Для чего предназначены базы данных?
В наш век компьютерных технологий практически ни одна информационная система не обходится без базы данных, позволяющей пользователям ПК с легкостью находить любые необходимые сведения в рассматриваемых предметных областях.
Сегодня такие хранилища используются повсеместно в магазинах, торговых компаниях и центрах услуг, государственных организациях, учебных учреждениях и даже для домашних нужд. Какую же функцию выполняют базы данных в разных сферах нашей жизни?
Книги в библиотеке
В библиотеках базы данных предназначены для составления каталогов, учета движения библиотечных изданий и определения месторасположения той или иной книги. При вводе в поиск нужного названия можно с точностью узнать, в каком ряду и на какой полке хранится книга. Кроме этого, при помощи базы данных легко находить издание по названию, тематике или имени автора.
Нередко такие базы способны обрабатывать сведения о резервировании материалов, уже взятых другим человеком, и даже информировать по электронной почте о том, что книга возвращена, и ее можно забрать.
Также система может отправлять напоминание о необходимости вернуть издание, если вы не удосужились это сделать в указанные сроки. Аналогично базы данных применяются в архивах, музеях и различных научных организациях.
Клиентская и складская база данных
Клиентская база данных содержит сведения о клиентах компании, причем как уже работавших с фирмой, так и потенциальных. Если ввести в такую базу имя любого покупателя или заказчика, то в считанные секунды можно получить информацию о его контактах (адрес, телефон), банковские реквизиты, историю сделок и множество других сведений, заложенных в процессе работы с ним.
В складской базе данных находится информация о количестве товаров, хранящихся на складе, их себестоимости, ценах, штрих-кодах.
Посредством специальных программ, содержащих базы данных, можно вести точный учет расхода и прихода продукции, движения денежных средств, взаиморасчетов с поставщиками и покупателями, а также анализировать остатки товаров и определять необходимость новых закупок.
Покупки в магазине
В магазине доступ к базе данных требуется во время оплаты, когда кассир считывает с товара штрих-код. Информация, полученная ручным сканером, передается в приложение базы, после чего программа находит цену каждого вида продукции и рассчитывает общую стоимость всех покупок. Одновременно с этим происходит анализ остатков товаров на складе и автоматическое формирование заказа, в случае если запасы становятся ниже определенного уровня.
База данных ГИБДД
База данных ГИБДД позволяет любому желающему получить полную информацию о владельце транспортного средства и непосредственно самом автомобиле. С ее помощью по номеру транспорта можно без труда узнать, кому он принадлежит, или какие именно автомобили находятся в собственности конкретного человека. Как правило, эти базы разбиты по регионам и городам, что значительно облегчает поиск.
Базы данных в домашних условиях
Если сидя дома в уютном кресле вы решите почитать книгу на экране монитора, к вашим услугам базы данных электронных библиотек. Как и в обычных книжных хранилищах, поиск нужного издания осуществляется по категориям. Вы можете просто ввести в поиск название нужного издания или просмотреть все имеющиеся в наличии книги по заданной тематике.
Как и в обычных книжных хранилищах, поиск нужного издания осуществляется по категориям. Вы можете просто ввести в поиск название нужного издания или просмотреть все имеющиеся в наличии книги по заданной тематике.
Точно так же из дома удобно делать покупки в интернет-магазинах или приобретать путевки на сайтах туристических агентств. В базах данных таких ресурсов находятся сведения о товарах и услугах, ценах и возможных скидках.
Преимущества использования базы данных
Пользователь базы данных получает ряд неоспоримых преимуществ, к числу которых относятся:
— компактность – отпадает необходимость хранения сведений в многотомной бумажной картотеке;
— скорость поиска – в компьютере она намного выше ручной;
— актуальность – всегда есть доступ к свежей информации.
Помимо этого, ввод любых сведений осуществляется в наиболее удобном для человека виде, а способ отображения данных может быть как текстовым или графическим, так и звуковым и даже в виде изображений.
Базы данных (тест №1)
Вопрос № 1База данных — это:
совокупность данных, организованных по определённым правиламсовокупность программ для хранения и обработки больших массивов информации
интерфейс, поддерживающий наполнение и манипулирование данными
Вопрос № 2
Наиболее распространенными в практике являются
распределенные базы данныхиерархические базы данных
сетевые базы данных
реляционные базы данных
Вопрос № 3
Наиболее точным аналогом реляционной базы данных может служить:
неупорядоченное множество данныхвектор
генеалогическое дерево
двумерная таблица
Вопрос № 4
Таблицы в базах данных предназначены:
для хранения данных базыдля отбора и обработки данных базы
для ввода данных базы и их просмотра
для автоматического выполнения группы команд
для выполнения сложных программных действий
Вопрос № 5
Что из перечисленного не является объектом Access?
модулитаблицы
макросы
ключи
формы
отчёты
запросы
Вопрос № 6
Для чего предназначены запросы?
для хранения данных базыдля отбора и обработки данных базы
для ввода данных базы и их просмотра
для автоматического выполнения группы команд
для выполнения сложных программных действий
для вывода обработанных данных базы на принтер
Вопрос № 7
Для чего предназначены формы?
для хранения данных базыдля отбора и обработки данных базы
для ввода данных базы и их просмотра
для автоматического выполнения группы команд
для выполнения сложных программных действий
для вывода обработанных данных базы на принтер
Вопрос № 8
Для чего предназначены модули?
для отбора и обработки данных базы
для ввода данных базы и их просмотра
для автоматического выполнения группы команд
для выполнения сложных программных действий
Вопрос № 9
Для чего предназначенны макросы?
для хранения данных базыдля отбора и обработки данных базы
для ввода данных базы и их просмотра
для автоматического выполнения группы команд
для выполнения сложных программных действий
Вопрос № 10
В каком режиме работает с базой данных пользователь?
в проектировочномв любительском
в заданном
в эксплутационном
Вопрос № 11
В каком диалоговом окне создают связи между полями таблиц базы данных?
таблица связейсхема связей
схема данных
таблица данных
Вопрос № 12
Почему при закрытии таблицы программа Access не предлагает выполнить сохранение внесенных данных?
недоработка программыпотому что данные сохраняются сразу после ввода в таблицу
потому что данные сохраняются только после закрытия всей базы данных
Вопрос № 13
Без каких объектов не может существовать база данных?
без модулейбез отчётов
без таблиц
без форм
без макросов
без запросов
Вопрос № 14
В каких элементах таблицы хранятся данные базы?
в поляхв строках
в столбцах
в записях
в ячейках
Вопрос № 15
Содержит ли какую-либо информацию таблица, в которой нет ни одной записи?
пустая таблица содержит информацию о структуре базы данных
пустая таблица содержит информацию о будущих записях
таблица без записей существовать не может
Вопрос № 16
Содержит ли какую-либо информацию таблица, в которой нет полей?
содержит информацию о структуре базы данныхне содержит никакой информации
таблица без полей существовать не может
содержит информацию о будущих записях
Вопрос № 17
В чём состоит особенность поля «счётчик»?
