Метод replace() | JavaScript справочник
basicweb.ru- HTML
- Учебник HTML
- Справочник тегов
- Атрибуты событий
- Глобальные атрибуты
- Коды языков
- Мнемоники
- Цвета
- Тесты знаний
- CSS
- Учебник CSS
- Справочник свойств
- Селекторы
- Функции
- Правила
- Flexbox генератор
- Grid генератор
- Учебник LESS
- JavaScript
- Интерфейсы веб API
- Объект Array
- Объект Date
- Объект Function
- Объект Global
- Объект JSON
- Объект Math
- Объект Number
- Объект Object
- Объект RegExp
- Объект Promise
- Объект String
- jQuery
- Селекторы
- События
- Методы DOM
- Перемещения
- Утилиты
- Эффекты
- AJAX
- Объект Callbacks
- Объект Deferred
HTML
- HTML учебник
- Справочник тегов
- Атрибуты событий
- Глобальные атрибуты
- Мнемоники
- Коды языков
- HTML цвета
- Тесты знаний
CSS
- CSS учебник
- Справочник свойств
- CSS селекторы
- CSS функции
- CSS правила
- Flexbox генератор
- Grid генератор
- LESS учебник
JavaScript
- Интерфейсы веб API
- Объект Array
- Объект Date
- Объект Function
- Объект Global
- Объект JSON
- Объект Math β
- Объект Number
- Объект Object
- Объект Promise
- Объект RegExp
- Объект String
jQuery
- jQuery селекторы
- jQuery события
- jQuery методы DOM
- jQuery перемещения
- jQuery утилиты
Регулярные выражения за 15 минут
- IT-шное
- Регулярные выражения за 15 минут
 org/BreadcrumbList»>
org/BreadcrumbList»>Регулярные выражения (regular expressions) — это текстовый шаблон, который соответствует какому-то тексту. И всё? Да, это всё, для чего они нужны.
Что можно делать с помощью регулярных выражений:
- Проверять то, что вводит пользователь, чтобы быть уверенным в правильности данных (например, правильно ли пользователь ввёл email или ip-адрес).
- Разбирать большой текст на меленькие кусочки (например, выбирать данные из большого лога).
- Делать замены по шаблону (например, убирать непечатаемые символы из XML).
- Показывать невероятную крутость тем, кто не знает регулярных выражений.

Большинство современных языков программирования и текстовых редакторов (по моему личному мнению) поддерживают регулярные выражения. Поддержим их и мы.
/Быть или не быть/ugi ¶
Синтаксис регулярных выражений прост и логичен. Он разделяется на символ-разделитель (он идёт в начале и конце выражения, обычно это /), шаблон поиска и необязательные модификаторы.
Формальный синтаксис такой:
[разделитель][шаблон][разделитель][модификаторы]
Разделителем может быть любой символ, но обычно это / или ~. Важно лишь то, чтобы шаблон начинался и заканчивался одним и тем же разделителем. В самом конце регулярных выражений идут модификаторы, которые нужны, чтобы менять логику работы шаблонов (например делать регистронезависимый поиск).
Давайте разберём выражение /Быть или не быть/ugi:
/ - начальный символ-разделитель Быть или не быть - шаблон поиска / - конечный символ-разделитель ugi - модификаторы (UTF-8, global, case insensitive)
Данное регулярное выражение будет искать текст Быть или не быть не зависимо от регистра по всему тексту неограниченное количество раз.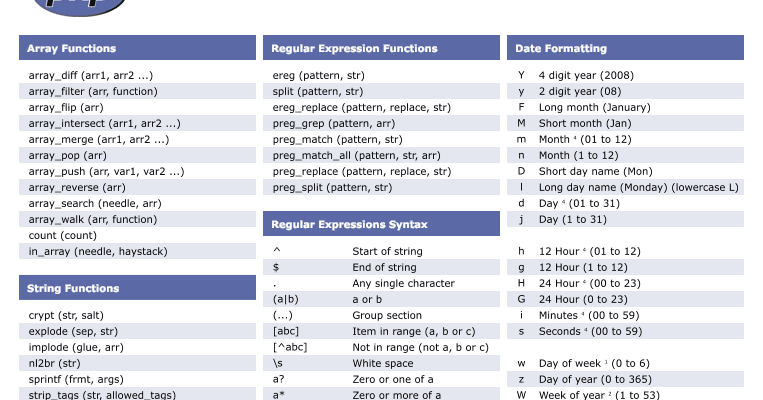 Дом/
Дом/
ДомроднойПетя любит Машу, так и Петя губит МашуВжх и ВжухВжх, Вжух, Вжуух, Вжууух и т.д.Вжух, Вжуух, Вжууух и т.д.Помимо базовых спец. символов есть мета-символы (или мета-последовательности), которые заменяют группы символов:
| Символ | Описание | Пример использования | Результат |
|---|---|---|---|
| \w | Буква, цифра или _ (подчёркивание) | /^\w+$/ | Соответствует целому слову без пробелов, например _Вася333_ |
| \W | НЕ буква, цифра или _ (подчёркивание) | /\W\w+\W/ | Найдёт полное слово, которое обрамлено любыми символами, например @Петя@ |
| \d | Любая цифра | /^\d+$/ | Соответствует целому числу без знака, например 123 |
| \D | Любой символ НЕ цифра | /^\D+$/ | Соответствует любому выражению, где нет цифр, например Петя |
| \s | Пробел или табуляция (кроме перевода строки) | /\s+/ | Найдёт последовательность пробелов от одного и до бесконечности |
| \S | Любой символ, кроме пробела или табуляции | /\s+\S/ | Найдёт последовательность пробелов, после которой есть хотя бы один другой символ |
| \b | Граница слова | /\bдом\b/ | Найдёт только отдельные слова дом, но проигнорирует рядом |
| \B | НЕ граница слова | /\Bдом\b/ | Найдёт только окночние слов, которые заканчиваются на дом |
| \R | Любой перевод строки (Unix, Mac, Windows) | /. *\R/ *\R/ | Найдёт строки, которые заканчиваются переводом строки |
Нужно отметить, что спец. символы \w, \W, \b и \B не работают по умолчанию с юникодом (включая кириллицу). Для их правильной работы нужно указывать модификатор u. К сожалению, на окончание 2019 года JavaScript не поддерживает регулярные выражения для юникода даже с модификатором, поэтому в js эти мета-символы работают только для латиницы.
Ещё регулярные выражения поддерживают разные виды скобочек:
| Выражение | Описание | Пример использования | Результат |
|---|---|---|---|
| (…) | Круглые скобки означают под-шаблон, который идёт в результат поиска | /(Петя|Вася|Саша) любит Машу/ | Найдёт всю строку и запишет воздыхателя Маши в результат поиска под номером 1 |
| (?:…) | Круглые скобки с вопросом и двоеточием означают под-шаблон, который НЕ идёт в результат поиска | /(?:Петя|Вася|Саша) любит Машу/ | Найдёт только полную строку, воздыхатель останется инкогнито |
(?P<name>. [:print:]]+/ [:print:]]+/ | Найдёт последовательность непечатаемых символов | ||
| {n} | Фигурные скобки с одним числом задают точное количество символов | /\w+н{2}\w+/u | Найдёт слово, в котором две буквы н |
| {n,k} | Фигурные скобки с двумя числами задают количество символов от n до k | /\w+н{1,2}\w+/u | Найдёт слово, в котором есть одна или две буквы н |
| {n,} | Фигурные скобки с одним числом и запятой задают количество символов от n до бесконечности | /\w+н{3,}\w+/u | Найдёт слово, в котором н встречается от трёх и более раз подряд |
Как правильно писать регулярные выражения ¶
Прежде, чем садиться и писать регулярно выраженного кракена, подумайте, что именно вы хотите сделать. Регулярное выражение должно начинаться с мысли «Я хочу найти/заменить/удалить то-то и то-то». Затем вам нужен исходный текст, который содержит как ПРАВИЛЬНЫЕ, так и НЕправильные данные. Затем вы открываете https://regex101. com/, вставляете текст и начинаете писать регулярное выражение. Этот замечательный инструмент укажет и покажет все ошибки, а также подсветит результаты поиска.
com/, вставляете текст и начинаете писать регулярное выражение. Этот замечательный инструмент укажет и покажет все ошибки, а также подсветит результаты поиска.
Для примера возьмём валидацию ip-адреса. Первая мысль должна быть: «Я хочу валидировать ip-адрес. А что такое ip-адрес? Из чего он состоит?». Затем нужен список валидных и невалидных адресов:
0.0.0.0
0.1.2.3
99.99.99.99
199.199.199.199
255.255.255.255
01.01.01.01
.1.2.3
1.2.3.
255.0.0.256
Валидный адрес должен содержать четыре числа (байта) от 0 до 255. Если он содержит число больше 255, это уже ошибка. Если бы мы делали валидацию на каком-либо языке программирования, то можно было бы разбить выражение на четыре части и проверить каждое число отдельно. Но регулярные выражения не поддерживают проверки больше или меньше, поэтому придётся делать по-другому.
Для начала упростим задачу: будем валидировать не весь ip-адрес, а только один байт. А байт это всегда есть либо одно-, либо дву-, либо трёхзначное число. Для одно- и двузначного числа шаблон очень простой — любая цифра. А вот для трёхзначного числа первая цифра либо единица, либо двойка. Если первая цифра единица, то вторая и третья могут быть от нуля до девяти. Если же первая цифра двойка, то вторая может быть только от нуля до пяти. Если первая цифра двойка и вторая пятёрка, то третья может быть только от ноля до пяти. Давайте формализуем:
Для одно- и двузначного числа шаблон очень простой — любая цифра. А вот для трёхзначного числа первая цифра либо единица, либо двойка. Если первая цифра единица, то вторая и третья могут быть от нуля до девяти. Если же первая цифра двойка, то вторая может быть только от нуля до пяти. Если первая цифра двойка и вторая пятёрка, то третья может быть только от ноля до пяти. Давайте формализуем:
от 0 до 9 \d
от 10 до 99 [1-9]\d
от 100 до 199 1\d\d
от 200 до 249 2[0-4]\d
от 250 до 255 25[0-5]
Теперь, зная все диапазоны байта, можно объединить их в одно выражение через вертикальную палочку | (ИЛИ):
\b(\d|[1-9]\d|1\d\d|2[0-4]\d|25[0-5])\b
Обратите внимание, что я использовал границу слова \b, чтобы искать полные байты. Пробуем регулярку в деле:
Как видим, все байты стали зелёненькими. Это значит, что мы на верном пути.
Осталось дело за малым: сделать так, чтобы искать четыре байта, а не один. Нужно учесть, что байты разделены тремя точками. То есть мы ищем три байта с точкой на конце и один без точки:
Нужно учесть, что байты разделены тремя точками. То есть мы ищем три байта с точкой на конце и один без точки:
(\b(\d|[1-9]\d|1\d\d|2[0-4]\d|25[0-5])\b\.){3}\b(\d|[1-9]\d|1\d\d|2[0-4]\d|25[0-5])\b
Результат выглядит так:
Подсветились только валидные ip-адреса, значит регулярное выражение работает корректно.
Если бы я сразу начал писать валидацию всего адреса, а не отдельного байта, то с большой долей вероятности допустил бы ошибку. Скопления скобочек, палочек и точечек трудно воспринимаются на глаз, поэтому задачу надо обязательно упрощать.
