Как получить дополнительное место по рекламной акции HP + Dropbox — Справка Dropbox
Если вы недавно приобрели новый компьютер или Android-планшет фирмы HP, то вам, вполне вероятно, полагаются бонусные 100 ГБ места в Dropbox. Чтобы получить бонусное место:
- Нажмите на значок Dropbox на панели задач, чтобы установить Dropbox на соответствующий условиям акции компьютер HP.
- Зарегистрируйтесь в Dropbox, заполнив форму ниже. Если у вас уже есть аккаунт Dropbox, нажмите здесь, чтобы войти.
- Выполните инструкции, чтобы получить полагающееся по условиям акции бонусное место для своего аккаунта.
Подробнее о том, что произойдет, когда закончится срок действия бонусного места
Часто задаваемые вопросы
На какое время предоставляется бонусное место? Если у меня уже есть аккаунт Dropbox, могу ли я получить бонусное место?
Все это зависит от того, когда именно вы приобрели устройство HP. Ниже в таблице вы найдете более подробную информацию.
Дата приобретения | Место в аккаунте | Продолжительность | Новый или существующий пользователь? |
|---|---|---|---|
| Приобретено до 23 октября 2015 года. | 25 ГБ | 6 месяцев | Для новых и существующих пользователей Dropbox |
| Приобретено после 23 октября 2015 года | 25 ГБ | 12 месяцев | Для новых и существующих пользователей Dropbox |
| Приобретено 1 сентября 2020 г. или позже | 100 ГБ | 12 месяцев | Для новых и существующих пользователей Dropbox |
Если я приобрету несколько устройств, на которые распространяются условия акции, смогу ли я получить бонусное место несколько раз?
Нет. Один аккаунт Dropbox может принять участие в акции определенного типа только один раз.
Можно ли перенести бонусное место в другой аккаунт Dropbox?
Нет. После того как вы получили бонусное место, его уже нельзя никому передать.
Можно ли получить бонусное место за использование бывшего в употреблении устройства?
Нет. Бонусное место может получить только первый покупатель устройства, на которое распространяются условия акции.
Почему мне не полагается бонусное место?
Если вы не смогли получить бонусное место, то это могло произойти по следующим причинам:
- Бонусное место, предлагаемое в определенного типа рекламной акции, можно получить только один раз. Например, вы только один раз сможете получить бонусное место за использование устройства HP, даже если приобретете несколько устройств HP.
- На вашем устройстве не было предустановлено приложение Dropbox.
- Вы купили подержанное устройство, и его предыдущий владелец уже получил причитающееся по акции бонусное место. Каждое устройство может участвовать в акции только один раз.
- Возможно, условия акции не распространяются на вашу страну или вашего поставщика.
- Некоторые рекламные акции HP действуют только для новых пользователей Dropbox.

Условия акции Dropbox для устройств HP
Владельцам компьютеров и планшетов HP с предустановленной программой Dropbox для участия в акции необходимо, во-первых, соответствовать критериям, перечисленным в таблице ниже, и, во-вторых, выполнить инструкции для получения бонусного места. По акции пользователям личного аккаунта Dropbox предоставляется дополнительное место на определенный период времени (точное количество места и длительность акции указаны в таблице ниже) в дополнение к уже имеющемуся месту в бесплатном аккаунте. Принять участие в такой акции можно только один раз. Акция может не распространяться на пользователей, которые уже получили бонусное место, приобретя устройство другой фирмы. По истечении срока действия акции дополнительное место будет автоматически удалено из аккаунта. Использование Dropbox регулируется «Условиями обслуживания Dropbox», «Политикой конфиденциальности» и другими правилами. В Иране, Китае, Крыму, Республике Куба, Северной Корее, Сирии и Судане, а также в других странах и регионах, где использование Dropbox запрещено законом, акция не действует.
Насколько полезна была для вас эта статья?
Мы очень сожалеем.
Дайте знать, как нам улучшить свою работу:
Благодарим за отзыв!
Дайте знать, насколько полезной была эта статья:
Благодарим за отзыв!
Особенности архитектуры распределённого хранилища в Dropbox / Хабр
Вниманию читателей «Хабрахабра» представляется расшифровка видеозаписи (в конце публикации) выступления Вячеслава Бахмутова на сцене конференции HighLoad++, прошедшей в подмосковном Сколково 7-8 ноября ушедшего года.
Меня зовут Слава Бахмутов, я работаю в Dropbox. Я Site Reliability Engineer (SRE). Я люблю Go и продвигаю его. С ребятами мы записываем подкаст golangshow.
Что такое Dropbox?
Это облачное хранилище, в котором пользователи хранят свои файлы. У нас 500 миллионов пользователей, у нас более 200 тысяч бизнесов, а также огромное количества данных и трафика (более 1.2 млрд новых файлов в день).
У нас 500 миллионов пользователей, у нас более 200 тысяч бизнесов, а также огромное количества данных и трафика (более 1.2 млрд новых файлов в день).
