Ссылка на видео ВКонтакте словом в тексте
Содержание этой статьи
Ссылка на видео ВКонтакте словом позволяет красиво оформлять тексты постов, повышает их читабельность, и для посетителей подобное оформление выглядит более привлекательно. Такие ссылки можно делать, как на личных страницах, так и в записях сообщества.
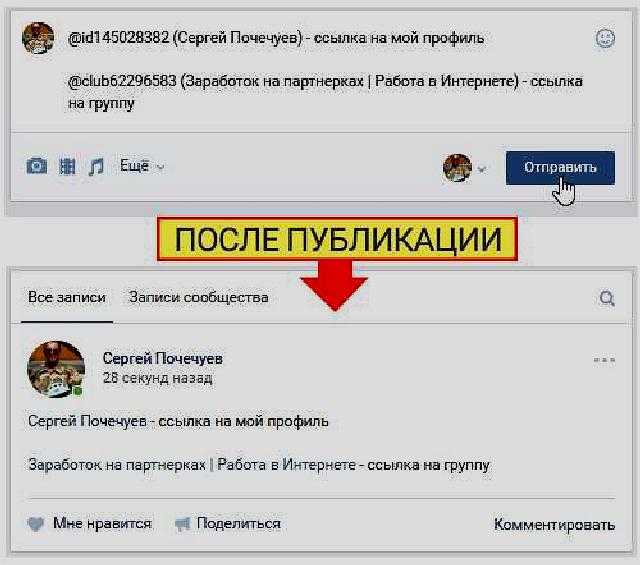
Вот так выглядит ссылка в реальной записиПри этом неважно, где изначально размещено видео: на личной стене или на стене сообщества (другого пользователя). Неважно, какое оно: ваше личное или чужое.
Процесс создания такой ссылки даже проще добавления ссылок на видео в меню ВКонтакте.
Как делается ссылка на видео ВКонтакте словом на компьютереДля создания таких ссылок применяется вот такая конструкция ссылки:
[ссылка на видео|описание ссылки]
Именно в этой конструкции получается анкорная ссылка, показанная на скриншоте выше.
Прямые ссылки на видео с других сайтов работать не будут!
Самым быстрым алгоритмом работы будет такой:
Шаг 1
В английской раскладке клавиатуры вставляем в запись последовательность знаков [|] и после этого переключаем раскладку обратно на русский яык.
Шаг 2
Копируем ссылку на видео и вставляем ее между первой квадратной скобкой [ и вертикальной чертой |.
При этом сама ссылка берется через клик правой кнопкой мыши по видео с последующим выбором соответствующей команды:
Шаг 3
Ставим курсор за вертикальную черту | перед закрывающей скобкой ] и пишем текст, который будет видеть пользователь вместо ссылки.
Ограничений здесь нет. Пишите хоть целое предложение. И в отличие от написания хештегов не нужно делать эту фразу без пробелов. То есть применяем обычное текстовое оформление.
Для примера, вот так выглядит конструкия ссылки на одно из моих видео в ВКонтакте:
[https://vk.com/video-62296583_456239330?list=408f9ab06fc1a0388c|смотрите это видео]
Подобную запись вы будете видеть на протяжении всего процесса редактирования, а сам анкор (текст вместо ссылки) появится после публикации заметки.
При этом на компьютере вы всегда будете иметь возможность изменить замещающий текст (анкор ссылки), потому что вся эта конструкия будет отображаться в режиме редактирования.
Особенности создания ссылки на видео ВКонтакте на телефонеДействия на телефоне примерно такие же, но есть и специфичные особенности.
Для того, чтобы взять ссылку, нужно тапнуть (нажать) на видео, чтобы оно открылось.
Ссылка берется нажатием на значок «Поделиться» и последующим выбором команды «Скопировать ссылку».
В процессе написания заметки, как только вы вставите ссылку в поле набора, ниже текста появиться превью (титульная картинка) видео. Но закрывать ее до окончания оформления видео не стоит, потому что она будет снова появляться. Сделать это нужно после оформления ссылки.
Сделать это нужно после оформления ссылки.
Одновременно с постановкой закрывающей скобки ссылка сразу превращается в анкорную.
Отредактировать ее (изменить замещающий текст) после этого не получится. Для изменения придется повторить все шаги заново.
Наглядно весь этот процесс я показал вот в этом видео:
Ссылка на видео ВКонтакте словом: на компьютере & на телефонеБудут ли работать эти ссылки на видео из YouTube?Они будут работать при следующих условиях
- вы поделились этим видео непосредственно из YouTube
- вы опубликовали видео путем размещения ссылки в тексте записи
- вы добавили видео через загрузчик видео в ВКонтакте
А по большому счету по другому они в ВК попасть не смогут. При этом Вконтакте «присваивает» каждому такому ролику чисто контактовский URL. И по моим наблюдениям раньше такого не было. Хотя может быть я и не прав, тогда поправьте меня в комментариях.
