Операции LEFT JOIN, RIGHT JOIN (Microsoft Access SQL)
Twitter LinkedIn Facebook Адрес электронной почты
- Статья
- Чтение занимает 2 мин
Область применения: Access 2013, Office 2013
Объединяют записи исходных таблиц при использовании в любом предложении FROM.
Синтаксис
FROM table1 [ LEFT | RIGHT ] JOIN table2 ON table1.field1compopr table2.field2
Операции LEFT JOIN и RIGHT JOIN состоят из следующих элементов:
таблица1, таблица2 | Имена таблиц, содержащих объединяемые записи. |
поле1, поле2 | Имена объединяемых полей. Поля должны относиться к одному типу данных и содержать данные одного вида. Однако имена этих полей могут быть разными. |
оператор_сравнения | Любой оператор реляционного сравнения: «=», «<«, «>,» «<=», «>=» или «<>». |
Операция RIGHT JOIN создает правое внешнее соединение.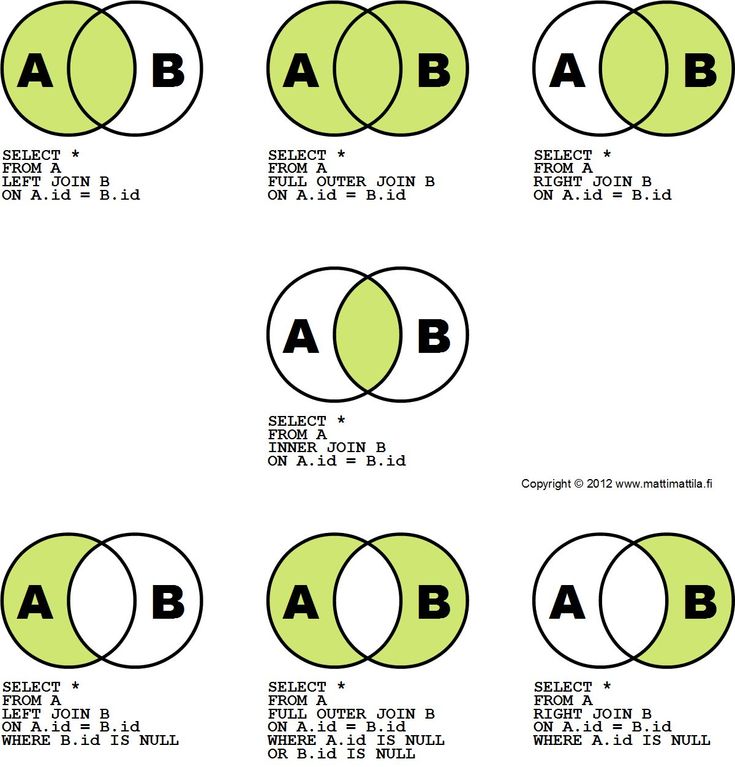 С помощью правого внешнего соединения выбираются все записи второй (правой) таблицы, даже если они не соответствуют записям в первой (левой) таблице.
С помощью правого внешнего соединения выбираются все записи второй (правой) таблицы, даже если они не соответствуют записям в первой (левой) таблице.
Например, в случае с таблицами «Отделы» (левая) и «Сотрудники» (правая) можно воспользоваться операцией LEFT JOIN для выбора всех отделов (включая те, в которых нет сотрудников). Чтобы выбрать всех сотрудников (в том числе и не закрепленных за каким-либо отделом), используйте RIGHT JOIN.
В следующем примере показано, как можно объединить таблицы Categories и Products по полю CategoryID. Результат запроса представляет собой список категорий, включая те, которые не содержат товаров.
SELECT CategoryName, ProductName FROM Categories LEFT JOIN Products ON Categories.CategoryID = Products.CategoryID;
В этом примере CategoryID является объединенным полем, но оно не включается в результаты запроса, поскольку не указано в инструкции SELECT. Чтобы включить объединенное поле в результаты запроса, укажите его имя в инструкции SELECT. В данном случае это Categories.CategoryID.
В данном случае это Categories.CategoryID.
Примечание.
- Чтобы создать запрос, результатом которого являются только те записи, для которых совпадают данные в объединенных полях, воспользуйтесь операцией INNER JOIN.
- Операции LEFT JOIN и RIGHT JOIN могут быть вложены в операцию INNER JOIN, но операция INNER JOIN не может быть вложена в операцию LEFT JOIN или RIGHT JOIN. Подробные сведения о вложении объединений можно найти в статье, посвященной операции INNER JOIN.
- Вы можете связать несколько предложений ON. Сведения о связывании предложений см. в статье, посвященной операции INNER JOIN.
- При попытке связи полей, содержащих данные типа Memo или объекты OLE, возникнет ошибка.
Пример
В этом примере:
Предполагается существование гипотетических полей Department Name (Название отдела) и Department ID (Код отдела) в таблице Employees (Сотрудники). Обратите внимание, что эти поля на самом деле не существуют в таблице Employees (Сотрудники) базы данных Northwind.

Выбираются все отделы, в том числе без сотрудников.
Выполняется вызов процедуры EnumFields, которую можно найти в примере для инструкции SELECT.
Sub LeftRightJoinX()
Dim dbs As Database, rst As Recordset
' Modify this line to include the path to Northwind
' on your computer.
Set dbs = OpenDatabase("Northwind.mdb")
' Select all departments, including those
' without employees.
Set rst = dbs.OpenRecordset _
("SELECT [Department Name], " _
& "FirstName & Chr(32) & LastName AS Name " _
& "FROM Departments LEFT JOIN Employees " _
& "ON Departments.[Department ID] = " _
& "Employees.[Department ID] " _
& "ORDER BY [Department Name];")
' Populate the Recordset.
rst.MoveLast
' Call EnumFields to print the contents of the
' Recordset.
Pass the Recordset object and desired
' field width.
EnumFields rst, 20
dbs.Close
End Sub
RIGHT JOIN — Учебник SQL — Schoolsw3.com
schoolsw3.com
САМОСТОЯТЕЛЬНОЕ ОБУЧЕНИЕ ДЛЯ ВЕБ РАЗРАБОТЧИКОВ
❮ Назад Далее ❯
RIGHT JOIN
Ключевое слово RIGHT JOIN возвращает все записи из правой таблицы (table2) и совпадающие записи из левой таблицы (table1). Результат равен нулю с левой стороны, когда нет совпадения.
Синтаксис RIGHT JOIN
SELECT column_name(s)
FROM table1
RIGHT JOIN table2
ON table1.column_name = table2.column_name;
Примечание: В некоторых базах данных RIGHT JOIN называется правым внешним соединением.
Демо база данных
В этом уроке мы будем использовать хорошо известный пример базы данных Northwind.