Концептуально, архитектура — это два больших куска. Первый кусок — это сервер метаданных, в нем хранится информация о файлах, связи между файлами, информация о пользователях, какая-то бизнес логика, и все это связано с базой данных. Второй большой кусок — это блочный storage в котором хранятся данные пользователей. Изначально, в 2011 году, все данные хранились в Amazon S3. В 2015 году, когда нам удалось перекачать все эксабайты к себе, мы рассказали о том, что написали свой облачный storage.
Мы назвали его Magic Pocket. Он написан на Go, частично на Rust и достаточно много на Python. Архитектура Magic Pocket, он кросс-зоный, есть несколько зон. В Америке это три зоны, они объединены в Pocket. Есть Pocket в Европе, с американским он не пересекается, потому что жители Европы не хотят, чтобы их данные были в Америке. Зоны между собой реплицируют данные. Внутри зоны есть ячейки. Есть Master, который управляет этими ячейками. Есть репликации между зонами. В каждой ячейке есть Volume Manager, который следит за серверами, на которых хранятся эти данные, там достаточно большие сервера.
Внутри зоны есть ячейки. Есть Master, который управляет этими ячейками. Есть репликации между зонами. В каждой ячейке есть Volume Manager, который следит за серверами, на которых хранятся эти данные, там достаточно большие сервера.
На каждом из серверов это все объединено в bucket, bucket – это 1 GB. Мы оперируем bucket’ами, когда перекидываем данные куда-то, когда что-то удаляем, очищаем, дефрагментируем, потому что сами блоки данных, которые мы сохраняем от пользователя, — это 4 MB, и оперировать ими очень сложно. Все компоненты Magic Pocket хорошо описаны в нашем техническом блоге, про них я не буду рассказывать.
Я буду рассказывать по архитектуру с точки зрения SRE. С этой точки зрения очень важна доступность и сохранность данных. Что же это такое?
Доступность — это сложное понятие и вычисляется для разных сервисов по-разному, но обычно это отношение количества выполненных запросов к общему количеству запросов, обычно описывается девятками: 999, 9999, 99999. Но по сути это некая функция от времени между катастрофами или какими-то проблемами ко времени за сколько вы почините это проблему. Неважно как вы это почините, в продакшне или просто откатите версию.
Но по сути это некая функция от времени между катастрофами или какими-то проблемами ко времени за сколько вы почините это проблему. Неважно как вы это почините, в продакшне или просто откатите версию.
Что такое сохранность?
Как мы вычисляем сохранность? Вы берете какие-то данные и сохраняете их на жесткий диск. Дальше вы должны дождаться пока они синхронизируются на диск. Это смешно, но многие пользуются nosql-решениями, которые просто пропускают этот шаг.
Как высчитывается сохранность?
Есть AFR – это годовая частота ошибок дисков. Есть различные статистики по тому, какие ошибки бывают, насколько часто бывают ошибки в тех или иных жестких дисках. Вы можете ознакомиться с этими статистиками:
Дальше вы можете реплицировать ваши данные на разные жесткие диски чтобы повысить durability. Вы можете использовать RAID, вы можете держать реплики на разных серверах или даже в разных дата-центрах. И если вы посчитаете цепочками Маркова, насколько вероятность потери одного байта, то у вас получится что-то около 27 девяток. Даже на масштабах Dropbox, где у нас эксабайты данных, мы не потеряем ни один байт в ближайшем будущем никогда практически. Но все это эфемерно, любая ошибка оператора, либо логическая ошибка в вашем коде — и данных нет.
И если вы посчитаете цепочками Маркова, насколько вероятность потери одного байта, то у вас получится что-то около 27 девяток. Даже на масштабах Dropbox, где у нас эксабайты данных, мы не потеряем ни один байт в ближайшем будущем никогда практически. Но все это эфемерно, любая ошибка оператора, либо логическая ошибка в вашем коде — и данных нет.
Как же мы на самом деле улучшаем доступность и сохранность данных?
Я разделяю это на 4 категории, это:
- Изоляция;
- Защита;
- Контроль;
- Автоматизация.
Автоматизация – это очень важно.
Изоляция бывает:
- Физическая;
- Логическая;
- Эксплуатационная.
Физическая изоляция. На масштабах Dropbox или компании вроде Dropbox нам очень важно общаться с дата центром, мы должны знать, как наши сервисы располагаются внутри дата центра, как к ним подводится энергия, какая сетевая доступность у этих сервисов.
Можно посмотреть на все это в другом измерении, с точки зрения производителя оборудования. Очень важно пользоваться разными производителями оборудования, разными прошивками, разными драйверами. Почему? Хоть производители оборудования и говорят, что их решения надежны, на самом деле они врут и это не так. Хорошо хоть не взрываются.
Исходя из всего этого, важно критические данные класть не только у себя где-то в бэкапах на своей инфраструктуре, но и во внешней инфраструктуре. Например, если вы у облака Google, то важные данные кладете в Amazon, и наоборот.
Логическая изоляция. Про нее практически все всё знают. Основные проблемы: если один сервис начинает создавать какие-то проблемы, то другие сервисы тоже начинают испытывать проблемы. Если баг был в коде у одного сервиса, то этот баг начинает распространяться на другие сервисы. У вас начинают поступать неправильные данные. Как с этим справиться?
