Весь комплекс печатных услуг в Перми. Общирная сеть печатных салонов в Перми. Цифровая печать, цветное и черно-белое копирование документов, сканирование документов, ризография в Перми
Group by sql: GROUP BY | SQL | SQL-tutorial.ru
Содержание
SQL SELECT Раздел GROUP BY — Группировка записей по полям
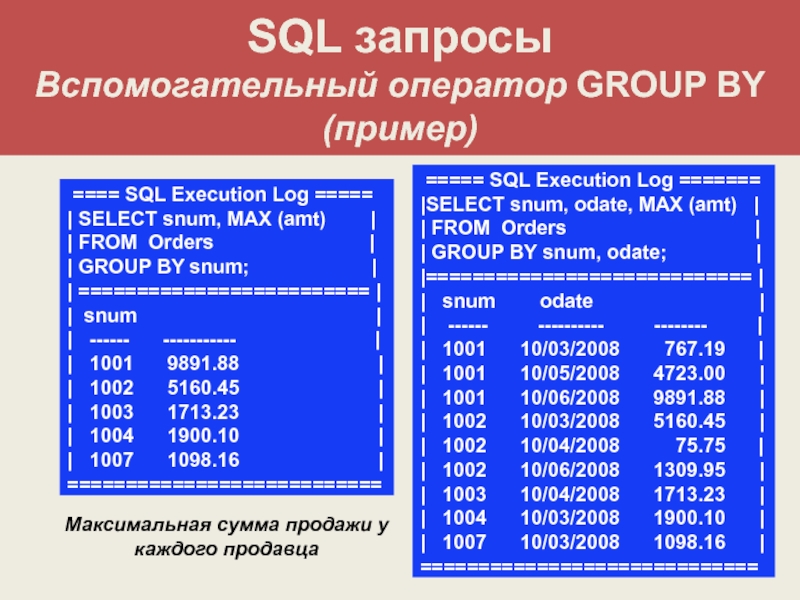
Если в табличном выражении присутствует раздел GROUP BY SQL, то следующим выполняется GROUP BY.
Если обозначить через R таблицу, являющуюся результатом предыдущего раздела (FROM или WHERE), то результатом раздела GROUP BY является разбиение R на множество групп строк, состоящего из минимального числа групп таких, что для каждого столбца из списка столбцов раздела GROUP BY во всех строках каждой группы, включающей более одной строки, значения этого столбца равны. Для обозначения результата раздела GROUP BY в стандарте используется термин “сгруппированная таблица”.
Если утверждение SELECT содержит предложение GROUP BY(SELECT GROUP BY), список выбора может содержать только следующие типы выражений:
Константы.
Агрегатные функции.
Функции USER, UID, и SYSDATE.
Выражения, соответствующие перечисленным в предложении GROUP BY.
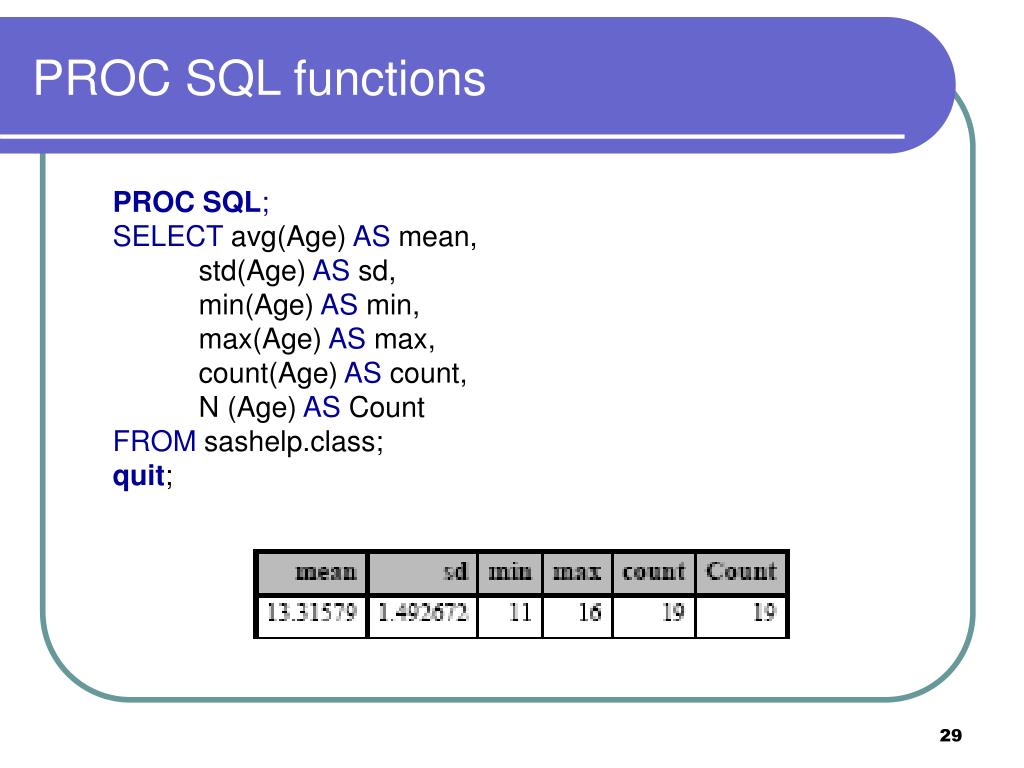
SELECT GROUP BY. Пример 1. Вычислить общий объем покупок для каждого товара:
SELECT stock, SUM(quant) FROM ordsale GROUP BY stock;
Фраза GROUP BY не предполагает упорядочивания строк. Для упорядочивания результата этого примера по кодам товаров, следует поместить фразу ORDER BY stock следом за фразой GROUP BY.
SELECT GROUP BY. Пример 2. Можно использовать группировки данных GROUP BY совместно с условием. Например, выбрать для каждого покупаемого товара его код и общий объем покупок, за исключением покупок покупателя с кодом 23:
SELECT stock, SUM(quant) FROM ordsale WHERE customerno<>23 GROUP BY stock;
Строки, не удовлетворяющие условию WHERE, исключаются перед группированием данных.