На этом тему ссылок на видео ВКонтакте словом я закончу. Надеюсь, что эта статья станет для вас полезной. Если остались какие-то вопросы, задавайте их в комментариях. С радостью на них отвечу.
С уважением, Сергей Почечуев
Можно ли играть ВКонтакте в Scrabble?
Нет! ВК нет в словаре Эрудита. Но если бы это было так, это дало бы вам 9 баллов.
Реклама
Словари Scrabble
| Словарь | Имя | Регион | Действительный |
|---|---|---|---|
| Offcl. Эрудит пл. Дикт. и внекл. Эрудит слова | ПОДУШКИ | Международный / Великобритания / Австралия | НЕТ |
| Список слов NASPA 2020 |  Also reffered to as Tournament Word List (TWL).»> СЗЛ2020 Also reffered to as Tournament Word List (TWL).»> СЗЛ2020 | НЕТ | |
| Список слов NASPA 2018 | СЗЛ2018 | США/Канада/Таиланд | НЕТ |
| Турнирный список слов 2016 | TWL16 | США/Канада/Таиланд | НЕТ |
| Турнирный список слов 2014 |  «> TWL14 «> TWL14 | США/Канада/Таиланд | НЕТ |
| Турнирный список слов 2006 | TWL06 | США/Канада/Таиланд | НЕТ |
| Турнирный список слов 1998 | ТВЛ98 | США/Канада/Таиланд | НЕТ |
| Коллинз Эрудит Слова 2019 | Международный / Великобритания / Австралия | НЕТ | |
| Коллинз Эрудит Слова 2015 |  «> CSW15 «> CSW15 | Международный / Великобритания / Австралия | НЕТ |
| Коллинз Эрудит Слова 2012 | CSW12 | Международный / Великобритания / Австралия | НЕТ |
| Коллинз Эрудит Слова 2007 | CSW07 | Международный / Великобритания / Австралия | № |
| Offcl. Словарь игроков в скрэббл |  «> ОСПД4 «> ОСПД4 | США/Канада/Таиланд | НЕТ |
| Австралийские начальные школы | Австралия | НЕТ | |
| Начальные школы Австралии | СОВ1 | Австралия | НЕТ |
| Слова с друзьями 2000 | ENABLE2K | Во всем мире | НЕТ |
| Words With Friends 1997 (на пенсии) | ВКЛЮЧИТЬ1 | Во всем мире | НЕТ |
| Высокая печать | Высокая печать | Во всем мире | НЕТ |
| Еще один список слов | ЯВЛ | Во всем мире | НЕТ |
| Показать больше | |||
Вы имели в виду?
айвер
агава
аджива
жив
выше
Пробовали?
Анаграммы ВК
Последние поиски
дрейфующий (анаграмма) deptall*lnygolvir*moffq*be*osksisqqqj (анаграмма) доверенное лицо (анаграмма) аморальный (анаграмма) отдел*lnygolvir*moffq*ritcwgycpthw (анаграмма)
Ваши последние поиски
вк (словарь)
Блог Khronos — The Khronos Group Inc
Введение
Компания Khronos представила новое расширение под названием VK_EXT_graphics_pipeline_library, которое позволяет компилировать шейдеры намного раньше, чем при полном создании Pipeline State Object (PSO). Используя это расширение, я смог избежать многих причин зависаний кадров из-за позднего создания PSO во время отрисовки в средстве визуализации Source 2 Vulkan. Спецификация расширения была выпущена сегодня, и вскоре последует поддержка SDK, вы можете отслеживать статус выпуска на https://github.com/KhronosGroup/Vulkan-Docs/issues/1808.
Используя это расширение, я смог избежать многих причин зависаний кадров из-за позднего создания PSO во время отрисовки в средстве визуализации Source 2 Vulkan. Спецификация расширения была выпущена сегодня, и вскоре последует поддержка SDK, вы можете отслеживать статус выпуска на https://github.com/KhronosGroup/Vulkan-Docs/issues/1808.
Движок Source 2 довольно сильно разработан на основе модели Direct3D11, в которой шейдеры создаются независимо, а объекты состояния предоставляются во время отрисовки. Таким образом, существует значительное количество информации, которую наш движок не знает в то время, когда шейдеры предоставляются нашей абстракции рендеринга: спаривание шейдеров на разных этапах, форматы вершин, форматы кадрового буфера, состояние глубины/стенсила, информация об области просмотра, состояние MSAA. , и ряд других. Это означает, что мы откладываем создание PSO до времени отрисовки, что может привести к задержкам, особенно при холодном кеше конвейера.