служит для ввода числовых данныхслужит для ввода действительных чисел
данные хранятся не в поле, а в другом месте, а в поле хранится только указатель на то, где расположен текст
имеет ограниченный размер
имеет свойство автоматического наращивания
Вопрос № 18
В чем состоит особенность поля «мемо»?
служит для ввода числовых данныхслужит для ввода действительных чисел
данные хранятся не в поле, а в другом месте, а в поле хранится только указатель на то, где расположен текст
имеет ограниченный размер
имеет свойство автоматического наращивания
Вопрос № 19
Какое поле можно считать уникальным?
поле, значения в котором не могут повторятьсяполе, которое носит уникальное имя
поле, значение которого имеют свойство наращивания
Вопрос № 20
Ключами поиска в системах управления базами данных (СУБД) называются:
диапазон записей файла БД, в котором осуществляется поисклогические выражения, определяющие условия поиска
поля, по значению которых осуществляется поиск
номера записей, удовлетворяющих условия поиска
❶ Зачем нужны базы данных 🚩 база данных представляет собой 🚩 Компьютеры и ПО 🚩 Другое
База данных представляет собой определенным образом структурированную совокупность данных, совместно хранящихся и обрабатывающихся в соответствии с некоторыми правилами.
 Как правило, база данных моделирует некоторую предметную область или ее фрагмент. Очень часто в качестве постоянного хранилища информации баз данных выступают файлы.
Как правило, база данных моделирует некоторую предметную область или ее фрагмент. Очень часто в качестве постоянного хранилища информации баз данных выступают файлы.Программа, производящая манипуляции с информацией в базе данных, называется СУБД (система управления базами данных). Она может осуществлять выборки по различным критериям и выводить запрашиваемую информацию в том виде, который удобен пользователю. Основными составляющими информационных систем, построенных на основе баз данных, являются файлы БД, СУБД и программное обеспечение (клиентские приложения), позволяющие пользователю манипулировать информацией и совершать необходимые для решения его задач действия.
Структурирование информации производится по характерным признакам, физическим и техническим параметрам абстрактных объектов, которые хранятся в данной базе. Информация в базе данных может быть представлена как текст, растровое или векторное изображение, таблица или объектно-ориентированная модель. Структурирование информации позволяет производить ее анализ и обработку: делать пользовательские запросы, выборки, сортировки, производить математические и логические операции.
Информация, которая хранится в базе данных, может постоянно пополняться. От того, как часто это делается, зависит ее актуальность. Информацию об объектах также можно изменять и дополнять.
Базы данных, как способ хранения больших объемов информации и эффективного манипулирования ею, используются практически во всех областях человеческой деятельности. В них хранят документы, изображения, сведения об объектах недвижимости, физических и юридических лицах. Существуют правовые базы данных, автомобильные, адресные и пр.
Базы данных используются в информационных системах, например, в тех, которые позволяют обеспечивать контроль и управление территориями на уровне государства. В базах данных таких систем хранятся сведения обо всех объектах недвижимости, расположенных на данных территориях: земельных участках, растительности, строениях, гидрографии, дорогах и пр. Базы данных позволяют анализировать информацию и осуществлять управление информационными потоками, использовать их для статистики, прогнозирования и учета.
Что такое базы данных и для чего они используются
- Подробности
- декабря 13, 2014
- Просмотров: 39958
База данных представляет собой хранилище данных, в которых данные хранятся в организованном порядке.
Это облегчает функции, такие как извлечение, обновление и добавление новых данных. Базы данных имеют многочисленные применения и преимущества, когда речь идет о больших объемах, данных.
Знаете ли вы что?
«База данных Интеграция» привела к революции в бизнесе, ИТ, и образовательном секторе, предоставляя широкий спектр возможностей для управления и анализа данных.
Структура базы данных
Система базы данных состоит из следующих элементов:
Таблицы: Данные хранятся в строках (записи) и столбцах (поля).
Формы: Формы разработаны с целью ввода новых данных. Чтобы можно было легче и без ошибок добавлять информацию в базу данных через форму, а не вводить данные непосредственно в таблицу.
Запросы: Запросы написаны для извлечения строк и / или столбцов на основе заранее определенного состояния.
Наиболее известные базы данных это: MySQL, SAP, Oracle, IBM DB2 и т.д. СУБД или «система управления базы данных» используется в качестве интерфейса для связи между пользователем и базой данных.
Что такое базы данных и для где они используются?
Хранение данных / Вставка: Начальная фаза (перед вводом данных) включает в себя создание структуры данных, таких как таблицы (с необходимым количеством строк и столбцов). Затем данные вносят в эту структуру.
Восстановление данных: Базы данных используются, когда данные, которые будут храниться в большом количестве нуждаются в постоянном поиске. Это делает процесс извлечения конкретной информации проще.
Это делает процесс извлечения конкретной информации проще.
Данные модификации / Updation: Статические данные не нуждаются в обновлении. Тем не менее, динамические данные нуждаются в постоянной модификации. Рассмотрим возраст сотрудников в организации. Она должна обновляться каждый год (периодическое обновление).
Пример
Рассмотрим развлекательный клуб, который имеет большое количество зарегистрированных людей. Секретарь должен постоянно отслеживать контактные данные всех зарегистрированных пользователей. Если эти записи хранятся в ряде технических описаний или списках, изменение деталей является трудоемкой задачей. Потому что, извлечение и модификация данных должна быть сделана во всех листах, содержащих эти записи в целях сохранения согласованности. Таким образом, целесообразно использовать четко определенную базу данных.
Преимущества баз данных
Емкость хранения: Базы данных хранят большее количество данных по сравнению с другими хранилищами данных. Малогабаритные данные можно вписаться в электронные таблицы или документы. Однако, когда дело доходит до тяжелых данных, базы данных являются лучшим выбором.
Малогабаритные данные можно вписаться в электронные таблицы или документы. Однако, когда дело доходит до тяжелых данных, базы данных являются лучшим выбором.
Ассоциация данных: записи данных из отдельных таблиц могут быть связаны. Это необходимо, когда определенный фрагмент данных существует в более чем одной таблице. Например, идентификаторы работников могут существовать в таких данных как «Заработная плата», а также «сотрудники». Связь имеет важное значение для того, чтобы иметь единые изменения в нескольких местах и тех же данных.
Несколько пользователей: Разрешения могут быть предоставлены для множественного доступа к базе данных. Это позволяет одновременно нескольким (более одного) пользователям, получить доступ и манипулировать данными.
Удаление данных: Нежелательные требования данных для удаления из базы данных. В таких случаях, записи должны быть удалены из всех связанных таблиц, чтобы избежать каких-либо нарушений данных. Это гораздо проще для удаления записей из базы данных с помощью запросов или форм, а не из других источников данных, таких как таблицы.
Это гораздо проще для удаления записей из базы данных с помощью запросов или форм, а не из других источников данных, таких как таблицы.
Безопасность данных: Файлы данных, хранятся в безопасности, в большинстве случаев. Эта особенность гарантирует, что злоумышленники не получит незаконный доступ к данным, и что их качество поддерживается.