Слабая связанность! Но это очень редко работает. Есть такие системы, которые не слабо связаны. Это базы данных, ZooKeeper. Если у вас большая нагрузка пошла на ZooKeeper, у вас кластер кворум упал, то он весь упал. С базами данными примерно то же самое. Если большая нагрузка на master, то скорее всего весь кластер упадет.
Что мы сделали в Dropbox?
Это высокоуровневая диаграмма нашей архитектуры. У нас есть две зоны, и между ними мы сделали очень простой интерфейс. Это практически put и get, это именно для storage. Это было очень сложно для нас, потому что мы хотели сделать все сложнее. Но это очень важно, потому что внутри зон все очень сложно, там и ZooKeeper, и базы данных, кворумы. И это все периодически падает, прям все сразу. И чтобы это не захватило остальные зоны, между ними есть этот простой интерфейс. Когда одна зона падает, то вторая скорее всего будет работать.
Но это очень важно, потому что внутри зон все очень сложно, там и ZooKeeper, и базы данных, кворумы. И это все периодически падает, прям все сразу. И чтобы это не захватило остальные зоны, между ними есть этот простой интерфейс. Когда одна зона падает, то вторая скорее всего будет работать.
Эксплуатационная изоляция. Как бы вы хорошо ни раскидали ваш код по разным серверам, как бы хорошо его логически ни изолировали, всегда найдется человек, который сделает что-то не так. Например, в «Одноклассниках» была проблема: человек раскатал на все сервера Bash shell, в котором что-то не работало, и все сервера отключились. Такие проблемы тоже бывают.
Еще шутят, что если бы все программисты и системные администраторы ушли куда-нибудь отдыхать, то система бы работала гораздо стабильнее, чем когда они работают. И это действительно так. Во время фризов многие компании имеют такую практику делать заморозку перед новогодними каникулами, система работает гораздо стабильнее.
Контроль доступа. Релиз процесс: все это активно тестируете, затем тестируете на staging, который использует, например, ваша компания. Дальше мы выкладываем изменения в одну зону. Как только мы удостоверились, что все нормально, мы раскладываем на остальные две зоны. Если что-то не нормально, то мы с них реплицируем данные. Это все касается storage. Продуктовые сервисы мы постоянно обновляем, раз в день.
Защита. Как же нам нужно защищать наши данные?
Это валидация операций. Это возможность восстановить эти данные. Это тестирование. Что такое валидация операций?
Самый большой риск для системы — это оператор.
Есть история. Маргарет Гамильтон, которая работала в программе «Аполлон», в какой-то момент во время тестирования к ней пришла дочка и повернула какой-то рычажок, и вся система навернулась. Этот рычажок очищал систему навигации этого «Аполлона». Гамильтон обратилась в НАСА и сказала, что есть такая проблема, предложила сделать защиту.Если корабль летит, то не будет очищать данные в этом корабле. Но в НАСА сказали, что астронавты — профессионалы, и они никогда не повернут этот рычажок. В следующем полете один из астронавтов нечаянно этот рычажок повернул, и все очистилось. У них было четкое описание проблемы, и они смогли восстановить эти навигационные данные.
У нас был похожий пример, у нас есть такой инструмент, который называется JSSH, это такой distributed shell, который позволяет выполнять команды на множестве серверов.
По сути, нам в этой команде нужно выполнить на серверах memcache, который находится в состоянии reinstall, то есть они уже не работают, и нам их нужно обновить. Нам нужно выполнить скрипт upgrade.sh. Обычно это все делается автоматически, но иногда нужно вручную это делать.
Тут есть проблема, это нужно было сделать все кавычках:
Так как это все было без кавычек, то у нас для всех memcach’ей установился аргумент lifecycle=reinstall и они все перезагрузились. Это не очень хорошо сказалось на сервисе. Оператор не виноват, всякое бывает.
Это не очень хорошо сказалось на сервисе. Оператор не виноват, всякое бывает.
Что мы сделали?
Мы поменяли синтаксис команды (gsh), чтобы не было больше таких проблем. Мы запретили выполнять деструктивные операции на живых сервисах (DB, memcache, storage). То есть нам нельзя ни к коем случае перезагрузить базу данных, не остановив её и не убрав её из production, так же с memcache. Все такие операции мы стараемся автоматизировать.
Мы добавили два слеша в эту операцию в конце и уже после этого указываем свой скрипт, такой маленький фикс позволил нам избегать таких проблем в дальнейшем.
Второй пример. Это SQLAlchemy. Это библиотека для Python для работы с базами данных. И в ней для update, insert, delete есть такой аргумент, который называется whereclause. В нем вы можете указать что вы хотите удалить, что вы хотите апдейтить. Но если вы туда передадите не whereclause, а where, то sqlalchemy ничего не скажет, он просто удалит все без where, это очень большая проблема. У нас есть несколько сервисов, например, ProxySQL. Это прокси для MySQL, который позволяет запретить многие деструктивные операции (DROP TABLE, ALTER, updates без where и т.д.). Так же в этом ProxySQL можно сделать throttling и для тех запросов, которые мы не знаем, ограничить их количество, чтобы умный запрос не положил нам master случайно.