Ниже приведен выбор из таблицы «Orders»:
| OrderID | CustomerID | EmployeeID | OrderDate | ShipperID |
|---|---|---|---|---|
| 10308 | 2 | 7 | 1996-09-18 | 3 |
| 10309 | 37 | 3 | 1996-09-19 | 1 |
| 10310 | 8 | 1996-09-20 | 2 |
И выбор из таблицы «Employees»:
| EmployeeID | LastName | FirstName | BirthDate | Photo |
|---|---|---|---|---|
| 1 | Davolio | Nancy | 12/8/1968 | EmpID1.pic |
| 2 | Fuller | Andrew | 2/19/1952 | EmpID2.pic |
| 3 | Leverling | Janet | 8/30/1963 | EmpID3.pic |
Пример SQL RIGHT JOIN
Следующая инструкция SQL вернет всех сотрудников и все заказы, которые они могли бы разместить:
Пример
SELECT Orders.OrderID, Employees. LastName, Employees.FirstName
LastName, Employees.FirstName
FROM Orders
RIGHT JOIN Employees ON Orders.EmployeeID = Employees.EmployeeID
ORDER BY Orders.OrderID;
Попробуйте сами »
Примечание: Ключевое слово RIGHT JOIN возвращает все записи из правой таблицы (Employees), даже если в левой таблице (Orders) нет совпадений.
Проверьте себя с помощью упражнений
Упражнение:
Выберите правильное предложение JOIN,
чтобы выбрать все записи из таблицы Customers плюс все совпадения в таблице Orders.
SELECT * FROM Orders ON Orders.CustomerID=
Customers.CustomerID;
Начните упражнение
❮ Назад Далее ❯
ВЫБОР ЦВЕТА
ТОП Учебники
HTML УчебникCSS Учебник
JavaScript Учебник
КАК Учебник
SQL Учебник
Python Учебник
W3.CSS Учебник
Bootstrap Учебник
PHP Учебник
Java Учебник
C++ Учебник
jQuery Учебник
ТОП Справочники
HTML СправочникCSS Справочник
JavaScript Справочник
SQL Справочник
Python Справочник
W3.
 CSS Справочник
CSS СправочникBootstrap Справочник
PHP Справочник
HTML Цвета
Java Справочник
Angular Справочник
jQuery Справочник
ТОП Примеры
HTML ПримерыCSS Примеры
JavaScript Примеры
SQL Примеры
Python Примеры
W3.CSS Примеры
Bootstrap Примеры
PHP Примеры
Java Примеры
XML Примеры
jQuery Примеры
Форум | О SchoolsW3
SchoolsW3 оптимизирован для бесплатного обучения, проверки и подготовки знаний. Примеры в редакторе упрощают и улучшают чтение и базовое понимание. Учебники, ссылки, примеры постоянно пересматриваются, чтобы избежать ошибок, но не возможно гарантировать полную правильность всего содержания. Некоторые страницы сайта могут быть не переведены на РУССКИЙ язык, можно отправить страницу как ошибку, так же можете самостоятельно заняться переводом. Используя данный сайт, вы соглашаетесь прочитать и принять
Условия к использованию,
Cookies и политика конфиденциальности.
Авторское право 1999- Все права защищены.
соединений SQL | Промежуточный SQL
Начиная здесь? Этот урок является частью полного учебника по использованию SQL для анализа данных. Проверьте начало.
В этом уроке мы рассмотрим:
- Введение в соединения SQL: реляционные концепции
- Анатомия сустава
- Псевдонимы в SQL
- ПРИСОЕДИНЯЙТЕСЬ И ВКЛЮЧАЙТЕ
Введение в соединения SQL: реляционные концепции
До этого момента мы работали только с одной таблицей за раз. Однако реальная мощь SQL заключается в одновременной работе с данными из нескольких таблиц. Если вы помните из предыдущего урока, все таблицы, с которыми вы работали до этого момента, являются частью одной и той же схемы в реляционной базе данных. Термин «реляционная база данных» относится к тому факту, что таблицы в ней «связаны» друг с другом — они содержат общие идентификаторы, которые позволяют легко комбинировать информацию из нескольких таблиц.
Чтобы понять, что такое объединения и почему они полезны, давайте подумаем о Twitter.
Twitter должен хранить много данных. Twitter мог бы (гипотетически, конечно) хранить свои данные в одной большой таблице, в которой каждая строка представляет один твит. Может быть один столбец для содержания каждого твита, один для времени твита, один для человека, который его написал, и так далее. Однако оказывается, что идентифицировать человека, написавшего твит, немного сложно. Личность человека в Твиттере зависит от многих факторов: имя пользователя, биография, подписчики, подписчики и многое другое. Twitter мог бы хранить все эти данные в виде такой таблицы:
Допустим, ради аргумента, что Твиттер действительно структурировал свои данные таким образом. Каждый раз, когда вы пишете твит, Twitter создает новую строку в своей базе данных с информацией о вас и твите.
Но это создает проблему. Когда вы обновите свою биографию, Твиттеру придется изменить эту информацию для каждого вашего твита в этой таблице. Если вы твитнули 5000 раз, это означает 5000 изменений. Если многие люди в Твиттере вносят много изменений одновременно, это требует больших вычислений. Вместо этого Twitter гораздо проще хранить информацию о профиле каждого пользователя в отдельной таблице. Таким образом, всякий раз, когда кто-то обновляет свою биографию, Твиттеру нужно будет изменить только одну строку данных вместо тысяч.
Если вы твитнули 5000 раз, это означает 5000 изменений. Если многие люди в Твиттере вносят много изменений одновременно, это требует больших вычислений. Вместо этого Twitter гораздо проще хранить информацию о профиле каждого пользователя в отдельной таблице. Таким образом, всякий раз, когда кто-то обновляет свою биографию, Твиттеру нужно будет изменить только одну строку данных вместо тысяч.
В такой организации Twitter имеет две таблицы. Первая таблица — таблица пользователей — содержит информацию о профиле и имеет по одной строке для каждого пользователя. Вторая таблица — таблица твитов — содержит информацию о твитах, включая имя пользователя отправителя твита. Путем сопоставления — или соединения с — этого имени пользователя в таблице твитов с именем пользователя в таблице пользователей, Твиттер по-прежнему может связывать информацию профиля с каждым твитом.
Анатомия объединения
К сожалению, мы не можем использовать данные Twitter ни в одном из рабочих примеров (для этого нам придется дождаться Учебника по SQL от АНБ), но мы можем рассмотреть похожую проблему.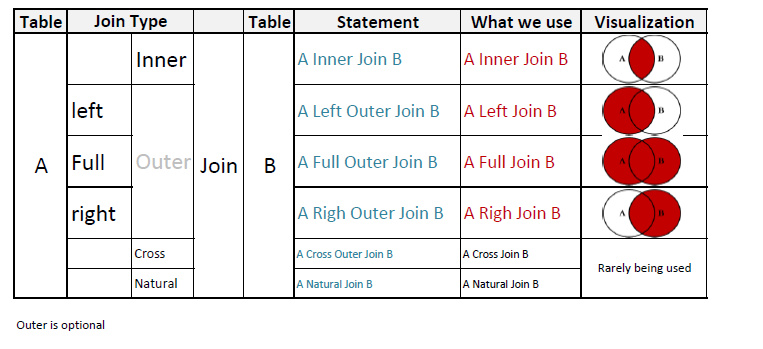
На предыдущем уроке по условной логике мы работали с таблицей данных о футболистах колледжа — benn.college_football_players . Эта таблица включала данные об игроках, включая вес каждого игрока и школу, за которую он играл. Однако в нем не было много информации о школе, такой как конференция, в которой участвует школа — эта информация находится в отдельной таблице, benn.college_football_teams .
Допустим, мы хотим выяснить, какая конференция имеет наибольший средний вес. Учитывая, что информация находится в двух отдельных таблицах, как вы это делаете? Присоединяйтесь!
