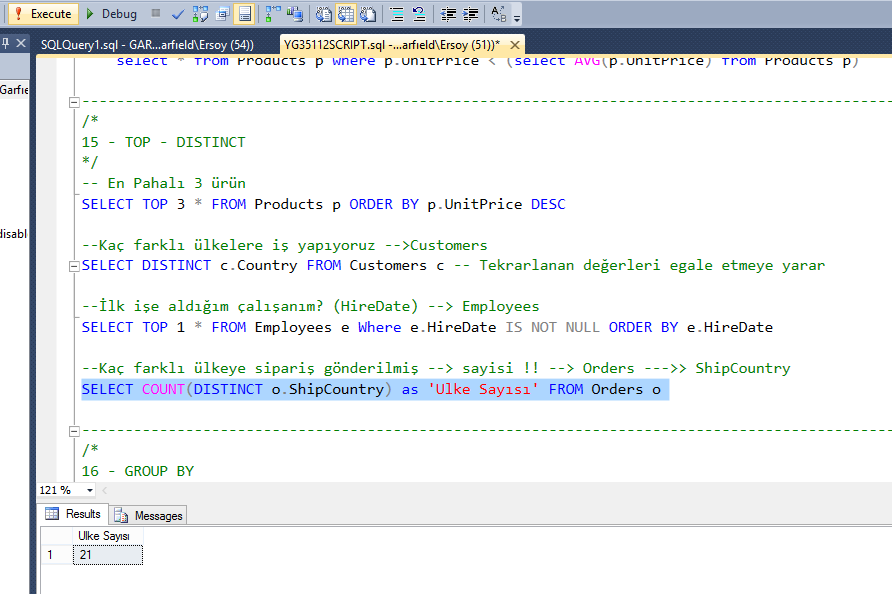
SQL — Group By
Предложение GROUP BY используется совместно с SELECT для организации одинаковых данных в группы. Предложение GROUP BY следует после условия WHERE в операторе SELECT и предшествует ORDER BY.
Синтаксис
Базовый синтаксис в GROUP BY показан в следующем блоке кода. Предложение GROUP BY должно следовать условиям в предложении WHERE и должно предшествовать ORDER BY, если он используется.
SELECT column1, column2 FROM table_name WHERE [ conditions ] GROUP BY column1, column2 ORDER BY column1, column2
Примеры
Рассмотрим таблицу CUSTOMERS, в котором присутствуют следующие записи:
+----+----------+-----+-----------+----------+ | ID | NAME | AGE | ADDRESS | SALARY | +----+----------+-----+-----------+----------+ | 1 | Maxim | 35 | Moscow | 21000.00 | | 2 | AndreyEx | 38 | Krasnodar | 55500.00 | | 3 | Oleg | 33 | Rostov | 34000.00 | | 4 | Masha | 35 | Moscow | 31500.00 | | 5 | Ruslan | 34 | Omsk | 43000.00 | | 6 | Dima | 32 | SP | 45000.00 | | 7 | Roma | 34 | SP | 10000.00 | +----+----------+-----+-----------+----------+
 00 |
| 5 | Ruslan | 34 | Omsk | 43000.00 |
| 6 | Dima | 32 | SP | 45000.00 |
| 7 | Roma | 34 | SP | 10000.00 |
+----+----------+-----+-----------+----------+
00 |
| 5 | Ruslan | 34 | Omsk | 43000.00 |
| 6 | Dima | 32 | SP | 45000.00 |
| 7 | Roma | 34 | SP | 10000.00 |
+----+----------+-----+-----------+----------+
Если вы хотите знать общую сумму заработной платы каждого клиента, то запрос с GROUP BY будет выглядеть следующим образом.
