Редактор PDF | Какой самый простой способ объединить PDF-файлы?
Юристы производят ошеломляющее количество документов. Каждый день в офис поступают новые документы, и это не говоря уже о проблемах, связанных с обнаружением и работой с документами, связанными с делом. Даже при работе с этими документами в цифровой среде остаются проблемы. В море сотен или даже тысяч файлов найти то, что вам нужно, часто бывает сложно.
Объединение похожих документов и консолидация рабочей нагрузки — простой способ справиться с этой трудностью, но как добиться таких результатов? Объединение файлов путем ручного копирования не только создает потенциальные проблемы с форматированием, но и требует значительного времени. С Kofax Power PDF требуется всего несколько шагов, чтобы объединить PDF в более крупный файл и выполнить множество других задач, связанных с документами, в интуитивно понятной программной среде.
Объединение PDF-файлов вручную — это утомительный и разочаровывающий процесс, который может привести к часам возни с настройками и форматированием, чтобы попытаться заставить страницы выглядеть так, как они выглядели по отдельности.
- Отправка важных юридических документов на подпись.
- Сбор контрактов из разных шаблонных источников и настройка информации в соответствии с требованиями.
- Защита конфиденциальных данных для передачи или хранения для предотвращения несанкционированного доступа.
Вместо того, чтобы тратить время на устаревшие процессы, снабдите свою команду передовым программным обеспечением, которое предоставляет необходимые вам функции по разумной цене.
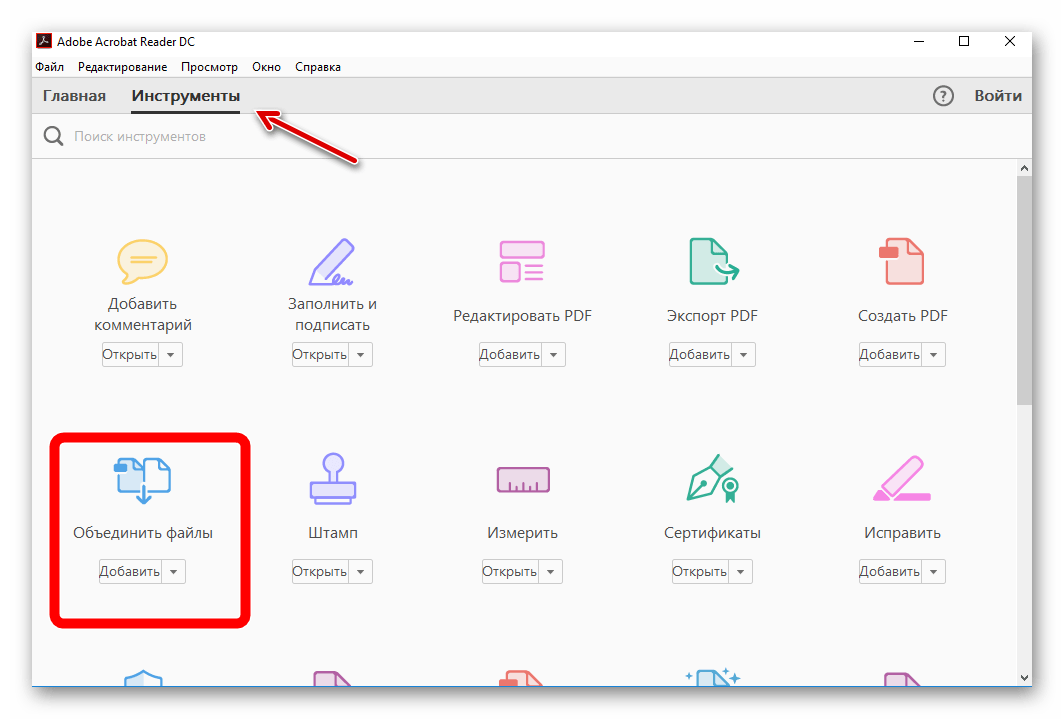
Что вам нужно сделать, если вы хотите объединить PDF в программе? Это просто, всего несколько шагов:- Выберите «Объединить файлы» на вкладке «Главная».
