Вытащить картинку из PDF | internet-lab.ru
- 13 августа 2018
Понадобилось вытащить картинку из PDF. Оказалось — задачка не для средних умов. Итак, действуем.
В статье приведены два способа:
- С помощью Foxit Reader
- С помощью Word 2016
С помощью Foxit Reader
Устанавливаем бесплатный Foxit Reader: Foxit Reader — бесплатный альтернативный PDF reader с полезным функционалом, функционал по вытаскиванию картинок появился недавно, возможно, потребуется свежая версия.
Открываем в нём наш PDF файл, находим требуемую картинку.
Нажимаем: Главная > Выбрать:
Кликаем левой кнопкой на картинку внутри PDF файла:
Картинка выделяется. Кликаем правой кнопкой на изображение, выбираем Копировать или Ctrl+C:
Открываем Paint. Можно быстрой командой mspaint:
В Paint нажимаем Ctrl+V или нажимаем кнопку Вставить:
Осталось сохранить файл Файл > Сохранить как > дальше разберётесь.
С помощью Word 2016
И уже когда дописал статью, вспомнил ещё один способ.
Правой кнопкой на PDF — открыть с помощью Word 2016. Это если у вас стоит Office.
Сначала Word преобразует документ, затем спросит, можно ли Редактировать. Соглашаемся, снова Word преобразует документ.
Находим картинку, кликаем правой кнопкой. Сохранить рисунок как.
Так даже проще, но когда Office не установлен, то с помощью Foxit Reader — быстрее.
Если у вас Linux, то Word также не помощник.
Теги
- soft
💰 Поддержать проект
Похожие материалы
Олег
- 20 июня 2018
- Подробнее о MXtoolbox — онлайн tool для почтовых администраторов
https://mxtoolbox.com — всем кто администрирует почтовые сервера будет полезно узнать об этом сайте.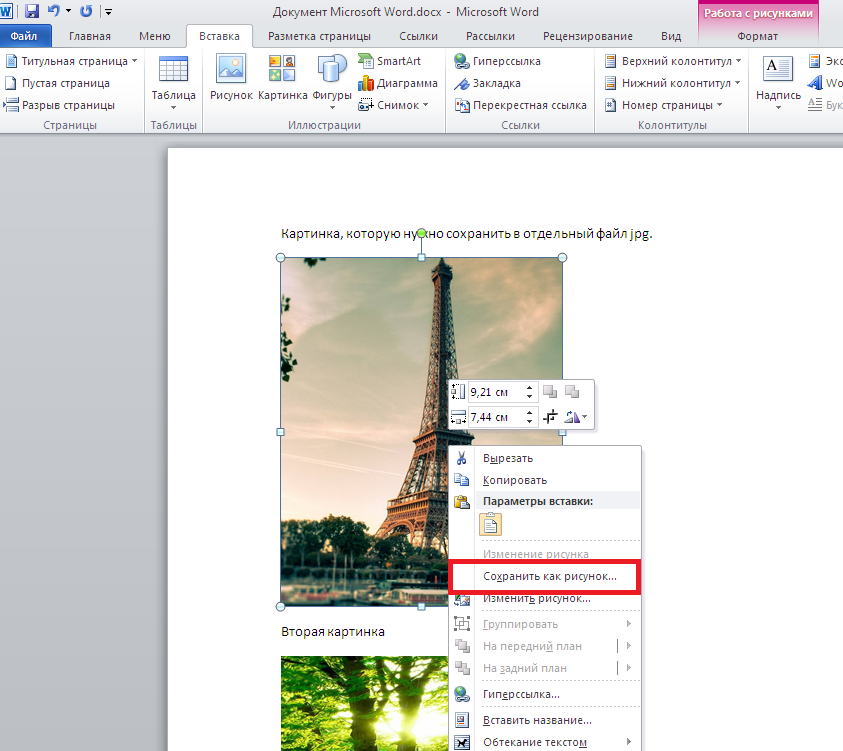 Это бесплатный онлайн инструмент для различных проверок вашего почтового сервера. Я пользовался проверкой Blacklist Check, DMARC, DKIM, SPF, MX… Примечательно, что проверять можно не только свой почтовик, но и любой другой.
Это бесплатный онлайн инструмент для различных проверок вашего почтового сервера. Я пользовался проверкой Blacklist Check, DMARC, DKIM, SPF, MX… Примечательно, что проверять можно не только свой почтовик, но и любой другой.