SQL> SELECT NAME, SUM(SALARY) FROM CUSTOMERS GROUP BY NAME;
Это произведет следующий результат:
+----+----------+----------+ | ID | NAME | SALARY | +----+----------+----------+ | 2 | AndreyEx | 55500.00 | | 6 | Dima | 45000.00 | | 4 | Masha | 31500.00 | | 1 | Maxim | 21000.00 | | 3 | Oleg | 34000.00 | | 7 | Roma | 10000.00 | | 5 | Ruslan | 43000.00 | +----+----------+----------+
Теперь, давайте посмотрим на таблицу CUSTOMERS, которая имеет следующие записи с повторяющимися именами:
+----+----------+-----+-----------+----------+ | ID | NAME | AGE | ADDRESS | SALARY | +----+----------+-----+-----------+----------+ | 1 | AndreyEx | 35 | Moscow | 21000.00 | | 2 | AndreyEx | 38 | Krasnodar | 55500.00 | | 3 | Masha | 33 | Rostov | 34000.00 | | 4 | Masha | 35 | Moscow | 31500.00 | | 5 | Dima | 34 | Omsk | 43000.00 | | 6 | Dima | 32 | SP | 45000.00 | | 7 | Roma | 34 | SP | 10000.00 | +----+----------+-----+-----------+----------+
Теперь же, если вы хотите знать, общую сумму заработной платы по каждому клиенту, то запрос GROUP BY будет выглядеть следующим образом:
SQL> SELECT NAME, SUM(SALARY) FROM CUSTOMERS GROUP BY NAME;
Это произведет следующий результат:
+----+----------+----------+ | ID | NAME | SALARY | +----+----------+----------+ | 2 | AndreyEx | 76500.00 | | 4 | Masha | 65500.00 | | 6 | Dima | 88000.00 | | 7 | Roma | 10000.00 | +----+----------+----------+
Если вы нашли ошибку, пожалуйста, выделите фрагмент текста и нажмите Ctrl+Enter.
Обзор предложения SQL GROUP BY
В этой статье кратко объясняется предложение SQL group by, когда его следует использовать и что следует учитывать при его использовании.
Примечание: Все примеры кода в этой статье сделаны с использованием SQL Server 2019 и База данных Stack Overflow 2010 .
Что такое «группировка» в SQL и зачем она нужна?
Учтите, что мы анализируем базу данных веб-сайта QA переполнения стека. Эта база данных содержит несколько таблиц, в которых хранится информация о пользователях сайта, размещенных вопросах, ответах, комментариях и выданных значках.
Например, возьмем таблицу «Сообщения». Эта таблица содержит всю информацию о различных типах сообщений на веб-сайте QA; вопросы, ответы, вики, номинации модераторов… Если мы хотим подсчитать количество сообщений каждого типа, с помощью простого оператора SELECT можно вернуть количество строк одного типа с помощью функции COUNT() помимо фильтрации результата. используя предложение WHERE:
Рисунок 1 – Расчет количества строк для одного типа поста
Если мы попытаемся добавить столбец PostTypeId перед COUNT(*), команда SQL не будет выполнена и выдаст следующее исключение, чтобы уведомить пользователя о том, что для выполнения этой операции требуется агрегирование:
Столбец StackOverflow2010. dbo.Posts.PostTypeId недопустим в списке выбора, поскольку он не содержится ни в агрегатной функции, ни в предложении GROUP BY.
dbo.Posts.PostTypeId недопустим в списке выбора, поскольку он не содержится ни в агрегатной функции, ни в предложении GROUP BY.
Предложение SQL GROUP BY упорядочивает аналогичные данные, хранящиеся в одном или нескольких столбцах, в группы, где для создания сводок применяется агрегатная функция. Например, подсчет количества постов для каждого пользователя.
Рисунок 2 – Расчет количества постов каждого типа
Порядок выполнения SQL-запроса
Прежде чем объяснять предложение SQL GROUP BY и когда мы должны его использовать, нам нужно знать, как SQL-запрос выполняется механизмом базы данных. После запроса на выполнение команды SQL механизм базы данных анализирует различные ее части в следующем порядке:
- ОТ / ПРИСОЕДИНЯЙТЕСЬ
- ГДЕ
- ГРУППА ПО
- НАЛИЧИЕ
- ВЫБИРАТЬ
- ОТЧЕТЛИВЫЙ
- СОРТИРОВАТЬ ПО
- КОМПЕНСИРОВАТЬ
Пункт GROUP BY
Как определено в официальной документации Microsoft, команда SELECT — GROUP BY — это предложение оператора SELECT, которое делит результат запроса на группы строк, обычно для выполнения одной или нескольких агрегаций в каждой группе. Оператор SELECT возвращает одну строку на группу».
