которой соответствует конкретному символу. К слову, кодировка может в себя вмещать не только лишь цифровой набор, но и буквы, и специальные знаки. А ввиду того, что в каждом языке используются разные символы, то и кодировка в разных странах отличается.
Как поменять кодировку в Word. Способ первый
После того, как этому явлению было дано определение, можно переходить непосредственно к тому, как поменять кодировку в Word. Первый способ можно осуществить при открытии файла в программе.
В том случае, когда в открывшемся файле вы наблюдаете набор непонятных символов, это означает, что программа неверно определила кодировку текста и, соответственно, не способна его декодировать. Все, что нужно сделать для корректного отображения каждого символа, — это указать подходящую кодировку для отображения текста.
Говоря о том, как поменять кодировку в Word при открытии файла, вам необходимо сделать следующее:
- Нажать на вкладку «Файл» (в ранних версиях это кнопка «MS Office»).
- Перейти в категорию «Параметры».
- Нажать по пункту «Дополнительно».
- В открывшемся меню пролистать окно до пункта «Общие».
- Поставить отметку рядом с «Подтверждать преобразование формата файла при открытии».
- Нажать»ОК».
Итак, полдела сделано. Скоро вы узнаете, как поменять кодировку текста в Word. Теперь, когда вы будете открывать файлы в программе «Ворд», будет появляться окно. В нем вы сможете поменять кодировку открывающегося текста.
Выполните следующие действия:
- Откройте двойным кликом файл, который необходимо перекодировать.
- Кликните по пункту «Кодированный текст», что находится в разделе «Преобразование файла».
- В появившемся окне установите переключатель на пункт «Другая».
- В выпадающем списке, что расположен рядом, определите нужную кодировку.
- Нажмите «ОК».
Если вы выбрали верную кодировку, то после всего проделанного откроется документ с понятным для восприятия языком. В момент, когда вы выбираете кодировку, вы можете посмотреть, как будет выглядеть будущий файл, в окне «Образец». Кстати, если вы думаете, как поменять кодировку в Word на MAC, для этого нужно выбрать из выпадающего списка соответствующий пункт.
Способ второй: во время сохранения документа
Суть второго способа довольно проста: открыть файл с некорректной кодировкой и сохранить его в подходящей. Делается это следующим образом:
- Нажмите «Файл».
- Выберите «Сохранить как».
- В выпадающем списке, что находится в разделе «Тип файла», выберите «Обычный текст».
- Кликните по «Сохранить».
- В окне преобразования файла выберите предпочитаемую кодировку и нажмите «ОК».
Теперь вы знаете два способа, как можно поменять кодировку текста в Word. Надеемся, что эта статья помогла вам в решении вопроса.
Как поменять кодировку в Word

MS Word заслужено является самым популярным текстовым редактором. Следовательно, чаще всего можно столкнуться с документами в формате именно этой программы. Все, что может в них отличаться, это лишь версия Ворда и формат файла (DOC или DOCX). Однако, не смотря на общность, с открытием некоторых документов могут возникнуть проблемы.
Урок: Почему не открывается документ Word
Одно дело, если вордовский файл не открывается вовсе или запускается в режиме ограниченной функциональности, и совсем другое, когда он открывается, но большинство, а то и все символы в документе являются нечитабельными. То есть, вместо привычной и понятной кириллицы или латиницы, отображаются какие-то непонятные знаки (квадраты, точки, вопросительные знаки).
Урок: Как убрать режим ограниченной функциональности в Ворде
Если и вы столкнулись с аналогичной проблемой, вероятнее всего, виною тому неправильная кодировка файла, точнее, его текстового содержимого. В этой статье мы расскажем о том, как изменить кодировку текста в Word, тем самым сделав его пригодным для чтения. К слову, изменение кодировки может понадобиться еще и для того, чтобы сделать документ нечитабельным или, так сказать, чтобы “конвертировать” кодировку для дальнейшего использования текстового содержимого документа Ворд в других программах.
Примечание: Общепринятые стандарты кодировки текста в разных странах могут отличаться. Вполне возможно, что документ, созданный, к примеру, пользователем, проживающим в Азии, и сохраненный в местной кодировке, не будет корректно отображаться у пользователя в России, использующего на ПК и в Word стандартную кириллицу.
Что такое кодировка
Вся информация, которая отображается на экране компьютера в текстовом виде, на самом деле хранится в файле Ворд в виде числовых значений. Эти значения преобразовываются программой в отображаемые знаки, для чего и используется кодировка.
Кодировка — схема нумерации, в которой каждому текстовому символу из набора соответствует числовое значение. Сама же кодировка может содержать буквы, цифры, а также другие знаки и символы. Отдельно стоит сказать о том, что в разных языках довольно часто используются различные наборы символов, именно поэтому многие кодировки предназначены исключительно для отображения символов конкретных языков.
Выбор кодировки при открытии файла
Если текстовое содержимое файла отображается некорректно, например, с квадратами, вопросительными знаками и другими символами, значит, MS Word не удалось определить его кодировку. Для устранения этой проблемы необходимо указать правильную (подходящую) кодировку для декодирования (отображения) текста.
1. Откройте меню “Файл” (кнопка “MS Office” ранее).
2. Откройте раздел “Параметры” и выберите в нем пункт “Дополнительно”.

3. Прокрутите содержимое окна вниз, пока не найдете раздел “Общие”. Установите галочку напротив пункта “Подтверждать преобразование формата файла при открытии”. Нажмите “ОК” для закрытия окна.
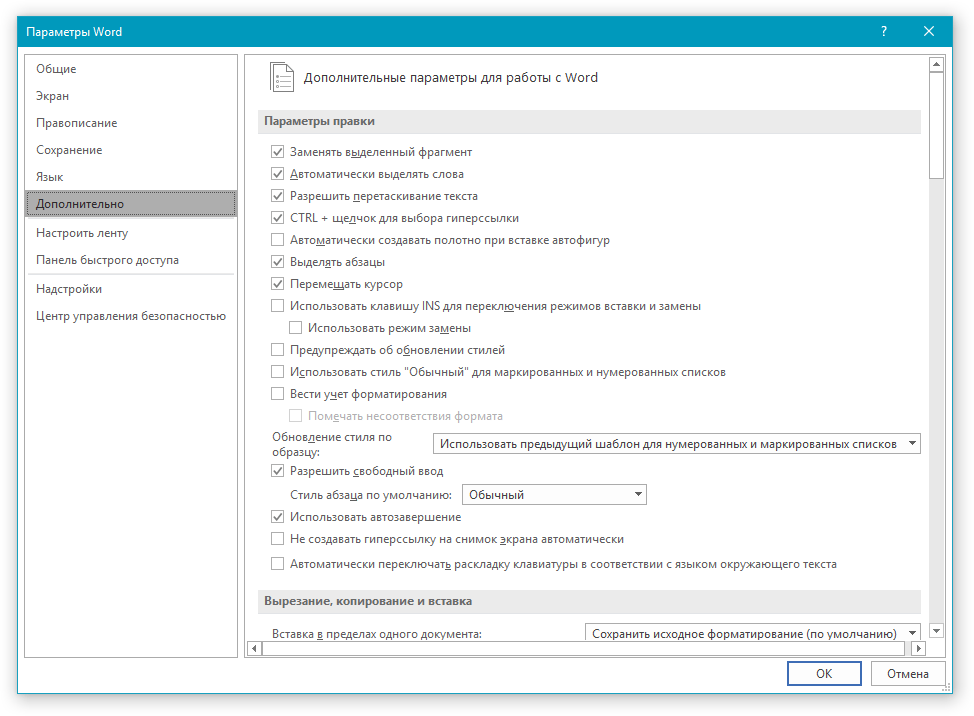
Примечание: После того, как вы установите галочку напротив этого параметра, при каждом открытии в Ворде файла в формате, отличном от DOC, DOCX, DOCM, DOT, DOTM, DOTX, будет отображаться диалоговое окно “Преобразование файла”. Если же вам часто приходится работать с документами других форматов, но при этом не требуется менять их кодировку, снимите эту галочку в параметрах программы.
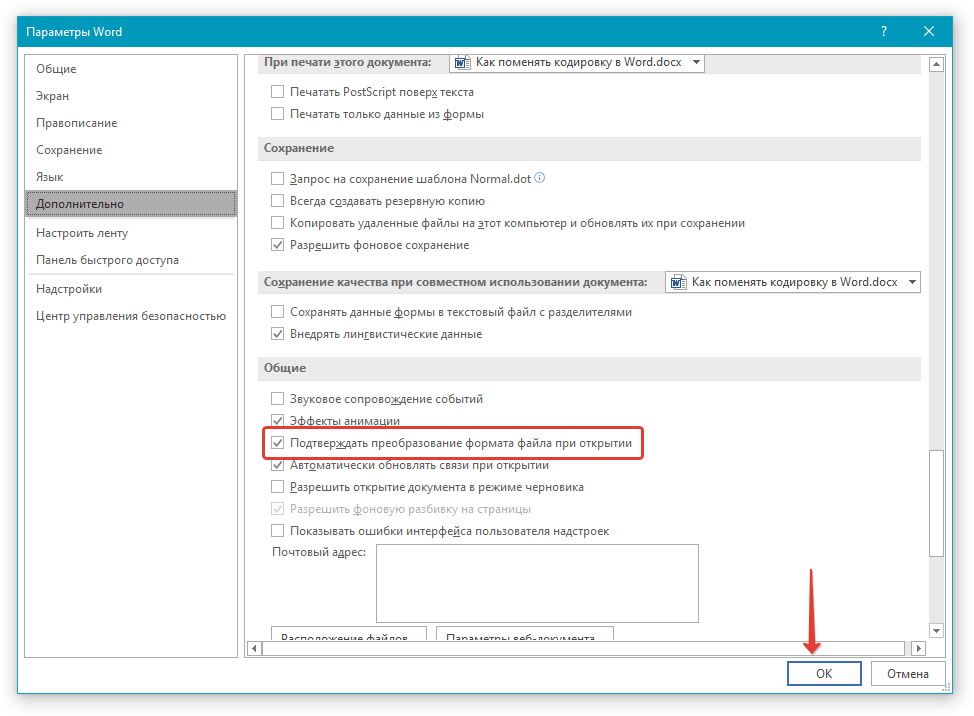
4. Закройте файл, а затем снова откройте его.
5. В разделе “Преобразование файла” выберите пункт “Кодированный текст”.