ВЫБЕРИТЕ team.conference КАК конференция,
AVG(players.weight) КАК средний_вес
ОТ игроков benn.college_football_players
ПРИСОЕДИНЯЙТЕСЬ к командам benn.college_football_teams
ON team.school_name = игроки.school_name
СГРУППИРОВАТЬ ПО team.conference
ORDER BY AVG(вес игроков) DESC
Здесь происходит много нового, так что давайте пошагово.
Псевдонимы в SQL
При выполнении соединений проще всего присвоить именам таблиц псевдонимы.
benn.college_football_players довольно длинный и утомительный для ввода — игроков гораздо проще. Вы можете дать таблице псевдоним, добавив пробел после имени таблицы и введя предполагаемое имя псевдонима. Как и в случае с именами столбцов, рекомендуется использовать все строчные буквы и знаки подчеркивания вместо пробелов.
После того как вы присвоили таблице псевдоним, вы можете ссылаться на столбцы этой таблицы в предложении SELECT , используя псевдоним. Например, первый столбец, выбранный в приведенном выше запросе, равен 9.0041 команды.конференция . Из-за псевдонима это эквивалентно benn.college_football_teams.conference : мы выбираем столбец Conference в таблице College_football_teams в схеме benn .
Практическая задача
Напишите запрос, который выбирает название школы, имя игрока, позицию и вес для каждого игрока в Джорджии, упорядоченные по весу (от самого тяжелого к самому легкому). Обязательно создайте псевдоним для таблицы и укажите ссылки на все имена столбцов по отношению к псевдониму.
Обязательно создайте псевдоним для таблицы и укажите ссылки на все имена столбцов по отношению к псевдониму.
Попробуйте. См. ответ. имена столбцов, разделенные знаком равенства.
Хотя оператор ON идет после JOIN , сначала будет немного проще объяснить его. ON указывает, как две таблицы (одна после FROM и одна после ПРИСОЕДИНЯЙТЕСЬ ) относятся друг к другу. Вы можете видеть в приведенном выше примере, что обе таблицы содержат поля с именами school_name . Иногда реляционные поля немного менее очевидны. Например, у вас может быть таблица school с полем id , которое можно соединить с school_id в любой другой таблице. Эти отношения иногда называют «отображениями». team.school_name и player.school_name , два столбца, которые сопоставляются друг с другом, называются «внешними ключами» или «ключами соединения». Их отображение записывается в виде условного оператора:
Их отображение записывается в виде условного оператора:
ВКЛ Teams.school_name = игроки.school_name
На простом английском это означает:
Соедините все строки из таблицы
playerсо строками в таблицеteam, для которых полеschool_nameв таблицеplayerравно полюschool_nameв таблицеteam.
Что это на самом деле делает? Давайте посмотрим на одну строку, чтобы увидеть, что происходит. Это строка в таблице игроков для широкого приемника Wake Forest Майкла Кампанаро:
Во время соединения SQL ищет school_name — в данном случае «Wake Forest» — в поле school_name таблицы team . Если есть совпадение, SQL берет все пять столбцов из таблицы команд и объединяет их с десятью столбцами таблицы игроков . Новый результат представляет собой таблицу из пятнадцати столбцов, а строка с Майклом Кампанаро выглядит так:

Из изображения вырезаны две колонки, но полный результат вы можете увидеть здесь.
При выполнении запроса с объединением SQL выполняет ту же операцию, что и выше, для каждой строки таблицы после оператора FROM . Чтобы увидеть полную таблицу, возвращенную объединением, попробуйте выполнить этот запрос:
SELECT *
ОТ игроков benn.college_football_players
ПРИСОЕДИНЯЙТЕСЬ к командам benn.college_football_teams
ON team.school_name = игроки.school_name
Обратите внимание, что SELECT * возвращает все столбцы из обеих таблиц, а не только из таблицы после ИЗ . Если вы хотите вернуть только столбцы из одной таблицы, вы можете написать SELECT player.* , чтобы вернуть все столбцы из таблицы player.
После создания этой новой таблицы после соединения вы можете использовать те же агрегатные функции из предыдущего урока. Запустив функцию AVG для весов игроков и сгруппировав по полю конференция из таблицы команд, вы можете вычислить средний вес каждой конференции.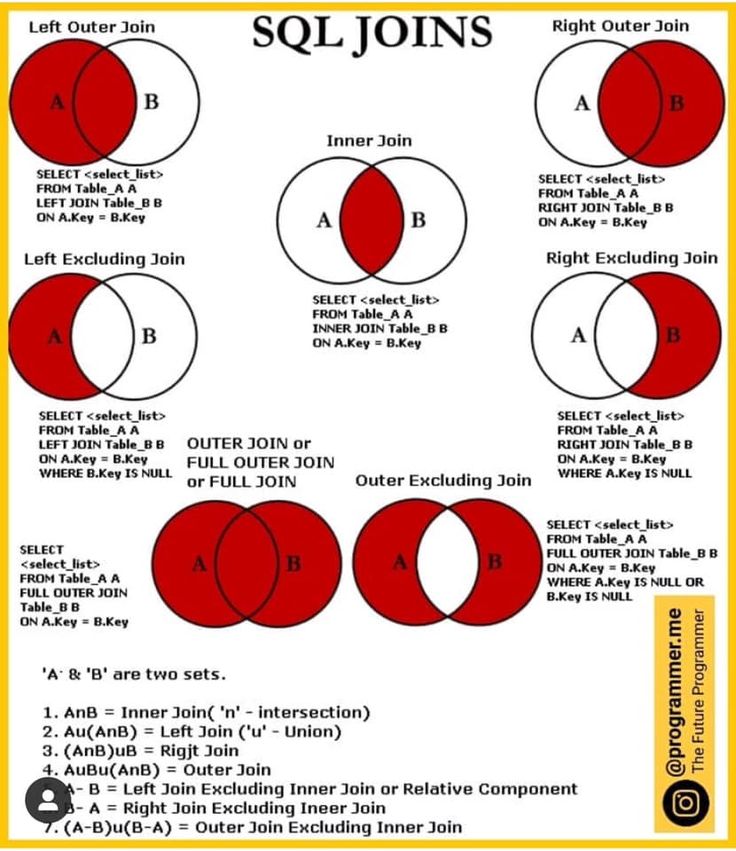
SQL JOINS (INNER, LEFT, RIGHT и FULL Join)
Обзор
Оператор соединения SQL объединяет данные или строки из двух или более таблиц на основе общего поля между ними. В этой статье дается краткое представление о различных типах соединений, таких как INNER/EQUI JOIN, NATURAL JOIN, CROSS JOIN, SELF JOIN и т. д.
Scope
СОЕДИНЯЕТ в SQL.
- В этой статье теоретически обсуждаются соединения SQL и примеры, связанные с ними.
- В этой статье также рассматриваются различные типы JOINS в SQL с подробными примерами каждого типа.
- В этой статье также обсуждается, когда использовать конкретное соединение.
- Наконец, мы обсудили несколько вопросов для интервью, основанных на СОЕДИНЕНИЯХ в SQL.
Что такое JOINS в SQL?