Прежде чем подробно рассказать о том, как мы интегрировали VK_EXT_graphics_pipeline_library в наш движок, я хочу сделать пару предостережений по поводу этого расширения. Прежде всего следует сказать, что есть очень веская причина, по которой Vulkan был разработан таким образом, чтобы работа по компиляции шейдеров происходила во время создания PSO с полным просмотром всего требуемого состояния. В то время как драйверы Direct3D11 создают иллюзию полной компиляции только с байтовым кодом шейдера, правда в том, что внутри драйверов происходят огромные героические усилия, чтобы сделать это так. Драйверы часто выполняют фоновую компиляцию в нескольких потоках, и на самом деле Direct3D11 не может гарантировать, что компиляция шейдера не произойдет во время отрисовки. Однако на практике поставщики графических процессоров исключительно хорошо справились с этой героической задачей, и типичный пользовательский опыт с драйвером Direct3D11 приводит к значительно меньшим задержкам, чем наш модуль рендеринга Vulkan без полностью предварительно прогретых конвейерных кешей. Тем не менее, приложения Vulkan, которые могут заранее знать все состояния шейдеров и конвейеров, гарантированно избегают задержек, поскольку работа по компиляции шейдеров будет полностью выполняться во время создания PSO.
Прежде всего следует сказать, что есть очень веская причина, по которой Vulkan был разработан таким образом, чтобы работа по компиляции шейдеров происходила во время создания PSO с полным просмотром всего требуемого состояния. В то время как драйверы Direct3D11 создают иллюзию полной компиляции только с байтовым кодом шейдера, правда в том, что внутри драйверов происходят огромные героические усилия, чтобы сделать это так. Драйверы часто выполняют фоновую компиляцию в нескольких потоках, и на самом деле Direct3D11 не может гарантировать, что компиляция шейдера не произойдет во время отрисовки. Однако на практике поставщики графических процессоров исключительно хорошо справились с этой героической задачей, и типичный пользовательский опыт с драйвером Direct3D11 приводит к значительно меньшим задержкам, чем наш модуль рендеринга Vulkan без полностью предварительно прогретых конвейерных кешей. Тем не менее, приложения Vulkan, которые могут заранее знать все состояния шейдеров и конвейеров, гарантированно избегают задержек, поскольку работа по компиляции шейдеров будет полностью выполняться во время создания PSO. В то время как с Direct3D11 такой гарантии нет.
В то время как с Direct3D11 такой гарантии нет.
Второе предостережение заключается в том, что если вы разрабатываете новый движок для Vulkan, вам действительно следует подумать, является ли хорошей идеей иметь большое количество перестановок шейдеров. Некоторые игры, такие как DOOM 2016/DOOM Eternal, сохранили очень небольшое количество PSO. Подробное описание этого пространства проектирования выходит за рамки этого поста в блоге, но я настоятельно рекомендую прочитать эту серию блогов из двух частей, в которой объясняется, почему многие движки имеют большое количество перестановок шейдеров (что является одной из основных причин многих задержек при компиляции во время отрисовки). ): Проблема перестановки шейдеров: как мы к этому пришли?
После всего сказанного Khronos слышал от многих разработчиков (включая нас), что в некоторых сценариях просто невозможно заранее знать все состояние PSO. Частично это привело к созданию нескольких новых расширений (ядро в Vulkan 1.3), которые позволяют сделать гораздо больше динамических состояний PSO.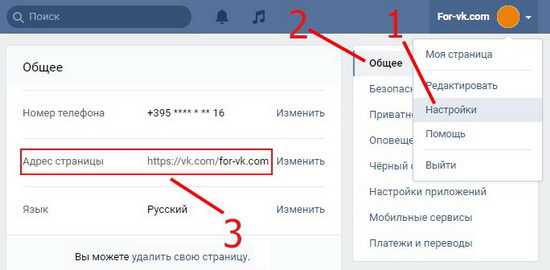 VK_EXT_graphics_pipeline_library делает еще один шаг вперед, позволяя полностью свести шейдеры к машинным инструкциям задолго до начала отрисовки. Благодаря этому расширению движки в стиле Direct3D11, такие как наш, могут обеспечить сравнимые (или даже лучшие!) возможности с компиляцией шейдеров по сравнению с Direct3D11. В следующих разделах я представлю обзор VK_EXT_graphics_pipeline_library и подробно опишу процесс интеграции расширения в движок Source 2.
VK_EXT_graphics_pipeline_library делает еще один шаг вперед, позволяя полностью свести шейдеры к машинным инструкциям задолго до начала отрисовки. Благодаря этому расширению движки в стиле Direct3D11, такие как наш, могут обеспечить сравнимые (или даже лучшие!) возможности с компиляцией шейдеров по сравнению с Direct3D11. В следующих разделах я представлю обзор VK_EXT_graphics_pipeline_library и подробно опишу процесс интеграции расширения в движок Source 2.