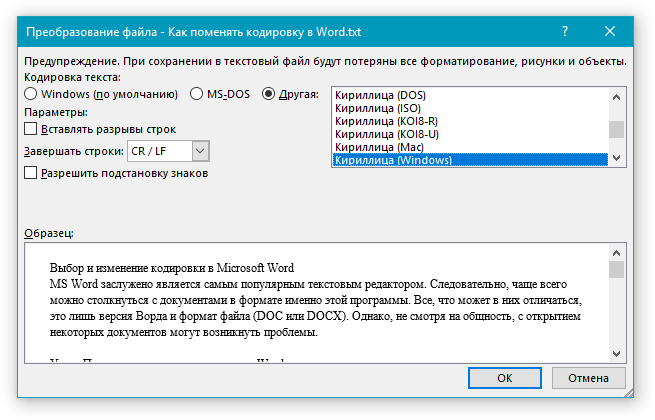
6. В открывшемся диалоговом окне “Преобразование файла” установите маркер напротив параметра “Другая”. Выберите необходимую кодировку из списка.
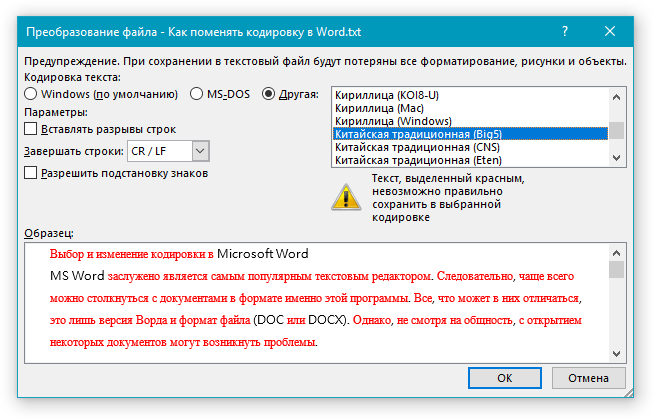
- Совет: В окне “Образец” вы можете увидеть, как будет выглядеть текст в той или иной кодировке.
7. Выбрав подходящую кодировку, примените ее. Теперь текстовое содержимое документа будет корректно отображаться.
В случае, если весь текст, кодировку для которого вы выбираете, выглядит практически одинаков (например, в виде квадратов, точек, знаков вопроса), вероятнее всего, на вашем компьютере не установлен шрифт, используемый в документе, который вы пытаетесь открыть. О том, как установить сторонний шрифт в MS Word, вы можете прочесть в нашей статье.
Урок: Как в Ворде установить шрифт
Выбор кодировки при сохранении файла
Если вы не указываете (не выбираете) кодировку файла MS Word при сохранении, он автоматически сохраняется в кодировке Юникод, чего в большинстве случаев предостаточно. Данный тип кодировки поддерживает большую часть знаков и большинство языков.
В случае, если созданный в Ворде документ вы (или кто-то другой) планируете открывать в другой программе, не поддерживающей Юникод, вы всегда можете выбрать необходимую кодировку и сохранить файл именно в ней. Так, к примеру, на компьютере с русифицированной операционной системой вполне можно создать документ на традиционном китайском с применением Юникода.
Проблема лишь в том, что в случае, если данный документ будет открываться в программе, поддерживающей китайский, но не поддерживающей Юникод, куда правильнее будет сохранить файл в другой кодировке, например, “Китайская традиционная (Big5)”. В таком случае текстовое содержимое документа при открытии его в любой программе с поддержкой китайского языка, будет отображаться корректно.
Примечание: Так как Юникод является самым популярным, да и просто обширным стандартном среди кодировок, при сохранении текста в других кодировках возможно некорректное, неполное, а то и вовсе отсутствующее отображение некоторых файлов. На этапе выбора кодировки для сохранения файла знаки и символы, которые не поддерживаются, отображаются красным цветом, дополнительно высвечивается уведомление с информацией о причине.
1. Откройте файл, кодировку которого вам необходимо изменить.
2. Откройте меню “Файл” (кнопка “MS Office” ранее) и выберите пункт “Сохранить как”. Если это необходимо, задайте имя файла.

3. В разделе “Тип файла” выберите параметр “Обычный текст”.

4. Нажмите кнопку “Сохранить”. Перед вами появится окно “Преобразование файла».
5. Выполните одно из следующих действий:

Примечание: Если при выборе той или иной (“Другой”) кодировки вы видите сообщение “Текст, выделенный красным, невозможно правильно сохранить в выбранной кодировке”, выберите другую кодировку (иначе содержимое файла будет отображаться некорректно) или же установите галочку напротив параметра “разрешить подстановку знаков”.
Если подстановка знаков разрешена, все те знаки, которые отобразить в выбранной кодировке невозможно, будут автоматически заменены на эквивалентные им символы. Например, многоточие может быть заменено на три точки, а угловые кавычки — на прямые.
6. Файл будет сохранен в выбранной вами кодировке в виде обычного текста (формат “TXT”).

На этом, собственно, и все, теперь вы знаете, как в Word сменить кодировку, а также знаете о том, как ее подобрать, если содержимое документа отображается некорректно.
 Мы рады, что смогли помочь Вам в решении проблемы. Опишите, что у вас не получилось.
Наши специалисты постараются ответить максимально быстро.
Мы рады, что смогли помочь Вам в решении проблемы. Опишите, что у вас не получилось.
Наши специалисты постараются ответить максимально быстро.Помогла ли вам эта статья?
ДА НЕТКак поменять кодировку текста в Word
Набор символов, которые мы видим на экране при открытии документа, называется кодировкой. Когда она выставлена неправильно, вместо понятных и привычных букв и цифр вы увидите бессвязные символы. Эта проблема часто возникала на заре развития технологий, но сейчас текстовые процессоры умеют сами автоматически выбирать подходящие комплекты. Свою роль сыграло появление и развитие utf-8, так называемого Юникода, в состав которого входит множество самых разных символов, в том числе русских. Документы в такой кодировке не нуждаются в смене и настройке, так как показывают текст правильно по умолчанию.

Современные текстовые редакторы определяют кодировку при открытии документа
С другой стороны, такая ситуация всё же иногда случается. И получить нечитаемый документ очень досадно, особенно если он важный и нужный. Как раз для таких случаев в Microsoft Word есть возможность указать для текста кодировку. Это вернёт его в читаемый вид.
Принудительная смена
Если вы получили из какого-то источника текстовый файл, но не можете прочитать его содержимое, то нужна операция ручной смены кодировки. Для этого зайдите в раздел «Сведения» во вкладке «Файл». Тут собраны глобальные настройки распознавания и отображения, и если вы будете изменять их в открытом документе, то для него они станут индивидуальными, а для остальных — не изменятся. Воспользуемся этим. В разделе «Дополнительно» появившегося окна находим заголовок «Общие» и ставим галочку «Подтверждать преобразование файлов при открытии». Подтвердите изменения и закройте Word. Теперь откройте документ снова, как бы применяя настройки, и перед вами появится окно преобразования файла. В нём будет список возможных форматов, среди которых находим «Кодированный текст», и получим следующий диалог.
В этом новом окне будет три переключателя. Первый, по умолчанию, — это CP-1251, кодировка Windows. Второй — MS-DOS. Нам нужен третий пункт — ручной выбор, справа от него перечислены разнообразные наборы символов. Но, как правило, пользователь не знает, какими символами был набран текст предыдущим автором, поэтому в нижней части этого окна есть поле под названием «Образец», в котором фрагмент из текста будет в реальном времени отображаться при выборе того или иного комплекта символов. Это очень удобно, потому что не нужно каждый раз закрывать и отрывать документ снова, чтобы подобрать нужную.
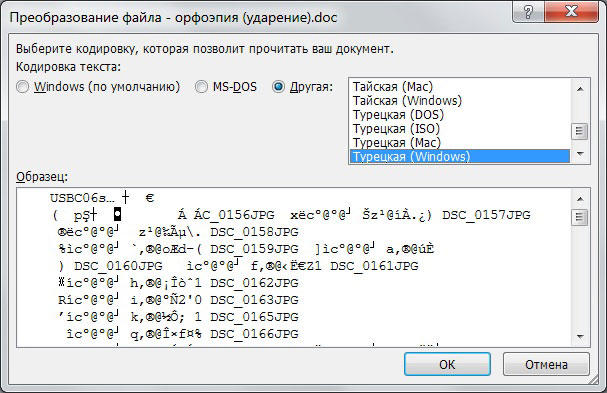
Перебирая варианты по одному и глядя на текст в поле образцов, выберите ту кодировку, при которой символы будут русскими. Но обратите внимание, что это ещё ничего не значит, — внимательно смотрите, чтобы они складывались в осмысленные слова. Дело в том, что для русского языка есть не одна кодировка, и текст в одной из них не будет отображаться корректно в другой. Так что будьте внимательны.
Нужно сказать, что с файлами, сделанными на современных текстовых процессорах, крайне редко возникают подобные проблемы. Однако есть ещё и такой бич современного информационного общества, как несовместимость форматов. Дело в том, что существует целый ряд текстовых редакторов, и каждым кто-то пользуется. Возможно, для кого-то не нужна функциональность Ворда, кто-то не считает нужным за него платить и т. п. Причин может быть множество.
Если при сохранении документа автор выбрал формат, совместимый в MS Word, то проблем возникнуть не должно. Но так бывает нечасто. Например, если текст сохранён с расширением .rtf, то диалог выбора кодировки отобразится перед вами сразу же при открытии текста. А вот форматы другого популярного текстового процессора OpenOffice Ворд даже не откроет, поэтому, если им пользуетесь, не забывайте выбирать пункт «Сохранить как», когда отправляете файл пользователю Office.