Импорт: Это еще один важный момент в использование баз данных. Он позволяет импортировать внешние объекты (данные из других баз данных). Импорт в основном делается для таблицы или запроса. При вводе, база данных создает копию импортируемого объекта.
Экспорт: В данном случае, таблицы или запросы импортируются другими базами данных.
Связи данных: Это делается для того, чтобы избежать создание копии объекта в базе. Ссылка определяется до требуемого объекта исходной базы данных.
Сортировки данных / Фильтрация: Фильтры могут быть применены к данным, которые имеют одинаковые значения данных. Примером одинаковых данных могут быть имена сотрудников организации с аналогичными фамилиями или именами. Аналогичным образом данные могут быть отсортированы как по возрастанию, так и по убыванию. Это помогает в просмотре или распечатки результатов в требуемом порядке.
Примером одинаковых данных могут быть имена сотрудников организации с аналогичными фамилиями или именами. Аналогичным образом данные могут быть отсортированы как по возрастанию, так и по убыванию. Это помогает в просмотре или распечатки результатов в требуемом порядке.
Индексация базы данных: Большинство баз данных содержат индекс для хранимых данных, что в конечном итоге повышает время доступа. Тот факт, что линейный поиск данных занимает много времени, делает эту особенность наиболее популярной.
Непрерывные связанные изменения данных: Таблицы с общими данными могут быть связаны с ключами (первичный, вторичный, и т.д.). Ключи очень полезны, потому что изменение общей организации в одной таблице отражается также в связанных таблицах.
Снижает накладные расходы: Передача данных отнимает много времени. Транзакции с помощью запросов очень быстры, таким образом производя более быстрые результаты.
Базы данных упрощают весь смысл хранения и доступа к информации. Тем не менее, предусмотрительность необходима со стороны создателя базы данных, так, чтобы иметь наиболее эффективную базу данных.
Тем не менее, предусмотрительность необходима со стороны создателя базы данных, так, чтобы иметь наиболее эффективную базу данных.
Читайте также
Реляционные базы данных — определение, структура, примеры
Особенности реляционных БД
БД используются для организации хранения данных. Структура реляционной базы данных полностью определяется перечнем названия полей с указанием их типов и свойств. Все записи имеют одинаковые поля, но в них показываются разные свойства объекта. Аналогом реляционной БД считается двумерная таблица. Характерные особенности файла БД:
- Уникальное имя для каждой таблицы.
- Фиксированное число полей.
- На пересечении строки и столбца всегда есть только одно значение.
- Записи отличаются друг от друга хотя бы одним значением элемента.
- Полям присваиваются индивидуальные имена.

- В каждый из столбцов необходимо вставлять однородные данные: целые числа, даты, суммы, имена или фамилии, названия предметов.
Реляционная БД чаще всего не ограничивается одной таблицей. Обычно создаются несколько таблиц со связанной информацией. Это позволяет исполнять более сложные операции над данными. Таблицы реляционной БД обязаны соответствовать требованиям понятия нормализации отношений, то есть ограничениям на формирование, которые позволят избежать дублирования и обеспечат непротиворечивость хранимой информации. Пусть создана таблица «Прокат», содержащая следующие поля: Шифр Клиента, Ф. И. О., Вид устройства, Дата выдачи, Оплата, Срок возврата. Эта организация хранения информации имеет несколько недостатков:
- дублирование информации (вид устройства повторяется для разных клиентов), что увеличивает объём БД;
- для обновления информации требуется обрабатывать каждую запись.
Для устранения этих недостатков необходима нормализация с разделением данных на разные таблицы.

Связывание таблиц
Для любой таблицы реляционной БД задаётся первичный ключ (primary key) — поле или сочетание полей, которые определяют каждую запись. Внешний или вторичный ключ (foreign key) — это одно или несколько полей, ссылающихся на поле primary key другой таблицы.
Составной ключ называется так, потому что создаётся из нескольких полей. При образовании составных ключей не рекомендуется включать в них поля, значения которых точно определяют запись. Например, не следует образовывать ключ, в котором находятся вместе поля «номер паспорта» и «шифр клиента», потому что оба эти атрибута однозначно определяют запись. Поля с повторяющимися в таблице значениями тоже нельзя делать составной частью ключа. По значению ключа возможно найти только одну запись.
Ячейка — это наименьший структурный элемент, который задаёт определённое значение соответствующего поля. Таблицы связываются друг с другом, и поэтому данные могут выбираться сразу из нескольких таблиц.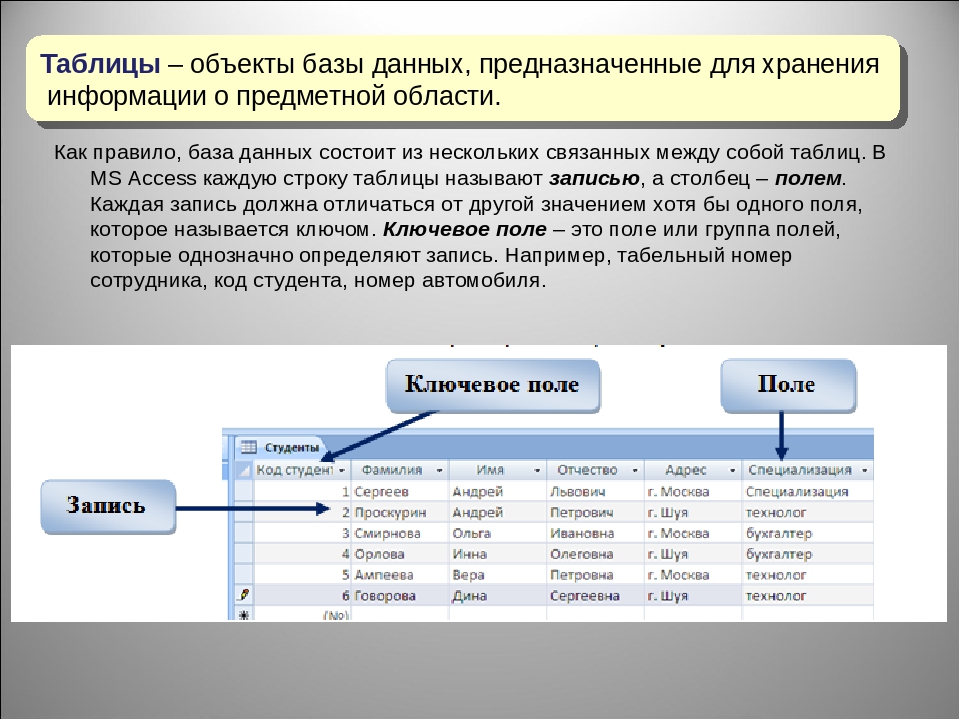 Связь создаётся, если в них присутствуют одинаковые поля. Типы связей:
Связь создаётся, если в них присутствуют одинаковые поля. Типы связей:
- один к одному;
- один ко многим;
- многие ко многим.