Практическое применение регулярных выражений ¶
Регулярными выражениями можно пользоваться не только для валидации, но и для обработки данных, например, в блокноте. Вот практический пример такой обработки: скопировать номера регионов и перевести в формат PHP-массива.
Your browser does not support HTML5 video.
Ссылки ¶
Хорошая статья, мне понравилась. Оставлю отзыв!
Что-то статья не очень. Поругаю-ка я автора.
Оставлю отзыв!
Что-то статья не очень. Поругаю-ка я автора.
© 2021 Антон Прибора. При копировании материалов с сайта, пожалуйста, указывайте ссылку на источник.
Шпаргалка по регулярным выражениям
Квантификаторы
| Аналог | Пример | Описание | |
|---|---|---|---|
| ? | {0,1} | a? | одно или ноль вхождений «а» |
| + | {1,} | a+ | одно или более вхождений «а» |
| * | {0,} | a* | ноль или более вхождений «а» |
Модификаторы
Символ «минус» (-) меред модификатором (за исключением U) создаёт его отрицание.
| Описание | |||
|---|---|---|---|
| g | глобальный поиск (обрабатываются все совпадения с шаблоном поиска) | ||
| i | игнорировать регистр | ||
| m | многострочный поиск. Поясню: по умолчанию текст это одна строка, с модификатором есть отдельные строки, а значит ^— начало строки в тексте, $— конец строки в тексте. a a | aaa aaa | начало строки |
| $ | a$ | aaa aaa | конец строки |
| \A | \Aa | aaa aaa aaa aaa | начало текста |
| \z | a\z | aaa aaa aaa aaa | конец текста |
| \b | a\b \ba | aaa aaa aaa aaa | граница слова, утверждение: предыдущий символ словесный, а следующий — нет, либо наоборот |
| \B | \Ba\B | aaa aaa | отсутствие границы слова |
| \G | \Ga | aaa aaa | Предыдущий успешный поиск, поиск остановился на 4-й позиции — там, где не нашлось a |
Якоря
Якоря в регулярных выражениях указывают на начало или конец чего-либо. Например, строки или слова. Они представлены определенными символами. К примеру, шаблон, соответствующий строке, начинающейся с цифры, должен иметь следующий вид:
^[0-9]+Здесь символ ^обозначает начало строки. Без него шаблон соответствовал бы любой строке, содержащей цифру.
Без него шаблон соответствовал бы любой строке, содержащей цифру.
Символьные классы
Символьные классы в регулярных выражениях соответствуют сразу некоторому набору символов. Например, \dсоответствует любой цифре от 0 до 9 включительно, \wсоответствует буквам и цифрам, а
\W— всем символам, кроме букв и цифр. Шаблон, идентифицирующий буквы, цифры и пробел, выглядит
так:
\w\sPOSIX
POSIX — это относительно новое дополнение семейства регулярных выражений. Идея, как и в случае с символьными классами, заключается в использовании сокращений, представляющих некоторую группу символов.
Утверждения
Поначалу практически у всех возникают трудности с пониманием утверждений, однако познакомившись с ними ближе, вы
будете использовать их довольно часто. Утверждения предоставляют способ сказать: «я хочу найти в этом документе
каждое слово, включающее букву “q”, за которой не следует “werty”». \s]*).
\s]*).
Кванторы
Кванторы позволяют определить часть шаблона, которая должна повторяться несколько раз подряд. Например, если вы хотите выяснить, содержит ли документ строку из от 10 до 20 (включительно) букв «a», то можно использовать этот шаблон:
a{10,20}По умолчанию кванторы — «жадные». Поэтому квантор +, означающий «один или больше раз», будет
соответствовать максимально возможному значению. Иногда это вызывает проблемы, и тогда вы можете сказать квантору
перестать быть жадным (стать «ленивым»), используя специальный модификатор. Посмотрите на этот код:
".*"Этот шаблон соответствует тексту, заключенному в двойные кавычки. Однако, ваша исходная строка может быть вроде этой:
<a href="helloworld.htm" title="Привет, Мир">Привет, Мир</a>Приведенный выше шаблон найдет в этой строке вот такую подстроку:
"helloworld.htm" title="Привет, Мир"Он оказался слишком жадным, захватив наибольший кусок текста, который смог.
".*?"Этот шаблон также соответствует любым символам, заключенным в двойные кавычки. Но ленивая версия (обратите внимание
на модификатор ?) ищет наименьшее из возможных вхождений, и поэтому найдет каждую подстроку в двойных
кавычках по отдельности:
"helloworld.htm" "Привет, Мир"Экранирование в регулярных выражениях
Регулярные выражения используют некоторые символы для обозначения различных частей шаблона. Однако, возникает
проблема, если вам нужно найти один из таких символов в строке, как обычный символ. Точка, к примеру, в регулярном
выражении обозначает «любой символ, кроме переноса строки». Если вам нужно найти точку в строке, вы не можете просто
использовать «.» в качестве шаблона — это приведет к нахождению практически всего. Итак, вам
необходимо сообщить парсеру, что эта точка должна считаться обычной точкой, а не «любым символом». Это делается с
помощью знака экранирования.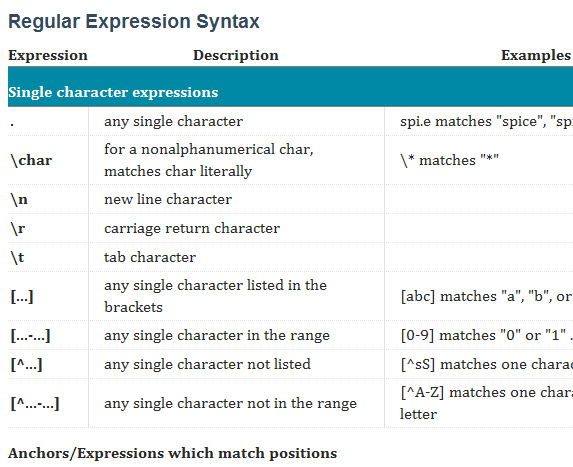
Знак экранирования, предшествующий символу вроде точки, заставляет парсер игнорировать его функцию и считать обычным символом. Есть несколько символов, требующих такого экранирования в большинстве шаблонов и языков. Вы можете найти их в правом нижнем углу шпаргалки («Мета-символы»).
Шаблон для нахождения точки таков:
\.Другие специальные символы в регулярных выражениях соответствуют необычным элементам в тексте. Переносы строки и табуляции, к примеру, могут быть набраны с клавиатуры, но вероятно собьют с толку языки программирования. Знак экранирования используется здесь для того, чтобы сообщить парсеру о необходимости считать следующий символ специальным, а не обычной буквой или цифрой.
Спецсимволы экранирования в регулярных выражениях
| Выражение | Соответствие |
|---|---|
| \ | не соответствует ничему, только экранирует следующий за ним символ. Это нужно, если вы хотите ввести метасимволы !$()*+.в качестве их буквальных значений. |
| \Q | не соответствует ничему, только экранирует все символы вплоть до \E |
| \E | не соответствует ничему, только прекращает экранирование, начатое \Q |
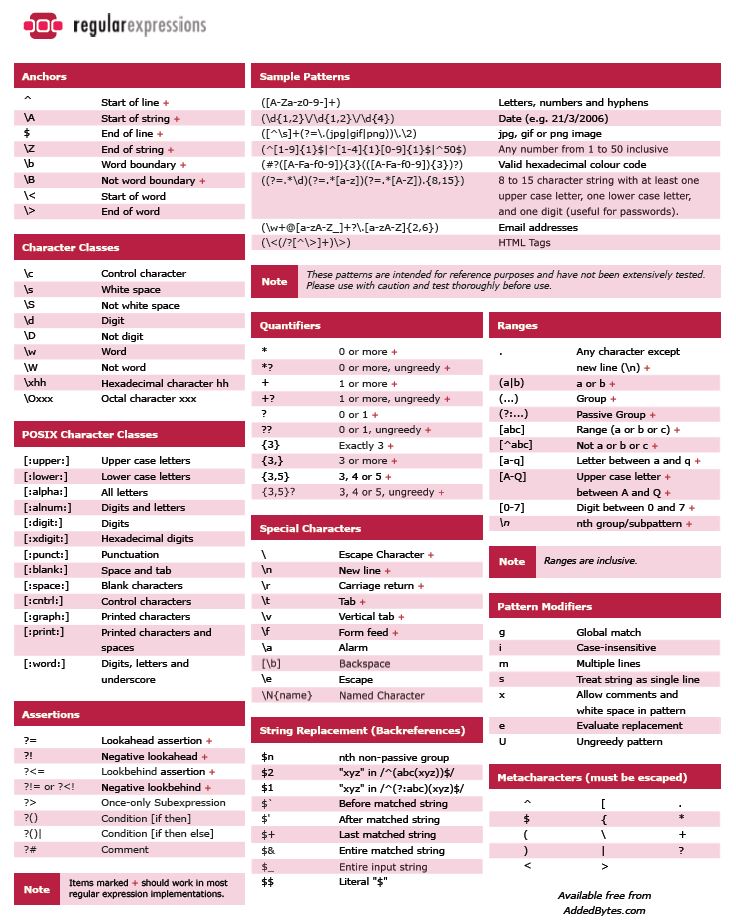 {|}
{|}Подстановка строк
Подстановка строк подробно описана в следующем параграфе «Группы и диапазоны», однако здесь следует упомянуть о существовании «пассивных» групп. Это группы, игнорируемые при подстановке, что очень полезно, если вы хотите использовать в шаблоне условие «или», но не хотите, чтобы эта группа принимала участие в подстановке.
