div (sm4 — asm) — Win32 apps
Twitter LinkedIn Facebook Адрес электронной почты- Статья
Разделение на уровне компонентов.
| div[_sat] dest[.mask], [-]src0[_abs][.swizzle], [-]src1[_abs][.swizzle] |
|---|
| Элемент | Описание |
|---|---|
| Dest | [in] Результат операции. |
| src0 | [in] Делимое. |
| src1 | [in] Делитель. |
В следующей таблице показаны результаты, полученные при выполнении инструкции с различными классами чисел, при условии, что ни переполнения, ни недополука не происходит.
Следует отметить две допустимые реализации деления: a/b и a*(1/b).
Одним из результатов этого является то, что в приведенной ниже таблице имеются исключения для больших значений знаменателя (больше 8,5070592e+37), где 1/знаменатель является денормом. Так как реализации могут выполнять деление как a*(1/b), а не a/b напрямую, и 1/[большое значение] является денормом, который может быть удален, в некоторых случаях в таблице будут даваться разные результаты.
В этой таблице F означает конечное-реальное число.
| src0 src1 —> | -Inf | -F | -denorm | -0 | +0 | +денорм | +F | +inf | Nan |
|---|---|---|---|---|---|---|---|---|---|
| -Inf | -inf | -inf | -inf | -inf | -inf | -inf | -inf | Не число | Не число |
| -F | -inf | src0 | src0 | src0 | src0 | +-F или +-0 | +inf | Не число | |
| -denorm | -inf | src1 | -0 | -0 | +0 | +0 | src1 | +inf | Не число |
| -0 | -inf | src1 | -0 | -0 | +0 | +0 | src1 | +inf | Не число |
| +0 | -inf | src1 | +0 | +0 | +0 | +0 | src1 | +inf | Не число |
| +денорм | -inf | src1 | +0 | +0 | +0 | +0 | src1 | +inf | Не число |
| +F | -inf | +-F или +-0 | src0 | src0 | src0 | src0 | +F | +inf | Не число |
| +inf | Не число | +inf | +inf | +inf | +inf | +inf | +inf | +inf | Не число |
| Не число | Не число | Не число | Не число | Не число | Не число | Не число | Не число | Не число | Не число |
Эта инструкция применяется к следующим этапам шейдера:
| Вершинный построитель текстуры | Шейдер геометрии | Построитель текстуры |
|---|---|---|
| x | x | x |
Эта функция поддерживается в следующих моделях шейдеров.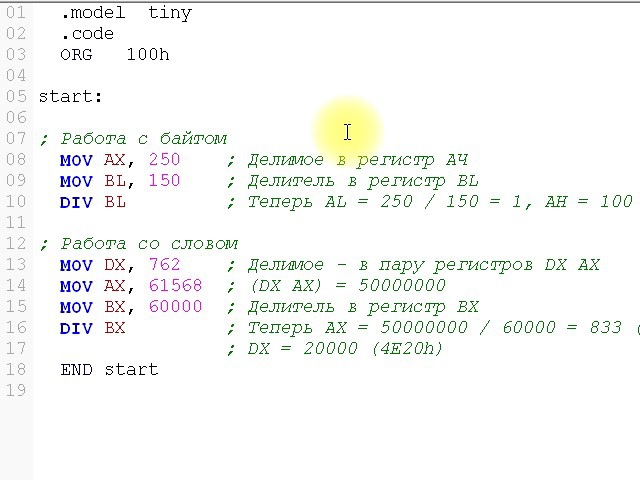
| Модель шейдера | Поддерживается |
|---|---|
| Модель шейдера 5 | да |
| Модель шейдера 4.1 | да |
| Модель шейдера 4 | да |
| нет | |
| Модель шейдера 2 (DirectX HLSL) | нет |
| Модель шейдера 1 (DirectX HLSL) | нет |
Сборка модели шейдера 4 (DirectX HLSL)
Ассeмблерные хаки из книги «xchg rax, rax» / Хабр
Привет Хабр! В 2014 году автор под никнеймом xorpd опубликовал книгу, которая полностью состоит из ассемблерного листинга, в ней нет ни одного комментария а в поле «от автора» написаны несколько строк машинного кода. Его задумка в том что бы читатели сами поняли что означают все эти строки кода и для чего они вообще нужны. Я самостоятельно разобрал эту книгу и хочу поделиться с вами интересными трюками, которые автор оставил читателям.
Я самостоятельно разобрал эту книгу и хочу поделиться с вами интересными трюками, которые автор оставил читателям.