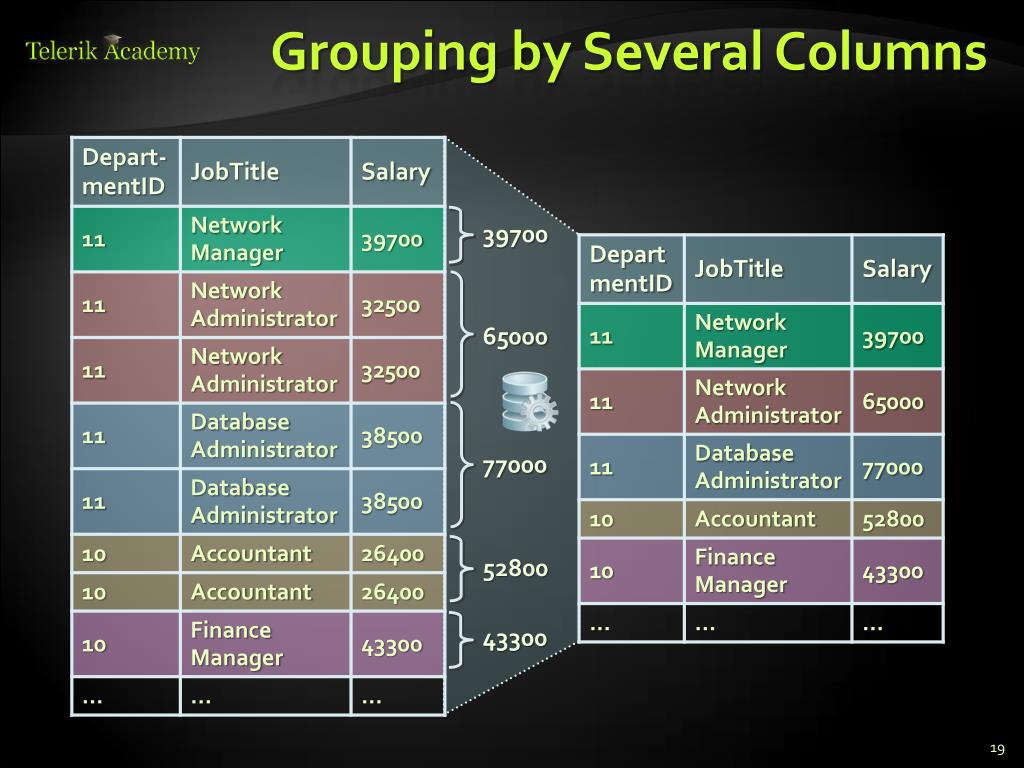
Строки таблицы можно группировать по любой комбинации ее полей. Если поле, по значениям которого осуществляется группирование, содержит какие-либо неопределенные значения, то каждое из них порождает отдельную группу.
Допустим, есть задача на вычисление количества какого-либо продукта. Поставщик поставляет нам продукцию по определённой цене. Вычислим общее количество каждого из продуктов. В этом нам поможет фраза GROUP BY. Результатом задачи станет таблица, состоящая из нескольких колонок. Поставки будут группироваться по ПР. Компоновка происходит по группам, которую и инициирует Group By SQL.
Необходимо отметить, что данная фраза предполагает применение фразы Select, она же в свою очередь определяет единственное значение для каждого выражения сформированной группы. Бывают три случая для конкретного выражения: оно принимает арифметическое значение, оно становится SQL-функцией, которая будет сводить все значения столбца к сумме или другому заданному значению, также выражение может стать константой. Строки таблицы не обязательно должны быть строго сгруппированы, они могут группироваться по любой комбинации столбцов таблицы. Необходимо учитывать, что упорядочивание запросы по ПР возможно в том случае, если будет сделан соответствующий запрос.
Заявление SQL GROUP BY
w3big.com
Latest web development tutorials
Функция SQL SUM (): Предыдущий
Далее: SQL предложения HAVING
GROUP BY заявления могут быть объединены с некоторыми агрегатных функций для использования
GROUP BY заявление
GROUP BY заявление используется для объединения агрегатные функции, в соответствии с одним или более столбцов в наборе результатов на группы.
SQL GROUP BY Синтаксис
SELECT column_name, aggregate_function(column_name)
FROM table_name
WHERE column_name operator value
GROUP BY column_name;
Демонстрационная база данных
В этом уроке мы будем использовать w3big образец базы данных.
SELECT site_id, SUM(access_log.count) AS
nums FROM access_log GROUP BY site_id;
Выполнить выше SQL вывода результатов заключаются в следующем:
SQL GROUP BY несколькими столами присоединяется
Теперь мы хотим, чтобы найти количество заказов для каждой курьерской доставки.
Ниже приводятся статистические данные инструкцию SQL записывает все посещенные сайты:
примеров
SELECT Websites.name,COUNT(access_log.aid) AS nums FROM
access_log LEFT JOIN Websites ON access_log.site_id=Websites.id
GROUP BY Websites.name;
Выполнить выше SQL вывода результатов заключаются в следующем:
Функция SQL SUM (): Предыдущий
Далее: SQL предложения HAVING
w3big.com |
HTML курс |
Web курс |
Web Tutorial
Учебное пособие по GROUP BY, COLLECT и SPLIT
Учебное пособие по GROUP BY, COLLECT и SPLIT
ГРУППА
ПО, СОБИРАТЬ,
и РАЗДЕЛИТЬ
часто используются вместе в запросах SELECT, которые работают с данными на основе
подгруппы интересов.
В этом разделе содержится учебное обсуждение
чтобы помочь связать воедино концепции, представленные в темах для этих трех
SQL-конструкции.
Предложение GROUP BY сообщает общий запрос
данные должны обрабатываться в подгруппах с использованием агрегатных функций, которые
обрабатывать каждую подгруппу каким-либо образом. Оператор COLLECT предоставляет
универсальный способ использования выражения SQL в качестве агрегата для обработки
каждую подгруппу в таблицу результатов. Предложение SPLIT преобразует
таблицу результатов из оператора COLLECT в поля, которые можно обработать
оператором SELECT.
Хотя GROUP BY идет последним в SELECT
заявление, это первый пункт, который вступает в силу:
Если у нас есть оператор SELECT формы
SELECT <агрегатная функция> FROM
GROUP
ПО <поле>
первое, что происходит, это то, что
GROUP BY создает подгруппы таблицы, а затем агрегатные функции
работать с каждой из подгрупп.
Например, если у нас есть ГРУППА
Предложение BY Jobs для нашего примера таблицы «Расходы»,
предложение GROUP BY создаст подгруппы таблицы, в которых каждый
в подгруппе есть записи с одинаковым заданием
ценности. Как будто таблица была реорганизована в отдельные таблицы
для каждой работы. Данные на самом деле не разбиваются на отдельные
таблицы, но внутренняя обработка механизма запросов работает так, как если бы
они были.
В исходной таблице с четырнадцатью записями
есть четыре типа работ: столярные, электрические, каменные и сантехнические.
Таким образом, GROUP BY на лету группирует четырнадцать записей.