Связи «один к одному» встречаются довольно редко. «Один ко многим» применяются чаще, например, кассир продаёт много билетов. «Многие ко многим» тоже встречаются часто. Например, студент изучает много предметов. Связи «многие ко многим» нельзя организовывать непосредственно. Для установления отношения необходимо сопоставить каждому primary key внешний ключ, который представляет собой primary key другой таблицы. Реляционные системы базируются на теории реляционной модели, которая включает в себя три аспекта:
- структурный — данные в базе рассматриваются как набор отношений, то есть упорядоченных пар, составленных из заголовка и полей;
- целостности — состоит в проверке правильности согласования данных при обновлении;
- обработки — использование операторов манипулирования таблицами, таких как реляционная алгебра и реляционное исчисление, которые генерируют новые таблицы на основании уже имеющихся.

Управление созданием и использованием БД осуществляется системами управления базами данных (СУБД).
Под их руководством:
- производится добавление, определение, удаление и поиск записей;
- изменяются значения полей.
Для проведения этих операций организуются запросы. Итогом выполнения запросов будут либо изменения в таблицах, либо получение таблицы данных. При этом поддерживается принцип безопасности информации. Для реляционной БД основным языком управления является SQL.
Стадии и пример проектирования хранилища
Приступая к созданию базы, разработчик составляет для объектов манипулирования и их связей представление в терминах реляционной БД (таблицы, поля, записи). Проектирование проходит несколько стадий:
- Первая стадия — это анализ требований. Разработчик должен разрешить главные проблемы: какие элементы данных будут содержаться, как и кто должен к ним обращаться.

- В следующей стадии проектируется логическая структура БД.
- В завершающей стадии проектирования логическая структура БД трансформируется в физическую. Элементы данных определяются как табличные столбцы.
Преимущества этой модели данных состоят в том, что информация отображается в удобной для пользователя форме, а для манипуляций используется развитой математический аппарат.
Примером реляционной базы данных может послужить проект оптимизации деятельности пункта проката. Требуется автоматизировать такие процедуры: учёт клиентов; регистрацию инвентаря, выданного в прокат; отслеживание даты выдачи, сроков возврата, оплаты; получение информации по этим позициям; формирование отчёта по задолженностям. Реляционная БД может быть задана в виде трёх связанных таблиц.
Используя имеющиеся данные, следует определить отношения и объекты этих отношений. Объектами будут являться клиенты и устройства. Отношения между ними состоят в том, что каждый клиент может брать в прокат одно или несколько устройств.
Атрибутами для сопоставления объектов друг другу должны выступать ячейки с уникальным содержимым. В таблицах есть по одному полю с уникальными данными. В № 1 «Клиент» — это шифр клиента, а в № 3 «Склад» — шифр устройства. Это и будут primary keys. Каждая строка таблицы «Прокат» будет связывать два внешних ключа между собой:
- Шифр Клиента — foreign key, ссылающийся на primary key в таблице «Клиент».
- Шифр устройства — foreign key, ссылающийся на первичный ключ в таблице «Склад».
Проблемы модели
Преимущество реляционных хранилищ состоит в том, что они способны обеспечить наилучшее соотношение устойчивости, производительности, гибкости, совместимости и масштабируемости. Реляционные БД предоставляют лёгкий доступ к составляемым отчётам и обеспечивают высокую надёжность и целостность информации из-за отсутствия избыточных данных. Но сейчас, когда всё большее количество приложений работает с высокой нагрузкой, увеличивается значение фактора масштабируемости.
Реляционные БД легко масштабируются, только когда они расположены на одном сервере. Если потребуется увеличить количество серверов и разделить нагрузку между ними, то возрастёт сложность хранилищ, что значительно снизит возможность использовать их как платформу для мощных распределённых систем. Поэтому приходится применять другие типы БД, которые обладают лучшей масштабируемостью и отказываться от возможностей, предоставляемых реляционными хранилищами.
Реляционная БД — это совокупность связей, которые способны структурировать данные, что даёт возможность рационального хранения и эффективного использования информационных материалов.
Типы баз данных NoSQL, что это такое и пример
- На главную
Тестирование
- Назад
- Гибкое тестирование
- BugZilla
- Cucumber
- Тестирование базы данных
ETL Тестирование базы данных- Назад
- JUnit
- LoadRunner
- Ручное тестирование
- Мобильное тестирование
- Mantis
- Почтальон
- QTP
- Назад
- Центр качества
- 0003000300030003 SoapUI
- Управление тестированием
- TestLink
SAP
- Назад
- ABAP
- APO
- Начинающий
- Basis
- BODS
- BI
- BPC
- CO
- Назад
- CRM
- Crystal Reports
- QM4000
- QM4
- Заработная плата
- Назад
- PI / PO
- PP
- SD
- SAPUI5
- Безопасность
- Менеджер решений
- Successfactors
- Учебники SAP
- Apache
 Net
Net- Назад
- Java
- JSP
- Kotlin
- Linux
- Linux js
- Perl
- Назад
- PHP
- PL / SQL
- PostgreSQL
- Python
- ReactJS
- Ruby & Rails
- Scala
- SQL 0000003 SQL000
- SQL 000
- UML
- VB.Net
- VBScript
- Веб-службы
- WPF
Обязательно учите!
- Назад
- Бухгалтерский учет
- Алгоритмы
- Android
- Блокчейн
- Business Analyst
- Создание веб-сайта
- Облачные вычисления
- COBOL
- Встроенные системы
- 0003 Эталон
- 9000 Дизайн 900 Ethical
9009
- Назад
- Prep
- PM Prep
- Управление проектом Salesforce
- SEO
- Разработка программного обеспечения
- VBA
Большие данные
- Назад
- AWS
- BigData
- Cassandra
- Cognos
- Хранилище данных
- DevOps Back
- DevOps Back
- HBase
- HBase2
- MongoDB
- NiFi
Что такое база данных? — GeeksforGeeks
База данных — неотъемлемая часть нашей жизни. Поскольку мы сталкиваемся с несколькими действиями, которые связаны с нашим взаимодействием с базой данных, например, в банке, на вокзале, в школе, в продуктовом магазине и т. Д. Это те места, где нам нужно собрать большой объем данных в одном месте и получение этих данных должно быть простым.
Поскольку мы сталкиваемся с несколькими действиями, которые связаны с нашим взаимодействием с базой данных, например, в банке, на вокзале, в школе, в продуктовом магазине и т. Д. Это те места, где нам нужно собрать большой объем данных в одном месте и получение этих данных должно быть простым.
База данных — это систематизированный набор данных, который также называется структурированными данными. К нему можно получить доступ или сохранить в компьютерной системе. Им можно управлять с помощью системы управления базами данных (СУБД), которая представляет собой программное обеспечение, которое используется для управления данными.База данных относится к связанным данным в структурированной форме.
В базе данных данные организованы в таблицы, которые состоят из строк и столбцов, и индексированы, поэтому данные легко обновляются, расширяются и удаляются. Компьютерные базы данных обычно содержат данные файловых записей, такие как транзакции денег с одного банковского счета на другой банковский счет, сведения о продажах и клиентах, сведения о платах учащихся и сведения о продуктах. Существуют различные типы баз данных, от наиболее распространенного подхода, реляционной базы данных, до распределенной базы данных, облачной базы данных или базы данных NoSQL.
