Как изменить кодировку в Word
Содержание
Немного теории
В редакторе Word предусмотрены несколько стандартов кодировки текста, который Вы набираете или просматриваете. В принципе построения текстовых кодов лежит соответствие каждому символу определенное числовое значение и для разных стандартов оно может не совпадать.
Например, в кодировке «кириллица» символу Й соответствует числовое значение 201, а в стандарте «западная Европа» этим значением определяется символ Е. Отсюда и пропадание символов или непонятный набор знаков при просмотре текста в кодировке, отличной от той, в которой был создан документ.
Наиболее универсальным стандартом, который широко применяется в редакторе Word, является «Юникод». Он имеет наиболее широкий набор символов, которые есть в большинстве языков, употребляемых при работе на компьютере. Это и объясняет его широкое применение не только в редакторе Word, но и других текстовых редакторах. В Word данный стандарт кодировки принят по умолчанию и при загрузке, сохранении файлов применяется автоматически.

Общие сведения о кодировке текста
Текст, который отображается в виде текста на экране, на самом деле сохраняется как числовые значения в текстовом файле. Компьютер переводит числовые значения в видимые символы. Для этого используется стандарт кодировки.
Кодировка — это схема нумерации, согласно которой каждому текстовому символу в наборе соответствует определенное числовое значение. Кодировка может содержать буквы, цифры и другие символы. В различных языках часто используются разные наборы символов, поэтому многие из существующих кодировок предназначены для отображения наборов символов соответствующих языков.
Различные кодировки для разных алфавитов
Сведения о кодировке, сохраняемые с текстовым файлом, используются компьютером для вывода текста на экран. Например, в кодировке «Кириллица (Windows)» знаку «Й» соответствует числовое значение 201. Когда вы открываете файл, содержащий этот знак, на компьютере, на котором используется кодировка «Кириллица (Windows)», компьютер считывает число 201 и выводит на экран знак «Й».
Например, в кодировке «Кириллица (Windows)» знаку «Й» соответствует числовое значение 201. Когда вы открываете файл, содержащий этот знак, на компьютере, на котором используется кодировка «Кириллица (Windows)», компьютер считывает число 201 и выводит на экран знак «Й».
Однако если тот же файл открыть на компьютере, на котором по умолчанию используется другая кодировка, на экран будет выведен знак, соответствующий числу 201 в этой кодировке. Например, если на компьютере используется кодировка «Западноевропейская (Windows)», знак «Й» из исходного текстового файла на основе кириллицы будет отображен как «É», поскольку именно этому знаку соответствует число 201 в данной кодировке.
Юникод: единая кодировка для разных алфавитов
Чтобы избежать проблем с кодированием и декодированием текстовых файлов, можно сохранять их в Юникоде.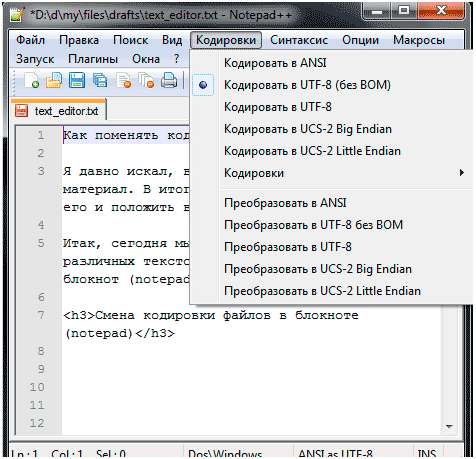 В состав этой кодировки входит большинство знаков из всех языков, которые обычно используются на современных компьютерах.
В состав этой кодировки входит большинство знаков из всех языков, которые обычно используются на современных компьютерах.
Так как Word работает на базе Юникода, все файлы в нем автоматически сохраняются в этой кодировке. Файлы в Юникоде можно открывать на любом компьютере с операционной системой на английском языке независимо от языка текста. Кроме того, на таком компьютере можно сохранять в Юникоде файлы, содержащие знаки, которых нет в западноевропейских алфавитах (например, греческие, кириллические, арабские или японские).
Выбор кодировки при открытии файла
Если в открытом файле текст искажен или выводится в виде вопросительных знаков либо квадратиков, возможно, Word неправильно определил кодировку. Вы можете указать кодировку, которую следует использовать для отображения (декодирования) текста.
Откройте вкладку Файл.
Нажмите кнопку Параметры.
Нажмите кнопку Дополнительно.
Перейдите к разделу Общие и установите флажокПодтверждать преобразование формата файла при открытии.
Примечание: Если установлен этот флажок, Word отображает диалоговое окно Преобразование файла при каждом открытии файла в формате, отличном от формата Word (то есть файла, который не имеет расширения DOC, DOT, DOCX, DOCM, DOTX или DOTM). Если вы часто работаете с такими файлами, но вам обычно не требуется выбирать кодировку, не забудьте отключить этот параметр, чтобы это диалоговое окно не выводилось.
Закройте, а затем снова откройте файл.