на четыре подгруппы, где каждая подгруппа имеет одну и ту же работу
значение в каждой записи. Суммируя общее количество записей в каждом
из подгрупп у нас осталось только четырнадцать записей.
GROUP BY не добавил и не удалил записи. Имеет только внутреннее
организовал их в подгруппы на основе работы
поле.
Затем каждая из этих четырех подгрупп независимо
обрабатывается агрегатной функцией в предложении SELECT. Если
результатом агрегатной функции является одна строка, результат каждой
такая агрегация помещается в одну из строк итоговой таблицы результатов.
Если у нас есть четыре подгруппы, результирующая таблица результатов будет
иметь четыре записи в нем. Если агрегатная функция генерирует
более одной строки (как может сгенерировать агрегатный оператор COLLECT), затем
в таблице результатов может быть более одной строки для каждой подгруппы.
Агрегатная функция работает по очереди
по обучению подгрупп. Например, если подгруппа Плотницкие работы
содержит пять записей, результат для этой подгруппы будет любым
является результатом агрегатной функции, использующей эти пять записей в
Столярная подгруппа. Тогда агрегатная функция будет работать
на двух записях в подгруппе Electrical и так далее.
Предположим, что используемая нами агрегатная функция
Сумма(Оплата). Что
принимает значения платежа
поле для всех записей в подгруппе и суммирует их, чтобы получить
общий. Мы можем написать запрос, который ВЫБИРАЕТ работу
поле, а также агрегат Сумма(Платеж),
так как поле Работа является полем
используется предложением GROUP BY:
ВЫБЕРИТЕ Задание, Сумма(Платеж)
ИЗ Расходов СГРУППИРОВАТЬ ПО ЗАДАЧАМ;
Выполнение этого запроса дает нам таблицу результатов
с четырьмя записями в ней (как и ожидалось, по одной для каждой подгруппы).
Результат
столбец в таблице результатов дает результат Sum(Payment)
совокупность для каждой подгруппы. Если мы вручную добавим все
Значения платежей для пяти записей
в подгруппе Carpentry, например, мы видим, что в сумме они составляют значение
из 248.
Хотя конечно удобно пользоваться
различные агрегатные функции, такие как Sum(
), которые предоставляются как встроенные, мы часто хотели бы использовать
Выражение SQL, как если бы оно было агрегатом, применяя его к каждой из подгрупп
по очереди.
Например, мы можем выбрать
только два самых больших платежных значения
из каждой подгруппы. Нет встроенного агрегата для выбора
два самых больших значения из подгруппы значений, но простой SQL
выражение может упорядочить список в порядке убывания и выбрать первое
два значения. Агрегат COLLECT позволяет нам использовать такие
выражение SQL как совокупность.
Если мы хотим выбрать два самых высоких
платежи в каждой категории работы, мы можем использовать COLLECT для создания агрегата
нашего собственного, который использует выражение SQL следующим образом:
ВЫБЕРИТЕ ЗАДАНИЕ, РАЗДЕЛИТЕ (СОБИРАЙТЕ ПОРЯДОК Оплаты по оплате
DESC FETCH 2)
ИЗ Расходов СГРУППИРОВАТЬ ПО ЗАДАЧАМ;
В приведенном выше примере мы используем COLLECT для агрегирования
Платежные значения в каждом
подгруппа с использованием простого, но полезного выражения SQL:
ПОЛУЧИТЬ ПОРЯДОК ПО ПЛАТЕЖУ DESC FETCH 2
В выражении оператора COLLECT используется
Поле оплаты, с
платеж ORDER BY в порядке убывания (сначала большие значения) и использование
FETCH 2, чтобы взять только два самых высоких значения.
это совокупность
команда, даже если она приводит не к одному значению, а к двум записям
в таблице. Предложение SPLIT отделяет значения полей от
таблицы, чтобы они могли использоваться оператором SELECT для построения оператора SELECT.
таблица результатов.
Если мы удалим пункты, которые упорядочивают
выводить и извлекать только две записи, мы получаем еще меньше «агрегата»,
в том, что он сообщает обо всех значениях платежа:
ВЫБЕРИТЕ Задание, РАЗДЕЛИТЬ (ВЗЯТЬ Платеж)
ИЗ Расходов СГРУППИРОВАТЬ ПО ЗАДАЧАМ;
Можем ли мы использовать COLLECT без GROUP
К? Да, хотя это упускает смысл использования COLLECT,
поскольку использование его без групп избыточно, в итоге получается то же самое, что и
простой SELECT без использования COLLECT.
ВЫБЕРИТЕ РАЗДЕЛИТЬ (ВЫБЕРИТЕ ПЛАТЕЖ)
ИЗ Расходов;
Когда GROUP BY является частью SELECT,
механизм запросов создает подгруппы на основе GROUP BY и применяет
СБОР по каждой подгруппе.
ВЫБЕРИТЕ Задание, РАЗДЕЛИТЬ (ВЗЯТЬ Платеж)
ИЗ Расходов СГРУППИРОВАТЬ ПО ЗАДАЧАМ;
Когда SELECT не имеет GROUP BY, COLLECT
по-прежнему действует как агрегат, но действует на целиком table, так как нет GROUP BY, которая упорядочивает записи в подгруппы.
Это как если бы существовала единственная подразумеваемая подгруппа, которая представляет собой всю
таблица:
ВЫБЕРИТЕ РАЗДЕЛИТЬ (ВЫБЕРИТЕ ПЛАТЕЖ)
ИЗ Расходов;
Использование COLLECT без GROUP BY
пример подразумеваемой группы, всей таблицы, потому что с помощью любого агрегата
в списке SELECT сообщает обработчику запросов, что SELECT относится к агрегатам
даже если нет GROUP BY. Предназначен для агрегатов,
SELECT будет обрабатывать список полей, настаивая на том, чтобы любые поля в этом списке
являются либо результатом агрегата, либо предметом GROUP BY.
Если нет GROUP BY, мы не можем использовать никакие поля, кроме результатов агрегатов, таких как COLLECT,
Сумма или другие агрегаты. Для
например, поскольку GROUP BY отсутствует, мы не можем написать
— НЕверный запрос
ВЫБЕРИТЕ Задание, РАЗДЕЛИТЬ (СОБИРАТЬ
Оплата)
ИЗ Расходов;
Это выдаст сообщение об ошибке
‘Expenses.Job’: поле должно быть любой частью GROUP BY
или часть агрегата.