Теги
- soft
Олег
- 20 июня 2018
- Подробнее о Postmaster — мониторинг ваших писем в mail.ru
https://postmaster.mail.ru/ — онлайн сервис от mail.ru для мониторинга отправляемых с вашего домена писем. Для регистрации домена вам понадобится подтвердить, что вы его владелец. Подтвердить пожно с помощью html файла, meta-тега или DNS записи. Права на поддомены подтверждаются автоматически, т.е. подтверждение прав на mail.ru приводит к автоматическому подтверждению прав на поддомен e.mail.ru.
Теги
- soft
Олег
- 29 июня 2018
- Подробнее о Hiren’s BootCD PE x64 (v1.
 0.1)
0.1)
Вышла новая версия легендарного аварийного дистрибутива Hiren’s BootCD. Спустя 6 лет. Утилита мега полезная для админа. Однозначно #musthave. В основе ОС Windows 10.
Теги
- soft
Почитать
Извлечение изображений из документов Word в Python
Одна картинка стоит тысячи слов. По этой причине изображения являются неотъемлемой частью документов, особенно документов Word. Изображения используются для того, чтобы сделать контент более привлекательным и привлекательным. При анализе документов Word вы можете столкнуться со сценарием, когда вам нужно извлечь изображения. Чтобы добиться этого программно, в этой статье рассказывается, как извлекать изображения из документов Word в Python.
- Библиотека Python для извлечения изображений из документов Word
- Извлечение изображений из документов Word
Aspose.Words for Python — это мощная и многофункциональная библиотека, которая используется для создания документов Word и управления ими. Мы будем использовать эту библиотеку для извлечения изображений из файлов DOCX или DOC. Вы можете установить его в свои приложения Python из PyPI с помощью следующей команды pip.
Мы будем использовать эту библиотеку для извлечения изображений из файлов DOCX или DOC. Вы можете установить его в свои приложения Python из PyPI с помощью следующей команды pip.
pip install aspose-words
Изображения в документах Word представлены узлами формы. Следовательно, чтобы получить изображения из документа, вам придется проанализировать фигуры. Следующие шаги показывают, как извлечь изображения из документа Word в Python.
- Сначала загрузите документ Word, используя класс Document.
- Затем извлеките все фигуры в объект с помощью метода Document.getchildnodes(NodeType.SHAPE, True).
- Переберите фигуры и для каждой фигуры выполните следующие операции:
- Приведите форму к типу Shape, используя метод asshape().
- Проверьте, есть ли у формы изображение, используя метод Shape.hasimage().
- Сохраните фигуру как изображение, используя метод Shape.imagedata.save(string).
В следующем примере кода показано, как извлечь изображения из документа DOCX в Python.
import aspose.words as aw
# load the Word document
doc = aw.Document("calibre.docx")
# retrieve all shapes
shapes = doc.get_child_nodes(aw.NodeType.SHAPE, True)
imageIndex = 0
# loop through shapes
for shape in shapes :
shape = shape.as_shape()
if (shape.has_image) :
# set image file's name
imageFileName = f"Image.ExportImages.{imageIndex}_{aw.FileFormatUtil.image_type_to_extension(shape.image_data.image_type)}"
# save image
shape.image_data.save(imageFileName)
imageIndex += 1
Получите бесплатную лицензию API
Вы можете получить временную лицензию на использование Aspose.Words for Python без ограничений на пробную версию.
Вывод
Изображения обычно используются в документах Word, чтобы сделать содержимое более привлекательным. В различных случаях изображения также требуется извлекать из документов вместе с текстом. Поэтому в этой статье вы узнали, как извлекать изображения из документов Word в Python. Кроме того, вы можете изучить документацию Aspose. Words для Python. Если у вас возникнут вопросы, сообщите нам об этом через наш форум.
Words для Python. Если у вас возникнут вопросы, сообщите нам об этом через наш форум.
Смотрите также
- Создавайте документы MS Word с помощью Python
- Преобразование документа Word в HTML с помощью Python
- Преобразование документов Word в PNG, JPEG или BMP в Python
- Документы Word в Markdown с использованием Python
- Сравните два документа Word в Python
Информация: Если вам когда-нибудь понадобится получить документ Word из презентации PowerPoint, вы можете использовать конвертер Aspose Presentation to Word Document.
Как извлечь изображения из слова, используя media_extract в r?
Задавать вопрос
спросил
Изменено 11 месяцев назад
Просмотрено 201 раз
Я работаю в rmarkdown, чтобы создать отчет, который извлекает и отображает изображения, извлеченные из слова.
Для этого я использую пакет Officer. У него есть функция media_extract, которая может «извлекать файлы из объекта rdocx или rpptx».
Словом, я пытаюсь найти изображение без столбца media_path.