Существуют различные типы баз данных, от наиболее распространенного подхода, реляционной базы данных, до распределенной базы данных, облачной базы данных или базы данных NoSQL.
- Реляционная база данных:
Реляционная база данных состоит из набора таблиц с данными, которые попадают в предопределенную категорию. - Распределенная база данных:
Распределенная база данных — это база данных, в которой части базы данных хранятся в нескольких физических местах и в которой обработка распределяется или реплицируется между различными точками сети.
- Облачная база данных:
Облачная база данных — это база данных, которая обычно работает на платформе облачных вычислений.Служба базы данных обеспечивает доступ к базе данных. Службы баз данных делают базовый программный стек прозрачным для пользователя.
Эти взаимодействия являются примером традиционной базы данных, где данные относятся к одному типу — текстовому. Развитие технологий привело к появлению новых приложений систем баз данных. Новые медиа-технологии сделали возможным хранение изображений, видеоклипов. эти важные функции делают мультимедийные базы данных.
Развитие технологий привело к появлению новых приложений систем баз данных. Новые медиа-технологии сделали возможным хранение изображений, видеоклипов. эти важные функции делают мультимедийные базы данных.
В настоящее время люди становятся умными, прежде чем принимать какие-либо решения, они анализируют факты и связанные с этим цифры, которые исходят из этих баз данных.Поскольку база данных упростила управление предыдущей информацией, мы можем ловить преступников и проводить глубокие исследования.
Вниманию читателя! Не прекращайте учиться сейчас. Получите все важные концепции теории CS для собеседований SDE с курсом CS Theory Course по приемлемой для студентов цене и будьте готовы к отрасли.
Лучшая база данных для хранения изображений, возможно, вовсе не база данных
Меня постоянно спрашивают о хранении изображений, документов, PDF-файлов или других двоичных объектов в Couchbase.Или, почти так же часто, Couchbase — лучшая база данных для хранения изображений?
Как архитектор сервисов и баз данных, я обычно отвечаю одинаково: для такого рода объектов хранить файлы в базе данных — посредственная идея.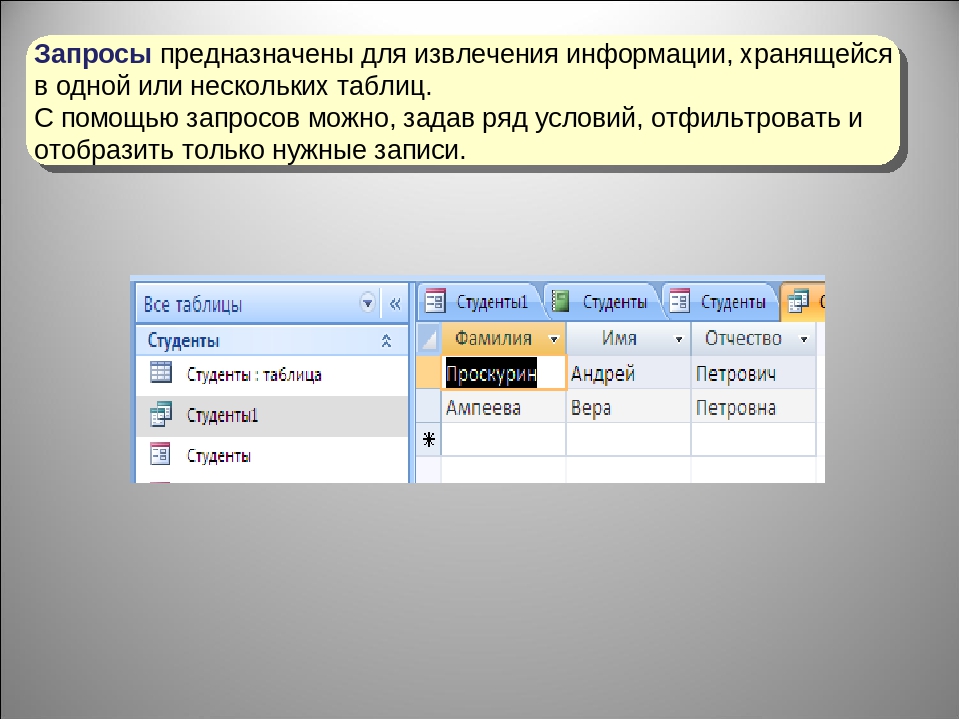 Когда я говорю это, я говорю из личного опыта в течение долгой карьеры, работая со многими реляционными базами данных и базами данных NoSQL.
Когда я говорю это, я говорю из личного опыта в течение долгой карьеры, работая со многими реляционными базами данных и базами данных NoSQL.
Я знаю, что с точки зрения разработчика легко и удобно хранить файлы в базе данных. Логически это даже имеет смысл.У меня есть данные, мне нужно их сохранить. Я хочу иметь информацию об этих данных, чтобы я мог найти ее и передать данные своим пользователям. Для меня все это тоже имеет смысл.
У меня есть два аргумента в пользу того, почему это посредственная идея хранить эти типы объектов в базе данных (Couchbase или иначе). Я также предложу решение, как лучше всего использовать Couchbase с наименьшими затратами и наилучшим образом обслуживать конечных пользователей. Вот почему мы все действительно здесь в конце, верно?
Эксплуатационные расходы и производительность
Постоянно сохраняя большие объекты в базе данных, вы будете использовать наиболее дорогостоящий и один из наиболее эффективных слоев для объектов, которые обычно статичны и редко меняются в большинстве случаев использования. Подумайте только о стоимости хранения одного гигабайта на инстансе EC2 в AWS по сравнению с хранением этого объекта в S3. Когда я использую калькулятор AWS на момент написания этой статьи, хранилище S3 стоило как минимум 1/5 стоимости самого дешевого хранилища EC2.
Подумайте только о стоимости хранения одного гигабайта на инстансе EC2 в AWS по сравнению с хранением этого объекта в S3. Когда я использую калькулятор AWS на момент написания этой статьи, хранилище S3 стоило как минимум 1/5 стоимости самого дешевого хранилища EC2.
Я говорю хотя бы потому, что настройки не являются сравнением возможностей 1: 1, поскольку они действительно предназначены для разных вещей. S3 специально предназначен для удержания большого количества статических объектов с очень высокой прочностью по очень разумной цене, а EC2 предназначен для оперативного хранения.
Теперь подумайте о физической стоимости хранения этого объекта в базе данных, а затем его репликации, резервного копирования и т. Д. В течение месяцев или лет. Становятся очевидными высокие затраты и время на транспортировку такого объема данных. Со временем эти объекты становятся корабельными якорями на шее оперативной группы. Кроме того, если вы не будете правильно управлять вещами, через два года у вас может быть база данных, в которой хранятся, резервные копии и репликация изображений от пользователя, который прекратил пользоваться вашим сервисом 1,5 года назад, в то время как вы по-прежнему платите за каждый КБ, использованный несколько раз. .