Оператор SELECT возвращает одну строку на группу».
Синтаксис предложения GROUP BY следующий:
1 2 3 4 5 6 7 8 9 |
GROUP BY { выражение-столбца | ROLLUP ( | CUBE ( | НАБОРЫ ГРУППИРОВКИ ( | HAVING ( <выражение фильтра> ) }
|
Предложение SQL GROUP BY можно использовать для выполнения агрегирования по каждой группе или даже для удаления повторяющихся строк на основе выражения группировки. Например, предположим, что нам нужно извлечь все различные местоположения пользователей Stack Overflow. Мы можем просто добавить ключевое слово DISTINCT после термина SELECT.
SELECT DISTINCT [Location] FROM [StackOverflow2010].
|
 [dbo].[Пользователи]
[dbo].[Пользователи]Или мы можем использовать команду SELECT – GROUP BY для достижения того же результата:
SELECT [Местоположение] FROM [StackOverflow2010].[dbo].[Пользователи] ГРУППИРОВАТЬ ПО [Местоположение]
|
Стоит отметить, что оба запроса имеют одинаковый план выполнения.
Рисунок 3 – Сравнение планов выполнения
Теперь мы можем добавить функцию агрегации в предложение SELECT, чтобы выполнять ее для каждой группы.
SELECT [Местоположение], COUNT(*) FROM [StackOverflow2010].[dbo].[Пользователи] GROUP BY [Местоположение] 9393 |
Как показано на изображении ниже, все значения NULL считаются равными и собираются в одну группу.
Рисунок 4. Добавление агрегатной функции к команде SELECT — GROUP BY
Проверяя план выполнения команды, мы видим, что после агрегирования данных внутри групп к каждой группе применяется скалярная функция.
Рисунок 5 – План выполнения, показывающий вычисление функции агрегации
ГРУППИРОВАТЬ ПО столбцам
Самый простой способ использовать SQL-предложение GROUP BY — выбрать столбцы, необходимые для операции группировки. Все столбцы, указанные в предложении SELECT, кроме функций агрегирования, должны быть указаны в предложении GROUP BY. Например, если мы выполним следующий запрос:
SELECT [Id], [Location],COUNT(*) FROM [StackOverflow2010].[dbo].[Users] GROUP BY [Location];
|
Выдается следующее исключение:
 dbo.Users.Id недопустим в списке выбора, поскольку он не содержится ни в агрегатной функции, ни в предложении GROUP BY.
dbo.Users.Id недопустим в списке выбора, поскольку он не содержится ни в агрегатной функции, ни в предложении GROUP BY.Еще одна вещь, о которой стоит упомянуть, это то, что псевдонимы столбцов нельзя использовать в предложении SQL GROUP BY, поскольку оно вычисляется механизмом SQL перед предложением SELECT.
ГРУППИРОВКА ПО определяемым пользователем функциям
Мы также можем использовать определяемые пользователем скалярные функции вместе со столбцами, указанными в предложениях SELECT и GROUP BY. Например, мы создали следующую функцию, чтобы узнать, есть ли у вопроса ответ или нет:
1 2 3 4 5 6 7 8 10 11 0003 12 13 0003 14 15 16 17 | Создать функцию Issolved ( @postid int) Возврат бит AS Begin Dercare @Exist 1 END FROM [StackOverflow2010].
RETURN @Exists
END
|
 [dbo].[Posts] WHERE [Id] = @PostID
[dbo].[Posts] WHERE [Id] = @PostIDСледующий запрос может быть успешно выполнен.