Если мы хотим добавить работу
поле для вывода SELECT, который использует COLLECT, но не использует GROUP
BY, мы можем добавить поле Job
НАБОР:
ВЫБРАТЬ РАЗДЕЛИТЬ (СОБИРАТЬ Задание, Оплата)
ИЗ Расходов;
COLLECT извлекает все значения из
всю таблицу, рассматривая всю таблицу как подгруппу. Но
это то, что делает SELECT без использования COLLECT — он также вытягивает
значения из всей таблицы. Использование COLLECT без GROUP BY просто
выполняет то же самое, что и простой SELECT без использования COLLECT:
ВЫБЕРИТЕ задание, оплата
ИЗ Расходов;
Поэтому пока можно писать валидно
запросы, использующие COLLECT, но не использующие GROUP BY, не делают
смысл так делать.
Поиск первых N значений в каждой группе
В приведенных выше примерах мы нашли верхнюю
два платежа в каждой группе заданий. Находим топ n значения по подгруппам очень распространены.
задача как в ГИС, так и в базе данных. Мы можем захотеть найти пять
самые большие города в каждой стране, десять самых высоких гор в каждом штате,
или три самых высокооплачиваемых сотрудника по округам в государственной организации.
Введите
SQL найти первые N значений
в группах
в качестве поискового запроса в поисковой системе, например
Google, и вы получите, казалось бы, бесконечное множество страниц, показывающих, как
сделать это с различными базами данных, обычно несколькими разными способами
решения проблемы. Что объединяет почти все из них, так это то, что
они намного сложнее, чем простые и понятные запросы, использующие SPLIT,
СОБИРАТЬ и ГРУППИРОВАТЬ ПО.
Пример
У нас есть таблица под названием Summits
в котором перечислены все горные вершины в США. Для каждой горы
у него есть Имя, Возвышение
в метрах, и государство, в котором
находится гора. Мы хотели бы найти десять самых высоких
гор в каждом штате.
Запрос для этого прост:
ВЫБЕРИТЕ Состояние,
РАЗДЕЛИТЬ (СОБИРАТЬ Имя, Высота
ЗАКАЗАТЬ ПО ВЫСОТЕ DESC FETCH 10)
ОТ Вершины
ГРУППА ПО СОСТОЯНИЮ
ORDER BY State;
Таблица результатов представляет собой список штатов США.
с названием и высотой каждой горной вершины:
Как работает запрос
Рассматривать запрос без окончательного ORDER
Предложение BY, которое просто упорядочивает таблицу по состоянию для отображения.
ВЫБЕРИТЕ состояние,
РАЗДЕЛИТЬ (СОБИРАТЬ Имя, Высота
ЗАКАЗАТЬ ПО ВЫСОТЕ DESC FETCH 10)
ОТ Вершины
GROUP BY State;
В предложении FROM указано использовать вершины
таблица как источник данных.
ГРУППА
ПО государству;
Первое, что происходит, оказывается последним
пункт, GROUP BY. GROUP BY сообщает оператору SELECT
настроить себя на работу с агрегатами по подгруппам, и это говорит
механизм запросов для организации одной большой таблицы в 51 подгруппу по штатам, по одной для каждого из штатов США.
плюс подгруппа для округа Колумбия.
СОБИРАЙТЕ Имя, Высота ORDER BY Elevation
DESC FETCH 10
Затем агрегат COLLECT применяется к
каждой из 51 подгруппы. Он создает таблицу из каждой подгруппы
собирая значения полей Name и Elevation, упорядочивая
n в порядке убывания высоты (сначала самые высокие значения), а затем выборка
первые 10 результатов.
РАЗДЕЛИТЬ ( )
SELECT работает с полями, а не с таблицами, поэтому
мы должны преобразовать таблицы, которые COLLECT создает для каждой подгруппы, в
поля. SPLIT делает это, извлекая имя
поля высот и их
значения из результатов COLLECT и объединение их с состоянием
значение поля для каждой подгруппы, которую SELECT
Часть состояния запроса получает от GROUP
Оговорка BY State.
Запись в таблицу
Если мы хотим сохранить результаты в
таблицу, мы можем настроить запрос для записи:
ВЫБЕРИТЕ Состояние,
РАЗДЕЛИТЬ (СОБИРАТЬ Имя, Высота
ЗАКАЗАТЬ ПО ВЫСОТЕ DESC FETCH 10)
INTO [10 лучших саммитов в каждом штате]
ОТ Вершины
GROUP BY State;
Мы не можем использовать ORDER BY, так как таблицы
не заказал. Поэтому ошибочно использовать ORDER BY при написании
записи в таблицу с помощью оператора SELECT … INTO. Что
выдаст ошибку.
Похожие задачи
Мы можем
настроить приведенный выше запрос для очень широкого спектра приложений, чтобы найти
верхние N или нижние N значений, представляющих интерес, по группам. Например, если мы
хотим найти 5 самых густонаселенных городов в каждой стране, мы могли бы написать
запрос вида:
ВЫБЕРИТЕ страну,
РАЗДЕЛИТЬ (СОБИРАТЬ Имя, Население
ЗАКАЗАТЬ ПО Населению DESC FETCH 5)
ИЗ Городов
ГРУППА ПО СТРАНЕ
ЗАКАЗАТЬ ПО СТРАНАМ;
Если мы хотим найти 20 SKU продуктов с наименьшей стоимостью (идентификационный
номер) в каждой категории в большом онлайн-каталоге электроники мы могли бы
написать:
ВЫБЕРИТЕ категорию,
РАЗДЕЛИТЬ (СОБИРАТЬ SKU, ЦЕНА ЗАКАЗАТЬ
ПО ЦЕНЕ ASC FETCH 20)
ИЗ продуктов
ГРУППИРОВКА ПО КАТЕГОРИИ
ЗАКАЗАТЬ ПО КАТЕГОРИЯМ;
Мы можем использовать и повторно использовать один и тот же шаблон запроса для многих задач.
Примечания
Без скобок
— В этой теме для уменьшения визуального беспорядка мы не используем квадратные скобки [ ]
вокруг простых имен полей и таблиц. Квадратные скобки
являются необязательными, если имя однозначно.
Заказ
выполнения — Когда мы описали выше, как GROUP BY сканирует
стол, чтобы найти все записи плотницких работ, а затем загрузил их в виде пакета в
функцию Sum для создания первой записи таблицы результатов, которая
представляет собой концептуальное описание, помогающее нам понять, что работа GROUP
BY должен работать как упаковщик и фидер для некоторой агрегатной функции. Что
на самом деле происходит внутри механизма запросов, это более сложно, но сеть
результат — это то, что описывает концептуальный нарратив.