У нас есть несколько сервисов, например, ProxySQL. Это прокси для MySQL, который позволяет запретить многие деструктивные операции (DROP TABLE, ALTER, updates без where и т.д.). Так же в этом ProxySQL можно сделать throttling и для тех запросов, которые мы не знаем, ограничить их количество, чтобы умный запрос не положил нам master случайно.
Восстановление. Очень важно не только создавать бэкапы, но и проверять, что эти бэкапы восстановятся. Facebook недавно выложил статью, где они рассказывают, как они постоянно делают бэкапы и постоянно восстанавливаются из этих бэкапов. У нас по сути все тоже самое.
Вот пример из нашего Orchestrator, за какой-то короткий отрезок времени:
Видно, что у нас постоянно делаются клоны баз данных, потому что у нас на одном сервере до 32 баз данных расположено, мы постоянно их перемещаем. Поэтому у нас постоянно происходит клонирование. Постоянно promotion идут в master и на slave и т.д. Так же огромное количество бэкапов. Мы бэкапимся к себе, также в Amazon S3. Но у нас также постоянно происходит recovery. Если мы не проверим, что каждая база данных, которую мы забэкапили, может восстановиться, то по сути у нас этого бэкапа нет.
Но у нас также постоянно происходит recovery. Если мы не проверим, что каждая база данных, которую мы забэкапили, может восстановиться, то по сути у нас этого бэкапа нет.
Тестирование
Все знают, что полезно и юнит-тестирование, и интеграционное тестирование. С точки зрения доступности, тестирование — это MTTR, время для восстановления, оно по сути равно 0. Потому что вы этот баг нашли не в production, а до production и пофиксили его. Availability не прогнулось. Это тоже очень важно.
Контроль
Кто-то всегда напортачит: либо программисты, либо операторы что-то сделают не так. Это не проблема. Нужно иметь возможность находить и исправлять это всё.
У нас для storage существует огромное количество верификаторов.
Их на самом деле 8, а не 5, как здесь. У нас коды верификаторов больше кодов самого storage. У нас 25% внутреннего трафика — это верификации. На самом низком уровне работают disk scrubber’ы, которые просто читают блоки с жесткого диска и проверяют контрольные суммы. Почему мы это делаем? Потому что жесткие диски врут, S.M.A.R.T. врут. Производителям невыгодно, чтобы S.M.A.R.T находил ошибки, потому что им приходится возвращать эти жесткие диски. Поэтому это нужно всегда проверять. И как только мы видим проблему, мы пытаемся восстановить эти данные.
Почему мы это делаем? Потому что жесткие диски врут, S.M.A.R.T. врут. Производителям невыгодно, чтобы S.M.A.R.T находил ошибки, потому что им приходится возвращать эти жесткие диски. Поэтому это нужно всегда проверять. И как только мы видим проблему, мы пытаемся восстановить эти данные.
У нас есть trash inspector. Когда мы что-то удаляем, либо перемещаем, либо что-то деструтивное делаем с данными, мы сначала кладём эти данные в некую корзину и потом проверяем эти данные, действительно ли мы хотели их удалить. Хранятся они там две недели, например. У нас capacity на это двухнедельное время удаленных данных, это очень важно, поэтому мы тратим на это деньги. Мы так же постоянно часть трафика, который приходит в storage, сохраняем эти операции в Kafka. Потом эти операции повторяем уже на storage. Мы обращаемся к storage как к blackbox, чтобы посмотреть, действительно ли там есть данные трафика, который к нам пришел, и те, которые записались, мы их можем забрать.
Мы постоянно проверяем, что данные среплицированны с одного storage на другой, то есть они соответствуют друг другу. Если данные есть в одном storage, они обязаны быть в другом storage.
Если данные есть в одном storage, они обязаны быть в другом storage.
Верификаторы — это очень важно, если вы хотите добиться высокого и качественного durability.
Также очень важно знать, что верификаторы, которые вы не протестировали, они по сути дела ничего не верифицируют. Вы не можете сказать, что они действительно делают то, что вы хотите.
Поэтому очень важно проводить Disaster Recovery Testing (DRT). Что это такое? Это когда вы, например, полностью отключаете какой-то внутренний сервис, от которого зависят другие сервисы, и смотрите, а смогли ли вы определить, что у вас что-то не работает, либо вы считаете, что все отлично. Смогли ли вы среагировать на это быстро, починить, восстановить это всё. Это очень важно, потому что мы ловим проблемы в production. Production отличается от staging тем, что там совсем другой трафик. У вас просто другая инфраструктура. Например, у вас в staging может быть на одном рэке одно количество сервисов, и они разные, например, веб-сервис, база данных, storage. А в production это может быть совершенно другая.
А в production это может быть совершенно другая.
У нас была такая проблема из-за того, что у нас база данных стояла с веб-сервисами, мы не могли вовремя её забэкапить. За этим тоже нужно следить.