Книга выложена в открытом доступе на одноименном сайте. (настоятельно рекомендую посетить, сайт очень интересный)
Так как я не видел ни одного обзора этой книги на Хабре или на каких-то русскоязычных ресурсах, надеюсь что моя статья о ней будет первой, а приведенные тут примеры окажутся полезными.
Я хочу разделить материал посвященный этой книге на несколько частей, в этой статье будут рассмотрены более простые фрагменты, а вторая и третья часть будут посвящаны более сложным хакам, связанным с алгоритмами
Для наглядонсти мы будем писать некоторые из примеров книги на fasm под LInux. Статья также подразумевает у читателя наличие базового понимания языка ассемблера для архитектуры х86 и базовых знаний битовой арифметики.
Стоит сказать так же пару слов о имени автора и названии книги, ведь они тоже являются ассемблерным кодом.
xorpd это инструкция предназначенная для того что бы ксорить 128-битные регистры. Что-то вроде «страшего брата» обычного xor. А название книги xchg rax, raxэто ни что иное как «перефразированная» инструкция nop. Которая не делает ничего. Компиляторы часто вставляют вместо нее подобного рода строчки. Инструкция xchgпросто меняет местами значения регистров.И так, начнем наверное вот с такого простого примера: (страница 0x01)
.loop:
xadd rax, rdx
loop .loopМожете подумать пару минут о том что же этот кусочек кода может делать 🙂С помощью этого маленького цикла можно вычислять числа Фибоначчи. Для кого-то это может прозвучать странно, но давайте разберемся как это работает.
Что-бы наглядно посмотреть работу этого кода, напишем простую функцию вывода десятичных чисел в терминал. Кладем в rax любое 64-битное число и вызываем нашу процедуру. Подробно ее работу я разбирать не буду, хоть в в ней и присутствеут определенная красота.
rax. Далее просто выводим каждый из символов в терминал с помощью системного вызова write(). Инфы про нее в интернете достаточно, так что думаю что все смогут разобраться.print_number:
xor rdx, rdx
mov rcx, 10
div rcx
add rdx, '0'
push rdx
or rax, rax
jz short .output
call print_number
.output:
pop rax
call print_symbol
ret
print_symbol:
push rdx
push rsi
push rdi
push rax
mov rax, 1
mov rdi, 1
mov rsi, rsp
mov rdx, 1
syscall
pop rax
pop rdi
pop rsi
pop rdx
ret
print_number нужно сохранять все регистры на стеке, да и в целом тут очень много стои поменять, но она тут исключительно для того, что-бы вывести результат работы кода.
И так, начнем с того что регистр rcx в циклах выступает счетчиком, от чего и называется «re-extended counter», соответственно мы будем вычислять rcx-ый элемент последовательности чисел Фибоначчи. rdx вначале должен быть равен единице, а rax нулю. Протестируем на данном примере:
Создадим для удобства простенький makefile и соберем нашу программку.
default: build run build: fasm test.asm && ld test.o -o test run: ./test
_start: mov rcx, 9 mov rdx, 1 .loop: xadd rax, rdx loop .loop call print_number
После запуска мы увидим результат 34, все работает корректно, давайте теперь разберем как это работает.
Инструкция loop отрабатывает метку, заданную в операнде rcx раз. Самое интересное происходит во время выполнения инструкции xadd. Она складываеет два операнда, после чего меняет их местами, в данном случае на первой итерации она складывает rax и rdx, сохраняя результат в rax, далее на следующей итерации уже оба регистра содержат единицу. Далее думаю уже не так сложно будет проследить этот механизм.
Далее думаю уже не так сложно будет проследить этот механизм.
Следущий в очереди вот такой код: (страница 0x15)
mov rdx,0xffffffff80000000
add rax,rdx
xor rax,rdxОбъянениеТут может быть не сразу понятно в чем дело, но это приведение 32-битного числа в младших 32 битах rax. Как же это работает? На самом деле все довольно просто.
После сложения с помощью инструкции add число изeax из за порядка хранения байтов от младшего к старшему, попадает в младшие байты числа из rdx, и например при rax=0x00000025, после сложения получится 0xfffffffff80000025, так как старшие байты rax равны нулю, в них ничего не меняется, а дальше после xor в rax остается уже расширенное до 64 бит число. Старшие байты rax и rdx совпадают и становятся нулями, далее совпадающие биты в младших байтах обнуляются оставляя нам наше число. Результат сохраняется уже как 64-битное число в
Результат сохраняется уже как 64-битное число в rax. Более подробно все это вы можете посмотреть в отладчике.