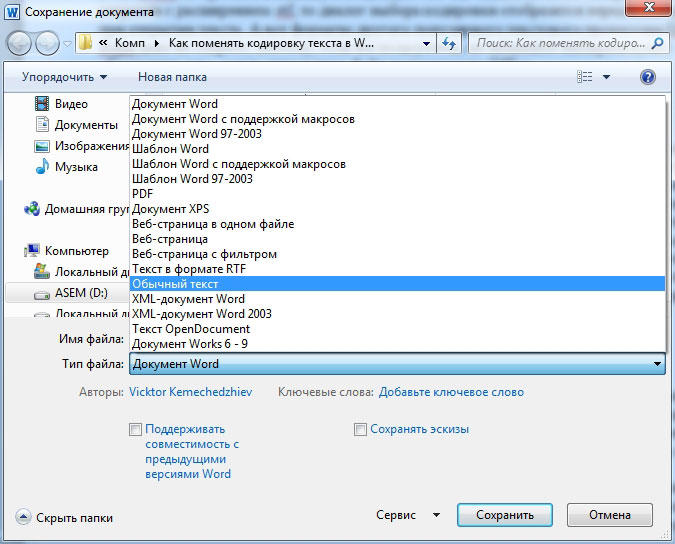
Сохранение с указанием кодировки
У пользователя может возникнуть ситуация, когда он специально указывает определённую кодировку. Например, такое требование ему предъявляет получатель документа. В этом случае нужно будет сохранить документ как обычный текст через меню «Файл». Смысл в том, что для заданных форматов в Ворде есть привязанные глобальными системными настройками кодировки, а для «Обычного текста» такой связи не установлено. Поэтому Ворд предложит самостоятельно выбрать для него кодировку, показав уже знакомое нам окно преобразования документа. Выбирайте для него нужную вам кодировку, сохраняйте, и можно отправлять или передавать этот документ. Как вы понимаете, конечному получателю нужно будет сменить в своём текстовом редакторе кодировку на такую же, чтобы прочитать ваш текст.
Заключение
Вопрос смены кодировки в Вордовских документах перед рядовыми пользователями встаёт не так уж часто. Как правило, текстовый процессор может сам автоматически определить требуемый для корректного отображения набор символов и показать текст в читаемом виде. Но из любого правила есть исключения, так что нужно и полезно уметь сделать это самому, благо, реализован процесс в Word достаточно просто.
То, что мы рассмотрели, действительно и для других программ из пакета Office. В них также могут возникнуть проблемы из-за, скажем, несовместимости форматов сохранённых файлов. Здесь пользователю придётся выполнить всё те же действия, так что эта статья может помочь не только работающим в Ворде. Унификация правил настройки для всех программ офисного пакета Microsoft помогает не запутаться в них при работе с любым видом документов, будь то тексты, таблицы или презентации.
Напоследок нужно сказать, что не всегда стоит обвинять кодировку. Возможно, всё гораздо проще. Дело в том, что многие пользователи в погоне за «красивостями» забывают о стандартизации. Если такой автор выберет установленный у него шрифт, наберёт с его помощью документ и сохранит, у него текст будет отображаться корректно. Но когда этот документ попадёт к человеку, у которого такой шрифт не установлен, то на экране окажется нечитаемый набор символов. Это очень похоже на «слетевшую» кодировку, так что легко ошибиться. Поэтому перед тем как пытаться раскодировать текст в Word, сначала попробуйте просто сменить шрифт.
Как изменить кодировку текста в Word
На экране иероглифы? Ваши действия. Не обязательно быть продвинутым компьютерщиком или пользоваться интернетом круглосуточно, чтобы столкнуться с проблемой «китайского текста» в Microsoft Word. И дело не в том, что Вы получили письмо из Японии или Гонконга. Непонятные символы на экране – результат другой кодировки текстового документа. Давайте рассмотрим подробнее причины возникновения подобных проблем и способы их устранения в редакторе Word.
Немного теории
В редакторе Word предусмотрены несколько стандартов кодировки текста, который Вы набираете или просматриваете. В принципе построения текстовых кодов лежит соответствие каждому символу определенное числовое значение и для разных стандартов оно может не совпадать.
Например, в кодировке «кириллица» символу Й соответствует числовое значение 201, а в стандарте «западная Европа» этим значением определяется символ Е. Отсюда и пропадание символов или непонятный набор знаков при просмотре текста в кодировке, отличной от той, в которой был создан документ.
Наиболее универсальным стандартом, который широко применяется в редакторе Word, является «Юникод». Он имеет наиболее широкий набор символов, которые есть в большинстве языков, употребляемых при работе на компьютере. Это и объясняет его широкое применение не только в редакторе Word, но и других текстовых редакторах. В Word данный стандарт кодировки принят по умолчанию и при загрузке, сохранении файлов применяется автоматически.
Перекодировка текста
К сожалению, в разных версиях Word необходимые действия для изменения кодировки различны, хотя и ведут к одинаковому результату. Рассмотрим подробнее необходимые шаги для разных версий в отдельности:
Word 2003
Для того, что бы сменить кодировку, зайдите в меню и выберите СЕРВИС, а затем ПАРАМЕТРЫ. После этого в разделе ЗАКЛАДКА –Общие подтверждаем преобразование при открытии. Теперь при каждом следующем открытии текстового файла, будет предоставлена возможность выбора системы кодирования;
Word 2010, 2007
Эти версии в плане изменения шрифтов ничем не отличаются. В главном меню через ФАЙЛ заходим в ПАРАМЕТРЫ. В новом, выпадающем, окне выбираем раздел ДОПОЛНИТЕЛЬНО и в самом низу окна у Вас будет возможность «разметить документ так, будто он создан … ». Вам будут представлена возможность и создавать, и читать документы в нужном формате.
Создание текста с нужной кодировкой
Иногда возникает необходимость создания текстового файла в другой системе кодов. Например, для графического редактора PDF программы Works-6 или других программных продуктов. Редактор Word поможет Вам решить эту проблему. Нужно набрать текст так, как делаете обычно, соблюдая необходимую структуру и требования к набираемой информации.
После создания файла, в главном меню редактора заходим в ФАЙЛ, а далее выбираем СОХРАНИТЬ КАК.
В выпадающем окне, кроме возможности определить будущее название файла, будут представлены варианты кодировки файла после сохранения.
Для предотвращения потери информации рекомендовано сохранить файл в обычном формате, а уже потом записать в требуемом.
Нужно учитывать, что существуют программы, которые не поддерживают переноса слов или строк текста. Поэтому, в данном случае, необходимо писать текст, избегая таких переносов.
Еще одна особенность при возникновении трудностей читаемости текста. Это небольшое отличие 2003 версии Worda от версий более поздних. Появился новый формат текстовых файлов – docx. Его отличие не носит вопрос кодировки, в том смысле, в котором мы его сейчас рассматриваем. И информацию такого рода на старой версии не просмотреть, необходимо обновление редактора.
Как поменять кодировку в Word
Когда человек работает с программой «MS Word», у него редко возникает потребность вникать в нюансы кодировки. Но как только появляется необходимость поделиться документом с коллегами, существует вероятность того, что отправленный пользователем файл может просто-напросто не быть прочитан получателем. Это случается из-за несовпадения настроек, а конкретно кодировок в разных версиях программы.
Как поменять кодировку в Word
Что представляет собой кодировка и от чего она зависит?
Для каждого региона кодировка может в значительной степени разниться. Для понимания кодировки необходимо знать то, что информация в текстовом документе сохраняется в виде некоторых числовых значений. Персональный компьютер самостоятельно преобразует числа в текст, используя при этом алгоритм отдельно взятой кодировки. Для стран СНГ используется кодировка файлов с названием «Кириллица», а для других регионов, таких как Западная Европа, применяется «Западноевропейская (Windows)». Если текстовый документ был сохранен в кодировке кириллицы, а открыт с использованием западноевропейского формата, то символы будут отображаться совершенно неправильно, представляя собой бессмысленный набор знаков.

При открытии документа, сохраненного одним типом кодировки, в другом формате кодировки невозможно будет прочитать
Во избежание недоразумений и облегчения работы разработчики внедрили специальную единую кодировку для всех алфавитов – «Юникод». Этот общепринятый стандарт кодировки содержит в себе практически все знаки большинства письменных языков нашей планеты. К тому же он преобладает в интернете, где так необходима подобная унификация для охвата большего количества пользователей и удовлетворения их потребностей.

Тип кодировок, которые используются, как стандартные для всех языков
«Word 2013» работает как раз на основе Юникода, что позволяет обмениваться текстовыми файлами без применения сторонних программ и исправления кодировок в настройках. Но нередко пользователи сталкиваются с ситуацией, когда при открытии вроде бы простого файла вместо текста отображаются только знаки. В таком случае программа «Word» неправильно определила существующую первоначальную кодировку текста.
Справка! Некоторые кодировки применяются к определенным языкам. Для японского языка специально была разработана кодировка «Shift JIS», для корейского – «EUC-KR», а для китайского «ISO-2022» и «EUC».
Изменение кодировки текста в «Word 2013»
Первый способ изменения кодировки в «Word»
Для исправления текстового документа, которому была неправильно определена изначальная кодировка, необходимо:
Шаг 1. Запустить текстовый документ и открыть вкладку «Файл».
Открываем вкладку «Файл»
Шаг 2. Перейти в меню настроек «Параметры».
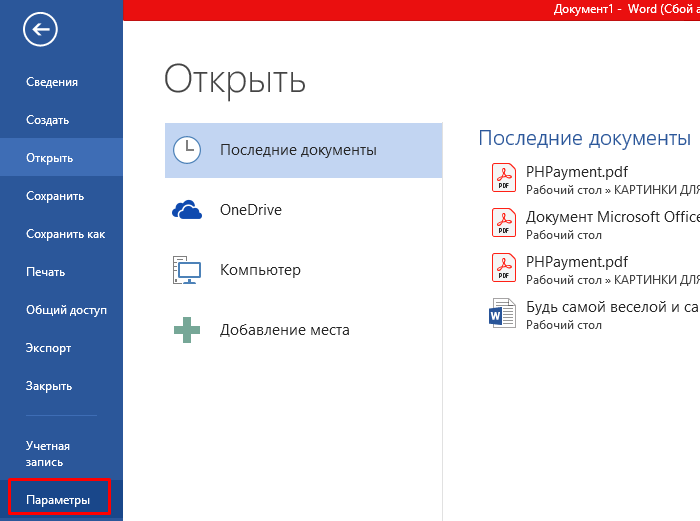
Переходим в меню настроек «Параметры»
Шаг 3. Выбрать пункт «Дополнительно» и перейти к разделу «Общие».