Обзор библиотеки графических конвейеров
Тем, кто ищет подробный обзор расширения VK_EXT_graphics_pipeline_library, настоятельно рекомендую ознакомиться с документом предложения. Вкратце, расширение разбивает PSO на четыре отдельных этапа конвейера вместо одного монолитного конвейера:
- Vertex Input Interface
- Шейдеры перед растеризацией
- Фрагментный шейдер
- Интерфейс вывода фрагментов
Интерфейс ввода вершин содержит информацию, которая обычно предоставляется объекту состояния полного конвейера с помощью VkPipelineVertexInputStateCreateInfo и VkPipelineInputAssemblyStateCreateInfo.
Шейдеры перед растеризацией содержат этапы вершинного, мозаичного и геометрического шейдера вместе с состоянием, связанным с VkPipelineViewportStateCreateInfo, VkPipelineRasterizationStateCreateInfo, VkPipelineTessellationStateCreateInfo и VkRenderPass (или динамической отрисовкой). Это может звучать как больше информации, чем ваш движок мог бы знать во время создания шейдера, это определенно было для нас. Однако ключевой момент заключается в том, что при объединении конвейерных библиотек с расширениями динамического состояния единственной информацией, которая действительно необходима для создания шейдера до растеризации, является код SPIR-V и схема конвейера. Это обсуждается более подробно ниже.
Этап фрагментного шейдера содержит фрагментный шейдер вместе с состоянием в VkPipelineDepthStencilStateCreateInfo и VkRenderPass (или динамическом рендеринге — хотя в этом случае требуется только viewMask). Как и на этапе предварительной растеризации, в сочетании с динамическим рендерингом вы можете создать конвейер фрагментного шейдера, используя только SPIR-V и макет конвейера. Это позволяет драйверу выполнять тяжелую работу по снижению аппаратных инструкций для предварительной растеризации и фрагментных шейдеров с очень небольшим количеством информации.
Как и на этапе предварительной растеризации, в сочетании с динамическим рендерингом вы можете создать конвейер фрагментного шейдера, используя только SPIR-V и макет конвейера. Это позволяет драйверу выполнять тяжелую работу по снижению аппаратных инструкций для предварительной растеризации и фрагментных шейдеров с очень небольшим количеством информации.
Наконец, есть интерфейс вывода фрагментов, который содержит VkPipelineColorBlendStateCreateInfo, VkPipelineMultisampleStateCreateInfo и VkRenderPass (или динамического рендеринга). Как и в случае интерфейса ввода вершин, на этом этапе требуется информация, которую мы не знаем до момента отрисовки, поэтому это состояние также хешируется, и конвейер интерфейса вывода фрагментов создается во время отрисовки. Ожидается, что он будет создан очень быстро, а также будет относительно небольшим по количеству.
После создания всех четырех отдельных этапов библиотеки конвейера приложение может выполнить окончательную связь с полным конвейером. Ожидается, что эта последняя ссылка будет очень быстрой — драйвер сделает компиляцию шейдера для отдельных этапов, и поэтому связь может быть выполнена во время отрисовки по разумной цене. Именно здесь проявляется большое преимущество расширения: мы заранее создали все наши прерастровые и фрагментные шейдеры, хешировали небольшое количество входных/выходных интерфейсов вершин и можем по запросу создать быстрый связанный конвейер. библиотеку во время отрисовки, что позволяет избежать ужасной заминки.
Ожидается, что эта последняя ссылка будет очень быстрой — драйвер сделает компиляцию шейдера для отдельных этапов, и поэтому связь может быть выполнена во время отрисовки по разумной цене. Именно здесь проявляется большое преимущество расширения: мы заранее создали все наши прерастровые и фрагментные шейдеры, хешировали небольшое количество входных/выходных интерфейсов вершин и можем по запросу создать быстрый связанный конвейер. библиотеку во время отрисовки, что позволяет избежать ужасной заминки.
Ранняя компиляция шейдеров с конвейерными библиотеками
В нашем движке шейдеры предоставляются нашему уровню абстракции рендеринга во время загрузки наших материалов (что происходит во время запуска или экранов загрузки). В Direct3D11 это напрямую приводит к вызову методов IDirect3D11Device::Create*Shader. В Vulkan, до VK_EXT_graphics_pipeline_library, единственное, что мы могли сделать в то время, это vkCreateShaderModule. Это передает SPIR-V драйверу, но на самом деле не запускает какую-либо значительную компиляцию шейдера, поскольку драйвер Vulkan должен сделать это во время создания PSO, когда известны все этапы шейдера, макеты наборов дескрипторов и требуемое состояние.
Таким образом, наш модуль визуализации Vulkan хранит хэш состояния и создаст полный конвейер во время отрисовки, когда все это состояние будет окончательно известно. С помощью VK_EXT_graphics_pipeline_library мы теперь можем компилировать шейдеры одновременно с Direct3D11. В следующих разделах я опишу изменения, которые были необходимы, чтобы сделать это возможным.