Очень важно доказывать наши суждения. То есть если что-то упало, и мы знаем, как это восстановить, мы написали этот скрипт, мы должны доказать, что если что-то упадет, то это действительно произойдет. Потому что код меняется, инфраструктура меняется, все может поменяться. Также это плюс и спокойствие для дежурных, потому что они не спят. Они не любят просыпаться ночью, у них потом проблемы могут возникнуть. Это факт, психологи изучали это.
Если дежурные знают, что будет какая-то проблема, то они к этому готовы. Они знают, как это восстановить в случае реальной проблемы. Это нужно регулярно делать и в production.
Автоматизация
Самая важная вещь. Когда у вас количество серверов растет линейно или экспоненциально, то количество людей не рождается линейно. Они рождаются, учатся, но с какой-то периодичностью. И вы не можете увеличивать количество людей равносильно количеству ваших серверов.
Они рождаются, учатся, но с какой-то периодичностью. И вы не можете увеличивать количество людей равносильно количеству ваших серверов.
Поэтому вам нужна автоматизация, которая будет выполнять работу за этих людей.
Что такое автоматизация?
В автоматизации очень важно собирать метрики с вашей инфраструктуры. Я практически ничего не говорил про метрики в своем докладе, потому что метрики — это ядро вашего сервиса и про него упоминать не надо, потому что это самая важная часть вашего сервиса. Если у вас нет метрик, вы не знаете, работает ваш сервис или нет. Поэтому очень важно собирать метрики быстро. Если, например, у вас метрики собираются раз в минуту, а проблема у вас в минуте, то вы про нее не узнаете. Также очень важно быстро реагировать. Если реагирует человек, например, у нас минута прошла, когда что-то случилось, что-то закладывается на то, что баг был в метрике, вам приходит alert. У нас policy в течение 5 минут. Вы должны начать что-то делать, реагировать на alert в это время. Вы начинаете что-то делать, начинаете разбираться, по сути у вас проблема решается в среднем минут 10-15, в зависимости от проблемы. Автоматизация позволяет вам ускорить, но не решить, в том плане, что она дает информацию об этой проблеме до того, как вы займетесь решением данной проблемы.
Вы начинаете что-то делать, начинаете разбираться, по сути у вас проблема решается в среднем минут 10-15, в зависимости от проблемы. Автоматизация позволяет вам ускорить, но не решить, в том плане, что она дает информацию об этой проблеме до того, как вы займетесь решением данной проблемы.
У нас есть такой инструмент Naoru — параноидальная автоматизация.
Автоматизация состоит из нескольких компонентов.
Она состоит из неких алертов, которые приходят. Это может быть простой пайтоновский скрипт, который коннектится к серверу и проверяет, что он доступен. Это может приходить из Nagios или Zabbix, неважно что вы используете. Главное, чтобы это приходило быстро. Дальше мы должны понять, что с этим делать, мы должны продиагностировать. Например, если сервер недоступен, мы должны попробовать подключится по SSH, подключится по IPMI, посмотреть, если нет ответа, он завис или еще что-то, вы прописываете какое-то лечение.
Дальше, когда вы пишите автоматизацию, все должно пройти через оператора. У нас есть policy, что мы любую автоматизацию, примерно 3-6 месяцев она решается через оператора.
У нас есть policy, что мы любую автоматизацию, примерно 3-6 месяцев она решается через оператора.
Мы собрали всю информацию о проблеме, и оператору вываливается эта информация, такой-то сервер недоступен по такой-то причине, и указывается, что нужно сделать, и спрашивается подтверждение у оператора. Оператор обладает очень важными знаниями. Он знает, что сейчас какая-то проблема с сервисом. Он, например, знает, что этот сервер нельзя перезагружать, потому что на нем еще что-то запущено. Поэтому его нельзя просто перезапустить. Поэтому каждый раз, когда оператор сталкивается с какой-то проблемой, он вносит какие-то улучшения в этот скрипт автоматизации, и с каждым разом он становится все лучше.
Здесь существует большая проблема, это лень операторов. Они начинают автоматизировать автоматизацию. Они автоматически вставляют сюда yes:
Поэтому некоторое время мы писали не yes/no, а: «Да, я действительно хочу то-то, то-то». В разном регистре, рандомно проверяли что это действительно консоль. Это очень важно.
Это очень важно.
Также важно иметь хуки. Потому что не всё всегда можно проверить. Хуки могут быть очень простыми, например, если на сервере запущен ZooKeeper, то нам нужно проверить что все члены группы работают (скрипт с ошибками), по сути мы просто проверяем что-то:
Эти хуки расположены по всему flow, везде после алертов есть хуки, в диагностическом плагине и т.д. Вы можете для вашего сервиса создать свой хук.
Дальше идет решение проблемы:
Оно может быть очень простым. Например, перезапустить этот сервер. Запустить puppet, chef и т.д.
Это Naoru. Это reactive remediation. Которое позволяет нам реагировать на событие очень быстро и чинить их очень быстро.
Также есть open-source решения. Самый популярный — это StackStorm от русских ребят. У них очень хорошее решение, достаточно популярное. Также это можно сделать своими решениями вроде riemann или OpsGenie и т.д.