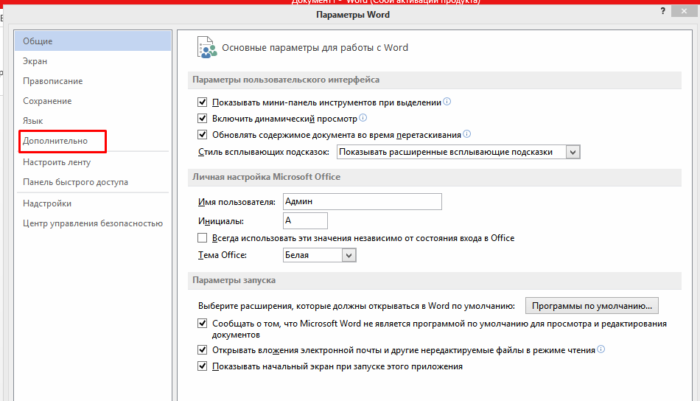
Выбираем пункт «Дополнительно»
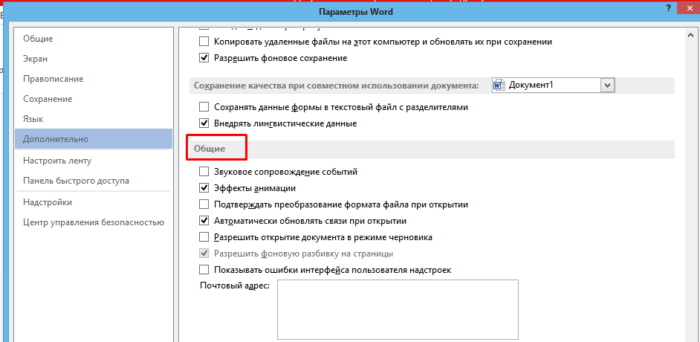
Прокрутив список вниз, переходим к разделу «Общие»
Шаг 4. Активируем нажатием по соответствующей области настройку в графе «Подтверждать преобразование формата файла при открытии».
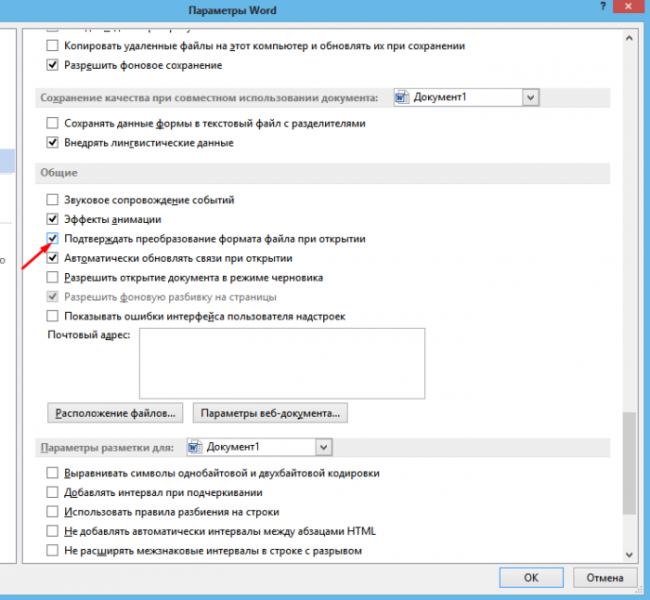
Отмечаем галочкой графу «Подтверждать преобразование формата файла при открытии», нажимаем «ОК»
Шаг 5. Сохраняем изменения и закрываем текстовый документ.
Шаг 6. Повторно запускаем необходимый файл. Перед пользователем появится окно «Преобразование файла», в котором необходимо выбрать пункт «Кодированный текст», и сохранить изменения нажатием «ОК».
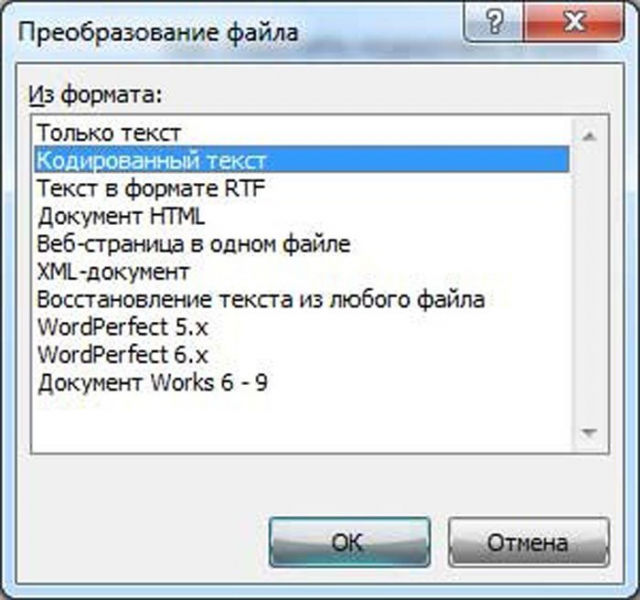
Выбираем пункт «Кодированный текст», сохраняем изменения нажатием «ОК»
Шаг 7. Всплывет еще одна область, в которой необходимо выбрать пункт кодировки «Другая» и выбрать в списке подходящую. Поле «Образец» поможет пользователю подобрать необходимую кодировку, отображаемую изменения в тексте. После выбора подходящей сохраняем изменения кнопкой «ОК».
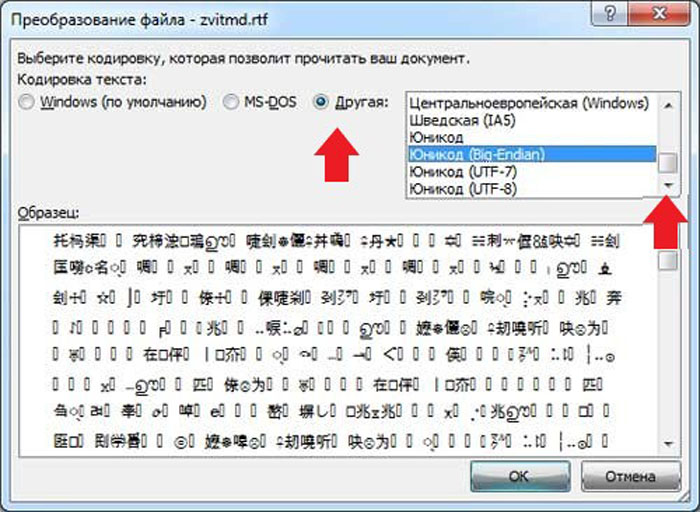
Отмечаем пункт кодировки «Другая», выбираем в списке подходящую, нажимаем «ОК»
Второй способ изменения кодировки в «Word»
- Производим запуск файла, кодировку текста которого необходимо произвести.
- Переходим во вкладку «Файл».
Открываем вкладку «Файл»
- Кликаем «Сохранить как».

Кликаем «Сохранить как»
- В области «Тип файла» необходимо выбрать «Обычный текст» и нажать «Сохранить».
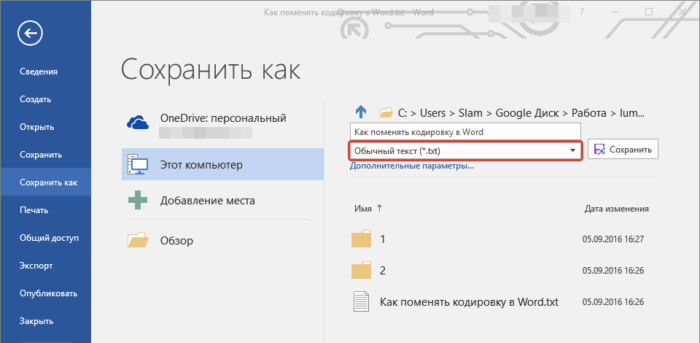
В области «Тип файла» выбираем «Обычный текст», нажимаем «Сохранить»
- В появившемся «Преобразование файла» выбираем кодировку «Другая» и в списке активируем нужную.
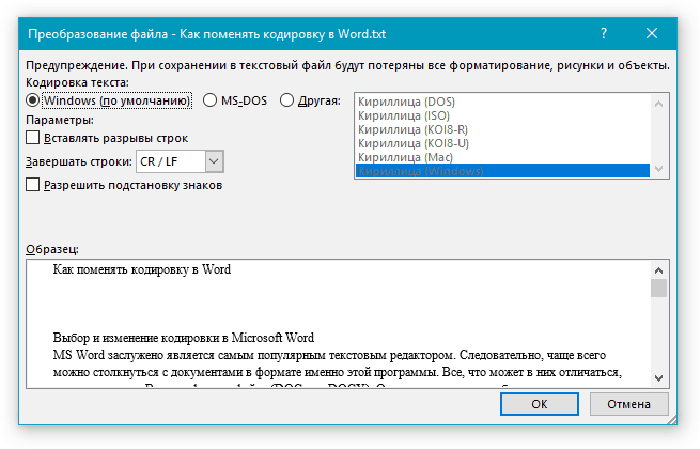
Отмечаем опцию «Другая», в списке активируем нужную, нажимаем «ОК»
Читайте полезную информацию, как работать в ворде
для чайников, в новой статье на нашем портале.

Изменение кодировки в программе «Notepad ++»
Подобное приложение используется многими программистами для создания сайтов, различных приложений и многого другого. Поэтому очень важно сохранять и создавать файлы, используя необходимую кодировку. Для того, чтобы настроить нужный вариант для пользователя, следует:
Шаг 1. Запустить программу и в верхнем контекстном меню выбрать вкладку «Кодировки».
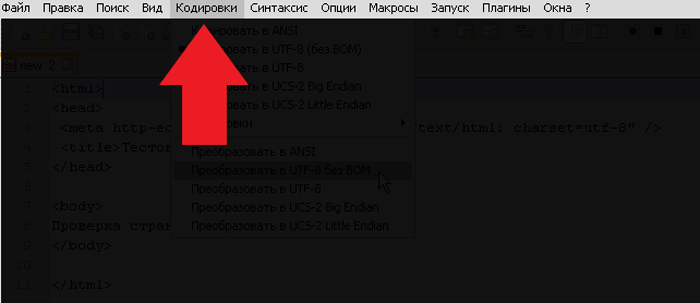
Выбираем вкладку «Кодировки»
Шаг 2. В выпадающем списке пользователю требуется выбрать из списка необходимую для него кодировку и щелкнуть на нее.