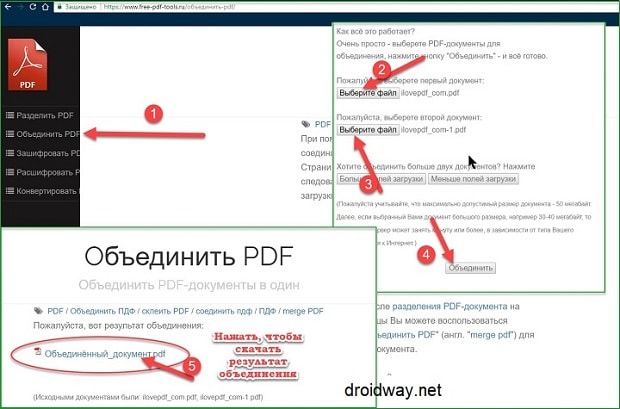
- Нажмите «Добавить» и перейдите в папку с файлами PDF, которые необходимо объединить. Выберите все ваши исходные файлы сразу.
- Сохраните новый объединенный PDF-файл в папку назначения по вашему выбору.
Легко, правда? Что, если вы все утро редактировали несколько файлов и готовы создать один единственный документ? Одним нажатием кнопки «Объединить все» Power PDF автоматически заполняет инструмент слияния всеми открытыми документами. Это не занимает времени вообще.
При таком простом процессе слияния PDF-файлов нет причин избегать консолидации информации и упрощения поиска данных, относящихся к любому отдельному делу в вашем офисе. Power PDF также соответствует экономически эффективным требованиям юридической работы с возможностью постоянного лицензирования. Заплатите один раз и наслаждайтесь бессрочным использованием программного обеспечения или запросите контракт на постоянное обслуживание для доступной поддержки и будущих обновлений.
Сделайте быструю работу по объединению документов сегодня. Узнайте больше о добавлении Power PDF в вашу компанию прямо сейчас.
Как объединить несколько файлов PDF на одну страницу с помощью pdftk?
Задавать вопрос
спросил
Изменено 1 год, 10 месяцев назадПросмотрено 124 тыс. раз
У меня есть ряд PDF-файлов 1.pdf , 2.pdf и т. д., которые я хотел бы объединить в один файл со всеми PDF-файлами, расположенными на одной странице.

В настоящее время я пытался pdftk объединить эти файлы, но они помещены на отдельные страницы:
pdftk 1.pdf 2.pdf ... cat output merged.pdf
Есть ли способ вместо этого разбить отдельные PDF-файлы на одну мастер-страницу на слит.pdf ?
- слияние
- pdftk
Не знаю, может ли pdftk это сделать, но pdfjam может. Его можно установить на Debian или производные с помощью sudo apt install texlive-extra-utils
pdfjam Page1.pdf Page2.pdf --nup 2x1 --landscape --outfile Page1+2.pdf
Помещает 2 страницы на одну страницу рядом. С --nup 1x2 --no-landscape вы можете разместить две страницы на одной странице друг над другом.
Не уверен, что вы имеете в виду под на одной странице . Я искал способ объединить несколько PDF-файлов на одной странице поверх другой. Это можно сделать с помощью
Это можно сделать с помощью pdftk следующим образом:
pdftk foreground.pdf background.pdf output merged.pdf
Вам может подойти pdfnup на основе pdfLaTeX. Если у вас много pdf-файлов, вам может понадобиться сделать длинный канал pdfjam или запустить его несколько раз.
В python также есть pdfnup.
Этот сценарий будет разбивать страницы pdf для вас. Измените фрагмент на то, что вам нужно на странице.
#!/usr/бин/рубин
латексхед = <<'EOF'
\documentclass{статья}
\usepackage[pdftex]{graphicx}
\usepackage[margin=0.1in]{геометрия}
\usepackage{pdfpages}
\начать{документ}
EOF
латекстейл = <<'EOF'
\конец{документ}
EOF
страницы = %x[pdfinfo #{ARGV[0]}].split(/\n/).select{|x| x=~ /Страницы://}[0].split(/\s+/)[1].to_i
кладет латексную головку
s = (1..pages).each_slice(4).to_a
s.each делать |a|
помещает "\\begin{figure}"
a.каждый сделать |p|
помещает "\\includegraphics[page=#{p},scale=0. 4,width=.5\\textwidth]{#{ARGV[0]}}"
конец
помещает "\\конец{рисунок}"
конец
ставит латексный хвост
4,width=.5\\textwidth]{#{ARGV[0]}}"
конец
помещает "\\конец{рисунок}"
конец
ставит латексный хвост
вы можете использовать монтаж из ImageMagick
$ монтаж *.pdf слияние.pdf
см. также http://www.imagemagick.org/script/montage.php
Если имена файлов расположены в «специфическом для системы» порядке, то pdftk *.pdf cat output merged.pdf должен работать нормально.