SELECT DBO.ISSOLVED ([ID]), COUNT (*) от [StackOverflow2010]. |
Рисунок 6 – Группировка по определяемой пользователем функции
GROUP BY выражения столбца
Другой способ сгруппировать результат — использовать выражения столбца. Например, если мы хотим сгруппировать столбцы на основе определенного вычисления, такого как математическое выражение или выражение CASE WHEN, мы можем просто использовать его аналогично одному столбцу. Например, предположим, что мы хотим подсчитать количество решаемых вопросов и количество открытых вопросов на веб-сайте Stack Overflow. Обратите внимание, что таблица сообщений содержит только столбец с именем AccetpedAnswerId, который содержит идентификатор ответа.
Выберите случай, когда принимается adcomeAnswerid = 0, затем 0 els 1 End, Count (*) из [Stackoverflow2010]. [DBO]. [Сообщения] Группа по случаю, когда принимается. |
Рисунок 7 – Группировка по выражению CASE WHEN
ГРУППА ПО НАЛИЧИИ
Мы не можем использовать предложение WHERE в этой операции для фильтрации результата запроса на основе результата групповой агрегированной функции, поскольку ядро базы данных выполняет предложение WHERE перед применением агрегирующей функции. Вот почему было найдено предложение HAVING.
Предложение HAVING можно использовать только с предложением SQL GROUP BY. Например, нам нужно получить местоположения, упомянутые более чем в 1000 и менее чем в 10000 профилях пользователей.
1 2 3 4 5 6 7 |
SELECT [Location],COUNT(*) FROM [StackOverflow2010]. GROUP BY [Location] ИМЕЕТ СЧЕТЧИК(*) ОТ 1000 ДО 10000 ПОРЯДОК ПО СЧЕТУ(*) DESC;
|
 [dbo].[Users]
[dbo].[Users]Рисунок 8. Использование ключевого слова HAVING для фильтрации результата операции группирования
НАБОРЫ ГРУППИРОВКИ, КУБА И ГРУППИРОВКИ
Чтобы объяснить параметры ROLLUP, CUBE и GROUPING SETS, мы создадим представление из таблиц Posts и Users со следующей структурой:
Сообщения.Id | Posts.CreationDate | Сообщения.PostType | Пользователи.Расположение |
ГРУППИРОВКА ПО СВОДКЕ
Предположим, мы хотим создать отчет, показывающий количество сообщений в каждом году, квартале и месяце для каждого типа сообщения. Результат должен быть следующим:
Создание_год | Creation_quarter | Создание_Месяц | Тип сообщения | Количество сообщений |
SQL GROUP BY ROLLUP позволяет нам создавать комбинации, которые существуют в данных, в дополнение к объединению в иерархическом порядке, который мы определяем в операторе ROLLUP. Например, попробуем выполнить следующий запрос:
Например, попробуем выполнить следующий запрос:
1 2 3 4 5 6 7 8 | Выбор Год ([[CreationDate]) в качестве Creation_year, DatePart (квартал, [CreationDate]) как Creation_quarter, месяц ([CreationDate]) как Creation_month, Count (*) as umf_posts от [ (*) as umf_posts от [ (*) agof_posts от [ (*) as umf_posts от [ (*) as umf_posts от [ (*) StackOverflow2010].[dbo].[vPosts] СГРУППИРОВАТЬ ПО ОБЪЕМУ (ГОД ([Дата Создания]) , ЧАСТЬ ДАТЫ (Квартал, [Дата Создания]) , МЕСЯЦ ([Дата Создания]))
|
Как показано на изображении ниже, результат включает три уровня агрегации:
- Количество постов в месяц
- Количество постов в квартал
- Количество постов в год
Рисунок 9. Использование оператора ROLLUP для применения агрегации на разных иерархических уровнях
Использование оператора ROLLUP для применения агрегации на разных иерархических уровнях
ГРУППА ПО КУБУ
Теперь давайте предположим, что нас попросили создать отчет, который показывает количество сообщений для каждого местоположения пользователя, тип сообщения или и то, и другое.