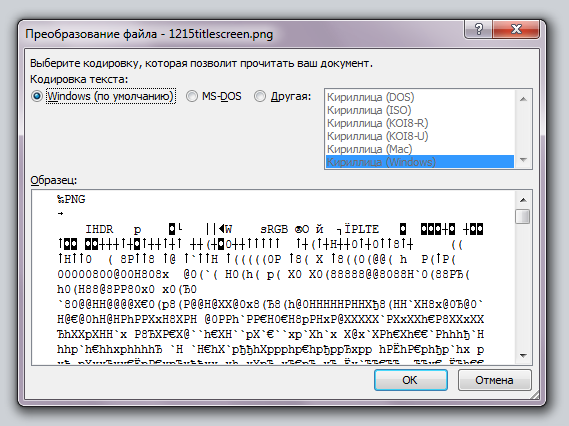
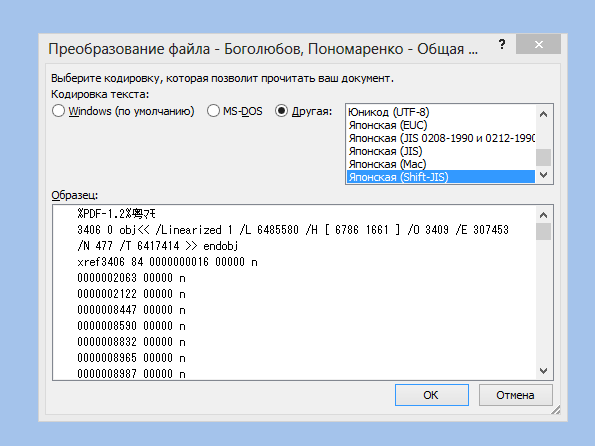
В диалоговом окне Преобразование файла выберите пункт Кодированный текст.

В диалоговом окне Преобразование файла установите переключатель Другая и выберите нужную кодировку из списка.
В области Образец можно просмотреть текст и проверить, правильно ли он отображается в выбранной кодировке.
Чтобы установить дополнительные шрифты, сделайте следующее:
Нажмите кнопку Пуск и выберите пункт Панель управления.
Выполните одно из указанных ниже действий.
В Windows 7
На панели управления выберите элемент Удаление программ.
В списке программ щелкните Microsoft Office или Microsoft Word, если он был установлен отдельно от пакета Microsoft Office, и нажмите кнопку Изменить.
В Windows Vista
На панели управления выберите раздел Удаление программы.
В списке программ щелкните Microsoft Office или Microsoft Word, если он был установлен отдельно от пакета Microsoft Office, и нажмите кнопку Изменить.
В Windows XP
На панели управления щелкните элемент Установка и удаление программ.
В списке Установленные программы щелкните Microsoft Office или Microsoft Word, если он был установлен отдельно от пакета Microsoft Office, и нажмите кнопку Изменить.
В группе Изменение установки Microsoft Office нажмите кнопку Добавить или удалить компоненты и затем нажмите кнопку Продолжить.
В разделе Параметры установки разверните элемент Общие средства Office, а затем — Многоязыковая поддержка.
Выберите нужный шрифт, щелкните стрелку рядом с ним и выберите пункт Запускать с моего компьютера.
Совет: При открытии текстового файла в той или иной кодировке в Word используются шрифты, определенные в диалоговом окне Параметры веб-документа. (Чтобы вызвать диалоговое окно Параметры веб-документа, нажмите кнопку Microsoft Office, затем щелкните Параметры Word и выберите категорию Дополнительно. В разделе Общие нажмите кнопку Параметры веб-документа.) С помощью параметров на вкладке Шрифты диалогового окна Параметры веб-документа можно настроить шрифт для каждой кодировки.
Выбор кодировки при сохранении файла
Если не выбрать кодировку при сохранении файла, будет использоваться Юникод. Как правило, рекомендуется применять Юникод, так как он поддерживает большинство символов большинства языков.
Как правило, рекомендуется применять Юникод, так как он поддерживает большинство символов большинства языков.
Если документ планируется открывать в программе, которая не поддерживает Юникод, вы можете выбрать нужную кодировку. Например, в операционной системе на английском языке можно создать документ на китайском (традиционное письмо) с использованием Юникода. Однако если такой документ будет открываться в программе, которая поддерживает китайский язык, но не поддерживает Юникод, файл можно сохранить в кодировке «Китайская традиционная (Big5)». В результате текст будет отображаться правильно при открытии документа в программе, поддерживающей китайский язык (традиционное письмо).
Примечание: Так как Юникод — это наиболее полный стандарт, при сохранении текста в других кодировках некоторые знаки могут не отображаться. Предположим, например, что документ в Юникоде содержит текст на иврите и языке с кириллицей.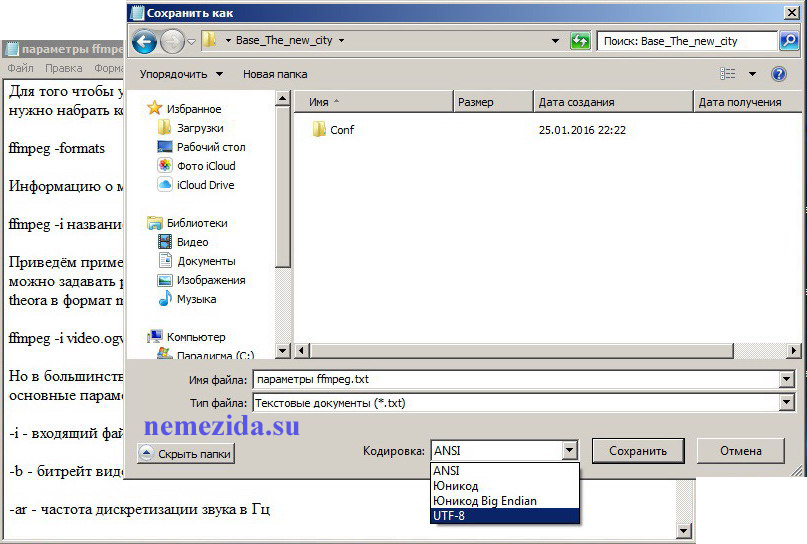 Если сохранить файл в кодировке «Кириллица (Windows)», текст на иврите не отобразится, а если сохранить его в кодировке «Иврит (Windows)», то не будет отображаться кириллический текст.