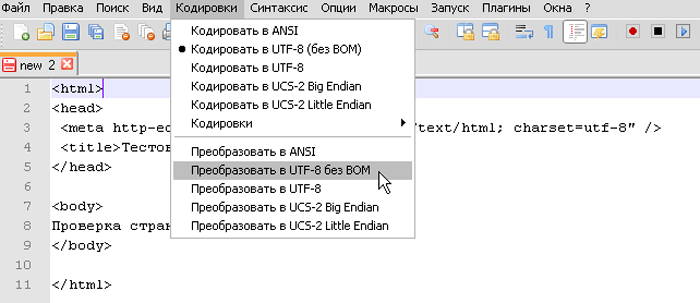
Выбираем из списка необходимую кодировку, щелкаем на ней
Шаг 3. Правильность проведения процедуры легко проверить, обратив внимание на нижнюю панель программы, которая будет отображать только что измененную кодировку.
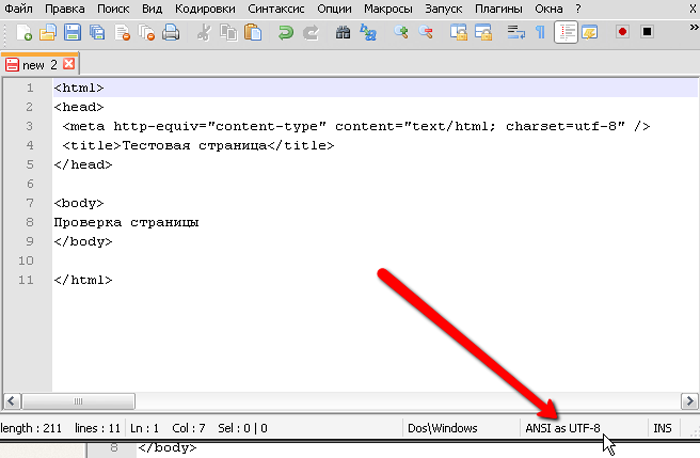
В нижней панели программы можно увидеть измененную кодировку
Важно! Перед началом работы в «Notepad ++» в первую очередь рекомендуется проверить установленную кодировку. При необходимости ее нужно изменить при помощи инструкции, приведенной ранее.
Корректировка кодировки веб-страниц
Кодировка символов – неотъемлемая часть работы браузеров для серфинга в интернете. Поэтому каждому из пользователей просто необходимо уметь ее настраивать. Чтобы быстро изменить кодировку «Google Chrome», необходимо будет установить дополнительное расширение, так как разработчики убрали возможность изменения данного параметра.
Для того, чтобы сменить кодировку на необходимую, нужно:
- Запустить браузер.
- Перейти по ссылке chrome://extensions/.
В адресную строку вводим указанный адрес, нажимаем «Enter»
- Затем кликнуть в левом верхнем углу по опции «Расширения».
Нажимаем по опции «Расширения» в левом верхнем углу страницы
- Внизу найти и открыть интернет-магазин браузера Хром.
В левом нижнем углу щелкаем по ссылке «Открыть Интернет-магазин Chrome»
- В поиске найти расширение и установить «Set Character Encoding», нажать «Enter».
В поле для поиска вводим Set Character Encodin, нажимаем «Enter»
- Рядом с приложением нажать «Установить».
Нажимаем по кнопке «Установить»
- Для того, чтобы с легкостью поменять значение кодировки, необходимо убедится в работоспособности расширения, после чего на любом сайте на пустой области правой кнопкой мыши вызвать контекстное меню. В нем следует перейти в «Set Character Encoding» и выбрать необходимое значение.
На пустой области нажимаем правой кнопкой мышки, левой кнопкой по пункту «Set Character Encoding», выбираем необходимое значение
Как поменять кодировку в «Mozilla Firefox»
Для этого пользователю потребуется:
Шаг 1. Запустить браузер и открыть меню, нажав по иконке трех линий левой клавишей мыши в правом верхнем углу страницы.
Нажимаем по иконке из трех линий в правом верхнем углу
Шаг 2. В контекстном меню запустить «Настройки».
Открываем «Настройки»
Шаг 3. Перейти во вкладку «Содержимое».
Переходим во вкладку «Содержимое»
Шаг 4. В разделе «Шрифты и цвета» нажать на блок «Дополнительные».
В разделе «Шрифты и цвета» нажимаем по блоку «Дополнительно»
Шаг 5. Перед пользователем отобразится специальная панель, на которой будет указана использующаяся кодировка. Для ее изменения потребуется нажать на название кодировки и выбрать нужную.
Нажимаем на название кодировки
Выбираем подходящую кодировку, нажимаем «ОК»
Установка кодировки в интерфейсе Блокнота
Тем юзерам, кому необходимо пользоваться стандартным приложением «Блокнот»

, будет полезно знать о том, что изменить кодировку можно следующим образом:
- Открыть текстовый документ и повторно сохранить его, нажав «Файл» и затем «Сохранить как».
Нажимаем по вкладке «Файл», затем по опции «Сохранить как»
- В появившемся окне помимо директории следует выбрать и кодировку, найдя необходимый формат, нажать «Сохранить».
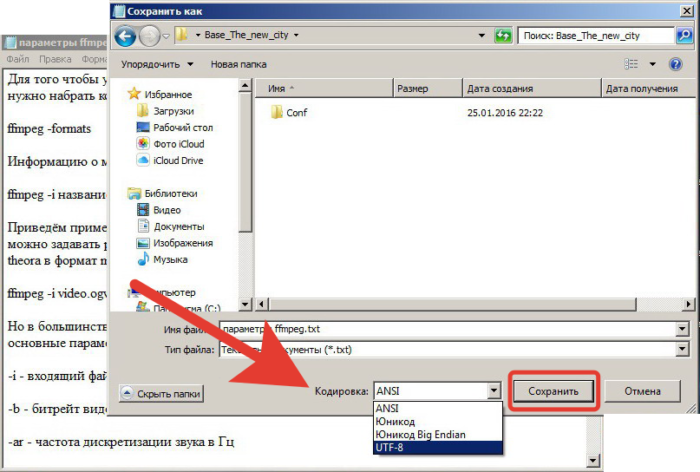
В параметре «Кодировка» выбираем подходящий формат, нажимаем «Сохранить»
После этого без труда можно открывать необходимый текст в нужной кодировке.
Благодаря правильно подобранной и установленной кодировке пользователь может избежать неприятностей при отправке файла другим юзерам. Все, что для этого требуется, – это выставлять перед началом работы необходимое значение.
Видео — Как изменить кодировку в Word
как преобразовать текст в числа
В области обработки естественных языков мы хотим создавать компьютерные программы, которые понимают, генерируют и, в более общем смысле, работают с человеческими языками. Звучит здорово! Но возникает проблема: мы, люди, общаемся словами и предложениями; Между тем, компьютеры понимают только цифры.
По этой причине мы должны отобразить эти слова (иногда даже предложения) на векторы: просто набор чисел. Это называется векторизация текста , и вы можете прочитать больше в этом руководстве для начинающих.Но подождите, не празднуйте так быстро, это не так просто, как присвоение номера каждому слову, гораздо лучше, если этот вектор чисел представляет слова и предоставленную информацию.
Что значит представлять слово? И что более важно, как мы это делаем? Если вы задаете себе эти вопросы, то я рад, что вы читаете этот пост.
Вложения Word против одного горячего кодировщика
Самый простой способ кодировать слово (или почти что-либо в этом мире) называется однократным кодированием: вы предполагаете, что будете кодировать слово из предопределенного набора из и из конечного набора возможных слов.В машинном обучении это обычно определяется как все слова, которые появляются в ваших данных обучения. Вы подсчитываете, сколько слов в словаре, скажем, 1500, и устанавливаете для них порядок от 0 до этого размера (в данном случае 1500). Затем вы определяете вектор i-го слова как все нули, кроме 1 в позиции i .
Представьте, что весь наш словарь состоит из 3 слов: Обезьяна, Обезьяна и Банан. Вектор для Обезьяны будет [1, 0, 0]. Один для Ape [0, 1, 0].И да, вы правильно догадались: тот, что для Банана [0, 0, 1].
Так просто, и все же это работает! Алгоритмы машинного обучения настолько мощны, что могут генерировать множество потрясающих результатов и приложений.
Однако представьте, что мы пытаемся понять, что ест животное, анализируя текст в Интернете, и мы обнаруживаем, что «обезьяны едят бананы». Наш алгоритм должен понимать, что информация в этом предложении очень похожа на информацию «обезьяны потребляют фрукты».Наша интуиция говорит нам, что они в основном одинаковы. Но если вы сравните векторы, которые один горячий кодер генерирует из этих предложений, единственное, что вы обнаружите, — это то, что между обеими фразами нет совпадения слов. В результате наша программа будет понимать их как две совершенно разные части информации! У нас, как у людей, никогда не было бы этой проблемы.
Даже когда мы не знаем слова, мы можем догадаться, что это значит, зная контекст , где оно используется.В частности, мы знаем, что значение слова аналогично значению другого слова, если мы можем их поменять, что называется гипотезой распределения.
Например, представьте, что вы читаете, что «Pouteria широко распространен во всех тропических регионах мира, и обезьяны едят свои плоды». Возможно, вы не знали, что такое Путерия, но держу пари, вы уже поняли, что это дерево.
Гипотеза о распределении является основой того, как создаются векторы слов, и мы владеем по крайней мере частью этого Джона Руперта Ферта, и, эй, это не будет правильным постом для встраивания слов, если мы не процитируем его:
слово характеризует компания, которую он держит — Джон Руперт Ферт
В идеале нам нужны векторные представления, в которых похожих слов заканчиваются одинаковыми векторами .Для этого мы создадим плотных векторов (где значения не только 0 и 1, но и любое десятичное число между ними). Таким образом, вместо того, чтобы иметь вектор для Monkey , равный [1, 0, 0], как раньше, у нас будет что-то вроде [0,96, 0,55… 0,32], и у него будет измерение (количество чисел), которое мы выбираем.
Более того, нам хотелось бы иметь больше похожих представлений, когда слова имеют некоторые общие свойства, например, являются ли они множественными или единственными числами, глаголами или прилагательными, или если они оба относятся к мужчине.Все эти характеристики могут быть закодированы в векторах. И это именно то, что Word2Vec показал в 2013 году и изменил поле векторизации текста.
Цели и метрики оценки
Итак, мы хотим, чтобы векторы лучше представляли слова, но что это значит? И как мы узнаем, что это хорошо?
Существует два основных способа узнать, как они работают: явные методы и неявные методы.
Явные методы
- Оценка человека: Первый метод так же прост, как взять несколько слов, измерить расстояние между векторами, сгенерированными для каждого из них, и спросить кого-то, что они думают об этом.Если они лингвисты, тем лучше. Однако это не масштабируется, отнимает много времени и требует тысяч, даже миллионов слов каждый раз, когда вы получаете новые векторы.