Оператор SQL GROUP BY CUBE создает все возможные комбинации между столбцами, упомянутыми в операторе CUBE. Например, давайте попробуем следующую команду:
1 2 3 4 5 6 | Выберите [местоположение], [Тип], COUNT (*) as umf_of_posts от [Stackoverflow2010]. [DBO].
|
Как показано на изображении ниже, результаты содержат три группы:
- Количество постов на локацию
- Количество постов каждого типа
- Количество постов на место и тип
Рисунок 10. Использование оператора GROUP BY CUBE
Использование оператора GROUP BY CUBE
ГРУППИРОВКА ПО НАБОРАМ
Иногда нас попросят создать отчет только для определенной комбинации столбцов и выражений. В этом случае использование CUBE или ROLLUP может быть неэффективным и занимать много времени.
По этой причине мы можем использовать оператор GROUPING SETS, где мы должны явно определить каждую комбинацию. Например, мы хотим только создать отчет, показывающий количество сообщений по местоположению, по типу и общее количество сообщений.
1 2 3 4 5 6 7 8 10 3 9 3 | Выберите [местоположение], [Тип], COUNT (*) as umber_of_posts из [Stackoverflow2010]. [DBO]. — Общее количество постов ([Расположение]), ([Тип]))
|
Как показано на изображении ниже, первые пять строк показывают количество сообщений для каждого типа, строка 6 th показывает общее количество сообщений, а остальные показывают количество сообщений для каждого местоположения.
Рисунок 11 – Использование оператора GROUPING SETS
Сводка
В этой статье кратко объясняется предложение SQL GROUP BY и способы его использования для выполнения статистических функций над данными. Мы также продемонстрировали доступные параметры, такие как группировка по набору столбцов, выражения и пользовательские функции. Кроме того, мы объяснили, как использовать ключевое слово HAVING для фильтрации и параметры ROLLUP, CUBE и GROUPING SETS для создания отчетов.
Чтобы узнать больше о функции SQL GROUP BY, вы можете обратиться к следующим статьям, ранее опубликованным в SQL Shack:
- Изучение SQL: агрегатные функции (Эмиль Дркусич)
- GROUP BY ROLLUP для анализа данных (Динеш Асанка)
- Автор
- Последние сообщения
Хади Фадлаллах
Хади — профессионал SQL Server с более чем 10-летним опытом. Его основная специализация — интеграция данных. Он является одним из ведущих участников ETL и SQL Server Integration Services на Stackoverflow.com. Кроме того, он опубликовал несколько серий статей о Biml, функциях SSIS, поисковых системах, Hadoop и многих других технологиях.
Он является одним из ведущих участников ETL и SQL Server Integration Services на Stackoverflow.com. Кроме того, он опубликовал несколько серий статей о Biml, функциях SSIS, поисковых системах, Hadoop и многих других технологиях.
Помимо работы с SQL Server, он работал с различными технологиями обработки данных, такими как базы данных NoSQL, Hadoop, Apache Spark. Он сертифицированный профессионал MongoDB, Neo4j и ArangoDB.
На академическом уровне Хади имеет две степени магистра в области компьютерных наук и бизнес-вычислений. В настоящее время он является доктором философии. кандидат наук о данных, специализирующийся на методах оценки качества больших данных.
Хади действительно любит узнавать что-то новое каждый день и делиться своими знаниями. Вы можете связаться с ним на его личном сайте.
Просмотреть все сообщения от Hadi Fadlallah
Последние сообщения от Hadi Fadlallah (посмотреть все)
SQL GROUP BY Предложение в запросе SELECT — Intermediate SQL
До сих пор результаты запроса были ориентированы на записи, что означает, что каждая строка в результате соответствует одной записи в таблице. Предложение SQL
Предложение SQL GROUP BY открывает возможность того, что запросы имеют строку в результате, представляющую группу записей. Кроме того, он позволяет вам использовать функции группировки: функции, которые возвращают некоторый результат (), вычисленный в группе записей, таких как сумма, среднее значение или количество.