Если сохранить файл в кодировке «Кириллица (Windows)», текст на иврите не отобразится, а если сохранить его в кодировке «Иврит (Windows)», то не будет отображаться кириллический текст.
Если выбрать стандарт кодировки, который не поддерживает некоторые символы в файле, Word пометит их красным. Вы можете просмотреть текст в выбранной кодировке перед сохранением файла.
При сохранении файла в виде кодированного текста из него удаляется текст, для которого выбран шрифт Symbol, а также коды полей.
Перекодировка текста
К сожалению, в разных версиях Word необходимые действия для изменения кодировки различны, хотя и ведут к одинаковому результату. Рассмотрим подробнее необходимые шаги для разных версий в отдельности:
Word 2003
Для того, что бы сменить кодировку, зайдите в меню и выберите СЕРВИС, а затем ПАРАМЕТРЫ.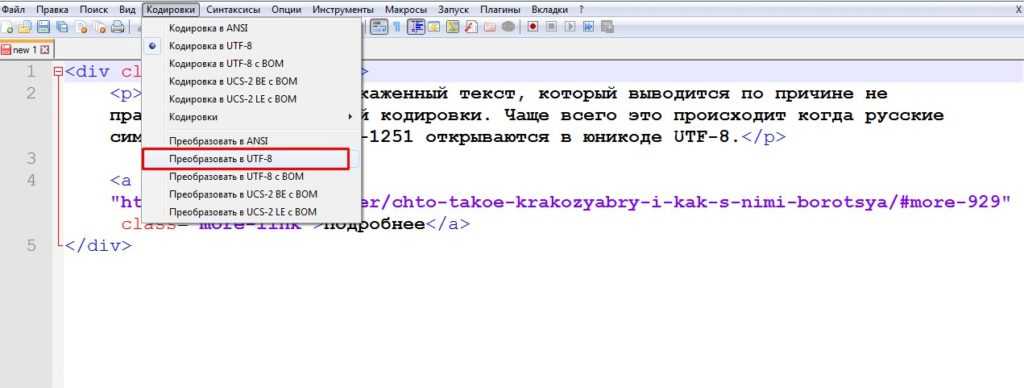 После этого в разделе ЗАКЛАДКА –Общие подтверждаем преобразование при открытии. Теперь при каждом следующем открытии текстового файла, будет предоставлена возможность выбора системы кодирования;
После этого в разделе ЗАКЛАДКА –Общие подтверждаем преобразование при открытии. Теперь при каждом следующем открытии текстового файла, будет предоставлена возможность выбора системы кодирования;
Word 2010, 2007
Эти версии в плане изменения шрифтов ничем не отличаются. В главном меню через ФАЙЛ заходим в ПАРАМЕТРЫ. В новом, выпадающем, окне выбираем раздел ДОПОЛНИТЕЛЬНО и в самом низу окна у Вас будет возможность «разметить документ так, будто он создан … ». Вам будут представлена возможность и создавать, и читать документы в нужном формате.
Создание текста с нужной кодировкой
Иногда возникает необходимость создания текстового файла в другой системе кодов. Например, для графического редактора PDF программы Works-6 или других программных продуктов. Редактор Word поможет Вам решить эту проблему. Нужно набрать текст так, как делаете обычно, соблюдая необходимую структуру и требования к набираемой информации.
После создания файла, в главном меню редактора заходим в ФАЙЛ, а далее выбираем СОХРАНИТЬ КАК.
В выпадающем окне, кроме возможности определить будущее название файла, будут представлены варианты кодировки файла после сохранения.
Для предотвращения потери информации рекомендовано сохранить файл в обычном формате, а уже потом записать в требуемом.
Нужно учитывать, что существуют программы, которые не поддерживают переноса слов или строк текста. Поэтому, в данном случае, необходимо писать текст, избегая таких переносов.
Еще одна особенность при возникновении трудностей читаемости текста. Это небольшое отличие 2003 версии Worda от версий более поздних. Появился новый формат текстовых файлов – docx. Его отличие не носит вопрос кодировки, в том смысле, в котором мы его сейчас рассматриваем. И информацию такого рода на старой версии не просмотреть, необходимо обновление редактора.
Инструкция
- Если у вас нет программы Word, то скачайте ее с официального сайта разработчиков и установите на свой компьютер.
 Если вы не собираетесь постоянно использовать эту программу, то платить за нее не нужно, вам хватит пробной версии.
Если вы не собираетесь постоянно использовать эту программу, то платить за нее не нужно, вам хватит пробной версии. - Нажмите на нужный файл правой клавишей мышки и откройте подменю «Открыть с помощью», укажите программу Word. Если данной программы нет в списке, то запустите Word обычным способом. Откройте меню «Файл» и выберите команду «Открыть», укажите расположение нужного документа на жестком диске и нажмите «Открыть». Будет предложено несколько вариантов открытия файла, связанных с его нестандартной кодировкой, укажите нужный и нажмите команду ОК.
Подбор кодировки - Далее нужно изменить кодировку и сохранить результат, для этого откройте меню «Файл» и нажмите пункт «Сохранить как». Укажите директорию для измененного документа, впишите новое имя и выполните команду «Сохранить». Загрузится окно атрибутов документа, выберите нужную кодировку и нажмите Enter (наиболее используемой кодировкой является «Юникод»).
- Внимательно отнеситесь к сохранению документа, если вы попытаетесь сохранить файл в прежнюю папку с прежним названием, то новый документ заменит собой старый файл.
 Чтобы сохранить на диске два разных документа, нужно использовать для них разные названия или папки.