- Синтаксические аналогии : Как бы глупо это ни звучало, помните, что векторы слов — это векторы, поэтому мы можем их складывать и вычитать. Таким образом, мы генерируем тесты вида « едят к едят , так как запускают к __», затем мы выполняем операцию еда — есть + бег и находим наиболее похожий вектор с этим результатом.Как вы уже догадались, это должен быть тот, кто соответствует и .
- Семантические аналогии: Они почти такие же, как синтаксические, но в этом случае аналогии будут больше похожи на « обезьяна животное , как банан __», и мы ожидаем фруктов в результате. Мы можем даже сделать более сложные аналогии, как обезьяна + еда = банан .
. Подумайте немного об этом: если мы сможем добиться успеха наших векторов в такого рода тестах, это означает, что они фиксируют форму и значение слов.Как будто они понимают слова .
Неявные методы
Но эй, как бы это ни было захватывающе и замечательно, кажется маловероятным, что наличие векторов слов является реальным решением реальной проблемы. Это всего лишь инструмент для создания всех интересных и действительно полезных вещей, которые мы можем сделать с помощью НЛП.
Итак, неявные методы так же просты, как использование векторов слов в некоторой задаче НЛП, и измеряют их влияние. Если они заставляют ваш алгоритм работать лучше, они хороши!
Если вы работаете, например, в классификаторе анализа настроений, неявный метод оценки будет состоять в том, чтобы обучить тот же набор данных, но изменить кодирование в одно касание, использовать вместо этого векторы встраивания слов и измерить повышение вашей точности.Если ваш алгоритм дает лучшие результаты, то эти векторы хороши для вашей проблемы. Кроме того, вы можете тренировать или получать новый набор векторов и снова тренироваться с ними, и сравнивать, какой из них дает лучшие результаты, а это означает, что они даже лучше в этом случае.
Как вы можете себе представить, это может быть очень и очень дорого, потому что требует большого количества экспериментов и тестирования того, что работает лучше. Таким образом, это не только означает создание различных наборов векторов, но также тренирует ваш алгоритм с каждым из них (возможно, много раз, так как вы хотите настроить гиперпараметры так, чтобы они были справедливыми в сравнении).Это означает много времени и вычислительных ресурсов.
Просто обезьяна ест банан, что еще ты хочешь?Как создаются векторы слов?
Ну, мы знаем, что такое векторы слов, мы знаем, почему мы хотим их, и мы знаем, как они должны быть. Но как мы их получим?
Как мы уже говорили, основная идея состоит в том, чтобы обучать большому количеству текста и фиксировать взаимозаменяемость слов и частоту их совместного использования. Вам интересно, сколько стоит «много текста»? Ну, это обычно порядка миллиардов слов .
Существует три больших семейства векторов слов, и мы кратко опишем каждый из них.
Статистические методы
Статистические методы работают путем создания матрицы совпадений. То есть: они устанавливают размер окна N (обычно это от 2 до 10). Затем они просматривают весь текст и подсчитывают, сколько раз каждая пара из двух слов находится вместе, что означает, что они разделены числом N слов.
Скажем для примера, что весь наш тренировочный набор состоит всего из двух текстов: «Я люблю обезьян» и «Обезьяны и обезьяны любят бананы», и мы установили размер нашего окна N = 2.Наша матрица будет:
| Матрица совместного появления | I | любовь | обезьяны | и | обезьян | бананов |
| I | 0 | 1 | 1 | 0 | 0 | 0 |
| любовь | 1 | 0 | 2 | 1 | 0 | 1 |
| обезьяны | 1 | 2 | 0 | 1 | 1 | 1 |
| и | 0 | 1 | 1 | 0 | 1 | 0 |
| обезьян | 0 | 0 | 1 | 1 | 0 | 0 |
| бананов | 0 | 1 | 1 | 0 | 0 | 0 |
Затем вы применяете некоторый метод для уменьшения размерности матрицы, такой как Разложение по сингулярному значению и вуаля , каждая строка вашей матрицы представляет собой слово вектор.Если вам интересно, что такое уменьшение размерности: если в матрице избыточные данные, вы можете сгенерировать меньшую с почти такой же информацией. Существует множество алгоритмов и способов сделать это, обычно все они связаны с поиском собственных векторов.
Однако все не так просто, как сказал бы Заза Пачулия, и нам еще предстоит решить некоторые проблемы:
- Число совпадений само по себе не является хорошим числом для измерения вероятности совпадения двух слов, поскольку оно не учитывает, сколько раз встречается каждое из них.
Представьте себе слова «the» и «monkey», их совместное вхождение в текстах будет очень большим, но это главным образом потому, что вхождение «the» огромно (мы его часто используем).
Чтобы решить эту проблему, мы обычно вызываем PMI (точечная взаимная информация) и оцениваем вероятности по совпадениям. Подумайте так: p («the») настолько велико, что знаменатель будет намного больше числителя, поэтому число будет близко к log (0) = отрицательное число.
Подумайте так: p («the») настолько велико, что знаменатель будет намного больше числителя, поэтому число будет близко к log (0) = отрицательное число.
С другой стороны, p («обезьяна») и p («банан») не будут даже ближе к p («the»), потому что мы не используем их так часто, поэтому их будет не так много. вхождения в текстах.Кроме того, мы найдем много текстов, где они появляются вместе. Другими словами: вероятность совпадения будет высокой, что делает PMI для «обезьян» и «бананов» также большим числом.
Наконец, когда два слова встречаются очень мало, результатом будет лог около 0: очень низкое отрицательное число.
- Этот метод PMI приводит ко многим записям log (0) (т.е. −∞) (каждый раз, когда два слова не встречаются). Кроме того, матрица плотная, в ней не так много нулей, что плохо с точки зрения вычислений, и помните, что мы говорим о матрице HUGE .
То, что иногда делается, — это использование положительного PMI, просто max (PMI, 0), вместо этого, чтобы решить обе проблемы. Интуиция позади PPMI состоит в том, что слова с отрицательным PMI встречаются «меньше, чем ожидалось», что является не очень ценной информацией и может быть просто вызвано недостаточным количеством текста. - Время вычисления для подсчета всего этого очень дорого, особенно если это сделано наивно. К счастью, есть способы сделать это, требуя всего один проход через весь корпус для сбора статистики.
Прогнозные методы
Предиктивные методы работают, обучая алгоритм машинного обучения делать предсказания на основе слов и их контекстов. Затем они используют некоторые весовые коэффициенты, которые алгоритм изучает для представления каждого слова. Их иногда называют нейронными методами, потому что они обычно используют нейронные сети.
На самом деле, использование нейронных сетей для создания встраивания слов не ново: идея была представлена в этой статье 1986 года. Однако, как и в любой области, связанной с глубоким обучением и нейронными сетями, вычислительная мощь и новые методы сделали их намного лучше в последние годы.
Первые подходы обычно делались с использованием нейронных сетей и обучали их предсказывать следующее слово в тексте, учитывая предыдущие N слов. Здесь важно то, что нейронная сеть обучена, чтобы лучше выполнять эту задачу, но вы на самом деле не заботитесь об этом результате: все, что вам обычно нужно, это вес матрицы, которая представляет слова.
Одним из ярких примеров такого подхода является статья, опубликованная Bengio et. и др. в 2003 году, очень важный документ в этой области, где они используют нейронную сеть с одним скрытым слоем, чтобы сделать это.
И затем, прорыв, работа, которая помещает вложения слов в крутой статус , который вы, вероятно, ожидали: Word2vec.
Миколов и соавт. сосредоточены на производительности: они удалили скрытые слои нейронной сети, чтобы заставить их тренироваться намного быстрее. Это может звучать как потеря «способности к обучению», и на самом деле — это , но тот факт, что вы можете тренироваться с огромным количеством данных, даже сотнями миллиардов слов, не только компенсирует это, но и доказал, что производить лучше результатов.
Кроме того, они представили два варианта обучения и множество оптимизаций, которые применимы к ним обоим. Давайте внимательнее посмотрим на каждый:
непрерывный пакет слов (CBOW)
Основная идея здесь состоит в том, чтобы установить скользящее окно размера N, в данном случае, скажем, N равно 2. Затем вы берете огромное количество текста и обучаете нейронную сеть, чтобы предсказать слово, вводящее N слов на каждой стороне.
Представьте, что у вас есть текст «Обезьяна ест банан», вы попытаетесь предсказать, что слово — это , учитывая, что два предыдущих слова — , обезьяна и — , а следующие два — , которые едят и а .Кроме того, вы научитесь предсказывать , съев , зная, что четыре окружающих слова — , обезьяна — , — это , — и — банан . И продолжай со всем текстом.
И помните, нейронная сеть очень мала, давайте рассмотрим ее шаг за шагом:
 В CBOW мы пытаемся предсказать слово «еда» с учетом закодированных векторов в одном контексте. В скип-граммах мы пытаемся предсказать контекст, учитывая слово «еда»
В CBOW мы пытаемся предсказать слово «еда» с учетом закодированных векторов в одном контексте. В скип-граммах мы пытаемся предсказать контекст, учитывая слово «еда»- Имеет входной слой, который принимает четыре закодированных слова в горячем виде, которые имеют размерность V (размер словаря).
- Это усредняет их, создавая один входной вектор.
- Этот входной вектор умножается на матрицу весов W (которая имеет размер VxD, причем D не меньше, чем размерность векторов, которые вы хотите создать). Это дает вам в результате D-мерный вектор.
- Затем вектор умножается на другую матрицу размером DxV. Результатом будет новый V-мерный вектор.
- Этот V-мерный вектор нормализован, чтобы сделать все записи числом от 0 до 1, и что все они суммируют 1, используя функцию softmax, и это вывод.В i-й позиции он имеет прогнозируемую вероятность того, что i-е слово в словаре будет тем, которое находится посередине для данного контекста.
Вот и все. О, вы задаетесь вопросом, где находятся векторы слов? Ну, они в этой матрице весов Вт. Помните, мы сказали, что его размер равен VxD, поэтому строка i — это D-мерный вектор, представляющий слово i в словаре.
Фактически, подумайте, что если бы вы использовали только одно слово в качестве контекста, ваш входной вектор был бы представлением этого слова в горячем кодированном виде, и умножение его на W было бы подобно выбору соответствующего вектора слова: все имеет смысл, право?