Группы и диапазоны
Группы и диапазоны очень-очень полезны. Вероятно, проще будет начать с диапазонов. Они позволяют указать набор подходящих символов. Например, чтобы проверить, содержит ли строка шестнадцатеричные цифры (от 0 до 9 и от A до F), следует использовать такой диапазон:
[A-Fa-f0-9]Чтобы проверить обратное, используйте отрицательный диапазон, который в нашем случае подходит под любой символ, кроме цифр от 0 до 9 и букв от A до F:
[^A-Fa-f0-9]Группы наиболее часто применяются, когда в шаблоне необходимо условие «или»; когда нужно сослаться на часть шаблона
из другой его части; а также при подстановке строк.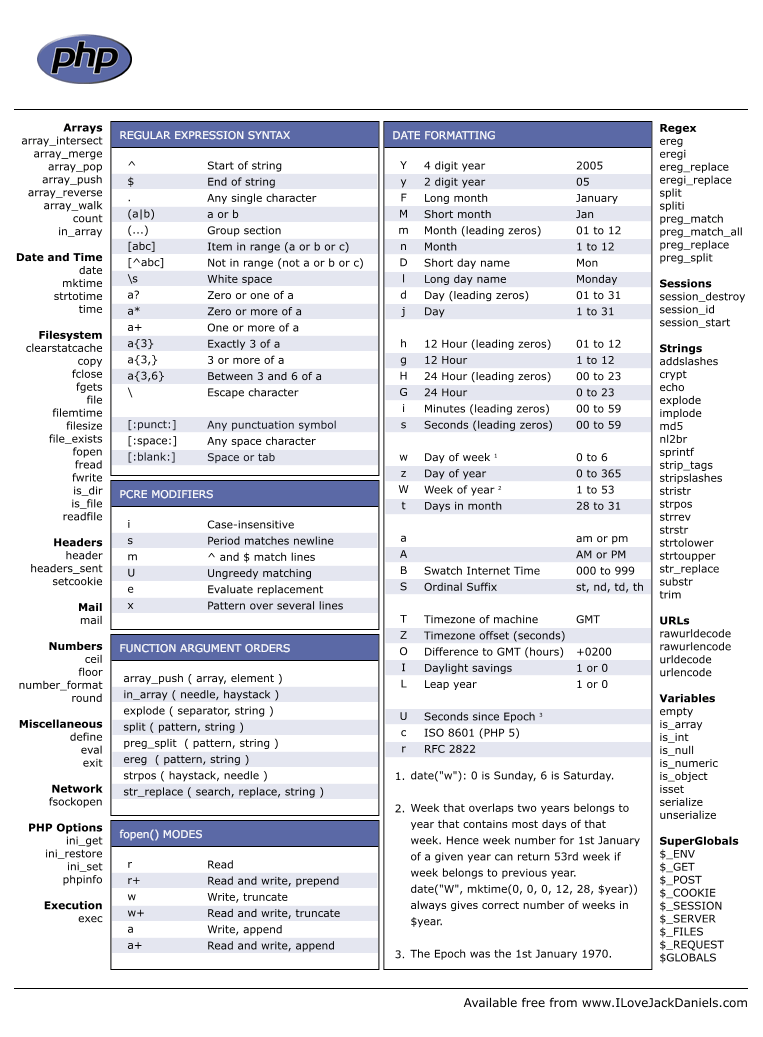
Использовать «или» очень просто: следующий шаблон ищет «ab» или «bc»:
(ab|bc)Если в регулярном выражении необходимо сослаться на какую-то из предшествующих групп, следует использовать
\n, где вместо nподставить номер нужной группы. Вам может понадобиться шаблон,
соответствующий буквам «aaa» или «bbb», за которыми следует число, а затем те же три буквы. Такой шаблон реализуется
с помощью групп:
(aaa|bbb)[0-9]+\1Первая часть шаблона ищет «aaa» или «bbb», объединяя найденные буквы в группу. За этим следует поиск одной или более
цифр ([0-9]+), и наконец \1. Последняя часть шаблона ссылается на первую группу и ищет то
же самое. Она ищет совпадение с текстом, уже найденным первой частью шаблона, а не соответствующее ему. Таким
образом, «aaa123bbb» не будет удовлетворять вышеприведенному шаблону, так как \1будет искать «aaa»
после числа. A-Za-z0-9])
A-Za-z0-9])
Он найдет любые вхождения слова «wish» вместе с предыдущим и следующим символами, если только это не буквы или цифры. Тогда ваша подстановка может быть такой:
$1<b>$2</b>$3Ею будет заменена вся найденная по шаблону строка. Мы начинаем замену с первого найденного символа (который не буква
и не цифра), отмечая его $1. Без этого мы бы просто удалили этот символ из текста. То же касается конца
подстановки ($3). В середину мы добавили HTML тег для жирного начертания (разумеется, вместо него вы
можете использовать CSS или <strong>), выделив им вторую группу, найденную по шаблону
($2).
Модификаторы шаблонов
Модификаторы шаблонов используются в нескольких языках, в частности, в Perl. Они позволяют изменить работу парсера.
Например, модификатор iзаставляет парсер игнорировать регистры.
Регулярные выражения в Perl обрамляются одним и тем же символом в начале и в конце. Это может быть любой символ (чаще
используется «/»), и выглядит все таким образом:
Это может быть любой символ (чаще
используется «/»), и выглядит все таким образом:
/pattern/Модификаторы добавляются в конец этой строки, вот так:
/pattern/iМета-символы
Наконец, последняя часть таблицы содержит мета-символы. Это символы, имеющие специальное значение в регулярных выражениях. Так что если вы хотите использовать один из них как обычный символ, то его необходимо экранировать. Для проверки наличия скобки в тексте, используется такой шаблон:
\(Шпаргалка представляет собой общее руководство по шаблонам регулярных выражений без учета специфики какого-либо языка. Она представлена в виде таблицы, помещающейся на одном печатном листе формата A4. Создана под лицензией Creative Commons на базе шпаргалки, автором которой является Dave Child. Скачать в PDF, PNG.
- Регулярные выражения
Регулярные выражения (regular expressions) — Блог программиста
Все мы используем поиск по строкам. Это касается не только программистов, но и любых бабушек, работающих с компьютером. При этом, одни люди страдают, а другие — используют регулярные выражения. Пара ситуаций для привлечения интереса:
Это касается не только программистов, но и любых бабушек, работающих с компьютером. При этом, одни люди страдают, а другие — используют регулярные выражения. Пара ситуаций для привлечения интереса:
- Вы пишете программу, в которой обрабатываются номера телефонов, допустим в формате +7(ххх)ххх-хх-хх. Возможно их надо найти в тексте, а может быть — проверить корректность. На месте номеров могли бы быть номер банковской карты, IP-адрес, электронная почта, ФИО (в формате Петров А.Ю.), да и вообще что угодно.
- В Microsoft Word при поиске и замене можно включить режим поддержки регулярных выражений поставив галочку напротив пункта «подстановочные знаки». Потом можно искать все то, что указано в первом пункте, но программу писать не требуется. И заменять можно. В LibreOffice/OpenOffice это тоже поддерживается.
- Естественно, регулярные выражения поддерживаются во всех современных средах разработки — Qt Creator, Microsoft Visual Studio, NetBeans, IntelliJ IDEA и даже блокнотах — Notepad++, kate, gedit и др.
 Вы пишете код и решили что-то переименовать, да как-то особенно…
Вы пишете код и решили что-то переименовать, да как-то особенно…
Остается научиться всем этим пользоваться. Значительную часть описанных ниже примеров можно проверить в том же Notepad++ или Microsoft Word. Для других (связанных с программированием) — можно использовать сервис regex101, он удобен не только для обучения, но и для реальной разработки.
Содержание:
- Теоретический раздел
- Одиночные символы
- Квантификация
- Группировка (подвыражения)
- Что есть еще?
- Практический раздел. Ссылки
1 Теоретический раздел
Регулярные выражения представляют собой своеобразный язык описания строк. При этом, как и в любом языке, в нем есть определенные синтаксические конструкции и правила.
1.1 Одиночные символы
Символ «точка» (.) заменяет в регулярных выражениях любой символ. Так, например, если в тексте есть слова "порог" и "пирог" — то выражение "п. будет удовлетворять обоим из них. Ниже приведен пример такого поиска в тектовом редакторе kate, остальные примеры будут даваться без скриншотов. рог"
рог"
Если же нас интересуют не все варианты замены символа — используется представление с квадратными скобками. В скобках перечисляются альтернативные символы. Также, в квадратных скобках можно задавать диапазоны символов с помощью «тире». Ниже приведена схема для выражения «var_[a-d][123]», можно попробовать выписать строки, которое оно описывает:
Если символ «тире» должен являться частью перечисления — его нужно ставить первым или последним. Например, в таком выражении:
ставить тире между
"+" и "*" нельзя, так как это будет интерпретировано как диапазон.Также с помощью перечислений можно искать «все символы кроме», для этого первым символом перечисления должен быть "^". 0-9]»
0-9]»
"\s""\S""\w""\W""\b""\B"Такие обозначения могут использоваться в качестве элементов перечисления, например "[\d\w]" соответствует букве или цифре.
1.2 Квантификация
Все, что написано выше не очень полезно без кванторов, с их помощью можно задавать количество повторений, стоящего слева от них символа. Все они приведены в таблице:
| Выражение | Количество повторений |
|---|---|
"*" | 0 или более раз |
"+" | 1 или более раз |
"?" | 0 или 1 раз |
"{n}" | точно n раз |
"{n,m}" | от n до m раз |
С помощью кванторов мы можем описать, например строку, содержащую номер банковской карты:
Под такое описание подойдут, например, строки "1234-1234-1234-1234" и "12345678 12345678".
1.3 группировка (подвыражения)
Выражение может состоять из подвыражений, заключенных в круглые скобки. Для программиста это очень важно, так как к подвыражению можно обратиться по индексу. Кроме того, подвыражения используются для задания альтернатив, которые можно перечислять с помощью вертикальной черты. Так, например, следующее выражение соответствует строкам «+7 902», «8(902)» и еще множеству вариантов:
Тут "\(" используется для экранирования скобок. Подвыражения на практике применяются очень часто, но нам не всегда нужна возможность получить подстроку, соответствующую подвыражению. При выборе подстрок в коде вашей программы «лишние» подвыражения мешают, из-за них «съезжают» индексы, исправить ситуацию можно с использованием следующего синтаксиса: "(?:pattern)". Кроме того, такая форма записи более эффективна, т.к. сохраняет меньше данных.
Также, с группами связано так называемое «заглядывание вперед» — это нечасто применяемая на практике техника позволяет проверить соответствие подвыражению, не смещая позицию поиска и не запоминая найденное соответствие. Синтаксис используется следующий "(?=pattern)". Пусть дан следующий файл со списком языков программирования:
Basic структурный Lua процедурный Prolog логический С++ объектно-ориентированный Lisp функциональный Logo функциональный
По выражению
мы ожидаемо получим три строки, однако что если, к уже найденному подвыражению требуется применить какие-то дополнительные «фильтры»? То есть, после этой проверки мы хотим еще раз проверить названия языков. Сделать это можно заменив
"?:" на "?=".Теперь будут получены только две строки — Lua и Lisp, а второе подвыражение "(. будет сопоставлено с типами соответствующих языков. *)"
*)"
Негативное заглядывания вперед ищет "(?!pattern)". Такое выражение выбирает подстроки, не соответствующие "pattern" без запоминания подстроки и не смещая текущую позицию поиска. Так, для рассмотренного выше примера, такой тип заглядывания вернет единственную строку с языком Logo. Первое подвыражение выберет строки с языками Basic, Prolog, С++ и Logo, а второе — оставит из них только те, чьи названия начинаются с символа "L".
1.4 Что есть еще?
Наряду с заглядыванием вперед, в некоторых реализациях поддерживается позитивное и негативное заглядывания назад — "(?<=шаблон)" и "(?<!шаблон)", соответственно. Полезно знать, что нечто подобное существует, чтобы в случае чего — найти в справочнике и применить.
Полезно знать, что нечто подобное существует, чтобы в случае чего — найти в справочнике и применить.
Описанное выше должно одинаково работать в любой среде, поддерживающей регулярные выражения, однако в отдельных реализациях доступно больше возможностей или синтаксис выражений может незначительно отличаться. С помощью регулярных выражений можно искать строки в тексте, однако в каком регистре выполняется поиск? — ответ зависит от реализации. Управлять регистром можно с помощью модификаторов : "(?i)" включает чувствительность к регистру, а "(?-i)" — выключает ее. Существуют и другие модификаторы, но они используются реже. Работа модификаторов зависит от реализации. Некоторые реализации поддерживают также флаги, которыми также можно управлять регистром.
Ряд реализаций поддерживает очень удобный поиск по условию: "(?(?=если)то|иначе)". Нечто подобное позволяет реализовать «просмотр вперед». «Если» условие выполнится — будет выполнено сопоставление с «то», в противном случае — с «иначе». Сопоставление в данном случае создает группу, к которой можно обратиться по индексу из вашего кода.
Нечто подобное позволяет реализовать «просмотр вперед». «Если» условие выполнится — будет выполнено сопоставление с «то», в противном случае — с «иначе». Сопоставление в данном случае создает группу, к которой можно обратиться по индексу из вашего кода.