Чтобы сохранить на диске два разных документа, нужно использовать для них разные названия или папки. - При сохранении файла также обратите внимание на его расширение. Если документ в дальнейшем будет открываться с помощью программы Word 2003 года выпуска и более старшими версиями, то используйте формат doc. Если документ нужен для программы 2007 года и более новых версий, то подойдет формат docx. Также стоит помнить, что формат doc открывается как на старых версиях программы, так и на новых, но у них ограниченное форматирование. Стоит понимать, что отображение текстового документа не стандартными символами – это не только признак неизвестной кодировки, возможно в используемом редакторе нет нужного шрифта, в таком случае нужно менять не кодировку, а шрифт.
Универсальный декодер
Сервис отлично справляется с кириллицей. Очень популярен среди юзеров рунета. Если вы выбрали его для работы, то необходимо сделать копию текста, нуждающегося в декодировании и вставить в специальное поле.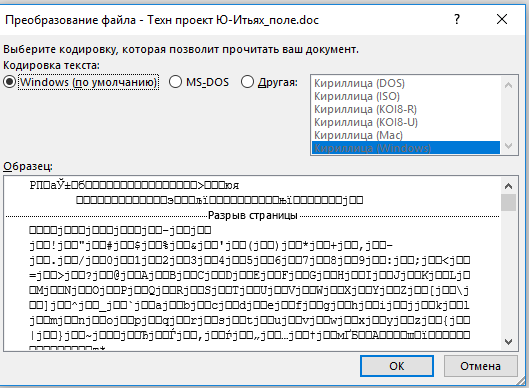 Следует размещать отрывок так, чтобы уже на первой строчке были непонятные знаки.
Следует размещать отрывок так, чтобы уже на первой строчке были непонятные знаки.
Если вы хотите, чтобы ресурс автоматически смог раскодировать, придется отметить это в списке выбора. Но можно выполнять и ручную настройку, указав выбранный тип. Итоги можете найти в разделе «Результат». Вот только тут есть определенные ограничения. К примеру, если в поле вставить отрывок более 100 Кб, софт не обработает его, так что нужно будет выбирать кусочки.
Как раскодировать текст онлайн с помощью Fox Tools
Здесь вы можете выбирать итоговый результат. Программа способна функционировать и в режиме «по умолчанию», который используется для неизвестных кодировок, но в таком случае необходимо отмечать самостоятельно вариант текстового объекта, подходящего больше всего. Инструмент простой и доступный, поэтому идеально подойдет даже новичкам.
Декодер Артемия Лебедева
Данный дешифратор способен взаимодействовать со всеми популярными кодировками. Приложение может предложить пользователю сложный и простой рабочий режим. В первом показывается не только исходник, но и преобразование. Еще можно указать кодировку, куда понадобилось перевести текст, из открывающегося списка. В правом блоке вы найдете результат для прочтения.
В первом показывается не только исходник, но и преобразование. Еще можно указать кодировку, куда понадобилось перевести текст, из открывающегося списка. В правом блоке вы найдете результат для прочтения.
Translit.net
Этот инструмент имеет сложный внешний вид, но по принципу работы он не отличается от остальных. Необходимо ввести текстовый отрывок и в ручном режиме установить настройки.
Видео: Как изменить кодировку в Word
Источники
- http://ExcelWords.ru/nastrojki/kak-izmenit-kodirovku-teksta.html
- https://support.office.com/ru-ru/article/%D0%B2%D1%8B%D0%B1%D0%BE%D1%80-%D0%BA%D0%BE%D0%B4%D0%B8%D1%80%D0%BE%D0%B2%D0%BA%D0%B8-%D1%82%D0%B5%D0%BA%D1%81%D1%82%D0%B0-%D0%BF%D1%80%D0%B8-%D0%BE%D1%82%D0%BA%D1%80%D1%8B%D1%82%D0%B8%D0%B8-%D0%B8-%D1%81%D0%BE%D1%85%D1%80%D0%B0%D0%BD%D0%B5%D0%BD%D0%B8%D0%B8-%D1%84%D0%B0%D0%B9%D0%BB%D0%BE%D0%B2-60d59c21-88b5-4006-831c-d536d42fd861
- https://besthard.
 ru/faq/kak-izmenit-kodirovku-v-vord/
ru/faq/kak-izmenit-kodirovku-v-vord/ - https://life-v.ru/decode-text-online/
Как сменить кодировку текстового файла с помощью Блокнота в Windows
- Таблицы кодировок русской раскладки клавиатуры
- Создание нового текстового документа в Windows
- Смена кодировки текстового файла с помощью Блокнота в Windows.
Таблицы кодировок русской раскладки клавиатуры.
Фишка кодировки текстовых фалов в том, что хранятся не сами буквы (символы), а ссылки на них в таблице кодировок. Если с латинским буквами, арабскими цифрами и основными символами типа точек, тире и запятых никаких проблем не возникает: во многих таблицах кодировок все эти буквы, цифры и символы находятся в одних и тех же ячейках, то с кириллицей всё сложно. Например, в разных кодировках буква Ы может находиться в ячейке 211, 114 и 69.
Именно поэтому на заре интернета чтобы посмотреть разные сайты с разными кодировками приходилось подбирать кодировку. (Но кто это помнит?) Сейчас кодировка страницы обычно прописана в заголовке страницы, что позволяет браузеру «автоматически» подбирать отображение символов на наших мониторах.
(Но кто это помнит?) Сейчас кодировка страницы обычно прописана в заголовке страницы, что позволяет браузеру «автоматически» подбирать отображение символов на наших мониторах.
То есть сервер отдаёт не просто HTML-страничку, а указывает, что у неё кодировка Windows-1251. Браузер таким образом, считывая информацию о кодировке полученного файла, подставляет символы из указанной кодировки.