.
Все эти накладные расходы просто для удобства разработки. Это просто не стоит того и неэффективно в долгосрочной перспективе. Опять же, это ни в коем случае не эксклюзивно для Couchbase.
Используйте каждый инструмент для наилучшего результата в
Couchbase может обслуживать объекты прямо из управляемого кеша в ОЗУ с высокой производительностью, если вы обращаетесь к нему через идентификатор объекта или если вы определили, какой объект вы хотите получить из запроса. Может ли Couchbase очень быстро хранить и обслуживать это изображение или более крупный двоичный файл из ОЗУ? Конечно, может, но для достижения такой производительности потребуются дорогие ресурсы сервера, а не только хранилище.Couchbase также имеет ограничение на размер объекта 20 МБ. Даже если ваши объекты не достигают этого размера, все же может быть плохой идеей постоянно хранить эти типы объектов в базе данных. Как я упоминал ранее, Amazon S3 и HDFS отлично подходят для хранения и обслуживания такого статического контента. Это то, для чего они были созданы. Они предлагают отличную производительность по отличной цене для такого типа нагрузки. Лучше всего использовать правильные инструменты для правильной работы. Хотя базы данных могут хранить большие статические объекты, это определенно не то, в чем они лучше всего справляются.
Это то, для чего они были созданы. Они предлагают отличную производительность по отличной цене для такого типа нагрузки. Лучше всего использовать правильные инструменты для правильной работы. Хотя базы данных могут хранить большие статические объекты, это определенно не то, в чем они лучше всего справляются.
Тогда как мне решить эту проблему? У меня есть вещи для хранения!
В этом примере мы будем говорить о хранилище изображений, поскольку это наиболее распространенный вариант использования, который я слышал, но это может быть любой большой статический объект. На высоком уровне для этого варианта использования вам следует искать в Couchbase только те данные, которые требуются приложению, когда пользователь ищет изображение. Планируя шаблоны доступа к данным и, следовательно, объектную модель базы данных, задайте себе несколько вопросов.
- Какие данные приложение должно предоставлять пользователю о каждом изображении и о том, когда оно находится в потоке?
- Какие поиски будут выполняться по изображению и как будут представлены результаты? (Ключевые слова, название, создатель, дата создания и т.
 Д.) Если это соответствует вашему варианту использования, вы можете даже сохранить крошечный эскиз изображения в базе данных для быстрой доставки.
Д.) Если это соответствует вашему варианту использования, вы можете даже сохранить крошечный эскиз изображения в базе данных для быстрой доставки. - Когда в потоке приложения потребуется каждый фрагмент данных?
- Каким будет шаблон идентификатора объекта для каждого объекта метаданных изображения? Дополнительные сведения о моделировании объектов Couchbase и примерах идентификаторов объектов читайте в моих сообщениях в блогах здесь и здесь, чтобы получить идеи.
Теперь, когда у вас есть данные, обращенные к пользователю, в Couchbase, вы можете выполнять быстрый поиск ключей, отображать уменьшенные представления или полные запросы N1QL к вторичным индексам, чтобы получить данные.Большие изображения должны храниться в чем-то вроде AWS S3, HDFS, сети доставки контента (CDN), веб-сервере, файловом сервере или в любом другом месте, которое отлично подойдет для обслуживания больших статических объектов в соответствии с вашим вариантом использования и бюджетом.
А теперь давайте углубимся и поговорим подробнее о том, как мы это проектируем.
Пример объектной модели
Я предлагаю два объекта в Couchbase для каждого фактического изображения в вашем приложении:
- Объект JSON, содержащий метаданные об изображении.Он будет в формате JSON, чтобы мы могли его индексировать, запрашивать с помощью N1QL или Views, в зависимости от потребностей приложения. В этом объекте также будет указатель на основное изображение в другой системе.
- Объект «ключ / значение», содержащий миниатюру основного изображения и хранящийся в отдельной корзине Couchbase. Мы храним миниатюру в Couchbase, чтобы быстро представить ее пользователю. Теоретически мы могли бы иметь это как значение в документе JSON с метаданными, но преимущества их разделения, когда дело доходит до индексации и использования ресурсов Couchbase, компенсируют это, особенно если вы планируете высокую скорость мутации данных.
Поскольку каждый объект в Couchbase должен иметь уникальный идентификатор объекта (в ведре), и у нас может быть 250 байтов в этом идентификаторе, давайте воспользуемся этим в наших интересах и разработаем стандартизованный шаблон идентификатора объекта для простого и быстрого поиска объекта. Стандартизованный идентификатор объекта поможет нам легко получить изображение и связанный с ним контент быстро из службы данных Couchbase или при запросе при использовании N1QL.
Стандартизованный идентификатор объекта поможет нам легко получить изображение и связанный с ним контент быстро из службы данных Couchbase или при запросе при использовании N1QL.
Шаблон идентификатора объекта для каждого документа будет следующим:
- объект метаданных: метаданные :: где уникальный идентификатор присваивается этому изображению приложением.Поскольку мы собираемся искать изображения с помощью запросов с помощью N1QL, я не собираюсь использовать более описательный идентификатор объекта.
- Объект эскиза: эскиз :: где имя — то, которое мы использовали для объекта метаданных. Таким образом мы устанавливаем неформальные отношения между объектами. Мы знаем, что каждый объект метаданных имеет соответствующий объект эскиза. Так что, если нам нужно получить их обоих, мы сможем. Как только мы узнаем UUID, мы сможем очень быстро получить эскиз или наоборот.
Для самих объектов:
- Объект метаданных будет документом JSON и может выглядеть следующим образом:
{ «title»: «Cute Kitty and Doggy»,
«file-location» »:« Https: // s3.
 amazonaws.com/kittypics/cutekittyanddoggy.jpg »,
amazonaws.com/kittypics/cutekittyanddoggy.jpg »,« thumbnail1 »:« thumbnail ::
»,
« размеры-px »:« 50 × 50 »
}
Часть эскиза, где написано, что
, конечно, будет заменена идентификатором этого объекта. Таким образом, когда мы получаем объект метаданных, у нас есть идентификатор объекта эскиза, и мы можем быстро его получить. Это один из тех случаев, когда, скорее всего, лучше сделать несколько вызовов Couchbase, чем в другой базе данных, где лучше сделать это за один вызов.
- Объект эскиза будет просто ключом / значением с двоичным значением.
Настройки для Couchbase
Ковши
Я предлагаю два ковша Couchbase. Один для документов JSON, содержащих метаданные о каждом изображении, и один для эскиза. Для этого есть две конкретные причины:
- Отдельные сегменты позволяют настраивать управляемый кэш в зависимости от потребностей объекта.