2 Практический раздел. Ссылки
Перед тем, как использовать регулярные выражения, стоит посмотреть в документацию по вашему языку программирования и используемой библиотеке, так как диалекты обладают особенностями. Например в Perl и некоторых версиях php можно описывать рекурсивные регулярные выражения, которые не поддерживаются большинством других реализаций; механизмом флагов отличается JavaScript и так далее. Незначительными отличиями могут обладать даже различные версии одной и той же библиотеки.
Отличаются регулярные выражения не только синтаксисом, но и реализацией. Регулярные выражения — это «не просто так». Строка, задающее выражение, преобразуется в автомат, от реализации которого зависит эффективность. Масштаб проблемы хорошо иллюстрирует график зависимости времени выполнения поиска от длины строки и реализации:
Масштаб проблемы хорошо иллюстрирует график зависимости времени выполнения поиска от длины строки и реализации:
Картинка взята из статьи «Поиск с помощью регулярных выражений может быть простым и быстрым«. В ней можно прочитать про различные реализации выражений, а также о том, как написать выражение так, чтобы оно работало быстрее. Кстати, так как выражение преобразуется в автомат, то зачастую его удобно визуализировать — для этого есть специальные сервисы, например. Для последнего выражения статьи будет построен такой автомат:
Примеры использования регулярных выражений:
- для валидации вводимых в поля данных: QValidator примеры использования. Ряд библиотек построения графического пользовательского интерфейса позволяют закреплять к полям ввода валидаторы, которые не позволяет ввести в формы некорректные данные. По приведенной выше ссылке можно найти валидацию номера банковской карты и номера телефона с помощью регулярных выражений библиотеки Qt.
 Аналогичные механизмы есть в других языках, например в Java для этого используется пакет
Аналогичные механизмы есть в других языках, например в Java для этого используется пакет javax.faces.validator.Validator; - для парсинга сайтов: Парсер сайта на Qt, использование QRegExp. В примере с сайта-галереи выбираются и скачиваются картинки заданных категорий;
- для валидации данных, передаваемых в формате JSON ряд библиотек позволяет задавать схему. При этом для строковых полей могут быть заданы регулярные выражения. В качестве упражнения можно попробовать составить выражение для пароля — проверить что строка содержит символы в разном регистре и цифры.
В сообществе Программирование и алгоритмы можно посмотреть дополнительную литературу по теме. Книгу Гойвертса и Левитана рекомендую посмотреть особенно, так как в ней по-полочкам разобраны десятки примеров, причем с учетом специфики реализации регулярных выражений в конкретных языках программирования.
Регулярные выражения онлайн конструктор
Все статьиРегулярные выражения онлайн конструктор Флаг:
PREG_SET_ORDERPREG_PATTERN_ORDERPREG_OFFSET_CAPTURE
Шаблон:
Текст:
Проверить
Управляющие символы
| Представление | Символ | Расшифровка |
|---|---|---|
| \t | Табуляция | Horizontal tabulation |
| \v | Вертикальная табуляция | Vertical tabulation |
| \r | Возврат каретки | Carriage return |
| \n | Перевод строки | Line feed |
| \f | Конец страницы | Form feed |
| \a | Звонок | Bell character |
| \e | Escape-символ | Escape character |
| \b | Забой Должен находиться внутри квадратных скобок (иначе интерпретируется как граница слова).\s] | Непробельный символ |
Символьные классы POSIX
| POSIX-класс | Эквивалент | Значение | |
|---|---|---|---|
| [:upper:] | [A-Z] | Символы верхнего регистра | |
| [:lower:] | [a-z] | Символы нижнего регистра | |
| [:alpha:] | [[:upper:][:lower:]] | Буквы | |
| [:digit:] | [0-9], т. е. \d | Цифры | |
| [:xdigit:] | [[:digit:]A-Fa-f] | Шестнадцатеричные цифры | |
| [:alnum:] | [[:alpha:][:digit:]] | Буквы и цифры | |
| [:word:] | [[:alnum:]_], т. е. \w | Символы, образующие «слово» | |
| [:punct:] | [-!»#$%&'()* ,./:;?@[\\\]_`{|}~] | Знаки пунктуации | |
| [:blank:] | [ \t] | Пробел и табуляция | |
| [:space:] | [[:blank:]\v\r\n\f], т.a | aaa aaa | |
| $ | Конец строки | a$ | aaa aaa |
| \b | Граница слова | a\b | aaa aaa |
| \ba | aaa aaa | ||
| \B | Не граница слова | \Ba\B | aaa aaa |
| \G | Предыдущий успешный поиск | \Ga | aaa aaa (поиск остановился на 4-й позиции — там, где не нашлось a) |
Представление символов по их коду
| Представление | Пояснение | Кодировка |
|---|---|---|
| \0n | n — восьмеричное число от 0 до 377 | 8-битная |
| \xdd | d — шестнадцатеричная цифра | |
| \udddd | 16-битная (Юникод) |
Квантификация (поиск последовательностей)
| Представление | Число повторений | Пример | Соответствие |
|---|---|---|---|
| {n} | Ровно n раз | colou{3}r | colouuur |
| {m,n} | От m до n включительно | colou{2,4}r | colouur, colouuur, colouuuur |
| {m,} | Не менее m | colou{2,}r | colouur, colouuur, colouuuur и т. д. |
| {,n} | Не более n | colou{,3}r | color, colour, colouur, colouuur |
 
| Представление | Число повторений | Эквивалент | Пример | Соответствие |
|---|---|---|---|---|
| * | Ноль или более | {0,} | colou*r | color, colour и т. д. |
| + | Одно или более | {1,} | colou r | colour, colouur и т. д. (но не color) |
| ? | Ноль или одно | {0,1} | colou?r | color, colour |
Перечисление
Вертикальная черта разделяет допустимые варианты. Например, gray|grey соответствует gray или grey. Следует помнить, что перебор вариантов выполняется слева направо, как они указаны.
Если требуется указать перечень вариантов внутри более сложного регулярного выражения, то его нужно заключить в группу.(?=.*[A-Z].*[A-Z])(?=.*[!@#$&*])(?=.*[0-9].*[0-9])(?=.*[a-z].*[a-z].*[a-z]).{8}$
Надежность пароля — довольно субъективное понятие, поэтому не существует универсального решения для проверки. Однако, приведенный выше пример регулярного выражения может стать хорошей отправной точкой, если вы не желаете придумывать выражение для проверки пароля с нуля.
Код цвета в шестнадцатеричном формате
?\#([a-fA-F]|[0-9]){3, 6}
Шестнадцатеричные коды цветов используются при веб-разработке очень часто. Это регулярное выражение может быть поможет сравнить: совпадает ли какая-либо строка с шаблоном шестнадцатеричного кода.
Проверка адреса электронной почты
?/[A-Z0-9._%+-]+@[A-Z0-9-]+.+.[A-Z]{2,4}/igm Одной из самых распространенных задач при разработке является проверка соответствия введенной пользователем строки формату адреса электронной почты. Существует множество различных вариантов выражений для решения этой задачи, автор этой статьи предлагает свой оригинальный вариант.
IP-адрес (v4)
?/\b(?:(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.){3}(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\b/ Как e-mail может использоваться для идентификации посетителя, так IP-адрес является идентификатором конкретного компьютера в сети. Приведенное регулярное выражение проверяет соответствие строки формату IP-адреса v4.
IP-адрес (v6)
?(([0-9a-fA-F]{1,4}:){7,7}[0-9a-fA-F]{1,4}|([0-9a-fA-F]{1,4}:){1,7}:|([0-9a-fA-F]{1,4}:){1,6}:[0-9a-fA-F]{1,4}|([0-9a-fA-F]{1,4}:){1,5}(:[0-9a-fA-F]{1,4}){1,2}|([0-9a-fA-F]{1,4}:){1,4}(:[0-9a-fA-F]{1,4}){1,3}|([0-9a-fA-F]{1,4}:){1,3}(:[0-9a-fA-F]{1,4}){1,4}|([0-9a-fA-F]{1,4}:){1,2}(:[0-9a-fA-F]{1,4}){1,5}|[0-9a-fA-F]{1,4}:((:[0-9a-fA-F]{1,4}){1,6})|:((:[0-9a-fA-F]{1,4}){1,7}|:)|fe80:(:[0-9a-fA-F]{0,4}){0,4}%[0-9a-zA-Z]{1,}|::(ffff(:0{1,4}){0,1}:){0,1}((25[0-5]|(2[0-4]|1{0,1}[0-9]){0,1}[0-9])\.){3,3}(25[0-5]|(2[0-4]|1{0,1}[0-9]){0,1}[0-9])|([0-9a-fA-F]{1,4}:){1,4}:((25[0-5]|(2[0-4]|1{0,1}[0-9]){0,1}[0-9])\.\s]*$ //соответствует фразе из 5 и более ключевых словЭто действительно полезные выражения для пользователей Google Analytics и инструмента для веб-мастеров. Ведь с помощью них можно отсортировать ключевые фразы, используемые посетителями при поиске по количеству слов, входящих в них.
Выражения могут проверять фразы, содержащие определенное количество слов (например, 5), а также фразы количество слов в которых более двух, трех и т.д. Одно из самых мощных выражений, используемое для сортировки данных аналитики.
Поиск валидной строки Base64 в PHP
?\?php[ \t]eval\(base64_decode\(\'(([A-Za-z0-9+/]{4})*([A-Za-z0-9+/]{3}=|[A-Za-z0-9+/]{2}==)?){1}\'\)\)\;
Если вы являетесь PHP-разработчиком, то иногда вам может понадобиться найти объект, закодированный в формате Base64. Указанное выше выражение может использоваться для поиска закодированных строк в любом PHP-коде.
Проверка телефонного номера
?^\+?\d{1,3}?[- .(?:0?[1-9]|1\d|2[0-8])(\/|-|\.)(?:(?:0?[1-9])|(?:1[0-2]))\4(?:(?:1[6-9]|[2-9]\d)?\d{2})$ Проверять даты сложно, потому что они могут быть представлены в различных форматах, в том числе содержащих и числа, и текст.
В PHP имеется отличная функция date(), но она не всегда подходит, ведь в нее может быть передана необработанная строка. Поэтому для проверки указанного формата даты нужно использовать приведенное выше регулярное выражение.
Совпадение строки с адресом видеоролика на YouTube
?/http:\/\/(?:youtu\.be\/|(?:[a-z]{2,3}\.)?youtube\.com\/watch(?:\?|#\!)v=)([\w-]{11}).*/gi
На протяжении нескольких лет на Youtube не меняется структура URL-адресов. Youtube является самым популярным видео хостингом в Интернет, благодаря этому, видео с Youtube набирают наибольший трафик.
Если вам необходимо получить ID какого-либо видеоролика с Youtube, воспользуйтесь приведенным выше регулярным выражением.\s*[a-zA-Z\-]+\s*[:]{1}\s[a-zA-Z0-9\s.#]+[;]{1}
Ситуация, когда придется воспользоваться указанным регулярным выражением, может сложиться очень редко, но не факт что не сложится никогда
Этот код можно использовать когда будет необходимо «вытянуть» какое-либо CSS-правило из списка правил для какого-нибудь селектора.
Удаление комментариев в HTML
?<!--(.*?)--> Если вам необходимо удалить все комментарии из блока HTML-кода, воспользуйтесь этим регулярным выражением. Чтобы получить желаемый результат, вы можете воспользоваться PHP-функцией preg_replace().