Динамическое состояние
Хотя использование VK_EXT_graphics_pipeline_library не требует, чтобы приложения использовали динамическое состояние, на практике для нашего движка они неразрывно связаны друг с другом. Без использования динамического состояния мы не смогли бы создавать конвейерные библиотеки для этапов предварительной растеризации и фрагментного шейдера во время загрузки материала. Сразу отмечу, что мы создаем пайплайны предрастеризации только для вершинных шейдеров и не заморачиваемся с шейдерами тесселяции и геометрии. У нас не так много случаев, когда мы используем геометрические шейдеры и шейдеры тесселяции, поэтому для целей остальной части этой статьи этап предварительной растеризации для нас относится только к вершинным шейдерам. Если конвейер использует шейдеры тесселяции или геометрии, мы возвращаемся к полному созданию PSO.
Если конвейер использует шейдеры тесселяции или геометрии, мы возвращаемся к полному созданию PSO.
Конкретные расширения динамического состояния, которые нам требуются в нашем движке, чтобы иметь возможность использовать VK_EXT_graphics_pipeline_library, следующие:
- VK_EXT_extended_dynamic_state
- ВК_EXT_extended_dynamic_state2
- VK_KHR_dynamic_rendering
К счастью, все эти три расширения являются частью Vulkan 1.3, поэтому можно ожидать, что они будут поддерживаться везде, где поддерживается VK_EXT_graphics_pipeline_library.
Для вершинного шейдера (конвейерной библиотеки до растеризации) информация в следующей таблице должна быть динамической, чтобы мы могли немедленно создать конвейерную библиотеку. То есть мы не знаем область просмотра, смещение глубины, режим отбраковки, цели рендеринга (или форматы) в то время, когда нам предоставляется вершинный шейдер, поэтому, сделав все это состояние динамическим, мы можем создать конвейерную библиотеку до растеризации.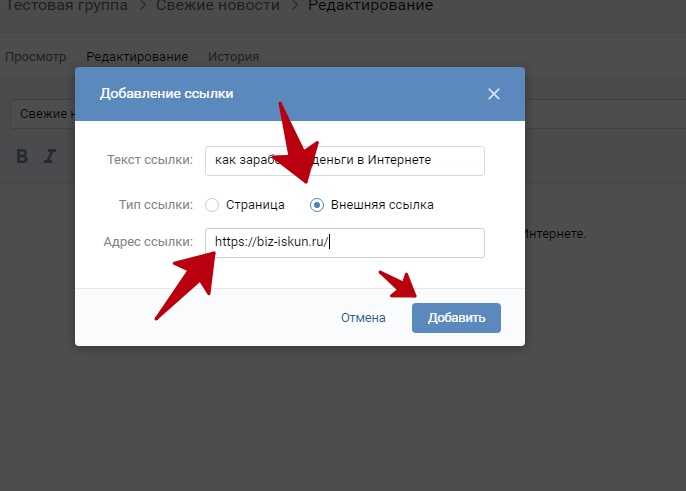 только с SPIR-V (и схемой конвейера, подробнее об этом позже).
только с SPIR-V (и схемой конвейера, подробнее об этом позже).
Динамическое состояние этапа перед растеризацией
| Состояние | Динамическое состояние |
|---|---|
| VkPipelineViewportStateCreateInfo | VK_DYNAMIC_STATE_VIEWPORT_WITH_COUNT_EXT VK_DYNAMIC_STATE_SCISSOR_WITH_COUNT_EXT |
| VkPipelineRasterizationStateCreateInfo | VK_DYNAMIC_STATE_DEPTH_BIAS VK_DYNAMIC_STATE_CULL_MODE_EXT VK_DYNAMIC_STATE_FRONT_FACE_EXT |
| VkRenderPass | Динамический (VK_NULL_HANDLE) с VK_KHR_dynamic_rendering |
Как и в случае с вершинным шейдером, для фрагментного шейдера существует множество состояний, о которых мы не знаем во время загрузки SPIR-V. В частности, мы не знаем состояния глубины/трафарета и рендерпасса, поэтому делаем их динамическими, как описано в следующей таблице.