Skipgram — это то же самое, что и CBOW, но с одним большим отличием: вместо того, чтобы предсказывать слово в середине, учитывая все остальные, вы тренируетесь, чтобы предсказать все остальные, учитывая одно в середине.
Да, зная только одно слово, он пытается предсказать четыре. Я давно знаком с word2vec, и эта идея все еще поражает меня. Это кажется абсурдным, но, эй, это работает! И это на самом деле работает немного лучше, чем CBOW.
Помимо алгоритмов, word2vec предложил много оптимизаций для них, таких как:
- Придайте больший вес более близким словам в окне.
- Удалить редкие слова (которые появляются только несколько раз) из текстов.
- Рассматривать общие пары слов, например «Нью-Йорк», как одно слово.
- Отрицательная выборка: это методика, позволяющая сократить время тренировки. Когда вы тренируетесь с одним словом и его контекстом, вы обычно обновляете все веса в нейронной сети (помните, что их много!). При отрицательной выборке вы просто обновляете веса, которые соответствуют фактическому слову, которое должно было быть предсказано, и некоторым другим случайно выбранным словам (предлагается выбрать от 2 до 20 слов), оставляя большинство из них такими, какие они были. Если вы хотите понять, больше о негативной выборке, я рекомендую вам прочитать этот хороший пост об этом.Отрицательная выборка настолько важна, что вы часто будете видеть алгоритм, называемый SGNS (Skip-Gram with Negative Sampling)
Комбинированные методы
Как обычно, когда два метода дают хорошие результаты, вы можете достичь еще лучших результатов, комбинируя их. В этом случае это означает обучение модели машинного обучения и получение векторов слов по ее весам, но вместо использования скользящего окна для получения контекстов, обучайтесь с использованием матрицы совместного использования.
Наиболее важным из этих комбинированных методов является GloVe.Они создали алгоритм, состоящий из очень простого алгоритма машинного обучения (регрессии взвешенных наименьших квадратов), который обучается создавать векторы, которые удовлетворяют: если вы возьмете вектор из двух слов i и j и умножите их, результат будет аналогичен логарифму записи ij в матрице совместного использования, то есть количеству совпадений для этих двух слов.
Они также делают некоторые оптимизации, такие как добавление некоторого веса, чтобы предотвратить редкие совместные события, чтобы внести шум, и очень распространенные из-за чрезмерного искажения цели.
Они делают явные и неявные методы тестирования (помните их?), Чтобы получить действительно хорошие результаты.
5 мифов, которым не следует верить
Я надеюсь, что к этому времени вы знаете, что такое векторы слов, как узнать, хорош ли какой-то набор векторов, и хотя бы иметь представление о том, как они создаются.
Но, как обычно случается, когда что-то приобретает крутой статус , есть несколько распространенных идей, которые я хотел бы пояснить, которые не соответствуют действительности:
1- Word2vec — лучший алгоритм векторного слова
Это не так во многих смыслах.В самом простом смысле: word2vec — это не алгоритм, это группа связанных моделей, тестов и кода. Как мы объясняли ранее, они представили два разных алгоритма в word2vec: Skip-gram и CBOW.
Кроме того, когда он был впервые опубликован, результаты, которые он получил, были определенно лучше, чем современные. Но важно отметить, что они представили, помимо алгоритмов, много оптимизаций, которые были переведены в статистические методы, улучшающие их результаты до сопоставимого (иногда даже лучшего) уровня.Эта замечательная статья объясняет, что это за оптимизации и как они использовались для улучшения статистических методов.
2- Векторы слов создаются путем глубокого обучения
Это просто не соответствует действительности. Как вы знаете, если вы вдумчиво прочитали этот пост, некоторые векторы создаются статистическими методами, и там нет даже нейронной сети, не говоря уже о глубокой нейронной сети.
И, на самом деле, одним из наиболее важных изменений в методах прогнозирования, введенных в word2vec, было удаление скрытых слоев нейронных сетей, поэтому было бы неправильно называть эту нейронную сеть «глубокой».
3- Векторные слова используются только при глубоком обучении
Векторы слов отлично подходят для использования в качестве моделей глубокого обучения, но это не исключение. Они также отлично подходят для поддержки SVM, MNB или почти любой другой модели машинного обучения, о которой вы только можете подумать.
4- Статистические и прогностические методы не имеют ничего общего друг с другом
Они были созданы отдельно как разные подходы к проблеме создания векторов, но их можно комбинировать, как мы видели в GloVe, и некоторые методы могут быть применены к обоим из них.
Фактически было доказано, что Skip-Gram с отрицательной выборкой неявно факторизует матрицу PMI, смещенную на глобальную константу. Очень важный результат, потому что он связывает два мира статистических и прогностических методов.
5- Существует идеальный набор векторов слов, которые можно использовать в каждом проекте НЛП
Вы дошли до последней части этого поста, поэтому я предполагаю, что вы уже знаете это: векторы слов зависят от контекста, они создаются с учетом текста.
Итак, если вы тренировали свои векторы с английскими новостями, вектор футбольный будет похож, скажем, на гол, нападающий, полузащитник, вратарь и Mess i. С другой стороны, если вы обучили свои векторы американским новостям, футбольный вектор будет похож на приземление, защитник, защитник и Брейди .
Это характеристика, которую необходимо учитывать, особенно при работе в определенных проблемах домена.
Сказав это, одно из самых значительных воздействий векторов слов состоит в том, что они действительно и хороши, когда используются в трансферном обучении: область использования полученных знаний для решения одной задачи для решения другой. Более того, очень необычно обучать ваши векторы с нуля при запуске проекта, в большинстве случаев вы начинаете с набора уже созданных векторов и обучаете их своим конкретным текстам.Заключение
Вложения слов не новы, но прогресс, достигнутый в этой области за последние годы, подтолкнул их к уровню техники НЛП.Не только вычислительная мощность позволила обучать их намного быстрее и обрабатывать огромные объемы текста, но также было создано много новых алгоритмов и оптимизаций.
В этом посте мы представили основы того, как работает большинство этих алгоритмов, но есть много других хитростей и настроек, которые нужно обнаружить. Кроме того, есть новые тенденции, такие как вложения на уровне подслов, реализованные в библиотеке FastText (я говорю вам, нам нравится FastText здесь, в MonkeyLearn, это , так быстро !), Другие библиотеки, такие как StarSpace, и многие другие интересные вещи.
Вложения в слова — это весело, их не так сложно понять, и они очень полезны в большинстве задач НЛП, поэтому я надеюсь, что вам понравилось узнавать о них!
Подпишитесь на нашу рассылку
Получите отличные посты и учебники по машинному обучению!
,- Товары
- Клиенты
- Случаи использования
- Переполнение стека Публичные вопросы и ответы
- Команды Частные вопросы и ответы для вашей команды
- предприятие Частные вопросы и ответы для вашего предприятия
- работы Программирование и связанные с ним технические возможности карьерного роста
- Талант Нанимать технический талант
- реклама Связаться с разработчиками по всему миру
Загрузка…
Введение в встраивание Word и Word2Vec | Dhruvil Karani
Встраивание слов — одно из самых популярных представлений словарного запаса документов. Он способен фиксировать контекст слова в документе, семантическое и синтаксическое сходство, связь с другими словами и т. Д.
Что такое встраивание слов? Грубо говоря, они являются векторными представлениями конкретного слова. Сказав это, что следует, как мы их генерируем? Что еще более важно, как они захватывают контекст?
Word2Vec — один из самых популярных методов изучения встраивания слов с использованием мелкой нейронной сети.Он был разработан Томасом Миколовым в 2013 году в Google.
Давайте займемся этой частью по частям.
Зачем они нам нужны?
Рассмотрим следующие похожие предложения: Хорошего дня и Хорошего дня. Они вряд ли имеют другое значение. Если мы создадим исчерпывающий словарь (назовем его V), у него будет V = {Хорошего, хорошего, хорошего дня}.
Теперь давайте создадим вектор с горячим кодированием для каждого из этих слов в V. Длина нашего вектора с горячим кодированием будет равна размеру V (= 5).У нас был бы вектор нулей, за исключением элемента в индексе, представляющего соответствующее слово в словаре. Этот конкретный элемент будет один. Кодировки ниже объяснят это лучше.
Иметь = [1,0,0,0,0] `; а = [0,1,0,0,0] `; хороший = [0,0,1,0,0] `; большой = [0,0,0,1,0] `; day = [0,0,0,0,1] `(` представляет транспонирование)
Если мы попытаемся визуализировать эти кодировки, мы можем представить 5-мерное пространство, где каждое слово занимает одно из измерений и не имеет ничего для делать с остальными (без проекции по другим измерениям).Это означает, что «хорошо» и «отлично» так же отличаются, как «день» и «иметь», что не соответствует действительности.
Наша цель состоит в том, чтобы слова со схожим контекстом занимали близкие пространственные позиции. Математически косинус угла между такими векторами должен быть близок к 1, то есть угол близок к 0.
Google ImagesЗдесь возникает идея генерации распределенных представлений . Интуитивно мы вводим зависимость одного слова от других слов. Слова в контексте этого слова получили бы большую долю этой зависимости . В одном представлении горячего кодирования все слова являются независимыми друг от друга , , как упомянуто ранее.
Как работает Word2Vec?
Word2Vec — это метод для создания такого встраивания. Его можно получить, используя два метода (оба с использованием нейронных сетей): пропустить грамм и общий пакет слов (CBOW)
CBOW модель: Этот метод принимает в качестве входных данных контекст каждого слова и пытается предсказать слово соответствует контексту.Рассмотрим наш пример: Хорошего дня.
Пусть слово для нейронной сети будет словом здорово. Обратите внимание, что здесь мы пытаемся предсказать целевое слово ( d ay ) , используя одно слово ввода контекста great. Более конкретно, мы используем одно горячее кодирование входного слова и измеряем выходную ошибку по сравнению с одним горячим кодированием целевого слова ( d ay). В процессе прогнозирования целевого слова мы изучаем векторное представление целевого слова.
Давайте посмотрим глубже на фактическую архитектуру.
CBOW МодельВходное слово или слово контекста является одним горячим закодированным вектором размера V. Скрытый слой содержит N нейронов, а выходной снова является вектор длиной V, элементами которого являются значения softmax.