Проверка на соответствие ссылке на Facebook-аккаунт
?/(?:http:\/\/)?(?:www\.)?facebook\.com\/(?:(?:\w)*#!\/)?(?:pages\/)?(?:[\w\-]*\/)*([\w\-]*)/ Если вам необходимо узнать у посетителя вашего сайта адрес его странички в Facebook, попробуйте это регулярное выражение. Оно поможет вам проверить правильность указанного пользователем URL..*MSIE [5-8](?:\.[0-9]+)?(?!.*Trident\/[5-9]\.0).*$
Несмотря на то, что Microsoft выпустил новый браузер Edge, многие пользователи до сих пор пользуются Internet Explorer. Веб-разработчикам часто приходится проверять версию этого браузера, чтобы учитывать особенности разных версий при работе над своими проектами.
Вы можете использовать это регулярное выражения в JavaScript-коде чтобы узнать какая версия IE (5-11) используется.
«Вытягиваем» цену из строки
?/(\$[0-9,]+(\.[0-9]{2})?)/ Цена какого-либо товара может быть указана в различных форматах: в ней могут встречаться запятые, знаки после запятой и символы валюты.
Указанное выше регулярное выражение учитывает различные форматы отображения цены, с его помощью вы сможете «вытянуть» цену из любой символьной строки.
Разбираем заголовки в e-mail
?/\b[A-Z0-9._%+-]+@(?:[A-Z0-9-]+\.)+[A-Z]{2,6}\b/iС помощью этого небольшого выражения вы сможете разобрать заголовок e-mail сообщения, чтобы извлечь оттуда список адресатов. ]*))/g
Вы можете составить свои собственные регулярные выражения для манипулирования результатами поиска по вашим запросам в поисковой системе Google. Например, знак плюс (+) добавляет дополнительные ключевые слова, а минус (-) означает, что слова должны быть проигнорированы и удалены из результатов.
Это довольно сложное выражение, но если разобраться как использовать его должным образом, приведенный код может стать основой для построения собственного алгоритма поиска.
Объект JavaScript RegExp — использование регулярных выражений с клиентскими сценариями
Регулярные выражения JavaScript являются частью стандарта ECMA-262 для этого языка. Это означает, что ваши регулярные выражения должны работать одинаково во всех реализациях JavaScript. В прошлом было много серьезных проблем, связанных с браузером. Но современные браузеры очень хорошо следуют стандарту JavaScript для регулярных выражений. Вам нужно только убедиться, что ваши веб-страницы имеют тип документа, который запрашивает у браузера использование стандартного режима, а не режима причуд.
Вкус регулярных выражений JavaScript
В исходном коде JavaScript регулярное выражение записывается в форме / pattern / modifiers, где «pattern» — это само регулярное выражение, а «modifiers» — это серия символов, обозначающих различные параметры. Часть «модификаторы» не является обязательной. Этот синтаксис заимствован из Perl. JavaScript поддерживает следующие модификаторы, подмножество модификаторов, поддерживаемых Perl:
- / g включает «глобальное» сопоставление. При использовании метода replace () укажите этот модификатор для замены всех совпадений, а не только первого.
- / i делает совпадение регулярного выражения нечувствительным к регистру.
- / m включает «многострочный режим». В этом режиме курсор и доллар совпадают до и после символов новой строки в строке темы.
Вы можете комбинировать несколько модификаторов, объединяя их вместе, как в / regex / gim. Примечательно, что отсутствует возможность сделать так, чтобы символы разрыва строки совпадали с точкой.
Поскольку прямые косые черты ограничивают регулярное выражение, любые косые черты, которые появляются в регулярном выражении, должны быть экранированы. Э.г. регулярное выражение 1/2 записывается в JavaScript как / 1 \ / 2 /.
Действительно, нет модификатора / s, чтобы точка соответствовала всем символам, включая разрывы строк. Чтобы соответствовать абсолютно любому символу, вы можете использовать класс символов, который содержит сокращенный класс и его инвертированную версию, например [\ s \ S].
JavaScript реализует регулярные выражения в стиле Perl. Однако ему не хватает целого ряда расширенных функций, доступных в Perl и других современных разновидностях регулярных выражений:
Многие из этих функций доступны в библиотеке XRegExp для JavaScript.
Методы регулярного выражения класса String
Чтобы проверить, совпадает ли конкретное регулярное выражение (часть) со строкой, вы можете вызвать метод match () строки: if (myString.\ d + $ / соответствует только строкам, полностью состоящим из цифр.
Чтобы выполнить поиск и заменить с помощью регулярных выражений, используйте строковый метод replace (): myString.replace (/ replaceme / g, «replace»). Использование модификатора / g гарантирует, что все вхождения «replaceme» будут заменены. Второй параметр — обычная строка с заменяющим текстом.
Использование метода строки split () позволяет разбить строку на массив строк, используя регулярное выражение для определения позиций, в которых строка разделяется.Например. myArray = myString.split (/, /) разбивает список, разделенный запятыми, на массив. Сами запятые не включаются в результирующий массив строк.
Как использовать объект RegExp JavaScript
Самый простой способ создать новый объект RegExp — просто использовать специальный синтаксис регулярного выражения: myregexp = / regex /. Если у вас есть регулярное выражение в строке (например, потому что оно было введено пользователем), вы можете использовать конструктор RegExp: myregexp = new RegExp (regexstring). Модификаторы можно указать в качестве второго параметра: myregexp = new RegExp (regexstring, «gim»).
Я рекомендую вам не использовать конструктор RegExp с буквальной строкой, потому что в литеральных строках необходимо экранировать обратную косую черту. Регулярное выражение \ w + может быть создано как re = / \ w + / или как re = new RegExp («\\ w +»). Последнее определенно труднее читать. Регулярное выражение \ соответствует одной обратной косой черте. В JavaScript это становится re = / \\ / или re = new RegExp («\\\\»).
Каким бы способом вы ни создавали myregexp, вы можете передать его в методы String, описанные выше, вместо буквального регулярного выражения: myString.заменить (myregexp, «замена»).
Если вы хотите получить часть совпавшей строки, вызовите функцию exec () созданного вами объекта RegExp, например: mymatch = myregexp.exec («subject»). Эта функция возвращает массив. Нулевой элемент в массиве будет содержать текст, который соответствует регулярному выражению. Следующие элементы содержат текст, совпадающий с захватывающими круглыми скобками в регулярном выражении, если таковые имеются. mymatch.length указывает длину массива match [], которая на единицу больше, чем количество групп захвата в вашем регулярном выражении.mymatch.index указывает позицию символа в строке темы, с которой совпало регулярное выражение. mymatch.input сохраняет копию строки темы.
Вызов функции exec () также изменяет свойство lastIndex объекта RegExp. Он сохраняет индекс в строке темы, с которой начнется следующая попытка сопоставления. Вы можете изменить это значение, чтобы изменить начальную позицию следующего вызова exec ().
Функция test () объекта RegExp — это ярлык для exec ()! = Null.Он принимает строку темы в качестве параметра и возвращает истину или ложь в зависимости от того, соответствует ли регулярное выражение части строки или нет.
Эти методы также можно вызывать для буквальных регулярных выражений. /\d/.test(subject) — это быстрый способ проверить, есть ли какие-либо цифры в строке темы.
Синтаксис замещающего текста
Функция String.replace () интерпретирует несколько заполнителей в текстовой строке замены. Если регулярное выражение содержит группы захвата, вы можете использовать обратные ссылки в тексте замены.$ 1 в тексте замены вставляет текст, совпадающий с первой группой захвата, $ 2 — второй и так далее до 99 $. Если в вашем регулярном выражении больше 1, но меньше 10 групп захвата, то $ 10 рассматривается как обратная ссылка на первую группу, за которой следует буквальный ноль. Если ваше регулярное выражение имеет менее 7 групп захвата, то $ 7 рассматривается как буквальный текст $ 7. $ & повторно вставляет все совпадение регулярного выражения. $ ‘(Обратная кавычка) вставляет текст слева от совпадения регулярного выражения, $ ‘(одинарная кавычка) вставляет текст справа от совпадения регулярного выражения.$$ вставляет единственный знак доллара, как и любые символы $, которые не образуют ни одного из описанных здесь заполнителей.
$ _ и $ + не входят в стандарт, но, тем не менее, поддерживаются некоторыми браузерами. В Internet Explorer $ _ вставляет всю строку темы. В Internet Explorer и Firefox $ + вставляет текст, соответствующий группе захвата с наибольшим номером в регулярном выражении. Если группа с наибольшим номером не участвовала в матче, $ + заменяется ничем. Это не то же самое, что $ + в Perl, который вставляет текст, совпадающий с группой захвата с наибольшим номером, которая фактически участвовала в совпадении.
Хотя такие вещи, как $ &, на самом деле являются переменными в Perl, которые работают где угодно, в JavaScript они существуют только как заполнители в строке замены, передаваемой в функцию replace ().
Протестируйте поддержку регулярных выражений JavaScript в вашем веб-браузере
Я создал пример веб-страницы, демонстрирующий поддержку регулярных выражений JavaScript в действии. Вы можете попробовать это прямо сейчас в своем браузере. Исходный код отображается под примером.
Сделайте пожертвование
Этот веб-сайт только что сэкономил вам поездку в книжный магазин? Сделайте пожертвование на поддержку этого сайта, и вы получите неограниченного доступа к этому сайту без рекламы!
JavaScript Kit — объект RegExp (регулярное выражение)
Объект RegExp (регулярное выражение)
Обновлено: 27 июня 2011 г.
Регулярные выражения — мощный инструмент для выполнения шаблонов совпадает в строках в JavaScript.Вы можете выполнять сложные задачи, которые однажды требуются длительные процедуры с помощью всего нескольких строк кода с использованием обычных выражения. Регулярные выражения реализуются в JavaScript двумя способами:
Синтаксис литерала:
// соответствие всем 7-значным числам
var phonenumber = / \ d {7} /
Динамически, с конструктором RegExp () :
// соответствие всем 7-значным числам (обратите внимание на «\ d»
определяется как «\\ d»)
var phonenumber = new RegExp («\\ d {7}», «g»)
Шаблон, определенный внутри RegExp () , должен быть заключен в
кавычки, с экранированием любых специальных символов, чтобы сохранить его значение (например: « \ d »
должен быть определен как « \\ d «).Метод RegExp () позволяет динамически создавать шаблон поиска как
строка, и полезно, когда шаблон не известен заранее.