Есть решения проприетарные. От Facebook это FBAR (facebook auto-remediation). Nurse от Linkedin’a. Они закрыты, но они постоянно рассказывают про эти решения. Например, Facebook недавно делал доклад о проблеме переноса всей стойки через свой инструмент.
Nurse от Linkedin’a. Они закрыты, но они постоянно рассказывают про эти решения. Например, Facebook недавно делал доклад о проблеме переноса всей стойки через свой инструмент.
Но автоматизация бывает не только реактивная (здесь и сейчас), но и автоматизация, которую нужно сделать за долгий промежуток времени. Например, нам нужно обновить 10 тысяч серверов, перезагрузив их. Например, нужно обновить драйвер, ядро и еще что-то сделать. Это может занять большой промежуток времени: месяц, год и т.д. В реактивной системе нельзя это постоянно контролировать.
Поэтому у нас есть еще такая система Wheelhouse.
Есть схема, как она работает. Сейчас я расскажу, что там.
По сути у нас есть кластер базы данных, у которой есть один master. A и есть два slave. Нам нужно заменить этот master, например, мы хотим обновить ядро. Чтобы его заменить нам нужно запромоутить slave, депромоутить тот master, удалить его. У нас есть требование в Dropbox, у нас в кластере всегда должно быть два slave для такой конфигурации. У нас есть некое состояние этого кластера. HostA находится в production, он master, он еще не освобожден, количество slave у нас два, но нам нужно три для этой операции.
У нас есть некое состояние этого кластера. HostA находится в production, он master, он еще не освобожден, количество slave у нас два, но нам нужно три для этой операции.
У нас есть некая стейт-машина, которая все это делает.
Из replace_loop (синяя стрелочка) мы видим, что наш сервер находится в production, и нам не хватает slave’ов, и мы переходим в состояние выделить еще slave. Мы приходим в это состояние, мы инициируем работу создать новый клон с master’a новый slave. Это запускается где-то в Orchestrator, мы ждем. Если работа завершена, и все хорошо, то мы переходим к следующему шагу. Если был fail, то переходим в состояние failure. Дальше мы добавляем в этот хост новый slave в production, тоже инициируем в Orchestrator эту работу, ждем и возвращаемся в replace_loop.
У нас теперь примерно такая схема:
Один хост — это master, есть три slave. Мы удовлетворяем условие что нам хватает slave’ов. После этого мы переходим в состояние promote.
На самом деле это depromote.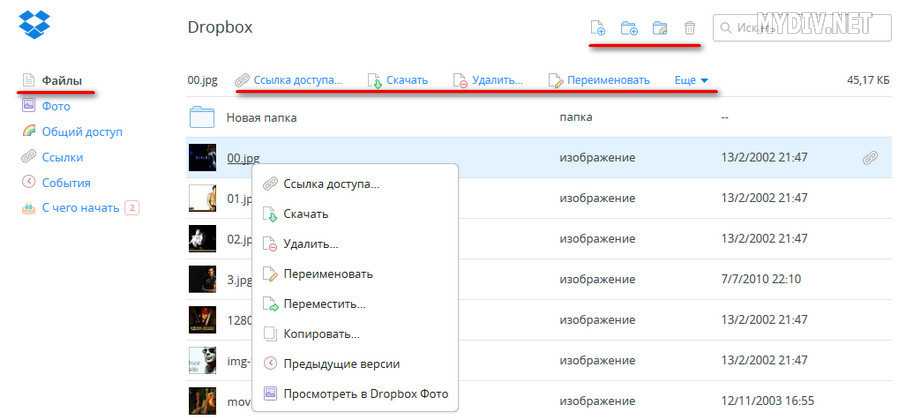 Потому что нам нужно master сделать slave’ом, а какой-то slave master’ом. Тут все тоже самое. Добавляется работа в Orchestrator, проверятся условие и так далее, остальные шаги примерно такие же. Мы после этого удаляем master с production, убираем с него трафик. Удаляем master в инсталлятор, чтобы люди, которые занимаются этим сервером, могли что-то обновить на нем.
Потому что нам нужно master сделать slave’ом, а какой-то slave master’ом. Тут все тоже самое. Добавляется работа в Orchestrator, проверятся условие и так далее, остальные шаги примерно такие же. Мы после этого удаляем master с production, убираем с него трафик. Удаляем master в инсталлятор, чтобы люди, которые занимаются этим сервером, могли что-то обновить на нем.
Этот блок очень маленький, но он участвует в более сложных блоках. Например, если нам нужно перенести целую стойку в другую стойку, потому что драйвера на свитчах меняются, и нам нужно просто всю стойку отключить чтобы перезагрузить свитч. У нас много описано таких диаграмм-состояний для разных сервисов, как их гасить, как их поднимать. Это все работает. Даже математически можно доказать, что у вас система всегда будет находиться в рабочем состоянии. Почему это сделано через STM, а не в режиме процедур? Потому что если это долгий процесс, например, клонирование может занимать час или около того, то у вас может случиться что-то еще, и состояние вашей системы изменится. В случае с машиной состояний вы всегда знаете, какое состояние и как на него реагировать.
В случае с машиной состояний вы всегда знаете, какое состояние и как на него реагировать.