Динамическое состояние этапа фрагмента
| Состояние | Динамическое состояние |
|---|---|
| VkPipelineDepthStencilStateCreateInfo | VK_DYNAMIC_STATE_STENCIL_COMPARE_MASK VK_DYNAMIC_STATE_STENCIL_WRITE_MASK VK_DYNAMIC_STATE_STENCIL_REFERENCE VK_DYNAMIC_STATE_DEPTH_TEST_ENABLE_EXT VK_DYNA MIC_STATE_DEPTH_WRITE_ENABLE_EXT VK_DYNAMIC_STATE_DEPTH_COMPARE_OP_EXT VK_DYNAMIC_STATE_STENCIL_TEST_ENABLE_EXT VK_DYNAMIC_STATE_STENCIL_OP_EXT VK_DYNAMIC_STATE_DEPTH_BOUNDS ВК_DYNAMIC_STATE_DEPTH_BOUNDS_TEST_ENABLE_EXT |
| VkRenderPass | Динамический (VK_NULL_HANDLE) с VK_KHR_dynamic_rendering |
Макеты конвейеров
С динамическими состояниями, использованными в предыдущем разделе, единственная дополнительная информация, которая нам нужна для создания библиотек конвейеров вершинных/фрагментных шейдеров, — это макет конвейера. На первый взгляд может показаться, что это довольно простая информация для сбора. Из отражения шейдера мы знаем, какие дескрипторы используются в шейдере, поэтому мы должны знать макеты наборов дескрипторов для каждого этапа. Это было бы очень просто, если бы вершинный и фрагментный шейдеры создавались вместе в паре, но это работает иначе (и я не представляю, сколько движков на базе Direct3D11 работает). Хотя наши шейдеры содержатся в одном и том же файле, комбинация шейдеров вершин и фрагментов, которая будет использоваться вместе, неизвестна до момента отрисовки. Например, в проходе только по глубине вершинный шейдер A связан с фрагментным шейдером A (т. е. который извлекает текстуру для выполнения альфа-теста). В прямом проходе вершинный шейдер A будет соединен с фрагментным шейдером B, который выполняет полное прямое освещение. И на самом деле есть много других сценариев, где точная комбинация не известна до момента розыгрыша.
На первый взгляд может показаться, что это довольно простая информация для сбора. Из отражения шейдера мы знаем, какие дескрипторы используются в шейдере, поэтому мы должны знать макеты наборов дескрипторов для каждого этапа. Это было бы очень просто, если бы вершинный и фрагментный шейдеры создавались вместе в паре, но это работает иначе (и я не представляю, сколько движков на базе Direct3D11 работает). Хотя наши шейдеры содержатся в одном и том же файле, комбинация шейдеров вершин и фрагментов, которая будет использоваться вместе, неизвестна до момента отрисовки. Например, в проходе только по глубине вершинный шейдер A связан с фрагментным шейдером A (т. е. который извлекает текстуру для выполнения альфа-теста). В прямом проходе вершинный шейдер A будет соединен с фрагментным шейдером B, который выполняет полное прямое освещение. И на самом деле есть много других сценариев, где точная комбинация не известна до момента розыгрыша.
Это создает проблему для библиотеки VK_EXT_graphics_pipeline_library, которой требуется полный макет конвейера, когда мы создаем этап предварительной растеризации или фрагментного шейдера. У нас просто нет этой информации — мы знаем дескрипторы, потребляемые этапом, который мы компилируем, но не другим этапом. К счастью, VK_EXT_graphics_pipeline_library содержит флаг, который позволяет вам создать макет конвейера, в котором каждому этапу нужны только используемые им наборы дескрипторов (VK_PIPELINE_LAYOUT_CREATE_INDEPENDENT_SETS_BIT_KHR). Пока макеты наборов дескрипторов совпадают с любыми общими наборами дескрипторов, мы можем не предоставлять другие макеты наборов дескрипторов этапа во время создания отдельных библиотек этапов.
У нас просто нет этой информации — мы знаем дескрипторы, потребляемые этапом, который мы компилируем, но не другим этапом. К счастью, VK_EXT_graphics_pipeline_library содержит флаг, который позволяет вам создать макет конвейера, в котором каждому этапу нужны только используемые им наборы дескрипторов (VK_PIPELINE_LAYOUT_CREATE_INDEPENDENT_SETS_BIT_KHR). Пока макеты наборов дескрипторов совпадают с любыми общими наборами дескрипторов, мы можем не предоставлять другие макеты наборов дескрипторов этапа во время создания отдельных библиотек этапов.
Простым способом справиться с этим может быть использование разных наборов дескрипторов для каждого этапа шейдера. Вы просто предоставляете схему конвейера, содержащую наборы дескрипторов для каждого этапа, для каждой библиотеки. Наше ядро, однако, этого не делает. Причина, по которой мы этого не делаем, частично связана с производительностью (чтобы мы могли выделить/обновить/связать один набор дескрипторов для динамических ресурсов в VS/FS вместо двух) и частично из-за того, что некоторые реализации Vulkan все еще имеют очень маленькую общее количество поддерживаемых наборов дескрипторов (в частности, некоторые мобильные графические процессоры имеют ограничение в 4).