Но и это ещё не всё веселье. Например, если на сервере установлена операционная система из семейства *nix (с кодировкой по умолчанию UTF-8), а мы шлём файл из нашей любимой ОС Windows, где кодировка текстовых фалов по умолчанию стоит почему-то ANSI, то как вы думаете сервер будет работать с текстом, кодировка которой не совпадает с его? Правильно! Как-то будет работать! Но результат работы может быть непредсказуемым и удивительным. =)
Надеюсь, что мотивация для обращение необходимого внимания на кодировку достаточная и можно перейти к сути вопроса: «Как же, чёрт возьми, сохранить файл в нужной кодировке?!»
В этой статье речь пойдёт как раз о том, как сохранить текстовый файл с помощью программы Блокнот (Notepad) в Windows в нужной кодировке.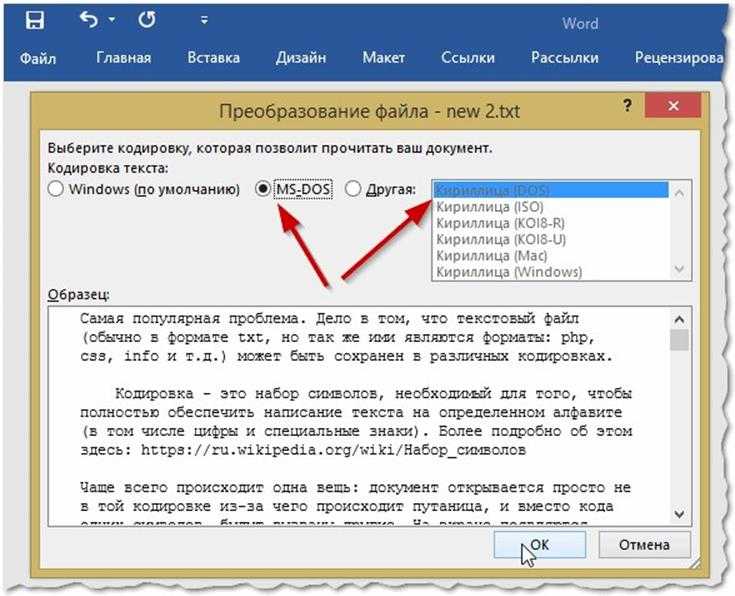
Создание нового текстового документа в Windows.
Для того, чтобы изменить кодировку текстового файла, конечно же сперва его нужно создать. А после того, как файл создан, нужно ещё суметь его открыть. Самый простой способ отрыть файл — это двойной клик левой кнопкой мыши по его иконке в проводнике:
Если до этого настройки Windows не менялись, то файлы с расширением .txt открываются в Блокноте. (Это ещё один способ, как отрыть Блокнот (Notepad).)
Смена кодировки текстового файла с помощью Блокнота в Windows.
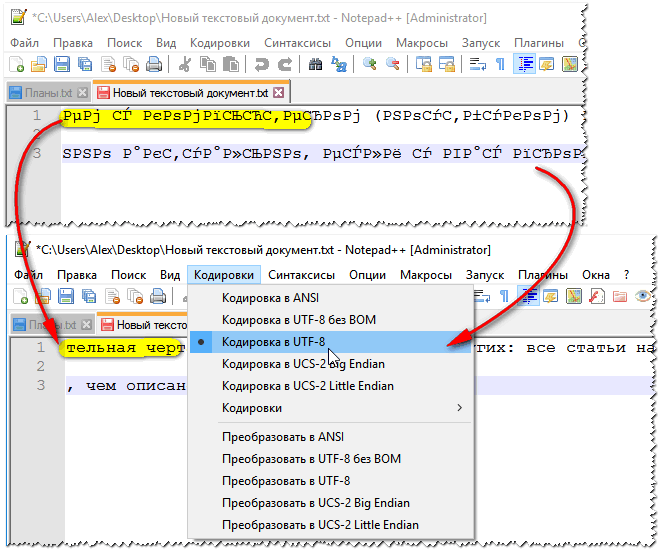
Чтобы поменять кодировку в открывшемся файле, нужно в меню «Файл» текстового редактора Блокнот выбрать пункт «Сохранить как…»:
Откроется диалоговое окно сохранения файла. Для смены кодировки, нужно выбрать из списка предлагаемых необходимый:
После того, как нужная кодировка выбрана, можно кликнуть на кнопку «Сохранить» или просто нажать Enter:
Так как мы не изменили имя файла, то будет перезаписан тот же самый файл.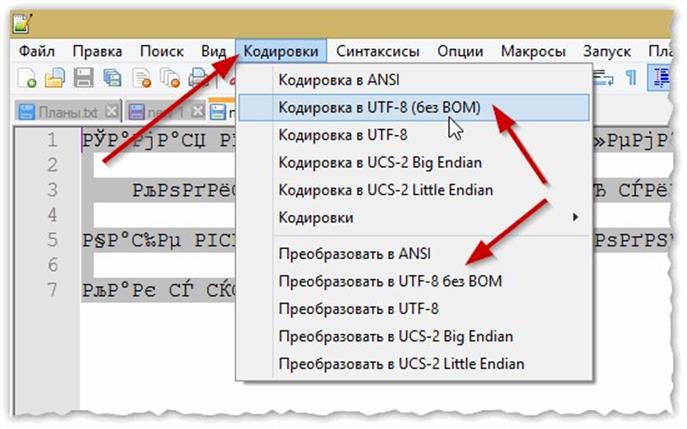 Поэтому возникает справедливый вопрос: «Файл с таким именем уже существует. Заменить?» Ну да, мы к этому и стремимся! Поменять кодировку у этого файла. Поэтому его нужно перезаписать с новой кодировкой. Соглашаемся:
Поэтому возникает справедливый вопрос: «Файл с таким именем уже существует. Заменить?» Ну да, мы к этому и стремимся! Поменять кодировку у этого файла. Поэтому его нужно перезаписать с новой кодировкой. Соглашаемся:
Всё! Миссия по смене кодировки в текстовом файле выполнена! Файл сохранён с новой кодировкой. Можно закрыть текстовый редактор и устроить празднование этого решающего события! =D
Заберите ссылку на статью к себе, чтобы потом легко её найти!