Соединения SQL в основном используются, когда пользователь пытается одновременно извлечь данные из нескольких таблиц (которые имеют отношения «один ко многим» или «многие ко многим»).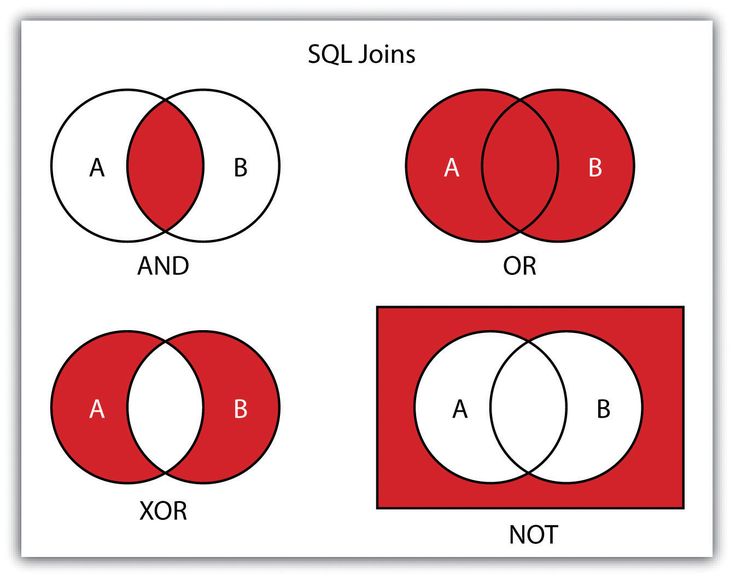 Ключевое слово join объединяет две или более таблиц и создает временный образ объединенной таблицы. Затем в соответствии с заданными условиями он извлекает необходимые данные из таблицы изображений, и после извлечения данных временный образ объединенных таблиц сбрасывается.
Ключевое слово join объединяет две или более таблиц и создает временный образ объединенной таблицы. Затем в соответствии с заданными условиями он извлекает необходимые данные из таблицы изображений, и после извлечения данных временный образ объединенных таблиц сбрасывается.
Большие базы данных часто подвержены избыточности данных, т. е. созданию повторяющихся аномалий данных путем вставки, удаления и обновления. Но с помощью соединений SQL мы способствуем нормализации базы данных, что уменьшает избыточность данных и устраняет избыточные данные.
В реляционных базах данных, таких как SQL, обычно используются два ключевых поля: первичный ключ и внешний ключ. В то время как первичный ключ необходим для того, чтобы таблица считалась частью реляционной базы данных и однозначно идентифицировала каждую строку таблицы, которой она принадлежит, внешний ключ отвечает за связывание двух таблиц в базе данных. Здесь внешний ключ должен быть первичным ключом другой таблицы. В некоторых случаях внешний и первичный ключи, на которые он ссылается, присутствуют в одной и той же таблице.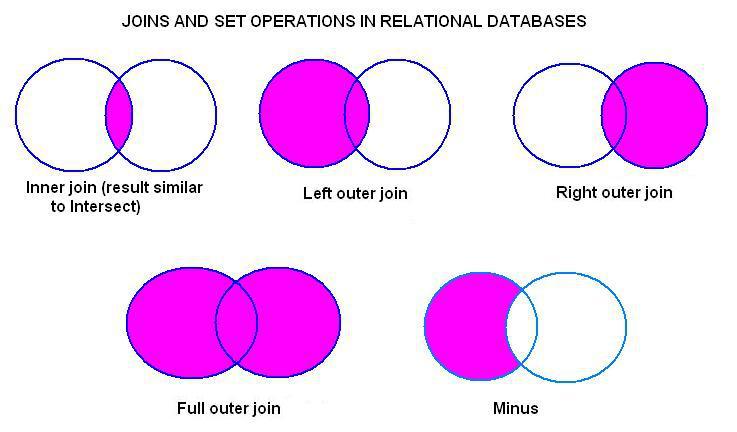 В таких случаях мы используем Самосоединение SQL . Когда мы используем SQL Joins, мы часто используем эти два ключевых поля, чтобы определить, что нужно пользователю, и соответствующим образом сформировать наши запросы.
В таких случаях мы используем Самосоединение SQL . Когда мы используем SQL Joins, мы часто используем эти два ключевых поля, чтобы определить, что нужно пользователю, и соответствующим образом сформировать наши запросы.
Пример SQL JOINS
У нас есть база данных сотрудников компании, где таблица 1 ( emp_dets ) содержит информацию о сотруднике, например: идентификатор сотрудника , имя сотрудника и идентификатор руководителя . Таблица 2 ( supervisor_dets ) включает информацию о руководителях, т. е. их id и имя .
Таблица 1 имеет emp_id в качестве первичного ключа, а Таблица 2 имеет supervisor_id в качестве первичного ключа. В Таблице 1 supervisor_id ссылается на Таблицу 2. Следовательно, это внешний ключ для Таблицы 1.
В зависимости от потребностей пользователей существует несколько типов соединений.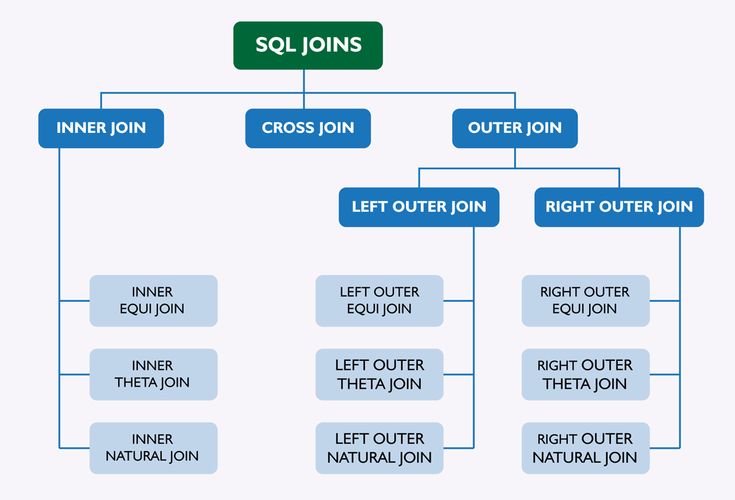 Эти соединения в целом подразделяются на четыре типа, т. е. перекрестное, внутреннее и внешнее.
Эти соединения в целом подразделяются на четыре типа, т. е. перекрестное, внутреннее и внешнее.
Типы СОЕДИНЕНИЙ в SQL
ПЕРЕКРЕСТНЫЕ СОЕДИНЕНИЯ в SQL
Декартово соединение, также известное как перекрестное соединение, представляет собой декартово произведение всех строк первой таблицы на все строки второй таблицы. Допустим, у нас есть m строк в первой таблице и n строк во второй таблице. Тогда результирующая декартова таблица соединений будет иметь m * n строк. Обычно это происходит, когда соответствующий столбец или условие WHERE не указаны.