Наборы дескрипторов разделов нашего движка примерно следующие:
- Набор дескрипторов 0 — динамические ресурсы не привязаны до времени отрисовки для всех этапов
- Набор дескрипторов 1 — статические дескрипторы вершинного шейдера
- Набор дескрипторов 2 — статические дескрипторы фрагментного шейдера
- Набор дескрипторов 3 — дескрипторы без привязки (общие для всех этапов)
Таким образом, для библиотек графических конвейеров мы создаем макеты конвейеров следующим образом:
- Набор дескрипторов 0 — «убер-набор», который содержит все возможные потребляемые динамически связанные ресурсы, которые могут совместно использоваться в VS/FS
- Набор дескрипторов 1 — предоставляется только библиотеке предварительной растеризации (вершинному шейдеру), если она используется
- Набор дескрипторов 2 — предоставляется только для библиотеки фрагментных шейдеров, если она используется
- Набор дескрипторов 3 — предоставляется для обеих ступеней, если используется
Другими словами, библиотека вершинных шейдеров создается с конвейерной компоновкой, содержащей наборы дескрипторов 0, 1 и 3. Библиотека фрагментных шейдеров создается с конвейерной компоновкой, содержащей наборы дескрипторов 0, 2 и 3. Мы знаем, что наборы 1, 2 и 3 будут иметь идентичные макеты на всех используемых этапах, и мы также гарантировали это для набора дескрипторов 0, сделав его «убер-набором», содержащим все возможные потребляемые ресурсы.
Библиотека фрагментных шейдеров создается с конвейерной компоновкой, содержащей наборы дескрипторов 0, 2 и 3. Мы знаем, что наборы 1, 2 и 3 будут иметь идентичные макеты на всех используемых этапах, и мы также гарантировали это для набора дескрипторов 0, сделав его «убер-набором», содержащим все возможные потребляемые ресурсы.
И последнее замечание: схема конвейера должна также содержать неизменяемые сэмплеры и константы push. Для нас push-константа является общим ресурсом для разных стадий, поэтому у нас есть информация, чтобы применить ее к обеим стадиям шейдера при создании макетов для каждой стадии (она уже не может различаться между стадиями из-за того, как мы ее используем). Точно так же неизменяемое состояние сэмплера известно заранее, поэтому мы можем включить его в макет конвейера.
Интерфейс ввода вершин и интерфейс вывода фрагментов
Используя то, что я описал до сих пор, мы теперь можем сразу скомпилировать наши вершинные и фрагментные шейдеры, используя только SPIR-V и компоновку конвейера. Нам нужно построить еще два этапа: входной интерфейс вершины и выходной интерфейс фрагмента. Эти биты информации все еще неизвестны до момента отрисовки, поэтому мы хешируем подмножество информации, необходимой для интерфейса ввода вершины и интерфейса вывода фрагмента. Эти этапы должны быть небольшими по количеству (я измерил менее сорока в рабочей нагрузке нашего движка), а также быстро создаваться. В отличие от других этапов, для компиляции драйвера не требуется кода шейдера.
Нам нужно построить еще два этапа: входной интерфейс вершины и выходной интерфейс фрагмента. Эти биты информации все еще неизвестны до момента отрисовки, поэтому мы хешируем подмножество информации, необходимой для интерфейса ввода вершины и интерфейса вывода фрагмента. Эти этапы должны быть небольшими по количеству (я измерил менее сорока в рабочей нагрузке нашего движка), а также быстро создаваться. В отличие от других этапов, для компиляции драйвера не требуется кода шейдера.
Окончательный связанный конвейер
Когда все четыре этапа готовы, мы можем создать окончательную библиотеку связанного конвейера непосредственно перед рисованием с использованием нового материала. Есть некоторые решения, которые необходимо принять при создании окончательного связанного конвейера, которые потенциально обменивают быстрое время соединения на ЦП на снижение производительности графического процессора. То есть, если вы создали отдельные библиотеки конвейеров с помощью VK_PIPELINE_CREATE_RETAIN_LINK_TIME_OPTIMIZATION_INFO_BIT_EXT, вы можете выбрать, хотите ли вы, чтобы драйвер создавал окончательный связанный конвейер с межэтапной оптимизацией.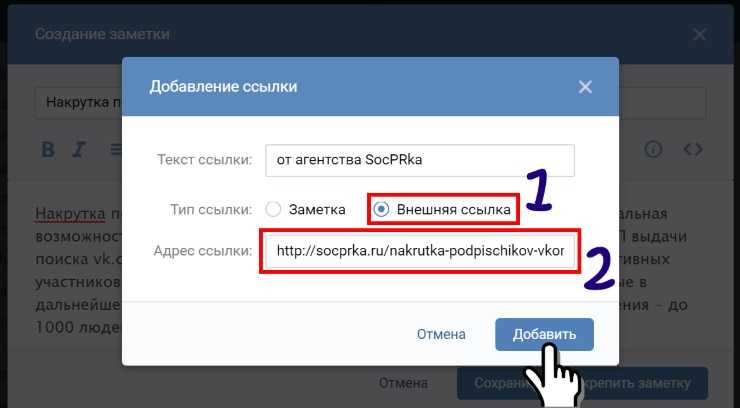 Ожидается, что выполнение кросс-стадийной оптимизации увеличит время ЦП за счет повышения производительности графического процессора.