Видео
Найдите проценты открытого пространства в областях почтового индекса
– Использует GROUP BY: Дано
слой многоугольников, представляющих почтовые индексы, и слой многоугольников, показывающий
открытые пространства, такие как парки и зеленые насаждения, найдите процент открытого пространства
в каждой области почтового индекса. В этом видео показано, как начать
завершить за несколько простых шагов, начиная с первоначального импорта шейп-файлов
до окончательных результатов всего за пять минут с дополнительными шестью минутами
объяснения того, что делает каждый шаг. Работает в выпуске коллектора 9или с помощью бесплатного средства просмотра Manifold Viewer.
См. также
Запросы
Командное окно
Запрос
Строитель
Агрегаты
Операторы SQL
СОБЕРИТЕ
ГРУППА ПО
ЗАКАЗАТЬ
РАЗДЕЛЕНИЕ Статья
SQL
Пример: Изучите SQL из запроса на редактирование — Объединение областей — Мы изучаем
как написать SQL-запрос, который выполняет слияние
: операция области (растворения) путем вырезания и вставки из того, что
Кнопка «Изменить запрос» создается автоматически.
SQL-функций (SUM, COUNT, MIN, MAX, AVG) и GROUP BY (учебник)
В этой статье я покажу вам наиболее важные функции SQL, которые вы будете использовать для вычисления агрегатов, например SUM , AVG , COUNT , MAX , MIN — в наборе данных. Затем я покажу вам, как они работают с предложением GROUP BY , чтобы вы могли использовать SQL для проектов сегментации. (Например, вы узнаете, как можно вычислять средние значения с помощью GROUP BY в SQL.) В конце концов вы научитесь некоторым промежуточным шагам SQL, используя ORDER BY и DISTINCT .
Хорошие новости: эти вещи не сильно меняются со временем. SQL-функции и GROUP BY в 2012 году были такими же, как и сегодня в 2022 году. Поэтому, если вы изучите их сейчас, вы будете хорошо владеть этими знаниями по крайней мере до 2032 года. 😉
В любом случае, здесь вы узнаете много нового… так что пристегнитесь — вам нужно знать все это, чтобы эффективно использовать SQL для анализа данных! О, и это будет очень интересно, так как мы по-прежнему будем использовать наш набор данных из 7 миллионов линий!
Примечание: чтобы получить максимальную отдачу от этой статьи, вы должны не просто прочитать ее, но и заняться программированием вместе со мной!
Прежде чем мы начнем…
…Я рекомендую сначала ознакомиться с этими статьями – если вы еще этого не сделали:
Настройте свой собственный сервер данных: Как настроить Python, SQL, R и Bash (для не-разработчиков)
Установите SQL Workbench, чтобы лучше управлять SQL-запросами: Как установить SQL Workbench для PostgreSQL
Читать первые два эпизода серии SQL для анализа данных: эпизод 1 и эпизод 2
Убедитесь, что у вас есть импортированный набор данных о задержках рейсов, а если нет, посмотрите это видео.
Функции SQL для агрегирования данных
Хорошо, давайте откроем SQL Workbench и подключимся к вашему серверу данных!
Вы можете вспомнить наш базовый запрос? Было:
ВЫБЕРИТЕ *
ОТ Flight_delays
ПРЕДЕЛ 10;
И он вернул первые 10 строк этого огромного набора данных.
Мы собираемся изменить этот запрос, чтобы получить ответы на 5 важных вопросов:
Сколько строк в нашей таблице SQL? (Для этого мы будем использовать функцию SQL COUNT .)
Каково общее эфирное время всех рейсов в нашей таблице? (это будет SQL 9Функция 0437 SUM .)
Каково среднее значение всех задержек прибытия в таблице и каково оно для всех задержек отправления? (функция SQL AVG .)
Каково максимальное значение расстояния в нашей таблице SQL? (функция SQL MAX .)
Каково минимальное значение расстояния в нашей таблице SQL? (функция SQL MIN . )
Получить ответы на все эти вопросы будет очень просто, обещаю. Но еще раз: убедитесь, что вы делаете кодирование вместе со мной . Кодирование легче всего изучить, делая это. Поэтому, пожалуйста, не жалейте усилий на этом этапе: введите все, что вы видите здесь, в свой менеджер SQL, и создайте прочную основу знаний!
Ладно, посмотрим!
Функция СЧЁТ SQL. Считаем строки!
Самая простая функция агрегирования — подсчет строк в таблице SQL. Именно для этого и предназначена функция COUNT . Единственное, что вам нужно изменить — по сравнению с приведенным выше базовым запросом — это что вы ВЫБРАТЬ из вашей таблицы . Помнить? Это может быть что угодно ( * ) или конкретные столбцы ( arrdelay , depdelay и т. д.). Теперь давайте расширим этот список функциями . Скопируйте этот запрос в SQL Workbench и запустите его:
SELECT COUNT(*)
ОТ Flight_delays
ПРЕДЕЛ 10;
Результат: 7275288 .
Сама функция называется COUNT , и она говорит подсчитывать строки, используя каждый столбец (*) … Вы можете изменить * на любое имя столбца (например, arrdelay ) — и вы получите тот же самый номер. Попробуйте это:
SELECT COUNT(arrdelay)
ОТ Flight_delays
ПРЕДЕЛ 10;
Верно? Тот же результат: 7275288 .
Итак, да, это означает, что у нас есть 7275288 строк в нашей таблице Flight_delays .
Примечание 1: Это верно только в том случае, если в вашей таблице нет значений NULL (пустых ячеек)! (У нас нет NULL значений в наборе данных Flight_delays .) Я вернусь к важности NULL позже. Примечание 2: на самом деле вам не понадобится предложение LIMIT в этом SQL-запросе, так как у вас на экране будет только одна строка данных. Но я подумал, что иногда лучше оставить его там, чтобы даже если вы что-то напечатали неправильно, SQL Workbench не зависнет из-за случайной попытки вернуть более 7 миллионов строк данных.
Функция SQL SUM. Рассчитать сумму!
Теперь хотим получить эфирное время на все рейсы – суммировалось. Другими словами: получите сумму всех значений в столбце эфирного времени . Функция СУММ работает по той же логике, что и функция СЧЕТ . Отличие только в том, что в случае SUM нельзя использовать * — придется указать столбец . В данном случае это будет столбец эфирного времени .
Попробуйте этот запрос:
ВЫБЕРИТЕ СУММА(эфирное время)
ОТ Flight_delays;
Общее эфирное время составляет 748015545 минут.
Функция SQL AVG. Рассчитайте средние значения… Я имею в виду *среднее*.