Выберите, то, чем пользуетесь чаще всего:
utf 8 — Как исправить кодировку файла?
спросил
Изменено 6 лет, 1 месяц назад
Просмотрено 214 тысяч раз
У меня есть текстовый файл с кодировкой ANSI, который не должен был быть закодирован как ANSI, поскольку там были акценты
символы, которые не поддерживает ANSI. Я бы предпочел работать с UTF-8.
Я бы предпочел работать с UTF-8.
Могут ли данные декодироваться правильно или они теряются при перекодировании?
Какие инструменты можно использовать?
Вот пример того, что у меня есть:
ç é
Из контекста я могу сказать (кафе должно быть кафе), что это должны быть два символа:
ç é
- кодировка
- utf-8
- кодировка символов
- текстовые файлы
- кодовые страницы
4
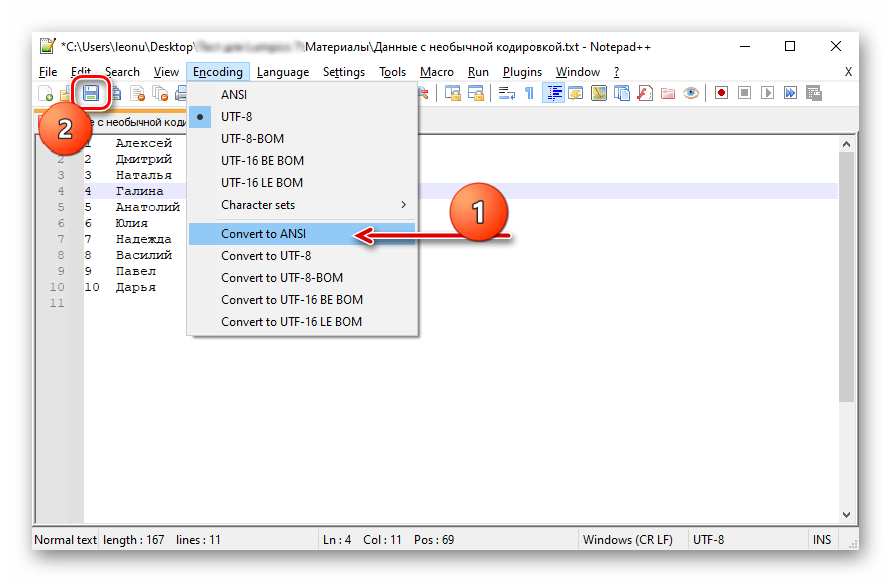
Выполните следующие действия в Notepad++
1- Скопируйте исходный текст
2- В Notepad++ откройте новый файл, измените кодировку -> выберите кодировку, которой, по вашему мнению, следует исходный текст. Попробуйте также кодировку «ANSI», так как иногда файлы Unicode читаются как ANSI некоторыми программами
3- Вставьте
4- Затем, чтобы преобразовать в Unicode, снова перейдите в то же меню: Кодировка -> «Кодировать в UTF-8».
Описанные выше действия применимы для большинства языков. Вам просто нужно угадать исходную кодировку перед вставкой в блокнот ++, а затем преобразовать через то же меню в альтернативную кодировку на основе Unicode, чтобы увидеть, станет ли что-то читабельным.
Большинство языков существует в двух формах кодировки: 1- Старая унаследованная форма ANSI (ASCII), всего 8 бит, изначально использовалась большинством компьютеров. 8 бит допускали только 256 вариантов, 128 из которых были обычными латинскими и управляющими символами, последние 128 бит читались по-разному в зависимости от языковых настроек ПК. 2- Новый стандарт Unicode (до 32 бит) дает уникальный код для каждого символа. на всех известных в настоящее время языках и на многих других. если файл имеет формат unicode, он должен быть понятен на любом ПК с установленным языковым шрифтом. Обратите внимание, что даже UTF-8 доходит до 32 бит и является таким же широким, как UTF-16 и UTF-32, только он пытается оставаться 8-битным с латинскими символами только для экономии места на диске
5
РЕДАКТИРОВАТЬ: Простую возможность исключить, прежде чем переходить к более сложным решениям: вы пытались установить набор символов на utf8 в текстовом редакторе, в котором вы читаете файл? Это может быть просто тот случай, когда кто-то отправляет вам файл utf8, который вы читаете в редакторе, настроенном на cp1252.
Просто взяв два примера, это случай чтения utf8 через призму однобайтовой кодировки, вероятно, одной из iso-8859.-1, iso-8859-15 или cp1252. Если вы можете опубликовать примеры других проблемных персонажей, это можно будет еще больше сузить.
Поскольку визуальный осмотр символов может ввести в заблуждение, вам также необходимо посмотреть на базовые байты: §, который вы видите на экране, может быть либо 0xa7, либо 0xc2a7, и это определит тип преобразования набора символов, который вам нужно преобразовать. делать.