Параметр media_path используется в качестве аргумента в функции media_extract для поиска изображения. См. пример кода из документации пакета ниже:
example_pptx <- system.file(package = "officer", "doc_examples/example.pptx") doc <- read_pptx(example_pptx) содержимое <- pptx_summary(doc) image_row <- content[content$content_type %in% "изображение", ] media_file <- image_row$media_file png_file <- tempfile(fileext = ".png") media_extract(doc, path = media_file, target = png_file)
Путь к файлу создается с использованием либо; docx_summary или pptx_summary, в зависимости от типа файла, которые создают сводку фрейма данных файлов. pptx_summary включает столбец media_path, в котором отображается путь к файлу изображения. Фрейм данных docx_summary не включает этот столбец.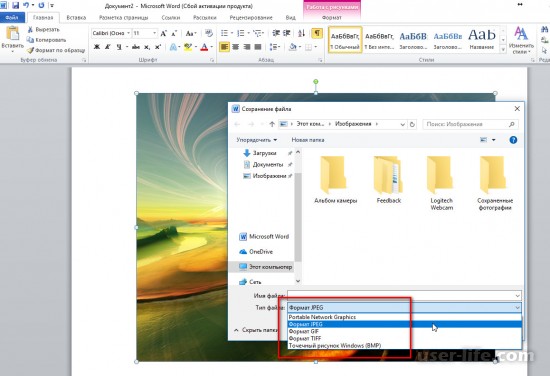 В другом сообщении stackoverflow было предложено решение для этого с использованием word/media/subdir, которое, похоже, сработало, однако я не уверен, что это значит и как его использовать?
В другом сообщении stackoverflow было предложено решение для этого с использованием word/media/subdir, которое, похоже, сработало, однако я не уверен, что это значит и как его использовать?
Как извлечь изображение из документа Word, используя word/media/subdir в качестве пути к медиафайлу?
- r
- изображение
- экстракт
- слово
- офицер
Я продолжил исследование и нашел ответ, поэтому я решил поделиться!
Трудности, с которыми я столкнулся при извлечении изображений из docx, были связаны с отсутствием столбца media_file во фрейме сводных данных (созданном с использованием docx_summary ), который используется для поиска нужного изображения. Этот столбец присутствует во фрейме данных, созданном для pptx 9.0043 pptx_summary и используется в примере кода из документации пакета.
При отсутствии этого столбца вам вместо этого нужно найти изображение, используя подкаталог документа (путь к файлу, если docx находится в формате XML), который выглядит так: media_path <- "/word/media/image3. png"
png"
Если вы хотите увидеть, как выглядит эта структура, вы можете щелкнуть правой кнопкой мыши на своем документе> 7-Zip> Извлечь файлы.. и папка, содержащая содержимое документа, будет быть создан, в противном случае просто измените номер изображения, чтобы выбрать нужное изображение. Примечание. Иногда имена изображений не соответствуют формату image.png, поэтому вам может потребоваться извлечь файлы, чтобы найти имя нужного изображения.
Пример использования media_extract с docx.
# извлечение изображения из документа Word с помощью пакета Officer
отчет <- read_docx("/Users/user.name/Documents/mydoc.docx")
png_file <- tempfile(fileext = ".png")
медиа_файл <- "/word/media/image3.png"
media_extract (отчет, путь = медиа_файл, цель = png_файл)
Искомый результат: вязания или (или другого метода).
include_graphics(png_file)
Зарегистрируйтесь или войдите в систему
Зарегистрируйтесь с помощью Google
Зарегистрироваться через Facebook
Зарегистрируйтесь, используя адрес электронной почты и пароль
Опубликовать как гость
Электронная почта
Обязательно, но не отображается
Опубликовать как гость
Электронная почта
Требуется, но не отображается
Два способа извлечения встроенных изображений из Word/Excel/PowerPoint
Просто получить документ Office, в котором сохранено множество изображений, которые вам очень нравятся? Вы хотите загрузить или сохранить изображения в документе Office? Статья о том, как извлечение изображений из файла Word/Excel/PowerPoint будет хорошим подспорьем для вас, если вы не хотите сохранять изображения одно за другим из документа Office.
- Способ 1. Использование встроенной в Windows поддержки .zip для извлечения изображений из файла docx/xlsx/pptx
- Способ 2: Использование бесплатного программного обеспечения для извлечения изображений из файла doc/xls/ppt
Способ 1. Извлечение изображений из документа Office с помощью встроенной в Windows поддержки .zip
Если вы получили файл Word (.docx), Excel (.xlsx) или PowerPoint (.pptx) с нужными извлечь их без какого-либо программного обеспечения. Вместо этого вы можете использовать встроенную в Windows поддержку .zip или в полной мере использовать форматы файлов на основе Office XML для извлечения из них встроенных изображений.