Наша следующая задача — рассчитать среднее значение задержки прибытия и среднее значение задержки отправления. Важно знать, что в математике существует много типов статистических средних. Но обычно мы обращаемся к среднему типу под названием , имеющему в виду — когда мы говорим «средний» в повседневной жизни. (Небольшое напоминание: среднее значение вычисляется путем вычисления суммы всех значений в наборе данных, а затем деления ее на количество значений.)
В SQL функция называется AVG (что, конечно, означает « средний») возвращает среднее значение… так что средний тип — это то, что мы от него ожидаем.
Примечание: ну, я должен добавить, что многие специалисты по данным считают немного ленивым и неоднозначным то, что в SQL общее слово «среднее» ( AVG ) используется для одного конкретного среднего типа: среднего. И они правы! Медиана и мода также являются средними. В Python/pandas, например, функция для вычисления среднего на самом деле называется означает , а затем есть еще один, который называется медиана для расчета медианы. Это гораздо более последовательно. Нравится вам это или нет, но в SQL у нас есть *AVG* для среднего значения.
Синтаксис и логика аналогичны предыдущим двум функциям SQL.
Вы можете попробовать это, выполнив этот запрос:
SELECT AVG(depdelay)
ОТ Flight_delays;
Результат: 11,36 .
Но, конечно же, вы получите точно такое же значение, если наберете:
ВЫБОР СУММ(задержка задержки )/ СЧЕТ(задержка задержки)
ОТ Flight_delays;
Но не будем забегать так далеко вперед… Вместо этого давайте также посчитаем среднее значение arrdelay :
SELECT AVG(arrdelay)
ОТ Flight_delays;
Результат: 10.19
Круто!
Функции SQL MAX и MIN. Получим максимальное и минимальное значения.
И, наконец, найдем максимальное и минимальное значения заданного столбца. Нахождение максимального и минимального расстояний для этих полетов звучит достаточно интересно. SQL-синтаксис, MIN и MAX работают так же, как SUM , AVG и COUNT .
Вот минимальное расстояние:
SELECT MIN(расстояние)
ОТ Flight_delays;
Результат: 11 миль. (Чувак, может, возьмешь велосипед в следующий раз.)
ВЫБОР МАКС(расстояние)
ОТ Flight_delays;
Результат: 4962
Хорошо! Вот и все — это основные функции SQL, которые вы должны знать.
СЧЕТ
СУММА
СРЕДНЕЕ
МАКС
9047 3 MIN
Пока это было не так сложно, так что пришло время немного подправить…
Представляем пункт GROUP BY !
SQL GROUP BY — для базового анализа сегментации и многого другого…
SQL GROUP BY — теория
Как специалист по данным, вы, вероятно, будете постоянно запускать проекты сегментации. Например, интересно узнать среднюю задержку вылета всех рейсов (мы только что узнали, что это 9 часов). 0437 11.36 ). Но когда дело доходит до бизнес-решений, это число вообще не имеет значения.
Однако, если мы преобразуем эту информацию в более удобный формат — скажем, разобьем ее по аэропортам — мы сразу же сможем действовать!
Вот упрощенная диаграмма, показывающая, как SQL использует GROUP BY для создания автоматической сегментации на основе значений столбца:
Процесс состоит из трех важных шагов:
ШАГ 1 — Укажите, с какими столбцами вы хотите работать в качестве входных данных. . В нашем случае мы хотим использовать список аэропортов ( origin столбец) и задержки отправления (столбец depdelay ).
ШАГ 2 — Укажите, из каких столбцов вы хотите создать сегменты. Для нас это столбец origin . SQL автоматически определяет каждое уникальное значение в этом столбце (в приведенном выше примере это были аэропорт 1, аэропорт 2 и аэропорт 3 ). Затем он создает из них группы (сегменты) и сортирует каждую строку из вашей таблицы данных в нужную группу.
ШАГ 3 . Наконец, он вычисляет средние значения (используя функцию SQL AVG ) для каждой группы (сегмента) и возвращает результаты на ваш экран.
Единственная новая вещь здесь — « группировка » на ШАГЕ 2. Для этого у нас есть предложение SQL. Это называется ГРУППА ПО . Посмотрим в действии.
SQL GROUP BY — в действии
Вот запрос, который объединяет функцию SQL AVG с GROUP BY — и делает именно то, что я описал в теоретическом разделе выше:
SELECT
СРЕДНЯЯ (отложенная задержка),
источник
ОТ Flight_delays
ГРУППА ПО ПРОИСХОЖДЕНИЮ ;
Фантастика!
Если вы прокрутите результаты, то увидите, что есть аэропорты со средней задержкой вылета более 30 или даже 40 минут. С точки зрения бизнеса важно понимать, что происходит в этих аэропортах. С другой стороны, стоит также присмотреться к тому, как хорошие аэропорты ( depdelay близко к 0 ) удается достичь этой идеальной фазы. (Хорошо, я знаю, бизнес-кейс слишком упрощен, но вы поняли.)
Но что только что произошло с точки зрения SQL?
Мы выбрали два столбца — origin и depdelay . origin было использовано для создания сегментов ( GROUP BY origin ). depdelay используется для расчета средних задержек прибытия в этих сегментах ( AVG (отложенная задержка) ).
Примечание. Как видите, логика SQL не так линейна, как для Python, pandas или bash. Если вы пишете SQL-запрос, первая его строка может сильно зависеть от последней строки. Когда вы пишете длинные и сложные запросы, это может привести к некоторым неожиданным ошибкам и, следовательно, к небольшой головной боли… Но именно поэтому я считаю очень, очень важным уделять себе достаточно времени, чтобы попрактиковаться в основах и убедиться, что вы полностью понимаете суть. отношения между различными предложениями, функциями и другими вещами в SQL.
Проверь себя #1 (SQL SUM + GROUP BY)
Вот небольшое задание для практики! Давайте попробуем решить эту задачу и перепроверим, что вы уже все поняли! Все просто: Распечатайте общее эфирное время по месяцам! . . . Готов? Вот мое решение:
ВЫБЕРИТЕ
месяц,
СУММ(эфирное время)
ОТ Flight_delays
СГРУППИРОВАТЬ ПО месяцам;
Я сделал почти то же самое, что и раньше, но теперь я создал группы/сегменты на основе месяцев — и на этот раз мне пришлось использовать 9Функция 0437 SUM вместо AVG .
Проверьте себя #2 (SQL AVG + GROUP BY)
А вот еще одно упражнение: Снова рассчитайте среднюю задержку вылета по аэропортам, но на этот раз используйте только те рейсы, которые пролетели более 2000 миль (вы найдете эту информацию в столбце расстояний ). . . . Вот запрос:
ВЫБЕРИТЕ
СРЕДНЯЯ (отложенная задержка),
источник
ОТ Flight_delays
ГДЕ расстояние > 2000
СГРУППИРОВАТЬ ПО происхождению;
Из этого задания можно сделать два вывода.