Можете ли вы предположить, что все ваши данные были искажены точно таким же образом — что они взяты из одного источника и претерпели одну и ту же последовательность преобразований, так что, например, в вашем тексте нет ни одной буквы é, это всегда ç? Если это так, проблема может быть решена с помощью последовательности преобразований набора символов. Если вы можете более конкретно указать среду, в которой вы находитесь, и базу данных, которую вы используете, кто-нибудь здесь, вероятно, может рассказать вам, как выполнить соответствующее преобразование.
В противном случае, если проблемные символы встречаются только в некоторых местах ваших данных, вам придется брать их экземпляр за экземпляром, основываясь на предположениях вроде «ни один автор не намеревался помещать ç в свой текст, поэтому всякий раз, когда видите, замените на ç». Последний вариант более рискован, во-первых, потому что эти предположения о намерениях авторов могут быть неверны, во-вторых, потому что вам придется самостоятельно определять каждого проблемного персонажа, что может быть невозможно, если текста слишком много для визуального осмотра или если он написан. на чужом для вас языке или системе письма.
2
С vim из командной строки:
vim -c "set encoding=utf8" -c "set fileencoding=utf8" -c "wq" имя файла
Когда вы видите такие последовательности символов, как ç и é, это обычно указывает на то, что файл UTF-8 был открыт программой, которая считывает его как ANSI (или аналогичный). Такие символы Юникода:
Такие символы Юникода:
U+00C2 Заглавная латинская буква A с циркумфлексом
U+00C3 Заглавная латинская буква A с тильдой
U+0082 Здесь разрешен разрыв
U+0083 Здесь нет разрыва
имеют тенденцию появляться в тексте ANSI из-за стратегии переменного байта, которую использует UTF-8. Эта стратегия очень хорошо объясняется здесь.
Преимущество для вас состоит в том, что появление этих странных символов позволяет относительно легко найти и, таким образом, заменить экземпляры неправильного преобразования.
Я считаю, что, поскольку ANSI всегда использует 1 байт на символ, вы можете справиться с этой ситуацией с помощью простой операции поиска и замены. Или, что более удобно, с помощью программы, которая включает в себя табличное сопоставление между оскорбительными последовательностями и нужными символами, например:
—> » # должен быть открывающей двойной фигурной кавычкой
—? -> ” # должен быть закрывающей двойной фигурной кавычкой
Любой данный текст, при условии, что он на английском языке, будет иметь относительно небольшое количество различных типов замен.
Надеюсь, это поможет.
0
В возвышенном текстовом редакторе файл -> открыть заново с кодировкой -> выбрать правильную кодировку.
Как правило, кодировка определяется автоматически, но если нет, вы можете использовать описанный выше метод.
Если вы видите вопросительные знаки в файле или акценты уже потеряны, возврат к utf8 не поможет вашему делу. например если кафе стало кафе — одной сменой кодировки не поможет (нужны исходные данные).
Не могли бы вы вставить сюда какой-нибудь текст, это поможет нам точно ответить.
Я нашел простой способ автоматического определения кодировок файлов — изменить файл на текстовый (на Mac переименовать расширение файла в .txt) и перетащить его в окно Mozilla Firefox (или Файл -> Открыть). Firefox обнаружит кодировку — вы можете увидеть, что она придумала, в разделе «Вид» -> «Кодировка символов».
Я изменил кодировку файла с помощью TextMate, как только узнал правильную кодировку.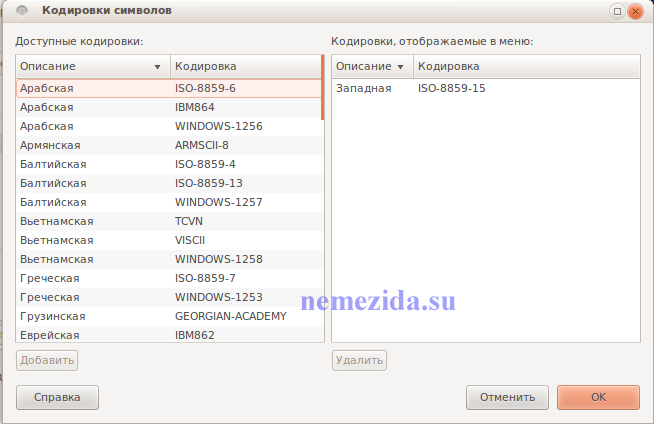 Файл -> Открыть заново, используя кодировку, и выберите свою кодировку. Затем «Файл» -> «Сохранить как» и измените кодировку на UTF-8 и окончания строк на LF (или что вы хотите)
Файл -> Открыть заново, используя кодировку, и выберите свою кодировку. Затем «Файл» -> «Сохранить как» и измените кодировку на UTF-8 и окончания строк на LF (или что вы хотите)
Я нашел этот вопрос при поиске решения проблемы с кодовой страницей, которая у меня была с китайскими иероглифами, но в В конце концов, моя проблема заключалась в том, что Windows неправильно отображала их в пользовательском интерфейсе.
Если у кого-то еще есть такая же проблема, вы можете решить ее, просто изменив локальный в Windows на Китай, а затем обратно.
Я нашел решение здесь:
http://answers.microsoft.com/en-us/windows/forum/windows_7-desktop/how-can-i-get-chinesejapanese-characters-to/fdb1f1da-b868- 40d1-a4a4-7acadff4aafa?page=2&auth=1
Также проголосовал за ответ Габриэля, поскольку просмотр данных в блокноте ++ был тем, что подсказало мне об окнах.
И еще есть более старая программа перекодирования.