Вот что я имею в виду под «системным заказом».
Пример:
У меня на Ubuntu 11.04 есть 3 файла: 1.pdf, 2.pdf, 10.pdf
Файлы объединены в следующем порядке: 10.pdf 1.pdf 2.pdf ( ls -l вернул тот же порядок, что и в объединенном файле)
Безопасное соглашение об именах: 0001.pdf, 0002.pdf и т. д.
3Если у вас есть большое количество PDF-файлов в одной структуре папок, и у вас есть установка TeX, этот скрипт помещает все PDF-файлы рекурсивно в один большой файл:
#!/bin/bash # # pdfdir OUTPUT_FILE # # создает один большой PDF-файл из всех PDF-файлов в формате ./\\includepdf[pages=-]{/; с/$/}%/' } tex_headline () { эхо "$1" | sed -e 's/_/\\_/g' } # текущая папка (уровень 0): список_pdf_файлов. >>"$ФАЙЛ.tex" # Беарбит Эбене 1: список_каталогов . | при чтении -r DIR1; делать # Есть ли PDF-файлы в папках ниже этого уровня? существующие_pdf_файлы "$DIR1" || продолжать # Да ... tex_headline "\section{${DIR1##*/}}%" # те: list_pdf_files "$DIR1" # Уровень 2: list_directories "$DIR1" | при чтении -r DIR2; делать существующие_pdf_файлы "$DIR2" || продолжать tex_headline "\subsection{${DIR2##*/}}%" list_pdf_files "$ DIR2" # Уровень 3: list_directories "$DIR2" | при чтении -r DIR3; делать существующие_pdf_файлы "$DIR3" || продолжать tex_headline "\subsubsection{${DIR3##*/}}%" list_pdf_files "$DIR3" # Уровень 4: list_directories "$DIR3" | при чтении -r DIR4; делать существующие_pdf_файлы "$DIR4" || продолжать tex_headline "\ paragraph{${DIR4##*/}}%" list_pdf_files "$DIR4" # Уровень 5: list_directories "$DIR4" | при чтении -r DIR5; делать существующие_pdf_файлы "$DIR5" || продолжать tex_headline "\subparagraph{${DIR5##*/}}%" list_pdf_files "$DIR5" сделанный сделанный сделанный сделанный сделано >
>"$FILE. tex" echo "\end{document}%" >>"$FILE.tex" echo "Исходный код в PDF напрямую [J/n]" читать -r ОТВЕТ случай "$ANSWER" в [JjYy]) ;; *) выход 0 ;; эсак pdflatex "$ ФАЙЛ" [$? -eq 0 ] && rm -f "$FILE.aux" "$FILE.log" "$FILE.tex"
Я не писал этот код, я получил его из обсуждения здесь: http://www.listserv.dfn.de/cgi-bin/wa?A2=ind1201&L=tex-d-l&T=0&P=10771
Это очень полезно. Я перевел некоторые немецкие комментарии на английский язык.
С уважением, Александр
Эта ссылка: http://www.verypdf.com/wordpress/201302/how-to-combine-4-page-pdf-into-1-page-pdf-file-to-save-ink-and- papers-34505.html показывает, что VeryPDF PDF Stitcher может выполнять эту работу вертикально или сбоку. Скачать по адресу: http://www.verypdf.com/app/pdf-stitch/index.html
Сохраните нужные страницы в PDF-документ с помощью чего-то вроде Acrobat Pro.
Печать документа с использованием функции нескольких страниц на страницу, обратно в документ PDF.
Несколько страниц на одной странице.