Общий синтаксис
SELECT имя(я) столбцов ИЗ таблицы1 ПЕРЕКРЕСТНОЕ СОЕДИНЕНИЕ таблица2;
SELECT используется для указания всех столбцов, которые нам нужно отобразить в результирующей таблице. FROM указывает таблицы, в которых нам нужно искать эти столбцы. Тип соединения, т. е. в данном случае CROSS JOIN, помещается между двумя таблицами, которые мы хотим соединить.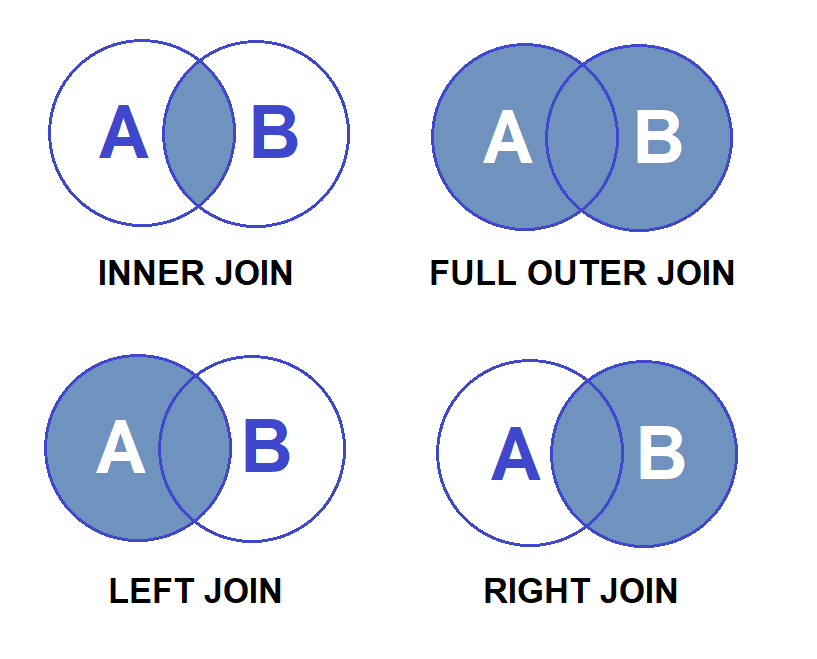
Пример
Рассмотрим сценарий, в котором первая таблица содержит сведения о клиенте, т. е. идентификатор клиента и имя клиента , а вторая таблица содержит сведения о покупках, т. е. идентификатор продукта и название продукта .
Постановка задачи
Напишите запрос, чтобы получить декартово произведение таблиц Customers и Shopping_Details.
Запрос
ВЫБЕРИТЕ * ОТ клиентов ПЕРЕКРЕСТНОЕ СОЕДИНЕНИЕ Shopping_Details;
SELF JOIN в SQL
В SQL Self Join таблица соединяется сама с собой. Это означает, что каждая строка таблицы соединяется сама с собой и со всеми другими строками, касающимися указанных условий, если таковые имеются. Другими словами, можно сказать, что это слияние двух копий одной и той же таблицы. Это чрезвычайно полезно, когда внешний ключ ссылается на первичный ключ той же таблицы.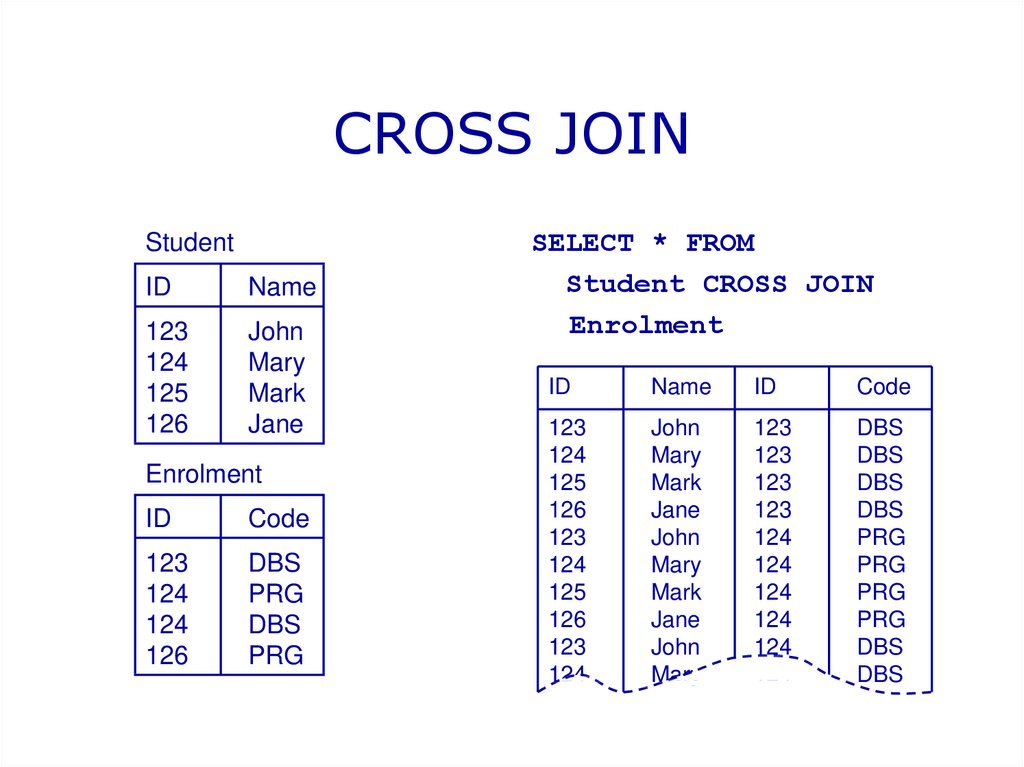
Общий синтаксис
SELECT a.column1 , b.column2 ИЗ table_name a, table_name b ГДЕ какое-то_условие;
Здесь мы ссылаемся на одну и ту же таблицу с разными именами, т. е. a и b. Это означает САМОСОЕДИНЕНИЕ.
Пример
Рассмотрим таблицу сотрудников со следующими данными, т. е. идентификатор сотрудника, имя, номер телефона и идентификатор руководителя . Руководители присутствуют непосредственно за рабочим столом. Следовательно, идентификатор руководителя действует как внешний ключ, который также является первичным ключом, поскольку он ссылается на идентификатор сотрудника.
Table_Name: Сотрудники
Постановка задачи
Напишите запрос, чтобы получить всех сотрудников, которые также являются руководителями некоторых других сотрудников из таблицы данного сотрудника.
Запрос
ВЫБЕРИТЕ Имя КАК Руководители ОТ Работники а, Работники б ГДЕ a.ID = b.supervisor_ID;
Здесь мы используем AS для переименования имени столбца результирующей таблицы.
ВНУТРЕННЕЕ СОЕДИНЕНИЕ в SQL
SQL Inner Join или Equi Join — это самое простое соединение, при котором все строки из нужных таблиц кэшируются вместе, если они соответствуют установленному условию. Для этого объединения требуется две или более таблиц. Inner Join можно использовать с различными условными операторами SQL, такими как WHERE, GROUP BY, ORDER BY и т. д.
Общий синтаксис
SELECT имя-столбца ИЗ таблицы-1 ВНУТРЕННЕЕ СОЕДИНЕНИЕ таблица-2 ГДЕ таблица-1.имя-столбца = таблица-2.имя-столбца;
В качестве альтернативы мы можем использовать только ключевое слово «JOIN» вместо «INNER JOIN».