Связанные руководства (настоятельно рекомендуется к прочтению)
Флаги (переключатели) паттернов
| Свойство | Описание | Пример |
|---|---|---|
| и | Не обращайте внимания на регистр символов. | / / I соответствует «the», «The» и «tHe» |
| г | Глобальный поиск всех вхождений шаблона | / ain / g соответствует обоим «ain» в слове «Нет боли, нет выигрыша», а не просто первый. |
| gi | Глобальный поиск без учета регистра. | / it / gi соответствует всем «it» в «Это наш ИТ-отдел». |
| м | Многострочный режим./ Соответствует «The» в «The night», а не «In The Night». | |
| $ | Соответствует только концу строки. | / и $ / совпадает с «и» в «земле», но не в «приземлении» |
| \ b | Соответствует любой границе слова (тестовые символы должны существуют в начале или в конце слова в строке) | / ly \ b / совпадает с «ly» в «Это действительно круто.» |
| \ B | Соответствует любой границе, не являющейся словом. | / \ Bor / соответствует «или» в «нормальном», но не «оригами». |
| (? = Узор) | Позитивный взгляд в будущее. Требует, чтобы следующий шаблон внутри ввода. Выкройка не входит в состав фактический матч. | / (? = Глава) \ d + / соответствует любым цифрам, когда он продолжается слова «Глава», например 2 в «Главе 2», но не «У меня 2 дети » |
| (?! Узор) | Негативный взгляд в будущее. Требуется, чтобы следующий шаблон не был внутри ввода. Выкройка не входит в состав фактический матч. | / JavaScript (?! Kit) / соответствует любому вхождению слова «JavaScript», кроме случаев, когда он находится внутри фразы «JavaScript Kit» |
Литералы
| Символ | Описание |
|---|---|
| Буквенно-цифровой | Все буквенные и числовые символы соответствуют друг другу буквально.Итак / 2 days / будет соответствовать «2 дням» внутри строки. |
| \ O | Соответствует символу NUL. |
| \ п | Соответствует символу новой строки |
| \ f | Соответствует символу подачи страницы |
| \ r | Соответствует символу возврата каретки |
| \ т | Соответствует символу табуляции |
| \ v | Соответствует символу вертикальной табуляции |
| [\ b] | Соответствует пробелу. |
| \ xxx | Соответствует символу ASCII, выраженному
восьмеричное число xxx. «\ 50» соответствует символу левой круглой скобки «(» |
| \ xdd | Соответствует символу ASCII, выраженному шестнадцатеричным числом.
номер дд. «\ x28» соответствует символу левой круглой скобки «(» |
| \ uxxxx | Соответствует символу ASCII, выраженному
UNICODE xxxx. «\ u00A3» соответствует «». |
Обратная косая черта (\) также используется, когда вы хотите сопоставить специальный буквально. Например, если вы хотите сопоставить символ «$» буквально вместо того, чтобы сигнализировать о конце строки, сделайте обратную косую черту: / \ $ /
Классы персонажей
| Символ | Описание | Пример |
|---|---|---|
| [xyz] | Соответствует любому символу, заключенному в символ набор.AN] BC / соответствует «BBC», но не «ABC» или «NBC». | |
| . | (Точка). Соответствует любому символу, кроме новой строки или другой строки Unicode терминатор. | /b.t/ соответствует «летучая мышь», «бит», «ставка» и так далее. |
| \ w | Соответствует любому буквенно-цифровому символу, включая нижнее подчеркивание.\ t \ r \ n \ v \ f]. |
Повторение
| Символ | Описание | Пример |
|---|---|---|
| {x} | Соответствует ровно x вхождений регулярного выражение. | / \ d {5} / соответствует 5 цифрам. |
| {x,} | Соответствует x или более вхождений регулярного выражение. | / \ s {2,} / соответствует как минимум двум пробелам. |
| {x, y} | Сопоставляет от x до y количество вхождений регулярного выражение. | / \ d {2,4} / соответствует не менее 2, но не более 4 цифрам. |
| ? | Соответствует нулю или одному вхождению. Эквивалентно
{0,1}. «?» также может использоваться после одного из квантификаторов | / a \ s? b / соответствует «ab» или «a b». / \ d {2,4}? / Соответствует «12» в строке «12345» вместо «1234» из-за «?» в конце квантификатора. |
| * | Соответствует нулю или более вхождений. Эквивалентно {0,}. | / we * / соответствует «w» в «почему» и «wee» между «между», но ничего в «Плохо» |
| + | Соответствует одному или нескольким вхождениям.Эквивалентно {1,}. | / fe + d / соответствует как «fed», так и «feed» |
Чередование и группировка
| Символ | Описание | Пример |
|---|---|---|
| () | Группировка символов вместе для создания предложения. Может быть вложенным. | / (abc) + (def) / соответствует одному или нескольким вхождениям «abc», за которыми следует один появление «def». |
| () | Помимо символов группировки (см. Выше), скобки также служат
для захвата желаемого подшаблона в шаблоне. Ценности
подшаблонов затем можно получить с помощью RegExp. $ 1 , RegExp. $ 2 и т. Д. После сопоставления самого шаблона
или сравнивал. Например, следующее соответствует «2 главы» в
«Мы читаем 2 главы за 3 дня», и, кроме того, изолирует
значение «2»: var mystring = «Читаем 2 главы
за 3 дня » mystring.match (игла) // соответствует «2 chapters» На подшаблон также можно ссылаться позже в основной узор. См. «Обратные ссылки» ниже. | Следующий текст находит текст «Джон Доу» и меняет местами их позиции, так что он
становится «Доу Джон»: «Джон Доу» .replace (/ (Джон) (Доу) /, «2 доллара за 1 доллар») |
| (?: X) | Соответствует x, но не захватывает его.Другими словами, нет нумерованных ссылки создаются для элементов в скобках. | /(?:.d){2}/ соответствует, но не записывает «cdad». |
| x (? = Y) | Положительный просмотр вперед: соответствует x, только если за ним следует y. Запись что y не входит в состав соответствия, действуя только как необходимое условие. | / Джордж (? = Буш) / соответствует «Джордж» в «Джордж Буш», но не «Джордж Майкл» или «Джордж Оруэлл».\ d + (?! years) / соответствует «5» из «5 дней» или «5 апельсинов», но не «5 лет». |
| | | Чередование объединяет предложения в одно обычное выражение, а затем соответствует любому из отдельных предложений. Аналогичный к оператору «ИЛИ». | / forever | young / соответствует «forever» или «young» / (ab) | (cd) | (ef) / соответствует и запоминает «ab», «cd» или «ef». |
Назад ссылки
| Символ | Описание |
|---|---|
| () \ n | «\ n» (где n — число от 1 до 9) при добавлении в конец
шаблон регулярного выражения позволяет вам ссылаться на
подшаблон в шаблоне, поэтому значение подшаблона
запоминается и используется как часть сопоставления.Подшаблон
создается путем заключения его в скобки в шаблоне.
Думайте о «\ n» как о динамической переменной, которая заменяется
значение подшаблона, на который он ссылается. Например: / (хабба) \ 1/ эквивалентно шаблону / hubbahubba /, поскольку «\ 1» означает заменяется значением первого подшаблона внутри узор, или (хубба), чтобы сформировать окончательный узор. Допустим, вы хотите сопоставить любое слово, которое встречается дважды в ряд, например «hubba hubba.»Используемое выражение: / (\ ш +) \ с + \ 1/ «\ 1» заменяется значением первого подшаблона по сути означает «соответствие любому слову, за которым следует пробел, затем снова то же слово «. Если в шаблоне было более одной пары скобок строка, которую вы должны использовать \ 2 или \ 3 для соответствия желаемому подшаблону в зависимости от порядка левой круглой скобки для этого подшаблона. В примере: / (а (б (в))) / ссылки «\ 1» (a (b (c))), ссылки «\ 2» (b (c)) и Ссылки «\ 3» (c). |
Методы регулярных выражений
| Метод | Описание | Пример |
|---|---|---|
| String.match (регулярное выражение) | Выполняет поиск совпадения в строке
на основе регулярного выражения. Он возвращает массив информации или null, если совпадений нет.
найден. Примечание. Также обновляет свойства $ 1… $ 9 в объекте RegExp. | var oldstring = «У Питера есть
8 долларов, а у Джейн 15 дюймов. newstring = oldstring.match (/ \ d + / g) // возвращает массив [«8», «15»] |
| RegExp.exec (строка) | Аналогично String.match () выше тем, что он возвращает массив информации или null, если совпадение не найдено найденный. Однако, в отличие от String.match (), вводимый параметр должен быть строка, а не шаблон регулярного выражения. | var match = /s(amp)le/i.exec(«Sample text «) // возвращает [» Sample «,» amp «] |
| Строка.replace (регулярное выражение, текст замены) | Ищет и заменяет регулярное выражение
часть (совпадение) с замененным текстом.
Для параметра «замещающий текст» вы можете использовать ключевые слова от 1 до 99 долларов, чтобы
заменить исходный текст значениями из подшаблонов, определенных в
основной узор. Следующий текст находит текст «Джон Доу» и меняет местами их позиции, поэтому он становится «Доу Джон»: var newname = «Джон Доу» .replace (/ (Джон) (Доу) /, «$ 2 1 доллар США) Следующие символы имеют специальное значение внутри «замещающего текста»:
Параметр «замещающий текст» также может быть заменен вместо этого с функцией обратного вызова.См. Пример ниже. | var
oldstring = «(304) 434-5454» newstring = oldstring.replace (/ [\ (\) -] / g, «») // возвращает «3044345454» (удаляет «(«, «)» и » — «) |
| String.split (строковый литерал или регулярное выражение) | Разбивает строку на массив подстрок на основе регулярного выражения или фиксированной строки. | var oldstring = «1,2, 3,
4, 5 « newstring = oldstring.split (/ \ s *, \ s * /) // возвращает массив [« 1 »,« 2 »,« 3 »,« 4 »,« 5 »] |
| Строка.поиск (регулярное выражение) | Проверяет соответствие в строке. Он возвращает индекс совпадения или -1, если не найдено. НЕ поддерживает глобальный поиск (например: флаг «g» не поддерживается). | «Эми и Джордж» .search (/ george / i) // возвращает 8 |
| RegExp .test (строка) | Проверяет, является ли данная строка совпадает с регулярным выражением и возвращает истину, если совпадает, и ложь, если нет. | var pattern = / george / i pattern.test («Эми и Джордж») // возвращает истинное значение |
Пример. Замените «<", ">«, «&» и кавычки («и ‘) эквивалентными HTML-объект вместо
function html2entities (sometext) {
var re = / [(<> «‘&] / g
arguments [i] .value = sometext.replace (re, function (m) {return
replacechar (m)})
}
функция replacechar (match) {
if (match == «<")
вернуть «& lt;»
иначе if (match == «>»)
вернуть «& gt;»
иначе if (match == «\» «)
вернуть «& quot;
иначе if (match == «‘»)
вернуть «& # 039;»
иначе if (match == «&»)
вернуть «& amp;»
}
html2entities (документ.form.namefield.value) // заменяем «<", ">«, «&» и кавычки в поле формы с соответствующей сущностью HTML вместо
Знайте свои регулярные выражения
Основные средства создания и тестирования регулярных выражений в системах UNIX
Майкл Штутц
Опубликовано 14 июня 2007 г.
Концепция регулярных выражений (regexps) — обозначение для описание шаблона, совпадающего с набором строк, является общим для много программ и языков.Эти различные реализации регулярного выражения отличаются некоторыми степени в их деталях, но принципы обучения строить регулярные выражения общие для всех.
В этой статье описаны некоторые полезные инструменты и методы для обучения построению и отточить регулярные выражения для ряда приложений UNIX®, в том числе:
Выделение совпадений в их контексте
При построении регулярного выражения помогает увидеть, какие строки шаблон
совпадает в контексте набора данных.Рассмотрим четырехстрочный вводимый текст
Листинг 1 и тривиальное регулярное выражение t [a-z] , который соответствует двухсимвольному шаблону.
Листинг 1. Четыре строки образца текста и регулярное выражение. что соответствует им
$ кот в середине лета Я знаю банк, где дует чабрец, Где волчьи челюсти и кивающая фиалка растут, Довольно увешанный сочным деревом, Со сладкими мускусными розами и эглантином. $ grep t [a-z] в середине лета Я знаю банк, где дует чабрец, Где волчьи челюсти и кивающая фиалка растет, Довольно заваленный сочным деревом, Со сладкими мускусными розами и эглантином.$
Поскольку он находит по крайней мере одно совпадение со своим двухсимвольным шаблоном в каждой строке,
команда grep выводит каждую строку во входном файле.