Далее вот такая строчка: (страница 0x04)
xor al, 0x20
Над ней я думал достаточно долго. Дело в том что разница в ascii кодировке заглавных и строчных символов везде равна 20. К примеру «А» = 41, а строчная «а» = 61 или «Z» = 5a, «z» = 7a. Эта строчка позволяет поменять строчный символ на заглавный, и наоборот всего за одну машинную инструкцию! Как именно происходит вычисление кодировки символа думаю можно не обьяснять. Красиво, неправда ли? Можем написать маленькую программку которая будет менять все символыстроки с использованием команды xlatb Эта инструкция возвращает байт по индексу, хранящемуся в al, из массива, на который указывает rbx
string db "hello world", 0
_start:
mov rbx, string
_loop:
cmp [rbx], byte 0
je short exit
xor al, al
xlatb
cmp al, 0x20
jz short _space
xor al, 0x20
call print_symbol
inc rbx
jmp short _loop
exit:
xor rbx, rbx
mov rax, 1
int 80h
_space:
call print_symbol
inc rbx
jmp short _loop
Создаем директиву со строкой, передаем ее в rbx, а потом просто увеличиваем его в цикле пока не дойдем до нуль терминатора, попутно возвращая байты по нулевому индексу в al. Тут я использую
Тут я использую jmp short вместо простого jmp т.к она занимает в разы меньше места, но передавать управление может только на 128(примерно) байт. Для вывода их на экран пользуемся процедурой print_symbol, реализованной выше. Так же проверяем строку на наличие пробелов и корректно обрабатываем их. Метка exit просто делает системный вызов exit() .Эта программа выведет «HELLO WORLD». Можете протестировать этот код самтостоятельно и проверить его работу.
Рассмотрим что-то более сложное: (страница 0x3a)
mov qword [rbx + 8*rcx],0
mov qword [rbx + 8*rdx],1
mov rax,qword [rbx + 8*rcx]
mov qword [rbx],rsi
mov qword [rbx + 8],rdi
mov rax,qword [rbx + 8*rax]Вот тут уже начинаете что-то более интересное.
Наверное для начала стоит пояснить, вычисления которые тут производятся: В языке ассемблера это является распространенным способом доступа к элементам массива. Выглядит он следующим образом:
Выглядит он следующим образом:
mov [ адресс начала массива + выравнивание * индекс ], значение
Под выравниваем очевидно имеется ввиду размер элементов в массиве, в данном случае размер элементов 8, значит массив выровнен по 8 байт.
И так в rbx у нас указывает на некую память, выровненную по 8 байт , далее rax и rcx должны содержать какие-то индексы, по котоым кладется единичка и ноль. Далее мы в rax возвращаем значение по индексу rcx
Кладем rsi и rdi по соседству в нашу память и возвращаем в rax что-то по индексу который мы вычеслили в первом блоке кода.
Можете так же подумать пару минут о том что же может происходить дальше 🙂
Суть магииИ так, если rcx == rdx (к примеру оба равны нулю) то сначала в нашу память по индексу rcx кладется 0, а потом туда же единица и индекс вычесленный в этом блоке будет равен единице, если же нет, то там будет 0 соответственно.
А дальше мы возвращаем в rax либо rdi либо rsi в зависимости от того какой получился индекс. По сути мы выполнили сравнение и условное перемещение с помощью одних только инструкций mov, мне кажется это весьма интересным.
Один проект с гитхаба, под названием M/o/Vfuscator, доводит эту идею до компилятора С, который выдает бинарники, содержащие только инструкции mov 🙂
Не судите слишком строго, это моя первая статья.
В следующей статье разберу более сложные примеры из этой книги, касающиеся алгоритмов. Если обнаружите в моем коде ошибки или недоработки, пишите в комменты, я буду очень рад выслушать ваши советы.
Всем большое спасибо за внимание!
Как использовать инструкцию div для поиска остатка в сборке x86?
Задавать вопрос
спросил
Изменено 7 лет, 9 месяцев назад
Просмотрено 29 тысяч раз
мов акс, 0 мов ебкс, 0 мов эдкс, 0 мов топор, 31 мул сх мов бх, 12 делитель bx добавить бп, топор движение акс, 0 мов ебкс, 0 мов бп, бп Мов аль, 7 раздел аль
может ли кто-нибудь сказать мне, что не так с инструкцией div al в этом блоке кода, так как я отлаживаю каждое вычисленное количество битов, когда я делю на al, это дает мне 1 в качестве остатка, почему это происходит?