 Например, возможно, я хочу, чтобы метаданные для каждого изображения всегда были доступны как можно быстрее.Я определяю квоту RAM для корзины «метаданных», чтобы все эти объекты находились в управляемом кэше для лучшей производительности. Миниатюры — это более крупные объекты, и, возможно, мы хотим немного сэкономить на размере наших экземпляров и не хранить их в кеше, потому что если они появятся через несколько секунд, ничего страшного. Мы могли бы установить квоту RAM для корзины метаданных равной 300 ГБ по кластеру, но эскизы — 50 ГБ по кластеру, даже если эскизы могут быть большим набором данных на диске.
Например, возможно, я хочу, чтобы метаданные для каждого изображения всегда были доступны как можно быстрее.Я определяю квоту RAM для корзины «метаданных», чтобы все эти объекты находились в управляемом кэше для лучшей производительности. Миниатюры — это более крупные объекты, и, возможно, мы хотим немного сэкономить на размере наших экземпляров и не хранить их в кеше, потому что если они появятся через несколько секунд, ничего страшного. Мы могли бы установить квоту RAM для корзины метаданных равной 300 ГБ по кластеру, но эскизы — 50 ГБ по кластеру, даже если эскизы могут быть большим набором данных на диске. - Нам никогда не нужно будет индексировать или запрашивать объекты эскизов. Мы всегда можем получить их по идентификатору объекта, который мы получили из документа метаданных JSON, или с помощью приложения, создающего его. Чтобы сделать еще один шаг в понимании того, почему мы хотим, чтобы эти объекты находились в двух отдельных сегментах; когда вы выполняете индексацию в Couchbase, каждый объект в корзине в какой-то момент опрашивается, чтобы увидеть, следует ли его включить в индекс.
 Это выполняется индексатором просмотра, если вы используете виды, или проектором, если вы используете GSI (глобальное вторичное индексирование).Если у нас есть эти два типа данных в разных сегментах, индексатор и проектор, нам никогда не придется беспокоиться об объектах эскизов и тратить циклы или ресурсы, поскольку индексы зависят от сегмента, чтобы запрашивать документы JSON. Еще один бонус заключается в том, что если вы используете представления Couchbase, которые хранятся вместе с данными, это должно уменьшить время перебалансировки кластера, поскольку снова индексатору представлений не нужно опрашивать миниатюры при перемещении данных. В целом это означает, что вам нужно меньше ресурсов сервера, поэтому это более рентабельно.
Это выполняется индексатором просмотра, если вы используете виды, или проектором, если вы используете GSI (глобальное вторичное индексирование).Если у нас есть эти два типа данных в разных сегментах, индексатор и проектор, нам никогда не придется беспокоиться об объектах эскизов и тратить циклы или ресурсы, поскольку индексы зависят от сегмента, чтобы запрашивать документы JSON. Еще один бонус заключается в том, что если вы используете представления Couchbase, которые хранятся вместе с данными, это должно уменьшить время перебалансировки кластера, поскольку снова индексатору представлений не нужно опрашивать миниатюры при перемещении данных. В целом это означает, что вам нужно меньше ресурсов сервера, поэтому это более рентабельно.
Для целей этого примера давайте назовем эти два сегмента загадочными словами, например «метаданными» и «эскизами».
Value Evict (по умолчанию) или Fully Evict
Скорее всего, вы захотите избежать использования функции полного выселения Couchbase для этого конкретного варианта использования. Это отличная функция, но отчасти причина для хранения этих объектов метаданных изображений в Couchbase заключается в функциональности, но также и в производительности, которую вы получаете от управляемого кеша. Скорее всего, ваш вариант использования потребует проверки существования объекта в какой-то момент в потоке приложения.В этом случае использовать полное выселение будет плохо, так как вам придется перейти на диск, чтобы проверить это. Если вы используете стандартное «исключение значений», то вы сможете очень быстро определить, существует ли объект, поскольку данные Couchbase о каждом объекте всегда будут находиться в управляемом кэше. Поэтому используйте эту функцию с умом и включайте полное выселение только в том случае, если вы точно знаете, что она сделает с вашим приложением и почему.
Это отличная функция, но отчасти причина для хранения этих объектов метаданных изображений в Couchbase заключается в функциональности, но также и в производительности, которую вы получаете от управляемого кеша. Скорее всего, ваш вариант использования потребует проверки существования объекта в какой-то момент в потоке приложения.В этом случае использовать полное выселение будет плохо, так как вам придется перейти на диск, чтобы проверить это. Если вы используете стандартное «исключение значений», то вы сможете очень быстро определить, существует ли объект, поскольку данные Couchbase о каждом объекте всегда будут находиться в управляемом кэше. Поэтому используйте эту функцию с умом и включайте полное выселение только в том случае, если вы точно знаете, что она сделает с вашим приложением и почему.
Исключение из правил
Как всегда, есть исключения, противоречащие правилам.Я знаю одного клиента Couchbase, который с поразительным успехом помещает двоичные объекты (в частности, аудиофайлы) в сервер Couchbase. Они делают это по очень конкретной причине, которая использует Couchbase в своих интересах. Они вставляют аудиозаписи в Couchbase, но главное в том, что их приложение разбивает аудиофайлы на более мелкие фрагменты и передает потоки каждый в Couchbase по мере их поступления вместе с документом метаданных для этой записи. Интересно то, что они не постоянно хранят аудиофайл в базе данных по причинам, которые я уже указывал в этой статье.Если через несколько минут к аудиофайлу не было доступа, фоновый процесс восстанавливает каждый файл и перемещает его в Amazon S3 для более длительного хранения. Затем они обновляют документ JSON с метаданными аудиофайла, добавляя указатель на файл на S3. Очень быстрое и высокоскоростное считывание с помощью Couchbase и долгосрочное хранение статических объектов с помощью S3. Это отличный пример использования лучших инструментов там, где они лучше всего.
Они делают это по очень конкретной причине, которая использует Couchbase в своих интересах. Они вставляют аудиозаписи в Couchbase, но главное в том, что их приложение разбивает аудиофайлы на более мелкие фрагменты и передает потоки каждый в Couchbase по мере их поступления вместе с документом метаданных для этой записи. Интересно то, что они не постоянно хранят аудиофайл в базе данных по причинам, которые я уже указывал в этой статье.Если через несколько минут к аудиофайлу не было доступа, фоновый процесс восстанавливает каждый файл и перемещает его в Amazon S3 для более длительного хранения. Затем они обновляют документ JSON с метаданными аудиофайла, добавляя указатель на файл на S3. Очень быстрое и высокоскоростное считывание с помощью Couchbase и долгосрочное хранение статических объектов с помощью S3. Это отличный пример использования лучших инструментов там, где они лучше всего.
Резюме
Не задавайте неправильные вопросы. Какая лучшая база данных для изображений? Какая база данных лучше всего подходит для хранения файлов? Постоянное размещение больших объектов в базе данных — это в лучшем случае посредственная идея, независимо от того, какую платформу базы данных вы используете. Даже если в базе данных есть специальная фиктивная файловая система, которая разбивает ваши большие двоичные файлы на более мелкие, чтобы хранить их в базе данных и автоматически собирать их для вас. Применяются те же концепции. Вы променяете простоту разработки на дорогую и более сложную с точки зрения эксплуатации жизнь в будущем. Это будет преследовать вас позже.