Вот пример таблицы. Предположим, вы работаете на ферме, выращивающей яблоки. База данных содержит одну таблицу с именем apple со всей историей производства. Таблица имеет следующую схему:
| Год | Разнообразие яблок | Количество деревьев в производстве | Произведенотонн | День сбора урожая | Цена за тонну | Первый летний шторм |
|---|---|---|---|---|---|---|
| 2020 | Красный Восхитительный | 2000 | 102 | 23.06.2020 | 54,50 | 03.07.2020 |
| 2020 | Волшебный зеленый | 700 | 33 | 12. 06.2020 06.2020 | 62,60 | 03.07.2020 |
| 2020 | Красный Глобус | 500 | 26 | 30.05.2020 | 71,50 | 03.07.2020 |
| 2019 | Красный вкусный | 1800 | 87 | 15.07.2019 | 52,25 | 12.07.2019 |
| 2019 | Волшебный зеленый | 500 | 26 | 28.06.2019 | 59,40 | 12.07.2019 |
| 2019 | Красный Глобус | 500 | 27 | 28.05.2019 | 68,00 | 12.07.2019 |
| 2018 | Красный вкусный | 1800 | 92 | 02.07.2018 | 56,75 | 03.06.2018 |
| 2018 | Красный Глобус | 500 | 24 | 30.05.2018 | 66. | 03.06.2018 |
| 2017 | Красный вкусный | 1500 | 76,5 | 18. 07.2017 07.2017 | 51,45 | 30.07.2017 |
| 2016 | Красный вкусный | 1500 | 72 | 26.06.2016 | 47,60 | 23.06.2016 |
Предположим, вы хотите получить общее количество яблок, произведенных за год. Это значение не является таблицей столбцов яблоко , но есть столбец тонн_производства для каждого сорта яблок. Если вы сгруппируете все записи за один и тот же год и суммируете значение в тонн_произведено для всех записей в группе, вы получите итоговое значение. Вот предложение GROUP BY , которое вы могли бы использовать:
ВЫБЕРИТЕ год,
СУММ(тонн_произведено) КАК Всего_произведено_яблок
ИЗ яблока
СГРУППИРОВКА ПО ГОДАМ
Этот запрос создает группы записей с одинаковым значением в столбце year. Первая группа относится к 2020 году с 3 записями, следующая группа — к 2019 году с 3 записями и так далее. Для каждой группы записей вы применяете агрегатные функции
Для каждой группы записей вы применяете агрегатные функции SUM ко всем записям в группе, чтобы получить общее количество тонн, произведенных за год. Вот результаты запроса:
| Год | Total_apple_produced |
|---|---|
| 2020 | 161 |
| 2019 | 140 |
| 2018 | 116 |
| 2017 | 76,5 |
| 2016 | 72 |
Использование SQL WHERE и SQL GROUP BY в SELECT
На этом уроке вы объедините все концепции или предложения, которые вы изучили, в один запрос. Вы используете предложение WHERE для фильтрации записей и GROUP BY для группировки записей в одном и том же операторе SELECT. Если вы хотите просмотреть предложение WHERE, вернитесь к уроку Использование предложения SQL WHERE с операторами сравнения.
Предложение WHERE применяется первым для фильтрации записей. Предложение
Предложение GROUP BY применяется к отфильтрованным записям. Вот запрос:
ВЫБЕРИТЕ год,
AVG(цена_за_тонну) AS avg_price_ton
ИЗ яблок
ГДЕ ИЗВЛЕЧЬ(МЕСЯЦ ОТ first_summer_storm) = 7
СГРУППИРОВКА ПО ГОДАМ
Запрос использует функцию EXTRACT для получения месяца из first_summer_storm для фильтрации записей за июль. После того, как записи отфильтрованы, вы создаете группы записей с ГРУППА ПО году, что означает, что все записи одного года находятся в одной группе. После этого рассчитывается среднее значение price_per_ton . Вот результаты запроса:
| Год | avg_price_ton |
|---|---|
| 2020 | 62,86 |
| 2019 | 59,88 |
| 2017 | 51,45 |
Название столбца со средней ценой переименовано в avg_price_ton по предложению AS в SELECT . Это обычная практика при использовании агрегатных функций, таких как
Это обычная практика при использовании агрегатных функций, таких как AVG , SUM или COUNT . Вы создаете вычисляемое значение, которое не исходит ни из одного столбца. Использование предложения AS назначает имя/описание в результате, поскольку база данных не знает, какое имя столбца использовать.