Мы теперь используем это в других проектах. Эти 4 метода, которые вы можете использовать, чтобы повышать доступность и сохранность ваших данных. Я не рассказывал про конкретные решения, потому что в любой крупной компании решения пишут все сами. Мы конечно используем какие-то стабильные блоки, например, для баз данных мы используем MySQL, но сверху мы навернули свой графовый storage. Для репликации мы использовали semi sync, но сейчас у нас своя репликация, что-то вроде Apache BookKeeper, также proxdb мы используем. Но в целом все решения у нас свои, поэтому я не упоминал про них, потому что они скорее всего не похожи на ваши. Но вот эти методы вы можете использовать с любыми вашими решениями, с open source или нет. Чтобы улучшить вашу доступность.
На этом все, спасибо!
Что такое акция Dropbox на 25 ГБ?
Эта акция дает вам 25 ГБ дополнительного места в Dropbox на один год. Промо-пространство предоставляется в дополнение к 2 ГБ, включенным в бесплатные учетные записи Dropbox Basic.
Промо-пространство предоставляется в дополнение к 2 ГБ, включенным в бесплатные учетные записи Dropbox Basic.
Чтобы получить право на участие в акции, вы должны быть новым пользователем Dropbox, который приобрел подходящий компьютер в Японии в марте 2015 года или позже.
Условия акции и право на участие
Как долго действует рекламное место?
25 ГБ рекламного пространства действительны в течение одного года. По истечении годичного рекламного периода остается 2 ГБ места в учетной записи Dropbox Basic.
Если я приобрел несколько устройств, участвующих в акции, могу ли я активировать одно и то же предложение несколько раз?
Нет, воспользоваться этой акцией можно только один раз для каждой учетной записи Dropbox.
Могу ли я претендовать на рекламное место с моей существующей учетной записью Dropbox?
Нет, промоакцией могут воспользоваться только новые пользователи, зарегистрировавшиеся в Dropbox на соответствующих устройствах.
Могу ли я перенести свое рекламное место в другую учетную запись Dropbox?
Нет, акционное место не подлежит передаче после того, как оно было использовано.
Могу ли я воспользоваться промоакцией на восстановленном или бывшем в употреблении устройстве?
Нет, рекламное место доступно только первоначальному покупателю соответствующего устройства.
Почему я не имею права на рекламное место?
- Вы не новый пользователь Dropbox.
- Вы пытаетесь выкупить покупку во второй раз.
- На вашем устройстве изначально не был установлен Dropbox.
- Вы купили устройство подержанным или восстановленным.
- Ваше устройство не соответствует требованиям из-за исключений страны или продавца.
Использование поощрения
Как воспользоваться поощрением?
- Нажмите Dropbox 25 ГБ в меню «Пуск».
- Создайте учетную запись Dropbox. После того, как вы выполните этот шаг, Dropbox автоматически установится и свяжется с вашим компьютером.

- Выполните пять из семи шагов «Начало работы».
Я не могу использовать рекламное место на подходящем устройстве. Почему?
Если вы не можете использовать свое рекламное место на соответствующем устройстве, проверьте следующее:
- Вы выполнили по крайней мере пять из семи шагов раздела «Начало работы»?
- Вы зарегистрировались в Dropbox с помощью установщика, предварительно загруженного на ваш компьютер? Чтобы иметь право на участие, зарегистрируйте новую учетную запись Dropbox, нажав Dropbox 25 ГБ в меню «Пуск» подходящего устройства.
- У вас уже есть аккаунт Dropbox? Воспользоваться промоакцией могут только новые пользователи Dropbox.
- Вы воспользовались другой рекламной акцией на устройство Dropbox? Если это так, вы не имеете права использовать рекламную акцию. Вы можете активировать промо-предложение одного и того же типа только один раз.
Как проверить, воспользовался ли я промо-акцией?
- Войдите на сайт dropbox.
 com.
com. - Нажмите на свой аватар.
- Нажмите Настройки .
- Нажмите План .
- До Заработайте больше места , ищите эту акцию.
Когда акция закончится
Как узнать, когда истечет срок действия моего рекламного места?
- Войдите на сайт dropbox.com.
- Нажмите на свой аватар.
- Нажмите Настройки .
- Нажмите План .
- Под Заработайте больше места , вы можете увидеть эту акцию и срок действия.
Что произойдет, когда истечет срок действия моего рекламного места?
Когда срок действия вашего рекламного места истечет, ваша квота места в Dropbox вернется к тому, что было раньше. Например, если у вас есть учетная запись Dropbox Basic, ваш лимит возвращается к 2 ГБ (вместе с любым пространством, которое вы заработали, пригласив людей в Dropbox или с помощью других рекламных акций).
Если вы превысите квоту места после истечения срока действия рекламного места, вы больше не сможете сохранять новые файлы в Dropbox. Чтобы добавить место в свою учетную запись, рассмотрите возможность перехода на Dropbox Plus.
Чтобы добавить место в свою учетную запись, рассмотрите возможность перехода на Dropbox Plus.