Пример
Рассмотрим две таблицы супермаркета. Первая таблица с именем Customers дает нам информацию о разных клиентах, то есть их идентификатор клиента , имя и номер телефона . Здесь CustID — это первичный ключ , который однозначно идентифицирует каждую строку. Вторая таблица с именем Shopping_Details дает нам информацию о товарах, купленных клиентами, то есть идентификатора товара 9.0004 , идентификатор клиента (ссылка на клиента, купившего товар), название товара и количество .
Здесь CustID — это первичный ключ , который однозначно идентифицирует каждую строку. Вторая таблица с именем Shopping_Details дает нам информацию о товарах, купленных клиентами, то есть идентификатора товара 9.0004 , идентификатор клиента (ссылка на клиента, купившего товар), название товара и количество .
Постановка задачи
Напишите запрос, чтобы получить всех клиентов, которые купили товары в магазине. Отображение их имени, купленного товара и количества.
Запрос
ВЫБЕРИТЕ Customers.Name, Shopping_Details.Item_Name, Shopping_Details.Quantity ОТ клиентов ВНУТРЕННЕЕ ПРИСОЕДИНЯЙТЕСЬ Shopping_Details ГДЕ Customers.ID==Shopping_Details.ID;
Особый случай ВНУТРЕННЕГО СОЕДИНЕНИЯ: ЕСТЕСТВЕННОЕ СОЕДИНЕНИЕ
Естественное соединение SQL — это тип внутреннего соединения, основанный на условии, что столбцы с одинаковым именем и типом данных присутствуют в обеих объединяемых таблицах.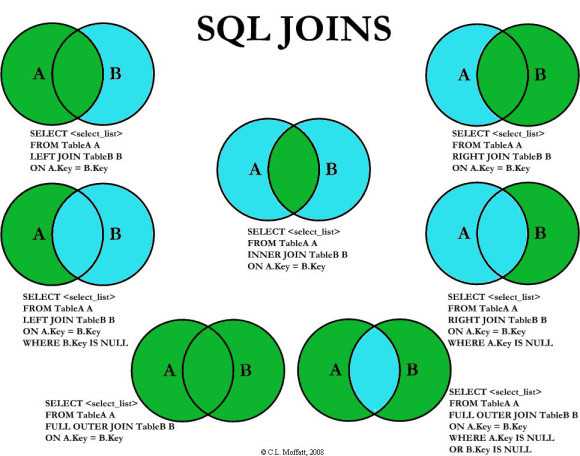
Общий синтаксис
SELECT * FROM таблица-1 ЕСТЕСТВЕННОЕ СОЕДИНЕНИЕ таблица-2;
Пример
Рассмотрим два стола в супермаркете. Первая таблица с именем Customers дает нам информацию о разных клиентах, т. е. их идентификатор клиента , имя и номер телефона . Здесь CustID — это первичный ключ , который однозначно идентифицирует каждую строку. Вторая таблица с именем Shopping_Details дает нам информацию о товарах, купленных покупателями, т. е. идентификатор товара , идентификатор клиента (ссылка на покупателя, купившего товар), название товара и количество .
Постановка задачи
Напишите запрос, чтобы найти все данные о покупателях, которые что-то купили в магазине.
Запрос
ВЫБЕРИТЕ * ОТ клиентов ЕСТЕСТВЕННОЕ ПРИСОЕДИНЕНИЕ Shopping_Details;
ВНЕШНИЕ СОЕДИНЕНИЯ в SQL
Внешние соединения SQL дают как совпадающие, так и несовпадающие строки данных в зависимости от типа внешнего соединения. Эти типы внешних соединений подразделяются на следующие типы:
Эти типы внешних соединений подразделяются на следующие типы:
- Левое внешнее соединение
- Правое внешнее соединение
- Полное внешнее соединение
1. ЛЕВОЕ ВНЕШНЕЕ СОЕДИНЕНИЕ
В этом соединении, также известном как левое соединение SQL, все строки левой таблицы, независимо от выполнения указанных условий, добавляются в выходную таблицу. При этом добавляются только совпадающие строки правой таблицы.
Строки, принадлежащие левой таблице и не имеющие значений из правой таблицы, представлены в результирующей таблице как значения NULL.
Общий синтаксис
SELECT имя(я) столбцов ИЗ таблицы1 ЛЕВОЕ ВНЕШНЕЕ СОЕДИНЕНИЕ таблица2 ON table1.column-name = table2.column-name;
Пример
Рассмотрим два стола супермаркета. Первая таблица с именем Customers дает нам информацию о разных клиентах, то есть их идентификатор клиента , имя и номер телефона .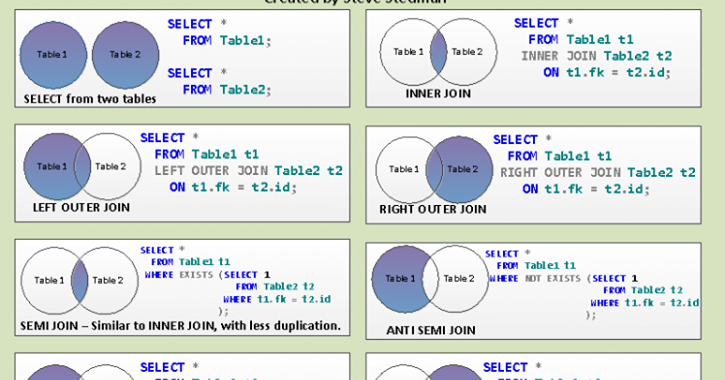 Здесь CustID — это первичный ключ , который однозначно идентифицирует каждую строку. Вторая таблица с именем Shopping_Details дает нам информацию о товарах, купленных покупателями, т. е. идентификатор товара , идентификатор клиента (ссылка на покупателя, купившего товар), название товара и количество .
Здесь CustID — это первичный ключ , который однозначно идентифицирует каждую строку. Вторая таблица с именем Shopping_Details дает нам информацию о товарах, купленных покупателями, т. е. идентификатор товара , идентификатор клиента (ссылка на покупателя, купившего товар), название товара и количество .
Постановка задачи
Напишите запрос для отображения всех клиентов независимо от того, куплены товары или нет. Отображение имени клиента и купленного товара. Если ничего не куплено, вывести NULL.
Запрос
ВЫБЕРИТЕ клиентов. Имя, Shopping_Details.Item_Name FROM Customers LEFT OUTER JOIN Shopping_Details; ON Customers.ID = Shopping_Details.ID;
2. ПРАВОЕ ВНЕШНЕЕ СОЕДИНЕНИЕ
Подобно левому внешнему соединению, в случае правого внешнего соединения, также известного как правое соединение SQL, все строки в правой таблице, независимо от соблюдения установленных условий, добавляется в выходную таблицу.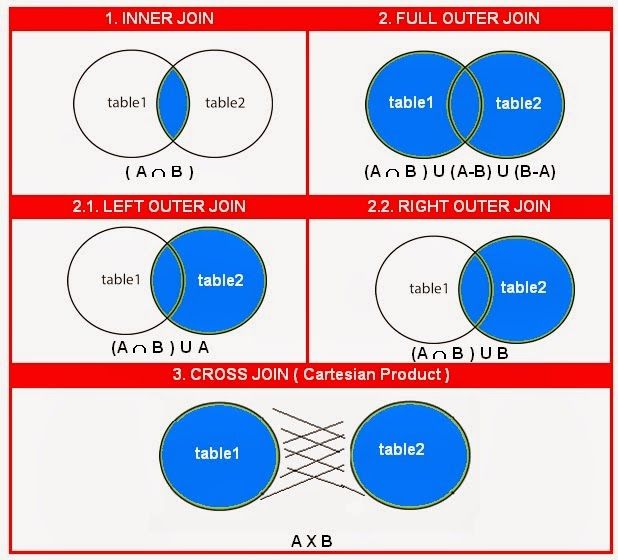 При этом добавляются только совпадающие строки левой таблицы.