Но каким символам и точно в этих строках ввода соответствовало регулярное выражение?
С таким тривиальным регулярным выражением, как это, легко уверенно взглянуть на него самим собой. Но поскольку вы создаете сложные регулярные выражения и имеете большие наборы данных или ввод файлов, может стать значительно труднее узнать, какая строка или строки regexp может совпадать.Полезно иметь возможность точно видеть, какой текст соответствует по каждой строке. И один из способов взглянуть на ваши регулярные выражения в контексте — это отметить их на выходе.
Это можно сделать с помощью нескольких приложений, в том числе grep , sed и Emacs.
Выделение с помощью grep
Некоторые из новых версий grep (например,
GNU grep ) основные моменты
регулярное выражение в цвете при использовании параметра --color , как
показано на рисунке 1.
Рисунок 1. Соответствующие строки раскрашено grep
Если ваш терминал поддерживает цвет, это полезный способ узнать, какой именно строки, совпадающие с вашим регулярным выражением.
Выделение с помощью sed
Вы также можете выделить регулярное выражение в sed , поток
редактор. Команда sed :
's / regexp / [&] / g'
выводит копию ввода со всеми экземплярами regexp , заключенными в скобки.В листинге 2 показан результат с образцом текста.
Листинг 2. Сопоставленные строки, отмеченные в sed
$ sed 's / t [a-z] / [&] / g' midsummer Я знаю банк, где дует дикий [th] yme, Где волчьи челюсти и кивающая фиалка растут, Qui [te] над навесом с [th] сочным деревом, С сладкими мускусными розами и с эглан [ти] нэ. $
Регулярные выражения можно пометить и другими способами. Если ваш ввод — документ Groff,
вы можете добавить жирный шрифт к регулярному выражению и отправить документ в groff для обработки:
$ sed 's / t [a-z] / \\ fB & \\ fP / g' infile. [, которое встречается дважды в листинге, является буквальным
escape-символ, поэтому вам нужно будет ввести этот список с помощью редактора, который
поддерживает ввод буквальных символов, таких как Emacs (где вы вводите
C-q ESC , чтобы войти в него).Модель 34
и 37 - это escape-коды Bash для указания
цвета синий и белый соответственно. Чтобы сделать скрипт исполняемым, введите:
$ chmod 744 hre
Затем запустите его, как показано на рисунке 2.
Рисунок 2. Соответствующие строки
раскрашено в sed
Хотя с помощью этого метода вы можете указать как выделение, так и простые цвета, он
есть свои предостережения. Сценарий, показанный в листинге 3, например,
работает только тогда, когда обычный текст терминала белый, потому что он восстанавливает
текст этого цвета.Если ваш терминал использует другой цвет для обычного текста
display измените escape-код в скрипте. (Например,
( 30 - черный.)
Выделение с помощью Emacs
В новых версиях редактора GNU Emacs isearch-forward-regexp и isearch-backward-regexp Функции выделяют все совпадения
в буфере. Если вы установили в своей системе последнюю версию Emacs, попробуйте
сейчас:
- Запустите Emacs, набрав:
$ emacs midsummer
- Тип
M-x isearch-forward-regexp . M-x - это обозначение Emacs для комбинации Meta-x,
который вы вводите в большинстве систем, нажав и удерживая Alt , нажав X , а затем отпустив обе клавиши или нажав Нажмите клавишу Esc , отпустив ее, а затем нажмите клавишу X .
- Введите регулярное выражение для поиска:
т [а-я] Поскольку поиск осуществляется с приращением , Emacs начинает выделять совпадения.
при вводе одного символа - в данном случае при нажатии T , все символы T в буфере подсвечиваются.Уведомление
что как только вы начнете вводить список символов в квадратных скобках,
выделение исчезает, и Emacs сообщает в минибуфере, что он
недостаточно данных, чтобы показать совпадение.
Ваш сеанс Emacs должен выглядеть, как показано на рисунке 3.
Рисунок 3. Буфер Emacs
отображение регулярного выражения в контексте
- Введите
C-x C-c для выхода из Emacs. Вы вводите это
комбинацию, нажав и удерживая клавишу Ctrl , нажав X ,
а затем нажав и удерживая клавишу Ctrl и нажав C .
isearch-forward-regexp и isearch-backward-regexp Функции обычно связаны
к M-S-s и M-S-r нажатия клавиш. (Чтобы создать их, нажмите и удерживайте клавишу Alt , Ctrl и ключ S или R .)
Показать только
совпадений, а не строк
Существует другой подход к проблеме контекста шаблона, а именно вывод
только сами совпадения, а не целые строки, в которых они встречаются.Есть
способы сделать это с помощью grep , sed и perl .
Показать только совпадения с grep
Параметр --only-matching (также -o ) изменяет поведение grep так что он выводит не все строки, содержащие совпадение с регулярным выражением, а только те, которые соответствуют самим себе . Как и в случае с - цвет вариант, описанный выше,
эта функция появляется в более новых версиях некоторых grep реализации, включая GNU grep , который открыт
исходный код и доступен для многих операционных систем.
Этот вариант предназначен для сбора данных, соответствующих регулярному выражению - это
отлично подходит для сбора IP-адресов, URL-адресов, имен, адресов электронной почты, слов и
вроде - но это также отличный способ выучить регулярные выражения. Например,
В листинге 4 показано, как использовать его для сбора всех слов из
образец текста листинга 1. Он выводит каждое слово, по одному
линия.
Листинг 4. Сбор всех слов из файла образца
$ egrep -o '[A-Za-z] +' midsummer
я
знать
а
банка
где
в
дикий
тимьян
удары
где
волчьи губы
и
в
кивает
Виолетта
растет
Вполне
над
под навесом
с участием
сочный
дровосек
С участием
сладкий
мускус
розы
и
с участием
эглантин
$
Фактически, когда вы строите особенно сложное регулярное выражение для определенного
задание, использование этого параметра - простой способ проверить его, чтобы убедиться, что вы создали
это правильно.Часто вы можете сразу увидеть, нуждается ли ваше регулярное выражение в исправлении.
Допустим, вы хотите вывести все слова в тестовом файле, содержащем строку th , и вы построили регулярное выражение, показанное на
Листинг 5 для этого.
Листинг 5. При выводе всех слов с «th» возьмите одно слово
$ egrep -o 'th [a-z] *' midsummer
в
тимьян
в
th
th
th
$
О, это не работает. Сразу видно, что некоторые матчи в
вывод - это вообще не слова.Лучше попробуйте еще раз: листинг 6 принимает
учитывать любые буквы в словах, которые могут стоять перед -й .
Листинг 6. Для вывода всех слов с «th» возьмите два
$ egrep -o '[a-z] * th [a-z] *' midsummer
в
тимьян
в
с участием
я
с участием
$
Намного лучше, но все же немного дешевле. Вы видите, что один "ith" показывает, что регулярное выражение
не соответствует прописным буквам. Исправьте это, вытащив -i , как показано в листинге 7.
Листинг 7. Для вывода всех слов с "th" возьмите три
$ egrep -o -i '[a-z] * th [a-z] *' midsummer
в
тимьян
в
с участием
С участием
с
Вот и все!
Использование -o и некоторых тестовых данных полезно в
построение регулярных выражений, потому что вы могли предположить, что регулярное выражение работает как строки
содержащие "th" были сопоставлены. Но вы не знали, что это выражение было на самом деле
немного нет.
Показать только совпадения с sed
Вы можете сделать аналогичные вещи в sed , используя команду:
s /.* \ (regexp \). * / \ 1 / p
для соответствия регулярному выражению sed . Эта команда выводит только
совпадающие шаблоны из ввода, а не строки ввода, содержащие совпадение.
Однако он выводит только последний экземпляр в данной строке, как показано на
Листинг 8.
Листинг 8. Вывод только совпадающих символов с помощью sed
$ sed -n 's /.* \ (th [a-z] \). * / \ 1 / p' midsummer
твой
в
$ grep -o th [a-z] в середине лета
в
твой
в
$
Показать только совпадения с Perl
Регулярные выражения также широко используются в языке Perl, но регулярные выражения Perl
отличается от тех, которые вы бы создали с помощью grep .В pcretest Инструмент позволяет тестировать регулярные выражения Perl. Вы можете использовать
этот инструмент, чтобы познакомиться с Perl-совместимым регулярным выражением
(PCRE), а также для отладки или тестирования регулярных выражений, которые вы создаете с ее помощью.
Регулярное выражение, как обычно, заключено в символы косой черты (/) и может сопровождаться
модификаторы, которые изменяют поведение поиска. Общие модификаторы регулярного выражения:
представлены в таблице 1.
Таблица 1. Общие модификаторы регулярного выражения для pcretest
| Модификатор | Описание |
|---|---|
8 | Этот модификатор поддерживает наборы символов Unicode (UTF-8). |
g | Этот модификатор выполняет поиск глобальных совпадений (более одного на линия). |
i | Этот модификатор игнорирует различия в регистре. |
m | Этот модификатор выполняет поиск по нескольким строкам. |
x | Этот модификатор использует расширенные регулярные выражения Perl. |
Попробуйте запустить pcretest в интерактивном режиме, как показано на
Листинг 9.
Листинг 9. Тестирование регулярного выражения с помощью pcretest
$ pcretest PCRE, версия 6.7, 4 июля 2006 г. re> / [a-z] * th [a-z] * / ig data> Со сладкими мускусными розами и эглантином. 0: С 0: с данные> $
Вы также можете запустить pcretest с входным файлом. Ввод
файлы содержат регулярное выражение для тестирования в одной строке, за которой следует любое количество строк
данные для тестирования. У вас может быть несколько регулярных выражений и их соответствующие данные,
разделив их пустой строкой; pcretest продолжение
чтение регулярных выражений и поиск в следующих строках данных до конца
файл (EOF).
Если указать имя второго файла, pcretest запишет
вывод в этот файл. В противном случае он записывает в стандартный вывод, как показано на
Листинг 10.
Листинг 10. Запуск pcretest из входного файла
$ cat midsummer.pre / w [привет] | th / gi Я знаю банк, где дует чабрец, Где волчьи челюсти и кивающая фиалка растет, Довольно заваленный сочным деревом, Со сладкими мускусными розами и эглантином. $ pcretest midsummer.pre PCRE версии 6.7 04-июл-2006 / w [привет] | th / gi Я знаю банк, где дует чабрец, 0: wh 0: чт 0: wi 0: чт Где волчьи челюсти и кивающая фиалка растет, 0: Втч 0: чт Довольно заваленный сочным деревом, 0: wi 0: чт Со сладкими мускусными розами и эглантином. 0: Wi 0: чт 0: wi 0: чт $
Вызов мастера
Сценарий txt2regex представляет собой интерактивный кроссплатформенный «мастер» регулярных выражений, созданный для оболочка Bash. Когда вы запустите его, он задаст вам ряд вопросов о шаблон, который вы хотите сопоставить, а затем он строит действительные регулярные выражения для любого количества двух дюжина различных приложений:
-
awk -
ed -
egrep -
emacs -
expect -
find -
gawk84 grep9 -
lex -
lisp -
mawk -
mysql -
ooo -
perl -
php -
postgres - 000
-
sed -
tcl -
vbscript -
vi -
vim - Запустите txt2regex и укажите регулярное выражение для
grep,sedи Emacs:$ txt2regex --prog grep, sed, emacs
- Вы хотите сопоставить символ T в любой части строки, а не только в
начало строки, поэтому введите
2, чтобы выбрать "в любом часть линии.« - Введите
2еще раз, чтобы выбрать« конкретный символ »и затем введитеt, когда вас спросят, какой символ соответствует.Теперь вам нужно ответить, сколько раз вы хотите его сопоставить.