Вы могли подозревать это, но теперь это подтверждено: вы можете использовать предложение SQL WHERE с GROUP BY и функциями SQL.
С помощью WHERE можно фильтровать даже те столбцы, которые не являются частью оператора SELECT .
SQL ORDER BY – для сортировки данных по значению одного (или нескольких) столбцов
Допустим, мы хотим узнать, какой аэропорт был самым загруженным в 2007 году.
Вы можете легко получить количество вылетов по аэропортам, используя функцию COUNT с предложением GROUP BY , верно? Мы делали это раньше в этой статье:
SELECT
СЧИТАТЬ(*),
источник
ОТ Flight_delays
СГРУППИРОВАТЬ ПО происхождению;
Проблема: этот список не отсортирован по умолчанию. .. Чтобы иметь и это, вам нужно добавить еще одно предложение SQL: ORDER BY . Когда вы используете его, вам всегда нужно указать, по какому столбцу вы хотите упорядочить… Это довольно просто:
ВЫБОР
СЧИТАТЬ(*),
источник
ОТ Flight_delays
СГРУППИРОВАТЬ ПО происхождению
ПОРЯДОК ПО количеству ;
Примечание: столбец, который вы получите после функции COUNT , будет новым столбцом… И он должен иметь имя — поэтому SQL автоматически называет его « count » (см. последний снимок экрана выше). Когда вы ссылаетесь на этот столбец в предложении ORDER BY , вы должны использовать это новое имя. Я вернусь к этому подробно в моей следующей статье. Если вам это покажется странным, давайте попробуем тот же запрос, но с ЗАКАЗАТЬ ПО ПРОИСХОЖДЕНИЮ – и вы это сразу поймете.
Хм, почти готово. Но проблема в том, что наименее загруженный аэропорт находится вверху — другими словами, мы получили список в порядке возрастания . Это значение по умолчанию для ORDER BY (по крайней мере, в нашей базе данных PostgreSQL). Но вы можете изменить это на в порядке убывания , просто добавив ключевое слово DESC в конце!
ВЫБОР
СЧИТАТЬ(*),
источник
ОТ Flight_delays
СГРУППИРОВАТЬ ПО происхождению
ЗАКАЗАТЬ ПО счету DESC ;
Отлично! Как раз то, что мы хотели увидеть!
SQL DISTINCT — получать только уникальные значения
Это последняя новинка на сегодня. И это будет коротко и мило.
Если вам интересно, сколько разных аэропортов в вашей таблице:
а) вы можете узнать это с помощью предложения GROUP BY . (Можете ли вы понять, как? :-)) б) вы можете узнать это еще проще, используя DISTINCT
DISTINCT удаляет все дубликаты. Попробуйте это:
SELECT DISTINCT(origin)
ОТ Flight_delays;
Теперь у вас есть уникальные аэропорты!
Кстати, версия GROUP BY выглядела бы так:
SELECT origin
ОТ Flight_delays
СГРУППИРОВАТЬ ПО происхождению;
Хотя с точки зрения результата это почти то же самое, предпочтительный способ сделать это — использовать синтаксис DISTINCT . (При написании более сложных запросов DISTINCT поможет упростить ваш запрос… Но я вернусь к этому в следующей статье.)
Проверьте себя #3
Сегодня вы узнали массу мелких, но полезных вещей. Я дам вам еще одно задание, которое обобщит почти все — даже предыдущие две статьи (эпизод 1 и эпизод 2). Это будет сложно, но вы справитесь! Если это не сработает, попробуйте разбить его на более мелкие задачи, затем создайте и протестируйте свой запрос, пока не получите результат. Задача:
Список:
5 лучших самолетов (обозначенных tailnum )
по количеству посадок
по PHX или SEA аэропорт
90 463 по воскресеньям
(например, если самолет с бортовым номером ' N387SW' приземлился 3 раза в PHX и 2 раза в SEA в 2007 году в любое воскресенье, тогда их всего 5. И нам нужны 5 лучших самолетов с наибольшим количеством.) Готовы? Набор! Идти! . . . Готово? Вот мое решение:
ВЫБОР
СЧИТАТЬ(*),
хвостовой номер
ОТ Flight_delays
ГДЕ день недели = 7
И пункт назначения ('PHX', 'SEA')
СГРУППИРОВАТЬ ПО хвостовому номеру
ЗАКАЗАТЬ ПО КОЛИЧЕСТВУ DESC
ПРЕДЕЛ 5;
И пояснение:
SELECT —» select…
COUNT(*), —» Эта функция подсчитывает количество строк в заданной группе; для этого ему понадобится пункт GROUP BY позже.
tailnum —» Это поможет указать группы (указанные в GROUP BY функция позже).
FROM Flight_delays –» название таблицы, естественно
WHERE dayofweek = 7 –» фильтр только для воскресенья
AND dest IN ('PHX', 'SEA') 9043 8 –» фильтр только для пунктов назначения PHX и SEA
GROUP BY tailnum –» Это предложение помогает нам поместить линии в разные группы по хвостовым номерам.



 Строки таблицы не обязательно должны быть строго сгруппированы, они могут группироваться по любой комбинации столбцов таблицы. Необходимо учитывать, что упорядочивание запросы по ПР возможно в том случае, если будет сделан соответствующий запрос.
Строки таблицы не обязательно должны быть строго сгруппированы, они могут группироваться по любой комбинации столбцов таблицы. Необходимо учитывать, что упорядочивание запросы по ПР возможно в том случае, если будет сделан соответствующий запрос.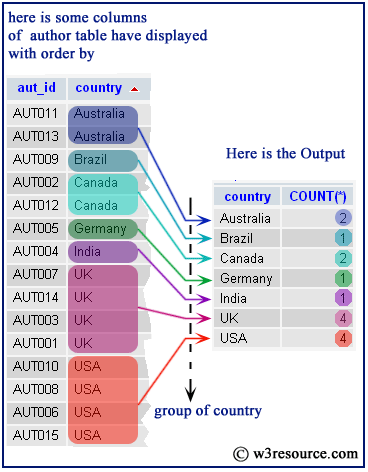
00 sec)


 Что
принимает значения платежа
поле для всех записей в подгруппе и суммирует их, чтобы получить
общий. Мы можем написать запрос, который ВЫБИРАЕТ работу
поле, а также агрегат Сумма(Платеж),
так как поле Работа является полем
используется предложением GROUP BY:
Что
принимает значения платежа
поле для всех записей в подгруппе и суммирует их, чтобы получить
общий. Мы можем написать запрос, который ВЫБИРАЕТ работу
поле, а также агрегат Сумма(Платеж),
так как поле Работа является полем
используется предложением GROUP BY:

 Для
например, поскольку GROUP BY отсутствует, мы не можем написать
Для
например, поскольку GROUP BY отсутствует, мы не можем написать
 Для каждой горы
у него есть Имя, Возвышение
в метрах, и государство, в котором
находится гора. Мы хотели бы найти десять самых высоких
гор в каждом штате.