Шаг 1: Переименуйте документ Word и сохраните его как ZIP-файл.
Щелкните встроенные изображения документа Word и нажмите F2, чтобы переименовать его. Измените его расширение с .docx на .zip. Нажмите Введите для подтверждения.
Советы: Если вы не видите расширение документа Word, снимите флажок Скрыть расширения для известных типов файлов в Инструмент > Параметры папки .
Шаг 2: Щелкните правой кнопкой мыши заархивированный файл и выберите «Извлечь все» во всплывающем меню.
Если на вашем компьютере установлен WinRAR, теперь вы можете выбрать Извлечь файлы и откроется окно Путь извлечения и параметры .
Затем вы можете изменить или подтвердить Путь назначения и нажать OK, чтобы извлечь ZIP-файл. Далее выполните шаг 4. Если нет, выполните шаг 3, пожалуйста.
Шаг 3: Выберите место для сохранения извлеченных файлов и отображения извлеченных файлов по завершении.
- В диалоговом окне Выберите место назначения и извлеките файлы , если вы не хотите сохранять извлеченные файлы в местоположении по умолчанию, вы можете нажать кнопку Обзор , чтобы изменить местоположение.
- Перейдите туда, куда вы хотите сохранить содержимое ZIP-файла после извлечения, щелкните Новая папка , чтобы создать новую папку, и щелкните Выбрать папку .

- Отметьте Показать извлеченные файлы после завершения , если вы хотите сразу увидеть извлеченные файлы после завершения извлечения. Нажмите Кнопка Extract , наконец, чтобы начать извлечение содержимого из zip-файла.
Шаг 4. Получите доступ к извлеченным изображениям.
1. Там будет папка с именем слово , которая включает извлеченное содержимое, например изображения.
2. Откройте папку word и дважды щелкните папку media . Все изображения из исходного документа Word находятся в папке «media» и названы серией номеров изображений.
Поздравляем! Вы успешно извлекли изображения из документа Word. Предположим, у вас есть еще одно требование извлечь текст из документа Word, когда у вас нет Microsoft Office для открытия документа Word, вы можете использовать тот же способ. Просто нужно открыть файл «document.xml» в папке «word» с помощью текстового редактора, вы увидите весь текст из исходного документа Word.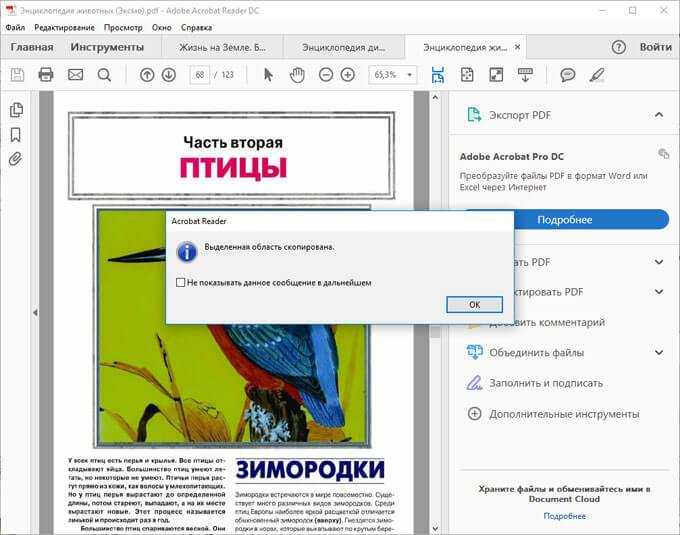
Способ 2. Извлечение изображений из документа Office с помощью бесплатного программного обеспечения
Если вы хотите упростить извлечение изображений из документа Office, особенно если документ Office имеет версию 2003 или более раннюю, бесплатное программное обеспечение Мастер извлечения изображений Office будет хорошим способом извлечения изображений из документа.
Шаг 1: Загрузите, установите и запустите мастер извлечения образов Office.
Шаг 2: Установите входной документ Word и выходную папку. Нажмите кнопку Далее .
1. Нажмите кнопку папки рядом с Документ , чтобы ввести документ Word, который вы хотите извлечь.
2. Тогда выходная папка будет установлена по умолчанию. Если вы хотите изменить его, нажмите кнопку папки рядом с ним и перейдите к месту, где вы хотите сохранить файлы, извлеченные из документа Word.
Шаг 3: Нажмите кнопку Start , чтобы начать извлечение введенного документа Word.