SQL GROUP BY Эффект свертывания записей
Это важный момент SQL разработчик должен понимать, чтобы избежать распространенной ошибки при использовании предложения GROUP BY . После того, как база данных создаст группы записей, все записи сворачиваются в группы. Вы больше не можете ссылаться на какой-либо отдельный столбец записи в запросе. В списке SELECT можно ссылаться только на столбцы, указанные в предложении GROUP BY . Столбцы, появляющиеся в группе, допустимы, поскольку они имеют одинаковое значение для всех записей в группе.
| Элементы, разрешенные для списка SELECT |
|---|
| КОЛОННЫ, ИСПОЛЬЗУЕМЫЕ В ГРУППЕ BY |
| Функции агрегирования (SUM, COUNT, AVG, MAX, MIN) |
| Константы (текст, число или значение даты) |
Вот пример недопустимого запроса:
ВЫБЕРИТЕ год,
first_summer_storm, -- НЕДЕЙСТВИТЕЛЬНЫЙ СТОЛБЦ
AVG(цена_за_тонну) AS avg_price_ton
ИЗ яблок
ГДЕ ИЗВЛЕЧЬ(МЕСЯЦ ОТ first_summer_storm) = 7
СГРУППИРОВКА ПО ГОДАМ
Ниже приведена ошибка, возвращенная базой данных:
ОШИБКА: Столбец «apple.
first_summer_storm» должен находиться в GROUP BY
LINE 2: first_summer_storm, – НЕДЕЙСТВИТЕЛЬНЫЙ СТОЛБЦ
В качестве упражнения для читателя выясните, почему столбец недействителен.
Агрегированные функции SQL с выражениями
До сих пор вы использовали агрегатные функции со столбцами таблицы в качестве одного параметра. Теперь пришло время использовать функции с выражениями на основе нескольких столбцов таблицы.
Для более сложного запроса предположим, что вы хотите получить показатель с именем долларов за дерево . вот математический расчет:
доллар_за_дерево = ( произведено_тонн * цена_за_тонну ) / количество_деревьев
Метрика долларов за дерево представляет собой значение, относящееся к каждому сорту яблок. Например, один сорт яблок может производить много тонн, но обычно имеет низкую рыночную цену, в то время как другие сорта производят меньше в пересчете на тонны, но имеют более высокую цену. долларов за дерево метрика может помочь вам определить относительную стоимость деревьев.
долларов за дерево метрика может помочь вам определить относительную стоимость деревьев.