Для каждой горы
у него есть Имя, Возвышение
в метрах, и государство, в котором
находится гора. Мы хотели бы найти десять самых высоких
гор в каждом штате.


 В этом видео показано, как начать
завершить за несколько простых шагов, начиная с первоначального импорта шейп-файлов
до окончательных результатов всего за пять минут с дополнительными шестью минутами
объяснения того, что делает каждый шаг. Работает в выпуске коллектора 9или с помощью бесплатного средства просмотра Manifold Viewer.
В этом видео показано, как начать
завершить за несколько простых шагов, начиная с первоначального импорта шейп-файлов
до окончательных результатов всего за пять минут с дополнительными шестью минутами
объяснения того, что делает каждый шаг. Работает в выпуске коллектора 9или с помощью бесплатного средства просмотра Manifold Viewer. Затем я покажу вам, как они работают с предложением
Затем я покажу вам, как они работают с предложением 
 )
) 

 (Небольшое напоминание: среднее значение вычисляется путем вычисления суммы всех значений в наборе данных, а затем деления ее на количество значений.)
(Небольшое напоминание: среднее значение вычисляется путем вычисления суммы всех значений в наборе данных, а затем деления ее на количество значений.) 

 0437 11.36 ). Но когда дело доходит до бизнес-решений, это число вообще не имеет значения.
0437 11.36 ). Но когда дело доходит до бизнес-решений, это число вообще не имеет значения. Затем он создает из них группы (сегменты) и сортирует каждую строку из вашей таблицы данных в нужную группу.
Затем он создает из них группы (сегменты) и сортирует каждую строку из вашей таблицы данных в нужную группу.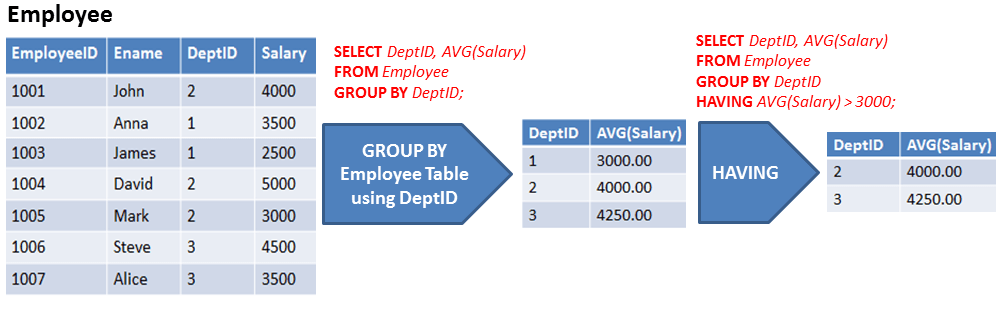 С другой стороны, стоит также присмотреться к тому, как хорошие аэропорты (
С другой стороны, стоит также присмотреться к тому, как хорошие аэропорты (  отношения между различными предложениями, функциями и другими вещами в SQL.
отношения между различными предложениями, функциями и другими вещами в SQL. 
 .. Чтобы иметь и это, вам нужно добавить еще одно предложение SQL:
.. Чтобы иметь и это, вам нужно добавить еще одно предложение SQL:  Это значение по умолчанию для
Это значение по умолчанию для  (При написании более сложных запросов
(При написании более сложных запросов 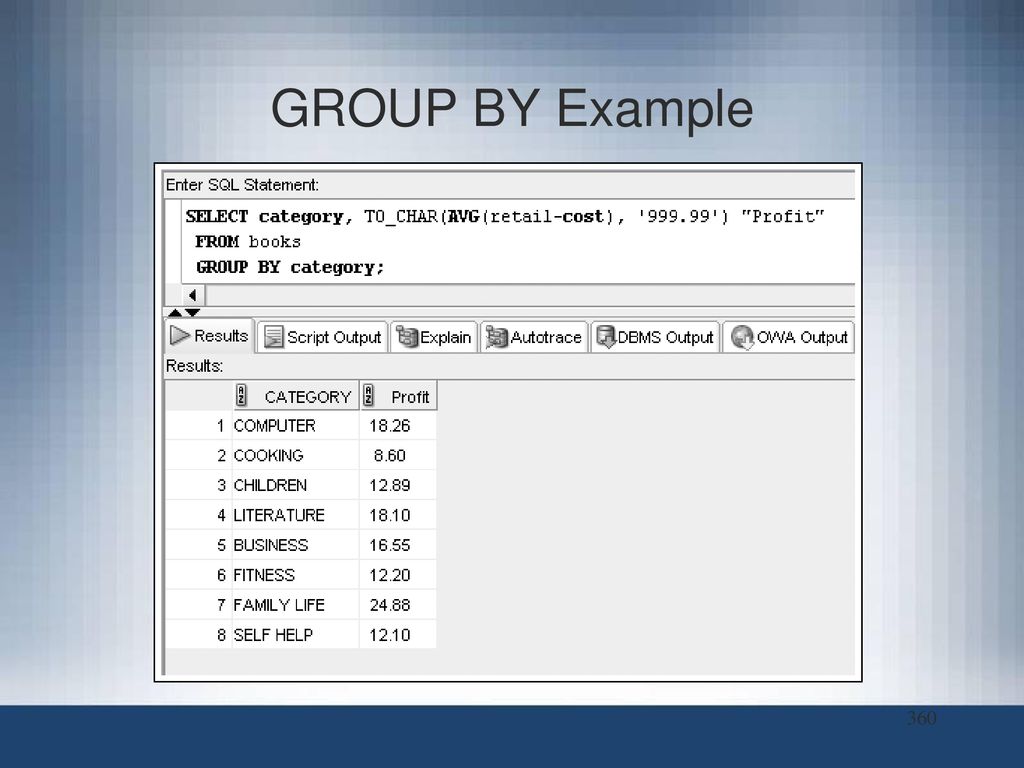 И нам нужны 5 лучших самолетов с наибольшим количеством.) Готовы? Набор! Идти!
И нам нужны 5 лучших самолетов с наибольшим количеством.) Готовы? Набор! Идти! 