Существуют программы, которые пытаются определить кодировку файла, например chardet.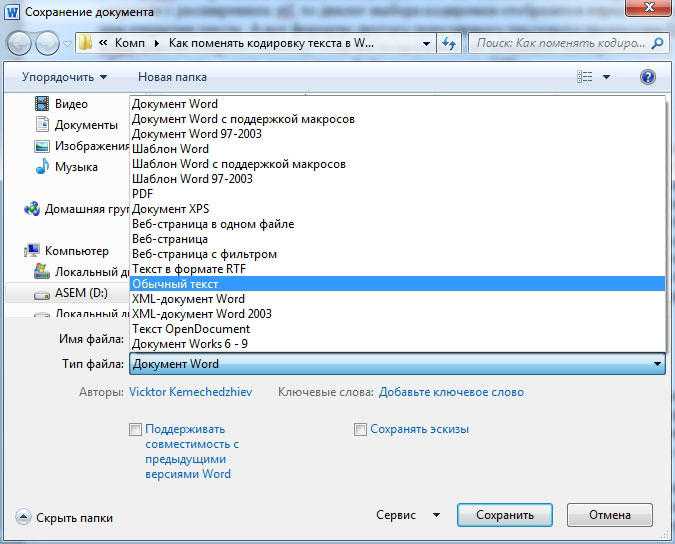 Затем вы можете преобразовать его в другую кодировку, используя iconv. Но для этого требуется, чтобы исходный текст оставался неповрежденным и никакая информация не терялась (например, путем удаления акцентов или целых букв с акцентами).
Затем вы можете преобразовать его в другую кодировку, используя iconv. Но для этого требуется, чтобы исходный текст оставался неповрежденным и никакая информация не терялась (например, путем удаления акцентов или целых букв с акцентами).
Зарегистрируйтесь или войдите в систему
Зарегистрируйтесь с помощью Google
Зарегистрироваться через Facebook
Зарегистрируйтесь, используя адрес электронной почты и пароль
Опубликовать как гость
Электронная почта
Обязательно, но не отображается
Опубликовать как гость
Электронная почта
Требуется, но не отображается
unicode.
 Как преобразовать кодировку текстового файла (который содержит текст на языке, отличном от английского) из «UTF-16 LE» в «UTF-8» в Python?
Как преобразовать кодировку текстового файла (который содержит текст на языке, отличном от английского) из «UTF-16 LE» в «UTF-8» в Python?Задавать вопрос
спросил
Изменено 3 года, 9 месяцев назад
Просмотрено 3к раз
У меня есть несколько текстовых файлов, содержащих текст на языке хинди в папке. Но эти текстовые файлы находятся в кодировке UTF-16 LE . Я хочу изменить кодировку на UTF-8 без изменения текста в нем. Как мне это сделать?
Я написал два файла Python, но ни один из них не работает должным образом. Когда я запускаю любой из них, вместе с изменением кодировки они очищают содержимое файла. Это код в моих файлах Python:
Файл 1:
import os для корня, каталогов, файлов в os.walk("."): для имени файла в файлах: #print(имя файла[-4:]) если (имя файла [-3:] == "txt"): f= открыть(имя файла,"w+") х = f.read() печать (х) е.закрыть() f1= открыть(имя файла, "w+", кодировка="utf-8") f1.записать(х) f1.закрыть()
Файл 2:
кодеки импорта
БЛОКРАЗМЕР = 1048576
с codecs.open("ee.txt", "r", "utf-16-le") в качестве исходного файла:
с codecs.open("ee.txt", "w", "utf-8") в качестве targetFile:
пока верно:
содержимое = sourceFile.read (РАЗМЕР БЛОКА)
распечатать (содержание)
если не содержание:
перерыв
targetFile.write(содержимое)
- python
- unicode
- utf-8
- utf-16
- файловые кодировки
Вы не указываете, что файлы находятся в utf-16 LE при чтении содержимого, и возникает эта путаница при попытке чтения и записи в один и тот же файл одновременно, что не сработает.
Кроме того, если вы не запускаете этот код на сервере, где может быть предпринята попытка атаки путем отправки вам чрезмерно большого текстового файла, вам не следует беспокоиться о размере файла, а просто читать все содержимое файла сразу. (Чтобы вы имели представление, Библия, которая представляет собой большую книгу, имеет размер порядка 3 МБ (с 8-битной кодировкой) — и даже на небольших серверах VPS будет порядка 200 МБ памяти, доступной для вашей программы — то есть вы могли конвертировать книгу размером более 30 библий одновременно). Типичные настольные компьютеры будут иметь в несколько раз больше памяти.
Кроме того, относительно недавняя библиотека Python «pathlib» может упростить просмотр всех ваших текстовых файлов, а ее методы Path.read_text и Path.write_text откроют файл, прочитают или запишут содержимое в правильной кодировке, и закрыть его одним выражением. Так как при использовании этого метода на момент записи файла чтение уже будет сделано, мы можем просто сделать это двумя вызовами:
import pathlib для пути к файлу в pathlib.Path(".").glob("**/*.txt"): данные = путь к файлу.read_text(encoding="utf-16 LE") filepath.write_text (данные, кодировка = "utf-8")
Если вы предпочитаете перестраховаться, с очень, очень малой вероятностью катастрофического сбоя компьютера в середине преобразования файла, вы можете записать в файл с другим именем, а затем удалить/переименовать — так что код такой:
import pathlib
для пути к файлу в pathlib.Path(".").glob("**/*.txt"):
данные = путь к файлу.read_text(encoding="utf-16 LE")
tmp_name = путь к файлу.имя + ".tmp"
filepath.with_name(tmp_name).write_text(данные, кодировка = "utf-8")
путь к файлу.unlink()
filepath.with_name(tmp_name).rename(filepath.name)
2
Прежде чем объяснять вам, что это не так, два полезных совета:
Я думаю, что вам следует удалить печать. Это просто запутает вас, и от операционной системы и среды зависит, какую кодировку он будет печатать.