В этом примере вы хотите получить среднее значение в долларах за дерево для каждого сорта яблок, а также максимальное и минимальное значение показателя. Группировать нужно по сортам яблок, а не по годам. Вот запрос:
ВЫБЕРИТЕ сорт_яблока,
AVG((произведено_тонн * цена_за_тонну)/количество_деревьев) КАК avg_доллар_за_дерево,
MAX((количество_произведенных_тонн * цена_за_тонну)/количество_деревьев) КАК max_доллар_за_дерево,
MIN((количество_произведенных_тонн * цена_за_тонну)/количество_деревьев) КАК min_доллар_за_дерево
ИЗ яблока
СГРУППИРОВАТЬ ПО apple_variety
Результат:
| apple_variety | avg_dollar_per_tree | max_dollar_per_tree | min_dollar_per_tree |
|---|---|---|---|
| Вкусный красный | 2,62 | 2,90 | 2,28 |
| Волшебный зеленый | 3.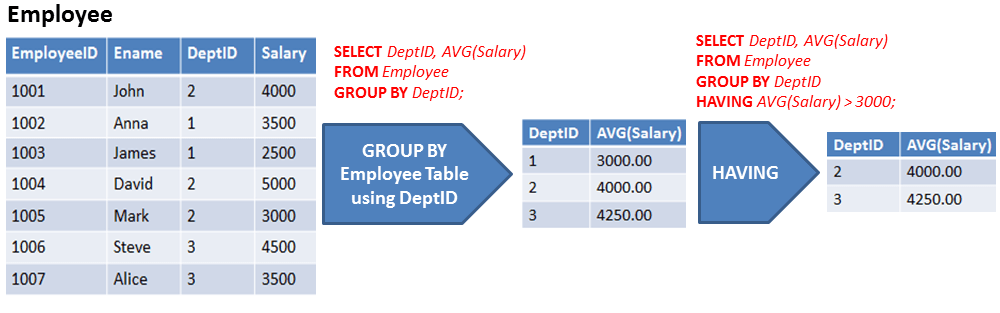 01 01 | 3,08 | 2,95 |
| Красный глобус | 3,51 | 3,71 | 3,16 |
Конечно, метрика долларов за дерево связана с годом, так как произведенных тонн зависит от погодных условий. Чтобы увидеть показатель для каждого года и каждого сорта яблок, используйте несколько столбцов GROUP BY :
ВЫБЕРИТЕ год,
яблоко_сорт,
AVG((произведено_тонн * цена_за_тонну)/количество_деревьев) КАК avg_доллар_за_дерево,
MAX((количество_произведенных_тонн * цена_за_тонну)/количество_деревьев) КАК max_доллар_за_дерево,
MIN((количество_произведенных_тонн * цена_за_тонну)/количество_деревьев) КАК min_доллар_за_дерево
ИЗ яблока
СГРУППИРОВАТЬ ПО году, сорт_яблока
Результат:
| год | яблоко_сорт | avg_dollar_per_tree | max_dollar_per_tree | min_dollar_per_tree |
|---|---|---|---|---|
| 2020 | Красный вкусный | 2,77 | 2,77 | 2,77 |
| 2020 | Волшебный зеленый | 2,95 | 2,95 | 2,95 |
| 2020 | Красный Глобус | 3,71 | 3,71 | 3,71 |
| 2019 | Красный вкусный | 2,52 | 2,52 | 2,52 |
| 2019 | Волшебный зеленый | 3,08 | 3,08 | 3,08 |
| 2019 | Красный Глобус | 3,67 | 3,67 | 3,67 |
| 2018 | Красный вкусный | 2,90 | 2,90 | 2,90 |
| 2018 | Красный Глобус | 3,16 | 3,16 | 3,16 |
| 2017 | Красный вкусный | 2,62 | 2,62 | 2,62 |
| 2016 | Красный вкусный | 2,28 | 2,28 | 2,28 |
Глядя на этот результат, обратите внимание, что несколько столбцов имеют одинаковые значения для AVG() , MAX() и MIN() результатов. Это связано с тем, что группы, созданные
Это связано с тем, что группы, созданные GROUP BY , имеют одну запись, что приводит к одинаковым средним, максимальным и минимальным значениям.
Заключительные слова
На этом уроке вы научились использовать SQL GROUP BY и агрегатные функции для повышения выразительности оператора SQL SELECT. Вы знаете о проблеме коллапса и понимаете, что не можете ссылаться на отдельные записи после использования предложения GROUP BY .
Если вам нужно получить доступ к отдельной записи, SQL предоставляет WINDOW FUNCTIONS , как вы узнаете из следующего урока. Например, если вы хотите, чтобы в отчете отображалась разница между ценой за_тонну за текущий год и средней ценой за цен за тонну , вам явно необходимо получить доступ к отдельной записи, чтобы получить цену за текущий год и среднюю цену, вы можете использовать ФУНКЦИИ SQL ОКНА.
На следующем уроке мы более подробно рассмотрим агрегатные функции.