Ожидается, что выполнение кросс-стадийной оптимизации увеличит время ЦП за счет повышения производительности графического процессора.
Наша цель — добиться отсутствия задержек во время отрисовки, поэтому мы изначально создаем наши связанные библиотеки без набора VK_PIPELINE_CREATE_LINK_TIME_OPTIMIZATION_BIT_EXT. Ожидается, что без установки этого бита создание связанной конвейерной библиотеки в драйвере будет происходить очень быстро. Это будет особенно быстро в реализациях, которые устанавливают VkPhysicalDeviceGraphicsPipelineLibraryPropertiesEXT.graphicsPipelineLibraryFastLinking (что верно, по крайней мере, для всех поставщиков настольных компьютеров — NVIDIA, AMD и Intel). Ожидается, что даже в тех реализациях, которые не задают GraphicsPipelineLibraryFastLinking, связывание библиотеки конвейера будет значительно быстрее, чем полное соединение PSO.
После создания конвейерной библиотеки с быстрым связыванием без оптимизации мы запускаем компиляцию конвейерной библиотеки с VK_PIPELINE_CREATE_LINK_TIME_OPTIMIZATION_BIT_EXT в фоновом потоке и подкачиваем ее, когда она будет готова.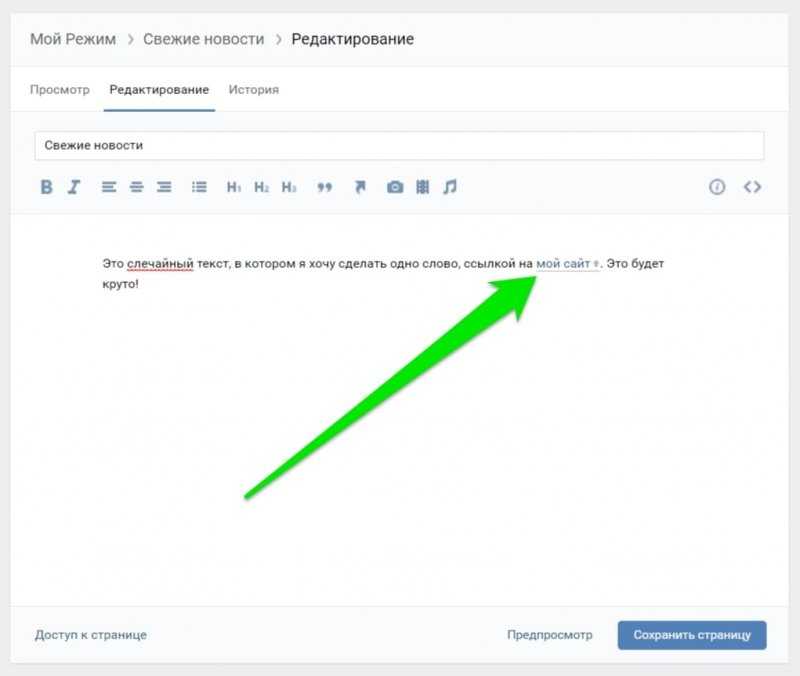 Таким образом, мы избегаем заминок при первом создании конвейерной библиотеки, но можем восстановить полную производительность графического процессора, как только у нас будет время выполнить кросс-стадийную оптимизацию в фоновом режиме. Этот выбор полностью зависит от приложения: некоторые приложения, менее чувствительные к заиканиям, могут всегда создавать конвейерную библиотеку, связанную с несколькими этапами. Они по-прежнему должны ожидать значительного улучшения ЦП по сравнению с созданием полного PSO, поскольку большая часть компиляции будет перемещена раньше.
Таким образом, мы избегаем заминок при первом создании конвейерной библиотеки, но можем восстановить полную производительность графического процессора, как только у нас будет время выполнить кросс-стадийную оптимизацию в фоновом режиме. Этот выбор полностью зависит от приложения: некоторые приложения, менее чувствительные к заиканиям, могут всегда создавать конвейерную библиотеку, связанную с несколькими этапами. Они по-прежнему должны ожидать значительного улучшения ЦП по сравнению с созданием полного PSO, поскольку большая часть компиляции будет перемещена раньше.
Заключение
VK_EXT_graphics_pipeline_library позволяет избежать задержек во время отрисовки за счет более ранней компиляции шейдеров. Хотя это связано с рядом компромиссов, мы считаем, что для некоторых движков, ограниченных существующим контентом / дизайном, это будет чрезвычайно полезно для уменьшения основной причины заминок конвейера. Сочетание библиотек графического конвейера и динамического состояния обеспечивает повышенную гибкость, позволяющую движкам избежать задержки компиляции шейдера до времени отрисовки.