При этом добавляются только совпадающие строки левой таблицы.
Строки, принадлежащие правой таблице и не имеющие значений из левой таблицы, представлены в результирующей таблице как значения NULL.
Общий синтаксис
SELECT имя(я) столбца ИЗ таблицы 1 ПРАВОЕ ВНЕШНЕЕ СОЕДИНЕНИЕ таблица 2 ON table1.column-name = table2.column-name;
Пример
Рассмотрим два стола в супермаркете. Первая таблица с именем Customers дает нам информацию о разных клиентах, то есть их идентификатор клиента , имя и номер телефона . Здесь CustID — это первичный ключ 9.0004, который однозначно идентифицирует каждую строку. Вторая таблица с именем Shopping_Details дает нам информацию о товарах, купленных покупателями, т. е. идентификатор товара , идентификатор клиента (ссылка на покупателя, купившего товар), название товара и количество .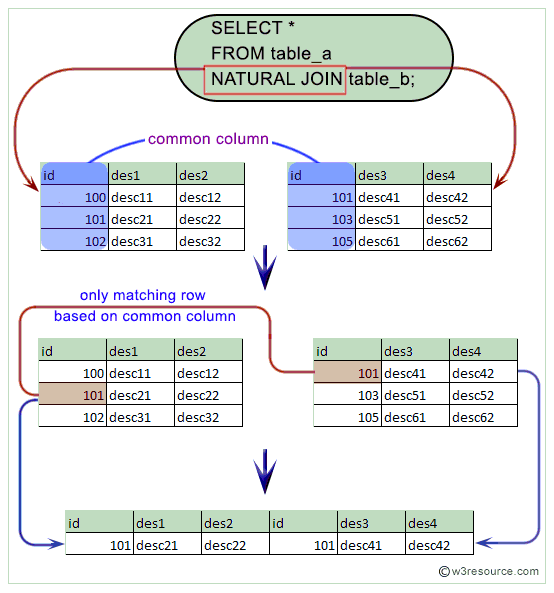
Постановка задачи
Напишите запрос, чтобы получить все товары, купленные клиентами, даже если клиент не существует в базе данных клиентов. Отображение имени клиента и названия товара. Если клиент не существует, отобразите NULL.
Запрос
ВЫБЕРИТЕ Customers.Name, Shopping_Details.Item_Name FROM Customers RIGHT OUTER JOIN Shopping_Details; ON Customers.ID = Shopping_Details.ID;
3. ПОЛНОЕ ВНЕШНЕЕ СОЕДИНЕНИЕ
Полное внешнее соединение (также известное как Полное соединение SQL) сначала добавляет все строки, соответствующие заданному условию в запросе, а затем добавляет оставшиеся несопоставленные строки из обеих таблиц. Нам нужны две или более таблицы для соединения.
После добавления совпадающих строк в выходную таблицу несовпадающие строки левой таблицы добавляются с последующими значениями NULL, а затем несовпадающие строки правой таблицы добавляются с последующими значениями NULL.
Общий синтаксис
SELECT имя(я) столбцов ИЗ таблицы 1 ПОЛНОЕ ВНЕШНЕЕ СОЕДИНЕНИЕ таблица 2 ON table1.column-name = table2.column-name;
Пример
Рассмотрим два стола в супермаркете. Первая таблица с именем Customers дает нам информацию о разных клиентах, то есть их идентификатор клиента , имя и номер телефона . Здесь CustID — это первичный ключ 9.0004, который однозначно идентифицирует каждую строку. Вторая таблица с именем Shopping_Details дает нам информацию о товарах, купленных покупателями, т. е. идентификатор товара , идентификатор клиента (ссылка на покупателя, купившего товар), название товара и количество .
Постановка задачи
Напишите запрос для получения данных обо всех покупателях и товарах, когда-либо купленных в магазине.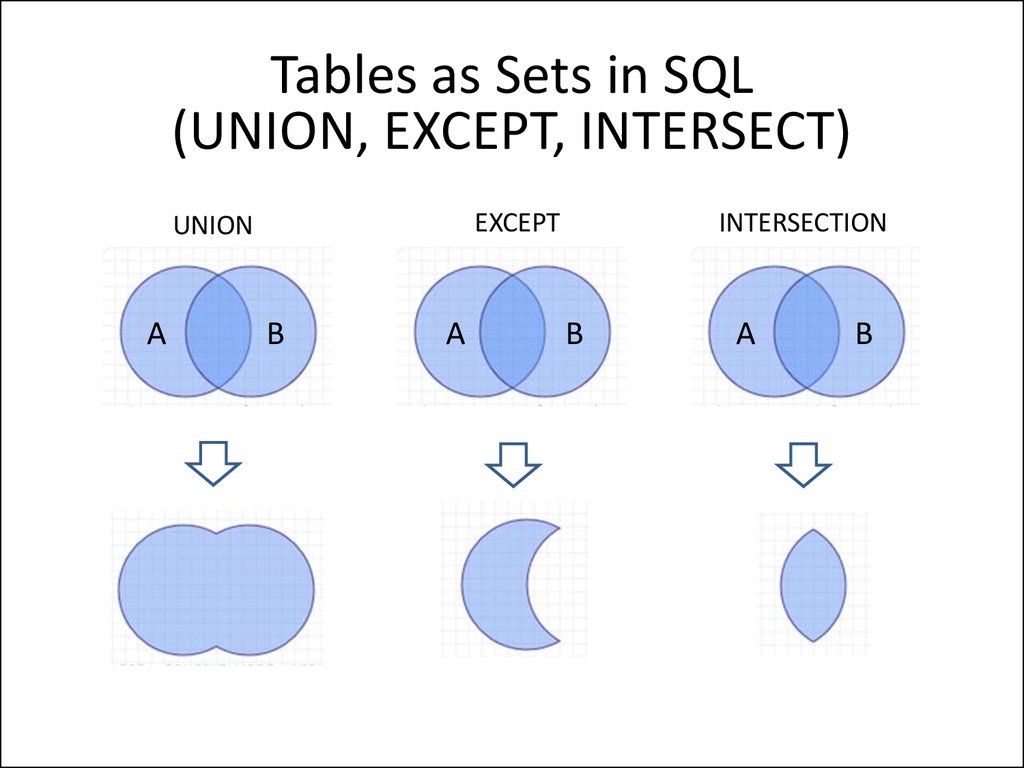 Отображение имени клиента и названия товара. Если какие-либо данные не существуют, отобразите NULL.
Отображение имени клиента и названия товара. Если какие-либо данные не существуют, отобразите NULL.
Запрос
ВЫБЕРИТЕ Customers.Name, Shopping_Details.Item_Name FROM Customers ПОЛНОЕ ВНЕШНЕЕ СОЕДИНЕНИЕ Shopping_Details ГДЕ Customer.ID = Shopping_Details.ID;
Когда использовать Что?