- Введите
1, чтобы указать ровно один раз. - Найдите любую строчную букву, набрав
6, чтобы выбрать "a специальная комбинация ", а затем введитеbдля соответствия строчные буквы. Тип.для выхода из комбинации подменю. - Введите строчную букву ровно один раз, набрав
1. - Запустить txt2regex без параметров:
$ txt2regex
- Введите
2для сопоставления в любой части строки. - Введите
6, чтобы задать специальную комбинацию, а затем введитеaиb, чтобы выбрать все прописные и строчные буквы. - Тип
., чтобы вернуться в главное меню, а затем введите4, чтобы указать, что он должен соответствовать одному или нескольким раз.
- 4 postgres
Помимо помощи в интерактивном построении регулярных выражений, txt2regex предоставляет краткий краткое изложение синтаксиса регулярных выражений для различных языков и приложений, список готовых regexs "для соответствия общим шаблонам, а также удобная таблица метасимволов регулярных выражений.
Создать регулярное выражение
Чтобы построить регулярное выражение для одного или нескольких из txt2regex
поддержанный
приложений, дайте названия тем
приложений в списке, разделенном запятыми, в качестве аргумента - опция программы .
Начните с попытки построить тривиальное регулярное выражение, возвращенное в Выделить соответствует в их разделе контекста, который соответствует символ T, за которым следует строчная буква:
По мере прохождения процедуры txt2regex строит регулярное выражение для каждого из три выбранных приложения и отображает их в верхней части экрана. Теперь, когда вы выбрали именно то, что хотите, вы можете видеть желаемые регулярные выражения для всех три приложения на рисунке 4.
Рисунок 4. Создание регулярного выражения с txt2regex
Введите .. для выхода.Список регулярных выражений останется включенным.
ваш терминал.
Да, все три регулярных выражения записываются как идентичные t [a-z] , но это только потому, что это простое регулярное выражение
и три выбранных приложения имеют аналогичный синтаксис регулярного выражения. Это не всегда будет
случай, когда построенные вами регулярные выражения выглядят одинаково для всех выбранных приложений.
Скажем, например, что вы хотите построить два регулярных выражения, которые вы использовали в Показывать только совпадения, а не раздел линий.Первый было одно слово из прописных или строчных букв:
Без параметров txt2regex по умолчанию создает регулярные выражения для Perl , PHP , postgres , питон , sed и vim приложений.
Когда вы просмотрите все вышесказанное, вы обнаружите, что первые четыре приложения используют
то же регулярное выражение, которое вы использовали с grep в
Листинг 4, но регулярные выражения для sed и vim немного отличаются.Это потому что
эти приложения используют несколько другую нотацию метасимволов,
как описано ниже.
Снова введите .. , чтобы выйти из программы; регулярные выражения для
различные приложения останутся в списке на вашем терминале. Вы можете использовать их как
отображать или редактировать их для дальнейшего уточнения. Например, как насчет соответствия
слова, содержащие символ апострофа (') & # 151; нет, кто, э'эр,
владельца, потому что, Джо, и так далее? Созданное вами регулярное выражение не будет соответствовать
их правильно, как вы увидите, показывая только совпадения (см.
Листинг 11).
Листинг 11. Неправильное сопоставление слов с апострофами
$ echo «Не пропустите ни слова, потому что оно неправильное». | egrep [A-Za-z] + Дон т скучать а слово просто причина Это s неправильно $
Вы захотите добавить символ дефиса в этот список в квадратных скобках и продемонстрировать его. снова, как показано в листинге 12. Обратите внимание, что вы должны указать регулярное выражение сейчас.
Листинг 12. Правильное сопоставление слов с апострофами
$ echo "Не пропустите ни слова, потому что оно неверное."| egrep" [A-Za-z '] + " Не надо скучать а слово просто потому что его неправильно $
Следующее регулярное выражение, которое вы использовали в
Показывать только совпадения, а не
раздел линий был для
одно слово, содержащее "th" в любом месте слова. Вы использовали регулярные выражения для egrep , sed и perl ; теперь попробуйте построить это на простом grep :
- Запустите txt2regex:
$ txt2regex
- Введите
/, чтобы выбрать программы, а затем введитеhkopqstx., так что только регулярное выражение дляgrepбудет построен. - Введите
26ab.3, чтобы выбрать ноль или более прописных букв или строчные буквы в любом месте строки. - Введите
2t12h2, а затем буквы T и H, каждое встречается ровно один раз. - Введите
6ab.3с нулем или более прописные или строчные буквы. - Введите
..для выхода из программы.
Вы можете протестировать только что построенное регулярное выражение, как показано на Листинг 13.
Листинг 13. Сопоставление слова, содержащего "th", с grep
$ grep -o [A-Za-z] * th [A-Za-z] * midsummer в тимьян в с участием С участием с участием $
Получить сводку опций регулярного выражения
Опция --showinfo просто выводит краткую сводку
информация о построении регулярных выражений для конкретной программы или языка. Включено
на выходе - название и версия приложения, метасимволы регулярного выражения,
метасимвол экранирования по умолчанию, метасимволы, требующие экранирования по умолчанию,
можно ли использовать символы табуляции в списках в квадратных скобках и поддерживает ли он
Выражения в квадратных скобках интерфейса переносимой операционной системы (POSIX).$
\ t в [] ДА
[: POSIX:] ДА $
Получить готовое регулярное выражение
Параметр --make описан его автором как «a
средство от головной боли «. Он выводит регулярное выражение для одного из нескольких распространенных шаблонов,
приведены в качестве аргументов, как указано в таблице 2.
Таблица 2. Список готовых регулярных выражений, доступных в txt2regex
| Аргумент | Описание |
|---|---|
дата | Этот аргумент соответствует датам в формате мм / дд / гггг ,
с 00/00/0000 по 99/99/9999. |
date2 | Этот аргумент соответствует датам в формате мм / дд / гггг ,
с 00/00/1000 по 19/39/2999. |
date3 | Этот аргумент соответствует датам в формате мм / дд / гггг ,
с 00/00/1000 по 31.12.2999. |
час | Этот аргумент соответствует времени в формате чч: мм , от
С 00:00 до 99:99. |
час2 | Этот аргумент соответствует времени в формате чч: мм , от
С 00:00 до 29:59. |
час3 | Этот аргумент соответствует времени в формате чч: мм , начиная с
С 00:00 до 23:59. |
число | Этот аргумент соответствует любому положительному или отрицательному целому числу. |
число2 | Этот аргумент соответствует любому положительному или отрицательному целому числу с необязательным значение с плавающей запятой. |
number3 | Этот аргумент соответствует любому положительному или отрицательному целому числу с необязательными запятыми. и необязательное значение с плавающей запятой. |
Например, вы можете использовать это, чтобы получить готовое регулярное выражение для любого действительного часа в военное время, как показано в листинге 15.
Листинг 15. Получение регулярного выражения даты с помощью txt2regex
$ txt2regex --make hour3 RegEx perl: ([01] [0-9] | 2 [0123]): [012345] [0-9] RegEx php: ([01] [0-9] | 2 [0123]): [012345] [0-9] RegEx postgres: ([01] [0-9] | 2 [0123]): [012345] [0-9] RegEx python: ([01] [0-9] | 2 [0123]): [012345] [0-9] RegEx sed: \ ([01] [0-9] \ | 2 [0123] \): [012345] [0-9] RegEx vim: \ ([01] [0-9] \ | 2 [0123] \): [012345] [0-9] $
Знайте свои метасимволы
Другой полезный параметр txt2regex — --showmeta , который
выводит таблицу, состоящую из всех метасимволов, используемых при построении регулярных выражений для
поддерживаемые приложения.Этот вариант показан на
Листинг 16.
Листинг 16. Отображение всех метасимволов с помощью txt2regex
$ txt2regex --showmeta
awk +? | ()
ed \ + \? \ {\} \ | \ (\)
egrep +? {} | ()
emacs +? \ | \ (\)
ожидать +? | ()
найти +? \ | \ (\)
gawk +? {} | ()
grep \ + \? \ {\} \ | \ (\)
javascript +? {} | ()
lex +? {} | ()
лисп +? \\ | \\ (\\)
mawk +? | ()
mysql +? {} | ()
ооо +? {} | ()
perl +? {} | ()
php +? {} | ()
postgres +? {} | ()
procmail +? | ()
питон +? {} | ()
sed \ + \? \ {\} \ | \ (\)
tcl +? | ()
vbscript +? {} | ()
vi \ {1 \} \ {01 \} \ {\} \ (\)
vim \ + \ = \ {} \ | \ (\)
ЗАМЕТКА: .] и * одинаковы во всех программах.
$ Изучите документы
Чтение руководств платно. В вашей системе может быть намного больше документации, включая страницы руководства по построению и использованию регулярных выражений, чем вы могли представить.
Например, grep , sed и
у других инструментов, подобных им, есть справочные страницы, которые описывают синтаксис регулярных выражений и дают
Примеры. Если в вашей системе установлены версии GNU, они также могут
иметь информационную документацию, которая содержит гораздо больше информации, чем обычный человек
страницы — иногда туда помещаются целые руководства пользователя.За
Например, если у вас установлен GNU sed и у вас есть info binary, вы можете прочитать руководство:
$ info sed
Документация Perl (обычно упаковывается и распространяется отдельно от основной Исходный код Perl или двоичный пакет) содержит исчерпывающую страницу руководства по регулярным выражениям Perl:
$ man perlre
И еще кое-что по этой теме. Шаблон pcrepattern справочная страница (распространяется с приложением pcretest ,
как описано выше) также описывает регулярные выражения Perl.
Наконец, справочная страница regex , доступная во многих UNIX
systems, предоставляет информацию о построении регулярных выражений POSIX. Информация об этом
страница руководства взята из библиотеки Генри Спенсера regex (см. Ресурсы).
Сводка
В системах UNIX доступно множество инструментов и методов для построения регулярных выражений. Вы только что узнали несколько лучших из них.
Эти инструменты предоставляют мощные возможности для создания, тестирования и оттачивания регулярных выражений.Используя эти инструменты и методы в системе UNIX, вероятно, лучший способ научиться создавать сложные регулярные выражения. И это тоже весело!
Ресурсы для загрузки
Связанные темы
- «Говорящий UNIX, часть 9: Регулярные выражения » (Мартин Штрайхер, developerWorks, апрель 2007 г.): эта статья представляет собой краткое руководство по Азбука регулярных выражений.
- Ознакомьтесь с другими написанными статьями и руководствами Автор: Майкл Штутц:
- Поиск в библиотеке AIX® и UNIX по теме:
- AIX и UNIX: Зона developerWorks по AIX и UNIX предоставляет обширную информацию, относящуюся к все аспекты системного администрирования AIX и расширения ваших навыков UNIX.
- Пробное программное обеспечение IBM: Создайте свой следующий проект разработки с помощью программного обеспечения, которое можно загрузить прямо с developerWorks.
- Технические мероприятия и веб-трансляции developerWorks: Будьте в курсе технических событий и веб-трансляций developerWorks.
- Подкасты: Следите за новостями и обращайтесь к техническим экспертам IBM.
- Веб-сайт проекта GNU: Загрузите бесплатную копию GNU
grepдля вашей операционной системы. - PCRE: Загрузите бесплатную копию PCRE.