Давайте получим термины на рисунке справа:
— Wvn — это матрица весов, которая отображает входные данные x на скрытый слой (V * N размерная матрица)
— W`nv — это матрица весов, которая отображает скрытые слой выводит на конечный выходной слой (N * V размерная матрица)
Я не буду вдаваться в математику.Мы просто получим представление о том, что происходит.
Нейроны скрытого слоя просто копируют взвешенную сумму входных данных на следующий слой. Там нет активации, как сигмоид, тан или ReLU. Единственная нелинейность — это расчеты softmax в выходном слое.
Но вышеупомянутая модель использовала одно контекстное слово для прогнозирования цели. Мы можем использовать несколько контекстных слов, чтобы сделать то же самое.
Google imagesВышеупомянутая модель принимает слова контекста C. Когда Wvn используется для вычисления входов скрытого слоя, мы берем среднее значение по всем этим входам слова контекста C.
Итак, мы увидели, как представления слов генерируются с использованием слов контекста. Но есть еще один способ, которым мы можем сделать то же самое. Мы можем использовать целевое слово (представление которого мы хотим сгенерировать), чтобы предсказать контекст, и в процессе мы создаем представления. Это делает другой вариант, называемый моделью Skip Gram.
Модель Skip-Gram:
Похоже, что модель CBOW с несколькими контекстами только что перевернулась. В какой-то степени это правда.
Вводим целевое слово в сеть.Модель выводит C вероятностных распределений. Что это значит?
Для каждой позиции контекста мы получаем C вероятностных распределений V вероятностей, по одному на каждое слово.
В обоих случаях сеть использует обратное распространение для обучения. Подробную математику можно найти здесь
Кто победит?
Оба имеют свои преимущества и недостатки. По словам Миколова, Skip Gram хорошо работает с небольшим количеством данных и, как оказалось, хорошо представляет редкие слова.
С другой стороны, CBOW быстрее и лучше отображает более частые слова.
Что впереди?
Приведенное выше объяснение является очень простым. Это просто дает вам общее представление о том, что такое встраивание слов и как работает Word2Vec.
Это намного больше. Например, чтобы сделать алгоритм более эффективным в вычислительном отношении, используются такие приемы, как Hierarchical Softmax и Skip-Gram Negative Sampling. Все это можно найти здесь.
Спасибо за чтение! Если у вас есть что спросить или поделиться, сделайте комментарий.Вы также можете связаться со мной на LinkedIn
.Когда я впервые начал работать с компьютерами, все было в ASCII ( Американский стандартный код для обмена информацией )
Однако сегодня, работая с сетевыми протоколами и сетевым программированием, вы столкнетесь с различными схемами кодирования данных и символов.
В этом уроке мы рассмотрим базовые схемы кодирования , используемые на компьютерах, а во второй части урока мы рассмотрим, как данные передаются по сети.
символов, целые числа, числа с плавающей запятой и т. Д.
При хранении и передаче данных вам необходимо будет представить следующие типы данных:
- знаков и цифр, например, A и 1
- Целые числа со знаком и без знака Длинные (32 бита) и Короткие (16 бит)
- с плавающей запятой одноместные и двухместные
- Boolean, т.е. True и False
Итак, как компьютер хранит букву А или цифру 1?
Как компьютер хранит номер типа 60101? или 62.0101?
Как передать букву А и т. Д. На другой компьютер по сети?
Компьютеры и кодировка символов
Чтобы сохранить текст в виде двоичных данных, необходимо указать для этого текста кодировку .
Компьютерные системымогут использовать различные схемы кодирования символов.
Пока данные остаются на компьютере, на самом деле неважно, как они кодируются.
Однако для передачи данных между системами должна быть принята стандартная схема кодирования.
В 1968 году ASCII (американский стандартный код для обмена информацией) был принят в качестве стандарта для кодирования текста для обмена данными.
ASCII
ASCII — американский стандарт, разработанный для кодирования английских символов и знаков препинания, используемый на пишущих машинках и телетайпах той эпохи (1960-е годы).
ASCII использует 8 бит, хотя фактически используются только 7 бит.
Поскольку ASCII был разработан во время работы устройств Teletype, он также содержит управляющих кода , предназначенных для управления устройством телетайпа.
В таблице ниже приведена сводная информация о распределении кода.
Таблица ASCII — Сводная таблица кодов | |
| Десятичное значение | Использование |
| 0-31 | Коды управления |
| 32-127 | печатные символы |
| 128-255 | Не используется |
ASCII Расширения
Поскольку ASCII не может кодировать символы, такие как знак фунта £ или общие символы, найденные в немецком и других европейских языках, были разработаны различные расширения.
Эти расширения сохраняли набор символов ASCII и использовали неиспользуемую часть адресного пространства и управляющие коды для дополнительных символов.
Наиболее распространенными являются windows 1252 и Latin-1 (ISO-8859).
Windows 1252 и 7-битный ASCII были наиболее широко используемыми схемами кодирования до 2008 года, когда UTF-8 стал самым распространенным.
ISO-8859-1, ISO-8859-15, Latin-1
ISO-8859 — это 8-битное кодирование символов, которое расширяет 7-битную схему кодирования ASCII и используется для кодирования большинства европейских языков.Смотрите вики для деталей.
ISO-8859-1 также известен как Latin-1, наиболее широко используемый, поскольку он может использоваться для большинства распространенных европейских языков, например, немецкого, итальянского, испанского, французского и т. Д.
Она очень похожа на схему кодирования windows-1252, но не идентична, см. Сравнение символов в Windows-1252, ISO-8859-1, ISO-8859-15
Unicode
В связи с необходимостью кодирования символов иностранного языка и других графических символов был разработан набор символов Unicode и схемы кодирования.
Наиболее распространенные схемы кодирования:
UTF-8 — наиболее часто используемая схема кодирования, используемая в современных компьютерных системах и компьютерных сетях.
Это схема кодирования с переменной шириной, разработанная для обеспечения полной обратной совместимости с с ASCII. Используется от 1 до 4 байтов. — вики
наборов символов и схем кодирования
Различие между этими двумя понятиями не всегда ясно, и термины, как правило, используются взаимозаменяемо.
Набор символов — это список символов, тогда как схема кодирования — это то, как они представлены в двоичном виде.
Это лучше всего видно с Unicode.
Схемы кодирования UTF-8, UTF-16 и UTF-32 используют набор символов Unicode, но кодируют символы по-разному.
ASCII — это набор символов и схема кодирования.
Метка заказа байта(BOM)
Метка порядка байтов (BOM) — это символ Unicode, U + FEFF , который появляется в виде магического числа в начале текстового потока и может сигнализировать о нескольких вещах программе, использующей текст: –Wiki
- Порядок байтов, или , порядковый номер , текстового потока;
- Тот факт, что кодировка потока текста является Unicode, с высоким уровнем достоверности;
- Какой кодировкой Unicode текстовый поток кодируется как.
Спецификация отличается для кодированного текста UTF-8, UTF-16 и UTF-32
Следующая таблица, взятая из Wiki, показывает это.
спецификация и текстовые редакторы
Как правило, большинство редакторов обрабатывают спецификацию правильно, и она не отображается.
Программное обеспечение Microsoft, например Блокнот, добавляет спецификацию при сохранении данных как UTF-8 и не может интерпретировать текст без спецификации , если это не чистый ASCII.
Спецификация Пример
На приведенном ниже снимке экрана показан простой текстовый файл, содержащий текст ТЕСТ , закодированный в блокноте как UTF-8:
Обратите внимание, что символы спецификации не видны.
Ниже приведен вывод простой программы на Python, которая отображает содержимое файла, содержащего символы ТЕСТ (4 символа), сохраненные как ASCII , UTF-8 , UTF-16-BE и UTF- 16-LE
Ссылка — Метка порядка байтов (BOM) в HTML
общих вопросов и ответов
В. Как узнать, какую кодировку символов использует файл?
A- Обычно нет, но некоторые текстовые редакторы, такие как notepad ++, отображают кодировку.Если вы получили файл, кодированный с использованием другой кодировки, чем ожидалось, вы можете получить ошибку при попытке прочитать его.
В. Мой файл находится в ASCII, но декодируется нормально, используя декодер UTF-8. Это почему?
A- Потому что UTF-8 обратно совместим с ASCII.
целых и чисел с плавающей запятой — большой и Little Endian
Примечание: Поскольку UTF-16 и UTF-32 используют 2-байтовые или 4-байтовые целые числа, следующее применяется к кодированию текста с использованием их
Число байтов, выделенных для целого числа или числа с плавающей запятой, зависит от системы.
ПунктTutorials описывает это для языка программирования C , и я буду использовать его для иллюстрации
Если мы берем короткое целое число 2 байта и длинное целое число 4 байта.
Поскольку они используют несколько байтов, возникает несколько вопросов:
- Какой байт представляет наиболее значимую часть числа?
- При сохранении в памяти, какой байт хранится первым
- При отправке по сети, байт которого передается первым.
Порядковый номер относится к последовательному порядку, в котором байты располагаются в большие числовые значения при хранении в памяти или при передаче по цифровым каналам связи.
Порядковый номер представляет интерес в информатике, поскольку широко используются два конфликтующих и несовместимых формата: слова могут быть представлены в формате с прямым порядком байтов или с прямым порядком байтов , в зависимости от того, упорядочены ли биты, байты или другие компоненты из старший конец (старший значащий бит) или младший конец (младший значащий бит.
В формате с прямым порядком байтов , при адресации памяти или посылке / сохранении слов байтовым способом сохраняется старший значащий байт — байт, содержащий старший значащий бит. сначала (имеет самый низкий адрес) или отправляется первым, затем следующие байты сохраняются или отправляются в порядке убывания значимости, причем младший значащий байт — тот, который содержит младший значащий бит — сохраняется последним (имеет самый высокий адрес) или отправляется последним.Wiki
На рисунке ниже показано использование python для отображения целого числа 16, представленного в виде , 4 байта, , с использованием порядка big и little-endian байтов.
Порядок сетевых байтов и Порядок системных байтов
Сетевой порядок байтов относится к тому, как организованы байты при отправке данных по сети. (TCP / IP — это обычно Big Endian ).
Это означает, что самый старший байт отправляется первым.
Системный или хост-порядок байтов относится к тому, как байты располагаются при хранении в памяти хост-системы.
ОС Windows — Little Endian .
Реф-бит и байтовый заказ видео
Связанные учебники
Пожалуйста, оцените? И используйте Комментарии, чтобы сообщить мне больше
[всего: 8 в среднем: 4,8 / 5] ,