SQL является важным навыком для людей, которые ищут должности в области инженерии данных, науки о данных и разработки программного обеспечения. Соединения в SQL — это одна из продвинутых концепций SQL, о которой часто спрашивают на собеседованиях. В этих вопросах прямо не указывается, какое соединение SQL использовать. Следовательно, нам нужно использовать четырехэтапный анализ, прежде чем мы начнем формировать наш SQL-запрос.
- Идентификация: Определите таблицы, относящиеся к постановке задачи. Нам также необходимо определить отношения между этими таблицами, порядок, в котором они связаны, а также первичные и внешние ключи.

Пример: Допустим, у нас есть таблицы A и B. Таблица A и таблица B имеют общее отношение «Сведения о сотруднике — Сведения об отделе». В таблице A есть три поля — ID, Name и DeptID. В таблице B есть два поля — DeptID и DeptName. Таблица A имеет идентификатор первичного ключа, а первичный ключ таблицы B — DeptID. Таблица A и таблица B связаны с внешним ключом в таблице A, то есть с первичным ключом таблицы B, DeptID.
- Наблюдение: посмотрите, какое объединение будет наиболее подходящим для данного сценария. Это означает, что он должен иметь возможность извлекать все необходимые столбцы и иметь наименьшее количество столбцов, которые необходимо исключить по условию.
Пример: Если все значения таблицы A требуются независимо от условия, зависящего от таблицы C, мы можем использовать левое внешнее соединение для A и C.
- Деконструкция: Теперь, когда у нас есть все требования для формирования нашего запроса , во-первых, нам нужно разбить его на подчасти.
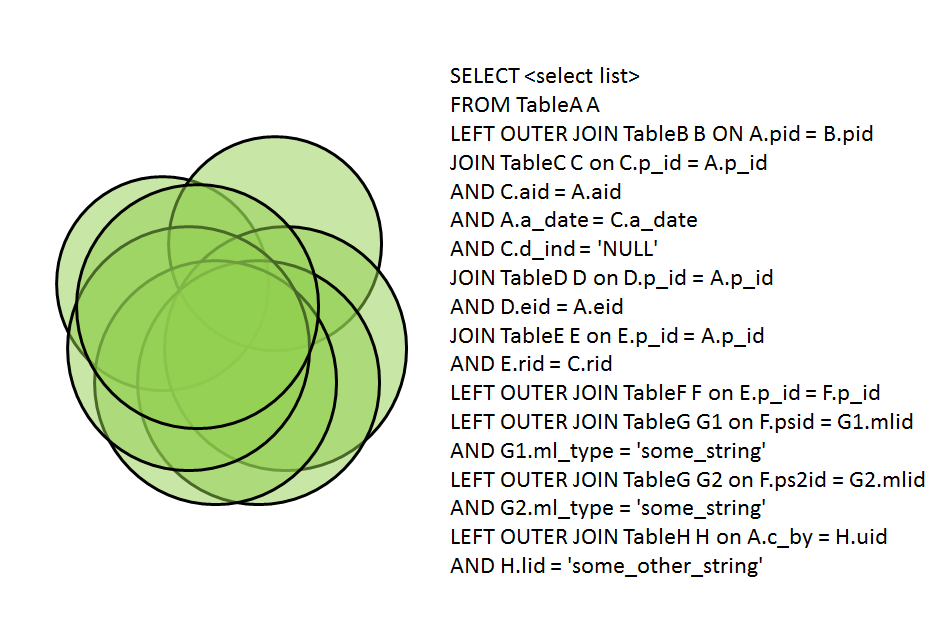 Это помогает нам быстрее сформировать запрос и быстрее понять структуру базы данных. Здесь же мы формируем условия на правильно выявленные связи.
Это помогает нам быстрее сформировать запрос и быстрее понять структуру базы данных. Здесь же мы формируем условия на правильно выявленные связи.
Пример: Вам необходимо представить данные из таблицы A и таблицы B. Но внешний ключ таблицы A — это первичный ключ таблицы C, который является внешним ключом таблицы B. Следовательно, разбивка запроса на результаты из таблицы B и C (скажем, Temp), а затем общие результаты между его Temp и таблицей A дадут нам правильное решение.
- Компиляция: Наконец, мы объединяем все части и формируем наш окончательный запрос. Мы можем использовать методы оптимизации запросов, такие как эвристическая оптимизация, что приводит к более быстрым ответам.
Давайте рассмотрим некоторые вопросы для собеседования, основанные на SQL Joins:
- Напишите запрос на SQL, чтобы найти названия отделов, в которых работает более двух сотрудников. Пример таблицы: emp_dept
| dpt_code | dpt_name |
|---|---|
| 57 | Sales |
| 63 | Finance |
| 47 | HR |
Sample Table: emp_details
| emp_id | emp_fname | emp_lname | emp_dpt |
|---|---|---|---|
| 1001 | Jim | Halpert 57 | 57 |
| 1002 | Kevin | Malone | 63 |
| 1003 | Дуайт | Шрут | 57 |
Решение
Запрос
SELECT eppt_namedmp.dept. ОТ emp_details ВНУТРЕННЕЕ СОЕДИНЕНИЕ emp_dept ON emp_dept = dpt_code СГРУППИРОВАТЬ ПО emp_department.dpt_name СЧЕТ(*) > 2;
Вывод:
dpt_name Продажи
Объяснение
Так как вопрос прямо дает одно условие, которое мы можем выполнить напрямую без каких-либо лазеек, мы напрямую связываем обе таблицы, используя ВНУТРЕННЕЕ СОЕДИНЕНИЕ.
- Напишите оператор SQL, чтобы составить список в порядке возрастания продавцов, которые работают на одного или нескольких клиентов или еще не присоединились ни к одному из клиентов.
Образец таблицы: клиенты
| cust_id | cust_name | city | salesman_id |
|---|---|---|---|
| 101 | Nick Rimando | New York | 648 |
| 102 | Brad Davis | Scranton | 271 |
| 103 | Грэм Зуси | Атланта | 271 |
| 104 | Джулиан Грин | Нью-Йорк | 0679 |
Образец таблицы: продавец
| salesman_id | salesman_name | city |
|---|---|---|
| 648 | Jim Halpert | New York |
| 271 | Dwight Shrute | Scranton |
| 017 | Pam Beesly | Scranton |
Решение:
Запрос:
ВЫБЕРИТЕ a.cust_name,a.city,b.name AS "Продавец", b.city ОТ клиента RIGHT OUTER JOIN продавец b ВКЛ b.salesman_id=a.salesman_id ЗАКАЗАТЬ ПО b.salesman_id;
Вывод:
| cust_name | city | Salesman | city |
|---|---|---|---|
| NULL | NULL | Pam Beesly | Scranton |
| Brad Davis | Scranton | Dwight Shrute | Scranton |
| Грэм Зуси | Атланта | Дуайт Шрут | Скрантон |
| Nick Rimando | New York | Jim Halpert | New York |
| Julian Green | New York | Jim Halpert | New York |
Explanation:
This question states, “one or больше клиентов или еще не присоединились ни к одному из клиентов». Если бы это был только «один или несколько клиентов», мы могли бы напрямую выполнить условие, используя ВНУТРЕННЕЕ СОЕДИНЕНИЕ.