Условия рекламной акции Dropbox на 25 ГБ пространства
Для соответствующих устройств, на которых предварительно загружен установщик приложения Dropbox, акция доступна для пользователя на этом устройстве, который (а) сначала зарегистрирует новую учетную запись Dropbox и (б ) завершает руководство Dropbox по началу работы. Акция заключается в том, что одна учетная запись Dropbox получает на 1 год дополнительные 25 ГБ дискового пространства в дополнение к пространству, которое Dropbox предлагает пользователям с бесплатными учетными записями. Каждый пользователь имеет право только на одну акцию этого типа. Акция может быть недоступна для пользователей, которые ранее получали рекламную акцию Dropbox при покупке устройства, не отвечающего требованиям. По истечении 1 года рекламного периода 25 ГБ рекламного пространства, добавленные к сервису Dropbox пользователя, будут автоматически удалены. Использование Dropbox регулируется Условиями обслуживания Dropbox, Политикой конфиденциальности и другими условиями, доступными на странице http://www.dropbox.com/terms. Акция недоступна в Китае, Кубе, Иране, Северной Корее, Судане, Сирии или в Крыму, а также в любых других странах, где служба Dropbox запрещена законом.
Использование Dropbox регулируется Условиями обслуживания Dropbox, Политикой конфиденциальности и другими условиями, доступными на странице http://www.dropbox.com/terms. Акция недоступна в Китае, Кубе, Иране, Северной Корее, Судане, Сирии или в Крыму, а также в любых других странах, где служба Dropbox запрещена законом.
Как воспользоваться рекламным предложением HP + Dropbox
Если вы недавно приобрели потребительский компьютер HP или планшет Android, вы можете иметь право на дополнительные 100 ГБ дискового пространства Dropbox. Чтобы воспользоваться этой акцией:
- Нажмите или коснитесь значка Dropbox на панели задач, чтобы установить Dropbox на соответствующий требованиям компьютер HP.
- Зарегистрируйте аккаунт Dropbox, заполнив данные на этой странице. Если у вас уже есть учетная запись Dropbox, нажмите , чтобы войти .
- Следуйте инструкциям, чтобы выкупить место в вашей учетной записи.
Узнайте, что произойдет после того, как истечет срок действия вашего рекламного места в хранилище.
Часто задаваемые вопросы
Как долго действует акция и могу ли я получить ее в своей существующей учетной записи Dropbox?
Ответ на эти вопросы зависит от того, когда вы приобрели устройство HP. Дополнительную информацию см. в таблице ниже.
Дата покупки | Космос | Продолжительность | Существующий или новый пользователь? |
|---|---|---|---|
| Приобретено до 23 октября 2015 г. | 25 ГБ | 6 месяцев | Новые или существующие пользователи Dropbox |
| Приобретено после 23 октября 2015 г. | 25 ГБ | 12 месяцев | Новые или существующие пользователи Dropbox |
| Приобретено 1 сентября 2020 г. или позднее | 100 ГБ | 12 месяцев | Новые или существующие пользователи Dropbox |
Если я приобрел несколько устройств, участвующих в акции, могу ли я активировать одно и то же предложение несколько раз?
Нет. Каждый аккаунт Dropbox может использовать один и тот же тип сделки только один раз.
Каждый аккаунт Dropbox может использовать один и тот же тип сделки только один раз.
Могу ли я перенести свое рекламное место в другой аккаунт Dropbox?
Нет, акционное место не подлежит передаче после того, как оно было использовано.
Могу ли я получить акцию на отремонтированное или бывшее в употреблении устройство?
Нет. Рекламное место доступно только первоначальному покупателю соответствующего устройства.
Почему я не могу использовать рекламное место?
Может быть множество причин, по которым вы не имеете права использовать рекламное место:
- Вы имеете право использовать один и тот же тип рекламного предложения только один раз. Например, вы не можете активировать рекламную акцию HP более одного раза, даже если вы покупаете несколько соответствующих устройств HP.
- Приложение Dropbox не было предварительно загружено на ваше устройство.
- Вы купили свое устройство, бывшее в употреблении или восстановленное, и предыдущий владелец воспользовался рекламной акцией, связанной с устройством.
 Каждое устройство может получить рекламное место только один раз.
Каждое устройство может получить рекламное место только один раз. - Ваше устройство может не участвовать в акции из-за исключений для некоторых стран и продавцов.
- Некоторые акции HP могут применяться только к новым пользователям Dropbox.
Условия акции Dropbox для устройств HP
Для ПК и планшетов HP с предустановленным приложением Dropbox акция доступна первому пользователю, который (а) соответствует критериям, указанным в таблице ниже, и (б ) завершает этапы погашения. Акция предназначена для одной учетной записи личного плана Dropbox, которая получает дополнительное пространство для хранения на фиксированный период времени (точная сумма и продолжительность указаны в таблице ниже) в дополнение к пространству для хранения, которое Dropbox предлагает пользователям с бесплатными учетными записями. Каждый пользователь имеет право на участие только в одной рекламной акции этого типа для одной учетной записи. Акция может быть недоступна для пользователей, которые ранее получали рекламную акцию Dropbox при покупке устройства не HP.