Даже если в базе данных есть специальная фиктивная файловая система, которая разбивает ваши большие двоичные файлы на более мелкие, чтобы хранить их в базе данных и автоматически собирать их для вас. Применяются те же концепции. Вы променяете простоту разработки на дорогую и более сложную с точки зрения эксплуатации жизнь в будущем. Это будет преследовать вас позже.
Для получения наилучшего решения используйте каждый инструмент по назначению. Храните в Couchbase документ JSON с метаданными для каждого объекта, возможно, самое большее — небольшой эскиз.В этом документе содержатся данные, которые вам нужны быстро об этом объекте в вашем приложении, а также указатель на специально созданное хранилище объектов, такое как S3, файловая система или HDFS. Вы получите лучшее из всех миров. Производительность, простота эксплуатации и рентабельность за небольшую дополнительную работу.
Не согласны? Есть еще одно исключение из правил? Добавьте это в комментарии, и давайте поговорим.
01 Управление базами данных
v0.37.6 / Руководство администратора / 01 Управление базами данных
Управление базами данных
Если вы уже подключили свою базу данных во время установки, вы, вероятно, охватили большую часть этой территории.Но если вам нужно добавить другую базу данных или управлять настройками уже подключенной, просто щелкните значок настроек в правом верхнем углу метабазы и выберите Admin .
Круто, теперь вы в административном разделе Metabase. Затем выберите Базы данных в строке меню в верхней части экрана, чтобы увидеть свои базы данных.
Добавление подключения к базе данных
Теперь вы увидите список ваших баз данных. Чтобы подключить другую базу данных к метабазе, нажмите Добавить базу данных . Метабаза в настоящее время поддерживает следующие типы баз данных:
Метабаза в настоящее время поддерживает следующие типы баз данных:
Не видите здесь нужную базу данных? Взгляните на нашу страницу драйверов сообщества, чтобы узнать, создал ли кто-то еще один или как начать создавать свой собственный.
Чтобы добавить базу данных, вам потребуется информация о ее подключении.
Получение информации о подключении к базам данных на Heroku:
- Перейдите на https://postgres.heroku.com/databases.
- Щелкните базу данных, которую вы хотите подключить к Metabase.
- Запишите следующую информацию на основе своей базы данных:
- Имя хоста
- Порт
- Имя пользователя
- Имя базы данных
- Пароль
Получение информации о подключении к базам данных на RDS Amazon:
- Перейдите в Консоль управления AWS.
- В разделе «Службы базы данных» щелкните «RDS».
- Затем щелкните «Экземпляры».
- Выберите базу данных, которую вы хотите подключить к Metabase.
- Запишите следующую информацию на основе своей базы данных:
- Имя хоста — указано как параметр «Конечная точка»
- Порт — Найдите параметр порта в разделе «Безопасность и сеть»
- Имя пользователя — найдите его в разделе «Сведения о конфигурации»
- Имя базы данных — найдите в разделе «Сведения о конфигурации»
- Пароль — запросите пароль у администратора базы данных.
Ошибки при подключении
Если при подключении к базе данных возникают ошибки, обратитесь за помощью к нашему руководству по устранению неполадок.
Уровень защищенных сокетов (SSL)
Metabase автоматически пытается подключиться к базам данных с SSL и без него. Если возможно подключиться к вашей базе данных с помощью SSL-соединения, Metabase сделает это значение по умолчанию для вашей базы данных. Вы всегда можете изменить этот параметр позже, если предпочитаете подключаться без этого уровня безопасности, но мы настоятельно рекомендуем держать SSL включенным, чтобы обеспечить безопасность ваших данных.
Синхронизация и анализ базы данных
По умолчанию Metabase выполняет легкую ежечасную синхронизацию вашей базы данных и каждую ночь более глубокий анализ полей в ваших таблицах, чтобы задействовать некоторые функции Metabase, такие как виджеты фильтров.
Если вы хотите изменить эти настройки по умолчанию, найдите и щелкните свою базу данных в разделе «Базы данных» панели администратора и включите переключатель в нижней части формы с надписью «Это большая база данных, поэтому позвольте мне выберите, когда метабаза синхронизируется и сканирует ». (Этот параметр раньше назывался «Включить углубленный анализ».)
Сохраните изменения, и вы увидите новую вкладку в верхней части формы под названием «Планирование». Нажмите на нее, и вы увидите параметры, позволяющие изменить время и частоту синхронизации и сканирования метабазы.
Синхронизация базы данных
Metabase хранит собственную информацию о различных таблицах и полях в каждой базе данных, которая добавляется для облегчения запросов. По умолчанию Metabase выполняет эту облегченную синхронизацию ежечасно для поиска изменений в базе данных, таких как новые таблицы или поля. Метабаза , а не копирует какие-либо данные из вашей базы данных. Он поддерживает только списки таблиц и столбцов.
По умолчанию Metabase выполняет эту облегченную синхронизацию ежечасно для поиска изменений в базе данных, таких как новые таблицы или поля. Метабаза , а не копирует какие-либо данные из вашей базы данных. Он поддерживает только списки таблиц и столбцов.
Синхронизация может быть установлена ежечасно или ежедневно в определенное время. Синхронизацию нельзя полностью отключить, иначе Metabase не будет работать.
Если вы хотите синхронизировать свою базу данных вручную в любое время, щелкните ее в списке «Базы данных» на панели администратора и нажмите кнопку «Синхронизировать схему базы данных сейчас» в правой части экрана:
Запросить настройки автозапуска
По умолчанию Metabase автоматически запускает запросы, когда вы используете кнопки Суммировать и Фильтр при просмотре таблицы или диаграммы. Если ваши пользователи изучают данные, которые хранятся в медленной базе данных, вы можете отключить автоматический запуск, чтобы избежать повторного выполнения запроса каждый раз, когда ваши пользователи изменяют параметр в представлении «Сводка». Отключение этого параметра дает пользователям возможность повторно запустить запрос, когда они захотят.
Отключение этого параметра дает пользователям возможность повторно запустить запрос, когда они захотят.
Поиск значений полей
Когда Metabase впервые подключается к вашей базе данных, она проверяет метаданные столбцов в ваших таблицах и автоматически присваивает им тип. Метабаза также берет образец каждой таблицы для поиска URL-адресов, JSON, закодированных строк и т. Д. Вы можете вручную редактировать метаданные таблицы и столбца в метабазе в любое время на вкладке Data Model в панели администратора .
По умолчанию Metabase также выполняет более интенсивную ежедневную выборку значений каждого поля и кэширует отдельные значения, чтобы флажки и фильтры выбора работали на информационных панелях и в вопросах SQL / native. Этот процесс может замедлить работу больших баз данных, поэтому, если у вас особенно большая база данных, вы можете включить параметр выбора времени сканирования метабазы и выбрать один из трех вариантов сканирования на вкладке «Планирование»:
- Регулярно, по расписанию позволяет вам выбирать сканирование ежедневно, еженедельно или ежемесячно, а также позволяет вам выбрать время суток или день месяца для сканирования.