остаток следует сохранить обратно в регистр ah
заранее спасибо
отредактированный код:
mov eax, 0 мов ебкс, 0 мов эдкс, 0 мов топор, 31 мул сх мов бх, 12 делитель bx добавить бп, топор движение акс, 0 мов ебкс, 0 мов топор, бп мов бл, 7 раздел бл мов аль, 0
- сборка
- x86
- разделение
Вы не можете использовать al в качестве делителя, потому что команда div предполагает, что x будет делимым.
Это пример деления б.п. на 7
mov ax,bp // ax - делимое mov bl,7 // подготовить делитель div bl // делим ax на bl
Это 8-битное деление, так что да, остаток будет храниться в 9-битном разряде.0035 ах . Результат al .
Чтобы уточнить: Если вы пишете на al вы частично перезаписываете ax !
|31..16|15-8|7-0|
|АХ.|АЛ.|
|AX.....|
|ЭАКС............|
5отредактированный код:
mov eax, 0 мов ебкс, 0 мов топор, 31 мул сх мов бх, 12 делитель bx добавить бп, топор движение акс, 0 мов ебкс, 0 мов эдкс, 0 мов топор, бп мов бх, 7 делитель bx мов эси, edx движение акс, 0
Зарегистрируйтесь или войдите в систему
Зарегистрируйтесь с помощью Google Зарегистрироваться через Facebook Зарегистрируйтесь, используя адрес электронной почты и парольОпубликовать как гость
Электронная почтаТребуется, но не отображается
Опубликовать как гость
Электронная почтаТребуется, но не отображается
Нажимая «Опубликовать свой ответ», вы соглашаетесь с нашими условиями обслуживания и подтверждаете, что прочитали и поняли нашу политику конфиденциальности и кодекс поведения.
Что делать
Для 32-битного / 32-битного => 32-битного деления: удлинить 32-битное делимое из EAX до 64-битного EDX:EAX с помощью нуля или знака.
Для 16-битных, AX в DX:AX с cwd или xor-zero.
- без знака:
XOR EDX,EDXзатемделитель DIV - подписано:
CDQзатемделитель IDIV
См. также Когда и почему мы подписываем расширение и используем cdq с mul/div?
Почему (TL;DR)
Для DIV регистры EDX и EAX образуют одно 64-битное значение (часто отображается как в этом случае по EBX .
Итак, если EAX = 10 или шестнадцатеричное A и EDX , скажем, 20 или шестнадцатеричное 14 , то вместе они образуют 64-битный значение шестнадцатеричное 14 0000 000A или десятичное 85899345930 . Если это разделить на
Если это разделить на 5 , результатом будет 17179869186 или шестнадцатеричное
4 0000 0002 , , что является значением, которое не помещается в 32 бита .
Вот почему вы получаете целочисленное переполнение.
Если бы, однако, EDX были только 1 , вы бы разделили шестнадцатеричное число 1 0000 000A на 5 , что дало бы шестнадцатеричное число
3333 3335 . Это не то значение, которое вам нужно, но оно не вызывает целочисленного переполнения.
Чтобы действительно разделить 32-битный регистр EAX на другой 32-битный регистр, убедитесь, что верхняя часть 64-битного значения, сформированного EDX:EAX , равна 0 .
Итак, перед одним делением, вы должны вообще установить EDX на 0 .
(Или для подписанного подразделения, cdq для подписи расширить EAX в EDX:EAX до idiv )
Но EDX не имеет всегда должно быть 0 . Он просто не может быть настолько большим, чтобы результат вызывал переполнение.
Он просто не может быть настолько большим, чтобы результат вызывал переполнение.
Один пример из моего кода BigInteger :
После деления на DIV частное находится в EAX , а остаток в EDX . Чтобы разделить что-то вроде BigInteger , состоящего из множества DWORDS , на 10 (например, чтобы преобразовать значение в десятичную строку), вы делаете что-то вроде следующего:0003
; ECX содержит количество «конечностей» (DWORD) для деления на 10 Исключающее ИЛИ EDX,EDX ; перед началом цикла установите EDX в 0 ДВИГАТЕЛЬ EBX, 10 LEA ESI,[EDI + 4*ECX - 4] ; теперь указывает на верхний элемент массива @DivLoop: MOV EAX,[ESI] РАЗДЕЛ ЕВХ ; разделите EDX:EAX на EBX. После этого, ; частное в EAX, остаток в EDX ДВИГАТЕЛЬ [ESI],EAX СУБ ЭСИ,4 ; остаток в EDX повторно используется как верхний DWORD... ДЕК ЕСХ ; ... для следующей итерации и НЕ установлен в 0.
